SASRec: Self-Attentive Sequential Recommendation¶
研究动机与背景¶
序列推荐(Sequential Recommendation)的核心目标是结合用户历史行为的"上下文"来预测下一个交互物品。在 SASRec 之前,主流方法分为两大类:
-
Markov Chain(MC)方法:假设下一个行为仅依赖于前一个(或前几个)行为。一阶 MC 方法在极度稀疏的数据集上表现良好(模型简洁、参数少),但无法捕获复杂的高阶转移模式。高阶 MC 的参数量随阶数指数增长,且阶数 $L$ 需要预先指定。
-
RNN 方法:通过隐状态汇总所有历史行为,理论上能捕获长程依赖。但 RNN 需要大量数据才能超越简单 baseline,且由于时间步之间的串行依赖,训练效率低下。
两类方法各有局限:MC 模型简洁但表达能力有限,RNN 表达力强但计算昂贵且在稀疏场景容易过拟合。SASRec 的动机是同时兼顾两者的优点——既能像 RNN 一样从所有历史行为中提取上下文,又能像 MC 一样在少量关键行为上做预测。
受 Transformer 在机器翻译中的成功启发,作者将 self-attention 机制引入序列推荐。Self-attention 的优势在于:(1) 可以直接建模任意两个位置之间的依赖关系,最大路径长度为 $O(1)$;(2) 每个 self-attention 层的计算可以完全并行化,适合 GPU 加速。
核心方法/模型架构¶
SASRec 的整体架构如 Figure 1 所示,由三个核心组件构成:Embedding Layer、Self-Attention Blocks(可堆叠多层)和 Prediction Layer。
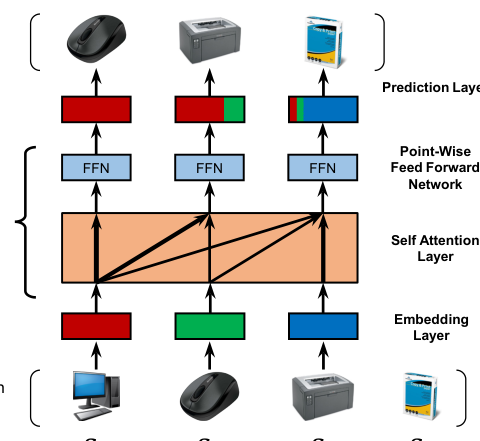
符号定义¶
论文使用的主要符号如 Table I 所定义:
| 符号 | 描述 |
|---|---|
| $\mathcal{U}, \mathcal{I}$ | 用户集合、物品集合 |
| $\mathcal{S}^u$ | 用户 $u$ 的历史交互序列 $(S_1^u, S_2^u, \ldots, S_{\|S^u\|}^u)$ |
| $d$ | 隐向量维度 |
| $n$ | 最大序列长度 |
| $b$ | self-attention block 数量 |
| $\mathbf{M} \in \mathbb{R}^{|\mathcal{I}| \times d}$ | 物品 embedding 矩阵 |
| $\mathbf{P} \in \mathbb{R}^{n \times d}$ | 位置 embedding 矩阵 |
| $\hat{\mathbf{E}} \in \mathbb{R}^{n \times d}$ | 输入 embedding 矩阵 |
| $\mathbf{S}^{(b)} \in \mathbb{R}^{n \times d}$ | 第 $b$ 层 self-attention 层输出 |
| $\mathbf{F}^{(b)} \in \mathbb{R}^{n \times d}$ | 第 $b$ 层 feed-forward 网络输出 |
Embedding Layer¶
给定用户交互序列 $\mathcal{S}^u = (S_1^u, S_2^u, \ldots, S_{|\mathcal{S}^u|-1}^u)$,将其转换为固定长度序列 $s = (s_1, s_2, \ldots, s_n)$,其中 $n$ 是模型可处理的最大长度。若序列长度超过 $n$,保留最近的 $n$ 个行为;若不足 $n$,在左侧填充 padding item。
创建物品 embedding 矩阵 $\mathbf{M} \in \mathbb{R}^{|\mathcal{I}| \times d}$,检索得到输入 embedding $\mathbf{E} \in \mathbb{R}^{n \times d}$,其中 $\mathbf{E}_i = \mathbf{M}_{s_i}$,padding item 使用全零向量。
位置嵌入(Positional Embedding):由于 self-attention 模型不包含循环或卷积模块,无法感知位置信息,因此注入可学习的位置嵌入 $\mathbf{P} \in \mathbb{R}^{n \times d}$:
$$\hat{\mathbf{E}} = \begin{bmatrix} \mathbf{M}_{s_1} + \mathbf{P}_1 \\ \mathbf{M}_{s_2} + \mathbf{P}_2 \\ \cdots \\ \mathbf{M}_{s_n} + \mathbf{P}_n \end{bmatrix} \tag{1}$$
作者也尝试了 Transformer 中的固定位置编码(正弦/余弦),但发现效果不如可学习的位置嵌入。
Self-Attention Block¶
缩放点积注意力(Scaled Dot-Product Attention):
$$\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d}}\right) \mathbf{V} \tag{2}$$
其中 $\mathbf{Q}$ 表示 query,$\mathbf{K}$ 表示 key,$\mathbf{V}$ 表示 value。缩放因子 $\sqrt{d}$ 用于避免内维度较大时内积值过大导致 softmax 梯度消失。
Self-Attention 层:在 NLP 中,attention 通常使用不同来源作为 Q、K、V(如 encoder-decoder 结构)。Self-attention 则使用相同的对象同时充当 query、key 和 value。SASRec 以输入 embedding $\hat{\mathbf{E}}$ 作为输入,通过线性投影得到三个矩阵:
$$\mathbf{S} = \text{SA}(\hat{\mathbf{E}}) = \text{Attention}(\hat{\mathbf{E}}\mathbf{W}^Q, \hat{\mathbf{E}}\mathbf{W}^K, \hat{\mathbf{E}}\mathbf{W}^V) \tag{3}$$
其中投影矩阵 $\mathbf{W}^Q, \mathbf{W}^K, \mathbf{W}^V \in \mathbb{R}^{d \times d}$。投影使模型更加灵活,能学习非对称交互(即 $\langle \text{query } i, \text{key } j \rangle$ 和 $\langle \text{query } j, \text{key } i \rangle$ 可以不同)。
因果性约束(Causality):预测第 $(t+1)$ 个物品时,模型只应考虑前 $t$ 个物品。但 self-attention 的第 $t$ 个输出 $\mathbf{S}_t$ 会包含后续物品的 embedding 信息。因此,作者通过禁止 $\mathbf{Q}_i$ 和 $\mathbf{K}_j$ 之间的连接($j > i$)来保证因果性,即使用 causal mask。
Point-Wise Feed-Forward Network:self-attention 虽然能以自适应权重聚合所有历史物品的 embedding,但本质上仍是线性模型。为了引入非线性并考虑不同隐维度之间的交互,对每个 $\mathbf{S}_i$ 施加相同的两层前馈网络(参数共享):
$$\mathbf{F}_i = \text{FFN}(\mathbf{S}_i) = \text{ReLU}(\mathbf{S}_i \mathbf{W}^{(1)} + \mathbf{b}^{(1)}) \mathbf{W}^{(2)} + \mathbf{b}^{(2)} \tag{4}$$
其中 $\mathbf{W}^{(1)}, \mathbf{W}^{(2)}$ 是 $d \times d$ 矩阵,$\mathbf{b}^{(1)}, \mathbf{b}^{(2)}$ 是 $d$ 维向量。注意 $\mathbf{S}_i$ 和 $\mathbf{S}_j$($i \neq j$)之间没有交互,保证信息不会从后向前泄露。
堆叠 Self-Attention Blocks¶
第一个 self-attention block 的输出 $\mathbf{F}_i$ 本质上聚合了所有历史物品的 embedding $\hat{\mathbf{E}}_j$($j \leq i$)。为了学习更复杂的物品转移模式,可以在 $\mathbf{F}$ 的基础上再堆叠 self-attention block。第 $b$ 层($b > 1$)定义为:
$$\mathbf{S}^{(b)} = \text{SA}(\mathbf{F}^{(b-1)}), \quad \mathbf{F}_i^{(b)} = \text{FFN}(\mathbf{S}_i^{(b)}), \quad \forall i \in \{1, 2, \ldots, n\} \tag{5}$$
第 1 层定义为 $\mathbf{S}^{(1)} = \mathbf{S}$,$\mathbf{F}^{(1)} = \mathbf{F}$。
当网络变深时,会出现过拟合、训练不稳定、参数增多等问题。受 Transformer 启发,作者采用以下技术:
正则化组合:对 self-attention 层和 feed-forward 层均施加:
$$g(x) = x + \text{Dropout}(g(\text{LayerNorm}(x))) \tag{6}$$
其中 $g(x)$ 代表 self-attention 层或 feed-forward 网络。即先 Layer Normalization,再经过子层 $g$,再 Dropout,最后加残差连接。
Layer Normalization:对每个样本的所有特征进行归一化(零均值、单位方差),与 Batch Normalization 不同,其统计量独立于同一 batch 中的其他样本:
$$\text{LayerNorm}(\mathbf{x}) = \boldsymbol{\alpha} \odot \frac{\mathbf{x} - \mu}{\sqrt{\sigma^2 + \epsilon}} + \boldsymbol{\beta} \tag{7}$$
其中 $\odot$ 是逐元素乘积,$\mu$ 和 $\sigma$ 是 $\mathbf{x}$ 的均值和方差,$\boldsymbol{\alpha}$ 和 $\boldsymbol{\beta}$ 是可学习的缩放和偏置参数。
残差连接(Residual Connections):在序列推荐中,最后一个访问物品对预测下一个物品至关重要。经过多层 self-attention block 后,最后一个物品的 embedding 会与所有历史物品纠缠;残差连接使低层信息(如最后一个物品的原始 embedding)能直接传播到最终层。
Dropout:以概率 $p$ 随机关闭神经元,防止过拟合。同时在 embedding $\hat{\mathbf{E}}$ 上也施加了 Dropout。
Prediction Layer¶
经过 $b$ 层 self-attention block 后,基于 $\mathbf{F}_t^{(b)}$ 预测下一个物品。采用 MF 层计算物品 $i$ 的相关性得分:
$$r_{i,t} = \mathbf{F}_t^{(b)} \mathbf{N}_i^T \tag{8}$$
其中 $\mathbf{N} \in \mathbb{R}^{|\mathcal{I}| \times d}$ 是物品 embedding 矩阵。
共享物品 Embedding(Shared Item Embedding):为了减少模型大小并缓解过拟合,SASRec 使用单一物品 embedding 矩阵 $\mathbf{M}$(即 $\mathbf{N} = \mathbf{M}$):
$$r_{i,t} = \mathbf{F}_t^{(b)} \mathbf{M}_i^T \tag{9}$$
注意 $\mathbf{F}_t^{(b)}$ 可以表示为物品 embedding 的函数 $\mathbf{F}_t^{(b)} = f(\mathbf{M}_{s_1}, \mathbf{M}_{s_2}, \ldots, \mathbf{M}_{s_t})$。使用共享 embedding 的一个关键优势是能表示非对称物品转移:前馈网络的非线性变换使得 $\text{FFN}(\mathbf{M}_i) \mathbf{M}_j^T \neq \text{FFN}(\mathbf{M}_j) \mathbf{M}_i^T$,而无需像 FPMC 那样使用两套异构 embedding。实验表明共享 embedding 显著提升了性能。
显式用户建模:作者也尝试添加显式用户 embedding $\mathbf{U}_u$,即 $r_{u,i,t} = (\mathbf{U}_u + \mathbf{F}_t^{(b)}) \mathbf{M}_i^T$,但发现并不能改善性能——因为模型已经通过考虑用户的所有行为隐式地建模了用户偏好。
Network Training¶
将每个用户序列(去掉最后一个行为)转换为固定长度序列 $s = \{s_1, s_2, \ldots, s_n\}$(通过截断或填充)。定义时间步 $t$ 的期望输出为:
$$o_t = \begin{cases} \langle\text{pad}\rangle & \text{if } s_t \text{ is a padding item} \\ s_{t+1} & 1 \leq t < n \\ S_{|\mathcal{S}^u|}^u & t = n \end{cases} \tag{10}$$
采用 Binary Cross Entropy(BCE)损失:
$$-\sum_{\mathcal{S}^u \in \mathcal{S}} \sum_{t \in \{1,2,\ldots,n\}} \left[ \log(\sigma(r_{o_t, t})) + \sum_{j \notin \mathcal{S}^u} \log(1 - \sigma(r_{j,t})) \right] \tag{11}$$
忽略 $o_t = \langle\text{pad}\rangle$ 的项。使用 Adam 优化器,每个 epoch 中为每个序列的每个时间步随机采样一个负样本。
关键技术细节¶
复杂度分析¶
空间复杂度:模型参数主要来自 embedding 和 self-attention 层、feed-forward 网络及 Layer Normalization,总参数量为 $O(|\mathcal{I}|d + nd + d^2)$。由于不随用户数增长(不像 MF 方法需要 $O(|\mathcal{U}|d + |\mathcal{I}|d)$ 参数),且 $d$ 在推荐问题中通常较小,空间复杂度适中。
时间复杂度:主要由 self-attention 层和 feed-forward 网络决定,为 $O(n^2 d + nd^2)$。$O(n^2 d)$ 来自 self-attention 层。关键优势是 self-attention 层的计算完全可并行化,适合 GPU 加速。相比之下,RNN(如 GRU4Rec)在时间步上有串行依赖,时间复杂度为 $O(n)$。实验表明 SASRec 比 RNN 和 CNN 方法快一个数量级以上。
与已有模型的关系¶
SASRec 可以视为多种经典协同过滤模型的泛化:
- FMC(Factorized Markov Chains):如果将 self-attention block 设为零、使用非共享物品 embedding、移除位置 embedding,SASRec 退化为 FMC。SASRec 也与 FPMC 密切相关。
- FISM(Factorized Item Similarity Models):如果使用一层 self-attention(去掉 FFN)、设置均匀注意力权重 $\frac{1}{|S^u|}$、使用非共享 embedding、移除位置 embedding,SASRec 退化为 FISM——一种自适应的、分层的序列物品相似度模型。
与 MC 方法相比,SASRec 的自适应注意力机制无需预先指定阶数 $L$,能在稀疏数据集上聚焦于最近的少数物品,在稠密数据集上关注更多历史物品。与 RNN 方法相比,SASRec 具有 $O(1)$ 的最大路径长度(有利于学习长程依赖),且支持完全并行计算。
实验设置¶
数据集¶
在 4 个来自不同领域、平台和稀疏度的真实数据集上评测:
| 数据集 | #用户 | #物品 | 平均行为/用户 | 平均行为/物品 | #总行为 |
|---|---|---|---|---|---|
| Amazon Beauty | 52,024 | 57,289 | 7.6 | 6.9 | 0.4M |
| Amazon Games | 31,013 | 23,715 | 9.3 | 12.1 | 0.3M |
| Steam | 334,730 | 13,047 | 11.0 | 282.5 | 3.7M |
| MovieLens-1M | 6,040 | 3,416 | 163.5 | 289.1 | 1.0M |
其中 Amazon Beauty 和 Amazon Games 是极度稀疏的数据集,Steam 有较高的物品平均行为数,MovieLens-1M 是最稠密的数据集。
数据预处理:将评分/评论视为隐式反馈,按时间戳排序,过滤少于 5 次交互的用户和物品。数据划分:每个用户的最后一个行为用于测试,倒数第二个用于验证,其余用于训练。
Baseline 方法¶
三组共 8 个 baseline:
通用推荐方法(不考虑序列顺序):
- PopRec:按物品流行度排序
- BPR:贝叶斯个性化排序,使用矩阵分解
一阶 MC 方法(基于最后一个物品):
- FMC:分解物品转移矩阵
- FPMC:融合矩阵分解和一阶 MC
- TransRec:用翻译向量建模物品转移
深度学习方法(考虑多个历史物品):
- GRU4Rec:基于 GRU 的 session-based 推荐
- GRU4Rec+:改进版,使用不同的损失函数和采样策略
- Caser:基于 CNN 的序列推荐,在最近 $L$ 个物品的 embedding 矩阵上做卷积
评估指标¶
采用两个 Top-N 指标:Hit Rate@10 和 NDCG@10。Hit@10 衡量真实下一个物品是否出现在推荐列表前 10 中,NDCG@10 是位置敏感的指标,给排名更高的物品更大权重。
评测时对每个用户随机采样 100 个负样本,与真实物品一起排序 101 个候选物品。
实现细节¶
- Self-attention blocks 数量 $b = 2$
- 使用可学习位置 embedding
- Embedding 层、self-attention 层和 prediction 层共享物品 embedding
- 使用 TensorFlow 实现
- Adam 优化器,学习率 0.001,batch size 128
- Dropout rate:MovieLens-1M 为 0.2,其他三个数据集为 0.5
- 最大序列长度 $n$:MovieLens-1M 为 200,其他为 50(约等于用户平均行为数)
- 隐维度 $d \in \{10, 20, 30, 40, 50\}$
- 验证集性能 20 个 epoch 不提升则停止训练
主要实验结果¶
推荐性能比较(RQ1)¶
Table III 展示了所有方法在 4 个数据集上的推荐性能:
| 数据集 | 指标 | PopRec | BPR | FMC | FPMC | TransRec | GRU4Rec | GRU4Rec+ | Caser | SASRec | vs 非神经 | vs 神经 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beauty | Hit@10 | 0.4003 | 0.3775 | 0.3771 | 0.4310 | 0.4607 | 0.2125 | 0.3949 | 0.4264 | 0.4854 | 5.4% | 13.8% |
| Beauty | NDCG@10 | 0.2277 | 0.2183 | 0.2477 | 0.2891 | 0.3020 | 0.1203 | 0.2556 | 0.2547 | 0.3219 | 6.6% | 25.9% |
| Games | Hit@10 | 0.4724 | 0.4853 | 0.6358 | 0.6802 | 0.6838 | 0.2938 | 0.6599 | 0.5282 | 0.7410 | 8.5% | 12.3% |
| Games | NDCG@10 | 0.2779 | 0.2875 | 0.4456 | 0.4680 | 0.4557 | 0.1837 | 0.4759 | 0.3214 | 0.5360 | 14.5% | 12.6% |
| Steam | Hit@10 | 0.7172 | 0.7061 | 0.7731 | 0.7710 | 0.7624 | 0.4190 | 0.8018 | 0.7874 | 0.8729 | 13.2% | 8.9% |
| Steam | NDCG@10 | 0.4535 | 0.4436 | 0.5193 | 0.5011 | 0.4852 | 0.2691 | 0.5595 | 0.5381 | 0.6306 | 21.4% | 12.7% |
| ML-1M | Hit@10 | 0.4329 | 0.5781 | 0.6986 | 0.7599 | 0.6413 | 0.5581 | 0.7501 | 0.7886 | 0.8245 | 8.5% | 4.6% |
| ML-1M | NDCG@10 | 0.2377 | 0.3287 | 0.4676 | 0.5176 | 0.3969 | 0.3381 | 0.5513 | 0.5538 | 0.5905 | 14.1% | 6.6% |
实验结论分析:
-
整体趋势:在所有 4 个数据集上,SASRec 均取得最佳性能,平均较最强 baseline 在 Hit Rate 上提升 6.9%,在 NDCG 上提升 9.6%。
-
稀疏 vs 稠密的分水岭:非神经方法(PopRec 到 TransRec)在稀疏数据集(Beauty、Games)上通常优于早期神经方法(GRU4Rec),而神经方法(GRU4Rec+、Caser)在稠密数据集(Steam、ML-1M)上更强。这是因为神经方法参数多、表达力强,但在数据不足时容易过拟合;简单模型反而更有效。
-
SASRec 的自适应性:SASRec 在稀疏和稠密数据集上均表现最佳。这得益于 self-attention 机制的自适应性——在稀疏数据集上,注意力倾向于聚焦最近的少数物品(类似 MC),在稠密数据集上则考虑更多历史物品(类似 RNN)。
隐维度影响¶
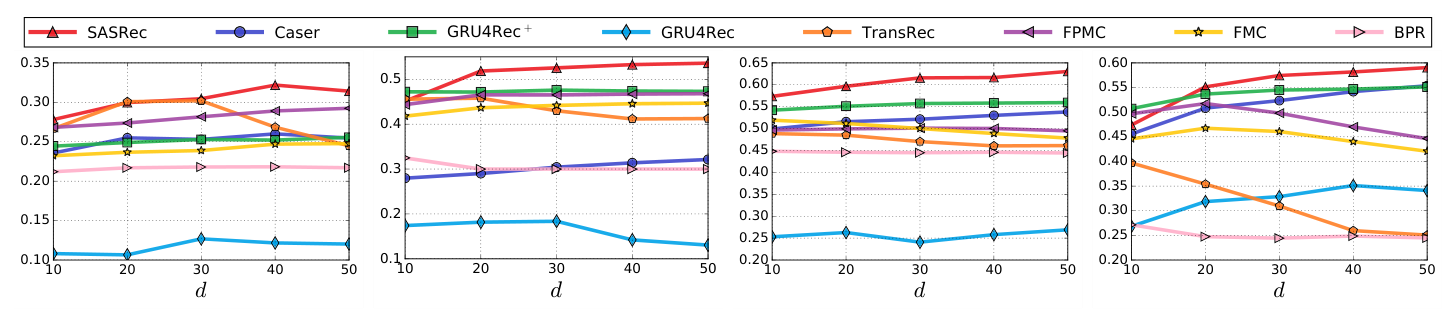
Figure 2 展示了所有方法在 $d$ 从 10 到 50 变化时的 NDCG@10。所有数据集上,SASRec 在 $d \geq 40$ 时即可达到满意性能。模型普遍从更大的隐维度中获益。
消融与分析¶
消融实验(RQ2)¶
Table IV 展示了默认模型和 8 种变体在 4 个数据集上的 NDCG@10($d = 50$):
| 架构变体 | Beauty | Games | Steam | ML-1M |
|---|---|---|---|---|
| (0) Default | 0.3142 | 0.5360 | 0.6306 | 0.5905 |
| (1) Remove PE | 0.3183 | 0.5301 | 0.6036 | 0.5772 |
| (2) Unshared IE | 0.2437↓ | 0.4266↓ | 0.4472↓ | 0.4557↓ |
| (3) Remove RC | 0.2591↓ | 0.4303↓ | 0.5693 | 0.5535 |
| (4) Remove Dropout | 0.2436↓ | 0.4375↓ | 0.5959 | 0.5801 |
| (5) 0 Block (b=0) | 0.2620↓ | 0.4745↓ | 0.5588↓ | 0.4830↓ |
| (6) 1 Block (b=1) | 0.3066 | 0.5408 | 0.6202 | 0.5653 |
| (7) 3 Blocks (b=3) | 0.3078 | 0.5312 | 0.6275 | 0.5931 |
| (8) Multi-Head | 0.3080 | 0.5311 | 0.6272 | 0.5885 |
注:↓ 表示性能下降超过 10%。
逐项分析:
-
移除位置嵌入 (1):在最稀疏的 Beauty 上反而略有提升,但在其他数据集上性能下降。这表明在极稀疏场景下,用户序列很短,位置信息不重要,注意力权重主要依赖物品 embedding 本身即可。
-
非共享物品 Embedding (2):使用两套独立 embedding(输入和输出各一套)导致所有数据集上的严重性能下降。这可能是因为参数翻倍导致过拟合。
-
移除残差连接 (3):性能显著下降,尤其在稀疏数据集上。这是因为残差连接让最后一个物品的 embedding 能直接传播到最终层,对稀疏场景下"最后一个物品决定下一个物品"的模式至关重要。
-
移除 Dropout (4):性能下降,尤其在稀疏数据集上更严重。稠密数据集上过拟合问题相对较轻。
-
Block 数量 (5)-(7):0 个 block 性能最差(仅依赖最后一个物品);1 个 block 效果不错;2 个 block(默认配置)在稠密数据集上进一步提升;3 个 block 与 2 个 block 性能相近。说明层次化的 self-attention 结构有助于学习更复杂的物品转移模式。
-
Multi-Head Attention (8):使用 2 个头的 multi-head attention 效果略差于单头。作者推测这是因为推荐问题中 $d$ 较小(如 50),不适合拆分为更小的子空间(在 Transformer 中 $d = 512$)。
训练效率与可扩展性(RQ3)¶
训练速度:在单张 GTX-1080 Ti GPU 上,SASRec 每个 epoch 仅需 1.7 秒(ML-1M 数据集),而 Caser 需要 19.1 秒/epoch,GRU4Rec+ 需要 30.7 秒/epoch。SASRec 比 Caser 快 11 倍以上,比 GRU4Rec+ 快 18 倍。
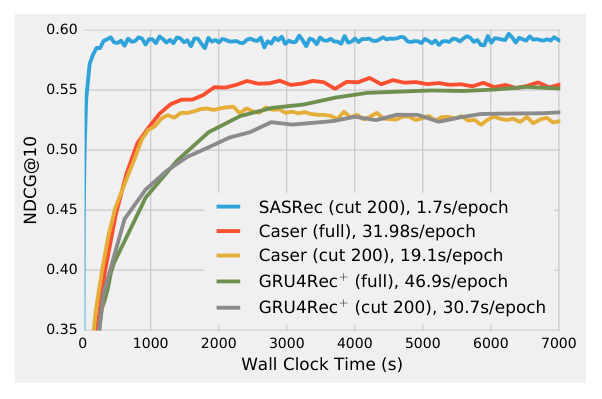
收敛时间:SASRec 在约 350 秒内达到最优性能,而其他方法需要更长时间。
可扩展性(Table V):改变最大序列长度 $n$,测量训练时间和 NDCG@10:
| $n$ | 10 | 50 | 100 | 200 | 300 | 400 | 500 | 600 |
|---|---|---|---|---|---|---|---|---|
| 时间(秒) | 75 | 101 | 157 | 341 | 613 | 965 | 1406 | 1895 |
| NDCG@10 | 0.480 | 0.557 | 0.571 | 0.587 | 0.593 | 0.594 | 0.596 | 0.595 |
性能在 $n \approx 500$ 时饱和(覆盖 99.8% 的用户行为),且即使 $n = 600$ 仍可在 2000 秒内完成训练,仍然快于 Caser 和 GRU4Rec+。
注意力权重可视化(RQ4)¶
位置注意力模式:

Figure 4 展示了 4 种设定下的平均注意力权重热力图:
- (a) Beauty, Layer 1:模型倾向于关注最近的物品,呈现类似一阶 MC 的模式,与稀疏数据集的特点一致。
- (b) ML-1M, Layer 1, w/o PE:没有位置嵌入时,注意力权重在所有位置上近乎均匀分布。
- (c) ML-1M, Layer 1:有位置嵌入的默认模型在稠密数据集上更倾向于关注最近的物品,说明位置信息有助于模型聚焦。
- (d) ML-1M, Layer 2:第二层注意力更聚焦于最近的位置。这可能是因为第一层已经聚合了所有历史物品的信息,第二层不需要再远距离关注。
整体来看,self-attention 机制表现出自适应、位置感知、层次化的行为。
物品间注意力模式:
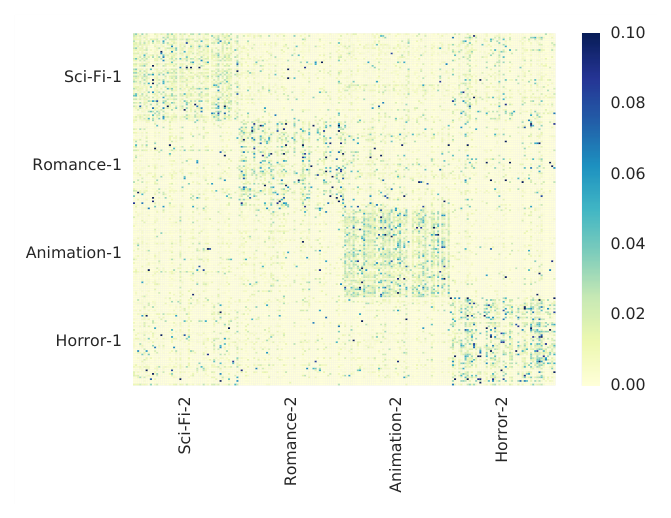
Figure 5 在 MovieLens-1M 上选取 4 个电影类别(Sci-Fi、Romance、Animation、Horror),各 200 部,展示类别之间的平均注意力权重。热力图近似为块对角矩阵,说明注意力机制能识别同类物品并赋予更高权重——这一切无需任何类别标签的监督。
讨论与局限性¶
核心贡献¶
- 首次将纯 self-attention 架构引入序列推荐:不依赖任何 RNN 或 CNN 组件,完全基于 self-attention 建模序列模式。
- 统一了 MC 和 RNN 两种范式的优点:通过自适应的注意力权重,在稀疏数据上表现得像 MC(聚焦少量近期物品),在稠密数据上表现得像 RNN(利用长程依赖)。
- 训练效率大幅提升:比 CNN/RNN 方法快一个数量级,得益于 self-attention 的完全并行化。
- 理论优雅性:SASRec 可以被视为 FMC、FPMC、FISM 等经典模型的泛化形式。
值得借鉴的设计¶
- 共享物品 Embedding:在输入和输出端共享同一物品 embedding 矩阵,既减少参数又提升性能,通过 FFN 的非线性变换实现非对称转移建模。
- 因果 mask 的使用:保证训练时信息不从未来泄露到过去,使得模型可以在每个时间步同时预测所有位置的下一个物品。
- 自适应注意力机制:无需人为指定 MC 阶数或 RNN 隐状态维度,模型自动学习应该关注哪些历史物品。
局限性¶
- 长序列处理:self-attention 的时间复杂度为 $O(n^2 d)$,对于极长的用户行为序列(如点击流)可能不可承受。作者提出了 restricted self-attention 和序列分段两种未来方向。
- 仅建模物品 ID 序列:未利用物品的内容特征(如文本、图片)、用户画像、时间戳、行为类型等丰富的上下文信息。
- 未在工业场景验证:实验仅在学术 benchmark 上进行,未验证在大规模工业推荐系统中的效果。
- 单头注意力优于多头:在推荐场景中隐维度 $d$ 较小(如 50),multi-head attention 的子空间过小,反而影响性能。这与 NLP 中的经验相反。
- 评测协议的局限:采用随机采样 100 个负样本的评估方式,可能与全排序评估结果存在偏差。
历史影响¶
SASRec 是序列推荐领域的里程碑式工作,后续大量方法(如 BERT4Rec、S3-Rec、CL4SRec、HSTU 等)均以 SASRec 为重要 baseline 或在其架构基础上改进。SASRec 证明了 Transformer 架构在推荐系统中的有效性,开启了推荐系统中 self-attention 方法的研究热潮。