Bending the Scaling Law Curve in Large-Scale Recommendation Systems¶
研究动机与背景¶
基于 Transformer 的序列建模已成为大规模推荐系统的新范式。HSTU (Hierarchical Sequential Transduction Units) 作为这一方向的代表性工作,首次在推荐系统中展示了类似大语言模型的有利 scaling law,并被 Meta、抖音、美团、阿里、快手、小红书、LinkedIn 等多家公司广泛采用。
然而,HSTU 等 Transformer 推荐模型面临 $O(L^2)$ 的自注意力复杂度瓶颈,当用户行为序列长度达到 $O(10k)$ 到 $O(100k)$ 时,在亚秒级延迟约束下难以部署。为缓解这一问题,工业界主流方案采用交叉注意力 (cross-attention),即仅用排序候选或截断后的用户历史作为 query,而非完整的自注意力。这些方法虽然大幅降低了计算复杂度,但同时也放弃了自注意力机制和深层网络架构带来的表征能力优势。
本文的核心发现是:自注意力在深度扩展方面仍然优于交叉注意力(见 Table 1 和 Table 5),特别是在需要更多层或更大计算量的场景下。因此,本文的方向不是消除自注意力,而是通过模型与系统的端到端联合优化(co-design),高效地发挥自注意力的优势,其优化思路受 DeepSeek-V2 启发。
作者提出 ULTRA-HSTU,在原始 HSTU 基础上实现了超过 5x 训练 scaling efficiency 和 21x 推理 scaling efficiency 的提升,有效地"弯曲"了推荐系统的 scaling law 曲线。ULTRA-HSTU 已在 Meta 大规模视频推荐平台部署,服务数十亿用户,线上消费指标提升 4%-8%,Top-line 指标提升 0.217%。
核心方法与模型架构¶
整体架构¶
ULTRA-HSTU 的整体架构如 Figure 2 所示,包含四个关键创新方向:(a) 输入序列优化、(b) 动作感知的序列特征预处理、(c) Semi-Local Attention 稀疏注意力、(d) Attention Truncation 动态拓扑设计。
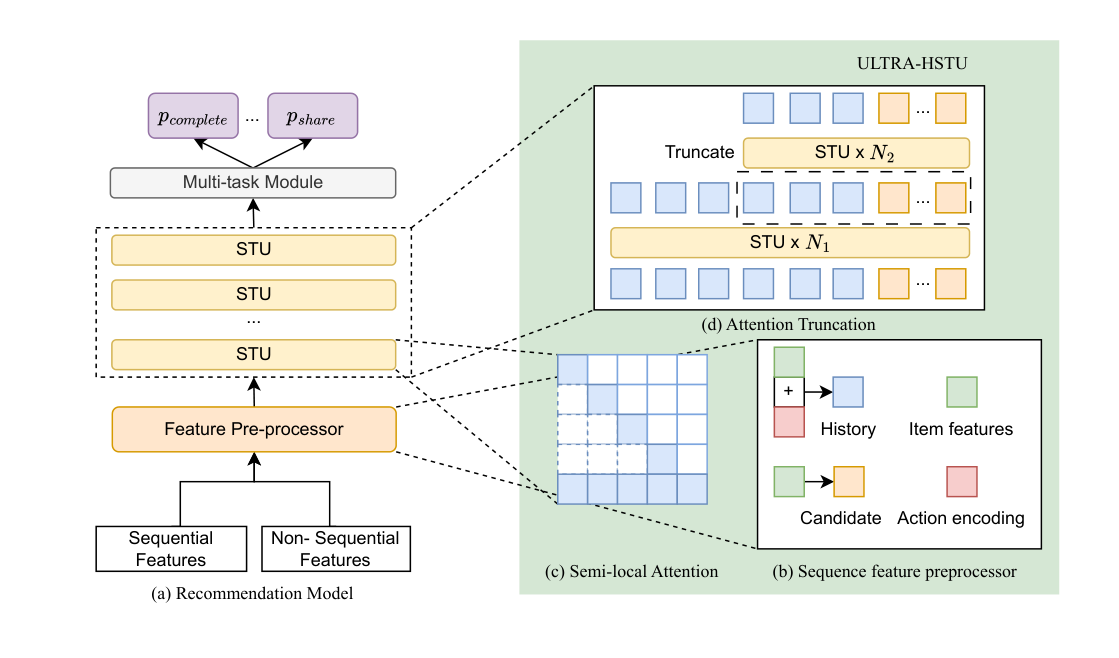
背景:HSTU 基础架构¶
ULTRA-HSTU 基于原始 HSTU 架构。给定用户 $i$ 的用户交互历史 (UIH) $X_i = \{I_i, A_i\}$,其中物品 embedding $I_i = \{I_{i,j}\}_{j=1}^{L_i} \in R^{L_i, d}$,动作 embedding $A_i = \{a_{i,j}\}_{j=1}^{L_i} \in R^{L_i, d}$。HSTU 的核心计算流程为:
$$\text{normalization: } X = \text{Norm}(Z) \tag{1}$$
$$\text{pre-attention: } U, Q, K, V = \phi_1(f_1(X)) \tag{2}$$
$$\text{attention: } A = \left(\phi_2(QK^T) \odot M\right)V \tag{3}$$
$$\text{post-attention: } Y = f_2\left(\text{Norm}(A) \odot U\right) \tag{4}$$
$$\text{residual connection: } Z = Y + Z \tag{5}$$
其中 $\odot$ 表示逐元素乘积,$f_1$ 和 $f_2$ 是 MLP(用于 pre-attention 和 post-attention 投影),$\phi_1$ 和 $\phi_2$ 是 SiLU 激活函数,$M$ 是因果注意力掩码。
4.1 输入序列优化¶
Item-Action 合并编码¶
原始 HSTU 将物品和动作交错排列为 $\{I_{i,1}, a_{i,1}, I_{i,2}, a_{i,2}, \ldots, I_{i,L_i}, a_{i,L_i}\}$,这导致排序阶段的序列长度翻倍。直接合并物品和动作可能泄漏候选物品的动作信息,因此 ULTRA-HSTU 将候选位置的动作 embedding 置零:$a_{i,j} = 0_d$(若 $j$ 是待排序候选)。最终,用户 $i$ 的序列输入为 $X_i = \{x_{i,j}\}_{j=1}^{L_i}$,其中 $x_{i,j} = I_{i,j} + a_{i,j}$。
作者假设通过动作编码的梯度可以更容易地传播。此外,ULTRA-HSTU 进一步增强了异质动作编码 (heterogeneous action embeddings),从隐式和显式信号以及用户上下文特征中构建。这一设计将序列长度减少为原始 HSTU 中 UIH 长度的一半,同时不牺牲模型质量。
负载均衡随机长度 (Load-Balanced Stochastic Length, LBSL)¶
原始 HSTU 使用 Stochastic Length (SL) 在训练阶段随机将用户历史截断至 $L^{\alpha/2}$($\alpha \in (1,2)$),将计算复杂度从 $O(L^2)$ 降至 $O(L^\alpha)$。但在分布式训练中,各 rank 的采样独立进行,导致输入/输出负载显著不均衡,降低同步训练效率。
LBSL 显式控制每个 rank 的计算负载。定义一个 rank 的负载为 $\sum_{u \in \text{rank}} n_u^\gamma$($n_u$ 为用户 $u$ 的序列长度,$\gamma \in (1,2)$ 捕捉 HSTU 的超线性成本)。LBSL 分三阶段运行:
- 预热阶段:使用标准 SL 截断,同时估计全局目标负载 $\bar{\ell}$
- 约束采样阶段:自适应选择未采样集合,使每个 rank 的实际负载尽可能接近目标 $\bar{\ell}$,同时保留 SL 对短序列的偏向(通过权重 $p_u$ 和加权无放回采样 + 贪心填充)
- 周期性重校准:在可配置间隔重新估计 $\bar{\ell}$ 以跟踪生产长度分布的缓慢变化
LBSL 使训练吞吐量提升 15%。
4.2 模型-系统联合优化¶
4.2.1 Semi-Local Attention (SLA)¶
原始 HSTU 使用全因果自注意力掩码:
$$A(X) = \phi_2\left(Q(X)K(X)^T\right) \odot MV(X) \tag{6}$$
其中 $M \in R^{L \times L}$,$M_{i,j} = 1$ 仅当 $j \leq L - i$(因果掩码)。这导致 $O(L^2)$ 的计算复杂度。
ULTRA-HSTU 提出 Semi-Local Attention (SLA),定义两个超参数:局部窗口大小 $K_1$ 和全局窗口大小 $K_2$。注意力掩码定义为:
$$M_{i,j} = \begin{cases} 1 & \text{if } L - K_1 \leq i + j \leq L \\ 1 & \text{if } j \leq K_2 \text{ and } j \leq L - i \\ 0 & \text{otherwise} \end{cases} \tag{7}$$
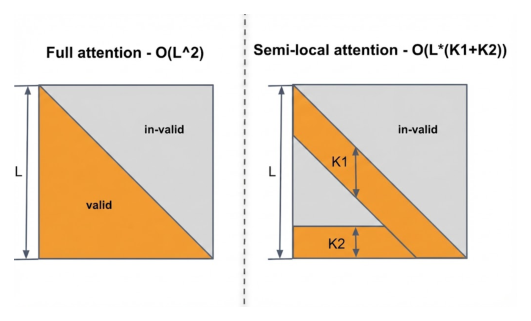
局部窗口 $K_1$ 控制最近用户行为的注意力范围,全局窗口 $K_2$ 聚焦于最早的 UIH 注意力模式,捕获用户长期兴趣。计算复杂度降为 $O((K_1 + K_2) \cdot L)$,即线性复杂度。
与 DeepSeek 的 Native Sparse Attention (NSA) 相比(仅使用局部窗口),SLA 同时使用局部和全局窗口。实验表明两者缺一不可:仅启用全局窗口($K_1=0$)导致 0.03% C-NE 退化,仅启用局部窗口($K_2=0$)导致 0.35% C-NE 退化,说明全局窗口在推荐场景中更为重要(用户长期行为模式对推荐至关重要)。
SLA 将推理 scaling efficiency 提升 5x 以上。
4.2.2 系统优化¶
混合精度训练与推理框架。ULTRA-HSTU 设计了推荐系统定制的 16/8/4-bit 混合精度框架:
- 大部分运算保持 BF16 以确保稳定性
- 主要的 GEMM 计算使用 FP8 加速
- 推理阶段的 embedding 通信使用 INT4 量化
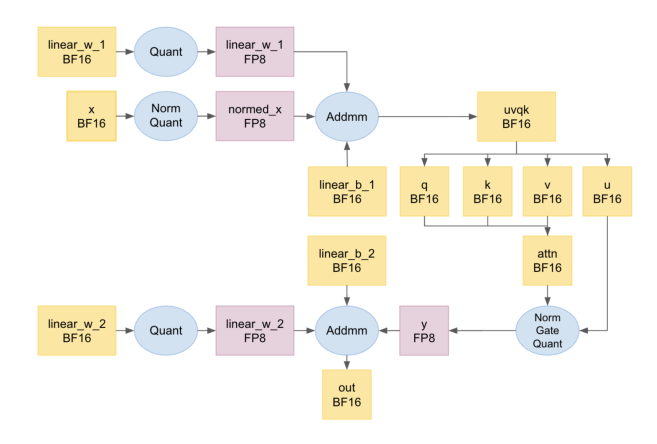
具体地,每层 HSTU 包含两个 GEMM:pre-attention 投影(将 $X$ 映射到 $U,Q,K,V$)和 post-attention 投影。两个 GEMM 均以 FP8 执行,其余运算保留 BF16。
关键技术细节:
- 融合量化内核:将逐行缩放和量化操作融合到前序内核中,消除额外的内存访问开销
- 2D bias 支持的 Triton FP8 GEMM:post-attention 投影需要与 2D 残差张量累加(Equation 5),PyTorch 内核仅支持 1D bias。作者开发了原生支持 2D bias 的 Triton FP8 内核,利用持久化调度、TMA、warp 专用化和 epilogue 流水线实现高吞吐量
- INT4 稀疏 embedding 量化:使用分组 INT4 量化(每行多个缩放因子),在推理阶段减少主机到设备的 embedding 传输量约 40%,峰值 QPS 提升超过 20%
混合精度框架在训练和推理中分别带来 10% 和 40% 的吞吐量提升。
高效 SLA 内核(异构硬件)。原始 HSTU 的注意力内核基于 Triton 实现 FlashAttention-V2 算法。ULTRA-HSTU 改进如下:
- NVIDIA H100:采用 FlashAttention-V3 设计,支持 HSTU 的非标准注意力(逐点 SiLU 激活 + SLA 掩码),实现 CUDA 内核族(全注意力和 SLA),比 FA-V2 baseline 快 2x
- AMD MI300x:由于缺乏 H100 的 TMA 和 warp 专用化异步执行特性,引入 MI300x 原生优化:XCD 感知调度、LDS 布局、显式 VMEM/MFMA 交错,比 Triton 内核 baseline 快 2x
内存优化。注意力实现的前向传播占用大量 GPU HBM,是超长序列训练的主要瓶颈:
- 选择性激活重材料化 (Selective Activation Rematerialization):跳过保存 6 个大型前向张量,在反向传播中以最小开销重建(复用保存的 layer-norm 统计量重建 normed $X$,重跑 GEMM 恢复 $U,Q,K,V$,在融合门控归一化内核中计算中间值 $Y$)。仅 5% 的额外开销,实现每层 67% 的内存减少
- 消除梯度拼接开销:消除 $dU, dQ, dK, dV$ 的梯度拼接,减少内存和内核开销
- 全 jagged tensor 训练:消除 padding 为密集张量的需求
以 512 维 embedding、256 batch size、3k 序列长度、BF16 为例,HBM 使用量从每层 7GB 降至 2.3GB。
4.3 动态拓扑设计¶
Attention Truncation¶
简单堆叠 HSTU + SLA 层的成本为 $O(DL)$($D$ 为深度),当 $L$ 超过 10k 时,更多层带来显著的训练、内存和推理开销。
核心洞察:不同用户信号的预测价值不同。用户最近的交互历史往往最重要。因此 ULTRA-HSTU 提出:
- 在完整序列上运行 $N_1$ 层 HSTU
- 从完整序列中选取长度为 $L'$ 的片段(实践中截取最近的 UIH 效果最好)
- 在截断片段上再堆叠 $N_2$ 层 HSTU
这实现了有针对性的计算资源分配:深层集中在高价值序列,浅层处理完整上下文。
Mixture of Transducers (MoT)¶
推荐模型天然处理多种输入序列(来自不同来源和类型的用户互动信号)。将所有信号聚合为单一序列会稀释高价值信号。MoT 通过独立的 transducer 处理不同的行为序列(如消费序列 C-seq 和互动序列 E-seq),再融合用户 embedding。这允许灵活的计算资源分配:
- 不同模块可以分配不同深度
- 分拆后的短序列显著降低注意力计算量
Attention Truncation 和 MoT 兼容且可组合。实验中主要使用 Attention Truncation(因其简单性和强大的效率-质量权衡),MoT 的研究详见附录 A。
实验设置¶
评估指标¶
使用 Normalized Entropy (NE) 衡量模型质量:
$$\text{NE} = \frac{-\frac{1}{N}\sum_{i=1}^{N}(y_i \log p_i + (1-y_i)\log(1-p_i))}{-p\log p - (1-p)\log(1-p)} \tag{8}$$
其中 $N$ 为样本数,$y_i \in \{0,1\}$ 为标签,$p_i$ 为模型预测,$p = \sum_i y_i / N$ 为正样本频率。NE 越低模型越好。报告 C-NE(消费任务,如视频完播)和 E-NE(互动任务,如分享)两个指标。根据经验,0.03%-0.05% 的 NE 改进即被视为显著,能带来可观的线上收益。
工业数据集¶
- 来自 Meta 大规模视频推荐平台的用户行为日志
- 超过 60 亿 训练样本
- 序列长度范围 3,072 - 16,384
- 时序划分:85% 训练 / 15% 评估
- 使用 LBSL 控制训练序列长度
Baseline 模型¶
- 短序列方法:DIN、SASRecs
- 长序列方法:Vanilla HSTU、STCA(Stacked Target-to-History Cross Attention)
- 内部优化 Transformer:增加了额外投影和归一化以稳定训练
公开数据集¶
KuaiRand(序列长度 256)用于验证通用性。
主要实验结果¶
5.1.2 工业数据集整体性能 (Table 1)¶
序列长度固定为 3,072,调整模型深度/参数量使各方法的 FLOP 近似匹配:
| Model | Delta C-NE | Delta E-NE |
|---|---|---|
| ULTRA-HSTU | 0% | 0% |
| HSTU | +0.43% | +0.04% |
| STCA | +0.94% | +0.74% |
| Transformer | +0.57% | +0.59% |
| DIN | +1.41% | +1.91% |
| SASRecs | +1.12% | +1.28% |
ULTRA-HSTU 显著优于所有方法。STCA 虽然使用交叉注意力实现线性复杂度,但因缺乏自注意力的表征能力,性能不及 ULTRA-HSTU。值得注意的是正值表示退化,ULTRA-HSTU 作为基准为 0%。
5.1.3 Scaling Law (Table 2)¶
固定 embedding 维度 $d = 512$,变化层数(6-18)和序列长度 $L \in \{3072, 8192, 16384\}$:
| Model | Sequence Length | # Layers | Delta C-NE | Training TFLOP | Inference TFLOP |
|---|---|---|---|---|---|
| HSTU | 3072 | 6 | 0.0% | 0.085 | 0.118 |
| HSTU | 8192 | 11 | -0.34% | 0.735 | 2.756 |
| HSTU | 16384 | 10 | -0.44% | 1.584 | 4.692 |
| ULTRA-HSTU | 3072 | 14 | -0.00% | 0.119 (up 40.0%) | 0.070 (down 40.7%) |
| ULTRA-HSTU | 8192 | 18 | -0.58% | 0.414 (down 43.7%) | 0.337 (down 87.8%) |
| ULTRA-HSTU | 16384 | 18 | -0.78% | 0.639 (down 59.7%) | 0.436 (down 90.7%) |
随着序列长度和层数增加,ULTRA-HSTU 的效率优势急剧扩大。在 16384 长度下,ULTRA-HSTU 以不到原始 HSTU 一半的训练 FLOP 和不到十分之一的推理 FLOP,达到更好的 C-NE。
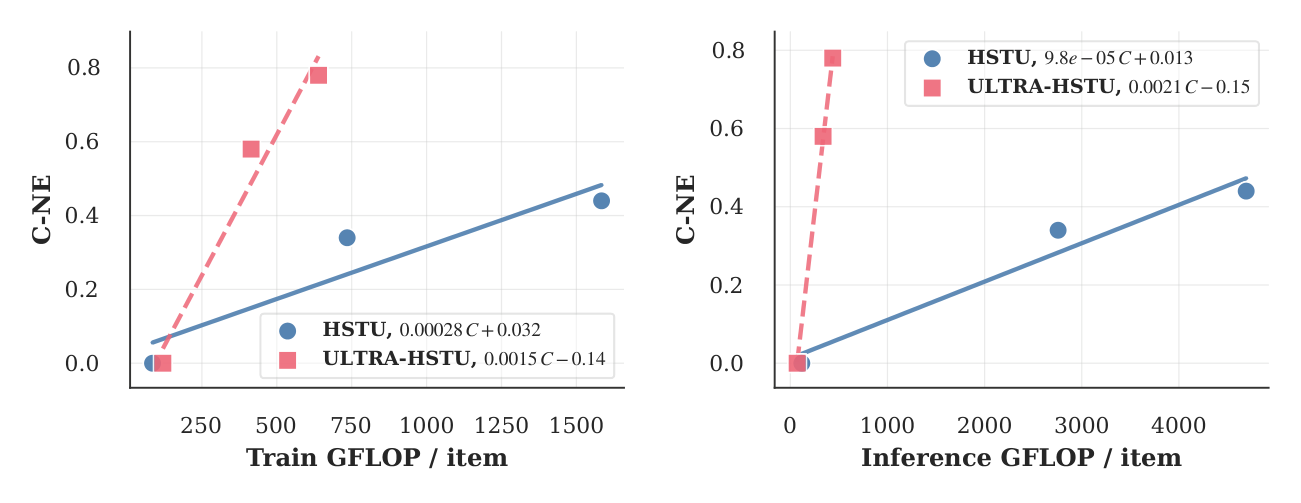
通过拟合 C-NE 对计算成本的线性回归,ULTRA-HSTU 实现了 5.3x 训练 scaling efficiency 提升 和 21.4x 推理 scaling efficiency 提升。
5.2 KuaiRand 公开数据集 (Table 3)¶
即使在短序列(长度 256)场景下,ULTRA-HSTU 也以最低的训练和推理 TFLOP 取得最佳 NE:
| Model | Training TFLOP | Inference TFLOP | NE |
|---|---|---|---|
| STCA | 626.49 | 208.75 | 0.8689 |
| Transformer | 802.39 | 267.46 | 0.8688 |
| SASRec | 550.92 | 176.51 | 0.8804 |
| DIN | 505.08 | 168.36 | 0.8685 |
| HSTU | 617.78 | 198.80 | 0.8676 |
| ULTRA-HSTU | 504.41 | 166.41 | 0.8626 |
STCA 在短序列场景下因昂贵的 pre-attention 投影而效率不佳。
消融与分析¶
5.3.1 输入序列优化¶
- 移除 item-action 交错排列 → 序列长度减半,训练 FLOP 减少 32.5%,推理 FLOP 减少 63.5%(UIH 长度 3072 时)
- 异质动作编码构建 → 相比 baseline 带来 0.45% C-NE 增益
- LBSL → 在世界大小 512 时实现 15% 训练加速
5.3.2 Semi-Local Attention (SLA)¶
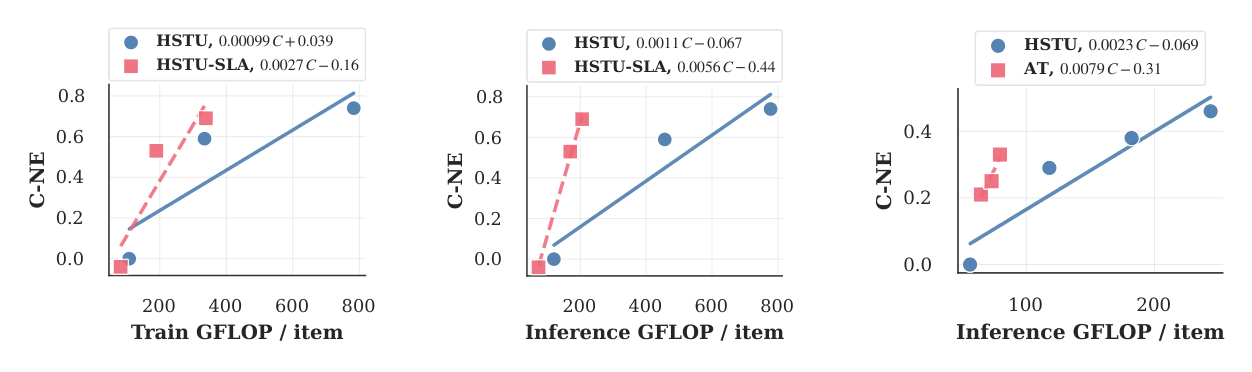
SLA 显著改善了 scaling law:训练 scaling efficiency 提升 2.7x,推理 scaling efficiency 提升 5.1x。
局部窗口 vs 全局窗口消融:
- 仅全局窗口($K_1=0$):0.03% C-NE 退化
- 仅局部窗口($K_2=0$):0.35% C-NE 退化
这说明全局窗口比局部窗口更重要,与 DeepSeek NSA(仅用局部窗口)的设计有本质区别。
5.3.3 动态拓扑设计¶
Attention Truncation 在推理端表现尤为突出。实验使用 $n_1$ 层全序列(3072)+ $n_2$ 层截断序列(512),$n_1 = 3,6,9$ 且 $n_2 = 0,3,6,9,12$。
| Model | Setup | Train TFLOP | Inference TFLOP | Delta C-NE | Delta E-NE |
|---|---|---|---|---|---|
| Vanilla HSTU | 3-layer | 0.0427 | 0.0561 | 0.00% | 0.00% |
| Vanilla HSTU | 6-layer | 0.0851 | 0.1180 | -0.29% | -0.27% |
| Vanilla HSTU | 9-layer | 0.1284 | 0.1821 | -0.38% | -0.47% |
| Vanilla HSTU | 12-layer | 0.1705 | 0.2438 | -0.46% | -0.65% |
| AT | 3-layer HSTU + 3-layer AT | 0.0626 | 0.0646 | -0.21% | -0.24% |
| AT | 3-layer HSTU + 6-layer AT | 0.0825 | 0.0729 | -0.25% | -0.31% |
| AT | 3-layer HSTU + 9-layer AT | 0.1020 | 0.0795 | -0.33% | -0.35% |
例如,3-layer HSTU + 6-layer AT 与 6-layer vanilla HSTU 相比,C-NE 和 E-NE 指标持平或更好,但训练 TFLOP 节省 3%,推理 TFLOP 节省 38%。在长序列(16384)下推理端的 scaling efficiency 提升达 3.4x。
Mixture of Transducers (MoT) (Table 8)¶
| Config | Raw Seq Length | Delta C-NE | Delta E-NE | Training TFLOP | Inference TFLOP |
|---|---|---|---|---|---|
| MoT vs 3k HSTU | 2k C-seq + 1k E-seq | +0.01% | -1.00% | 0.138 (up 6%) | 0.076 (down 53%) |
| MoT vs 16k HSTU | 10k C-seq + 3k E-seq | +0.05% | -0.30% | 0.872 (down 45%) | 1.03 (down 69%) |
MoT 在 E-NE 上显著优于单一序列 HSTU(E-NE 提升高达 1%),同时大幅降低推理 FLOP(最高降低 69%)。通过将异质信号解耦到专用模块,MoT 缓解了信号竞争问题。
深度扩展:自注意力 vs 交叉注意力 (Table 5)¶
| Attention Type | # Layers | Delta C-NE | Delta E-NE |
|---|---|---|---|
| Cross-attention | 3 | 0.00% | 0.00% |
| Cross-attention | 6 | -0.09% | -0.05% |
| Cross-attention | 9 | -0.14% | -0.15% |
| Cross-attention | 12 | -0.14% | -0.17% |
| Self-attention | 3 | 0.00% | -0.27% |
| Self-attention | 6 | -0.29% | -0.27% |
| Self-attention | 9 | -0.38% | -0.47% |
| Self-attention | 12 | -0.46% | -0.65% |
在序列长度 3072 附近,交叉注意力在 9 层时性能趋于饱和,而自注意力随层数增加持续提升。这一关键发现是 ULTRA-HSTU 选择保留自注意力的核心依据。
Scaling Law 分析 (Appendix F)¶
假设 NE 作为计算预算 $C$ 的函数遵循幂律形式:
$$L(C) = \alpha C^{-\beta} \tag{9}$$
由于假设 $L(C) \to 0$ 当 $C \to \infty$,估计的 scaling exponent 为:
$$\hat{\beta} = \beta^* \left(1 - \frac{L_\infty}{L}\right) \tag{10}$$
其中 $\beta^*$ 是真实参数,$L_\infty$ 是不可约误差。两个模型的 scaling 比率:
$$\frac{\hat{\beta}_1}{\hat{\beta}_2} = \frac{\beta_1^*}{\beta_2^*} \cdot \frac{(1-L_\infty/L_1)}{(1-L_\infty/L_2)} = \frac{\beta_1^*}{\beta_2^*} R \tag{11}$$
ULTRA-HSTU 对 HSTU 的 scaling exponent 改进:训练 FLOP 维度 3.09x,推理 FLOP 维度 3.52x。
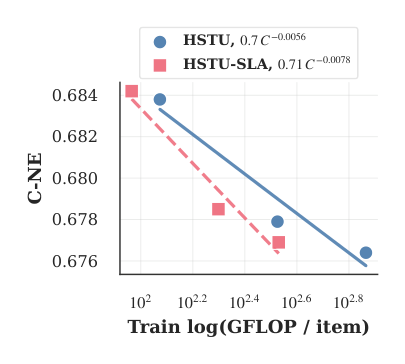
SLA 单独贡献:训练 scaling exponent 提升 1.39x,推理提升 1.69x。AT 单独在推理端提升 1.8x。
系统效率基准¶
FP8 GEMM 效率 (Table 7):
| (m, k & n) | Bias-Fused FP8 | Bias-Split FP8 | BF16 |
|---|---|---|---|
| (1M, 512) | 414 | 236 | 292 |
| (1M, 1K) | 734 | 468 | 410 |
| (250K, 512) | 414 | 238 | 281 |
| (250K, 1K) | 721 | 466 | 399 |
融合 2D bias 的 FP8 GEMM(Bias-Fused FP8)比 Torch FP8 + 分离 bias(Bias-Split FP8)快 1.75x。
FP8 端到端加速 (Table 10):
| Part | Quant-Fused FP8 | Quant-Separate FP8 |
|---|---|---|
| Pre-attn | 3.19X | 2.34X |
| Post-attn | 1.99X | 1.01X |
融合量化的 FP8 方案在 pre-attention 阶段相比 BF16 实现 3.19x 加速。
INT4 Embedding 量化 (Table 11):
| Dtype | Latency | Peak QPS |
|---|---|---|
| Int8 | 13ms | 3.6K |
| Int4 | 7.9ms (down 40%) | 4.4K (up 22%) |
INT4 量化将数据传输延迟降低 40%,峰值 QPS 提升 22%,且对线上模型精度无明显影响。
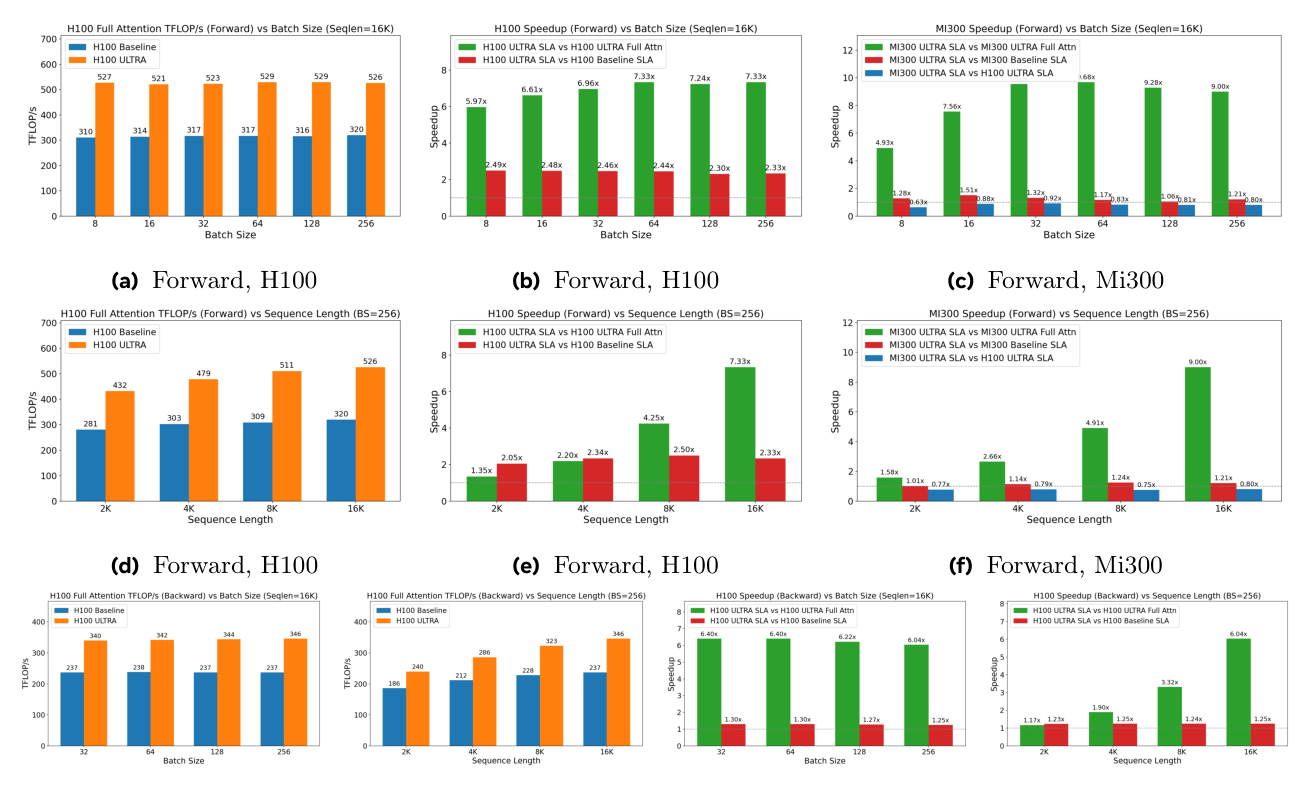
注意力内核效率 (Figure 6):
在 H100 上,ULTRA 的因果注意力实现在 16K 序列长度下达到 520+ TFLOP/s,比 FA-V2 baseline 快 1.64x。SLA 内核在 H100 上最高加速 2.5x。在 MI300x 上,ULTRA 内核最高加速 1.51x。
线上 A/B 实验 (Table 4)¶
将生产模型从 vanilla HSTU 升级为 ULTRA-HSTU(18 层自注意力、16k 用户序列、数百块 H100 GPU 训练),在大规模视频推荐平台上进行 30 天线上 A/B 测试:
| Metric | Gain |
|---|---|
| Online C-Metric 1 | 4.11% |
| Online E-Metric 2 | 2.27% |
| Online E-Metric 3 | 8.2% |
| Online E-Metric 3 | 4.34% |
| Online Top-line 1 | 0.217% |
| Online Top-line 2 | 0.037% |
消费指标提升 4.11%,互动指标提升 2%-8%。Top-line 指标(如日活、访问次数等平台健康指标)提升 0.217% 和 0.037%。在 Meta 的系统中,Top-line 的 0.05% 和消费/互动的个位数百分比提升已被视为重大突破。这是 Meta 推荐平台过去数年最大的模型影响之一。
讨论与局限性¶
核心贡献¶
- Self-attention 优于 Cross-attention 的实证:这是本文最重要的研究发现。虽然工业界为了效率普遍采用交叉注意力,但本文展示了在同等计算预算下,自注意力的深度扩展能力远优于交叉注意力,且这一差距随层数增加而扩大。
- 模型-系统联合优化范式:借鉴 DeepSeek-V2 的思路,将算法创新(SLA、AT、MoT)与系统工程(FP8 内核、内存优化、INT4 量化)深度融合,而非单独优化某一方面。
- Scaling Law 分析方法论:通过拟合幂律模型的 scaling exponent 来量化不同优化的贡献,提供了可解释的效率改善度量。
值得借鉴的设计¶
- SLA 的双窗口设计:局部窗口 + 全局窗口的组合是为推荐场景量身定制的。用户最近行为(局部)和长期偏好(全局/早期行为)对推荐都至关重要,这与 NLP 中纯局部窗口注意力(如 Longformer)有本质区别
- Attention Truncation:极其简洁的深层加速方案,无需额外参数,仅通过截断序列即可在深层节省大量计算
- LBSL:在工业级分布式训练中具有实用价值,可推广到任何使用 Stochastic Length 的训练框架
局限性¶
- 所有核心实验均基于 Meta 内部数据集,可复现性有限。公开数据集(KuaiRand)的序列长度仅为 256,无法充分验证 ULTRA-HSTU 在超长序列上的优势
- 论文仅报告了 NE 指标,未报告 AUC、LogLoss 等常见指标(作者声称这些指标与 NE 方向一致)
- MoT 的实验较为初步(仅在附录中),消费/互动序列的最优拆分策略未深入探讨
- 缺少与其他长序列推荐方案(如 SIM、TWIN、Longer)的直接对比
工业部署价值¶
ULTRA-HSTU 代表了工业推荐系统中模型规模的新标杆:18 层自注意力、16k 序列长度、数百块 H100 训练。线上 4%-8% 的消费/互动提升和 0.217% 的 Top-line 提升在 Meta 的量级下意味着巨大的商业价值。该工作也验证了在推荐系统中持续扩大模型规模和序列长度的方向是可行的。