TokenFormer: Unify the Multi-Field and Sequential Recommendation Worlds¶
研究动机与背景¶
推荐系统长期沿着两条独立路线发展:多域特征交互模型(建模静态类别特征间的关联,如 FM、DeepFM、DCN、xDeepFM)和序列推荐模型(从用户历史行为序列中捕捉兴趣演化,如 SASRec、BERT4Rec、HSTU)。工业级推荐系统通常需要同时处理稀疏异构的多域特征和长行为序列,但这两条路线在算子设计、归纳偏置和 scaling 策略上差异显著,导致统一建模一直是开放挑战。
传统做法通过异构子网络、专家网络或 late-fusion 管线将两者拼接。近期的 InterFormer、OneTrans、HyFormer、Kunlun 等工作虽然在统一方向上迈出一步,但仍在内部保留了结构上的分叉——混合堆叠或交替组件。论文指出,尚不存在一种在单一一致的计算流中原生建模 field-field、sequence-sequence 和 sequence-field 交互的全同构架构。
论文发现了统一建模中一个此前未被充分探索的关键障碍:Sequential Collapse Propagation (SCP)。在工业场景中,许多非序列特征(如人口统计桶、粗粒度上下文)信息量低、基数低,其 embedding 容易坍缩到低维子空间。在分离式模型中,这种坍缩局限于非序列侧。但在统一模型中,坍缩倾向的静态 token 通过共享算子直接与序列行为 token 交互,导致序列表示的维度也发生坍缩。
如 Figure 1 所示,纯序列 Transformer(绿色)保持了较高维的序列表示空间但判别性较弱(缺少非序列信号),而 naive 联合建模 Transformer(蓝色)虽然互信息显著提升,却呈现更陡峭的谱衰减和更低的 effective rank——即 SCP 现象。
值得注意的是,论文对 SCP 的分析停留在现象描述和经验验证层面,未给出坍缩传播的理论机制。注意力算子具体通过什么数学过程将低秩特征的坍缩传递给序列特征(是 softmax 归一化导致的注意力权重集中,还是 value 矩阵的线性组合直接拉低了输出秩),坍缩传播速度与静态特征数量 $M$、基数、序列长度 $T$ 的关系,残差连接为何未能阻止传播——这些关键机制问题均未讨论。Appendix D.2 仅引用了 [12](Ads Recommendation in a Collapsed and Entangled World)的 Interaction Collapse Theory 一句话带过。BFTS 和 NLIR 的设计也是基于直觉而非从坍缩机制推导得出,整体上是工程驱动的发现-解决路径。

为此,论文提出 TokenFormer,一种同构 decoder-only 架构,包含三项核心创新:
- Bottom-Full-Top-Sliding (BFTS) 注意力调度:浅层使用全因果注意力建立全局跨域交互,深层切换为收缩滑动窗口注意力聚焦局部时序精炼
- Non-Linear Interaction Representation (NLIR):对注意力输出施加单侧非线性乘性门控,恢复表示维度鲁棒性
- 统一 token 流:将多域特征、行为序列和目标特征拼接为单一 entity stream,用统一的位置编码和交互块处理
核心方法 / 模型架构¶
问题形式化¶
推荐输入由三组实体构成:非序列多域特征 $\mathcal{F}$、序列行为 token $\mathcal{T}$、目标特征 $\mathcal{V}$。现有模型通常只操作其中一个子集:
- 特征交互模型主要处理 $(\mathcal{F}, \mathcal{V})$:
$$\hat{y} = \phi(g_{\text{FI}}(\mathcal{F}, \mathcal{V})) \tag{1}$$
- 序列模型主要处理 $\mathcal{T}$,或 $(\mathcal{T}, \mathcal{V})$(target-aware):
$$\mathbf{H} = g_{\text{self}}(\mathcal{T}) \tag{2}$$
$$\mathbf{u} = g_{\text{target}}(\mathcal{T}, \mathcal{V}) \tag{3}$$
- 跨特征序列模型处理 $(\mathcal{F}, \mathcal{T})$:
$$\mathbf{z} = g_{\text{cross}}(\mathcal{F}, \mathcal{T}) \tag{4}$$
论文指出,统一推荐可以被形式化为在完整实体集 $\mathcal{E} = \mathcal{F} \cup \mathcal{T} \cup \mathcal{V}$ 上学习所有六种交互类型($\mathcal{F} \leftrightarrow \mathcal{F}$、$\mathcal{T} \leftrightarrow \mathcal{T}$、$\mathcal{V} \leftrightarrow \mathcal{V}$、$\mathcal{T} \leftrightarrow \mathcal{V}$、$\mathcal{F} \leftrightarrow \mathcal{T}$、$\mathcal{F} \leftrightarrow \mathcal{V}$)。TokenFormer 基于这一原则构建。
4.1 统一 Token 流(Unified Entity Stream)¶
TokenFormer 将所有输入拉平为统一 token 序列。设 $M$ 为特征域数量,$T$ 为历史序列长度,$K$ 为目标 item 数量,$N_{\text{sep}}$ 为特殊分隔符数量,则总输入长度为:
$$S_L = \begin{cases} M + T + K + N_{\text{sep}} & \text{without actions,} \\ M + 2T + K + N_{\text{sep}} & \text{with actions,} \end{cases} \tag{6}$$
以 action-aware 场景为例,初始序列构造为:
$$\mathbf{X}^{(0)} = \left[\underbrace{\mathbf{x}_1^{\mathcal{F}}, \ldots, \mathbf{x}_M^{\mathcal{F}}}_{\text{non-seq tokens}}, \mathbf{e}_{\text{sep}}, \underbrace{\mathbf{x}_{a_1}^{\mathcal{T}}, \mathbf{x}_{a_T}^{\mathcal{T}}}_{\text{seq tokens}}, \mathbf{e}_{\text{sep}}, \underbrace{\mathbf{x}_{e_1}^{\mathcal{V}}, \ldots, \mathbf{x}_K^{\mathcal{V}}}_{\text{target tokens}}\right]^\top \tag{7}$$
关键设计:TokenFormer 放弃了显式 type embedding,改用统一的 Rotary Positional Embedding (RoPE) 跨越整个序列。位置分配策略如下:
$$p_i = \begin{cases} 0 & \text{if } x_i \in \mathcal{F}, \\ pos(x_i) & \text{if } x_i \in \mathcal{T}, \\ \bar{S}_L + 1 & \text{if } x_i \in \mathcal{V}, \end{cases} \tag{8}$$
其中 $pos(\cdot)$ 提取行为 token 的时序索引,$\bar{S}_L$ 为最大序列长度。静态特征共享位置 0(映射为前缀),行为 token 按时间顺序排列,目标 token 位于末尾。这一设计保持了静态特征的位置不变性,同时维护了行为序列的时序敏感性。
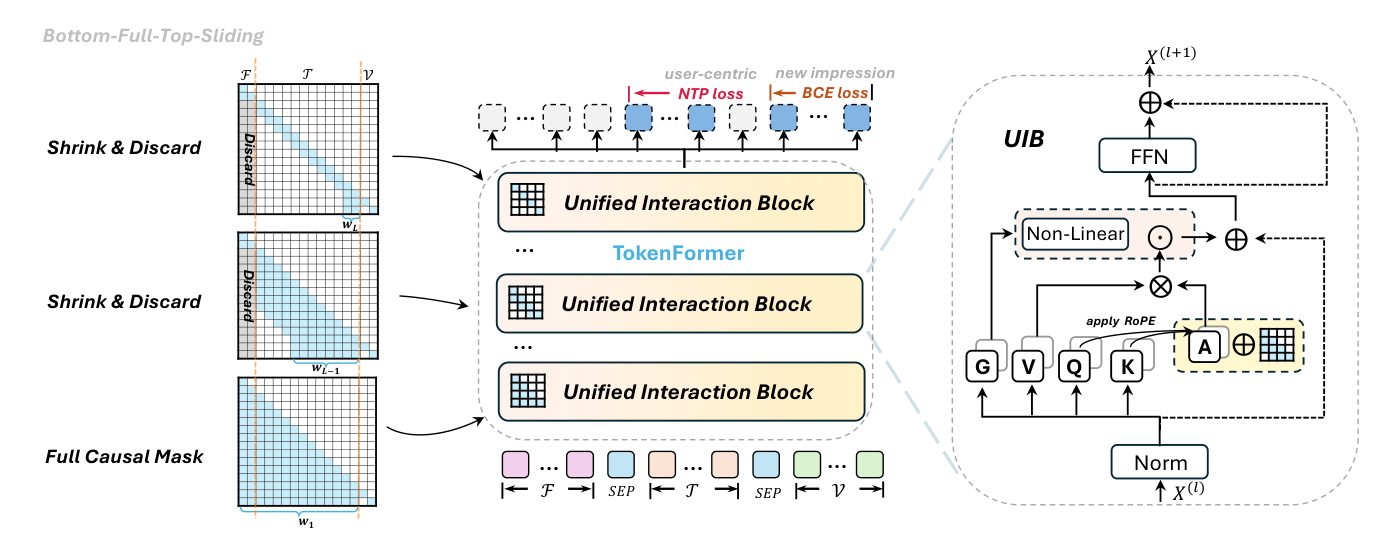
4.2 Unified Interaction Block (UIB)¶
TokenFormer 采用同构 decoder-only 骨干,堆叠 $L$ 个 Unified Interaction Block (UIB)。每个 UIB 是标准注意力块的变体,增加了两项创新:BFTS 注意力调度和 NLIR 门控机制。第 $l$ 层的核心变换为:
$$\tilde{\mathbf{A}}^{(l)} = \text{Attn}(\mathbf{X}^{(l)}, \mathcal{M}_{BFTS}^{(l)}) \tag{9}$$
$$\mathbf{X}^{(l+1)} = \text{FFN}(\text{NLIR}(\tilde{\mathbf{A}}^{(l)}, \mathbf{X}^{(l)})) \tag{10}$$
通过堆叠这样的 block,TokenFormer 在浅层逐步整合全局上下文信息,在深层强调局部时序结构,同时通过非线性交互增强注意力输出的表达力。
4.3 BFTS 注意力机制¶
给定归一化输入 $\mathbf{X}^{(l)}$,先投影为 $\mathbf{Q}$、$\mathbf{K}$、$\mathbf{V}$,用 RoPE 编码相对位置信息,计算注意力输出:
$$\tilde{\mathbf{A}}^{(l)} = \text{Softmax}\left(\frac{\mathcal{R}(\mathbf{Q}, \Theta)\,\mathcal{R}(\mathbf{K}, \Theta)^\top}{\sqrt{d_k}} + \mathcal{M}^{(l)}\right)\mathbf{V} \tag{11}$$
其中 $\mathcal{R}(\cdot, \Theta)$ 为 RoPE 变换,$\mathcal{M}^{(l)}$ 为第 $l$ 层的可见性掩码。
滑动窗口注意力 (SWA):限制每个 token 只关注最近 $w$ 个前驱 token:
$$\mathcal{M}_{i,j}^{(l)} = \begin{cases} 0, & \text{if } j \leq i \text{ and } i - j < w, \\ -\infty, & \text{otherwise.} \end{cases} \tag{12}$$
SWA 将注意力范围从全序列缩减为局部窗口,适用于推荐中大量细粒度行为依赖具有局部性的场景。
为何不能对所有层统一使用 SWA:TokenFormer 的输入序列不仅包含序列行为 token,还包含异构静态特征 token。早期层需要足够宽的感受野来建立全局跨域交互。若从第一层就限制为局部窗口,模型将过早丧失在统一序列上传播全局上下文的能力。
Bottom-Full-Top-Sliding (BFTS) 机制:浅层使用全因果注意力建立全局交互,深层切换为收缩窗口注意力精炼局部时序结构。设 $L$ 层骨干中有 $l_f$ 层全注意力层和 $l_s$ 层滑动窗口层($L = l_f + l_s$),整体变换为:
$$\mathbf{X}^{(L)} = \left(\mathcal{F}_{\text{SWA}}^{(w_1)} \circ \cdots \circ \mathcal{F}_{\text{SWA}}^{(w_{l_s})}\right) \circ \left(\mathcal{F}_{\text{Full}}^{(\infty)} \circ \cdots \circ \mathcal{F}_{\text{Full}}^{(\infty)}\right)(\mathbf{X}^{(0)}) \tag{13}$$
采用收缩窗口策略,窗口大小 $\{w_k\}_{k=1}^{l_s}$ 递减($w_{l_s} < w_{l_s-1} < \cdots < w_1$),层依赖的可见性掩码定义为:
$$\mathcal{M}_{i,j}^{(l)} = \begin{cases} 0, & \text{if } j \leq i \text{ and } i - j < \omega(l), \\ -\infty, & \text{otherwise,} \end{cases} \quad \omega(l) = \begin{cases} \infty, & l \leq l_f, \\ w_l, & l > l_f. \end{cases} \tag{14}$$
窗口大小逐层缩减,迫使模型将宽泛的全局依赖提炼为越来越精细和局部化的表示。
Non-Sequence Token Discarding:静态特征 token $X^{\mathcal{F}}$ 主要在初始层充当全局上下文先验。一旦信息被充分整合到序列表示中,保留它们就变得冗余。因此在第 $l_f$ 层之后,模型完全停止关注前 $M$ 个非序列 token:
$$\mathcal{M}_{i,j}^{(l)} = -\infty, \quad \forall\, l \geq l_f, \quad i \in [M, S_L - 1],\; j \in [0, M-1]. \tag{15}$$
这确保深层将全部表达能力和注意力带宽分配给行为演化和 target-aware 交互,进一步强化跨特征交互在浅层完成的分工。
4.4 Non-Linear Interaction Representation (NLIR)¶
TokenFormer 融入非线性乘性交互范式,旨在增强表示判别性和恢复维度鲁棒性。与传统 gating 机制将调制分支视为被动系数不同,NLIR 将其解释为与主特征流做乘性交互的学习非线性变换。
注意力中的乘性交互:对注意力输出 $\mathbf{A}^{(l)}$ 施加逐元素乘性门控。先从层输入计算 gate 投影:
$$\mathbf{G}^{(l)} = \mathbf{X}^{(l)} \mathbf{W}_g^{(l)}, \quad \mathbf{W}_g^{(l)} \in \mathbb{R}^{d \times d} \tag{16}$$
然后用它调制注意力输出:
$$\tilde{\mathbf{I}}^{(l)} = \sigma(\mathbf{G}^{(l)}) \odot \mathbf{A}^{(l)} \tag{17}$$
其中 $\sigma(\cdot)$ 为 sigmoid 函数。这将高阶非线性注入 token mixing 过程,增强特征交互的判别性和潜在表示的多样性。通过乘性门控调制注意力输出,模型有效保持了特征空间的秩丰富度,为后续阶段产出更具表达力的交互表示。
对应的 post-attention 残差状态:
$$\mathbf{I}^{(l)} = \mathbf{X}^{(l)} + \tilde{\mathbf{I}}^{(l)} \tag{18}$$
4.5 SwiGLU 前馈网络¶
在门控注意力操作之后,TokenFormer 使用 SwiGLU-based FFN。先 RMSNorm,然后计算:
$$\bar{\mathbf{I}}^{(l)} = \text{RMSNorm}(\mathbf{I}^{(l)}),$$
$$\mathbf{H}^{(l)} = \left(\text{Swish}(\bar{\mathbf{I}}^{(l)} \mathbf{W}_1) \odot (\bar{\mathbf{I}}^{(l)} \mathbf{W}_2)\right) \mathbf{W}_3, \tag{19}$$
$$\mathbf{X}^{(l+1)} = \mathbf{I}^{(l)} + \mathbf{H}^{(l)},$$
其中 $\mathbf{W}_1$、$\mathbf{W}_2$、$\mathbf{W}_3$ 为可学习权重矩阵。该设计保持标准残差前馈更新的同时,与注意力分支中的乘性交互原则一致。
4.6 统一优化目标¶
Action 的定义¶
论文中的 action 指用户对 item 的反馈类型(click、like、follow、comment、forward 等),是一个多类别标签。Appendix B.1 定义每条样本的 label 为 $\mathbf{y}_i = (y_i^{(1)}, \dots, y_i^{(A)}) \in \{0,1\}^A$,其中 $A$ 为 action 类型数。
公式 (6) 中 with/without actions 的区别在于输入序列的构造:with actions 时每个 item token 后跟一个 action token(记录历史反馈类型),序列长度从 $T$ 变为 $2T$;without actions 时只有 item token。两种构造的预测目标相同,区别仅在于输入信息量不同。需要注意的是,并非序列中每个位置都计算 loss——只有 item 位置(预测用户对该 item 的 action)才有意义,action→item 是完全不同的预测任务(next-item prediction),因此论文虽借用了 "Next-Token Prediction" 的说法,但 $I_{\text{loss}}$ 是稀疏选取的,并非 LLM 式的每个位置都算 loss 的纯自回归。
两种训练设置¶
TokenFormer 支持两种独立的训练范式,每个模型只选一种(不会同时使用,推荐场景的 one-epoch 特性使得重复训练会快速过拟合):
User-Centric 设置(NTP loss):一条样本 = 一个用户的完整行为序列,对序列中每个 item 位置都算 loss(密集监督)。每个用户在训练集中只出现一次,因此历史 item 在当前样本中被监督和在其他样本中作为 target 的重复问题不存在。
New Impression Only 设置(BCE loss):一条样本 = 一次曝光事件,历史行为只做 context 不参与 loss,loss 仅施加在新曝光的 target candidate 上。
两种设置下的样本构造差异¶
论文公式 (7) 的三段式序列构造 $[\mathcal{F}, \text{SEP}, \mathcal{T}, \text{SEP}, \mathcal{V}]$ 严格来说只适用于 New Impression Only。在 User-Centric 下,因果掩码使每个位置同时充当前面的 context 和自身的 target,不存在明确的"历史-目标"分界点,因此没有独立的 $\mathcal{V}$ 段,也无处插入第二个 SEP。User-Centric 的实际序列应为 $[\mathcal{F}, \text{SEP}, \text{item}_1, \text{action}_1, \text{item}_2, \text{action}_2, \dots]$。
此外,User-Centric 下非序列特征 $\mathcal{F}$ 作为共享前缀只有一份,隐含假设了 context 特征在整个序列时间跨度内是静态的。但实际中用户的城市、设备、兴趣标签等会随时间变化。工业实践中通常通过两种方式缓解:(1) 将时变特征从 $\mathcal{F}$ 下沉到每个 item token 中,$\mathcal{F}$ 只保留真正静态的特征;(2) 按时间窗口截断序列,缩短窗口内 context 特征的变化幅度。
Loss 函数¶
对每个被监督的 index $t \in I_{\text{loss}}$,最终输出表示 $\mathbf{X}_t^{(L)} \in \mathbb{R}^d$ 经线性头映射到 $A$ 维 action 空间:
$$\boldsymbol{t}_t = \mathbf{W}_L \mathbf{X}_t^{(L)} + \mathbf{b}_L, \quad \boldsymbol{t}_t \in \mathbb{R}^N \tag{20}$$
用 softmax + Cross-Entropy 损失训练:
$$\mathcal{L}_{\text{CE}} = -\frac{1}{|I_{\text{loss}}|} \sum_{t \in I_{\text{loss}}} \log \left(\frac{\exp(\boldsymbol{t}_{t,c_t})}{\sum_{a=1}^{A} \exp(\boldsymbol{t}_{t,a})}\right) \tag{21}$$
其中 $c_t \in \{1, \ldots, N\}$ 为 position $t$ 的 ground-truth action label。使用多类别 action 预测而非二分类 CTR loss,提供了更丰富的监督信号(点赞、转发代表比点击更强的兴趣),也与工业场景中多目标优化的需求对齐。
实验设置¶
数据集¶
- KuaiRand-27K:公开序列推荐 benchmark,包含约 27k 用户交互轨迹,划分为 19k/2k/5k(训练/验证/测试)
- Tencent Ads 工业平台:包含数十亿交互日志,特征极度稀疏,用户意图动态变化
训练细节¶
- 优化器:AdamW,学习率 0.001
- 训练范式:Next-Token Prediction (NTP)
- 评估指标:Macro AUC
实验设置说明¶
Table 1 按 baseline 类别分为两组:User-Centric(对标 HSTU 系列,NTP loss)和 New Impression Only(对标 OneTrans/HyFormer,target loss)。论文的重点实验几乎全在 User-Centric 下——RQ2-RQ4 的 MI/effective rank/注意力分析、RQ5 的 BFTS 配置对比、RQ6 消融、RQ7 scaling law 均使用 User-Centric 设置。New Impression Only 仅在 Table 1 中报告了一行 TokenFormer-S* 的结果。
但论文未明确说明 User-Centric 下 TokenFormer 的具体样本构造细节——序列是否包含独立的 $\mathcal{V}$ 段、是否有第二个 SEP、$I_{\text{loss}}$ 具体选了哪些位置,均未交代。考虑到对标的 HSTU 是纯序列模型(无独立 target 段),User-Centric 组的 TokenFormer 大概率也没有 $\mathcal{V}$ 段,但这与论文统一框架公式 (7) 的三段式叙述存在不一致。线上 A/B 实验在腾讯广告的工业排序场景,大概率使用 New Impression Only(对新候选集打分),但论文同样未明确说明。
模型规模配置¶
| Model | Depth | Dim | Head Num |
|---|---|---|---|
| TokenFormer-T | 4 | 64 | 4 |
| TokenFormer-S | 4 | 256 | 4 |
| TokenFormer-M | 6 | 256 | 4 |
| TokenFormer-L | 4 层→8 层 | 256 | 8 |
主要实验结果¶
整体性能对比(RQ1)¶
Table 1: KuaiRand-27K 主实验结果。$\Delta$ 为相对同范式 Transformer baseline 的 AUC 提升(‰)。
| Paradigm | Model | Macro AUC | $\Delta$ (‰) | Params | GFLOPs |
|---|---|---|---|---|---|
| User-Centric | Transformer | 0.85467 | - | 3.41M | 3.7G |
| HSTU | 0.85694 | +2.27 | 0.50M | 0.3G | |
| HSTU-Ultra | 0.85762 | +2.95 | 0.50M | 0.2G | |
| TokenFormer-T | 0.85967 | +5.00 | 0.48M | 0.8G | |
| TokenFormer-S | 0.86043 | +5.76 | 3.77M | 3.5G | |
| TokenFormer-M | 0.86116 | +6.49 | 5.64M | 5.3G | |
| TokenFormer-L | 0.86282 | +8.15 | 10.14M | 9.8G | |
| New Impression Only | Transformer* | 0.84019 | - | 3.41M | 3.7G |
| OneTrans | 0.84663 | +6.44 | 3.91M | 0.1G | |
| HyFormer | 0.85063 | +10.44 | 2.78M | 0.2G | |
| TokenFormer-S* | 0.85161 | +11.42 | 3.77M | 3.5G |
关键发现:
- TokenFormer 在 sequence-preserving 类别中全面超越所有 baseline。Tiny 版本即以 +5.00‰ AUC 超过 Transformer baseline,超过强力 baseline HSTU-Ultra +2.05‰
- NTP loss 优化的模型普遍优于 target-loss 对应版本,说明保持用户序列的完整时序一致性是更丰富的监督信号
- 在 New Impression Only 设置下,TokenFormer-S* 同样达到最优(+11.42‰),展现跨损失函数的适配性
NLIR 和 BFTS 对表示判别性的影响(RQ2)¶
论文通过 Mutual Information (MI) 分析——将 post-attention 表示空间用 K-Means 离散化后计算与 target label 的互信息。
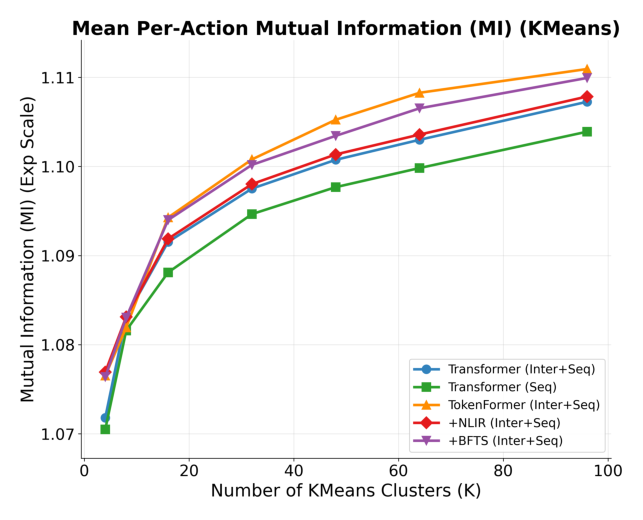
在所有聚类粒度 $K$ 下,BFTS 和 NLIR 的加入都带来一致且显著的 MI 提升。随着 $K$ 增大,性能差距进一步扩大,确认两个模块对捕捉 label-predictive 特征不可或缺:NLIR 通过显式非线性乘性交互丰富表示容量,BFTS 通过结构化感受野约束引导注意力分配。
NLIR 和 BFTS 对维度鲁棒性的影响(RQ3)¶
论文通过逐层 effective rank(基于奇异值分布的熵定义)分析序列行为 token $\mathcal{T}$ 的隐状态维度利用情况。
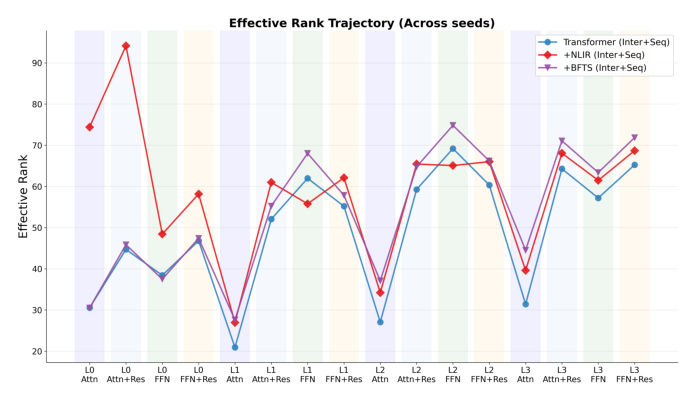
vanilla 联合建模 Transformer 呈现更陡峭的谱衰减,确认低秩静态特征的引入导致序列表示被严重坍缩。+BFTS 和 +NLIR 分别独立贡献于维度恢复:
- BFTS 通过在深层施加局部化注意力先验,限制坍缩的传播——防止低秩静态噪声在深层稀释高频行为信号
- NLIR 通过引入非线性乘性交互恢复表示秩,促进特征去相关,确保模型捕获高度表达性的表示而非坍缩到少数主导特征
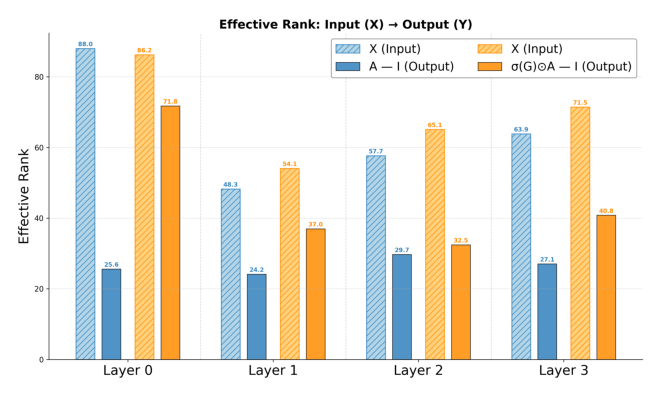
Figure 5 进一步聚焦序列行为 token,虽然 effective rank 随深度逐渐下降,但启用 NLIR 时退化被大幅缓解。vanilla 变体呈现更剧烈的下降,表明序列表示被渐进压缩到低维空间。
残差连接的几何效应分析:
- Attention-Residual Restoration:$\mathbf{I}^{(l)} = \mathbf{X}^{(l)} + \tilde{\mathbf{I}}^{(l)}$ 后的 erank 系统性高于 erank($\mathbf{I}^{(l)}$),说明注意力残差不仅稳定优化,还主动恢复纯注意力变换中丧失的维度多样性
- FFN-Residual Regularization:$\mathbf{X}^{(l+1)} = \mathbf{I}^{(l)} + \mathbf{H}^{(l)}$ 后的 erank 趋向中间值,FFN 残差起到临界正则化作用,防止表示偏离过远
逐层注意力分配分析(RQ4)¶
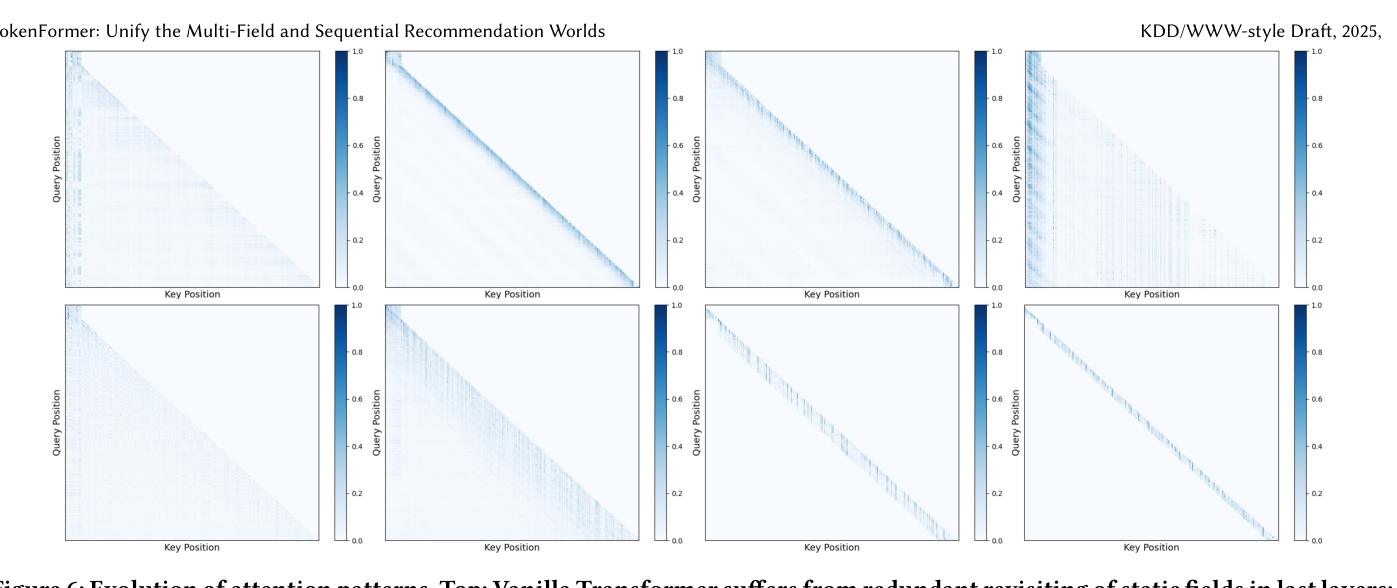
论文可视化了 Vanilla Transformer 和 TokenFormer 在不同层的注意力 mask 模式:
- Vanilla Transformer(上排):首层和末层都大量关注前 $M$ 个静态 token,中间层呈现局部带状对角线模式。末层出现"注意力漂移"——持续回溯到远处的非序列位置。直方图分析显示 vanilla Transformer 的注意力感受野在末层反常扩大(从中间层的 40.0 增至 46.4)
- TokenFormer(下排):浅层展现显著更丰富、更宽泛的跨 $M$ 个非序列 token 的交互(感受野 52.7 vs 40.0),确保更充分的跨域特征整合。深层完全丢弃对非序列位置的注意力,窗口内呈现稀疏性——只动态关注最相关的邻近 token
效率与效果权衡(RQ5)¶
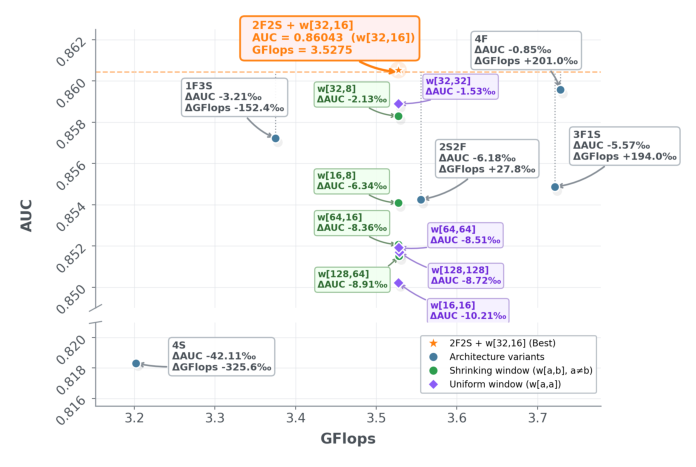
论文在 2F2S(2层 Full + 2层 SWA)框架内比较了不同 BFTS 配置:
- 2F2S + $w$[32, 16] 配置在所有方案中 AUC 最佳,GFLOPs 同时降低 201.0‰(相比 4F baseline)
- 反转顺序为 2S2F 导致 AUC 大幅下降 6.18‰,确认浅层必须使用全注意力
- 4S(全部滑动窗口)导致灾难性退化 -36.35‰
- 收缩窗口一致优于均匀窗口:$w$[32, 16] 比均匀 $w$[32, 32] 高 1.53‰ AUC
复杂度分析:
- Full attention: $C_{\text{full}} = O(L^2 d)$ \tag{22}
- Window attention: $C_{\text{window}} = O(Lwd)$,$w \ll L$ \tag{23}
- BFTS 混合: $C_{\text{hybrid}} = O(L_f L^2 d + L_w L w d)$ \tag{25}
BFTS 在下层保留全局建模的同时,通过上层局部注意力降低成本。
Serving 优化:论文采用解耦推理策略,将用户侧 token 编码一次并压缩为 $N$ 个 summary token,再与每个候选广告组合打分:
$$C_{\text{serve}}^{\text{decouple}} = O(L_u^2 d + B(N + L_a)^2 d) \tag{29}$$
实际部署中 QPS 从 126 提升到 695(5.5x 加速)。
消融实验(RQ6)¶
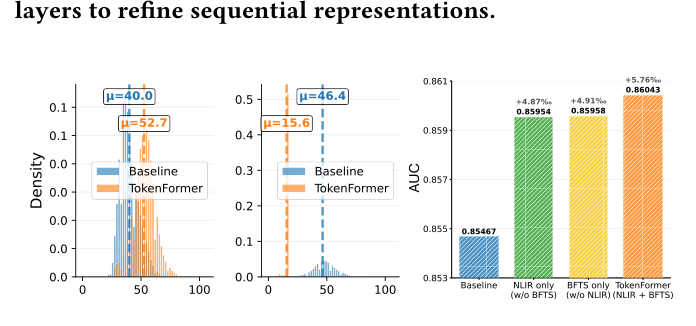
消融实验在 KuaiRand-27K 上进行,结果汇总在 Figure 7 右侧的 AUC 柱状图中:
- +NLIR alone:+4.87‰ AUC over Vanilla Transformer。NLIR 引入显式高阶乘性交互,增强表达力并缓解表示坍缩
- +BFTS alone(4S 全滑动窗口):-36.35‰ AUC,灾难性退化——受限感受野无法捕获长程依赖和全局序列模式
- BFTS strategy(即 2F2S 分层配置):+4.91‰ AUC over Vanilla Transformer,验证分层感受野的必要性
- BFTS + NLIR (TokenFormer):最优性能,两者互补
在线消融(Tencent Ads 生产环境,AUC 评估):
- Full-attention TokenFormer(无 BFTS):AUC 相对生产 baseline -0.16%
- +BFTS mechanism:AUC 翻正为 +0.14%
- +BFTS +NLIR(完整 TokenFormer):AUC +0.22%
模型 Scaling 与经验观察(RQ7)¶
从 Tiny 到 Large 逐步增大模型深度和隐藏维度,在 KuaiRand-27K 上观察到清晰的 scaling law 现象:模型复杂度提升时排序精度持续增长(Table 1)。
但在 TokenFormer-L 配置之后出现平台期,论文将此归因于 KuaiRand-27K 数据集的基数瓶颈——有限的样本量不足以正则化如此高容量的模型,导致边际过拟合。
相比之下,在腾讯广告的工业级数据规模上,TokenFormer 持续取得性能提升,未出现过早饱和的迹象。这一差异表明该架构具有较高的理论上界,其全部潜力在数据丰富的大规模工业场景中才能充分释放。
在线 A/B 实验(RQ8)¶
TokenFormer 部署于微信朋友圈广告(WeChat Channels advertising)信息流推荐场景,进行为期约 2 个月的 A/B 实验(2026年1月至2月),处理组占 5% 在线流量。
生产 baseline 是传统 DLRM 架构,采用解耦设计分别处理序列和非序列特征,在持续积累的业务数据上增量训练。TokenFormer 用两年历史数据从零训练后部署。
结果:TokenFormer 在 A/B 测试期间实现 GMV 提升 4.03%,确认离线增益可以转移到真实 serving 环境,证明统一架构在大规模工业部署中的实用性和有效性。
讨论与局限性¶
核心贡献¶
- 首次识别 Sequential Collapse Propagation (SCP):论文提供了经验证据表明,坍缩倾向的非序列特征可以通过共享骨干诱导序列表示的维度坍缩,这是统一推荐建模的核心挑战
- 同构统一架构:TokenFormer 是首个在单一 token stream 中原生建模 field-field、sequence-sequence 和 sequence-field 全部六种交互的同构 decoder-only 架构
- BFTS + NLIR 互补设计:BFTS 提供结构化的注意力分层(全局→局部),NLIR 提供非线性乘性门控恢复维度鲁棒性,两者从不同角度缓解 SCP
- 详尽的分析工具链:MI 诊断、effective rank 轨迹、注意力可视化、奇异值谱分析等,为理解统一推荐中的表示几何提供了系统化的分析框架
RoPE 位置编码的巧妙设计¶
论文在 Appendix D.1 中详细分析了 RoPE 在统一架构中的独特优势:
- 静态特征共享位置 $p_0 = 0$,利用 $\mathbf{R}_{0-0} = \mathbf{I}$ 的性质,field token 间的注意力退化为纯语义点积 $\text{Attn}(0,0) = \mathbf{q}^\top \mathbf{k}$,等价于 Factorization Machine 的多阶特征交互——无位置干扰
- 序列 token 与静态特征交互时,相对旋转 $\mathbf{R}_{n-0}$ 允许模型根据用户旅程的时序阶段 $n$ 动态调节对静态先验的依赖权重
局限性¶
- SCP 缺乏理论机制分析:论文发现了 SCP 现象并提供经验验证,但未解释坍缩传播的具体数学机制,解法基于直觉设计而非理论推导
- 统一框架的叙述不严谨:公式 (7) 的三段式序列构造 $[\mathcal{F}, \text{SEP}, \mathcal{T}, \text{SEP}, \mathcal{V}]$ 仅适用于 New Impression Only,User-Centric 下不存在独立 $\mathcal{V}$ 段和第二个 SEP,但论文用同一公式描述两种设置。两种设置的样本构造、$I_{\text{loss}}$ 范围、loss 类型(NTP CE vs BCE)等关键差异未充分区分
- User-Centric 下 context 特征时变问题未讨论:非序列特征 $\mathcal{F}$ 作为共享前缀假设在整个序列内静态,但用户 context 实际会随时间变化
- KuaiRand-27K 数据集基数有限:大模型容易过拟合(one-epoch 训练下尤为明显),scaling 行为受限。论文的工业实验弥补了这一点,但公开 benchmark 上的 scaling 分析不够充分
- 计算开销:TokenFormer-S 的 GFLOPs(3.5G)与 Transformer baseline 持平,但 HSTU/HSTU-Ultra 仅需 0.2-0.3G。虽然 BFTS 降低了深层成本,浅层的全注意力在超长序列场景下仍然昂贵
- 仅在单一工业平台验证:在线实验限于微信朋友圈广告,未覆盖搜索、电商等其他推荐场景
与已有工作的比较¶
相比 HyFormer 的双块交替策略和 OneTrans 的混合参数化,TokenFormer 的核心差异在于完全同构的块设计——不存在专门处理序列或特征的异构组件。BFTS 通过掩码调度而非架构分叉实现功能分层,这使得模型在概念上更简洁、在实现上更统一。相比 HSTU 的乘性 gating,NLIR 的 gate 投影来自层输入(而非注意力输出本身),形成输入→输出的非线性调制路径,在几何上更有效地保持了表示秩。