HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction¶
研究动机与背景¶
工业级大规模推荐模型(LRM)面临同时建模长程用户行为序列和异构非序列特征的挑战。当前主流架构采用分离式两阶段流水线("先长序列建模,再异构特征交互"):
- 序列建模阶段:用 LONGER、Full Transformer 等专用序列模型压缩长序列,输出 query token
- 特征交互阶段:将序列压缩后的 query token 与用户画像、上下文、交叉特征等非序列特征拼接,通过 RankMixer、Wukong 等 token-mixing 模块做特征交叉
这种分离式设计存在三个根本性局限:
- Query 建模过度简化:序列压缩阶段的 query token 通常仅由候选 item 相关或全局特征的有限子集派生,约束了对长期用户兴趣的建模能力。直接增加 query token 数量会在 KV-Cache 和 M-Falcon 机制下导致 serving 效率显著下降
- 信息交互单向且延迟:序列压缩后的 token 与异构非序列特征的交互仅发生在模型的后期阶段,属于压缩后的、单向的、隐式的浅层融合,无法捕捉多行为序列与异构特征组之间的细粒度依赖
- Scaling 效率低:由于交互模块只操作已压缩的序列表示,增大模型容量或序列长度主要改善各独立组件,而非增强联合表示。这导致性能提升相对于额外的计算预算增长缓慢
论文提出 HyFormer(Hybrid Transformer),一个统一的混合 Transformer 架构,将长序列建模和特征交互紧密集成到单一骨干网络中。
核心方法 / 模型架构¶
问题定义¶
设用户集 $\mathcal{U}$、物品集 $\mathcal{I}$,用户 $u \in \mathcal{U}$ 的行为历史 $S = [i_1^{(u)}, \ldots, i_K^{(u)}]$,非序列描述符 $u$(画像、上下文、交叉特征),候选物品 $v \in \mathcal{I}$。目标是估计用户 $u$ 对物品 $v$ 的交互概率:
$$P(y = 1 \mid S, u, v) \in [0, 1] \tag{1}$$
训练目标为标准二元交叉熵:
$$\mathcal{L} = -\frac{1}{|\mathcal{D}|} \sum_{(S,u,v,y) \in \mathcal{D}} \left[y \log \hat{y} + (1-y) \log(1-\hat{y})\right] \tag{2}$$
其中 $\hat{y} = f_\theta(S, u, v)$ 为模型预测。
整体框架¶
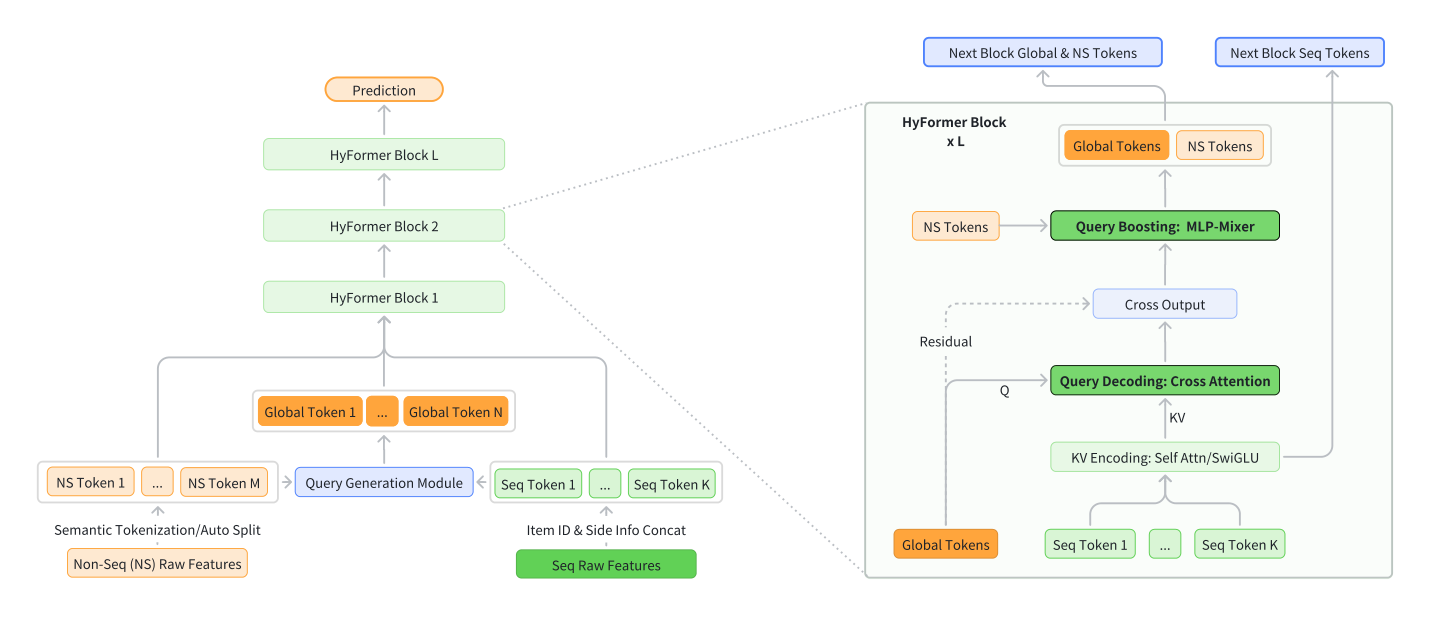
HyFormer 引入一组 Global Tokens,作为长行为序列与异构特征之间的共享语义接口。通过交替堆叠的 HyFormer 层,每层包含两个互补机制:
- Query Decoding:将非序列特征扩展为多个语义 global tokens,通过 cross-attention 解码长序列的逐层 key-value 表示,让全局上下文直接塑造序列表示
- Query Boosting:通过 MLP-Mixer 风格的 token mixing 增强跨 query 和跨序列的异构交互,逐层丰富语义表示
Query Generation(查询生成)¶
Input Tokenization:沿用 RankMixer 的语义分组(semantic grouping)策略,将输入 token 按内在语义(用户、上下文、行为)分组。
Query Generation Module:将异构非序列特征向量 $F_1, F_2, \ldots, F_M \in \mathbb{R}^{1 \times D}$ 拼接并映射,同时加入序列的全局池化摘要作为共享输入:
$$\text{Global Info} = \text{Concat}(F_1, \ldots, F_M, \text{MeanPool}(Seq)) \tag{4}$$
$$Q = [\text{FFN}_1(\text{Global Info}), \ldots, \text{FFN}_N(\text{Global Info})] \in \mathbb{R}^{N \times D} \tag{3}$$
生成 $N$ 个 global token 作为 query。在深层 HyFormer 层中,query 不再重新生成,而是复用前一层 cross-attention 的输出作为更新后的 query,使其逐层携带更丰富的语义。
Query Decoding(查询解码)¶
序列表示编码¶
HyFormer 支持多种序列编码策略以适配不同的容量-效率权衡:
(i) Full Transformer Encoding(最高建模能力):
$$H_l = \text{TransformerEnc}_l(S) \tag{5}$$
通过完整自注意力捕捉长程依赖。
(ii) LONGER 风格高效编码(用 cross-attention 替代全自注意力):
$$H_l = \text{CrossAttn}(S_{\text{short}}, S, S) \tag{6}$$
其中 $S_{\text{short}}$ 是长度 $L_H \ll L_S$ 的紧凑短序列作为 query,$S$ 作为 key/value。计算复杂度从 $O(L_S^2)$ 降至 $O(L_H L_S)$。
(iii) Decoder 风格轻量编码(最低延迟):
$$H_l = \text{SwiGLU}_l(S) \tag{7}$$
纯前馈无注意力,以牺牲上下文建模能力换取极低计算成本。
所有变体最终通过线性投影获得逐层的 key-value 状态:
$$K_l = H_l W_l^K, \quad V_l = H_l W_l^V \tag{8}$$
Key-value 状态在每层重新计算,允许序列特征随 decoder 深度共同演化。
Cross-Attention 解码¶
对每个行为序列 $S$ 在第 $l$ 层,HyFormer 用 global token 作为 query,序列的逐层 key-value 作为 key/value:
$$\tilde{Q}_{(l)} = \text{CrossAttn}(Q_{(l)}, K_{(l)}, V_{(l)}) \tag{9}$$
这使全局非序列特征能直接 attend 到长行为序列,将上下文信号注入序列感知的 query 表示。解码后的 $\tilde{Q}_{(l)}$ 成为后续交互和 boosting 模块的语义接口。
Query Boosting(查询增强)¶
解码步骤后,query 已包含序列感知信息,但与静态非序列特征之间的交互尚未充分挖掘。Query Boosting 通过 MLP-Mixer 风格的 token mixing 来增强。
将解码后的 query 与非序列 token 拼接为统一表示:
$$Q = [\tilde{Q}_{(l)}, F_1, \ldots, F_M] \in \mathbb{R}^{T \times D} \tag{10}$$
其中 $T = N + M$。每个 query token $q_t$ 被切分为 $T$ 个通道子空间:
$$q_t = [q_t^{(1)} \| q_t^{(2)} \| \cdots \| q_t^{(T)}], \quad q_t^{(h)} \in \mathbb{R}^{D/T} \tag{11}$$
MLP-Mixer 在各子空间内聚合所有 token 位置的信息:
$$\tilde{q}_h = \text{Concat}(q_1^{(h)}, q_2^{(h)}, \ldots, q_T^{(h)}) \in \mathbb{R}^D \tag{12}$$
$$\hat{Q} = [\tilde{q}_1, \tilde{q}_2, \ldots, \tilde{q}_T] \in \mathbb{R}^{T \times D} \tag{13}$$
再通过逐 token 独立的 Per-Token FFN 精炼:
$$\bar{Q} = \text{PerToken-FFN}(\hat{Q}) \tag{14}$$
最后加残差连接保持原始解码语义:
$$Q_{\text{boost}} = Q + \bar{Q} \tag{15}$$
HyFormer 模块(完整层)¶
每个 HyFormer 层由 Query Decoding + Query Boosting 组成。在第 $l$ 层:
$$\tilde{Q}^{(l)} = \text{CrossAttn}(Q^{(l-1)}, K^{(l)}, V^{(l)}) \tag{16}$$
$$\bar{Q}^{(l)} = \text{QueryBoost}(\text{Concat}(\tilde{Q}^{(l)}, \text{NS Tokens})) \tag{17}$$
通过堆叠多层,HyFormer 逐步精炼语义 query,使更深层能以更丰富的表示去抽象长序列。最终层的输出送入下游 MLP 做预测。
多序列建模¶
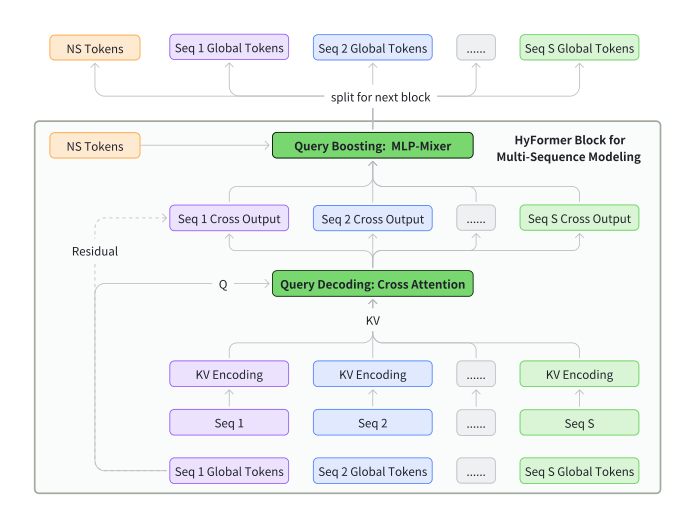
工业推荐中用户行为通常组织为多条异构序列(如视频观看序列、商品购买序列)。HyFormer 不合并不同序列,而是为每条序列独立构建 query token 集,在每层独立执行 Query Decoding,然后通过 query 级别的 token mixing 实现跨序列交互。
这种设计保留了不同序列的固有区分性,允许对重要序列自适应分配更多 global token。
训练与部署优化¶
GPU Pooling for Long-Sequence:长序列特征中真正唯一的 ID 通常仅占总 token 的 25%。HyFormer 利用这种稀疏性,在 GPU 上使用压缩嵌入表 + 高性能前向算子重建原始序列特征,大幅减少 Host-to-Device 的内存传输。
Asynchronous AllReduce:启用异步梯度同步,使第 $k$ 步的梯度聚合与第 $k+1$ 步的前向/反向计算重叠。稠密参数使用前一步梯度更新($W_k = W_{k-1} + g_{k-1}$),引入一步 staleness,但实验表明不影响收敛质量。
实验设置¶
数据集¶
抖音搜索系统(Douyin Search System)的真实工业 CTR 预测数据集:
- 70 天连续在线用户交互日志的子集
- 30 亿样本
- 特征包括:用户特征、查询特征、文档特征、交叉特征、多条序列特征
- 三条主要序列:
- 长期序列:用户长期搜索和点击行为序列,上限 3000
- 搜索序列:用户 top-50 搜索行为 item
- Feed 序列:用户 top-50 feed 行为 item
Baselines¶
传统两阶段模型(BaseArch):
- 序列建模:LONGER / Full Transformer
- 特征交互:RankMixer / Full Transformer / Wukong
统一架构模型(UniArch):
- MTGR/OneTrans(with LONGER)
- MTGR/OneTrans(with Full Transformer)
评估指标¶
- 离线:Query-level AUC(按查询计算 AUC 后取均值)
- 效率:稠密参数量(×10⁶)、训练 FLOPs(×10¹²,batch size 2048)
- 线上:Average Watch Time Per User、Video Finish Play Count Per User、Query Change Rate
实现细节¶
- 冷启动训练用于离线评估,预热 checkpoint 用于线上评估
- Batch size 2048,所有 baseline 使用相同优化器设置
- 输入 token 数统一为 16(MLPMixer 模块)
- 多序列 HyFormer:13 非序列 token + 3 个 global token(每条序列 1 个),共 16 个 token
- 64 GPU 集群训练
主要实验结果¶
整体性能(Table 1)¶
| Sequence Modeling | Feature Interaction | AUC↑ | ΔAUC | Params (×10⁶) | FLOPs (×10¹²) |
|---|---|---|---|---|---|
| BaseArch: Traditional Two-Stage Models | |||||
| LONGER | RankMixer | 0.6478 | — | 386 | 3.5 |
| LONGER | Full Transformer | 0.6472 | -0.09% | 416 | 6.2 |
| LONGER | Wukong | 0.6465 | -0.20% | 385 | 5.2 |
| Full Transformer | RankMixer | 0.6481 | +0.05% | 388 | 6.6 |
| Full Transformer | Full Transformer | 0.6474 | -0.06% | 418 | 9.3 |
| Full Transformer | Wukong | 0.6468 | -0.15% | 387 | 8.3 |
| UniArch: Unified-Block Models | |||||
| MTGR/OneTrans (w/ LONGER) | 0.6480 | +0.03% | 406 | 6.6 | |
| MTGR/OneTrans (w/ Full Transformer) | 0.6483 | +0.08% | 450 | 21.9 | |
| HyFormer (Ours) | 0.6489 | +0.17% | 418 | 3.9 |
关键结论:
- HyFormer 在所有模型中取得最高 AUC(0.6489),超越最强 BaseArch(Full Transformer + RankMixer,0.6481)+0.12%
- HyFormer 的 FLOPs 仅为 3.9×10¹²,显著低于大多数竞争者(MTGR/OneTrans + Full Transformer 为 21.9×10¹²)
- 统一架构(MTGR/OneTrans)依赖 Self-Attention 做特征交互,计算效率低且效果受限
- HyFormer 的核心优势:不在序列 key-value 侧做复杂建模或自注意力,而是通过迭代 query decoding + boosting 实现双向信息流
消融实验(Table 2)¶
| Configuration | AUC↑ | ΔAUC | Params (×10⁶) | FLOPs (×10¹²) |
|---|---|---|---|---|
| Ablation of Query Global Context | ||||
| HyFormer | 0.6489 | — | 418 | 3.9 |
| Query w/o Seq Pooling Tokens | 0.6486 | -0.05% | 415 | 3.9 |
| Query w/o Nonseq and Seq Pooling Tokens | 0.6484 | -0.08% | 414 | 3.8 |
| Ablation of Query Boosting | ||||
| HyFormer | 0.6489 | — | 418 | 3.9 |
| HyFormer w/o Global Tokens | 0.6484 | -0.08% | 414 | 3.8 |
| BaseArch w/ Global Tokens | 0.6480 | -0.14% | 505 | 3.6 |
| BaseArch w/o Global Tokens | 0.6478 | -0.17% | 387 | 3.5 |
| Ablation of Multi-Sequence Modeling | ||||
| HyFormer | 0.6489 | — | 418 | 3.9 |
| HyFormer + Merge Seq | 0.6485 | -0.06% | 397 | 3.9 |
逐项分析:
- Query Global Context:去除序列池化 token 后 AUC 下降 0.05%,进一步去除非序列特征后下降 0.08%。说明跨序列交互(inter-sequence interaction)是有价值的
- Query Boosting:
- 去除 Global Tokens(即 HyFormer 退化为 query 不参与 boosting)下降 0.08%
- 在 BaseArch 上加 Global Tokens 仅提升 0.03%(从 0.6478 到 0.6480),而在 HyFormer 内提升 0.08%——说明 Query Boosting 在 HyFormer 的双向交互框架中效果更强
- Multi-Sequence:合并序列导致 0.06% AUC 下降。这也部分解释了为什么 MTGR 和 OneTrans(合并序列)表现不如 HyFormer
Scaling 分析¶
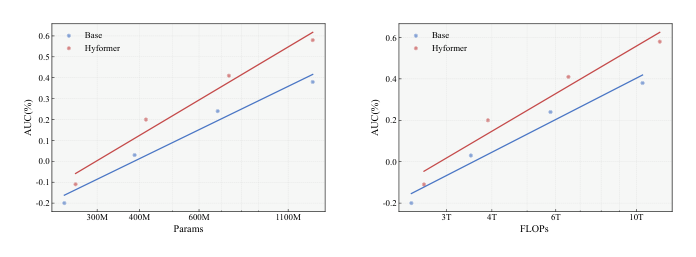
参数量与 FLOPs Scaling(Figure 3)¶
模型规模从 200M 到 1B+ 参数。HyFormer 初始即优于 LONGER + RankMixer 基线,且保持更陡峭的 scaling 斜率。在 FLOPs 维度上,AUC 随 FLOPs 稳步提升,遵循强 power-law 趋势。
HyFormer 的架构设计优先通过丰富的异构特征交互获取每参数更大增益,形成更陡峭的 scaling 曲线。
序列稀疏维度 Scaling(Table 3)¶
| Seq Length | Arch | Seq Sparse Dim | AUC↑ | ΔAUC | ΔAUC Gap |
|---|---|---|---|---|---|
| 1k | BaseArch | 64 | 0.6478 | — | — |
| 1k | BaseArch | 224 | 0.6484 | +0.09% | — |
| 1k | HyFormer | 64 | 0.6489 | — | — |
| 1k | HyFormer | 224 | 0.6497 | +0.12% | +0.03% |
| 3k | BaseArch | 64 | 0.6486 | — | — |
| 3k | BaseArch | 224 | 0.6490 | +0.06% | — |
| 3k | HyFormer | 64 | 0.6499 | — | — |
| 3k | HyFormer | 224 | 0.6507 | +0.12% | +0.06% |
结论:
- 扩展序列稀疏维度(从 64 到 224,即增加辅助信息类型数从 3 种到 7 种)对 HyFormer 的增益始终大于 BaseArch
- 性能差距随序列长度增长而扩大(1k: +0.03%, 3k: +0.06%),说明 HyFormer 能更好地利用丰富的序列 key-value 信息
- 根因:HyFormer 的双向信息流使序列 KV 信息能通过 LONGER 和 Mixer 的交替堆叠被更充分地利用
线上 A/B 测试(Table 4)¶
在抖音搜索平台(Douyin Search)上进行大规模线上 A/B 测试,对比已部署的 RankMixer baseline:
| Online Test Metrics | Gain |
|---|---|
| Average Watch Time Per User ↑ | +0.293% |
| Video Finish Play Count Per User ↑ | +1.111% |
| Query Change Rate ↓ | -0.236% |
分析:
- 人均观看时长 +0.293%,完播数 +1.111%,查询变更率(反映用户需要细化搜索的概率,越低越好)-0.236%
- 这些在十亿级用户平台上是显著的实际收益
- HyFormer 目前已在字节跳动全量部署,每天服务数十亿用户
讨论与局限性¶
核心贡献¶
- 重新定义 query token 的角色:将传统的"序列压缩产物"转变为"全局语义接口"(Global Tokens),同时承载非序列特征和序列信息
- 交替优化的双向信息流:Query Decoding(序列 → query)和 Query Boosting(query ↔ 非序列特征)交替执行,打破了单向、延迟融合的限制
- 高效的统一架构:FLOPs 仅为 3.9×10¹²(低于 LONGER + RankMixer 的 3.5×10¹²),却取得最高 AUC
- 更优的 Scaling Law:在参数量和 FLOPs 两个维度上均展现更陡峭的 scaling 斜率
- 工业级验证:抖音搜索全量部署,服务十亿级用户
值得借鉴的设计¶
- Global Token 作为桥梁:不直接让序列和非序列在同一注意力空间交互(如 MTGR/OneTrans),而是通过 global token 作为中介,保持计算效率
- 序列 KV 每层重算:允许序列表示随 decoder 深度演化,不像 LONGER 那样只算一次
- 独立多序列建模:为每条序列分配独立 query token,保留序列间的区分性,通过 Query Boosting 实现跨序列交互
- MLP-Mixer 替代 Self-Attention 做特征交互:避免了 MTGR/OneTrans 使用 Self-Attention 带来的高 FLOPs
局限性¶
- 仅验证搜索场景:实验在抖音搜索一个数据集上进行,未在推荐 feed、广告等其他场景验证
- 未与 HSTU/ULTRA-HSTU 对比:这两个重要的生成式推荐架构未出现在 baseline 中
- 序列编码选择的消融不完整:论文提到三种序列编码策略(Full Transformer、LONGER、SwiGLU),但实验中未明确报告使用哪种配置及其消融
- A/B 测试时间和流量未披露:线上实验的具体持续时间和分流比例未报告
- Scaling 实验的绝对 AUC 值未给出:Figure 3 只展示了趋势线,缺少具体数值