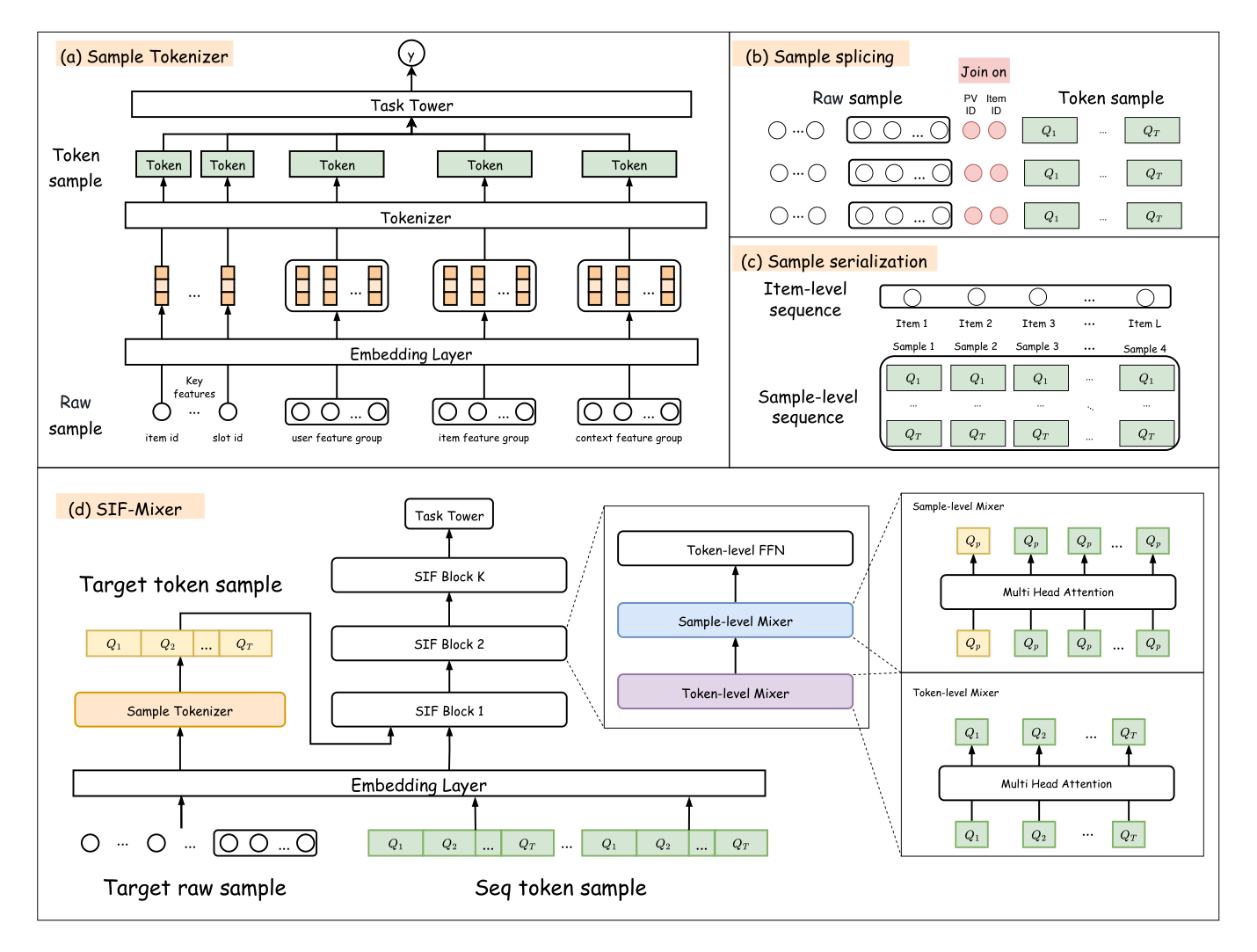
Sample Is Feature:从 Item-Level 到 Sample-Level 的统一大规模推荐模型¶
研究动机与背景¶
工业推荐系统的扩展路径一直沿着两个平行范式演进:样本信息扩展(sample information scaling) 和 模型容量扩展(model capacity scaling)。
- 样本信息扩展通过延长或加深每个训练样本的信息含量提升召回与排序质量。其中又分两条子路径:
- 序列延展(sequence lengthening):把用户历史行为从几十条扩展到数千条。代表工作包括 DIN、DIEN、SIM、ETA、TWIN、LONGER。
-
序列加宽(sequence widening):在每个历史 token 中塞入更多上下文信息。代表工作有 DSAN、CAIN、HSTU 等。
-
模型容量扩展则通过统一的 Transformer 主干同时建模序列与特征交互,消除独立模块。代表工作包括 HyFormer、OneTrans、MixFormer,它们把所有特征字段(包括历史 token)送入单一深层架构以获得跨字段交互。
尽管两个方向各有进展,SIF 作者指出它们仍面临两项结构性瓶颈:
- 样本信息扩展只编码了每次历史交互的一个子集。受限于存储与在线服务成本,现有方法只保留 bare item embedding,或额外拼接少量手工挑选特征,大量原始样本语境(用户画像、实时上下文、行为结果、预计算交叉)完全被丢弃。更关键的是,这种架构在结构上无法建模 样本级、随时间变化的特征——例如"凌晨优惠券激活时的点击"与"正午吃饭高峰的点击"在 bare item ID 下看起来完全一致,但真实请求上下文天差地别。
- 模型容量扩展受困于序列 vs 非序列特征的结构异质性。历史 token 只是单字段 item embedding,而当前请求 token 是多字段拼接后的丰富表征。把二者塞进同一注意力空间会产生"信息密度不对称",模型难以充分发挥其表达容量。
作者以两个刚好点击同一家餐厅的用户举例:一个是深夜优惠活跃时段,另一个是午间通勤高峰。仅凭 item embedding 这两条行为完全等价,但其真实样本上下文传递着截然不同的用户意图信号。
SIF 的核心洞察:训练日志里每条历史交互本身就已经记录了完整的 request 上下文(用户特征、商品特征、上下文、预计算交叉)。瓶颈不在数据可得性,而在表征方式。SIF 通过 Sample Tokenizer 把离线的 Raw Sample 压缩为紧凑的 Token Sample(HGAQ,hierarchical group-adaptive quantization),再通过 SIF-Mixer 在同构样本 token 序列上做 token 级与样本级的双向混合交互,完整利用每个历史样本的完整上下文,同时消除历史 token 与当前请求 token 之间的异质性。
论文在美团本地生活大规模工业数据集上做了充分实验,相对 HyFormer 最多获得 +0.88% GAUC 离线提升,在线 A/B 带来 +2.03% CTR、+1.21% CVR、+1.35% GMV/session 的收益,并已部署至美团外卖排序管线。
关键符号与问题形式化¶
论文用到的关键符号(见原文 Table 1):
| 符号 | 含义 |
|---|---|
| $L$ | 行为序列长度 |
| $N$ | SIF Block 数量 |
| $G$ | 语义特征组数 |
| $K_g$ | 组 $g$ 内的 sub-token 数 ($K_g = \lceil |\mathcal{F}_g|/B \rceil$) |
| $T$ | 每个样本的总 sub-token 数 ($T = \sum_{g=1}^G K_g$) |
| $B$ | sub-token 粒度:每个 sub-token 负责的特征字段数 |
| $M$ | RVQ 残差量化层数 |
| $V$ | 每层码本大小 |
| $\mathcal{S} \in \mathbb{R}^{d_s}$ | Raw Sample(某次历史交互的完整特征快照) |
| $\mathcal{Q}$ | Token Sample:$T \times M$ 离散码本索引 |
| $\mathbf{z}_l^{(g,k)} \in \mathbb{R}^{d_0}$ | sub-token $(g,k)$ 的 embedding(码本查表) |
| $\mathbf{H}^0$ | SIF-Mixer 输入 |
| $W_{\text{res}}^{(g,k)}$ | target sub-token 投影矩阵 |
形式化:设 $\mathcal{U}, \mathcal{I}, \mathcal{C}$ 分别为用户、物品、上下文集合。在某次请求时间 $\tau$,排序模型收到当前请求特征元组 $\mathbf{f}^\tau = (\mathbf{f}^{\text{user}}, \mathbf{f}^{\text{item}}_j, \mathbf{f}^{\text{ctx}})$ 以及行为序列 $\mathcal{B} = \{i_l\}_{l=1}^L$——用户在 $\tau$ 之前的最近 $L$ 次正向交互,按时间有序。模型输出交互概率 $\hat{y} \in [0,1]$。
在标准统一架构里,行为序列被编码为 item embedding $\{\mathbf{e}_{i_1}, \ldots, \mathbf{e}_{i_L}\}$;SIF 用每条历史记录的完整特征快照 $\mathcal{S}$ 替换这些 bare embedding,压缩为 Token Sample $\mathbf{z}$。
核心方法:SIF 框架¶
SIF 由两大组件组成:
- Sample Tokenizer $\mathcal{T}: \mathcal{S} \mapsto \mathcal{Q}$——离线把每条 Raw Sample 量化成一组紧凑的码本索引 $\mathcal{Q} = (q^{(g,k,m)})$。
- SIF-Mixer——在线阶段通过码本查表恢复 $\mathcal{Q}$ 的 embedding,在 Token Sample 序列上执行分层注意力。
4.1 Sample-Level Token 的定义¶
在交互时刻 $t$,Raw Sample 被定义为完整的特征元组:
$$ \mathcal{S} = [\mathbf{f}^{\text{user}} \mid \mathbf{f}^{\text{item}} \mid \mathbf{f}^{\text{ctx}} \mid \mathbf{f}^{\text{cross}}] \tag{1} $$
其中 $\mathbf{f}^{\text{user}}$ 是用户画像特征,$\mathbf{f}^{\text{item}}$ 是商品属性,$\mathbf{f}^{\text{ctx}}$ 是上下文信号,$\mathbf{f}^{\text{cross}}$ 是预计算好的交叉特征(如 user-category 亲和度、item-context 共现统计)。Raw Sample $\mathcal{S} \in \mathbb{R}^{d_s}$ 维度很高(数千字段),Sample Tokenizer 的任务就是把它压缩成 Token Sample。
作者区分两类特征:
- point features(点特征):用户属性、商品属性、上下文信号等——可量化的静态字段。
- sequential features(序列特征):用户历史交互序列 $\mathcal{B}$——带有时间有序信息,不做样本级量化,而是由 SIF-Mixer 通过跨样本注意力直接建模 inter-sample 动态。
换言之,SIF 把序列内每一帧历史快照的 point 特征离散化压缩,时间维的结构由 Mixer 层继续承担。
4.2 Sample Tokenizer:Hierarchical Group-Adaptive Quantization (HGAQ)¶
Sample Tokenizer $\mathcal{T}: \mathcal{S} \mapsto \mathcal{Q}$ 把每条 Raw Sample 映射成 Token Sample $\mathcal{Q} = (q^{(g,k,m)})$——一组共 $T \times M$ 个离散码本索引。在线服务时仅需存储这些 int 索引,embedding 通过 Mixer 内部维护的码本实时查表。
4.2.1 Group-Wise Decomposition¶
SIF 并不用一个大码本统一覆盖所有特征字段,而是先把 $\mathcal{S}$ 切成 $G=4$ 个语义组:
$$ \mathcal{S} = [\underbrace{\mathbf{f}^{\text{user}}}_{G_1} \mid \underbrace{\mathbf{f}^{\text{item}}}_{G_2} \mid \underbrace{\mathbf{f}^{\text{ctx}}}_{G_3} \mid \underbrace{\mathbf{f}^{\text{cross}}}_{G_4}] \tag{2} $$
这种分组设计灵活:高基数强 ID(如 item_id)可以自己独占一个 singleton 组,以确保其判别信号不会被共享码本里的低基数特征稀释。
Adaptive intra-group sub-tokenization:每个语义组内部进一步按 sub-token granularity $B$ 均分为 $K_g$ 个 sub-token,数量自适应于该组的特征数:
$$ K_g = \left\lceil \frac{|\mathcal{F}_g|}{B} \right\rceil \tag{3} $$
$B$ 默认为 32(即每 32 个特征字段映射为一个 sub-token)。特征多的组自然会获得更多 sub-token,在 Token-level Mixer 里也就拿到更多位置。组 $g$ 内 $|\mathcal{F}_g|$ 个特征被均分为 $K_g$ 个不重叠子集 $\{\mathcal{F}_g^{(k)}\}_{k=1}^{K_g}$;每个子集通过组-槽位特定的线性投影压成 $d_0$ 维的 sub-token 向量:
$$ \tilde{\mathbf{f}}^{(g,k)} = W_{\text{proj}}^{(g,k)} \mathbf{f}^{(g,k)} \in \mathbb{R}^{d_0} \tag{4} $$
所有 sub-token 共享相同维度 $d_0=16$。每个样本的总 sub-token 数 $T = \sum_{g=1}^G K_g$,总 token embedding 维度 $d = T \cdot d_0$。每个 sub-token $(g,k)$ 拥有独立的 codebook $C_{g,k} = \{\mathbf{c}_v^{(g,k,m)}\}_{m,v}$,$V=256$ 码,每码 $d_0$ 维。
4.2.2 Residual Quantization (RVQ)¶
在每个 sub-token $(g,k)$ 上应用 $M$ 层残差向量量化:
$$ q^{(g,k,m)} = \arg\min_v \|\mathbf{r}^{(g,k,m-1)} - \mathbf{c}_v^{(g,k,m)}\|_2, \quad \mathbf{r}^{(g,k,m)} = \mathbf{r}^{(g,k,m-1)} - \mathbf{c}_{q^{(g,k,m)}}^{(g,k,m)} \tag{5} $$
初始残差 $\mathbf{r}^{(g,k,1)} = \tilde{\mathbf{f}}^{(g,k)}$。Token Sample 把所有 sub-token 索引序列拼接:
$$ \mathcal{Q} = \left[ (q^{(g,k,1)}, \ldots, q^{(g,k,M)}) \right]_{g=1,\ldots,G;\ k=1,\ldots,K_g} \tag{6} $$
在 $G=4, B=32, M=3, V=256$ 的默认配置下,按美团的特征 schema 总 sub-token 数 $T=27$,每个样本被压缩为 $T \times M \times \log_2 V = 27 \times 3 \times 8 = 648$ bits。
4.2.3 Label-Supervised Codebook Training¶
Sample Tokenizer 和排序目标联合训练——这是与 VQ-Rec/TIGER 等纯无监督量化的关键不同。RVQ 重建 $\hat{\mathbf{s}}$ 被送入一个轻量 MLP 预测 pCTR:
$$ \hat{\mathbf{s}} = \left[\sum_m \mathbf{c}^{(g,k,m)}_{q^{(g,k,m)}}\right]_{g,k}, \quad \hat{y}^{\text{token}} = \sigma(\mathrm{MLP}(\hat{\mathbf{s}})) \tag{7} $$
附加的 pCTR loss $\mathcal{L}_{\text{token}} = \mathcal{L}_{\text{BCE}}(\hat{y}^{\text{token}}, y)$ 加入总损失,确保码本按 预测相关性 组织,而非单纯重建误差。重要类别特征(如 item ID)保留独立字段组,防止高基数标识符被混入低判别力特征里稀释。
4.3 Sample Splicing 与 Serialization¶
标准行为日志仅记录 item ID 序列;SIF 把每条记录升级为一次特征快照,并压缩为 Token Sample:
$$ \underbrace{\{i_1, \ldots, i_L\}}_{\text{item sequence (standard)}} \xrightarrow{\mathcal{T}} \underbrace{\{\mathcal{Q}_1, \ldots, \mathcal{Q}_L\}}_{\text{sample sequence (SIF)}} \tag{8} $$
每个 $\mathcal{Q}_l \in \{1,\ldots,V\}^{T \times M}$ 仅 $T \times M \times 8$ bits(默认 648 bits),远比 float32 raw 快照紧凑。Token Sample 离线预计算后以 KV 存储。按时间排好序的 Token Sample 序列就是 SIF-Mixer 的离线输入(见 Figure 1b, 1c)。
Sample splicing 用 Token Sample 替换 item embedding;Sample serialization 把历史 Token Sample 按时间附上位置编码。
4.4 SIF-Mixer¶
SIF-Mixer 是受 MLP-Mixer 风格分解设计启发的主干。它堆叠 $N$ 个相同结构的 SIF Block,每个 Block 把交互分解成三段:Token-level Mixer、Sample-level Mixer、Token-level FFN。分解设计让 intra-sample 特征交互与 inter-sample 时序交互解耦,把注意力复杂度从 $O((LT)^2)$ 降到 $O(L^2T + LT^2)$,同时保留两个维度的信息流。
Input layout:SIF-Mixer 的输入 $\mathbf{H}^0 \in \mathbb{R}^{(L+1) \times T \times d_0}$,$T = \sum_g K_g$ 为每个样本的 sub-token 总数。输入由两部分组成:
- Seq Token Samples $(l=1,\ldots,L)$:离线样本序列 $\{\mathcal{Q}_1, \ldots, \mathcal{Q}_L\}$(§4.3)通过码本查表,每个 sub-token $(g,k)$ 位置用 M 层残差和 + recency embedding:
$$ \mathbf{z}_l^{(g,k)} = \sum_{m=1}^M \mathbf{c}^{(g,k,m)}_{q^{(g,k,m)}_l} \in \mathbb{R}^{d_0}, \quad \mathbf{H}_{l,*}^0 = [\mathbf{z}_l^{(1,1)} \| \cdots \| \mathbf{z}_l^{(G,K_G)}] + \mathbf{p}_{L-l} \tag{9} $$
- Target Token Sample $(l=0)$:当前请求特征 $\mathbf{f}_\tau^{(g)}$ 在服务时才可得,不能预量化。所以不量化,而是通过学到的线性投影映射到与码本同空间:
$$ \mathbf{H}_{0,(g,k)}^0 = W_{\text{res}}^{(g,k)} \mathbf{f}_\tau^{(g,k)} \tag{10} $$
对齐损失 $\mathcal{L}_{\text{align}}$(下文公式 18)确保每个 $W_{\text{res}}^{(g,k)}$ 映射到对应码本空间,使 $L+1$ 行在跨时序注意力下兼容。
SIF Block¶
每个 Block $n \in \{1, \ldots, N\}$ 操作在 $\mathbf{H}^{n-1}$——一个 $(L+1) \times T$ 的 $d_0$ 维向量矩阵(行是样本,列是 sub-token 位置):
$$ \mathbf{H}^n = \begin{bmatrix} \mathbf{H}^n_{0,1} & \cdots & \mathbf{H}^n_{0,T} \\ \mathbf{H}^n_{1,1} & \cdots & \mathbf{H}^n_{1,T} \\ \vdots & \ddots & \vdots \\ \mathbf{H}^n_{L,1} & \cdots & \mathbf{H}^n_{L,T} \end{bmatrix} \tag{11} $$
Block 依次执行三个 sub-operation(MHA: multi-head attention;LN: pre-norm LayerNorm):
(i) Token-level Mixer 沿 每一行 做 self-attention,建模同一样本内 $T$ 个 sub-token 之间的交互。因为来自不同特征组、同组不同子概念的 sub-token 占据不同列,注意力能同时捕获:
- 跨组相关性(user-item-context)
- 组内子概念交互(商品价格信号与评论信号)
$$ \tilde{\mathbf{H}}_l^n = \mathbf{H}_l^{n-1} + \mathrm{MHA}(\mathrm{LN}(\mathbf{H}_l^{n-1})), \quad l = 0, \ldots, L \tag{12} $$
(ii) Sample-level Mixer 沿 每一列 做 self-attention,建模 $L+1$ 个样本在同一 sub-token 位置的跨时间交互——关键是 Target Token Sample($l=0$)能 attend 到所有 Seq Token Samples 获取历史上下文:
$$ \hat{\mathbf{H}}^n_{*,p} = \tilde{\mathbf{H}}^n_{*,p} + \mathrm{MHA}(\mathrm{LN}(\tilde{\mathbf{H}}^n_{*,p})), \quad p = 1, \ldots, T \tag{13} $$
(iii) Token-level FFN 对每个位置做 position-wise 非线性变换:
$$ \mathbf{H}_{l,p}^n = \hat{\mathbf{H}}_{l,p}^n + \mathrm{FFN}(\mathrm{LN}(\hat{\mathbf{H}}_{l,p}^n)) \tag{14} $$
Prediction head:$N$ 个 SIF Block 后,对 target sample 的 $T$ 个 sub-token 输出做 mean pooling:
$$ \mathbf{h} = \frac{1}{T} \sum_{p=1}^T \mathbf{H}_{0,p}^N \tag{15} $$
经过两层 MLP + sigmoid 输出排序分:
$$ \hat{y} = \sigma(\mathbf{w}_2^\top \mathrm{ReLU}(\mathbf{W}_1 \mathbf{h} + \mathbf{b}_1) + b_2) \tag{16} $$
训练目标¶
$$ \mathcal{L} = \mathcal{L}_{\text{BCE}} + \beta \mathcal{L}_{\text{VQ}} + \gamma \mathcal{L}_{\text{align}} \tag{17} $$
其中 $\beta = 1.0, \gamma = 0.25$。
- $\mathcal{L}_{\text{BCE}}$:主排序 BCE 损失。
- $\mathcal{L}_{\text{VQ}}$:标准 VQ commitment loss($\lambda=0.25$),拉近组编码器输出与 RVQ 重建。
- $\mathcal{L}_{\text{align}}$:对齐损失,使 target 投影 $W_{\text{res}}^{(g,k)}$ 映射到和码本一致的空间,从而 target 与历史 token 表征在推理时可跨时间交互:
$$ \mathcal{L}_{\text{align}} = \sum_{g=1}^G \sum_{k=1}^{K_g} \left\| W_{\text{res}}^{(g,k)} \mathbf{f}^{(g,k)} - \mathrm{sg}(\mathbf{e}_{g,k}) \right\|^2 \tag{18} $$
其中 $\mathrm{sg}(\cdot)$ 是 stop-gradient,$\mathbf{e}_{g,k} = \sum_m \mathbf{c}^{(g,k,m)}_{q^{(g,k,m)}}$ 是 Tokenizer 对 sub-token $(g,k)$ 的码本重建。训练阶段 $\mathbf{e}_{g,k}$ 通过当前请求 Raw Sample $\mathcal{S}_\tau$ 经 Sample Tokenizer 得到 RVQ 重建 $\mathbf{e}_{g,k} = \sum_m \mathbf{c}^{(g,k,m)}_{q^{(g,k,m)}_\tau}$,作为对齐 target。服务阶段 Tokenizer 前向被跳过,只应用 $W_{\text{res}}^{(g,k)}$。
关键点:因为每个 Raw Sample $\mathcal{S}$ 承载了原始交互的行为结果(label),排序监督信号 $\mathcal{L}_{\text{BCE}}$ 会通过 VQ 反传到码本学习,使码本按预测相关性而非重建误差组织样本——这是 SIF 区别于 item-VQ 的关键:Sample-level VQ 必须用 label-aware 监督 + 对异质多字段特征的组分解。
复杂度¶
每个 SIF Block 复杂度为 $O(T^2 \cdot (L+1) \cdot d_0 + (L+1)^2 \cdot T \cdot d_0)$。因为 $T \ll L+1$($T \approx 27$ vs $L=1000$),Sample-level Mixer 主导开销 $O(L^2 \cdot T \cdot d_0)$,与同序列长度下标准注意力相当。自适应 sub-tokenization 相对固定 $G$ 设计增加了 $T$,但 $T$ 仍保持较小($B=8$ 时也不超 20),Token-level Mixer 开销可忽略。
实验设置¶
数据集¶
Industrial Dataset (Meituan Local-Life):
- 1B+ 展现记录(跨 90 天)
- 50M+ 用户、5M+ 商品
- 每条样本包含约 600+ 特征字段,涵盖用户画像、商品属性、上下文信号
- 1000-item 行为序列
- 完整利用 $G_1 \sim G_4$ 四个语义组,自适应 sub-tokenization 下 $B=32$
所有 baseline 模型使用相同的当前请求特征集;差异仅在于如何表征历史行为序列——baseline 用标准 item embedding,SIF 用 HGAQ 压缩的 Token Sample。
评估指标¶
AUC、GAUC(Group AUC,按用户分组)、FLOPs;结果取 5 次独立 run 的均值,paired t-test($p<0.01$)。
Baseline¶
按特征交互组件和序列建模组件两个维度组合:
- Varying feature interaction:DCNv2(base)、Wukong、RankMixer。
- Varying sequence modeling:DIN、SIM、LONGER。
- Unified frameworks(两个组件联合优化):HyFormer、OneTrans。
Implementation Details¶
- 硬件:8×A100-80G GPU
- SIF-Mixer:$N=4$ SIF Block,8 attention heads,sub-token 维度 $d_0=16$,FFN 维度 $4 \times d_0$,pre-norm LayerNorm,$T$ 个 sub-token 输出 mean pool
- Sample Tokenizer:$G=4, B=32, M=3, V=256, d_0=16$
- 优化器:Adam,lr $=10^{-3}, \beta_1=0.9, \beta_2=0.999$,权重衰减 $10^{-5}$
- batch size 4096,序列长度 $L=1000$
主要实验结果¶
Table 2(原文)是核心效果表,列出所有 baseline 与 SIF 的 CTR、CVR AUC/GAUC 与效率:
| Feature Interaction | Sequence Modeling | CTR AUC↑ | CTR GAUC↑ | CVR AUC↑ | CVR GAUC↑ | Params (M) | TFLOPs |
|---|---|---|---|---|---|---|---|
| DCNv2 | DIN | 0.7832 | 0.7614 | 0.8103 | 0.7891 | 48 | 0.31 |
| Wukong | SIM | +0.41% | +0.38% | +0.35% | +0.33% | 56 | 0.38 |
| Wukong | LONGER | +0.53% | +0.49% | +0.44% | +0.41% | 62 | 0.42 |
| RankMixer | SIM | +0.67% | +0.61% | +0.58% | +0.54% | 51 | 0.35 |
| RankMixer | LONGER | +0.79% | +0.72% | +0.68% | +0.63% | 53 | 0.40 |
| HyFormer | — | +1.12% | +1.01% | +0.97% | +0.88% | 120 | 0.87 |
| OneTrans | — | +1.08% | +0.96% | +0.91% | +0.83% | 115 | 0.82 |
| SIF (Ours) | — | +2.03% | +1.89% | +1.74% | +1.61% | 128 | 0.93 |
(所有增量相对 DCNv2+DIN base;5 次 run 均值;paired t-test $p<0.01$。)
分析:
-
SIF vs 统一 baseline。SIF 相对 HyFormer 绝对提升 CTR AUC +0.91%、GAUC +0.88%,CVR AUC +0.77%、GAUC +0.73%($p<0.01$)。把历史序列 token 从 item-level 升级到 sample-level 带来稳定可靠的增益。
-
专用模型 vs 统一框架。在专用模型里,以序列建模为主的方法(SIM、LONGER)整体优于以特征交互为主的方法(Wukong、RankMixer),印证行为数据丰富的工业场景里序列建模的重要性。统一框架(HyFormer、OneTrans)进一步超越所有专用模型,证实"联合建模序列 + 特征交互"这一架构范式。
-
工业级意义。SIF 对 HyFormer 的 AUC 提升 +0.91% 相对、+0.0071 绝对(CTR AUC)在工业规模下有实际意义:业界经验法则是 0.001 绝对 AUC ≈ 在线 A/B 0.1%+ CTR 提升,按此推算 SIF 预期带来 +0.7%+ 在线 CTR。实际在线观测到的 +2.03% 远超这一推算,说明 sample-level token 富集贡献了 AUC 评估无法捕捉的时变物品热度 + 上下文需求漂移等互补信号。
消融与分析¶
5.3.1 Sample Tokenizer 消融¶
Table 3(原文)比较四种历史 token 表征策略。指标为相对 SIF full 的 GAUC gap、存储压缩比(原始 raw snapshot bits / 存储 token bits)。
| Token Representation | ΔCTR-GAUC | ΔCVR-GAUC | Comp. Ratio |
|---|---|---|---|
| SIF (HGAQ token, ours) | — | — | ≈237× |
| Item ID only | -1.00% | -0.86% | ≈2400× |
| Item ID + key features | -0.60% | -0.51% | ≈185× |
| Raw sample emb ($d=512$, dense) | -0.27% | -0.23% | ≈9× |
存储压缩比定义为:
$$ \text{Storage Compression Ratio} = \frac{b_{\text{snapshot}}}{b_{\text{token}}} \tag{19} $$
其中 $b_{\text{snapshot}}$ 是完整非 item 快照在 float32 下的 bit 数($|\mathcal{F}_{\text{non-seq}}| \times d_e \times 32$ bits),$b_{\text{token}}$ 是存储 token 的 bit 数。作者设 $|\mathcal{F}_{\text{non-seq}}|=600, d_e=8$,给出 $b_{\text{snapshot}} = 153{,}600$ bits。HGAQ 仅存 $T \times M$ 离散索引(8 bits/index),$b_{\text{token}} = 27 \times 3 \times 8 = 648$ bits,压缩比 $\approx 237\times$。关键是这一压缩比来自真正的压缩——完整快照语境在推理时通过码本查表恢复,而不是丢弃特征。
变体描述:
- Item ID only:每个历史位置用一个 item-ID embedding 表示,相当于标准 item-embedding 序列 backbone。跨字段组与 Token-level Mixer 失效。存储 $64$ bits(≈2400× 压缩比,但因为是简单丢弃)。
- Item ID + key features:item-ID embedding 拼接少量手挑重要特征(价格分桶、类别、CTR 统计等),再线性投影回 512 维。存储 $64 + \approx 24 \times 32 = 832$ bits(≈185×)。
- Raw sample emb ($d=512$, dense):所有 raw 快照特征拼接后线性投影到 512 维,不做量化。存储 $512 \times 32 = 16{,}384$ bits(≈9×)。Token-level Mixer 生效但缺少量化结构。
分析:
- Item ID only 最差(−1.00% CTR-GAUC、−0.86% CVR-GAUC),比 OneTrans 还低,因为非 item 快照上下文全被丢弃,Token-level Mixer 完全用不上。虽然存储比 ≈2400× 看起来高,但其实是信息丢失而不是真实压缩。
- Item ID + key features 恢复了部分 gap(−0.60%/−0.51%,≈185×),仍然丢弃了大部分快照字段。
- HGAQ(≈237×)比"Item ID + key features"(≈185×)的压缩比还高,且保留了全部 800+ 特征字段的完整快照语义。
- Dense raw-sample embedding ($d=512$) 保留所有快照特征却仍不如 HGAQ(−0.27%/−0.23%),压缩足迹相近(≈9×)。说明信息量越大并不直接等于序列建模越好。作者解释其原因有三:
- 512 维 dense token 在尺寸上与 HGAQ token($T \cdot d_0 = 432$ 维)相当,但缺乏离散结构:$L=1000$ 位置下大 token 维让跨时序注意力更难优化——参数增加、梯度方差上升、收敛慢。
- HGAQ 的离散码本施加了隐式聚类约束:历史上相似的快照被映射到相同或邻近码上,提供无约束线性投影无法提供的自然正则化。
- 因为所有历史位置共享相同码本,HGAQ token 在时间上语义对齐,让 Token-level 和 Sample-level Mixer 能更有效学习跨时序模式。
简而言之:HGAQ 用信息量换 learnability——结构化、紧凑、时间对齐的 token 表征比原始高维 dense 向量对下游 Mixer 更有用。
延伸讨论:raw-sample 基线 −0.27% 的归因问题¶
作者给出的"难收敛"解释是观察而非因果解释。$p<0.01$ 的稳定 gap 不是增加 epoch 就能抹平的,背后更可能是三个耦合因素共同作用,但 SIF 的消融把它们混成了一个 bucket:
- Label-supervised 压缩 ≡ 预测导向的特征选择。HGAQ 码本由 pCTR 辅助 loss 训练,码本位置天然落在"预测相关性方向上的 prototype";而 dense 线性投影对 600+ 字段一视同仁,噪声字段(冗余 ID、低判别力统计特征)占满带宽。
- 共享码本 ⇒ 跨时序语义对齐。$L=1000$ 位置共享同一码本,意味着"午夜低流量 context"在位置 5 和位置 500 映射到同一码,Sample-level 列注意力开箱即得到这个先验。Dense 投影没有这个约束——相同语义的 context 在不同时刻落到任意方向,注意力必须从数据里从头发现对齐关系。这是归纳偏置差异,不是算力差异。
- 离散化 ⇒ 隐式正则。$V^M = 256^3$ 的状态空间在高噪声 CTR label 下限制过拟合,类比 VQ-VAE/TIGER 的观察:离散瓶颈本身提供信息而非只是压缩损失。
理想的阶梯实验应该这样设计:
| 变体 | 监督? | 共享空间? | 离散? | 预期 GAUC |
|---|---|---|---|---|
| Raw dense 512(SIF 做了) | ✗ | ✗ | ✗ | baseline(最差) |
| + pCTR 辅助 loss | ✓ | ✗ | ✗ | 接近 HGAQ |
| + 每位置共享投影 | ✓ | ✓ | ✗ | 很接近 HGAQ |
| HGAQ(full) | ✓ | ✓ | ✓ | SIF |
| HGAQ 但无 pCTR loss(VQ-Rec 风格) | ✗ | ✓ | ✓ | 退化 |
缺了这张表,"压缩 > dense"的结论其实在"监督压缩 / 共享码本 / 离散化"三个因素上都没做因果归因。IAT 的连续 InsEmb 恰好是一个天然对照组——监督压缩 + 连续表征 + 非共享空间——如果能并入 Table 3 对比,就能把"离散量化"和"监督压缩"解耦,可惜两篇论文没对上。
Sensitivity to Sub-Token Granularity $B$¶
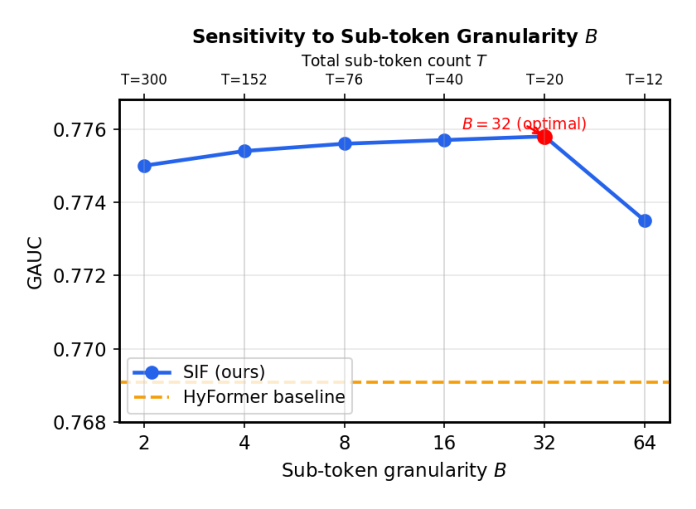
作者扫 $B \in \{2,4,8,16,32,64\}$,对应总 sub-token 数 $T \approx \lceil 600/B \rceil$。$B=32$ 达到最佳 GAUC(0.7758),在 intra-group 拆分与模型紧凑性之间取得最佳平衡。$B=2$(细粒度拆分,$T=300$)时 GAUC 略降至 0.7750,因为 token 序列过长,Token-level Mixer 优化困难。$B=64$(粗粒度,$T=12$)GAUC 跌至 0.7735,接近固定 $G$ 设计——intra-group 分解不足。SIF 在全部 $B$ 取值下都优于 HyFormer(GAUC=0.7691),展现跨粒度选择的鲁棒性。默认 $B=32$($T=20$)。
5.3.2 SIF-Mixer Architecture 消融¶
Table 4(原文)比较 SIF-Mixer 不同注意力策略:
| Attention Strategy | ΔCTR-GAUC | ΔCVR-GAUC |
|---|---|---|
| SIF-Mixer (factored row+col) | — | — |
| Flat attention | −0.24% ± 0.01 | −0.20% ± 0.01 |
| Pooled-then-attend | −0.81% ± 0.02 | −0.68% ± 0.02 |
策略描述:
- Flat attention:所有 $(L+1) \times T$ sub-token 展平成单一序列,标准 full self-attention,复杂度 $O((LT)^2)$。
- Pooled-then-attend:先对每个样本的 $T$ sub-token 做 mean pool 成单一向量,再在 $L+1$ pooled 向量上做标准注意力,复杂度 $O(L^2)$。现有融合 side information 的序列模型常用做法。
- SIF-Mixer (factored row+col):intra-sample Token-level Mixer(行注意力,$O(T^2 \cdot L)$)后接 inter-sample Sample-level Mixer(列注意力,$O(L^2 \cdot T)$),合计 $O(L^2 T + LT^2) \approx O(L^2 T)$。
分析:Pooled-then-attend 下降最大(−0.81%/−0.68%):池化前丢弃了 intra-sample 特征结构,让模型无法捕获每个历史快照内用户-商品-上下文-交叉特征之间的细粒度交互。尽管其绝对 CTR-GAUC(+1.08% over DCNv2+DIN)略高于 HyFormer(+1.01%),但显示仅靠 pooled token 浪费了 Sample Token 的丰富性。Flat attention(−0.24%/−0.20%)通过全 attend 恢复大部分 gap,但缺少行/列显式归纳偏置,且 $O((LT)^2)$ 在 $L=1000$ 下代价难以承担。Factored Mixer 以更低成本达到最佳质量:分解沿行与列轴,充分利用 token 矩阵的二维结构,同时保持复杂度相对 $T$ 是线性的。
5.4 Scaling Analysis¶
作者研究两个 scaling 维度:模型深度 与 序列长度。
Model Depth ($N$):
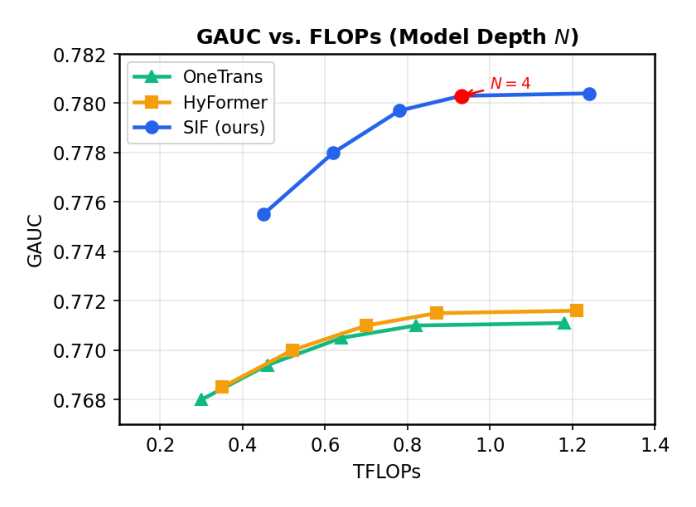
$N \in \{1,2,3,4,5,6\}$。SIF 在整个深度范围内保持更优的 GAUC-FLOPs trade-off:匹配 FLOPs 下(0.87 TFLOPs,$N=4$)SIF 达到 GAUC 0.7803,vs HyFormer 0.7715(+0.0088)、OneTrans 0.7710(+0.0093)。HyFormer 受限于每层 full attention 的高 per-layer cost 过早饱和,OneTrans 同样在较低 GAUC 天花板即 plateau。SIF 持续改进到 $N=4$,默认采用此设置。
Sequence Length ($L$):
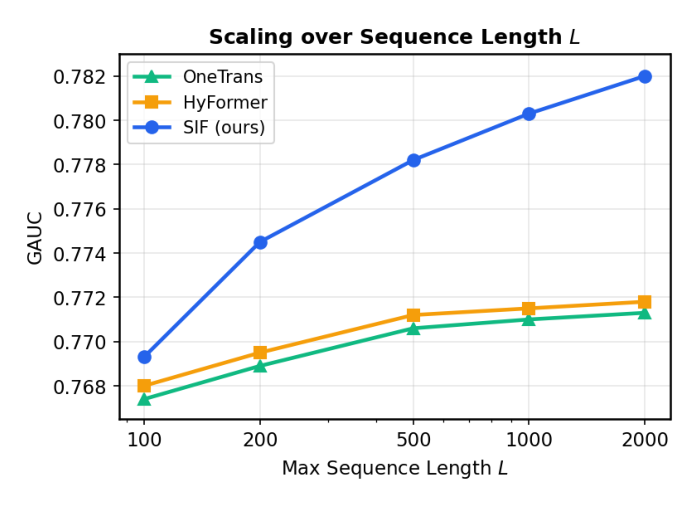
Table 5(原文):
| Seq. Length $L$ | OneTrans | HyFormer | SIF (ours) | Δ(SIF−Hyf) |
|---|---|---|---|---|
| 100 | 0.7674 | 0.7680 | 0.7693 | +0.0013 |
| 200 | 0.7689 | 0.7695 | 0.7745 | +0.0050 |
| 500 | 0.7706 | 0.7712 | 0.7782 | +0.0070 |
| 1000 | 0.7710 | 0.7715 | 0.7803 | +0.0088 |
| 2000 | 0.7713 | 0.7718 | 0.7820 | +0.0102 |
三个模型都随序列变长提升,但收益分化显著:HyFormer 和 OneTrans 很快饱和——从 $L=500$ 到 $L=2000$ GAUC 仅提升 +0.0005 与 +0.0006。这与 item-level 序列架构的编码瓶颈一致。SIF 收益明显更陡峭:$L=100$ 时 SIF(0.7693)已与 HyFormer($L=200$, 0.7695) 相当,$L=500$ SIF(0.7782) 已超越 HyFormer($L=1000$, 0.7715)。与 HyFormer 的 gap 从 $L=100$ 的 +0.0013 单调扩大到 $L=2000$ 的 +0.0102。这反映 SIF 的 token 设计:每个附加历史位置向跨时序注意力贡献完全语境化的 Raw Sample,而 item-level 方法把每个位置压到 bare item embedding,遭遇表征天花板。
5.5 Online A/B 实验¶
SIF 部署至美团本地生活推荐管线,5% 流量持有 7 天,对比 HyFormer 生产 baseline:
整体提升:+2.03% CTR, +1.21% CVR, +1.35% GMV/session
按行为序列长度 $L$ 分层(Table 6):
| Sequence Length | ΔCTR | ΔCVR | ΔGMV/session |
|---|---|---|---|
| $L < 10$(冷用户) | +0.53% | +0.31% | +0.37% |
| $10 \le L < 100$ | +1.18% | +0.71% | +0.84% |
| $100 \le L < 500$ | +2.07% | +1.24% | +1.38% |
| $L \ge 500$(重度用户) | +3.12% | +1.87% | +2.06% |
| Overall | +2.03% | +1.21% | +1.35% |
分析:
- 三个指标都随 $L$ 单调递增。重度用户($L \ge 500$)受益最大(+3.12% CTR, +1.87% CVR, +2.06% GMV),因为 Sample-level Mixer 拥有更丰富的完全语境化 Token Sample 做跨时序推理。
- 即便冷用户($L<10$)也有有意义的提升(+0.53% CTR, +0.31% CVR),作者主要归因于 Sample Tokenizer:当前请求特征经 $W_{\text{res}}^{(g,k)}$ 投影到与历史 Token Sample 共享的码本空间,Target Token Sample 表征更有表达力且语义上更对齐——这一收益与序列长度正交。
- 整段实验在所有用户分层上保持一致正向,符合 SIF "token 设计更富"的理论直觉,而非仅在特定场景生效。
讨论与局限性¶
核心贡献¶
- 把历史序列 token 从 item-level 提升到 sample-level:SIF 从根本上重新定义了历史行为序列在排序模型中的表示。每个历史交互已经在训练日志里有完整的 request 快照,只是过去被丢弃;SIF 通过 HGAQ 恢复这一信息却仍保持紧凑可服务。
- Sample Tokenizer (HGAQ) 设计:Group decomposition + adaptive sub-tokenization + RVQ + label supervision 的组合是真正针对工业推荐场景设计的。对比 item-VQ(VQ-Rec、TIGER),SIF 需要:(a) 异质多字段特征的组分解;(b) label-aware 监督让码本按预测相关性组织。这两点都不出现在基于生成式检索的 item-VQ 设置里。
- SIF-Mixer 分解注意力:Token-level(行)+ Sample-level(列)的 factored 设计把复杂度从 $O((LT)^2)$ 降到 $O(L^2T + LT^2)$,使得 $L=1000$ 级别的 sample-level 序列在生产级 FLOPs 预算下可行。与 MLP-Mixer-style 设计不同,SIF 对两个轴都用 attention 而非 MLP,保留动态的、跨样本交互能力。
值得借鉴的设计点¶
- Label-supervised 码本训练:pCTR MLP on RVQ 重建是让 Sample-level VQ 在工业排序场景落地的关键,避免纯重建误差把重要 item ID 和低基数特征混在一起。
- Target 与 history 的共享码本空间:$\mathcal{L}_{\text{align}}$ 保证在线投影 $W_{\text{res}}^{(g,k)}$ 落在与离线 VQ 相同的空间——这让冷启动用户也能受益(因为 target sample 本身的表征更好)。
- 离线 VQ + 在线查表服务:存储 27×3×8=648 bits 每样本的离散索引,服务时只做码本查表,是真正可接入生产 KV store 的方案。相比 HSTU 式 float16 快照需要 float16 数组级别存储($O(10^4)$ bytes/样本),SIF 的存储成本低两个数量级。
- 分组自适应 sub-token:按字段数自动决定每组 sub-token 数,比固定 $G$ 更灵活。高基数 ID(item_id)可独立成组,保留判别信号。
局限性与争议¶
- 依赖 Raw Sample 的完整训练日志记录:SIF 假设训练日志已经保存了每次交互的完整特征快照。对很多实际系统而言这可能需要额外的 logging 基础设施调整。
- 与生成式推荐范式的差异:SIF 是判别式排序模型(pCTR),不是 OneRec/HSTU 这类生成式推荐。Sample-level token 的想法是否能迁移到生成式设置(如以 Token Sample 作为生成模型的输入)是开放问题。
- 冷启动收益相对有限:尽管 target tokenizer 带来了一定程度的冷用户提升(+0.53% CTR),但 SIF 的主要收益仍来自重度用户。冷启动场景可能需要额外设计(如从新用户画像直接补全 sample-level context)。
- 消融缺乏对 $M, V, G$ 的系统扫描:作者只扫了 $B$ 与 attention strategy,RVQ 深度 $M$、码本大小 $V$、组数 $G$ 的敏感性没有系统报告。
- 与 HSTU 的比较留白:作者在 Related Work 里指出 HSTU "编码丰富的 per-interaction side information",但 Table 2 没有直接对比 HSTU。考虑到 HSTU 和 SIF 都关注丰富化历史 token,这一对比缺失略遗憾。
- "压缩 > dense"结论的归因未分离(见 5.3.1 延伸讨论):raw-sample dense 基线同时缺失监督压缩、共享码本、离散化三个要素,作者归因于"难收敛 + 正则 + 语义对齐"其实是三个假设混在一起。需要阶梯实验才能判断哪个因素主导,否则无法回答"是否只要监督+共享就够了,离散化本身是否必需"这个工程决策问题。
- 两阶段架构的可扩展性天花板:SIF 和 IAT 都采取"先压缩、再建模"的两阶段路线,核心洞察(序列 token 和当前请求同源、用历史样本而非 bare item embedding)很对,但两阶段解耦意味着压缩器和下游模型无法联合端到端优化整条链路——码本一旦固化,下游 Mixer 只能在受限表征空间里发挥。相比之下,HSTU/OneTrans 这类单阶段统一主干虽然存储重,但参数量 scaling 时能同时扩充"如何表征历史"和"如何建模序列",长期上限可能更高。两阶段路线的工程优势明显(离线生产、KV 存储便宜),但是否是最可扩展的范式仍待验证。
工业落地价值¶
- 部署:SIF 已在美团本地生活排序管线生产部署,7 天 5% 持有实验带来 +2.03% CTR, +1.21% CVR, +1.35% GMV/session。
- 兼容已有基础设施:HGAQ 离线执行,产出 648 bits/样本的离散索引,可直接接入既有 KV 存储。在线服务时间几乎等同于标准 item-embedding lookup。
- 放大现有序列建模投资:SIF 与 SIM/LONGER 等 retrieval/lengthening 工作正交——后者决定"保留哪 $L$ 条历史",SIF 决定"每条历史用什么表征"。二者叠加可获得叠加收益。
结论¶
SIF(Sample Is Feature)提出把每条历史序列 token 从 bare item embedding 升级到完整 sample-level 表征。每条过往交互在训练日志里都已经有完整的请求记录,但现有架构把它们压成 bare item ID。SIF 通过 Sample Tokenizer(HGAQ 离线压缩 Raw Sample 为紧凑 Token Sample)+ SIF-Mixer(token-level 与 sample-level mixing 的同构表征注意力)填补了这一 gap。离线实验相对最强统一 baseline 提升 +0.88% GAUC;美团平台在线 A/B 带来 +2.03% CTR, +1.21% CVR, +1.35% GMV/session,收益随用户历史长度单调扩大。SIF 的价值是把历史交互当作第一类、语境丰富的对象,从而解锁 item embedding 根本无法捕捉的 sample-level、时变信号。