DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-Scale Learning to Rank Systems¶
研究动机与背景¶
学习排序(Learning to Rank, LTR)是现代推荐系统和搜索引擎的核心技术之一。在 LTR 模型中,有效的特征交叉(feature crosses)对模型性能至关重要——它们能提供超越单个特征的额外交互信息。例如,"country"和"language"的组合比任何单一特征都更具信息量。
在深度学习时代之前,ML 从业者依赖手工构造特征交叉,这在大规模稀疏、高维的 web 应用中既不可扩展也不可泛化。Embedding 技术的引入使得将高维稀疏特征映射到低维稠密向量成为可能。Factorization Machines(FM)通过 embedding 向量的内积学习 pairwise 特征交互。随着算力增长,工业界 LTR 模型逐步从线性模型、FM 模型迁移到深度神经网络(DNN),模型性能显著提升。
然而,近期研究发现 DNN 在学习显式特征交叉方面并不高效——即便是 2 阶或 3 阶的特征交叉,DNN 也难以精确近似。为此,一系列工作提出了同时利用显式交叉(explicit cross,通过明确的公式建模交叉阶数可控)和隐式交叉(implicit cross,通过 DNN 端到端学习)的方法。
原始 Deep & Cross Network(DCN)是其中的代表性工作,它通过 cross network 自动学习显式的有界阶特征交叉。但 DCN 存在明显局限:cross network 的表达能力有限,其多项式类仅由 $O(\text{input size})$ 个参数刻画,灵活性不足以建模复杂的随机交叉模式。此外,cross network 和 DNN 之间的容量分配不均衡——绝大部分参数被分配给了 DNN 来学习隐式交叉,这一问题在大规模生产数据上尤为突出。
本文提出 DCN-V2,在保持 DCN 简洁优雅的公式结构的同时,大幅提升 cross network 的表达能力,使其建模的函数类是 DCN 的严格超集。DCN-V2 已在 Google 多个大规模 web-scale LTR 系统中成功部署,取得了显著的离线精度和在线业务指标收益。
核心方法/模型架构¶
Embedding 层¶
DCN-V2 的输入是类别特征(categorical,稀疏)和稠密特征(dense)的组合。对于第 $i$ 个类别特征,通过 embedding 矩阵将其从高维稀疏空间映射到低维稠密向量:
$$\mathbf{x}_{\text{embed},i} = W_{\text{embed},i} \mathbf{e}_i \tag{1}$$
其中 $\mathbf{e}_i \in \{0,1\}^{v_i}$ 是 one-hot 向量,$W \in \mathbb{R}^{e_i \times v_i}$ 是学习到的 embedding 矩阵,$v_i$ 和 $e_i$ 分别是词表大小和 embedding 维度。对于多值特征(multivalent features),取所有 embedded 向量的均值。
与许多要求所有特征 embedding 维度相同的工作不同,DCN-V2 支持任意 embedding 维度,这对于工业推荐系统尤为重要——因为不同类别特征的词表大小从 $O(10)$ 到 $O(10^5)$ 差异巨大。
所有 embedded 向量与归一化后的稠密特征拼接为:
$$\mathbf{x}_0 = [\mathbf{x}_{\text{embed},1}; \ldots; \mathbf{x}_{\text{embed},n}; \mathbf{x}_{\text{dense}}] \tag{2}$$
Cross Network¶
Cross network 是 DCN-V2 的核心组件,负责生成显式特征交叉。第 $(l+1)$ 层 cross layer 的公式为:
$$\mathbf{x}_{l+1} = \mathbf{x}_0 \odot (W_l \mathbf{x}_l + \mathbf{b}_l) + \mathbf{x}_l \tag{3}$$
其中 $\mathbf{x}_0 \in \mathbb{R}^d$ 是包含原始特征的基础层(通常即 embedding 输入层),$\mathbf{x}_l, \mathbf{x}_{l+1} \in \mathbb{R}^d$ 分别是第 $l$ 和 $(l+1)$ 层 cross layer 的输入和输出,$W_l \in \mathbb{R}^{d \times d}$ 和 $\mathbf{b}_l \in \mathbb{R}^d$ 是学习到的权重矩阵和偏置向量,$\odot$ 表示 Hadamard(逐元素)乘积。
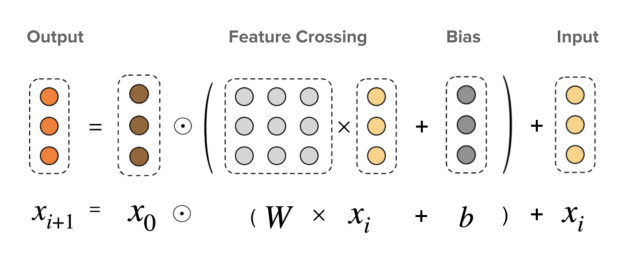
与 DCN 的关键区别:在原始 DCN 中,$W$ 仅为一个向量 $\mathbf{w} \in \mathbb{R}^d$,即 $W = \mathbf{1} \times \mathbf{w}^\top$——这意味着权重矩阵实际上是秩 1 的。DCN-V2 将其升级为完整的 $d \times d$ 矩阵,使得 DCN-V2 建模的函数类是 DCN 的严格超集。
对于一个 $l$ 层的 cross network,它能学习的最高多项式阶数为 $l+1$,网络包含所有从 1 到最高阶的特征交叉。
Deep Network¶
Deep network 是标准的全连接前馈网络,用于学习隐式特征交互。第 $l$ 层的公式为:
$$\mathbf{h}_{l+1} = f(W_l \mathbf{h}_l + \mathbf{b}_l) \tag{4}$$
其中 $\mathbf{h}_l \in \mathbb{R}^{d_l}$,$\mathbf{h}_{l+1} \in \mathbb{R}^{d_{l+1}}$ 分别是第 $l$ 层 deep layer 的输入和输出,$W_l \in \mathbb{R}^{d_l \times d_{l+1}}$ 是权重矩阵,$\mathbf{b}_l \in \mathbb{R}^{d_{l+1}}$ 是偏置,$f(\cdot)$ 是逐元素的激活函数(通常为 ReLU)。
Deep 和 Cross 的组合方式¶
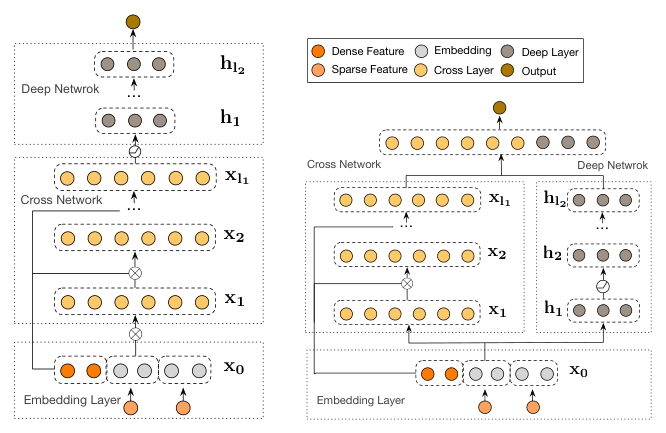
DCN-V2 提供两种组合结构:
Stacked 结构(Figure 1a):$\mathbf{x}_0$ 先经过 cross network 再经过 deep network,最终输出层为:
$$\mathbf{x}_{\text{final}} = \mathbf{h}_{L_d}, \quad \mathbf{h}_0 = \mathbf{x}_{L_c} \tag{5}$$
即数据流为 $f_{\text{deep}} \circ f_{\text{cross}}$。
Parallel 结构(Figure 1b):$\mathbf{x}_0$ 同时馈入 cross network 和 deep network,两者的输出拼接后进入最终输出层:
$$\mathbf{x}_{\text{final}} = [\mathbf{x}_{L_c}; \mathbf{h}_{L_d}] \tag{6}$$
即数据流为 $f_{\text{cross}} + f_{\text{deep}}$。
最终预测为:
$$\hat{y}_i = \sigma(\mathbf{w}_{\text{logit}}^\top \mathbf{x}_{\text{final}}) \tag{7}$$
其中 $\sigma(x) = 1/(1+\exp(-x))$ 为 sigmoid 函数。
训练损失使用 Log Loss 加 $L_2$ 正则:
$$\text{loss} = -\frac{1}{N} \sum_{i=1}^{N} y_i \log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i) + \lambda \sum_l \|W_l\|_2^2 \tag{8}$$
低秩混合 Cross Network(Cost-Effective Mixture of Low-Rank DCN)¶
在实际生产中,模型容量常常受限于服务资源和延迟要求。为了在精度和效率之间取得更好的平衡,作者观察到 DCN-V2 学习到的权重矩阵呈现明显的低秩特性:
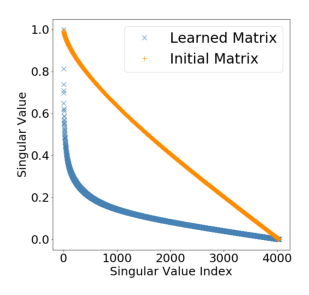
图 3(左)展示了生产模型中学到的 $W$ 矩阵的奇异值衰减模式——与随机初始化矩阵相比,学到的矩阵有更快的谱衰减,说明矩阵具有显著的低秩结构。
基于此观察,作者提出低秩 cross layer:
$$\mathbf{x}_{l+1} = \mathbf{x}_0 \odot \left( U_l (V_l^\top \mathbf{x}_l) + \mathbf{b}_l \right) + \mathbf{x}_l \tag{9}$$
其中 $U_l, V_l \in \mathbb{R}^{d \times r}$,$r \ll d$。这有两层含义:1)先将输入投影到低维子空间 $\mathbb{R}^r$,在子空间中学习特征交叉,再投影回 $\mathbb{R}^d$;2)利用两个瘦矩阵近似稠密矩阵 $W$,降低计算成本。
进一步,受 Mixture-of-Experts(MoE)思想的启发,作者提出低秩专家混合(Mixture of Low-Rank DCN, DCN-Mix):
$$\mathbf{x}_{l+1} = \sum_{i=1}^{K} G_i(\mathbf{x}_l) E_i(\mathbf{x}_l) + \mathbf{x}_l \tag{10}$$
$$E_l(\mathbf{x}_l) = \mathbf{x}_0 \odot \left( U_l^i (V_l^{i\top} \mathbf{x}_l) + \mathbf{b}_l \right) \tag{11}$$
其中 $K$ 是专家数量,$G_i(\cdot): \mathbb{R}^d \to \mathbb{R}$ 是 gating 函数(常用 sigmoid 或 softmax),$E_i(\cdot): \mathbb{R}^d \to \mathbb{R}^d$ 是第 $i$ 个低秩专家。当 $G(\cdot) \equiv 1$ 时,公式退化为单个低秩 cross layer(公式 9)。
还可以进一步在投影空间内引入非线性变换来增强表达力:
$$E_l(\mathbf{x}_l) = \mathbf{x}_0 \odot \left( U_l^i \cdot g(C_l^i \cdot g(V_l^{i\top} \mathbf{x}_l)) + \mathbf{b}_l \right) \tag{12}$$
其中 $g(\cdot)$ 是任意非线性激活函数。
复杂度分析¶
设 embedding 维度为 $d$,cross layer 层数为 $L_c$,低秩专家数为 $K$,秩为 $r$:
- 全秩 cross network:时间和空间复杂度为 $O(d^2 L_c)$
- 低秩混合 DCN-Mix:当 $rK \ll d$ 时,复杂度为 $O(2drKL_c)$,显著低于全秩版本
模型理论分析¶
多项式逼近视角¶
DCN-V2 的 cross network 可以从多项式逼近的角度分析。
定理 4.1(Bitwise):假设输入为 $\mathbf{x} \in \mathbb{R}^d$,$l$ 层 cross network 的输出为 $f_l(\mathbf{x}) = \mathbf{1}^\top \mathbf{x}^l$,第 $i$ 层定义为 $\mathbf{x}^i = \mathbf{x} \odot W^{(i-1)} \mathbf{x}^{i-1} + \mathbf{x}^{i-1}$,则 $f_l(\mathbf{x})$ 可以再现如下多项式类:
$$\left\{ \sum_{\boldsymbol{\alpha}} c_{\boldsymbol{\alpha}}\left(W^{(1)}, \ldots, W^{(l)}\right) x_1^{\alpha_1} x_2^{\alpha_2} \ldots x_d^{\alpha_d} \;\middle|\; 0 \leq |\boldsymbol{\alpha}| \leq l+1, \boldsymbol{\alpha} \in \mathbb{N}^d \right\} \tag{13}$$
定理 4.2(Feature-wise):假设输入 $\mathbf{x} = [\mathbf{x}_1; \ldots; \mathbf{x}_k]$ 包含 $k$ 个特征 embedding,$l$ 层 cross network 能生成直到 $l+1$ 阶的所有特征交互。具体地,其 $p$ 阶交互项的形式为:
$$\sum_{I \in P_l} \sum_{J \in C_p^{p-1}} \mathbf{x}_{i_1} \odot \left(W_{i_1, i_2}^{(j_1)} \mathbf{x}_{i_2} \odot \ldots \odot \left(W_{i_k, i_{k+1}}^{(j_k)} \mathbf{x}_{i_{l+1}}\right)\right) \tag{14}$$
从 bitwise 和 feature-wise 两个视角看,cross network 都能生成直到 $l+1$ 阶的所有特征交叉。与 DCN 相比,DCN-V2 刻画的是同样的多项式类但拥有更多参数,因此更具表达力。DCN-V2 的特征交互可以从 bitwise 和 feature-wise 两种视角理解,而 DCN 只能从 bitwise 视角理解。
与现有模型的联系¶
作者详细分析了 DCN-V2 与其他特征交互方法的联系:
- DCN:DCN 的高效投影视角下,它隐式生成所有 $d^2$ 个 pairwise 交互并投影到低维空间。DCN-V2 使用类似的投影结构,但权重矩阵从对角矩阵升级为全矩阵
- DLRM 和 DeepFM:两者本质上是 2 阶 FM,等价于带有结构化权重矩阵的 1 层 DCN-V2(公式 3 去掉残差项)
- AutoInt:AutoInt 采用多头自注意力,从高层视角看其第 1 层编码所有 2 阶特征交互后馈入第 2 层学习更高阶交互——这与 DCN-V2 相同。但低层公式中,AutoInt 的非线性来自 ReLU,而 DCN-V2 使用 $\mathbf{x}_i \odot W_{i,j} \mathbf{x}_j$
- PNN:OPNN 显式创建所有 $d^2$ 个 pairwise 交互后投影到低维;DCN-V2 则隐式地通过结构化矩阵创建交互
实验设置¶
数据集¶
| 数据集 | 样本数 | 特征数 | 词表大小 |
|---|---|---|---|
| Criteo | 45M | 39 | 2.3M |
| MovieLens-1M | 740k | 7 | 3.5k |
| Production | > 100B | NA | NA |
Criteo:最流行的 CTR 预估 benchmark,包含 7 天用户日志。前 6 天为训练集,最后一天随机分为验证集和测试集。对 13 个连续特征做 log 归一化,26 个类别特征做 embedding。
MovieLens-1M:最流行的推荐系统数据集,包含 (user-features, movie-features, rating) 三元组。评分 1-2 归为 0,4-5 归为 1,3 被移除。数据按 80%/10%/10% 随机划分。
Baseline 模型¶
论文对比了 6 种 SOTA 特征交互学习算法:
| 模型 | 交互阶数 | 显式交互公式 | 最终目标 |
|---|---|---|---|
| PNN | 2 | $\mathbf{x}_o = [\mathbf{v}_i^\top \mathbf{v}_j \| \forall i,j]$(IPNN)/ $\mathbf{x}_o = [\text{vec}(\mathbf{v}_i \otimes \mathbf{v}_j) \| \forall i,j]$(OPNN) | $f_i \circ f_e$ |
| DeepFM | 2 | $\mathbf{x}_o = [\mathbf{v}_i^\top \mathbf{v}_j \| \forall i,j]$ | $f_i + f_e$ |
| DLRM | 2 | $\mathbf{x}_o = [\mathbf{v}_i^\top \mathbf{v}_j \| \forall i,j]$ | $f_i \circ f_e$ |
| DCN | $\geq 2$ | $\mathbf{x}_{l+1} = \mathbf{x}_0 \otimes \mathbf{x}_l \mathbf{w}_l$ | $f_i \circ f_e$ |
| xDeepFM | $\geq 2$ | $\mathbf{v}_k^h = \sum_{i,j} w_{ij}^{k,h} (\mathbf{v}_{i,*}^{k-1} \odot \mathbf{v}_j)$ | $f_i + f_e$ |
| AutoInt | NA | 自注意力 gating | $f_i + f_e$ |
| DCN-V2 (ours) | $\geq 2$ | $\mathbf{x}_l = \mathbf{x}_0 \odot (W_l \mathbf{x}_l)$ | $f_i \circ f_e$ / $f_i + f_e$ |
其中 $f_i$ 表示隐式交互(ReLU 层),$f_e$ 表示显式交互,$+$ 表示在 logit 层面相加。
实现细节¶
- 所有模型使用 TensorFlow v1 实现
- 所有 baseline 和 DCN-V2 在 feature interaction 组件之外的部分完全相同
- Embedding 维度固定为 $\text{Avg}(\sum_{\text{vocab}} 6 \cdot (\text{vocab cardinality})^{1/4})$,Criteo 为 39,MovieLens-1M 为 30
优化设置¶
- 优化器:Adam,batch size 512(Criteo)/ 128(MovieLens)
- 初始化:He Normal
- 偏置初始化为 0
- Gradient clipping norm:10
- EMA decay:0.9999
超参数搜索¶
为保证公平性和可复现性,对所有 baseline 和提出的方法进行了广泛的两阶段超参数搜索:
- 学习率:先在 $[10^{-4}, 10^{-1}]$ log scale 粗搜,再在 $[10^{-4}, 5 \times 10^{-4}]$ linear scale 细搜
- 训练步数:从 {150k, 160k, 200k, 250k, 300k} 中搜索
- DNN 隐层数:{1, 2, 3, 4},隐层大小在 {562, 768, 1024} 中搜索
- 正则化 $\lambda$:{0, $3 \times 10^{-5}$, $10^{-4}$}
- 每种最优配置运行 5 次,报告均值和标准差
模型特定超参数:
- DCN/DCN-V2:cross layers 1-4
- AutoInt:attention embedding {20, 32, 40},attention heads 2-3
- xDeepFM:CIN layer size {100, 200},depth {2, 3, 4}
- DLRM:bottom MLP sizes {(512, 256, 64), (256, 64)}
- PNN:kernel type {full matrix, vector, number}
- 所有模型参数量上限 $1024^2 \times 5$
合成数据实验(RQ1:特征交叉技术的理解)¶
多项式拟合实验¶
作者在干净的合成数据上验证各组件的效果,使用已知真实模型来评估。假设每个特征 $x_i$ 是 1 维的,单项式 $x_1^{\alpha_1} x_2^{\alpha_2} \cdots x_d^{\alpha_d}$ 表示 $|\boldsymbol{\alpha}|$ 阶交互。
Table 1: RMSE and Model Size (# Parameters) for Polynomial Fitting of Increasing Difficulty
| DCN (1Layer) | DCN-V2 (1Layer) | DNN (1Layer) | DNN (large) | |
|---|---|---|---|---|
| RMSE / Size | RMSE / Size | RMSE / Size | RMSE / Size | |
| $f_1$ | 8.9E-13 / 12 | 5.1E-13 / 24 | 2.7E-2 / 24 | 4.7E-3 / 41K |
| $f_2$ | 1.0E-01 / 9 | 4.5E-15 / 15 | 3.0E-2 / 15 | 1.4E-3 / 41K |
| $f_3$ | 2.6E+00 / 300 | 6.7E-07 / 10K | 2.7E-1 / 10K | 7.8E-2 / 758K |
其中 $f_1(x) = x_1^2 + x_1 x_2 + x_3 x_1 + x_4 x_1$,$f_2(x) = x_1^2 + 0.1 x_1 x_2 + x_2 x_3 + 0.1 x_2^2$,$f_3(x) = \sum_{(i,j) \in S} w_{ij} x_i x_j$($\mathbf{x} \in \mathbb{R}^{100}$,$|S|=100$)。
关键发现:
- 当交叉模式简单($f_1$)时,DCN 和 DCN-V2 都很高效
- 当模式变得复杂($f_3$)时,DCN 退化而 DCN-V2 仍然精确
- DNN 即使用大得多的模型(41K-758K 参数),仍远不如 DCN-V2
各组件作用分析¶
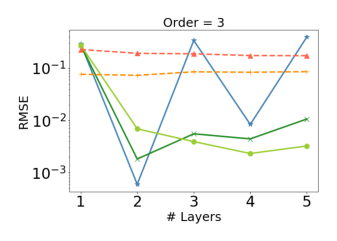
图 4 展示了不同组件在 order-3 和 order-4 齐次多项式上的拟合能力。$\mathbf{x}_0 \odot (W\mathbf{x}_i)$ 在第 $d-1$ 层建模 $d$ 阶交叉,因此 order-3 多项式在第 2 层取得最佳性能。偏置和残差项的作用在于创建并维持所有从低到高阶的交叉项,减小冗余特征交互引入时的性能退化。
Table 2: Combined-order (1-4) Polynomial Fitting (RMSE)
| #Layers | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| DCN-V2 | 1.43E-01 | 2.89E-02 | 9.82E-03 | 9.87E-03 | 9.92E-03 |
| DNN | 1.32E-01 | 1.03E-01 | 1.03E-01 | 1.09E-01 | 1.05E-01 |
随着层数增加,DCN-V2 能捕获更高阶的特征交叉,性能持续提升。在 3 层之后性能不再退化(得益于偏置和残差项)。DNN 即使用更大更深的网络,在显式特征交叉上的表现也远不如 cross network。
主要实验结果¶
RQ2:Feature Interaction Component Alone¶
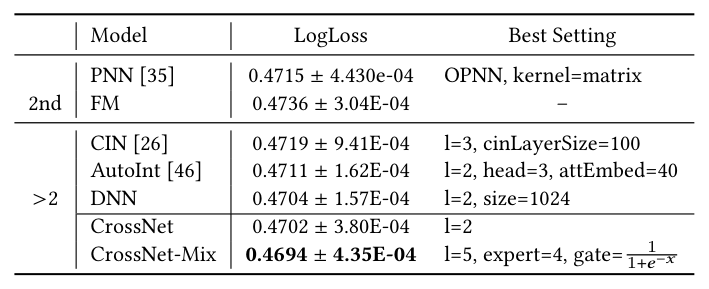
仅考虑特征交互组件(不包含 DNN),仅使用类别特征。结果显示:
| 模型 | LogLoss | Best Setting |
|---|---|---|
| PNN | 0.4715 ± 4.43e-04 | OPNN, kernel=matrix |
| FM | 0.4736 ± 3.04E-04 | - |
| CIN | 0.4719 ± 9.41E-04 | l=3, cinLayerSize=100 |
| AutoInt | 0.4711 ± 1.62E-04 | l=2, head=3, attEmbed=40 |
| DNN | 0.4704 ± 1.57E-04 | l=2, size=1024 |
| CrossNet | 0.4702 ± 3.80E-04 | l=2 |
| CrossNet-Mix | 0.4694 ± 4.35E-04 | l=5, expert=4, gate=$\frac{1}{1+e^{-x}}$ |
关键发现: 1. 高阶方法(CrossNet, AutoInt, CIN)整体优于 2 阶方法(PNN, FM),说明 Criteo 数据集中高阶交叉有意义 2. 在高阶方法中,cross network 取得最佳或接近最佳性能,且优于 DNN 3. DCN-Mix 利用低秩混合进一步降低了 30% 的内存和计算开销,同时维持了精度
RQ3:与 Baseline 的端到端对比¶
Table 6: LogLoss and AUC (test) on Criteo and MovieLens-1M
| Baseline | Criteo LogLoss | Criteo AUC | Criteo Params | Criteo FLOPS | MovieLens-1M LogLoss | MovieLens-1M AUC | ML Params | ML FLOPS |
|---|---|---|---|---|---|---|---|---|
| PNN | 0.4421 (5.8E-4) | 0.8099 (6.1E-4) | 3.1M | 6.1M | 0.3182 (1.4E-3) | 0.8955 (3.3E-4) | 54K | 110K |
| DeepFM | 0.4420 (1.4E-4) | 0.8099 (1.5E-4) | 1.4M | 2.8M | 0.3202 (1.0E-3) | 0.8932 (7.7E-4) | 46K | 93K |
| DLRM | 0.4427 (3.1E-4) | 0.8092 (3.1E-4) | 1.1M | 2.2M | 0.3245 (1.1E-3) | 0.8890 (1.1E-3) | 7.7K | 16K |
| xDeepFM | 0.4421 (1.6E-4) | 0.8099 (1.8E-4) | 3.7M | 32M | 0.3251 (4.3E-3) | 0.8923 (8.6E-4) | 160K | 990K |
| AutoInt+ | 0.4420 (5.7E-5) | 0.8101 (2.6E-5) | 4.2M | 8.7M | 0.3204 (4.4E-4) | 0.8928 (3.9E-4) | 260K | 500K |
| DCN | 0.4420 (1.6E-4) | 0.8099 (1.7E-4) | 2.1M | 4.2M | 0.3197 (1.9E-4) | 0.8935 (2.1E-4) | 110K | 220K |
| DNN | 0.4421 (6.5E-5) | 0.8098 (5.9E-5) | 3.2M | 6.3M | 0.3201 (4.1E-4) | 0.8929 (2.3E-4) | 46K | 92K |
| DCN-V2 | 0.4406 (6.2E-5) | 0.8115 (7.1E-5) | 3.5M | 7.0M | 0.3170 (3.6E-4) | 0.8950 (2.7E-4) | 110K | 220K |
| DCN-Mix | 0.4408 (1.0E-4) | 0.8112 (9.8E-5) | 2.4M | 4.8M | 0.3160 (4.9E-4) | 0.8964 (2.9E-4) | 110K | 210K |
| CrossNet | 0.4413 (2.5E-4) | 0.8107 (2.4E-4) | 2.1M | 4.2M | 0.3185 (3.0E-4) | 0.8937 (2.7E-4) | 65K | 130K |
关键发现:
- DCN-V2 在所有 baseline 上取得一致性提升。在 Criteo 上,0.001 级别的 LogLoss 改进被认为是显著的。DCN-V2 达到了 0.4406 的 LogLoss 和 0.8115 的 AUC,显著优于所有 baseline
- DCN-Mix 在效率和精度之间取得更优平衡——参数量仅为 DCN-V2 的约 68%,但精度仅有微小损失
- CrossNet 单独使用(不含 DNN)也超越了多数 baseline,这令人惊讶且意义深远
- Stacked 结构在 Criteo 上更优,Parallel 结构在 MovieLens-1M 上更优——最佳架构依赖数据
模型质量分析:DNN 是万能逼近器,经过精细调优后能与大多数 baseline 持平甚至超越部分模型。这表明隐式特征交互和精调的 DNN 的重要性。然而,DCN-V2 持续优于 DNN,说明它成功地同时利用了显式和隐式特征交互,在 cross network 和 deep network 之间取得了表达力的平衡。
RQ4:超参数影响分析¶
Cross layer 深度的影响:
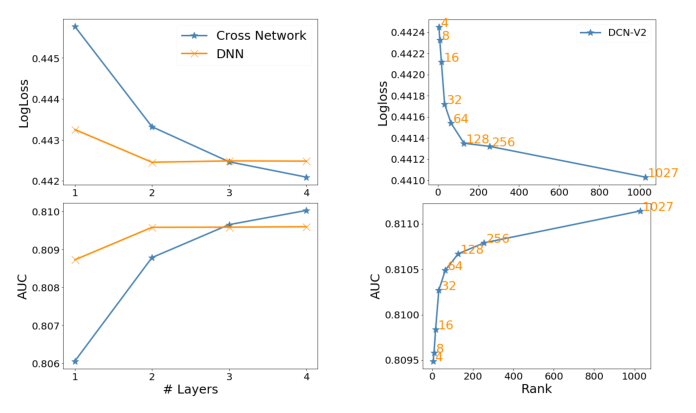
图 5a 展示了 Criteo 上随层数增加的 LogLoss 和 AUC 变化。cross network 随着层数加深持续改善,捕获更多有意义的交叉特征。但改善速率在更深层时放缓,说明高阶交叉的贡献低于低阶交叉。当层数 $\leq 2$ 时,DNN 优于 cross network;当层数增多后,cross network 开始追平并超越 DNN。
权重矩阵秩的影响:
图 5b 展示了矩阵秩 $r$ 对性能的影响。模型设置为 3 层 cross layer + 3 层 512 维隐层。$r$ 从 4 增到 64 时,LogLoss 近乎线性下降(模型持续改善);$r$ 从 64 增到 full rank 时,改善速率显著放缓。作者将 64 称为 threshold rank,并假设其值为 $O(k)$,其中 $k$ 为特征数(Criteo 为 39)。
Expert 数量的影响:总秩固定为 256 的 2 层 cross layer,Expert 数从 1 到 32 变化时,LogLoss 分别为 0.4418、0.4416、0.4416、0.4422、0.4420。低秩 expert 的性能并未优于单个高秩 expert,作者认为更先进的 gating 机制(如 Gumbel-softmax、温度调节)可能有助于进一步发挥多 expert 的潜力。
RQ4 续:固定内存预算下的对比¶
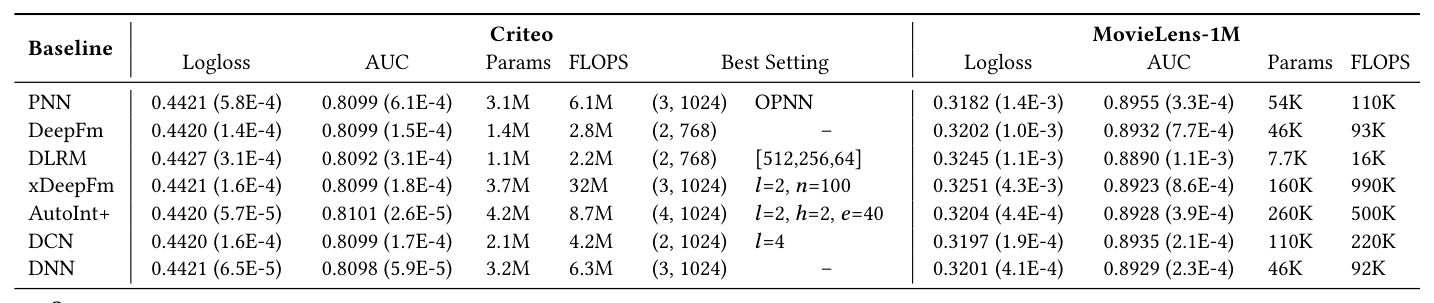
| #Params | 7.9E+05 | 1.3E+06 | 2.1E+06 | 2.6E+06 |
|---|---|---|---|---|
| CrossNet LogLoss | 0.4424 | 0.4417 | 0.4416 | 0.4415 |
| DNN LogLoss | 0.4427 | 0.4426 | 0.4423 | 0.4423 |
| CrossNet AUC | 0.8096 | 0.8104 | 0.8105 | 0.8106 |
| DNN AUC | 0.8091 | 0.8094 | 0.8096 | 0.80961 |
在固定内存预算下,通过变化 cross layer 数量和大小({128, 256})、隐层数和大小来匹配参数量。最佳性能由 5 层 cross network 取得,说明真实数据可被多项式很好地逼近。在每个预算水平下,cross network 在 LogLoss 和 AUC 上都优于 DNN。
这一结果令人惊讶——ReLU 层是各类神经网络(RNN、CNN)的基础组件,但 cross layer 在捕获显式特征交叉方面展现出了可替代 ReLU 层的潜力。
RQ5:模型可解释性¶
DCN-V2 的权重矩阵 $W$ 直接揭示了学到的特征交叉的重要性。具体地,将权重矩阵按特征 embedding 分块后:
$$\mathbf{x} \odot W\mathbf{x} = \begin{bmatrix} \mathbf{x}_1 \\ \vdots \\ \mathbf{x}_k \end{bmatrix} \odot \begin{bmatrix} W_{1,1} & \cdots & W_{1,k} \\ \vdots & & \vdots \\ W_{k,1} & \cdots & W_{k,k} \end{bmatrix} \begin{bmatrix} \mathbf{x}_1 \\ \vdots \\ \mathbf{x}_k \end{bmatrix} \tag{15}$$
第 $(i,j)$ 块 $W_{i,j}$ 的 Frobenius 范数表征了第 $i$ 和第 $j$ 个特征之间交互的重要性。
在生产模型中,权重矩阵的对角块(自交互,即 $x^2$ 项)对应的权重较大。在 MovieLens-1M 上,Gender × UserId 和 MovieId × UserId 的交互最强——这与推荐系统的直觉一致。
工业部署:Google 大规模推荐系统¶
排序问题设定¶
给定用户和候选物品集合,排序系统需要返回用户最可能互动的 top-k 物品。训练数据为 $\{(\mathbf{x}_i, y_i)\}_{i=1}^N$,其中 $\mathbf{x}_i$ 包含多模态特征(用户兴趣、物品元数据、上下文特征),$y_i$ 是用户行为标签(如 click)。
生产数据与模型¶
- 训练数据:数百亿用户日志
- 词表大小:稀疏特征词表从 2 到百万级
- 基线模型:全连接 MLP + ReLU 激活
生产部署效果¶
Table 8: Relative AUCLoss of DCN-V2 v.s. same-sized ReLUs
| 1layer ReLU | 2layer ReLU | 1layer DCN-V2 | 2layer DCN-V2 | |
|---|---|---|---|---|
| 0% | -0.15% | -0.19% | -0.45% |
与生产模型对比,DCN-V2 带来 0.6% 的 AUCLoss(1-AUC)改进。对于该特定模型,AUCLoss 0.1% 的改进即被视为显著提升。同时还观察到显著的在线业务指标收益。
Table 8 进一步验证:将同等大小的 ReLU 层替换为 cross layer 即可获得收益——AUCLoss 持续改善,2 层 cross layer 带来 0.45% 的相对提升。
实践经验总结¶
- Cross layer 应插入在输入和 DNN 隐层之间,而非 DNN 顶部——因为特征表示的物理含义在远离输入后逐渐减弱
- Stacking 或 concatenating 1-2 层 cross layer 即可获得一致性收益
- Stacking 和 concatenating 两种结构在实践中均有效——stacking 学习更高阶交互,concatenating 捕获互补交互
- 使用低秩 DCN,秩设为 (input size)/4 即可保持全秩 DCN-V2 的精度
讨论与局限性¶
核心贡献¶
DCN-V2 的核心贡献在于将原始 DCN 的秩 1 权重矩阵升级为全秩矩阵,同时保持了公式的简洁性。这一看似简单的改进带来了多方面的价值:
- 表达力大幅提升:建模的函数类是 DCN 的严格超集,能学习更复杂的交叉模式
- 可解释性:权重矩阵可直接可视化,揭示特征交互的重要性
- 实用性强:支持任意 embedding 维度、可作为即插即用的构建模块
值得借鉴的设计¶
- 低秩混合专家(DCN-Mix):观察到权重矩阵的低秩特性后,用 MoE 思想在子空间中分别学习特征交叉,既降低了计算成本又维持了表达力——这一范式可推广到其他需要降低大矩阵计算成本的场景
- 系统性的实验方法论:论文对每个模型都进行了广泛的超参数搜索和 5 次随机种子实验,这在 CTR 预估领域的可复现性问题上树立了标杆
- 从合成数据到真实数据再到工业部署的完整验证链条
局限性¶
- MoE gating 机制较为朴素:论文使用简单的 sigmoid 或 softmax gating,实验中低秩 expert 并未显著优于单个高秩 expert。更先进的 gating 策略(如 Gumbel-softmax、top-k routing)可能释放更多潜力
- 理论分析仅限于多项式视角:cross layer 的非线性系统组合对全局训练动态(Jacobian、Hessian)的影响留待未来研究
- 实验仅在 Criteo 和 MovieLens-1M 两个公开数据集上进行,虽然有工业部署验证,但公开 benchmark 的多样性不足
- cross layer 能否在更广泛的架构(RNN、CNN)中替代 ReLU——论文提出了这一有趣的假设但未充分验证
工业落地价值¶
DCN-V2 已在 Google 多个 web-scale LTR 系统中部署,实现了:
- 离线 AUCLoss 0.6% 的显著提升
- 显著的在线业务指标收益
- 简单的即插即用部署方式——将 ReLU 层替换为 cross layer 即可
这使得 DCN-V2 成为工业界 CTR 预估的事实标准之一。