LoopCTR: Unlocking the Loop Scaling Power for Click-Through Rate Prediction¶
研究动机与背景¶
CTR 预估在过去几年里基本完成了从早期 DNN(DLRM、DIN、DCNv2)向 Transformer 系(HSTU、OneTrans、MTGR、HiFormer 等)的迁移。工业界目前主流的 scaling 思路沿着三个维度走:depth scaling(叠更多层)、width scaling(拉大 token embedding 维度)、input scaling(把用户历史序列拉得更长)。这些路径有效,但代价是参数量与算力同步线性甚至超线性增长,与"低延迟、低显存、毫秒级响应"的工业部署约束之间裂缝越来越大。
LoopCTR 提出了一个正交于上述三条路线的第四种 scaling 维度——computation scaling through recursive reuse:训练时把同一组共享层反复执行多轮(loop),让计算量随 loop 数线性增长,但参数量保持不变。这条路径源自 NLP 社区的 looped Transformer 系列(Universal Transformer、MoEUT、LoopLM、ETD),其核心好处有两个:
- 参数效率:在同等参数预算下,递归循环能换来更深的 latent reasoning,对推荐这种稀疏数据更友好(更难过拟合);
- 共享层先验:被反复使用的同一组参数,被迫学到跨深度仍然有效的"通用化"表示,本身就是一种 inductive bias,相当于在结构上做了正则。
但是把 looped Transformer 直接搬到 CTR 上有两个硬约束:
- Expressiveness bottleneck:标准 Transformer block 的计算流程是固定的、静态的(固定 $h + f(h)$ 残差,1:1 比例),同一层反复执行很容易落入"重复 = 等价"的退化。需要赋予共享层在不同 loop 深度下表现出不同行为的能力。
- Efficiency bottleneck:哪怕训练时多 loop 真的有效,部署阶段如果还要走 $L$ 次 loop,CTR 模型的 P99 延迟就直接爆掉了。需要某种机制把"多 loop 训练带来的收益"内化到一次前向里。
LoopCTR 的两个核心技术创新都是针对这两个瓶颈给出的答案:Hyper-Connected Residuals (HCR) 解 expressiveness bottleneck;多深度 process supervision + train-multi-loop / infer-zero-loop 策略解 efficiency bottleneck。结果是:在 Amazon、TaobaoAds、KuaiVideo、InHouse 四个数据集上 LoopCTR 全面 SOTA,而且零 loop(直接跳过 Loop Block)的推理就已经超过所有 baseline——这个发现是文章的最大亮点。
核心方法 / 模型架构¶
Sandwich 三段式架构¶
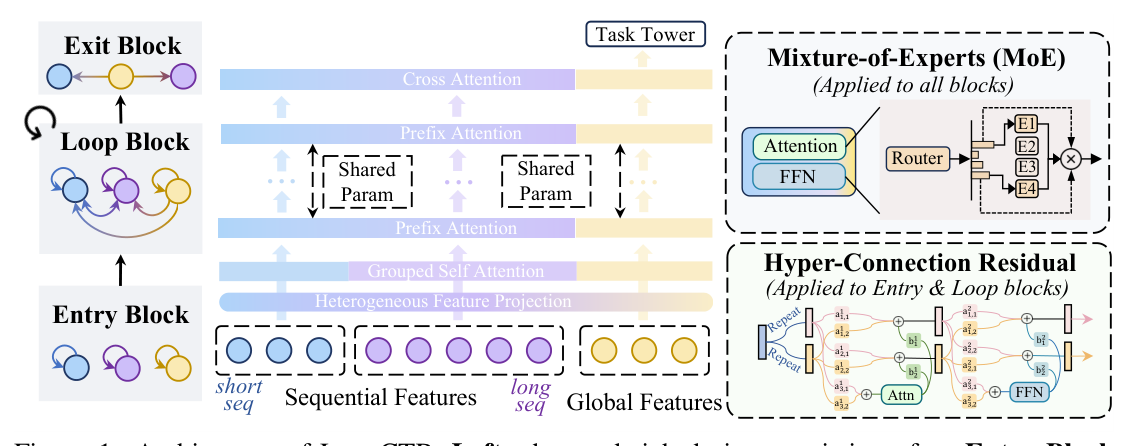
LoopCTR 将整个网络拆成三个职能分明的模块(图 1 左半部分):
- Entry Block:异构特征投影 + grouped self-attention,负责把多源异构输入编码到统一表征空间;
- Loop Block:核心模块,所有 loop 迭代共享同一份参数,做迭代 latent refinement;
- Exit Block:cross-attention + task tower,把精炼后的表征聚合并产出最终的 CTR 概率。
这三段分离的设计带来的关键好处是:Loop Block 的执行次数在训练时和推理时可以解耦。训练时 loop $L$ 次($L=1,2,3$),推理时可以选择 loop $i \in \{0, 1, \dots, L\}$ 次,其中 $i=0$ 直接跳过 Loop Block,由 Entry → Exit 直连完成预测。
输入表示¶
给定用户 $u$ 与候选物品 $v$,CTR 模型预测点击概率 $\hat{y} = p(\text{click}|u, v)$。输入特征记为 $\mathbf{x} = (\mathbf{x}^u, \mathbf{x}^v, \mathcal{S}^s, \mathcal{S}^l, \mathbf{x}^c, \mathbf{x}^\times)$,其中:
- $\mathbf{x}^u$:用户画像(ID、年龄、性别、城市等);
- $\mathbf{x}^v$:物品特征(ID、类目、商家、价格等);
- $\mathcal{S}^s$:短期行为序列(保留原始 item token,捕获 fine-grained 近期兴趣);
- $\mathcal{S}^l$:长期行为序列(受 Q-Former 启发,引入一组可学习 query token,通过 cross-attention 把 $\mathcal{S}^l$ 压缩成紧凑表征,避免 $>1000$ token 的全注意力开销,InHouse 上压缩 query 数固定为 16);
- $\mathbf{x}^c$:上下文(设备、时段等);
- $\mathbf{x}^\times$:cross 统计特征(预先算好的用户-物品亲和度)。
特征切成 sequential features($\mathcal{S}^s$、压缩后的 $\mathcal{S}^l$)和 global features(其余),经 tokenization 后整体记作 token 集合 $\mathbf{T}$。模型 $f_\theta(\mathbf{T})$ 输出 $\hat{y} \in [0,1]$,用 BCE loss 训练:
$$\mathcal{L}_{\text{BCE}} = -\frac{1}{N} \sum_{i=1}^{N} \big[ y_i \log \hat{y}_i + (1-y_i)\log(1-\hat{y}_i) \big]. \tag{1}$$
Entry Block:异构组分投影 + 组内自注意力¶
由于 $\mathbf{T}$ 由语义分布完全不同的特征组拼成,统一线性投影会把这些表征强行拉到同一坐标系,损失各自的特征空间结构。Entry Block 采用 group-specific projection:第 $g$ 组的每个 token $\mathbf{t} \in \mathbb{R}^d$ 经
$$\mathbf{h} = \mathbf{t} \mathbf{W}_g + \mathbf{b}_g$$
投到统一维度 $d'$,其中每个行为序列、每个独立的 global token 都构成单独的组。投影后在每个 group 内做完整 self-attention(组间不交互),从而完全并行:
$$\mathbf{H}_{\text{entry}} = \big[ \text{SelfAttn}(G_1); \dots; \text{SelfAttn}(G_K) \big]. \tag{2}$$
Loop Block:共享参数的多轮迭代精炼¶
记 $\mathbf{H}_{\text{seq}}$ 与 $\mathbf{H}_{\text{glb}}$ 为 sequential / global token 表征。每一次 loop 迭代 $l$ 执行:
$$\mathbf{H}^{(l)} = \text{PrefixAttn}\big( [\mathbf{H}^{(l-1)}_{\text{seq}}; \mathbf{H}^{(l-1)}_{\text{glb}}], \mathbf{M} \big), \tag{3}$$
其中 $\text{PrefixAttn}(\cdot, \mathbf{M})$ 是带 mask 的 multi-head attention,$\mathbf{M}$ 编码了非对称 prefix attention:
$$\mathbf{M}[i,j] = \begin{cases} 1, & \text{if } i \in \text{seq and } j \in \text{seq}, \\ 1, & \text{if } i \in \text{glb}, \\ 0, & \text{otherwise}. \end{cases} \tag{4}$$
直观地说:sequential token 只看自己组(不被 global features 污染),global token 既能看自己也能看 sequential(聚合上下文)。这个设计有两个工程价值:
- 防止 global features 主导 sequential 表征;
- 天然支持 KV cache:因为 sequential 部分的 KV 不依赖 global token 与候选物品,每次请求里 sequential KV 只算一次,所有候选共用——大幅省线上算力。
为了让单一共享层在反复调用时还能保持表达力,Loop Block 还配上了 HCR(Section 3.3)和 MoE-Augmented attention/FFN(Section 3.4)。整体上 MoE 应用到所有 block,HCR 仅用于 Entry/Loop。
Exit Block¶
Global token 通过 cross-attention 拉取 sequential context,concat 后过 MLP:
$$\hat{y} = \text{MLP}\big( \big[ \text{CrossAttn}(\mathbf{H}_{\text{glb}}, \mathbf{H}_{\text{seq}}) \big] \big). \tag{5}$$
值得强调的工程含义:整套架构里 sequential token 永远不会 attend 到 global token,意味着 user-side 计算(含 Entry Block 处理行为序列、Loop Block 中 seq-to-seq 部分)可以在每个用户请求里只算一次,跨成百上千个候选 item 复用 KV——这也是 LoopCTR 在线 latency 远低于 OneTrans/HSTU 的根本原因。
3.3 Hyper-Connected Residuals (HCR)¶
标准 Transformer block 的残差是 $\mathbf{h} + f(\mathbf{h})$,一个固定的 1:1 混合。这种结构在共享层反复调用时是致命的——同一层的输出和输入按固定比例叠加,多次循环下"信息流方向"几乎被锁死。受 Hyper-Connections(Zhu et al., 2024)和 Manifold-constrained HC(Xie et al., 2025)启发,LoopCTR 用 HCR 替换标准残差。
多流复制:把单流隐状态 $\mathbf{h} \in \mathbb{R}^d$ 复制成 $n$ 个并行流 $\mathbf{H} \in \mathbb{R}^{n \times d}$。给定 $\mathbf{H}$ 和子层 $\mathcal{T}$(attention 或 FFN),HCR 的更新式为:
$$\hat{\mathbf{H}} = \underbrace{\mathbf{A}_r^\top \mathbf{H}}_{\text{residual mixing}} + \underbrace{\mathbf{B}^\top \cdot \mathcal{T}((\mathbf{H}^\top \mathbf{A}_m)^\top)}_{\text{layer contribution}}, \tag{6}$$
其中 $\mathbf{A}_m \in \mathbb{R}^{n \times 1}$ 把 $n$ 个流融合成单一输入喂给 $\mathcal{T}$,$\mathbf{B} \in \mathbb{R}^{1 \times n}$ 把 $\mathcal{T}$ 的输出再分发回 $n$ 个流,$\mathbf{A}_r \in \mathbb{R}^{n \times n}$ 控制 $n$ 个流之间的残差混合矩阵。
输入相关的动态系数:与标准残差固定 1:1 不同,HCR 让所有三个矩阵都依赖输入。设 $\bar{\mathbf{H}} = \text{RMSNorm}(\mathbf{H})$,每个系数由"可学的静态部分 + 动态扰动"两部分构成:
$$\tilde{\mathbf{A}}_m = \mathbf{A}_m + s_\alpha \odot \tanh(\bar{\mathbf{H}} \mathbf{W}_m), \quad \tilde{\mathbf{A}}_r = \mathbf{A}_r + s_\alpha \odot \tanh(\bar{\mathbf{H}} \mathbf{W}_r), \quad \tilde{\mathbf{B}} = \mathbf{B} + s_\beta \odot \tanh(\bar{\mathbf{H}} \mathbf{W}_\beta), \tag{7}$$
其中 $\mathbf{A}_m, \mathbf{A}_r, \mathbf{B}$ 是可学习的静态 loop-invariant 参数,$\tanh$ 项提供输入感知的动态调整,$s_\alpha, s_\beta$ 是可学缩放系数。前向时用 $\tilde{\mathbf{A}}_m, \tilde{\mathbf{A}}_r, \tilde{\mathbf{B}}$ 替换 (6) 中的 $\mathbf{A}_m, \mathbf{A}_r, \mathbf{B}$。
初始化技巧:$\mathbf{W}_m, \mathbf{W}_r, \mathbf{W}_\beta$ 全部初始化为 0,使得 $\tanh$ 扰动消失,HCR 在训练初始时刻塌缩回标准 Pre-Norm 残差。第 $s$ 个 sub-layer($s=0$ 是 attention,$s=1$ 是 FFN)的静态部分初始化为:
$$\begin{pmatrix} \mathbf{0}_{1\times 1} & \mathbf{B} \\ \mathbf{A}_m & \mathbf{A}_r \end{pmatrix} = \begin{pmatrix} \mathbf{0}_{1\times 1} & \mathbf{1}_{1\times n} \\ \mathbf{e}_{s \bmod n} & \mathbf{I}_{n\times n} \end{pmatrix}, \tag{8}$$
其中 $\mathbf{e}_{s \bmod n}$ 是 one-hot 基向量,把第 $s$ 个 sub-layer 绑定到指定的流。这样初始化下,每个 sub-layer 从一个固定流读,全部流通过 identity residual 保留——等价于标准 Pre-Norm Transformer。这点对训练稳定性极重要:HCR 不会在训练早期就破坏掉熟悉的 Pre-Norm 行为。
为什么 HCR 对 looped 架构特别重要: 1. Parallel multi-stream computation:$n$ 流并行可以更好利用硬件; 2. Flexible blending:固定 1:1 残差被可学的 per-stream 混合系数取代; 3. Input-dependent adaptivity:动态系数让共享层 instance-adaptive 且隐式 loop-aware——同一组参数在不同 loop 深度面对不同输入分布时表现出不同的"行为模式",无需显式 loop index 编码。文章实验(图 7)显示 HCR 学到的系数确实在不同 loop 迭代下表现出不同分布,确认了这种自适应性。
实验中 $n=2$,attention 和 FFN 两个 sub-layer 各占一个流。
3.4 MoE-Augmented Transformer¶
HCR 改善了计算流的灵活性,但单一共享层的参数容量仍可能不足以承载推荐数据中的多样化交互模式。LoopCTR 在 attention 与 FFN 两处都引入 MoE。
Attention MoE:标准 multi-head attention 写成
$$\text{Attn}(\mathbf{X}) = \text{softmax}\left( \frac{\mathbf{Q}\mathbf{K}^\top}{\sqrt{d_k}} \right) \mathbf{V} \cdot \mathbf{W}_O, \tag{9}$$
其中 $\mathbf{Q} = \mathbf{X}\mathbf{W}_Q, \mathbf{K} = \mathbf{X}\mathbf{W}_K, \mathbf{V} = \mathbf{X}\mathbf{W}_V$。LoopCTR 把 $\mathbf{W}_V$ 和 $\mathbf{W}_O$ 替换为 MoE 层:每个 token 通过 router 路由到稀疏专家子集;$\mathbf{W}_V$ 和 $\mathbf{W}_O$ 共享同一个 router(对每个 token 选同一组专家),从而省路由开销。$\mathbf{W}_Q, \mathbf{W}_K$ 全 token 共享,保持相似度计算的一致性。
FFN MoE:标准 FFN 替换为 MoE,每个 token 经 gating network 路由到 top-$k$ 专家,配合 load-balancing auxiliary loss 防 expert collapse。
辅助损失(附录 B.1)的形式是经典 Switch Transformer 设计:
$$f_e = \frac{1}{Nk} \sum_{i=1}^N \mathbf{1}[e \in \text{top-}k(\mathbf{r}_i)], \quad p_e = \frac{1}{N} \sum_{i=1}^N \text{softmax}(\mathbf{r}_i)_e, \tag{11, 12}$$
$$\mathcal{L}_{\text{bal}} = E \cdot \sum_{e=1}^E f_e \cdot p_e, \quad \mathcal{L} = \mathcal{L}_{\text{total}} + \lambda \cdot \mathcal{L}_{\text{bal}}. \tag{13, 14}$$
通过 MoE,模型获得了远大于一组 dense 参数的"参数池",但每个 token 只激活其中稀疏子集,保住在线 latency。
3.5 训练目标:Multi-depth Process Supervision¶
这是文章的另一个关键武器,也是让"infer-zero-loop"能 work 的根本原因。
标准 looped Transformer 的训练只在最终深度 $l = L$ 处算一次 loss。LoopCTR 改为在每一个 loop 深度上都过一次 Exit Block 算 BCE loss:在深度 $l \in \{0, 1, \dots, L\}$($l=0$ 对应 Entry Block 直出、未进任何 loop 的表征),用 Exit Block 算预测 $\hat{y}^{(l)}$,最终 loss 是所有深度的平均:
$$\mathcal{L}_{\text{total}} = \frac{1}{L+1} \sum_{l=0}^L \mathcal{L}^{(l)}_{\text{BCE}}. \tag{10}$$
为什么这件事这么重要:
- Zero-loop inference 可行:因为每一个 loop 深度都被显式监督,模型在 $l=0$(不进 Loop Block,仅过 Entry → Exit)就被强制要求产出有效预测。结果:推理时直接走 Entry → Exit,完全跳过 Loop Block 的 latency,但仍获得高质量预测。
- Implicit self-distillation:附录 A.3(a) 的 cosine similarity 分析显示,深 loop 的表征会 progressively align 浅 loop 表征——更深的 loop 像 teacher,把"经过多次精炼后的优势"通过共享参数蒸馏回浅 loop。这解释了为什么 zero-loop 在很多样本上甚至可以比多 loop 还好。
- Weight sharing 的归纳偏置:共享参数被强制在 0 → L 多个深度都有用,反过来逼迫模型学习更通用、更不易过拟合的表征。
最后,zero-loop inference 时 Loop Block 完全不参与,因此严格部署时可以把整个 Loop Block 从 deployed model 里删掉(active params 和 deployed params 都更小),进一步节省 GPU 显存。
关键技术细节与实现¶
- 优化器:8 块 NVIDIA H20 GPU,AdamW,固定 lr 0.001,batch size 2048,embedding dim 64;
- MoE:total experts 在 $\{2, 3, 4, 5\}$ 中搜索(推荐 4),activated experts 推荐 2;load-balancing 权重 $\lambda \in \{0, 0.01, 0.1\}$;
- HCR:$n = 2$ 流,attention 一流、FFN 一流;
- InHouse 长序列压缩:query token 数固定 16;
- Group-specific projection:每个行为序列、每个 global token 各一组。
实验设置¶
数据集¶
| Statistic | Amazon | TaobaoAds | KuaiVideo | InHouse |
|---|---|---|---|---|
| # Interactions | 2,993,570 | 25,029,426 | 13,661,383 | 6,115,949 |
| # Users | 63,001 | 1,061,768 | 10,000 | 600,000 |
| # Items | 192,403 | 827,006 | 3,240,282 | 2,081,279 |
| # Fields (Seq./Non-Seq.) | 2 / 4 | 3 / 19 | 4 / 5 | 8 / 33 |
| Max Seq. Len | 100 | 50 | 100 | 50 / 1024 |
Amazon、TaobaoAds、KuaiVideo 是公开 benchmark;InHouse 是阿里电商一线生产日志(2026/01/21–2026/01/29 共 9 天),独有的卖点是 长序列长度可达 1024,专门用来测 long-sequence 场景。
Baselines¶
- DNN-based:DLRM、DIN、DCNv2、Wukong;
- Transformer-based feature interaction:DHEN、AutoInt、HiFormer;
- Unified sequence + feature modeling:InterFormer、OneTrans、HSTU、MTGR;
- Iso-FLOPs 对照组:StackCTR(3) — 把 LoopCTR 的共享 Loop Block 替换成 3 个独立参数的异构层,FLOPs 与 LoopCTR(3/3) 相同,专门用来 disentangle "weight sharing" vs "stacking" 的贡献。
指标¶
AUC、GAUC(per-user AUC 后聚合)、NE(normalized entropy;越低越好)。
记号约定¶
LoopCTR(i/L) 表示训练 loop 数为 $L$、推理 loop 数为 $i$ 的配置。
主要实验结果(RQ1)¶
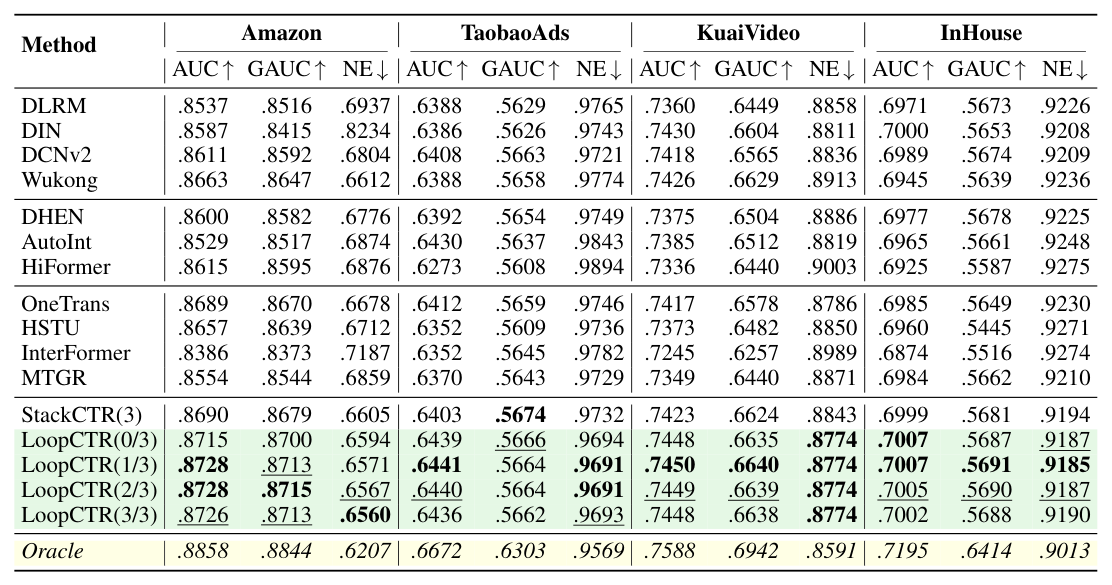
完整数据见下表(重排自原文 Table 2):
| Method | Amazon AUC | Amazon GAUC | Amazon NE | TaobaoAds AUC | TaobaoAds GAUC | TaobaoAds NE | KuaiVideo AUC | KuaiVideo GAUC | KuaiVideo NE | InHouse AUC | InHouse GAUC | InHouse NE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DLRM | .8537 | .8516 | .6937 | .6388 | .5629 | .9765 | .7360 | .6449 | .8858 | .6971 | .5673 | .9226 |
| DIN | .8587 | .8415 | .8234 | .6386 | .5626 | .9743 | .7430 | .6604 | .8811 | .7000 | .5653 | .9208 |
| DCNv2 | .8611 | .8592 | .6804 | .6408 | .5663 | .9721 | .7418 | .6565 | .8836 | .6989 | .5674 | .9209 |
| Wukong | .8663 | .8647 | .6612 | .6388 | .5658 | .9774 | .7426 | .6629 | .8913 | .6945 | .5639 | .9236 |
| DHEN | .8600 | .8582 | .6776 | .6392 | .5654 | .9749 | .7375 | .6504 | .8886 | .6977 | .5678 | .9225 |
| AutoInt | .8529 | .8517 | .6874 | .6430 | .5637 | .9843 | .7385 | .6534 | .8819 | .6965 | .5661 | .9248 |
| HiFormer | .8615 | .8595 | .6876 | .6273 | .5608 | .9894 | .7336 | .6440 | .9003 | .6925 | .5587 | .9275 |
| OneTrans | .8689 | .8670 | .6678 | .6412 | .5659 | .9746 | .7417 | .6578 | .8786 | .6985 | .5649 | .9230 |
| HSTU | .8657 | .8639 | .6712 | .6352 | .5609 | .9736 | .7373 | .6482 | .8850 | .6960 | .5445 | .9271 |
| InterFormer | .8386 | .8373 | .7187 | .6352 | .5645 | .9782 | .7245 | .6257 | .8989 | .6874 | .5516 | .9274 |
| MTGR | .8554 | .8544 | .6859 | .6370 | .5643 | .9729 | .7349 | .6440 | .8871 | .6984 | .5662 | .9210 |
| StackCTR(3) | .8690 | .8679 | .6605 | .6403 | .5674 | .9732 | .7423 | .6624 | .8843 | .6999 | .5681 | .9194 |
| LoopCTR(0/3) | .8715 | .8700 | .6594 | .6439 | .5666 | .9694 | .7448 | .6635 | .8774 | .7007 | .5687 | .9187 |
| LoopCTR(1/3) | .8728 | .8713 | .6571 | .6441 | .5664 | .9691 | .7450 | .6640 | .8774 | .7007 | .5691 | .9185 |
| LoopCTR(2/3) | .8728 | .8715 | .6567 | .6440 | .5664 | .9691 | .7449 | .6639 | .8774 | .7005 | .5690 | .9187 |
| LoopCTR(3/3) | .8726 | .8713 | .6560 | .6436 | .5662 | .9693 | .7448 | .6638 | .8774 | .7002 | .5688 | .9190 |
| Oracle | .8858 | .8844 | .6207 | .6672 | .6303 | .9569 | .7588 | .6942 | .8591 | .7195 | .6414 | .9013 |
核心结论:
-
LoopCTR 全面 SOTA:四个数据集上 LoopCTR 系列的 AUC、GAUC、NE 全部刷榜。Amazon 上比最强 baseline OneTrans 高 0.0039 AUC(0.8728 vs 0.8689),KuaiVideo 上比 DIN 高 0.0020 AUC(0.7450 vs 0.7430)。CTR 行业里 0.001 AUC 提升即被认为统计显著且工业有意义,这些 gain 都达到 $p < 0.05$ 的 paired $t$-test 显著性。
-
Zero-loop inference 已经超过所有 baseline:LoopCTR(0/3) — 推理时完全跳过 Loop Block,仅 Entry → Exit 直连 — 在四个数据集上的 AUC 都已超过所有 baseline。InHouse 上 LoopCTR(0/3) 仅 13.38M FLOPs / 9.26ms latency,对比 HSTU 的 2150M FLOPs / 775.72ms 和 OneTrans 的 417.97M FLOPs / 494.58ms,FLOPs 缩 30–160 倍、latency 缩 50–80 倍。LoopCTR(0/3) 与最佳多 loop 推理之间的差距极小(Amazon 上 0.0013 AUC),证明 process supervision 真的把"多 loop 训练带来的好处"完整内化进了共享参数。
-
Shared parameters > Stacked layers(iso-FLOPs 对照):LoopCTR(3/3) 与 StackCTR(3) FLOPs 完全相同,但 LoopCTR(3/3) 在 Amazon (0.8726 vs 0.8690)、InHouse (0.7002 vs 0.6999) 等多数据集上稳赢——说明共享参数本身就是更强的 inductive bias,在稀疏 CTR 数据上比"叠不同层"更不易过拟合。
-
Oracle 揭示巨大 untapped headroom:每个样本如果都能选到最优的 loop 深度,能再带 0.013–0.023 AUC 的提升(如 TaobaoAds 上 oracle 0.6672 vs realized 0.6441,gap 0.0231)。这暗示 adaptive inference(每样本动态决定 loop 数)是一条值得探索的未来方向。
Loop Scaling 详解(RQ2)¶
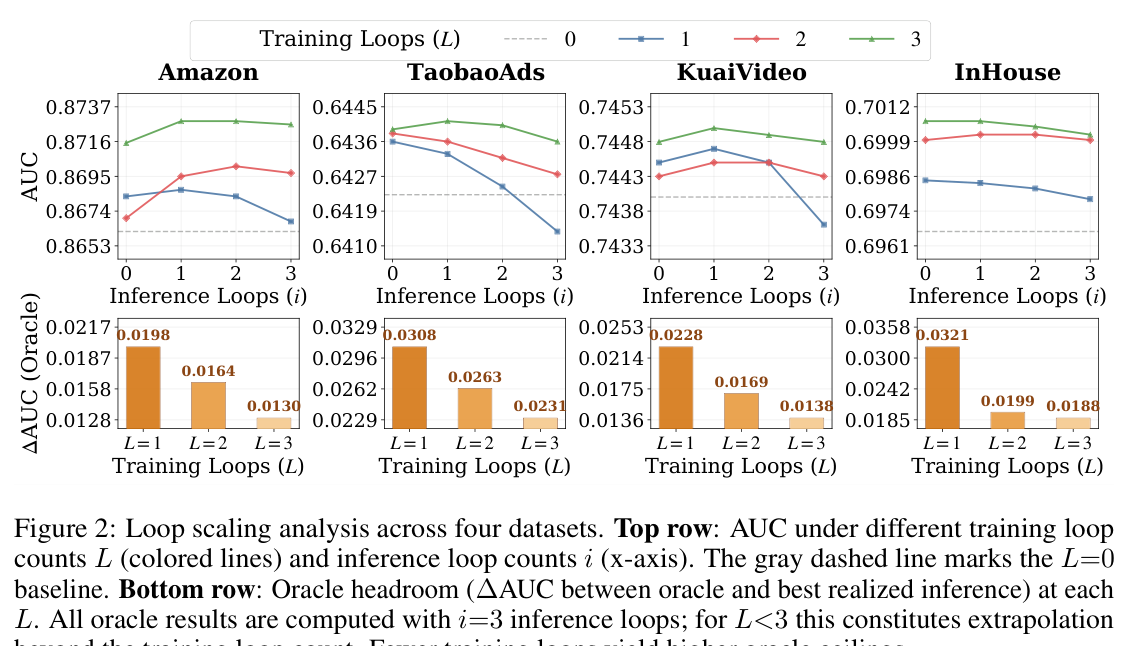
完整 loop scaling 数据见 Table 3:
| L | Config | Amazon AUC | TaobaoAds AUC | KuaiVideo AUC | InHouse AUC |
|---|---|---|---|---|---|
| 0 | i=0 | .8662 | .6423 | .7440 | .6985 |
| 1 | i=0 | .8683 | .6438 | .7445 | .6985 |
| 1 | i=1 | .8687 | .6436 | .7447 | .6984 |
| 1 | Oracle | .8885 | .6744 | .7675 | .7306 |
| 2 | i=0 | .8670 | .6438 | .7443 | .7000 |
| 2 | i=2 | .8701 | .6432 | .7445 | .7002 |
| 2 | Oracle | .8865 | .6701 | .7614 | .7201 |
| 3 | i=0 | .8715 | .6439 | .7448 | .7007 |
| 3 | i=1 | .8728 | .6441 | .7450 | .7007 |
| 3 | Oracle | .8858 | .6672 | .7588 | .7195 |
三条关键现象:
-
More training loops ⇒ better realized performance:$L$ 从 0 → 3,Amazon AUC 从 0.8662 → 0.8728,InHouse 从 0.6985 → 0.7007。Loss landscape 可视化(图 4)显示更多 loop 训练得到的 minima 更宽、更平坦——经典的 flatness ↔ generalization 关联。
-
Inference loops 边际递减:固定 $L=3$,第 1 个推理 loop 几乎贡献了全部增益(i=0 → i=1:0.8715 → 0.8728),i=2、i=3 几乎不增甚至微降。这点至关重要:单 loop(i=1)就够用,对部署是好消息。
-
Fewer training loops ⇒ higher oracle ceiling(反直觉):$L=1$ 的 oracle 0.8885 > $L=3$ 的 oracle 0.8858(Amazon);InHouse 上 $L=1$ oracle 0.7306 vs $L=3$ oracle 0.7195。文章用 loss landscape 给出了几何解释:$L=3$ 的最优点更平坦、generalization 更好(所以 realized 性能更高),但代价是不同深度的表征更趋同(implicit self-distillation 的副作用),所以 per-sample adaptive 选择的空间反而小;$L=1$ 的最优点更尖锐,但不同深度表征更多样化,给 adaptive inference 留了更大上限。
消融实验(RQ3)¶
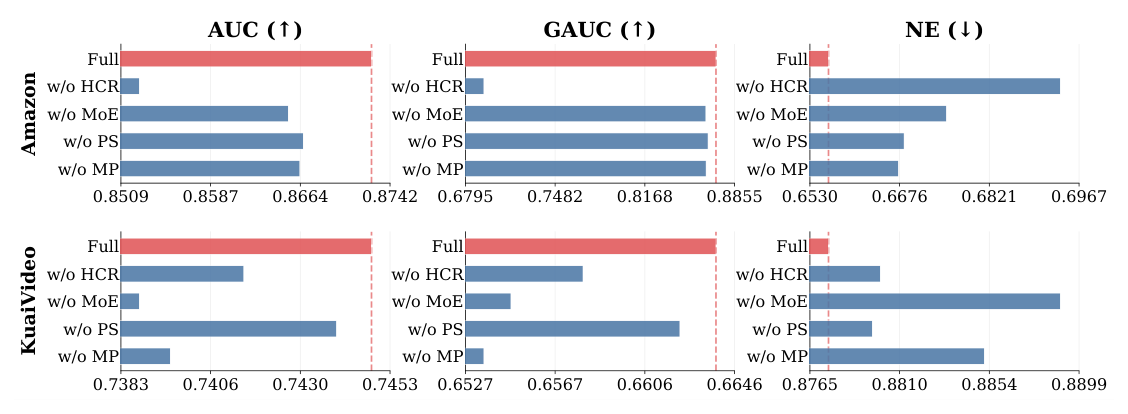
四个组件单独移除的影响:
| Variant | Amazon AUC | Amazon GAUC | Amazon NE | KuaiVideo AUC | KuaiVideo GAUC | KuaiVideo NE |
|---|---|---|---|---|---|---|
| Full | .8742 | .8855 | .6530 | .7453 | .6646 | .8765 |
| w/o HCR | .8509 (-.0233) | .6795 | .6967 | .7383 | .6527 | .8899 |
| w/o MoE | .8587 | .7482 | .6821 | .7406 (-.0047) | .6567 | .8854 |
| w/o PS(process supervision) | .8664 | .8168 | .6676 | .7430 | .6606 | .8810 |
| w/o MP(heterogeneous projection) | .8742 ≈ Full | .8855 | .6530 | .7453 ≈ Full | .6606 | .8765 |
(注:原文图 3 是 bar chart,数值为图中读数;NE 越低越好。原表中 w/o MP 在 Amazon 上数值与 Full 差不多,说明 MP 在 KuaiVideo 上更关键,整体仍是 incremental positive。)
- HCR 在 Amazon 上影响最大(-0.0201 AUC),印证:在 looped 架构下,让共享层在不同 loop 下表现出不同行为是头等大事,否则共享层只能产出"等价"输出;
- MoE 在 KuaiVideo 上影响最大(-0.0060 AUC),KuaiVideo 的 sequential 特征更丰富,共享层一组 dense 参数容量不够,需要 MoE 扩参数池;
- Process supervision 在两个数据集都贡献正向,验证其作为多深度蒸馏机制对各 loop 表征质量的拉升作用;
- Heterogeneous projection 在 KuaiVideo 上比 Amazon 更关键(KuaiVideo 多源异构 sequential 特征更多)。
四个组件分别对应一个 distinct bottleneck,没有冗余。
MoE 参数敏感性(附录 B.2)¶
| Config | Amazon AUC | KuaiVideo AUC |
|---|---|---|
| 1/4 (1 of 4 activated) | .8660 | .7440 |
| 2/4 | .8726 | .7448 |
| 3/4 | .8690 | .7428 |
| 4/4 (dense) | .8670 | .7437 |
| 2/2 | .8719 | .7441 |
| 2/3 | .8705 | .7423 |
| 2/4 | .8726 | .7448 |
| 2/5 | .8688 | .7446 |
最优配置 2/4:activated = 2、total = 4。activated=1 缺乏 routing diversity,activated=4(密集)失去稀疏正则;total > 4 收益归零。
专家路由分布(附录 B.3)¶
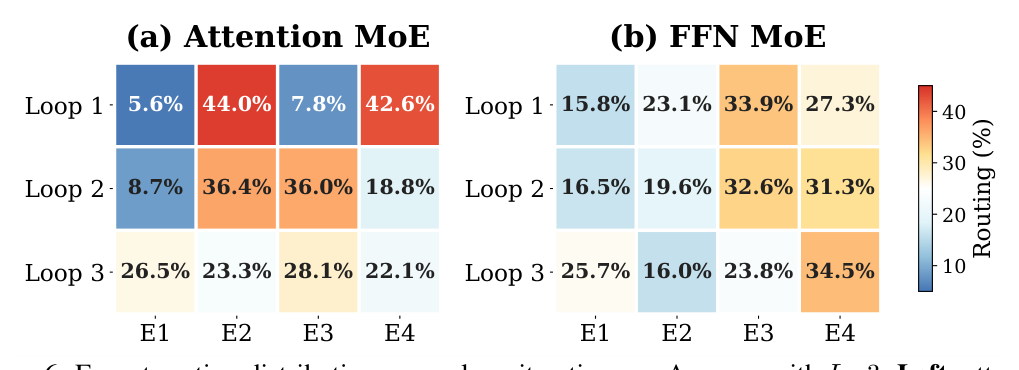
L=3 设置下 attention 与 FFN MoE 的专家激活率随 loop 演化:
- Attention MoE:第 1 次 loop 高度集中于 E2 (44.0%) 与 E4 (42.6%),第 3 次 loop 趋近均匀(~22-28%)。说明早期 loop 走特化的专家通路,后期 loop 需要更平衡的算力做精修。
- FFN MoE:从开始就比较均衡(16-34%),但仍随 loop 演化(E3 从 33.9% 降到 23.8%,E4 上升到 34.5%)。
这是直接证据:共享 Loop Block 不是机械重复同一计算,而是在不同 loop 深度自适应调整计算路径。
HCR 系数可视化(附录 C)¶
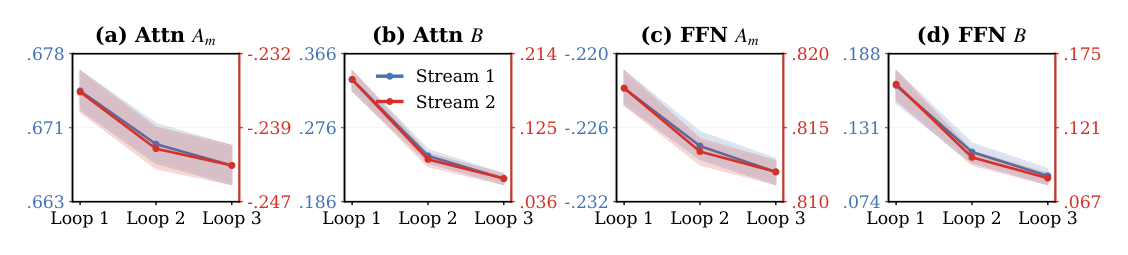
attention 与 FFN 两个 sub-layer 的 $\mathbf{A}_m$、$\mathbf{B}$ 系数在三次 loop 上呈现不同的动态——attention 流的 $\mathbf{A}_m$ 从 0.366 涨到 0.678(stream 1)同时 stream 2 从 -0.232 降到 -0.247;FFN 类似但分布形状不同。这定量证实了 HCR 让共享层 instance-adaptive 且 implicitly loop-aware 的设计意图。
Loss Landscape(附录 A.2)¶
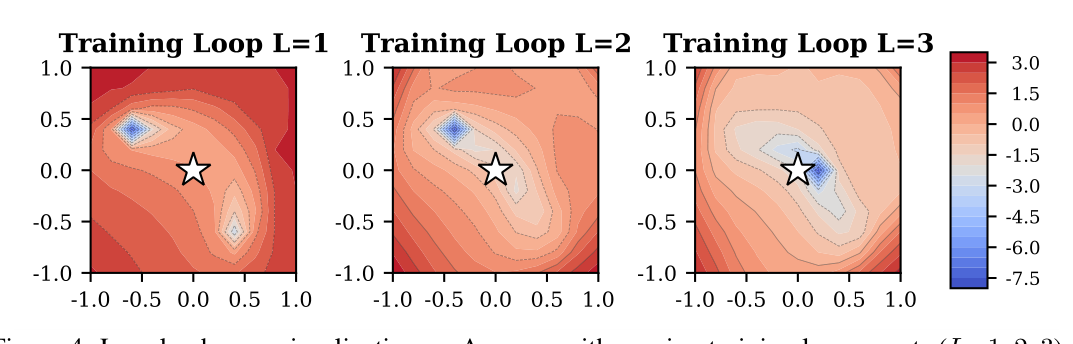
filter-normalized random direction 法可视化 Amazon 数据集 loss landscape。$L=1$ 的 minimum 周围低 loss 区窄、形状不规则;$L=3$ 的低 loss 区显著扩张、等高线均匀——这给"更多 training loops ⇒ 更好泛化"提供了几何解释。
推理深度多样性(附录 A.3)¶
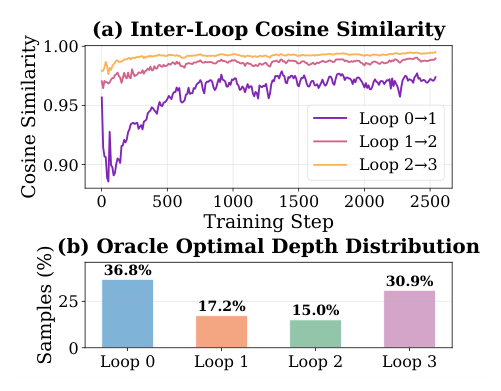
- (a) Inter-loop cosine similarity:训练过程中相邻 loop 表征的 cosine 相似度上升但 < 1.0,且越靠后 loop 之间的相似度(loop 2→3)越高于早期(loop 0→1)。这就是隐式 self-distillation 的直接证据:深 loop 把"refined" 信号通过共享参数蒸馏回浅 loop。
- (b) Oracle 最优深度分布:36.8% 样本最佳深度是 loop 0、30.9% 是 loop 3、loop 1 占 17.2%、loop 2 占 15.0%——典型的 bimodal 分布。这说明"什么样本该过几次 loop"是高度个性化的;目前固定 loop 深度的方案仍浪费大量算力——这跟 LLM reasoning 里的 overthinking 现象一脉相承。
效率对比(附录 D.3)¶
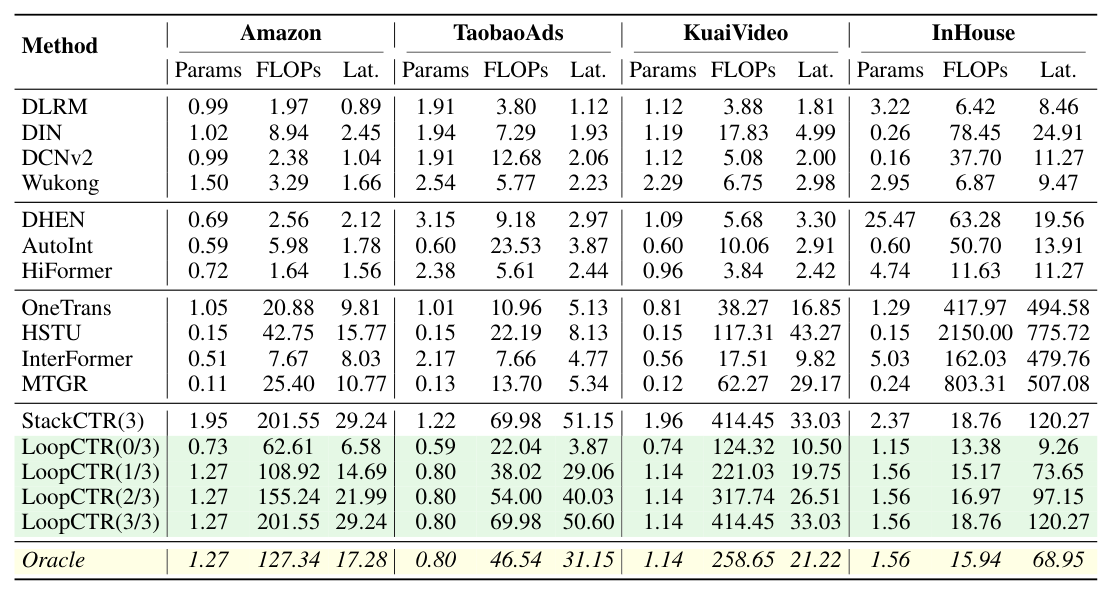
四个数据集的参数量、FLOPs、latency 对比(节选 InHouse):
| Method | Params (M) | FLOPs (M) | Latency (ms) |
|---|---|---|---|
| HSTU | 0.15 | 2150.00 | 775.72 |
| OneTrans | 1.29 | 417.97 | 494.58 |
| MTGR | 0.24 | 803.31 | 507.08 |
| StackCTR(3) | 2.37 | 18.76 | 120.27 |
| LoopCTR(0/3) | 1.15 | 13.38 | 9.26 |
| LoopCTR(1/3) | 1.56 | 15.17 | 73.65 |
| LoopCTR(3/3) | 1.56 | 18.76 | 120.27 |
关键观察:
- LoopCTR(0/3) 是 efficiency-effectiveness 帕累托最优:在 InHouse 上比 HSTU 少 160× FLOPs、少 84× latency,同时 AUC 仍超过所有 baseline。这是"严格零 loop 部署 → Loop Block 可以从模型里整块删掉"的功劳,active params 都从 1.56M 降到 1.15M。
- Active params 与推理 loop 数解耦:LoopCTR(1/3) 与 LoopCTR(3/3) active params 完全相同(1.56M),FLOPs 与 latency 才与 inference loop 数线性相关。
- iso-FLOPs 对比 StackCTR:LoopCTR(3/3) 与 StackCTR(3) latency 同为 120.27ms,但 active params 缩 1.5×(1.56M vs 1.95M),还顺便多了 0.0036 AUC——共享参数省存储又赢精度。
与已归档相关工作的对比¶
Step 2.5: no semantically twin papers found in archive.
文档库中所有 deeply_read 论文(含 HSTU、OneTrans、MTGR、TokenMixer-Large、MixFormer、HyFormer、ULTRA-HSTU、RankMixer、Wukong、UniMixer、Zenith 等工业 ranking scaling 工作)一致采用"堆叠不同参数层"的路线(depth/width/input scaling),没有任何一篇采用 共享层递归复用 + 多深度 process supervision + train-multi/infer-zero 这套配方。LoopCTR 引用的 looped Transformer 谱系(Universal Transformer、MoEUT、LoopLM、ETD)原本属于 NLP/语言建模社区,本档案库尚未收录。HSTU/OneTrans 等仅作为 LoopCTR 的 baseline 出现并被原文 §4.2 / Appendix D.3 充分对比,结构化对比已在 DAG 中登记,无需重复叙事。
讨论与局限性¶
核心贡献:
- 新 scaling 维度:提出 looped CTR 范式,把"训练时算力"和"参数规模"解耦——这是与 depth/width/input scaling 正交的第四种 scaling。
- 架构落地:sandwich 三段式 + HCR + MoE + Prefix attention 这套组合是真正解决"共享层多次调用退化"的工程化答案。每个组件对应一个 distinct bottleneck(HCR ↔ expressiveness、MoE ↔ capacity、PS ↔ inference cost、grouped attention ↔ heterogeneity)。
- Train-multi-loop / Infer-zero-loop:通过 process supervision 把多 loop 训练的优势"压缩"进共享参数,使得部署时完全跳过 Loop Block 仍能拿到 SOTA——直接撕掉了 looped 架构在低延迟服务场景下最大的硬伤。
- Oracle 揭示 adaptive inference 的巨大空间:0.02-0.04 AUC 的未挖掘 headroom 大于绝大多数模型创新的提升,预示下一个紧迫方向——per-sample adaptive loop scheduling。
值得借鉴的设计:
- Process supervision over depth:在 looped 架构下用"每深度都监督"的方式做隐式 self-distillation,思路非常优雅,既解了 inference cost 问题,又赋予了 zero-loop 部署可能性,启示意义可能不限于 CTR——LLM 的 looped/recursive 推理体系(CoT compression、early-exit)也可以套这一招。
- HCR 的 input-dependent 残差:把传统 1:1 残差升级为可学的多流混合,是看待"weight sharing"之外的又一个维度——传统看法是参数贵就重用,但 HCR 表明"残差融合方式"也是 looped 架构的关键自由度。
- Sandwich 解耦 + Prefix attention mask:通过非对称 mask(sequential 不看 global)天然支持 KV cache,user 侧计算只算一次跨候选共享——这种"模型层面就考虑 serving cost"的设计风格非常 production-friendly。
局限与未明之处:
- 没有线上 A/B 实验:InHouse 数据集只是离线评测,没有真正的工业 A/B 收益数字。考虑到 LoopCTR 的卖点之一是 latency 超低,缺一条线上效果 + 线上 latency 的 closed-loop 实证是遗憾。
- Oracle 与 realized 差距如何弥合:文章承认 oracle gap 0.02-0.04 AUC 是 future work。如何 learn 一个 per-sample loop selector(不依赖 oracle)是论文留下的最大悬念,目前没有任何尝试。
- HCR 只在 $n=2$ 上验证:流数 $n$ 的影响、与 loop 数 $L$ 的交互效应没做 sweep。是否 $n=3, 4$ 能让共享层承载更多深度的 distinct behavior,未知。
- $L \in \{1, 2, 3\}$ 范围太窄:实验最大只到 $L=3$,无法外推大规模 looped 架构在更深训练 loop 下的表现。NLP 端 LoopLM 等工作通常做到 $L=8$ 甚至 $L=16$;CTR 端是否也有类似的 deeper-loop 收益?文章没有给出。
- 只比 dense baseline,没比同期 looped 系工作:文章把自己定位成"first to bring loop scaling to CTR",但与 NLP 端的 LoopLM/MoEUT 在等价基础设施下做对照,似乎有空间——例如 MoEUT 也是 weight-tied + MoE,与 LoopCTR 的 Loop Block 结构非常接近。
- MoE 与稀疏 routing 的训练稳定性:文章只在 $E \in \{2,3,4,5\}$ 范围内 sweep,是否能 scale 到工业级 MoE($E \in \{32, 64\}$)未知;load-balancing loss $\lambda$ 的鲁棒性也未深究。
工业落地价值:LoopCTR(0/3) 的 latency 数据(InHouse 9.26ms、Amazon 6.58ms)放在毫秒级 ranking 场景里非常有竞争力,特别适合:
- 已有 CTR 模型在 latency 上卡死、想 squeeze 更多 quality 但加不动参数的场景;
- 显存受限的边缘部署(zero-loop 时 Loop Block 可整块删掉,active params 仅 0.73-1.56M);
- Long-sequence ranking(InHouse 上序列到 1024)配合压缩 query token 后效率与精度俱佳。
短板是缺线上数据,工业落地真实收益还有待后续阿里集团自己(论文作者 Tang 在 Alibaba 实习完成此工作)的 production deployment 报告。