1. 研究背景与动机¶
工业推荐系统的排序阶段通常包含两个独立模块:
- 序列建模(Sequence Modeling):将用户多行为序列编码为候选物品感知的表示,典型方法包括 DIN、SASRec、BERT4Rec、LONGER 等。
- 特征交互(Feature Interaction):对非序列特征(用户画像、物品属性、上下文)学习高阶交叉,典型方法包括 DCNv2、Wide&Deep、FM/DeepFM、Wukong、HiFormer、RankMixer 等。
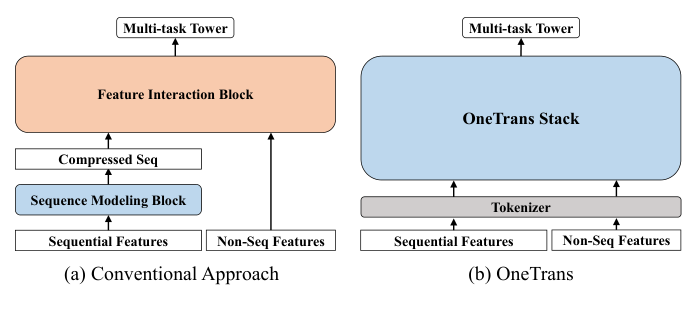
传统做法是 encode-then-interaction 流水线:先将用户行为压缩为固定长度向量,再与非序列特征拼接送入特征交互模块。这种分离式设计存在两个核心问题:
- 信息流受限:序列建模和特征交互之间缺乏双向信息交换,静态/上下文特征无法影响序列表示的构建过程。
- 优化与扩展困难:两个独立模块阻碍了统一优化,且无法复用 LLM 领域成熟的工程优化(KV 缓存、FlashAttention、混合精度训练等)。
本文提出 OneTrans,用单一因果 Transformer 骨干网络同时完成序列建模和特征交互,消除两个模块间的架构壁垒。
2. 方法详解¶
2.1 整体框架¶
OneTrans 的核心思想是将所有输入统一为一个 token 序列,送入堆叠的 OneTrans Block 处理。框架包含三个关键组件:
- 统一分词器(Unified Tokenizer):将序列特征映射为 S-tokens,非序列特征映射为 NS-tokens
- 金字塔式堆叠的 OneTrans Block:逐层处理并裁剪 token 序列
- 任务塔(Task Tower):基于最终 NS-token 状态进行多任务预测
![Figure 2: System Architecture. (a) OneTrans overview. Sequential (S, blue) and non-sequential (NS, orange) features are tokenized separately. After inserting [SEP] between user behavior sequences, the unified token sequence is fed into stacked OneTrans Pyramid Blocks that progressively shrink the token length until it matches the number of NS tokens. (b) OneTrans Block: a causal pre-norm Transformer Block with RMSNorm, Mixed Causal Attention and Mixed FFN. (c) Mix Parameterization: S tokens share one set of QKV/FFN weights, while each NS token receives its own token-specific QKV/FFN.](figures/fig_02.png)
初始 token 序列表示为:
$$\mathbf{X}^{(0)} = [\text{S-tokens}; \text{NS-tokens}] \in \mathbb{R}^{(L_S + L_{NS}) \times d}$$
每个 OneTrans Block 的计算过程为:
$$\mathbf{Z}^{(n)} = \text{MixedMHA}(\text{Norm}(\mathbf{X}^{(n-1)})) + \mathbf{X}^{(n-1)}$$
$$\mathbf{X}^{(n)} = \text{MixedFFN}(\text{Norm}(\mathbf{Z}^{(n)})) + \mathbf{Z}^{(n)}$$
2.2 特征分词与编码¶
2.2.1 非序列特征分词(Non-Sequential Tokenization)¶
非序列特征 $NS$ 包含数值型(价格、CTR)和类别型(用户ID、物品类别)输入。提供两种分词方式:
Group-wise Tokenizer(对齐 RankMixer):特征按语义分组 $\{g_1, \ldots, g_{L_{NS}}\}$,每组通过独立 MLP 编码:
$$\text{NS-tokens} = [\text{MLP}_1(\text{concat}(g_1)), \ldots, \text{MLP}_{L_{NS}}(\text{concat}(g_{L_{NS}}))]$$
Auto-Split Tokenizer:所有特征拼接后通过单一 MLP 投影,再切分为 $L_{NS}$ 个 token:
$$\text{NS-tokens} = \text{split}(\text{MLP}(\text{concat}(NS)), L_{NS})$$
Auto-Split Tokenizer 通过单一稠密投影减少了 kernel launch 开销。
2.2.2 序列特征分词(Sequential Tokenization)¶
OneTrans 接受多行为序列 $S = \{S_1, \ldots, S_n\}$,每个序列 $S_i = [e_{i1}, \ldots, e_{iL_i}]$ 包含 $L_i$ 个事件 embedding。每个事件 $e_{ij}$ 由物品 ID 与侧信息(类别、价格等)拼接构成。
对每个序列 $S_i$,使用共享投影 MLP 将事件映射到统一维度 $d$:
$$\tilde{S}_i = [\text{MLP}_i(e_{i1}), \ldots, \text{MLP}_i(e_{iL_i})] \in \mathbb{R}^{L_i \times d}$$
多序列合并为单一 token 序列,有两种策略:
- Timestamp-aware:按时间交错排列所有事件,附加序列类型指示符
- Timestamp-agnostic:按事件影响力排序(purchase → add-to-cart → click → impression),在序列间插入可学习 [SEP] token
$$\text{S-Tokens} = \text{Merge}(\tilde{S}_1, \ldots, \tilde{S}_n) \in \mathbb{R}^{L_S \times d}, \quad L_S = \sum_{i=1}^{n} L_i + L_{\text{SEP}}$$
消融实验表明,timestamp-aware 规则优于 impact-ordered 替代方案。
2.3 OneTrans Block¶
每个 OneTrans Block 是一个 pre-norm 因果 Transformer,输入为 $L_S$ 个 S-tokens 后接 $L_{NS}$ 个 NS-tokens。
核心创新在于 混合参数化(Mixed Parameterization):同质的 S-tokens 共享一组参数,异质的 NS-tokens 各自拥有独立参数。
采用 RMSNorm 作为 pre-norm,对所有 token 统一归一化,防止 S-tokens 和 NS-tokens 之间数值范围差异导致的注意力坍塌和训练不稳定。
2.3.1 混合因果注意力(Mixed Causal Attention)¶
标准多头注意力(MHA)配合因果注意力掩码。Q/K/V 投影采用混合参数化:
设 $\mathbf{x}_i \in \mathbb{R}^d$ 为第 $i$ 个 token,Q/K/V 的计算为:
$$(\mathbf{q}_i, \mathbf{k}_i, \mathbf{v}_i) = (\mathbf{W}_i^Q \mathbf{x}_i, \mathbf{W}_i^K \mathbf{x}_i, \mathbf{W}_i^V \mathbf{x}_i)$$
其中投影矩阵 $\mathbf{W}_i^\Psi$($\Psi \in \{Q, K, V\}$)遵循混合参数化策略:
$$\mathbf{W}_i^\Psi = \begin{cases} \mathbf{W}_S^\Psi, & i \leq L_S \quad \text{(S-tokens 共享)} \\ \mathbf{W}_{NS,i}^\Psi, & i > L_S \quad \text{(NS-tokens 各自独立)} \end{cases}$$
因果掩码的语义: 1. S 侧:每个 S-token 仅注意其之前的 S-token,支持时间戳感知和意图过滤 2. NS 侧:每个 NS-token 可注意完整的 S 历史,等效于 target-attention 聚合序列证据,同时也注意前面的 NS-token 3. 金字塔支持:因果掩码天然将信息向后聚集,支持逐层裁剪
2.3.2 混合 FFN(Mixed FFN)¶
前馈网络同样采用混合参数化策略:
$$\text{MixedFFN}(\mathbf{x}_i) = \mathbf{W}_i^2 \phi(\mathbf{W}_i^1 \mathbf{x}_i)$$
$\mathbf{W}_i^1$ 和 $\mathbf{W}_i^2$ 对 $i \leq L_S$ 共享,对 $i > L_S$ token-specific。
2.4 金字塔裁剪(Pyramid Stack)¶
因果注意力将信息集中到序列末尾位置。利用这一特性,OneTrans 采用金字塔调度:在每个 OneTrans Block 层,只有最近的 S-tokens 子集发起 query,而 key/value 仍计算全序列。
设输入 token 列表 $\mathbf{X} = \{\mathbf{x}_i\}_{i=1}^L$,$Q = \{L - L' + 1, \ldots, L\}$ 为尾部索引集($L' \leq L$):
$$\mathbf{q}_i = \mathbf{W}_i^Q \mathbf{x}_i, \quad i \in Q$$
注意力后仅保留 $i \in Q$ 的输出,token 长度从 $L$ 减至 $L'$,逐层形成金字塔结构。
金字塔设计的优势:
- 渐进蒸馏:长行为历史被漏斗式压缩到尾部 query 中,聚焦于最具信息量的事件
- 计算效率:注意力成本变为 $O(LL'd)$,FFN 与 $L'$ 线性相关
在固定 FLOPs 预算下,金字塔设计支持比全长设计长 1.75 倍的序列。
2.5 训练与部署优化¶
2.5.1 跨请求 KV 缓存(Cross-Request KV Caching)¶
工业推荐系统中,同一请求的多个候选物品共享相同的 S-tokens(用户行为历史),仅 NS-tokens 因候选物品不同而变化。OneTrans 利用这一特性,将推理分为两阶段:
- Stage I(S 侧,每请求一次):处理所有 S-tokens,缓存其 key/value 对和注意力输出
- Stage II(NS 侧,每候选一次):计算每个候选的 NS-tokens,与缓存的 S 侧 key/value 做 cross-attention
KV 缓存将 S 侧计算分摊到所有候选物品上,时间复杂度从 $O(C)$ 降至 $O(1)$($C$ 为候选数)。
由于用户行为序列是追加式的,还可跨请求复用缓存:每次新请求只需计算新增行为的增量 key/value,复杂度从 $O(L)$ 降至 $O(\Delta L)$。
2.5.2 统一 LLM 优化¶
- FlashAttention-2:通过 tiling 和 kernel fusion 减少注意力的 I/O 和内存占用
- 混合精度训练(BF16/FP16)+ Activation Recomputation:丢弃前向激活值并在反向传播时重新计算,以额外计算换取大幅内存节省
3. 实验¶
3.1 实验设置¶
数据集:大规模工业排序场景的生产日志,按时间切分,所有个人信息匿名化。
| 指标 | 值 |
|---|---|
| 样本数 (Impressions) | 29.1B |
| 用户数 (unique) | 27.9M |
| 物品数 (unique) | 10.2M |
| 日均曝光数 (mean +/- std) | 118.2M +/- 14.3M |
| 日均活跃用户数 (mean +/- std) | 2.3M +/- 0.3M |
任务与指标:CTR 和 CVR 两个二分类排序任务,使用 AUC 和 UAUC(曝光加权用户级 AUC)评估。
评估方式:Next-batch evaluation,按时间顺序处理每个 mini-batch,先预测再训练,AUC/UAUC 按天计算后跨天宏平均。
效率指标:参数量(Params,不含稀疏 embedding)和训练 TFLOPs(batch size 2048)。
Baselines(encode-then-interaction 范式):
- 特征交互模块:DCNv2 → Wukong → HiFormer → RankMixer
- 序列建模模块:StackDIN → Transformer → LONGER
- 基准组合:DCNv2 + DIN(生产基线)
OneTrans 设置:
- OneTrans_S:6层,$d = 256$,$H = 4$ heads,约 100M 参数
- OneTrans_L:8层,$d = 384$,约 330M 参数
- 输入处理:timestamp-aware 融合、Auto-Split 非序列分词
- 金字塔调度:序列 query tokens 从 1190/1500 线性缩减到 12/16
- 优化器:双优化器策略,稀疏 embedding 用 Adagrad ($\beta_1 = 0.1, \beta_2 = 1.0$),稠密参数用 RMSProp (lr=0.005, alpha=0.99999, momentum=0)
- Pre-Norm + global grad-norm clipping
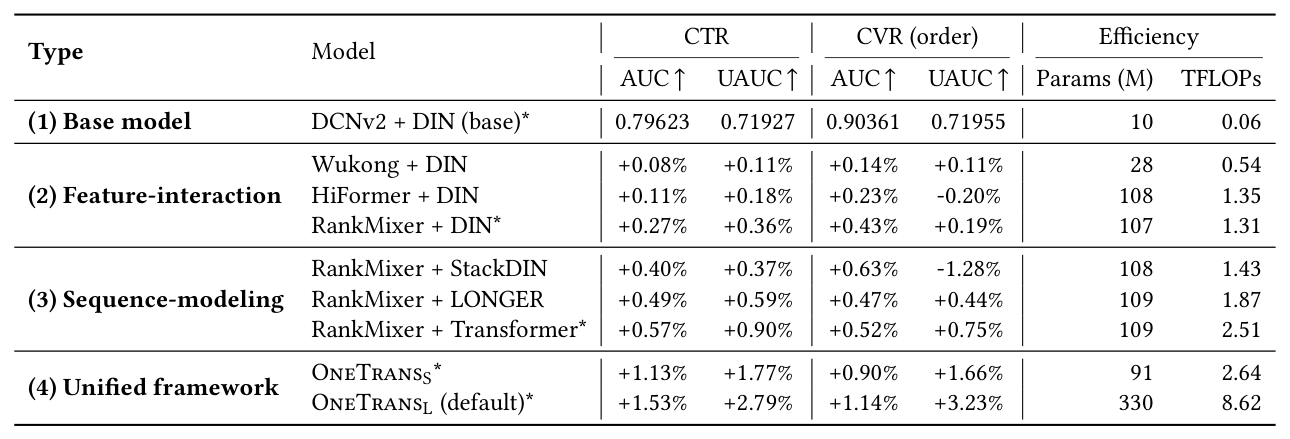
3.2 RQ1:性能评估(Table 2)¶
| 类型 | 模型 | CTR AUC | CTR UAUC | CVR AUC | CVR UAUC | Params (M) | TFLOPs |
|---|---|---|---|---|---|---|---|
| 基线 | DCNv2 + DIN | 0.79623 | 0.71927 | 0.90361 | 0.71955 | 10 | 0.06 |
| 特征交互 | Wukong + DIN | +0.08% | +0.11% | +0.14% | +0.11% | 28 | 0.54 |
| 特征交互 | HiFormer + DIN | +0.11% | +0.18% | +0.23% | -0.20% | 108 | 1.35 |
| 特征交互 | RankMixer + DIN* | +0.27% | +0.36% | +0.43% | +0.19% | 107 | 1.31 |
| 序列建模 | RankMixer + StackDIN | +0.40% | +0.37% | +0.63% | -1.28% | 108 | 1.43 |
| 序列建模 | RankMixer + LONGER | +0.49% | +0.59% | +0.47% | +0.44% | 109 | 1.87 |
| 序列建模 | RankMixer + Transformer* | +0.57% | +0.90% | +0.52% | +0.75% | 109 | 2.51 |
| 统一框架 | OneTrans_S* | +1.13% | +1.77% | +0.90% | +1.66% | 91 | 2.64 |
| 统一框架 | OneTrans_L | +1.53% | +2.79% | +1.14% | +3.23% | 330 | 8.62 |
结论:
- 在 encode-then-interaction 范式下,单独升级特征交互模块或序列建模模块均能带来一致的增益。
- OneTrans_S 在相近参数量和 TFLOPs(2.64T vs 2.51T)下,比最强 baseline RankMixer+Transformer 在 CTR AUC/UAUC 上分别提升 +1.13%/+1.77%,CVR AUC/UAUC 提升 +0.90%/+1.66%。
- OneTrans_L 进一步扩展后,CTR UAUC 提升 +2.79%,CVR UAUC 提升 +3.23%,展现出可预测的质量-容量正相关关系。
- 统一建模比分别扩展各组件更可靠且计算效率更高。
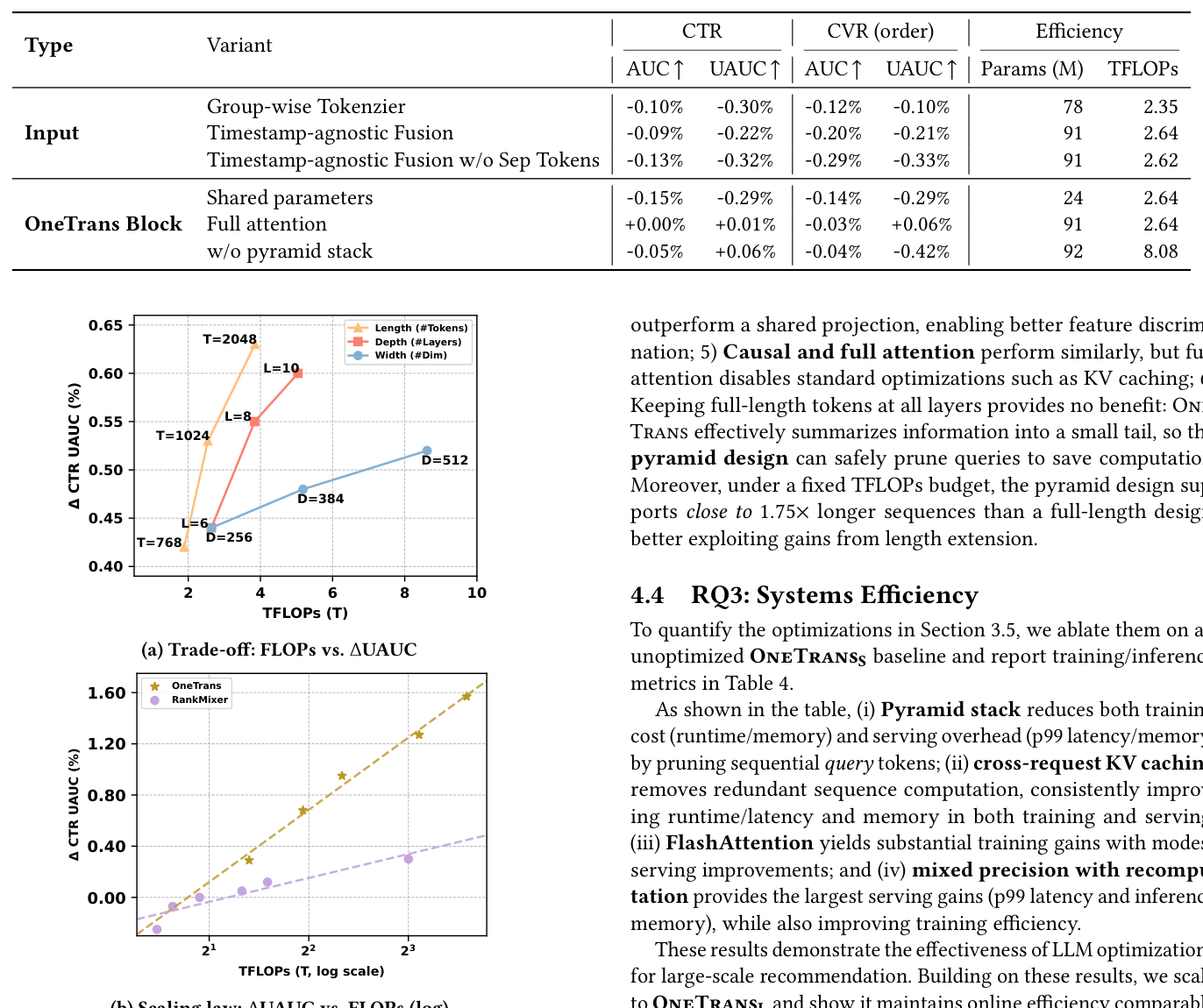
3.3 RQ2:消融实验(Table 3)与 Scaling Law(Figure 3)¶
以 OneTrans_S 为基准,消融各设计选择:
| 类型 | 变体 | CTR AUC | CTR UAUC | CVR AUC | CVR UAUC | Params (M) | TFLOPs |
|---|---|---|---|---|---|---|---|
| 输入 | Group-wise Tokenizer | -0.10% | -0.30% | -0.12% | -0.10% | 78 | 2.35 |
| 输入 | Timestamp-agnostic Fusion | -0.09% | -0.22% | -0.20% | -0.21% | 91 | 2.64 |
| 输入 | Timestamp-agnostic w/o Sep Tokens | -0.13% | -0.32% | -0.29% | -0.33% | 91 | 2.62 |
| Block | Shared parameters | -0.15% | -0.29% | -0.14% | -0.29% | 24 | 2.64 |
| Block | Full attention | +0.00% | +0.01% | -0.03% | +0.06% | 91 | 2.64 |
| Block | w/o pyramid stack | -0.05% | +0.06% | -0.04% | -0.42% | 92 | 8.08 |
结论: 1. Auto-Split Tokenizer 优于手工分组的 Group-wise Tokenizer,表明自动构建 token 比人工特征分组更有效 2. Timestamp-aware 融合优于按意图排序的 timestamp-agnostic 方案 3. 在 timestamp-agnostic 下,可学习 [SEP] token 有助于模型区分不同序列 4. NS-tokens 的 token-specific 参数优于全共享参数,表明异质特征需要独立投影 5. 因果注意力与全注意力性能相近,但全注意力禁用了 KV 缓存等关键优化 6. 金字塔裁剪在不损失性能的前提下将 TFLOPs 从 8.08 降至 2.64(减少约 67%)
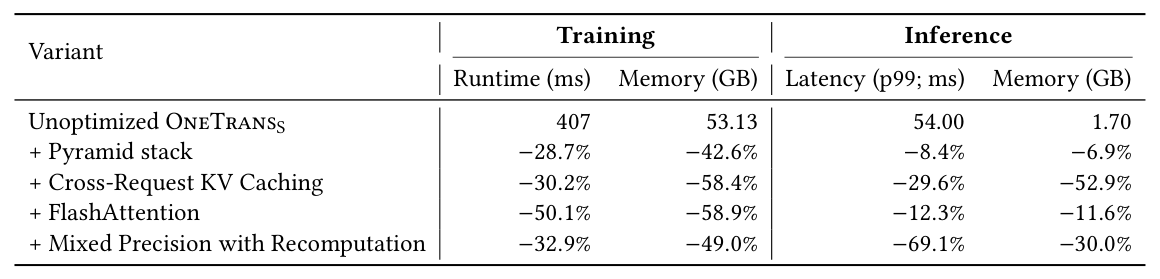
3.4 RQ3:系统效率(Table 4)¶
在未优化的 OneTrans_S 上逐步叠加优化:
| 变体 | 训练 Runtime (ms) | 训练 Memory (GB) | 推理 Latency p99 (ms) | 推理 Memory (GB) |
|---|---|---|---|---|
| Unoptimized OneTrans_S | 407 | 53.13 | 54.00 | 1.70 |
| + Pyramid stack | -28.7% | -42.6% | -8.4% | -6.9% |
| + Cross-Request KV Caching | -30.2% | -58.4% | -29.6% | -52.9% |
| + FlashAttention | -50.1% | -58.9% | -12.3% | -11.6% |
| + Mixed Precision w/ Recomputation | -32.9% | -49.0% | -69.1% | -30.0% |
结论:金字塔裁剪大幅降低训练成本;跨请求 KV 缓存显著减少推理延迟和内存;FlashAttention 主要提升训练效率;混合精度+重计算带来最大的推理增益(p99 延迟降低 69.1%)。
3.5 OneTrans_L 与 DCNv2+DIN 效率对比(Table 5)¶
| 指标 | DCNv2+DIN | OneTrans_L |
|---|---|---|
| TFLOPs | 0.06 | 8.62 |
| Params (M) | 10 | 330 |
| MFU | 13.4 | 30.8 |
| 推理 Latency p99 (ms) | 13.6 | 13.2 |
| 训练 Memory (GB) | 20 | 32 |
| 推理 Memory (GB) | 1.8 | 0.8 |
结论:尽管 OneTrans_L 参数量和 TFLOPs 远大于 DCNv2+DIN,经过系统优化后在线推理延迟甚至更低(13.2 vs 13.6 ms),推理内存也更小(0.8 vs 1.8 GB),证明统一 Transformer 骨干可直接享用 LLM 优化技术。
3.6 RQ4:Scaling Law 验证¶
沿三个轴扩展 OneTrans:
- Length(输入序列长度):增加长度带来最大增益
- Depth(层数):增加深度通常优于增加宽度,更深的堆叠可提取更高阶交互
- Width(隐藏维度):增加宽度对并行更友好,但性能增益略低于深度
在 log 尺度下绘制 $\Delta$UAUC vs TFLOPs 曲线,OneTrans 和 RankMixer 均呈现近对数线性趋势,但 OneTrans 的斜率更陡,表明其参数效率和计算效率更优。
3.7 RQ5:在线 A/B 测试(Table 6)¶
在两个大规模工业场景中部署 OneTrans_L(处理组)vs RankMixer+Transformer(对照组,约 100M 参数),使用用户级哈希随机分流。
| 场景 | click/u | order/u | gmv/u | Latency (p99) |
|---|---|---|---|---|
| Feeds | +7.737%** | +4.351%* | +5.685%* | -3.91% |
| Mall | +5.143%** | +2.577%** | +3.670%* | -3.26% |
( 表示 $p < 0.05$,* 表示 $p < 0.01$)
结论:
- OneTrans_L 在两个场景中均取得显著的业务指标提升
- Feeds 场景:click/u +7.737%,order/u +4.351%,gmv/u +5.685%
- Mall 场景:click/u +5.143%,order/u +2.577%,gmv/u +3.670%
- 推理延迟反而降低 3-4%
- 额外观察:用户 Active Days 提升 +0.7478%,冷启动商品 order/u 提升 +13.59%
4. 核心贡献总结¶
- 统一框架:提出 OneTrans,用单一 Transformer 替代传统的 encode-then-interaction 流水线,实现序列建模和特征交互的联合优化
- 混合参数化:S-tokens 共享参数、NS-tokens 独立参数的设计,兼顾同质序列特征的高效建模和异质非序列特征的表达能力
- 金字塔裁剪 + 跨请求 KV 缓存:在不损失精度的前提下大幅降低训练和推理开销
- Scaling Law 验证:OneTrans 展现近对数线性的性能增益,且斜率优于 RankMixer
- 显著的线上收益:gmv/u 提升 5.68%,同时推理延迟降低,具备生产级部署能力