Beyond Dense Connectivity: Explicit Sparsity for Scalable Recommendation¶
SIGIR'26 · Alibaba International Digital Commercial Group (AliExpress) · Yantao Yu, Sen Qiao, Lei Shen, Bing Wang, Xiaoyi Zeng
本文针对工业推荐(CTR 排序)中"堆大 MLP 却收益递减"这一老问题给出了一种架构层面的解决方案——SSR(Explicit Sparsity for Scalable Recommendation)。作者通过对线上 CTR 模型 FC 层权重分布的统计,发现稠密连接与推荐数据本征稀疏性之间存在结构错配:超过 92% 的连接学到的权重被压到接近零,而 80% 的"权重能量"集中在前 4% 的输入维度上。这意味着堆叠稠密层本质上是在让模型"用 L2 慢慢把无用连接磨掉",其表达容量被大量不相关特征稀释。SSR 将"先过滤再融合(filter-then-fuse)"显式写进架构:用Static Random Filter(SSR-S)做静态维度级稀疏,用Iterative Competitive Sparse (ICS, SSR-D)做动态、可微、基于生物学"最适者生存"思想的样本级稀疏选择,之后再在各稀疏子空间里做独立稠密融合。论文在 3 个公开 CTR 数据集(Avazu/Criteo/Alibaba)和 AliExpress 亿级工业数据集上做了广泛实验,并在 AliExpress 电商主链路上了 2 周的线上 A/B,CTR +2.1%、Orders +3.2%、GMV +3.5%,单次 serving latency 仅增加约 1 ms。
1. 研究动机与背景¶
1.1 Scaling 到了推荐系统为何失效¶
LLM 时代,业界反复验证了"参数越多性能越强"的 scaling 规律。然而在推荐系统中,DeepFM、DLRM、Wukong、RankMixer 等主流判别式排序骨干几乎都维持在 3–4 层 MLP 的深度。大量先前工作(如 [17, 22])已经观察到:简单加深加宽 MLP 会出现 diminishing returns,甚至性能下降。
作者认为,这一现象的根源在于推荐数据与语言数据的本质差异:
- 语言 token 分布是高信息密度、连续激活的;
- 推荐输入维度(数百万 sparse feature 的 embedding 拼接)则高度稀疏:对于任何一次推荐请求(如"用户上午在浏览运动鞋"),只有极小一部分维度真正承载与该请求相关的信号,其余大部分维度是弱相关甚至噪声。稠密 FC 层会把所有输入不加筛选地混合在一起,稀释真正有用的维度,同时放大噪声,迫使后续非线性层花大力气去"抑制噪声"而非"建模复杂模式"。
1.2 经验证据:稀疏性已经自发出现¶
作者对线上 CTR 模型的某一隐藏层权重做了直方图分析,观察到两个关键事实(Figure 1):
- 92% 的权重绝对值 < 10⁻³,说明模型已经自发地把绝大部分连接"训练成零";
- 80% 的权重能量集中在前 4% 的输入维度上,说明真正起作用的只是少量维度。
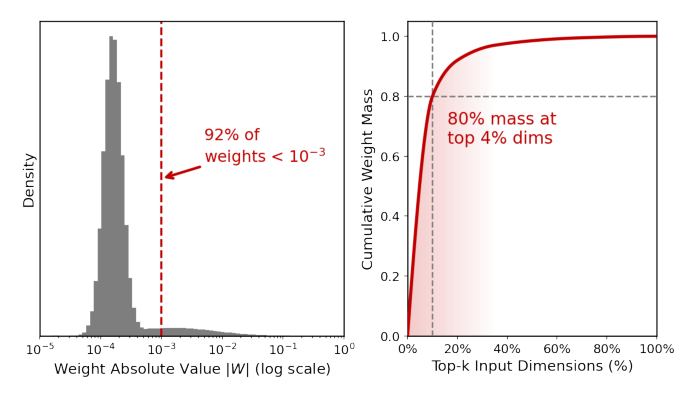
这种隐式权重抑制(implicit suppression)效率极低:大量连接只是被 L2/梯度慢慢拖到零,既不阻止噪声的前向传播,也不能在 scaling 时真正释放容量。它还会造成训练时的信号稀释——梯度中有用信号被大量零权重连接"平均"掉,出现作者称之为 signal dilution 的现象。
作者由此得出本文的核心观点:不要让模型"隐式地"学稀疏,而要把稀疏显式地写进架构——先按维度过滤掉弱相关信号,再在被净化的小子空间上做稠密融合。这样就能让扩容的参数完全用在真正有用的维度上。
1.3 已有方法的局限¶
作者系统比较了两类已有稀疏方法:
- Feature Selection 路线(AutoFIS[17], PLE[26]):先学后剪,剪完再重训,无法在前向推理时自适应样本;
- Mixture-of-Experts(MMoE[19], MoE[29])等软门控:虽然可以提升容量,但门控仍是稠密 softmax,路由扩容仍绕不开 feature saturation;
- Top-k / Statistical Top-k(如 STE [31]):引入硬选择会有离散梯度、训练不稳定的问题;
- Graph/Attention 稀疏化(IntentGC [35]):图构造代价大且工业落地成本高。
SSR 的位置是:通过静态随机过滤 + 动态可微竞争稀疏的组合,实现"零 FLOP 维度裁剪 + 全可微 + 样本自适应",从源头阻断噪声。
2. SSR 框架核心方法¶
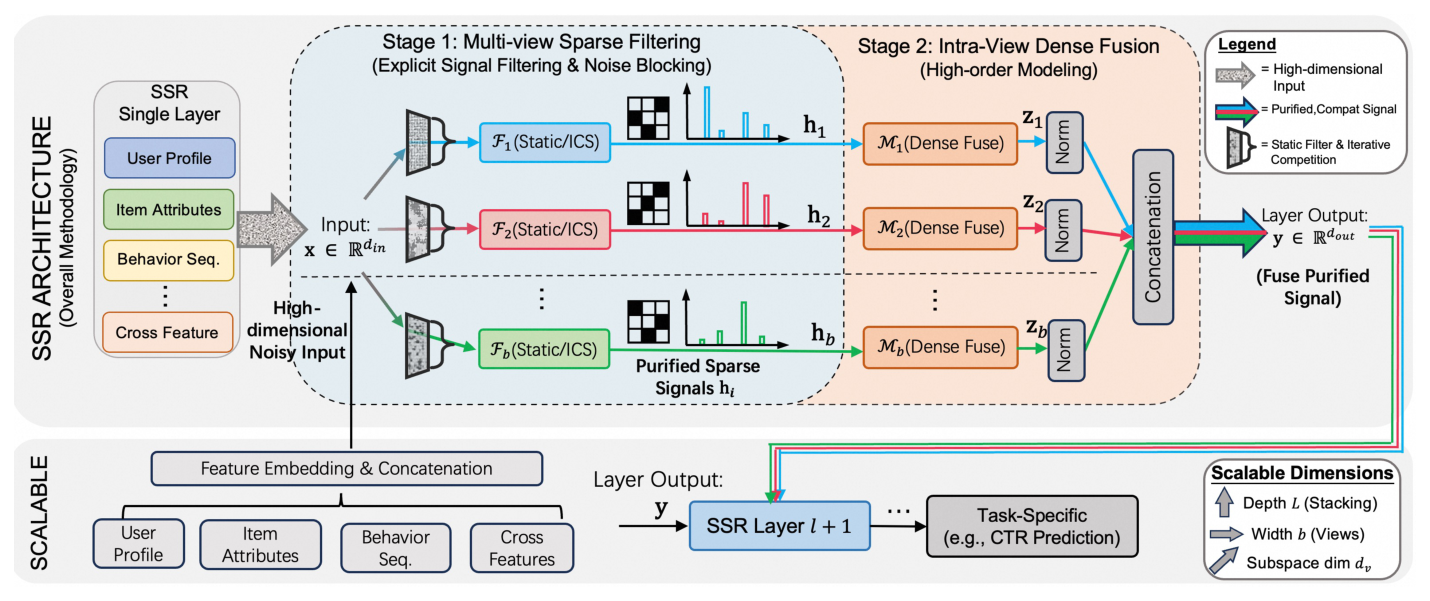
SSR 框架的核心范式是 "first filter, then fuse":一层 SSR Layer 由两个顺序子模块组成:
- Stage 1: Multi-view Sparse Filtering——用 b 个稀疏过滤器 $\mathcal{F}_i$ 把高维输入 $\mathbf{x}\in\mathbb{R}^{d_{in}}$ 投影到 b 个低维子空间(view),每个 view 只保留一部分输入维度;
- Stage 2: Intra-view Dense Fusion——对每个 view 的稀疏表示 $\mathbf{h}_i$ 独立地用稠密层 $\mathcal{M}_i$ 做非线性交互,然后 LayerNorm 后拼接。
SSR Layer 的输出再作为下一层 SSR Layer 的输入,或连接到任务 head(如 CTR 的 sigmoid)。
2.1 Overview 与数据流¶
输入 $\mathbf{x}\in\mathbb{R}^{d_{in}}$(User Profile / Item Attributes / Behavior Sequence / Cross Feature 四类 embedding 拼接后的高维稀疏向量)依次经过 b 个过滤器 $\mathcal{F}_1,\dots,\mathcal{F}_b$ 得到 b 个净化后的 view,每个 view 再各自经过一个 dense fuse 模块,最后拼接得到这一层的输出:
$$ \mathbf{y} = \mathrm{Concat}(\phi_1(\mathbf{x}), \phi_2(\mathbf{x}), \dots, \phi_b(\mathbf{x})) \in \mathbb{R}^{b\cdot d_v} \tag{1} $$
其中每个 view 的处理函数 $\phi_i$ 是一个严格两阶段的复合算子:先做 Sparse Filtering $\mathcal{F}_i$,再做 Dense Fusion $\mathcal{M}_i$。
2.2 Multi-view Sparse Filtering(稀疏过滤阶段)¶
这一阶段是 SSR 的结构主张:用一个维度级别的、上下文无关的随机稀疏算子代替稠密线性变换。第 i 个 view 的过滤操作为:
$$ \mathbf{h}_i = \mathcal{F}_i(\mathbf{x}) \in \mathbb{R}^{d_v} \tag{2} $$
作者提出两种实例化策略:
2.2.1 SSR-S:Static Random Filter(静态实例化)¶
$\mathcal{F}_i$ 是一个上下文无关的固定选择器。具体实现是在初始化时采样一个二值选择矩阵 $M_i\in\{0,1\}^{d_{in}\times d_v}$,其中每列严格是一个 one-hot 向量(即每列只选中一个输入维度)。采样是均匀无放回的,保证一个 view 内部不重复。但不同 view 之间允许重叠——这样做的动机是制造 "Feature Bagging"[3] 效果:允许不同 view 在部分维度上协同工作,同时保留足够的结构多样性。过滤计算:
$$ \mathbf{h}_i = \mathbf{x}M_i \tag{3} $$
由于 $M_i$ 的每一列只选一个维度,这一步在实现上不是真正的矩阵乘法,而是零 FLOP 的 gather/direct slicing 操作——它直接在输入源头就切掉了未选中的维度,完全避免对那些维度做任何计算。这是与传统 Top-k / STE 方法的本质区别之一:后者只是将输出 mask 为零,但前向与反向传播过程中无效维度依旧存在 O(d²) 的计算开销。
2.2.2 SSR-D:Iterative Competitive Sparse(ICS,动态实例化)¶
SSR-S 的缺陷是上下文无关:一个静态 view 无法根据输入语义动态聚焦。为此作者设计了ICS 动态算子。给定先做一次线性降维得到 $\mathbf{x}\mathbf{W}_i^{proj}\in\mathbb{R}^{d_v^\star}$($d_v^\star$ 通常稍大于 $d_v$ 以便后续竞争过滤),ICS 将它视作一个"特征种群",在种群内部做 T 轮非线性竞争演化,保留强响应、抑制弱响应:
$$ \mathbf{h}_i = \mathrm{ICS}_T(\mathbf{x}\mathbf{W}_i^{proj}) \tag{4} $$
其中 $\mathbf{W}_i^{proj}\in\mathbb{R}^{d_{in}\times d_v^\star}$ 是可学习线性投影。关键在于 ICS 这个稀疏化子模块本身是严格可微的——它的整个动力学用标准非线性算子组成,因此可以像任何稠密算子一样参与反向传播。
2.3 Intra-view Dense Fusion(稠密融合阶段)¶
经过上一阶段的稀疏过滤,每个 view 的输入都已经是被净化的、信息密度更高的子空间表示。在这个阶段,SSR 在每个 view 内部用一个独立的稠密 MLP 做非线性交互。由于所有 view 共享同一个输入 $\mathbf{x}$,但各自的权重是不同的,作者用分块对角矩阵 $\mathbf{W}_{\mathrm{block}} = \mathrm{diag}(\mathbf{V}_1,\dots,\mathbf{V}_b)$ 来描述这一操作。每个 $\mathbf{V}_i\in\mathbb{R}^{d_v\times d_v}$(static 情形)或 $\mathbf{V}_i\in\mathbb{R}^{d_v^\star\times d_v}$(dynamic 情形)。第 i 个 view 的融合输出为:
$$ \mathbf{z}_i = \sigma(\mathbf{h}_i \mathbf{V}_i + \mathrm{bias}_i) \tag{5} $$
其中 $\sigma(\cdot)$ 是非线性激活(作者使用 GELU)。然后对 b 个 view 做 LayerNorm 并拼接得到整个 SSR Layer 的输出:
$$ \mathbf{y} = \mathrm{concat}(\mathrm{LayerNorm}(\mathbf{z}_1),\dots,\mathrm{LayerNorm}(\mathbf{z}_b)) \tag{6} $$
参数量分析:采用 block-diagonal 结构后,SSR 层的参数量为 $O(b\cdot d_v^2)$,而等价的稠密 FC 层参数量为 $O((b\cdot d_v)^2)$。只要 $b>1$,SSR 就以 1/b 的参数/计算 保留了同等输出宽度,从而可以在同一算力预算下做更多的"等效宽度"扩容。
2.4 可扩展维度¶
SSR 架构同时支持沿三个正交维度 scaling:
- Depth (L):堆叠多层 SSR Layer,获取层次化特征抽象;
- Width (b):增加 view 数,扩大逻辑视野、捕获更多样的 feature interaction;
- Subspace dim ($d_v$):增加每个 view 的容量,提升单 view 表达力。
这为工业部署提供了按算力调节精度的灵活"旋钮"。
3. Iterative Competitive Sparse(ICS)机制细节¶
ICS 是 SSR-D 的核心创新。动机是:推荐中"哪些维度重要"是样本相关的,需要动态、可微、且在梯度空间下稳定的稀疏选择器。传统的 discrete Top-k / STE 方法会因为 indicator 函数不可导而出现梯度偏差;soft attention 又过于稠密。作者借鉴进化生物学中的"最适者生存(survival of the fittest)"思想,把稀疏化看作一个连续动力学过程。
3.1 Initialization 与 Competitive Dynamics¶
设 view 的初始投影为 $\mathbf{p}\in\mathbb{R}^{d_v^\star}$(即 $\mathbf{p}=\mathbf{x}\mathbf{W}^{proj}$)。由于后续动力学需要"非负强度"语义,先用 ReLU 把负值截零得到初态:
$$ \mathbf{x}^{(0)} = \mathrm{ReLU}(\mathbf{p}) \tag{7} $$
然后进入 T 轮迭代。第 t 轮引入一个全局抑制场 $\mu^{(t)}$,等于当前种群的均值:
$$ \mu^{(t)} = \frac{1}{d_v^\star}\sum_{j=1}^{d_v^\star} x_j^{(t)} \tag{8} $$
随后以学习到的 extinction rate $\alpha_t\in\mathbb{R}$ 施加"灭绝压力"——只有强度显著大于抑制场 $\mu^{(t)}$ 的维度才能存活,其余维度被 ReLU 截成零:
$$ \mathbf{x}^{(t+1)} = \mathrm{ReLU}(\mathbf{x}^{(t)} - \alpha_t\cdot\mu^{(t)}) \tag{9} $$
这个更新规则的物理含义是:平均以下、且差距大于 $\alpha_t\mu^{(t)}$ 的维度被消除,平均以上的幸存者继续参与下一轮竞争。由于每一步都是 ReLU + 减法 + 求均值,整个操作 O(N)(不需要排序),T 轮总复杂度 $O(T\cdot N)$,在实际 T=5 下比 $O(N\log N)$ 的 Top-k 更便宜。
关键的稳定性结论:由于 $\alpha_t,\mu^{(t)}\geq 0$,每一步都单调不增,故种群总能量满足
$$ \|\mathbf{x}^{(t+1)}\|_1 \leq \|\mathbf{x}^{(t)}\|_1 \tag{10} $$
这意味着 ICS 是一个能量单调衰减的动力系统,不会出现爆炸;同时由于不用排序或 argmax,整个过程严格可微,梯度可以正常穿过整个 T 步。
作者特别强调 T>1 的必要性:单步阈值化(T=1)只依赖一次静态均值估计,噪声分布本身并不稳定;多步迭代相当于逐步精化噪声基线,使过滤趋向"动态收敛",更接近非线性稀疏化而非线性截断。
3.2 Signal Recovery(梯度与尺度稳定)¶
迭代过程不可避免地会吸收信号总能量(每步都减了一次均值)。为对冲这种整体衰减,ICS 在输出端加一个可学习的 rescaling 向量 $\gamma\in\mathbb{R}^{d_v^\star}$,对每一维做独立缩放:
$$ \mathbf{y} = \gamma\odot\mathbf{x}^{(T)} \tag{11} $$
$\gamma$ 的作用不是一个标量 scalar multiplication——作者解释它提供了按维度 recover dynamic range 的能力,从而充当了"variance stabilizer + 动态范围校正器",保证训练时数值稳定,同时给反向传播提供合理的梯度尺度。
3.3 与已有 Top-k 机制的比较¶
作者明确论述了 ICS 相对 STE Top-k[2]、Statistical Top-k[31] 的两点核心优势: 1. 真正可微:ICS 的非线性迭代不再是离散选择。STE 用 straight-through 伪梯度绕过离散问题,但会带来梯度偏差;ICS 则是严格的连续非线性动力系统,梯度流无偏; 2. 严格 O(T·N) 复杂度:标准 Top-k 需要 O(N log N),在高维推荐 embedding 上(N 可能达到 1M)十分昂贵;ICS 只需 T 次线性扫描; 3. 信号驱动稀疏:Top-k 必然选出前 k 个"相对最大"的维度,即使它们整体都很弱;ICS 则通过和全局均值比较,只保留真正"超出平均水平"的维度,其余硬性置零。
3.4 Algorithm 1:ICS Forward Pass 伪代码¶
输入: 投影特征 z∈R^{d_v*}, 迭代步数 T, 可学习 extinction rates {α_t}_{t=0}^{T-1}, 可学习 rescale γ
输出: 稀疏特征向量 y∈R^{d_v*}
1: x^(0) ← ReLU(z)
2: for t = 0 ... T-1 do
3: μ^(t) ← Mean(x^(t))
4: x^(t+1) ← ReLU(x^(t) - α_t · μ^(t))
5: end for
6: y ← γ ⊙ x^(T)
7: return y
所有步骤都是 differentiable、O(N) 每步,且只含逐元素算子,可以在 GPU 上完美并行。
4. 实验设计¶
4.1 研究问题¶
论文将实验组织为 4 个 RQ:
- RQ1 Effectiveness & Efficiency:SSR 是否在主流 CTR 数据集上同时击败 SOTA 精度和 FLOPs;
- RQ2 Scalability:扩大模型规模(L/b/$d_v$)后 SSR 是否持续受益;
- RQ3 Ablation & Mechanism:稀疏过滤 vs 稠密融合各自贡献、ICS 与 Top-k 的差异;
- RQ4 Online A/B:实际业务场景下 SSR 能带来多少业务指标提升。
4.2 数据集¶
实验一共使用 4 个数据集:3 个公开 + 1 个亿级工业:
| Data | #Samples | Positive Ratio | #Categorical | #Numerical | #Feature Values |
|---|---|---|---|---|---|
| Avazu | 40,428,967 | 16.98% | 23 | 0 | 1,544,489 |
| Criteo | 45,840,617 | 25.62% | 26 | 13 | 998,974 |
| Alibaba | 42,299,905 | 3.89% | 26 | 0 | 1,342,817 |
| Industrial (AliExpress) | 1,003,204,206 | 3.45% / 0.08% | 183 | 129 | — |
工业数据来自 AliExpress 全球电商平台,183 个 categorical 特征 + 129 个 numerical 特征,10 亿+样本,含两个任务:click 任务正样本率 3.45%,pay 任务正样本率 0.08%。工业数据以最近一天的数据作为 test,8:1:1 train/val/test 分割。数值特征做 log 变换+离散化;low-frequency(<5 次)特征全部统一为 OOV token。
4.3 评估指标与协议¶
- Effectiveness: AUC 与 LogLoss(公开数据集);工业数据则同时报告 AUC 与 GAUC(group AUC,按用户分组后的 AUC 加权平均,能缓解 user activity bias,更贴近线上 intra-user 排序质量);
- Efficiency: Params(只计 backbone,不计 embedding table 以隔离架构复杂度)+ FLOPs(单次前向的计算代价)。
4.4 Baselines(4 类)¶
- Classic Deep Models: DeepFM[5]、DCNv2[28]
- Attention-based & Dynamic: AutoInt[23]、MMoE[19]
- Feature Selection / AutoML: AutoML[7]、AutoFIS[17]、AFN[6]
- SOTA Scalable Architectures: Wukong[33]、RankMixer[36]
所有模型在 TensorFlow、A100 单卡训练,embedding 维度固定 16,Adam 优化器,batch 1024,T=5(ICS 迭代步数),$\alpha_t$ 初始化 0.1,$\gamma$ 初始化全 1 向量。
5. 主要实验结果¶
5.1 Industrial 数据集结果(RQ1)¶
Table 2 在 AliExpress 工业数据上对比各模型的 Click/Pay 两任务 AUC/GAUC 与参数量/FLOPs:
| Model | CLICK AUC | CLICK GAUC | PAY AUC | PAY GAUC | #Params | FLOPs/1 |
|---|---|---|---|---|---|---|
| Dense MLP | 0.6593 | 0.6281 | 0.8083 | 0.6770 | 60M | 3.4G |
| DeepFM | 0.6563 | 0.6251 | 0.8053 | 0.6750 | 13M | 0.6G |
| DCNv2 | 0.6571 | 0.6262 | 0.8065 | 0.6742 | 15M | 0.9G |
| MMoE | 0.6575 | 0.6267 | 0.8063 | 0.6757 | 21M | 1.2G |
| AutoInt | 0.6594 | 0.6279 | 0.8078 | 0.6769 | 26.2M | 1.7G |
| AutoFIS* | 0.7802 | 0.6289 | 0.8085 | 0.6777 | 23M | 0.5G |
| Wukong | 0.6692 | 0.6285 | 0.8085 | 0.6777 | 93M | 2.9G |
| RankMixer | 0.6621 | 0.6305 | 0.8122 | 0.6815 | 101M | 3.2G |
| SSR-S | 0.6644 | 0.6326 | 0.8142 | 0.6841 | 57M | 2.3G |
| SSR-D | 0.6667 | 0.6351 | 0.8194 | 0.6862 | 103M | 3.3G |
结论分析:
- SSR-S(静态)在 57M 参数 / 2.3G FLOPs 下已超过 RankMixer 的 101M / 3.2G,仅用 ~56% 参数、~72% FLOPs 就获得更优 AUC。这直接验证了 "Feature Bagging + block-diagonal" 的参数效率;
- SSR-D(动态)在与 RankMixer 等参数量级下进一步把 CLICK AUC 从 0.6621 → 0.6667(+0.46),PAY AUC 从 0.8122 → 0.8194(+0.72)。这两个提升在推荐工业中已经非常显著,PAY 任务 GAUC 的 +0.47 尤其关键(pay 正样本率仅 0.08%,评测噪声大);
- AutoFIS 的 CLICK AUC=0.7802 为 pre-train 阶段指标,不可与主结果直接比较(已有标注*);
- Wukong 容量大但 GAUC 提升并不突出,说明单纯"扩容 MLP-like 结构"在这个数据分布下已经饱和;SSR-D 用相似算力却撕开了明显差距。
5.2 公开数据集结果(RQ1)¶
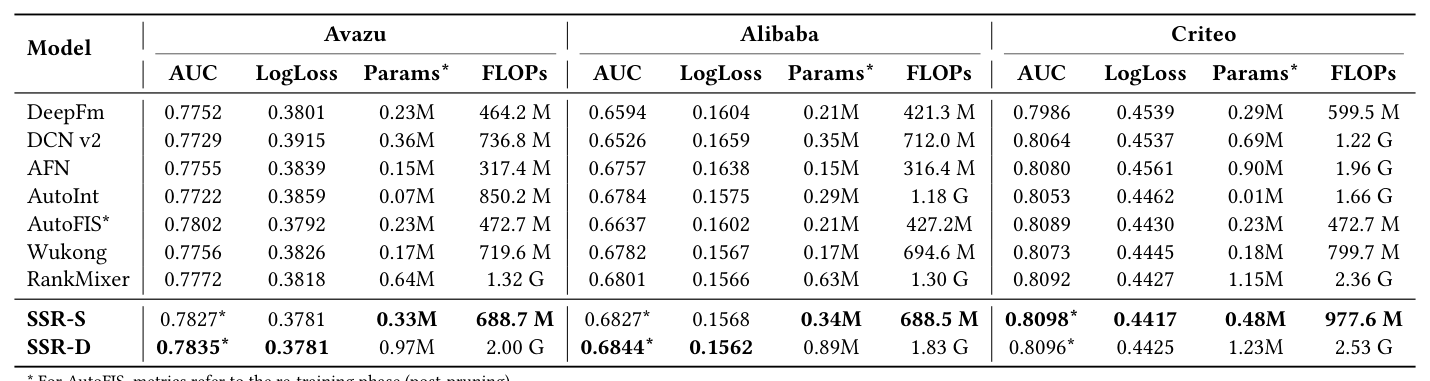
Table 3 展示在 Avazu / Alibaba / Criteo 上的详细对比:
| Model | Avazu AUC | Avazu LogLoss | Avazu Params | Avazu FLOPs | Alibaba AUC | Alibaba LogLoss | Alibaba Params | Alibaba FLOPs | Criteo AUC | Criteo LogLoss | Criteo Params | Criteo FLOPs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepFM | 0.7752 | 0.3801 | 0.23M | 464.2M | 0.6594 | 0.1604 | 0.21M | 421.3M | 0.7986 | 0.4539 | 0.29M | 599.5M |
| DCN v2 | 0.7729 | 0.3915 | 0.36M | 736.8M | 0.6526 | 0.1659 | 0.35M | 712.0M | 0.8064 | 0.4537 | 0.69M | 1.22G |
| AFN | 0.7755 | 0.3839 | 0.15M | 317.4M | 0.6757 | 0.1638 | 0.15M | 316.4M | 0.8080 | 0.4541 | 0.69M | 1.96G |
| AutoInt | 0.7722 | 0.3859 | 0.07M | 850.2M | 0.6784 | 0.1575 | 0.29M | 1.18G | 0.8053 | 0.4462 | 0.01M | 1.66G |
| AutoFIS* | 0.7782 | 0.3792 | 0.23M | 472.7M | 0.6637 | 0.1602 | 0.22M | 472.7M | 0.8089 | 0.4430 | 0.23M | 472.7M |
| Wukong | 0.7756 | 0.3826 | 0.17M | 719.6M | 0.6782 | 0.1567 | 0.17M | 694.6M | 0.8073 | 0.4445 | 1.15M | 799.7M |
| RankMixer | 0.7772 | 0.3818 | 0.09M | 1.32G | 0.6801 | 0.1566 | 0.63M | 1.30G | 0.8092 | 0.4427 | 1.15M | 2.36G |
| SSR-S | 0.7827* | 0.3781 | 0.33M | 688.7M | 0.6827* | 0.1568 | 0.34M | 688.5M | 0.8098 | 0.4417 | 0.48M | 977.6M |
| SSR-D | 0.7835* | 0.3781 | 0.97M | 2.00G | 0.6844* | 0.1562 | 0.76M | 1.83G | 0.8096* | 0.4417 | 1.15M | 2.53G |
结论分析:
- SSR-D 在三个数据集上都取得最佳 AUC:Avazu 0.7835(vs RankMixer 0.7772, +0.63);Alibaba 0.6844(vs 0.6801, +0.43);Criteo 0.8098/0.8096(vs 0.8092, +0.06);
- SSR-S 甚至只用 RankMixer 一半算力就能超过它:例如 Avazu 上 SSR-S 仅 0.33M 参数、688M FLOPs,而 RankMixer 是 0.09M / 1.32G,AUC 0.7827 > 0.7772;Alibaba 上 SSR-S 0.34M / 688.5M 显著击败 RankMixer 0.63M / 1.30G。这意味着静态稀疏过滤已经是一个效率/精度 Pareto 更优的架构选择;
- Criteo 上三种方法差距很小(因为 Criteo 的特征质量高、已有 baseline 接近饱和),但 SSR 仍以 0.8098/0.8096 领先;Alibaba 上 SSR 的提升最大,说明越是高稀疏电商数据 SSR 越有优势——这正契合 "filter-then-fuse" 的设计动机。
5.3 Scalability 分析(RQ2)¶
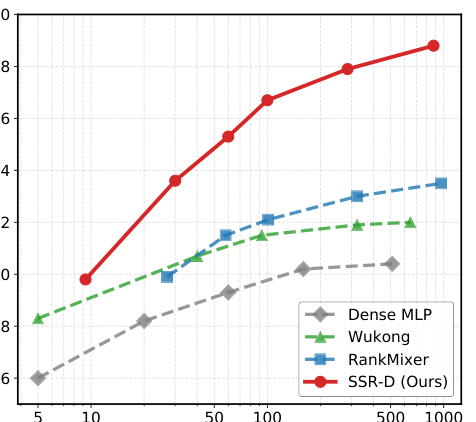
Figure 4 画的是在 AliExpress 工业数据上,四种模型(Dense MLP / Wukong / RankMixer / SSR-D)在 5M → 900M 参数区间的 AUC 曲线:
- Dense MLP 在 100M 处就开始 plateau,甚至出现负增益;
- Wukong 在 300M 附近饱和,继续加参数反而更糟;
- RankMixer 有较好的 scaling 斜率,但在 500M 后也开始放缓;
- SSR-D 在整个区间几乎线性上升,直到 900M 都没有饱和迹象。
这支持了作者的核心论点:稠密网络在扩容时会因"无效连接稀释信号"而饱和;SSR 通过显式稀疏过滤把"扩容的每一个参数都用在被过滤后的有效子空间上",从而突破这一瓶颈。
此外,作者在 Industrial / Avazu 两个数据集上做了三个 scaling 维度的消融(Figure 3 面板 a/b)。主要观察:
- Views (b) 是最鲁棒的 scaling 维度。在工业数据上从 b=8 扩到 b=16 仍获得显著提升;在 Avazu 上从 8 → 16 后 subspace dim 变化带来的增益有限(因为小数据集下 d=128 附近模型已达容量上限);
- Subspace dim ($d_v$) 在小数据集上也有效,但在工业数据下单独 scale $d_v$ 超过一定阈值会触发饱和;
- Depth (L) 是最弱的 scaling 维度——单独加深 SSR Layer 的增益最小。作者建议优先 scale views,其次 subspace dim,最后才加 depth。这给出一个清晰的工业扩容 playbook。
5.4 消融实验与机制分析(RQ3)¶
Table 4 在 Avazu 与 Industrial 上把 SSR-D 作为 baseline 逐项消掉每个组件,报告 ΔAUC (×10⁻²):
| Setting | ΔAUC Avazu | ΔAUC Industrial |
|---|---|---|
| Component Effectiveness | ||
| w/o Sparse Filtering | −0.50 | −0.37 |
| w/o Multi-view Strategy | −0.22 | −0.15 |
| Mechanism Analysis | ||
| Static (SSR-S) vs Dynamic | −0.12 | −0.23 |
| Top-k (STE) vs ICS | −0.18 | −0.29 |
| Dropout vs SSR-S | −0.32 | −0.45 |
结论分析:
- Sparse Filtering 是最大贡献项:去掉 sparse filtering(等价于直接用多 view 稠密 MLP),Avazu 下降 0.50pt、Industrial 下降 0.37pt。这比"去多 view 策略"的降幅更大,说明"稀疏过滤"本身比"多视角"更关键,验证了论文的中心观点——dense connectivity 才是 scalability 的真正瓶颈;
- Multi-view(单 view 化):b=1 时 Avazu -0.22, Industrial -0.15,说明并行多 view 确实捕获了互补信号;
- Dynamic vs Static:SSR-D 比 SSR-S 在工业数据上多涨 0.23pt,在 Avazu 上多 0.12pt。工业数据的提升更大,符合预期——工业场景特征分布更复杂,样本级动态选择更有价值;
- ICS vs STE Top-k:用 STE 式 Top-k 替换 ICS 后 Avazu -0.18、Industrial -0.29,说明 differentiable 的非线性竞争选择比"硬 mask + 伪梯度"更有效;
- Dropout vs SSR-S:用 Dropout 代替 Static Random Filter,Avazu -0.32、Industrial -0.45,降幅最大,说明 SSR 的效果不仅仅来自正则化作用(Dropout 也提供正则化),而是来自结构性的维度级信号隔离——SSR 学到了有意义的稀疏模式,而不是随机扰动。
Table 5 对 Avazu 做了 ICS 的敏感度分析:
| Setting | Param Value | Sparsity (%) | AUC |
|---|---|---|---|
| (A) Iterations T (α₀=0.1, w/ γ) | T=1 (Single Step) | 76.4% | 0.7821 |
| T=2 | 88.6% | 0.7826 | |
| T=5 (Default) | 91.0% | 0.7835 | |
| (B) Extinction α₀ (T=5, w/ γ) | α₀=0.01 | 80.4% | 0.7832 |
| α₀=0.1 (Default) | 91.0% | 0.7835 | |
| α₀=0.3 | 93.3% | 0.7833 | |
| α₀=0.5 | 94.0% | 0.7828 | |
| (C) Rescaling γ (T=5, α₀=0.1) | w/o γ | 94.5% | 0.7832 |
| w/ γ (Default) | 91.0% | 0.7835 |
结论分析:
- T 的作用:T=1 只能做到 76.4% 稀疏、AUC 0.7821;T=5 达到 91% 稀疏、AUC 0.7835,验证了多轮迭代精化确实必要;
- $\alpha_0$ 的敏感度:$\alpha_0\in[0.01,0.5]$ 区间内 AUC 都在 0.7828–0.7835,非常鲁棒。这说明 learnable $\alpha_t$ 本身会自适应调节,初值对结果影响不大——这是一个工业落地友好的性质(无需精心调参);
- γ 的必要性:去掉 rescale 后稀疏率反而更高(94.5%)但 AUC 略降到 0.7832。作者解释是:γ 补偿了迭代过程中必然产生的信号衰减,让"过滤后的动态范围"回到合理区间,从而为后续非线性层提供更好的数值条件。
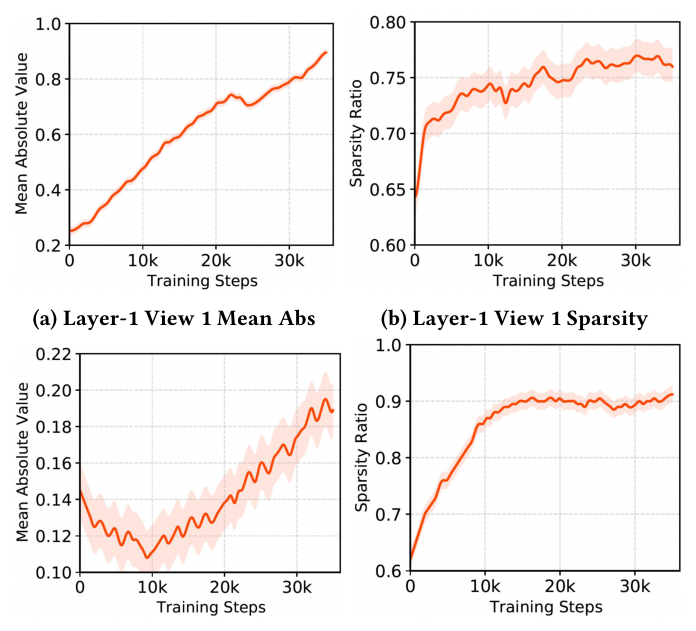
Figure 5 追踪了 ICS 训练过程中两层内部 view-1 的 mean absolute value 与 sparsity ratio 在前 35k 步的变化:
- Layer 1 稀疏率快速上升到约 75% 并保持;特征 magnitude 在前 10k 步略降后缓慢回升,说明模型先快速找到"明显无用"的维度剔掉,再对剩余维度微调强度;
- Layer 2 收敛较慢但最终达到 ~90% 稀疏率,且 magnitude 比 Layer 1 高约 ~75%。这揭示了一个有趣现象:SSR 的深层 view 自动学到了更高的稀疏度与更强的有效维度强度,隐含层次化稀疏结构;
- 后期阶段 magnitude 和 sparsity 都平稳,说明 ICS 的训练是稳定的(没有 hard top-k 常见的 oscillation 或 dead neuron 问题)。
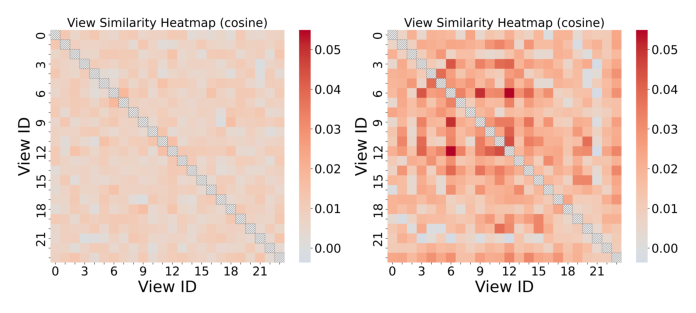
Figure 6 展示 Layer 1/Layer 2 的 view 投影矩阵两两余弦相似度:
- 所有 off-diagonal 元素都非常低(< 0.1),说明多 view 并未发生 representational collapse,各 view 学到了近似正交的表示子空间;
- 这从经验上验证了 SSR 的多 view 架构确实捕获了互补的特征交互,同时自然避免了冗余——无需额外添加显式正交化正则项,总损失本身就能驱动正交化。
5.5 线上 A/B 测试(RQ4)¶
在 AliExpress 核心推荐场景做了 2 周 A/B,baseline 是生产版本的 RankMixer(同参数量级)。结果 Table 6:
| Model | Latency | CTR Lift | Orders Lift | GMV Lift |
|---|---|---|---|---|
| SSR-D (Ours) | 26ms (+1ms) | +2.1% | +3.2% | +3.5% |
结论分析:
- CTR +2.1% 是推荐业务中非常显著的提升,意味着 SSR 学到的高 SNR 子空间确实更好地迁移到了线上用户反馈;
- Orders +3.2%、GMV +3.5% 说明提升不仅来自点击率,更转化为真实的商业成交——这是在 AliExpress 平台上的真金白银收益;
- Latency 仅 +1 ms(26 ms vs 25 ms):由于 block-diagonal 结构的参数与计算与 dense MLP 等价(甚至更低),加上 ICS 是 O(T·N) 的线性算子,serving 端成本几乎可忽略。这一点对工业部署至关重要——很多 scaling 工作虽然精度好但推理耗时翻倍以上,SSR 则没有这个问题。
6. 讨论与相关工作比较¶
6.1 From Global Dense to Sparse Filtering¶
作者把相关工作串成一条线:
- Hybrid 模型 (Wide&Deep[5], DeepFM[11]):把 FM-like 的低阶交互与 MLP 的高阶交互并联,但仍假设 dense connectivity;
- Self-Attention 类 (AutoInt[23], AFN[6]):用 attention 捕捉 pair-wise 交互,但 attention 本质仍是全连接图,只是 reweighting 方式不同;
- Explicit Interaction (DCN, DCNv2[28], RankMixer[36]):用显式 cross / mix 模块建模高阶交互,但输入仍是 fully mixed;
- Graph-based (IntentGC[35]):用 GNN 限制邻居来稀疏化,但图构造与邻居采样开销大;
- SSR 的定位:通过 "filter-then-fuse",在 dense 交互发生之前就已经做了维度级的信号隔离,从根源上防止 signal dilution。
6.2 From Pruning to Structural Sparsity¶
显式稀疏化可大致分为:
- Feature Selection (AutoFIS[17], MMoE/PLE[19,26]):训练后剪 / 软路由,但仍需做完整的 dense 前向;
- MoE[29]:稀疏路由扩容,但 router 本身是 dense softmax,仍受 saturation 制约;
- Sparse Auto-encoder[24]:用稀疏正则进行表示压缩,但缺乏样本自适应性;
- SSR:从一开始就用"零权重连接"切断无效维度,且 ICS 在训练时动态决策——本质上是把"pruning 过程"内嵌到了每次前向里。
6.3 From Gating to Global Inhibition¶
常见的 gating(MaskNet[30], LHUC[33])都是 element-wise mask + 独立投影 + 稠密 softmax,本质是独立决策:每一维是否通过只看自己。ICS 引入全局抑制场——每一维的存活概率同时依赖于其他维度的相对强度,类似生物神经网络中的横向抑制(lateral inhibition)。这种"population-level"选择能学到更 robust 的全局稀疏策略,而非对单个特征的局部阈值化。
6.4 核心贡献总结¶
- 诊断:通过 Figure 1 揭示工业 CTR 模型的 "92% / 80%" 稀疏现象,把 scaling 瓶颈从 "模型容量不够" 重新定位为 "结构错配";
- 架构:SSR 将 filter-then-fuse 显式写入,通过 SSR-S 与 SSR-D 两种实例化同时覆盖"高效率"与"高精度"两个工业需求点;
- ICS 算子:一个严格 O(TN) 可微非线性稀疏化机制,相比 STE Top-k 既更便宜又无梯度偏差,相比 soft attention 又真正稀疏;
- Scaling law:在 5M→900M 参数区间给出第一条没有 plateau 的 dense-free CTR 曲线;
- 工业验证:AliExpress 的 2 周 A/B,+2.1% CTR / +3.2% Orders / +3.5% GMV,且 latency 只 +1ms。
6.5 局限与未解决的问题¶
- 视角数 b 的上限:论文最高实验到 b=16,没有探索 b=32 甚至 b=64 时的表现;实际工业中 FLOPs 预算与 memory footprint 是否仍然线性可控需要更多实验;
- ICS 与 LLM 风格 scaling:当前 SSR 仍是判别式 CTR 场景,能否把 ICS 的 "competitive sparse" 思想迁移到 HSTU / OneRec / LLaMARec 这种 sequence-centric 架构中尚未探讨;
- 可解释性:作者展示了 Figure 5/6 的稀疏动力学,但 ICS 具体"保留了哪些特征"并没有给出语义层面的分析(如不同业务场景下 SSR 学到的稀疏图差异);
- 稀疏率超过 94% 后略微下降:Table 5 中 α₀=0.5 时稀疏 94% 反而 AUC 0.7828,说明过度稀疏仍然会抹掉有用信号——这意味着存在一个"最佳稀疏率",如何自适应地找到它仍待研究;
- 公开数据集与工业数据的增益差异:Criteo 上提升最小,Avazu/Alibaba/Industrial 上提升明显,说明 SSR 更受益于"原生高度稀疏 + 电商多场景"这一特定分布。
6.6 工业落地要点¶
对想复现/部署 SSR 的团队,论文隐含的要点是:
- 优先 scale views (b):这是最鲁棒的扩容方向,b 从 4→16 的 ROI 非常可观;
- block-diagonal 融合:把 b 个 view 的 fusion 写成分块对角形式,参数省 1/b,对 GPU 端的 kernel fusion 非常友好;
- T=5, α₀=0.1, γ 初始化为 1:这组默认超参在 Avazu 和工业数据上都是最优,几乎无需调参;
- SSR-S 是一个"零成本"替换:如果线上已有 MLP backbone,直接换成 SSR-S 就能拿到显著 AUC 提升 + 更低 FLOPs;若预算允许再上 SSR-D;
- serving 层:ICS 是完全逐元素运算,O(T·N) 线性复杂度,2 周 A/B 测得 +1 ms latency,基本可以直接替换现网 RankMixer。
7. 总结¶
SSR 给出的核心洞察是:在推荐系统中,稀疏不是需要回避的麻烦,而是需要显式利用的结构先验。稠密 MLP 的扩容饱和并非是模型能力上限问题,而是架构与数据性质不匹配:稠密连接把有用维度和噪声维度同等对待,迫使优化器花大量参数去抑制噪声。SSR 用 filter-then-fuse 显式消除这一浪费,Iterative Competitive Sparse 又在样本级别实现动态可微的 "fittest survives" 选择,从而首次让推荐 backbone 的 scaling 曲线在 900M 参数处仍未饱和。论文的工业落地非常扎实:在亿级 AliExpress 数据上既跑通了效果,也做了 2 周 A/B,得到 GMV +3.5% / CTR +2.1% 的真实收益,且 serving latency 几乎不变。对未来而言,作者指出"explicit filtering 也许将成为下一代可 scaling 基础推荐模型的关键设计范式"——如果 HSTU/OneRec/RankMixer 这条"工业 backbone scaling"赛道真有一条类似 Transformer 的清晰主线,那么 SSR 定义的 filter-then-fuse 很可能是其中关键一环。