Long-Term Embeddings for Balanced Personalization¶
Zalando SE 的 Andrii Dzhoha 与 Egor Malykh 在 UMAP'26 Industry Track 发表的工业论文。针对基于 Transformer 的序列推荐器在生产环境中普遍存在的"短期意图压制长期偏好"以及"离线/在线嵌入版本错配"两大顽疾,作者提出 Long-Term Embeddings (LTE) 框架:用一组固定的、基于内容的语义基底(CLIP-based item embeddings)线性组合来刻画用户长期偏好,并以加了滞后窗口 (lagged window) 的方式注入到一个 SASRec 风格的排序器中。在 Zalando Browse 与 Search 两大场景、25 个市场、上千万活跃用户上完成了大规模 A/B 实验,整体 engagement 提升 +0.61%,revenue 提升 +0.42%,其中 Browse engagement 提升 +1.16%($p < 0.05$)。
1 研究动机与背景¶
1.1 短期 vs 长期偏好的张力¶
现代 Transformer 架构(SASRec、BERT4Rec 等)能够刻画用户短时间窗口内的行为序列,在 next-item prediction 中表现出色,但存在若干根本性缺陷:
- Quadratic attention 的计算瓶颈:$O(N^2)$ 的注意力复杂度使得不可能把用户一整年的交互历史(动辄几千乃至上万个事件)塞进序列。
- Recency bias:即便拉长序列,训练过程中模型会自动"聚焦"最近几次点击,更早期的稳定偏好(例如对某个品牌或特定衣服尺码的长期偏爱)会被逐步遗忘。这一点在时尚电商场景下尤其致命,因为用户的"是否穿 M 码"、"是否偏好极简风格"这类偏好是在月度/年度尺度上才能被观察到的。
- 对即时输入高度敏感:比如一次搜索"红色连衣裙"就会完全主导 ranking 结果,把用户平时的风格完全冲掉。
因此作者希望引入一种持久的、高惯性的长期偏好表示——既能作为稳定的语义锚(semantic anchor),又可以和 Transformer 排序器无缝集成。
1.2 工业部署带来的独立于方法的新约束¶
长期嵌入一旦进入生产环境,还必须同时解决两类系统层的新难题:
- 训练/服务一致性偏移 (Training-serving skew):模型是在 $T$ 天前的离线数据上训练的,但 feature store 只保存"今天最新"的 LTE,导致训练样本看到的 LTE 与服务样本看到的 LTE 出现时间漂移。
- 版本回滚 (rollback) 的不兼容性:当线上出新 ranker 遇到 bug 需要回滚时,特征存储里的 LTE 可能已经更新了一个版本(例如换了新的 encoder),旧 ranker 看到"新版 LTE"根本无法正确工作——回到旧模型在技术上几乎不可行。
为支持高性能的 real-time ranking,feature store 一般只托管最新快照([11] Li 等 2017),这种单版本设定直接暴露了 point-in-time consistency 的不匹配问题。
论文的核心主张是:与其像 [24] 那样用 Orthogonal Procrustes / SVD 之类的后处理来对齐不同版本的嵌入,不如从一开始就把 LTE 约束在一个固定的语义基底 (fixed semantic basis) 上——一旦底座不动,跨时间、跨版本就天然兼容。
1.3 论文贡献¶
- high-inertia LTE 框架:用 lagged sliding window + 固定语义基底保证 LTE 跨版本稳定。
- 集成方法研究:系统比较了三种 LTE 注入 CLM ranker 的策略,指出 contextual anchoring (prefix token) 是最佳做法。
- Attention migration 分析:给出了细粒度的经验分析,说明 LTE 如何重新分配 Transformer 的注意力权重。
- Asymmetric autoencoder 行为微调:在只有内容 embedding 的基础上,通过不对称自编码器学到行为驱动的 LTE,同时保持高惯性。
- 大规模线上验证:在 Zalando 上完成的 A/B 在 engagement 和 revenue 上都有显著提升。
2 相关工作¶
作者把相关文献组织为三条线:
- Sequential + Transformer-based Recommendation:SASRec [9]、BERT4Rec [19] 使用自注意力建模行为序列,但计算成本受限于 next-item 任务,本质上只适合短序列。单纯拉长序列带来的边际收益非常小(与作者自己的 preliminary 实验结果一致,见 §5.3)。
- Lifelong / Long-term user modeling:MIMN [15]、HPMN [18] 等引入 memory-augmented 网络维护外部状态;PinnerSage [14] 用聚类表达多面偏好;TransAct-V2 [22] 把 multi-year 的序列直接送入 top-k 检索步骤但会导致复杂度上涨;DMT [8]、LONGER [2]、GPSD [21] 则聚焦于延长序列的训练动力学。作者认为这些方法都有"要么模型体量过大、要么 per-sample 相似度检索昂贵"的问题,而基于 content-grounded LTE 的方案则能在实时 ranking 中保持轻量。
- Industrial constraints & embedding stabilization:[11] 说明工业部署面临 single-versioned feature stores、严格延迟预算、rollback 期间的 point-in-time 一致性等限制。[24] 尝试用 Orthogonal Procrustes / SVD 后处理对齐不同版本的嵌入,但需要维护 seed training run、保存变换矩阵,且并未解决 cold-start 下的 item turnover。作者把"稳定性"当作一等公民,在 design 阶段直接锚定到像 CLIP [17] 这样跨版本兼容的基础模型。
作者用 temporal inertia 这个新造术语来形容他们追求的设计目标:表示随时间的稳定性。
3 问题形式化与基础模型¶
3.1 问题定义¶
给定用户 $u$ 的历史交互 $(x^u_i)_{i=1}^{N+1}$,以及长期用户信号 $l^u_{t+1}$,目标是估计下一次交互 $x^u_{t+1}$ 的候选分布:
$$ \mathbb{P}\bigl(x^u_{t+1} = x \mid x^u_1, \dots, x^u_t,\; l^u_{t+1}\bigr), \quad x \in X \tag{1} $$
其中 $N$ 是观察到的交互数,第 $(N+1)$ 项即预测目标。
3.2 Base model — SASRec 风格的 CLM ranker¶
作者采用深度自注意力 Transformer,训练目标为 causal language modeling,整体结构与 SASRec 对齐:
- 输入 embedding $X^{(1)} \in \mathbb{R}^{N \times D}$;
- $H$ 个自注意力块,每块含 multi-head attention、feed-forward、residual、layer norm:
$$ X^{(h+1)} = \mathrm{ATT}\bigl(X^{(h)}\bigr) \tag{2} $$
- attention 操作受 causal mask 限制,只能看过去;
- 每个位置的候选相关度由一次前向计算:
$$ Y^u = X^{(H+1)} W_O A^\top \in \mathbb{R}^{N \times |X|} \tag{3} $$
其中 $W_O$ 是输出投影,$A \in \mathbb{R}^{|X| \times D}$ 是 item embedding 矩阵。训练使用带 padding mask 的 categorical cross-entropy;variable-length 序列通过 padding 对齐。推理阶段取最后一个位置的表征 $X^{(H+1)}_N$ 作为用户向量,与 $A$ 做点积排序。
3.3 三种 LTE 注入方式¶
为了把 $l^u_{t+1}$ 引入模型,作者考虑三种集成策略:
- Late fusion (LTE outside the transformer):Transformer 保持不变,在输出 projection 阶段把 LTE 直接拼到每个序列位置上,然后再与 item embedding 做点积:
$$ Y^u = (X^{(H+1)} + \mathbf{1}_N L_u) W_O A^\top \tag{4} $$
其中 $\mathbf{1}_N \in \mathbb{R}^{N \times 1}$ 是全 1 向量。这种做法有效地绕过了自注意力层,模型不能在 long-term profile 与 short-term sequence 之间学到任何复杂依赖。
- Contextual anchoring (prefix token):把 LTE 当作一个额外的上下文 token 预置到序列最前面(位置 0),然后把序列长度变为 $N+1$。为了保持 causal 性,LTE token 放在 index 0 使得所有后续 item $x_i$ 都能 attend 到它:
$$ X^{(1)} = \mathrm{ATT}\bigl(\bigl[L_u; X^{(1)}\bigr]\bigr) \tag{5} $$
其中 $[\cdot ; \cdot]$ 表示按行拼接。这种方式让每层的每个 item 表示都被 long-term profile 所条件化。在 CLM 下,LTE prefix token 会直接影响所有后续位置的隐状态,但这也意味着 long-term 信号与 short-term 序列之间必然存在时间重叠——于是作者用 lagged window 去避数据泄漏(即 LTE 使用 $[365, T]$ 区间而非 $[365, 0]$,其中 $T$ 默认 60 天,剔除 transformer 输入中最近的 $T$ 天交互)。
- Feature injection (LTE added to item embeddings):把 LTE 加到序列中每个 item 的 embedding 上:
$$ X^{(2)} = \mathrm{ATT}\bigl(X^{(1)} + \mathbf{1}_N L_u\bigr) \tag{6} $$
这种做法让 long-term 信号不仅影响 value 位置,也同时影响 query、key,使得 attention 可以基于用户画像与"当前 item × 偏好"交互来动态重新加权。与 prefix token 方案一样,需要 lagged $[365, T]$ 窗口以防止泄漏。
4 Approach:加权平均的内容嵌入做 LTE¶
4.1 高惯性的核心思想¶
作者用 content-based item embedding(CLIP-based 的多模态 vision-language 向量 [17])的加权平均作为 LTE。这样做有几个优点:
- 语义上直观:CLIP embedding 本身就编码了 item 的视觉风格、品类、颜色、材质等属性;
- 高度可解释:向量就是 item 属性的线性组合;
- 框架天然稳定:只要底层的 content embedding 矩阵 $E$ 不动(即不换新的 encoder),不同时间段算出来的 LTE 就位于同一个空间,跨版本无缝兼容——这正是作者所追求的 fixed semantic basis。
作者从两个维度系统研究 LTE 的构造:
- 权重方案:
- Uniform average:对窗口内所有 item embedding 做简单平均;
-
Recency-weighted average:用指数衰减加权,更重视最近的交互。
-
集成架构:前面 §3.3 的 3 种(Late fusion / Prefix token / Feature injection)。
4.2 滞后窗口¶
由于 transformer 的 short-term 序列与 LTE 在时间上可能重合,作者使用 lagged window $[365, T]$(即包含 365 天前到 $T$ 天前的交互)来计算 LTE。默认取 $T = 60$ 天,这样 transformer 输入的最新 60 天不会再出现在 LTE 中,避免数据泄漏。
5 离线实验¶
5.1 Base model 与训练设置¶
- 架构:two-tower,[4, 6] 的训练流程,遵循 §3.2 的 SASRec 架构;
- user tower:2 个 residual block,每个含 4-head attention($H = 2, d_{\mathrm{head}} = 4$)+ 4 层 FFN,产生 item tower 与 A 中所用 item embedding;
- item embedding 独立训练但联合部署以实现检索与 real-time user embedding,使用最近 100 次交互(60 天窗口内)做最近邻搜索;
- loss:sampled softmax with log-uniform sampling(0.5% 负样本);
- 每个 item 的输入:interacted item embedding、interaction type、categorical timestamp embedding 的拼接。
5.2 数据集与评测协议¶
- 时间跨度:过去 60 天,包括点击、add-to-wishlist、add-to-cart、checkout,25 个市场所有场景;
- 规模:7000 万+ unique users across 25 markets;评测集 100 万+ users;
- 时序切分:训练集严格早于评测集;为避免数据泄漏,从 production retraining cycle 的次日开始 holdout(与 daily retraining 对齐);
- 指标:NDCG@500(在 holdout 下对每次 next-item 预测算累积增益),评估候选排名的质量。
5.3 长序列的边际收益¶
作为预备实验,作者把 base transformer 的 max sequence length 从 60 递增到 360 天,对应地扩展训练样本。两个月后 NDCG 提升几乎消失(marginal improvements were observed after two months),但计算代价线性上升、训练耗时飙升 8×、数据准备时间同样增长。这说明:
- 直接拉长序列在工业尺度上不是一条经济路径;
- 真正有效地利用长序列需要架构上的实质性修改(如 memory 或 compressed attention);
- 这个观察正面支撑了"把长期信息压缩成 LTE"的思路——LTE 作为 compressed memory 或 long-term anchor。
5.4 集成结果与讨论¶
离线评测中,作者将每个 LTE 用线性层 projection 到 item embedding 空间,LTE 是用户在窗口内点击过的 item 的 content embedding 平均;content embedding 是 CLIP-based,512 维,把产品图像与描述映射到共享语义空间。对缺乏足够长序列的冷启用户,作者统一以零向量替代作为默认 LTE。
作者对每种 integration architecture 尝试了不同 layer 数(1 或 2 层)、线性/GELU 激活、中间维度 128/256/512/1024,报告最佳配置。recency-weighted 使用指数衰减。全部增益均 经 paired t-test,$p < 0.05$。
Table 1: NDCG@500 uplift for LTE integration strategies
| Integration method | Window | Uniform | Recency |
|---|---|---|---|
| Late fusion (outside) | $[365, 60]$ | $-0.70\%$ | $-3.05\%$ |
| Feature injection (added) | $[365, 60]$ | $+0.45\%$ | $+0.42\%$ |
| Contextual anchoring | $[365, 60]$ | $+\mathbf{1.31\%}$ | $+0.87\%$ |
关键发现与分析:
- Contextual anchoring 最优:prefix token + lagged window + uniform average 得到最高的 +1.31% NDCG@500 uplift,证实 long-term 信号作为 global context 让 self-attention 能够有针对性地调节 short-term 意图,同时保留稳定偏好——就好像给了 Transformer 一个"预设语境"。
- Uniform vs recency-weighted:recency-weighted 在所有集成策略下都输给 uniform average。一个合理解释是 Transformer 的序列建模已经在 short-term 位置上过度聚焦最近点击,再把 LTE 也做 recency 加权等于"重复刺激"——反而把本应提供的 long-term 信号稀释了。Uniform average 恰好提供互补的长期信号。不过作者承认可能还有其他因素(如 exponential decay rate 与 window size 之间的交互),需要进一步消融。
- Late fusion / feature injection 为何吃亏:Late fusion 绕过了 self-attention,根本没机会让 LTE 与短序列交互;feature injection 把 LTE 直接加到每个 item embedding 上,虽然让 query/key 都能感知 LTE,但也污染了模型对"具体 item"的 fine-grained 判别能力,效果低于 prefix token。
5.5 数据泄漏消融实验¶
为了定量验证 lagged window 的必要性,作者用最佳的 prefix token 集成方式对比:
- (i) LTE over $[365, 60]$(有 lagged window);
- (ii) LTE over $[365, 0]$(无 lagged window,与 short-term 序列重叠)。
结果:用 $[365, 0]$ 相比 $[365, 60]$ 的 NDCG 下降 0.5%。说明虽然 overlap window 还是带来了整体的提升(相对 baseline),但数据泄漏确实会损害泛化。这给作者的"滞后窗口是必要设计"提供了直接证据。
6 Attention redistribution 的经验分析¶
作者试图回答一个问题:LTE 到底是如何改变 Transformer 的内部注意力分配的?他们聚焦在第 2 层注意力($H = 2$),在最近 50 次交互的上下文里分析。
6.1 Recency intensity¶
定义 recency intensity:最后一次交互 $x_N$ 分配到的注意力权重与更早交互 $x_{N-49}$ 的比值。取 holdout 上序列长度至少 50 的用户:
- Baseline(无 LTE):recency intensity = 2.83;
- LTE 增强(prefix token):recency intensity = 2.62。
这意味着 recency intensity 下降 7.64%。解读:LTE 把模型从"对最近一次点击过度依赖"中拉回来,让它在整体历史上做更平衡的分配——正是作者想要的 high-inertia anchor 效果。
6.2 Attention migration(迁移分析)¶
为了确定注意力到底从哪里流向哪里,作者定义 attention migration delta:对每一个用户计算 LTE 模型 vs baseline 在最近 50 次交互上每个位置的 相对 注意力份额的差值(用相对份额避免总量差异的干扰)。
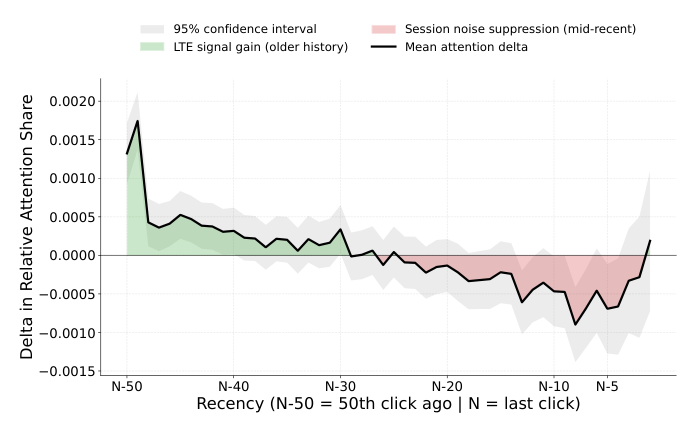
图 1 显示了两种可能解释共同作用的结果:
- Memory reclamation(记忆回收):模型把注意力从中段位置($x_{N-49}$ 到 $x_{N-25}$ 附近)转移到更早的位置,挽救被 decay 衰减掉的远端历史,使模型能看到用户稳定身份。
- Noise suppression(噪声抑制):同时模型削减了中段位置($x_{N-24}$ 到 $x_{N-1}$)的权重,这些位置往往对应 session 层级的波动(漂移的点击、误触等),与用户稳定长期身份不一致。
两条解读并不矛盾:attention budget 既从"近中段的噪音"处省出来,又流向"更稳定的远端历史"。图 1 中灰色置信区间证实了这种模式在 holdout 集群上是稳定的、非偶然的。
7 Temporal stability 与生产弹性分析¶
尽管 $[365, 60]$ 的 lagged window 防止了数据泄漏,它也引入了一种潜在的 version mismatch:下游 ranker 按同步日程(比如每天)重训,但如果 rollback 到 $X$ 天前的版本,就得处理"$X$ 天后"的 LTE feature(因为 feature store 只保存最新版)。作者通过 temporal inertia 这个新概念来量化 LTE 的版本稳定性。
7.1 理论 drift bound¶
定义 turnover rate $\tau$:rollback 窗口 $X$ 天内进入或离开 365 天交互集合的 item 比例:
$$ \tau = \frac{|S_{\mathrm{in}}| + |S_{\mathrm{out}}|}{N} \tag{7} $$
其中 $N$ 是交互集合的总 item 数,$S_{\mathrm{in}}$ 是当前版本新进的 item 集合,$S_{\mathrm{out}}$ 是旧版本已淘汰的 item 集合。那么当前版本 $\mathrm{LTE}_t$ 与旧版本 $\mathrm{LTE}_{t-X}$ 之间的 drift 可以上界为:
$$ \|\mathrm{LTE}_t - \mathrm{LTE}_{t-X}\| \leq \tau \cdot \max\|e\| \tag{8} $$
其中 $e$ 是单个 content-based embedding。对于 L2 归一化的 embedding,最大 drift 就直接简化为 $\tau$。
若假设用户的购物活动随时间近似均匀分布(短 rollback 窗口 $X \leq 10$ 天下成立),那么对于短 rollback,turnover 将很小。此外作者指出:由于用户行为呈现强烈的一致性,新交互往往与已有偏好高度吻合,所以即便低活跃用户在 $\tau$ 较高时,得到的 LTE 向量仍保持语义上接近上一个版本,不会出现剧烈的 latent profile 切换。
7.2 评估协议与抗回滚实验¶
为了隔离出 LTE 版本不匹配的影响(而不是一般意义上的模型陈旧),作者对比:
- LTE-augmented model(加 prefix LTE)
- baseline transformer(只靠 short-term 序列)
定义 relative resilience = LTE 模型与 baseline 在 rollback 下 NDCG 衰减的差值。值为正,说明 LTE 模型衰减得更慢,起到了稳定作用。
Table 2: Stability and resilience of LTE under version mismatch
| Rollback offset $X$ | Avg. turnover rate $\tau$ | Mean cosine sim. | Relative resilience |
|---|---|---|---|
| 1 Day | 0.7% | 0.997 | $+0.69\%$ |
| 5 Days | 2.8% | 0.994 | $+1.01\%$ |
| 10 Days | 5.4% | 0.985 | $+1.65\%$ |
结论与分析:
- Relative resilience 随回滚窗口变大而提高:从 1 天的 +0.69% 到 10 天的 +1.65%。虽然两个模型的性能都会自然退化,但 LTE 模型退化得更慢。这表明 LTE 的语义锚点正在提供"稳定化"作用。
- 高平均 cosine 相似度 表明在潜在流形 (semantic manifold) 内,LTE 确实位于 transformer 训练时所见过的局部区域,没有显著漂出训练分布。
- 工业意义:这种 "stability-by-design" 让工业团队可以维护一个 single-versioned 的 LTE setup,而无需牺牲 rollback 或重部署时的性能——这是 embedding 后处理对齐 [24] 等方案想做却做不到的。
8 在线实验¶
离线实验的正面结果推动 LTE 框架在 Zalando 的浏览 (Browse) 与搜索 (Search) 两个主要推荐场景上线 A/B 实验。
- 配置:prefix token 集成 + $[365, 60]$ lagged window + uniform average(离线表现最优组合);
- 市场:25 个市场;
- 用户规模:millions of active users;
- 采用 equal traffic split,统计功效足以检测 minimum detectable effect = 1.16%,主要指标显著性阈值 $p < 0.05$;
- Engagement:指加入愿望单、加入购物车这类 high-value 行为;Revenue:per-user 净商品成交额。
Table 3: A/B test results for integrating LTE into the ranking model
| Browse | Search | All | Revenue | |
|---|---|---|---|---|
| Estimate | $+1.16\%$ | $+0.15\%$ | $+\mathbf{0.61\%}$ | $+0.42\%$ |
| 95% CI | $[0.79, 1.53]\%$ | $[-0.2, 0.5]\%$ | $[0.32, 0.9]\%$ | $[0.07, 0.76]\%$ |
结论与分析:
- Browse 场景受益最大,engagement 显著提升 +1.16%,$p < 0.05$。这与 Browse 的属性高度契合:用户意图模糊、处于开放式探索状态,一个稳定的长期锚点能把推荐与用户的历史风格对齐。
- Search 场景只有 +0.15%,不显著。作者解释是:在 Search 中用户已经显式表达了 fine-grained 查询,这本身就是相关性的主要驱动信号,长期风格偏好作用有限。
- 整体:engagement +0.61%、revenue +0.42%,$p < 0.05$。结果证明 LTE 框架在高流量生产环境里可以在不牺牲 short-term intent 的前提下 引入 long-term 偏好,兼具经济和技术价值。
9 行为驱动的 LTE 微调:非对称自编码器¶
初始部署采用的是"CLIP embedding 一年均值"这一简单启发式。它有两个局限:
- 平等对待所有历史交互,无法区分"偶尔的无意点击"与"真正定义用户的核心品味";
- 内容向量无法涵盖行为性亲和力,例如价格点敏感度 (price-point sensitivity)、对 item 稀有度/质量的偏好等——这些信息只能从行为数据中学出来。
为了在不放弃 high-inertia 框架的前提下融入行为信号,作者提出 asymmetric autoencoder:它学会把 content-based embeddings 的加权平均变成行为校准过的版本,同时保持重构出来的 LTE 仍然位于内容嵌入张成的空间内。这里"asymmetric"的关键就是 decoder 固定 / encoder 可学。
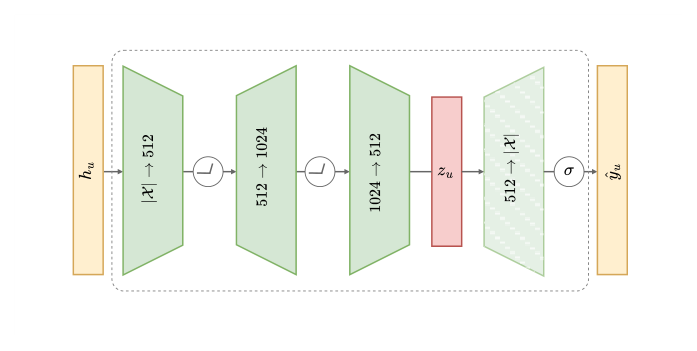
9.1 架构与目标¶
模型把用户一整年的行为表达为一个 sparse multi-hot 向量 $h_u \in \{0, 1\}^{|X|}$。架构:
- Encoder:把 sparse 历史通过多层非线性投影映射到 latent bottleneck $z_u$。第一层用 CLIP-based content embedding 初始化(加速收敛、提高稳定性),但仍可学习以捕捉行为模式。为避免模型"偷懒"记忆 input 而失去内容嵌入的可重构性,作者使用 wide intermediate layers($4D$ 和 $2D$,其中 $D = 512$)+ ReLU,并对所有 encoder 权重应用 $L_2$ 正则(包括最后一层投影到 latent bottleneck $z_u$)。
- Fixed decoder:用冻结的 content embedding 矩阵 $E$ 做 decoder。没有可学参数(除了 bottleneck $z_u$ 和最后一次输出)。这恰好把"固定语义基底"的约束做到了结构层面——decoder 是一面固定的"镜子",encoder 必须将行为信息映射到其中可解释的位置。
latent bottleneck $z_u$ 就是微调后的 LTE。重构输出 $\hat{y}_u$ 直接通过矩阵乘法给出:
$$ \hat{y}_u = z_u E^\top \tag{9} $$
训练损失是 binary cross-entropy reconstruction loss:
$$ \mathcal{L} = -\frac{1}{|X|} \sum_{j \in X} \Bigl[ h_{u,j} \log \sigma(\hat{y}_{u,j}) + (1 - h_{u,j}) \log(1 - \sigma(\hat{y}_{u,j})) \Bigr] \tag{10} $$
其中 $\sigma(\cdot)$ 是 sigmoid 函数。为缓解 "hard negative mining"(即大量无交互 item),作者按对数-均匀流行度分布 (log-uniform popularity) 采样 500 个负样本,使用 popularity 因子以保证 unbiased AUC 和 precision。
对于没有行为数据的用户,encoder 得到零 multi-hot 输入;在这种情况下第一层的权重矩阵直接充当 bias,把 "平均用户画像 / 全局趋势" 作为 default LTE。这种信号向剩余 encoder 层传播,产生冷启用户的常量 $z_u$,作为 pre-computed baseline。
9.2 讨论与性能¶
这种设计带来几个系统级好处:
- 跨版本兼容性 & seamless fallback:$z_u$ 被强制位于 content-based embedding 的线性 span 内,语义上与 heuristic 平均 LTE 位于同一流形,可以无缝替换。
- 行为协作信号:尽管 decoder 是固定的,encoder 学到了协作过滤意义上的 item 亲和度模式,结合 content-side 的 strength 得到 collaborative + content 的混合。
- 稳定性保证:encoder 可训但 $E$ 固定,模型行为受到强约束,不会漂出内容流形。
- 工业可扩放:所有可训练参数都集中在 encoder,生产环境友好。
- 冷启 fallback:零输入 → encoder 偏置 → 一个跨用户"平均画像"的默认 LTE。
- OOV 鲁棒:新 item 即使不在 encoder 输入词表中,只要在 decoder 矩阵 $E$ 中存在,就能继续参与重构。
离线评测显示:这种 behavioral fine-tuning 在 prefix token 集成下相比 uniform average baseline 得到 +2.1% NDCG@500(相对提升)。这说明 autoencoder 成功识别了"哪些历史交互最能代表用户长期品味",同时没有漂出稳定的 content-based manifold。
作者提到这版 fine-tuned LTE 还需要走一次线上 A/B 才能给出结论,并且应当与基于 Transformer 的 long-term embedding learning 做更直接的对比——这是论文 future work 的一部分。
10 讨论与局限性¶
核心贡献:
- 把 long-term user preference 表示问题从"更强的模型"转向"结构上保证稳定的表示",用 fixed semantic basis (content embedding linear span) 取代了普通 trainable embedding;
- 用简单而可解释的机制(加权平均 + lagged window + prefix token)达成目标,工业部署友好;
- 提供一整套经验分析:attention redistribution、recency intensity、temporal inertia drift bound,让"稳定性"这个抽象概念变得可测量;
- 在真实的 Zalando 25 市场场景下完成大规模 A/B 验证,engagement +1.16%(Browse)、revenue +0.42%,有清晰的商业价值。
值得借鉴的设计:
- 固定语义基底 fixed semantic basis 的思路可推广到任何需要"跨版本稳定嵌入"的推荐/检索场景——关键在于拿一个不会变的 foundation model(如 CLIP/SigLIP/DINOv2)做 anchor;
- lagged window 是一种朴素但直接的数据泄漏防护,尤其适合 CLM 风格 training;
- prefix token 集成是把"全局上下文信号"接到 Transformer 里的通用方案,值得在 LLM-based recommender 中借鉴;
- asymmetric autoencoder 用冻结 decoder 约束 latent space,这个 trick 可以用到其他"需要 behavioral + content 同时存在"的表示学习任务上。
局限性:
- Search 场景 +0.15% 不显著:long-term 信号在强查询意图下价值有限,意味着框架并非万能;
- uniform vs recency-weighted 的优势差异未能完全拆解(见 §5.4 中作者自述);
- asymmetric autoencoder 版 LTE 目前只有离线结果,没有在线 A/B,且与 Transformer 长序列基线(如 MIMN/TransAct-V2/DMT)的直接对比缺失;
- LTE 只靠一年历史 + 内容嵌入的加权平均,可能错失超过一年的季节性趋势或基于跨 item 的复杂组合偏好;
- temporal inertia 的 drift bound 假设用户行为均匀分布,短 rollback 窗口 $X \leq 10$ 天下成立,但在更极端场景下不一定成立。
与已有工作的差异:
- 相较 MIMN/HPMN 的 memory-augmented 网络:作者避开 memory module 的额外状态与运维复杂度;
- 相较 TransAct-V2 的超长序列:作者避开 $O(N^2)$ 的代价;
- 相较 [24] 的 SVD/Orthogonal Procrustes 后处理对齐:作者从 design 层面直接锚定到固定基底,不需要保存变换矩阵、不需要维护 seed training run;
- 相较 LONGER/GPSD 的 learning dynamics 优化:作者走的是另一条路——"把长期信号编码成 compressed memory"而不是"提高长序列训练的效率"。
工业落地细节与业务收益(单列):
- 平台:Zalando 的 Browse 与 Search 两大 recommender surface;
- 规模:25 markets,百万级活跃用户;
- 部署方式:LTE 作为 pre-computed feature 存在 feature store,仅保存最新版;在 ranker 阶段以 prefix token 方式注入到 SASRec 风格 Transformer;
- lagged window = 60 天(与 short-term sequence 的无重叠区分);
- 业务收益:engagement +0.61%(整体)/ +1.16%(Browse),revenue +0.42%,主要指标都在 $p < 0.05$ 水平达到显著;
- 可维护性:因 LTE 锚定在固定 content embedding space,ranker 版本回滚时不会出现 feature 不兼容的问题,抗回滚 resilience 随回滚窗口变大反而更强;
- 推理代价:LTE 仅是 prefix 的一个 token,带来的额外 FLOPs 近似忽略。
综上,论文用一个"极简但强结构约束"的方法解决了工业推荐系统里一个经常被方法论研究忽视但在生产中至关重要的问题——长期偏好的稳定表示与跨版本兼容。它不是理论上最强的方案,但很可能是"性价比最高、部署最容易"的一条路径。