CAST: Modeling Semantic-Level Transitions for Complementary-Aware Sequential Recommendation¶
1 研究动机与背景¶
1.1 任务场景¶
序列推荐(Sequential Recommendation, SR)的目标是基于用户历史行为序列预测下一次交互。一个在工业场景中被广泛验证但未被主流 SR 方法充分利用的信号是物品之间的互补关系(complementary relations)——即具有功能依赖、常在同一决策链中共同出现的物品(典型例子:Camera → SD Card、iPhone → USB-C Charger)。Tan 等人([31],2021)和 Xu 等人([37],2020)指出,互补关系往往比"语义相似"更能刻画用户真实的消费动机:用户在购买 Camera 之后买 SD Card,并不是因为它们"相似",而是因为它们在功能链上存在依赖。
1.2 主流方法的两个根本缺陷¶
缺陷一:co-purchase 统计把真假互补信号混在一起。 现有捕捉互补关系的方法(如 [34,37])几乎都依赖共购频率 $\mathrm{freq}(v_i, v_j)$。作者指出这是一个纯统计量而非功能依赖:
- 受 popularity bias、seasonality、曝光偏差等外生因素干扰;
- 经典的"啤酒与尿布"场景就是反例:高频共购 ≠ 功能互补;
- 在稀疏或冷启场景下共购频率更不可靠,模型会把巧合当作规律学进去。
论文在图 1(a) 中用啤酒配尿布的例子直接展示这个失败模式。

缺陷二:已有 semantic-aware 方法走的是"先聚合再建模"的路径。 近年 semantic-ID 类工作(VQ-Rec [7]、CCFRec [17]、TIGER 谱系等)已经把文本 embedding 量化为离散语义码。但这些方法在喂给序列模型之前,先把一个 item 的 D 个子空间语义码聚合(mean pooling / attention fusion)成一个整体 item embedding。作者把这种做法称为 "aggregation-then-modeling paradigm",认为它有两个后果: 1. 聚合过程模糊了"到底是哪几位语义码在驱动两个 item 的兼容性"; 2. 模型只能看到 item-level 的转移模式,看不到 code-level 的转移——而互补关系往往绑定在某个具体语义属性上(例如图 1(b) 中 "USB-C" 这个子码才是 iPhone → Charger 成立的真正原因)。
1.3 核心主张¶
作者提出 CAST(Complementary-Aware Semantic Transition),论断有两条:
- 要发现真正的互补关系,不能依赖共购频率,必须利用 item semantics 中体现功能兼容性的细粒度属性;
- 要把这些细粒度属性在序列建模中用起来,不能先聚合再建模,必须直接在离散语义码空间里显式建模 code-level 的动态转移。
围绕这两条主张,CAST 做了四件事:用 LLM 构建可信互补关系集 $\mathcal{R}_c$、用 OPQ 把 item 文本量化为子空间码、用 subspace-preserving alignment 对齐语义码与文本、用一个可学习的语义转移张量 $\mathcal{T}$ 注入 self-attention。
2 任务定义¶
设用户集合 $\mathcal{U}$、物品集合 $\mathcal{V}$,$\mathcal{X} = \{x_v\}_{v \in \mathcal{V}}$ 为物品的文本特征集合(title, categories, brand 的拼接)。用户历史序列记为 $s = [v_1, v_2, \ldots, v_n]$,$v_t \in \mathcal{V}$,$n = |s|$。在训练时,模型以前 $t$ 个 items 作为输入,预测下一个 $v_{t+1}$($1 < t < |s|$)。
3 方法¶
CAST 的整体结构如下图所示,由四大模块构成:(1) Complementary Relation Construction(LLM 验证互补对);(2) Semantic Code Embeddings & Alignment(OPQ + subspace-preserving 对齐);(3) Complementary-Aware Sequence Modeling(转移张量 + 转移引导的 self-attention);(4) Model Optimization(next-item + 转移一致性正则)。
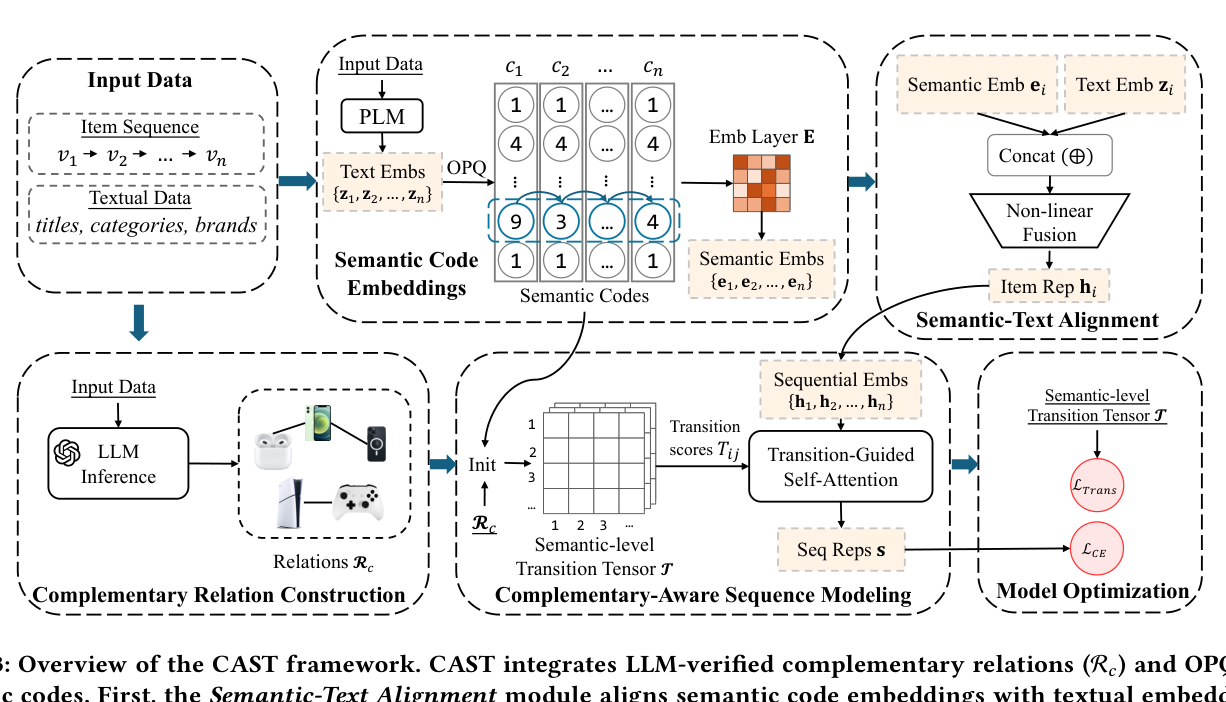
3.1 Complementary Relation Construction(3.1 节)¶
目标:构造一个"经过 LLM 验证"的互补关系集合 $\mathcal{R}_c$,作为后面转移张量 $\mathcal{T}$ 的先验。整套流程对应论文 Algorithm 1,可分为四步。
Step 1:共购候选过滤。在序列 $s = [v_1, v_2, \ldots, v_n]$ 上滑窗,窗口内两两物品计数,得到共购频率 $\mathrm{freq}(v_i, v_j)$。用频率阈值 $\theta_f$ 滤掉低频噪声,得到粗候选集 $\mathcal{R}_c^0 = \{(v_i, v_j) \mid \mathrm{freq}(v_i, v_j) \geq \theta_f\}$。
Step 2:LLM 功能性验证。对 $\mathcal{R}_c^0$ 中每一对 $(v_i, v_j)$,调用 LLM 给出互补置信度 $w_{ij} \in [0, 1]$。prompt 模板见图 2:

prompt 强调三条评价准则:(1) Direct Interaction(是否常在同一意图下共同使用);(2) Functional Enhancement(是否增强彼此功能);(3) Market Relationship(是否存在市场层面的共现)。LLM 要求先逐条引用准则做 step-by-step 推理,再输出一个 0–1 的数值。用 $\theta_c$ 过滤低置信度对:
$$\mathcal{R}_c = \{(v_i, v_j, w_{ij}) \mid w_{ij} \geq \theta_c\} \tag{1}$$
Step 3:替代集 $\mathcal{R}_s$ 构建。对所有物品对 $(v_i, v_j)$,若其 PLM 文本嵌入相似度 $\mathrm{sim}(\mathrm{PLM}(x_i), \mathrm{PLM}(x_j)) \geq \theta_s$,则加入替代集 $\mathcal{R}_s$。这个集合本身不当互补用,而是用来做 Step 4 的传递扩展。
Step 4:通过替代传递扩展互补。利用一条传递规则:若 $(v_i, v_j) \in \mathcal{R}_c$ 且 $(v_i, v_k) \in \mathcal{R}_s$(即 $v_k$ 与 $v_i$ 高度可替代),则推出 $(v_k, v_j, w_{ij}) \in \mathcal{R}_c$(即 $v_k$ 也与 $v_j$ 互补,权重沿用原对)。最后对 $\mathcal{R}_c$ 做对称化(互补关系是无向的)。
实际参数(见 4.1.4):滑窗 $w = 3$、$\theta_f = 2$、$\theta_c = 0.5$、$\theta_s = 0.85$;LLM 用 gemma-3-27b-it。
3.2 Semantic Code Embeddings(3.2 节)¶
用冻结的 PLM encoder 得到每个物品的文本嵌入:
$$\hat{\mathbf{z}}_i = \mathrm{PLM}(x_i) \in \mathbb{R}^{d_{\text{text}}} \tag{2}$$
然后用 Optimized Product Quantization (OPQ, Ge et al. [5]) 把 $\hat{\mathbf{z}}_i$ 切成 $D$ 个互不相交的子向量,每个子向量量化到一个大小为 $C$ 的子码本。设第 $k$ 个子空间的码本为 $\mathbf{E}^{(k)} \in \mathbb{R}^{C \times d}$,第 $m$ 行 $\mathbf{E}^{(k)}[m]$ 是第 $k$ 个子空间中码元 $m$ 的可学习 embedding。这样物品 $v_i$ 得到一个离散码序列:
$$\mathbf{c}_i = (c_i^{(1)}, c_i^{(2)}, \ldots, c_i^{(D)}), \quad c_i^{(k)} \in \{1, \ldots, C\} \tag{3}$$
论文举例:若 $D=3$,一个无线鼠标可能被编码为 $\mathbf{c}_i = (12, 245, 5)$——每一位表示在对应子空间内的"潜在属性聚类"。查表得到 code-wise embedding:
$$\mathbf{e}_i^{(k)} = \mathbf{E}^{(k)}[c_i^{(k)}], \quad k = 1, \ldots, D \tag{4}$$
每个 item 由一组子空间 embedding $\mathbf{e}_i = (\mathbf{e}_i^{(1)}, \ldots, \mathbf{e}_i^{(D)})$ 表示。关键点:子码本只共享在 item 之间、不跨子空间共享,而且每个子空间位置保留独立(后面的对齐和 transition 都依赖这个 subspace-disjoint 假设)。
实现细节(见 4.1.4):PLM 用 Qwen3-4B,输出嵌入经 PCA 降维到 $d_{\text{text}} = 128$;OPQ 用 Faiss [11] 实现;$D = 32$,$C = 256$。
3.3 Subspace-Preserving Semantic-Text Alignment(3.3 节)¶
如果直接对 $(\mathbf{e}_i^{(1)}, \ldots, \mathbf{e}_i^{(D)})$ 做 mean pooling 或 attention,子空间的独立语义就被揉在一起,后续的 code-level transition 就没有意义了。作者设计了subspace-preserving 对齐:
Step 1:扁平拼接 + 文本投影。把各子空间 embedding 和文本嵌入各自准备好:
$$\mathbf{h}_i^{\text{flat}} = \mathbf{e}_i^{(1)} \oplus \mathbf{e}_i^{(2)} \oplus \cdots \oplus \mathbf{e}_i^{(D)} \in \mathbb{R}^{D \cdot d} \tag{5}$$
$$\mathbf{z}_i = \mathbf{W}_{\text{proj}} \hat{\mathbf{z}}_i \in \mathbb{R}^d, \quad \mathbf{W}_{\text{proj}} \in \mathbb{R}^{d \times d_{\text{text}}} \tag{6}$$
Step 2:MLP 非线性融合 + 降维。
$$\mathbf{h}_i = \mathrm{MLP}(\mathbf{h}_i^{\text{flat}} \oplus \mathbf{z}_i) = \mathbf{W}_2 \phi_\eta(\mathbf{W}_1 (\mathbf{h}_i^{\text{flat}} \oplus \mathbf{z}_i) + \mathbf{b}_1) + \mathbf{b}_2 \tag{7}$$
其中 $\mathbf{W}_1 \in \mathbb{R}^{d' \times (D+1)d}$,$\mathbf{W}_2 \in \mathbb{R}^{d \times d'}$,$\phi_\eta(\cdot)$ 为 GeLU 后接 dropout(概率 $\eta$)。
这个 MLP 同时干两件事:(1) 非线性映射——把每个子空间在文本语义上的对应关系学出来;(2) 降维——把 $(D \cdot d)$ 维的扁平输入压回 $d$ 维,去冗余。
作者特别强调这个设计替代了 CCFRec 等方法中昂贵的 cross-attention($O(N^2)$),改为线性 MLP 投影($O(N)$),大规模候选集下更高效(见 4.5 效率分析)。
3.4 Complementary-Aware Sequence Modeling(3.4 节)¶
3.4.1 语义级转移张量 $\mathcal{T}$ 的构造¶
定义一个可学习的子空间转移张量 $\mathcal{T} \in \mathbb{R}^{D \times C \times C}$:$\mathcal{T}_{k, c, c'}$ 表示子空间 $k$ 中,从语义码 $c$ 转移到 $c'$ 的转移分数。这是 CAST 区别于"aggregation-then-modeling"范式的关键——转移不是在 item 之间,而是在 subspace code 之间。
Prior Initialization via Complementary Relations。$\mathcal{T}$ 不是随机初始化,而是由 $\mathcal{R}_c$ 注入先验:对 $\mathcal{R}_c$ 中每个互补对 $(v_i, v_j, w_{ij})$,把 item-level 的 pair 映射到 subspace-specific token-level pair。对每个子空间 $k$,维护一个共现矩阵 $\mathbf{M}_k \in \mathbb{R}^{C \times C}$(初始化为 0),更新规则为:
$$\mathbf{M}_k[c_i^{(k)}, c_j^{(k)}] \leftarrow \mathbf{M}_k[c_i^{(k)}, c_j^{(k)}] + w_{ij}, \quad \forall k = 1, \ldots, D \tag{8}$$
由于互补关系无向,做对称化:
$$\tilde{\mathbf{M}}_k = \frac{1}{2}(\mathbf{M}_k + \mathbf{M}_k^\top) \tag{9}$$
再加平滑常数 $\epsilon$ 后取 log,作为转移张量初始值:
$$\mathcal{T}_{k, c_i^{(k)}, c_j^{(k)}}^{(0)} = \log(\tilde{\mathbf{M}}_k[c_i^{(k)}, c_j^{(k)}] + \epsilon) \tag{10}$$
训练中 $\mathcal{T}$ 与其他参数一起端到端学习。
3.4.2 Transition-Guided Self-Attention¶
把 $\mathcal{T}$ 注入 self-attention 作为加性 bias。先做 Z-score 标准化以保证尺度可比:$\mathbf{P}_k = \mathrm{Standardize}(\tilde{\mathcal{T}}_k)$,其中 $\mathbf{P}_k$ 的每项即子空间 $k$ 内标准化后的 log-probability。
对输入序列 item $v_i$,按常规做 $\mathbf{Q}_i = \mathbf{W}_Q \mathbf{h}_i$、$\mathbf{K}_i = \mathbf{W}_K \mathbf{h}_i$、$\mathbf{V}_i = \mathbf{W}_V \mathbf{h}_i$,其中 $\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V \in \mathbb{R}^{d \times d}$。定义两个 item 之间的语义转移分数:
$$T(v_a, v_b) = \sum_{k=1}^{D} \omega_k \cdot \mathbf{P}_k[c_a^{(k)}, c_b^{(k)}] \tag{11}$$
其中 $\omega_k$ 为可学习的子空间重要度(经 softmax 归一化)。注意这是有向的:从 $v_a$ 到 $v_b$ 的分数 $\neq$ 从 $v_b$ 到 $v_a$ 的分数(虽然先验是对称的,但标准化和 softmax 后会有方向性调整)。
然后改写 attention logit:
$$\alpha_{i, j} = \frac{\exp(\mathbf{Q}_i^\top \mathbf{K}_j / \sqrt{d} + \lambda \cdot T(v_j, v_i))}{\sum_{p=1}^{i} \exp(\mathbf{Q}_i^\top \mathbf{K}_p / \sqrt{d} + \lambda \cdot T(v_p, v_i))} \tag{12}$$
注意这里 bias 是 $T(v_j, v_i)$——从历史 item $v_j$ 到当前 item $v_i$——显式建模"$v_j$ 之后有多大可能到 $v_i$",方向性是从 past 到 current。$\lambda$ 控制 transition prior 的强度。
最后 attention head 输出 $\mathbf{o}_i = \sum_j \alpha_{i,j} \mathbf{V}_j$,再经标准 MHA 和 FFN 堆叠 $L$ 层:
$$\mathbf{H}^{(l)} = \mathrm{FFN}(\mathrm{MHA}_{\text{rel}}(\mathbf{H}^{(l-1)})), \quad l \in \{1, \ldots, L\} \tag{13}$$
其中 $\mathbf{H}^{(0)} = [\mathbf{h}_1 + \mathbf{p}_1, \ldots, \mathbf{h}_n + \mathbf{p}_n]$ 为带位置编码的输入。按惯例取最后一层 last token 的隐状态 $\mathbf{s} = \mathbf{h}_n^{(L)}$ 为序列表示。
3.5 Model Optimization(3.5 节)¶
3.5.1 Next-item Prediction¶
$$\mathcal{L}_{\mathrm{CE}} = -\log \frac{\exp(\mathbf{s}^\top \mathbf{h}_{v_{t+1}} / \tau)}{\sum_{v' \in \mathcal{V}} \exp(\mathbf{s}^\top \mathbf{h}_{v'} / \tau)} \tag{14}$$
其中 $\tau$ 为温度。注意这里做的是 full-ranking 的 softmax(对全 item vocab),不是 sampled softmax。
3.5.2 Transition Consistency Regularization¶
CE loss 只间接监督了 $\mathcal{T}$(通过 attention logits),作者另加一个直接的 pairwise ranking 约束:对每个正转移 $(v_t, v_{t+1})$,要求其转移分数严格高于从 $v_t$ 到随机负例 $v^-$ 的转移分数。负例取自 in-batch uniform 分布 $P_B$(等价于 in-batch negative sampling,零额外采样代价):
$$\mathcal{L}_{\mathrm{Trans}} = -\sum_{(v_t, v_{t+1}) \in \mathcal{S}} \mathbb{E}_{v^- \sim P_B}\left[\log \sigma(T(v_t, v_{t+1}) - T(v_t, v^-))\right] \tag{15}$$
3.5.3 总目标¶
$$\mathcal{L} = \mathcal{L}_{\mathrm{CE}} + \gamma \mathcal{L}_{\mathrm{Trans}} \tag{16}$$
$\gamma$ 调节 transition 正则的权重。这一项本质上是在说:即使 CE loss 关心的是最终 item retrieval,$\mathcal{T}$ 也要被明确地塑造成能区分真互补和随机对——防止模型在稀疏下退化到只学共现统计。
4 实验设置¶
4.1 数据集¶
三个来自 Amazon Reviews 2023 的类别子集(刻意选择具有功能互补结构的类目):
| Dataset | #Users | #Items | #Interactions | Sparsity | Avg.len |
|---|---|---|---|---|---|
| Industrial | 50,985 | 25,848 | 361,962 | 99.972% | 7.10 |
| Office | 223,308 | 77,551 | 1,577,570 | 99.991% | 7.07 |
| Baby | 150,777 | 36,013 | 1,090,306 | 99.977% | 8.23 |
5-core 过滤,文本特征由 title + categories + brand 拼接得到。
4.2 Baselines¶
全部在 RecBole 框架下统一实现:
- ID-based SRs:SASRec、BERT4Rec、SINE、CORE、CL4SRec、DuoRec、FEARec、SASRecCPR;
- Text-enhanced SRs:TedRec;
- Semantic ID-based SRs:VQRec、CCFRec。
4.3 协议¶
- Leave-one-out:倒数第 2 个作为验证、最后 1 个作为测试;
- Full-ranking 评估(不是 sampled negatives);
- 指标:Recall@K、NDCG@K,$K \in \{5, 10, 20\}$;
- 统一 backbone:2 层 Transformer、2 个 head、$d=128$、FFN 内维 256;
- 优化:Adam,lr=0.001,batch size 1024,patience=10 epochs early stopping(基于 val NDCG@10);
- CAST 超参:$D=32$、$C=256$、$\lambda=1.2$、$\gamma=1.0$、$\eta=0.2$(Industrial/Office)或 $0.1$(Baby)、$\tau=0.07$;
- 硬件:1× A100-40G。
5 主要实验结果¶
5.1 Overall Performance(RQ1,Table 2)¶
| Dataset | Industrial | Office | Baby | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@5 | R@10 | N@5 | N@10 | R@5 | R@10 | N@5 | N@10 | R@5 | R@10 | N@5 | N@10 | ||
| SASRec | 2.45 | 3.90 | 1.38 | 1.84 | 2.56 | 3.83 | 1.49 | 1.90 | 2.27 | 3.66 | 1.39 | 1.84 | |
| BERT4Rec | 1.64 | 2.73 | 1.05 | 1.40 | 1.67 | 2.59 | 1.10 | 1.39 | 1.69 | 2.80 | 1.10 | 1.45 | |
| SINE | 2.27 | 3.60 | 1.47 | 1.90 | 2.17 | 3.27 | 1.42 | 1.77 | 1.93 | 3.10 | 1.21 | 1.59 | |
| CORE | 1.54 | 3.27 | 0.77 | 1.33 | 1.90 | 3.20 | 1.01 | 1.43 | 1.61 | 2.84 | 0.92 | 1.32 | |
| CL4SRec | 2.65 | 4.20 | 1.66 | 2.16 | 2.55 | 3.75 | 1.65 | 2.04 | 2.37 | 3.79 | 1.47 | 1.93 | |
| DuoRec | 2.28 | 3.54 | 1.34 | 1.75 | 2.36 | 3.48 | 1.40 | 1.76 | 2.14 | 3.44 | 1.27 | 1.68 | |
| FEARec | 2.51 | 3.87 | 1.43 | 1.86 | 2.59 | 3.80 | 1.50 | 1.89 | 2.25 | 3.64 | 1.36 | 1.81 | |
| SASRecCPR | 2.18 | 3.45 | 1.43 | 1.83 | 2.15 | 3.11 | 1.49 | 1.80 | 2.11 | 3.41 | 1.39 | 1.80 | |
| TedRec | 2.58 | 4.01 | 1.67 | 2.13 | 2.51 | 3.78 | 1.62 | 2.03 | 2.20 | 3.58 | 1.36 | 1.80 | |
| VQRec | 2.81 | 4.40 | 1.50 | 2.02 | 2.30 | 3.39 | 1.51 | 1.86 | 2.12 | 3.40 | 1.30 | 1.71 | |
| CCFRec | 3.18 | 5.10 | 1.93 | 2.55 | 2.68 | 4.02 | 1.75 | 2.18 | 2.68 | 4.24 | 1.71 | 2.21 | |
| CAST | 3.45 | 5.45 | 2.16 | 2.81 | 3.14 | 4.73 | 2.02 | 2.53 | 2.77 | 4.42 | 1.79 | 2.31 | |
| Improv. | 8.49% | 6.86% | 11.92% | 10.20% | 17.16% | 17.66% | 15.43% | 16.06% | 3.36% | 4.25% | 4.68% | 4.50% |
结论分析:
-
ID-only 方法几乎被 text-enhanced / semantic-ID 方法系统性压制——这再次印证了"文本语义比纯 ID 更能表达物品"在 SR 上成立。SASRec 仅靠 self-attention 拿到 baseline 级的结果,frequency-domain 的 FEARec 也只是略胜。
-
在 text-enhanced 阵营中 CCFRec 是最强 baseline,尤其在 Office / Baby 上明显领先 TedRec 和 VQRec。这正说明 discrete semantic-ID 路径(相对于 continuous text embedding)在功能结构清晰的类目上的优势。
-
CAST 在全部 3 数据集 × 12 指标上全胜:其中在 Office 上 Recall@10 提升 17.66%、NDCG@10 提升 16.06%,这是最显著的一组——Office 恰好是"办公用品链"这种功能依赖非常强的类目(墨盒配打印机、装订夹配装订机),CAST 的功能互补建模能力最能发挥。Industrial 上提升次之,Baby 上最小——Baby 的互补关系相对更依赖"同场景使用"(如奶瓶配奶嘴)而非强功能依赖,作者在 discussion 中也承认 CAST 的"功能互补假设"在这类场景下会有所弱化。
-
对比同样基于 OPQ/RQ 系列的 VQRec 和 CCFRec,CAST 最大的差异就是不再 aggregate 再建模——这支持了作者的核心论断:aggregation 会丢失 code-level 的细粒度信号。
5.2 Ablation(RQ2,Table 3)¶
| Dataset | Industrial | Office | Baby | ||||
|---|---|---|---|---|---|---|---|
| R@10 | N@10 | R@10 | N@10 | R@10 | N@10 | ||
| (0) CAST | 5.45 | 2.81 | 4.73 | 2.53 | 4.42 | 2.31 | |
| (1) w/o Sem. Codes | 3.91 | 1.99 | 2.72 | 1.51 | 2.87 | 1.48 | |
| (2) w/o Alignment | 4.87 | 2.49 | 4.32 | 2.19 | 4.19 | 2.18 | |
| (3) w/o Trans. Guide | 4.99 | 2.58 | 4.45 | 2.38 | 4.29 | 2.24 |
三个变体:
- w/o Semantic Codes (Text-Only):完全去掉 OPQ,直接用 PLM 输出的连续文本嵌入喂 sequence model;
- w/o Alignment:把 3.3 节的 subspace-preserving MLP 融合换成 mean pooling + element-wise addition;
- w/o Trans. Guide:$\lambda = 0, \gamma = 0$,回退到 vanilla self-attention。
分析:
- (1) 掉得最狠——在 Office 上 R@10 从 4.73 掉到 2.72(-42%),N@10 从 2.53 掉到 1.51(-40%)。说明 discrete semantic codes 提供的信号不是 continuous text embedding 可以替代的,这是反直觉的:按理说 continuous embedding 信息量更大,但在 SR 任务里它反而更分散、更容易被 attention 拉偏。量化过程相当于一层隐式的聚类降噪。
- (3) 的降级说明 transition prior 的作用——在 Office 上 R@10 掉到 4.45(-6%),N@10 掉到 2.38(-6%)。transition bias 提供的是"在稀疏场景下 attention 不会全被 similarity dominate"的纠偏能力。
- (2) 的降级说明对齐方式的必要性,subspace-preserving 的 MLP 比 mean pooling 好。
5.3 Hyperparameter Analysis(RQ3,Figure 4)¶
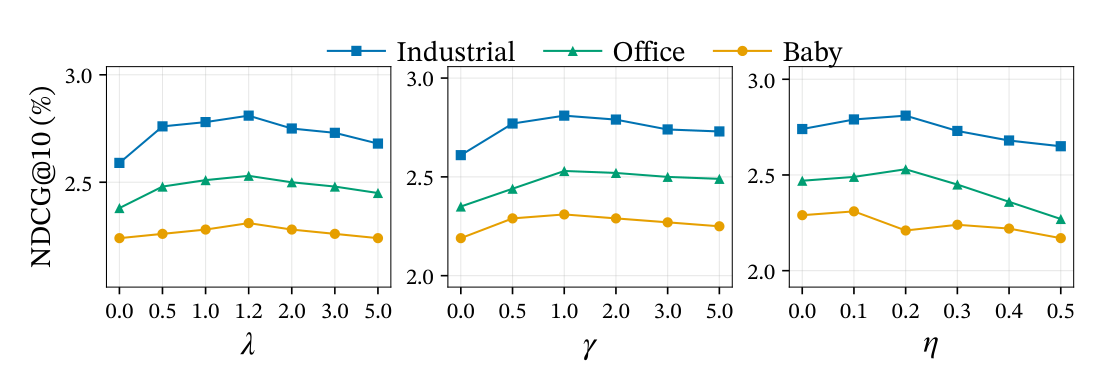
- $\lambda$(转移强度):在 $[0, 5]$ 范围扫,峰值在 $\lambda = 1.2$。$\lambda = 0$ 退化为 vanilla attention 性能差;$\lambda > 2.0$ 开始掉——注入过强的全局 transition 会压过 personalized attention signals。
- $\gamma$(transition 正则权重):峰值约在 $[1.0, 2.0]$。$\gamma = 0$ 性能明显下降,说明即使有先验初始化,没有持续监督 $\mathcal{T}$ 也会在 CE loss 的隐式梯度下被稀释。
- $\eta$(alignment dropout):峰值在 $\eta = 0.2$;$\eta \geq 0.4$ 开始过度正则化,code-text 对齐被破坏。
5.4 PLM Encoder 对比(Table 4)¶
| Dataset | Industrial | Office | Baby | ||||
|---|---|---|---|---|---|---|---|
| Model | R@10 | N@10 | R@10 | N@10 | R@10 | N@10 | |
| T5-base | 5.36 | 2.75 | 4.46 | 2.41 | 4.32 | 2.24 | |
| T5-xxl | 5.21 | 2.67 | 4.52 | 2.44 | 4.32 | 2.23 | |
| Qwen3-4B | 5.45 | 2.81 | 4.73 | 2.53 | 4.42 | 2.31 |
Qwen3-4B 在全部 3 数据集上最好。有趣的是 T5-xxl 并不明显优于 T5-base——说明一味增加 PLM 参数量并不能单调提升 SID 质量;训练语料多样性(Qwen3 的大规模多样语料)比纯参数量更重要。
5.5 效率对比(Table 5)¶
在 Office 数据集上:
| Model | Time/epoch (s) | GPU Memory (MB) | R@10 |
|---|---|---|---|
| SASRec | 34 | 2,480 | 3.83 |
| FEARec | 59 | 2,579 | 3.80 |
| CL4SRec | 373 | 3,114 | 3.75 |
| TedRec | 60 | 3,384 | 3.79 |
| CCFRec† | 4944 | 35,803 | 4.51 |
| CAST | 76 | 3,866 | 4.73 |
† CCFRec 受硬件限制只能 batch=128 训练,而其他方法用 batch=1024。
CAST 相对最强 baseline CCFRec:训练时间 65.05× 加速、GPU 显存 9.26× 节省,同时 R@10 还更高。这个加速的来源是 3.3 节用 MLP 替代 cross-attention——把 $O(N^2)$ 降到 $O(N)$,transition 部分额外带来 $O(L^2 d)$ 但这是标准 attention 的常数复杂度。
5.6 Complementary Transition Learning 分析(RQ4,Figure 5)¶
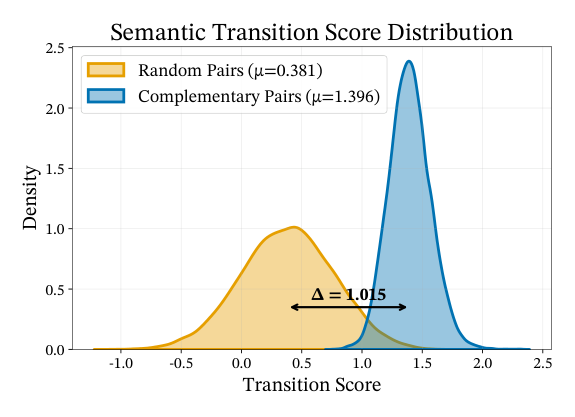
从 $\mathcal{T}$ 中采样两组 pair:复杂对($\mathcal{R}_c$ 中)vs 随机对。分数分布:
- 互补对:$\mu_{\text{comp}} = 1.396$
- 随机对:$\mu_{\text{rand}} = 0.381$
- 差距:$\Delta = 1.015$,两分布仅有极少重叠
这说明 $\mathcal{T}$ 学到了真的能判别互补关系的信号,不是简单退化到 co-occurrence 分布。
6 核心贡献总结¶
- 范式层面的主张:指出"aggregation-then-modeling"是 semantic-ID SR 的根本瓶颈——聚合掩盖了 code-level 的细粒度转移——并给出直接在 $\mathbb{R}^{D \times C \times C}$ 转移张量空间建模的替代方案。
- 互补关系的去噪思路:用 LLM 对共购候选做功能性验证(prompt 设计包含 Direct Interaction / Functional Enhancement / Market Relationship 三准则),然后通过"文本替代 → 传递扩展"增密 $\mathcal{R}_c$。
- subspace-preserving alignment:用 MLP 代替 cross-attention 做 code-text 对齐,把 $O(N^2)$ 降到 $O(N)$,配合 subspace 独立假设保留 $\mathcal{T}$ 的可定义性。
- transition consistency 正则:in-batch 采样零成本,pairwise ranking 约束让 $\mathcal{T}$ 显式学到 complementary 判别信号,防止被 CE loss 稀释。
- 实验结论:三个 Amazon 类目上全面领先,Office 上 R@10/N@10 提升超 17%/16%;相对最强 baseline CCFRec 训练速度 65×、显存 9×;学到的 $\mathcal{T}$ 能明确区分互补对与随机对($\Delta = 1.015$)。
7 讨论与局限性¶
7.1 与 aggregation-based semantic-ID 工作的差异¶
和 VQ-Rec、CCFRec 最根本的区别是——后两者尽管用了离散码,但在喂给 sequence model 之前都有一步 aggregate(codes) → item embedding,这一步把 subspace 独立性彻底破坏。CAST 的 MLP 对齐是非破坏性的(subspace-preserving),$D$ 个子空间一直到 $\mathcal{T}$ 都是独立的。这个设计选择是全文最关键的架构决定。
7.2 和 co-purchase graph 方法的差异¶
SRGNN-style / bipartite graph 方法([29, 37])在共购图上直接做 GNN,CAST 则显式用 LLM 先对 co-purchase 做筛,只把验证过的高置信度对喂给模型。这个差异的代价是:依赖 LLM 的 prompt 质量和互补定义——作者在 prompt 里明确限定了三条评价准则,但如果下游任务对"互补"的定义不同(如"内容消费"场景),prompt 就要重新设计。
7.3 局限性¶
作者在结论中明确两条:
- 场景限制:CAST 的设计基于"功能互补"假设(functional complementarity),最适合 e-commerce(电子产品、办公用品)。在内容消费(音乐、视频、新闻等)这类主要由 topical similarity 驱动的场景中,效果会衰减。从 Baby 数据集的较小提升幅度(+3.36%)已经能观察到这种趋势的萌芽。
- 可解释性缺口:OPQ 学出来的 semantic codes 是 latent 的,没有直接映射到"USB-C"、"24oz"、"ceramic" 这种具体属性——虽然 CAST 在 attention bias 中用到了,但无法向用户解释"为什么推荐这个"。这是所有 semantic-ID 路线的共性问题。
7.4 值得借鉴的设计¶
- LLM 做数据筛选而非端到端生成:把 LLM 放在 offline pipeline 的"高质量监督信号生成"位置,而不是运行时 reasoning,既拿到了 world knowledge 又避免了推理延迟。gemma-3-27b-it 在离线构造 $\mathcal{R}_c$ 时只跑一次。
- Prior + Learnable:$\mathcal{T}$ 的"先验初始化 + 端到端学习"设计很值得 industrial setting 借鉴——冷启时有先验托底,量足够大时又不会被先验限制。
- in-batch 负采样做正则:$\mathcal{L}_{\text{Trans}}$ 零额外采样成本,跟已经做的 CE loss 复用同一批数据,这是工业场景下加辅助任务的典型思路。
7.5 未来方向(作者展望)¶
- Adaptive Multi-Intent Modeling:泛化到同时有 functional 和 topical 动机的场景;
- Interpretable Attribute Alignment:把 latent semantic codes 对齐到显式 attribute——这对 explainable recommendation 有直接价值。
7.6 工业部署视角¶
论文本身未报告工业部署。但从架构上看:
- 推理阶段 $\mathcal{T}$ 是静态 lookup,只增加 O(1) 的 attention bias 计算,延迟友好;
- 冷启场景友好——新 item 只要有文本就能量化到 SID,不需要交互历史;
- 主要瓶颈在 offline $\mathcal{R}_c$ 构造——需要对候选 item 对跑一遍 LLM 推理。在商品规模 $\sim 10^5$ 的中小场景可行,百万级以上需要加入更强的 prefilter(论文已用共购 $\theta_f$ 做了第一层)。