Objective Shaping with Hard Negatives: Windowed Partial AUC Optimization for RL-based LLM Recommenders¶
研究动机与背景¶
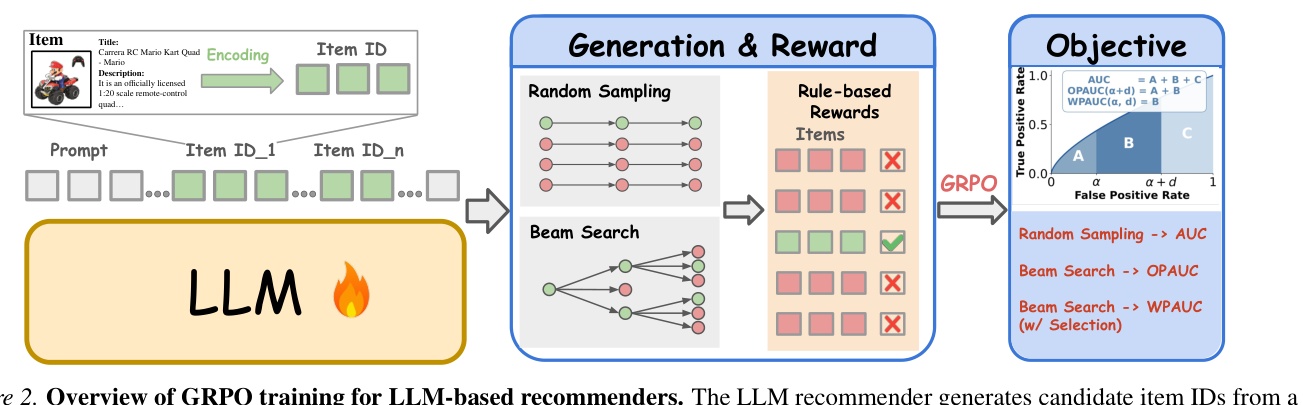
LLM-based 生成式推荐(TIGER 系、OneRec 系、BigRec/ReRe 系)正逐步替代传统的"打分式 + 重排"管线:以用户历史交互序列为 prompt,用 LLM 直接生成下一个目标 item 的 token 序列,由 trie / RQ-VAE 约束到合法 item 词表。Post-SFT 阶段越来越依赖 RL 后训练(GRPO 及其衍生 DAPO、GSPO)来直接对齐 Top-$K$ 推荐指标。
在这一套 RL 管线里,负样本是怎么生成的实质决定了 policy 朝哪个方向走。已有工作(Tan et al., 2025;Zhou et al., 2025b;Kong et al., 2025)实证报告:用 constrained beam search 解码出来的负样本进入 GRPO,比直接 constrained random sampling 有非常稳定的 Top-$K$ 提升。本文图 1(a) 在 Toys / Industrial / Office 三个数据集上做了完整复现,Beam Search 在 Recall@3 上一致优于 Random Sampling,本文方法 TAWin 进一步显著领先(约 +5-10% relative)。
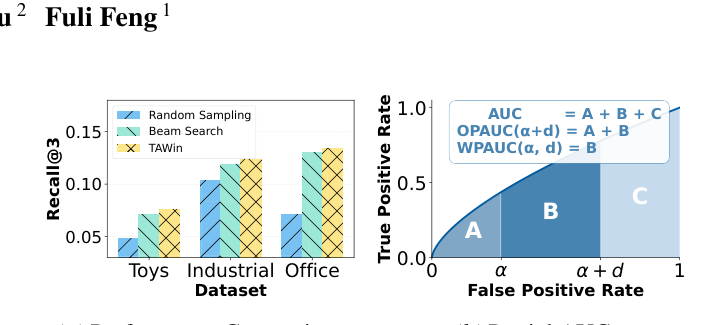
但为什么 beam search 负样本更好这件事,过去的解释停留在"beam search 提供更 informative 的训练信号"这种信息论层面的描述,缺少能直接指导算法设计的形式化论证。本文要做的事情正是把这个 gap 补上:在 GRPO + 二值奖励 + constrained 解码这一套设定下,给"负采样分布"和"被隐式优化的排序指标"建立可验证的等价关系,并由此推出一个可控的 Top-$K$ 对齐目标。
作者给出两条核心论断:
- Optimizing LLM-based recommenders with GRPO algorithms (Guo et al., 2025) under binary reward is theoretically equivalent to maximizing the AUC metric——但 AUC 与 Top-$K$ 指标的相关性较弱,所以默认 GRPO 不天然 Top-$K$ 对齐;
- Incorporating hard negative items generated by beam search into GRPO shifts the objective toward One-way Partial AUC (OPAUC)——把 FPR 限制在低端,因此与 Top-$K$ 对齐变好,"hard negatives 有效"得到了机制层面的解释。
但 OPAUC 也并不完美:对每个具体 $K$,OPAUC 只是一个上界约束,没法精确控制对齐到目标 $K$ 的强度。基于此,作者提出 WPAUC(Windowed Partial AUC),把 FPR 区间从 $[0, \alpha+d]$ 收窄到一个滑动窗口 $[\alpha, \alpha+d]$,并证明 WPAUC 对 Recall@$K$ 给出比 OPAUC 严格更紧的双边界。配套的优化方法是 TAWin(Threshold-Adjusted Windowed reweight):用一个温度可控、可微的 soft Top-$K$ 算子,在 beam-search 候选负样本上做窗口化软重加权,避免"硬截断"带来的样本浪费和梯度方差。
总体框架与符号¶
把 LLM 推荐写成约束生成形式。对每个用户 $u$,交互历史 $H_u = \{i_1, \dots, i_n\}$ 中每个 item 用其文本(如 title)做 verbalization;目标是生成 ground-truth target $i_t$ 在受约束 item 词表 $\mathcal{I}$ 下对应的 token 序列:
$$Y = \mathcal{G}(\pi_\theta, H_u, \mathcal{I}), \quad i = \phi(Y), \tag{1}$$
其中 $\mathcal{G}$ 是约束生成策略(constrained random sampling 或 constrained beam search,详见下文),$\phi(\cdot)$ 是 token 序列到 item ID 的反序列化。两类约束生成在 Appendix A 给出形式定义:
- Constrained Random Sampling:对当前 prefix $y_{<j}$,从 base LM 分布 $\pi_\theta(\cdot \mid y_{<j}, H_u)$ 中仅在合法下一 token 集合 $\mathcal{A}(y_{<j}; \mathcal{I})$ 上重归一化采样;
- Constrained Beam Search:维护宽度为 $B$ 的 beam,每步只在合法 token 上扩展,按累计 log-likelihood $h_\theta(y_{1:j}; H_u) = \sum_{t=1}^{j} \log \pi_\theta(y_t \mid y_{<t}, H_u)$ 选 Top-$B$,最终返回 $B$ 条完整序列。详细伪码见原文 Algorithm 1。
GRPO 阶段为每个 prompt 采样 $G$ 个候选 $\{i_m\}_{m=1}^G$,按规则性奖励
$$R_\text{rule}(i_m, i_t) = \begin{cases} 1, & \text{if } i_m = i_t \\ 0, & \text{otherwise} \end{cases} \tag{2}$$
打分。组内归一化得到 token-level advantage $\hat{A}_{m,j} = (r_m - \text{mean}) / \text{std}$,用 PPO clip 替代损失更新(忽略 KL 正则项):
$$\mathcal{J}(\theta) = \mathbb{E}_{H_u, \{i_m\}\sim \pi_\text{old}(\cdot\mid H_u)}\Bigl[\frac{1}{G}\sum_{m=1}^G \frac{1}{|Y_m|}\sum_{j=1}^{|Y_m|} \min(\rho_{m,j,u} \hat{A}_{m,j}, \text{clip}(\rho_{m,j,u}, 1-\epsilon, 1+\epsilon)\hat{A}_{m,j})\Bigr], \tag{3}$$
其中 $\rho_{m,j,u} = \pi_\theta(y_{m,j}|y_{m,<j}, H_u) / \pi_\text{old}(y_{m,j}|y_{m,<j}, H_u)$。整个训练流程的示意见图 2:rollout 由 LLM 通过 random / beam 解码产出,进 rule-based reward → GRPO 更新。Random sampling 隐式优化 AUC;beam search 把 OPAUC 提上来;TAWin 在 beam-search 候选上加上窗口化重加权,进一步把 WPAUC 提上来。
AUC、OPAUC 与 WPAUC 的精确定义¶
对用户 $u$,设正例集 $\mathcal{I}_u^+$、负例集 $\mathcal{I}_u^-$($n^- = |\mathcal{I}_u^-|$),item $i$ 的预测分数
$$f_{u,i} = \prod_{j=1}^{|Y|} \pi_\theta(y_j \mid y_{<j}, H_u), \quad i = \phi(Y) \tag{5}$$
即受约束生成下整个 token 序列的联合概率。
AUC(标准定义):
$$\text{AUC} = \Pr_{i^+ \sim \mathcal{I}_u^+, i^- \sim \mathcal{I}_u^-}[f_{u,i^+} > f_{u,i^-}]. \tag{4}$$
OPAUC $(\alpha+d)$:把负样本限制在分数最高的 $\alpha + d$ 分位(即 FPR $\leq \alpha+d$)。形式上,定义阈值 $\eta_{\alpha+d}$ 使 $\Pr_{i^- \sim \mathcal{I}_u^-}[f_{u,i^-} \geq \eta_{\alpha+d}] = \alpha + d$,仅在 $\{i^- : f_{u,i^-} \geq \eta_{\alpha+d}\}$ 上算 AUC。直观上,OPAUC 对应 ROC 曲线的左侧带状区域 $\mathbb{A} + \mathbb{B}$(图 1(b))。
WPAUC $(\alpha, d)$:把降序排好的负样本 $f_{u, i_{(1)}^-} \geq \dots \geq f_{u, i_{(n^-)}^-}$ 截出窗口
$$\mathcal{W}_u^-(\alpha, d) := \{i_{(\sigma)}^- \in \mathcal{I}_u^- : \lceil \alpha n^-\rceil < \sigma \leq \lceil (\alpha + d) n^-\rceil\}, \tag{11}$$
WPAUC 就是只在该窗口与正例之间算 AUC:
$$\text{WPAUC}_u(\alpha, d) = \Pr_{i^+ \sim \mathcal{I}_u^+, i^- \sim \mathcal{W}_u^-(\alpha, d)}[f_{u,i^+} > f_{u,i^-}]. \tag{12}$$
OPAUC 和 AUC 都是 WPAUC 的特例:$\text{OPAUC}(\alpha+d) = \text{WPAUC}(0, \alpha+d)$,$\text{AUC} = \text{WPAUC}(0, 1)$。WPAUC 对应 ROC 曲线上的窗口区域 $\mathbb{B}$(图 1(b))。
核心理论:负采样如何隐式塑形 GRPO 目标¶
Lemma 3.1:GRPO 的 pairwise 重写¶
陈述:在 binary reward 与 constrained random sampling 假设下,GRPO 目标 $\mathcal{J}(\theta)$(公式 3)可以重写为:
$$\mathcal{J}(\theta) = \mathbb{E}_{H_u}\sqrt{p(H_u)(1 - p(H_u))} \cdot \mathbb{E}_{Y^+ \sim \pi^+_\text{old}, Y^- \sim \pi^-_\text{old}}[s_\theta^+(Y^+, H_u) - s_\theta^-(Y^-, H_u)], \tag{7}$$
其中 $p(H_u) := \Pr_{Y \sim \pi_\text{old}(\cdot|H_u)}[r(Y \mid H_u) = 1]$,$\pi^+_\text{old}$ / $\pi^-_\text{old}$ 是 old policy 在产生正 / 负 rollout 条件下的条件分布,
$$s_\theta^\pm(Y^\pm, H_u) := \frac{1}{|Y|}\sum_{j=1}^{|Y|}\begin{cases}\min(\rho_{j,u}, 1+\epsilon), & (+) \\ \max(\rho_{j,u}, 1-\epsilon), & (-)\end{cases} \tag{8}$$
是 token-level 的 clipped 似然比。
完整证明在 Appendix B。证明的关键步骤:population-normalized advantage 把 $\hat{A}_{m,j}$ 写成 $r_m \mapsto \pm\sqrt{(1-p)/p}$ / $\mp\sqrt{p/(1-p)}$ 的两种形态,再分别在正例 / 负例事件上拆开期望,最终把 GRPO 写成"正例 token-clipped 推力"减去"负例 token-clipped 推力"。
直观解释:GRPO + 二值奖励的本质是正负样本之间的 token-level pairwise push。每一步训练都在让正样本的 likelihood 比负样本更高一点,对应 AUC 视角下的"pairwise concordance"目标。
从 sequence-level 到 item-level¶
把 sequence 通过 $\phi$ 映射回 item:$i^+ = \phi(Y^+)$,$i^- = \phi(Y^-)$。注意到 $s_\theta^+$ 和 $s_\theta^-$ 在对应的 item score $f_{u,i^+}$、$f_{u,i^-}$ 上是单调非减的,因此 GRPO 的方向梯度等价于一个 item-level pairwise ranking push:
$$\Pr_{i^+ \sim \mathcal{I}_u^+, i^- \sim \mathbb{P}_\text{neg}(\cdot|u)}[f_{u,i^+} > f_{u,i^-}], \tag{9}$$
其中 $\mathbb{P}_\text{neg}(\cdot \mid u)$ 是由解码策略决定的隐式负采样分布:换 random / beam,就换了 $\mathbb{P}_\text{neg}$,从而换了被隐式优化的排序目标。这是本文整套理论的支点:RL 解码策略 $\Leftrightarrow$ 负采样分布 $\Leftrightarrow$ 被隐式优化的排序目标。
Lemma 3.2:Beam Search 等价于 hard-negative quantile 采样¶
陈述:在 beam width $B \to \infty$ 的极限下,constrained beam search 恰好等价于"按 $f_{u,i^-}$ 排序后取前 $\eta_{\alpha+d}$ 分位数"——即从
$$\mathcal{Q}_u^-(\alpha + d) = \{i^- \in \mathcal{I}_u^- : f_{u, i^-} \geq \eta_{\alpha+d}\} \tag{10}$$
中均匀采样负例。
证明在 Appendix C。核心论证:约束生成下,item score $f_{u,i}$ 等于受约束 token 序列的联合概率(公式 44);当 $B$ 足够大时,beam search 在每一深度都保留所有合法 prefix,最终返回的 Top-$K$ completed sequences 严格按 $f_{u,i}$ 排序。
实践解读:有限 $B$ 时是近似——beam 越宽越接近"取最高分负样本",但即使中等 $B$,beam search 也明显偏向 $f_{u,i^-}$ 高端,这与"hard negative mining"的直觉吻合。关键 takeaway 是:beam search 不是均匀负采样,它有强烈的 high-score 偏置。
Proposition 3.3:GRPO + beam search = OPAUC¶
把 Lemma 3.2 的 $\mathbb{P}_\text{hard}(\cdot \mid u) = \text{Uniform}(\mathcal{Q}_u^-(\alpha + d))$ 代入 Lemma 3.1 的 pairwise objective(公式 9):
$$\Pr_{i^+ \sim \mathcal{I}_u^+, i^- \sim \mathbb{P}_\text{hard}(\cdot|u)}[f_{u,i^+} > f_{u,i^-}].$$
由 OPAUC 的定义(仅在 $f_{u, i^-} \geq \eta_{\alpha+d}$ 的负样本上算 pairwise rank),这正是 $\text{OPAUC}(\alpha + d)$。证明在 Appendix D。
至此第一个核心理论叙事闭合:
- Random sampling → 隐式 AUC;
- Beam search → 隐式 OPAUC($\alpha + d = K / n^-$ 时即 Top-$K$ 邻域)。
对 Top-$K$ 对齐的意义:Shi et al. (2023) 已经证明 OPAUC 与 Top-$K$ 排序的相关性比 AUC 强(因为 Top-$K$ 错排只发生在 ROC 曲线左侧)。所以 beam search 的优势不是"信息更多",而是它把 GRPO 的目标从 AUC 切换到了一个 Top-$K$ 对齐更好的 partial-AUC 子目标。
WPAUC:从上界到窗口的精度提升¶
设计动机¶
OPAUC 把 FPR 限制在 $[0, \alpha + d]$ 这种"前缀"形态——它给出的是"FPR 不超过 $\alpha+d$"这一上界约束。对每个具体的 Top-$K$(即每个具体的 $\alpha + d = K / n^-$ ),上界并不是一个紧约束。本文的关键洞察是:用一个滑动窗口 $[\alpha, \alpha + d]$ 替代前缀,能更精确地刻画"我希望优化的那段 ROC"。
Theorem 3.4:WPAUC 给出更紧的 Recall@K 双边界¶
设有 $n^+$ 个正例、$n^-$ 个负例($n^+ < K$,$n^- > K$),任意打分函数 $f$ 排序。取
$$\alpha = \frac{K - n^+}{n^-}, \quad d = \frac{n^+}{n^-}, \tag{13}$$
则有:
$$\frac{\lceil n^+(1 - \sqrt{1-w})\rceil}{n^+} \leq \text{Recall@}K \leq \frac{\lfloor n^+ \sqrt{w}\rfloor}{n^+}, \tag{14}$$
其中 $w = \text{WPAUC}(\alpha, d)$。对同一 $K$,公式 (14) 的区间严格紧于由 OPAUC$(\alpha + d)$ 给出的对应边界(证明在 Appendix E)。
证明的几何意象:把 ranks 中的"top-$K$ prefix"分成"上界硬负 $\mathcal{H}^-$"(rank $1 \dots K-n$)和"窗口负 $\mathcal{W}^-$"(rank $K-n+1 \dots K$)。OPAUC 是这两块的混合统计 $\text{OPAUC}(\alpha+d) = (K-n)/K \cdot A + n/K \cdot B$,其中 $B = \text{WPAUC}(\alpha, d)$。给定 OPAUC $= o$,$B$ 只能被定位到一个非退化区间 $[o, \min(1, K \cdot o / n)]$,因此基于 OPAUC 推 Recall@$K$ 必须对 $B$ 的不确定性兜底;而直接用 $B$(即 WPAUC)则没有这个不确定性,区间自然更紧。
Lemma 3.5:单正例时 WPAUC = Recall@K¶
更极端的情况:用户只有一个正例 $i^+$,$K \geq 2$,取 $\alpha = (K-1)/n^-$、$d = 1/n^-$(窗口宽度恰好为一个负样本),则
$$\text{WPAUC}(\alpha, d) = \text{Recall@}K. \tag{15}$$
这条引理把 WPAUC 直接锚到了 Recall@$K$ 上:在单正例(typical next-item recommendation)下,TAWin 优化 WPAUC 就是在直接优化 Recall@$K$,等价关系而非近似。
实证验证:Top-K 与 WPAUC 的相关性¶
为了验证 Theorem 3.4 的 Top-$K$ 对齐效果,作者做了 Monte Carlo 模拟:每次生成 10 个正例 + 200 个负例的随机排序,遍历 $(\alpha, d) \in [0, 1]^2$ 网格,对 $K \in \{5, 10, 20\}$ 三种情况计算 Recall@$K$ 与 WPAUC$(\alpha, d)$ 在 10000 次试验上的 Pearson 相关系数。结果见图 3:

观察到两条规律:
- 对每个固定 $K$,相关系数在某个 $(\alpha, d)$ 处取得最大值(红星),最大相关系数 0.9462 / 0.9615 / 0.9647($K=5,10,20$),均接近 1;
- 最大值随 $K$ 单调右移:$K$ 越大,最优 $\alpha$ 越大(即窗口起点越深入低分负例尾),$d$ 大致稳定。这与 Theorem 3.4 完全一致。
这说明 WPAUC$(\alpha, d)$ 是一个可以通过参数选择对齐到具体 $K$ 的可控替代指标——比 OPAUC 多了一个"窗口起点"的控制旋钮。
TAWin:可微的 soft 窗口重加权¶
为什么需要 soft¶
WPAUC 的 RL 实现的"硬法"是对 beam-search 候选做 hard 截断,只保留落在窗口 $[\alpha, \alpha+d]$ 内的负样本。这在工程上有两个明显问题: 1. 样本浪费:rollout 是昂贵的(单条候选需要 $L \times G$ 次 LLM forward),硬丢弃落在窗口外的样本意味着大量 RL 计算被浪费; 2. 梯度方差:截断是不连续的,候选样本是否被纳入更新会随分数微小变化突变,造成梯度方差爆炸,训练不稳。
TAWin 的设计目标因此是:用一个温度可控的 soft 窗口算子,在 rollout 出来的所有 beam 候选上构造一组连续权重,既保留窗口的 inductive bias,又不丢弃样本、不引入硬截断。
Soft Top-K 选择算子¶
记候选向量 $x \in \mathbb{R}^n$。Hard Top-$K$ 算子 $T_K(x) \in \{0,1\}^n$ 是 $K$-hot indicator。Soft Top-$K$ 算子 $S_{K,\tau}(x) \in [0,1]^n$ 满足:
$$\Delta_K^{n-1} := \{p \in [0,1]^n : \sum_{i=1}^n p_i = K\}. \tag{16}$$
要求两条性质:(i) 单调性:$x_i \geq x_j \Rightarrow [S_{K,\tau}(x)]_i \geq [S_{K,\tau}(x)]_j$;(ii) 一致性:$\lim_{\tau \to 0^+} S_{K,\tau}(x) = T_K(x)$(温度趋零退化为硬 Top-$K$)。
按 Su (2024) 的 clipped exponential 实例化:
$$\mathcal{T}_{K,\tau}(x) := \min\Bigl(\mathbf{1}, \exp\bigl(\frac{x - \lambda(x)\mathbf{1}}{\tau}\bigr)\Bigr), \quad \text{s.t.} \sum_i \mathcal{T}_{K,\tau}(x)_i = K, \tag{17}$$
其中阈值 $\lambda(x)$ 唯一确定整体质量为 $K$。把 $x$ 排序 $x_{(1)} \geq \dots \geq x_{(n)}$,存在一个 $m < K$ 使 $x_{(m)} \geq \lambda \geq x_{(m+1)}$,此时闭式解:
$$\lambda(x) = \tau \log\Bigl(\sum_{i=m+1}^{n}\exp(\tfrac{x_{(i)}}{\tau})\Bigr) - \tau \log(K - m), \tag{18}$$
通过对 $m \in \{0, \dots, K-1\}$ 短扫描即可定位 $m$。当 $\tau \to 0^+$,$\mathcal{T}_{K,\tau}$ 趋近于硬 Top-$K$ 选择器。
TAWin 的窗口构造¶
对 user $u$ 的 beam-search 候选负样本 $\mathcal{Y}_u^- = \{Y_1, \dots, Y_n\}$($n$ 是候选数,对应实验中 $n = 16$),按模型得分 $f$ 升序映射到 rank $\sigma_u(Y) \in \{1, \dots, n\}$(得分越高 rank 越小)。归一化 rank $\tilde{\sigma}(\sigma) := (\sigma - 1)/(n - 1) \in [0,1]$,并设一个目标窗口的低 FPR 边界 anchor $\sigma_*$(对应 WPAUC 中的 $\alpha$)。
每个候选基于 rank 距离 anchor 的距离,得到 logit:
$$x_u(Y) := -|\tilde{\sigma}(\sigma_u(Y)) - \tilde{\sigma}(\sigma_*)|. \tag{19}$$
距离 anchor 越近 logit 越大。把所有候选的 logits 喂进 soft Top-$K$ 算子:
$$w_u = \mathcal{T}_{K,\tau}([x_u(Y_1), \dots, x_u(Y_G)]). \tag{20}$$
这里 $K$ 控制窗口宽度(对应 WPAUC 中的 $d$),$\sigma_*$ 控制窗口起点(对应 $\alpha$)。$\tau \to 0^+$ 时 $w_u$ 退化为硬窗口选择器;$\tau$ 大则平滑过渡。
最终权重函数:
$$\omega_u(Y) = \begin{cases} 1, & Y \in \mathcal{Y}_u^+ \\ \text{Rescale}(w_u)_{\sigma_u(Y)}, & Y \in \mathcal{Y}_u^- \end{cases} \tag{21}$$
其中 $\text{Rescale}(w_u)_\sigma = n \cdot w_{u,\sigma} / \sum_{\sigma'=1}^{n} w_{u, \sigma'}$ 做 mass normalization 保证总权重不变。正样本权重恒为 1,所有窗口塑形只发生在负样本上。详细伪码见 Appendix F 的 Algorithm 2。
TAWin 的 RL 目标¶
把 $\omega_u(Y_m)$ 作为 sequence-level reweighting,乘进 GRPO 的 PPO clipped 目标:
$$\mathcal{J}_\text{TAWin}(\theta) = \mathbb{E}_{H_u, Y_m}\Bigl[\frac{1}{n}\sum_{m=1}^{n}\omega_u(Y_m) \cdot \frac{1}{|Y_m|}\sum_{j=1}^{|Y_m|} \min\bigl(\rho_{m,j,u}\hat{A}_{m,j}, \text{clip}(\rho_{m,j,u}, 1-\epsilon, 1+\epsilon)\hat{A}_{m,j}\bigr)\Bigr], \tag{22}$$
其中 $\rho_{m,j,u}$ 同 GRPO。形式上 TAWin 是 GRPO 的一个 drop-in:rollout 与外层 KL 不动,只把 advantage 乘了一个 user-side 计算出的 token-invariant reweighting 系数。这个 reweighting 唯一目的是让 RL 把"概率质量"重点搬到目标 Top-$K$ 窗口对应的负样本对照上去。
实验设置¶
数据集:四个真实公开数据集——Amazon Review (Lakkaraju et al., 2013) 的 Toys / Industrial / Office 三个子类目,以及 Yelp (2021)。预处理沿用 Tan et al. (2025):固定时间窗(Toys/Office 2016-10 至 2018-11,Industrial 1996-10 至 2018-11,Yelp 2021),过滤掉缺失/低质量元数据 item,迭代 $K=5$ core filtering,sliding window 取最多 10 个历史 item,按时间戳 8:1:1 分 train/valid/test。Dataset 统计如下:
| Datasets | Toys | Industrial | Office | Yelp |
|---|---|---|---|---|
| Items | 11,252 | 3,685 | 3,459 | 8,785 |
| Train | 112,754 | 36,259 | 38,924 | 77,097 |
| Valid | 14,095 | 4,532 | 4,866 | 9,637 |
| Test | 14,095 | 4,533 | 4,866 | 9,638 |
注意"Industrial"是 Amazon 的 Industrial & Scientific 子类目,不是工业部署数据——本文没有线上 A/B 实验。
指标:Recall@$K$(R@$K$)和 Normalized Discounted Cumulative Gain(N@$K$),其中 $K \in \{1, 3\}$。Top-$K$ 列表通过 constrained beam search 在 $\pi_\theta$ 上生成 $\mathcal{R}_u^K = \{\phi(Y_1), \dots, \phi(Y_K)\}$ 后按 model likelihood 排序得到。
Baselines 三大类:
- 传统序列推荐:GRU4Rec、Caser、SASRec;
- 生成式推荐:TIGER、LC-Rec、MiniOneRec;
- LLM-based 推荐:BigRec、D3、S-DPO、ReRe。
实现细节:所有 LLM-based recommender(含 TAWin)都用 Qwen2.5-0.5B 作 backbone。SFT 用 lr $3 \times 10^{-4}$、AdamW,最多 10 epochs early stopping。RL 阶段 lr $1 \times 10^{-5}$、batch size 512、$n = 16$ 候选、KL 系数 $\beta = 1 \times 10^{-3}$、训练 2 epochs(从 vanilla Qwen2.5-0.5B SFT checkpoint 初始化)。TAWin 自身超参:$K \in \{1, 2\}$、$\tau \in \{1/2, 1/3, 1/4, 1/5, 1/6\}$、anchor $\sigma_* \in \{0, 1, 2\}$,全网格搜索。硬件 8× H800。
主要实验结果(RQ1)¶
Table 1 是四个数据集 × $K \in \{1, 3\}$ 的完整 SOTA 对比。
| Method | Toys R@1 | Toys R@3 | Toys N@3 | Industrial R@1 | Industrial R@3 | Industrial N@3 | Office R@1 | Office R@3 | Office N@3 | Yelp R@1 | Yelp R@3 | Yelp N@3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GRU4Rec | 0.0090 | 0.0169 | 0.0135 | 0.0461 | 0.0657 | 0.0576 | 0.0384 | 0.0631 | 0.0529 | 0.0074 | 0.0164 | 0.0125 |
| Caser | 0.0125 | 0.0219 | 0.0180 | 0.0371 | 0.0624 | 0.0523 | 0.0450 | 0.0734 | 0.0614 | 0.0079 | 0.0217 | 0.0158 |
| SASRec | 0.0216 | 0.0359 | 0.0298 | 0.0567 | 0.0761 | 0.0682 | 0.0641 | 0.0923 | 0.0807 | 0.0074 | 0.0175 | 0.0133 |
| TIGER | 0.0224 | 0.0383 | 0.0305 | 0.0632 | 0.0852 | 0.0742 | 0.0624 | 0.0986 | 0.0852 | 0.0068 | 0.0154 | 0.0113 |
| LC-Rec | 0.0253 | 0.0406 | 0.0341 | 0.0727 | 0.0986 | 0.0877 | 0.0900 | 0.1196 | 0.1074 | 0.0094 | 0.0174 | 0.0140 |
| MiniOneRec | 0.0271 | 0.0458 | 0.0378 | 0.0831 | 0.1100 | 0.0990 | 0.0972 | 0.1219 | 0.1137 | 0.006 | 0.0163 | 0.0120 |
| BigRec | 0.0329 | 0.0510 | 0.0433 | 0.0732 | 0.1012 | 0.0895 | 0.0861 | 0.1201 | 0.1048 | 0.0092 | 0.0187 | 0.0148 |
| D3 | 0.0371 | 0.0612 | 0.0512 | 0.0810 | 0.1103 | 0.0980 | 0.0810 | 0.1204 | 0.1040 | 0.0120 | 0.0309 | 0.0228 |
| S-DPO | 0.0275 | 0.0534 | 0.0449 | 0.0635 | 0.1032 | 0.0906 | 0.0390 | 0.1169 | 0.1033 | 0.0189 | 0.0342 | 0.0395 |
| ReRe | 0.0411 | 0.0709 | 0.0583 | 0.0783 | 0.1184 | 0.1115 | 0.0830 | 0.1304 | 0.1115 | 0.0206 | 0.0360 | 0.0295 |
| TAWin | 0.0471 | 0.0761 | 0.0639 | 0.0904 | 0.1237 | 0.1099 | 0.0961 | 0.1341 | 0.1187 | 0.0227 | 0.0370 | 0.0301 |
主要观察:
- TAWin 全表 SOTA:在所有 4 数据集 × 3 指标共 12 项 cell 上均是最佳,相对 LLM-based 类 baseline(BigRec / D3 / S-DPO / ReRe)平均提升约 5.5%,相对生成式 baseline 类平均 +52%,相对传统序列模型 +84.9%。
- LLM-based > 生成式 > 传统:分层规律稳定,作者归因于 LLM 自带的语义先验和世界知识增强了 user interest modeling。
- RL 优于 SFT:MiniOneRec(含 RL)vs TIGER(SFT)平均 +22.6%;TAWin vs BigRec(SFT)平均 +49.4%。这与原文叙事一致——RL 显式建模相对偏好,比 likelihood-based SFT 与推荐目标对齐更好。
TAWin 的 Top-K 控制机制(RQ2)¶
Anchor σ* 的单峰行为¶
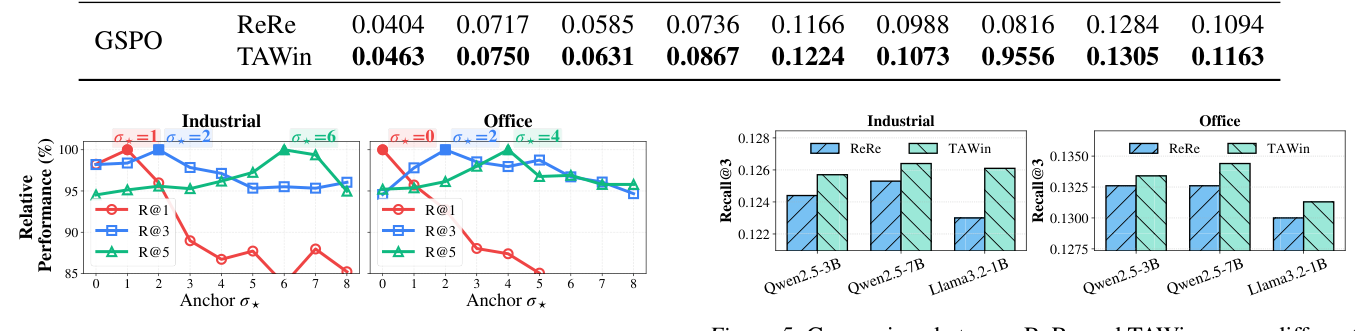
图 4 在 Industrial / Office 两个数据集上扫描 anchor $\sigma_* \in \{0, 1, ..., 8\}$,画出 R@1 / R@3 / R@5 三条曲线(相对最佳值的 100% 归一化)。
两条关键观察:
- 对每条 R@$K$ 曲线,相对性能随 $\sigma_*$ 都是 unimodal 的:anchor 太小(窗口起点压在 ROC 顶端)和太大(窗口太靠后、丢失对正例的对比)都会损失性能;
- 最优 anchor 随 $K$ 增大而右移:R@1 在 $\sigma_* = 1$(Industrial)或 $\sigma_* = 0$(Office)取峰;R@5 在 $\sigma_* = 6$ 或 $\sigma_* = 4$ 取峰。这与 Theorem 3.4 的"最优 $\alpha$ 随 $K$ 单调增"完全吻合,说明 TAWin 真的可以通过超参控制具体目标 $K$ 的对齐。
这是本文区别于其他 hard-negative 方法的关键 demo——不仅"hard 一点更好",而是"窗口位置可调",提供了显式 Top-$K$ 控制旋钮。
泛化性分析(RQ3)¶
Backbone 泛化¶
图 5 在 Industrial / Office 上对比 ReRe vs TAWin,覆盖 Qwen2.5-0.5B/3B/7B 与 Llama-3.2-1B 四种 backbone。TAWin 在所有 backbone 上都超过 ReRe,且差距随模型规模并不衰减——说明窗口塑形是 model-agnostic 的,并具备一定的 scaling 友好性。
Optimizer 泛化¶
Table 2 把 GRPO 换成 DAPO 和 GSPO 重做实验:
| Algorithm | Method | Toys R@1 | Toys R@3 | Toys N@3 | Industrial R@1 | Industrial R@3 | Industrial N@3 | Office R@1 | Office R@3 | Office N@3 |
|---|---|---|---|---|---|---|---|---|---|---|
| DAPO | ReRe | 0.0416 | 0.0711 | 0.0588 | 0.0814 | 0.1202 | 0.1039 | 0.0832 | 0.1276 | 0.1098 |
| DAPO | TAWin | 0.0471 | 0.0737 | 0.0626 | 0.0875 | 0.1248 | 0.1089 | 0.0910 | 0.1317 | 0.1149 |
| GSPO | ReRe | 0.0404 | 0.0717 | 0.0585 | 0.0736 | 0.1166 | 0.0988 | 0.0816 | 0.1284 | 0.1094 |
| GSPO | TAWin | 0.0463 | 0.0750 | 0.0631 | 0.0867 | 0.1224 | 0.1073 | 0.9556 | 0.1305 | 0.1163 |
(Office DAPO 行的 0.9556 看起来是排版异常;其余 cell TAWin 全部领先。)
DAPO 和 GSPO 都是 GRPO 衍生的 RL 优化器,本身仍属"组内归一化 + 似然比 clip"框架。Lemma 3.1 的 pairwise 重写对它们也成立,因此 TAWin 的窗口塑形可以平移,结果一致优于 ReRe。
Item-encoding 泛化¶
Table 3 把 TAWin 应用到 MiniOneRec 的 SID-based 编码上(标记为 MiniOneRec-TAWin),对比 MiniOneRec 自身的 SFT 与 GRPO 训练:
| Dataset | Method | R@1 | R@3 | N@3 |
|---|---|---|---|---|
| Industrial | MiniOneRec - SFT | 0.0726 | 0.0986 | 0.0877 |
| Industrial | MiniOneRec - GRPO | 0.0831 | 0.1100 | 0.0989 |
| Industrial | MiniOneRec - TAWin | 0.0862 | 0.1158 | 0.1033 |
| Office | MiniOneRec - SFT | 0.0900 | 0.1196 | 0.1074 |
| Office | MiniOneRec - GRPO | 0.0969 | 0.1325 | 0.1174 |
| Office | MiniOneRec - TAWin | 0.0974 | 0.1378 | 0.1253 |
即使把底层 item 表征从 title-based 换成 semantic-ID-based,TAWin 仍在 GRPO 之上一致提升。这印证了 TAWin 的核心机制是 RL 阶段的"目标塑形",与 item encoder 无关。
重加权消融:TAWin vs ReRe* (Appendix H)¶
文中把 ReRe 的另一种变体——ReRe* with ranking reward——也纳入了对比。Proposition H.1 形式化证明:在 one-positive-per-group 假设下,ReRe 的 ranking reward 等价于 GRPO advantage 的一个确定的 rank-dependent 重加权*:
$$\hat{A}_k = \omega_k \hat{A}_k^{(0)}, \quad \omega_t = \frac{1 - \bar{R}}{1 - 1/G}, \quad \omega_k = \frac{R_\text{rank}(e_k, e_\star) - \bar{R}}{-1/G} \quad (k \neq t). \tag{65}$$
也就是说 ReRe* 也是一种"sequence-level reweighting",但它的权重函数是 rank 的固定函数(启发式),没有显式的 Top-$K$ 对齐目标。Table 5(Appendix)显示 TAWin 在四个数据集所有指标上都打败 ReRe*:
| Method | Toys R@1 | Toys R@3 | Toys N@3 | Industrial R@1 | ... | Yelp N@3 |
|---|---|---|---|---|---|---|
| ReRe* | 0.0442 | 0.0740 | 0.0615 | 0.0882 | ... | 0.0295 |
| TAWin | 0.0471 | 0.0761 | 0.0639 | 0.0904 | ... | 0.0301 |
作者的总结是:ReRe 是一个没有显式 Top-$K$ 对齐目标的启发式重加权;TAWin 是从 WPAUC 推出的有显式低 FPR 窗口对齐目标的可微重加权*。两者的实验差异印证了"有理论根据的目标塑形"优于"启发式 rank-based reweighting"。
核心贡献总结¶
-
Theoretical Analysis(机制层面):首次形式化证明 binary-reward GRPO + constrained random sampling 等价于 AUC 最大化(Lemma 3.1);beam-search 把 GRPO 的隐式目标从 AUC 推到 OPAUC(Proposition 3.3)。这是"hard negatives 为什么有效"的第一性原理解释。
-
Methodological Innovation(指标设计):提出 WPAUC$(\alpha, d)$,用滑动窗口替换前缀,证明它对 Recall@$K$ 给出严格更紧的双边界(Theorem 3.4),并在单正例时与 Recall@$K$ 完全等价(Lemma 3.5)。
-
Practical Algorithm(可微实现):提出 TAWin,用 Su (2024) 的 clipped exponential soft Top-$K$ 算子在 beam-search 候选上构造连续窗口权重,避免硬截断带来的样本浪费和梯度方差。是一个 plug-in 的 GRPO drop-in,跨 backbone(0.5B–7B)、跨 RL optimizer(GRPO/DAPO/GSPO)、跨 item encoding(title / semantic ID)一致有效。
-
Empirical Validation:在 Toys / Industrial / Office / Yelp 四个数据集上全面 SOTA,对 ReRe(最强 LLM-based baseline)平均 +5.5%,对生成式类平均 +52%。Anchor $\sigma_*$ 的扫描实验直接验证了 Theorem 3.4 的"最优 $\alpha$ 随 $K$ 单调右移"预测。
与已归档相关工作的对比¶
ReCast ReCast: Recasting Learning Signals for RL in Generative Recommendation (Huawei, 2026-04-24)¶
关系:独立并发(同一日发布,互不引用)· 已加载对方精读
- 共同关注的问题:两篇都把矛头对准 GRPO 在 LLM-based 生成式推荐 RL 阶段within-group signal 与 Top-$K$ 推荐目标对齐不足这一 root cause。两篇都接受 outer RL 框架(KL 正则 + clipped policy gradient)不动,只重构组内的 advantage / weight 构造作为 plug-in。
- 相近的技术骨架:两篇都把 GRPO 的"全组 reward 归一化"重写成一个对正负样本子集做差异化重加权的形式,从而显式控制学习信号的"形状"。技术骨架抽象出来都是「对 rollout 候选做选择性 reweight」。
- 差异化的诊断 root cause:本文(TAWin)认为问题出在 decoding-induced negative sampling distribution(被隐式优化的排序指标是 AUC 而不是 Top-$K$),于是把"窗口位置"作为可调旋钮;ReCast 认为问题出在 group-level learnability degeneracy(85% group 全零、13% 单 hit),于是把"先用 ground-truth anchor 修复组、再做最强正 vs 最难负的边界对比"作为机制。
- 本文的差异与推进:TAWin 提供了 WPAUC ↔ Recall@$K$ 的精确指标层等价(Theorem 3.4 + Lemma 3.5),有"窗口位置控制 Top-$K$"的可解释 hyperparameter ($\sigma_*$, $K$, $\tau$);ReCast 强调的是"搜索宽度 $G$ 与 actor 更新宽度解耦"的 cost-efficiency 视角,更面向 sparse-hit 场景的 sample budget 优化。两者实质上是同一类问题(GRPO 的 within-group signal 设计)的两个互补正交角度。
- 可比的方法 / 实验差异:TAWin 用 4 个 Amazon/Yelp 公开数据集 + Qwen2.5-0.5B/3B/7B 全 grid;ReCast 用 OpenOneRec 设置(不同的开放生成推荐管线)。两文使用的"strongest LLM-based baseline"也分别是 ReRe 和 OpenOneRec,没有直接 head-to-head;可以预期两种思路联用(先 ReCast 修组 + 再 TAWin 加窗口 reweight)会产生进一步增益。
讨论与局限性¶
值得借鉴的设计:
- "RL 解码策略 ↔ 隐式负采样分布 ↔ 被隐式优化的排序指标"这一三元等价是非常清晰的分析框架,可以推广到任何 sample-based RL post-training(不只是推荐),帮助回答"为什么换 sampler 就能改性能"。
- WPAUC 是一个被低估的指标设计:把"前缀"换成"窗口"看似 trivial,但带来了 Recall@$K$ 的精确锚定。在任何需要"对齐特定阈值或 cutoff"的场景下都值得套用(如 retrieval 的 P@K、广告的 CTR 阈值等)。
- TAWin 的 "soft Top-$K$ 算子做 reweighting" 模式,与 ReCast 的 "anchor 注入修复 + 边界对比" 模式,都示范了 GRPO 之上的"sequence-level reweighting drop-in"是性价比极高的改造点。
局限:
- 没有线上 A/B 实验:所有实验都在 Amazon Review / Yelp 公开数据集上,"Industrial"是 Amazon 子类目而非真实工业部署。LLM-based 推荐在工业环境的延迟、吞吐、长 tail 表现没有验证。
- backbone 仅到 7B:没有探索 30B+ 规模上 TAWin 是否仍有同等增益;soft Top-$K$ 算子在大候选数 $n$ 下的稳定性也未细测。
- 超参较多:TAWin 引入 $K$ / $\sigma_*$ / $\tau$ 三个新超参,需 grid search。Theorem 3.4 提供了 $\sigma_*$ 随 $K$ 单调右移的方向性指引,但还没有给出闭式最优值。
- 窗口形态是单段:实际 ROC 曲线上可能存在多段感兴趣区域(如同时关注 R@1 和 R@10),单窗口塑形难以同时对齐。多窗口 / 加权窗口是自然的扩展。
- 理论建立在 $B \to \infty$ 极限:Lemma 3.2 的"beam search = top-$d$ quantile"在有限 $B$ 下只是近似,论文没有给出有限 $B$ 下的非渐近误差界。
与 OPAUC 系列工作的关系:本文站在 Shi et al. (2023, 2024) 的"OPAUC 与 Top-$K$ 对齐"以及 Yang et al. (2019, 2021, 2022) 的 partial AUC 优化工作之上。WPAUC 可以看作是把"上界约束"细化为"区间约束"的自然下一步,对比 SVM_PAUC^tight、TPAUC、Lower-Left Partial AUC 等工作,本文最大的新意在于把它精确套到了 LLM-based RL 推荐的 GRPO 设定下,并用 soft Top-$K$ 算子给出了第一个可微高效的实现。