ReCast: Recasting Learning Signals for Reinforcement Learning in Generative Recommendation¶
研究动机与背景¶
生成式推荐(generative recommendation)正逐步把候选打分式范式替换为直接「生成下一个 item」的 LLM 风格管线(TIGER、OneRec、P5 等系列)。在这套管线中,post-SFT 阶段越来越多地引入 RL 后训练来直接优化 hit-oriented 指标(如 Pass@K)。当前主流做法几乎全部是通用 group-based RL——以 GRPO 为代表:对每个 prompt 采样一组 $G$ 条响应,按 group 内相对奖励做 advantage 归一化后更新 policy。
ReCast 直击这一套做法在稀疏命中(sparse-hit)单目标下一个 item 推荐场景下的隐含假设:「采样并打分得到的 group 自动构成一个可学习单元」。作者在代表性 OpenOneRec RL 设置下观察到(图 1):训练 20K 步后,约 85% 的 group 仍是 all-zero(零正样本)、13% 是 single-hit(仅 1 条 hit)、只有 2% 是 multi-hit;从样本粒度看,约 96% 的响应仍是 zero-reward。这意味着大部分 rollout 预算被困在不可学习或弱可学习的 group 里,并没有转化为可靠的策略改进信号。
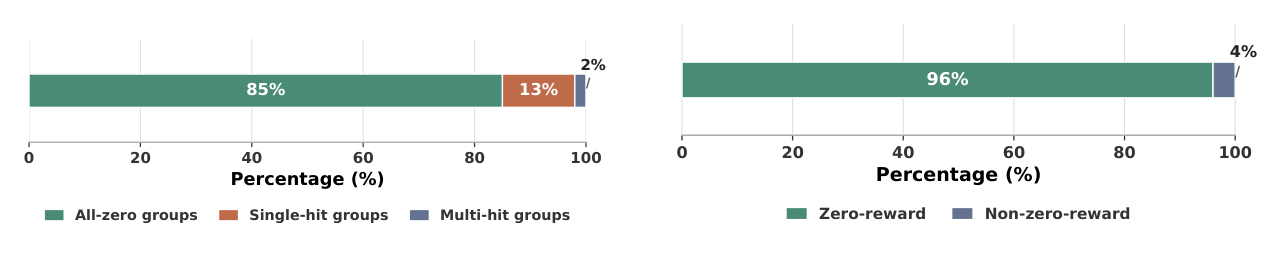
作者总结出三种失败模式:
- All-zero groups ($K(q) = 0$):组内不存在正负边界,所有响应奖励都是 0,advantage 也都是 0,无法构成 policy-improvement 单元;
- Single-hit groups ($K(q) = 1$):理论上可学,但更新被一条偶然命中和 group 噪声主导,对采样波动极敏感;
- Near-miss collapse:二值奖励把结构上或语义上接近正例的「近似命中」与完全无关的负例都打成 0,丢失了细粒度的推荐结构。
由此 ReCast 给出本文 RL 设计的中心命题:生成式推荐 RL 的关键问题不仅是「怎么分配奖励」,而是「能不能从稀疏、结构化的监督里构造出可学习的优化事件」。这本质上是一个学习信号设计问题,而不是奖励塑形或更广义的策略稳定性问题。
默认 Group-based RL 的假设¶
为了给改造提供形式化基础,作者先把通用 group-based RL 的形态明写出来。对每个 prompt $q$ 用旧策略 $\pi_\text{old}$ 采样一组响应:
$$\mathcal{G}(q) = \{R_1, \dots, R_G\}, \quad R_i \sim \pi_\text{old}(\cdot \mid q). \tag{1}$$
每条响应有奖励 $r_i = r(R_i; q, s) \in \{0, 1\}$($s$ 是 ground-truth target item)。GRPO 风格的 within-group advantage 归一化为:
$$\mu_q = \frac{1}{G}\sum_{i=1}^G r_i, \quad \sigma_q = \sqrt{\frac{1}{G}\sum_{i=1}^G (r_i - \mu_q)^2}, \quad \hat{A}_i = \frac{r_i - \mu_q}{\sigma_q + \epsilon}. \tag{2}$$
整体目标:
$$\mathcal{L}_\text{GRPO}(\theta) = \mathbb{E}_{q \sim \mathcal{D}, \mathcal{G}(q) \sim \pi_\text{old}}\left[\frac{1}{G}\sum_{i=1}^G \hat{A}_i \log \pi_\theta(R_i \mid q)\right] - \beta\,\text{KL}(\pi_\theta(\cdot \mid q) \| \pi_\text{ref}(\cdot \mid q)). \tag{3}$$
作者明确指出:(2) 中所有响应都被赋予某个 $\hat A_i$ 并参与梯度回传——即「sampled group 已经是 usable learning unit」是一条硬性假设;只要稀疏命中,这条假设就会塌掉。
设计要求¶
由此推出三条改造原则:
- 学习不能只指望「侥幸命中」:all-zero 的 group 应被恢复,而不是浪费;
- 一旦 group 变得可学,更新应聚焦在局部决策边界,而不是粗糙的 group 统计;
- 推荐结构信息(语义上接近的 near-miss)要被利用,而不是被二值奖励压平。
这直接对应一个两步信号设计:先 repair 让组可学;再 contrast 精炼边界。
ReCast: Repair-then-Contrast 信号设计¶
ReCast 的总体形态:保持 rollout 采样过程与外层 RL 目标(带 KL 约束的策略梯度)不变,只重构 within-group 的 advantage 构造。两步流水线:(a) Rollout Repair 解决「组是否可学」;(b) Boundary Contrastive Update 解决「一旦可学如何更新」。整体对比见图 2:上方是 OpenOneRec-RL 的全组归一化更新,下方是 ReCast 的 anchor 注入 + 边界对比更新。
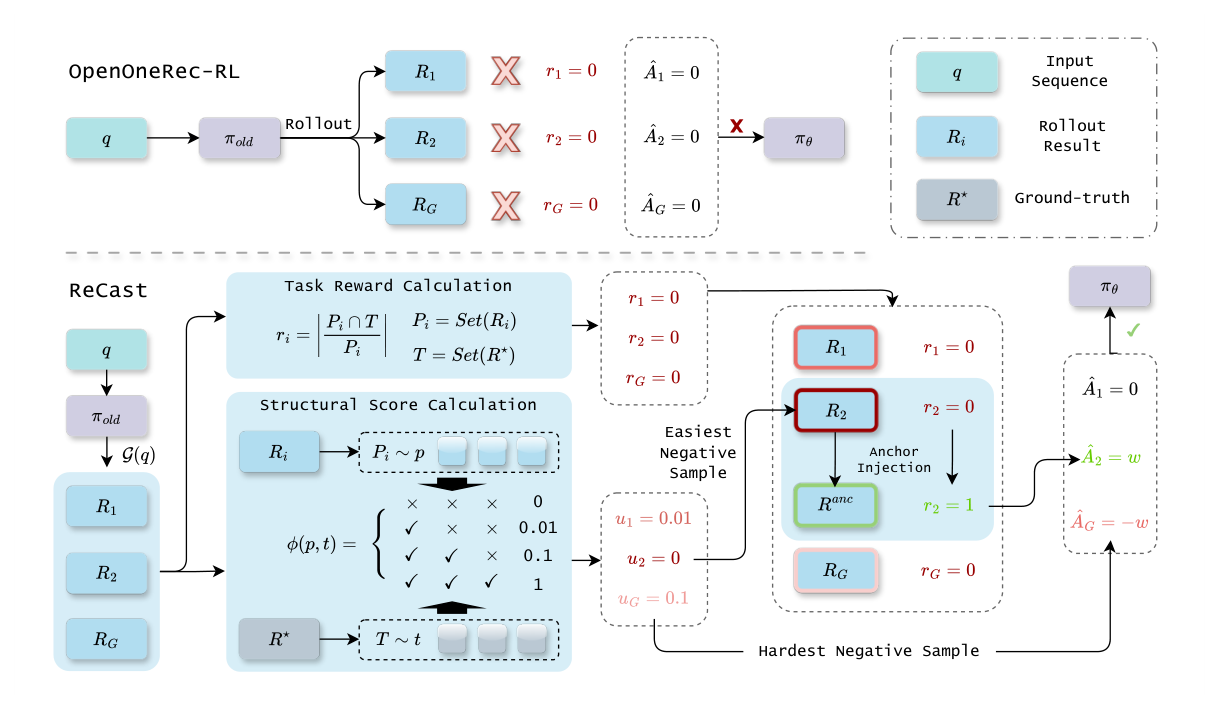
任务奖励与结构分数¶
对响应 $R_i$ 与 ground-truth $R^\star$,定义 target-ID 集合 $P_i = \text{Set}(R_i)$、$T = \text{Set}(R^\star)$。虽然这是 single-target next-item 设定,但生成响应被 parse 出来后可能含 0/1/多个有效 ID,所以两侧都用集合表示。
任务奖励(与外层 RL 的「成功定义」严格对齐):
$$r_i = \begin{cases} 0, & \text{if } P_i = \varnothing \text{ or } T = \varnothing \\ \frac{|P_i \cap T|}{|P_i|}, & \text{otherwise.} \end{cases} \tag{4}$$
在 single-target、single-prediction 场景下退化为标准的二值 hit reward。
结构分数(仅用于 within-group 信号构造,不进入外层 reward):把每个 target ID 拆成层次化三元组 $p = (p_a, p_b, p_c)$、$t = (t_a, t_b, t_c)$(与 SID/RQ-VAE 的层次结构对齐),定义匹配核:
$$\phi(p, t) = \begin{cases} 1, & \text{if } p = t \\ 0.1, & \text{if } (p_a, p_b) = (t_a, t_b) \text{ and } p_c \neq t_c \\ 0.01, & \text{if } p_a = t_a \text{ and } p_b \neq t_b \\ 0, & \text{otherwise.} \end{cases} \tag{5}$$
响应 $R_i$ 的结构分数:
$$u_i = \begin{cases} 0, & \text{if } P_i = \varnothing \text{ or } T = \varnothing \\ \frac{1}{|P_i|}\sum_{p \in P_i} \max_{t \in T} \phi(p, t), & \text{otherwise.} \end{cases} \tag{6}$$
关键区分:$r_i$ 定义任务成功(决定 reward / 是否是正样本),$u_i$ 仅用于在 group 内对结构相似度排序——把语义上接近的 near-miss 暴露出来。这样既不改变外层奖励语义,又把推荐的层次结构带进了信号构造。
Rollout Repair¶
仅在「整组都没有正例」时触发。给定 $\mathcal{G}(q) = \{R_1, \dots, R_G\}$,若 $\sum_{i=1}^G r_i = 0$,则构造一条满足 $r(R^\text{anc}; q, s) > 0$ 的 valid positive anchor $R^\text{anc}$。实践上 $R^\text{anc}$ 直接由 ground-truth $R^\star$ 派生(因此一定能产生正奖励)。
为最小化干预,被替换的位置不是随便挑的,而是结构最不 informative 的那条响应:
$$j_\text{rep} = \arg\min_{1 \leq i \leq G} u_i, \quad \widetilde{\mathcal{G}}(q) = (\mathcal{G}(q) \setminus \{R_{j_\text{rep}}\}) \cup \{R^\text{anc}\}. \tag{7}$$
由于 $u_i$ 排了结构亲缘度,被替换的总是「最远离 target 的那条」,从而最大化保留 group 内更 informative 的负例。Repair 后重新计算 $\{r_i, u_i\}$ 进入下一步。如果 group 本身已经有正例,repair 跳过。
注意三点:
- Anchor 来自 ground-truth,所以 repair 步骤不依赖额外采样预算;
- Repair 的触发条件只是「全零」,并不掩盖 outer reward——奖励仍按 $r$ 算;
- Repair 是在 within-group 信号构造前的一次「可学性挽救」,从信息论上可以理解为:用一条 deterministic 正例把整组从「无边界」状态拽到「至少有一对正负」的最小可学状态。
边界对比更新¶
对(修复后或本身就可学的)$\widetilde{\mathcal{G}}(q)$,ReCast 不再做全组 reward 归一化,而是只挑两条:
$$i^+ = \arg\max_{i: r_i > 0} r_i, \quad i^- = \arg\max_{i: r_i = 0} u_i. \tag{8}$$
「最强正例」由任务奖励决定,「最难负例」由结构相似度决定(即 hardest near-miss)。然后只对这一对赋 advantage:
$$A_i^\text{ReCast} = \begin{cases} +w, & i = i^+ \\ -w, & i = i^- \\ 0, & \text{otherwise,} \end{cases} \tag{9}$$
默认 $w = 1$。这等价于把 GRPO 的「全组 reward 归一化」替换为「一条最佳正样本 + 一条最难负样本的常数尺寸主动子集更新」。学到的更新方向不再是「在整组里重分配信用」,而是把概率质量从最难的非命中往最强的正例上搬。
如果一个本身可学的 group 中没有非命中响应(极少见),跳过对比更新(保留定义完备性,对实验影响可忽略)。
外层目标¶
ReCast 不改 outer RL 框架。把(修复后的)$\widetilde{\mathcal{G}}(q)$ 与 $A_i^\text{ReCast}$ 套回标准 KL 正则化策略梯度:
$$\mathcal{L}_\text{ReCast}(\theta) = \mathbb{E}_{q \sim \mathcal{D}, \mathcal{G}(q) \sim \pi_\text{old}}\left[\frac{1}{G}\sum_{i=1}^G A_i^\text{ReCast} \log \pi_\theta(R_i \mid q)\right] - \beta\,\text{KL}(\pi_\theta(\cdot \mid q) \| \pi_\text{ref}(\cdot \mid q)). \tag{10}$$
「ReCast 是 within-group 信号设计而不是外层 RL 重设计」这个定位很重要:它意味着 ReCast 是一个 lightweight drop-in,可以替换掉任何 group-based 推荐 RL 管线里的 advantage 计算模块,而不动 rollout / KL / reference 三件套。
搜索-更新解耦¶
这是论文第二个核心机械结构。常规 group-based RL 中,group 大小 $G$ 同时控制两件事:
- 搜索宽度 $W_\text{search} = G$:每个 prompt 采几条候选;
- actor 端更新宽度 $W_\text{update}^\text{base} = G$:actor forward-backward 优化要吃多少条样本。
在稀疏命中场景下这两件事的最优 scaling 显然不同:搜索宽度想大(自然命中少,需要扩大 candidate coverage),但 actor 端只需要在小的「局部决策边界子集」上学就够了。ReCast 正好分离这两个量:
$$W_\text{search} = G, \quad W_\text{update}^\text{ReCast} = O(1). \tag{11}$$
每组的训练成本因此变成:
$$C_\text{base} = G c_\text{roll} + G c_\text{upd}, \quad C_\text{ReCast} = G c_\text{roll} + O(1) c_\text{upd}. \tag{12}$$
actor-side 学习成本不再线性依赖于 $G$。这一设计直接带来三种 scaling 改善:
- 模型规模:$c_\text{upd}$ 随 backbone 参数变大而显著上升,把 update support 钉在常数尺寸越来越值钱;
- 搜索宽度:$G$ 变大只增加 rollout 成本,不再放大 actor 更新成本,因此 $G$ 是更友好的 scaling 旋钮;
- 系统效率:actor-side 工作量减小直接落到 wall-clock、显存峰值、actor MFU 上。
实验设置¶
Benchmark:在 OpenOneRec / RecIF-Bench 协议下评估,覆盖 5 个任务——Ad Recommendation、Product Recommendation、Short Video Recommendation、Interactive Recommendation、Label-Conditional Recommendation。任务定义、数据预处理、指标都沿用原 benchmark。
对照设置:所有方法都从同一个 OpenOneRec post-SFT checkpoint 起步,rollout temperature、group size、batch size、optimizer、KL 系数 $\beta$、最大生成长度、总 RL 预算都对齐。Baseline 是 OpenOneRec-RL(Zhou et al. 2025a,应用 GRPO 风格的 within-group reward 归一化,即论文中用作 OpenOneRec-Think 系统的 RL 阶段)。
骨干:默认 Qwen3-1.7B;模型 scaling 实验用 Qwen3-1.7B / 8B / 14B;搜索宽度与系统效率实验用 Qwen3-8B(更容易暴露 actor 端 workload reduction)。
硬件:64 张 Ascend NPU。所有方法在同一对照实验里硬件相同。关键实现细节:ReCast 把 inactive 样本在物理上提前从 old_log_prob / ref_log_prob / update_actor 三个阶段过滤掉,因此报出的 system-efficiency 数字是真实减负,而不是 post-hoc masking。
指标:离线推荐质量 Pass@1、Pass@32、Recall@32;学习效率与 scaling 用 matched-budget 比较。
主要实验结果(Q1)¶
离线指标(表 1):在同一 RL 预算下 ReCast 在 5 个任务的 9/15 指标上一致优于 OpenOneRec-RL,Pass@1 相对提升 9.1%–36.6%,Pass@32 与 Recall@32 也都有稳定改善——说明它不只优化 top-1 命中,还提升了候选集覆盖。
| Task | Metric | OpenOneRec-RL | ReCast | Rel. Improv. |
|---|---|---|---|---|
| Short Video Rec | Pass@1 | 0.0285 | 0.0311 | +9.12% |
| Pass@32 | 0.1088 | 0.1140 | +4.78% | |
| Recall@32 | 0.0150 | 0.0158 | +5.33% | |
| Ad Rec | Pass@1 | 0.0138 | 0.0160 | +15.90% |
| Pass@32 | 0.1689 | 0.1782 | +5.50% | |
| Recall@32 | 0.0558 | 0.0602 | +7.90% | |
| Product Rec | Pass@1 | 0.0230 | 0.0252 | +9.60% |
| Pass@32 | 0.1694 | 0.1882 | +11.10% | |
| Recall@32 | 0.0420 | 0.0465 | +10.70% | |
| Label-Cond. Rec | Pass@1 | 0.0041 | 0.0056 | +36.60% |
| Pass@32 | 0.0289 | 0.0292 | +1.00% | |
| Recall@32 | 0.0116 | 0.0120 | +3.40% | |
| Interactive Rec | Pass@1 | 0.0860 | 0.0970 | +12.80% |
| Pass@32 | 0.4310 | 0.4390 | +1.86% | |
| Recall@32 | 0.2865 | 0.2973 | +3.80% |
最大的提升出现在 Label-Conditional Recommendation 的 Pass@1(+36.6%)——这是论文里命中最稀疏的设置,刚好是 ReCast 设计动机最强的地方。
早期学习效率(图 3):在所有评估任务上,ReCast 训练 1K 步就已超过 OpenOneRec-RL 训练 20K 步的水平。例如 Label-Cond. Rec 上,ReCast@1K 的 Pass@1=0.0053,已经超过 OpenOneRec-RL@20K 的 0.0050。由于 20K 步还在第一个 epoch 内,作者特别强调这是「真正更早进入有用学习区」的信号,而不是 baseline 后期退化造成的假象。
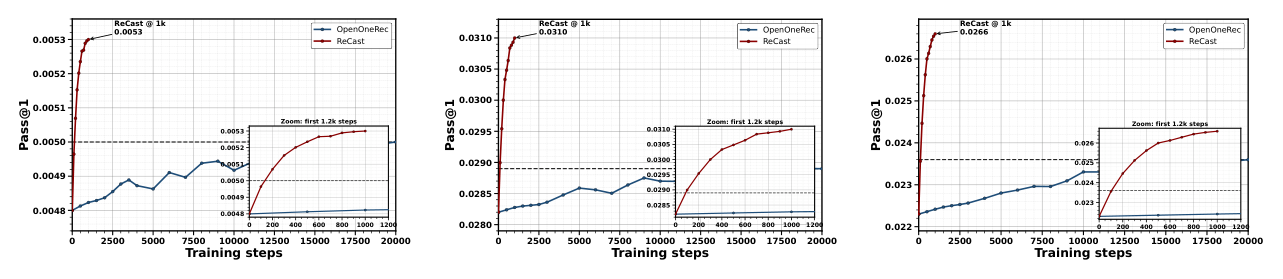
对应的 matched-budget 比较:ReCast 仅用 baseline 4.1% 的 rollout 预算就达到 baseline 在 20K 步的目标性能,且这一优势随模型规模和搜索宽度变大而进一步放大。
机制分析(Q2)¶
机制分析一共四块:持续退化、修复作用、边界稳定性、回归依赖性的消融。
持续信号退化¶
表 2 揭示一个非常反直觉的事实:OpenOneRec-RL 的 RL 训练没有自动逃出 all-zero / single-hit 区。从 1K 到 40K 步,all-zero group 比例只从 88% 下降到 85%,single-hit 从 10% 上升到 13%,zero-reward 样本比例从 97.2% 下降到 96.0%——也就是说,「随训练进展自然命中会变多」是一种幻觉,瓶颈不是 sample-level 的奖励稀疏,而是 group-level 的退化持续存在。
| Metric | 1K | 20K | 40K | Δ(40K–1K) |
|---|---|---|---|---|
| All-zero group ratio | 88% | 85% | 85% | -3% |
| Single-hit group ratio | 10% | 13% | 13% | +3% |
| Zero-reward sample ratio | 97.2% | 96.3% | 96.0% | -1.2% |
这个观察恰好为 repair 提供了存在性论据:如果不主动注入 anchor,绝大多数 rollout 永远不会自发地变成可学单元。
Repair 恢复可学性¶
表 3 分两块看 repair 的作用:
| Immediate effect of repair | Repair recedes over training |
|---|---|
| Before repair: 13% trainable | Repair trigger ratio: 88% (1K) → 61% (10K) → 44% (20K) |
| After repair: 100% trainable | Naturally trainable group ratio: 12% (1K) → 39% (10K) → 56% (20K) |
- 即时效果:repair 把可训练 group 比例从 13%(自然能产生正例的比例)拉到 100%;
- 逐步退场:随着 backbone 通过 repair 学到更准确的 boundary,自然 trainable 比例也水涨船高(12%→39%→56%),repair 的触发频率反而下降(88%→61%→44%)。
这两条曲线合在一起是一种很好的解释:repair 不是把 RL 训练变成「在 anchor 上模仿」,而是借 anchor 把 boundary 提前注入 backbone,让 backbone 在后续逐步具备「自己产生 trainable group」的能力。
边界聚焦带来的优化稳定性¶
图 4 给出三条标准的更新稳定性曲线:KL loss(policy 偏离 reference 的程度)、梯度范数(信号的幅度与抖动)、PPO-KL(每步实际更新的有效步长)。三条曲线都显示 ReCast 比 OpenOneRec-RL 波动更小、突刺更少、更早稳定。
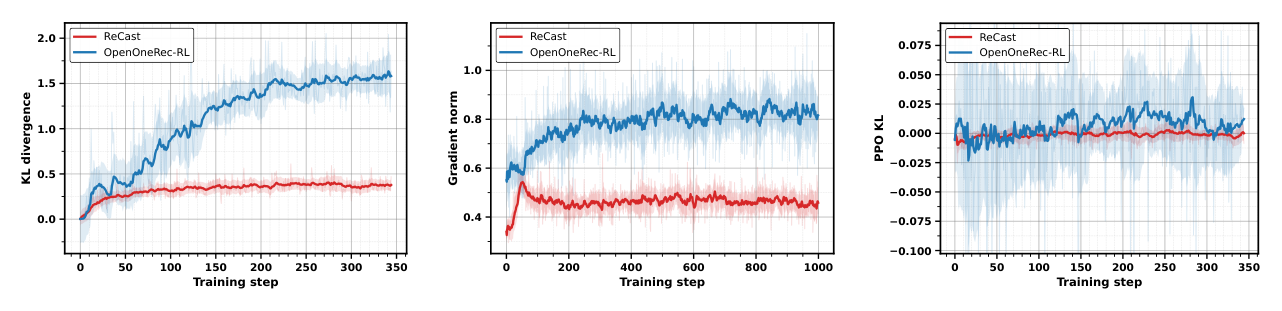
机制层面与信号路径一致:OpenOneRec-RL 通过 within-group reward 归一化把信用分给整组,因此优化方向被 group 组成(恰好命中几条、负例长什么样)显著扰动;ReCast 把信号集中到由「最强正例 + 最难负例」定义的 boundary 上,因此对 group statistics 不敏感、对 backbone 已知的 boundary 改进更平滑。
消融:Repair 与 Boundary 的相对作用是 regime-dependent¶
四个变体:OpenOneRec-RL、Repair-only、Boundary-only、Full ReCast。图 5 揭示一个非常细致的现象——
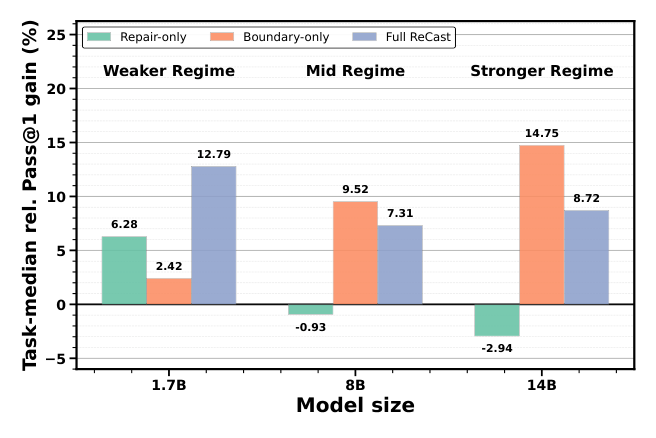
- 弱 regime(1.7B):Repair-only(+6.28%) 比 Boundary-only(+2.42%) 更有效,瓶颈是「能不能学得到」;
- 中 regime(8B):Boundary-only(+9.52%) 反超 Repair-only(-0.93%),能否「学得稳」开始变成关键;
- 强 regime(14B):Boundary-only 进一步占优(+14.75%),Repair-only 转负(-2.94%)——backbone 已经能自然产生 trainable group,强行注入 anchor 反而与模型自身的 sampled boundary 不一致,给更新带来 bias。
作者借此小心地表态:这条消融不该被读成「Full ReCast = 最优固定配方」,而应被读成「learnability vs. preservation 是 regime-dependent 的 tradeoff」。这点也出现在第 6 节的 limitations 里:repair 在更强 backbone 下应该自适应地降级或退场。
扩展性分析(Q3)¶
模型规模¶
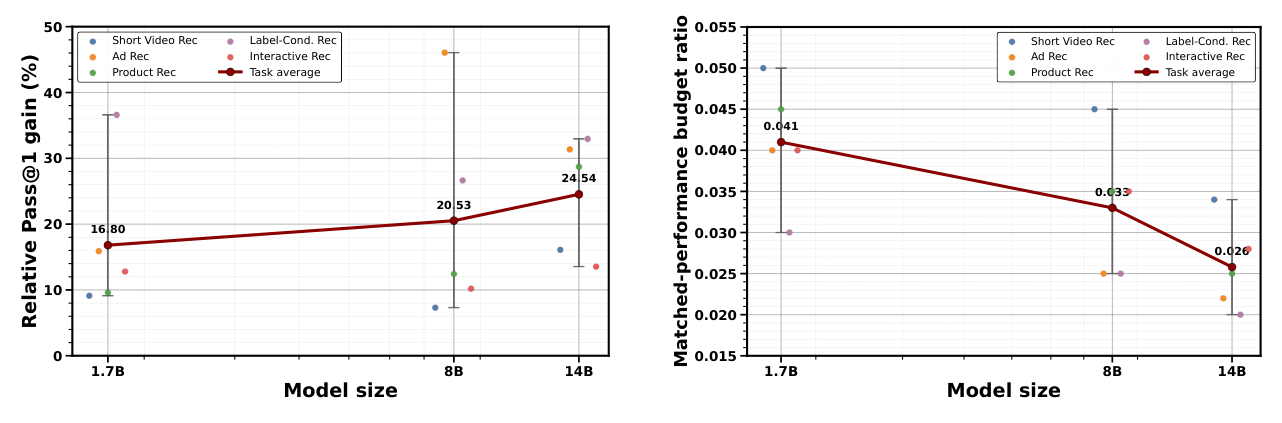
定义 matched-performance budget ratio = ReCast 复刻 OpenOneRec-RL@20K 性能所需 RL 步数 / 20000。图 6 显示随 model size 增加,ReCast 的固定预算优势放大、matched budget ratio 缩小:1.7B / 8B / 14B 分别为 4.1% / 3.3% / 2.6%。论文给出明确的解释:actor-side 优化随骨干变大而越来越贵,而 update support 始终是常数 $O(1)$,所以「钉死 actor 端」的设计随 scale 越来越赚。
搜索宽度¶
固定 backbone 改 group size $G$(图 7):随 $G$ 增大,ReCast 的 matched-budget ratio 持续下降;更鲜明的是 actor-side update 时间——在 $G=32$ 时,OpenOneRec-RL 需要 211.0s/step,ReCast 只需 12.7s/step,16.6× 加速;在 $G=64$ 时差距进一步拉大到 32.5×(422s vs ~13s)。
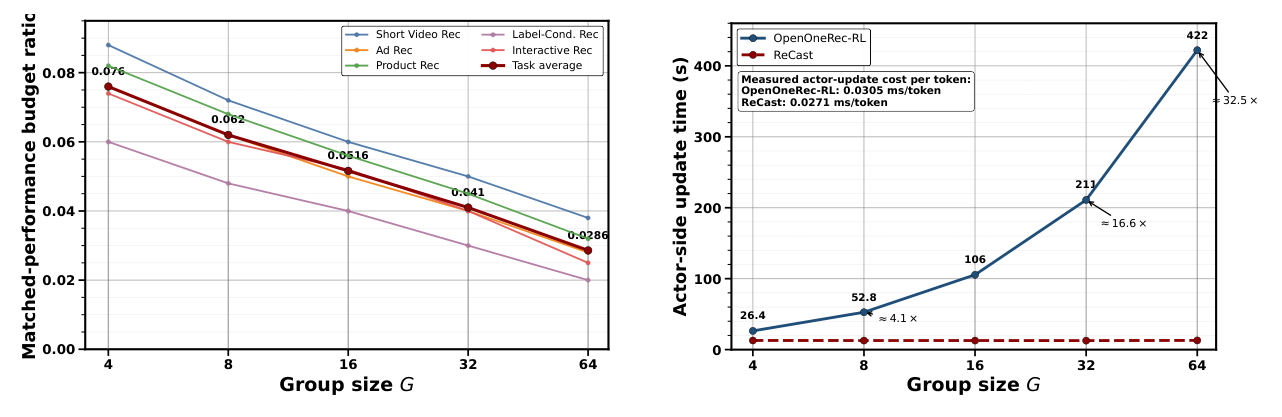
这正是 search-update decoupling 的直接经验证据:在 baseline 中 actor-side cost 随 $G$ 线性甚至超线性扩张,在 ReCast 中接近水平线。
系统级效率($G = 32$,Qwen3-8B)¶
| Metric | OpenOneRec-RL | ReCast | Improvement |
|---|---|---|---|
| Step time (s) | 371.54 | 77.00 | 4.82× faster |
| Actor update (s) | 211.04 | 12.71 | 16.60× faster |
| Old log-prob (s) | 56.27 | 4.13 | 13.63× faster |
| Reference forward (s) | 47.63 | 3.12 | 15.25× faster |
| Actor-side effective tokens / step | 6.93M | 0.47M | 14.78× fewer |
| Peak allocated memory (GB) | 43.89 | 36.65 | 16.5% lower |
| Actor MFU | 0.0763 | 0.0872 | +14.2% |
| Actor update cost (ms/token) | 0.0305 | 0.0271 | 11.0% lower |
注意:
- 加速并非局限在 actor update 一处——
old_log_prob与 reference forward 也都拿到 13–15× 的提速,说明整个 actor-side 流水线都被压缩; - per-token 成本本身不增加(反而略降),所以 wall-clock 改善的来源是有效 token 数从 6.93M 降到 0.47M——不是「单 token 更快」而是「actor 端工作量本身更少」;
- 显存峰值从 43.89GB 降到 36.65GB,MFU 从 7.63% 提到 8.72%,硬件利用率同步改善。
与已归档相关工作的对比¶
Step 2.5: no semantically twin papers found in archive.(OneRec-Think 是本论文的直接 baseline,关系是 system 迭代而非独立并发,已通过 Step 4 DAG 边登记。)
讨论与局限性¶
推荐 RL 的 regime-shift 视角¶
论文整体最值得带走的判断:稀疏命中生成式推荐 RL 不是「带不同 reward 的偏好对齐」——很多训练步采样到的 rollout 根本就不构成有意义的「优化事件」。瓶颈随 regime 变化:
- 弱 regime:瓶颈是 learnability——大量 group 永远不会变成 trainable event;
- 强 regime:瓶颈转向 preserving / refining「已经可用的信号」。
这一观点也带来一个不太舒服但很重要的副产品:更高效的 RL 更新不一定带来更好结果——ReCast 提高了「有效梯度密度」,但效率本身只是放大现有梯度方向。当 learnability 是真瓶颈时这种放大是直接收益;一旦 RL 目标的单标量稀疏奖励和 backbone 自然形成的决策边界开始漂移,更高效的更新只会更快地放大这个 mismatch。Repair 在 14B 下转负就是这个效应的直接征兆。
局限性¶
作者列出四条局限,与上面的 regime-shift 视角紧密扣在一起:
- 验证范围:仅在 offline post-training、single-target next-item 场景下验证。multi-objective、long-horizon、delayed-feedback 场景里,「sampled group 是否可学」与「干预是否会扭曲自然 boundary」是更纠缠的问题;
- 结构侵蚀未被显式测量:观察到「repair 在强 backbone 下转负」,但还没有直接量化 SFT-induced 哪些结构(template、SID 语义对齐、候选约束、表征 drift)被强 RL 抹掉;
- 静态 repair:anchor 注入是 rule-based、static——更长远应该是 adaptive repair,自适应判断「何时该恢复 learnability、何时该减弱干预、何时该转向 preservation」;
- 窄化的 reward 接口:更深的问题不是 repair rule,而是「单标量奖励本身只暴露了 SFT backbone 中很小一部分结构化行为」。一个更激进的方向是离开 single-scalar reward,往更密集、多事件的目标走(如 world-model-based 或 multi-head event prediction)。
读到这一段会感觉到本文有意识地把自己定位为「regime-aware signal-design 视角的一个具体实例」,而不是「永远好使的固定方案」——这个开放性的态度对生成式推荐 RL 的后续设计是有指导意义的。
核心贡献总结¶
- 诊断 sparse-hit 推荐 RL 的真实瓶颈:不是奖励稀疏,而是 group-level 的可学性退化(85% all-zero / 13% single-hit 在 20K 步仍持续存在),并且这种退化不会随训练自动消失;
- Repair-then-contrast 信号设计:repair 用 ground-truth-derived anchor 替换 group 中结构最远的响应,恢复最小可学性;boundary contrastive update 用 hardest 正负对替换全组 reward 归一化,把信号钉在局部决策边界上;
- search-update decoupling:把 actor-side update 钉成 $O(1)$ 子集,使 search width 与 actor update cost 解耦——broader rollout 不再代价线性扩张;
- 大幅经验提升:5 个 RecIF-Bench 任务上 Pass@1 +9.1%–36.6%,4.1% rollout 预算就达 baseline 20K 步水平,actor update 16.6× 加速,显存 -16.5%,MFU +14.2%;
- regime-aware 的诚实定位:在更强 backbone 下 repair 可能转为负面,论文明确把 ReCast 摆在「regime-aware signal-design 实例」位置,而非通用最优配方。
值得借鉴的设计思路:
- 把 RL 信号设计从「奖励塑形」往前推一步到「能不能形成可学事件」,这是一个比奖励工程更早的层次;
- structural score $\phi$ 是个低成本但漂亮的注入:把 SID 的层次结构作为 within-group ranking 的二级信号,不污染 outer reward;
- 「actor-side update support 是常数」是工业 RL post-training 一个被低估的杠杆,特别在 backbone 越大越贵的趋势下,把 update 与 search 解耦的回报会越来越大。