Factorized Latent Reasoning for LLM-based Recommendation¶
作者:Tianqi Gao(独立研究员), Chengkai Huang(Macquarie / UNSW), Zihan Wang(Meituan LongCat Interaction Team, 通讯), Cao Liu(Meituan LongCat), Ke Zeng(Meituan LongCat), Lina Yao(UNSW)
ArXiv:2604.26760 · 2026-04-29 · 代码:https://github.com/ToAdventure/FLR
1. 研究动机与背景¶
把大语言模型 (LLM) 用作生成式序列推荐器的范式正在快速扩张:传统做法把推荐任务转化为对下一物品的语言建模,但最朴素的 LLM-Rec 仅用最终隐状态作为用户表示,难以承载多步偏好推断。为补偿这一缺陷,社区出现了两条路径:
- 显式 CoT 推理 (Explicit CoT):CoT-Rec、Reason4Rec 等让模型先生成自然语言推理文本再产出推荐结果。优点是可读、可干预;缺点是依赖高质量 CoT 标注,自回归 token 输出在大词表/低延迟场景代价巨大。
- 隐式 / 潜在推理 (Latent Reasoning):LARES(深层递归潜在表征)、LatentR³(基于 GRPO 的连续 latent token RL 优化)等放弃显式 token,让模型在连续向量空间里"思考",直接在 latent 中完成多步表征精炼,同时去除 CoT 标注依赖。
但作者指出,现有 latent reasoning 方案存在一个结构性缺陷:它们用一个潜在向量(或一段同质的 latent token 序列)压缩所有推理,等于把多面用户意图全部塞进单个瓶颈维度。在协同过滤年代,矩阵分解早就揭示过——用户偏好需要被分解为多个独立潜在因子(风格、价格敏感度、品牌偏好等),单一向量只是次优近似。Latent reasoning 同样应当如此。
围绕这个观察,作者提出 FLR (Factorized Latent Reasoning):
- 方法层面:把 latent reasoning 拆成 $K$ 个互相解耦的偏好因子,用一个轻量化的 multi-factor attention + gating 模块迭代地对单个 thought token 嵌入做就地更新,并施加正交、注意力多样性、稀疏三类正则保证因子真正解耦。
- 训练层面:在 LatentR³ 的两阶段范式上进一步压低代价——先 SFT 预热,再用 GRPO 在 latent 空间做策略优化;提出向 thought token 嵌入注入高斯噪声替代 token-by-token 采样的 latent space exploration,并设计 token-confidence + sequence-exact-match 的混合稀疏奖励。
- 结果层面:四个 Amazon 子集(Toys / CDs / Games / Instruments)上 FLR 平均相对提升传统模型 84.6%、未微调 LLM 256.4%、显式 CoT-Rec 244.5%、强 LLM 基线 BIGRec/LatentR³ 16.5%/3.2%。Games 域 N@5 相对 LatentR³ 提升 10.26%。推理时仅多 1 个 thought token,与非推理 LLM Rec 几乎等价,远低于 CoT 方法的 100+ token 开销。
2. 相关工作与定位¶
2.1 LLM-based Recommendation¶
- 显式推理路径:EXP3RT、ReasoningRec、SLIM、Rec-SAVER 通过生成 CoT 监督信号来提升小模型;CoT4Rec、Reason4Rec 用聚类或 review 构造文本级偏好;CoT-Rec、R2Rec 集成 reasoning 模块到检索-排序管线;OneRec-Think、R4ec 用慢思考 / 双模型协作扩展推理深度;RecZero 用 GRPO/PPO 直接优化推荐指标,让推理行为隐式涌现。这些方案普遍受限于 CoT 噪声、高推理时延和昂贵的标注。
- 隐式 / 潜在推理路径:受 COCONUT(连续 latent 计划)、Huginn(深度递归 test-time compute)等通用 LLM 工作启发;推荐侧 LARES 用深层递归注意力刻画隐式偏好演化,LatentR³ [44] 把 reasoning token 改造为连续 latent,引入双阶段 SFT + 修改版 GRPO 训练。
FLR 直接接在 LatentR³ 之后:保留 latent reasoning 的低延迟优势,但用多因子分解打破单 latent 容量瓶颈,再在同一 GRPO 框架里把奖励 / 优势 / 探索三件全部重新设计以匹配新的 reasoning 结构。
2.2 LLM Latent Reasoning¶
文章把 latent reasoning 的脉络梳理为:通用 LLM 的 COCONUT、Huginn ➜ 推荐里的 LARES(深层递归)、ReaRec(推理位置嵌入)、LatentR³(GRPO + 连续 token)。FLR 的差异化:所有先前方法在每一步都使用单头 / 单 latent 注意力,而 FLR 引入多头解耦因子注意力作为 reasoning 的结构先验。
3. 问题定义与符号¶
数据集 $\mathcal{D}$ 中每个样本 $(u, h, y)$ 对应用户 $u$、历史交互序列 $h$(已转写为 textual prompt $x$)和目标物品 $y$。把推荐转化为语言生成:
$$x \xrightarrow{\text{LLM}} r \xrightarrow{\text{LLM}} \hat y, \tag{1}$$
其中 $r$ 是论文称为 thought 的中间 latent reasoning 表示,$\hat y$ 是生成的下一物品 textual identifier。训练目标是在没有外部 CoT 标注的前提下,让 LLM 自监督地学会产出有利于 $\hat y$ 的中间 $r$。FLR 把 $r$ 进一步因子化。
4. 方法¶
整体架构见 Figure 2:左侧是模型架构 + Stage-1 SFT 预热,右侧是 Stage-2 GRPO RL。FLR 模块嵌入 LLM 主干之前,对单个 thought token 做 $N$ 次就地刷新;最终 latent 与原 prompt 一起送入冻结的 LLM 解码出 $\hat y$。
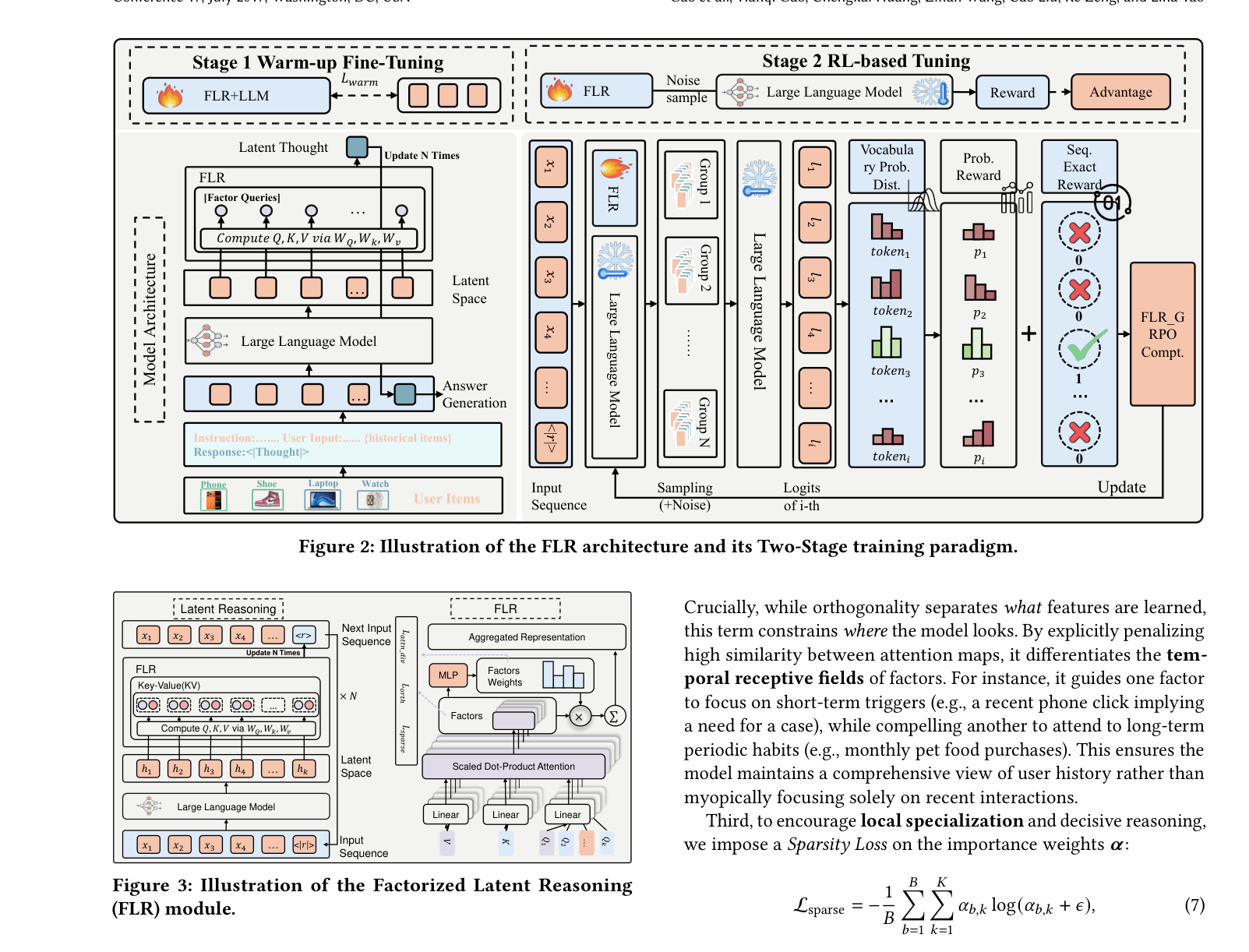
4.1 FLR 模块:多因子注意力 + 门控¶
输入扩展:在历史交互序列 $\mathbf{x}$ 末尾追加一个特殊 token <|Thought|>,得到 $\tilde{\mathbf{x}} = [\mathbf{x}; \texttt{<|Thought|>}]$。设初始嵌入矩阵为 $\mathbf{E}^{(0)}$,记 thought token 在序列中的位置为 $\text{pos}_{\texttt{<|Thought|>}}$。FLR 的核心是用 $N$ 步迭代刷新 thought 嵌入:
$$\mathbf{E}^{(n)}[\text{pos}_{\texttt{<|Thought|>}}] \leftarrow \mathbf{z}^{(n)},\tag{2}$$
其中第 $n$ 步隐状态 $\mathbf{H}^{(n)} = \Phi(\mathbf{E}^{(n-1)})$ 由 LLM 主干 $\Phi$ 输出,$\mathbf{z}^{(n)}$ 由因子化注意力计算。
因子查询原型:维护 $K$ 个可学习因子 query 原型 $\mathbf{Q}_f \in \mathbb{R}^{K\times D}$;对每个 query 应用 RoPE 引入时间位置感知,再与映射后的隐状态求注意力分数:
$$\mathbf{A}^{(n)} = \text{softmax}\!\left(\frac{\mathbf{W}_q\mathbf{Q}_f \,(\text{RoPE}(\mathbf{W}_k\mathbf{H}^{(n)}))^\top}{\sqrt{D}} + \mathbf{M}\right) \in \mathbb{R}^{K\times L_{\text{in}}},\tag{3}$$
$\mathbf{M}$ 是因果 mask。每个因子提取出一组上下文表示 $\mathbf{F}^{(n)} = \mathbf{A}^{(n)}\mathbf{V}^{(n)}\in\mathbb{R}^{K\times D}$。
门控聚合:用 MLP gating 学习因子的重要性权重 $\boldsymbol\alpha^{(n)}$,最终得到该步的精炼 latent:
$$\mathbf{z}^{(n)} = \sum_{k=1}^K \alpha_k^{(n)} \mathbf{F}_k^{(n)}, \quad \boldsymbol\alpha^{(n)} = \text{softmax}(\text{MLP}(\text{flatten}(\mathbf{F}^{(n)}))).\tag{4}$$
聚合结果回写到 thought token 嵌入位置,形成"边思考边把思想结晶到嵌入空间"的递归过程。
直觉上,每个因子负责一种用户意图轴:例如服饰场景下 $F_1$ 偏视觉风格、$F_2$ 偏价格敏感度,门控决定当前预测要靠哪一个因子做主。
4.2 三种结构正则¶
只靠 attention head 数量做 factorization 会因为信号偷懒坍缩到同一子空间(mode collapse)。FLR 同时施加三条正则。
(1) 正交性损失(防全局退化):把因子矩阵按行 L2 归一化为 $\tilde{\mathbf{F}}_b$(保证 $\|\tilde{\mathbf{F}}_{b,k}\|_2=1$),让因子相关阵尽量接近单位阵:
$$\mathcal{L}_{\text{orth}} = \frac{1}{B}\sum_{b=1}^B \|\tilde{\mathbf{F}}_b \tilde{\mathbf{F}}_b^\top - \mathbf{I}_K\|_F^2.\tag{5}$$
物理含义:强制每个因子向量张成各自正交的子空间——否则所有 head 都会去拟合最强信号(如热门偏好),失去"多视角"价值。
(2) 注意力多样性损失(局部专长,时间感受野各异):
$$\mathcal{L}_{\text{div}} = \frac{2}{K(K-1)}\sum_{i<j}\cos(\mathbf{A}_i, \mathbf{A}_j).\tag{6}$$
正交性管"看了什么 (what)",多样性管"看哪里 (where)"——惩罚两个 head 注意力分布过度重合。一个被引导关注短期触发(最近一次手机点击意味着想买配件),另一个被推到长期周期性偏好(每月固定宠物粮)。
(3) 稀疏性损失(局部专精,winner-take-all):
$$\mathcal{L}_{\text{sparse}} = -\frac{1}{B}\sum_{b=1}^B\sum_{k=1}^K \alpha_{b,k}\log(\alpha_{b,k}+\epsilon).\tag{7}$$
最小化熵 = 让权重分布趋于 one-hot,使每个具体预测只由一个主导因子驱动,例如用户在"露营装备"这个语境下,决定就该交给"品类需求"因子,而不是"视觉风格"等无关因子稀释信号。
最终损失:
$$\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{rec}} + \lambda_1\mathcal{L}_{\text{orth}} + \lambda_2\mathcal{L}_{\text{div}} + \lambda_3\mathcal{L}_{\text{sparse}}.\tag{8}$$
权重 $\lambda_1, \lambda_2, \lambda_3$ 用 [Kendall et al., 2018] 的 uncertainty-based 多任务自适应方案:每个 weight 实化为 $\lambda = \frac{1}{2\exp(s)}$,$s$ 初始为 0,与主任务一起学习,无需手调。
4.3 Latent Reasoning via GRPO(Stage 2)¶
预热完毕后冻结 LLM 主干,仅训练 FLR 模块的参数 $\theta$,采用 GRPO 风格的 RL 进行 latent 空间优化。
Latent space exploration(公式 9):常规 GRPO 通过自回归采样获取多条 trajectory,token 级采样开销大。FLR 在 thought token 嵌入上加高斯噪声:
$$\tilde{\mathbf{e}}_{\texttt{<|T|>}}^{(i)} = \mathbf{e}_{\texttt{<|T|>}} + \boldsymbol\epsilon_i,\quad \boldsymbol\epsilon_i = \begin{cases}0, & i=1\\ \mathcal{N}(0,\sigma^2 \mathbf{I}), & \text{otherwise}\end{cases}\tag{9}$$
第一条始终是无扰动 baseline,用作组内 advantage 估计的方差缩减锚点。
混合奖励(公式 10):把稠密 token 置信度与离散精确匹配信号合二为一:
$$r(x,y) = \alpha\cdot\underbrace{\frac{1}{L}\sum_{t=1}^L \log\pi_\theta(y_t|x,y_{<t})}_{\text{Token Confidence}} + \beta_r\cdot\underbrace{\mathbb{I}(\hat y = y)}_{\text{Exact Match}}.\tag{10}$$
token confidence 解决推荐场景里 exact match 经常全 0、组内 reward 全相同、advantage 退化的稀疏性问题;精确匹配保证最终对齐目标。最优值 $\alpha=0.1$,$\beta_r=1.0$。
Group-relative advantage estimation(公式 11):组内归一化用 L2 而非 z-score,更鲁棒于 hybrid reward 量纲:
$$\hat A_i = \frac{r_i - r_{\text{base}}}{\|\mathbf{r}_{2:G} - r_{\text{base}}\|_2 + \epsilon}.\tag{11}$$
目标函数(公式 12)使用非对称 clipping ($\epsilon_l=0.2,\epsilon_h=0.28$) 和反向 KL 近似稳定训练:
$$\mathcal{L}_{\text{token}} = \min\!\left(\rho_t\hat A_t,\,\text{clip}(\rho_t,\,1-\epsilon_l,\,1+\epsilon_h)\hat A_t\right) - \beta_{\text{KL}} D_{\text{KL}},\tag{12}$$
$\rho_t = \pi_\theta(y_t|x)/\pi_{\theta_{\text{old}}}(y_t|x)$,$D_{\text{KL}} \approx e^\Delta - \Delta - 1$($\Delta=\log\pi_{\text{ref}} - \log\pi_\theta$)。
最终 RL 阶段总损失保留 FLR 三正则项:
$$\mathcal{L}_{\text{total}} = \mathbb{E}_{\mathcal{D}}[-\mathcal{L}_{\text{token}}] + \lambda_1\mathcal{L}_{\text{orth}} + \lambda_2\mathcal{L}_{\text{div}} + \lambda_3\mathcal{L}_{\text{sparse}}.\tag{13}$$
5. 实验¶
5.1 数据集与评估协议¶
四个 Amazon 子集 + 动态时间窗 + 5-core 过滤;为保证 item 数 $\le 5000$ 适配 LLM 词表,反向滚动起始日期直到满足上限:
| Dataset | Train | Valid | Test | #Item |
|---|---|---|---|---|
| Toys | 53,898 | 6,737 | 6,738 | 6,299 |
| CDs | 49,251 | 6,156 | 6,158 | 5,841 |
| Games | 75,175 | 9,397 | 9,397 | 5,308 |
| Instruments | 66,500 | 8,312 | 8,313 | 5,030 |
按时间 8:1:1 切;最大序列长度 10。指标 HR@K / NDCG@K(K∈{5,10}),报五次不同 seed 的平均值。LLM 部分用 Qwen2.5-1.5B 作 backbone;SFT lr 调在 $\{3,4,5\}\times 10^{-5}$;RL lr $\{1,5\}\times 10^{-5}$;因子数 $K\in\{2,3,4\}$ 验证集网格搜(CDs 选 3,Toys/Games/Instruments 选 4);reasoning 步数 $T=2$。Beam size 4,prefix-trie 约束生成保证落在合法目录。所有实验在 2×A100 完成。
5.2 主实验(RQ1)¶
Table 2 是 FLR 与各路 baseline 的对比,HR/N 为分数小数。RI 行为 FLR 相对该 baseline 在 8 项指标上的平均提升。
| Dataset | Metrics | Caser | GRU4Rec | SASRec | Base (Qwen) | CoT | AlphaRec | BIGRec | LatentR³ | FLR | Improv. (vs LatentR³) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Toys | H@5 | 0.0251 | 0.0417 | 0.0601 | 0.0203 | 0.0261 | 0.0579 | 0.0701 | 0.0781 | 0.0814 | +4.23% |
| H@10 | 0.0384 | 0.0564 | 0.0760 | 0.0359 | 0.0496 | 0.0893 | 0.0931 | 0.1068 | 0.1077 | +0.84% | |
| N@5 | 0.0170 | 0.0305 | 0.0458 | 0.0128 | 0.0153 | 0.0347 | 0.0508 | 0.0579 | 0.0611 | +5.53% | |
| N@10 | 0.0214 | 0.0352 | 0.0510 | 0.0178 | 0.0229 | 0.0448 | 0.0582 | 0.0674 | 0.0695 | +3.12% | |
| CDs | H@5 | 0.0469 | 0.0481 | 0.0841 | 0.0195 | 0.0302 | 0.0479 | 0.0757 | 0.0816 | 0.0857 | +5.02% |
| H@10 | 0.0689 | 0.0669 | 0.1054 | 0.0252 | 0.0406 | 0.0774 | 0.0929 | 0.0992 | 0.1013 | +2.12% | |
| N@5 | 0.0312 | 0.0365 | 0.0622 | 0.0148 | 0.0213 | 0.0278 | 0.0616 | 0.0662 | 0.0689 | +4.08% | |
| N@10 | 0.0382 | 0.0425 | 0.0691 | 0.0167 | 0.0246 | 0.0373 | 0.0672 | 0.0719 | 0.0741 | +3.06% | |
| Games | H@5 | 0.0324 | 0.0322 | 0.0416 | 0.0236 | 0.0120 | 0.0558 | 0.0461 | 0.0593 | 0.0639 | +7.76% |
| H@10 | 0.0538 | 0.0517 | 0.0633 | 0.0311 | 0.0194 | 0.0893 | 0.0709 | 0.0889 | 0.0908 | +2.14% | |
| N@5 | 0.0211 | 0.0207 | 0.0280 | 0.0190 | 0.0082 | 0.0397 | 0.0334 | 0.0419 | 0.0462 | +10.26% | |
| N@10 | 0.0280 | 0.0270 | 0.0350 | 0.0214 | 0.0105 | 0.0515 | 0.0414 | 0.0515 | 0.0548 | +6.41% | |
| Instruments | H@5 | 0.0781 | 0.0766 | 0.0793 | 0.0154 | 0.0135 | 0.0813 | 0.0938 | 0.1029 | 0.1032 | +0.29% |
| H@10 | 0.0977 | 0.0960 | 0.0950 | 0.0192 | 0.0199 | 0.1051 | 0.1158 | 0.1214 | 0.1248 | +2.80% | |
| N@5 | 0.0564 | 0.0630 | 0.0708 | 0.0296 | 0.0261 | 0.0564 | 0.0807 | 0.0882 | 0.0886 | +0.45% | |
| N@10 | 0.0627 | 0.0692 | 0.0758 | 0.0411 | 0.0346 | 0.0640 | 0.0879 | 0.0941 | 0.0955 | +1.49% | |
| Avg RI | 84.6% | 66.9% | 32.6% | 265.4% | 244.5% | 38.2% | 16.5% | 3.2% | – | – |
带 * 的 FLR 数字均通过 paired t-test 在 $p<0.05$ 显著优于次强 baseline。
关键观察:
- 三大类传统 baseline(Caser/GRU4Rec/SASRec)相比 FLR 平均落后 32–85%,说明纯结构化序列建模虽然 efficient 但缺乏 LLM 蕴含的语义先验。
- 未微调 LLM (Base) 与 CoT 表现极差(特别是 Games 域 N@5 仅 0.0082),说明对推荐任务 zero-shot prompting 远远不够。
- 在 LLM 类强基线中,BIGRec → LatentR³ 提升约 16% 验证 latent reasoning 的价值;FLR → LatentR³ 提升 3.2% 看似微小,但在已经成熟的赛道里这是有意义的边际收益(Games N@5 +10.26% 说明在偏好多样的领域提升尤其显著)。
- Instruments 数据集 FLR 收益最小(H@5 仅 +0.29%)。作者解释:乐器场景偏好"职业性"明显(演奏需要 / 乐器型号需求),意图维度本身较低,单 latent 已基本够用,多因子分解的边际价值受限。
5.3 因子解耦消融(RQ2)¶
Table 3 给出 Games / Toys 两个数据集上三种正则的逐项消融。"None" 行表示去掉所有正则的纯多 head 注意力 baseline。
| Methods | Games H@5 | H@10 | N@5 | N@10 | Toys H@5 | H@10 | N@5 | N@10 |
|---|---|---|---|---|---|---|---|---|
| None | 0.0596 | 0.0882 | 0.0435 | 0.0528 | 0.0779 | 0.1065 | 0.0585 | 0.0678 |
| attn_div | 0.0627 | 0.0886 | 0.0450 | 0.0533 | 0.0822 | 0.1073 | 0.0600 | 0.0681 |
| orth | 0.0625 | 0.0893 | 0.0460 | 0.0546 | 0.0793 | 0.1089 | 0.0594 | 0.0690 |
| sparse | 0.0631 | 0.0895 | 0.0458 | 0.0542 | 0.0782 | 0.1072 | 0.0590 | 0.0683 |
| attn_div+orth | 0.0623 | 0.0898 | 0.0456 | 0.0545 | 0.0801 | 0.1069 | 0.0593 | 0.0678 |
| attn_div+sparse | 0.0625 | 0.0902 | 0.0455 | 0.0544 | 0.0815 | 0.1076 | 0.0607 | 0.0691 |
| orth+sparse | 0.0607 | 0.0879 | 0.0443 | 0.0531 | 0.0794 | 0.1100 | 0.0586 | 0.0685 |
| attn_div+orth+sparse | 0.0639 | 0.0908 | 0.0462 | 0.0548 | 0.0814 | 0.1077 | 0.0611 | 0.0695 |
结论:
- 任何正则单独使用都比无正则的 None 强(H@5 在 Games 上 +5–6%),证明多 head 不加约束几乎只会冗余。
- 三者协同最佳:直观看 attn_div 决定"看哪里"、orth 决定"看什么"、sparse 决定"由谁主导",三轴互补。
- 个别情况下 orth+sparse 可在 Toys H@10 单项夺魁,说明在静态品类偏好的场景里时间多样性约束(attn_div)边际价值更小。
定性解耦(Figure 4,Toys/Games 因子相关阵):
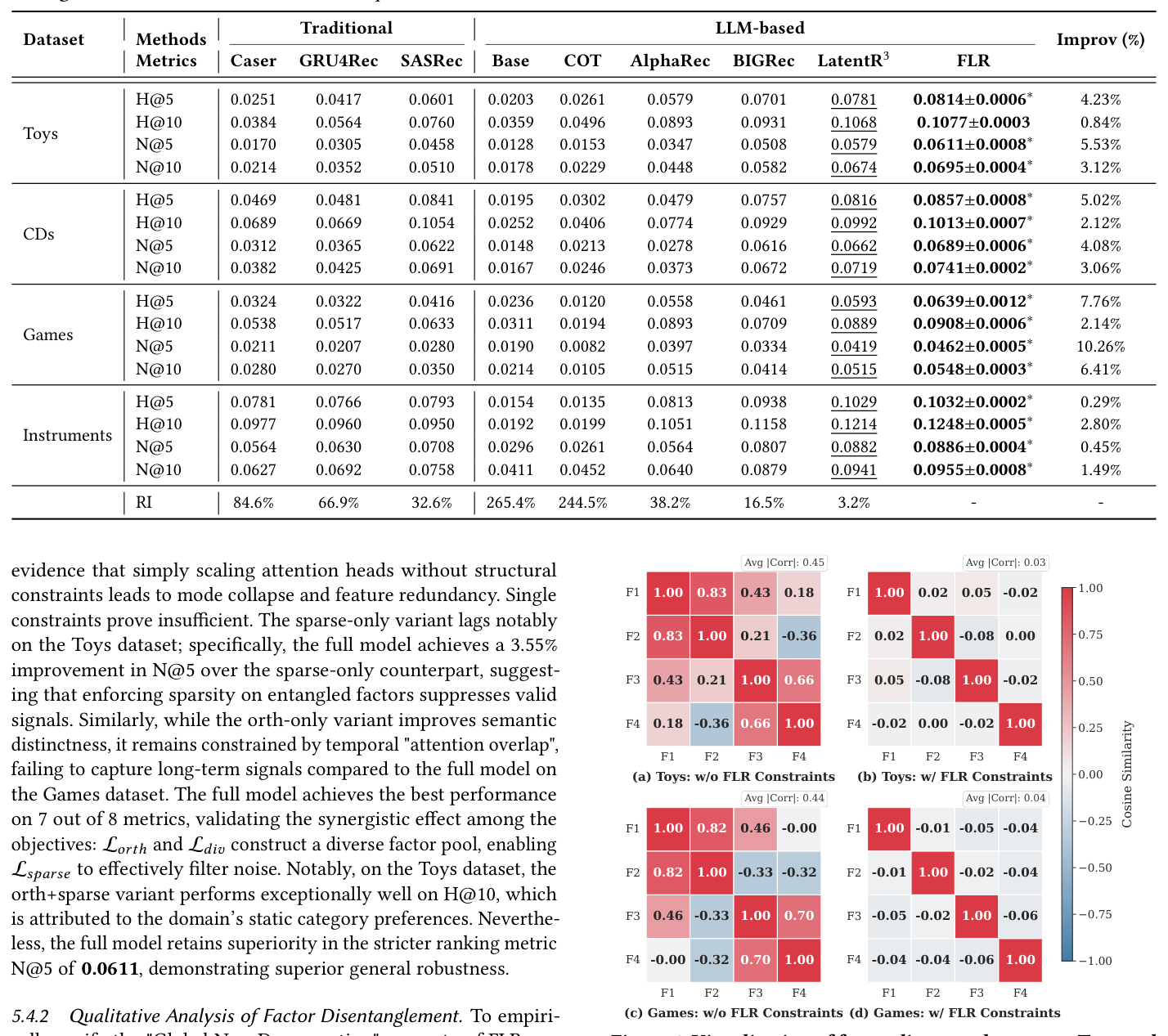
无正则版本 Avg|Corr|≈0.44,因子彼此高度相关(mode collapse);加上完整正则后 Avg|Corr|≈0.03,因子矩阵接近对角。这是后续多因子注意力分析能讲故事的前提。
5.4 GRPO 设计消融(RQ3)¶
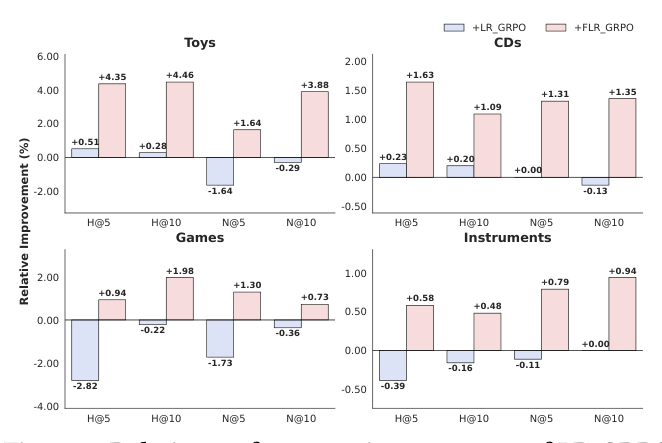
Figure 5 比较"通用 GRPO + FLR"(LR-GRPO,对应 LatentR³ 风格 RL)vs "FLR-GRPO"(论文方案:hybrid reward + L2 advantage + 噪声探索)对 FLR baseline 的相对改进。
观察:
- LR-GRPO 在难数据集上反向迁移:Games 上 H@5 -2.82%,Instruments 上 H@5 -0.39%——直接套用通用 GRPO 不解耦地施加在多 head latent 上反而引入梯度噪声,使模型偏离最优策略。
- FLR-GRPO 全 16 项指标全部正向:Games 上 H@5 反转为 +0.94%,Toys 上 H@10 +4.46%、N@10 +3.88% 显著超越通用版本。说明 hybrid reward 与因子结构的耦合是稳定收益的关键。
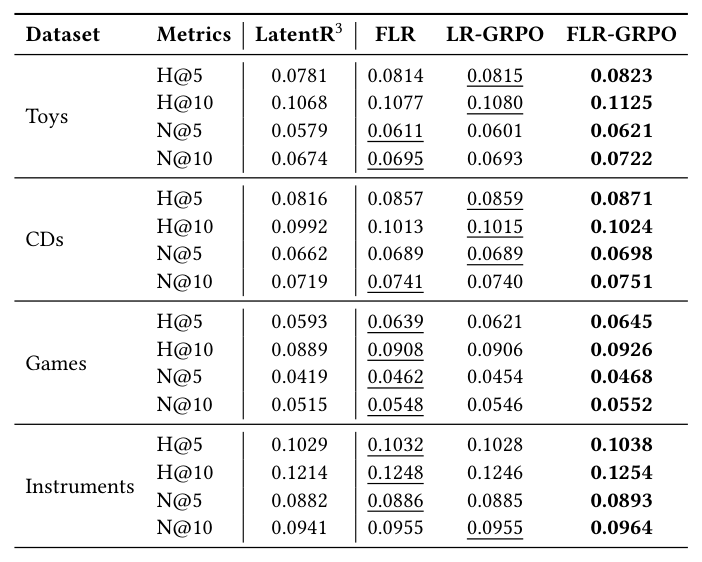
Table 4 给出与 LatentR³ 的细粒度对比:
| Dataset | Metrics | LatentR³ | FLR | LR-GRPO | FLR-GRPO |
|---|---|---|---|---|---|
| Toys | H@5 | 0.0781 | 0.0814 | 0.0815 | 0.0823 |
| H@10 | 0.1068 | 0.1077 | 0.1080 | 0.1125 | |
| N@5 | 0.0579 | 0.0611 | 0.0601 | 0.0621 | |
| N@10 | 0.0674 | 0.0695 | 0.0693 | 0.0722 | |
| CDs | H@5 | 0.0816 | 0.0857 | 0.0859 | 0.0871 |
| H@10 | 0.0992 | 0.1013 | 0.1015 | 0.1024 | |
| N@5 | 0.0662 | 0.0689 | 0.0689 | 0.0698 | |
| N@10 | 0.0719 | 0.0741 | 0.0740 | 0.0751 | |
| Games | H@5 | 0.0593 | 0.0639 | 0.0621 | 0.0645 |
| H@10 | 0.0889 | 0.0908 | 0.0906 | 0.0926 | |
| N@5 | 0.0419 | 0.0462 | 0.0454 | 0.0468 | |
| N@10 | 0.0515 | 0.0548 | 0.0546 | 0.0552 | |
| Instr. | H@5 | 0.1029 | 0.1032 | 0.1028 | 0.1038 |
| H@10 | 0.1214 | 0.1248 | 0.1246 | 0.1254 | |
| N@5 | 0.0882 | 0.0886 | 0.0885 | 0.0893 | |
| N@10 | 0.0941 | 0.0955 | 0.0955 | 0.0964 |
FLR-GRPO 在所有 16 个 cell 全面领先,且大多数 cell 较 LR-GRPO 有明确间隙。
5.5 Attention 解耦定性分析(RQ4)¶
Figure 6 在 Amazon Video Games 上选典型用户,展示 4 个因子 head 的注意力分布。
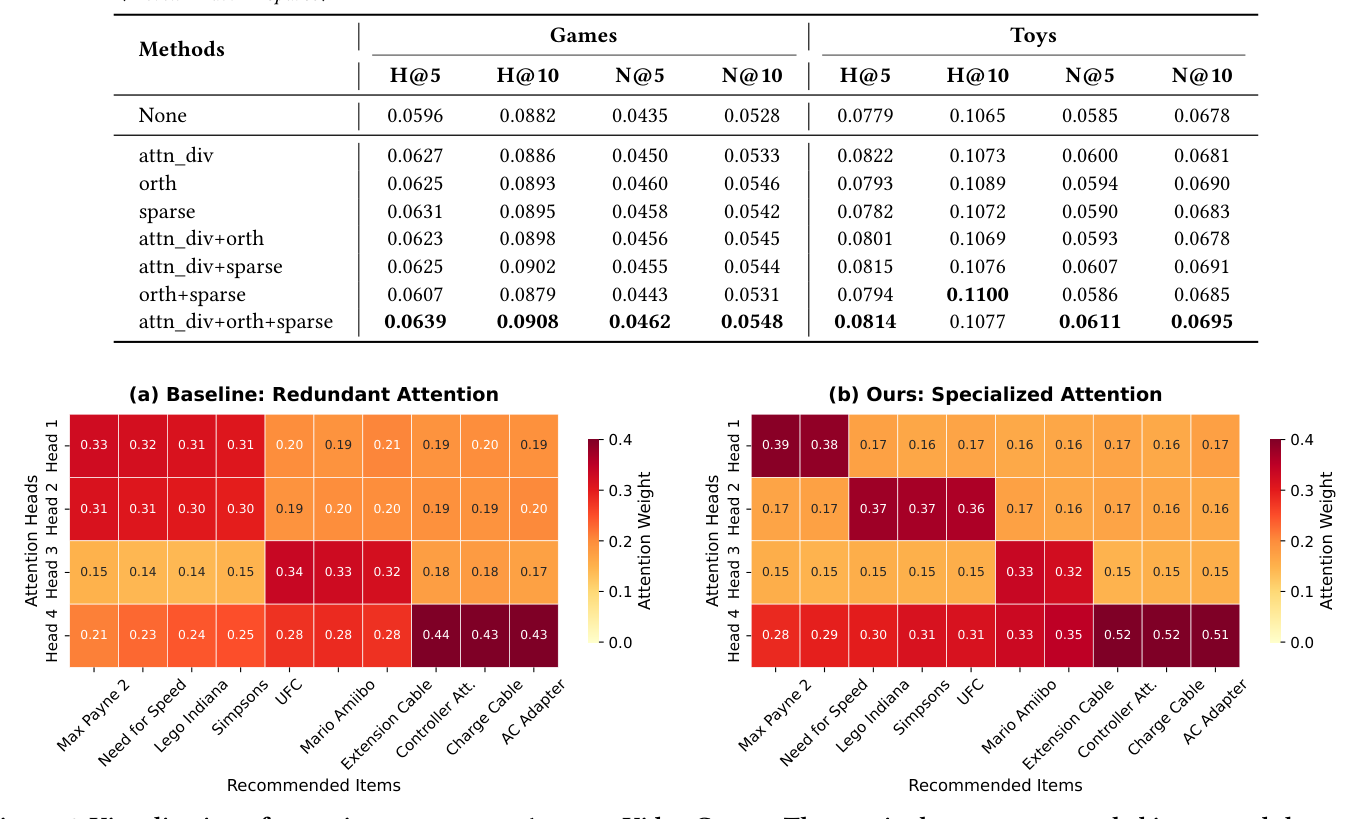
(a) 预训练 baseline:Head 1 与 Head 2 的注意力模式高度重合,都集中在动作 / 赛车类的热门游戏(如 Max Payne 2),说明信号坍缩到单一通道。(b) FLR-GRPO:四头各司其职——Head 1 专注核心玩法(Action/Racing),Head 2 转向类型探索(如 Lego Indiana),Head 3 锁定收藏品(Mario Amiibo),Head 4 关注配件实用品(Controller Cable / AC Adapter)。
定量解耦得分 $DS = (1 - S_{avg}) \times A_{max}$(结合相互独立性 $1-S_{avg}$ 与单 head 焦点锐度 $A_{max}$)相对 baseline 提升 80.1%。说明多因子机制在 RL 后真正学到了跨语义通道的"注意力预算分配"。
5.6 长尾物品收益(RQ5)¶
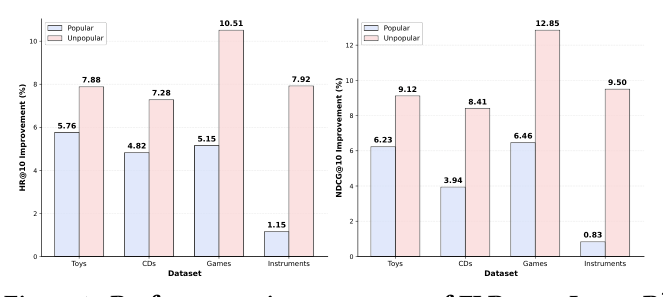
Figure 7 把测试 item 按训练集出现频率分成 popular(top 20%)vs unpopular(bottom 80%),分别画 FLR 相对 LatentR³ 的提升。
- 各 dataset 上 unpopular 增益均高于 popular。Games 上 N@10 unpopular +12.85% vs popular +6.46%;Instruments 上 unpopular +9.50% vs popular +0.83%;Games/Instruments 的 H@10 unpopular 提升达 10.51% / 7.92%,明显超过 popular 组的 5.15% / 1.15%。
- 解释:热门 item 已被协同信号强化,FLR 因子拆分语义线索的空间小;冷门 item 依赖语义推理而非交互频次,多因子刚好补足 collaborative-only 模型缺失的视角。
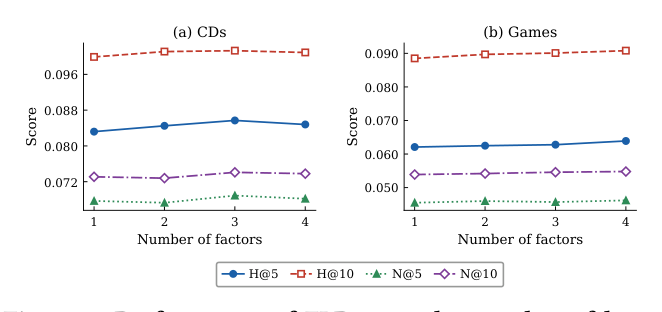
5.7 因子数 $K$ 的敏感性(RQ6)¶
Figure 8 在 CDs / Games 上扫 $K\in\{1,2,3,4\}$。
- $K=1$ 在所有 dataset 上一致最差,验证多因子建模的必要性。
- CDs 在 $K=3$ 见顶(H@5=0.0857, N@5=0.0689),$K=4$ 略降——领域三个正交意图轴已足,再加一个引入冗余。
- Games 单调上升至 $K=4$,与品类多样性匹配。
- 整体波动幅度温和,FLR 对精确 $K$ 选择不敏感,工程上不需要细调。
5.8 推理代价(RQ7)¶
Figure 9 比较四种推荐范式的推理时延(A100, batch=4, beam=10, 100 sample):
- BIGRec / LatentR³ / FLR 推理时间几乎重叠(30–40 秒区间),多出来的 thought token 数量极少(默认 $T=2$ 步、单 token),相对 item title 本身长度已被淹没。
- CoT 在 Games / Instruments 上跳到 600+ 秒,主要是自回归生成长 reasoning text 的代价;FLR 用 latent 空间内"无 token 化"思考从源头规避此开销。
实用结论:FLR 在线开销与最朴素的 LLM-Rec 相当,是其能在工业级低延迟约束下落地的前提。
6. 与已归档相关工作的对比¶
OneRec-Think OneRec-Think (Kuaishou, 2025-10-13)¶
关系:显式引用(FLR §2 将 OneRec-Think 列为「在 GR 中扩展显式推理深度」的代表 [25],但未做架构层对比)· 已加载对方精读
- 共同关注的问题:两者都在挑战"生成式推荐里 LLM 只是隐式预测器"这一痛点——光靠最终隐状态做下一物品 ID 自回归,无法显式做多步偏好推断。
- 相近的技术骨架:都采用「SFT 预热 + GRPO 强化」的两段式训练;GRPO 阶段都设计了应对 reward sparsity 的特殊 reward(OneRec-Think 是 Rollout-Beam reward 取 beam 内最佳命中,FLR 是 token-confidence + exact-match 混合 reward)。
- 本文的差异与推进:OneRec-Think 走显式 CoT 路线——在文本空间生成可读 rationale 序列再生成 itemic token,需要离线蒸馏 prune 后的 CoT 蒸馏数据,并在 Think-Ahead 部署架构里用预计算 thinking 调和延迟;FLR 走隐式 latent 路线——只新增一个
<|Thought|>token 在嵌入空间迭代刷新,零 CoT 标注、零 token 化生成,推理时延与无推理 LLM 等价。 - 可比的方法 / 实验差异:OneRec-Think 在 Kuaishou 工业短视频场景做工业部署(APP Stay Time +0.159%),公开 benchmark 用 Toys/Beauty 等 Amazon 子集;FLR 集中在 Amazon 四子集学术评估,未做工业 A/B。两者都展示了 reasoning 能在生成式推荐里带来非平凡增益,但代表了"explicit CoT 走通 + 工业延迟通过 Think-Ahead 化解"与"latent factor 拆分省去 CoT"两条迥异路径。
MLLMRec-R1 MLLMRec-R1 (Hefei Univ. of Technology, 2026-03-06)¶
关系:独立并发(FLR 未引用 MLLMRec-R1,两者殊途同归)· 已加载对方精读
- 共同关注的问题:都试图把 GRPO 风格 RL 引入 LLM 序列推荐场景,且都直面同一难题——推荐里 group-level reward 极易稀疏(rollout 全部不命中 → advantage 归零退化),需要重新设计 reward 让信号在组内仍有梯度。
- 相近的技术骨架:两者都采用「SFT → GRPO」两阶段、用相对组内归一化的 advantage,并都强调 reward 必须包含格式 / 命中之外的稠密成分(MLLMRec-R1 用 format reward + hit reward 的离散组合 + 离线蒸馏 CoT 监督;FLR 用 token confidence 稠密项 + exact match 离散项的连续组合 + 噪声扰动 latent 探索替代 token 采样)。
- 本文的差异与推进:MLLMRec-R1 的核心解法在数据 / 监督侧——MCoT 构建(caption + pseudo-CoT + DeepSeek-R1 精炼)+ 混合粒度数据增强(modality / prediction consistency 过滤)保证 GRPO 阶段拿到高质量 CoT 监督;FLR 的核心解法在结构 / 表征侧——多因子注意力 + 三正则保证 latent 本身可被 GRPO 高效优化。前者保留显式 CoT 但优化数据;后者删除 CoT 但优化结构。
- 可比的方法 / 实验差异:MLLMRec-R1 用 Qwen3-VL-8B + DeepSeek-R1 + LoRA、做多模态序列推荐(Microlens / Netflix / Movielens);FLR 用 Qwen2.5-1.5B 全参数微调,做纯文本序列推荐(Amazon × 4)。两者代表了"靠数据精炼让显式 CoT-GRPO 稳定" vs "靠结构因子化让隐式 latent-GRPO 稳定"的双胞胎对照。
7. 核心贡献总结¶
- 首次把多因子分解显式注入 latent reasoning:在 LLM-Rec 的 reasoning 表征上引入 K-head 因子注意力 + gating,打破 LARES / LatentR³ 单 latent 表达瓶颈。
- 三正则系统保障 disentanglement:orth (what)、attn-div (where)、sparse (who decides) 三轴互补,定量实验显示因子相关性从 0.44 降至 0.03。
- 为 latent 推荐 GRPO 量身定制 RL 设计:噪声扰动替代 token 采样、token-conf + exact-match 混合 reward、L2 归一 advantage、非对称 clipping + 反向 KL,使得 RL 阶段全 16 项指标稳定正向,逆转通用 GRPO 在 Games/Instruments 上的负迁移。
- 推理时延友好:与最朴素 LLM-Rec 几乎等价(仅一个 thought token),相比显式 CoT 推理时间快 10–20 倍,是工程落地的关键前提。
- 长尾增益突出:unpopular item 上的提升幅度系统性高于 popular,说明多因子 latent 推理捕捉到了 collaborative-only 信号缺失的语义维度。
8. 讨论与局限性¶
- 数据规模:仅 Amazon 四个 ≤5k item 子集,没有工业级 A/B 实验。OneRec-Think 提供了一个对照——latent reasoning 的工业可部署性可能依赖类似 Think-Ahead 这样的部署架构,但 FLR 的"零 token 化思考"特性反而让上线门槛更低。这一点亟待工业验证。
- K 的选择仍偏经验:虽然论文展示 K∈[2,4] 区间结果稳定,但跨数据集自动搜 K(uncertainty-based 自适应 weighting 已经在 $\lambda_i$ 上演示)是值得做的延伸。
- 与 OneRec-Think 的合流:理论上 FLR 的多因子 latent 与 OneRec-Think 的可读 CoT 不互斥——可以让每个因子对应一段可解释 CoT(类似"每个 attention head 触发一个 rationale 模块"),既保留 latent 的延迟优势,又能在调试 / 用户解释时输出可读理由。这是一个明显的 follow-up。
- uncertainty-based 多任务权重的稳定性:论文使用 [Kendall 2018] 自适应权重,但未在不同 random seed 下做敏感性分析;同样 FLR-GRPO 的 $\alpha=0.1, \beta_r=1.0$ 是 grid search 出的最优,跨数据集的鲁棒性需要更多验证。
- 可解释性距 explicit CoT 仍有差距:Figure 6 的 head 解读依赖事后人工标注(Action/Racing、Collectibles 等),并没有自动化机制把 head 标签对外暴露给用户或下游系统,是后续可优化方向。
整体来看,FLR 是一篇结构创新 + RL 适配双轮驱动的 latent reasoning 推荐工作:不靠生猛 CoT 标注堆量、不靠超大模型,而是从"多面用户偏好需要多因子 latent 容量"这一可证伪假设出发,做出可量化、可消融、可定性观察的设计,是 LLM-Rec 推理化路线中相对 cleanest 的一篇。