FEDIN: Frequency-Enhanced Deep Interest Network for Click-Through Rate Prediction¶
研究动机与背景¶
CTR(Click-Through Rate)预测是现代推荐系统的核心组件,连接用户偏好与候选物品。CTR 模型的效果在很大程度上取决于其从历史行为序列中提取真实用户兴趣的能力。深度序列模型(RNN [5,18,22]、Transformer [1,6,9,13,20]、SSM 等)虽然在捕捉时间依赖方面取得了进展,但在处理真实世界的用户行为时面临天然挑战:用户行为往往混合着长期周期性习惯和短期随机噪声,纯时域方法(包括 DIN、DIEN、TIN 等带 target attention 的模型)对这种点级噪声非常敏感,难以从随机点击中分离出稳定的周期性模式。
为解决时域建模的局限,频域分析成为一个有前景的方向,其在长程时间序列预测中已有成功先例 [2,17,25,26]。傅里叶变换(Fourier Transform)能提供信号周期性的全局视角,天然适合做去噪与模式识别。受此启发,序列推荐领域出现了一批频域方法:
- FMLP-Rec [24]、FEARec [3] 引入可学习滤波器抑制随机噪声;
- DIFF [7](SOTA 代表)用离散傅里叶变换 + 多序列滤波,强化长期稳定兴趣。
然而,作者指出即使是 DIFF 这类先进方法,仍然独立于候选物品对用户序列做频域分析。论文的核心论点是:用户行为序列是多形态的(polymorphic)——同一序列在没有目标物品上下文时,频谱中真实信号与背景噪声难以区分;只有在目标物品的条件下,频谱才会呈现明显的低熵集中模式。
为支撑这一论点,作者做了一个关键的实证观察。在标准 target attention 骨干上,他们统计了 attention 分数在不同目标物品下的频谱:
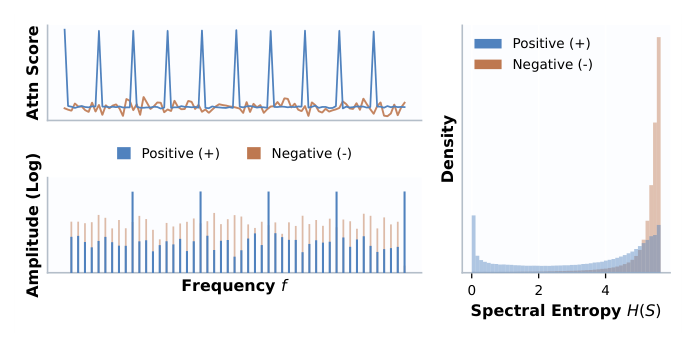
核心实证发现: 1. 当目标物品是"正样本"(用户实际感兴趣)时,target attention 在历史序列上的响应呈现强周期共振,频谱表现为少数高幅度的尖峰,频谱熵低; 2. 当目标物品是"负样本"(用户不感兴趣)时,attention 响应分布平坦,频谱接近白噪声,频谱熵高; 3. 这一现象在 Tmall、Taobao、Alipay 三个数据集上稳定复现。
这意味着目标物品本身充当了一个天然的频率选择器,单纯对原始行为序列做频谱分析是不够的——必须把目标条件信息注入频域。这正是 FEDIN 的核心立论:频域分析应该是目标感知的(target-aware)。
核心方法:FEDIN 整体架构¶
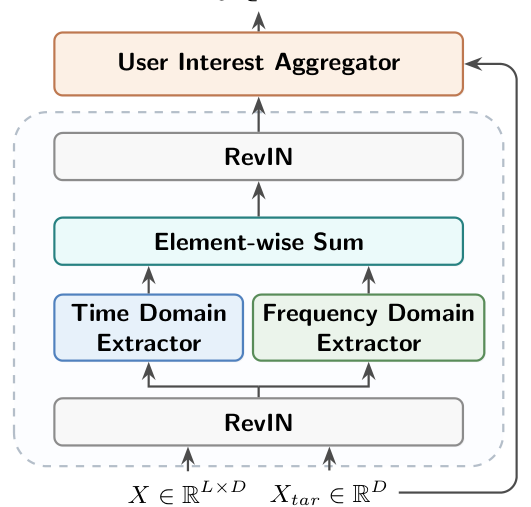
FEDIN 沿用 Embedding & MLP 范式,输入为用户行为序列 $\mathbf{X} \in \mathbb{R}^{L \times D}$ 与目标物品 $\mathbf{X}_{\text{tar}} \in \mathbb{R}^{D}$,输出用户兴趣表示 $\mathbf{U} \in \mathbb{R}^{D}$。整体由四个模块串联:
- RevIN 预处理:用 Reversible Instance Normalization [8] 缓解用户行为序列的非平稳与分布漂移问题;
- 时域分支(Time-Domain Branch):捕捉局部序列演化;
- 频域分支(Frequency-Domain Branch):通过目标感知的频谱滤波恢复全局周期共振;
- User Interest Aggregator:用 Top-k Target Attention 动态融合两个视图。
两条分支高度并行化(互不依赖),适合实时部署。
时域分支(Time-Domain Branch)¶
时域分支的目标是从时域序列中精细抽取兴趣演化。由于直接在原始序列上跑 Transformer 既低效也未必能拿到更好的精度(受噪声主导),作者设计了一个粗-细两阶段流程。
Step 1:Target Attention 粗滤波。先用 target-aware 的注意力对点级噪声做粗筛:
$$ \mathbf{X}_{\text{attn}} = \text{Softmax}(\mathbf{X}_{\text{tar}} \mathbf{X}^{\top} / \alpha) \odot \mathbf{X} \tag{1} $$
其中 $\alpha$ 为缩放因子,$\odot$ 为按元素乘。注意:与传统 target attention 做加权 pooling 不同,这里得到的是一个加权的序列 $\mathbf{X}_{\text{attn}} \in \mathbb{R}^{L \times D}$,保留时间维度供后续细粒度建模使用。
Step 2:Patching + Transformer 细粒度演化。为高效捕捉演化模式且支持长序列,借鉴 PatchTST [11] 的 patching 策略:把 $\mathbf{X}_{\text{attn}}$ 切分为 $N$ 个非重叠 patch(每 patch 大小 $P$),得到 $\mathbf{X}_{\text{patch}} \in \mathbb{R}^{N \times P \times D}$。若 $L$ 不能整除 $P$ 则补零。每个 patch 拍平后线性投影到维度 $D$,再交给 Transformer encoder 建模 patch 间依赖,最后由 MLP 输出时域兴趣表示 $\mathbf{X}_{\text{time}} \in \mathbb{R}^{L' \times D}$。
这一设计将"什么样的物品被关注"(target attention)与"关注模式如何随时间演化"(patch Transformer)解耦。
频域分支(Frequency-Domain Branch)¶
频域分支的目标是通过目标感知的频谱滤波,从噪声序列中恢复集中的谐波模式。
Step 1:目标条件下的 attention 分数序列。计算原始 target attention 分数(不做 softmax):
$$ \mathbf{X}_{\text{score}} = \mathbf{X} \mathbf{X}_{\text{tar}}^{\top} / \alpha \tag{2} $$
得到 $\mathbf{X}_{\text{score}} \in \mathbb{R}^{L}$,刻画每个历史行为对目标物品的相关性。
Step 2:目标感知的频谱构造。让 $\hat{\mathbf{X}}_{\text{score}} = \mathcal{F}(\mathbf{X}_{\text{score}}) \in \mathbb{C}^{L}$ 表示 target-conditioned 频谱。与既往工作直接对原始 $\mathbf{X}$ 做 FFT 不同,FEDIN 用 attention 分数频谱去调制行为序列频谱,使最终频谱携带目标条件信息:
$$ \hat{\mathbf{X}}_{\text{attn}} = \text{Softmax}(\text{Amp}(\hat{\mathbf{X}}_{\text{score}})) \otimes \mathcal{F}(\mathbf{X}) \tag{3} $$
其中 $\mathcal{F}(\cdot)$ 为 FFT,$\otimes$ 为沿维度 $D$ 的广播按元素乘,$\text{Amp}(\cdot)$ 取复数幅值。这一操作的物理含义:在用户对目标物品有强共振(特定频率下幅值高)的频段上,进一步加权放大行为序列的对应频率成分。
Step 3:可学习的复值滤波器。为隔离信号与噪声,需要一个能抑制高熵频率、放大低熵频率的滤波器。FEDIN 不用固定滤波器,而是引入复值 MLP(Complex-Valued MLP)作为可学习滤波器,遵循 [15] 提出的标准复数 MLP 表述以严格保留频谱的相幅耦合:
$$ \hat{\mathbf{X}}_{\text{freq}} = \mathcal{F}^{-1}(\text{MLP}(\hat{\mathbf{X}}_{\text{attn}})) \tag{4} $$
复 MLP 在复频谱上学习一个非线性映射,把含噪输入谱映射到清洁兴趣谱,自适应地放大主导谐波并抑制噪声分量。
Step 4:自适应共振缩放(Adaptive Resonance Scaling)。并不是所有 user-item 对都呈现强周期性。基于"正样本谱熵更低"的实证观察,作者引入一个由谱清晰度(spectral clarity)驱动的门控:
$$ \mathbf{X}_{\text{freq}} = \text{Sigmoid}(\text{MLP}(\text{Amp}(\hat{\mathbf{X}}_{\text{score}}))) \cdot \hat{\mathbf{X}}_{\text{freq}} \tag{5} $$
当检测到清晰共振模式时,模型更依赖频域视图;否则回落到时域视图。这条门控让 FEDIN 在弱周期场景下不会被频域噪声误导。
复杂度分析:频域分支由 FFT 主导,复杂度 $O(L \log L)$,相比标准自注意力 $O(L^2)$ 在长序列场景下有显著效率优势。
User Interest Aggregator¶
时域分支提供局部演化 $\mathbf{X}_{\text{time}}$,频域分支提供全局周期 $\mathbf{X}_{\text{freq}}$。先按元素相加得到混合表示 $\mathbf{X}_{\text{mix}}$,再用 Top-k Target Attention 得最终兴趣:
$$ \mathbf{U} = \text{Softmax}(\text{Top-}k(\mathbf{X}_{\text{tar}} \mathbf{X}_{\text{mix}}^{\top}/\alpha, k)) \cdot \mathbf{X}_{\text{mix}} \tag{6} $$
与传统 target attention 不同,Top-k 版本只保留与目标最相似的 $k$ 个位置:在 softmax 前把非 top-$k$ 的注意力分数 mask 为 $-\infty$,确保可微分性同时让梯度仅经过被选索引。这一思路借鉴自多任务学习中"参数隔离防止 seesaw"[10,12,14] 的策略,避免冲突或弱兴趣信号稀释最终预测。
实验¶
数据集与评估协议¶
在三个公开数据集上评测:Tmall¹、Taobao²、Alipay³。划分为训练 / 验证 / 测试三段,按全局时间线划分。评估指标为 AUC 与 Group AUC(GAUC)[21]。
¹https://tianchi.aliyun.com/dataset/dataDetail?dataId=42 ²https://tianchi.aliyun.com/dataset/dataDetail?dataId=649 ³https://tianchi.aliyun.com/dataset/dataDetail?dataId=53
Baselines¶
对比 6 个 SOTA CTR/序列推荐模型:DIN [21]、DIEN [22]、SASRec [6]、BERT4Rec [13]、GRU4Rec [5]、BST [1] 和 DIFF [7]。另加 Sum Pooling 作 base。其中 DIFF 原本面向 next-item 预测,作者为公平起见将其输出层从 ranking-based 替换为 MLP 预测头并融入候选物品 embedding,使其适配 target-aware CTR 任务。
实现细节¶
所有模型基于 FuxiCTR [27] 实现:Adam 优化器,学习率 $5 \times 10^{-4}$,batch size 2048,embedding 维度 32,最大序列长度 100。
整体性能¶
Table 1:三个公开推荐数据集上各方法的总体表现。粗体为最佳,下划线为基线最佳。星号表示相对最佳基线提升达 $p < 0.05$ 显著。
| Model | Tmall GAUC | Tmall AUC | Alipay GAUC | Alipay AUC | Taobao GAUC | Taobao AUC |
|---|---|---|---|---|---|---|
| Sum Pooling | 0.8978 | 0.8873 | 0.8557 | 0.8345 | 0.9345 | 0.9337 |
| DIN | 0.9547 | 0.9518 | 0.8897 | 0.8832 | 0.9689 | 0.9664 |
| DIEN | 0.9237 | 0.9434 | 0.8980 | 0.8953 | 0.9443 | 0.9442 |
| SASRec | 0.9183 | 0.9246 | 0.9238 | 0.9312 | 0.9583 | 0.9584 |
| BERT4Rec | 0.9103 | 0.9157 | 0.9179 | 0.9189 | 0.9523 | 0.9535 |
| GRU4Rec | 0.9210 | 0.9242 | 0.9268 | 0.9289 | 0.9618 | 0.9638 |
| BST | 0.9233 | 0.9269 | 0.9264 | 0.9285 | 0.9562 | 0.9576 |
| DIFF | 0.8513 | 0.8618 | 0.8962 | 0.8995 | 0.9463 | 0.9475 |
| FEDIN | 0.9658* | 0.9666* | 0.9335* | 0.9320* | 0.9740* | 0.9729* |
结论分析:
- FEDIN 在三个数据集上 GAUC/AUC 均一致达到 SOTA,验证了频域增强方案的有效性。
- 基线模型在不同数据集上稳定性差异大:注意力类模型(DIN)在 Tmall/Taobao 表现优异,但在 Alipay 上明显落后;这反映出 Alipay 数据稀疏度与行为复杂度异于电商场景。
- DIFF 作为频域 SOTA,反而成绩最差。作者归因于其原 next-item 设计与 CTR 任务的不匹配——尽管做了适配改造,target-agnostic 频谱滤波在 CTR 场景下仍显劣势,间接支撑了"频谱必须 target-aware"这一立论。
- FEDIN 的稳定性来自双分支设计:当时域特征不稳(数据稀疏 / 噪声大)时,频域分支提供补偿。
消融研究¶
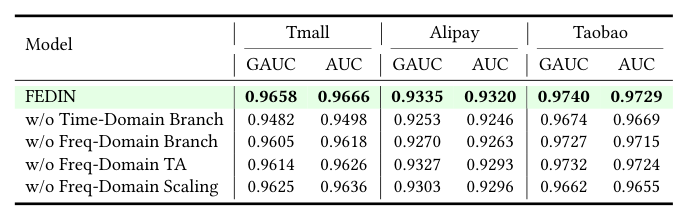
| Model | Tmall GAUC | Tmall AUC | Alipay GAUC | Alipay AUC | Taobao GAUC | Taobao AUC |
|---|---|---|---|---|---|---|
| FEDIN | 0.9658 | 0.9666 | 0.9335 | 0.9320 | 0.9740 | 0.9729 |
| w/o Time-Domain Branch | 0.9482 | 0.9498 | 0.9253 | 0.9246 | 0.9674 | 0.9669 |
| w/o Freq-Domain Branch | 0.9605 | 0.9618 | 0.9270 | 0.9263 | 0.9727 | 0.9715 |
| w/o Freq-Domain TA | 0.9614 | 0.9626 | 0.9327 | 0.9293 | 0.9732 | 0.9724 |
| w/o Freq-Domain Scaling | 0.9625 | 0.9636 | 0.9303 | 0.9296 | 0.9662 | 0.9655 |
逐项分析:
- 双分支必要性(w/o Time-Domain Branch、w/o Freq-Domain Branch):去掉任一分支均导致明显下降,证实两个视图捕捉互补信息——频域负责全局周期模式,时域负责局部精细演化。
- 目标感知频谱滤波(w/o Freq-Domain TA):把式 (3) 中由 attention 分数生成的 target-aware 频谱替换为静态可学习权重矩阵(即退化为 target-agnostic 滤波器),三个数据集上指标均下降。这一变体直接验证了核心论点:仅用用户行为谱不足以分离信号和噪声,目标物品才是激活共振模式的必要条件。
- 自适应缩放(w/o Freq-Domain Scaling):去掉式 (5) 的门控(直接使用未缩放的频域输出),性能下降表明并非所有 user-item 交互都呈强周期性。自适应缩放使模型能在频域信号清晰时优先依赖频域、在弱周期场景下回退,提升了模型灵活性。
超参分析¶
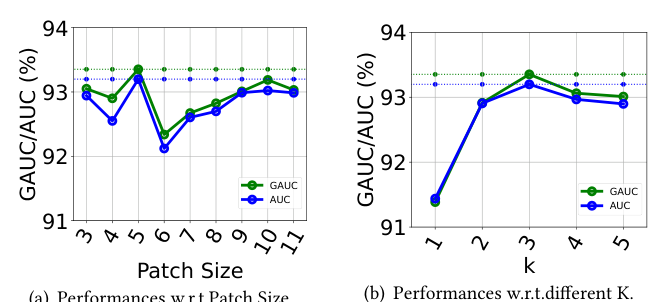
FEDIN 有两个对性能影响显著的超参:
- Patch Size $P$(时域分支):极端值(过小 / 过大)会破坏局部上下文或导致信息损失,存在最优中间值。
- Top-k 数量 $K$(User Interest Aggregator):需要在兴趣多样性与噪声抑制间平衡——$K$ 太小覆盖度不够,$K$ 太大引入无关信号、加剧 seesaw 现象。
噪声抗性分析¶
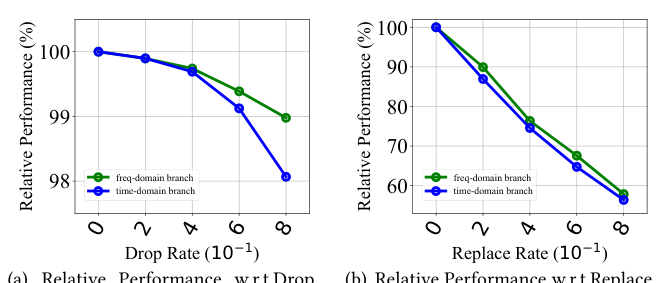
为进一步验证频域增强设计的鲁棒性,作者构造了合成噪声实验,在不同腐蚀比 $\rho \in \{0, 0.2, 0.4, 0.6, 0.8\}$ 下模拟两类真实噪声场景:
- Drop Noise:随机删除行为,模拟数据缺失;
- Replace Noise:用均匀采样物品替换真实行为,模拟探索性 / 误点击。
对比 FEDIN 的频域分支与时域分支在腐蚀下的相对性能衰减:
结论分析:
- 频域分支稳定性显著高于时域分支;当 $\rho$ 增大时,时域分支在 Drop / Replace 两种场景下都出现陡降(标准 RNN/Transformer 因点级误差传播);
- 频域分支表现出温和的性能衰减——随机噪声在频域上呈分散的高熵波动,而核心兴趣集中能量于少数共振峰,谱滤波天然抑制高熵噪声。
- 在 Replace Rate 0.6-0.8 时,频域分支仍能保持 60-80% 的相对性能,时域分支已跌至 60% 以下。
这一实验从机制层面解释了为什么频域增强提升了 CTR 模型在真实数据下的鲁棒性。
核心贡献总结¶
- 新的实证发现:通过 attention 分数频谱的统计分析,首次揭示用户兴趣在频域呈现目标条件下的低熵签名——目标物品扮演天然的频率选择器,为频谱推荐提供了新的理论依据。
- 目标感知频域滤波:用 target attention 分数构造频谱调制(式 3),并用复值 MLP(式 4)替代固定滤波器,让频域分析显式注入目标条件信息。
- 双分支混合架构:频域(全局周期 / 抗噪)与时域(局部演化 / 精度)互补;自适应共振缩放门控在弱周期场景下回退到时域;Top-k Target Attention 隔离冲突信号、抑制 seesaw。
- 复杂度优势:频域分支为 $O(L \log L)$,相比 $O(L^2)$ 自注意力在长序列下更高效。
讨论与局限性¶
值得借鉴的设计:
- "Target item 作为频率选择器"是一个干净的认识论翻转——既往频域工作(FMLP-Rec / FEARec / DIFF)默认 user 序列频谱本身就有可分离结构,FEDIN 用一张实证图(Figure 1 右)就证伪了这一假设。这种从"统计分布差异"出发提出建模假设的研究路径值得借鉴。
- 用 target attention 分数频谱去调制行为序列频谱(式 3)是一个非常轻量的目标条件注入手段,几乎没有额外参数代价。
- 复值 MLP 严格保留相幅耦合是一个细节但重要的设计选择——常见做法是把复数拆成实部虚部分别走实数 MLP,这会破坏频域的几何结构。
存在的局限: 1. 缺少工业 A/B:仅在三个公开数据集上评测,没有线上部署收益,作者也未声称工业落地。Tencent 团队的论文但缺乏腾讯线上实验是一个明显短板。 2. 序列长度有限:实验 max length = 100,对于工业场景动辄几千甚至上万的 lifelong sequence,频谱滤波的 $O(L \log L)$ 优势没有得到充分展示。 3. DIFF 基线表现异常差:DIFF 在 Tmall 上 GAUC 只有 0.8513,远低于其他基线,作者只用一句"原 next-item 设计与 CTR 任务不匹配"解释。一个更公平的实验是把 DIFF 也包入完整的 target-aware 适配框架,否则"target-aware 频谱比 target-agnostic 频谱好"的论证有些刷分嫌疑。 4. 频域分支的 RevIN 复杂度:FFT 假设序列平稳,RevIN 处理了一阶分布漂移,但用户行为序列存在更复杂的非平稳性(兴趣漂移、突发热点),单次 RevIN 是否够用值得商榷。 5. 复值 MLP 的训练稳定性:复数 backprop 实现细节(如复梯度、复数初始化)论文未深入讨论,复用门槛高于纯实数模型。
与已有工作的差异:
- 相比 FMLP-Rec / FEARec:用了 target-aware 而非 target-agnostic 频谱;用了复值 MLP 而非简单门控滤波器。
- 相比 DIFF:DIFF 通过多序列离散傅里叶滤波突出长期稳定兴趣,但仍 target-agnostic;FEDIN 的核心 delta 是把 target item 写进频谱构造。
- 相比 DIN/DIEN:传统 target attention 仅做时域加权 pooling;FEDIN 用 target attention 同时驱动时域 patch 序列与频域调制谱,是 target attention 概念在频域的扩展。
整体上 FEDIN 是一篇机制清晰、实证扎实、动机鲜明的中等规模论文,方法贡献集中在"如何把目标信息正确地注入频域分析",对正在做 CTR 长序列建模 / 频域去噪 / target attention 改进的团队都有借鉴价值;但工业部署细节缺失是其影响力上限。