自回归 Semantic ID 生成的表达力极限:从解码树到 Latte 隐 token 解耦¶
Authors: Yupeng Hou¹, Haven Kim¹, Clark Mingxuan Ju², Eduardo Escoto¹, Neil Shah², Julian McAuley¹
Affiliations: ¹ University of California, San Diego ² Snap Inc.
ArXiv: 2605.06331 (2026-05-07)
Code: https://github.com/hyp1231/Latte
1. 研究动机与背景¶
1.1 生成式推荐与 Semantic ID 范式¶
生成式推荐 (Generative Recommendation, GR) 已成为序列推荐的主流范式。其核心做法是把每个 item $i$ tokenize 为一段离散 token 序列——Semantic ID (SID) $(c^{(1)}, c^{(2)}, \ldots, c^{(m)})$,其中每个 token $c^{(j)}$ 选自一个大小为 $M$、跨所有 item 共享的 codebook $\mathcal{C}^{(j)}$。给定用户历史 $u = (i_1, i_2, \ldots, i_{t-1})$(每条历史也以 SID 形式编码),模型自回归生成下一目标 item 的 SID:
$$ \mathbb{P}(i_t \mid u) = \prod_{j=1}^{m} \mathbb{P}\bigl(c_t^{(j)} \mid c_t^{(1)}, \ldots, c_t^{(j-1)}, u\bigr) \tag{1} $$
这一范式催生了 TIGER、LETTER、ActionPiece、PSID、OneRec、PLUM 等一系列工作。其中绝大多数研究的焦点是 如何更好地 tokenize——RQ-VAE、RQ-KMeans、OPQ、加入协作信号、多模态融合、collision 控制等。但自回归生成过程本身对模型表达能力的影响却被长期忽视,即使它直接决定了每个候选 item 的得分如何被组合与约束。
本文是 Yupeng Hou 团队 (UCSD + Snap) 自 TIGER 之后又一篇直击 GR 范式根基的理论 + 方法论文,第一次正式分析 AR-NTP 解码过程的表达力极限,并提出极简补救方案 Latte:仅在 SID 序列前预置一个随机 latent token,平均带来 NDCG@10 +3.45% 的相对提升。
1.2 一句话核心观察¶
把 SID 序列的自回归生成视为"在解码树 $\mathcal{T}$ 上从根走到叶"。两条共享长前缀的 SID(即 tree distance 小)必然在前 $k$ 个 token 上贡献完全相同的概率因子,因此对任意用户,它们的生成概率都强相关:
$$ \rho(i, i') := \mathrm{Corr}\bigl(\mathbb{P}(i \mid u), \mathbb{P}(i' \mid u)\bigr) \uparrow \quad \text{when} \quad d_{\mathcal{T}}(i, i') \downarrow. $$
这种结构性耦合限制了模型对两类基本现象的表达能力:
- rank reversal(用户级排序反转):不同用户对 (Pokémon Scarlet, Pokémon Sun) 这种结构相邻的 item 应有不同偏好顺序,但模型被迫给所有用户类似的相对排序;
- forced transitivity(强制传递性):如果模型把 $i_1, i_2$ 判为相似(共同被 $G_A$ 用户群偏好)、把 $i_2, i_3$ 判为相似(共同被 $G_B$ 偏好),它会被迫把 $i_1, i_3$ 也判为相似,无法捕获两者实际不相似的事实。
这两类局限性可以用最简单的协同过滤模型轻松表达,却被 GR 模型的解码树结构强制压制。
1.3 解决方案:Latte = Latent + Latte(forest of trees)¶
Latte 的修改极简:训练时对每个目标 SID $(c_t^{(1)}, \ldots, c_t^{(m)})$,从一个小的 latent token 词表 $\mathcal{L} = \{\ell_1, \ldots, \ell_{M'}\}$ 中均匀采样一个 $\ell$,得到增广序列 $(\ell, c_t^{(1)}, \ldots, c_t^{(m)})$,按标准 next-token loss 训练;推理时模型先自回归生成 $\ell$,再生成 SID。等价地,原来的"单棵解码树"被替换成"以 super-root 为根、$|\mathcal{L}|$ 棵子树拼成的森林"——结构上越接近的两个 item 现在有概率走入不同 latent 路径,从而获得动态的、依赖用户与采样的 effective tree distance。
实验在 Amazon Reviews 2023 三类目(Instruments / Scientific / Games)一致超越 GRU4Rec / BERT4Rec / SASRec / FMLP-Rec / HSTU / FDSA / S³-Rec / TIGER / LETTER / ActionPiece / PSID 等所有主流 baseline,平均带来 NDCG@10 +3.45% 提升。Latte 还作为一种通用 modification,与 OPQ / RQ-VAE / RQ-KMeans 三种 tokenizer 都兼容。
1.4 一个延伸视角:把 latent token 与归纳偏置绑定¶
第 6 节进一步探索把 latent token 与具体的归纳偏置绑定的可能性。在多模态场景下,每个 SID token 来自某种模态(playlist / tag / metadata),固定模态序对所有用户都是次优——不同用户对不同模态的偏好不同。Latte 自然把每个 latent token 绑定到 SID 的一个特定 permutation,让模型在推理时为每个用户自主选择最优模态序。在 Million Playlist Dataset 上,模型选择频率与 fixed-order baseline 表现强相关,自动浮现出最优模态序。
2. 符号与背景¶
| 符号 | 含义 |
|---|---|
| $i, i_t$ | item、第 $t$ 个交互 item |
| $u = (i_1, \ldots, i_{t-1})$ | 用户历史(以 SID 序列表示) |
| $(c^{(1)}, \ldots, c^{(m)})$ | 一个 SID,长度 $m$ |
| $\mathcal{C}^{(j)}, M$ | 第 $j$ 位 codebook 与其大小 |
| $\mathcal{T}$ | 由所有合法 SID 形成的深度 $m$ 解码树 |
| $d_{\mathcal{T}}(i, i')$ | $i$ 与 $i'$ 在 $\mathcal{T}$ 中的 tree distance |
| $\rho(i, i')$ | item 生成概率在用户群上的 Pearson 相关 |
| $\sigma^2$ | 单个 item 生成概率在用户群上的方差 |
| $\mathcal{R}(i, i')$ | item pair $(i, i')$ 上的 rank reversal 事件 |
| $\mu = \lvert \mathbb{E}[\mathbb{P}(i \mid u) - \mathbb{P}(i' \mid u)]\rvert$ | 期望概率差(全局趋势) |
| $\mathcal{L} = \{\ell_1, \ldots, \ell_{M'}\}$ | latent token 词表,$M' \ll M$ |
Definition 2.1 (Decoding Tree) $\mathcal{T}$ 是深度 $m$ 的树:root 表示空序列,深度 $j$ 的节点对应一个长度为 $j$ 的 token 前缀 $(c^{(1)}, \ldots, c^{(j)})$;只有当子节点的前缀恰好以一个 valid token 扩展父节点的前缀时存在边。每个叶节点唯一对应一个 item。
Definition 2.2 (Tree Distance) 设两个 item 的 SID 共享长度为 $k$ 的最长公共前缀,则 $$ d_{\mathcal{T}}(i, i') = 2(m - k). \tag{2} $$
注意 $d_{\mathcal{T}}$ 满足 ultrametric inequality:$d_{\mathcal{T}}(i_1, i_3) \le \max\bigl(d_{\mathcal{T}}(i_1, i_2), d_{\mathcal{T}}(i_2, i_3)\bigr)$,这一点在第 5 节 forced transitivity 的证明中起核心作用。
3. 自回归 SID 生成的表达力局限¶
3.1 生成 = 解码树遍历¶
公式 (1) 的因式分解决定:从 root 出发逐 token 生成 SID,等价于在 $\mathcal{T}$ 上从 root 走到某个叶节点,每生成一个 token 即下沉一层。这种几何视角把"两个 item 有多少共享 token 前缀"转化为可严格度量的 tree distance,是后续所有理论分析的基石。
3.2 Tree distance vs. 生成概率:耦合现象¶
动机推导。设两个 item 共享长度为 $k$ 的前缀,则它们的生成概率可分解为:
$$ \mathbb{P}(i \mid u) = \underbrace{\prod_{j=1}^{k} \mathbb{P}(c^{(j)} \mid c^{(1)}, \ldots, c^{(j-1)}, u)}_{\text{shared prefix}} \cdot \prod_{j=k+1}^{m} \mathbb{P}(c^{(j)} \mid c^{(1)}, \ldots, c^{(j-1)}, u), \tag{3} $$
$$ \mathbb{P}(i' \mid u) = \underbrace{\prod_{j=1}^{k} \mathbb{P}(c'^{(j)} \mid c'^{(1)}, \ldots, c'^{(j-1)}, u)}_{\text{shared prefix}} \cdot \prod_{j=k+1}^{m} \mathbb{P}(c'^{(j)} \mid c'^{(1)}, \ldots, c'^{(j-1)}, u), \tag{4} $$
其中前 $k$ 项完全相同(因为 $c^{(j)} = c'^{(j)}$ for $j \le k$),它们仅依赖共享前缀和用户。这意味着:tree distance 越小(共享前缀越长),生成概率受同一个"共享因子"主导越多,跨用户表现越相似。
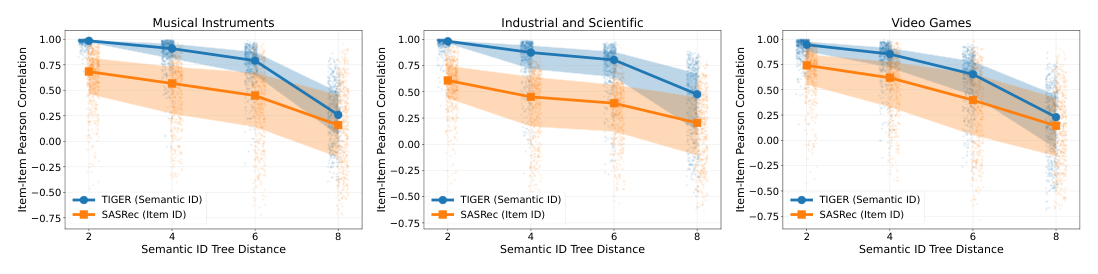
实证验证。在 Amazon-2023 三个数据集上,作者把 1,024 对 item 按 tree distance $\in \{2, 4, 6, 8\}$ 分箱,每对在 512 个用户上计算两个生成概率序列的 Pearson 相关 $\rho(i, i')$。结果显示:
- TIGER 在 distance 2 上的 $\rho$ 接近 1.0;distance 4 仍 > 0.8;随 distance 增大单调下降;
- 作为对照,item-ID-based 的 SASRec 没有 tree 结构,$\rho$ 在所有 distance bin 都明显更低且无单调依赖。
Assumption 3.3 (Monotonic Coupling) 对任意阈值 $\delta$,$\mathbb{P}(\rho(i, i') > \delta)$ 关于 $d_{\mathcal{T}}(i, i')$ 单调递减——即结构相邻的 item 高概率耦合更强。
3.3 局限 1:用户级偏好不可表达 (Rank Reversal)¶
定义。两个独立用户 $u, u' \overset{\text{iid}}{\sim} \mathcal{U}$ 上的 rank reversal 事件为
$$ \mathcal{R}(i, i') := \bigl\{\mathbb{P}(i \mid u) > \mathbb{P}(i' \mid u),\ \mathbb{P}(i \mid u') < \mathbb{P}(i' \mid u')\bigr\} \cup \bigl\{\text{symmetric}\bigr\}. \tag{5} $$
如果 $\mathcal{R}$ 的概率为零,则两个 item 对所有用户的相对顺序固定,等价于"非个性化"——这在推荐里是致命缺陷。
Theorem 3.4 (Correlation Suppresses Rank Reversals) 设 $\mu = \lvert \mathbb{E}[\mathbb{P}(i \mid u) - \mathbb{P}(i' \mid u)]\rvert$,$\sigma^2$ 为生成概率的方差(假设 $i, i'$ 共享同一 $\sigma^2$),$\rho = \rho(i, i')$。则 rank reversal 事件的概率上界为
$$ \mathbb{P}(\mathcal{R}(i, i')) \le \frac{4\sigma^2(1 - \rho)}{\mu^2 + 2\sigma^2(1 - \rho)}. \tag{6} $$
证明骨架(见原文 Appendix B):
- Lemma B.2(reversal 分解):由 $u, u'$ 独立可得 $\mathbb{P}(\mathcal{R}) = 2\mathbb{P}(D > 0)\mathbb{P}(D < 0)$,其中 $D := \mathbb{P}(i \mid u) - \mathbb{P}(i' \mid u)$;
- Lemma B.3(gap variance):在等方差假设下 $\mathrm{Var}(D) = 2\sigma^2(1 - \rho)$;
- Cantelli 不等式:$\mathbb{P}(D - \mu \le -\mu) \le \frac{\mathrm{Var}(D)}{\mathrm{Var}(D) + \mu^2}$,代入 (B.3) 得 (6)。
直观含义:由 Assumption 3.3,结构相邻 ($d_{\mathcal{T}}$ 小 $\Rightarrow \rho \to 1$) 的 item 满足 $\mathbb{P}(\mathcal{R}) \to 0$——模型几乎无法对它们产生用户级排序反转。即"Alice 偏好 Pokémon Scarlet > Sun" + "Bob 偏好 Sun > Scarlet"这种朴素分歧,在 GR 中会被结构性压制。
3.4 局限 2:item-item 相似性不可表达 (Forced Transitivity)¶
视角切换。从 collaborative filtering 的角度看,item-item similarity 由用户偏好矩阵的行内积刻画。本文形式化地定义:
$$ \rho(i, i') = \mathrm{Corr}(\mathbf{P}_{i, :}, \mathbf{P}_{i', :}) = \left\langle \frac{\mathbf{P}_{i, :} - \bar{P}_i}{\sigma_i},\ \frac{\mathbf{P}_{i', :} - \bar{P}_{i'}}{\sigma_{i'}} \right\rangle, $$
其中 $\mathbf{P}_{i, :}$ 是 item $i$ 在所有用户上的生成概率向量(见 Appendix C.2)。$\rho(i, i') \approx 1$ 意味着 item-item similar;$\rho \approx 0$ 意味着 dissimilar。
考虑三件 item $i_1, i_2, i_3$ 与两个不重叠的用户群 $G_A, G_B$:
- $i_1$:仅 $G_A$ 喜欢;
- $i_2$:$G_A$ 和 $G_B$ 都喜欢;
- $i_3$:仅 $G_B$ 喜欢。
一个灵活的 CF 模型应同时表达 $i_1 \sim i_2$(共同被 $G_A$ 偏好)和 $i_2 \sim i_3$(共同被 $G_B$ 偏好),同时 $i_1 \not\sim i_3$(用户群不相交)。这种 intransitive similarity 是真实推荐场景的常态。
Theorem 3.5 (Forced Transitivity) 在 Assumption 3.3 下,假设高相似性 ($\rho > \tau$) 蕴含小 tree distance ($d_{\mathcal{T}} \le \delta$),反之亦然。若模型同时捕获 $\rho(i_1, i_2) > \tau$ 与 $\rho(i_2, i_3) > \tau$,则它被强制给出 $\rho(i_1, i_3) > \tau$,无法表达 $i_1, i_3$ 的不相似。
证明骨架(见 Appendix C.3):
- 由假设:$\rho(i_1, i_2) > \tau \Rightarrow d_{\mathcal{T}}(i_1, i_2) \le \delta$,同理 $d_{\mathcal{T}}(i_2, i_3) \le \delta$;
- Lemma C.1:tree distance 满足 ultrametric 不等式 $d_{\mathcal{T}}(i_1, i_3) \le \max\bigl(d_{\mathcal{T}}(i_1, i_2), d_{\mathcal{T}}(i_2, i_3)\bigr) \le \delta$;
- 由双向假设:$d_{\mathcal{T}}(i_1, i_3) \le \delta \Rightarrow \rho(i_1, i_3) > \tau$。
直观含义:解码树作为 ultrametric 空间,在物理上不允许"$i_2$ 同时与 $i_1, i_3$ 邻近,但 $i_1, i_3$ 互不邻近"——这正是常规度量空间允许、却被树结构禁止的拓扑。
4. Latte:用 latent token 把单棵树展开成森林¶
4.1 总体框架¶
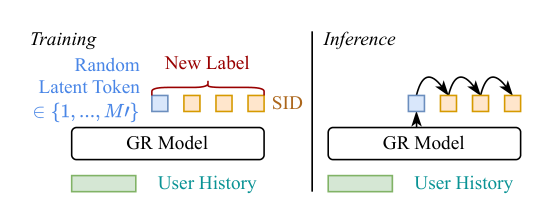
Latte 在标准 GR 框架上做的修改极小:
- 训练:定义 latent token 词表 $\mathcal{L} = \{\ell_1, \ldots, \ell_{M'}\}$,$M' \ll M$。对每个训练样本,随机均匀采样 $\ell \in \mathcal{L}$ 并预置到目标 SID 前,新目标序列为 $(\ell, c_t^{(1)}, c_t^{(2)}, \ldots, c_t^{(m)})$,按标准 next-token CE loss 训练;
- 推理:不施加任何对 latent token 的约束,模型先自回归生成 $\ell$,然后生成 SID。item 得分按 latent token 边缘化得到:
$$ \mathbb{P}(i_t \mid u) = \mathop{\mathrm{Agg}}_{\ell \in \mathcal{L}}\Biggl(\mathbb{P}(\ell \mid u) \cdot \prod_{j=1}^{m} \mathbb{P}(c_t^{(j)} \mid \ell, c_t^{(1:j-1)}, u)\Biggr), \tag{7} $$
其中 $\mathrm{Agg}$ 是聚合算子(实践中 $\mathrm{sum}$ 或 $\mathrm{max}$,本文 main table 用 $\mathrm{max}$,beam search 高效近似)。
4.2 Dynamic tree distance:从单树到森林¶
标准 GR 的 tree distance $d_{\mathcal{T}}(i, i')$ 是常量。Latte 在 root 之上引入 super-root,下挂 $|\mathcal{L}|$ 棵原始解码树的 copies——形成一个 forest of trees。引入 dominant latent token $\ell^*(i, u) := \arg\max_\ell \mathbb{P}(\ell \mid u)\mathbb{P}(i \mid \ell, u)$,则在 $\mathrm{Agg} = \max$ 下,$(i, i')$ 在用户 $u$ 视角下的 effective distance 变为:
$$ d_{\mathrm{eff}}(i, i'; u) = \begin{cases} d_{\mathcal{T}}(i, i'), & \text{if } \ell^*(i, u) = \ell^*(i', u), \\ 2(m + 1), & \text{if } \ell^*(i, u) \ne \ell^*(i', u). \end{cases} \tag{8} $$
也就是说,结构相邻的 item 一旦走入不同 latent 路径,effective distance 直接跳到森林的最大深度 $2(m+1)$,前缀立即在 super-root 之下分叉。这放松了概率耦合:相邻 item 不再被强制走一段共同前缀,从而打破公式 (3-4) 揭示的"shared prefix 因子主导跨用户行为"。
4.3 表达力提升的形式化分析¶
Proposition C.2(Latte 松弛 rank-reversal 约束):在 $\mathbb{P}(\ell^*(i, u) = \ell^*(i', u)) \approx 1/M'$ 的均匀近似下,
$$ \rho_{\text{Latte}} \approx \frac{1}{M'} \rho + \Bigl(1 - \frac{1}{M'}\Bigr) \rho_{\text{low}} < \rho, \tag{9} $$
其中 $\rho_{\text{low}} < \rho$ 是 latent 路径分叉时的低相关。代入 Theorem 3.4 的上界 $B(\rho) = \frac{4\sigma^2(1-\rho)}{\mu^2 + 2\sigma^2(1-\rho)}$,可证 $B(\rho_{\text{Latte}}) > B(\rho)$,即 Latte 放宽了 rank reversal 的概率上界。证明思路:先通过 dominant latent 概率的均匀分布合成 effective $\rho_{\text{Latte}}$,再利用 $B(\cdot)$ 在 $\rho$ 上单调递减得出更宽松的 reversal 上界。Games 数据集 $M' = 8$ 时,每个 latent token 的实际生成频率近似 $0.125$(见 Table 10),与均匀假设吻合。
5. 实验¶
5.1 实验设置¶
- Datasets:Amazon Reviews 2023 的 Instruments / Industrial-Scientific / Video-Games 三个类目,leave-one-out 划分。统计:
| Dataset | #Users | #Items | #Interactions | Avg #t |
|---|---|---|---|---|
| Instruments | 57,439 | 24,587 | 511,836 | 8.91 |
| Scientific | 50,985 | 25,848 | 412,947 | 8.10 |
| Games | 94,762 | 25,612 | 814,586 | 8.60 |
- Backbone:与 TIGER 一致——T5-style encoder-decoder,4 层 Transformer block + embedding dim 128,beam size 500;
- Tokenizer:base 模型 PSID 默认 RQ-KMeans,$m = 3$,$M = 256$;ESM 算法消除 SID 冲突;
- Latte 超参:$M' \in \{2, 4, 8\}$ 网格搜索,aggregator 用 $\max$;
- Baselines:discriminative 类 GRU4Rec / BERT4Rec / SASRec / FMLP-Rec / HSTU / FDSA / S³-Rec;generative 类 TIGER / LETTER / ActionPiece / PSID;
- Evaluation:Recall@K & NDCG@K,$K \in \{5, 10\}$。
5.2 主结果¶
Latte 在三个数据集 12 个指标上全面优于 PSID 与所有 baseline,所有提升均统计显著 ($p < 0.05$):
| Method | Inst. R@5 | Inst. R@10 | Inst. N@5 | Inst. N@10 | Sci. R@5 | Sci. R@10 | Sci. N@5 | Sci. N@10 | Game R@5 | Game R@10 | Game N@5 | Game N@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GRU4Rec | 0.0324 | 0.0501 | 0.0209 | 0.0266 | 0.0202 | 0.0338 | 0.0129 | 0.0173 | 0.0499 | 0.0799 | 0.0320 | 0.0416 |
| BERT4Rec | 0.0307 | 0.0485 | 0.0195 | 0.0252 | 0.0186 | 0.0296 | 0.0119 | 0.0155 | 0.0460 | 0.0735 | 0.0298 | 0.0386 |
| SASRec | 0.0333 | 0.0523 | 0.0213 | 0.0274 | 0.0259 | 0.0412 | 0.0150 | 0.0199 | 0.0535 | 0.0847 | 0.0331 | 0.0438 |
| FMLP-Rec | 0.0339 | 0.0536 | 0.0218 | 0.0282 | 0.0269 | 0.0422 | 0.0155 | 0.0204 | 0.0528 | 0.0857 | 0.0338 | 0.0444 |
| HSTU | 0.0343 | 0.0577 | 0.0191 | 0.0271 | 0.0271 | 0.0429 | 0.0147 | 0.0198 | 0.0578 | 0.0903 | 0.0334 | 0.0442 |
| FDSA | 0.0347 | 0.0545 | 0.0230 | 0.0293 | 0.0262 | 0.0421 | 0.0169 | 0.0213 | 0.0544 | 0.0852 | 0.0361 | 0.0448 |
| S³-Rec | 0.0317 | 0.0496 | 0.0199 | 0.0257 | 0.0263 | 0.0418 | 0.0168 | 0.0219 | 0.0485 | 0.0769 | 0.0315 | 0.0406 |
| TIGER | 0.0370 | 0.0564 | 0.0244 | 0.0306 | 0.0264 | 0.0422 | 0.0175 | 0.0226 | 0.0559 | 0.0868 | 0.0366 | 0.0467 |
| LETTER | 0.0372 | 0.0580 | 0.0246 | 0.0313 | 0.0279 | 0.0435 | 0.0182 | 0.0232 | 0.0563 | 0.0877 | 0.0372 | 0.0473 |
| ActionPiece | 0.0383 | 0.0615 | 0.0243 | 0.0318 | 0.0284 | 0.0452 | 0.0182 | 0.0236 | 0.0591 | 0.0927 | 0.0382 | 0.0490 |
| PSID | 0.0390 | 0.0602 | 0.0256 | 0.0325 | 0.0278 | 0.0445 | 0.0181 | 0.0235 | 0.0599 | 0.0939 | 0.0391 | 0.0500 |
| Latte | 0.0401 | 0.0618 | 0.0261 | 0.0331 | 0.0304 | 0.0470 | 0.0196 | 0.0249 | 0.0618 | 0.0958 | 0.0406 | 0.0515 |
| Δ vs. PSID | +2.82% | +0.49% | +1.95% | +1.85% | +7.04% | +3.98% | +7.69% | +5.51% | +3.17% | +2.02% | +3.84% | +3.00% |
结论:Latte 仅靠预置一个 latent token这一极简改动,平均带来 NDCG@10 +3.45%。在 Scientific(最稀疏的数据集)上提升幅度最大,Games(最密集的数据集)上提升仍稳健。
5.3 Tree-structure 相关性诊断¶
为了量化 Latte 是否真的解耦了 tree-distance 与生成概率,作者计算 Kendall's $\tau$(tree distance vs. item-item Pearson 相关):值越接近 $\pm 1$ 表示结构耦合越强;值越接近 0 表示越解耦。
| Model | Instruments (↑) | Scientific (↑) | Games (↑) |
|---|---|---|---|
| TIGER | -0.7170 | -0.6137 | -0.6462 |
| PSID | -0.6225 | -0.4611 | -0.6072 |
| Latte | -0.6030 | -0.4451 | -0.5958 |
Latte 在 SID 完全相同的情况下,仍把 Kendall's $\tau$ 拉得离 0 更近——这是直接证据:latent token 的引入实质性地放松了由解码树结构强加的耦合。需要注意 TIGER 与 PSID 用了不同的 SID(TIGER 深度 4 vs PSID 深度 3),因此 TIGER 的更负值不能直接比较——本表只用于"Latte 与同 SID 的 PSID"之间的对照。
5.4 In-Depth Analysis¶
5.4.1 跨 tokenization 通用性 (Table 3)¶
| Tokenizer | Model | Inst. NDCG@10 | Sci. NDCG@10 | Games NDCG@10 |
|---|---|---|---|---|
| OPQ | PSID / Latte | 0.0313 / 0.0318 (+1.68%) | 0.0232 / 0.0235 (+1.37%) | 0.0478 / 0.0493 (+3.24%) |
| RQ-VAE | PSID / Latte | 0.0325 / 0.0331 (+2.02%) | 0.0241 / 0.0247 (+2.76%) | 0.0490 / 0.0502 (+2.55%) |
| RQ-KMeans | PSID / Latte | 0.0325 / 0.0331 (+2.02%) | 0.0235 / 0.0249 (+5.90%) | 0.0500 / 0.0515 (+3.11%) |
结论:Latte 在三种 tokenizer 上都稳健提升 ($p < 0.05$)。值得注意的是:base model 在 RQ-VAE 上最强,但 Latte 在 RQ-KMeans 上提升最大——作者推测 RQ-KMeans 缺少端到端目标优化,留下了更多优化空间。
5.4.2 Aggregation 选择 (Table 4)¶
| Agg | Inst. | Sci. | Games |
|---|---|---|---|
| PSID (no agg) | 0.032462 | 0.023531 | 0.049994 |
| Latte (sum) | 0.033134 | 0.024301 | 0.051176 |
| Latte (max) | 0.033114 | 0.024920 | 0.051547 |
$\mathrm{sum}$ 与 $\mathrm{max}$ 都明显优于 base,且彼此差距很小——aggregation 选择对结论稳健。Beam search 在 $\mathrm{max}$ 下天然实现 top-K 边缘化近似,工程上更划算。
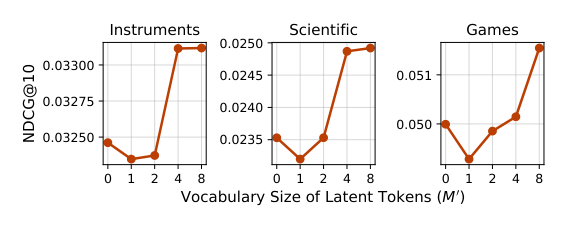
5.4.3 Latent vocab size $M'$ (Figure 4)¶
$M' \in \{0, 1, 2, 4, 8\}$ 扫描显示:
- $M' = 1, 2$ 偶尔劣于 base PSID——latent 词表过小时 latent token 预测的累积错误超过结构松弛收益;
- $M' = 4, 8$ 三个数据集一致超越 base;
- 最优 $M'$:Instruments $= 4$,Scientific $= 8$,Games $= 8$(见 Table 9)。
实践建议:从 $M' = 8$ 起步,按数据集稀疏度向下调小。
5.5 噪声 vs. 结构松弛 (Appendix Table 13/14)¶
为了排除"提升仅来源于训练过程的隐式正则化(噪声扰动)"这一替代解释,作者用 Dropout 与 Swap 两种 token 级 augmentation 作对比:
| Model | Inst. NDCG@10 | Sci. NDCG@10 | Games NDCG@10 |
|---|---|---|---|
| PSID | 0.0325 | 0.0235 | 0.0500 |
| Dropout | 0.0322 | 0.0239 | 0.0499 |
| Swap | 0.0300 | 0.0208 | 0.0462 |
| Latte | 0.0331 | 0.0249 | 0.0515 |
更进一步的 Kendall's $\tau$(Table 14)显示:Dropout / Swap 不能改变 tree-distance 与 item-similarity 的耦合(与 PSID 几乎一致),而 Latte 把数值显著拉离 ±1。这条对照实验直接锁定 Latte 的提升来源是结构性松弛而非噪声正则化。
5.6 推理开销 (Appendix Table 12)¶
| Model | Inst. 单 epoch 推理时间 |
|---|---|
| TIGER | 98s |
| PSID | 66s |
| Latte ($M' = 4$) | 76s |
| Latte ($M' = 8$) | 76s |
| Latte ($M' = 16$) | 78s |
Latte 仅多 1 个 token 解码步——单一 beam search 流程内串联完成,不需要 $|\mathcal{L}|$ 次独立 beam。相对 PSID 增加 ~15% 推理成本,仍显著快于 TIGER(其 SID 深度 4 对比 PSID 深度 3)。
6. 把 latent token 与归纳偏置绑定:模态序自适应¶
6.1 Motivation¶
第 4 节里的 latent token 只是 random latent。第 6 节探索一个延伸问题:能否让 latent token 携带具体的语义意义,从而把任务的归纳偏置注入解码过程?
多模态 SID 是一个自然测试场——每个 SID token 来自某个 modality(例如 playlist / tag / metadata 三类)。已有工作通常人为指定一个固定的模态序(如 metadata → tag → playlist),但:
- 不同用户对不同模态的偏好不同;
- 不同任务最优的全局模态序未必相同;
- 枚举所有 $3! = 6$ 种 permutation 单独训练计算上不可行。
6.2 设计¶
把 latent token 词表 $\mathcal{L}$ 与 SID 的 permutation 集合一一绑定:每个 $\ell$ 代表一个特定的模态序。训练时仍然 uniform sampling $\ell$,按 $\ell$ 对应的 permutation 重排目标 SID,然后拼接 $(\ell, \text{permuted SID})$ 进行 next-token CE。推理时模型自主生成 $\ell$(即"挑选"哪条模态序),再生成 SID,最后按 $\ell$ 反 permute 还原原始 SID。
6.3 实验¶
- 数据:Million Playlist Dataset (MPD),按 Doh et al. (2025) 流程过滤:每个 song 至少保留 3 条模态(playlist / tag / metadata),每个 playlist 至少 6 首歌;按 8:1:1 划分;
- 模态嵌入:playlist → song co-occurrence 训练 Word2Vec;tag 取离散类别(如 genre);metadata 用预训练 text encoder(Qwen3)抽取;每个模态 $k$-means 聚 1024 类作为 codebook;
- Latent vocab:$M' = 3! = 6$,对应六种 permutation;
- Baselines:六种 fixed-order 训练(每种 permutation 一个独立模型)。
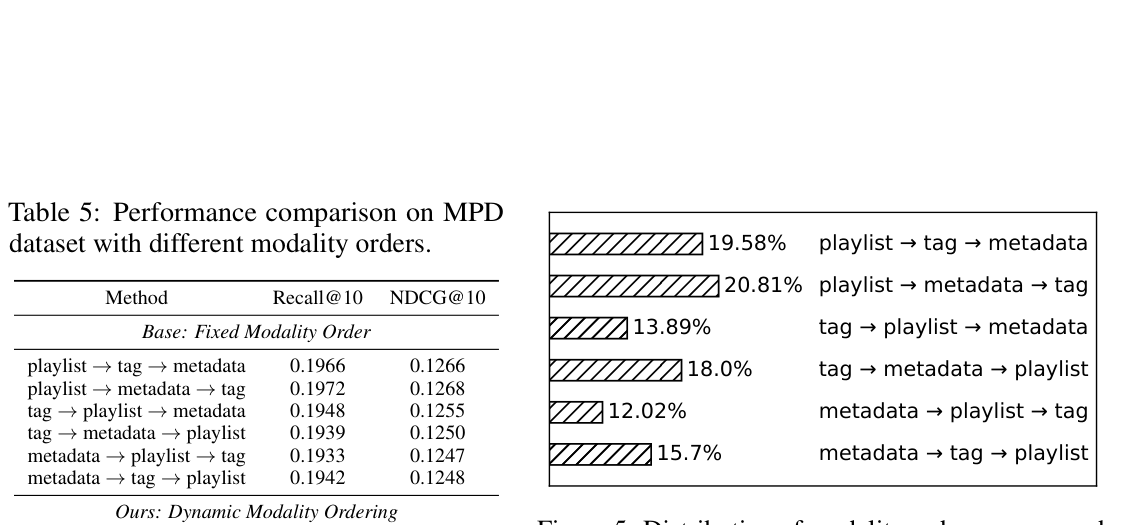
| Method | Recall@10 | NDCG@10 |
|---|---|---|
| playlist→tag→metadata (best fixed) | 0.1966 | 0.1266 |
| playlist→metadata→tag | 0.1972 | 0.1268 |
| tag→playlist→metadata | 0.1948 | 0.1255 |
| tag→metadata→playlist | 0.1939 | 0.1250 |
| metadata→playlist→tag | 0.1933 | 0.1247 |
| metadata→tag→playlist | 0.1942 | 0.1248 |
| Latte (max) | 0.2060 | 0.1335 |
| Latte (sum) | 0.2107 | 0.1353 |
关键观察:
- Latte 一致优于所有 fixed-order baseline;
- 模型自主选择频率最高的两种 permutation("playlist 放第一位")也正是 fixed-order baseline 中表现最佳的两种——模型通过数据自动发现了最优模态序,无需人工搜索;
- metadata 第一位的两种 permutation 在模型选择频率(12.02% / 15.7%)和 fixed-order 表现上都垫底,进一步印证模型选择与最优性的一致性。
这个 case 提示:latent token 不必是 random latent,绑定到具体归纳偏置(如 permutation、modality、scenario、time-of-day)后可以成为更通用的"动态结构选择器"。
7. 与已归档相关工作的对比¶
On the Equivalence Between Auto-Regressive Next Token Prediction and Full-Item-Vocabulary Maximum Likelihood Estimation in Generative Recommendation--A Short Note On the Equivalence between AR-NTP and FV-MLE (Kuaishou, 2026-04-17)¶
关系:独立并发(本文未引用)· 已加载对方精读
- 共同关注的问题:自回归 Semantic ID 生成 ($k$-token AR-NTP) 在生成式推荐中究竟意味着什么?两文都直接攻击"逐 token 预测"作为 item-level 建模的理论基底;
- 相近的技术骨架:两文都基于 Bayesian chain rule 把 item-level 联合概率分解为 token-level 因子积,并以共享前缀对联合概率的影响为分析对象;
- 本文的差异与推进:Kuaishou 的等价性证明给出正向结论——在 bijective tokenizer 下 AR-NTP 数学等价于全词表 MLE,因此"表达能力等价"。本文给出反向视角——即使 representable distribution 等价,学习出的模型因为参数化与 inductive bias 的限制,对结构相邻 item 仍施加严格的概率耦合。两个结论并不矛盾:等价性是函数类层面的(最优 logits 可表达任意分布),耦合现象是学习动力学层面的(梯度流偏置 + 共享前缀因子让训练后的 logits 受 tree distance 主导);
- 可比的方法 / 实验差异:两篇都做了 generic GR theory,但 Kuaishou 文章是纯理论备忘录,没有实验补救;本文则在理论之外提供 Latte 这个最小修补,把 forced transitivity 与 rank reversal 上界都松开。两文合在一起能给出更完整图景——"AR-NTP 的最优解可以是 FV-MLE,但实际学习器距离最优解还差一个'结构松弛'的步骤"。
APAO APAO: Adaptive Prefix-Aware Optimization (DCST Tsinghua, 2026-03-03)¶
关系:独立并发(本文未引用)· 已加载对方精读
- 共同关注的问题:两文都把矛头指向SID 解码过程的前缀树结构——同一前缀承担多个 item 的概率因子是 GR 的双刃剑。Latte 看到的副作用是"概率耦合",APAO 看到的副作用是"训练-推理不一致"——CE loss 优化总 likelihood 但 beam search 按前缀剪枝;
- 相近的技术骨架:两者都保留 tokenizer 不变,只在原 NTP 训练流程上做轻量级修补;
- 本文的差异与推进:APAO 的修补在优化目标侧——加上 prefix-level pointwise / pairwise loss + adaptive worst-prefix weighting,让模型对中间前缀也产生排序约束;Latte 的修补在结构侧——预置 latent token 把单棵解码树展开成森林。两套思路解决的问题不同(APAO 解决 beam search 早剪枝伤害弱前缀,Latte 解决相同前缀强制概率耦合),但都揭示一个共同信号——SID 前缀树是 GR 表达力 / 训练目标层最大的结构性 frictions 所在;
- 可比的方法 / 实验差异:两文都在 Amazon 序列推荐数据集上 benchmark;APAO 用 Llama-3.1-8B 提取 embedding + 4 层 RQ-K-Means、$T = 4$;本文用 PSID 默认配置 $m = 3$。指标层面 NDCG@10 提升量级相近(本文均值 +3.45%,APAO 单数据集典型 +5%),但因 backbone / 数据集差异不能直接合并比较。未来工作:两套修补在原理上正交——可以把 Latte 的 latent token 与 APAO 的 prefix-level 损失叠加,预期能进一步逼近 GR 的理论上界。
8. 核心贡献总结¶
- 第一次正式提出"自回归 SID 生成 = 解码树遍历"的视角,并以 tree distance / Pearson 相关 / Kendall's $\tau$ 三组工具量化结构耦合。
- 理论刻画两类不可表达性——Theorem 3.4 给出 rank reversal 概率上界(受 $\rho$ 主导),Theorem 3.5 利用 ultrametric 不等式证明 forced transitivity——为生成式推荐提供了第一批负向表达力定理。
- Latte 这一极简补丁—预置随机 latent token 把单棵树展开为森林,在 Amazon 三类目 12 项指标上一致显著超越 11 个 baselines,平均 NDCG@10 +3.45%;推理开销仅 +15%(对 PSID)。
- 跨 tokenizer / 跨 aggregator 通用:在 OPQ / RQ-VAE / RQ-KMeans 上都 work,sum 与 max aggregator 表现接近。
- 延伸视角:把 latent token 与具体归纳偏置(如 SID permutation)绑定,模型能自动发现最优模态序,给"用 latent 注入领域知识"提供了一个具体设计 pattern。
9. 讨论与局限性¶
9.1 局限¶
作者在 Appendix F 自述三条主要 limitations:
- 额外推理代价:单一 beam search 流程下 +1 token 解码步,对延迟敏感场景仍不可忽略;
- 退化风险:极端情况下若不同 latent token embedding 收敛到几乎相同,latent token 失效退化成 base PSID;
- 未完全消除结构约束:相同 latent path 下的 item 仍共享原始 prefix tree。Latte 是减弱而非消除结构耦合。
补充我的观察:
- Theorem 3.4 的 $\sigma^2$ 等方差假设、Theorem 3.5 的 $\rho$-vs-$d_{\mathcal{T}}$ 双向假设都需要在更大规模工业数据上经受考验;
- 本文实验基本停留在 Amazon Reviews 公开数据集(最大 ~94K 用户),还没有上工业 A/B;Snap 内部的部署结果未在论文中呈现;
- $M'$ 的最优值是经验调参——不存在闭式选择规则。
9.2 值得借鉴的设计模式¶
- 几何视角分析自回归生成:把 next-token 因式分解几何化为 tree traversal,再用 ultrametric / 概率耦合的语言提出表达力定理。这种思路可以迁移到 dialog generation、code generation 等任何"嵌入到合法序列空间"的自回归任务;
- Latent token as forest expander:在保持 tokenizer 与 inference pipeline 不变的前提下,仅靠1 个 token 的额外编码空间就实现结构松弛——这是一个非常便宜的"架构插件";
- Latent token bound to inductive bias:Section 6 的 modality permutation 是一个具体 instance;可以推广到 scenario routing、time-of-day routing、context preset 等任何"用户层异质性"的注入场景;
- Kendall's $\tau$ / Pearson 相关作为"模型结构性"诊断指标:值得作为 GR 范式的标准 evaluation tool。
9.3 工业落地价值¶
虽然论文没有直接的工业 A/B 数据,但 Snap 作为通讯作者方早已在 PSID(Ju et al., 2025)和 Snapchat SID 部署文(Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices)里展示了 SID-based GR 的产品化能力;Latte 是个真正"可即插即用"的修改——只需要改训练数据 pipeline 把每条目标 SID 前面拼一个 random latent token,模型架构不变、推理流程不变。对已经部署 PSID / TIGER / LETTER 的工业系统来说,Latte 是几乎零成本的潜在性能升级。
总体来看,这是一篇罕见的"问题陈述清晰 + 理论严谨 + 方法极简 + 实验充分"的小而美的论文,给生成式推荐范式注入了一个新的研究问题维度:SID 解码过程的几何结构会不会成为下一代 GR 模型的瓶颈?——本文给出了第一个肯定的回答,以及一个简单但有效的解药。