Similar Users-Augmented Interest Network (SUIN)¶
研究动机与背景¶
点击率(CTR)预测是推荐系统的核心任务之一。用户行为序列作为最有效的特征之一,能够准确反映用户偏好,对预测精度提升至关重要。最近一系列工作(DIN、DIEN、SIM、ETA、SDIM、TWIN、TIN 等)持续表明,延长用户行为序列长度能够带来 CTR 的实质性增益:序列越长,模型对用户长期兴趣的刻画越完整。两阶段方法(SIM、ETA、SDIM、TWIN)通过先做粗粒度行为检索、再做细粒度 target attention,把可建模的序列长度推到了上千;近期 LONGER 等工作甚至通过 request-level amortization 把端到端序列推到了万级。
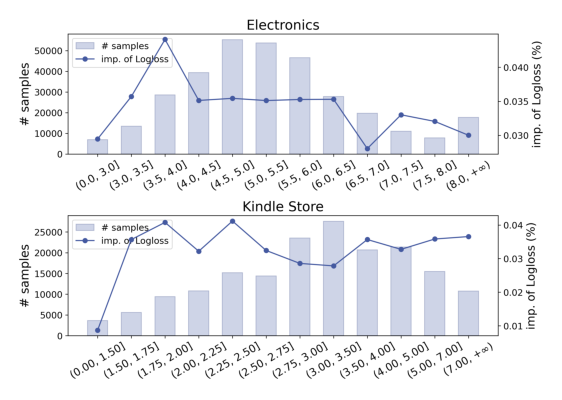
但作者在 Amazon Electronics 和 Taobao 两个公开数据集上做了一个简单的探究性实验:把用户按行为序列长度分桶,分别统计 DIN(短序列模型)和 TWIN(长序列模型)的 logloss。如 Figure 1 所示,整体上序列越长 logloss 越低,但分布严重长尾——短序列用户占据大量样本。在长尾内容平台(电影、图书)这种现象尤其严重;高反馈、低频但高价值的行为(购买、点赞)也天然稀疏。
作者由此提炼出一个被现有方法回避的瓶颈:当前所有序列建模方法都只看目标用户自己的行为序列,而真实场景下大量用户的行为序列短到不足以支撑准确建模。如果能够在 inference 阶段为 sparse 用户额外补上相似用户的行为序列作为额外上下文,就有机会突破单用户行为不足的瓶颈。
这一思路的灵感来自 LLM 时代成熟的 Retrieval-Augmented Generation (RAG) 范式:把外部相关上下文检索回来增强当前 query。SUIN 把这一范式翻译到 CTR:把目标用户的行为序列视作 query,把全体用户的行为序列作为检索池,为目标用户检索出最相似的 top-k 用户,并把这些用户的行为序列拼接进目标用户的序列形成 augmented sequence。论文的核心贡献是:
- 跨用户上下文增强策略:首次系统性地用相似用户的行为序列做序列扩充(区别于既有方法的"用户自身长序列"或"item 级图传播")。
- SUIN 框架:包含 user-specific target-aware position encoding (UTPE) 和 user-aware target attention (UTA) 两个核心模块,分别解决"多用户行为如何编码位置"与"如何缓解相似用户引入的噪声"两个具体问题。
- 在 4 个公开数据集(短/长两种序列设置)上系统验证,相对最强 baseline 都有稳定的 AUC/Logloss 收益。
任务形式化与基础架构¶
任务定义¶
CTR 预测的目标是学习二分类模型 $f: \mathbb{R}^d \to \mathbb{R}$,使得:
$$\hat{y}_i = \sigma(f(\mathbf{x}_i)) \tag{1}$$
其中 $\mathbf{x}_i \in \mathbb{R}^d$ 是第 $i$ 个样本的特征向量(包括用户 profile、行为历史、上下文、目标 item),$y_i \in \{0,1\}$ 是 click/no-click 标签。模型用二元交叉熵(BCE)损失训练:
$$\mathcal{L}_{\text{BCE}} = -\frac{1}{N}\sum_{i=1}^{N}\left[y_i \log(\hat{y}_i) + (1 - y_i)\log(1 - \hat{y}_i)\right] \tag{2}$$
经典 Embedding & Feature Interaction 范式¶
主流深度 CTR 模型都遵循 Embedding + Sequence Pooling + Feature Interaction 三段式:
Embedding layer:对类别特征 $F$,将原始 one-hot/multi-hot 编码 $\mathbf{x}_F \in \{0,1\}^{v_F}$ 映射到稠密向量:
$$\mathbf{e}_F = \mathbf{x}_F \mathbf{E}_F \tag{3}$$
其中 $\mathbf{E}_F \in \mathbb{R}^{v_F \times d}$。用户行为序列 $S = [s_1, s_2, \ldots, s_L]$ 的 embedding 为 $\mathbf{e}_S = [\mathbf{e}_1, \mathbf{e}_2, \ldots, \mathbf{e}_L] \in \mathbb{R}^{L \times d}$,目标 item embedding 记作 $\mathbf{e}_t$。
Sequence pooling layer:将 $L \times d$ 的序列表示压缩为定长 $d$ 维向量:
$$\mathbf{e}_{\text{pooling}} = \text{pooling}(\mathbf{e}_1, \mathbf{e}_2, \ldots, \mathbf{e}_L) \in \mathbb{R}^d \tag{4}$$
Feature interaction layer:把 $\mathbf{e}_{\text{pooling}}$ 和其他特征拼接后送入 MLP/DCN/AutoInt 等做交互。SUIN 把改造重点放在 sequence pooling 层——它正是用户兴趣建模的关键组件——其余部分使用标准 MLP,与所有 baseline 公平对比。
核心方法:SUIN 整体框架¶
SUIN 由三个核心组件构成(如 Figure 2 所示):(1) User Retrieval Pool 构造,(2) Behavior Sequence Augmentation,(3) User-Aware Target Attention。
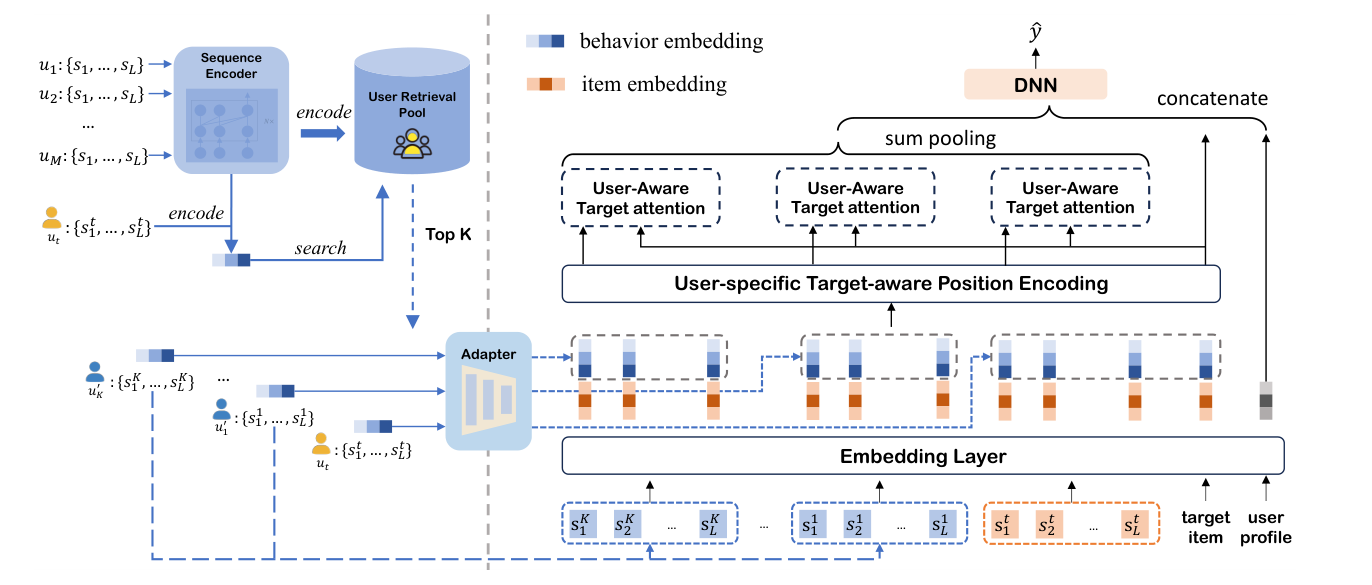
3.1 User Retrieval Pool¶
3.1.1 Sequence Encoder¶
SUIN 假设"行为模式相近的用户对增强目标用户画像更有价值",因此用每个用户的行为序列作为该用户的表示。这要求一个能把变长行为序列编码成稠密向量的 sequence encoder:
$$\mathbf{e}_b = \text{SE}([s_1, s_2, \ldots, s_L]) \in \mathbb{R}^{d'} \tag{5}$$
论文采用 SASRec(self-attention 的代表性序列推荐模型)作为默认 encoder,并以 BCE 损失在训练数据上预训练。这一 encoder 是可替换组件——Section 4.5.1 验证了换成 GRU4Rec / BERT4Rec 同样有效。
3.1.2 Construction of User Retrieval Pool¶
用预训练好的 SE 把所有用户的行为序列编码为 behavior embedding,构成:
$$\mathcal{P} = \{\mathbf{e}_b^1, \ldots, \mathbf{e}_b^M\} \tag{6}$$
其中 $\mathbf{e}_b^i$ 是第 $i$ 个用户的行为 embedding,$M$ 是用户总数。注意为防止数据泄漏,pool 中仅包含训练集用户,验证集和测试集用户被排除。这是一个全离线步骤,CTR inference 时不增加任何额外计算。
3.2 Behavior Sequence Augmentation¶
3.2.1 Behavior Sequence Augmentation via Similar Users¶
对于目标用户 $u_t$,先用同一个 SE 得到其 behavior embedding $\mathbf{e}_b^t$,然后用 cosine similarity 与 retrieval pool 中所有用户做相似度比较:
$$\text{Similarity}(u_t, u_c) = \frac{\mathbf{e}_b^t \mathbf{e}_b^{c\top}}{|\mathbf{e}_b^t| \cdot |\mathbf{e}_b^c|} \tag{7}$$
选出 top-$K$ 最相似用户 $\{u_1', u_2', \ldots, u_K'\}$。这一步可以离线计算(用户行为相对稳定),CTR inference 时直接查表即可,不引入额外 latency。
类比 naïve RAG 的"把检索文档与原始 query 拼接成 extended prompt",SUIN 把 top-$K$ 相似用户的行为序列按相似度降序拼接到目标用户序列前面,形成 augmented sequence:
$$S'_t = \{s_1^K, s_2^K, \ldots, s_L^K, \ldots, s_1^1, s_2^1, \ldots, s_L^1, s_1^t, s_2^t, \ldots, s_L^t\} \tag{8}$$
其中 $\{s_1^k, s_2^k, \ldots, s_L^k\}$ 是第 $k$ 个相似用户的行为序列,$\{s_1^t, \ldots, s_L^t\}$ 是目标用户自己的序列。最相似用户 ($k=1$) 离目标用户序列最近,最不相似的 ($k=K$) 排在最前。
Section 4.5.2 进一步验证了 cosine 之外的相似度度量(inner product、Euclidean、Jaccard、User-Swing)也都能带来增益,但 cosine 在大多数数据集上最稳。
3.2.2 User-Specific Target-Aware Position Encoding (UTPE)¶
仅做拼接还不够。Augmented sequence 横跨多个用户,标准的 absolute / target-aware position encoding 都无法刻画其结构。SUIN 提出 UTPE,要求位置编码同时具备三个性质:
- Awareness of which user each behavior belongs to:模型必须能区分同一行为属于哪个用户。
- Awareness of relative position of behaviors across users:相似度更高的用户应当被分配"更近"的位置。
- Awareness of relative position of behaviors within a user:同一用户内部的行为时序信息也要保留。
具体公式:对 augmented sequence $S'_t$,假设每个用户的序列长度都被对齐为 $L$(不足左 pad),UTPE 给出的位置 ID 序列为:
$$\text{POS}'_t = \{\ldots, kL+L-1, \ldots, kL+1, kL, \ldots, L-1, \ldots, 1, 0\} \tag{9}$$
具体规则:
- 第 $k$ 个最相似用户的行为段起始 position ID 为 $kL$,最远侧为 $kL+L-1$($k=0$ 对应目标用户)。换句话说,每个用户得到一个长度 $L$、不重叠的 position 段。
- 段内最靠近目标 item(最新行为)的 position ID 最小,段内最早行为的 position ID 最大。这是 target-aware position encoding 的标准做法(target item 视作位置 0)。
三个性质同时满足:通过非重叠段实现 (1),通过段间偏移 $kL$ 实现 (2),通过段内 position 实现 (3)。
Figure 3 给出了一个 toy example:序列长 $L=5$,目标用户 $\{s_1^t, s_2^t, s_3^t, s_4^t\}$(左 pad 到 5),top-2 相似用户是 $\{s_1^1, s_2^1\}$ 和 $\{s_1^2, s_2^2, s_3^2\}$。UTPE 给出的位置编号是 [12, 11, 10, 6, 5, 4, 3, 2, 1, 0],颜色区分用户,浅色表示距离目标 item 越远。
UTPE 与"先 concat 全部行为再统一打 target-aware position"的朴素方案根本不同:因为不同用户行为序列长度不同(左 pad 不同),后者的 $k$-th 相似用户内部 position ID 不固定,破坏了"用户感知"性质。论文在 Section 4.5.3 与朴素方案 TPE / 全用户共享的 STPE 做了对比(详见实验部分)。
3.3 User-Aware Target Attention¶
3.3.1 Challenges in Leveraging Augmented Behavior Sequences¶
把 augmented sequence 直接喂给现有的 target-attention 模型(DIN、TIN)效果如何?论文先做了一个朴素实验(Table 1):
Table 1: AUC results of naive utilization of augmented behavior sequences on DIN and TIN
| TopK | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| DIN | 0.8833 | 0.8837 | 0.8854 | 0.8849 | 0.8848 |
| TIN | 0.8856 | 0.8846 | 0.8849 | 0.8791 | 0.8785 |
结论:(1) 增益非常微弱(DIN 仅 +0.21%);(2) TIN 反而下跌——超过某个 top-k 后大幅恶化。说明朴素拼接存在严重的噪声:相似用户的行为对目标用户来说是嘈杂的辅助信息,不能完全等同于用户自身行为对待。
作者进一步做了 threshold-based 过滤实验(Figure 4):把相似度低于阈值 $\tau$ 的行为整段丢弃。
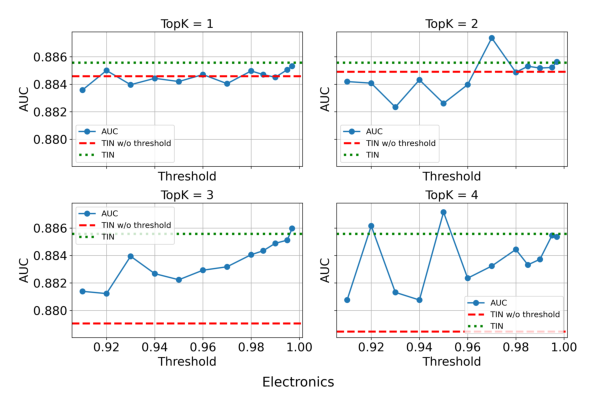
结论:阈值合适时确实能让 augmented sequence 略微超过 backbone,证明信号是存在的;但 threshold 是粗粒度的"整段保留 or 整段丢弃",缺乏行为级别的差异化处理,且阈值本身需要手工调优。需要一个能够同时考虑相似度与行为有用性的细粒度方案——这正是 UTA 的设计动机。
3.3.2 Design of User-Aware Target Attention¶
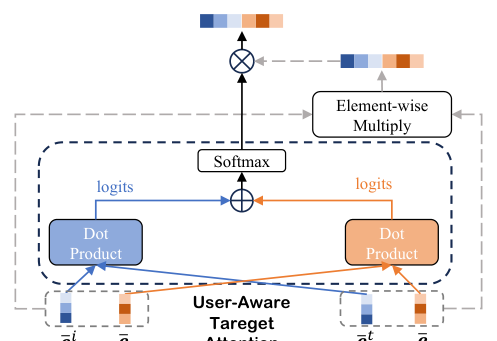
相比标准 target attention 仅靠 item-item 相关性决定权重,augmented sequence 的注意力权重应当由两个因子共同决定:
- Item-item 相关性:目标 item 与序列中行为 item 的相关性(标准 target attention 关注的)。
- User-user 相关性:目标用户与该行为所属用户的相关性(既有方法忽视的)。
Behavior embedding adapter:相似用户的行为 embedding $\mathbf{e}_b$ 是 SE 输出(维度 $d'$,论文 $d'=32$),与 CTR 模型 embedding 维度 $d=16$ 不一致。SUIN 用一个 2 层 MLP 做 adapter:
$$\bar{\mathbf{e}}_b = \text{MLP}(\mathbf{e}_b) \tag{10}$$
输入 $d'=32$、输出 $d=16$,ReLU 激活。这些 behavior embedding 是 frozen(保持序列编码器学到的信息),可以离线预计算,不增加在线推理开销。
Item-item 相关性:augmented sequence 中第 $i$ 个行为 $s_i$ 的 embedding 是 $\mathbf{e}_i$,position embedding 由 UTPE 决定。设 $p(\cdot)$ 返回 position ID,$\mathbf{P}_{\text{item}}$ 为 item 的 position embedding 表,定义 position-aware item embedding:
$$\bar{\mathbf{e}}_i = \mathbf{e}_i + \mathbf{P}^{p(s_i)}_{\text{item}}, \quad \bar{\mathbf{e}}_t = \mathbf{e}_t + \mathbf{P}^0_{\text{item}}$$
其中 target item 的 position 取 0(最近)。Item-item attention logit:
$$\alpha^i_{\text{item}} = \frac{(\mathbf{W}^Q_{\text{item}} \bar{\mathbf{e}}_t)^\top (\mathbf{W}^K_{\text{item}} \bar{\mathbf{e}}_i)}{\sqrt{d_{\text{item}}}} \tag{11}$$
User-user 相关性:第 $i$ 个行为属于用户 $u_i$,其 behavior embedding 经 adapter 投影后为 $\bar{\mathbf{e}}_b^i$,加上 user-side position:
$$\bar{\mathbf{e}}_b^i = \bar{\mathbf{e}}_b^i + \mathbf{P}^{p(s_i)}_{\text{user}}, \quad \bar{\mathbf{e}}_b^t = \bar{\mathbf{e}}_b^t + \mathbf{P}^0_{\text{user}}$$
User-user attention logit:
$$\alpha^i_{\text{user}} = \frac{(\mathbf{W}^Q_{\text{user}} \bar{\mathbf{e}}_b^t)^\top (\mathbf{W}^K_{\text{user}} \bar{\mathbf{e}}_b^i)}{\sqrt{d}} \tag{12}$$
最后 attention 权重通过两路 logits 相加再 softmax:
$$\boldsymbol{\alpha} = \text{Softmax}(\boldsymbol{\alpha}_{\text{item}} + \boldsymbol{\alpha}_{\text{user}}) \tag{13}$$
其中 $\boldsymbol{\alpha}_{\text{item}} = [\alpha^1_{\text{item}}, \ldots, \alpha^{KL}_{\text{item}}]$,$\boldsymbol{\alpha}_{\text{user}}$ 同理。
Aggregation:聚合时对 item 和 user 两路特征都做 target-aware multiplication(TIN 的 trick),最后向量 concat:
$$\mathbf{e}_{\text{SUIN}} = \alpha_i \cdot \left([\mathbf{W}^Q_{\text{item}}\bar{\mathbf{e}}_t; \mathbf{W}^Q_{\text{user}}\bar{\mathbf{e}}_b^t] \odot [\mathbf{W}^V_{\text{item}}\bar{\mathbf{e}}_i; \mathbf{W}^V_{\text{user}}\bar{\mathbf{e}}_b^i]\right) \tag{14}$$
其中 $\odot$ 表示 element-wise 乘,$[\cdot;\cdot]$ 表示拼接。该向量与其他特征 embedding concat 后送入 MLP feature interaction 层。
信息流总结:UTA 把"相似用户的行为是否值得参考"分解成"行为本身是否与目标 item 相关"+"行为来自的用户是否与目标用户兴趣相近",两个信号在 logit 级别相加。这在结构上避开了 threshold 方案的粗粒度问题——同一相似用户内部的行为可以根据其 item 相关性获得不同权重,同时强化了高相似用户的整体贡献。
实验设置¶
数据集与切分¶
Table 2: Statistics of the datasets after preprocessing
| Setting | Dataset | #Users | #Items | #Inters | Avg Len |
|---|---|---|---|---|---|
| Short | Electronics | 1,641,026 | 368,228 | 15,473,536 | 9 |
| Short | Kindle Store | 892,164 | 466,576 | 16,070,783 | 18 |
| Long | Taobao | 987,994 | 4,162,024 | 100,150,807 | 101 |
| Long | Alipay | 498,308 | 2,200,271 | 35,179,371 | 70 |
- 短序列数据集:Amazon Electronics 与 Kindle Store。任务是 leave-last-out CTR:每个用户最后一条 review 是正样本,随机抽一条作为负样本。按用户 8:1:1 切分。
- 长序列数据集:Taobao(淘宝 11/25-12/3 2017,全场景行为)与 Alipay(支付宝 7/1-11/30 2015 在线支付)。8:1:1 时间切分;负采样 1:1,最大序列长 300。
Baselines¶
- 短序列 baselines:Avg-Pooling、DIN、BST、DIEN、DSIN、DMIN、TIN。
- 长序列 baselines:SIM-hard、SIM-soft、ETA、SDIM、TWIN。
- 共有 baseline:SASRec(独立列出,因为 dual-tower 架构未做 target-item 交互,作为参考下界)。
评估指标¶
AUC(越高越好)和 Logloss(越低越好),CTR 领域标准设置。
实现细节¶
- Sequence encoder:SASRec,BCE 损失预训练。
- Embedding 维度:16;DNN:[200, 80, 1],ReLU。
- Optimizer:Adam, lr=0.001;early stop patience 1;max epochs 5。
- Batch size:长序列 256,短序列 512。
- Adapter MLP:[32, 16],ReLU;dropout ∈ {0, 0.1, 0.2, 0.5} 调优。
- 最优 Top-K:Electronics 4,Kindle 2,Taobao 2,Alipay 1。
- 长序列设置:SUIN 借鉴 TWIN,CP-GSU 与 ESU 共享参数实现两阶段建模。
- 代码框架:FuxiCTR,所有 baseline 用论文推荐参数。
主要实验结果¶
4.2 Overall Performance¶
Table 3: Results on short-term sequence datasets
| Model | Electronics AUC ↑ | Electronics Logloss ↓ | Kindle Store AUC ↑ | Kindle Store Logloss ↓ |
|---|---|---|---|---|
| SASRec | 0.8750 | 0.4691 | 0.8750 | 1.3271 |
| Avg-Pooling | 0.8793 | 0.4319 | 0.8974 | 0.4048 |
| DIN | 0.8833 | 0.4287 | 0.8910 | 0.4150 |
| BST | 0.8862 | 0.4256 | 0.8952 | 0.4238 |
| DIEN | 0.8873 | 0.4187 | 0.8977 | 0.4059 |
| DSIN | 0.8849 | 0.4275 | 0.8900 | 0.4197 |
| DMIN | 0.8859 | 0.4273 | 0.8866 | 0.4299 |
| TIN | 0.8856 | 0.4282 | 0.9002 | 0.3988 |
| SUIN | 0.8911 | 0.4132 | 0.9068 | 0.3857 |
| Δ% | +0.42% | +1.31% | +0.73% | +3.29% |
Table 4: Results on long-term sequence datasets
| Model | Taobao AUC ↑ | Taobao Logloss ↓ | Alipay AUC ↑ | Alipay Logloss ↓ |
|---|---|---|---|---|
| SASRec | 0.8056 | 1.2106 | 0.8170 | 0.6749 |
| Avg-Pooling | 0.8807 | 0.4327 | 0.8384 | 0.4890 |
| SIM-hard | 0.9252 | 0.3476 | 0.8718 | 0.4461 |
| SIM-soft | 0.9339 | 0.3259 | 0.9031 | 0.3885 |
| ETA | 0.9091 | 0.3819 | 0.853 | 0.4719 |
| SDIM | 0.9070 | 0.3848 | 0.8775 | 0.4377 |
| TWIN | 0.9314 | 0.3328 | 0.9056 | 0.3818 |
| SUIN | 0.9384 | 0.3165 | 0.9121 | 0.3669 |
| Δ% | +0.48% | +2.90% | +0.72% | +3.90% |
结论分析:
- SASRec 全面落后——dual-tower 架构没有 target-item 交互,验证了 SUIN 的提升不是来自"用了一个强 sequence encoder"。
- 短序列数据集:DIN 系(DIEN/BST/DSIN/DMIN/TIN)相对 DIN 各有改进,DIEN 在 Electronics 上是最强 baseline,TIN 在 Kindle 上是最强 baseline。SUIN 在两个数据集上都拿下最佳。
- 长序列数据集:SIM-soft 和 TWIN 凭借 dot-product 检索 + 强 target attention 拿到亚军,SUIN 在两个数据集都是冠军。
- 整体:SUIN 相对最强 baseline 在 AUC 上有 +0.42% / +0.73% / +0.48% / +0.72% 的相对提升(CTR 领域 +0.1% AUC 已经非常显著)。
4.3 Ablation Study¶
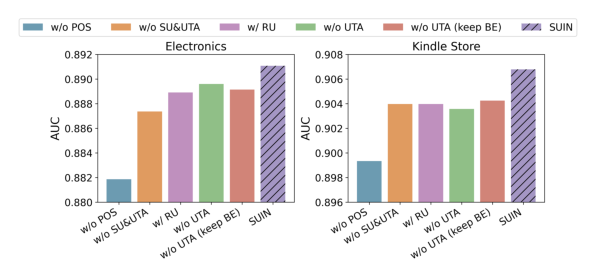
设计了如下消融变体:
- w/o UTA:去掉 user-aware target attention。
- w/o UTA (keep BE):去掉 UTA,但保留经过 adapter 投影的目标用户和相似用户 behavior embedding 作为 feature interaction 层的额外输入。
- w/ RU:把相似用户替换为随机抽样的用户,其他模块都保留。
- w/o SU&UTA:同时去掉相似用户增强和 UTA,退化为标准 target-attention 模型。
- w/o POS:去掉 UTPE 位置编码。
关键观察:
- w/o UTA 性能明显下降,证明 UTA 是有效杠杆 augmented sequence 的关键。
- w/o UTA (keep BE) 与 w/o UTA 接近,说明 UTA 的价值不是简单地把 behavior embedding 作为附加特征注入,而是在架构层面同时建模 item-item 和 user-user 相关性。
- w/ RU 与 w/o SU&UTA 都大幅退化,证明性能增益主要来自相似用户提供的上下文信息,而非架构本身的改动。w/ RU 退化也说明 SUIN 的提升是"相似用户结构"+"UTA 架构"的协同效应,单纯加架构换随机用户不行。
- w/o POS 是最差的——没有 position embedding,模型既无法识别行为位置关系也无法识别用户归属,对相似用户引入的噪声毫无防御。UTPE 的位置编码是 SUIN 中最关键的单一组件。
4.4 Hyper-parameter Analysis: 相似用户数量¶
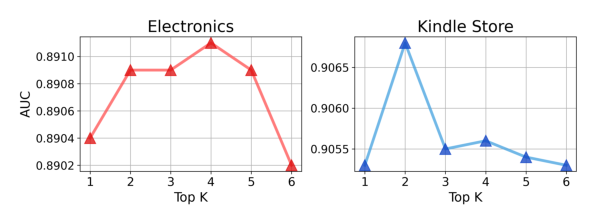
结论:top-K 走势明显单峰——Electronics 在 K=4 最优,Kindle Store 在 K=2 最优。在低 K 时增加相似用户带来更丰富的上下文;超过最优值后噪声超过信号,性能下降。即使过了最优值,SUIN 仍然优于无相似用户增强的 backbone——说明 UTA 的噪声抑制能力对 K 选择有相当鲁棒性。
4.5 Further Analysis¶
4.5.1 Compatibility with other sequence encoders¶
Table 5: Performance of SUIN equipped with different behavior sequence encoders
| Encoder | Electronics AUC ↑ | Electronics Logloss ↓ | Kindle Store AUC ↑ | Kindle Store Logloss ↓ |
|---|---|---|---|---|
| - (no augmentation, w/o SU&UTA) | 0.8874 | 0.4201 | 0.9040 | 0.3931 |
| GRU4Rec | 0.8907 | 0.4132 | 0.9045 | 0.3925 |
| SASRec | 0.8911 | 0.4132 | 0.9068 | 0.3857 |
| BERT4Rec | 0.8910 | 0.4124 | 0.9057 | 0.3869 |
所有 encoder 都比 backbone(无相似用户)有提升,证明 SUIN 框架对 encoder 不挑食。Attention-based 模型(SASRec/BERT4Rec)整体优于 RNN-based GRU4Rec,与"更强 encoder ⇒ 更好 behavior embedding ⇒ 更准的相似用户检索 ⇒ 更高 CTR"的直觉一致。
4.5.2 Compatibility with other user similarity measures¶
Table 6: Performance of different similarity measures
| Measure | Electronics AUC ↑ | Electronics Logloss ↓ | Kindle Store AUC ↑ | Kindle Store Logloss ↓ |
|---|---|---|---|---|
| - (backbone) | 0.8874 | 0.4201 | 0.9040 | 0.3931 |
| Cosine | 0.8911 | 0.4132 | 0.9068 | 0.3857 |
| Inner Product | 0.8910 | 0.4136 | 0.9059 | 0.3874 |
| Euclidean | 0.8909 | 0.4132 | 0.9052 | 0.3897 |
| Jaccard | 0.8901 | 0.4150 | 0.9065 | 0.3865 |
| User-Swing | 0.8901 | 0.4144 | 0.9071 | 0.3851 |
任何相似度指标都超 backbone,框架对相似度选择鲁棒。Jaccard / User-Swing 是基于共现的统计指标,可视为"统计 + 深度表征的集成"——在 Kindle 上 User-Swing 略好于 cosine。综合考虑稳定性和成本,cosine 是性价比最高的默认选项。
4.5.3 Comparison with other position encoding methods¶
Table 7: Performance of different position encoding
| Pos Encoding | Properties (1,2,3) | Electronics AUC ↑ | Electronics Logloss ↓ | Kindle Store AUC ↑ | Kindle Store Logloss ↓ |
|---|---|---|---|---|---|
| UTPE | ✓ ✓ ✓ | 0.8911 | 0.4132 | 0.9068 | 0.3857 |
| TPE | ✗ ✓ ✓ | 0.8893 | 0.4162 | 0.9051 | 0.3879 |
| STPE | ✗ ✗ ✓ | 0.8840 | 0.4244 | 0.9006 | 0.3996 |
| None | ✗ ✗ ✗ | 0.8819 | 0.4276 | 0.8993 | 0.3990 |
三个性质:(1) 用户归属感知,(2) 用户间相对位置感知,(3) 用户内相对位置感知。
- TPE(Target-aware Position Encoding):把所有行为拼接后统一打 target-aware position,由于不同用户序列长度不同,每个相似用户内部的 position 不固定,丢掉了"用户归属"信号。
- STPE(Shared Target-aware Position Encoding):所有用户共用同一套位置编码表,丢掉了"用户间相对位置"。
- None:完全没有位置编码,最差。
UTPE 同时满足三个性质,在两个数据集上都最优;缺一个性质就明显下降——证明三个性质的设计没有冗余。
4.5.4 Performance across different sequence augmentation ratios¶
定义 augmentation ratio = augmented sequence 长度 / 原序列长度。论文按 ratio 分组分析。
低 ratio 时增益随 ratio 增长——augmented sequence 提供越多上下文越好;ratio 超过某个峰值后开始下降,但所有 ratio 段都有正向收益。这进一步印证了"相似用户行为是有用信号但伴随噪声"的核心假设。
与已归档相关工作的对比¶
Step 2.5: searched all 80 deeply_read papers; nearest candidates (IAT, SIF, LTE, Next-User Retrieval) all share the broad "RAG-style augmentation for CTR" flavor but none are problem+solution dual isomorphic with SUIN's user-level sequence-augmentation paradigm. SUIN's related work explicitly contrasts itself with sample-level retrieval methods (RIM/DERT/PET/RAT/RAR), which are not in the archive.
剔除候选与理由(仅记录,未生成对比子节):
- IAT (2604.08933, ByteDance):把同一用户的历史训练实例压缩为 token 来做序列增强——granularity 是 sample-level 而非 user-level;问题陈述是"hand-crafted sequential feature 的信息瓶颈",与 SUIN 的"target user 行为稀疏"是不同的 root cause。剔除。
- SIF (2604.15650, Meituan):Sample-level token 化——同 IAT 类似的反例,与 SUIN 的 user-level 检索不同构。剔除。
- LTE (2604.08181, Zalando):长期 user embedding 作为 prefix token 注入序列模型——是 user 自身的长期表征,没有"跨用户检索"环节。剔除。
- Next-User Retrieval (2506.15267, ByteDance):为冷启 item 预测下一个潜在 user——方向相反(item-side cold start),与 SUIN 的 user-side 行为增强不同构。剔除。
- HSTU/MTGR/STCA/RankMixer 等工业排序工作:都是单用户长序列的 capacity scaling,不涉及"跨用户检索"路径。剔除。
讨论与局限性¶
核心贡献¶
- 首次系统化把 RAG 思想应用到用户行为序列层面。既有的"retrieval-augmented for recsys"工作要么在 sample 级别(RIM/DERT),要么在 user-item ID 级别(RAR),SUIN 把检索目标对准"行为模式相似的整段用户序列",避免了 sample 级别 retrieval 的"行为时序信号丢失"问题。
- UTPE 的三性质设计是一个值得借鉴的位置编码模板:当输入序列由多个独立子序列拼接而成时(augmented sequence、cross-domain sequence、multi-modal sequence),UTPE 的"段间偏移 + 段内 target-aware"模板能够同时表达跨段相对位置和段内时序,且保留每段的来源标识。
- UTA 把"行为级噪声抑制"分解为 item-item × user-user 双相关性——这个分解在结构上比 threshold 过滤更细粒度,比 attention bias / gate 更直接。w/ RU vs SUIN 的大幅退化也说明该架构对"信号源的 user 级一致性"有强依赖。
值得借鉴的设计¶
- 离线相似用户检索 + 在线复用:CTR inference 不增加任何额外计算,所有用户对都可以离线计算相似度并落表。这种"用空间换时间 + 把检索移到训练之外"的工程手法,对 latency-critical 的工业排序系统很友好(虽然论文本身是学术工作)。
- frozen behavior embedding + adapter MLP:用预训练 sequence encoder 的输出作为额外特征但保持 frozen,避免双阶段联合训练的梯度耦合问题;adapter MLP 的成本低([32→16])。
- 多用户 augmented sequence 的位置编码思路可以迁移到 cross-domain CTR、multi-modal sequence 模型等场景。
局限性¶
- 没有工业部署 / A/B 实验——四个数据集都是公开学术数据集(Taobao 和 Alipay 来自阿里 TIANCHI),无在线收益证明。SUIN 论文实质是"提出了一个学术框架并在公开基准上做了充分对比",距离生产系统还有差距。
- 检索池规模 vs 检索质量 trade-off——论文用全部训练集用户构建检索池,单数据集最多 ~165 万用户,离线计算成本可控;但工业场景下用户数量在 1 亿级,离线全对相似度计算和存储都是巨大开销。论文没有讨论 ANN 检索 / 桶检索等近似方案的影响。
- 冷启动用户的处理:当目标用户行为序列极短(甚至 0 行为)时,SE 输出的 behavior embedding 信号薄弱,相似用户检索质量必然下降。论文未给出冷启用户的特别分析(虽然 Figure 1 指出短序列恰恰是 SUIN 的目标痛点)。
- 方法论可扩展性:SUIN 是"两阶段 + 静态预训练 encoder"模式——SE 训练完成后冻结,下游 CTR 模型在 frozen embedding 上做交互。在 LLM 时代的 trend 下(端到端联合训练、scaling 一切),这种 decoupled 设计可能限制 long-term 上限。但相比 IAT/SIF 的"先量化压缩再建模",SUIN 至少没有强信息损失环节。
与既有工作的差异¶
- 区别于 SIM/TWIN 等长序列方法:SIM/TWIN 是在目标用户自身长序列中筛选相关行为,需要用户本身有足够长的历史;SUIN 在全体用户中筛选相似用户,覆盖了短/稀疏序列用户。两者正交——可以拼起来用(SUIN 用 long-sequence backbone,相似用户也用其长序列)。
- 区别于 NI-CTR/DG-ENN 等用户-用户图方法:图方法只把 user 当作图节点,user-user 边权决定一切,没有显式利用相似用户的细粒度行为序列;SUIN 直接把整段行为序列接入注意力,保留了行为级时序信号。
- 区别于 RIM/RAR 等样本/ID 级 retrieval:RIM 检索"相似训练样本"通过 feature field 聚合,RAR 检索"相似 user/item ID"。SUIN 的检索单位是"用户的整段行为序列"——粒度居中,时序信息更完整。
总评:这是一个问题诊断清晰、方法设计完整、实验严谨的学术工作。最大短板是缺工业 A/B 验证;但其 RAG-for-CTR 的范式、UTPE 的位置编码设计、UTA 的双相关性分解,都是有迁移价值的方法论贡献。