GenRec 精读¶
1 研究动机与背景¶
1.1 工业级生成式检索面临的三大挑战¶
生成式检索(Generative Retrieval, GR)作为下一代推荐范式,将检索任务重构为一个条件序列生成问题——给定用户历史行为 $\mathcal{H} = \{v_1, \ldots, v_n\}$,模型通过 Next-Token Prediction(NTP)直接生成目标物品的 Semantic ID。相较于传统的 retrieve-and-rank 双塔流水线,GR 将"匹配"过程内化到 Transformer 的参数记忆中,结构上更统一、更接近 LLM 范式。然而,当把 GR 真正部署到 JD App 这种十亿级用户规模的首页推荐场景时,作者观察到三个以往论文很少涉及的工业级难题:
(i) 分页请求机制导致 one-to-many 标签歧义。 工业推荐系统普遍采用分页拉取(pagination)机制:用户每次下滑请求返回一页 $K$ 个物品。同一个用户历史 $\mathcal{H}$ 在同一页内可能对应多个同时发生的正向交互(点击、转化),也就是一个前缀 $\mathcal{H}$ 同时对应 $K$ 个"正确"的 next item $\{v^{(k)}\}_{k=1}^K$。传统 point-wise NTP 的做法是把这 $K$ 个标签拆成 $K$ 个独立的 $(\mathcal{H}, v^{(k)})$ 训练对——结果等价于在同一个前缀上去拟合一个展平的、近乎均匀的多模态分布,既稀释了每个物品的概率质量,又放大了梯度方差,直接损伤 top-$K$ 精度。作者把这种现象命名为 cardinality mismatch:一个 session 天然对应多个正样本,point-wise 训练却把它们相互孤立化,丢弃了 intra-session 的页面结构。
(ii) 多码 Semantic ID 导致 prompt 过长、推理成本激增。 现代 GR 方案普遍使用 RQ-VAE 或 RQ K-means 将每个物品编码为 $m$ 个离散码字(本文 $m=3$),也就是说输入历史序列的 token 数会被放大 $\sim 2\times\sim 3\times$。对于需要用"长行为序列"刻画用户兴趣的工业场景(典型要建模上百次历史),这直接带来两个后果:训练显存/算力翻倍;在线推理 prefill 延迟无法满足严苛的 SLA。
(iii) 生成策略与用户满意度信号的对齐鸿沟。 SFT 阶段基于 offline log 的 next-token likelihood 来训练,本质上只是在"模仿历史行为",并不直接优化用户偏好。而 offline log 又相当稀疏、非平稳(新物品、新兴趣每天涌现),naive 地用 RL 对齐容易出现 reward hacking:策略生成一些在奖励模型上分数很高、但实际上与用户无关的 SID 组合。
1.2 本文贡献¶
面对以上三个痛点,作者提出 GenRec,一个在 JD App 首页 feed 生产流量下已经全量上线的 decoder-only 生成式推荐框架。三项核心设计对应上面三个挑战:
- Page-Wise NTP(PW-NTP) SFT 目标:把监督粒度从单个 item 抬到整张 interaction page,让一次 forward 同时拟合页面内多个正样本的排序,消除 cardinality mismatch;同时提供更密的梯度信号,训练收敛更快。
- Token Merger:仅在 prefilling 侧插入一层线性 projection,把每个物品的多码 SID embedding 压成一个 latent 向量(prompt 缩短约 $2\times$),而 decoding 侧依然保留原始多码 SID 不做合并,做到"输入压缩、输出不动"的非对称设计。
- GRPO-SR:在 GRPO 基础上引入 Hybrid Rewards(SIM 偏好打分 × gating 过滤)抑制 reward hacking,再叠加一项 NLL 正则把策略强锚定到真实用户正向轨迹上,稳定 RL 训练并避免过拟合到奖励。
在月级在线 A/B 实验中,GenRec 相对现有 JD 多阶段生产流水线取得 click count +9.5%、transaction count +8.7% 的增益,长尾物品指标 exposure rate +10%、click +16%、transaction +13%。
2 预备知识:生成式检索的形式化¶
给定用户历史 $\mathcal{H} = \{v_1, \ldots, v_n\}$,任务是预测下一个交互物品 $\mathcal{Y}$。每个物品 $v$ 通过多模态编码器(Qwen2.5-VL)编码后再做 collaborative 微调,最后用 RQ K-means 对残差向量做层次化聚类,得到三码元 Semantic ID:
$$\mathrm{SID}(v_i) = \{s_i^1, s_i^2, s_i^3\} \tag{1}$$
于是一段历史 $\mathcal{H}$ 就展开为一个 SID token 序列。传统做法(如 TIGER、LC-Rec)直接在这个展开序列上做 point-wise NTP 训练:给定前缀 $[\mathrm{SID}(v_1), \ldots, \mathrm{SID}(v_{n-1})]$,监督模型生成 $\mathrm{SID}(v_n)$。
3 核心方法¶
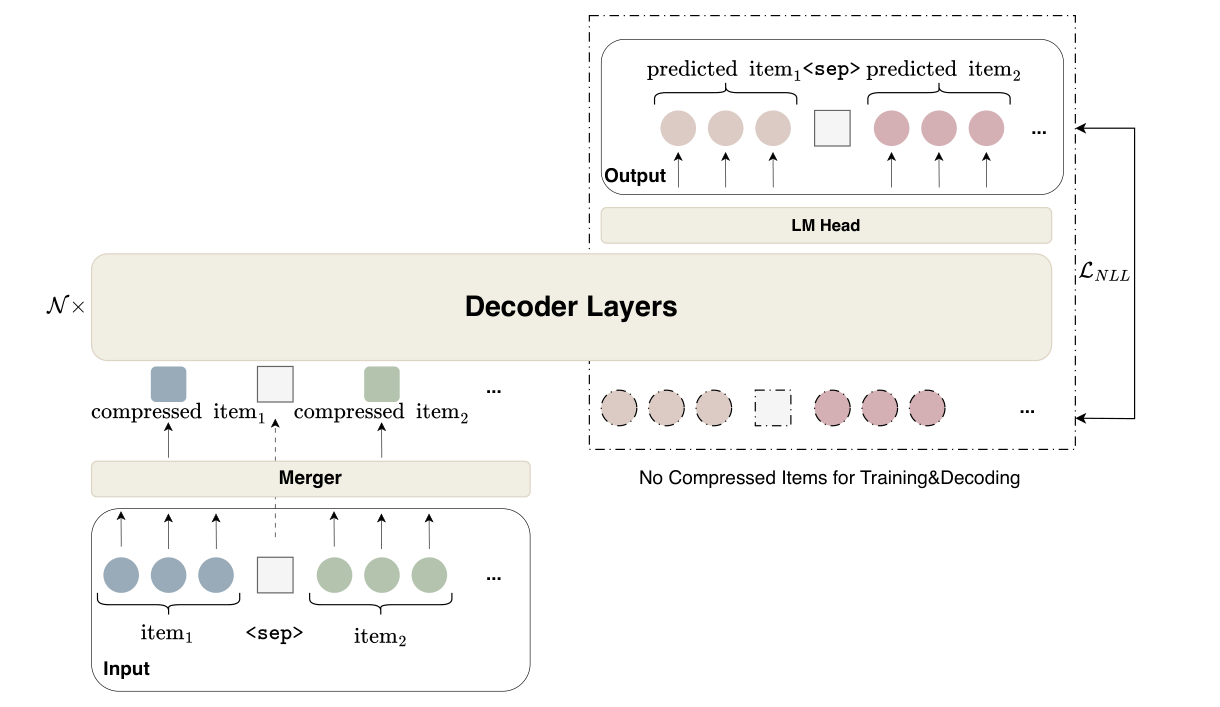
整个 GenRec 仍是 decoder-only 架构,但对"输入如何压、训练目标如何选、对齐如何做"三件事做了重构,如 Figure 1。从输入端自下而上:原始 SID 三码 embedding $\to$ Merger 压缩成一个 latent token $\to$ 与特殊分隔符 <sep> 一起喂给 Decoder $\to$ 输出端保持未压缩的多码 SID 以保证细粒度生成。训练目标由 PW-NTP SFT 主导,外加 RL 阶段的 GRPO-SR 对齐。
3.1 User-Centric Page-Wise NTP SFT¶
传统 point-wise 协议(TIGER、LC-Rec 等)的做法是"给定用户历史,预测下一个物品",训练和推理都是点对点的。在 JD 的分页场景里,作者明确把训练样本从"下一个 item"改为"下一整页 item":
输入定义。 沿用 Eq.1,把用户历史重写为 composite prompt:
$$S_u = [\mathrm{SID}(v) : v \in \mathcal{H}]_{>} \tag{2}$$
其中 $[\cdot]_>$ 表示按时间顺序展平拼接。
Page-wise 监督。 目标序列定义为一整页内用户涉及的物品,按"交互强度"降序排列:已下单 $O$、已点击 $C$、已曝光但无交互 $\mathcal{E}$:
$$Y_{\text{page}} = [\mathrm{SID}(v) : v \in O \cup C \cup \mathcal{E}]_{>} \tag{3}$$
页面内部还用 <sep> token 显式分隔不同物品,使结构信息保留在 token stream 中。训练目标就是标准的自回归 SFT:
$$\mathcal{L}_{\text{SFT}} = -\sum_{t=1}^{|Y_{\text{page}}|} \log P_\theta(y_t \mid S_u, y_{<t}) \tag{4}$$
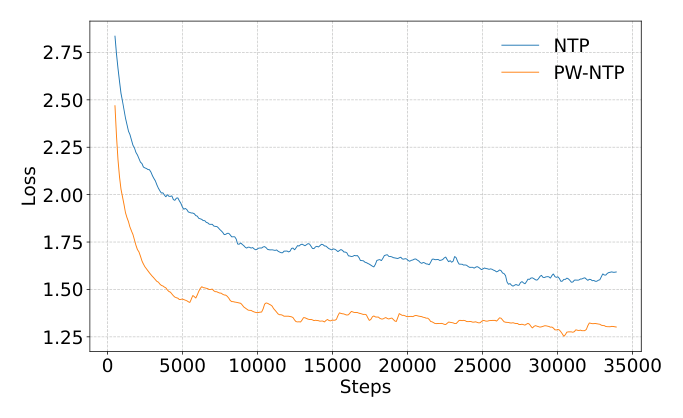
这项设计的收益有两层:(a) 一次 forward 提供页面内多个正样本的 supervision,密集梯度信号让 1.5B/3B/7B 模型 SFT loss 都显著下降(Figure 2a);(b) 解决 cardinality mismatch——以前一个前缀对多个 $v^{(k)}$ 的冲突标签,现在被合并成一个有序序列,不再互相"拉扯"概率质量。作者还观察到 PW-NTP 让 hallucination rate(HaR,生成 invalid SID 的比例)相对 LC-Rec 的 7.80% 降到 4.96%,并指出联合建模页面可以学到更一致的物品顺序,从而减少生成 SID 组合"不对应任何真实物品"的幻觉。
Point-wise beam search 推理。 线上推理阶段仍然保留 point-wise beam search:每次请求跑 beam search 生成 beam-width 个候选物品,每个候选是一个完整的三码 SID(单物品粒度),而不是训练目标那种"一整页多 item + <sep> 分隔的有序序列"。作者刻意保持训练-推理的非对称——训练 list-wise(更密的梯度),推理 point-wise(兼容生产 beam search 流水线)。论文原文明说:"list-wise training provides richer supervision of model gradients, while point-wise inference maintains compatibility with the production beam search pipeline."这种设计避免了为上线改造工程链路的成本,也是工业落地的重要妥协。
训练时 page 内 item 互相可见。 Eq (4) 是标准 decoder-only causal attention,目标序列 $Y_\text{page}$ 里第 $t$ 个 token 能看到它之前的所有 token(含前面 item 的 3 码 SID 和 <sep>),所以后面 item 会 attend 到前面 item 的 KV。论文没有额外施加 item-level mask——"joint prediction encourages more coherent item ordering"(3.2.1 节)的效果正来自这里:后位 item 以前位 item 为条件生成,学到了"订单 → 点击 → 曝光未点"的 intra-page 条件分布,这也是 HaR 从 LC-Rec 的 7.80% 降到 4.96% 的机理之一。
3.2 Token Merger:非对称的 prefilling 压缩¶
动机。 多码 SID 的直接后果是历史序列长度被放大 $\sim 3\times$,以 100 次历史为例,展开后就是 300 个 token 再加 99 个 <sep>,逼近 400-token 级别,在 Qwen2.5 3B/7B 的推理延迟预算内非常吃力。
结构。 对某物品 $v_i$ 的三码 SID 三元组 $\{s_i^1, s_i^2, s_i^3\}$,先分别查 embedding table 拿到三个向量 $\boldsymbol{e}(s_i^1), \boldsymbol{e}(s_i^2), \boldsymbol{e}(s_i^3)$,Concat 后过一层线性映射压缩回与 Decoder 同维度的 latent:
$$\mathbf{h}_{v_i} = \mathrm{Linear}(\mathrm{Concat}(\boldsymbol{e}(s_i^1), \boldsymbol{e}(s_i^2), \boldsymbol{e}(s_i^3))) \tag{5}$$
这一步只发生在 prompt 部分(prefilling 侧),也就是说:Decoder 看到的输入序列每个物品只占 1 个 token(加 <sep> 分隔),序列长度直接减半级别;而目标侧(decoding/output)仍然是完整的三码 SID,loss 也在原始 SID 粒度上计算。这种"输入低秩、输出高秩"的非对称设计有几个关键好处:
- 降成本不降粒度:压缩只作用于用户历史,减轻了最大的显存/延迟大头(prefill),而生成端保留了 $K^3$ 级别的 SID 空间,检索精度不损失
- 兼容现有 SFT/RL 管线:因为输出还是原始 token,PW-NTP、beam search、GRPO 等都不需要改造
- token-level 结构不丢:
<sep>等结构 token 保持 uncompressed,作为显式的物品边界信号
消融实验(Table 1 的 "w/o TM" 行)显示去掉 Token Merger 后 HR@10 从 0.4456 变到 0.4467、HaR 从 4.96% 变到 4.89%,性能几乎持平——说明 Merger 在把序列压缩一半的同时并没有牺牲检索质量,压缩本身是近乎"免费"的。
3.3 GRPO-SR:带奖励防 hack 的偏好对齐 RL¶
PW-NTP 本质上还是在"模仿行为日志",没有显式优化用户满意度。RL 阶段的目标是把策略向"用户真正偏好的物品"再校准一次。作者选了 GRPO(Group Relative Policy Optimization)作为底座,因为它不需要 value network、直接用组内相对优势,更适合物品离散组合的高方差场景。
Reward 设计:Hybrid Rewards。 仅靠点击标签作为 reward 过稀疏,作者用一个基于 SIM(Search-based Interest Model,SIGIR 2020)的稠密 preference 模型给 rollout 出的每个候选 $o_i$ 打连续分 $r_i^{\text{pref}} \in [0, 1]$。但稠密 reward 有个致命风险——reward hacking:模型会生成一些语法合法、SID 也在词表内,但其实根本没对应真实物品的组合,照样能拿到非零 $r^{\text{pref}}$(因为 SIM 只看 embedding 相似度)。
为抑制这种 hack,作者加了 gate 机制:定义 $\mathcal{G}_i = \mathbb{I}(s_i > \tau)$,只有当 rollout 出的候选被 SIM 判定分数超过阈值 $\tau$ 才视为"有效",否则 reward 直接被抹零。最终 hybrid reward 为:
$$r_i = \mathcal{G}_i \cdot r_i^{\text{pref}} \tag{6}$$
此外在组内还做了一次校准:对落在真实正样本集合 $\mathcal{D}^+ = O \cup C$ 内的候选,把它们的 reward 强制拉到组内最大值 $r_{\max}$,防止 SIM 模型对真实 engagement 物品估计偏低:
$$\tilde{r}_i = [1 - \mathbb{I}(o_i \in \mathcal{D}^+)] \cdot r_i + \mathbb{I}(o_i \in \mathcal{D}^+) \cdot r_{\max} \tag{7}$$
GRPO-SR 目标函数。 最终的损失函数把 group-relative policy optimization 和 NLL 正则组合起来:
$$ \mathcal{L}_{\text{GRPO-SR}}(\theta) = -\mathbb{E}_{S_u \sim T, \{o_i\}_{i=1}^G \sim \pi_\theta(\cdot \mid S_u)} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \frac{\pi_\theta(o_{i,t} \mid S_u, o_{i,<t})}{\mathrm{sg}(\pi_\theta(o_{i,t} \mid S_u, o_{i,<t}))} \hat{A}_{i,t} \right] - \alpha \cdot \mathbb{E}_{v \sim \mathcal{D}^+} \left[ \sum_{t=1}^{|v|} \log \pi_\theta(v_t \mid S_u, v_{<t}) \right] \tag{8} $$
其中:
- $T$ 是训练集;$G$ 是每条 prompt 采样的 rollout 数;$\hat{A}_{i,t}$ 是用 group-relative reward 算出的 token-level advantage
- 第一项是 GRPO 的 importance sampling policy gradient,梯度只通过 $\pi_\theta/\mathrm{sg}(\pi_\theta)$ 传递($\mathrm{sg}$ 是 stop gradient),形式上等价于单步策略更新
- 第二项(权重 $\alpha$)是对真实正样本轨迹 $\mathcal{D}^+$ 的 NLL 损失,作者将其称作 Supervised Regularization("SR"的来源)
和标准 KL-divergence 正则不同,NLL 正则显式地把策略拉向"真实用户行为分布"而不是"参考模型分布",因而对 reward over-optimization 有更硬的约束——reference policy 本身可能也带偏,而 user behavior log 是 ground truth。更精确地说,这里 anchor 的是"真实用户点击/下单的单 item 分布",并不是完整的 page 轨迹(见下)。
样本粒度:RL 阶段退回 point-wise。 这里有个容易被忽略的设计切换——SFT 阶段样本是 page 粒度($Y_\text{page}$ 一整页多 item 有序序列),到 RL 阶段 GRPO rollout 和 NLL anchor 都退回 item 粒度:rollout $o_i$ 是模型生成的单个 item SID(3 个 token),$\mathcal{D}^+ = O \cup C$ 在论文原文里被定义为 "the set of ordered and clicked items from the interaction page",$v \sim \mathcal{D}^+$ 采样的也是单个 item($|v|$ = 3 码 SID 长度)。这是必须的——只有样本组织一致,GRPO 和 NLL 两项 loss 才能在 Eq (8) 里干净加和;如果 NLL 直接沿用 SFT 的 $Y_\text{page}$ list-wise 目标,两项 loss 就对不上。
换句话说 GenRec 是两阶段训练:
- SFT 阶段用 PW-NTP 的 page-wise 目标建模 intra-page 结构
- RL 阶段用 GRPO-SR(point-wise rollout + point-wise NLL)对齐偏好
论文对这个切换只在 2.3 节开头一句话带过:"Unlike PW-NTP SFT stage, the RL stage aligns with the point-wise beam search inference protocol: each rollout generates a single item sequence per query",给的理由是"与线上推理一致"。更深层动机论文没展开——可能原因:一是 GRPO 在 list-wise 长序列上 group-relative advantage 方差会爆炸;二是 rollout 采样成本随序列长度线性增长,point-wise 更划算;三是 NLL anchor 保留 page 级 intra-page ordering 会让"真实行为分布"定义变得复杂(因为 ordering 本身就是 PW-NTP 的先验人工设计)。
4 实验设置¶
数据。 JD.com 首页 feed 一个月的用户交互序列,约 5.6 亿条 sequence,最后一天作为测试集,其余做训练。这是本文最具工业分量的部分——学界开源数据集很难复现这种 scale。
模型与训练。 backbone 采用 Qwen2.5 decoder-only 架构,主实验使用 3B 版本;另外对 1.5B / 3B / 7B 都跑了 scaling 实验。所有模型在 SID 语料上做继续预训练 + PW-NTP SFT + GRPO-SR RL。优化器 AdamW,学习率前 1% 步数线性 warmup 再 cosine decay,分布式训练使用 8× NVIDIA H100 GPU。
Baselines。 传统方法:BERT4Rec、SASRec;生成式方法:TIGER、LC-Rec(均复现为 vanilla point-wise NTP)。为公平比较,LC-Rec 也用 Qwen2.5 3B backbone 重训。
评价指标。 Offline 用 HitRate@K(HR@1/10/50)、NDCG@K(N@10/50),以及 Hallucination Rate(HaR,生成无效 SID 的比例);RL 部分用 Reward@K(top-K 候选的平均 SIM 分)。Online 在 JD App 首页 feed 以 10% 流量做了月级 A/B 测试,观测 Exposure Rate、Click Count、Transaction Count。
5 主要实验结果¶
5.1 Offline 主表:Next-item vs Next-sequence¶
下表复现自 Table 1:
| Model | HR@1 | HR@10 | N@10 | HR@50 | N@50 | HaR↓ |
|---|---|---|---|---|---|---|
| BERT4Rec | 0.0315 | 0.0968 | 0.0412 | 0.1832 | 0.0689 | - |
| SASRec | 0.0383 | 0.1048 | 0.0492 | 0.1976 | 0.0776 | - |
| TIGER | 0.0518 | 0.1660 | 0.0803 | 0.3556 | 0.1409 | 15.46% |
| LC-Rec | 0.0947 | 0.3669 | 0.2146 | 0.6226 | 0.2717 | 7.80% |
| GenRec | 0.1189 | 0.4456 | 0.2635 | 0.7192 | 0.3247 | 4.96% |
| GenRec w/o TM | 0.1193 | 0.4467 | 0.2653 | 0.7201 | 0.3276 | 4.89% |
分析。 几个关键观察:
- 对 LC-Rec(同 backbone 同 SID)的绝对增益极大:HR@1 从 0.0947 提到 0.1189(+25.6%),HR@50 从 0.6226 提到 0.7192(+15.5%)。由于唯一的差异是把 point-wise NTP 换成 PW-NTP(再加 Token Merger),这条对比直接证明页面级监督的价值
- HaR 下降最显著:TIGER 15.46% → LC-Rec 7.80% → GenRec 4.96%,说明把整页监督一起丢给模型学,让模型对 SID 词表的联合分布学得更扎实,生成的组合更容易对应真实物品
- Token Merger 是"压成本不压精度"的:GenRec vs GenRec w/o TM 几乎所有指标差距都在 1e-4 量级,HaR 甚至略优;意味着 2× 的 prefill 压缩基本是白给的工程红利
作者解释 PW-NTP 带来大幅提升的两个机理:(1) vanilla NTP 的 one-to-many 标签歧义会增加优化难度和梯度方差,PW-NTP 在单次 forward 内聚合多个监督信号,等价于方差减少 + gradient batching;(2) 页面内联合建模使模型学会 coherent item ordering,降低 hallucination。
5.2 Scaling 行为¶
复现自 Table 2:
| Model Size | HR@1 | HR@10 | N@10 | HR@50 | N@50 | HaR↓ |
|---|---|---|---|---|---|---|
| 1.5B | 0.1077 | 0.4103 | 0.2484 | 0.6527 | 0.1885 | 5.34% |
| 3B | 0.1189 | 0.4456 | 0.2635 | 0.7192 | 0.3247 | 4.96% |
| 7B | 0.1221 | 0.4483 | 0.2649 | 0.7216 | 0.3269 | 5.42% |
分析。
- 1.5B → 3B 的性能跳跃非常大(HR@1 +10.4%),但 3B → 7B 只有微小改善(HR@1 +2.7%),~2.3× 的参数量仅换来边际提升
- 作者做了结构分析:3B 比 7B 更深(36 层 vs 28 层),隐藏维度 2048 vs 3584,指出在生成式推荐场景下,增加深度可能比增加宽度更有效,原因是 user-item 交互建模更依赖多次非线性变换(更多层)而不是更宽的特征通道
- 这一结论与"capacity density"假说(Xiao 等 2025 的 arXiv:2412.04315 系列)一致:对于下游能力密度而言,depth-over-width 更 efficient
- HaR 方面 3B 最低(4.96%),7B 反而略升(5.42%),暗示过多容量在 SID token 任务上可能带来轻微 overfit 或 over-generation
Figure 2b 同时显示 3B 和 7B 的 SFT loss 曲线几乎贴合,而 1.5B 明显更高——这也和下游表现差距的分布一致。
5.3 RL 对齐:GRPO-SR 与 Reward Hacking 消融¶
复现自 Table 3:
| Setting | HR@50 | R@1 | R@10 | R@50 | HaR↓ |
|---|---|---|---|---|---|
| Baseline | |||||
| GenRec (Base SFT) | 0.7192 | 0.1027 | 0.1519 | 0.1776 | 4.96% |
| Policy Gradient Variants | |||||
| GRPO | 0.7248 | 0.1177 | 0.1650 | 0.1861 | 6.03% |
| GRPO-SR | 0.7438 | 0.1212 | 0.1679 | 0.1892 | 2.68% |
| Reward Variants | |||||
| GRPO w/o $\mathcal{G}$ | 0.6975 | 0.1045 | 0.1608 | 0.1797 | 1.75% |
| GRPO-SR w/o $\mathcal{G}$ | 0.7016 | 0.1067 | 0.1598 | 0.1813 | 1.96% |
分析。
- GRPO-SR 全面超过 vanilla GRPO:HR@50 从 0.7248 升到 0.7438,Reward@1 更是从 SFT baseline 的 0.1027 跃升到 0.1212(相对 SFT +18.01%),说明 RL 确实能把输出分布朝"高偏好候选"迁移,且 NLL 正则让这种迁移不会跑偏
- Gate $\mathcal{G}$ 是 reward hacking 的关键开关:去掉 gate 后(两个 "w/o $\mathcal{G}$" 行),HaR 看起来极低(1.75% / 1.96%),这不是好事——作者指出这其实是 reward hacking 的经典信号:模型已经学会了"只生成 SIM 认为高分但未必对应真实物品"的组合,HaR 定义里这种组合被判为"可解析 SID"所以不算 hallucination,但 HR@50 大幅下滑(从 0.7438 掉到 0.7016)暴露了其实真实推荐质量在劣化。换句话说 低 HaR 并不等于高质量,需要结合 HR 一起看
- NLL 正则进一步提升稳定性:在 w/o $\mathcal{G}$ 的两行对比里,GRPO-SR(有 NLL 正则)的 HR@50 比 GRPO 高 0.004 左右,reward 指标也更好——NLL 正则像是给优化轨迹加了一条"用户真实行为"的强锚
5.4 Online A/B 测试¶
复现自 Table 4,流量分配各 10%,持续一个月:
| Setting | Exposure Rate | Click Count | Transaction Count |
|---|---|---|---|
| GenRec (Base SFT) | 48.7% | +8.5% | +7.3% |
| + GRPO-SR alignment | 57.3% | +9.5% | +8.7% |
$p < 0.05$ 双尾检验显著。对长尾物品单独拉出来看:Exposure Rate +10%、Click Count +16%、Transaction Count +13%——这说明 GenRec 不仅提升了整体 GMV,还显著改善了长尾分发,很可能是因为生成式范式不再依赖 head embedding 的稠密学习,对新 / 冷门物品更友好。
作者指出 GenRec + GRPO-SR 对齐版本已经全量部署在 JD App 首页 feed 推荐生产环境,替代了原来的多阶段召回 + 排序流水线。
6 讨论与局限性¶
6.1 设计亮点¶
- Cardinality mismatch 的提法非常有原创性。 以往论文把"为什么分页场景不能直接套 LC-Rec"讲清楚的很少,而作者从 one-to-many 标签歧义角度切入,给出了很直接的解释。PW-NTP 实际上是把推荐的隐式 list-wise 结构重新编码回训练信号,这与 listwise LTR 在工业界反复被验证的价值是同源的
- 非对称架构(输入压缩 + 输出不动)的工程品味。 这是全文最聪明的一笔:多码 SID 的双刃剑被"只压输入"化解了,prefill 2× 提速,而生成侧保留 $K^3$ 空间不牺牲检索精度。这种设计对所有 RQ-VAE 系 GR 系统都有直接的借鉴价值
- NLL 正则 vs KL 正则的区别。 大部分 RLHF/RLAIF 方案用 KL 约束到参考策略,而这里显式把 NLL 的 anchor 设为"真实用户轨迹 $\mathcal{D}^+$"。工业场景下 reference model 本身是 SFT 后的产物,未必是最可信的 anchor;用真实 engagement 数据做 anchor 在道理上更合适,也更抗 reward over-optimization
- Reward hacking 的诊断技巧。 作者用"低 HaR 但 HR 掉"这种组合信号来识别 hack,是非常实用的工业经验——单看 HaR 或单看 Reward 都会被 hack 欺骗
6.2 局限与值得追问¶
- HR@1 和 HR@10 在"w/o TM"上略高。 Table 1 中去掉 Token Merger 的版本其实在 HR@1(0.1193)和 HR@10(0.4467)上都略优于完整 GenRec(0.1189 / 0.4456),这提示 Merger 带来的 latency gain 并不是完全免费的,精度上可能有 $<1\%$ 级别的 trade-off。论文对此没展开。
- PW-NTP 的目标序列排序依赖人工设计。 作者采用"订单 > 点击 > 曝光"的先验排序作为目标序列 $Y_{\text{page}}$,但在长尾/多目标场景下这个固定排序是否最优?比如有没有可能让模型自适应学习 intra-page ordering?
- gate 阈值 $\tau$ 的敏感性没有分析。 Hybrid Reward 里 $\tau$ 是一个"小常数",但论文没给具体值也没做 sweep,实际落地时这是关键超参。
- Semantic ID 的冷启。 基于 Qwen2.5-VL + RQ K-means 的 SID 生成本身对新物品需要 reindex,论文没讨论 SID 词表的在线更新机制,对于一个 560M 规模、每天大量新 SKU 上架的电商环境这是个工程难题。
- Scaling 到 7B 的边际收益递减。 3B → 7B 几乎没有显著性能提升,如果想继续 scale 到更大模型,目前的架构可能面临 diminishing return,需要换 MoE 或者引入更多推荐特定的 inductive bias。
- 样本粒度切换只用一句话交代。 两阶段训练 SFT(list-wise) → RL(point-wise) 的粒度切换在 2.3 节开头仅用 "Unlike PW-NTP SFT stage..." 一句话带过,没有分析:为什么 RL 不沿用 list-wise?NLL anchor 为什么退化成 item 集合而不用 page 轨迹?RL 后 PW-NTP 学到的 intra-page ordering 会不会被 point-wise 梯度冲淡(RL 后 HaR 是否回升、页内 coherence 是否衰减)?缺乏对应消融。这是全文最值得展开但被跳过的设计点。
- NLL vs KL 正则缺少直接对比。 论文强调 NLL 用真实 behavior log 做 anchor 比 KL-to-reference 更合适,但没给同条件下 KL 正则的对照实验。"reference policy 本身带偏"是合理 argument,但缺量化证据。
6.3 与已有工作的关系¶
- vs TIGER:TIGER 开创了生成式检索 + Semantic ID 范式,但 SFT 策略是 vanilla point-wise NTP,HaR 高达 15.46%。GenRec 在同一 SID 基础上把监督换成 PW-NTP,HaR 降到 4.96%
- vs LC-Rec:LC-Rec 优化了 codebook 端到端学习,但仍采用 point-wise NTP 的训练/推理 pipeline。GenRec 的 PW-NTP 是在 LC-Rec 的 Qwen backbone 上正交地追加的监督变化,直接带来 HR@1 +25% 级的提升
- vs OneRec(Kuaishou):OneRec 同样使用 RQ K-means 和 decoder-only 架构,但更强调业务目标的一体化训练;GenRec 的 GRPO-SR 在 RL 对齐方法上更具体,hybrid reward + NLL 正则的组合是 OneRec 未明确讨论的
- vs HSTU(Meta):HSTU 走的是"gated linear recurrence 代替 attention"的效率路线,不用 Semantic ID;GenRec 选择保留标准 Transformer + SID 范式,但用 Token Merger 解决效率问题,两者代表两种不同的工业化取向
6.4 工业落地细节总结¶
- 部署规模:JD App 首页 feed 推荐主通路,10% A/B 流量 × 1 个月,最终 100% rollout
- 硬件:8× H100 做训练;推理侧 Token Merger 将 prefill 序列长度压缩 $\sim 2\times$,满足生产延迟 SLA
- Backbone 选择:3B 的 Qwen2.5(36 层深结构),在 performance/latency trade-off 上最优
- 上线增益:click +9.5%,transaction +8.7%,长尾物品曝光 +10%、click +16%、transaction +13%
总体来看,GenRec 是一篇信号密度非常高的 SIGIR 短文:三个看似独立的模块(PW-NTP / Token Merger / GRPO-SR)每一个都对应一个明确的工业痛点,都有干净的消融,并在真实 10 亿用户流量上走完了完整的"offline→online→全量"闭环。对下一代工业级生成式推荐系统(尤其想从 LC-Rec / TIGER 升级的团队)来说,这三个模块都可直接借鉴落地。