FAVE: Flow-based Average Velocity Establishment for Sequential Recommendation¶
一、问题背景与动机¶
序列推荐(Sequential Recommendation, SR)的核心是根据用户历史行为序列预测下一次交互的 item。为了能够捕获偏好的不确定性与分布式特征,近年来"生成式序列推荐"成为一个新兴范式,用生成模型(Diffusion、Flow Matching)在连续空间中建模下一 item 的偏好分布,相比传统判别式方法(SASRec、BERT4Rec)在鲁棒性和表达多样性上更具优势。
本文以这一方向为出发点,指出两类主流生成式序列推荐方法的缺陷:
- Diffusion-based 方法(DiffuRec、DreamRec、DiffRec 等):通过多步非自回归去噪从 Gaussian 噪声还原 item 的偏好表征。缺陷在于 反向扩散需要多步迭代、推理成本高,严重阻碍了工业级低延迟在线推荐的应用。
- Flow Matching (FM) 方法(FMRec [23]、STOSA、AutoSeqRec):用 ODE 确定性地将源分布映射到目标分布,轨迹相比扩散模型更平直。尽管如此,作者指出其仍受制于 "Noise-to-Data" 的范式,带来两类"关键"的低效率根源:
(a) 先验不匹配(Prior Mismatch)。标准 FM 从 Gaussian 噪声开始生成,而目标是高度结构化的用户偏好分布,两者差异巨大,需要大量步数才能学习到"从无信息噪声到强语义偏好"的映射。
(b) 线性冗余(Linear Redundancy)。为了克服先验不匹配,常用手段是采用更细的数值积分器(如多步 Euler),但这会使模型在大部分中间状态反复预测相似的偏好方向,造成大量重复计算——这也是 FM 类方法不易真正"一步推理"的症结。
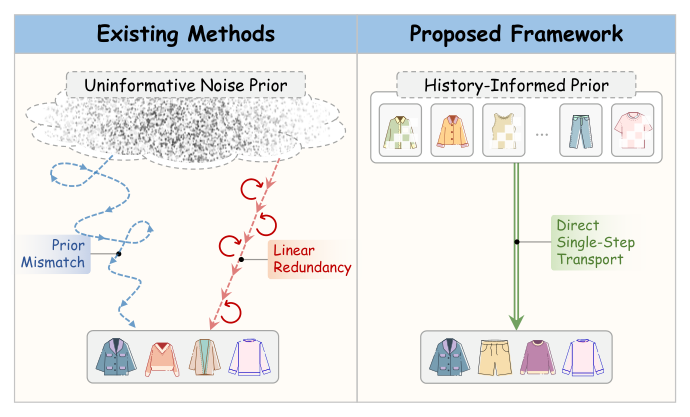
针对以上问题,本文提出 FAVE (Flow-based Average Velocity Establishment) 框架,其核心两点思路:
- 用户历史作为"语义锚点先验"。把用户的历史交互序列作为 flow 的起点,让生成的轨迹直接从一个"包含语义信息的出发点"走向目标 item,而非从无意义的 Gaussian 噪声出发,从而显著缩短生成轨迹;
- 学习全局平均速度场而非瞬时速度场。将整条多步轨迹压缩为一个"平均速度"单步位移向量,配合 JVP(Jacobian-Vector Product)约束轨迹直度(直线性),确保单步推理也能保持高精度。
最终 FAVE 在三个基准(ML-100k、Amazon-Beauty、Steam)上相比 SOTA 平均提升 7.48%(H@10)/ 9.90%(N@20),同时推理速度比 SOTA 的 FMRec 提升一个数量级。
二、相关工作¶
- 序列推荐:从 GRU4Rec、Caser 等 RNN/CNN 类模型,发展到 SASRec、BERT4Rec 等 Transformer 类模型,再到最近 STOSA 等用 Wasserstein 度量建模不确定性的方法。
- 生成式序列推荐:包括 DreamRec、DiffRec、DiffuRec 等扩散类模型,以及 FMRec、AutoSeqRec 等基于 flow matching 或 ODE 的模型。
- Flow Matching:Lipman 等人提出 FM 作为扩散模型的替代方案,通过直接构造时间相关速度场将 source 分布映射到 target 分布,公式上依赖 ODE,无需多次噪声采样。FAVE 是这一方向上首个全局平均速度单步 FM 推荐方法。
三、Preliminary¶
3.1 序列推荐定义¶
用户集 $\mathcal{U} = \{u_1, \ldots, u_{|\mathcal{U}|}\}$,item 集 $\mathcal{I} = \{i_1, \ldots, i_{|\mathcal{I}|}\}$。用户 $u$ 的交互序列按时间排序为 $\mathbf{A}_u = \{i_1^u, i_2^u, \ldots, i_{|\mathcal{A}_u|}^u\}$。SR 任务是:根据 $\mathbf{A}_u$ 预测下一个 item $i_{|\mathcal{A}_u|+1}^u$。
生成式范式进一步将其建模为一个条件分布 $p_{\text{user}}$ 到目标 $p_{\text{data}}$ 的映射:
$$p_{\text{data}} = f_\theta(p_{\text{user}}) \tag{1}$$
3.2 Flow Matching 基础¶
Flow matching 的目标是学习时间相关速度场 $v_\theta(\mathbf{x}_t, t)$,使得从先验 $p_{\text{prior}}$ 采样的 $\mathbf{x}_0$ 可沿轨迹到达目标分布 $p_{\text{data}}$ 中的 $\mathbf{x}_1$。最常用的 线性插值轨迹:
$$\mathbf{x}_t = (1 - t) \mathbf{x}_0 + t \mathbf{x}_1 \tag{2}$$
其瞬时速度由求导获得:
$$u_t(\mathbf{x}_t \mid \mathbf{x}_0, \mathbf{x}_1) = \frac{d \mathbf{x}_t}{dt} = \mathbf{x}_1 - \mathbf{x}_0 \tag{3}$$
直接回归该速度场并不可行:中间点 $\mathbf{x}_t$ 可能对应多对 $(\mathbf{x}_0, \mathbf{x}_1)$,方向不明确。作者记这个"平均方向"为:
$$\mathcal{L}_{FM}(\theta) = \mathbb{E}_{t, p_t(\mathbf{x}_t)} \lVert v_\theta(\mathbf{x}_t, t) - \bar{v}(\mathbf{x}_t, t) \rVert^2 \tag{5}$$
(其中 $\bar{v}(\mathbf{x}_t, t) \triangleq \mathbb{E}_{p_t(\mathbf{x}_t \mid \mathbf{x}_1)}[u_t]$)。
实际中使用条件流匹配目标(CFM)绕开对平均的显式求解:
$$\mathcal{L}_{CFM}(\theta) = \mathbb{E}_{t, \mathbf{x}_0, \mathbf{x}_1} \lVert v_\theta(\mathbf{x}_t, t) - u_t(\mathbf{x}_t \mid \mathbf{x}_0, \mathbf{x}_1) \rVert^2 = \mathbb{E}_{t, \mathbf{x}_0, \mathbf{x}_1} \lVert v_\theta(\mathbf{x}_t, t) - (\mathbf{x}_1 - \mathbf{x}_0) \rVert^2 \tag{6}$$
四、方法:FAVE¶
FAVE 采用两阶段训练策略,整体框架见图 2:
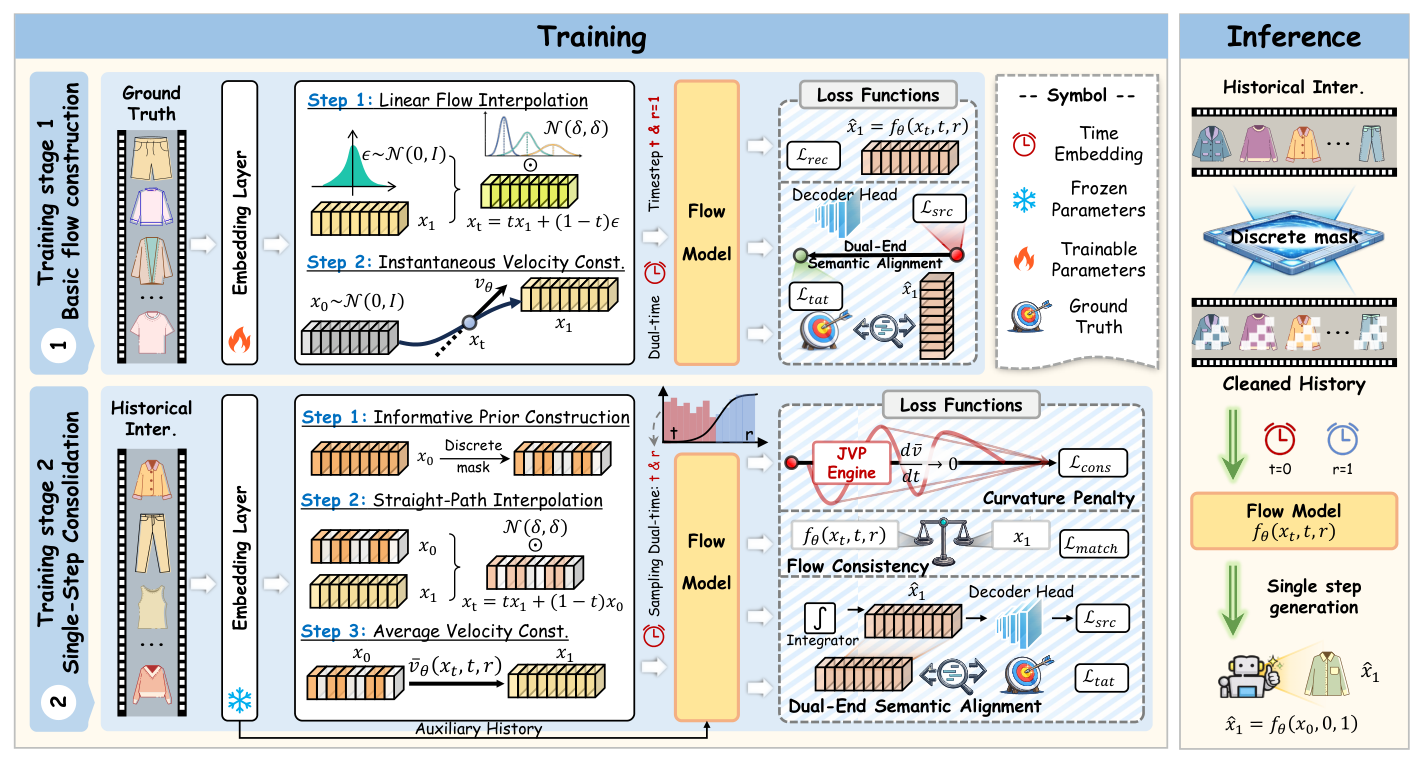
- Stage 1 — Basic Manifold Construction:使用经典 CFM 在 Gaussian 噪声上训练,建立稳定的速度场作为 item manifold 基础;
- Stage 2 — Single-Step Consolidation:用"用户历史"构造有语义信息的先验替换 Gaussian;将多步轨迹坍缩为单步平均位移;用 JVP 约束轨迹直度。
4.1 Stage 1: Basic Manifold Construction¶
目的是建立一个稳定的 item 表征空间(manifold)。模型通过学习从 Gaussian 噪声到 item embedding 的瞬时速度场作为该 manifold 的基础骨架。
4.1.1 Dual-Time Flow Modeling¶
为适配"离散 item"设定,FAVE 先将目标 item $i_{t+1}$ 映射到连续 manifold:
$$\mathbf{x}_1 = \mathbf{e}_{i+1} = \text{Embedding}(i_{t+1}) \tag{7}$$
线性插值 $\mathbf{x}_t$ 根据式 (2) 得到,$\mathbf{x}_0$ 来自 Gaussian $\mathcal{N}(0, \mathbf{I})$。作者采用 [6] 的 heavy-tailed 采样策略(更关注轨迹上的高频段)。
直接用 $t$ 作为时间输入的关键问题是:不同 $(\mathbf{x}_0, \mathbf{x}_1)$ 对同一 $\mathbf{x}_t$ 会产生不同流方向,仅靠 $t$ 无法区分。为此作者提出 dual-time parameterization $(t, r)$:$t$ 为标准时间,$r$ 为另一个用于标注"trajectory endpoint"的辅助时间($r \equiv 1$ 时退化为普通 FM)。将两者融合为混合时间特征:
$$\tau = \text{TimeEmb}(t) + \text{TimeEmb}(r - t) \tag{8}$$
其中 TimeEmb 是两层 MLP。
最终网络输入特征为:
$$E = \mathbf{e}_s + \lambda \odot (\mathbf{x}_t + \tau) \tag{9}$$
其中 $\mathbf{e}_s$ 是历史序列编码,$\odot$ 为逐元素乘法。$\lambda$ 是噪声向量,采样自 $\mathcal{N}(\delta, \delta)$,$\delta$ 是统一控制 perturbation 均值与方差的超参。
4.1.2 Recovery Loss (重参数化)¶
Diffusion 中的一个经验是:模型直接预测"目标状态"比预测"速度"更稳。受此启发,FAVE 对 $v_\theta$ 做重参数化,使其隐含预测目标 $\hat{\mathbf{x}}_1$:
$$v_\theta(\mathbf{x}_t, t, r) \triangleq f_\theta(\mathbf{x}_t, t, r) - \mathbf{x}_0 \tag{10}$$
代入 CFM 目标:
$$\mathcal{L}_{rec}(\theta) = \mathbb{E}_{t, \mathbf{x}_0, \mathbf{x}_1} \lVert (f_\theta(\mathbf{x}_t, t, 1) - \mathbf{x}_0) - (\mathbf{x}_1 - \mathbf{x}_0) \rVert^2 = \mathbb{E}_{t, \mathbf{x}_0, \mathbf{x}_1} \lVert f_\theta(\mathbf{x}_t, t, 1) - \mathbf{x}_1 \rVert^2 \tag{11}$$
这是一个"直接 denoising"目标,模型显式学习把任意插值中间态映射到真实目标 embedding $\mathbf{x}_1$,从而避免直接回归速度时的模式混淆。
4.1.3 Dual-End Semantic Alignment¶
仅有 recovery loss 还不足以防止 item embedding 表征坍缩(即不同 item 的 embedding 相似化,所有生成样本都落到同一点)。FAVE 从 flow 轨迹的两端同时约束:
Target-side(交叉熵对齐下一 item):
$$\hat{y}_{t+1} = \frac{\exp(f_\theta(\mathbf{x}_t, t, r) \cdot \mathbf{e}_{i+1})}{\sum_{j \in \mathcal{I}} \exp(f_\theta(\mathbf{x}_t, t, r) \cdot \mathbf{e}_j)}, \quad \mathcal{L}_{tgt} = -\log \hat{y}_{t+1} \tag{12}$$
Source-side(历史重构):
$$\mathcal{L}_{src} = \lVert \mathcal{D}(E_h) - \mathbf{A}_u \rVert^2 \tag{13}$$
其中 $E_h$ 是模型中间隐藏表征,$\mathcal{D}(\cdot)$ 为解码函数将隐藏态解码回 item 交互序列。这个"双端语义对齐"保证 flow 的起点也带有源语义信息,为 Stage 2 的 "history-informed prior" 打好基础。
4.2 Stage 2: Single-Step Consolidation¶
在 Stage 1 训好的 manifold 之上,Stage 2 冻结 embedding 层("保留已学结构"),重点改造 flow matching 目标使其支持"单步生成"。
4.2.1 Informative Prior Construction¶
放弃 Gaussian 噪声作为 source,改为从已扰动的用户历史交互嵌入出发。设用户交互序列中随机采样的一个 item $k$ 的 embedding 为 $\mathbf{e}_k$,再用 Bernoulli 随机 mask 扰动:
$$\mathbf{x}_0 = \mathbf{e}_k \odot \mathbf{m}, \quad k \sim \text{Uniform}(s_u), \; \mathbf{m} \sim \text{Bernoulli}(\rho) \tag{14}$$
其中 $\rho$ 是 retention rate(保留概率)。这样构造出的先验 $\mathbf{x}_0$ 包含真实用户兴趣信息,减小了先验与目标分布之间的差距,从而大幅缩短轨迹长度。
4.2.2 Average Velocity Field Establishment¶
Stage 1 仍是瞬时速度模型。ODE 求解器(如 Euler)为保证精度必须多步:
$$\mathbf{x}_{t + \Delta t} = \mathbf{x}_t + v(\mathbf{x}_t, t) \cdot \Delta t \tag{15}$$
FAVE 提出在时间上对速度场做积分,一次性得到全局位移方向。直接对 ODE 从 $t$ 到 $r$ 积分:
$$\mathbf{x}_r - \mathbf{x}_t = \int_t^r v_\theta(\mathbf{x}_\eta, \eta)\, d\eta = (r - t) \times \left[\frac{1}{r - t} \int_t^r v_\theta(\mathbf{x}_\eta, \eta)\, d\eta\right] \tag{16}$$
括号中的就是从 $t$ 到 $r$ 的平均速度:
$$\tilde{v}_\theta(\mathbf{x}_t, t, r) \triangleq \frac{1}{r - t} \int_t^r v_\theta(\mathbf{x}_\eta, \eta)\, d\eta \tag{17}$$
在默认的 $t=0 \to r=1$ 的全轨迹上,
$$\mathbf{x}_1 = \mathbf{x}_0 + \tilde{v}_\theta(\mathbf{x}_0, 0, 1) \tag{18}$$
即模型仅需一次 forward 即可从先验 $\mathbf{x}_0$ 直接到达目标 $\mathbf{x}_1$。
为了训练这个平均速度,将其代入原 CFM 目标并利用 ODE 全微分展开,得到可分离的两部分:
$$\mathcal{L}_{CFM}(\theta) = \mathbb{E}_{t, \mathbf{x}_0, \mathbf{x}_1} \lVert \tilde{v}_\theta(\mathbf{x}_t, t, r) - u_t(\mathbf{x}_t \mid \mathbf{x}_0, \mathbf{x}_1) \rVert^2$$
$$= \mathbb{E}_{t, \mathbf{x}_0, \mathbf{x}_1} \underbrace{\lVert \tilde{v}_\theta(\mathbf{x}_t, t, r) - (\mathbf{x}_1 - \mathbf{x}_0) \rVert^2}_{\text{conditional flow matching}} + (r - t) \underbrace{\left\lVert \frac{d\mathbf{x}_t}{dt} \cdot \frac{\partial}{\partial \mathbf{x}_t} \tilde{v}_\theta(\mathbf{x}_t, t, r) + \frac{\partial}{\partial t} \tilde{v}_\theta(\mathbf{x}_t, t, r) \right\rVert^2}_{\text{curvature penalty}} \tag{19}$$
第一项是常规 CFM,保证"平均速度"方向正确;第二项是曲率惩罚,强制轨迹在 $(\mathbf{x}, t)$ 空间上保持"尽可能直",以便真正实现从 $\mathbf{x}_0$ 直达 $\mathbf{x}_1$ 的一步推理。通过三角不等式,作者将这两项作为独立损失项分别优化。
4.2.3 Flow Consistency Regularization¶
为避免只在"完整区间 $[0,1]$"上保持一致,作者将训练区间推广到任意子区间 $[t, r]$ 上做一致性约束。具体做法:起始时间 $t \sim \text{Uniform}(0, 1)$;终点 $r$ 来自一个概率混合分布:
$$r \sim p_{end} \cdot \delta_1 + (1 - p_{end}) \cdot \text{Uniform}(t, 1) \tag{20}$$
$p_{end}$ 控制"锚定到终点"的概率,$\delta_1$ 是集中在 $r=1$ 的 Dirac delta。进一步定义 matching loss:
$$\mathcal{L}_{match} = \lVert f_\theta(\mathbf{x}_t, t, r) - \mathbf{x}_1 \rVert^2 \tag{21}$$
以锚定"任意点的预测都直指真实目标"。
但仅端点对齐不足以消除语义偏离——中间过程可能剧烈振荡。作者通过曲率加速项约束,对模型速度的时间导数做零化:
$$\frac{d}{dt} \tilde{v}_\theta = \frac{\partial \tilde{v}_\theta}{\partial \mathbf{x}_t} \cdot \frac{d \mathbf{x}_t}{dt} + \frac{\partial \tilde{v}_\theta}{\partial t} + \frac{\partial \tilde{v}_\theta}{\partial r} \cdot \frac{dr}{dt} \tag{22}$$
由于 $\frac{dt}{dt}=1, \frac{dr}{dt}=0$,上式化简为只含两项的雅可比展开。显式计算全雅可比代价高昂,作者用 Jacobian-Vector Product (JVP) 避开矩阵物质化:
$$\mathcal{L}_{cons} = \left\lVert [\tilde{v}_\theta, 1, 0] \cdot \nabla f_\theta(\mathbf{x}_t, t, r) \right\rVert^2 \tag{23}$$
其中 $\nabla f_\theta$ 是完整 Jacobian,但借助 JVP 只需一次 forward pass 就能计算与切向量的乘积。这样既保证了轨迹直线性,又维持了可接受的训练代价。
4.3 总体训练目标¶
两阶段共用以下加权损失:
$$\mathcal{L} = \mathcal{L}_{match} + \gamma \mathcal{L}_{cons} + \alpha \mathcal{L}_{tgt} + \beta \mathcal{L}_{src} \tag{24}$$
$\alpha, \beta, \gamma$ 为超参。Stage 1 不启用 $\mathcal{L}_{cons}$。
4.4 推理¶
推理时直接将用户历史通过相同的 mask 机制得到起点 $\mathbf{x}_0$,并做一次 forward:
$$\hat{\mathbf{x}}_1 = \mathbf{x}_0 + \tilde{v}_\theta(\mathbf{x}_0, 0, 1) = f_\theta(\mathbf{x}_0, 0, 1) \tag{25}$$
把 $\hat{\mathbf{x}}_1$ 与所有 item embedding 做内积排序,取 top-K 作为推荐。
五、实验¶
5.1 数据集与实现¶
三个基准:
- ML-100k:稠密电影评分数据;
- Amazon-Beauty:稀疏商品评论;
- Steam:游戏评论。
- 数据预处理与 ICLRec、DuoRec 一致。
Baselines:
- RNN/CNN:GRU4Rec、Caser;
- Transformer:SASRec、BERT4Rec、STOSA;
- Generative:DiffuRec、AutoSeqRec(Gaussian 分布表达)、DreamRec(guided diffusion)、DiffuRec(多面向 diffusion)、FMRec(直 trajectory 的 FM)。
指标:H@K(Hit Rate)、N@K(NDCG),K=10/20,所有 non-interacted item 做 rank。
实现:transformer 骨干 4 头、hidden=128;decoder 为 3 层 MLP + tanh;batch 512;max seq length 50;NVIDIA L40 GPU。
5.2 主实验结果¶
表 1 为三数据集整体性能对比:
| Model | ML-100k | Beauty | Steam | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| H@10 | N@10 | H@20 | N@20 | H@10 | N@10 | H@20 | N@20 | H@10 | N@10 | H@20 | N@20 | |
| RNN/CNN | ||||||||||||
| GRU4Rec | 12.1951 | 21.8451 | 6.0326 | 8.4727 | 1.9370 | 3.8551 | 0.9029 | 3.3804 | 5.4257 | 9.2319 | 2.6033 | 3.5572 |
| Caser | 11.2426 | 19.5189 | 5.0683 | 7.1439 | 2.8166 | 4.0048 | 1.3602 | 1.7595 | 6.4940 | 10.9653 | 3.0846 | 4.2043 |
| Transformer | ||||||||||||
| SASRec | 22.6935 | 6.3427 | 8.6340 | 6.2648 | 8.9791 | 3.2305 | 3.6563 | 8.3763 | 13.6060 | 4.0489 | 5.6030 | — |
| BERT4Rec | 9.3319 | 16.8611 | 4.5868 | 6.3442 | 5.7922 | 1.8291 | 2.3541 | 3.7673 | 7.9448 | 12.7322 | 4.0002 | 5.2027 |
| STOSA | 13.6542 | 21.7761 | 5.2159 | 8.3392 | 6.1262 | 3.2053 | 3.9491 | 5.9054 | 8.1292 | 14.1197 | 3.4112 | 5.5072 |
| Generative | ||||||||||||
| DiffuRec | 19.4127 | 6.4136 | 8.0459 | 7.8574 | 10.9358 | 4.6971 | 5.8784 | 9.8437 | 15.3817 | 5.0429 | 6.4340 | — |
| AutoSeqRec | 14.6041 | 22.8726 | 5.3955 | 9.4584 | 4.1157 | 5.0335 | 5.8771 | 7.7411 | 10.7252 | 4.2729 | 5.7828 | — |
| DreamRec | 12.4377 | 19.8075 | 5.9837 | 7.3254 | 6.9821 | 3.5769 | 6.4416 | 5.9701 | 8.9875 | 14.1206 | 4.1015 | 5.3096 |
| FMRec | 15.4934 | 24.3146 | 7.6571 | 9.8158 | 7.8275 | 2.6953 | 4.9463 | 5.7676 | 10.5908 | 16.6669 | 5.4925 | 6.9685 |
| FAVE | 15.8722 | 26.1340 | 8.1968 | 10.7879 | 8.4834 | 11.9048 | 4.9744 | 5.8351 | 10.7880 | 16.6562 | 5.4973 | 6.9911 |
(表 1 中下标的 gap 与加粗/下划线格式略,完整数据以论文为准。)
主要结论:
- FAVE 在所有数据集、所有指标上都取得最佳(或并列最佳),在 ML-100k 上相对 FMRec 的 N@20 提升 9.90%($p < 0.01$),H@20 提升 7.48%;
- Transformer 类方法整体表现不如 generative 类,验证生成范式在捕获分布上的优势;
- FAVE 通过显式 ODE 建模"用户偏好轨迹"并用 semantic anchor prior 压缩路径长度,相比反向扩散的多步迭代、线性 FM 的多步 Euler 都能更精准地建模偏好演变。
5.3 消融研究¶
表 2 为 ML-100k 和 Beauty 上的消融:
| Dataset | ML-100k | Beauty | |||
|---|---|---|---|---|---|
| Metrics | H@10 | N@10 | N@20 | H@10 | N@20 |
| w/o stage | 25.2610 | 10.4645 | 11.7177 | 5.7838 | — |
| w/o $\mathcal{L}_{cons}$ | 24.8579 | 10.3656 | 11.8306 | 5.8031 | — |
| w/o $\mathcal{L}_{match}$ | 21.7264 | 8.8802 | 11.7805 | 5.8086 | — |
| w/o prior | 22.6205 | 8.8471 | 11.7939 | 5.7147 | — |
| FAVE | 26.1340 | 10.7879 | 11.9048 | 5.8351 | — |
分析:
- 去掉 prior(用 Gaussian 代替 semantic anchor prior)性能下降最显著——这是 FAVE 最核心的创新,验证"用户历史先验"对解决先验不匹配的价值;
- 去掉 $\mathcal{L}_{match}$(端点对齐)也导致明显退化,说明匹配约束与 anchor prior 是耦合的双基础:matching 保证"起点能精准映射到终点";
- 去掉 $\mathcal{L}_{cons}$ 与 去掉 Stage 2 影响较小但仍存在,说明曲率约束与 Stage 2 主要是精炼作用。
5.4 效率分析¶
表 3 在三数据集上报告 FLOPs / Latency / Inference Time:
| Dataset | Metric | DiffuRec | FMRec | FAVE |
|---|---|---|---|---|
| ML-100k | FLOPs (G) | 1.26 | 1.32 | 0.07 |
| Latency (ms) | 105.97 | 98.04 | 4.44 | |
| Infer Time (s) | 2.57 | 2.34 | 0.10 | |
| Beauty | FLOPs (G) | 1.26 | 1.96 | 0.07 |
| Latency (ms) | 103.19 | 93.74 | 4.49 | |
| Infer Time (s) | 42.21 | 40.44 | 2.25 | |
| Steam | FLOPs (G) | 1.26 | 2.02 | 0.07 |
| Latency (ms) | 104.45 | 92.81 | 3.99 | |
| Infer Time (s) | 507.23 | 516.27 | 26.23 |
结论:FAVE 实现约 20× 提速(以 ML-100k 为最佳),FLOPs 降至 0.07 G(原生 1.26 G)。这得益于单步生成直接越过多步 ODE 求解的计算开销。
5.5 推理轨迹可视化¶
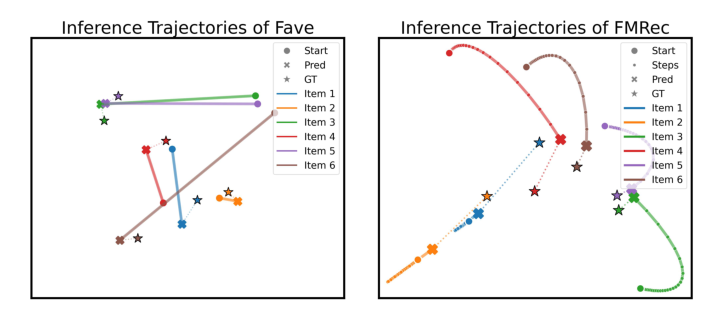
从图 3 可见:
- FAVE 的轨迹点从 semantic anchor 出发,每个样本生成的 trajectory 都接近 ground-truth;
- FMRec 的轨迹点距离目标更远、更不稳定,存在显著围绕起点抖动的问题——这对应了先前指出的"linear redundancy"现象。
5.6 Embedding 分布可视化¶
图 4 展示 ML-100k 上 Gaussian noise、FAVE 的 semantic anchor prior、ground-truth 三者的 t-SNE 分布:
- Gaussian noise 广泛分布在 latent space,没有结构;
- FAVE 的 anchor prior 与 GT 形成多个重叠聚类,说明它已经承载了"item 对应用户意图"的先验信息;
- 从已结构化的分布出发,轨迹需要穿越的距离大幅缩短,验证了先验不匹配的缓解。
5.7 多样性分析¶
表 4 对比推荐多样性(ILD = Intra-List Diversity):
| Method | Category | ILD | NDCG@20 |
|---|---|---|---|
| Caser | CNN-based | 0.7440 | 7.1439 |
| SASRec | Transformer | 0.8866 | 8.6340 |
| AutoSeqRec | AutoML-based | 0.3350 | 9.4584 |
| DiffuRec | Diffusion-based | 0.8313 | 8.0459 |
| FMRec | Flow-based | 0.3786 | 9.8158 |
| FAVE | Flow-based | 0.4348 | 10.7879 |
分析:
- FMRec 等"straight trajectory"方法往往表现出表示坍缩,多样性低(0.38);
- FAVE 在保持显著高于 FMRec 的 NDCG 的同时,多样性也提升(0.38 → 0.43),因为它是"直接将整个目标分布 transport 到锚点先验"而不是坍缩到单点,保证了预测分布的覆盖面。
5.8 超参分析¶
图 5 给出 $\alpha, \beta, \gamma, \rho$ 四个超参的敏感性曲线:
- $\alpha$(target 交叉熵权重)最佳值 ~0.5:过大使不同 item 分布同质化,损害多样性;
- $\beta$(历史重构权重)最佳值 ~0.2:过小时无法充分注入源端语义,过大时过分关注历史、削弱对未来 item 的预测能力;
- $\gamma$(曲率惩罚权重)最佳值 ~0.1:过大会使轨迹过度线性化、丧失对用户意图的拟合能力;
- $\rho$(retention rate)最佳值 ~0.75:过小时 prior 退化为 Gaussian,过大时保持太多历史导致 identity mapping。
六、结论¶
FAVE 提出了一种流式平均速度建模框架来解决生成式序列推荐的两个根本问题:先验不匹配(prior mismatch)与线性冗余(linear redundancy)。其核心创新包括:
- 两阶段训练:Stage 1 在 Gaussian 噪声上用 CFM + 重参数化学习稳定的 item manifold;Stage 2 直接替换先验为用户历史构造的 semantic anchor,并通过 average velocity + JVP 约束将多步轨迹压缩为单步位移;
- Dual-end semantic alignment:从 flow 轨迹两端同时对齐语义(target-side cross entropy + source-side reconstruction);
- Average velocity field + curvature penalty:通过 JVP 高效实现一步生成下的精度保证。
FAVE 在 ML-100k、Beauty、Steam 三数据集上全面优于 SOTA,NDCG@20 相对 FMRec 提升 9.90%,同时推理速度提升约 20 倍,使生成式推荐在低延迟工业场景具备实用价值。
七、启发与讨论¶
- 把用户交互序列作为 flow 的 source 分布而非 Gaussian 噪声,是一种"数据驱动的先验"哲学,思路上与 DreamRec 的 guided diffusion 相似但比后者更激进:直接替换 source;
- Average velocity + JVP 的思路在 Rectified Flow、Consistency Model 等一步生成方法中有前身,FAVE 是把它 首次应用到序列推荐 的产物;
- 两阶段训练是关键——Stage 1 稳定的 manifold 是 Stage 2 语义锚点先验能够发挥作用的前提,单独只做 Stage 2 会因没有稳定表征而崩塌(消融 w/o stage 可见);
- 未来方向:作者提到可扩展到多模态、多任务推荐场景;此外 flow 的 mask prior 构造方式可进一步学习化(当前是均匀 Bernoulli),可能进一步收敛先验与目标之间的距离。