CARD: Non-Uniform Quantization of Visual Semantic Unit for Generative Recommendation¶
一、研究动机与背景¶
生成式推荐(Generative Recommendation, GeneRec)以「将物品离散化为 Semantic ID(SID) + 自回归 next-SID 预测」为统一范式,相比 ID-based 模型在稀疏交互、冷启动场景下展现出更好的泛化性。SID 通常通过 RQ-VAE / RQ-KMeans / OPQ 等量化方法,把物品的连续 embedding 映射为 $L$ 层离散 codebook 索引。Semantic ID 的质量直接决定下游生成式推荐器的上限。
CARD 的作者从工业级 SID 实践中观察到两条尚未被现有方法解决的关键瓶颈:
Challenge 1:Insufficient Supervision Limits Heterogeneous Information Fusion for SID Quantization.
主流 GeneRec 流程把"SID 构造"和"自回归推荐"解耦成两个独立阶段——先离线训练 tokenizer,再冻结 SID 训下游推荐器。这种解耦让 SID 学习严重缺乏来自下游推荐目标的直接监督;当物品同时携带文本、视觉、协同信号等多模态异质信息时,现有做法基本依赖事后对齐:
- 用对比损失(contrastive loss)跨模态对齐 embedding 或 SID([43, 56, 59] 等);
- 用 modality-specific encoder 各自编码,再后融合(late fusion)。
强对齐会忽视模态间的本质差异,导致过度同质化——某些模态的特性反而被抹平,下游量化时不同模态的语义信号会冲突或被一种主导模态吃掉。CARD 提出的疑问是:能否在 SID 学习完全缺乏下游监督的设定下,绕开复杂的跨模态融合机制,对异质语义做整体性建模?
Challenge 2:Non-Uniform Embeddings Result in Codeword Imbalance and Generation Bias.
传统量化器(如 RQ-VAE)的训练目标是"最小化全局重建误差",隐式假设了 latent space 上 embedding 分布大致均匀——只有这样,把 codebook 容量"均匀"地分配到 latent 空间才合理。但是推荐场景下物品 embedding 极度非均匀:语义相近的热门 item 会聚成致密簇,而长尾 item 散布在稀疏区。把均匀量化粗暴地用在这种偏斜分布上,会导致两个连锁后果:
- Codebook 利用失衡:致密簇里少数 codeword 承担了大量 item,稀疏区的 codeword 几乎没人用;
- 生成端偏差被进一步放大:自回归生成器倾向于复现训练 SID 中频率最高的 token,少数 codeword 的"主导"会传染到生成结果中。
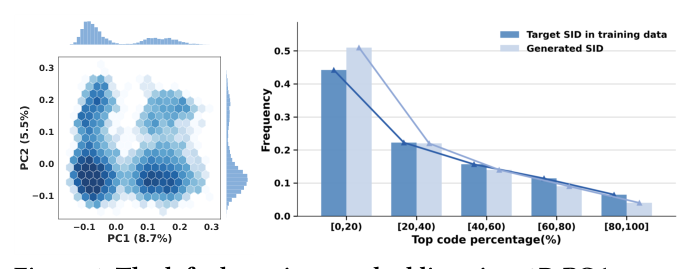
作者的核心观点:与其在量化阶段被动接受这种偏斜分布,不如显式地把 latent 分布"矫正"到更均匀的形态再做量化。
为同时回应这两个挑战,作者提出 CARD(Card-style Attentive RecommenDation framework),名字源自《Slay the Spire》一类卡牌游戏——一张卡牌把多种属性和效果统一在一个紧凑视觉单元上。CARD 由两个互补设计构成:
- Visual Semantic Unit:把物品的视觉、文本、协同信号统统"渲染"成一张结构化卡牌图像,用一个统一的视觉-语言编码器(SigLIP2)整体编码。这种设计在编码前就完成了异质信息的融合,无需事后对齐。
- NU-RQ-VAE (Non-Uniform Residual Quantized Variational Autoencoder):在残差量化前插入一个可学习的可逆非线性变换,把非均匀 latent 映射到近似均匀空间再量化,用 inverse transform 在解码时还原原始语义空间。文中提供两种变换方案:基于 Kumaraswamy CDF 的参数化变换(CARD$_K$)与基于 scaled logistic-logit 的变换(CARD$_S$)。
二、CARD 框架总览¶
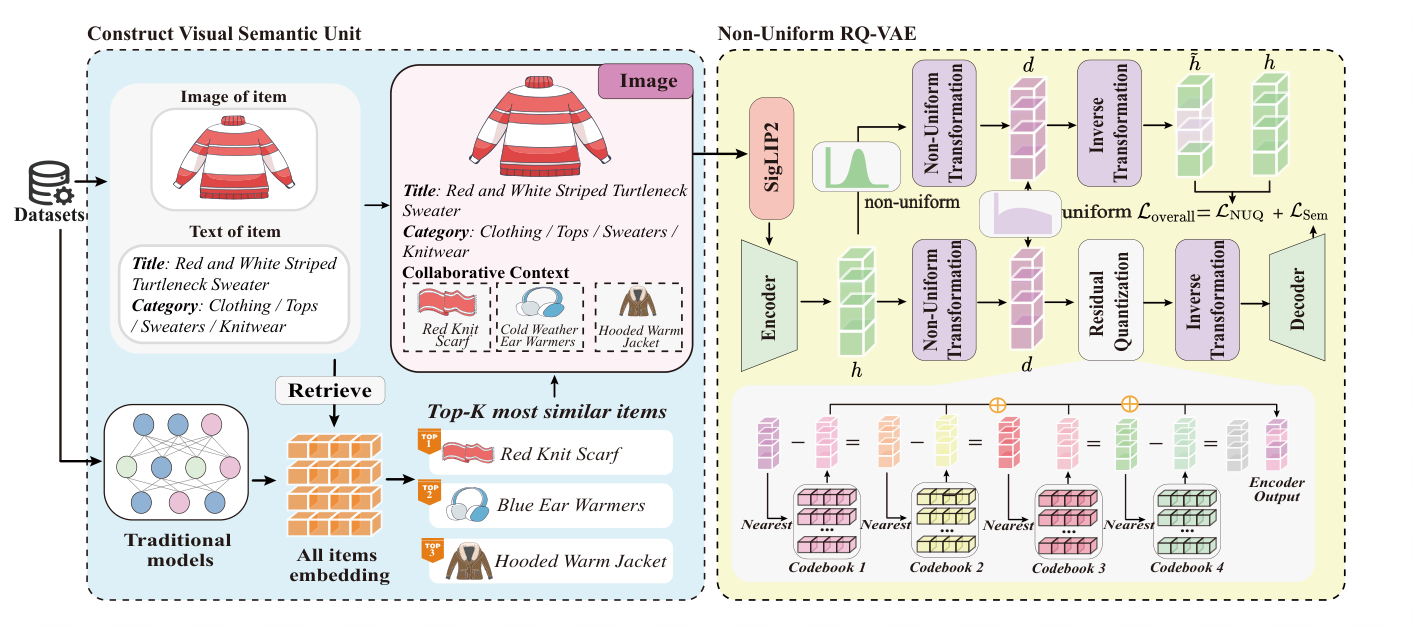
整个 pipeline 拆成三段:
- 构造视觉语义单元 $\mathcal{G}_i$:将文本、视觉、协同信号渲染为单张卡牌图像;
- 统一编码 + 非均匀量化:用 SigLIP2 编码 $\mathcal{G}_i$ 得到 $\mathbf{z}_i$,再用 NU-RQ-VAE 量化为 SID $[c_1, c_2, \dots, c_K]$;
- 自回归生成式推荐:用 T5-style encoder-decoder 在用户的 SID 序列上做 next-SID 自回归生成。
下面分别展开。
三、Card-style Unified Item Representation¶
3.1 视觉语义单元的三个区域¶
CARD 把每个物品 $i$ 编码为一张 $H \times W \times 3$ 的卡牌图像 $\mathcal{G}_i \in \mathbb{R}^{H \times W \times 3}$,由三个功能互补的区域组成:
(1) Visual region $x_i^{\text{img}}$:原始物品图像,提供最直观、最具区分度的视觉线索;放在卡牌顶部。
(2) Textual semantic region:把结构化文本属性(title, category 等)渲染成一段文字,用固定模板(fixed template)布局成文字面板,放在视觉区下方。关键设计:用"渲染成图像"取代"用文本编码器编码"——这样异构信号天然统一在像素空间。
(3) Collaborative signal region:把协同信号也渲染进卡牌底部,做法是先用一个传统序列推荐器(如 SASRec [16])学习物品协同 embedding $\mathbf{u}_i \in \mathbb{R}^d$,然后给目标物品 $i$ 检索协同邻居:
$$\mathcal{N}(i) = \arg\max_{\mathcal{N} \subset \mathcal{I} \setminus \{i\}, |\mathcal{N}| = K_{\text{neighbors}}} \sum_{j \in \mathcal{N}} s(i, j) \tag{1}$$
其中 $s(i, j) = \mathbf{u}_i^\top \mathbf{u}_j$。$K_{\text{neighbors}}$ 设为 3。检索到的邻居物品的缩略图 + 文本标题被水平拼接到卡牌底部,作为协同上下文。

每张视觉语义单元最终是一张 $512 \times 512$ 图像。这种设计的本质是用渲染替代融合:跨模态对齐被替换成"在像素空间里直接拼接",编码器面对的输入永远是单一视觉模态,避免了多模态融合时的语义冲突或主导效应。
3.2 统一视觉-语言编码¶
构造好的视觉语义单元 $\mathcal{G}_i$ 输入到预训练视觉-语言编码器 $f(\cdot)$,得到 $m$ 维语义 embedding:
$$\mathbf{z} = f(\mathcal{G}_i) \in \mathbb{R}^m \tag{2}$$
CARD 选用 SigLIP2 [40] 作为编码器——它在大规模图像-文本对上预训练,对包含文字与图像的复合视觉输入有较强表现力,能稳定地从渲染图中提取文本字符的语义。
至此,文本/视觉/协同三类异构信号被统一塑形成一个连续 embedding $\mathbf{z}_i$,但这个 embedding 在真实推荐场景中仍然高度非均匀,需要进入下一步的非均匀量化。
四、Non-Uniform Quantization Module(NU-RQ-VAE)¶
4.1 RQ-VAE 量化过程回顾¶
NU-RQ-VAE 是在标准 RQ-VAE 上的"插件式"改造。先回顾 RQ-VAE:由 Encoder $\text{Encoder}(\cdot)$、Decoder $\text{Decoder}(\cdot)$ 与 $K$ 层 codebook $\{\mathcal{C}_1, \dots, \mathcal{C}_K\}$ 组成,每层 codebook $\mathcal{C}_k = \{e_i\}_{i=1}^N$ 含 $N$ 个 $d$ 维 codeword。
对每个 item,先把 $\mathbf{z}$ 投影到 $\mathbf{h} = \text{Encoder}(\mathbf{z})$,再做 $K$ 层残差量化:
$$\begin{cases} c_k = \arg\min_i \lVert \mathbf{r}_{k-1} - \mathbf{e}_i \rVert^2, \quad \mathbf{e}_i \in \mathcal{C}_k, \\ \mathbf{r}_k = \mathbf{r}_{k-1} - \mathbf{e}_{c_k}, \end{cases} \tag{3}$$
其中 $\mathbf{r}_0 = \mathbf{h}$。逐层的 SID 拼成 $\hat{i} = [c_1, c_2, \dots, c_K]$,量化后 embedding $\hat{\mathbf{h}} = \sum_{k=1}^K \mathbf{e}_{c_k}$,最后由 Decoder 重建得到 $\hat{\mathbf{z}} = \text{Decoder}(\hat{\mathbf{h}})$。
整体 RQ-VAE 损失是重建项 $\mathcal{L}_{\text{Recon}}$ 加上量化项 $\mathcal{L}_{\text{RQ}}$:
$$\begin{cases} \mathcal{L}_{\text{Recon}} = \lVert \mathbf{z} - \hat{\mathbf{z}} \rVert^2, \\ \mathcal{L}_{\text{RQ}} = \sum_{k=1}^K \left( \lVert \text{sg}[\mathbf{r}_{k-1}] - \mathbf{e}_{c_k} \rVert^2 + \mu \lVert \mathbf{r}_{k-1} - \text{sg}[\mathbf{e}_{c_k}] \rVert^2 \right), \\ \mathcal{L}_{\text{Sem}} = \mathcal{L}_{\text{Recon}} + \mathcal{L}_{\text{RQ}}, \end{cases} \tag{4}$$
其中 $\text{sg}[\cdot]$ 为 stop-gradient,$\mu$ 控制 commitment loss 强度。$\mathcal{L}_{\text{Recon}}$ 保证语义精度;$\mathcal{L}_{\text{RQ}}$ 联合训练 encoder 与 codebook。
4.2 NU-RQ-VAE 关键改造¶
NU-RQ-VAE 在 Encoder 输出 $\mathbf{h}$ 与残差量化之间,插入一个可学习的可逆非线性变换 $\mathcal{T}(\cdot)$:
$$\mathbf{d} = \mathcal{T}(\mathbf{h}) \quad \xrightarrow{\text{Residual Quantization}} \quad \hat{\mathbf{d}} \quad \xrightarrow{\mathcal{T}^{-1}(\cdot)} \quad \hat{\mathbf{h}} = \mathcal{T}^{-1}(\hat{\mathbf{d}})$$
$\mathcal{T}$ 把非均匀 latent $\mathbf{h}$ 映射到近似均匀空间 $\mathbf{d}$,残差量化在这个均匀空间执行;解码端用 $\mathcal{T}^{-1}$ 把量化结果反变换回原语义空间,再送入 Decoder 重建 $\mathbf{z}$。这样既享受了"在均匀空间量化"的语义敏感性,又保留了原 latent 的语义结构。
CARD 给出两种 $\mathcal{T}/\mathcal{T}^{-1}$ 实例化方式:
4.2.1 Kumaraswamy 分布变换(CARD$_K$)¶
Kumaraswamy 分布是定义在 $[0, 1]$ 上的双参数分布,与 Beta 分布表达力相当但 PDF / CDF / quantile 都有闭式解。其 CDF 和 quantile 函数为:
$$F_{\text{KS}}(x; a, b) = 1 - (1 - x^a)^b \tag{5}$$
$$F_{\text{KS}}^{-1}(y; a, b) = \left( 1 - (1 - y)^{1/b} \right)^{1/a} \tag{6}$$
其中 $x \in [0, 1]$,$a, b \in \mathbb{R}_+$。$F_{\text{KS}}$ 单调可逆,且参数 $a, b$ 控制"压扁/拉伸"效果——这正是把非均匀分布矫正到近似均匀所需要的"可调节标尺"。
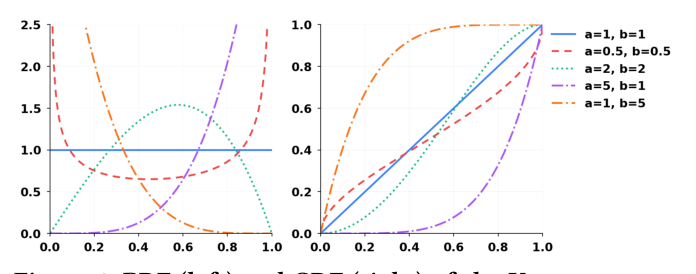
由于实际 latent 取值不在 $[0, 1]$ 内,作者用 min-max 归一化把每维 $x_i$ 映射到 $[0, 1]$:$x_i \mapsto (x_i - x_{\min})/(x_{\max} - x_{\min})$,其中 $x_{\min} = \min_i x_i$ 与 $x_{\max} = \max_i x_i$ 在每个维度独立计算。
4.2.2 Scaled Logistic & Scaled Logit 变换(CARD$_S$)¶
CARD 进一步分析了不同 encoder 输出的实际分布形态:
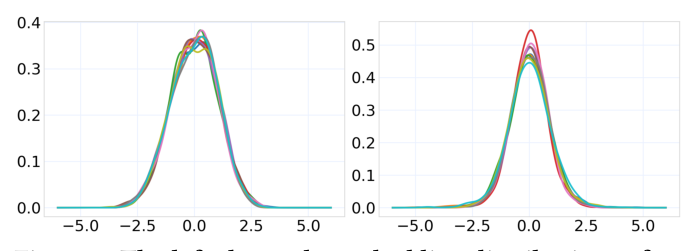
观察到无论是文本 encoder 还是视觉-语言 encoder,单维度上的 embedding 经验分布都呈钟形对称。这启发作者引入更适合钟形分布的 logistic / logit 函数对作为可逆映射。
标准 logistic 与 logit:
$$\text{logistic}(x; \alpha, x_0) = (1 + \exp(-\alpha (x - x_0)))^{-1} \tag{7}$$
$$\text{logit}(y; \alpha, x_0) = \alpha^{-1} \log\!\left(\frac{y}{1 - y}\right) + x_0 \tag{8}$$
为了把它们用到任意区间 $[x_{\min}, x_{\max}]$,CARD 定义 scaled logistic 与 scaled logit 函数:
$$\text{logistic}_{\text{SCALED}}(x; \alpha, x_0) = \frac{\text{logistic}(\delta^{-1} x; \alpha, x_0) - \text{logistic}(\delta^{-1} x_{\min}; \alpha, x_0)}{\Delta} \tag{9}$$
$$\text{logit}_{\text{SCALED}}(y; \alpha, x_0) = \delta \,\text{logit}(\Delta y + \text{logistic}(\delta^{-1} x_{\min}; \alpha, x_0); \alpha, x_0) \tag{10}$$
其中 $\Delta = \text{logistic}(\delta^{-1} x_{\max}; \alpha, x_0) - \text{logistic}(\delta^{-1} x_{\min}; \alpha, x_0)$,$\delta = x_{\max} - x_{\min}$。引入 $\delta$ 把输入归一到尺度无关的状态后再喂入 logistic,可以把 scaled 变换重写为参数 $\bar\alpha = \delta^{-1} \alpha$ 与 $\bar x_0 = \delta x_0$ 的标准 logistic 函数。
最终的可逆变换对:
$$\mathcal{T}(\cdot), \mathcal{T}^{-1}(\cdot) = \begin{cases} (F_{\text{KS}}(\cdot; a, b), F_{\text{KS}}^{-1}(\cdot; a, b)) & \text{(CARD}_K\text{)} \\ (\text{logistic}_{\text{SCALED}}(\cdot; \alpha, x_0), \text{logit}_{\text{SCALED}}(\cdot; \alpha, x_0)) & \text{(CARD}_S\text{)} \end{cases} \tag{11}$$
两个变体在 NU-RQ-VAE 中仅替换 $\mathcal{T}/\mathcal{T}^{-1}$ 的实例,框架其余部分完全相同。$a, b$ 或 $(\alpha, x_0)$ 都是可学习参数,每个维度独立。
4.3 NUQ Consistency Loss¶
为了保证可逆变换不会因数值误差累积导致语义丢失,CARD 引入一个 NUQ consistency loss:用 $\mathcal{T}^{-1}$ 把变换后的 $\mathbf{d}$ 还原回 $\tilde{\mathbf{h}} = \mathcal{T}^{-1}(\mathcal{T}(\mathbf{h}))$,惩罚还原误差:
$$\mathcal{L}_{\text{NUQ}} = \lVert \mathcal{T}^{-1}(\mathcal{T}(\mathbf{h})) - \mathbf{h} \rVert_2^2 \tag{12}$$
总目标:
$$\mathcal{L}_{\text{overall}} = \mathcal{L}_{\text{Sem}} + \lambda_{\text{NUQ}} \mathcal{L}_{\text{NUQ}} \tag{13}$$
$\lambda_{\text{NUQ}}$ 是控制一致性项强度的超参,文中在 $[0.01, 1]$ 范围内调优。
五、Training and Recommendation¶
Tokenization 训练完成后,每个 item 都有一个稳定的 SID $\hat{i} = [c_1, \dots, c_K]$。
Recommendation 阶段:用户的历史交互 $[\hat{i}_1, \dots, \hat{i}_M]$ 转译为长度为 $M \cdot K$ 的 SID 序列;目标是预测下一个交互物品的 SID 序列 $\hat{i}_{M+1}$。模型采用 T5 [33] encoder-decoder,token 级负对数似然训练:
$$\mathcal{L} = -\sum_{t=1}^{K} \log P_\theta\!\left( y_t^{(\xi)} \mid y_{<t}^{(\xi)}, x^{(\xi)} \right) \tag{14}$$
推理用 beam search,保留 top-$B$ 部分序列。
六、实验¶
6.1 实验设置¶
数据集:三个 Amazon 数据集 [31] —— Food(Grocery and Gourmet Food)、Phones(Cell Phones and Accessories)、Clothing(Clothing, Shoes and Jewelry)。沿用 [16, 34, 43] 的 5-core 过滤、leave-one-out 划分(最末次交互测试,倒数第二验证)、用户历史截断为 20 步。
| Dataset | #Users | #Items | #Interaction | Sparsity | Avg. len |
|---|---|---|---|---|---|
| Food | 14,681 | 8,713 | 151,254 | 99.882% | 10.30 |
| Phones | 27,879 | 10,429 | 194,439 | 99.933% | 6.97 |
| Clothing | 39,387 | 23,033 | 278,677 | 99.969% | 7.08 |
评估指标:Recall@K 与 NDCG@K(K = 5, 10, 20),全集合 full-ranking。
实现细节:
- NU-RQ-VAE encoder/decoder 用 3 层 MLP;codebook 配置与 [34, 43] 相同:$N = 256$,$K = 4$,$d = 32$。
- 优化器 AdamW [17],学习率 0.001,batch size 1024;$\lambda_{\text{NUQ}}$ 在 $[0.01, 1]$ 调。
- T5 主干 4 层 encoder + 4 层 decoder,每层 6 头 self-attention,head dim = 64。
- 视觉语义单元图像尺寸 $512 \times 512$,主图、文字面板、协同邻居各占一区;具体布局可按数据集内容微调。
- 公平比较:MQL4GRec 不使用大规模额外类目数据预训练。
Baselines:
- 传统序列推荐:GRU4Rec、HGN、BERT4Rec、SASRec
- 基于量化的生成式推荐:VQ-Rec、TIGER、LETTER、MQL4GRec、MACRec
6.2 主实验¶
Table 2 给出三个数据集上 Recall@K / NDCG@K 全部对比。两个 CARD 变体(CARD$_K$ Kumaraswamy 和 CARD$_S$ scaled logistic)几乎一致地拿下所有指标的 SOTA:
| Dataset | Metric | GRU4Rec | HGN | BERT4Rec | SASRec | VQ-Rec | TIGER | LETTER | MQL4GRec | MACRec | CARD$_K$ | CARD$_S$ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Food | R@5 | 0.0345 | 0.0364 | 0.0325 | 0.0386 | 0.0423 | 0.0394 | 0.0437 | 0.0445 | 0.0492 | 0.0520 | 0.0547 |
| R@10 | 0.0540 | 0.0575 | 0.0523 | 0.0596 | 0.0646 | 0.0617 | 0.0683 | 0.0697 | 0.0779 | 0.0819 | 0.0853 | |
| R@20 | 0.0849 | 0.0829 | 0.0806 | 0.0874 | 0.0982 | 0.0891 | 0.1004 | 0.1023 | 0.1137 | 0.1212 | 0.1238 | |
| N@5 | 0.0218 | 0.0237 | 0.0209 | 0.0239 | 0.0275 | 0.0256 | 0.0283 | 0.0289 | 0.0322 | 0.0333 | 0.0364 | |
| N@10 | 0.0280 | 0.0302 | 0.0264 | 0.0306 | 0.0351 | 0.0327 | 0.0362 | 0.0369 | 0.0410 | 0.0428 | 0.0462 | |
| N@20 | 0.0358 | 0.0367 | 0.0340 | 0.0361 | 0.0426 | 0.0397 | 0.0439 | 0.0448 | 0.0486 | 0.0527 | 0.0559 | |
| Phones | R@5 | 0.0483 | 0.0438 | 0.0450 | 0.0504 | 0.0511 | 0.0526 | 0.0544 | 0.0540 | 0.0561 | 0.0596 | 0.0585 |
| R@10 | 0.0783 | 0.0671 | 0.0707 | 0.0762 | 0.0766 | 0.0794 | 0.0830 | 0.0838 | 0.0850 | 0.0904 | 0.0880 | |
| R@20 | 0.1102 | 0.1008 | 0.1034 | 0.1075 | 0.1095 | 0.1132 | 0.1179 | 0.1158 | 0.1172 | 0.1284 | 0.1250 | |
| N@5 | 0.0310 | 0.0255 | 0.0276 | 0.0315 | 0.0318 | 0.0338 | 0.0353 | 0.0350 | 0.0355 | 0.0385 | 0.0388 | |
| N@10 | 0.0407 | 0.0347 | 0.0365 | 0.0405 | 0.0417 | 0.0425 | 0.0443 | 0.0441 | 0.0453 | 0.0486 | 0.0474 | |
| N@20 | 0.0519 | 0.0451 | 0.0455 | 0.0505 | 0.0492 | 0.0510 | 0.0536 | 0.0533 | 0.0546 | 0.0578 | 0.0570 | |
| Clothing | R@5 | 0.0094 | 0.0140 | 0.0134 | 0.0141 | 0.0145 | 0.0152 | 0.0158 | 0.0170 | 0.0175 | 0.0191 | 0.0187 |
| R@10 | 0.0159 | 0.0213 | 0.0225 | 0.0223 | 0.0232 | 0.0257 | 0.0263 | 0.0273 | 0.0281 | 0.0297 | 0.0301 | |
| R@20 | 0.0255 | 0.0316 | 0.0322 | 0.0330 | 0.0382 | 0.0418 | 0.0436 | 0.0441 | 0.0450 | 0.0483 | 0.0480 | |
| N@5 | 0.0061 | 0.0072 | 0.0074 | 0.0076 | 0.0081 | 0.0093 | 0.0092 | 0.0097 | 0.0096 | 0.0114 | 0.0112 | |
| N@10 | 0.0082 | 0.0097 | 0.0106 | 0.0102 | 0.0114 | 0.0113 | 0.0110 | 0.0135 | 0.0133 | 0.0150 | 0.0145 | |
| N@20 | 0.0106 | 0.0122 | 0.0127 | 0.0130 | 0.0144 | 0.0167 | 0.0152 | 0.0167 | 0.0170 | 0.0192 | 0.0185 |
(bold 表示与最强 baseline 在 $p \le 0.01$ 水平上显著优于的结果,斜体下划线为最强 baseline)
结论: 1. CARD 全面领先。三个数据集每个指标 CARD$_K$ 或 CARD$_S$ 几乎都是最佳,相对 MACRec / MQL4GRec 这两个最强多模态 baseline 提升幅度普遍 5%~16%。两种变体的差距很小:CARD$_S$ 在 Food 上微胜,CARD$_K$ 在 Phones / Clothing 上略好。 2. CARD 的提升来自两个互补设计:(a) 视觉语义单元在 SID 编码阶段就把多模态信息融合好,避免了"separate-then-fuse"流程下的语义鸿沟;(b) 非均匀量化显式补偿真实分布偏斜,提升 codebook 利用率与生成稳定性。
6.3 消融实验¶
Table 3 / Table 4 在 Food / Phones 上分别对 CARD$_K$ 与 CARD$_S$ 做组件消融:
CARD$_K$ 消融:
| Ablation | Food R@5 | Food R@10 | Phones R@5 | Phones R@10 |
|---|---|---|---|---|
| CARD$_K$ | 0.0520 | 0.0819 | 0.0596 | 0.0904 |
| w/o Unit-V | 0.0452 | 0.0711 | 0.0564 | 0.0835 |
| w/o Unit-T | 0.0463 | 0.0732 | 0.0557 | 0.0820 |
| w/o Unit-C | 0.0491 | 0.0768 | 0.0571 | 0.0863 |
| w/o Unit (text only) | 0.0432 | 0.0683 | 0.0542 | 0.0809 |
| w/o NUT (NU-RQ-VAE → RQ-VAE) | 0.0478 | 0.0745 | 0.0560 | 0.0841 |
CARD$_S$ 消融 趋势完全一致(略)。
关键发现: 1. 三种模态信号都有贡献:去掉视觉(V)/ 文字(T)/ 协同(C)任一区域都会带来显著下降;其中视觉区域(V)下降最多——它是直觉性最强、最具辨识力的区域。 2. 完全 fallback 到纯文本(w/o Unit)下降最厉害。这印证了视觉-语言编码器对协同上下文 + 文字 + 图像的整体感知确实抓住了文本所抓不到的语义。 3. 去掉非均匀变换(w/o NUT)退化为标准 RQ-VAE,性能在所有数据集都显著下降——表明在非均匀 latent 分布下,标准 RQ-VAE 的均匀容量假设确实是性能上限的硬瓶颈。
视觉单元 + 非均匀量化两条主线互补、缺一不可。
6.4 进一步分析¶
6.4.1 Fusion Strategy 对比¶
CARD 把视觉语义单元(Unit)和三种代表性多模态融合策略对比:
- Concat:modality-specific encoder 各自编码后特征拼接;
- Align:用对比学习预训练对齐多模态再融合;
- MLLM:LLaMA3-8B 作多模态联合编码器,提取隐表征作 item embedding。
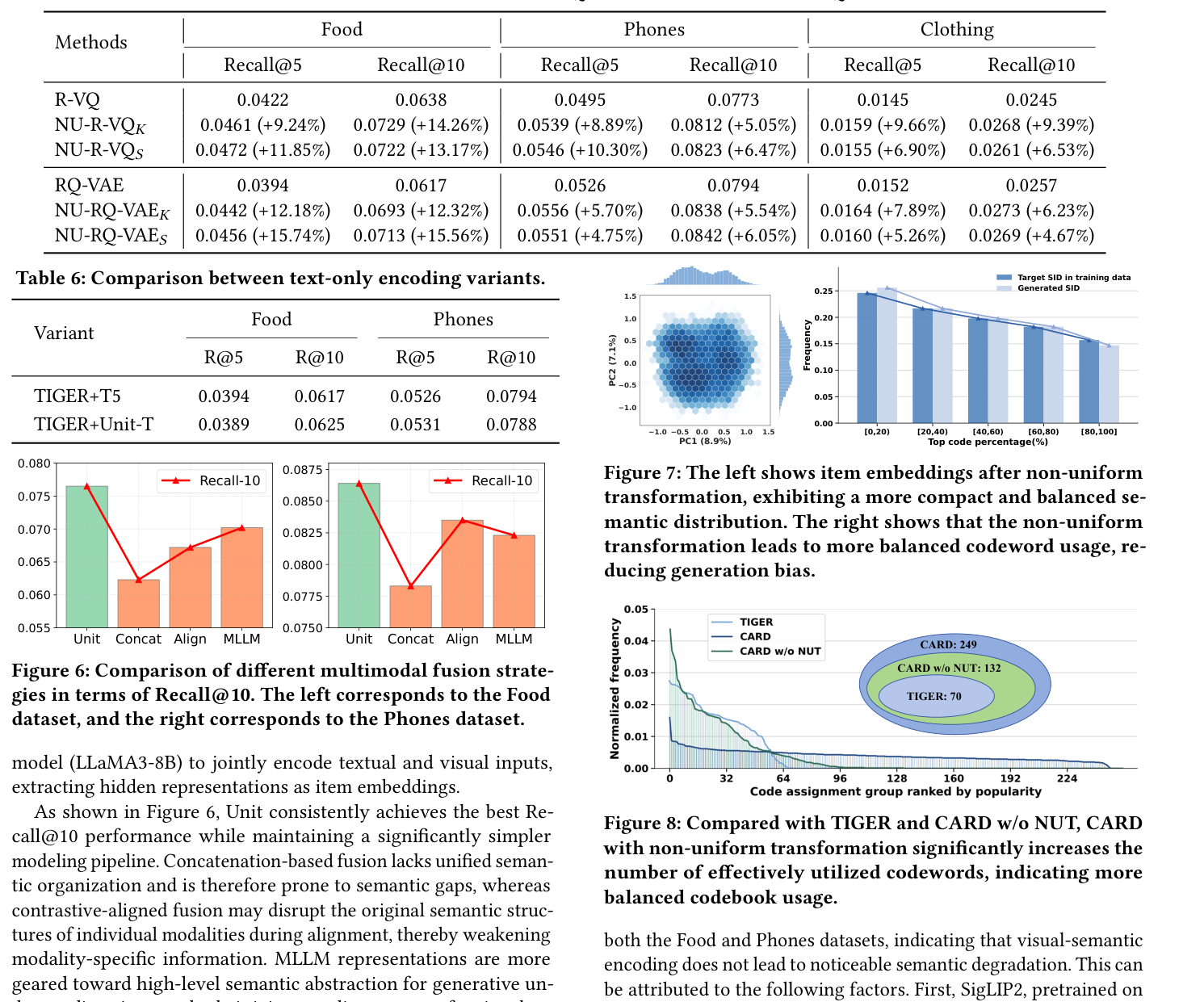
观察:
- Concat 缺乏统一的语义组织,模态之间存在 semantic gap;
- Align 在对齐时可能破坏单模态的特异性,反而削弱了模态特定信息;
- MLLM 倾向于做高度抽象的语义压缩,难以保留两种模态共同贡献的细粒度线索;
- Unit 保留连续的语义结构、稳定的分布、对量化更友好。
这说明"渲染成图像"看似粗暴,实际上是用一种极简而稳健的方式实现了"模态间结构对齐 + 模态内特异性保留"。
6.4.2 Unit-based vs Text-only Encoding¶
为排除"渲染掉了文本信息"的疑虑,CARD 把 Unit 退化为 only-text 渲染(TIGER+Unit-T),与原始的 TIGER+T5(直接用 T5 编码文本)做对比:
| Variant | Food R@5 | Food R@10 | Phones R@5 | Phones R@10 |
|---|---|---|---|---|
| TIGER + T5 | 0.0394 | 0.0617 | 0.0526 | 0.0794 |
| TIGER + Unit-T | 0.0389 | 0.0625 | 0.0531 | 0.0788 |
二者基本持平——说明把文字属性"渲染"成图像不会带来明显信息损失;这归因于 (a) SigLIP2 在大规模 image-text pair 上预训练,对图像中的文字字符语义提取强;(b) 视觉单元用固定模板布局,文字背景干净;(c) 推荐场景下文字本就短而结构化。可以放心把"文本信号"也通过视觉模态承载。
6.4.3 非均匀量化的即插即用性(Plug-and-Play)¶
NU 变换不是 RQ-VAE 专属,对一般残差量化器(R-VQ)也有效。Table 5 对比 R-VQ vs NU-R-VQ 与 RQ-VAE vs NU-RQ-VAE 在三个数据集上的 Recall@5 / Recall@10:
| Methods | Food R@5 (rel.) | Food R@10 (rel.) | Phones R@5 (rel.) | Phones R@10 (rel.) | Clothing R@5 (rel.) | Clothing R@10 (rel.) |
|---|---|---|---|---|---|---|
| R-VQ | 0.0422 | 0.0638 | 0.0495 | 0.0773 | 0.0145 | 0.0245 |
| NU-R-VQ$_K$ | 0.0461 (+9.24%) | 0.0729 (+14.26%) | 0.0539 (+8.89%) | 0.0812 (+5.05%) | 0.0159 (+9.66%) | 0.0268 (+9.39%) |
| NU-R-VQ$_S$ | 0.0472 (+11.85%) | 0.0722 (+13.17%) | 0.0546 (+10.30%) | 0.0823 (+6.47%) | 0.0155 (+6.90%) | 0.0261 (+6.53%) |
| RQ-VAE | 0.0394 | 0.0617 | 0.0526 | 0.0794 | 0.0152 | 0.0257 |
| NU-RQ-VAE$_K$ | 0.0442 (+12.18%) | 0.0693 (+12.32%) | 0.0556 (+5.70%) | 0.0838 (+5.54%) | 0.0164 (+7.89%) | 0.0273 (+6.23%) |
| NU-RQ-VAE$_S$ | 0.0456 (+15.74%) | 0.0713 (+15.55%) | 0.0551 (+4.75%) | 0.0842 (+6.05%) | 0.0160 (+5.26%) | 0.0269 (+4.67%) |
提升幅度最大达 +15.74%——非均匀变换对底层量化器是真正不可知的(quantizer-agnostic)即插即用模块。
6.4.4 非均匀变换的效果可视化¶


直观地:原始空间里"超热门 + 长尾稀疏"的双峰被 NU 变换"摊平"成更均衡的形态,残差量化的覆盖范围因此更广,有效 codeword 数从 TIGER 的 70 → CARD w/o NUT 的 132 → 完整 CARD 的 249——三倍以上的 codebook 利用率提升直接对应到下游生成质量的稳定性。
七、与已归档相关工作的对比¶
CRAB CRAB: Codebook Rebalancing for Bias Mitigation in Generative Recommendation (Walmart Global Tech, 2026-04-06)¶
关系:独立并发(CARD 未引用 CRAB,CRAB 也未引用 CARD,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都把 GeneRec 性能瓶颈归因到"item embedding 分布严重非均匀 → 少数热门 codeword 承担过多 item → 训练数据偏斜被生成端进一步放大形成偏差/精度损失"。CARD 称之为 "codeword imbalance and generation bias",CRAB 称之为 "over-popular token amplifying popularity bias",根因完全同构。
- 相近的技术骨架:两者都把 codebook 利用率视作 SID 质量的关键指标(CARD Figure 8 数有效 codeword 数量;CRAB 用 token-level Group Unfairness);都不动下游生成器主体,而是在 tokenizer/codebook 一侧做修复。
- 本文(CARD)的差异与推进:CARD 走"预防式(pre-quantization)"路线——用一个可学习可逆的非线性变换把 latent 提前矫正到近似均匀,让残差量化在公平的输入分布上进行;变换可学、可逆、对量化器无关,直接植入 RQ-VAE/R-VQ 都涨点 5%–16%。CRAB 走"事后修复(post-hoc)"路线——在已训练好的 RQ-KMeans codebook 上对 top-5% 过热门 token 做"正则化 K-means 拆分 + 层次语义对齐 embedding 微调",约束子节点不能拆散。前者改 latent、不动 codebook 结构;后者改 codebook 拓扑、不动 encoder。
- 可比的方法 / 实验差异:评测目标不同——CARD 报 Recall/NDCG(精度),CRAB 重点报 DGU/MGU(公平性)+ Recall(精度),两者数据集也不重叠(CARD 用 Amazon Food/Phones/Clothing,CRAB 用 Industrial + Office)。架构层面:CARD 的 NU 变换是 quantizer-agnostic 的预处理插件;CRAB 的拆分依赖 RQ-KMeans 的层次树结构,扩展到 RQ-VAE 时需要修改 popularity 定义。两条路线完全可以叠加:理论上先用 NU 变换让分布更均衡,再对残留不平衡的少量热门 token 做 CRAB 拆分,应能进一步提升公平性与精度。这是该方向独立并发工作之间最直接的协同想象空间。
八、核心贡献总结¶
CARD 的两条主线对应解决 SID 学习的两类根因,且彼此完全互补:
- Visual Semantic Unit 把多模态融合提前到"渲染"阶段,利用 SigLIP2 对图像/文字/缩略图的整体感知能力,在 SID 监督缺位的情况下绕开复杂跨模态对齐;
- NU-RQ-VAE 把非均匀分布矫正提前到量化前,用可学习可逆变换(Kumaraswamy CDF 或 scaled logistic)让残差量化在均匀空间进行,显著提升 codebook 利用率与下游生成稳定性。
工程上的几条值得借鉴的细节:
- 用"渲染成图像 + 通用 VLM 编码"取代"模态-specific 编码 + 后融合"——在缺乏端到端监督的解耦 SID 设定下,这是简化系统、提升稳定性的极强基线;
- "可逆非线性变换 + consistency loss"是一类很轻、对底层量化器不敏感的 SID 改造工具,可移植到 R-VQ / RQ-VAE / OPQ 等多种量化器;
- Kumaraswamy / scaled-logistic 这两类闭式分布在矫正"宽底"或"钟形"经验分布上各擅一边——agent 可根据 encoder 输出经验分布形态选择更合适的 $\mathcal{T}$。
九、讨论与局限性¶
贡献的独特价值:CARD 是少数同时在多模态融合策略与 codebook 利用率两条主线上拿出系统性方案的 SID 论文。它和 CRAB 这种 post-hoc 派别共同确认了"latent distribution skew → codebook bias"是 GeneRec 真实存在的瓶颈;CARD 的 pre-quantization 路线更倾向于一次性根治;CRAB 的 post-hoc 路线更适合在已有量化器上做最小代价补丁。
局限性: 1. 仅在公开 Amazon 学术数据集(Food / Phones / Clothing)上验证,无工业 A/B 实验;论文的 figures 7-8 显示的有效 codeword 数提升仅基于学术数据,不能直接折合成线上 GMV/CTR 收益。 2. 视觉语义单元的 layout 仍然是手工设计——主图位置、文字字号、邻居数量都是人工先验,作者明确把"自动化构造视觉语义单元"列为 future work。 3. NU 变换基于经验分布选择——论文展示了 Kumaraswamy(适合宽底分布)与 scaled logistic(适合钟形)两种实例,但二者哪个更优依赖经验观测;若 latent 分布形态多样或多峰,可能需要更灵活的参数族(Mixture / Normalizing Flow)。 4. 训练成本:渲染 + SigLIP2 编码 + NU-RQ-VAE 训练管线显著重于纯 T5 文本编码方案;论文未报告 tokenization 的离线训练耗时与显存。 5. 协同信号依赖于一个独立的 SASRec embedding,意味着 CARD 的"协同邻居"质量被该外部模型上限锁死;如果协同 embedding 不强,整个视觉语义单元的协同区域贡献会萎缩。
整体看,CARD 给"如何在 SID 监督薄弱的设定下融合异质模态 + 矫正非均匀分布"提供了一种简洁、统一、可移植的解决路径,其核心思想("渲染替代融合"、"可学习可逆变换替代均匀量化")独立于具体下游推荐架构,具有较强的通用性。