CRAB: Codebook Rebalancing for Bias Mitigation in Generative Recommendation¶
一、问题背景与动机¶
生成式推荐(Generative Recommendation, GeneRec)是一种将 item 表示为离散 token 并以生成方式预测下一个 item 的新范式,近年来在序列推荐任务上展现出强大的性能。其典型流程由两部分组成: 1. Tokenizer:将每个 item 的文本描述(或其它模态)通过预训练 encoder 编码为连续向量,再用残差量化(Residual Quantization,如 RQ-KMeans / RQ-VAE)将向量映射为 L 级离散 token,形成一个层次化的 Semantic ID(SID); 2. 自回归生成器:通常是 LLM,通过串联用户历史交互中所有 item 的 SID,在训练中学习预测下一个 item 的 token 序列。
这种范式具有高效率、强泛化能力、易于接入 LLM 序列建模能力等优势,但本文指出:尽管在多任务上 GeneRec 表现强劲,现有方法在流行度偏差(popularity bias)上依然严重,甚至会放大原有偏差。
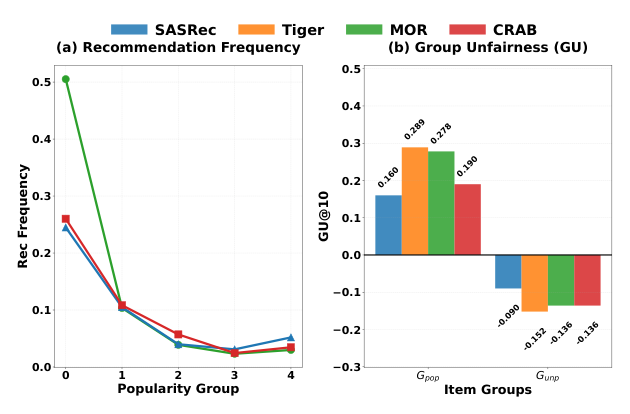
作者对工业数据集上 GeneRec 的统计分析揭示两个现象(图 1 左):
- 相比 SASRec 这类传统序列推荐方法,GeneRec(MOR、TIGER)对不流行 item 所属 token 的暴露率下降更明显;
- 具体而言,MiniOneRec (MOR) 将热门 item 推荐频率提升 6.7%,不流行 item 下降 3.8%;TIGER 分别是 +7.2% / −4.1%。
作者进一步从根因上将这种现象归结为两点:
- 分词阶段继承并加剧偏差:RQ-KMeans / RQ-VAE 等 tokenizer 在训练时使用 item 的 embedding 进行聚类,语义相近的热门 item 会被聚到同一个 token 上,同时由于聚类过程没有考虑频率平衡,热门 item 对应的 token 承载了远高于其它 token 的训练样本,造成 token 频率严重不平衡;
- 训练过程对不流行 token 学习不足:热门 token 样本过多、不流行 token 样本稀少,导致 LLM 对不流行 token 的表征质量差,进一步被模型忽略、生成概率更低,形成恶性循环。
现有 LLM-based 去偏方法(MOR [6]、TIGER [11] 所引用的去偏工作)多关注模型层面(损失重加权、propensity scoring 等),忽视了偏差起源于 tokenizer 构造出的 codebook 本身。即便一些方法尝试构造更均衡的 codebook [2,5,9],其方式通常是严格限制每个 token 最多被分配的 item 数,导致语义一致性被破坏。
本文动机是:在保留 codebook 层次语义结构的前提下,识别并拆分过度热门的 token,同时通过层次化语义对齐正则器增强不流行 token 的表征。
核心贡献:
- 问题:首次系统性地指出"codebook 不均衡会导致 GeneRec 存在 over-popular token、进而放大流行度偏差";
- 方法:提出 CRAB 框架,通过 (1) 基于正则化 K-means 的 codebook 重平衡(Codebook Rebalancing)与 (2) Hierarchical Semantic Alignment(HSA)两阶段后处理,在不破坏层次结构的前提下减轻偏差;
- 性能:在工业与 Office 两个数据集上相对 MOR 流行度偏差(DGU@10)降低 16.5%,同时保持具有竞争力的推荐效果。
二、背景与符号¶
2.1 残差量化(Residual Quantization)¶
设用户集合 $\mathcal{U}$、item 集合 $\mathcal{I}$,用户 $u$ 的行为序列为 $\mathcal{H}_u = \{i_1, \dots, i_T\}$,目标是预测下一个 item $i_{T+1}$。
每个 item $i \in \mathcal{I}$ 的文本描述通过冻结的 encoder 得到连续 embedding $\mathbf{z}_i$。通过 $L$ 层层次化 codebook $\mathcal{C}^l = \{c_k^l \mid k=1,\dots,K\}$(每层 $K$ 个 codeword,每个 codeword 是 embedding $\mathbf{c}_k^l$)进行从粗到细的量化:
$$s_i^l = \arg\min_k \lVert \mathbf{r}_i^l - \mathbf{c}_k^l \rVert^2, \quad \mathbf{r}_i^{l+1} = \mathbf{r}_i^l - \mathbf{c}_{s_i^l}^l \tag{1}$$
其中 $\mathbf{r}_i^1 = \mathbf{z}_i$。在 RQ-KMeans 中 $\mathbf{c}_k^l$ 就是 K-means 聚类中心,即该簇中 item 残差的均值。最终 item $i$ 的 SID 为 $(s_i^1, s_i^2, \dots, s_i^L)$。
2.2 自回归生成¶
将每个 item $i_t$ 替换为其 SID 序列后,用户历史展开为 token 序列:
$$X = \underbrace{s_1^1, s_1^2, \dots, s_1^L}_{i_1}, \dots, \underbrace{s_T^1, s_T^2, \dots, s_T^L}_{i_T}, \qquad Y = s_{T+1}^1, s_{T+1}^2, \dots, s_{T+1}^L$$
LLM 通过如下目标训练:
$$\mathcal{L}_{Rec} = -\sum_{l=1}^{L} \log F(Y_l \mid X, Y_{<l}) \tag{2}$$
其中 $F$ 是 LLM 的条件概率。
三、动机分析:Codebook 导致的偏差放大¶
本文量化衡量 token 级别的暴露不均。对第 $l$ 层 codebook、第 $k$ 个 token $c_k^l$,记它对应的 item 集合为 $\mathcal{I}_{c_k^l} = \{i \in \mathcal{I} \mid s_i^l = c_k^l\}$,则其 token popularity score 定义为:
$$P(c_k^l) = \sum_{i \in \mathcal{I}_{c_k^l}} f_i \tag{3}$$
其中 $f_i$ 是 item $i$ 的历史交互频率。
在每一层上,将 token 按 $P$ 排序,top 5% 记作"过热门 token"集 $T_{pop}$,剩余 95% 记作"不流行 token"集 $T_{unp}$。对两组分别计算 Group Unfairness 指标 $G_{pop}$、$G_{unp}$ [6],用于刻画推荐曝光量与历史交互量之间的差值。
图 1 右显示:MOR 中过热门 token 的 GU 达到 0.42,高达 SASRec 的 1.8 倍,表明 GeneRec 对热门 token 的过度暴露远高于传统 baseline。
作者进一步从机制上给出解释:语义相近的热门 item 被聚到同一个 token,一方面使得该 token 挂载的训练样本远超其它 token;另一方面自回归生成器在训练过程中就被"引导"高概率生成该 token,进一步加剧其暴露。
四、方法:CRAB¶
CRAB 是一个训练完后进行的后处理(post-hoc)框架,在已训练好的 GeneRec 模型上修改 tokenizer 与对应 LLM embedding。整体架构见图 2:先在 codebook 上拆分过热门 token(4.1 节),再通过 Hierarchical Semantic Alignment 正则器微调 LLM 层的 token embedding(4.2 节)。
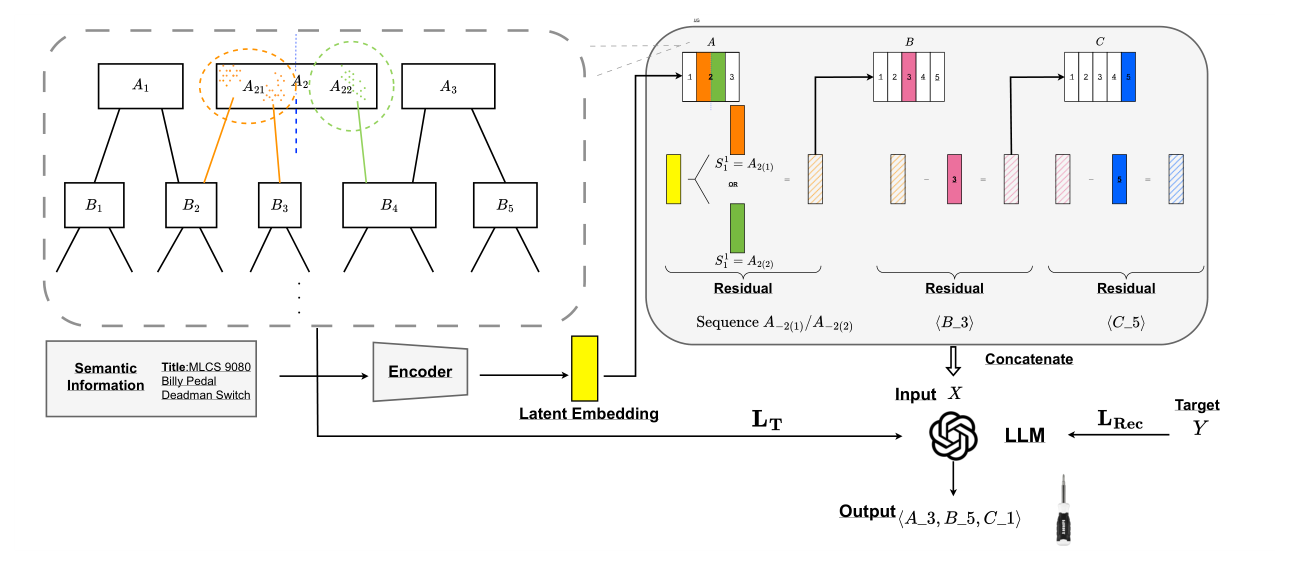
4.1 Codebook 重平衡¶
父子关系定义。层次化 codebook 中 token $c_k^l$ 的"子 token"集定义为:
$$\mathrm{Ch}(c_k^l) = \{c_j^{l+1} \in \mathcal{C}^{l+1} \mid c_k^l \to c_j^{l+1}\} \tag{4}$$
即至少存在一个 item 先在第 $l$ 层被分配到 $c_k^l$,再在第 $l+1$ 层被分配到 $c_j^{l+1}$。
拆分策略。对每个过热门 token $c_k^l$,通过对其子 token 集合 $\mathrm{Ch}(c_k^l)$ 进行聚类,将其拆分为 $M$ 个新 token(即生成 $M$ 个新的第 $l$ 层 token)。为保持第 $l+1$ 层本身的语义完整性,CRAB 对"拆分"方式做出一个硬约束:同一个 $(l+1)$ 层子 token 下挂载的所有 item 必须被分配到同一个新父 token。这等价于在树结构上"裁剪-重接"子树:只调整父节点,不打破子节点内部结构。
于是拆分 $c_k^l$ 就归结为把 $\mathrm{Ch}(c_k^l)$ 中的子 token重新聚到 $M$ 个新父 token 上。
目标函数。对子 token $c_j^{l+1}$ 引入 one-hot 分配向量 $z_j \in \mathbb{R}^M$,其中 $z_j[m] \in \{0,1\}$ 表示是否被分到第 $m$ 个新 token。为使新 token 间尽量频率均衡,作者在"新 token 的 popularity 之方差"上施加一个正则项,最终形式为:
先写出每个新 token $c_{k_{(m)}}^l$ 的 popularity 表达式:
$$P(c_{k_{(m)}}^l) = \sum_{j=1}^{|\mathrm{Ch}(c_k^l)|} z_j[m] \, P(c_j^{l+1}), \quad \mathcal{L}_{bal} = \sum_{m=1}^{M} \left(P(c_{k_{(m)}}^l) - \bar{P}\right)^2 \tag{5}$$
其中 $\bar{P}$ 是 $M$ 个新 token popularity 的均值。整体目标为:
$$\min_{\mathbf{z}} \sum_{m=1}^{M} \sum_{j=1}^{|\mathrm{Ch}(c_k^l)|} z_j[m] n_j \lVert \mathbf{r}_j^l - \bar{\mu}_m \rVert^2 + \lambda \mathcal{L}_{bal}, \quad n_j = |\mathcal{I}_{c_j^{l+1}}| \tag{6}$$
$$\text{s.t.} \quad z_j[m] \in \{0,1\}, \quad \sum_{m=1}^{M} z_j[m] = 1, \; \forall c_j^{l+1} \in \mathrm{Ch}(c_k^l)$$
其中:
- $\mathbf{r}_j^l$ 是 $c_j^{l+1}$ 下所有 item 在第 $l$ 层残差的均值;
- $\bar{\mu}_m$ 是新父 token $m$ 的聚类中心(由分到它的 $\mathbf{r}_j^l$ 加权求得);
- 第一项是加权的 K-means 目标(每个子 token 权重 $n_j$ 为该子 token 下 item 数),保留了语义相近性;
- 第二项 $\mathcal{L}_{bal}$ 拉平新 token 间的 popularity 差异;$\lambda$ 为超参。
这是一个正则化 K-means 问题,其第一项等价于一般 K-means 的均值聚类目标。作者通过 K-means 方差分解 [1] 说明:由于 $\mathcal{I}_{c_j^{l+1}}$ 内的 item 必然被分入同一个簇,该部分的簇内方差为常数,因此优化可退化为只对簇中心进行更新的子问题:
$$\sum_{i=1}^{n_j} \lVert \mathbf{r}_i^l - \bar{\mu}_m \rVert^2 = \sum_{i=1}^{n_j} \lVert \mathbf{r}_i^l - \bar{\mathbf{r}}_j^l \rVert^2 + n_j \lVert \bar{\mathbf{r}}_j^l - \bar{\mu}_m \rVert^2, \quad \bar{\mathbf{r}}_j^l = \frac{\sum_{i=1}^{n_j} \mathbf{r}_i^l}{n_j} \tag{7}$$
整个正则化 K-means 可以在 [14] 所提出的正则化 K-means 框架下高效优化。
RQ-VAE 场景的扩展。上述推导假设树结构严格成立(即每个子 token 只有一个父 token,这在 RQ-KMeans 下天然满足)。然而在 RQ-VAE [8] 中,同一个子 token 可能同时是多个父 token 的孩子。为此作者修改公式 (5) 中子 token popularity 的计算方式:仅聚合同时属于 $c_j^{l+1}$ 与 $c_k^l$ 的 item:
$$P(c_{k_{(m)}}^l) = \sum_{j=1}^{|\mathrm{Ch}(c_k^l)|} z_j[m] P(c_j^{l+1} \mid c_k^l), \quad P(c_j^{l+1} \mid c_k^l) = \sum_{i \in \mathcal{I}_{c_j^{l+1}} \cap \mathcal{I}_{c_k^l}} f_i \tag{8}$$
从而适配 DAG 型 codebook。
4.2 Hierarchical Semantic Alignment(层次语义对齐)¶
当过热门 token $c_k^l$ 被拆成 $M$ 个新 token 后,LLM 的 embedding table 也需要扩展相应的 $M$ 个新 embedding。CRAB 不随机初始化这些新 embedding,而是设计了一个基于层次结构的正则器 $\mathcal{L}_T$ 来引导 embedding 学习,核心思想是:"同层兄弟 token 的 embedding 应接近其子 token embedding 的均值":
$$\mathcal{L}_T = \sum_{l=1}^{L-1} \sum_{c \in \mathcal{C}^l} \frac{1}{|\mathrm{Ch}(c_k^l)|} \sum_{c \in \mathrm{Ch}(c_k^l)} \lVert e(c) - \bar{e}_c^l \rVert_2^2 \tag{9}$$
其中 $e(c)$ 是 LLM 中 token $c$ 的 embedding,$\bar{e}_c^l$ 是其子 token embedding 的均值。作者强调这个正则有两个作用:
- 对缺乏监督的不流行 token 提供隐式监督:没有足够训练样本的 token 可以通过与其语义邻居(兄弟或父)对齐获得合理的表征;
- 为新拆分出的 token 实现知识迁移:新 token 的 embedding 可以从其 children 的平均 embedding 中继承层次语义先验。
4.3 模型优化¶
整体目标是推荐损失加上层次正则:
$$\mathcal{L} = \mathcal{L}_{Rec} + \gamma \mathcal{L}_T \tag{10}$$
$\gamma$ 为控制正则强度的超参。CRAB 在 re-balance 之后继续训练,但只更新 embedding 层(所有旧 token + 新 token),同时在 attention 层应用 LoRA(rank=4)以提高效率。
五、实验¶
5.1 实验设置¶
数据集:两个真实数据集:
- Industrial:工业数据集;
- Office:公开数据集。
两者均经过至少五次交互的 user/item 过滤,时间顺序切分为训练/验证/测试(比例 8:1:1)。
评估指标:
- 推荐性能:NDCG@K、HR@K(K=10);
- 偏差/公平性:DGU@K、MGU@K(越小越好)[6];
- 效率指标:训练时间。
Backbone:CRAB 在 MOR 框架上实现,LLM 为 Qwen2-0.5B,在 4 × NVIDIA A100 上训练,batch size=128。优化器 AdamW,学习率 $1 \times 10^{-4}$,权重衰减 0.01。LoRA rank=4、$\alpha=16$,仅作用于 attention 层。codebook splitting 比例默认为 5%;每个过热门 token 新增 token 数 $M$ 由"目标 token 平均频率 / 目标 token 频率"确定,上限 $M \leq 3$。
Baselines:
- GeneRec backbone:TIGER、MiniOneRec (MOR);
- 三种后处理去偏基线(基于 MOR):
- RW (Reweighting) [6]:通过 popularity 反比来加权损失;
- RR (Reranking):事后对生成结果重排序;
- D²LR [11]:基于倾向性评分(propensity)的 LLM 去偏。
5.2 主实验¶
Table 1 给出 Industrial 与 Office 上的主结果:
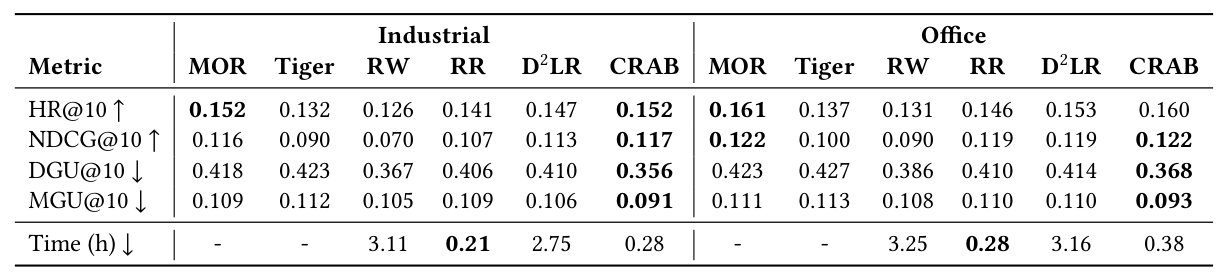
| Metric | MOR | Tiger | RW | RR | D²LR | CRAB |
|---|---|---|---|---|---|---|
| Industrial | ||||||
| HR@10 ↑ | 0.152 | 0.132 | 0.126 | 0.141 | 0.147 | 0.152 |
| NDCG@10 ↑ | 0.116 | 0.090 | 0.070 | 0.107 | 0.113 | 0.117 |
| DGU@10 ↓ | 0.418 | 0.423 | 0.367 | 0.406 | 0.410 | 0.356 |
| MGU@10 ↓ | 0.109 | 0.112 | 0.105 | 0.109 | 0.106 | 0.091 |
| 训练耗时 | 3.11 | 0.21 | 2.76 | 1.06 | ||
| Office | ||||||
| HR@10 ↑ | 0.161 | 0.137 | 0.131 | 0.146 | 0.153 | 0.160 |
| NDCG@10 ↑ | 0.122 | 0.100 | 0.090 | 0.119 | 0.119 | 0.122 |
| DGU@10 ↓ | 0.423 | 0.427 | 0.386 | 0.410 | 0.414 | 0.368 |
| MGU@10 ↓ | 0.111 | 0.113 | 0.108 | 0.110 | 0.110 | 0.093 |
| 训练耗时 | 3.25 | 0.28 | 3.16 | 0.38 |
结论: 1. 准确率层面:CRAB 在两个数据集上的 HR@10 / NDCG@10 与最强的 MOR 基线持平甚至略优(Industrial 上 NDCG@10 从 0.116→0.117;Office 上与 0.122 持平),证明去偏并未损害推荐能力; 2. 偏差层面:CRAB 的 DGU@10 / MGU@10 全面领先, - Industrial:DGU@10 相较 MOR 降低 14.8%(0.418→0.356),相较 D²LR 降低 13.2%; - MGU@10 相较 MOR 降低 16.5%,相较 D²LR 降低 14.2%; 3. 效率层面:Reweighting 与 D²LR 都需要完整再训练,训练耗时约为 CRAB 的 10~11 倍。Reranking 耗时最低但其依赖于后处理排序,效果明显较差。 4. 精度-公平的权衡:CRAB 是所有 baseline 中唯一能在不损失精度的前提下显著降低偏差的方法。
5.3 In-depth 分析¶
拆分比例的影响。图 3 左展示了在 MOR 下 Codebook splitting ratio 从 5% 到 25% 的表现:
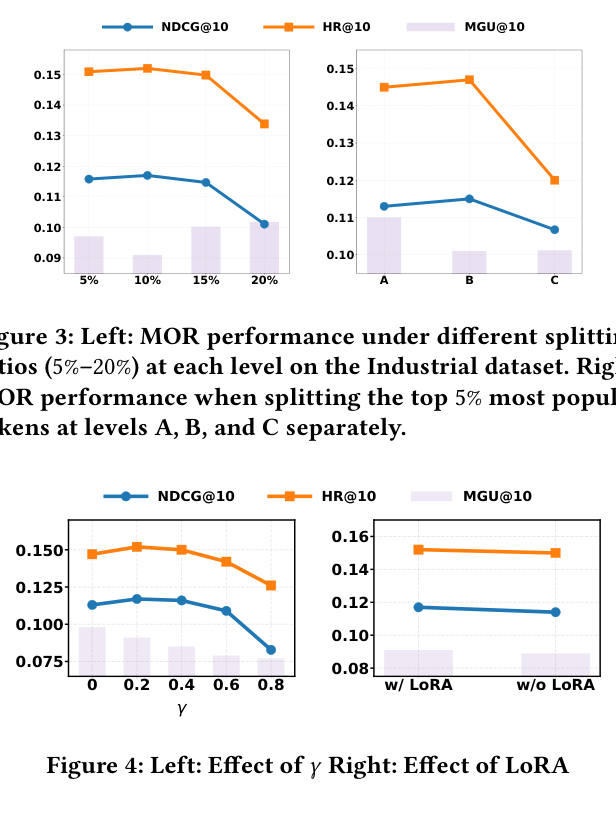
随着比例上升,指标先改善后下降,说明拆分少量最热门 token(5%~10%)能有效平滑 token 分布并提升不流行 token 表征;拆分过多则破坏 codebook 的层次语义完整性,反而损害性能。
拆分位置的影响。图 3 右对 MOR 的三个层 A、B、C 分别只拆分 top-5% 过热门 token:
- 在 level B(中层) 进行拆分效果最佳,作者类比"Hourglass" 现象 [9]:中间层 token 聚合了最有效的语义信息;
- 在 level A(最上层) 拆分效果较差,因为顶层 token 本身语义粒度较粗,拆分收益有限;
- 在 level C(最下层) 因语义已经细粒度,几乎看不到性能变化。
超参数 $\gamma$ 的影响(消融)。图 4 左显示 CRAB 对 $\gamma$ 较不敏感:当 $\gamma \leq 0.2$ 时推荐性能稳定,当 $\gamma > 0.2$ 时 NDCG 快速下降;默认 $\gamma = 0.2$。
LoRA 的必要性。图 4 右消融是否使用 LoRA:去掉 LoRA 后 NDCG@10 与 HR@10 均明显下降,表明仅依赖 embedding 更新不足以完全适配 codebook 重平衡,attention 层的轻量微调是必要的。
六、结论¶
本文系统地指出:生成式推荐中的流行度偏差起源于 codebook 不均衡,即 RQ 类 tokenizer 会把语义相近的热门 item 聚到同一 token,从而使训练过程和推荐输出都被该 token 主导。针对这一问题,CRAB 提出两阶段后处理方案:(1) 在保持 codebook 层次结构不被破坏的前提下,用正则化 K-means 拆分过热门 token;(2) 通过层次化语义对齐正则器增强不流行 token 与新拆分 token 的 embedding。实验表明 CRAB 能在基本不损失精度(NDCG@10、HR@10 与 MOR 基本持平)的情况下,显著降低流行度偏差(DGU@10 相较 MOR 降低 14.8%,MGU@10 降低 16.5%),且相比其它去偏方法训练效率高 10 倍以上。
七、启发与讨论¶
- CRAB 把"去偏"问题重构为"tokenizer 结构重整 + embedding 表征对齐",这对 Semantic ID 类生成式推荐系统有普适价值:只要是基于 RQ-KMeans / RQ-VAE 构造的 codebook,都面临 token 级别频率不均问题;
- 作者强调拆分与重训练是解耦的:先训练 GeneRec,再做 codebook 重平衡,最后仅用 LoRA + embedding 轻量微调,这对工业级部署相当友好;
- 硬约束"子 token 内部结构不变"在保护语义整体性、降低优化复杂度方面起到关键作用,避免了以往均匀 codebook 方法(如强制每 token 最多挂载 $N$ 个 item)造成的语义碎片化;
- 实验仅在两个数据集(Industrial + Office)上展开,评估数据集偏少;且未对更极端的长尾场景、多目标(CTR + CVR)等做系统分析,是潜在扩展方向。