AIR:把 LLM 跨域意图推理"离线化",在线只做轻量意图检索¶
AIR = Atomic Intent Reasoning(原子意图推理)。来自香港理工大学 + 快手(Kuaishou Technology),核心作者 Zhuohang Jiang 在快手实习期间完成,已全量部署在快手电商短视频场景,服务超过 4 亿月活用户。一句话:把"用 LLM 对跨域用户行为做语义意图推理"这件昂贵的事整体搬到离线——离线用 LLM 把用户行为拆解成"原子行为-意图对"灌进意图知识库;在线只做检索 + 组装意图树 + 目标感知检索 + 多头注意力融合,不调用任何在线 LLM,以约 400× 的吞吐增益换取实时 LLM 级别的语义能力,在快手电商线上 A/B 取得 +3.446% GMV。
研究动机与背景¶
内容到电商:一个紧耦合的转化闭环¶
在快手、抖音、TikTok 这类内容平台上,用户的在线行为越来越跨多个场景:在内容侧看直播、刷短视频,在电商侧浏览或购买商品,从而形成一个紧耦合的"内容→电商(content-to-commerce)"闭环。这个闭环天然驱动了跨域推荐(Cross-Domain Recommendation, CDR):利用用户在内容侧的在线行为去捕捉其个性化偏好,预测电商侧下一个 item(即商品)的购买意图,从而提升电商侧的 GMV(Gross Merchandise Value,商品交易总额)。
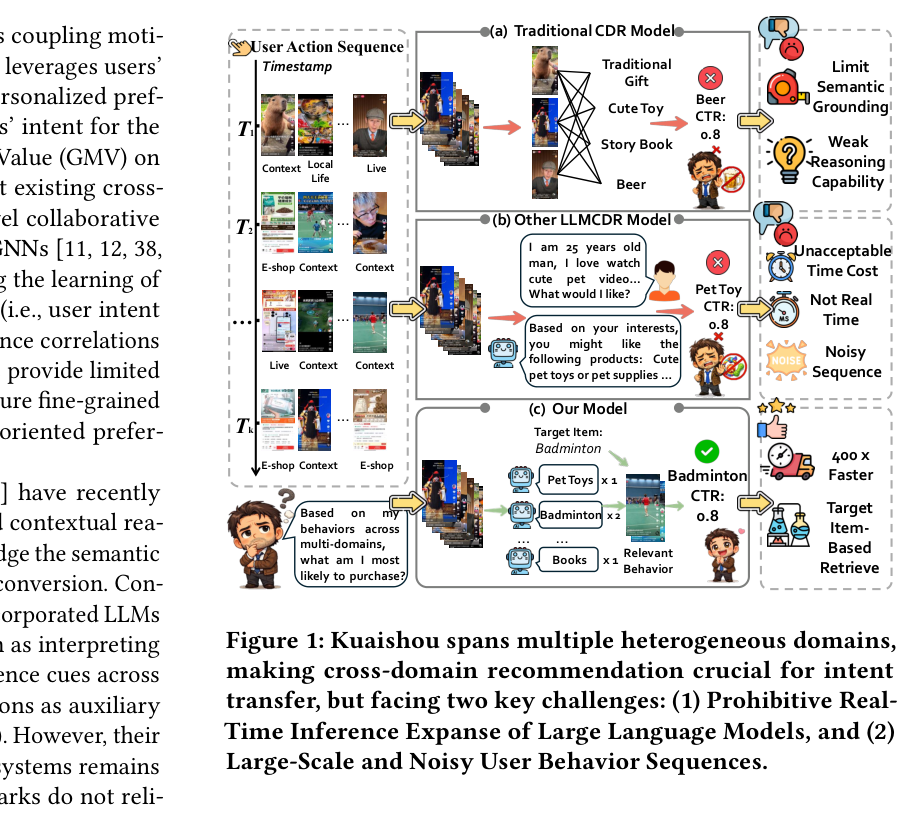
如 Figure 1(a) 所示,现有大多数 CDR 方法依赖 ID 级协同迁移(如共享 embedding [3,47] 或图神经网络 [11,12,38,40]),通过跨场景连接实体来学习用户对下一个 item 的偏好。这类方法擅长捕捉共现相关性,但缺乏强语义接地(semantic grounding),往往无法刻画细粒度的意图迁移,也难以从内容侧行为里准确推断面向购买的偏好。
LLM 是机会,但有两道工业落地的硬坎¶
大语言模型(LLM)展现出强大的语义理解和上下文推理能力,天然适合在内容侧"参与"与电商侧"转化"之间架起语义桥梁(Figure 1(b))。但论文一针见血地指出,把 LLM 用进真实的内容到电商系统,有两个本质难题:
- First(实时推理代价):在线 LLM 推理在毫秒级延迟约束下代价高得不可接受;而周期性的离线用户画像更新又跟不上快速演化的用户兴趣,损害推荐时效性。
- Second(行为序列又长又脏):用户行为历史通常极其冗长、异构、充满噪声;在海量跨场景事件中,对某个目标 item 真正有证据价值的只是一小部分子集。把原始行为序列直接喂给模型不仅放大语义噪声,还带来巨大的计算开销——面向目标 item 的行为筛选才是可扩展且精准预测的关键。
AIR 的总思路:解耦 + 离线化¶
为同时满足上述两点,AIR 采用一个离线→在线的解耦流水线(Figure 1(c)):
- 离线阶段:用 LLM 把"用户事件 + 用户属性 + item 描述"转化成稳定、可复用的原子行为-意图单元(atomic behavior-intent units),组织进一个高吞吐的意图知识库(intent knowledge base)。
- 在线阶段:系统检索并组装这些缓存的原子意图,实时构造出一份最新的用户意图表征,完全不调用 LLM,从而大幅降低服务延迟,同时保留语义信号。
为进一步应对又长又脏的多场景序列,AIR 构造一棵统一用户意图树(unified user intent tree),并相对当前目标 item 做目标感知的语义检索(target-aware semantic retrieval),得到一条紧凑、高证据、强相关的意图链;最后用一个多头注意力(MHA)模块把检索到的目标相关意图与互补的用户兴趣信号融合,做细粒度偏好建模。
四条核心贡献¶
- 提出 AIR:一个 LLM 驱动、面向内容到电商系统的跨域推荐框架,在保持毫秒级服务延迟的同时取得与"实时调用 LLM"相当的效果,并在公开 benchmark 上达到 SOTA。
- 设计原子意图缓存与组装机制:用户事件被离线蒸馏成原子行为-意图单元,经高吞吐意图知识库服务,相比实时 LLM 调用带来约 400× 吞吐增益。
- 提出目标感知意图检索(target-aware intent retrieval):从又长又脏的多场景历史里抽取紧凑、高证据的意图,并用多头注意力与其它用户兴趣信号融合做细粒度偏好建模。
- 公开 benchmark 上的大量实验 + 工业 A/B 共同验证有效性,线上 GMV +3.446%。
核心方法 / 模型架构¶
3.1 总览:四阶段流水线¶
AIR 把"在工业延迟约束下使用 LLM 语义理解"操作化为一个解耦的离线→在线框架,把原始跨域行为转化为目标相关的意图表征。如 Figure 2 所示,整体含四个阶段:
- Atomic Intent Pair Generation(原子意图对生成,离线)——做语义接地。
- Real-time Unified User Intent Tree Construction(实时统一用户意图树构造,在线)——把行为序列结构化。
- Target-aware Intent Retrieval(目标感知意图检索,在线)——做相关性精炼。
- MHA-based Intent Extraction(基于多头注意力的意图抽取,在线)——做整体偏好融合。
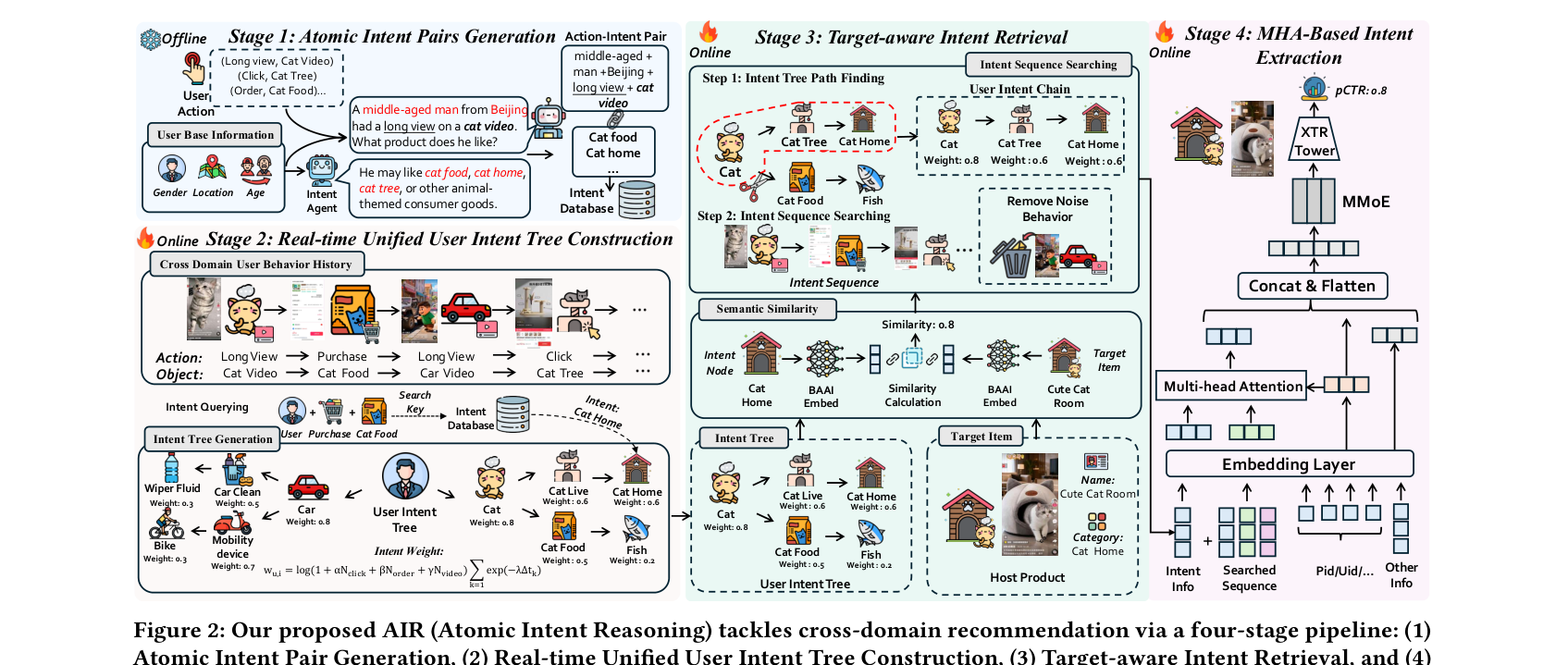
核心设计原则:离线阶段用 LLM 构造"原子行为-意图对",存进高并发意图知识库;在线服务时这些原子对被高效检索并动态组装成实时统一用户意图树,把海量异构行为序列转成结构化语义表征;再以目标 item 为条件,在意图树上做目标感知检索,蒸馏出紧凑高证据的行为子序列;最后用 MHA 把目标相关意图与互补的用户兴趣信号整合。这套四阶段框架把 LLM 推理彻底从在线移到离线,既保留实时语义感知,又实现低延迟、高吞吐的工业级推荐。
3.2 Atomic Intent Pair Generation(原子意图对生成)¶
为消除 LLM 的实时推理开销,AIR 提出离线的原子用户意图对生成方法,把 LLM 推理从在线流水线中解耦出来。关键洞察:复杂多行为序列背后的潜在意图,可以由若干"单行为原子意图"组合逼近。于是把跨域用户交互序列分解(decompose)成原子行为单元,每个单元映射到一份细粒度意图表征;再把这些原子意图组合,就构造出用户潜在偏好演化的统一语义表征——这是对"整序列级语义推理"的高效近似。这样的设计让 AIR 能用"离线意图缓存 + 在线轻量检索"来实时模拟 LLM 驱动的推理。
形式化:把每个用户事件定义为 $e = (a, o, u)$,其中 $a$ 是行为类型(如 click、long-view、purchase),$o$ 是行为对象(如视频或商品),$u = (\text{gender}, \text{age}, \text{location})$ 是用户画像属性。用户事件 $(a,o,u)$ 被喂进一个 LLM 提示词,该提示词组合了 (i) 用户上下文、(ii) 行为语义、(iii) 对象描述。LLM 输出一组层级意图路径:
$$\mathcal{P}(e) = \{p_1, \dots, p_m\}, \quad \forall p = [c_1 \to c_2 \to \cdots \to c_k], \tag{1}$$
其中 $m$ 是潜在用户意图数量,$k$ 是意图类目层数。每个 $c_\ell$ 表示第 $\ell$ 层的意图类目,从而形成一条"由粗到细"的意图轨迹。
为支持可扩展的实时推理,再构造行为类型特定(action-specific)的意图缓存:
$$\mathcal{P}_a = \bigcup_{e:\, a_e = a} \mathcal{P}(e), \tag{2}$$
让不同行为类型在下游建模时以差异化的重要性做贡献。由此推导出的一整套原子意图对,随后被用于检索与意图树构造。
直观理解:这一步是 AIR 全部"LLM 成本"的所在地——而它发生在离线。LLM 把"中年北京男性 long-view 了一条猫视频"这样的事件,翻译成"宠物/猫 → 猫粮/猫窝 → 动物主题消费品"这样的层级意图路径,落库成可复用的原子对。在线时再也不需要 LLM。
3.3 Real-time Unified User Intent Tree Construction(实时统一用户意图树)¶
为更好刻画用户意图的多层结构和不同行为类型的差异化重要性,缓存的行为类型特定意图路径被聚合成一棵统一的 action-related 意图树。树中每个节点是某个抽象层级上的意图类目,边编码层级父子关系;每个节点维护行为类型特定的统计量,以便对异构行为类型做差异化加权。
对一个节点 $u$(一个意图类目),其偏好权重 $w_u$ 由"多行为计数 + 时间衰减"组合而成:
$$w_u = \log\big(1 + N(u)\big) \sum_{k=1}^{n_u} \exp(-\lambda \, \Delta t_k), \tag{3}$$
$$N(u) = \alpha N_{\text{click}}(u) + \beta N_{\text{order}}(u) + \gamma N_{\text{view}}(u), \tag{4}$$
其中 $N_{\text{click}}(u)$、$N_{\text{order}}(u)$、$N_{\text{view}}(u)$ 分别是来自 click / order / video(或 long-view)证据的节点命中计数,$\alpha, \beta, \gamma$ 是平衡三者贡献的系数。$\Delta t_k$ 是第 $k$ 个支撑事件与当前时间的时间间隔,$\lambda$ 控制衰减强度。式 (3) 中的对数项稳定了重尾频率,衰减项则强调近期行为(即更强的短期意图)。
除偏好权重外,每个节点还存储其按行为类型分组的支撑行为对象 ID:
$$\mathcal{I}_a(u) = \{o_i \mid e_i = (a, o_i, u_i),\ p \in \mathcal{P}(e_i),\ u \in p\}, \tag{5}$$
其中 $\mathcal{I}_a(u)$ 表示在行为类型 $a$ 下,贡献到节点 $u$ 的行为对象(视频或商品)集合;它们将在后续阶段作为目标感知检索的显式证据。这棵意图树通过对缓存意图路径做轻量聚合在线构造,既支持高效实时服务,又保留了丰富的多行为信号。
服务时,用户级意图表征通过合并用户近期行为历史 $\mathcal{H}_{\text{user}}$ 对应的意图来动态组装(对应式 (2)):
$$\mathcal{P}_{\text{user}} = \bigcup_{e \in \mathcal{H}_{\text{user}}} \mathcal{P}(e). \tag{6}$$
这一设计消除了昂贵的在线 LLM 推理,同时保留细粒度意图信号,从而支撑工业级个性化推荐。
3.4 Target-aware Intent Retrieval(目标感知意图检索)¶
由于用户行为序列通常跨多个域、规模庞大且噪声重,直接在在线模型里编码整段生命周期历史既算力不可承受,又容易受与当前目标无关行为的语义干扰。受此启发,AIR 引入以候选 item $v$ 为条件的目标感知序列检索,把用户行为历史压缩成一条针对 $v$ 定制的紧凑用户意图链(user intent chain)。该检索框架包含三个关键过程:语义表征构造、意图链查找、意图序列搜索。
语义表征构造(Semantic Representation Construction)。 为目标 item 和用户意图节点分别构造语义表征。记 $\mathbf{e}_v$ 为目标 item $v$ 的 embedding(由其标题、类目、属性,可选地融合多模态信号得到);$\mathbf{e}_u$ 为意图节点 $u$ 的 embedding(由其标准名称和语义扩展得到)。目标-意图相关性用语义相似度衡量:
$$s(u, v) = \cos(\mathbf{e}_u, \mathbf{e}_v). \tag{7}$$
基于该相关性分数,从意图树 $\mathcal{T}$ 中选出一个小的候选意图节点集合:
$$\mathcal{U}_v = \text{Top-}M_{\,u \in \mathcal{T}}\; s(u, v). \tag{8}$$
对每个候选节点 $u$,沿其祖先递归回溯到根,构造一条层级意图链——即一条由粗到细、保留语义抽象过程的深度有序路径。
意图链查找(Intent Chain Finding)。 候选意图链通过"联合考虑目标相关性 + 用户偏好强度"打分。一个简单有效的打分函数定义为:
$$\text{score}(u; v) = s(u, v) \cdot g(w_u), \tag{9}$$
其中 $w_u$ 是节点 $u$ 上累积的用户偏好权重,$g(\cdot)$ 是单调映射(如 $g(w) = \log(1 + w)$)。排名靠前的意图链被保留,并去重合并成一条短的、层级的用户意图链 $\mathcal{C}_v$。这种表征可解释性强:每个节点都在语义上与目标 item 对齐,并接地于偏好感知的用户行为证据。
意图序列搜索(Intent Sequence Searching)。 在意图骨架确定后,再从缓存的行为特定来源里检索支撑证据:对链上每个节点,检索一份紧凑的支撑行为实例(如 click、order、视频交互),并在需要时做轻量去噪以抑制无关信号。去噪手段可包括:(i) 丢弃与目标语义相似度低的证据;(ii) 通过时间衰减过滤掉陈旧证据;(iii) 限制每个节点关联的证据预算。最终得到一串紧凑的意图 token + 其关联支撑证据,为下游 CTR 预测和细粒度排序提供高信息量信号,同时保证在线计算复杂度有界。
3.5 MHA-based Intent Extraction(基于多头注意力的意图抽取)¶
检索到的意图链通过多头注意力(multi-head attention, MHA)进一步转化成目标感知的兴趣表征。记 $\mathbf{q}_v$ 为目标 item embedding,$\mathbf{X} = [\mathbf{x}_1; \dots; \mathbf{x}_L]$ 为 $L$ 个检索到的意图链 token 的 embedding(可选地融合行为/来源与时间特征)。MHA 产出一个目标条件化的表征:
$$\mathbf{z}_v = \text{MHA}(\mathbf{q}_v, \mathbf{X}, \mathbf{X}). \tag{10}$$
该机制让不同注意力头分别捕捉用户意图的互补侧面,如粗粒度类目对齐、细粒度偏好模式、异构证据源。得到的 $\mathbf{z}_v$ 随后与标准的用户/item 特征整合,送入下游 CTR 预测或排序模型(Figure 2 Stage 4 中的 Concat & Flatten → MMoE → XTR Tower → pCTR)。这样,LLM 驱动的语义迁移通过"检索"实现,而服务时计算依旧轻量、可扩展。
4. 部署(Deployment)¶
工业级推荐与广告系统必须在严格延迟预算(通常几十到几百毫秒)下处理海量请求,这使得直接部署 LLM 用户意图建模极具挑战。在快手这类平台上,用户行为横跨多域,产生又长又脏的跨域行为序列;再叠加秒级推理延迟和大规模离线更新的开销,直接走 LLM 路线在实时工业服务里不现实。
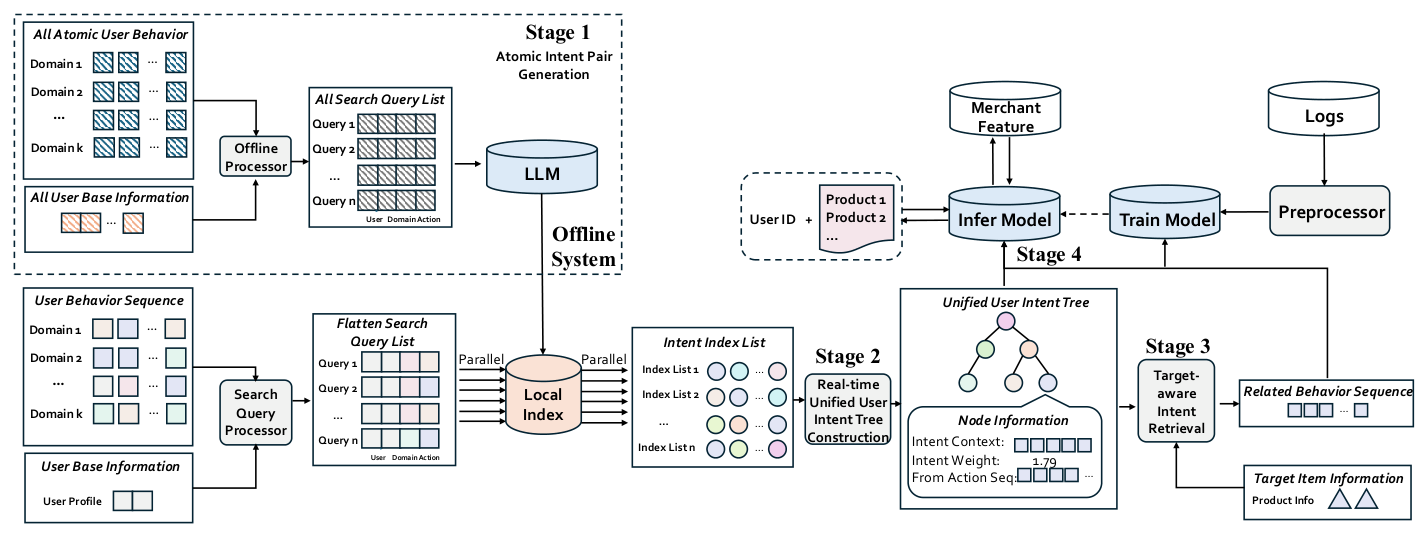
如 Figure 3,AIR 通过"把慢速语义推理与实时服务解耦"来把 LLM 的推理能力接入工业在线系统:
- 离线服务:AIR 构建一条工业级 LLM 语义生成流水线,处理用户画像属性(年龄、性别、地域)和多样历史行为,推断出"行为-意图"关系,再原子化成稳定、可复用的细粒度意图单元,以紧凑的 key-value 形式存进本地检索结构。这一步把计算密集的 LLM 推理整体卸载到离线。
- 在线服务:Search Query Processor 把又长又异构的行为序列分解成轻量的并行意图查询,在本地意图索引上并行执行,达到毫秒级检索;检索到的原子意图被动态聚合成层级统一用户意图树(含 action-specific 权重与上下文信息);再与 CTR 预测对齐,做目标 item 感知的序列检索,抽取与候选 item 相关的高证据行为子序列,从而有效抑制来自大规模跨域历史的噪声。在线推理因此只依赖轻量检索、并行聚合、树形意图组装,完全绕过直接 LLM 执行,在功能上等价于实时 LLM 推理,同时满足严苛的延迟、可扩展性与高 QPS 要求。
5. 实验设置¶
5.1 数据集¶
在三个 benchmark 上评测:两个公开 CDSR 数据集(从公开 Amazon 数据集构造,选了四个域组成两对跨域对:Movie–Book 和 Food–Kitchen),以及一个工业数据集(来自快手电商平台,服务 4 亿+ 月活;数据为商家内容短视频与直播照片,含 photo 级与 item 级电商数据,规模达数百亿条记录)。在线 A/B 中,5.08% 的平台流量被分配给本方案与现有生产 baseline 对比。统计见 Table 1。
| Dataset | Domain | Users | Items | Avg. Seq Length |
|---|---|---|---|---|
| Movie-Book | Movie | 9,485 | 12,875 | 9.01 |
| Movie-Book | Book | 52,908 | 93,860 | 9.01 |
| Food-Kitchen | Food | 10,822 | 8,661 | 8.22 |
| Food-Kitchen | Kitchen | 41,670 | 27,637 | 8.22 |
| Industrial | Merchant Content | 0.4 billion | billions ~ tens of billions | thousands |
5.2 评测配置¶
- 协议:leave-one-out;每个验证/测试样本从对应域 item 池中随机采样 999 个负样本,与 ground-truth 正样本一起排序。
- 指标:HR@k(Hit Ratio)与 NDCG@k。
- 数据清洗:为支持 LLM 基于文本描述的跨域意图生成,剔除缺文本元数据的 item;Movie–Book 移除交互 <10 的用户/item,Food–Kitchen 阈值为 5。
- 序列切分:按时间顺序排列并用固定时间窗切成更短子序列(Movie–Book 用 1 个月,Food–Kitchen 用 1 年);每条跨域子序列要求每域至少 2 个 item,每条单域子序列至少 5 个 item;按 80%/10%/10% 切训练/验证/测试,且严格按时间顺序避免信息泄漏;每条子序列最后一个交互 item 作为 ground-truth 目标。
- 跨域意图生成:Action Intent Pair Generation 用 Qwen3-4B 模型推断跨域意图,再用 BAAI/bge-m3 文本 embedding 模型映射到电商标签,促进意图跨域迁移。
5.3 对比方法(Competitors)¶
- 六个单域序列推荐(SR):FPMC、Caser、GRU4Rec、SRGNN、FEARec、SASRec。
- 五个跨域序列推荐(CDSR):TPUF、π-Net、C2DSR、MGCL、LLMCDSR(其中 LLMCDSR 用 LLM 生成并过滤的伪跨域交互 + 协同信号 + 元学习,是此前最强 baseline)。
6. 主要实验结果¶
6.1 公开 benchmark 整体对比(Table 2)¶
下表是 Amazon 四个域上的 NDCG@10 / HR@10(粗体为最优):
| Method | Movie NDCG@10 | Movie HR@10 | Book NDCG@10 | Book HR@10 | Food NDCG@10 | Food HR@10 | Kitchen NDCG@10 | Kitchen HR@10 |
|---|---|---|---|---|---|---|---|---|
| TPUF | 0.035 | 0.068 | 0.029 | 0.059 | 0.017 | 0.040 | 0.012 | 0.025 |
| π-Net | 0.039 | 0.077 | 0.044 | 0.089 | 0.032 | 0.063 | 0.036 | 0.078 |
| C2DSR | 0.035 | 0.064 | 0.014 | 0.031 | 0.069 | 0.131 | 0.023 | 0.046 |
| MGCL | 0.047 | 0.097 | 0.036 | 0.071 | 0.041 | 0.085 | 0.041 | 0.082 |
| LLMCDSR | 0.055 | 0.107 | 0.117 | 0.214 | 0.221 | 0.433 | 0.252 | 0.439 |
| FPMC | 0.031 | 0.062 | 0.061 | 0.108 | 0.126 | 0.229 | 0.086 | 0.153 |
| Caser | 0.031 | 0.057 | 0.053 | 0.102 | 0.058 | 0.133 | 0.085 | 0.166 |
| FEARec | 0.030 | 0.062 | 0.063 | 0.109 | 0.052 | 0.107 | 0.068 | 0.125 |
| GRU4Rec | 0.034 | 0.070 | 0.068 | 0.126 | 0.118 | 0.232 | 0.130 | 0.247 |
| SRGNN | 0.037 | 0.073 | 0.042 | 0.080 | 0.108 | 0.207 | 0.100 | 0.181 |
| SASRec | 0.032 | 0.065 | 0.102 | 0.189 | 0.213 | 0.400 | 0.249 | 0.450 |
| AIR | 0.072 | 0.151 | 0.127 | 0.215 | 0.263 | 0.437 | 0.285 | 0.452 |
结论分析(why):
- AIR 在两对跨域场景的全部四个域上,两个指标(NDCG@10、HR@10)全面超过所有 baseline。在 Movie–Book 上,HR@10 达到 0.151(Movie)/0.215(Book),分别比次优的 LLMCDSR 提升 41.31% 和 0.65%;在 Food–Kitchen 上提升更明显,HR@10 达 0.437(Food)/0.452(Kitchen),分别比 LLMCDSR 高 0.78% 和 3.07%。
- 传统 CDSR(TPUF、π-Net、C2DSR、MGCL)总体效果有限,甚至常常打不过单域 SR 模型——这暴露了它们对重叠用户的依赖,以及对单域信号利用不足。
- LLMCDSR 在 Food–Book 上有竞争力,但在 Movie–Book 上优势不明显;AIR 则在两类场景里都稳定保持领先,展示了更强的鲁棒性与泛化能力。
- 这两点共同说明:把 LLM 语义意图(而非纯 ID 协同)引入跨域建模,并辅以目标感知检索过滤噪声,是 AIR 取胜的根本原因。
6.2 消融实验(Table 3,Food–Kitchen)¶
| Method | Food NDCG@10 | Food HR@10 | Kitchen NDCG@10 | Kitchen HR@10 |
|---|---|---|---|---|
| AIR(完整) | 0.2630 | 0.4367 | 0.2850 | 0.4521 |
| w/o MHA | 0.2626 | 0.4200 | 0.2457 | 0.3705 |
| w/o Intent Retrieval | 0.1637 | 0.3200 | 0.1950 | 0.3564 |
| w/o Intent Tree | 0.1735 | 0.3633 | 0.1892 | 0.3469 |
| w/o Intent Tree + Intent Retrieval | 0.1590 | 0.2900 | 0.1031 | 0.1821 |
逐组件分析:
- 去掉 MHA(w/o MHA):性能只小幅下降——多头注意力是有益的"锦上添花"模块,但不是命门。
- 去掉 Intent Retrieval 或 Intent Tree(单独):各自导致 HR@10 在 Food 域下降 21–27%、Kitchen 域下降 17–23%,说明二者都不是可有可无的附加模块,而是强耦合、不可或缺的核心组件。
- 同时去掉两者(w/o Intent Tree + Intent Retrieval):出现灾难性崩塌,NDCG@10 与 HR@10 跨域分别暴跌 40–64% 和 34–60%。
- 机制解读:Intent Retrieval 支撑跨域知识迁移以缓解数据稀疏,Intent Tree 把这些知识组织、整合成层级意图建模;两者的协同是 AIR 在真实非重叠场景下持续超越现有方法的关键。
6.3 进一步分析¶
(a) 商品类目稀疏度分析(Table 4,Category HHI)。 用 Herfindahl–Hirschman Index(HHI)衡量类目集中度,HHI 越低 = 用户交互分布越均衡 = 多样性越好。
| Model | Level 1 | Level 2 | Level 3 | All |
|---|---|---|---|---|
| Base | 0.3762 | 0.0758 | 0.4434 | 0.1223 |
| AIR | 0.3769 | 0.0749 | 0.4168 | 0.1201 |
| Decrease Rate | +0.19% | −1.20% | −5.99% | −1.80% |
AIR 在多个层级一致降低 HHI,在 Level 2 和 Level 3 尤其明显(分别 −1.20% 与 −5.99%),说明它缓解了类目过度集中、促进了更广的类目覆盖,尤其在细粒度/中间层级提升类目多样性。
(b) 用户活跃度分析(Table 5,GMV Uplift by Activity Level)。
| Activity Level | Low | Mid | High | Ultra |
|---|---|---|---|---|
| Lift rate | +4.32% | +2.46% | +8.04% | +7.21% |
AIR 在所有活跃度层级都带来 GMV 提升,幅度 +2.46% ~ +8.04%。值得注意的是:低活跃用户 +4.32% 表明 LLM 生成的用户行为意图树能有效缓解冷启动(把稀疏的跨域交互转成更全面的行为表征);高/超高活跃用户 +8.04% / +7.21% 则进一步验证了"目标 item 条件化的推理压缩机制"在建模超长行为序列、剔除噪声、保留行为显著信号方面的有效性。
6.4 延迟分析(Latency Analysis)¶
直接调用 Qwen3-4B 做在线推理的延迟约为 8 秒;通过把用户行为意图对原子化、离散化,AIR 在保留"等价于实时大规模 LLM 推理"效果的同时,把延迟降到 20.134 ms,实现约 400× 吞吐增益。这一推理成本的大幅削减,是实时服务与工业级落地的关键。
6.5 工业在线 A/B 测试(Table 6)¶
AIR 已部署在快手电商短视频场景,严格在线 A/B 结果如下:
| Metric | Paid Order Count | GMV | GPM | OPM |
|---|---|---|---|---|
| Lift rate | +1.043% | +3.446% | +3.662% | +1.254% |
- Paid Order Count +1.043%:转化能力增强。
- GMV +3.446% / GPM +3.662%:更强的变现能力(GPM = 每千次曝光 GMV)。
- OPM +1.254%:整体利润效率提升(OPM = 每千次曝光订单)。
- 这些一致且显著的核心业务指标提升,为 AIR 在真实工业推荐场景中的实用价值提供了强力证据。
核心贡献总结¶
- 范式层面:把"用 LLM 对跨域用户行为做意图推理"这件事整体离线化——这是全文最关键的一招。LLM 只在离线生成可复用的原子行为-意图对,在线彻底无 LLM,从而在毫秒延迟下保留 LLM 语义,约 400× 吞吐增益。
- 结构层面:用"原子意图 → 统一意图树(action-specific 权重 + 时间衰减)→ 目标感知意图链检索 → MHA 融合"四步,把又长又脏的多场景行为序列压缩成紧凑、可解释、目标相关的意图表征。
- 验证层面:公开 Amazon 四域 benchmark 全面 SOTA + 快手电商真实 A/B(+3.446% GMV),且对低活跃冷启动用户(+4.32% GMV)与超长序列高活用户(+8.04% GMV)都有效。
与已归档相关工作的对比¶
RGCD-Rep RGCD-Rep:用 MLLM 推理蒸馏打通"短视频→直播"跨域表征(Kuaishou,2026-06-03)¶
关系:独立并发(本文未引用 RGCD-Rep,两者相隔 6 天、同出快手,殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都来自快手、都在 2026 年 6 月初投出,都在解决同一个 root cause——在工业级跨域推荐中引入 (M)LLM 的语义/推理能力,但在线 LLM 推理代价高到无法部署(AIR 的 "First" 挑战 ≈ RGCD-Rep 的 Ch1 算力成本)。两者都把"内容侧高流量域"桥接到"高价值转化域":AIR 是短视频内容 → 电商商品(冲 GMV),RGCD-Rep 是短视频 → 直播(冲观看/打赏/follow)。两者都明确指出纯 ID 协同 / 预抽取静态特征语义接地弱,需要 LLM 级语义。
- 相近的技术骨架:两者都采用"把 (M)LLM 推理整体搬到离线 → 生成结构化语义产物 → 在线只做轻量服务、不调用 LLM → 融进工业推荐链路"这一相同配方,且都把语义分解成原子/结构化单元(AIR:原子行为-意图对,层级意图路径 $c_1\to\cdots\to c_k$;RGCD-Rep:三语义维度 K = 垂类/关键主体/内容主题 + pair→item 分解)。两者都强调"在线可独立编码/检索、低成本落库"。
- 本文(AIR)的差异与推进:AIR 的离线产物是用户侧的原子意图缓存,在线检索 + 组装意图树 + 目标感知意图链检索,产出针对候选 item 的用户意图表征——它不在线跑任何模型权重,纯检索/组装 + 一个下游 CTR 的 MHA;强调延迟(20.134 ms,400×)与意图树的时间衰减/多行为加权。RGCD-Rep 的离线产物是item 侧可迁移表征:用冻结 35B 教师 MLLM 生成推理,蒸馏进一个轻量学生 MLLM(学生作为离线编码器跑出 embedding),并显式把 item 表征解耦成"可迁移分量 + 领域残差分量"以对抗负迁移。
- 可比的方法 / 实验差异:AIR 离线生成器是 Qwen3-4B + bge-m3 映射电商标签,公开 benchmark 用 Amazon 四域 HR/NDCG;RGCD-Rep 用 35B→轻量学生的蒸馏 + InfoNCE 跨域对比 + 可迁移路由,主打工业数据 + 直播召回部署。两者都在快手 4 亿级用户上线;一个侧重"用检索彻底替代在线 LLM"的延迟优势,一个侧重"用蒸馏 + 残差解耦"对抗负迁移与冷启动。可以认为 AIR 与 RGCD-Rep 是快手在"LLM 语义离线化做工业 CDR"这条主线上同期、互补的两个分支(用户意图缓存 vs item 表征蒸馏)。
已剔除的近似候选(防止门槛放水):RecGPT-Mobile(RecGPT-Mobile, Taobao) 同样想压低 LLM 在线成本,但其方案是"端侧 Qwen 仍在线推理 + 意图漂移触发器把调用降到 21%",是减少而非消除在线 LLM,配方不同;LGCD(LGCD, 安徽大学) 同属 CDR 冷启动 + LLM,但解法是"LLM 合成伪重叠交互 + 条件扩散生成目标域偏好",是数据增强/扩散生成,而非离线意图缓存 + 检索;IDProxy(IDProxy, 小红书) 虽也"离线 MLLM → 产物 → 接 CTR",但解决的是 item 冷启动的 proxy ID embedding,而非用户跨域意图的原子化与检索;IAT(IAT, ByteDance) 与 AIR 都"把海量行为压成紧凑 token",但 IAT 是可学习的样本级 embedding 压缩(无 LLM、单域),路径实质偏离。
讨论与局限性¶
核心贡献与借鉴价值:AIR 最值得借鉴的是它给出的一套"LLM 语义离线化"工业范式——当在线延迟预算容不下 LLM 时,不要在"上 LLM"和"不上 LLM"之间二选一,而是把 LLM 的推理产物原子化、可组合、可检索地预计算落库,在线用检索 + 组装来"模拟"实时推理。配合"目标 item 条件化检索"对超长噪声序列做剪枝,这套思路对任何"想用 LLM 语义但被延迟卡死"的工业推荐/广告系统都有直接参考价值。意图树的可解释性(每个节点语义对齐 + 行为证据接地)也是工程上很友好的副产物。
局限与争议:
- 离线-在线一致性 / 时效性:原子意图对是离线生成的,虽然在线用时间衰减 + 实时行为组装来逼近"最新意图",但对突发的、全新类型的跨域意图(离线 LLM 尚未见过的行为对象),系统只能等下一轮离线刷新——这正是论文自己指出的"周期性离线更新跟不上快速演化兴趣"问题的残留,AIR 缓解但未根除。
- 意图质量依赖离线 LLM:整个语义质量被 Qwen3-4B 的推理质量 + bge-m3 的标签映射质量"锁死";若离线 LLM 产出含噪意图,在线检索会忠实地把噪声放大。论文未系统讨论离线意图的质量校验/纠错机制(对照 RGCD-Rep 专门设计了 behavior-grounded 监督来对抗 MLLM 知识偏移)。
- 去噪与超参较多:意图链查找/序列搜索里的 Top-M、衰减 $\lambda$、多行为系数 $\alpha,\beta,\gamma$、证据预算等超参较多,论文未给出充分的敏感性分析。
- 公开 benchmark 的协议差异:Table 2 中传统 CDSR 普遍弱于单域 SR,可能与"非重叠用户占比高 + 999 负采样"的特定协议有关;AIR 的领先幅度在 Book/Food/Kitchen 上相对 LLMCDSR 其实不大(0.65%~3.07%),主要优势集中在 Movie 域(+41%),普适性还需更多数据集验证。
工业落地价值:论文的工业属性极强——已在快手电商短视频全量上线,5.08% 流量 A/B 得到 GMV +3.446%、GPM +3.662% 等一致正向核心指标,叠加 8s → 20ms 的 400× 延迟优化,部署细节(离线 KV 落库 + 在线并行意图查询 + 本地索引)清晰可复现,对内容到电商闭环的工业团队有很高的直接借鉴价值。