LGCD: From Clues to Generation — Language-Guided Conditional Diffusion for Cross-Domain Recommendation¶
- 作者:Ziang Lu, Lei Sang, Lin Mu, Yiwen Zhang*(安徽大学,Anhui University)
- Arxiv:2604.05365 / SIGIR'26
- 关键词:Cross-Domain Recommendation; Sequential Recommendation; Diffusion Models; LLM
研究动机与背景¶
Cross-Domain Recommendation (CDR, 跨域推荐) 的作用是利用跨多个业务域的用户行为来缓解单域的数据稀疏与冷启动问题。在 intra-domain CDR(同域辅助信息迁移)之外,更具挑战的是 inter-domain CDR:为那些在源域(source domain, A)有历史行为,但在目标域(target domain, B)从未产生交互的用户做推荐——这属于严格意义上的"跨域冷启动"。
现有 inter-domain 方法可归入两大范式: 1. Embedding-and-Mapping (EMCDR, SSCDR 等):学一个显式的 mapping function 把源域表征迁移到目标域; 2. Unified Representation Learning (UniCDR, UCLR 等):把源域与目标域 embeddings 拉到一个统一空间里,做不变特征抽取。
两种范式都严重依赖 overlapping users(在两个域都有行为的用户)作为对齐 anchor。但在真实场景里 overlapping user 通常是极少数子集,绝大多数用户只有单域行为——此时缺乏显式 alignment signal 使得细粒度偏好迁移变得非常困难。一些工作尝试用非 overlapping 数据做补充,但多数停留在"迁移粗粒度 domain 知识",难以给出针对冷启用户的个性化推荐。
作者提出核心洞察:大规模单域用户可以被大语言模型(LLM)"变废为宝"——让 LLM 从单域行为里推理出该用户在另一个域的潜在偏好,构造 pseudo-overlapping interactions(伪重叠交互)。这相当于用 LLM 作为语言桥梁,把单域用户"投射"到跨域 anchor 池中。然后把跨域推荐问题形式化为一个 conditional generation:给定 LLM 生成的伪 target-domain 信号 + 真实 source-domain 行为作为 condition,生成目标域的 user representation。作者选择 Diffusion Models 作为生成器,因为它们在复杂分布拟合与条件生成上有良好纪录。
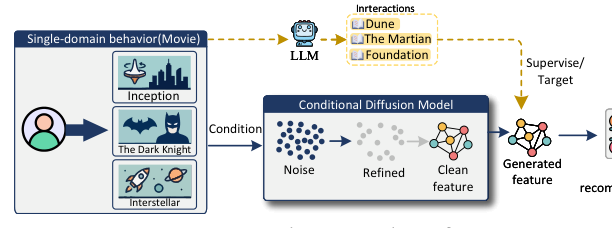
但直接用 LLM+Diffusion 的朴素组合会遇到三个结构性挑战:
- Misalignment between Open-ended Generation and Discrete Item Spaces:LLM 输出的是自由文本,不一定对应目标域真实 item;没有对齐机制会产生漂移与幻觉。
- Gap between Semantic and Collaborative Signals:LLM 生成的 pseudo-item 依赖 textual reasoning,忽视了用户实际协同信号(如共现模式)。天真地把 pseudo-interaction 当成 ground-truth 会误导 diffusion 过程。
- Controllability of Diffusion-based Transfer:diffusion 太强的 condition 容易过拟合 source pattern、太弱又无法生成 target-domain 风格的特征。
LGCD 针对这三个挑战分别设计了三个核心机制:
- LPG(LLM-based Pseudo-Interaction Generation):用 LLM 生成 pseudo-item 的文本描述,再在目标域真实 item 池里用语义相似度检索 top-k 的真实 item 作为 pseudo-overlapping interaction,保证每个 pseudo-item 都锚定在目标域离散空间中。
- CDPG(Conditional Diffusion Preference Generator):用 multi-modal(ID + 文本)条件信号 + cyclic mini-batch 训练策略 + cross-attention 降噪网络 + alignment loss 共同约束 diffusion 的生成方向,避开语义漂移。
- MoE Fusion Module:门控 MoE 融合 condition 信号与 diffusion 恢复出的 target feature,平衡保守性与生成性。
主要贡献: 1. LGCD 是首个把 LLM 与 Diffusion 联合用于 inter-domain sequential CDR 的框架; 2. 提出了 LLM-driven pseudo-overlap 构造机制 + cyclic batch 训练策略; 3. 设计了 cross-attention 降噪 + MoE 融合的条件 diffusion 架构; 4. 在 Movie-Book 和 Food-Kitchen 两个 Amazon 子数据集上全面超越 SOTA。
方法概览¶
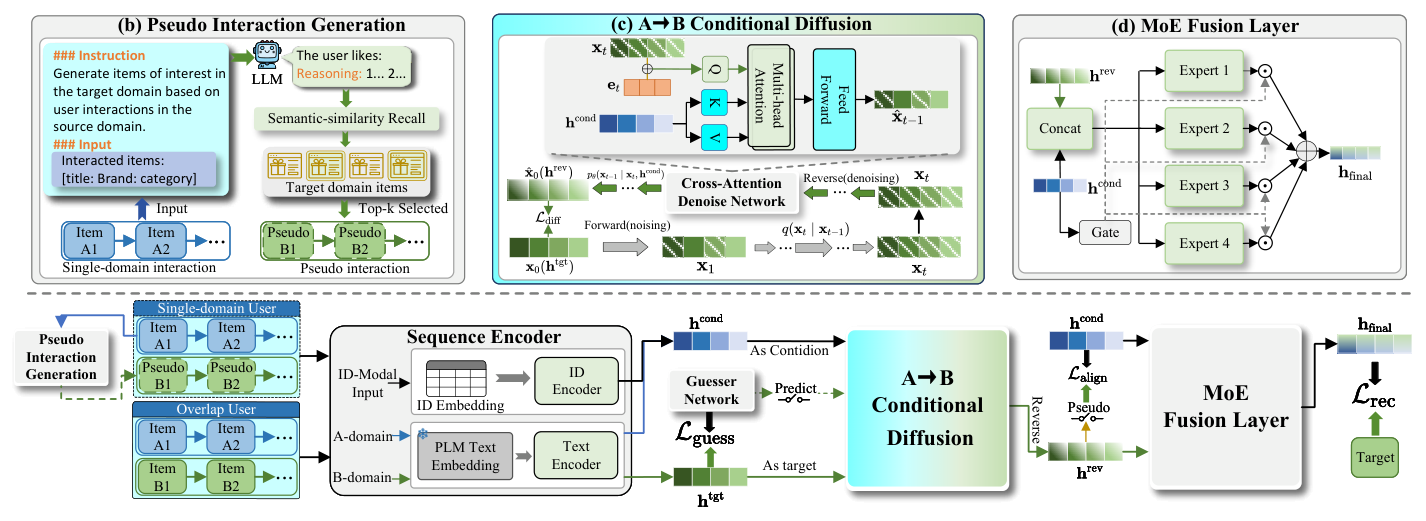
LGCD 由三个模块组成:LPG、CDPG、MoE Fusion。符号约定:两个域 A、B,item 集合 V^A, V^B;用户集合 U^O 是 overlapping users,U^A 和 U^B 是单域用户。每个用户 u 有 ID 交互序列 S_j^A = {v_1^{aj}, ..., v_{n_{aj}}^{aj}} 和文本交互序列 C_j^A = {c_1^{aj}, ..., c_{n_{aj}}^{aj}},c 是 item title/brand/category 的文本表示。目标:对给定 u_i^A ∈ U^A,预测其在 B 域下一个最可能交互的 item。
LPG: LLM-based Pseudo-Interaction Generation¶
Pre-trained Sequence Encoder¶
两个 modality 分别建立 encoder,均基于 Transformer 架构:
$$ h_i^{\text{ID}} = \text{Encoder}^A_{\text{ID}}(S_i^A),\quad h_i^{\text{text}} = \text{Encoder}^A_{\text{text}}(C_i^A) \tag{1} $$
融合两个 modality: $$ h_i^{\text{fusion}} = W^A_{\text{fusion}}[h_i^{\text{ID}} \oplus h_i^{\text{text}}] + b_i^A \tag{2} $$
W^A_{fusion} ∈ R^{d×2d}, b^A_{fusion} ∈ R^d 是可学习参数。作者在 A 域和 B 域分别预训练这两个 encoder,loss 为标准的 next-token prediction:
$$ \mathcal{L}^A_{\text{pre}} = -\frac{1}{|S_A|}\sum_{S_j^A \in \chi_A} \log p(v_{t+1}^A \mid S_j^A) \tag{3} $$
其中 p(v_{t+1}^A | S_j^A) = \text{Softmax}(h_j^{\text{fusion}} E_{\text{fusion}}^A), E_{\text{fusion}}^A = W_{\text{fusion}}[E_{\text{ID}}^A ; E_{\text{text}}^A] + b_{\text{fusion}}^A。B 域同理。
Pseudo Interaction Generation by LLM¶
对每个单域用户 u_i^A ∈ U^A,作者构造一个 instruction prompt 包含其文本序列 C_j^A,并指示 LLM 生成若干"该用户可能在 B 域交互的 item 的文本描述":
$$ \overline{C}_i^B = \{\bar c_1^B, \bar c_2^B, ..., \bar c_{n_K}^B\} = \text{LLM}(C_i^A) \tag{4} $$
其中 \bar c^B 是 LLM 输出的文本,可能偏离真实 item 集合。为将这些 pseudo-text "落地"到 B 域真实 item 空间,作者把 \overline{C}_i^B 送入 B 域的预训练 text encoder 得到:
$$ \hat h_i^B = \text{Encoder}^B_{\text{text}}(\overline{C}_i^B) \tag{5} $$
然后用 cosine 相似度检索 B 域 item pool 中最相似的 n_K 个真实 item:
$$ S_i^B = \{v_1^B, v_2^B, ..., v_{n_K}^B\} = \text{Top-}k\big(\cos(\hat h_i^B, e_j^B)\mid e_j^B \in E_{\text{text}}^B\big) \tag{6} $$
最后把这批真实检索到的 items 随机插入原序列 S_i^A 对应位置得到伪重叠序列 \hat S_i^A = \{v_1^A, v_2^B, v_3^A, ...\}。这保证 pseudo-interaction 一定在真实 item 空间内,解决 Challenge 1。
CDPG: Conditional Diffusion Preference Generator¶
Construction of Conditional Signals and Target Features¶
目标:为每个用户构造 condition 与 target。判断序列最后一个 item 所属域:
- 若最后一个 item 在 B 域,则该序列用于 B→A 训练方向;
- 若最后一个 item 在 A 域,则用于 A→B 训练方向。
以 A→B 为例:取用户 A 域序列 S_j^A 作为 condition source;对目标 B 域,把最后一个 B 域 item v_m^B ∈ V^B 作为目标,从序列中抽出其前序 B 域 textual interaction sequence C_j^B 作为 target feature source。
condition representations 融合 collaborative + semantic:
$$ h_j^{\text{tgt}} = \text{Encoder}^B_{\text{text}}(C_j^B) \tag{7} $$
对 condition 信号:先拿 A 域完整序列 S_j^A(含 ID、text)得到 collaborative rep h_j^O 和 semantic rep h_j^{\text{rp1}}(通过 A 域的 \text{Encoder}^A_{\text{ID}} 和 \text{Encoder}^A_{\text{text}}),再融合:
$$ h_j^{\text{cond}} = f_{\text{fusion}}^A(h_j^O \oplus h_j^{\text{rp1}}) \tag{8} $$
关键点:对 pseudo-overlapping 序列的 condition 构造,作者只用 collaborative(ID)部分,不用 text——因为 pseudo interactions 的 text 来自 LLM 的语义泛化,时序噪声大,混入 text modality 会让 condition 漂向源域表面语义。这个设计防止 diffusion 学偏。
Forward Process¶
用线性递增 noise schedule β_t ∈ [√β_{min}, √β_{max}],前向过程 Markov 链:
$$
q(x_t \mid x_{t-1}) = N(\sqrt{α_t}\ x_{t-1},\ β_t I),\quad α_t = 1 - β_t \tag{9}
$$
闭式边际: $$ q(x_t \mid x_0) = N(\sqrt{\bar α_t}\ x_0,\ (1-\bar α_t)I),\quad \bar α_t = \prod_{τ=1}^{t} α_τ \tag{10} $$ $$ x_t = \sqrt{\bar α_t}\ x_0 + \sqrt{1 - \bar α_t}\ ε,\quad ε \sim N(0, I) \tag{11} $$
其中 x_0 = h_j^{\text{tgt}}(真实 B 域 target feature)。
Cross-Attention Denoising Network¶
受 manifold 假设(clean data 位于低维流形上)启发,作者不让 diffusion 去预测噪声 ε,而是直接回归 clean target features,这样模型能力聚焦于 target manifold;同时用 cross-attention 把 condition 作为 query 的 kv。
具体:先把 time step embedding e_t 加到 noisy feature:
$$
\tilde x_t = x_t + e_t \tag{12}
$$
然后用 condition 作为 kv 做 cross attention: $$ \tilde x_t = \text{CrossAttn}(\tilde x_t,\ h^{\text{cond}},\ h^{\text{cond}}) \tag{13} $$
residual: $$ x_t^{(1)} = \tilde x_t + x_t \tag{14} $$
再接 FFN 输出: $$ x_t^{(2)} = x_t^{(1)} + \text{FFN}(x_t^{(1)}) \tag{15} $$
最终预测: $$ \hat x_0 = f_\theta(x_t, t, \mathbf Z^{\text{cond}}) = x_t^{(2)} \tag{16} $$
Diffusion loss: $$ \mathcal{L}_{\text{diff}} = \mathbb E_{x_0, t, ε}\Big[\big\| f_\theta(\sqrt{\bar α_t}x_0 + \sqrt{1-\bar α_t}ε, t, h^{\text{cond}}) - x_0 \big\|^2\Big] \tag{17} $$
Reverse Process¶
推理时用 "guesser network" 替代纯高斯初始化: $$ \mathbf h^{\text{init}} = \begin{cases} g_{A→B}(h^{\text{cond}}),\ A→B \\ g_{B→A}(h^{\text{cond}}),\ B→A \end{cases} \tag{18} $$
引入 start-step ratio λ ∈ (0,1],只从 t_{start} = λT 开始反向采样(而不是从 T 开始)。先做一次初始 forward 得到部分加噪 x_{t_{start}},再做 reverse:
$$
p_θ(x_{t-1} \mid h^{\text{cond}}) = N(\mu_θ(x_t, t, h^{\text{cond}}), Σ_t) \tag{19}
$$
$$
μ_θ(x_t, t, h^{\text{cond}}) = \frac{\sqrt{\bar α_{t-1}}\beta_t}{1-\bar α_t}\ \hat x_0 + \frac{\sqrt{α_t}(1-\bar α_{t-1})}{1-\bar α_t}\ x_t \tag{20}
$$
最终 diffusion 恢复的特征 h^{\text{rev}}。
Alignment Loss for Overlapping Users¶
对真实 overlapping users,额外加一个 alignment constraint: $$ \mathcal{L}_{\text{align}} = \|h^{\text{rev}} - h^{\text{cond}}\|^2 \tag{21} $$
这保证生成的 target 不会完全抛弃 source 的 condition 风格(防止过度创造),保持 cross-domain style 过渡的平滑性。
Guesser Network Training Loss¶
$$ \mathcal{L}_{\text{guess}} = \|g_{A→B}(h^{\text{cond}}) - h^{\text{tgt}}\|^2 \tag{22} $$
guesser 给 reverse process 提供一个合理的 warm start,减少反向步数 + 稳定训练。
MoE Fusion Module¶
用 MoE gating 把 h^{\text{rev}}(diffusion 恢复的 target feature)与 h^{\text{cond}}(来自 source 的条件)自适应融合:
$$ α_i = [α_{i,1}, ..., α_{i,n_e}] = \text{Softmax}(W_{\text{gate}}\ h^{\text{cond}}) \tag{23} $$
最后融合: $$ \mathbf h^{\text{final}} = \sum_{n=1}^{n_e} α_{i,n} \text{Expert}([h^{\text{cond}}_i \oplus h^{\text{rev}}_i]) \in R^d \tag{24} $$
note: 关键是 gating 以 condition 作为输入而非生成特征——因为 condition 是 deterministic 锚点,而 h^{\text{rev}} 可能还残留噪声,用它做 gating 会让 experts 选择不稳定。
任务损失¶
推荐损失(标准 NTP): $$ \mathcal{L}_{\text{rec}} = -\frac{1}{|S_A|}\sum_{S_j^A \in \chi_A}\log P(v_{t+1}^B \mid S_j^A) \tag{25} $$
其中 P(v_{t+1}^B | S_j^A) = \text{Softmax}(h^{\text{final}} E^B_{\text{fusion}})。
overlapping users 总 loss: $$ \mathcal{L}^O_{\text{total}} = \mathcal{L}_{\text{diff}} + \mathcal{L}_{\text{guess}} + \mathcal{L}_{\text{rec}} \tag{26} $$
单域用户(A 或 B)总 loss(额外加 alignment 约束): $$ \mathcal{L}^{A,B}_{\text{total}} = \mathcal{L}_{\text{diff}} + \mathcal{L}_{\text{align}} + \mathcal{L}_{\text{rec}} \tag{27} $$
Cyclic Batch Training¶
最后一个关键 trick:每个 mini-batch 都强制包含 fixed number of real overlapping users——真实 overlap 用户极少数,按比例采样的话一些 batch 可能完全没有 overlap 样本,导致 alignment signal 间歇断流。Cyclic batch 把它们"隐式加权"到训练目标里,保证每一步训练都有 cross-domain alignment gradient。
实验设置¶
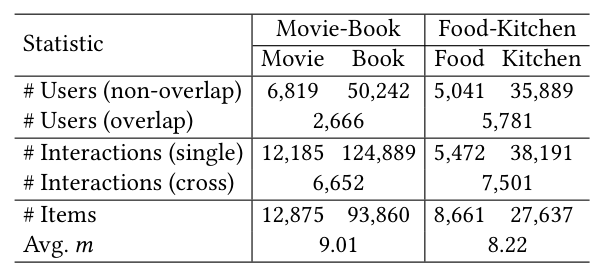
数据集(Table 2)¶
用两个 Amazon 数据集对:
| Statistic | Movie-Book | Food-Kitchen | ||
|---|---|---|---|---|
| Movie | Book | Food | Kitchen | |
| # Users (non-overlap) | 6,819 | 50,242 | 5,041 | 35,889 |
| # Users (overlap) | 2,666 | 5,781 | ||
| # Interactions (single) | 12,185 | 124,889 | 6,257 | 38,191 |
| # Interactions (cross) | 6,652 | 7,501 | ||
| # Items | 12,875 | 93,860 | 8,661 | 27,637 |
| Avg. m | 9.01 | 8.22 |
Movie-Book 采用 10-core 过滤取最新一个月交互(follow 前人),Food-Kitchen 采用 5-core 过滤取过去一年交互。
Baselines(三组)¶
- Single-domain:GRU4Rec, DiffuRec, SASRec, FEARec, UniSRec
- Intra-domain:Tri-CDR, MGCL, CTT
- Non-overlapping:DA-DAN, LLMCDSR, PLCR
- Inter-domain:SSCDR, UniCDR, UCLR, CD-CDR
实现细节¶
- PyTorch, NVIDIA RTX 4090
- hidden dim d=64
- Adam lr=0.001
- batch size 128(单域),overlapping 单独用一个 iterator(随机小批量,持续渗入训练流程)
- LPG 模块使用 Baichuan2-7B-Chat 作为 LLM,jina-embeddings-v2-base-en 作为 text encoder
- n_K(每个用户检索的 pseudo-item 数)= 10
- CDPG: noise schedule β_min=0.0001, β_max=0.1
- denoising network 4 heads, 总 diffusion 步数 T=100
- α=0.7 (Movie-Book), 0.7 (Food), 0.3 (Kitchen)
- MoE 的 expert 数 = 8
评估¶
随机抽 999 负样本加 ground-truth 做候选,使用 HR@N、NDCG@N (N=5, 10)。
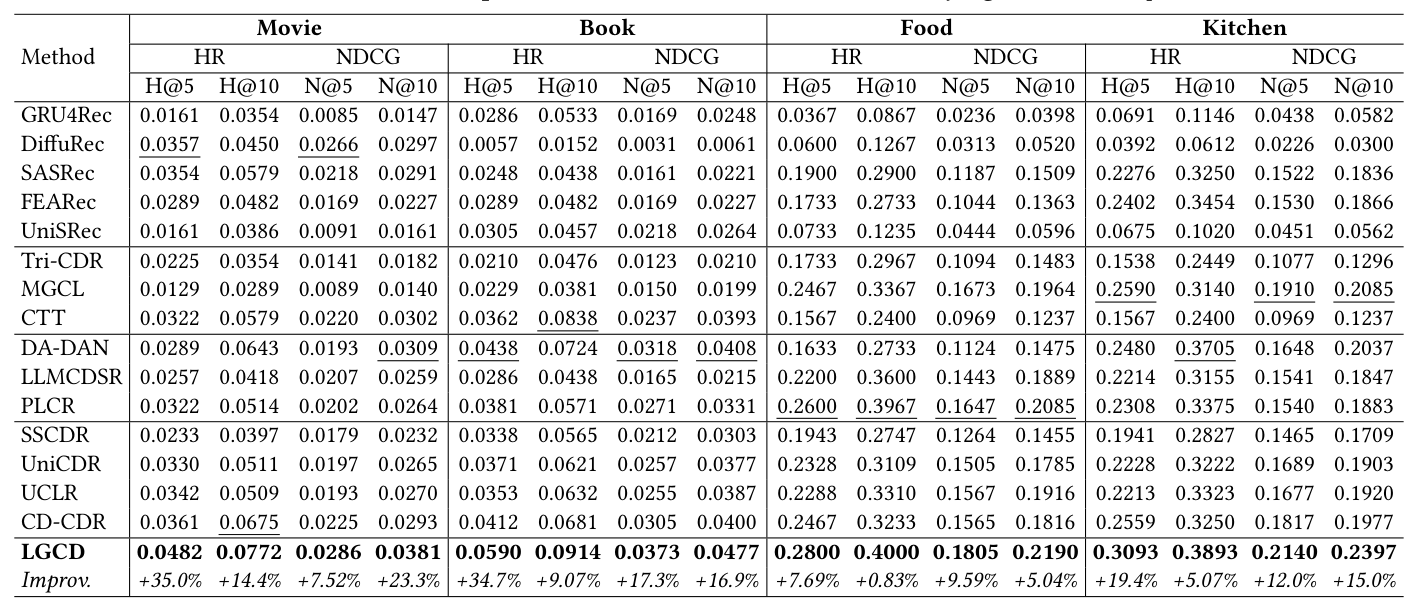
主要实验结果(Table 1)¶
Movie-Book 数据集¶
| Method | HR@5 | H@10 | NDCG@5 | N@10 | HR@5 (Book) | H@10 | NDCG@5 | N@10 |
|---|---|---|---|---|---|---|---|---|
| GRU4Rec | 0.0161 | 0.0354 | 0.0085 | 0.0147 | 0.0226 | 0.0533 | 0.0149 | 0.0227 |
| DiffuRec | 0.0351 | 0.0450 | 0.0206 | 0.0297 | 0.0057 | 0.0152 | 0.0031 | 0.0061 |
| SASRec | 0.0154 | 0.0579 | 0.0218 | 0.0291 | 0.0248 | 0.0438 | 0.0161 | 0.0221 |
| FEARec | 0.0289 | 0.0482 | 0.0169 | 0.0227 | 0.0289 | 0.0482 | 0.0169 | 0.0227 |
| UniSRec | 0.0161 | 0.0386 | 0.0091 | 0.0161 | 0.0305 | 0.0457 | 0.0218 | 0.0264 |
| Tri-CDR | 0.0225 | 0.0354 | 0.0141 | 0.0182 | 0.0210 | 0.0476 | 0.0123 | 0.0210 |
| MGCL | 0.0129 | 0.0289 | 0.0089 | 0.0140 | 0.0229 | 0.0376 | 0.0150 | 0.0199 |
| CTT | 0.0289 | 0.0579 | 0.0220 | 0.0302 | 0.0243 | 0.0400 | 0.0165 | 0.0218 |
| DA-DAN | 0.0289 | 0.0643 | 0.0219 | 0.0309 | 0.0438 | 0.0724 | 0.0318 | 0.0408 |
| LLMCDSR | 0.0257 | 0.0418 | 0.0207 | 0.0259 | 0.0286 | 0.0600 | 0.0199 | 0.0301 |
| PLCR | 0.0192 | 0.0353 | 0.0129 | 0.0188 | 0.0260 | 0.0382 | 0.0190 | 0.0229 |
| SSCDR | 0.0233 | 0.0397 | 0.0179 | 0.0232 | 0.0338 | 0.0565 | 0.0212 | 0.0285 |
| UniCDR | 0.0330 | 0.0511 | 0.0167 | 0.0265 | 0.0371 | 0.0662 | 0.0257 | 0.0377 |
| UCLR | 0.0342 | 0.0509 | 0.0193 | 0.0270 | 0.0353 | 0.0632 | 0.0255 | 0.0318 |
| CD-CDR | 0.0260 | 0.0675 | 0.0225 | 0.0293 | 0.0412 | 0.0681 | 0.0305 | 0.0400 |
| LGCD | 0.0482 | 0.0726 | 0.0286 | 0.0381 | 0.0590 | 0.0874 | 0.0373 | 0.0477 |
| Improv. | +35.0% | +14.4% | +7.52% | +23.3% | +34.7% | +9.07% | +17.3% | +16.9% |
Food-Kitchen 数据集¶
| Method | HR@5 (Food) | H@10 | NDCG@5 | N@10 | HR@5 (Kitchen) | H@10 | NDCG@5 | N@10 |
|---|---|---|---|---|---|---|---|---|
| GRU4Rec | 0.1033 | 0.1780 | 0.0667 | 0.0867 | 0.0691 | 0.1146 | 0.0438 | 0.0582 |
| DiffuRec | 0.0600 | 0.1267 | 0.0333 | 0.0526 | 0.0509 | 0.0890 | 0.0320 | 0.0444 |
| SASRec | 0.1700 | 0.2900 | 0.1187 | 0.1509 | 0.2276 | 0.3250 | 0.1522 | 0.1836 |
| FEARec | 0.1733 | 0.2733 | 0.1044 | 0.1363 | 0.2402 | 0.3454 | 0.1530 | 0.1866 |
| UniSRec | 0.1800 | 0.2700 | 0.1125 | 0.1470 | 0.1996 | 0.3000 | 0.1322 | 0.1648 |
| Tri-CDR | 0.1733 | 0.2967 | 0.1094 | 0.1486 | 0.1538 | 0.2449 | 0.1027 | 0.1326 |
| MGCL | 0.2467 | 0.3367 | 0.1673 | 0.1964 | 0.2590 | 0.3140 | 0.1910 | 0.2085 |
| CTT | 0.1567 | 0.2400 | 0.0969 | 0.1237 | 0.1567 | 0.2400 | 0.0969 | 0.1237 |
| DA-DAN | 0.1633 | 0.2733 | 0.1124 | 0.1475 | 0.2480 | 0.3705 | 0.1648 | 0.2037 |
| LLMCDSR | 0.2057 | 0.0418 | 0.1407 | 0.1816 | 0.2214 | 0.3155 | 0.1541 | 0.1847 |
| PLCR | 0.2600 | 0.3967 | 0.1647 | 0.2085 | 0.2308 | 0.3375 | 0.1501 | 0.1883 |
| SSCDR | 0.1943 | 0.2747 | 0.1264 | 0.1455 | 0.1941 | 0.2827 | 0.1465 | 0.1709 |
| UniCDR | 0.2328 | 0.3109 | 0.1505 | 0.1785 | 0.2228 | 0.3252 | 0.1689 | 0.1903 |
| UCLR | 0.2288 | 0.3310 | 0.1567 | 0.1916 | 0.2213 | 0.3323 | 0.1677 | 0.1920 |
| CD-CDR | 0.2467 | 0.3233 | 0.1565 | 0.1836 | 0.2467 | 0.3230 | 0.1804 | 0.1977 |
| LGCD | 0.2800 | 0.4000 | 0.1805 | 0.2190 | 0.3093 | 0.3893 | 0.2214 | 0.2397 |
| Improv. | +7.69% | +0.83% | +9.58% | +5.04% | +19.4% | +5.07% | +12.0% | +15.0% |
结论: 1. LGCD 在全部 4 个 target domain / 全部指标上均为 SOTA,HR@5 平均提升 19% 以上。 2. 单域方法(SASRec、FEARec)在 Food-Kitchen 上反而强于一些跨域方法,作者认为这是因为这两个 intra-domain 方法完全服务于 overlapping 用户;相比之下,普通 CDR 方法把单域行为混入反而破坏了 overlap 学出来的跨域关系。 3. Non-overlapping 方法(DA-DAN、PLCR)在 intra-domain signal 缺失的情况下也有竞争力,但仍被 LGCD 超越——说明生成式建模比简单的表示学习更能在稀疏 overlap 场景下产生个性化信号。 4. LLMCDSR 虽然也用 LLM 但只做检索式 refinement,当用户完全没有 target-domain 交互时性能显著衰退。LGCD 通过 diffusion 生成替代了"mapping",为无 target 交互的用户提供了连续空间的偏好扩散,更具灵活性。
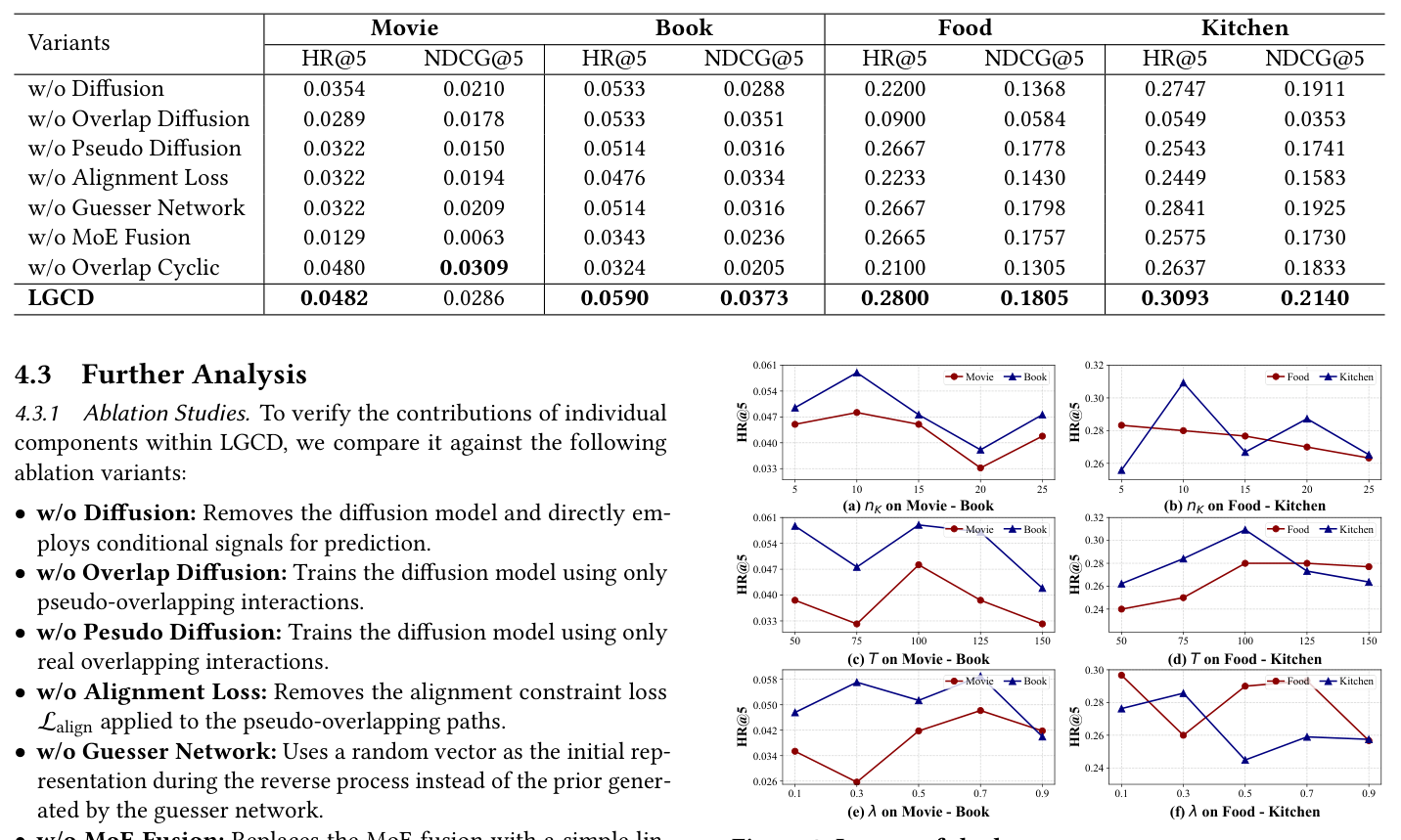
消融与分析¶
Ablation Study(Table 3)¶
| Variant | Movie HR@5 | Movie NDCG@5 | Book HR@5 | Book NDCG@5 | Food HR@5 | Food NDCG@5 | Kitchen HR@5 | Kitchen NDCG@5 |
|---|---|---|---|---|---|---|---|---|
| w/o Diffusion | 0.0354 | 0.0210 | 0.0533 | 0.0288 | 0.2200 | 0.1368 | 0.2747 | 0.1911 |
| w/o Overlap Diffusion | 0.0289 | 0.0178 | 0.0514 | 0.0351 | 0.0900 | 0.0584 | 0.0549 | 0.0353 |
| w/o Pseudo Diffusion | 0.0322 | 0.0150 | 0.0514 | 0.0316 | 0.2667 | 0.1778 | 0.2824 | 0.1741 |
| w/o Alignment Loss | 0.0322 | 0.0194 | 0.0476 | 0.0334 | 0.2233 | 0.1430 | 0.2449 | 0.1583 |
| w/o Guesser Network | 0.0322 | 0.0209 | 0.0514 | 0.0316 | 0.2667 | 0.1798 | 0.2841 | 0.1925 |
| w/o MoE Fusion | 0.0129 | 0.0063 | 0.0343 | 0.0236 | 0.2665 | 0.1757 | 0.2575 | 0.1730 |
| w/o Overlap Cyclic | 0.0480 | 0.0309 | 0.0324 | 0.0205 | 0.2100 | 0.1305 | 0.2637 | 0.1833 |
| LGCD (full) | 0.0482 | 0.0286 | 0.0590 | 0.0373 | 0.2800 | 0.1805 | 0.3093 | 0.2140 |
观察: 1. w/o MoE Fusion 跌幅最大(Movie HR@5 从 0.0482 跌到 0.0129),说明简单线性融合无法选择性地保留 condition 中的稳定偏好与 diffusion 恢复出的新颖特征;MoE 的 expert 选择性起到了决定性作用。 2. w/o Overlap Diffusion(只用伪 overlap 训 diffusion)在 Food 掉到 0.09,说明真 overlap 用户的监督信号是 diffusion 训练的锚点,不能丢。 3. w/o Pseudo Diffusion(只用真 overlap 训 diffusion)在大部分指标也下跌,证明伪 overlap 是必要的数据增强源。 4. w/o Diffusion(直接用 condition 预测)在所有指标均下跌,说明单纯把 condition 当 user rep 不足以表达 target domain 偏好。 5. w/o Alignment Loss 下跌显著,证明单域用户这一支的 cross-domain style 约束是必需。 6. w/o Overlap Cyclic(丢掉固定 overlap batch 策略)在 Book/Kitchen 上出现严重退化(Book HR@5 0.0590→0.0324),证实"每步都要有 overlap supervision"的重要性。
超参数敏感性(Figure 3)¶
n_K(每个用户生成的伪 item 数量):Movie-Book 最佳 5,Food-Kitchen 最佳 10。过多 pseudo item 会引入噪声反而破坏 cross-domain constraints。T(diffusion 步数):峰值在 100 步左右,过少欠去噪、过多累计误差。λ(start-step ratio):Movie-Book 最佳 0.7,Food 0.5,Kitchen 0.3;这个参数控制高噪 timestep 保留 cross-domain 信号的程度,不同场景差异大。
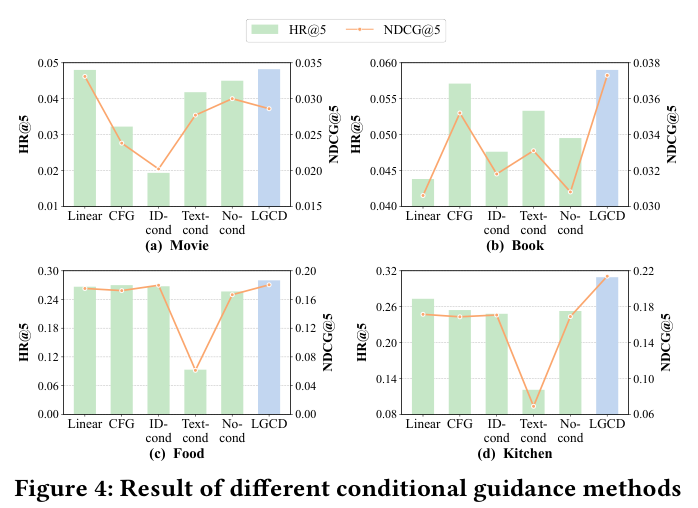
Conditional Guidance Methods(Figure 4)¶
- ID-cond(只用协同信号做条件):在 Movie-Book 上表现最差,说明单协同信号不足以在两个语义空间差距大的域之间桥接;
- Text-cond(只用语义信号做条件):在 Food-Kitchen 上最差,说明两个在语义上很相似的域(都属于厨房日用相关),光用 text 容易产生混淆;
- CFG / Linear 融合策略都比 LGCD 的 cross-attention 弱;
- LGCD 的 cross-attention 同时利用两个 modality 能在不同类型的域对上都保持最优。
Diffusion Training Target(Figure 5)¶
直接预测 target feature 明显优于预测 noise。作者解释:推荐任务需要准确还原 semantic-rich feature,而噪声预测不具备这种"锚定"特性;manifold 假设支持这一选择。
Overlap Ratio 影响(Figure 6)¶
- LGCD 在 overlap ratio 0.2 时就已全面超过 baseline;
- 大约 0.6 之后 baseline 们开始追上,但 LGCD 提升曲线更平稳——说明 LGCD 的 pseudo overlap 构造机制在"超低 overlap"场景下带来了额外的伪监督,这是它相对于 baseline 的核心优势来源。
讨论与局限性¶
核心贡献 1. 首个将 LLM 与 Diffusion Models 结合的 inter-domain sequential CDR 框架。把 LLM 当"跨域偏好推理器"而非"检索器"——这是该工作相较于 LLMCDSR、PLCR 等前作的本质区别。 2. LPG 机制通过"LLM 生成 pseudo-text → B 域 text encoder 检索真实 item"把 LLM 的开放式生成锚定到真实 discrete item pool。 3. CDPG 设计了 cross-attention 降噪 + alignment loss + guesser init + cyclic batch 的 4 点组合拳来稳定化 diffusion 在跨域语境下的训练。 4. MoE Fusion 让 condition 作为门控输入、而非生成特征作为门控输入,保持 gating 决策的稳定性。
值得借鉴的设计
- LLM 做"数据增强器"的新范式:把单域用户(原本无用)转化为有 pseudo target-domain 行为的用户,极大扩充 alignment 样本量;
- direct target prediction 而非 noise prediction 是 diffusion 在推荐语境下的优选,manifold 假设给出了理论支撑;
- cyclic batch 是一个工程上小但关键的 trick,强制让 alignment gradient 在每一步都可见;
- α(start-step ratio)随域对特性调整:语义差异大用大 α,语义接近用小 α。
局限与可扩展方向
- 依赖 Baichuan2-7B-Chat 和 jina embedding 作为 LLM 模块,推理成本与质量耦合度高;换更强的 LLM 或重型 RAG 可能收益更大。
- 只在 Amazon 的两对数据上验证(Movie-Book / Food-Kitchen),工业级 CDR(不同平台/多模态场景)上的泛化性未验证。
- Diffusion 推理延迟较重(T=100 步),对在线排序不友好;论文未讨论如何做蒸馏或加速。
- n_K 的最优值因数据集而异,没有自适应机制。
- MoE expert 数固定为 8,未讨论动态 experts 或 sparse-gating 的扩展。
与已有工作的差异
- vs LLMCDSR:LLMCDSR 仅检索跨域知识,LGCD 生成伪交互再用 diffusion 建模生成分布;
- vs DiffuRec/DiffuSR:这些是单域 diffusion recommender,LGCD 首次把 diffusion 扩展到 cross-domain condition;
- vs UniCDR/UCLR:后者依赖大量 overlap users,LGCD 明确针对稀疏 overlap;
- vs CDR 通用方法(SSCDR, CD-CDR):LGCD 通过生成建模把"迁移"问题改成"生成"问题,在冷启动场景更自然。
结论¶
LGCD 是一个设计精巧的 inter-domain sequential CDR 框架,核心贡献在于"LLM 生成 pseudo interaction + Conditional Diffusion + MoE Fusion"的三模块协同。它解决了一个长期被忽视的问题——绝大多数真实场景 overlapping users 极少,现有 CDR 方法基本无能为力。作者用生成模型的视角重新定义了这个问题:不再是迁移,而是条件生成。在 Amazon 两对数据集上的大幅提升(HR@5 最多 +35%)证实了该思路的有效性。对学术界而言这是一个很有启发性的 paradigm shift,对工业界则需要后续解决 diffusion 推理效率的问题才能落地。