RGCD-Rep:用 MLLM 推理蒸馏打通"短视频→直播"跨域表征¶
RGCD-Rep = Reasoning-Guided Cross-Domain Representation Learning。来自快手(Kuaishou Technology),已全量部署在快手 + 快手极速版的直播推荐召回链路,服务超过 4 亿日活用户。核心一句话:用一个冻结的大教师 MLLM 生成"短视频与直播是否在用户兴趣上可迁移"的结构化推理,蒸馏进一个轻量学生 MLLM,再把学生 MLLM 当作共享编码器,学出可离线落库、可直接接入工业召回的跨域可迁移表征。
研究动机与背景¶
直播是高价值但行为稀疏的转化场景¶
YouTube、TikTok、快手等平台同时提供短视频与直播来满足用户和创作者的多样需求。两类内容在生态里扮演着互补角色:
- 短视频:流量大、行为信号丰富,用户通过虚拟礼物和各种互动行为活跃参与。
- 直播:是核心转化场景,用户实时互动并贡献大量平台收入。
但直播相比短视频有一个结构性劣势:由于曝光差异(exposure differences),直播的行为数据通常稀疏,而 follow、虚拟打赏等高价值行为尤其稀少[8, 16]。更糟的是,直播场景的冷启动对新主播和新用户特别严重——新开的直播间和刚进入直播的用户都缺乏足够交互来支撑推荐。
跨域推荐(CDR)是自然解法,但已有方法在多模态上"浅尝辄止"¶
为缓解直播的数据稀疏与冷启动,一个直接思路是跨域推荐(Cross-Domain Recommendation, CDR):把行为丰富的短视频域与稀疏的直播域连接起来,将用户在短视频上表达的兴趣迁移到直播推荐[14, 15, 35]。已有 CDR 工作主要从三个角度切入:
- 迁移模块把源域表征整合进目标域推荐[12, 22];
- 图神经网络 / 序列模型捕捉跨域行为依赖[2, 13, 20, 32];
- 多模态内容(视觉、音频、文本)被引入以增强 CDR[6, 33]——例如 MOTKD[33] 用多模态图注意力网络建模用户偏好并迁移到目标域,UniEmbedding[6] 通过 domain-aware 多模态适配器 + user-view 投影模块抽取 item 级多模态表征。
然而,既有研究普遍依赖预抽取、模态特定(modality-specific)的表征[6, 33]。论文一针见血地指出其局限:
这类静态特征在深层语义推理上能力受限,只能对"为什么两个域的 item 在行为上可迁移"给出薄弱解释。(Such static features are limited in deep semantic reasoning ... and provide weak explanations for why items from two domains can be behaviorally transferable.)
多模态大模型(MLLM)是机会,但有三道工业落地的坎¶
MLLM 能把多模态信息整合进统一的文本语义空间,提升推荐系统理解和解释复杂多模态输入的能力[7, 18],天然适合对跨域用户行为做更精确的建模。但论文明确总结了 MLLM 增强 CDR 仍面临的三大挑战:
- Ch1(算力成本):大规模 MLLM 推理算力开销巨大,直接工业部署不现实[1, 34]。
- Ch2(知识偏移):仅依赖 MLLM 的开放世界知识,可能给出与任务无关或不准确的解读[34]。
- Ch3(兴趣不一致 / 负迁移):CDR 中用户行为模式复杂,跨域兴趣并不总是一致。直接聚合两个域的领域特有信息会导致负迁移(negative transfer)[24, 37]。
针对这三道坎,RGCD-Rep 给出对应设计:
- 应对 Ch1:设计 reasoning-aware distillation(推理感知蒸馏)——用 CoT 提示让大教师 MLLM 生成结构化推理知识,再蒸馏让轻量学生 MLLM 学会逐步推理模式并执行结构化跨域推理。
- 应对 Ch2:设计 behavior-grounded 两阶段训练框架——通过构造行为接地(behavior-grounded)的跨域样本与学习目标,把模型端到端 fine-tune 到真实行为信号上,而非任由 MLLM 自由发挥开放知识。
- 应对 Ch1 + Ch3:在学生 MLLM 之上设计 transferable-residual query-aware aggregation(可迁移-残差查询感知聚合)模块,把 item 表征解耦成可迁移分量与领域残差分量,既支持离线落库低成本部署,又显式隔离会导致负迁移的领域特有信息。
三条核心贡献¶
- 首次把 MLLM 推理引入 CDR,为复杂多模态 item 之间的迁移提供了新视角(to the best of our knowledge, the first study)。
- 提出 RGCD-Rep 框架:通过推理感知蒸馏把大教师 MLLM 的 CoT 推理迁移给轻量学生 MLLM,再通过 behavior-grounded 端到端 fine-tune 学出可迁移表征,资源高效、可工业部署。
- 在工业数据集 + 线上部署上验证有效性,离线指标与线上业务指标均有显著提升。
核心方法 / 模型架构¶
Preliminaries:问题形式化¶
聚焦短视频域(源域)→ 直播域(目标域)的多模态 CDR(方法也适用于一般的跨域知识迁移)。记:
- 用户集 $\mathcal{U} = \{u_1, \dots, u_{N_U}\}$、直播集 $\mathcal{L} = \{l_1, \dots, l_{N_L}\}$、短视频集 $\mathcal{S} = \{s_1, \dots, s_{N_S}\}$;
- 直播域用户交互矩阵 $\mathbf{E}_{UL} \in \{0,1\}^{N_U \times N_L}$,$e_{ul}=1$ 表示用户 $u$ 与直播 $l$ 交互过;
- 短视频域用户交互矩阵 $\mathbf{G} \in \{0,1\}^{N_U \times N_S}$,$g_{us}=1$ 表示用户 $u$ 与短视频 $s$ 交互过;
- 每个 item 含多模态内容:视频帧、OCR/ASR 转录、标题文本、其它元数据。
目标:学习一个通用的跨域可迁移表征,它捕捉短视频域与直播域共享的用户兴趣因子,同时过滤掉可能引发负迁移的领域残差信息。
总览:两阶段框架¶
RGCD-Rep 是一个两阶段跨域表征学习框架(总览见 Figure 1),目标是在资源高效的前提下引入 MLLM 多模态理解与推理,学出可离线部署的跨域可迁移 item 表征。
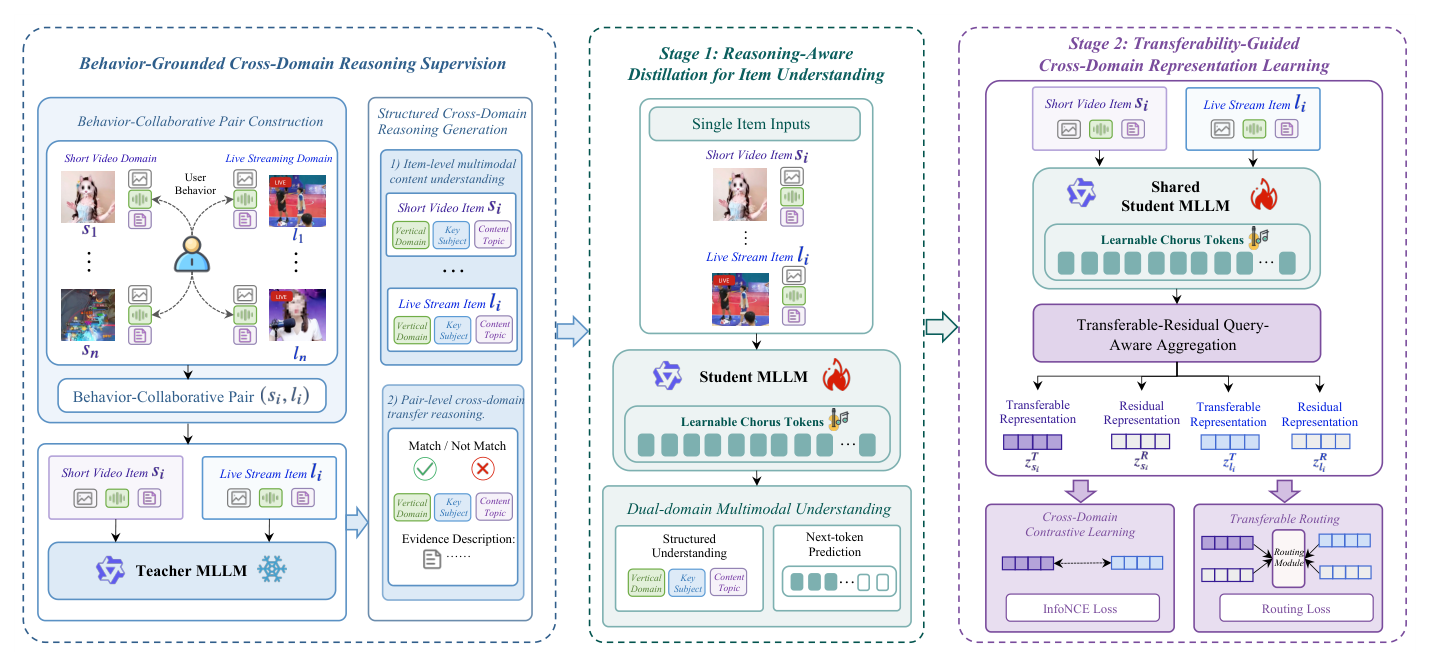
整体两阶段:
- Stage 1 — Reasoning-Aware Distillation for Item Understanding:把 item 级多模态内容理解知识蒸馏进一个轻量学生 MLLM,让它在两个域上都具备多模态理解能力。
- Stage 2 — Transferability-Guided Cross-Domain Representation Learning:学生 MLLM 作为共享编码器,通过 transferable-residual query-aware aggregation 学出跨域可迁移表征与领域残差表征,用跨域对比学习 + 可迁移路由(transferable routing)建模 pair 级迁移关系,缓解负迁移。
下面分别展开。在此之前,先看作为两阶段共同监督来源的 behavior-grounded 推理监督。
4.2 Behavior-Grounded 跨域推理监督¶
4.2.1 行为协同对构造(Behavior-Collaborative Pair Construction)¶
跨域迁移的一个关键挑战是找到真正反映用户兴趣的 item 对。直觉是:如果一个用户在同一时间窗口内对一个短视频和一个直播都表现出强兴趣,那么这两个 item 很可能从用户视角共享潜在的偏好因子。
形式化地,从用户交互日志构造行为协同对数据集:
$$\mathcal{D} = \{(s_i, l_i, b_i)\}_{i=1}^{N_\mathcal{D}}, \tag{1}$$
其中 $s_i$ 是短视频,$l_i$ 是直播,$b_i$ 是对迁移强度(pair transferability strength)。$b_i$ 由两个信号计算:
- 行为共现(behavioral co-occurrence):衡量 $s_i$ 和 $l_i$ 在同一时间窗口内、在同一用户群中共同出现的频率;
- 行为强度(behavioral intensity):衡量用户与两个 item 的交互强度。对短视频,考虑观看时长、完播率、点赞、评论、分享;对直播,考虑观看时长、虚拟打赏、follow、点赞、评论。
最终按 $b_i$ 保留行为对,作为 Stage 1 与 Stage 2 共同的训练数据。
4.2.2 结构化跨域推理生成(Structured Cross-Domain Reasoning Generation)¶
用一个冻结的 35B MLLM 作为教师,为 4.2.1 构造的行为协同对生成结构化跨域迁移推理知识。对每个对 $(s_i, l_i)$,教师 MLLM 以两个 item 的多模态内容为输入,被提示判断"短视频中反映的用户兴趣是否可迁移到直播"。
关键设计:不直接用 free-form CoT 文本作监督,而是把教师的推理结果转换成结构化监督信号。具体生成两类推理知识:
(a) item 级多模态内容理解(item-level multimodal content understanding)。 对短视频 $s_i$ 和直播 $l_i$,教师把内容分解到三个语义维度:
$$\mathcal{K} = \{\text{vertical domain},\ \text{key subject},\ \text{content topic}\}. \tag{2}$$
(即"垂类领域""关键主体""内容主题"。)对每个维度 $k \in \mathcal{K}$,教师输出一个语义标签 + 一段简短的证据描述(evidence description)。
(b) pair 级跨域迁移推理(pair-level cross-domain transfer reasoning)。 对每个语义维度 $k$,教师判断短视频与直播在该维度上是否匹配:
$$m_i^k \in \{0,1\}, \tag{3}$$
$m_i^k = 1$ 表示两个 item 在语义维度 $k$ 上匹配,$0$ 表示不匹配;教师同时为每个匹配判断生成一段简短理由(rationale)。再把三个维度的匹配标签聚合成一个教师推理视角下的语义可迁移分数:
$$r_i = \frac{1}{|\mathcal{K}|} \sum_{k \in \mathcal{K}} m_i^k. \tag{4}$$
该分数衡量对 $(s_i, l_i)$ 从教师推理视角看的语义可迁移强度。注意这是与 4.2.1 中行为强度 $b_i$ 互补的另一路信号(一个来自行为,一个来自语义推理),二者在 Stage 2 的 routing 中被联合使用。
4.3 Stage 1:面向 item 理解的推理感知蒸馏¶
4.3.1 Pair-to-Item 推理分解(Pair-to-Item Reasoning Decomposition)¶
教师 MLLM 是在短视频-直播对上做推理的,但如果直接用成对输入训练学生,会损害学生在工业推荐系统里的可部署性(线上要能独立编码任意单个 item)。因此论文把教师生成的 pair 级推理知识分解(decompose)成 item 级蒸馏数据集 $\mathcal{D}_{\text{item}}$。
对每个对 $(s_i, l_i)$,把 item 级多模态内容理解结果分别拆成两条监督样本——一条给 $s_i$、一条给 $l_i$。每条样本含对应于三个语义维度 $\mathcal{K}$ 的语义标签和证据描述。通过这种分解:
- 学生 MLLM 从双域视角(dual-domain perspective)获得多模态内容理解能力;
- 同时能独立编码任意单个短视频或直播,支持大规模离线 embedding 生成。
4.3.2 带可学习 Chorus Token 的学生 MLLM 骨干¶
RGCD-Rep 采用一个轻量 MLLM + 可学习 chorus token作为学生骨干,遵循 CREM[19] 的设计。核心想法是:插入一组紧凑的可学习 token,在保留模型原生生成能力的同时,把视觉、音频、文本的多模态语义聚合进少量表征 token,降低表征 token 数量。相比直接用单个 pooled token 或 EOS token 作 item 表征,chorus token 为多模态理解与下游 embedding 任务提供了更丰富、更灵活的表征接口。
形式化:对 item $x$(可以是短视频或直播),其多模态输入含视频帧、OCR/ASR 文本、标题及其它元数据。插入 $N_C$ 个可学习 chorus token:
$$C = [c_1, c_2, \cdots, c_{N_C}], \tag{5}$$
$c_i$ 表示第 $i$ 个 chorus token。学生 MLLM 联合编码多模态输入与 chorus token,输出最后一层这些 chorus token 的 hidden state:
$$H_x = [h_x^1, h_x^2, \cdots, h_x^{N_C}] \in \mathbb{R}^{N_C \times d}, \tag{6}$$
$h_x^i$ 是第 $i$ 个 chorus token 对应的 hidden state,$d$ 是 hidden 维度。本文遵循 CREM 默认设置取 $N_C = 16$。
4.3.3 学生 MLLM 蒸馏目标¶
学生是一个可训练的轻量 2B MLLM,从通用多模态骨干初始化。教师生成的 item 级内容理解结果被转成学生的监督样本。对每个 item $x$,输入 prompt $q_x$ 由 item 的多模态内容 + 一条任务指令(要求模型抽取垂类、关键主体、内容主题)构成;目标答案 $y_x = \{y_1, y_2, \cdots, y_{A_x}\}$ 是教师生成的 item 级多模态内容理解结果(即 4.3.1 的分解结果)。每条样本表示为 $(q_x, y_x)$。
学生用标准 next-token 预测目标优化:给定输入 prompt $q_x$、chorus token $C$、以及之前生成的目标 token $y_{<t}$,学生预测下一个 token $y_t$:
$$\mathcal{L}_{\text{NTP}} = -\sum_{x \in \mathcal{D}_{\text{item}}} \sum_{t=1}^{A_x} \log P_\theta(y_t \mid q_x, C, y_{<t}), \tag{7}$$
$\theta$ 是学生参数,$A_x$ 是 item $x$ 目标答案序列长度,$\mathcal{D}_{\text{item}}$ 是 item 级蒸馏数据集。Stage 1 训练后,学生 MLLM 对短视频与直播都具备了结构化多模态理解能力,且不再依赖教师——这是后续大规模离线编码的前提。
4.4 Stage 2:可迁移性引导的跨域表征学习¶
4.4.1 权重共享 MLLM 编码器(Weight-Sharing MLLM Encoder)¶
Stage 2 把 Stage 1 蒸馏好的学生 MLLM 当作短视频域与直播域共享的编码骨干。这样设计有两个好处:其一,把短视频和直播映射到统一语义空间;其二,把 Stage 1 学到的结构化理解能力迁移到 Stage 2 的表征学习。具体:
$$H_s = f_\theta(s_i), \quad H_l = f_\theta(l_i), \tag{8}$$
$f_\theta(\cdot)$ 是权重共享的学生 MLLM 编码器。不依赖单个 pooled 表征,而是取最后一层 chorus token 的 hidden state作为 item 表征。对 item $x$,编码器输出为:
$$H_x = [h_x^1, h_x^2, \cdots, h_x^{N_C}] \in \mathbb{R}^{N_C \times d}, \tag{9}$$
$h_x^c$ 是第 $c$ 个特殊 chorus token 的 hidden state。
4.4.2 可迁移-残差查询感知聚合(Transferable-Residual Query-Aware Aggregation)¶
即使共享编码器把两个域的 item 映射进统一语义空间,chorus-token 表征里仍可能纠缠着可迁移因子与领域特有因子。因此论文进一步从 chorus token 中抽取领域可迁移表征与领域残差表征。
给定 item $x$ 的 chorus-token 表征 $H_x$,用两个独立的可学习查询向量对 token 序列做加权聚合,得到两个语义视图:可迁移视图(transferable view) 与残差视图(residual view)。
可迁移视图:用可学习查询向量 $q^T \in \mathbb{R}^d$ 计算 token 注意力权重,再加权 pooling:
$$\alpha_x^T = \mathrm{softmax}\!\left(\frac{H_x q^T}{\sqrt{d}}\right) \in \mathbb{R}^{N_C}, \tag{10}$$
$$z_x^T = \mathrm{Norm}\!\left(\sum_{c=1}^{N_C} \alpha_{x,c}^T\, h_x^c\right). \tag{11}$$
残差视图:用另一个可学习查询向量 $q^R \in \mathbb{R}^d$:
$$\alpha_x^R = \mathrm{softmax}\!\left(\frac{H_x q^R}{\sqrt{d}}\right) \in \mathbb{R}^{N_C}, \tag{12}$$
$$z_x^R = \mathrm{Norm}\!\left(\sum_{c=1}^{N_C} \alpha_{x,c}^R\, h_x^c\right). \tag{13}$$
模块为每个 item 输出可迁移表征 $z_x^T$ 与残差表征 $z_x^R$。其参数为短视频域与直播域分别实例化(separately instantiated),但在同一域内的 item 间共享。这一解耦是缓解负迁移的关键:可迁移分量承载跨域共享兴趣,残差分量吸收领域特有 / 行为噪声。
4.4.3 跨域对比学习(Cross-Domain Contrastive Learning)¶
跨域对比学习优化可迁移 embedding。给定 mini-batch $\mathcal{B} = \{(s_i, l_i)\}_{i=1}^{B}$,每个 behavior-collaborative 对的可迁移 embedding $(z_{s_i}^T, z_{l_i}^T)$ 视为正样本对;对每个 item,batch 内来自对面域的未匹配 item 作 in-batch 负样本。
短视频域→直播域的对比损失:
$$\mathcal{L}_{s \to l} = -\frac{1}{|\mathcal{B}|} \sum_{i=1}^{|\mathcal{B}|} \log \frac{\exp\!\big(\mathrm{sim}(z_{s_i}^T, z_{l_i}^T)/\tau\big)}{\sum_{j=1}^{|\mathcal{B}|} \exp\!\big(\mathrm{sim}(z_{s_i}^T, z_{l_j}^T)/\tau\big)}. \tag{14}$$
对称地,直播域→短视频域:
$$\mathcal{L}_{l \to s} = -\frac{1}{|\mathcal{B}|} \sum_{i=1}^{|\mathcal{B}|} \log \frac{\exp\!\big(\mathrm{sim}(z_{l_i}^T, z_{s_i}^T)/\tau\big)}{\sum_{j=1}^{|\mathcal{B}|} \exp\!\big(\mathrm{sim}(z_{l_i}^T, z_{s_j}^T)/\tau\big)}. \tag{15}$$
最终跨域对比损失为二者平均:
$$\mathcal{L}_{\text{con}} = \frac{1}{2}\big(\mathcal{L}_{s \to l} + \mathcal{L}_{l \to s}\big). \tag{16}$$
$\mathrm{sim}(\cdot,\cdot)$ 是余弦相似度,$\tau$ 是温度系数。
4.4.4 可迁移路由(Transferable Routing)¶
仅靠行为共现并不能保证真正的跨域可迁移性。 对低可迁移性的对,如果硬把它们的可迁移 embedding 拉到一起,反而会引发负迁移。为此引入 transferable routing 目标:判断一个对应当主要由可迁移空间还是残差空间来解释。
对一个对 $(s_i, l_i)$,在两个空间分别计算匹配分:
$$s_T(s_i, l_i) = (z_{s_i}^T)^\top z_{l_i}^T, \tag{17}$$
$$s_R(s_i, l_i) = (z_{s_i}^R)^\top z_{l_i}^R. \tag{18}$$
"该对应当由可迁移空间解释"的概率:
$$P_T(s_i, l_i) = \sigma\!\big(\gamma\,(s_T(s_i, l_i) - s_R(s_i, l_i))\big), \tag{19}$$
$\sigma(\cdot)$ 是 sigmoid,$\gamma$ 是 routing-logit 缩放系数。
路由标签 $\pi_i$ 同时由行为迁移强度 $b_i$ 与语义可迁移分数 $r_i$ 构造(分别来自 4.2.1 和 4.2.2),先算联合可迁移分数:
$$q_i = b_i + r_i. \tag{20}$$
再按 $q_i$ 对所有训练对排序。记 $\mathcal{T}^+$ 为 top $p\%$、$\mathcal{T}^-$ 为 bottom $p\%$。$\mathcal{T}^+$ 视为高纯度可迁移对,$\mathcal{T}^-$ 视为低纯度对:
$$\pi_i = \begin{cases} 1, & (s_i, l_i) \in \mathcal{T}^+,\\ 0, & (s_i, l_i) \in \mathcal{T}^-. \end{cases} \tag{21}$$
中间的不确定样本被排除在 routing loss 之外。 routing loss 为:
$$\mathcal{L}_{\text{route}} = -\frac{1}{|\mathcal{B}_{\text{route}}|} \sum_{i \in \mathcal{B}_{\text{route}}} \Big[ \pi_i \log P_T(s_i, l_i) + (1-\pi_i) \log\big(1 - P_T(s_i, l_i)\big) \Big], \tag{22}$$
$\mathcal{B}_{\text{route}}$ 是 mini-batch 内参与 routing 训练的高纯度与低纯度对。对高纯度对,routing loss 鼓励 $s_T(s_i,l_i) > s_R(s_i,l_i)$,即该对主要由可迁移 embedding 表示;对低纯度对,鼓励 $s_R(s_i,l_i) > s_T(s_i,l_i)$,允许 embedding 把领域特有因子 / 行为噪声吸收进残差空间。这正是显式缓解负迁移(Ch3)的机制。
4.4.5 总训练目标¶
Stage 2 总目标 = 跨域对比损失 + 可迁移路由损失:
$$\mathcal{L}_{\text{stage2}} = \mathcal{L}_{\text{con}} + \lambda_{\text{route}}\,\mathcal{L}_{\text{route}}, \tag{23}$$
$\lambda_{\text{route}}$ 控制 routing loss 权重。训练后,可迁移表征 $z^T$ 作为最终的跨域可迁移 item 表征,传入下游推荐召回任务。
实验¶
实验在快手直播服务(快手 + 快手极速版)上展开,回答五个研究问题:
- RQ1:RGCD-Rep 在离线召回任务上相比已有方法表现如何?
- RQ2:各关键模块各自贡献多少?
- RQ3:RGCD-Rep 能否改善长尾推荐?
- RQ4:RGCD-Rep 能否惠及行为稀疏用户?
- RQ5:线上 A/B 表现如何?
5.1 实验设置¶
数据集¶
在 Kuaishou 数据集(基于 2026 年快手直播平台连续一周的真实用户行为日志)上做离线实验,随机采样 109,523 个同时访问短视频与直播服务的用户,记录其在两个域的历史正向交互。训练集用前六天数据,测试集用第七天:每个用户在第七天的最后一次正向直播交互作为预测目标。每个 item 含多模态信息(视频帧、OCR/ASR 转录、标题文本、其它元数据)。
Table 1: Kuaishou 数据集统计
| Domain | Users | Items | Interactions | Avg. Len |
|---|---|---|---|---|
| Live streaming | 109,523 | 98,190 | 2,275,888 | 20.78 |
| Short video | 109,523 | 3,787,061 | 24,635,008 | 224.93 |
数据直观印证了动机:短视频域交互量(24.6M)是直播域(2.3M)的约 10.8 倍,人均序列长度 224.93 vs 20.78(约 10.8 倍),直播域确实极度稀疏。
Baseline(三组)¶
- 单域多模态推荐:FREEDOM[36]、SMORE[23]、AlphaRec[27]——只在单域内建模偏好或 item 表征。
- 跨域单模态推荐:UniSRec[11]、VQ-Rec[10]——利用跨域信息缓解目标域稀疏与冷启动,但跨域桥接只用单模态表征。
- 跨域多模态推荐:MISSRec[28]、PMMRec[17]、UniEmbedding[6]——从文本 / 视觉内容学跨域表征,但直接用预抽取的、静态浅层的模态特定特征,缺乏对多模态内容的深层语义推理。
实现细节¶
- 框架:PyTorch,8× NVIDIA H800(140GB) GPU。
- 教师模型:Qwen3.6-35B-A3B[26];学生模型:Qwen2-VL-2B-Instruct[29]。
- fine-tune 样本:Stage 1 60,000 条,Stage 2 250,000 条。
- Stage 1:LoRA rank = 32,Adam 优化器,batch size = 8,lr = $1\times 10^{-4}$。
- Stage 2:batch size = 64,lr = $1\times 10^{-4}$。
- 损失超参:温度 $\tau = 0.05$,routing loss 权重 $\lambda_{\text{route}} = 0.05$,routing-logit 缩放 $\gamma = 10$,routing 标签构造比例 $p = 20$。
- 最终可迁移 embedding 维度 1536。
- chorus token 数 $N_C = 16$。
- 所有 baseline 都仔细调过超参取最佳表现。
评估指标¶
遵循 [6, 33],在召回任务上用 HR@K 与 NDCG@K,$K = 10$。
5.2 RQ1:离线召回性能¶
Table 2 对比 RGCD-Rep 与所有 baseline 及消融变体。对 RGCD-Rep,把用户交互过的短视频的可迁移表征做 mean-pool 作为用户兴趣表征,再对候选直播的可迁移表征做最大内积检索(MIPS)。
Table 2: 离线召回性能 + 消融研究(加粗为最优,下划线为最强 baseline)
| Metric | FREEDOM | SMORE | AlphaRec | UniSRec | VQ-Rec | MISSRec | PMMRec | UniEmbedding | RGCD-Rep | w/o Stage 1 | w/o Stage 2 | w/o Stage 2 MLLM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HR@10 | 0.0040 | 0.0089 | 0.0117 | 0.0134 | 0.0087 | 0.0147 | 0.0089 | 0.0216 | 0.0254 | 0.0249 | 0.0101 | 0.0189 |
| NDCG@10 | 0.0018 | 0.0032 | 0.0050 | 0.0059 | 0.0041 | 0.0066 | 0.0040 | 0.0097 | 0.0127 | 0.0122 | 0.0046 | 0.0088 |
三点观察:
- 单域多模态方法表现相对最弱(FREEDOM/SMORE/AlphaRec):虽然利用了多模态 item 内容,但主要面向单域推荐,缺乏对兴趣迁移的显式建模,难以缓解直播稀疏。
- 跨域方法整体更强:MISSRec、PMMRec、UniEmbedding 同时利用多模态内容与跨域行为协同信号,学到更有效的匹配表征。其中 UniEmbedding 是最强 baseline,说明"多模态内容 + 跨域行为信号"组合能更好捕捉短视频与直播间的共享兴趣。
- RGCD-Rep 在所有指标上最优,相对最强 baseline 分别提升 HR@10 +17.59%((0.0254−0.0216)/0.0216)、NDCG@10 +30.93%((0.0127−0.0097)/0.0097),证明它学到的跨域可迁移表征更适配直播召回。
注:绝对数值偏低(HR@10 ~0.025)是直播冷启动召回任务的典型量级(候选池近 10 万直播、目标极稀疏),应看相对提升。
5.3 RQ2:消融研究¶
基于 Table 2 右四列:
- w/o Stage 1(移除 Stage 1 训练目标):HR@10 0.0254→0.0249,轻微下降。说明推理感知蒸馏提供了有益的语义初始化。
- w/o Stage 2(移除 Stage 2 训练目标):HR@10 0.0254→0.0101,大幅下降。说明仅靠 Stage 1 蒸馏得到的 item 级多模态内容理解不足以支撑短视频→直播的推荐;Stage 2 的 pair-wise 跨域表征学习显式对齐了基于行为协同的跨域兴趣关系,是性能的关键来源。
- w/o Stage 2 MLLM(Stage 2 冻结 MLLM 骨干、只训 transferable-residual query-aware aggregation 模块):HR@10 0.0254→0.0189,明显低于全模型。说明固定的多模态表征对 CDR 而言过于静态,无法充分建模短视频与直播间的深层语义关联与迁移关系——MLLM 骨干必须参与 Stage 2 的端到端微调。
三个消融合起来讲了一个连贯的故事:Stage 1 提供语义底座(贡献小但正向),Stage 2 的行为接地表征学习是主引擎,且 Stage 2 必须解冻 MLLM 才能让表征"活"起来。
5.4 RQ3:长尾 item 表现¶
按训练集出现频率给 item 排序,top 50% 标为 head,其余为 tail。tail item 的交互仅占全部交互的 10.90%,直播确实存在明显的交互稀疏问题。Figure 2 给出不同方法在 head / tail item 上的表现。
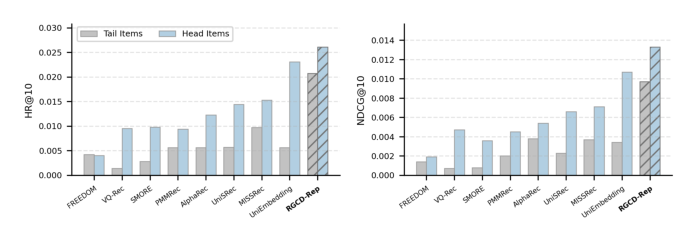
所有方法在 tail 上都比 head 差,说明长尾推荐更难。RGCD-Rep 在 head 与 tail 上均取得最佳,且在 tail item 上优势更突出——表明它在稀疏长尾场景下能维持更可靠的推荐表现,得益于同时建模协同信息与多模态信息。
5.5 RQ4:不同用户群表现¶
为进一步评估对目标域行为稀疏的缓解能力,把测试用户按历史直播反馈分为冷启动用户与活跃用户:若用户在预测日前六天没有任何正向直播反馈、仅在预测日产生正向反馈,则视为冷启动用户;否则视为活跃用户。冷启动用户占测试用户的 14.65%。Figure 3 给出两类用户群上的结果。
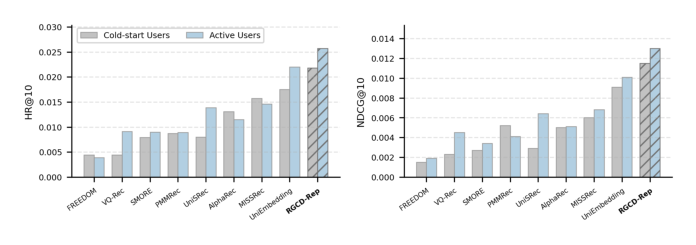
RGCD-Rep 对冷启动用户与活跃用户都超过所有 baseline,说明它不仅对活跃用户、也对直播行为稀疏的用户改善了推荐。更重要的是,对冷启动用户的提升幅度比活跃用户更大——这表明 RGCD-Rep 的收益并非仅来自对既有直播行为的建模,而是真正把短视频域的用户兴趣迁移过来,在直播行为稀疏时补足了用户偏好信号,从而缓解了用户侧冷启动。
5.6 RQ5:线上 A/B 测试¶
把 RGCD-Rep 部署到快手与快手极速版的直播推荐召回阶段,服务数亿用户,做了为期一周的线上 A/B。部署方式:
- 从近期生产日志重建训练数据,选约 100 万行为对训练学生 MLLM;
- 训练后,学生 MLLM 离线为所有短视频与直播生成可迁移表征,存入 item 特征系统;
- 线上检索时,基于这些离线 embedding 建跨域最近邻索引,根据用户的短视频兴趣检索可迁移的直播候选,作为一条新的召回通道。
Table 3: 快手 / 快手极速版直播服务线上 A/B 收益
| Application | Exposure | Click | Effective Room-entry | Follow |
|---|---|---|---|---|
| Kuaishou | +0.37% | +0.34% | +0.28% | +0.83% |
| Kuaishou Lite | +0.38% | +0.13% | +0.22% | +0.93% |
两个应用上 RGCD-Rep 都带来显著收益。Follow 提升最明显(+0.83% / +0.93%),Exposure、Click、Effective Room-entry 等核心指标也稳步上升。这说明引入基于 MLLM 的跨域推理表征学习,能准确捕捉"从短视频兴趣到直播主播"的迁移关系,尤其改善了用户对新主播的关注,并促进直播内容更高效的分发。论文将此归因于:RGCD-Rep 在直播行为稀疏时,用短视频兴趣有效补足了用户偏好信号,缓解了直播域的用户侧冷启动。
核心贡献总结¶
- 方法论上:首次把 MLLM 的显式语义推理引入跨域推荐,把"两个域 item 为何可迁移"从静态浅层特征升级为可学习的结构化推理信号。
- 工程上:用"大教师 MLLM 推理 → 蒸馏 → 轻量学生 MLLM → 离线落库表征"的链路,把 MLLM 的语义能力以可工业部署、低成本的形式落地(表征离线算好直接接入召回)。
- 缓解负迁移:transferable-residual 解耦 + 行为/语义双信号驱动的 transferable routing,显式把领域特有因子隔离进残差空间,正面回应 CDR 的负迁移难题。
- 落地验证:已全量部署于快手/快手极速版,服务 4 亿+ 日活,离线 + 线上指标双双显著提升。
与已归档相关工作的对比¶
FLUID FLUID: From Ephemeral IDs to Multimodal Semantic Codes (TikTok / ByteDance, 2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇是文档库中问题最同构的一对——都直面短视频与直播两个域的跨域表征 + 直播侧严重冷启动。FLUID 用"直播间中位生命周期仅 ~40 分钟、item ID 始终欠训练"量化冷启动根因,RGCD-Rep 则强调"直播行为稀疏、高价值行为(follow/打赏)尤其稀少"。两者都主张:不能靠目标域(直播)自身的协同信号,必须借助行为更稠密的短视频域 + 多模态内容来桥接。
- 相近的技术骨架:两者都用一个联合在短视频与直播上训练的跨域 VLM/MLLM 编码器产出 item 内容表征,供工业推荐使用,从而绕开直播侧 ID 的冷启动。FLUID 用 SigLIP2 ViT + Qwen3-Embedding-0.6B,RGCD-Rep 用 Qwen2-VL-2B 学生。
- 本文的差异与推进:(1) 目标链路不同——FLUID 服务排序(ranking),把内容表征离散成 LUCID 语义码、late-fusion 进 token-based 排序器并彻底退役 item ID;RGCD-Rep 服务召回(retrieval),产出连续的可迁移表征建跨域最近邻索引,作为新增召回通道(并不替换 ID)。(2) 是否引入推理——FLUID 用 Q2I 对比 + RQ-KMeans 量化,不含语义推理;RGCD-Rep 的核心新意正是用大教师 MLLM 生成结构化 CoT 推理("两 item 为何可迁移")再蒸馏,这是 FLUID 没有的维度。(3) 负迁移处理——RGCD-Rep 显式做 transferable/residual 解耦 + routing;FLUID 通过 room-level vs slice-level LUCID 区分持久 / 瞬态语义,关注点不同。
- 可比的方法 / 实验差异:FLUID 报告 +0.55% Quality Watch Duration、+2.05% Cold-Start Room Views(十亿级);RGCD-Rep 报告 Follow +0.83%/+0.93%、Click +0.34%/+0.13% 等(快手/极速版召回)。两者指标体系不同(ranking watch-time vs retrieval follow/click),不可直接比数值,但都验证了"短视频→直播跨域多模态表征"在生产环境的有效性。
Zero-shot CDKD Zero-shot Cross-Domain Knowledge Distillation (Google, 2026-03-30)¶
关系:独立并发(本文未引用 CDKD)· 已加载对方精读
- 共同关注的问题:两者都解决"目标域数据稀疏/低流量,借数据丰富的源域 + 蒸馏来补足"这一 root cause。CDKD 的目标域是 YouTube Music(数据量仅视频域 1/100),RGCD-Rep 的目标域是直播(交互量约为短视频 1/10、人均序列 1/10),都属于"为小/稀疏目标域单独养大模型不划算,转而从富源域迁移"。
- 相近的技术骨架:骨架都是"大模型当教师 → 蒸馏 → 轻量学生服务",以降低线上成本(对应 RGCD-Rep 的 Ch1)。CDKD 在学生上挂一个辅助蒸馏塔预测教师 soft label;RGCD-Rep 用 next-token 目标蒸馏教师生成的结构化内容理解。两者都强调学生最终独立服务、不再依赖教师。
- 本文的差异与推进:(1) 蒸馏的对象不同——CDKD 蒸馏的是预测 logits(soft label / 暗知识),教师是一个大规模多任务排序模型,迁移的是预测能力;RGCD-Rep 蒸馏的是 MLLM 的语义推理与多模态内容理解,教师是 35B MLLM,迁移的是"内容怎么理解、跨域为何可迁移"的语义知识。(2) 跨域桥接的依据不同——CDKD 是零样本(教师不在目标域微调、不假设共享用户);RGCD-Rep 依赖同平台重叠用户构造 behavior-collaborative 对作为接地信号,并把"行为强度 $b_i$ + 语义可迁移分数 $r_i$"合成路由标签。(3) 产物不同——CDKD 直接增强一个排序模型;RGCD-Rep 学的是可离线落库、可被多个下游召回复用的通用跨域表征。CDKD 证明"即使教师在目标域精度更低,蒸馏仍能让学生超过 control"(暗知识有效),与 RGCD-Rep "Stage 1 蒸馏带来语义初始化、轻微但正向"的消融结论相互呼应。
备注:另有两篇近似候选被剔除——Rec-Distill(ByteDance, 2605.29755) 虽同样是"大教师→轻量服务学生"蒸馏且涉及直播,但其 root cause 是 scaling-law 收益的成本摊销(teacher 绝对性能↑),并非跨域兴趣迁移,且无 MLLM/推理/跨域 item 表征,问题非同构,剔除;MLLMRec-R1(2603.06243) 虽同用 MLLM CoT 推理于多模态推荐,但是单域序列推荐 + GRPO 强化学习,无跨域迁移、无蒸馏,解法骨架偏离,剔除。
讨论与局限性¶
核心贡献与可借鉴设计。 RGCD-Rep 最值得借鉴的是它把"大模型语义能力工业化"的链路做得很干净:大教师 MLLM 只在离线生成结构化(而非 free-form)推理监督,经蒸馏沉淀进 2B 学生,学生再离线为全量 item 算好表征落库——线上零 MLLM 推理。这套"推理离线化 + 表征落库"模式对任何想用 MLLM 但被算力卡住的工业召回都有参考价值。第二个亮点是 transferable-residual 解耦 + 双信号路由:用行为信号 $b_i$ 和教师语义信号 $r_i$ 的和来判定一个跨域对该不该"拉近",并把不确定样本(中间 $p\%$)直接排除出 routing loss,是对负迁移相当务实的工程化处理。
局限与争议。 (1) 绝对指标低、线上增益温和:HR@10 仅 ~0.025,线上核心指标多在 +0.2%~+0.4% 量级(Follow 最高 ~+0.9%),收益真实但不算激进,反映直播冷启动召回本身上限有限。(2) 缺与 FLUID 类"语义码 + ID 退役"路线的直接对比:RGCD-Rep 的 baseline 集中在 UniEmbedding/MISSRec 等表征类方法,未与同期 ID-free / 量化码路线对比,难判断"连续可迁移表征 + routing" vs "离散语义码"孰优。(3) 数据集私有、不可复现:实验只在快手私有数据上做,无公开学术数据集结果,外部难以复现或横向比较。(4) 教师质量依赖:整套方法的语义信号 $r_i$ 与蒸馏知识都来自 35B 教师 MLLM,Ch2(开放知识偏移)虽靠 behavior-grounded 微调缓解,但教师对垂类/主体/主题三维判断的系统性偏差如何影响最终路由,论文未做敏感性分析。
工业落地价值。 已全量部署于快手 + 快手极速版直播召回,服务 4 亿+ 日活。部署成本可控的关键在于:学生 MLLM 离线为全量短视频/直播生成可迁移表征并入库,线上只需在这些表征上建跨域最近邻索引、作为一条新增召回通道运行,不引入任何线上大模型推理开销。业务上以 Follow(对新主播关注)提升最为突出,印证了"用短视频兴趣为直播侧用户冷启动补足偏好信号"的核心主张。