FLUID:用多模态语义码彻底退役直播推荐中的"短命 item ID"¶
FLUID = Framework for Live Universal ID-free Recommendation。来自 TikTok / ByteDance,部署在合计超过十亿用户的工业直播推荐系统上。这是首个在生产级直播排序中彻底弃用候选侧 item ID 的框架。
研究动机与背景¶
直播场景的根本困境:item ID 是"易逝品"(ephemeral)¶
现代推荐系统普遍依赖 ID-based 协同过滤:每个 item 用一个唯一的 ID embedding 表示,该 embedding 在用户交互中不断累积协同信号。这套范式在长生命周期的物品(视频以天/月计、电商以月/年计)上行之有效,因为 ID embedding 有足够长的时间窗口去累积交互、收敛到有意义的表征。
但直播场景打破了这个前提。论文给出的关键事实是:在其领先的直播平台上,一个直播间的中位生命周期只有约 40 分钟(median ~40 min)。这意味着:
- item ID 持续处于冷启动状态:直播间还没来得及让自己的 ID embedding 训练充分,就已经下播。
- ID-centric 排序模型无法泛化:大型推荐模型(LRM)把绝大部分容量放在 ID embedding 表里,这些表只记住了短命的曝光信号,在直播场景下无法泛化。
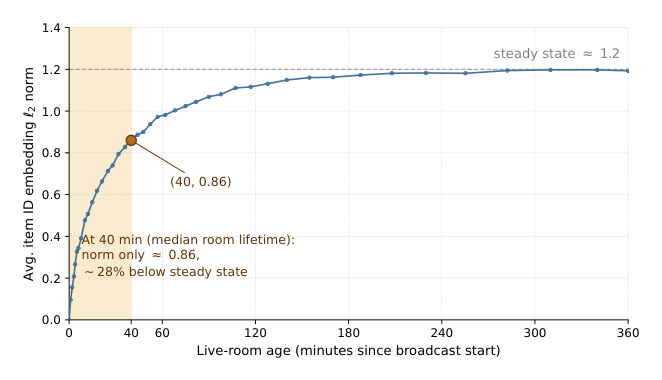
论文用 Figure 1 直接量化了这个现象:统计一整天生产流量,把直播间按"开播时长(live-room age)"分桶,绘制 item ID embedding 的 $\ell_2$ 范数随直播间年龄的变化曲线。结果显示范数收敛到稳态约 1.2,但在中位 40 分钟的直播间生命周期内 ID 范数还远未收敛——在 40 分钟时范数仅 0.86,比稳态低约 28%。也就是说,大多数直播间在其整个生命周期里都带着"欠训练"的 ID embedding。
两个尚未解决的技术挑战¶
一个自然的解法是用内容衍生信号(content-derived signals)减少排序器对 ID 记忆的依赖。但论文指出在直播场景这条路有两个非平凡的挑战:
挑战一:为直播生成高质量语义表征非平凡。 直播内容天然是多模态且快速变化的——视觉、语音、屏上文字、主播元数据、观众信号都在分钟级演变。内容表征既要捕捉瞬态动态(transient dynamics),又要捕捉持久的直播间特征(persistent room characteristics)。此外,与视频/电商不同(那里内容有明确主题、用户反馈密集),直播更难用有限的监督信号去清晰刻画,给编码器训练带来困难。
挑战二:把语义表征注入 ID-centric 排序器很困难。 即使在 ID-based 排序器上加了多模态特征,排序器往往会走 ID embedding 的"捷径"(shortcut),欠利用多模态输入,需要显式对齐、优化再平衡或对比正则来强化多模态贡献。ID-dominant 效应(ID 主导效应)在直播场景尤其严重,因为 item ID 是易逝的、携带的协同信息远少于其他内容场景,但排序器仍倾向于依赖它。
FLUID 的核心主张¶
针对这两个挑战,论文提出 FLUID——首个完全替换 item ID 为内容衍生语义码的框架。其核心论点(在贡献部分明确为 Problem framing):当 item ID 是易逝的,ID-dominance 效应从"可容忍的麻烦"变成了"根本性瓶颈",因此为了优化排序性能应当彻底退役 item ID,而不是像以往工作那样让多模态信号在 ID 旁边作为补充共存。
论文的三条贡献:
- Problem framing(问题框架):论证易逝 item ID 下 ID-dominance 从可容忍麻烦升级为根本瓶颈,从而 motivate 完全退役 item ID。
- Cross-domain semantic representations(跨域语义表征):一个联合在短视频和直播上训练的多模态编码器,产出离散分层语义码,通过 prefix-n-gram 方案转成 embedding。
- Late-fusion ID-free ranker(后融合无 ID 排序器):得益于分阶段 warmup 方案,部署了首个生产级 ID-free 直播排序器——该方案先加入 LUCID,再替换掉 item ID。
线上收益(十亿级用户基数,跨平台合计):+0.55% Quality Watch Duration、+2.05% Cold-Start Room Views、+2.87% Niche Room Views、+1.63% Unique Watched Tags、+0.05% Active Hours。
核心方法 / 模型架构¶
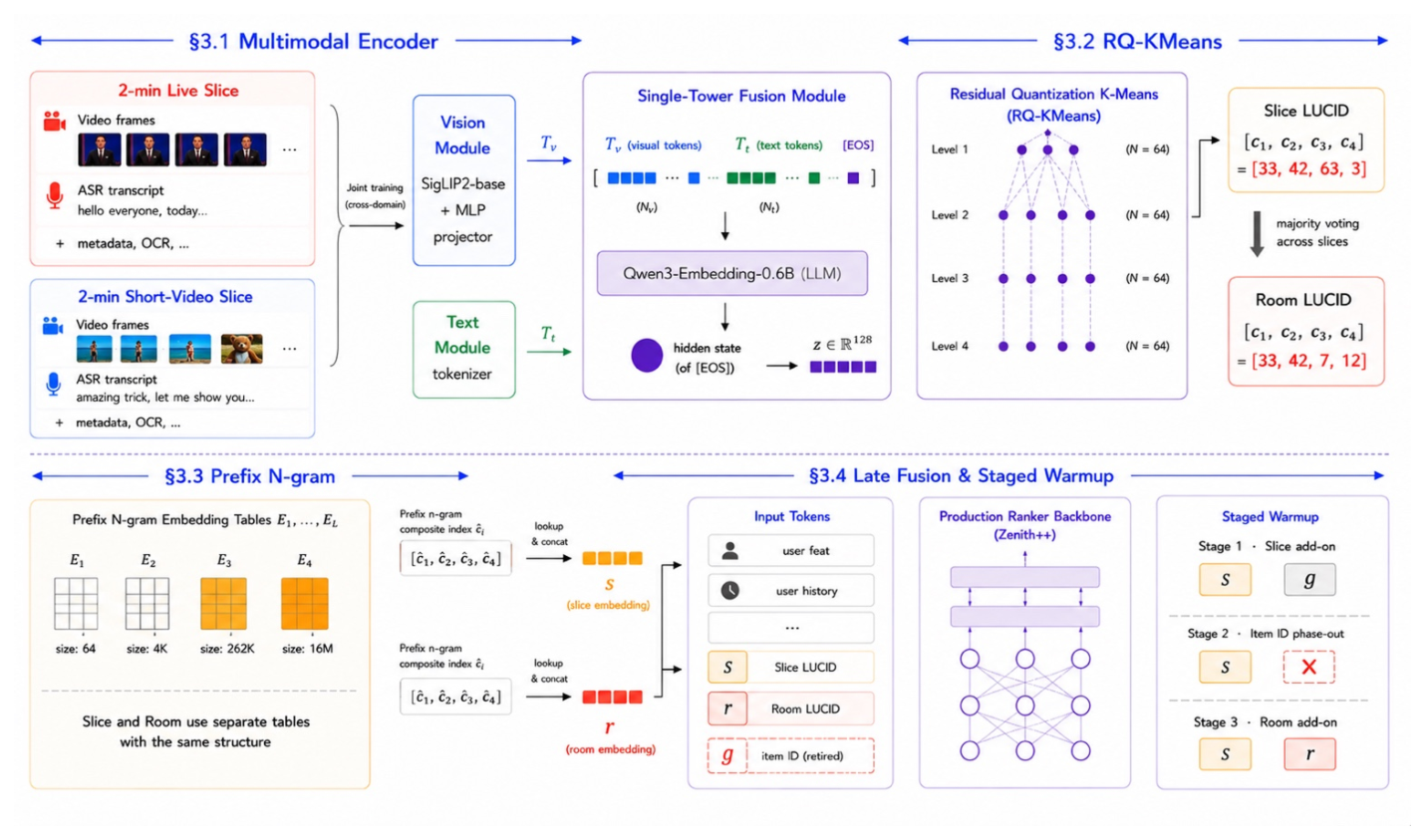
FLUID 的流水线用内容衍生的多模态码替换候选侧 item ID,分为四个阶段(见 Figure 2):
- 跨域多模态编码器(§3.1):为每个直播切片产出内容 embedding。
- RQ-KMeans(§3.2):把 embedding 离散化为分层码,即 LUCID(Live Universal Content IDentifier)。
- Prefix n-gram 方案(§3.3):把每个 LUCID 元组映射成可学习 embedding。
- 后融合 ID-free 排序器(§3.4):把 LUCID 作为独立的候选侧 token 引入,通过分阶段 warmup 退役 item ID。
3.1 多模态编码器¶
直播间太短命,排序器学不到有用的 per-item ID embedding,所以 FLUID 的第一阶段就是用一个多模态编码器产出内容衍生信号来取代 item ID。
3.1.1 跨域训练数据(Cross-domain Training Data)。 训练编码器需要"查询-内容切片"对,标签来自用户互动(点赞、分享、观看完成度)。但很多直播间在累积到足够互动前就下播了。FLUID 因此联合在直播和短视频上训练单个编码器,共享一个 embedding 空间——短视频域更密集的互动信号能提升泛化能力。这是论文反复强调的 cross-domain 设计:短视频域提供密集监督,迁移到极端冷启动的直播域。
3.1.2 架构(Architecture)。 多模态编码器(Figure 2 顶部)由三个组件构成:
- Vision Module:基于 SigLIP2-base(原生分辨率 ViT),后接两层 MLP projector,产出视觉 token $T_v \in \mathbb{R}^{N_v \times D_h}$。
- Text Module:tokenize 丰富的元数据——标题、OCR、ASR 转录、作者简介、观众评论、贴纸标签——成文本 token $T_t \in \mathbb{R}^{N_t \times D_h}$。
- Single-Tower Fusion Module:基于 Qwen3-Embedding-0.6B(一个 LLM),处理拼接序列 $T = [T_v, T_t, \texttt{[EOS]}]$,最终把
[EOS]hidden state 线性投影到一个 128 维 embedding $z$。
FLUID 采用 single-tower 架构(视觉与文本在 LLM 全深度交互),而非 dual-tower(只在输出层相遇)。论文称这个 single-tower 优势在检索和分类基准上都稳定成立(§4.3.1)。
3.1.3 训练配方(Training Recipe)。 编码器用 query-to-item (Q2I) 对比任务训练,损失为 InfoNCE,并带 false-negative masking(假负样本掩码)。query 是用户搜索词或 MLLM 合成的关键词;item 是从直播和短视频抽取的 2 分钟内容切片,正样本对由用户行为信号(点赞、分享、观看完成)构造。为保留 LLM 的预训练语义,训练分两步:
- Alignment(对齐):只训练 MLP projector 和输出投影。
- Joint fine-tuning(联合微调):整个模型解冻,以更低学习率端到端微调。
每个 batch 内,丢弃那些 query embedding 与正样本对相似度超过预定阈值的负样本对,以减少伪负样本。
3.2 通过 RQ-KMeans 做离散表征¶
直接把对应 2 分钟内容切片的多模态 embedding $z$ 当排序器输入是次优的:(1) 通用视觉-语言目标产出的 embedding 与用户-物品交互信号 misaligned;(2) 一个共享的、作用在 frozen 多模态 embedding 上的 MLP,其表达力不及排序器的 embedding 查找表。因此 FLUID 通过 Residual Quantization K-Means (RQ-KMeans) 把 $z$ 离散化成一个 $L$ 级码字元组,称为 LUCID,它可以像其它稀疏 ID 特征一样进入排序器的 embedding 表并与之共同训练。
为什么用 RQ-KMeans 而非 RQ-VAE? 论文明确指出:RQ-VAE 在其在线流式重训练节奏(online streaming retraining cadence)下会码本坍塌(codebook collapse),而 K-means 一旦拟合好就给出稳定划分。设置 $L=4$、$N=64$(4 级,每级 64 个簇)。最终 LUCID 是一个元组 $[c_1, \ldots, c_4]$,例如 $[33, 42, 63, 3]$。
Slice-level vs Room-level LUCID。 这是 FLUID 的关键设计——区分瞬态与持久两种语义:
- Slice-level LUCID 编码 2 分钟内容动态——比如主播从聊天切换到唱歌这种短期变化。
- Room-level LUCID 捕捉直播间的持久身份:主播风格、受众、话题焦点在整场广播中保持一致,需要一个稳定的 room 级标识符。
获取 room-level 标识符的方法是逐级多数投票(majority voting at each level):在每个量化深度 $l$,取该会话所有累积切片中最频繁的码字。由于残差量化把粗-细语义解耦,per-level 投票能在不混合层级的前提下蒸馏出主导内容。Figure 2 右侧展示了:slice LUCID $= [33, 42, 63, 3]$,经各切片多数投票后 room LUCID $= [33, 42, 7, 12]$(粗层级一致,细层级被投票稳定化)。
3.3 Prefix N-gram LUCID Embedding¶
每个 LUCID 码(无论 slice 级还是 room 级)是一个元组 $[c_1, \ldots, c_L]$,$c_l \in \{0, 1, \ldots, N-1\}$。需要把它映射成排序器骨干消费的可学习 embedding $\mathbf{e}_{\text{LUCID}}$。
为什么不用 level-wise decoding? 早期方法(如 [20, 25])用 level-wise decoding:建 $L$ 个独立的 embedding 查找表 $\mathbf{E}_1, \ldots, \mathbf{E}_L$,$\mathbf{E}_l \in \mathbb{R}^{N \times d}$,令 $\mathbf{e}_{\text{LUCID}}$ 为各级 $\mathbf{E}_l(c_l)$ 的拼接。但在残差量化中,深层级编码的是相对于前缀路径的细化(refinement):同一个 $c_l$ 在不同 $[c_1, \ldots, c_{l-1}]$ 前缀下索引的是完全不同的语义区域。举例:两个切片 $c_1=0$ 和 $c_1=3$ 恰好都有 $c_2=2$,level-wise decoding 会让它们共享 $\mathbf{E}_2(2)$ 这同一个 entry,但残差量化的几何结构表明这两个子区域是不相关的。
Prefix n-gram 方案。 FLUID 采用一种 prefix n-gram embedding 方案(源自 [48]),对每一级的 embedding 以完整前缀路径为条件——类比经典 n-gram 神经语言模型 [1],但把 context 显式做成一个复合 key。定义复合索引:
$$\bar{c}_l = \sum_{k=1}^{l} c_k \cdot N^{l-k}, \quad l = 1, \ldots, L, \tag{1}$$
其中 $\bar{c}_l$ 唯一标识从根到第 $l$ 级的路径。以 $N=4$ 为例,上面两个例子($c_1=0, c_2=2$ 与 $c_1=3, c_2=2$)会得到不同的复合索引:$\bar{c}_2 = 2$ vs $\bar{c}_2 = 14$,即 $\mathbf{E}_2$ 中不同的槽位。每个第 $l$ 级的表从 $N$ 行扩展为 $N^l$ 行,最终:
$$\mathbf{e}_{\text{LUCID}} = \mathbf{E}_1(\bar{c}_1) \,\|\, \mathbf{E}_2(\bar{c}_2) \,\|\, \cdots \,\|\, \mathbf{E}_L(\bar{c}_L). \tag{2}$$
第 $l$ 级的 embedding 现在是其自身父路径的细化,而非跨不相关子树共享的特征。Figure 2 左下角展示了这套 prefix n-gram embedding 表:表 $E_1, E_2, E_3, E_4$ 的尺寸分别约为 64、4K、262K、16M(随级数指数增长,对应 $N^l$),slice 和 room 用结构相同但独立的两套表。
3.4 后融合(Late Fusion)与分阶段 Warmup¶
最后一步把 LUCID embedding 接入生产排序器。FLUID 的排序器骨干是一个 transformer-like backbone(论文标注为引用 [44],即 ByteDance 的 Zenith++ 系统),基于 token 级特征交互——不同组的特征 embedding 用不同 token 表示。
3.4.1 Room 级与 slice 级 LUCID 整合。 slice-level LUCID 描述当前 2 分钟内容段、捕捉短期变化(如主播从聊天切到唱歌);room-level LUCID 由 §3.2 的多数投票得到,提供更稳定的直播间描述符。两者互补:slice token 提供瞬态多模态证据,room token 提供持久候选身份。两者都用 prefix n-gram 方案,但用各自独立的 embedding 表参数化——若共享同一套表,稳定的 room 语义和快变的 slice 语义会被塞进同一参数空间,经验上削弱表达力(共享表的消融见 §4.3.3)。
3.4.2 与现有 item ID 的融合。 设 $\mathbf{g}$ 为候选 item 现有的 item ID embedding,$\mathbf{s}$ 和 $\mathbf{r}$ 分别为 slice 级和 room 级 LUCID 的 prefix-n-gram embedding。内容 embedding 与 ID-based embedding 的融合分两类:早融合(early fusion) 和 后融合(late fusion)。
早融合先把 item ID 和 LUCID embedding 映射成单个候选表征 $\mathbf{h}$,例如:
$$\mathbf{h}_{\text{replace}} = \mathbf{s}, \tag{3}$$
$$\mathbf{h}_{\text{concat}} = \mathbf{W}[\mathbf{g} \,\|\, \mathbf{s}], \quad \mathbf{W} \text{ a learnable projection}, \tag{4}$$
$$\mathbf{h}_{\text{gate}} = \alpha \mathbf{g} + (1 - \alpha)\mathbf{s}, \quad \alpha = \sigma(f(\mathbf{u})), \tag{5}$$
其中 $\mathbf{u}$ 可以是 item ID embedding 本身或诸如曝光计数、item ID embedding 范数之类的边信息。这些公式涵盖了直接替换、拼接、规则门控、可学习 LARM 风格门控。骨干把最终表征当作单个 token:
$$\mathcal{T}_{\text{early}} = \{\mathbf{h}\}. \tag{6}$$
论文指出:早融合虽然直观(把两种 item 侧信息合并成一个 token),但实验中会因 item ID 的强记忆效应而无法从 LUCID 提取有用信息(后续 §4.3.4 验证)。
后融合则让每个信号保持独立 token,让骨干学习它们的交互:
$$\mathcal{T}_{\text{late}} = \{\mathbf{g}, \mathbf{s}\}. \tag{7}$$
这种后融合配置能充分利用排序器骨干的强交互能力,在 item ID 之上学习来自 LUCID 的增量多模态信息。
但是,保留候选侧 item ID 会限制排序器的泛化天花板,尤其在 item ID 短命的直播排序中(§4.3.4 验证)。因此 FLUID 的最终架构彻底退役候选侧 item ID,用 room 级 LUCID 取而代之,同时保留 slice 级 LUCID:
$$\mathcal{T}_{\text{FLUID}} = \{\mathbf{r}, \mathbf{s}\}, \quad \mathbf{g} \notin \mathcal{T}_{\text{FLUID}}. \tag{8}$$
这个设计既缓解了对短命 item ID embedding 的依赖,又用两路独立信号刻画候选:stable room identity(稳定房间身份) + transient slice dynamics(瞬态切片动态)。
3.4.3 生产中的分阶段 warmup(Staged warmup)。 直接从 item-ID 表征切到 $\mathcal{T}_{\text{FLUID}}$ 是不稳定的,因为 LUCID embedding 表是全新引入的、而下游交互层是围绕一个"带 item ID 的候选表征"训练出来的。更深层的原因是 item ID 与 LUCID 之间的优化非对称性(optimization asymmetry):item ID embedding 虽然泛化差,但携带强 item 级记忆信号,会在联合训练早期被骨干优先吸收,从而压制更慢但更具泛化性的 LUCID 信号——这个坍塌在 §4.3.4 直接被测出。因此 FLUID 用一个三阶段 warmup(见 Figure 3),每个阶段只改一个 item 侧组件,其余保持稳定锚点:
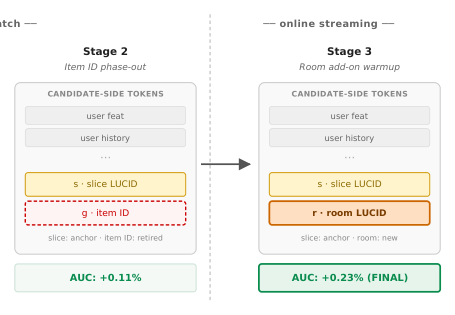
- Slice add-on:从一个收敛好的 item-ID checkpoint 初始化,把 slice LUCID 作为独立 token 加进去(此时 item ID 仍在)。
- Item ID phase-out:逐步把候选侧 item ID 归零(zero out),让模型过渡到只依赖 slice LUCID。
- Room add-on:用 warm 的 slice 级 LUCID embedding 表初始化 room 级 LUCID 表,然后独立训练它去专门刻画持久的房间身份。
三个阶段后,在 item-ID-free 配置上(同时带 slice 级和 room 级 LUCID)继续做生产环境的在线增量训练。
实验设置¶
两个被独立评估的模型。 FLUID 包含两个分别训练的模型:(1) §3.1 的多模态编码器,产出 LUCID 码;(2) §3.4 的排序模型,LUCID 码注入其中。
排序模型。 所有排序实验在工业直播平台的生产排序数据集上进行,合计服务超过十亿全球用户。采用生产系统 Zenith++ pipeline [44] 的完整骨干、数据集和训练配置(数据集统计见 Table 2),在 Zenith++ 骨干之上插入由 RQ-KMeans 产出的 slice 级和 room 级 LUCID($L=4$ 残差级、每级 $N=64$ 簇)。
Table 2:排序模型训练数据集统计(与生产 Zenith++ pipeline 共享)
| # Instances | # Features | # Targets | |
|---|---|---|---|
| Industrial Live Ranking | 168B | 4,552 | 98 |
数据规模相当大:1680 亿条样本、4552 个特征、98 个目标。
多模态编码器。 在 Q2I 对比目标下,跨短视频和直播联合训练(配方见 §3.1)。在一个内部基准套件上评估,覆盖检索(直播 + 视频 keyphrase 检索、电商检索、live I2I 检索)和语义分类(直播分类法分类、视频电商检索),在 linear-probing 和 full fine-tuning 两种设定下评估。
评估指标。 排序实验用 CTR AUC 和 Logloss;多模态编码器检索用 Q2I R@10/50 和 I2Q R@10/50(双向 Recall);在线 A/B 用工业指标(详见下)。
主要实验结果¶
4.2 模型性能:四种排序配置对比¶
Table 3 在 CTR 目标上对比四种排序器配置:
Table 3:四种配置在 CTR 目标上的性能
| Configuration | AUC | Logloss |
|---|---|---|
| baseline (with item ID) | 0.7784 | 0.1264 |
| baseline + Slice LUCID | 0.7801 (+0.22%) | 0.1263 (−0.08%) |
| baseline w/o item ID | 0.7748 (−0.47%) | 0.1273 (+0.65%) |
| baseline w/o item ID + Slice & Room LUCID (FLUID) | 0.7802 (+0.23%) | 0.1262 (−0.19%) |
结论分析: (1) 把 slice LUCID 作为独立 token 加到 item ID 旁,AUC +0.22%,说明多模态语义携带增量信号。(2) 直接移除 item ID 而不补内容码,AUC 锐降 −0.47%,印证排序器对 item ID 记忆的依赖。(3) FLUID(退役 item ID + slice & room LUCID + 分阶段 warmup)在两个指标上都超过 baseline,AUC +0.23%、Logloss −0.19%。(4) FLUID 还比 +Slice LUCID 配置再多 +0.01% AUC、−0.11% Logloss——表明 LUCID 真正实现了作为 item ID 的"继任者"(successor),而非补充(supplement)。这里 +0.23% 的 AUC 提升在 1680 亿样本的工业排序里是显著的(工业 CTR AUC 的提升通常以 0.1% 量级计)。
在线 A/B 测试¶
为验证离线增益,在生产环境对三个 arm(+Slice = baseline + Slice LUCID;−ID = baseline w/o item ID;FLUID = 退役 item ID + Slice & Room LUCID)做 A/B,对比生产 baseline。
Table 4:在线 A/B 结果(相对生产 baseline 的相对变化;"n.s." 表示 $p < 0.05$ 下不显著)
| Metric | +Slice | −ID | FLUID |
|---|---|---|---|
| Engagement quality | |||
| Quality Watch Duration | +0.43% | −0.02% | +0.55% |
| Quality Watch Session | +0.39% | −0.10% | +0.51% |
| Cold-start, niche content, and diversity | |||
| Cold-Start Room Views | +1.15% | +1.58% | +2.05% |
| Niche Room Views | +0.69% | +2.23% | +2.87% |
| Unique Watched Tags | +0.55% | +0.20% | +1.63% |
| Retention | |||
| Stay Duration | n.s. | −0.05% | +0.07% |
| Active Hours | n.s. | n.s. | +0.05% |
结论分析(这是全文最关键的一张表,揭示了三个 arm 的本质差异):
- +Slice LUCID 提升了 engagement 和 diversity,但 retention 不变(n.s.),说明 LUCID 在此扮演次要的语义信号(secondary signal)而非内容标识符——它只是 item ID 的补充。
- −ID(移除 item ID 但不补内容码) 提升了冷启动和长尾曝光(Cold-Start +1.58%、Niche +2.23%,因为释放了被 item ID 压制的长尾流量),但代价是 Stay Duration −0.05%——更广的曝光以牺牲推荐效率为代价,说明 item ID 和"广曝光"是此消彼长、无法共存的。
- 只有 FLUID 在三个维度上同时取得一致增益:engagement(Quality Watch Duration +0.55%)、diversity(Cold-Start Room Views +2.05%)、retention(Stay Duration +0.07%)。这证明了 room 级 LUCID 真正替换了候选侧的 item ID,而不仅仅是补充它——它既释放了长尾曝光,又没有牺牲推荐效率。
消融与分析¶
4.3.1 多模态模型消融(Table 6)¶
消融编码器的三个设计选择:backbone、fusion paradigm、training schedule。指标为双向 keyphrase 检索的 Q2I/I2Q R@10/R@50。
Table 6:多模态编码器在 backbone、fusion paradigm、training schedule 上的消融
| Method | Live Q2I R@10/50 | Live I2Q R@10/50 | Video Q2I R@10/50 | Video I2Q R@10/50 |
|---|---|---|---|---|
| Backbone | ||||
| Baseline (CLIP-B/32 + Albert-V2) | 43.96/59.95 | 45.57/60.87 | 73.40/84.36 | 72.86/83.46 |
| + Qwen3-Embedding | 46.15/60.43 | 47.18/61.32 | 84.74/91.97 | 85.30/91.40 |
| + SigLip2 ViT | 47.44/61.62 | 48.67/62.71 | 87.10/93.35 | 87.20/93.39 |
| Fusion paradigm | ||||
| Dual tower (shallow fusion) | 45.37/59.90 | 47.00/61.42 | 83.68/90.91 | 84.59/91.52 |
| Single tower (ours) | 47.44/61.62 | 48.67/62.71 | 87.10/93.35 | 87.20/93.39 |
| Training schedule | ||||
| Single stage | 45.01/59.83 | 45.78/60.53 | 84.13/91.47 | 84.10/91.43 |
| Two stage (ours) | 47.44/61.62 | 48.67/62.71 | 87.10/93.35 | 87.20/93.39 |
结论分析: (1) backbone 换代贡献最大的提升——从 CLIP+Albert 换到 Qwen3-Embedding,Video Q2I R@10 从 43.96→84.74 大幅跳升(换 LLM 文本骨干带来质变),再加 SigLip2 ViT 在每一列都进一步提升。(2) single-tower 融合优于 dual-tower 的 shallow fusion(视觉文本只在输出层相遇),印证了 §3.1.2 的 single-tower 设计。(3) two-stage 训练(先 alignment 再 joint fine-tuning)优于 single-stage 端到端,印证 §3.1.3 的训练配方。
4.3.2 跨域编码器案例分析(Figure 4)¶
用两个代表性 LUCID 簇做 case review:$(39, 41)$ 对应 "swimming"、$(17, 26)$ 对应 "dancing"。展示了直播切片和短视频在同一 LUCID 码下保持语义一致,尽管两个域的内容风格不同。这定性验证了跨域编码器的有效性:同一 LUCID 码聚到一起的 item 在语义上确实连贯。
4.3.3 LUCID Embedding 设计(Table 5)¶
消融两个设计选择:(i) embedding 方案——prefix n-gram(§3.3)vs level-wise decoding;(ii) slice 与 room LUCID 码是否共享一套 embedding 表。
Table 5:LUCID embedding 设计消融
| Variant | AUC |
|---|---|
| Baseline (item ID only) | 0.7784 |
| Embedding scheme | |
| Level-wise decoding | 0.7793 (+0.12%) |
| Prefix n-gram (ours) | 0.7802 (+0.23%) |
| Embedding tables | |
| Shared table | 0.7798 (+0.18%) |
| Independent tables (ours) | 0.7802 (+0.23%) |
结论分析: prefix n-gram 比 level-wise decoding 多 +0.11% AUC(因为它把每一级 embedding 以完整前缀路径为条件,避免跨不相关子树共享 entry,印证了 §3.3 的核心动机);独立的 slice/room 表比共享表多 +0.05% AUC(避免稳定 room 语义与快变 slice 语义挤进同一参数空间)。prefix n-gram 提供了更大的增益。
4.3.4 候选侧 LUCID 整合:融合机制与训练配方(Table 7)¶
这是揭示 FLUID 设计动机最深的消融,跨两个维度:(i) 融合机制(slice LUCID 与 item ID 早融合还是后融合);(ii) 训练配方(如何训练 slice LUCID、如何逐步退役 item ID、最后如何加 room LUCID)。
Table 7:候选侧 LUCID 与现有 item ID 整合的消融(ΔAUC 相对 baseline item-ID-only,AUC = 0.7784)
| Category | Method | AUC | ΔAUC |
|---|---|---|---|
| Fusion mechanism | Early: Replace item ID with LUCID | 0.7774 | −0.13% |
| Early: Concat item ID + LUCID | 0.7785 | +0.01% | |
| Early: LARM learnable gate [18] | 0.7783 | −0.01% | |
| Early: LARM feature gate [18] | 0.7785 | +0.01% | |
| Early: EM3 CIC alignment loss [7] | 0.7785 | +0.01% | |
| Late: Independent token (= Stage 1 below) | 0.7801 | +0.22% | |
| Training recipe | Naive: joint training from scratch | 0.7784 | +0.00% |
| Staged warmup (ours, §3.4): | |||
| Stage 1: Slice add-on (item ID + slice) | 0.7801 | +0.22% | |
| Stage 2: Item ID phase-out (slice only) | 0.7793 | +0.11% | |
| Stage 3: Room add-on (slice + room, FLUID) | 0.7802 | +0.23% |
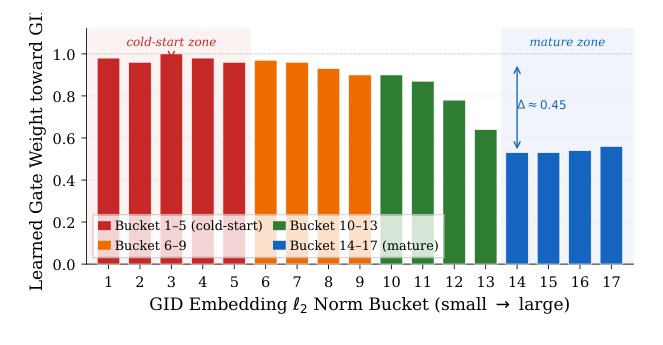
融合机制结论: 四种早融合方法(Replace、Concat、LARM 可学习门、LARM 特征门)中,没有一个产出有意义的提升(最高 +0.01%、最低 −0.13%)。Figure 5 解释了为什么 LARM 可学习门失效:把收敛后的门权重按 item ID embedding $\ell_2$ 范数分桶绘制,发现门权重发生反转(gate inversion)——门权重坍缩到 item ID 一侧(cold-start 桶 1-5 的门权重接近 1.0,即几乎全压给 item ID),slice LUCID 几乎被弃用,mature 桶(14-17)和 cold-start 桶之间门权重差 $\Delta \approx 0.45$。换言之,即便给了可学习门,模型还是因为 item ID 的强记忆而走捷径。论文因此转向后融合:把 slice LUCID 和 item ID 当作独立 token,AUC 跳到 +0.22%。
训练配方结论: Naive joint training(所有 embedding 表和排序器骨干从头重新初始化联训)产出 +0.00% 提升——排序器坍塌回 item-ID-only 解,slice 和 room LUCID 完全没有贡献(这就是 §3.4.3 说的优化非对称性)。而 FLUID 的分阶段 warmup:Stage 1 加 slice LUCID(+0.22%,证明 slice LUCID 在 item ID 之外提供增量信号);Stage 2 移除 item ID(+0.11%,揭示 slice LUCID 单独已能在很大程度上替换 item ID);Stage 3 进一步加 room LUCID(+0.23% AUC,完全补偿了退役 item ID 的损失)。论文还试了在 Stage 3 之后再把 item ID 加回去,仅再带来 +0.01% AUC——确认 LUCID 已经完全吸收了 item ID 此前提供的候选侧信息。EM3 的 CIC alignment loss 7也只有 +0.01%;去掉对齐损失、保留独立 token 反而到 +0.22%——这个配置正好就是 FLUID 的 Stage 1。
核心贡献总结¶
- 问题重构(Problem framing):首次论证在直播这种 item ID 易逝的场景里,ID-dominance 效应从"可容忍麻烦"升级为"根本性瓶颈",从而 motivate完全退役 item ID 这一激进设计,而非延续"多模态信号 alongside item ID"的主流做法。
- 跨域多模态语义码 LUCID:用 SigLIP2 + Qwen3-Embedding 的 single-tower 编码器,联合在短视频和直播上训练(借短视频密集监督迁移到直播极端冷启动),经 RQ-KMeans(而非易坍塌的 RQ-VAE)离散化为 4 级码,并区分 slice 级(瞬态)与 room 级(持久,多数投票得到)两种粒度。
- prefix n-gram embedding:以完整前缀路径为条件做层级 embedding,避免残差量化中跨不相关子树共享 entry(比 level-wise decoding +0.11% AUC)。
- 后融合 + 三阶段 warmup:用 late fusion(独立 token)绕开 item ID 的捷径效应,用 slice add-on → item ID phase-out → room add-on 的三阶段 warmup 解决 item ID 与 LUCID 的优化非对称性,首个在生产级直播排序中真正退役候选侧 item ID 并稳定上线。
- 十亿级线上验证:Quality Watch Duration +0.55%、Cold-Start Room Views +2.05%、Niche Room Views +2.87%、Unique Watched Tags +1.63%、Active Hours +0.05%,且 retention 不降反升(Stay Duration +0.07%)。
与已归档相关工作的对比¶
Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices Snap Inc. Semantic IDs 大规模部署 (Snap Inc., 2026-04-05)¶
关系:独立并发(本文未引用 Snap 的这篇部署论文,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都把原子 item ID 的冷启动 / 长尾欠训练视为根本瓶颈,都主张用多模态衍生的离散语义码替代或补充 item ID。
- 相近的技术骨架:都是"多模态编码器 → 残差量化成离散分层码 → 接入工业排序 / 检索系统"。Snap 用 RQ-VAE,FLUID 因在线流式重训练会让 RQ-VAE 码本坍塌而改用 RQ-KMeans——这是两者在量化器选型上一个有意思的分歧点。
- 本文的差异与推进:Snap 在排序器里仍把 SID 当辅助特征(item ID 保留、互补共存),只有在短视频生成式检索分支才真正用 SID 替换原子 ID;FLUID 则在生产排序器内部用三阶段 warmup 彻底退役候选侧 item ID,并显式刻画"瞬态 slice + 持久 room"两种粒度,这是 Snap 没有的直播专属设计。
- 可比的方法 / 实验差异:Snap 报告短视频 GR 在线 video view +0.57%、send +2.54%、share +4.39%、DPA add-to-cart 离线 AUC +0.67%;FLUID 报告直播排序 AUC +0.23%、Cold-Start Room Views +2.05%。两者都用 STE / 码本坍塌缓解作为关键工程点(Snap STE 使 uniqueness +83.4%,FLUID 直接换 K-means 规避坍塌)。
IDProxy IDProxy: 用 MLLM 生成代理 ID embedding (Xiaohongshu, 2026-03-02)¶
关系:独立并发(本文未引用 IDProxy,两者针对冷启动 ID 的不同解法)· 已加载对方精读
- 共同关注的问题:同一 root cause——新 / 短命物品的 item ID embedding 训练不充分,冷启动期 CTR 预测差。IDProxy 针对小红书持续高速上传的内容,FLUID 针对直播间 ~40 分钟的短命生命周期。
- 相近的技术骨架:都用预训练多模态大模型(IDProxy 用 InternVL,FLUID 用 SigLIP2+Qwen3)把内容编码成可注入 CTR 排序器的表征,都强调要让内容信号与"用户-物品交互信号"对齐(IDProxy 用对比学习把代理嵌入拉向真实 ID embedding,FLUID 用 RQ-KMeans 在排序器表里共同训练)。
- 本文的差异与推进:这是两者最本质的分叉——IDProxy 产出 dense 代理嵌入塞进 ID 槽位,且保留 item ID(item ID + coarse + fine 三者拼接,代理是补充);FLUID 产出离散分层码并彻底退役 item ID。FLUID 在 Table 4 用 A/B 证明了"保留 item ID 当补充信号"(对应其 +Slice arm)retention 不变,只有真正退役 item ID 才能同时拿到 engagement+diversity+retention——这恰好可以视作对 IDProxy 式"补充"路线的一个反驳论据。
- 可比的方法 / 实验差异:IDProxy 报告新笔记在线 ΔAUC +0.23%~0.32%、内容 Time Spent +0.22%、广告 ADVV +1.93%;FLUID 报告排序 AUC +0.23%、Quality Watch Duration +0.55%。两者离线 AUC 量级接近,但 FLUID 在"是否退役 ID"这个维度上走得更远。
讨论与局限性¶
核心贡献与值得借鉴的设计。 FLUID 最大的价值是把"item ID 易逝"这个直播专属痛点,升级成一个值得彻底重构候选侧表征的结构性问题,并给出了一条干净的落地路径:跨域训练编码器解决直播监督稀疏 → RQ-KMeans 规避在线重训码本坍塌 → prefix n-gram 尊重残差量化的前缀结构 → 后融合 + 三阶段 warmup 绕开 item ID 的捷径与优化非对称。其中几个 insight 很有迁移价值:(1) gate inversion 现象(Figure 5)用实证说明了"给可学习门也救不了早融合"——强记忆信号会霸占门权重,这对所有"内容信号 + ID 信号融合"的工作都是警示;(2) 优化非对称性的诊断和三阶段 warmup 的对策,为"如何把一个强记忆组件平滑替换掉"提供了可复用的工程范式;(3) slice / room 双粒度 + 多数投票得到稳定房间身份,是针对短生命周期内容的巧妙设计。
局限与争议。
-
离线增益偏小,主要靠在线 A/B 说话。 退役 item ID 并补 LUCID 后,离线 CTR AUC 仅 +0.23%(相对 +Slice 配置只多 +0.01%),提升主要体现在冷启动 / 长尾 / 多样性这些离线 AUC 难以反映的维度。FLUID 的价值高度依赖"直播 item ID 短命"这一前提,在 item 生命周期较长的场景(电商、点播视频)其结论未必成立——论文也明确把适用范围限定在直播。
-
两阶段解耦 + 固化码本,存在 scaling 隐患。 多模态编码器(产出 LUCID)与排序器是两个分别训练的模型,LUCID 码本一旦由 RQ-KMeans 拟合就固化下来,排序器只能在固定的离散 token 空间上学习——这是典型的"先离线压缩再下游建模"范式。当未来想 scaling 排序器参数量时,"如何表征 item(LUCID 码本)"和"如何建模序列 / 交互(排序器骨干)"两条路径无法端到端协同扩张;码本的表达力(4 级 × 64 簇)成为下游表征空间的上界。这是该路线相对端到端可微方案的长期天花板风险。
-
room-level LUCID 依赖会话内累积。 room 级码靠多数投票得到,直播刚开播、切片很少时 room 身份还不稳定;论文用三阶段 warmup 让 room 表从 warm 的 slice 表初始化来缓解,但"开播初期 room LUCID 冷启动"这个二阶冷启动问题论文未深入讨论。
-
依赖具体生产骨干。 后融合方案绑定在 token 级特征交互的 Zenith++ 骨干上,对非 token-based 的排序器(如纯 DCN / DeepFM 结构)能否同样把 LUCID 当独立 token 并享受同等收益,论文未验证。
工业落地价值。 这是一篇扎实的工业部署论文:十亿级用户、1680 亿训练样本、完整的三 arm 在线 A/B、把 retention / engagement / diversity 拆开看的细致指标体系,以及 gate inversion、优化非对称性这些来自真实生产的 debugging insight。对正在做"多模态语义码替代 / 补充 item ID"的工业团队,FLUID 关于"补充 vs 替代"的 A/B 拆解(Table 4)和"早融合为何失效"(Table 7 + Figure 5)是非常有参考价值的负面 / 正面证据。