IAT: Instance-As-Token Compression for Historical User Sequence Modeling in Industrial Recommender Systems¶
研究动机与背景¶
现代推荐系统中,序列建模(sequence modeling)是捕捉用户动态偏好的核心手段。现有的序列建模方法主要沿两个方向发展:(1) 提升序列模型架构本身的能力,如 DIN、LONGER、Transformer 等;(2) 改进特征工程以增强序列特征与非序列特征之间的信息交互。
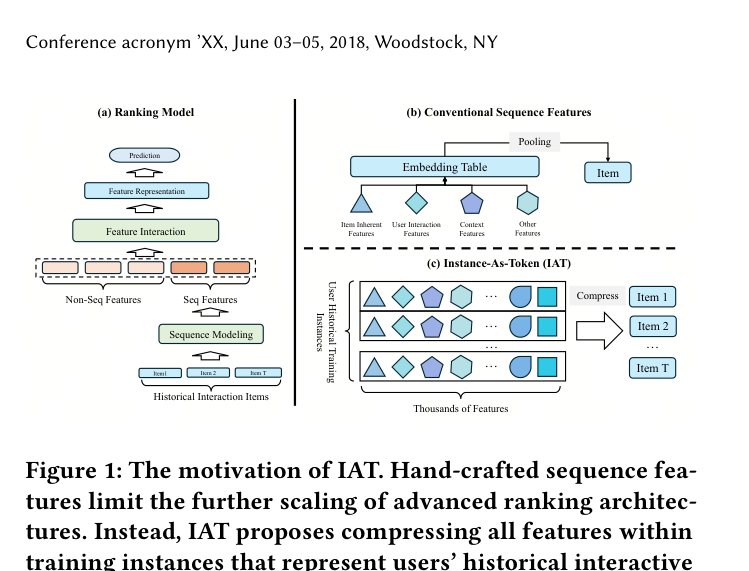
然而,这些方法存在一个根本性的信息瓶颈:它们依赖于手工构造的序列特征(hand-crafted sequential features)。如 Figure 1 左侧所示,传统方案中排序模型的行为序列特征(如 item ID、类目、交互类型、时间戳等)是从候选特征集中挑选出来的稀疏、有限的特征子集。这种方式导致:
- 存储和计算约束限制了可用特征的数量和粒度,细粒度特征(如价格、频率等)被排除在外
- 稀疏特征表示和模型性能退化是手工特征工程的固有缺陷
- 特征工程本身涉及特征设计、开发和验证的高昂工业成本
与此同时,一个用户的训练样本(training instance)可以通过其底层特征完整地描述该次历史交互行为,通常包含数千维特征。IAT 的核心思想是:将每个历史训练样本压缩为一个紧凑的实例嵌入(Instance Embedding, InsEmb),用这些 InsEmb 作为 token 来进行序列建模,从而突破传统手工序列特征的信息容量限制。
核心方法 / 模型架构¶
整体框架¶
IAT(Instance-As-Token)是一个两阶段序列建模框架:
- Stage I — IAT Compression:通过 source model 将每个训练样本压缩为低维的 InsEmb,存储到集中式的参数服务器(Parameter Server, PS)
- Stage II — IAT Sequence Modeling:下游模型从 PS 检索 InsEmb,构造 IAT 序列,进行序列建模并与候选特征交互完成预测
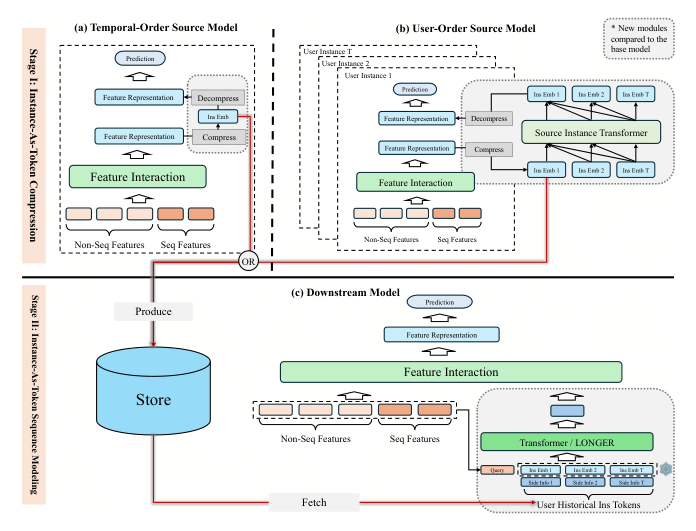
基础排序模型(Base Model)¶
论文首先定义了一个标准的工业排序模型作为基础架构。用户的特征由序列特征 $x_{\text{seq}}$ 和非序列特征 $x_{\text{non-seq}}$ 组成。序列特征通常包含 $T$ 个历史交互行为 $\{x_1, x_2, \ldots, x_T\}$,先通过序列模型 $\mathcal{F}_{\text{seq}}$ 处理,再与非序列特征进行深层特征交互:
$$h = \mathcal{F}_{\text{interaction}}\left(x_{\text{non-seq}}, \mathcal{F}_{\text{seq}}(x_{\text{seq}})\right) \tag{1}$$
其中 $h$ 是最终的特征表示,用于预测 CTR 或 CVR:
$$\hat{y} = P(y = 1 \mid u, o, h) \tag{2}$$
训练使用二元交叉熵损失(BCE):
$$\mathcal{L} = -\frac{1}{|\mathcal{D}|}\sum_{(u,o,y) \in \mathcal{D}} \left(y \log \hat{y} + (1-y)\log(1-\hat{y})\right) \tag{3}$$
Stage I: IAT Compression¶
IAT 提出两种压缩方案来生成 InsEmb:
3.3.1 Temporal-Order Source Model(时序源模型)¶
最直观的方案是直接利用基础排序模型通过复杂特征交互得到的表示 $h$(Eq. 1),在其上添加一个压缩-解压缩层。假设原始维度为 $D_{\text{raw}}$,压缩维度为 $D$:
$$h_{\text{compress}} = \sigma\left(\mathbf{W}_1 h + b_1\right) \tag{4}$$
其中 $\mathbf{W}_1 \in \mathbb{R}^{D \times D_{\text{raw}}}$,$b_1 \in \mathbb{R}^D$ 是可训练参数,$\sigma$ 是激活函数。$h_{\text{compress}} \in \mathbb{R}^D$ 即为 InsEmb,$D \ll D_{\text{raw}}$。
为了联合训练,InsEmb 通过一个解压缩 MLP 投影回原始维度参与最终预测和损失优化:
$$h_{\text{decompress}} = \sigma\left(\mathbf{W}_2 h_{\text{compress}} + b_2\right) \tag{5}$$
其中 $\mathbf{W}_2 \in \mathbb{R}^{D_{\text{raw}} \times D}$。这确保压缩后的 InsEmb 保留了高价值信息。
3.3.2 User-Order Source Model(用户序源模型)¶
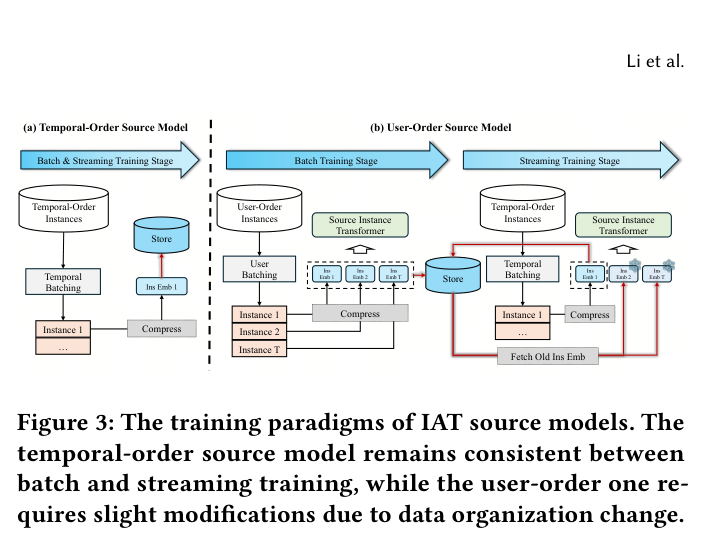
时序源模型逐样本独立压缩,忽略了同一用户历史行为之间的信息流动,且压缩模块可能导致轻微的性能下降。为此,论文提出用户序源模型,引入 Source Instance Transformer (SIT) 来增强跨实例的信息交互。
用户序训练策略:不同于时序模型按时间戳逐条处理样本,用户序模型按用户组织训练数据。在批训练阶段,假设一个 batch 仅包含同一用户的所有历史交互实例(实际中按时间段聚合同一用户的样本)。给定该用户的 $T$ 个历史实例,先用基础排序模型得到各自的压缩表示(Eq. 4),然后组织为一个序列输入 SIT:
$$H_{\text{out}} = \text{Perceiver}\left(\text{Concat}\left(H_{\text{InsEmb}}, H_{\text{bias}}\right)\right) \tag{6}$$
其中 Perceiver 是标准的 Transformer 架构。$H_{\text{InsEmb}}$ 是按时间戳逆序排列的该用户所有 InsEmb,$H_{\text{bias}}$ 是 batch 内 instance 的位置偏置。SIT 严格遵循因果约束(causal constraint),即每个元素只能访问历史实例的信息,不能看到未来。
如 Figure 2(b) 所示,最左端是当前实例(最新),右侧是历史实例按逆序排列。当前实例的 InsEmb 先经过压缩层生成,再通过 SIT 与历史 InsEmb 交互后获得更丰富的表示,最终用于解压缩和预测。
用户序模型的两个优势:
- 增强源模型性能:SIT 使得同一用户不同实例之间的信息可以流动,可能显著提升基础模型的性能(如实验部分所示)
- 增强 InsEmb 的序列建模能力:SIT 不仅生成更紧凑和信息丰富的 InsEmb,还隐式地为 InsEmb 赋予了序列建模的能力,提升了下游模型的迁移性(transferability)
流式训练(Streaming Training):在流式训练阶段,SIT 的输入是一个序列,最新元素是当前实例的 InsEmb(由压缩层实时生成),其余元素是该用户从存储中检索的历史 InsEmb。序列按当前实例在前、历史实例按逆序在后的方式排列,保持因果约束。为加速,论文将流式训练阶段 SIT 的输入长度截断为 256(批训练阶段设为 Eq. 6 中 batch 大小)。
模型架构在批训练和流式训练阶段保持一致,只有 batching 策略不同:批训练阶段按用户聚合实例,流式训练阶段从存储中检索历史 InsEmb。这种一致性避免了由于架构变化导致的轻微修改问题。
SIT 的训练范式¶
论文在 Section 3.3.3 中详细描述了训练流程:
- 批训练(Batch Training):用户序源模型在固定大小的 batch 上训练。一个 batch 内按时间段聚合同一用户的实例,通过 SIT 处理后,所有 InsEmb 都被送入解压缩器参与预测和损失计算。后续操作的用户实例先被编码后存储
- 流式训练(Streaming Training):模型进入实时更新阶段,源模型和下游模型同步更新。源模型持续生成新的 InsEmb 并存储到 PS
具体训练细节:在 SIT 的前向传播中,batch 大小为 $B$,InsEmb 维度为 $d$。SIT 输入为 $H_{\text{InsEmb}} \in \mathbb{R}^{B \times T \times d}$,按用户序列组织。梯度仅对当前最新的 InsEmb 进行反向传播:
$$H_{\text{new\_emb}} = \mathcal{F}_{\text{decompress}}\left(H_{\text{InsEmb}[:, 0, :]}\right) \tag{7}$$
其中 sg 表示 stop gradient 操作,$H_{\text{InsEmb}[:, 0, :]}$ 是 batch 中每个用户最新实例的 InsEmb。历史 InsEmb 仅做前向传播(forward-only),不参与梯度回传,当前 InsEmb 保持正常梯度流。
Side Information(辅助信息)¶
InsEmb 主要压缩底层特征表示,但某些辅助信息也对序列建模有价值:
- Label Side Information:训练样本的多任务标签(如是否点击、是否购买),这些标签与用户行为高度相关
- Other Task-Related Side Information:时间戳等行为归因相关的特征
辅助信息是可选的(optionally utilized),通过常规特征工程方法处理,得到表示 $E_{\text{side}} \in \mathbb{R}^{B \times T \times d_{\text{side}}}$,其中 $B$ 是 batch 大小,$T$ 是序列长度,$d_{\text{side}}$ 是辅助信息的嵌入维度(实验中 $d_{\text{side}} = 64$)。
InsEmb Adaptation Mechanism¶
从 PS 检索到的历史 InsEmb 记为 $E_{\text{InsEmb}} \in \mathbb{R}^{B \times T \times d}$,其中 $d$ 是 InsEmb 的压缩维度($d = D = 64$)。由于 InsEmb 是低维紧凑空间,需要投影到高维空间以匹配下游模型的特征空间。论文引入一个自适应 MLP:
$$E_{\text{InsEmb\_adapt}} = \sigma\left(E_{\text{InsEmb}} \mathbf{W}_{\text{adapt}}^{\top} + b_{\text{adapt}}\right) \tag{8}$$
其中 $\mathbf{W}_{\text{adapt}} \in \mathbb{R}^{d_{\text{adapt}} \times d}$,$b_{\text{adapt}} \in \mathbb{R}^{d_{\text{adapt}}}$,$d_{\text{adapt}}$ 是适配后的维度(实验中 $d_{\text{adapt}} = 64$,设 $d_{\text{adapt}} \geq d$)。
Instance-As-Token (IAT) Sequence¶
将适配后的 InsEmb 与辅助信息拼接构成 IAT 序列:
$$E_{\text{InsToken}} = \text{Concat}\left(E_{\text{InsEmb\_adapt}}, E_{\text{side}}\right) \tag{9}$$
其中 $E_{\text{InsToken}} \in \mathbb{R}^{B \times T \times (d_{\text{adapt}} + d_{\text{side}})}$ 即为 IAT 序列嵌入。
Query Token 构造:IAT 序列本身是纯用户特征,不包含候选 item 信息。为了更好地对齐下游排序模型,论文将候选 item 的序列和非序列特征 token 拼接后压缩为 query token:
$$Q = \mathcal{F}_{\text{compress}}\left(\text{Concat}\left(x_{\text{seq}}, x_{\text{non-seq}}\right)\right) \tag{10}$$
其中 $Q \in \mathbb{R}^{B \times d_{\text{query}}}$,$d_{\text{query}}$ 是 query token 的维度(实验中 $d_{\text{query}} = 512$)。
IAT 序列建模:将 Eq. 10 得到的 query token 投影到与 IAT 序列相同的维度空间后,即可输入任意主流序列建模架构(如 LONGER、Transformer)进行建模。论文实验发现,将建模结果作为输入送入上层的复杂特征交互模块(如 RankMixer)效果最佳。
存储架构设计¶
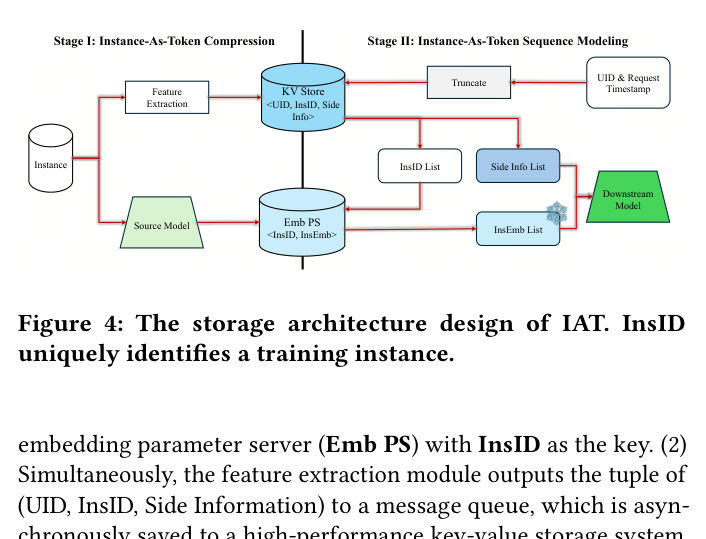
Figure 4 展示了 IAT 的完整存储架构:
- Source Model 处理训练样本,生成 InsEmb,写入嵌入参数服务器(Emb PS),key 为 InsID
- 同时,特征提取模块输出 (UID, InsID, Side Information) 到消息队列,异步写入高性能 key-value 存储系统
- 请求到来时,下游模型先根据 UID 检索 InsID 列表,按时间戳截断为长度 $T$,再根据 InsID 列表从 Emb PS 检索 InsEmb,与 Side Info 组装为 IAT 序列
InsID 构造:InsID 是训练实例的唯一标识符,通过哈希时间戳和任务相关 ID(如广告系统中的 request ID 和 creative ID)生成。
存储成本估算:使用 FP32 存储时:
$$\text{PS Storage Bytes} = N_{\text{daily}} \times T \times d \times 4 \tag{11}$$
其中 $N_{\text{daily}}$ 是日均训练样本数,$T$ 是保留的历史天数,$d$ 是 InsEmb 维度。例如,存储 2 年 64 维 InsEmb、日均数亿样本,消耗约数 TB 的 PS 存储空间。
实验设置¶
数据集¶
实验在一个工业级 CVR 预测数据集上进行,来自真实广告系统。数据集包含 4 个连续月份的训练数据,总量达数百亿训练样本,是工业界大规模推荐场景的典型代表。特征空间包括用户特征、item 特征、上下文特征和传统行为序列特征,其中序列特征仅保留稀疏的核心辅助信息(如 ID、类目、动作类型)。所有训练数据经过匿名化和特征 ID 哈希处理。
Baselines¶
选择 3 种主流工业序列建模架构作为基础排序模型:
- DIN:经典的深度兴趣网络
- LONGER:利用 Perceiver 技术和 token merge 减少长序列 Transformer 的计算负担
- Transformer:标准 Transformer 架构
特征交互模块统一使用 RankMixer 以消除融合策略差异。每种基础模型分别搭配 Temporal-Order IAT 和 User-Order IAT 两种 IAT 序列。
评估指标¶
- 性能指标:AUC(Area Under Curve)、LogLoss(Logarithmic Loss)
- 效率指标:Dense Parameters、Training FLOPs/Batch
超参数配置¶
- 原始特征维度 $D_{\text{raw}} \approx 6000$,压缩维度 $D = 64$
- User-Order Source Model 中 SIT 为 2 层 Transformer,模型维度 64,FFN 中间层维度 128
- 批训练阶段 SIT 输入长度 = batch size(Eq. 6),流式训练阶段截断为 256
- 下游模型适配维度 $d_{\text{adapt}} = 64$,序列长度 $T = 256$
- $d_{\text{side}} = 64$,$d_{\text{query}} = 512$(Eq. 10-11)
- 传统行为序列长度也设为 512
- 所有实验在分布式 GPU 集群上训练,batch size $B = 1024$
主要实验结果¶
Source Model 性能(4.2.1)¶
分别训练 Temporal-Order 和 User-Order 两种源模型:
- Temporal-Order Source Model 在 AUC 上有轻微下降(约 0.05%),这是引入压缩模块的代价
- User-Order Source Model 获得 0.6% AUC 增益,因为 SIT 引入了用户历史实例间的信息流动
但用户序源模型由于资源消耗过大,不能直接部署上线,仅作为 InsEmb 的生产模型。
下游模型整体性能(Table 1)¶
| 模型 | AUC (↑) | ΔAUC (%) | LogLoss (↓) | ΔLogLoss (%) | Params | FLOPs/Batch (G, ×10⁷) |
|---|---|---|---|---|---|---|
| DIN Base | 0.83620 | - | 0.45210 | - | 49M | 73G |
| +Temporal IAT (Trans) | 0.83725 | +0.13% | 0.45089 | -0.27% | 52M | 85G |
| +User IAT (Trans) | 0.83821 | +0.24% | 0.44979 | -0.51% | 52M | 85G |
| LONGER Base | 0.83705 | - | 0.45113 | - | 55M | 89G |
| +Temporal IAT (Trans) | 0.83830 | +0.15% | 0.44969 | -0.32% | 60M | 97G |
| +User IAT (Trans) | 0.83967 | +0.31% | 0.44812 | -0.67% | 60M | 97G |
| Transformer Base | 0.83739 | - | 0.45075 | - | 50M | 126G |
| +Temporal IAT (Trans) | 0.83868 | +0.15% | 0.44928 | -0.33% | 50M | 137G |
| +User IAT (Trans) | 0.83984 | +0.29% | 0.44792 | -0.63% | 54M | 137G |
关键结论:
- 三种架构下 IAT 均一致提升:User-Order IAT 在 AUC 上提升最高达 0.31%,LogLoss 降低最高达 0.67%,参数量和 FLOPs 增加适度
- User-Order IAT 一致优于 Temporal-Order IAT:因为 SIT 增强了 InsEmb 的信息质量和序列建模能力
- 对比传统方案的优势:在真实工业场景中,引入长度为 256 的手工序列特征到基础模型中几乎无法获得 0.1% 的 AUC 增益,而 IAT 可达 0.24%-0.31%
- LONGER 和 Transformer 架构获益更大:用 DIN 建模 IAT 序列仅带来微小增益,说明 Transformer 系列架构更适合建模 IAT 序列
下游模型架构选择(Table 2)¶
当下游序列模型统一使用 User-Order IAT、基础模型使用 Transformer 时:
| 下游架构 | AUC | ΔAUC (%) | LogLoss | ΔLogLoss (%) |
|---|---|---|---|---|
| Base | 0.8373 | - | 0.4507 | - |
| +IAT (DIN) | 0.8376 | +0.03% | 0.4505 | -0.06% |
| +IAT (LONGER) | 0.8399 | +0.31% | 0.4477 | -0.66% |
| +IAT (Trans) | 0.8398 | +0.29% | 0.4479 | -0.63% |
这说明 Transformer 系列架构更适合建模 IAT 序列,DIN 的注意力机制在 IAT 序列上表现不佳。后续实验默认使用 Transformer 建模 IAT 序列。
IAT 序列长度分析¶
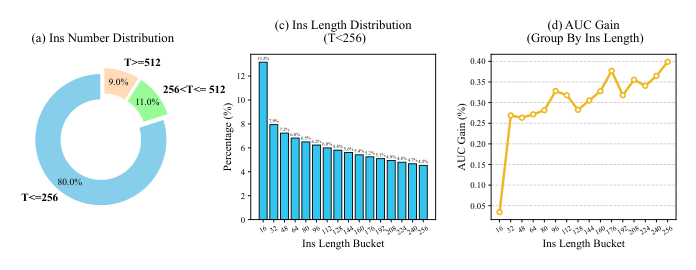
论文进一步分析了 AUC 增益与 IAT 序列长度的关系(Figure 5):
- 约 80% 的用户历史训练样本少于 256 条,因此下游模型的最大 IAT 序列长度设为 256
- 将用户按 IAT 序列长度分桶后发现,更长的 IAT 序列带来更显著的 AUC 增益,最高约 0.4%
Scaling 实验¶
4.3.1 Scaling Up Base Model(Table 3)¶
在工业场景中,IAT 可以普遍应用于各种规模的基础模型。论文通过三种方式扩展基础模型:
| Scaling 方法 | Params | Source 增益 | Downstream 增益 |
|---|---|---|---|
| Dense Scaling | 150M | +0.54% | +0.5% |
| Seq. Len. Scaling | 350M | +0.51% | +0.30% |
| Feat. Int. Scaling | 1B | +0.41% | +0.33% |
关键发现:当模型规模增大至 1B 参数级别时,User-Order IAT 序列仍能带来显著的性能提升,且此时微小的增益变得更有价值。
4.3.2 Scaling Up SIT in User-Order Source Model(Figure 6)¶
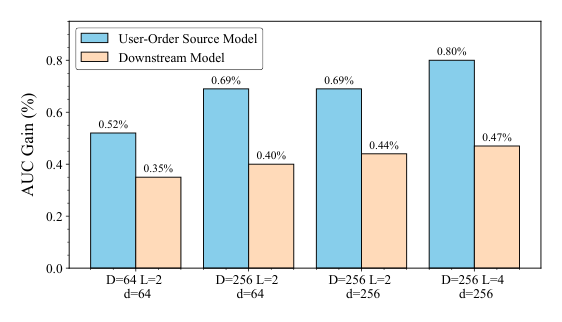
论文用 $D$、$L$、$d$ 分别表示 InsEmb 输入维度、SIT 层数和最终压缩 InsEmb 维度。实验结果表明:
- 增大 InsEmb 维度或增加 SIT 层数,均能为源模型和下游模型带来显著增益
- AUC 增益范围从 0.52% 提升至 0.80%
- 下游模型的性能也显著且持续改善
4.3.3 Scaling Up Downstream Model(Figure 7)¶
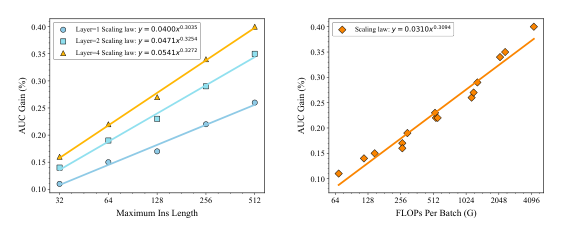
探索下游 Transformer 的层数(1, 2, 4)和 IAT 序列最大长度(64, 128, 256, 512)的 scaling 行为:
- 下游 Transformer 的 scaling 符合标准的 scaling law,随层数增加性能持续提升
- AUC 增益相对于最大 IAT 序列长度和 FLOPs 均呈现良好的 scaling 曲线
消融实验(Table 4)¶
| 设置 | T-IAT | U-IAT |
|---|---|---|
| Source 模型 | ||
| Larger $B = 2048$ | +0.0% | +0.02% |
| w/ InsEmb Stored after SIT | - | -0.09% |
| Downstream 模型 | ||
| w/o label sideinfo | -0.06% | -0.10% |
| w/o other sideinfo | -0.05% | -0.01% |
| w/ ID-based query | -0.06% | -0.09% |
| w/ IAT after Feat. Int. | -0.04% | -0.06% |
逐项分析:
- Larger Batch Size (B=2048):对 T-IAT 无影响,对 U-IAT 有微小提升(因为更大 batch 可以覆盖更多同一用户的历史实例)
- InsEmb Stored after SIT:在 SIT 之后而非之前存储 InsEmb 会导致 -0.09% 的性能下降。原因是 SIT 之后的 InsEmb 丢失了部分基础信息,与注意力机制更相似,而当前 IAT 序列同时包含 InsEmb 和辅助信息(如多任务标签),SIT 之后的 InsEmb 在丢弃标签辅助信息后信息不完整
- 去除 Label Side Information:导致明显的 AUC 下降(-0.06% 至 -0.10%),因为 InsEmb 中包含的标签信息较少,标签辅助信息对序列建模至关重要
- 去除 Other Side Information:对 T-IAT 有负面影响,对 U-IAT 几乎无影响
- ID-based Query:用简单的 ID 特征构造 query(Eq. 10)替代压缩候选特征,导致 -0.06% 至 -0.09% 的下降,说明使用丰富的候选特征作为 query 更有优势
- IAT after Feature Interaction:将 IAT 序列建模结果放在特征交互模块之后而非之前,导致性能下降。因为 InsToken 包含丰富的信息,放在特征交互模块之前可以实现更充分的底层 token 信息流动
IAT 位置的最佳实践:将 IAT 序列建模的输出作为输入送入上层的复杂特征交互模块(如 RankMixer),效果最佳(如 Figure 8(b) 所示)。
线上 A/B 实验¶
In-Domain A/B(Table 5)¶
在真实广告场景中部署 IAT 序列,基线是一个已长期在线运行的强排序模型:
| 模型 | ADSS | ADVV |
|---|---|---|
| Temporal-Order IAT | +0.685% | +0.653% |
| User-Order IAT | +1.557% | +1.340% |
ADSS(Advertiser Score)和 ADVV(Advertiser Value)是核心广告收入指标。IAT 在两项指标上均取得显著提升,User-Order IAT 的 ADSS 提升 1.557%,ADVV 提升 1.340%,这在工业场景中是非常显著的收益。
Cross-Domain A/B(Table 6)¶
IAT 的强泛化能力还体现在跨场景迁移上。将广告场景中产出的 IAT 序列直接应用到其他推荐场景:
| 场景 | 模型 | 指标 | 提升 |
|---|---|---|---|
| 商城广告(Mall Advertising) | CVR | ADVV | +1.482% |
| 信息流广告(Feed Advertising) | CVR | ADSS | +0.5% |
| 信息流广告 | CTR | ADSS | +3.015% |
| NOC 广告 | CVR | ADSS | +1.19% |
| 直播电商(Live Streaming E-Com.) | CT-CVR | GMV | +0.151% |
跨域结果分析:IAT 在所有跨域场景中均取得正向提升,尤其在 Feed Advertising CTR 场景中 ADSS 提升高达 3.015%。这说明 IAT 生成的 InsEmb 具有强大的领域迁移能力——在一个广告场景中训练的 IAT 序列可以有效迁移到其他推荐场景。
讨论与局限性¶
核心贡献¶
- 范式创新:IAT 提出了一种全新的序列建模范式——用训练实例的压缩嵌入代替手工构造的序列特征,从根本上突破了传统特征工程的信息瓶颈
- 工业可行性强:完整的存储架构设计(PS + key-value storage + InsID),支持流式训练和实时更新,已在多个工业场景验证
- 灵活的两阶段解耦:源模型和下游模型解耦,允许使用计算量更大但不上线的用户序源模型来生成高质量 InsEmb,下游模型则保持轻量
值得借鉴的设计¶
- User-Order Source Model + SIT:通过跨实例的 Transformer 注意力增强压缩质量,是一种优雅的解决方案
- Query Token 构造:将候选 item 的完整特征压缩为 query token 与 IAT 序列交互,比简单的 ID-based query 更有效
- IAT 位置选择:放在特征交互模块之前,作为 bottom feature 参与信息流动
局限性¶
- 存储成本:虽然单条 InsEmb 仅 64 维 FP32,但在日均数亿样本的规模下,存储数 TB 的 PS 空间仍是不可忽视的基础设施成本
- 用户序源模型不能上线:User-Order 源模型的计算成本过高(批训练阶段需要按用户聚合),仅用于离线生产 InsEmb,这意味着线上预测仍依赖传统的基础排序模型
- Historical InsEmb 的一致性问题:流式训练阶段使用的历史 InsEmb 是由过去的模型版本生成的,可能与当前最新模型存在不一致。论文在 Appendix A.2 中讨论了两种解决方案(Store Retrieval vs. Recomputation),但 Recomputation 的计算开销过大(256x),实际中只能采用 Store Retrieval
- 实验仅在单一工业数据集上验证:没有在公开学术数据集上的实验,限制了可复现性和与其他方法的公平对比
部署细节与业务收益¶
IAT 已在字节跳动的多个真实工业推荐系统中成功部署,覆盖电商广告、信息流广告、商城广告、直播电商等多个场景。核心广告收入指标(ADSS、ADVV)和 GMV 均获得显著提升。论文提到 IAT 的跨域迁移能力特别突出——在一个广告场景中训练的 IAT 序列可以直接应用到其他场景并获得正向收益,这极大降低了多场景部署的成本。