RecGPT-Mobile: On-Device Large Language Models for User Intent Understanding in Taobao Feed Recommendation 精读¶
研究动机与背景¶
随着电商生态的快速演化,"用户下一步想搜什么"成为现代推荐系统的关键问题。准确预测用户的 next-query(下一搜索意图)能让 Feed 流提前调用相关商品,显著提升信息分发效率与转化。
近年大语言模型(LLM)在语义推理上的强能力,使其成为 next-query 预测的天然候选——已有大量工作(包括同团队 2025 年的 RecGPT 技术报告)将 LLM 用于训练数据构造、意图重写与解释生成。然而,这些应用都默认 LLM 部署在云端:在工业流量下,云端 LLM 调用带来三类突出的瓶颈:
- 推理延迟:电商 Feed 是毫秒级实时场景,端-云一次往返已是不可忽略的开销,叠加 LLM 解码时间后无法满足在线响应要求;
- 推理成本:每用户每会话调用 LLM,按 DAU 上亿级的 Mobile Taobao 规模,token 成本巨大;
- 隐私与数据本地化:完整用户行为序列若上传至云端做意图理解,存在合规与隐私顾虑。
与此并行的另一条研究线则是 on-device 推荐系统(EdgeRec 2020、DIR 2023 等)——把模型直接部署到客户端 CPU/NPU,做行为本地化、推理本地化。但这些工作大多围绕传统的 ranking / re-ranking 模型,LLM 直接部署到端侧仍是空白:1B 量级的 LLM 在动辄 4-6GB 内存预算的中端机型上推理,未经压缩就直接 OOM;即便能跑起来,每次行为变化都触发一次 LLM 推理也会迅速耗尽电量。
本文提出 RecGPT-Mobile——首个把 LLM 真正下沉到 Mobile Taobao 客户端做用户意图理解的 next-query 预测框架。其核心设计目标可拆为三层:
- 轻量化 LLM:用 LoRA 微调 + 量化把 Qwen3-0.6B 压缩到能在主流安卓/iOS 机型上常驻;
- 自适应 Prompt 构建:针对端侧严格的 token / 内存预算,做模板和结构两级 prompt 适配;
- 触发频率控制:用 entropy + Jaccard + JS 三类信号做"意图漂移检测",只在用户真正切换兴趣时才调用本地 LLM,把日均推理次数压到 21% 触发率,功耗降到 40% 基线。
工业 A/B 在 Mobile Taobao 4 个场景跑了一个月,平均 +1.8% CLICK / +2.7% PAY / +2.5% GMV。
核心方法¶
系统总览¶
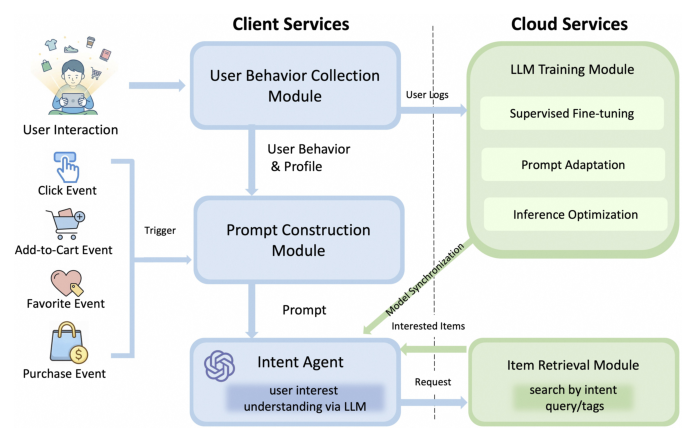
整个系统的横切面被显式拆为 客户端(Client) 与 云端(Cloud) 两侧:
客户端常驻 4 个模块:
- User Behavior Collection Module:本地仓库,缓存点击 / 加购 / 收藏 / 购买等用户事件;
- Prompt Construction Module:被高意图行为触发后,把原始行为流和用户画像合成结构化 prompt;
- Intent Agent:消费 prompt 的本地 LLM,输出明确的搜索 query 或意图标签;
- Item Retrieval Module:拿生成的 query 调本地或云端的检索服务,把候选 items 反传到客户端。
云端只做训练和适配,不参与在线推理:
- Supervised Fine-tuning、Prompt Adaptation、Inference Optimization 三个子模块组成 LLM Training Module,负责把基座 Qwen3-0.6B 加工成可下发到端侧的 LoRA + Quant 权重。
值得注意的设计:Item Retrieval 的"intent query / tags"通道允许客户端在生成的搜索 query 之外,输出更细粒度的标签——这给了系统在不同 Feed 位面下灵活配置的余地。
任务定义¶
设用户行为序列为:
$$\mathcal{B} = \{(i_1, a_1, t_1), (i_2, a_2, t_2), \ldots, (i_T, a_T, t_T)\}, \tag{1}$$
其中 $i_T$ 表示在时间戳 $T$ 上交互的物品;$a_T \in \{\text{click}, \text{cart}, \text{favorite}, \text{purchase}\}$ 是动作类型;$t_T$ 是动作发生时间。
模型目标为:在观察到 $\mathcal{B}$ 的条件下,找到最有可能反映用户当下隐式需求的下一搜索 query $q^* \in \mathcal{Q}$($\mathcal{Q}$ 为搜索 query 空间):
$$q^* = \arg\max_{q \in \mathcal{Q}} P(q \mid \mathcal{B}) \quad \text{s.t.\ Resource Constraints}, \tag{2}$$
其中 $P(q \mid \mathcal{B})$ 是给定行为序列下搜索 query 的条件概率。"Resource Constraints" 是端侧 LLM 区别于云端方案最核心的硬约束——它不仅是延迟阈值,更是包括内存、token 预算、电量在内的一组多目标限制。
监督微调与训练样本构造¶
为让 0.6B 量级模型在异构行为输入下也能稳定生成有意义的 query,作者从四类互补来源合成训练集,组成如下:
Table 1:训练样本构造与配比
| Sample Type | Data Source | Ratio |
|---|---|---|
| Behavior-driven | Purchase & search logs | 60% |
| Co-purchase | Co-purchase item matrix | 20% |
| LLM-based | GPT-based rewriting | 15% |
| Human-annotated | Manually annotated data | 5% |
四类样本各自捕捉用户意图的不同侧面:
- Behavior-driven (60%):从购买日志 + 搜索日志中抽对——把"买完 X"的用户随后在搜索框输入的 query $q$ 作为 ground-truth,强训"行为 → query"的因果对齐;
- Co-purchase (20%):从 item-level 共购矩阵自动派生——若用户买了 A,A 与 B 强共购,则把 B 的类目 / brand 作为意图标签,这条信号补足购买日志覆盖不到的"互补品意图";
- LLM-based (15%):用云端 GPT 把规则样本做语言改写以增加表述多样性,降低端侧模型在 prompt 表达上过度过拟合的风险;
- Human-annotated (5%):人工标注的"金标",用于质量校准与离线评估。
监督微调使用以下提示:
Prompt 1: Next-query Prediction Prompt
Input: Given a timestamp $t$ and a user behavior sequence $\mathcal{B} = \{(i_1, a_1, t_1), (i_2, a_2, t_2), \ldots, (i_n, a_n, t_n)\}$, please infer the user's next search intent, and generate the most likely search query that reflects the user's latent requirement.
Output:
.
自适应 Prompt 构建(Adaptive Prompt Construction)¶
端侧 LLM 受制于严格的 token / 内存 / 延迟预算,全量原始行为序列直接灌入 prompt 几乎必然超预算,而粗暴截断又会丢失意图信号。作者把 prompt 构建做成一个 4 阶段的搜索-决策算法:
Algorithm 1: Adaptive Prompt Construction with Template & Structural Adaptation
Input: Behavior sequence B = {(i_t, a_t, t_t)}_{t=1}^T;
scenario s; template pool T_s; component set C; scorer M_score;
on-device budget C_max (latency/memory/token).
Output: Adaptive prompt P*.
Stage 1: Feature Extraction
Compute behavior features Φ ← Φ(B) = [Φ_act, Φ_rec, Φ_div, Φ_freq],
where Φ_act = action-type 分布,
Φ_rec = recency,
Φ_div = diversity,
Φ_freq = action frequency.
Stage 2: Template-level Adaptation
for all T_k ∈ T_s do
α_k ← M_score(T_k, Φ, s)
end for
p_k ← exp(βα_k) / Σ_j exp(βα_j)
T* ← arg max_{T_k ∈ T_s} p_k
Initialize prompt P ← T*
Stage 3: Structural-level Adaptation
for all c ∈ C do
Δ(c) ← M_score(P ⊕ c, Φ, s) − M_score(P, Φ, s)
if Δ(c) > τ and Cost(P ⊕ c) ≤ C_max then
P ← P ⊕ c
end if
end for
Stage 4: Budget Enforcement & Finalization
P* ← arg max_{P' ⊆ P} M_score(P', Φ, s) s.t. Cost(P') ≤ C_max
Instantiate behavior tokens from B into P*
return P*
四阶段的设计动机:
- Stage 1(特征抽取):把杂乱的行为流抽成 4 维数值特征 $\Phi = [\Phi_\text{act}, \Phi_\text{rec}, \Phi_\text{div}, \Phi_\text{freq}]$。这一层是后续所有打分的输入摘要——直接喂原始 token 进 scorer 太贵,先做粗粒度抽象;
- Stage 2(模板级适配):在场景 $s$(不同 Feed 位面有不同模板池 $\mathcal{T}_s$)下,用轻量打分器 $M_\text{score}$ 对每个候选模板打分 $\alpha_k$,softmax 取最大概率模板 $T^*$ 作为基座;
- Stage 3(结构级适配):在选中的模板上贪心地试加 / 不加每个结构组件 $c$(如行为时间戳块、共购侧栏、用户画像段),仅当增益 $\Delta(c)$ 超过阈值 $\tau$ 且累计成本仍在预算 $C_\text{max}$ 内时才纳入;
- Stage 4(预算执行与最终化):对完整 prompt 再做一次预算闭包剪枝——这一步是 hard constraint,保证最终 $P^*$ 严格不超 $C_\text{max}$,再把行为 token 实例化进去。
整个流程的工程意义:把 prompt 构建从"硬编码模板 + 截断"升级成"特征驱动的搜索-剪枝",让同一个端侧 LLM 在不同场景、不同行为分布下都能拿到最有信息量的输入,同时严格符合机器算力。
移动端推理触发优化(Mobile Inference Trigger)¶
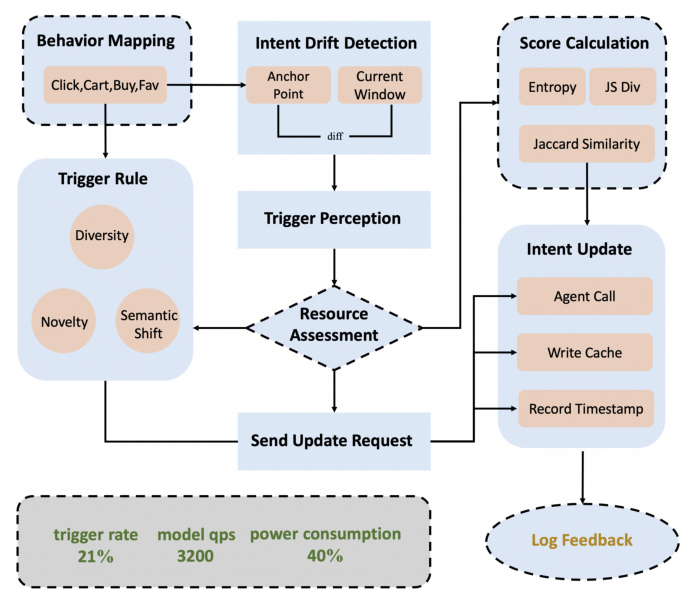
即便 prompt 已经被压到极致,每次行为更新都跑一次端侧 LLM 仍然是不可承受的——按用户每分钟数次行为计,会让 CPU 持续高占用并迅速耗电。作者把"是否触发 Intent Agent"做成一个独立的轻量决策模块,命名为 Mobile Intent Agent Trigger Pipeline:
整个管线由 5 个子模块组成:
- Behavior Mapping:将 Click/Cart/Buy/Fav 等事件映射为标签流;
- Intent Drift Detection:以"上一次触发的锚点窗口"为基准 vs."当前滑动窗口",做意图漂移测算;
- Score Calculation:用熵、JS 散度、Jaccard 相似度三个统计量量化漂移;
- Trigger Rule:综合 Diversity / Novelty / Semantic Shift 三个触发维度,配合资源评估(trigger rate, model qps, power consumption)做最终判定;
- Intent Update:触发后调用 Agent → 写缓存 → 记录时间戳 → 反馈日志。
核心是 Intent Drift Detection——给定行为序列 $\mathcal{B}$ 在滑动窗口内,每次交互被映射为离散语义标签(例如 category / brand / intent type),由此得到当前窗口与上一触发点的标签分布 $P_\mathcal{B}^{(t)}, P_\mathcal{B}^{(t-1)}$。
信号 1:分布熵变化
$$H(P_\mathcal{B}) = -\sum_k P_\mathcal{B}(k) \log P_\mathcal{B}(k). \tag{3}$$
绝对熵差:
$$\Delta H = \big| H(P_\mathcal{B}^{(t)}) - H(P_\mathcal{B}^{(t-1)}) \big|. \tag{4}$$
它度量"用户当下意图变得更聚焦还是更发散"。意图突然收敛(熵下降)或突然探索(熵上升)都是值得触发的信号。
信号 2:Jaccard 相似度(语义重叠)
设 $\mathcal{Z}^{(t)}$ 为窗口内观察到的标签集合:
$$JA(\mathcal{Z}^{(t)}, \mathcal{Z}^{(t-1)}) = \frac{|\mathcal{Z}^{(t)} \cap \mathcal{Z}^{(t-1)}|}{|\mathcal{Z}^{(t)} \cup \mathcal{Z}^{(t-1)}|}. \tag{5}$$
Jaccard 越低代表语义焦点漂得越远,需要重新让 LLM 解读。
信号 3:JS 散度(分布偏移)
$$JS\!\left(P_\mathcal{B}^{(t)}, P_\mathcal{B}^{(t-1)}\right) = \tfrac{1}{2} KL\!\left(P_\mathcal{B}^{(t)} \,\Vert\, M\right) + \tfrac{1}{2} KL\!\left(P_\mathcal{B}^{(t-1)} \,\Vert\, M\right), \tag{6}$$
其中 $M = \tfrac{1}{2}\!\left(P_\mathcal{B}^{(t)} + P_\mathcal{B}^{(t-1)}\right)$。Jaccard 是集合层面的硬指示,JS 散度则是分布层面的软指示——两者互补。
复合漂移得分:把三类信号融合:
$$\Delta_\text{intent} = \lambda_1 \cdot \Delta H + \lambda_2 \cdot \big(1 - JA(\mathcal{Z}^{(t)}, \mathcal{Z}^{(t-1)})\big) + \lambda_3 \cdot JS\!\left(P_\mathcal{B}^{(t)}, P_\mathcal{B}^{(t-1)}\right), \tag{7}$$
其中 $\lambda_1, \lambda_2, \lambda_3 \geq 0$ 且 $\lambda_1 + \lambda_2 + \lambda_3 = 1$。只有当 $\Delta_\text{intent} > \tau$ 时才触发本地 LLM 调用:
$$\Delta_\text{intent} > \tau, \tag{8}$$
阈值 $\tau$ 是预定义超参。Online 实测下 $\lambda_1 = 0.4, \lambda_2 = 0.3, \lambda_3 = 0.3, \tau = 0.8$ 是最优配置(Section 4.2),此时触发率维持在 21%、模型 QPS 3200、相对常驻调用模式电量降到 40%。这一组参数显示 熵变化 > Jaccard ≈ JS 散度 的相对重要性——熵的语义最直接(聚焦/探索的二元切换最具决策意义),Jaccard 与 JS 主要用于细粒度漂移补正。
设计上这套 trigger 管线的最大价值是 把 LLM 推理频率与"意图变化频率"绑定,而不是与"行为变化频率"绑定。前者比后者稀疏一个数量级以上——绝大部分行为只是在已识别意图框架内的探索,不需要重新让 LLM 解读。
实验¶
离线评估 Prompt¶
为定量评估生成 query 的质量,作者用 LLM-as-a-Judge 把生成质量分解为三个互补维度:
Prompt 2: LLM-based Evaluation Prompt
Input: Given a user behavior sequence $\mathcal{B} = \{(i_1, a_1, t_1), (i_2, a_2, t_2), \ldots, (i_n, a_n, t_n)\}$ and a candidate search query $q$ generated for next-query prediction, please evaluate the quality of $q$ from the following three aspects:
- Semantic Consistency: whether $q$ is semantically aligned with the latent intent implied by $\mathcal{B}$.
- Logical Coherence: whether $q$ reflects a reasonable intent transition given the behavior sequence.
- Expression Quality: whether $q$ avoids trivial template reuse and is expressed in a natural manner.
Output: Three normalized scores $S_\text{sem}, S_\text{logic}, S_\text{style} \in [0, 1]$.
最终总分为三个分数的加权聚合 $S_\text{total}$,提供生成质量的整体评价。
离线自动评估结果¶
Table 2: LLM-based 自动评估结果
| Eval. Model | Target | $S_\text{sem}$ | $S_\text{logic}$ | $S_\text{style}$ | Total |
|---|---|---|---|---|---|
| Qwen3-4B | Base | 0.752 | 0.621 | 0.657 | 0.677 |
| LoRA | 0.885 | 0.792 | 0.811 | 0.829 | |
| LoRA+Quant | 0.844 | 0.754 | 0.785 | 0.794 | |
| Qwen3-8B | Base | 0.657 | 0.554 | 0.627 | 0.613 |
| LoRA | 0.807 | 0.755 | 0.786 | 0.783 | |
| LoRA+Quant | 0.780 | 0.746 | 0.754 | 0.760 | |
| Qwen3-30B | Base | 0.671 | 0.654 | 0.663 | 0.654 |
| LoRA | 0.839 | 0.797 | 0.787 | 0.808 | |
| LoRA+Quant | 0.812 | 0.774 | 0.762 | 0.780 |
实验设置:基座为 Qwen3-0.6B,对比同 LoRA 适配 + 量化(参考 Dettmers 2022, GPT3.int8)后在不同评估模型尺寸(4B/8B/30B)下的总分。值得展开的现象:
- LoRA 适配是关键:从 Base → LoRA,三个评估器下总分跃升 +0.15 ~ +0.17,意味着 0.6B 基座本身在 next-query 任务上能力不足,监督微调的 task-aware 信号是主要驱动力;
- Quant 损失可控:从 LoRA → LoRA+Quant,总分回退仅 0.02 ~ 0.03,表明 4-bit / INT8 级量化没有破坏 LoRA 学到的语义/逻辑/风格能力。这一性质对端侧部署至关重要——它意味着量化压缩"几乎免费";
- 评估模型规模与判分趋势一致:4B / 8B / 30B 的评估器都把 LoRA > LoRA+Quant > Base 的偏好关系打出来,且大模型的判分更"严格"(同样 LoRA 配置下 8B 评估器给的分普遍低于 4B),但相对排序鲁棒。
在线 A/B 实验¶
实验在 Mobile Taobao 4 个场景跑一个月,覆盖数千万用户。考虑端侧存储约束,RecGPT-Mobile 部署用的是 Qwen3-0.6B-Quant,超参取 $\lambda_1 = 0.4, \lambda_2 = 0.3, \lambda_3 = 0.3, \tau = 0.8$(通过启发式实验搜索得到)。
Table 3: 在线实验结果
| Scenario | CLICK | PAY | GMV |
|---|---|---|---|
| Payment Success Page | +1.3% | +2.3% | +2.5% |
| Shipment Tracking Page | +2.4% | +2.9% | +3.0% |
| Shopping Cart Page | +2.5% | +2.7% | +2.9% |
| Order List Page | +0.8% | +1.8% | +1.8% |
| Average | +1.8% | +2.7% | +2.5% |
四个场景在三个核心电商指标上一致提升——尤其购物车页和物流追踪页这两个传统 Feed"次要场景"的提升最大(CLICK +2.4 ~ +2.5%),说明 RecGPT-Mobile 在原本 Feed 模型信号弱的场景下增量最显著。订单列表页相对最低(CLICK +0.8%),可能因为订单页的用户意图偏"完成消费闭环"而非"探索新意图",意图理解的边际价值较小。
端侧推理稳定性¶
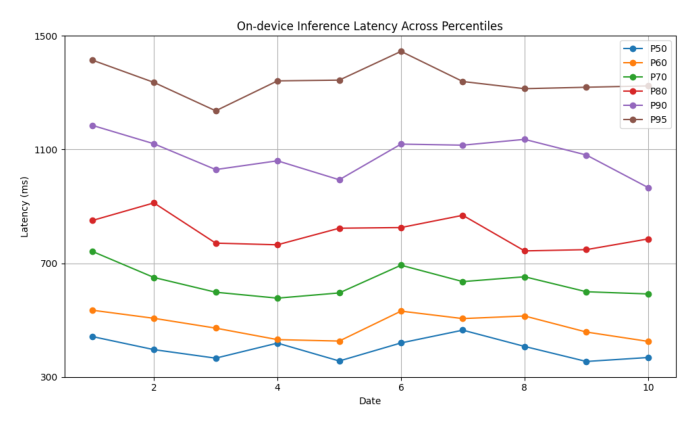
作者在真实手机用户人群上做了 30 天的跨日 latency 监测(多 percentile):
- 各 percentile 横向走势在整 30 天保持稳定,没有系统性退化;
- 高 percentile(P95、P99)即便存在意料之中的 tail latency 抬升,整体波动幅度仍可控;
- percentile 之间的方差更多来源于真实设备多样性(不同机型 CPU/NPU 性能差异)而非系统性能漂移。
这一结果说明:在移动客户端复杂运行环境(系统负载、电量管理、多应用切换、热降频)下,整套部署仍维持可预测的响应——这对工业落地的稳定性是关键保证。
与已归档相关工作的对比¶
MobileLLM-Pro MobileLLM-Pro: 1B Foundation Model for On-Device Inference (Meta, 2025-11-10)¶
关系:独立并发(本文未引用 MobileLLM-Pro,两者殊途同归地解决"在手机上跑 LLM"的根本问题)· 已加载对方精读
- 共同关注的问题:1B 量级 LLM 直接在手机/可穿戴等资源受限设备上推理时,浮点权重 / 激活无法满足内存与延迟约束,且简单 PTQ 会带来 >10% 的能力回退。两者都把"端侧 LLM 部署的精度-效率权衡"作为核心 root cause;
- 相近的技术骨架:都通过 4-bit 等级量化(RecGPT-Mobile 的 LoRA+Quant、MobileLLM-Pro 的 4-bit QAT)+ 基座蒸馏 / 适配把 1B 级模型压到端侧可执行,且都强调"量化后能力回退要可控";
- 本文的差异与推进:MobileLLM-Pro 投入大量精力做通用基座——四阶段预训练(语料收集、隐式位置蒸馏到 128k、specialist merging、4-bit QAT)+ 1.4T token 训练预算,目标是替代 Gemma 3-1B / Llama 3.2-1B 这类通用模型;RecGPT-Mobile 则把基座当作既得(直接用 Qwen3-0.6B),把所有创新集中在 任务侧适配:监督微调 + 自适应 Prompt 构建 + 触发频率控制。两者形成漂亮的互补——MobileLLM-Pro 解决"什么基座能装到手机上",RecGPT-Mobile 解决"装上去后怎么针对一个推荐任务把它用好且省电";
- 可比的方法 / 实验差异:MobileLLM-Pro 在 11 项通用 benchmark 上做评估(HellaSwag、ARC、TriviaQA 等),关心的是知识 + 推理;RecGPT-Mobile 用 LLM-as-a-Judge 的语义/逻辑/风格三维评分 + 在线 GMV / CLICK / PAY 提升,关心的是任务相关性与商业转化。MobileLLM-Pro 的 4-bit QAT 在 CPU 上回退仅 0.7%,RecGPT-Mobile 的 LoRA+Quant 总分回退 ~0.03(≈ 3.6% 相对回退),考虑后者用的是 0.6B 而非 1B 基座、且没做 QAT,差距合理。
RecoGEM RecoGEM: FP8 Inference for OneRec-V2 (Kuaishou, 2026-03-12)¶
关系:独立并发(本文未引用 RecoGEM,两者面向同一目标但部署位置正交)· 已加载对方精读
- 共同关注的问题:LLM-style 生成式推荐模型推理成本过高,单纯靠训练侧投入无法匹配工业流量预算,必须在推理侧通过模型压缩 + 系统优化把延迟与吞吐拉到产线可承受。两者都明确指出"传统推荐模型权重/激活高方差使量化困难、生成式 LLM-rec 范式更适合量化"这一前提;
- 相近的技术骨架:都把"PTQ + 推理基础设施优化"作为主线——RecoGEM 用 FP8(per-channel 权重 + per-token 激活 + block-wise MoE GEMM)+ TensorRT 算子库优化;RecGPT-Mobile 用 LoRA+Quant 的 INT4/INT8 等级量化 + 端侧推理优化。两者都接受"量化必然带来精度损失",并通过工程手段把损失压到可接受范围;
- 本文的差异与推进:RecoGEM 彻底走服务器侧——优化的是 H100 集群上的 OneRec-V2 4B fat-MoE 推理,目标是 49% 延迟降 + 92% 吞吐升;RecGPT-Mobile 彻底走客户端侧——优化的是中端手机上的 0.6B 单分支 LLM 常驻推理,目标是 60% 电量降 + 21% 触发率。两者代表了"LLM-based recommendation 的两种降本路径":一种通过提升服务器侧效率维持云端调用模式,另一种把推理整体迁移到客户端从根本上消除 RPC 开销;
- 可比的方法 / 实验差异:RecoGEM 的核心创新在数值分析(系统对比传统 rec / OneRec-V2 / Qwen3-8B 的权重激活分布)和 kernel 层优化(RadixTopK / TMA-enabled grouped GEMM);RecGPT-Mobile 的核心创新在 prompt 适配(4 阶段算法)和触发控制(熵+Jaccard+JS 三信号融合),完全不在同一层栈。但两者一个共同启示是:生成式 LLM-rec 与传统 rec 模型相比,权重/激活分布更接近 LLM 的"低方差"特性,使主流的量化技术可以直接迁移——这是 RecoGEM 在数值层面证实、RecGPT-Mobile 在工业 A/B 端侧落地间接验证的同一个现象。
讨论与局限性¶
核心贡献总结¶
- 首个端侧 LLM-based 工业推荐系统:把 0.6B 量级 LLM 真正下沉到 Mobile Taobao 客户端,覆盖 4 个场景与数千万用户,证明了端侧 LLM 在工业 next-query 预测中的可行性;
- 自适应 Prompt 构建算法:把硬编码模板替换为"特征抽取 → 模板打分 → 结构裁剪 → 预算闭包"的 4 阶段搜索流程,让同一个端侧 LLM 在不同场景下都能拿到最有信息量的输入;
- 意图漂移触发机制:用熵 + Jaccard + JS 散度的复合信号把 LLM 调用频率与"意图变化频率"对齐,把电量损耗压到 40%、触发率 21%;
- 工业级 A/B 验证:4 个场景一个月覆盖数千万用户,CLICK +1.8% / PAY +2.7% / GMV +2.5% 平均提升。
值得借鉴的设计¶
- "基座既得 + 任务侧最大化":放弃自己造 1B 通用基座,用现成的 Qwen3-0.6B 配合 LoRA + 任务数据,把所有工程预算集中在意图理解的具体任务上——这种"任务驱动的轻量化"在工业场景普遍适用;
- "频率绑定意图而非行为":trigger 管线的设计哲学是把"什么值得 LLM 解读"从原本的连续行为流降到稀疏的"意图切换事件"。这条设计思路对所有"端侧 LLM 应用"都有迁移价值:手机助手、本地 RAG、智能输入法都能从中受益;
- 多源训练样本融合:60% 行为驱动 + 20% 共购 + 15% LLM 改写 + 5% 人工标注的配比,覆盖"主信号 + 互补品 + 表述多样性 + 金标"四个维度,是相对成熟的工业训练数据构造范式。
存在的局限与争议¶
- 方法描述偏概略:作为 4 页的 short paper,关键的 $M_\text{score}$(prompt 打分器)实现细节、$\Phi$ 各分量的具体定义、$C_\text{max}$ 的数值边界、量化方案(INT4 / INT8)的具体配置均未披露。读者较难复现;
- 触发参数靠启发式:$\lambda_{1,2,3}$ 与 $\tau$ 用"实验启发式搜索"得到,没有报告 grid 范围或敏感性分析。在不同行为分布的场景下泛化性未验证;
- 缺少消融:自适应 prompt 构建(4 阶段)每一阶段的边际增益、触发管线 vs. 全量调用的离线对比、4 类训练样本的剪枝消融均未提供——只剩下"端到端 A/B 提升"作为最终佐证;
- 对比基线偏弱:在线对比是 RecGPT-Mobile vs. 现有推荐基线(未明确说明),而非与"云端 LLM next-query 预测"这一最直接的同任务方案对比。考虑到云端方案理论上能用更大的模型(甚至 Qwen3-30B),端 vs. 云的能力-成本权衡缺少实证;
- 未与 MobileLLM-Pro / RecoGEM 等并发工作互引:本文 2026-05-06 上线、5 页篇幅,且自身引用上线于 2025-11 的 RecGPT 技术报告(同团队),却未引用同时段同样关注 LLM 端侧 / 量化的 MobileLLM-Pro(2025-11)和 RecoGEM(2026-03)——是 short paper 的版面限制还是确实未察觉,存疑。
工业落地价值¶
这是一篇典型的"工程驱动的应用论文"——重点不在算法新颖性,而在把一系列既有技术(LoRA、量化、prompt engineering、漂移检测)端到端串成可工业部署的方案,并在 Mobile Taobao 这种亿级 DAU 流量下验证。其对从业者的最大启示:
- 端侧 LLM 已具备工业可部署性:0.6B 量级 + 量化 + LoRA 的组合在主流安卓机型上可常驻推理,没有不可逾越的性能门槛;
- 触发频率比模型本身更值得优化:当模型能力达到工业基线后,进一步压力转移到"什么时候不调"——RecGPT-Mobile 用 21% 触发率取得 +1.8 ~ +2.7% 业务提升,本质是用调用稀疏化在能力守恒的前提下实现成本-效率帕累托改进;
- 客户端比云端更适合个性化意图理解:用户行为的局部聚类性(短时间内意图集中)让端侧滑动窗口式漂移检测天然奏效,云端拿不到这种"行为本地连续性"的细粒度信号。