MobileLLM-Pro Technical Report 精读¶
研究动机与背景¶
近年大语言模型(LLM)通过堆叠参数规模与算力,把通用能力推向新高度,但同时也带来了不可接受的推理延迟、能耗与服务器成本。与之并行的另一条研究路线,则聚焦在 2B 参数以内 的"小型基座模型"——它们牺牲少量绝对能力,换来三个对端侧 AI 至关重要的特性:(1) 不依赖网络往返、降低响应延迟;(2) 离线可用、保障隐私;(3) 易于在手机、可穿戴等资源受限硬件上常驻部署。
然而,把 1B 级模型真正打磨到"可用于手机"的状态,作者归纳出三条尚未被充分解决的难题:
- 训练鲁棒性差:小模型对数据质量与分布漂移的敏感度远高于大模型,跨阶段切换数据混合方案时极易出现性能塌陷;
- 长上下文能力难以延伸:当前主流 1B 模型的训练上下文普遍停在 8k~32k token,要把窗口扩到 128k 既要应对 KV-cache 的内存压力,又要解决"训练-推理位置分布失配";
- 极致压缩带来的精度损失:要在端侧 CPU/NPU 上运行,权重和激活必须降到 4bit;而对 1B 模型直接做 PTQ(post-training quantization)通常会带来 >10% 的能力回退。
本工作介绍 MobileLLM-Pro,Meta Reality Labs 推出的 1B 参数(实际 1.084B)端侧基座模型。在 11 项常用预训练 benchmark 上同时超越 Gemma 3-1B 与 Llama 3.2-1B,支持 128k 上下文,4-bit 量化后平均仅回退 ~0.7%~1.3%(CPU/NPU)。其能取得 SOTA 的关键,作者总结为四项相互配合的创新:
- Simulation-Driven Data Mixing(基于 Automixer/SDM 的离线模拟数据配比);
- Implicit Positional Distillation(隐式位置蒸馏,在不接触长上下文数据的前提下把模型扩展到 128k);
- Specialist Model Merging(多专家并行训练 + 非均匀加权合并,无参数膨胀);
- 4-bit Quantization-Aware Training(量化范围学习 + 自蒸馏)。
模型权重、量化权重与代码均已开源在 HuggingFace facebook/mobilellm-pro 系列下。
模型架构¶
MobileLLM-Pro 以标准 Transformer 为基础,并融合 Llama 系列的若干设计选择。其细节如下:
| 维度 | 数值 |
|---|---|
| Layers | 30 |
| Attention Heads | 20 |
| KV Heads | 4 |
| Hidden Dim | 1280 |
| FFN Hidden Dim | 6144(≈ 4.8× upscaling) |
| Vocab Size | 202,048(沿用 Llama 4 词表) |
| Total Params | 1,084 M |
| Context Length | 128k tokens |
| Embeddings | Tied / Shared |
| Attention | Local-Global 交错(Local 滑动窗口=512,每 4 层一个 Global) |
几项非平凡的设计取舍值得展开:
- 共享 Embedding(Tied / shared embeddings):1B 模型若沿用 Llama 4 的 202,048 词表,单独的输入 embedding 与 LM head 会占整模 ~25%(约 260M 参数)。共享之后参数预算可被释放给 Transformer 主干,提升表达能力。
- GQA(Grouped-Query Attention)4 KV-heads:把 KV 投影压到 4 头,KV-cache 体积是 dense 的 1/5,对 128k 长序列推理的内存压力直接缓解。
- 3:1 Local-Global Attention:每 3 层 local(512 token 滑窗)配 1 层 global(全 128k);首层和末层强制为 global 以保留全局信号。Local 层的 QPS/吞吐显著优于 dense attention,又不至于完全放弃跨段信息。
- 128k 上下文:相比 Gemma 3-1B(32k)、Qwen 3-0.6B(32k)、Llama 3.2-1B(128k)四倍于多数同体量模型。
四阶段预训练流程概览¶
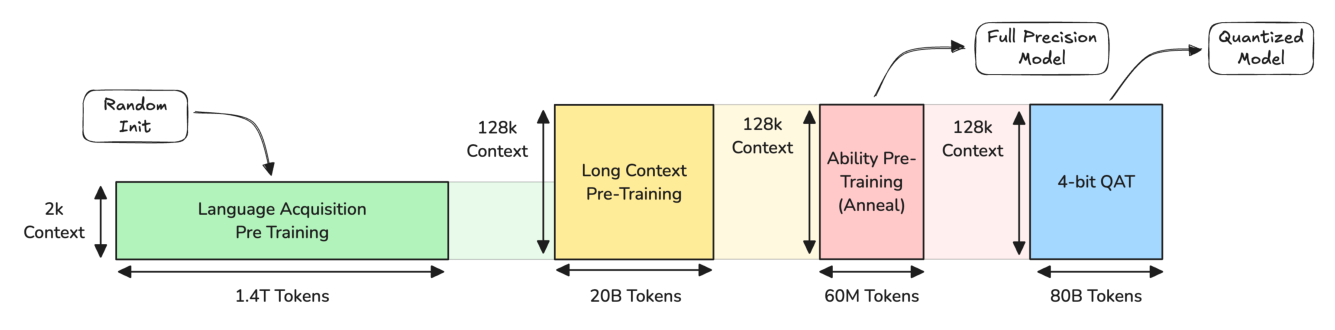
整个预训练分为四个功能-数据预算双重不对称的阶段:
| 阶段 | 目标 | Token 预算 | 上下文 |
|---|---|---|---|
| Phase 1 — Language Acquisition | 通用语言能力 | 1.4 T | 2k |
| Phase 2 — Long-Context Pre-Training | 扩窗到 128k | 20 B | 128k |
| Phase 3 — Ability Anneal(Specialist Merging) | 能力分化与融合 | 60 M | 128k |
| Phase 4 — 4-bit QAT | 端侧高效推理 | 80 B | 128k |
值得注意的是 Phase 3 仅 60M token——这是在已有稳定权重之上的极小步长 annealing,意在让若干并行 specialist 在同一收敛盆地内做小幅分化,再被合并回主权重。Phase 4 (QAT) 则是用 ~5% 的全精度训练算力做最后的"量化对齐"。
整个流程贯穿一项设计原则:所有 Phase 都做 logit-based KD——以 Llama 4-Scout 为 teacher,使用 forward-KL 损失替代标准的 one-hot 交叉熵。教师不仅给出 next-token 分布,更隐式地携带了"长上下文位置关系"信息(详见 Phase 2)。形式上:
$$\mathcal{L}_{\text{KD}} = \sum_{v \in \mathcal{V}} p_T(v \mid x_{<t})\, \log\frac{p_T(v \mid x_{<t})}{p_S(v \mid x_{<t})} \tag{1}$$
其中 $p_T, p_S$ 分别为教师和学生在词表 $\mathcal{V}=$ 202,048 上的概率分布。该信号对 1B 学生而言比 one-hot 更"密集",是后续若干阶段的载体。
Phase 1 — 基于离线模拟的数据混合(Language Acquisition)¶
Phase 1 是最长(1.4T tokens)也是最敏感的一阶段,从随机初始化起步。作者沿用 Scalable Data Mixer (SDM, Chang et al., 2025b) 的思路:与其"线上动态调整每一个 batch 的数据采样比",不如先做一次离线模拟,把整个语料过一遍轻量统计语言模型(SLM),再据此一次性导出静态采样权重 $w_i$。
形式上,SDM 把样本 $x$ 对域 $\mathcal{D}$ 的影响定义为:用 $x$ 更新 SLM 前后,$\mathcal{D}$ 上交叉熵损失的差值。所有 sample-level 的 domain influence 聚合成影响向量 $\Delta$;再用一个轻量神经回归器把 $\Delta$ 映射为该 domain 的 downstream utility $\hat{y}$。最终的静态采样权重 $w_i$ 即由各域的 $\hat{y}$ 决定。该方法的优势是避免在线动态调权的训练开销,又不像静态 uniform mix 那样浪费高 utility 数据。
Phase 1/2 实际使用的 7 个数据域如下:
| Dataset | Rows (M) | Tokens (B) | Weight (%) |
|---|---|---|---|
| Fineweb-EDU (2024) | 1279.6 | 1300 | 89.75 |
| Starcoder (2023) | 206.6 | 263.8 | 4.66 |
| Open Web Math (2023) | 6.1 | 12.6 | 1.92 |
| Arxiv (2023) | 1.5 | 28 | 1.35 |
| Wiki | 7.2 | 3.7 | 1.02 |
| Stack Exchange (2023) | 29.2 | 19.6 | 1.02 |
| Algebraic Stack (2023) | 3.4 | 12.6 | 0.24 |
| Total | 1500 | 1640.3 | 100 |
关键观察:高质量教育语料 Fineweb-EDU 占 ~90%,但 Starcoder(代码)+ OpenWebMath + Arxiv + Stack Exchange 等"理科 / 推理"信号合计接近 9%,并未被淹没。这一权重并非手调,而是 SDM 模拟跑后给出的稳态分布。
训练超参:max LR = $4\times 10^{-4}$,warmup 10k 步、cosine decay 到 0;effective batch ~ 2M tokens;总 step = 640,000;vocab 全 202,048 logit 都从 Llama 4-Scout 蒸馏。
Phase 2 — Implicit Positional Distillation(核心创新①)¶
直接把 Phase 1 的 2k checkpoint 喂入 128k 长上下文数据来 fine-tune,几乎必然带来两个问题:(a) 数据分布漂移——长文档与 Phase 1 的语言分布显著不同;(b) 数据稀缺——真正高质量、跨段 128k 强相关的语料极少。
作者提出绕过"喂长文档"的方案:让学生在 2k 数据上继续训练,但从一个已经在 128k 上训练过的教师那里以 logit-distillation 方式吸收长上下文位置关系。
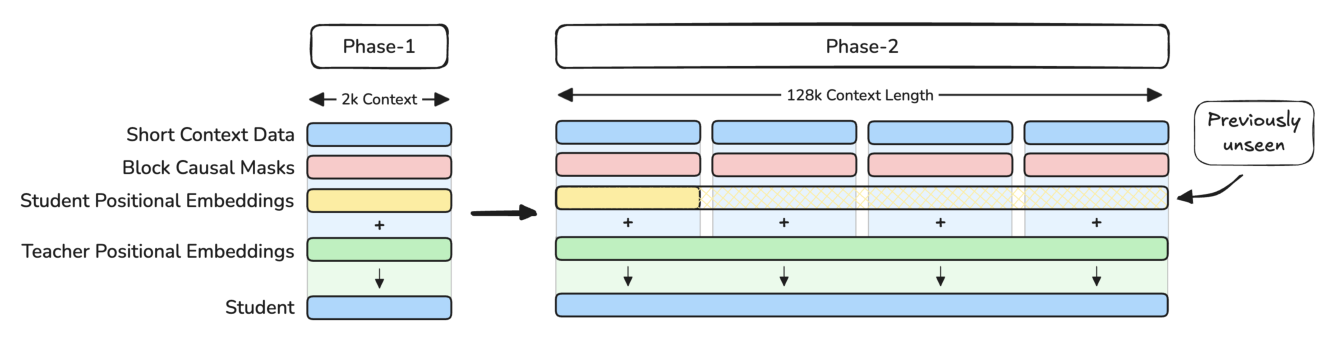
机制的关键是 RoPE、block-causal masking 与 logit KD 三者的协同效应。RoPE 把位置编码进位置-相关的旋转矩阵:
$$\begin{bmatrix} x'_i \\ x'_{i+1}\end{bmatrix} = \begin{bmatrix}\cos(\theta_i p) & -\sin(\theta_i p) \\ \sin(\theta_i p) & \cos(\theta_i p) \end{bmatrix} \begin{bmatrix} x_i \\ x_{i+1}\end{bmatrix} \tag{2}$$
其中 $\theta_i = 10000^{-2i/d}$,$p$ 是绝对位置。Phase 1 训练时学生最大上下文 $L_{\text{short}}$,模型只见过角度区间 $[0, \theta_i \cdot L_{\text{short}}]$,对超出这个范围的角度旋转完全没有信号。
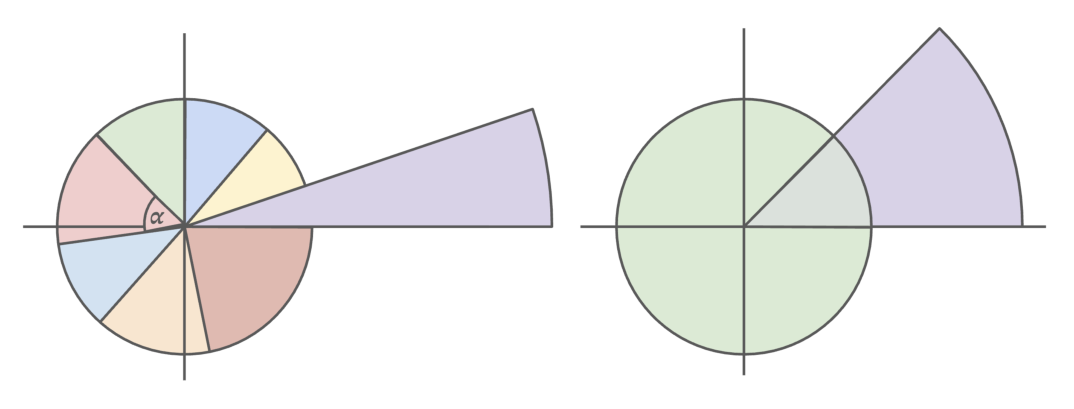
更微妙的是:即便把多个 2k 文档拼接到 128k 长填进 batch(packed batching),由于 block-causal mask 阻断了跨文档信息流,每个文档内部的有效语义距离仍只到 $\alpha = \theta_{\max} - \theta_{\min}$(即文档长度),跨过 $\alpha$ 之后就没有真实长依赖学习信号。
但是!block-causal mask 阻断的是"信息直接跨文档传递",并不阻断"教师 logit 把长上下文位置关系编码进自身的下一 token 分布"。当 teacher(Llama 4-Scout,已在 128k 上训过)对 packed batch 的每个位置都给出一个 logit 分布,这个分布隐含了 teacher 学到的全角度空间位置依赖。学生只要拟合 teacher 的 logit,就在间接吸收这套位置关系——而不需要任何真正的长上下文数据。
这条机制被作者命名为 Implicit Positional Distillation(隐式位置蒸馏)。它带来两个直接收益:
- Phase 2 完全沿用 Phase 1 的 2k 短文档数据,避免数据分布漂移;
- Phase 2 训练量可以做得很短——只需 100k 步、20B token,max LR 降到 $4\times 10^{-5}$,cosine 退火到 0,model parallelism 提升以承载 64× 长的样本。
最终 NIH(Needle-In-Haystack)从 Phase 1 的 6.7 直接拉满到 99.78(详见 §12.3 消融),同时其他基准平均分仅微跌 0.17 点(见 Table 13)。
Phase 3 — Specialist Model Merging(核心创新②)¶
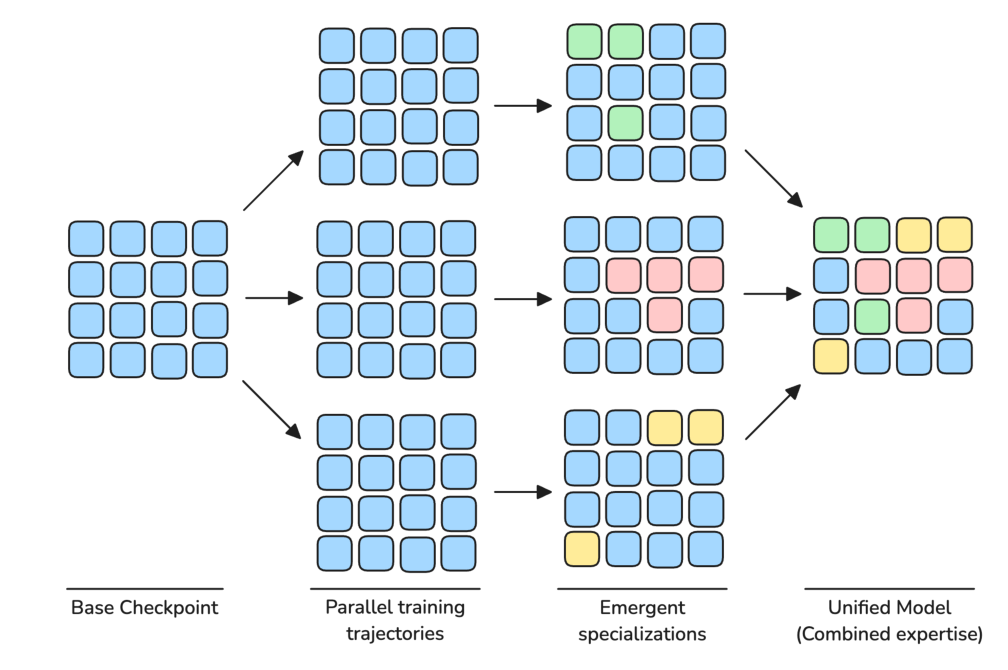
经过 Phase 1 + 2 后,模型已具备通用能力,但缺乏对"reasoning / coding / factuality"等具体能力的针对性强化。常规做法是再拿一段"高质量目标域数据"做 anneal。作者发现:当 anneal 数据涉及多个能力域时,它们之间会互相"挤压"——比如同时灌 reasoning + factual QA 数据,最终模型在两个维度上都不如单灌一个域的专才。
解决方案:并行训练 $n$ 个 domain specialist,再非均匀加权平均合并。形式化地:
- 从 Phase 2 final checkpoint 出发,分支为 $B = (b_1, b_2, \ldots, b_n)$ 共 $n$ 个 specialist,每个 $b_i$ 在单一域 $\mathcal{D}_i$ 上独立训练;
- 训练完毕后,用 per-domain 权重 $w_b$($\sum_b w_b = 1$)对所有分支的全部权重张量做加权平均得到最终模型 $M$:
$$M = \frac{1}{n} \sum_{b=1}^{n} \theta_b \cdot w_b \tag{3}$$
每个 specialist 仅训 60M token / 500 步,学习率从 $1\times 10^{-5}$ 线性退火到 0——这种"小步长 anneal"本身就是 specialist merging 起作用的硬条件:
Specialist Model Merging only works if (1) the model is already in a stable weight-space (i.e. effective only in late pre-training stages); and (2) the parallel updates have to be small to ensure model weights do not divert too far from the initial distribution.
也就是说:作者只在 Phase 3 做这件事,且每个分支训得很短,刻意把所有 specialist 都"留在同一个收敛盆地"内——只有这样,对它们做线性平均才能保留每一个的特长,而不是落到"多个局部最小值之间的鞍点"。
§12.4 的消融非常说明问题(Table 14):
| Model | Pre-Anneal | Specialist 1 | Specialist 2 | Specialist 3 | Specialist 4 | Weight Avg. |
|---|---|---|---|---|---|---|
| HellaSwag | 65.77 | 66.69 | 66.87 | 66.31 | 67.04 | 67.58 |
| BoolQ | 71.28 | 76.51 | 76.94 | 73.64 | 78.47 | 76.82 |
| PIQA | 75.57 | 75.14 | 76.50 | 75.46 | 76.17 | 76.55 |
| SIQA | 47.29 | 47.90 | 50.97 | 46.88 | 50.31 | 51.23 |
| TriviaQA | 36.61 | 36.78 | 40.07 | 37.48 | 39.91 | 40.18 |
| Natural Questions | 12.02 | 12.22 | 15.84 | 11.83 | 16.01 | 16.29 |
| ARC-Challenge | 50.64 | 53.05 | 52.19 | 51.33 | 53.05 | 54.16 |
| ARC-Easy | 71.37 | 75.22 | 76.45 | 73.66 | 76.74 | 76.96 |
| WinoGrande | 63.30 | 63.06 | 63.14 | 62.90 | 63.06 | 63.54 |
| OBQA | 41.80 | 41.40 | 43.40 | 41.80 | 43.40 | 44.00 |
| NIH | 100 | 100 | 100 | 100 | 100 | 100 |
| Average | 53.57 | 54.80 | 56.24 | 54.13 | 56.42 | 56.73 |
可以看到:每个 specialist 在自己擅长的几项上提升明显(如 Specialist 4 把 BoolQ 从 71.28 拉到 78.47),但常常以另一些指标的回退为代价(如 Specialist 1 在 PIQA、Specialist 3 在 ARC-Easy)。Weight Avg.(合并模型)几乎在每一项上都不弱于任何单个 specialist,平均分(不含 NIH)从 Pre-Anneal 的 53.57 → 56.73,比最好的单 specialist(56.42)还高 0.31。作者把这种现象解释为 specialist 之间的 symbiotic relationship——它们在权重空间中各自向不同方向拐了一小步,平均后正好把所有方向的有用信号叠加而抵消掉单方向的负面影响。
至此得到的 checkpoint 命名为 MobileLLM-Pro-base。
Phase 4 — 量化感知训练(QAT)¶
为了真正部署到手机,作者必须把 1B BF16 模型(2.2 GB)压到 4-bit 等级。直接 PTQ 会带来巨大回退(详见 §12.5 Table 17:PTQ 在 CPU 上平均回退 17 分),因此使用 QAT。两种量化方案:
量化方案对照¶
| CPU | Accelerator | |
|---|---|---|
| Weights & Embeddings | INT4 sym, group-size 32 | INT4 sym, channel-wise |
| Activations | INT8 dyn asym per-token | BF16 |
| KV cache | INT8 dyn asym per-token | BF16 |
| QAT algorithm | Vanilla | Learnable quant ranges |
CPU 方案(INT4 group-wise):每 32 个权重共享一个 fp scale 与 zero-point。激活以 per-token 动态非对称 INT8 量化:
$$Q(x_{in}) = s_x \times \text{clip}\!\left(\text{round}\!\left(\frac{x_{in} - z}{s_x}\right), 0, 255\right) + z, \quad s_x = \frac{\max x_{in} - \min x_{in}}{255},\; z = \min x_{in} \tag{4}$$
KV cache 同样 per-token INT8。后端为 xnnpack。
Accelerator 方案(INT4 channel-wise):Apple ANE / Qualcomm HTP 不支持或对 group-wise 支持差,因此每个输出通道共享一个量化 scale。激活与 KV cache 保持 BF16。
QAT 训练目标¶
$$Q(W_g) = s_w \times \text{clip}\!\left(\text{round}\!\left(\frac{W_g}{s_w}\right), -8, 7\right), \quad s_w = \frac{1}{7.5}\max(-w_{\min}, w_{\max}) \tag{5}$$
其中 $W_g$ 是某输出神经元对应的一组权重,$s_w$ 是该组的 scale,$[w_{\min}, w_{\max}]$ 是范围。Vanilla 方案直接把 $w_{\min}, w_{\max}$ 取自 $W_g$ 的实际 min/max;Learnable 方案则把 $w_{\min}, w_{\max}$ 作为可学参数纳入反向传播。
由于 channel-wise 量化的"颗粒度"远粗于 group-wise,learnable range 几乎是 channel-wise 方案能否追上 fp32 性能的关键。Table 15 验证:
| QAT algorithm | Avg. score |
|---|---|
| Compute $w_{\min/\max}$ | 55.67 |
| Learn $w_{\min/\max}$ | 60.46 |
learnable 比 fixed 提升 +4.79 个绝对点。
自蒸馏代替外部教师¶
Phase 4 的另一项设计:用 Phase 3 的 full-precision checkpoint 作为 teacher(而非继续用 Llama 4-Scout)。原因是 self-distillation 让 quant 学生在 logit 层面尽可能逼近 fp 母模型,而不必再拟合一个分布更"远"的教师。Table 16:
| KD setting | Avg. score |
|---|---|
| No KD | 58.61 |
| KD from FP ckpt | 61.04 |
self-distillation 带来 +2.43 点的增益。
QAT 总训练量:80B token,约为 Phase 1 的 5%。
经过 Phase 4 后:
- CPU 模型大小:2.2 GB → 590 MB(embedding + 主干 INT4,权重共享);
- Accelerator 模型大小:720 MB(embedding 不与 LM head 共享,因为多数 NPU 不支持权重共享)。
指令微调(Instruction Fine-Tuning)¶
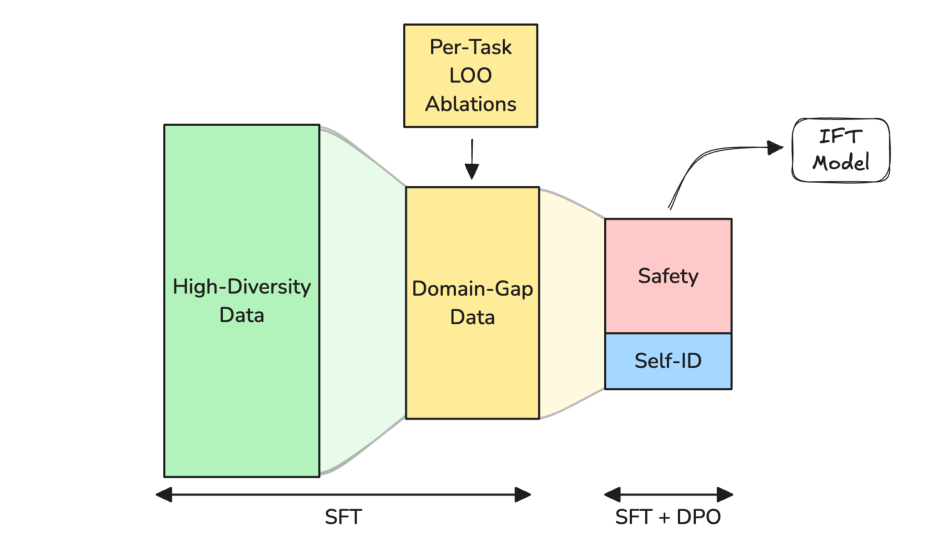
在 MobileLLM-Pro-base 之上,作者继续做了 3 阶段 IFT,得到面向"端侧 AI 助理"场景的指令模型。整个 IFT 沿用 128k 上下文与 local-global attention,但训练目标改为标准 cross-entropy。
Stage 1 — Diversity-First IFT¶
第一阶段用全部 7 个开源 IFT 数据集,按各数据集的样本数自然分布混合(不强行 over-sample 小数据集)。共 7.64M 样本:
| Dataset | Samples (M) |
|---|---|
| Nemotron Math (2025) | 2.70 |
| Nemotron Safety (2025) | 0.03 |
| Nemotron Code (2025) | 0.65 |
| Nemotron Chat (2025) | 0.04 |
| Nemotron Science (2025) | 0.48 |
| Flan (2021) | 2.80 |
| Tulu 3 (2024) | 0.94 |
| Total | 7.64 |
一个值得关注的负面观察:在初始 IFT 阶段尝试 over-sample 小数据集(如 Nemotron Chat / Safety)反而损害整体性能。这与"把分布拉平能提升弱域表现"的直觉相反,但与 §12.1 Table 11 一致:在 IFT 阶段引入 SDM 数据混合让平均分从 17.94% 跳升到 45.23%(uniform 反而极差)。
Stage 2 — Leave-One-Out 调优¶
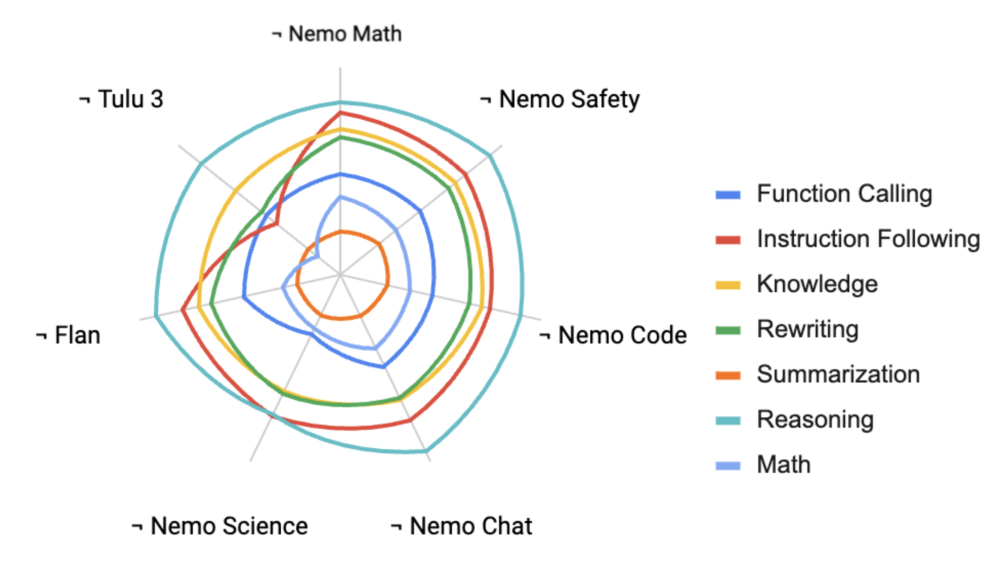
第二阶段做 7 次 leave-one-out(LOO):每次去掉一个数据集,测量在 7 个能力(Function Calling, Instruction Following, Knowledge, Rewriting, Summarization, Reasoning, Math)上的回退。从雷达图可见:
- ¬Tulu 3 与 ¬Nemotron Science 把模型多项能力都拉低最显著——意味着这两个数据集承载了最多的"独家信号";
- ¬Nemotron Math 几乎完全垮掉数学能力;
- ¬Flan 影响相对均匀但温和。
依据 LOO 结果,作者重新加权 Stage 2 数据混合,向 Tulu 3 / Nemotron Science 方向倾斜。
Stage 3 — Safety + Self-ID 对齐¶
第三阶段联合 SFT + DPO(Direct Preference Optimization, Rafailov et al. 2024),数据为内部合成。目标是提升安全性(拒答、有害问询识别)与自我身份认同(who-am-I 类问答),代价是部分 benchmark 分数回退——这是工业部署中典型的 trade-off。
最终 IFT checkpoint 命名为 MobileLLM-Pro(不带 base 后缀)。
主要实验结果¶
预训练 Benchmark(Table 4)¶
11 项常用 1B-class 预训练 benchmark:
| Benchmark | Metric | MobileLLM-Pro | Gemma 3-1B | Llama 3.2-1B |
|---|---|---|---|---|
| HellaSwag | acc_char | 67.11 | 62.30 | 65.69 |
| BoolQ | acc_char | 76.24 | 63.20 | 62.51 |
| PIQA | acc_char | 76.55 | 73.80 | 75.14 |
| SIQA | acc_char | 50.87 | 48.90 | 45.60 |
| TriviaQA | em | 39.85 | 39.80 | 23.81 |
| Natural Questions | em | 15.76 | 9.48 | 5.48 |
| ARC-Challenge | acc_char | 52.62 | 38.40 | 38.28 |
| ARC-Easy | acc_char | 76.28 | 73.00 | 63.47 |
| WinoGrande | acc_char | 62.83 | 58.20 | 61.09 |
| OBQA | acc_char | 43.60 | – | 37.20 |
| NIH | em | 100.00 | – | 96.80 |
亮点:
- 每一项都是当列最优;
- BoolQ +13.04 / NQ +6.28 / ARC-Challenge +14.22 (vs Gemma)、TriviaQA +16.04 (vs Llama) 这种 ≥5pt 的领先在 1B 量级上属"代际差异";
- NIH 满分(100 vs Llama 96.8),印证 implicit positional distillation 的长上下文检索能力。
量化前后对比(Table 5)¶
| Benchmark | Full Precision | Quant-CPU | Quant-Accelerator |
|---|---|---|---|
| HellaSwag | 67.11 | 64.89 | 65.10 |
| BoolQ | 76.24 | 77.49 | 76.36 |
| PIQA | 76.55 | 76.66 | 75.52 |
| SIQA | 50.87 | 51.18 | 50.05 |
| TriviaQA | 39.85 | 37.26 | 36.42 |
| Natural Questions | 15.76 | 15.43 | 13.19 |
| ARC-Challenge | 52.62 | 52.45 | 51.24 |
| ARC-Easy | 76.28 | 76.58 | 75.73 |
| WinoGrande | 62.83 | 62.43 | 61.96 |
| OBQA | 43.60 | 44.20 | 40.40 |
| NIH | 100.00 | 96.44 | 98.67 |
| Average | 61.81 | 61.08 | 60.42 |
总体而言:CPU 版(INT4 group-wise + INT8 激活)平均仅回退 0.73%,Accelerator 版(INT4 channel-wise + BF16 激活)回退 1.39%。在多项指标上甚至出现量化模型超过 fp 母模型的反常现象(如 Quant-CPU 的 BoolQ +1.25, OBQA +0.6),可能源于 QAT 阶段额外的 80B 训练数据带来的弱正则。
指令微调结果(Table 7)¶
9 项 chat-based benchmark,覆盖 Knowledge / IF / Code / QA / Function-Call / Rewrite / Summarization 7 个能力维度:
| Benchmark | Metric | MobileLLM-Pro | Gemma 3-1B | Llama 3.2-1B |
|---|---|---|---|---|
| MMLU | macro_avg/acc | 44.8 | 29.9 | 49.3 |
| IFEval | acc | 62.0 | 80.2 | 59.5 |
| MBPP | pass@1 | 46.8 | 35.2 | 39.6 |
| HumanEval | pass@1 | 59.8 | 41.5 | 37.8 |
| ARC-Challenge | acc | 62.7 | – | 59.4 |
| HellaSwag | acc | 58.4 | – | 41.2 |
| BFCL v2 | acc | 29.4 | – | 25.7 |
| Open Rewrite | micro_avg/rougeL | 51.0 | – | 41.6 |
| TLDR9+ | rougeL | 16.8 | – | 16.8 |
观察:
- 9 项中 7 项 SOTA;MMLU、IFEval 落后于其他对手——前者是知识考试(1B 模型上 MMLU 极依赖训练数据"事实密度"),后者 IFEval 是 Gemma 团队特别针对的强项;
- 在 coding(MBPP / HumanEval)上对 Llama 3.2-1B 有 +7~22pt 优势;
- 端侧"助理"最关心的 Rewrite / Recall / Tool-Calling 三项均最强。
人类评测(Table 8、9)¶
针对 Summarization / Rewrite / Recall / Tool Calling 4 维度各 100 prompt,由人类评审做三向偏好(A 胜 / B 胜 / 平),其中 Tool Calling 因结构化响应可验证,使用 Llama 3-70B 当评审。
vs Gemma 3-1B:MobileLLM-Pro 在 Recall(47/30)、Tool Calling(53/24)上明显领先;在 Summarization、Rewrite 上 Gemma 微胜。 vs Llama 3.2-1B:MobileLLM-Pro 几乎全维度领先,尤其 Recall 56/8、Rewrite 53/30。
端侧延迟(Table 10)¶
在 Samsung Galaxy S25 CPU + S24 HTP 上用 ExecuTorch + xnnpack/HTP 后端测:
| Benchmark | Metric | 2k | 4k | 8k |
|---|---|---|---|---|
| CPU Prefill Latency | s | 8.9 | 24.8 | 63.5 |
| HTP Prefill Latency | s | 2.0 | 3.4 | 9.8 |
| CPU Decode Speed | toks/s | 33.6 | 24.8 | 19.7 |
| HTP Decode Speed | toks/s | 31.6 | 29.0 | 22.8 |
| KV Cache Size | MB | 14.0 | 23.0 | 40.0 |
要点:HTP(NPU)在 prefill 阶段比 CPU 快 4×~6.5×(8k 时 9.8s vs 63.5s);decode 速度差异较小但 HTP 仍占优。值得注意的是 KV-cache 在 8k 也只有 40 MB——主要归功于 GQA + INT8 KV 量化。
消融实验¶
§12.1 数据混合(SDM vs Uniform)¶
| Stage | Tokens | Source | Avg. (%) |
|---|---|---|---|
| pre-training | 1.4T | uniform | 38.70 |
| SDM | 49.31 | ||
| Instruction Tuning | 80B | uniform | 17.94 |
| SDM | 45.23 |
预训练 +10.6pt,IFT +27.3pt——SDM 在 IFT 阶段尤其重要,因为多个 IFT 数据集大小差异巨大(Math 2.7M vs Chat 0.04M),uniform mix 几乎被极小数据集淹没。
§12.2 KD vs CE Loss¶
| Approach | Avg. |
|---|---|
| CE | 49.31 |
| KD | 53.74 |
在 Phase 1 同 FLOP-aligned 比较下,logit KD 相比 one-hot CE 提升 +4.43,验证 teacher logit 的"密集监督"对小模型尤为关键。
§12.3 Implicit Positional Distillation 对比¶
| Stage | NIH | Avg. (excl. NIH) |
|---|---|---|
| Phase-1 (no long-context) | 6.7 | 53.74 |
| Phase-2 (long-context data) | 80.22 | 47.86 |
| Phase-2 (Implicit Pos Distillation) | 99.78 | 53.57 |
这一表是全文最有说服力的结果之一:直接喂长上下文数据虽然能把 NIH 拉到 80,但其他基准平均回退 5.88pt(53.74→47.86),这正是数据分布漂移的代价。隐式位置蒸馏则同时把 NIH 拉到 99.78(接近满分)且通用能力仅回退 0.17pt——可以说在小模型扩窗这件事上做到了近乎"白吃午餐"。
§12.5 QAT 消融(部分见上文)¶
PTQ vs QAT 的代际差距(Table 17):
| Quant setting | Regression vs FP |
|---|---|
| PTQ (round-to-nearest) | 17 |
| QAT | 0.4 |
PTQ 直接套到 Phase 3 checkpoint 会带来 17 点的灾难性回退;QAT + learnable range + self-KD 后只剩 0.4。这与 RecoGEM(OneRec-V2 的 FP8 PTQ)形成对照——RecoGEM 在工业推荐场景下用 PTQ 就能保持精度,因为推荐模型的权重/激活分布更接近 LLM;而通用语言任务的 1B 模型在 4-bit 下必须 QAT。
讨论与局限性¶
核心贡献
- 第一次系统性给出"1B 端侧基座 LLM 全流程蓝图"——从架构选型、4 阶段预训练、专家合并、QAT 直到指令微调,每一步都给出消融与公开 checkpoint;
- 隐式位置蒸馏是本文最具普适性的贡献:它把"长上下文能力"剥离为一种"可被 KD 传递的 logit-level 知识",从而让小模型规避了对长上下文数据的稀缺与高成本采集需求。这一点对学术界(普遍没有 128k 高质量长文本)和工业界(蒸馏成本远低于自训)都很有吸引力;
- Specialist Model Merging 在 60M token 极小预算下取得显著收益,提供了一种"零参数膨胀"的 anneal 方案——尤其适合端侧场景,模型大小被严格约束;
- 量化方面,channel-wise + learnable range + self-KD 的组合,把 1B 级模型在 4-bit 上的回退从 17 点压到 0.4 点,是非常实用的工程贡献。
值得借鉴的设计
- Logit KD 在 Phase 1 即贯穿,而非传统"先 CE pretrain、再蒸馏 finetune"——对小模型这是明显更划算的选择;
- 4 阶段预算高度不对称(1.4T : 20B : 60M : 80B):把绝大多数算力放在通用能力,把 anneal 阶段切到极小预算;
- IFT 阶段坚持自然数据分布,而不是 over-sample 小数据集(与"传统智慧"相反);
- LOO 是评估"哪个数据集贡献了什么"的廉价方法,比 grid search 数据权重便宜得多。
局限性与争议
- 依赖大教师:整套方案对 Llama 4-Scout(数百亿参数)作为持续 teacher 有重度依赖,没有 teacher 的情形下能否复制存在疑问;隐式位置蒸馏要求 teacher 已具备长上下文能力,这一前提对自训 1B 团队不友好。
- Specialist Merging 的解释偏经验:作者将其归因于"symbiotic relationship"和"stable weight-space + small updates",但缺乏理论刻画。在更长 anneal、更多 specialist 或更强差异化数据下,merging 是否仍稳定存在疑问。
- MMLU 落后:1B 在 MMLU 上尤其依赖事实知识密度;MobileLLM-Pro 的 IFT MMLU(44.8)显著低于 Llama 3.2-1B(49.3)。这反映其训练数据偏 reasoning/code 而非"纯事实"。
- 未单独披露 IFT 数据 SDM 权重:作者说 IFT 也用了 SDM,但只给了 base mix 的样本数表,未公开 Stage 1/2 的具体加权——复现性受影响。
- 真实长上下文任务覆盖薄:核心长上下文实验只用 NIH("大海捞针"),其难度低于 LongBench / Ruler / Loong 等多任务长文本 benchmark。NIH 100% 能否外推到真实长文档摘要、跨段推理仍待验证。
- 能耗未披露:端侧场景下功耗和发热往往是真实瓶颈,本文只汇报延迟、未给出 CPU/HTP 工作负载下的功耗数据。
与已有工作的差异
- 相对 MobileLLM (Liu et al. 2024):本文不再聚焦"亚十亿参数下的架构设计"(深窄/embedding sharing 等),而是把 1B 当作大模型的"小化版",将更多精力投入数据与训练流程;
- 相对 SmolLM2 / Qwen3-0.6B / Gemma 3-1B:差异点在 implicit positional distillation 与 specialist merging——其他模型主要靠"更多 tokens + 更好数据";
- 相对 LLaMA-Guard 3-1B-int4 (Fedorov et al. 2024):那是工程上面向 safety 的端侧落地;本文是更通用的基座 + 助手范式。
核心贡献总结¶
MobileLLM-Pro 用工程上极为细致的"全流水线打磨",把 1B 端侧 LLM 的状态推到了一个新的工业可用点:1.084B 参数、128k 上下文、INT4 量化下 590 MB(CPU),同时在 11 项预训练 benchmark 与 9 项 IFT benchmark 上同时领先 Gemma 3-1B 与 Llama 3.2-1B。两项最具普适价值的方法——隐式位置蒸馏(用 logit KD 替代长上下文数据的扩窗手段)与 Specialist Model Merging(用并行短 anneal + 非均匀加权平均替代多域联合微调)——具备脱离当前模型规模与 1B 设定后的更广迁移潜力,也是其他端侧基座工作可以直接借鉴的设计。