SSRLive:用动态语义 ID 驱动的直播推荐¶
SSRLive = Dynamic Semantic ID-guided Streaming Recommendation for Live platforms。来自阿里巴巴淘宝天猫集团(Taobao & Tmall Group of Alibaba),已全量部署在淘宝直播的 pre-ranking(粗排)阶段,服务数亿活跃用户。核心主张:给每个直播间同时生成"静态 SID"和"动态 SID",并把 SID 当作辅助判别式排序的特征(而非生成式检索的目标),配合用户-主播交互信号做多任务粗排预测。
研究动机与背景¶
直播推荐的两个结构性挑战¶
直播已成为增长最快的在线媒体形态之一,支持内容即时广播与用户-主播的实时互动。但论文指出,现有直播推荐算法普遍受制于计算资源利用率低、FLOPs 偏低——传统深度学习推荐模型(Deep Learning Recommendation Models, DLRM,通常由 attention + MLP 构成)在线表现已经很强,但架构层面的进一步打磨只能带来边际收益,且 DLRM 的 Model FLOPs Utilization(MFU)很低,限制了进一步的性能提升。
近年大语言模型(LLM)驱动了生成式推荐(Generative Recommendation)的兴起,其工业落地成功主要来自两点:(1) 可扩展性(Scalability)——基于 Transformer 的模型只要增大参数量就能提升在线指标;(2) 语义 ID(Semantic IDs, SID)——用语义 ID 表示 item,能更好地整合多模态信号、捕捉 item-item 相关性,优于传统 item ID。
然而,把生成式方法直接搬到直播场景面临两个非平凡的挑战(这是全文的核心 motivation):
挑战一:静态 SID 与直播的实时性根本错配。 现有 SID(如短视频场景所用的)是静态且不变(static and invariant)的,而直播间内容随时间实时变化。静态 SID 无法刻画一个直播间的实时信息。
挑战二:纯生成式方法往往无法显式建模用户-主播交互。 用户与主播之间的交互(如点赞 like、下单 order)对于刻画用户对主播和所展示商品的双重意图至关重要,尤其在电商直播场景。但许多现有生成式框架无法有效融入这类交叉交互信号。

Figure 1 用一个主播带货的实例直观呈现了这两个特征:同一直播间在不同时刻人气(观看人数、点赞、订单)持续变化(实时动态),而用户的点赞、下单行为(用户-主播交互)正是判别式排序所依赖的核心个性化信号。
SSRLive 的核心主张¶
针对上述两个挑战,论文提出 SSRLive,采用生成式-判别式混合(hybrid generative-discriminative)架构,联合刻画直播内容的实时性与用户-主播交互:
- 生成式模块(Generative module):为每个直播间构造静态 SID 和动态 SID。静态 SID 来自主播的静态多模态信息(历史直播片段),动态 SID 反映直播间内容的实时变化。用一个 encoder-decoder 架构同时生成两套 SID。
- 判别式模块(Discriminative module):为有效建模用户-主播的交互特征,与现有"直接生成 SID 用于检索"的方法不同,SSRLive 把 SID 当作辅助信息(auxiliary information) 来强化下游判别式任务。为每个任务设置多个可学习 query(learnable queries),从 SID 与用户特征中抽取任务专属表征;抽取出的表征再与 low-rank 特征、cross 特征融合,送入多任务预测层得到最终输出。
论文的三条贡献:
- 提出 SSRLive,一个生成式-判别式混合架构。生成式模块生成静态和动态 SID 以捕捉直播的实时特性;判别式模块从 SID 中抽取任务相关信息,并与 cross 特征整合以建模用户-直播交互。
- 在工业级数据集上的大量离线实验与分析研究表明,SSRLive 同时超越了线上 baseline 和代表性推荐模型。
- 线上 A/B 测试展示了切实的业务收益:观看时长(watch time)+3.38%、GMV +0.72%、关注增长(follower growth)+3.12%、互动量(interaction volume)+2.92%。SSRLive 现已全量部署,服务数亿活跃用户。
预备知识:问题形式化与 pre-ranking 定位¶
问题形式化。 令 $\mathcal{U}$、$\mathcal{S}$、$\mathcal{V}$ 分别表示用户集合、主播集合、当前正在直播的直播间集合。每个用户 $u \in \mathcal{U}$ 由画像特征 $f_u$(如 ID、性别、年龄)和序列特征 $f_h$(如看过的直播间、交互过的商品)描述;每个主播 $s \in \mathcal{S}$ 有特征 $f_s$(如粉丝数、历史开播);每个直播间 $v \in \mathcal{V}$ 有特征 $f_v$(如观看人数、多模态内容)。此外存在用户-直播交互 $c_{u,v}$(如点赞、下单)。目标是:给定这些特征,从 $\mathcal{V}$ 中为用户 $u$ 推荐 top-$k$ 直播间。
Pre-ranking(粗排)定位。 SSRLive 面向推荐流水线中介于检索(retrieval) 与精排(ranking) 之间的粗排(pre-ranking) 阶段。三阶段的形式化对比为:
$$ \begin{aligned} \text{Retrieval:} \quad & \hat{y}_{u,v} = \text{Enc}_u(\mathbf{u}) \cdot \text{Enc}_v(\mathbf{v}), \\ \text{Pre-Ranking:} \quad & \hat{y}_{u,v} = \text{Net}_{\text{pre-rank}}(\text{Enc}_u(\mathbf{u}), \text{Enc}_v(\mathbf{v})), \\ \text{Ranking:} \quad & \hat{y}_{u,v} = \text{Net}_{\text{rank}}(\mathbf{u}, \mathbf{v}), \end{aligned} \tag{1} $$
其中 $\text{Enc}_u$、$\text{Enc}_v$ 是用户、item 编码器,$\text{Net}_{\text{pre-rank}}$ 是轻量交互网络(如 MLP),$\text{Net}_{\text{rank}}$ 是复杂的特征交互网络,$\hat{y}_{u,v}$ 是预测偏好分。检索阶段用双塔分别编码 user 与候选 item 再算点积;精排阶段用单塔把原始特征送进复杂交互网络;粗排居中:user 与 item 先各自被双塔编码,再喂进一个轻量交互网络。
在 SSRLive 中,$\text{Enc}_u$ 主要充当生成式模块,对每个用户只计算一次,负责生成静态和动态 SID;$\text{Net}_{\text{pre-rank}}$ 是轻量的判别式模块,负责捕捉用户-主播交互信息,需要对每个候选直播间分别计算。这个"用户侧重计算一次、直播间侧轻量计算"的设计,是 SSRLive 能在粗排阶段控制延迟的关键。
核心方法 / 模型架构¶
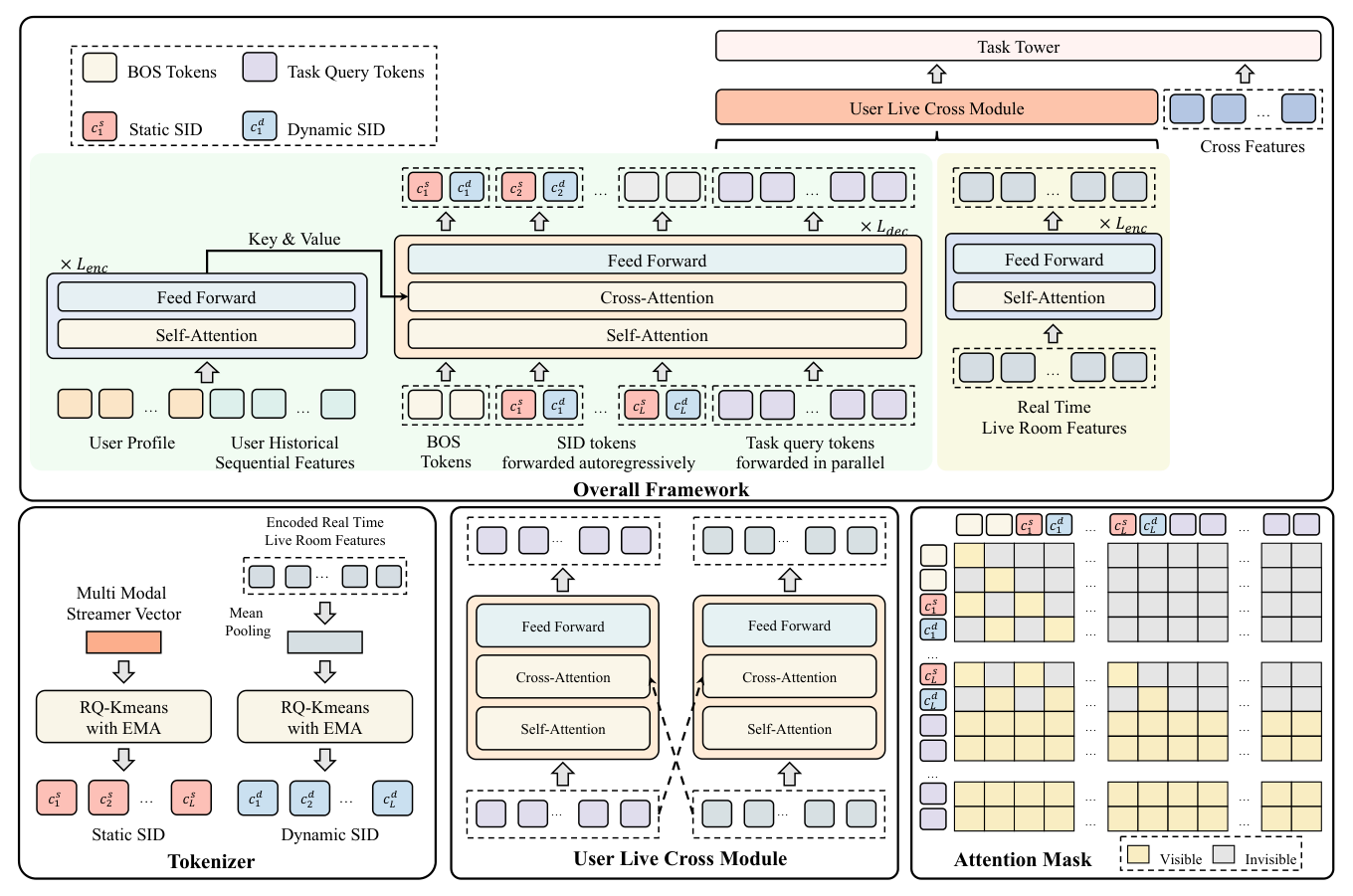
SSRLive 是一个生成式-判别式混合架构(Figure 2)。生成式模块用 encoder-decoder 生成 §4.1 得到的静态和动态 SID;判别式模块为每个任务分配一组可学习 query,从生成的 SID 中抽取任务相关信息用于最终判别式预测,同时利用 cross 特征建模用户-主播交互。下面按"直播间 tokenization → 整体架构 → 训练 → 推理 → 复杂度"展开。
4.1 直播间 Tokenization(Live Room Tokenization)¶
由于直播间内容实时多变,短视频常用的静态 SID 无法刻画其瞬态动态。SSRLive 给每个直播间分配两个互补的标识符:从历史多模态片段导出的静态 SID(§4.1.1)和从当前实时表征生成的动态 SID(§4.1.2)。两者合在一起更完整地刻画直播间信息。
4.1.1 静态 SID(Static Semantic ID)¶
静态 SID 捕捉不随当前直播内容变化的相对稳定特征,由历史多模态片段构造的多模态向量导出。
多模态主播向量(Multimodal Streamer Vector)。 编码主播最近 $M$ 天历史直播间片段的多模态内容(如图像、音频)。每天采样 $N_{\text{seg}}$ 个片段,每个主播共得到 $M \times N_{\text{seg}}$ 个片段。每个片段用一个微调过的多模态模型嵌入成 $\mathbf{e}_{\text{seg}} \in \mathbb{R}^d$,拼接成 $\mathbf{E}_{\text{seg}} \in \mathbb{R}^{(M \times N_{\text{seg}}) \times d}$。这些嵌入在训练中冻结(frozen)。一个 Transformer encoder 处理 $\mathbf{E}_{\text{seg}}$,其隐状态的平均池化构成主播向量:
$$ \mathbf{h}_s = \text{Mean}(\text{TrmEnc}(\mathbf{E}_{\text{seg}})), \quad \mathbf{h}_s \in \mathbb{R}^d, \tag{2} $$
其中 $\text{TrmEnc}(\cdot)$ 是 Transformer encoder,$\text{Mean}(\cdot)$ 对其输出做 mean pooling。
融入协同信号(Incorporating Collaborative Signals)。 $\mathbf{h}_s$ 虽含丰富多模态语义,但协同信息有限——而协同信息对推荐至关重要。为此采用 Swing 算法挖掘正向主播对,并做主播级对比学习:
$$ \mathcal{L}_{\text{SCL}} = \frac{\exp(\text{sim}(\mathbf{h}_s, \mathbf{h}_s^{+}))}{\sum_{\mathbf{h}_s^{-} \in \mathcal{H}_s^{\text{Neg}}} \exp(\text{sim}(\mathbf{h}_s, \mathbf{h}_s^{-}))}, \tag{3} $$
其中 $\mathbf{h}_s^{+}$ 是 Swing 挖出的正样本,$\mathcal{H}_s^{\text{Neg}}$ 是 in-batch 负样本集合,$\text{sim}(\cdot)$ 是相似度(点积或余弦)。该过程让主播向量同时编码多模态与协同信号。
量化为静态 SID。 训练好的主播向量 $\mathbf{h}_s$ 用 RQ-KMeans(残差量化 K-Means)和 $L$ 级码本量化,得到静态 SID:
$$ C_s = [c_1^s, c_2^s, \ldots, c_L^s], \tag{4} $$
其中 $c_\ell^s$($\ell = 1, \ldots, L$)是第 $\ell$ 级码本中选中码字的索引。
4.1.2 动态 SID(Dynamic Semantic ID)¶
由于直播内容天然实时,只编码主播历史广播信息的静态 SID 无法捕捉直播间的瞬时状态。为此引入动态 SID 表示实时内容信号。
实时直播间编码(Real-Time Live Room Encoding)。 实时直播编码既用于生成动态 SID,也支撑下游多任务判别(§4.2.4)。对一个正在广播的直播间 $v \in \mathcal{V}$,抽取实时特征(如当前观看人数、瞬时片段级内容)$\mathbf{E}_{f_v} \in \mathbb{R}^{N_{f_v} \times d}$,$N_{f_v}$ 是实时特征字段数。
为支持多任务建模,$\mathbf{E}_{f_v}$ 被展平、经 MLP 投影、再 reshape 成 $\widehat{\mathbf{E}}_{f_v} \in \mathbb{R}^{(T \times Q) \times d}$,其中 $T$ 是任务数、$Q$ 是每个任务的 query 数:
$$ \widehat{\mathbf{E}}_{f_v} = \text{Reshape}(\text{MLP}_v(\text{Flatten}(\mathbf{E}_{f_v}))). \tag{5} $$
切片 $\widehat{\mathbf{E}}_{f_v, t} \in \mathbb{R}^{Q \times d}$ 用于学习每个任务 $t$ 的任务专属表征(§4.2.4)。变换后的嵌入送入 Transformer encoder,对其隐状态 mean pooling 得到实时表征:
$$ \mathbf{H}_v = \text{TrmEnc}(\widehat{\mathbf{E}}_{f_v}), \quad \mathbf{h}_v = \text{Mean}(\mathbf{H}_v) \in \mathbb{R}^d. \tag{6} $$
直播间 encoder 参数用一个预训练好的直播推荐模型warm-start,以借用先验的协同与内容知识,加速收敛、提升表征质量。
量化为动态 SID。 实时直播间向量 $\mathbf{h}_v$ 用 RQ-KMeans 配 $L$ 级码本量化,得到动态 SID:
$$ C_d = [c_1^d, c_2^d, \ldots, c_L^d], \tag{7} $$
其中 $c_\ell^d$($\ell = 1, \ldots, L$)是第 $\ell$ 级码本中选中码字的索引。
4.1.3 码本更新(Update of Codebook)¶
实时直播间向量持续变化,固定码本不足以捕捉这种快速变化的表征。为此采用 EMA(Exponential Moving Average,指数移动平均) 方案自适应更新码本条目。
设 $\{\mathbf{h}_v^1, \mathbf{h}_v^2, \ldots, \mathbf{h}_v^B\}$ 为当前 batch 中距离某码向量 $\mathbf{e}_c \in \mathbb{R}^d$ 最近的所有实时向量,EMA 更新定义为:
$$ \begin{cases} N_c^{(t)} = \gamma N_c^{(t-1)} + (1 - \gamma) B, \\[4pt] \mathbf{m}_c^{(t)} = \gamma \mathbf{m}_c^{(t-1)} + (1 - \gamma) \sum_{b=1}^{B} \mathbf{h}_v^b, \\[4pt] \mathbf{e}_c^{(t)} = \mathbf{m}_c^{(t)} / N_c^{(t)}, \end{cases} \tag{8} $$
其中 $N_c$ 是分配给 $\mathbf{e}_c$ 的向量总数,$\mathbf{m}_c \in \mathbb{R}^d$ 是这些向量之和,$t$ 是第 $t$ 个更新步。平滑因子 $\gamma \in (0, 1)$ 取接近 1(如 $\gamma = 0.99$)以保证稳定更新。
对于多模态主播向量(静态侧),由于更新较不频繁、码本相对稳定,EMA 仅在底层向量被刷新时才施加。这一非对称设计呼应了静态/动态 SID 的本质差异:静态侧追求稳定,动态侧追求时效。
4.2 SSRLive 架构¶
SSRLive 是生成式-判别式混合架构(Figure 2)。生成式模块用 encoder-decoder 生成 §4.1 的静态和动态 SID;判别式模块为建模用户-主播交互信息(如点赞、下单)以及 cross 特征,为每个任务分配一组可学习 query,从生成的 SID 中抽取任务相关信息用于最终判别式预测。这一设计让判别式模块既能融入丰富的 cross 特征,又能利用 SID 携带的语义信息。
4.2.1 用户编码器(User Encoder)¶
用每个用户的画像特征 $\mathbf{E}_{f_u} \in \mathbb{R}^{N_{f_u} \times d}$ 和历史交互序列特征 $\mathbf{E}_{f_h} \in \mathbb{R}^{N_{f_h} \times d}$(如过去看过的直播间)表示用户。$N_{f_u}$ 是静态特征字段数,$N_{f_h}$ 是所有历史序列的总长。
静态与历史特征嵌入拼接、加上位置编码,送入 Transformer encoder:
$$ \mathbf{E}_u = [\mathbf{E}_{f_u}; \mathbf{E}_{f_h}] \in \mathbb{R}^{(N_{f_u} + N_{f_h}) \times d}, \quad \widehat{\mathbf{E}}_u = \mathbf{E}_u + \mathbf{P}_u, \quad \mathbf{H}_{\text{Enc}} = \text{TrmEnc}(\widehat{\mathbf{E}}_u), \tag{9} $$
其中 $\mathbf{P}_u$ 是可学习位置嵌入,$\text{TrmEnc}(\cdot)$ 是 $L_{\text{enc}}$ 层的 Transformer encoder。输出 $\mathbf{H}_{\text{Enc}}$ 供后续 decoder 使用。
4.2.2 语义 ID 解码器(Semantic ID Decoder)¶
decoder 的输入序列由三部分组成:先放两个 BOS token($[\text{BOS}]_s$、$[\text{BOS}]_d$,分别用于静态和动态 SID),接着是交错排列(interleaved) 的静态/动态 SID token,最后是一组用于下游多任务的可学习 query:
$$ \text{DecInp} = \{[[\text{BOS}]_s, [\text{BOS}]_d], [c_1^s, c_1^d], \ldots, [c_L^s, c_L^d], [q_1^1, \ldots, q_Q^1, \ldots, q_1^T, \ldots, q_Q^T]\}, \tag{10} $$
其中 $Q$ 是每任务 query 数、$T$ 是任务数。静态/动态 SID 交错组织(如第 $i$ 级是 $[c_i^s, c_i^d]$),使二者在每一级同时生成,避免了朴素拼接导致的双倍生成时间。
为所有 SID token、BOS token、可学习 query 维护专用嵌入表,通过查表得到 decoder 输入嵌入:
$$ \mathbf{E}_{\text{DecInp}} = [\mathbf{e}_{[\text{BOS}]_s}; \mathbf{e}_{[\text{BOS}]_d}; \mathbf{e}_{c_1^s}; \mathbf{e}_{c_1^d}; \ldots; \mathbf{e}_{c_L^s}; \mathbf{e}_{c_L^d}; \mathbf{e}_{q_1^1}; \ldots; \mathbf{e}_{q_Q^1}; \ldots; \mathbf{e}_{q_1^T}; \ldots; \mathbf{e}_{q_Q^T}], \tag{11} $$
其中 $\mathbf{E}_{\text{DecInp}} \in \mathbb{R}^{(2 + 2L + TQ) \times d}$。加位置编码后送入 Transformer decoder:
$$ \widehat{\mathbf{E}}_{\text{DecInp}} = \mathbf{E}_{\text{DecInp}} + \mathbf{P}_{\text{Dec}}, \quad \mathbf{H}_{\text{Dec}} = \text{TrmDec}(\widehat{\mathbf{E}}_{\text{DecInp}}, \mathbf{H}_{\text{Enc}}, \mathbf{H}_{\text{Enc}}), \tag{12} $$
其中 $\mathbf{P}_{\text{Dec}} \in \mathbb{R}^{(2 + 2L + TQ) \times d}$ 是可学习位置嵌入,$\text{TrmDec}(\cdot)$ 是 $L_{\text{dec}}$ 层 Transformer decoder,把 encoder 输出 $\mathbf{H}_{\text{Enc}}$ 同时作为 key 和 value。
Attention Mask(注意力掩码)。 decoder 的自注意力掩码设计见 Figure 2 右下。关键规则:(1) 所有 task query 在一次前向中联合传播、彼此可见,同时可注意到所有在它之前的 SID token;(2) 对于 SID 位置,静态 SID 只注意之前生成的静态 SID,动态 SID 只注意之前生成的动态 SID——保持两类信息的分离(information separation)。这一掩码设计既允许 task query 一次性并行抽取信息(降低延迟),又保证静态/动态语义不互相污染。
4.2.3 User-Live Cross Module(用户-直播交叉模块)¶
取 $\mathbf{H}_{\text{Dec}}$ 的最后 $T \times Q$ 个隐状态作为 $\mathbf{H}_u \in \mathbb{R}^{(T \times Q) \times d}$,对应所有可学习 query。这些状态编码了从 SID 表征和用户特征中抽取出的任务相关信息。
为建模用户-直播交互,在 $\mathbf{H}_u$ 与来自 Eq.(6) 的直播间表征 $\mathbf{H}_v$ 之间做 cross-attention。直播间分支为:
$$ \widehat{\mathbf{H}}_v = \text{SelfAttn}(\mathbf{H}_v), \quad \widehat{\mathbf{H}}_v = \text{FFN}(\text{CrossAttn}(\widehat{\mathbf{H}}_v, \mathbf{H}_u, \mathbf{H}_u) + \widehat{\mathbf{H}}_v), \tag{13} $$
其中 $\widehat{\mathbf{H}}_v \in \mathbb{R}^{(T \times Q) \times d}$ 是经交叉交互信息增强后的直播间特征。对用户分支对称地施加相同流程,得到 $\widehat{\mathbf{H}}_u$。这个模块是 SSRLive 显式建模"用户-主播交互"这一挑战的落点——它让用户侧的任务表征和直播间侧的实时表征互相注意、互相增强。
4.2.4 多任务预测(Multi-Task Prediction)¶
用增强后的用户特征 $\widehat{\mathbf{H}}_u$、直播间特征 $\widehat{\mathbf{H}}_v$(来自 §4.2.3)和 cross 特征 $\mathbf{c}_{u,v} \in \mathbb{R}^d$ 做多任务预测:
$$ \mathbf{h}_t = \text{Concat}(\text{Flatten}(\widehat{\mathbf{H}}_{u,t}), \text{Flatten}(\widehat{\mathbf{H}}_{v,t}), \mathbf{c}_{u,v}), \quad \hat{y}_t = \text{MLP}_t(\mathbf{h}_t), \tag{14} $$
其中 $\text{Flatten}(\cdot)$ 把矩阵展平成 1D 向量,$\widehat{\mathbf{H}}_{u,t}, \widehat{\mathbf{H}}_{v,t} \in \mathbb{R}^{Q \times d}$ 是对应任务 $t$ 的切片。该设计让每个预测目标都能学到任务专属表征,$\hat{y}_t$ 是任务 $t$ 的预测分。注意 $\mathbf{c}_{u,v}$(用户-直播历史交互特征,如分类目/品牌的 CTR、点赞、订单统计)直接进入预测层——这正是把"判别式个性化信号"注入生成式 SID 框架的关键。
4.3 SSRLive 训练¶
4.3.1 语义 ID 预测(Semantic ID Prediction)¶
用 $\mathbf{H}_{\text{Dec}}$ 的前 $2L$ 个隐状态同时预测静态和动态 SID,交叉熵损失为:
$$ \mathcal{L}_{\text{NTP}} = -\frac{1}{L} \sum_{i=3}^{2+2L} \begin{cases} \log P\big(c_{\lfloor i/2 \rfloor}^d \mid \text{DecInp}_{<i}\big), & i \bmod 2 = 0, \\[4pt] \log P\big(c_{\lceil i/2 \rceil}^s \mid \text{DecInp}_{<i}\big), & i \bmod 2 = 1, \end{cases} \tag{15} $$
其中 $i \bmod 2 = 0$ 指动态 SID token、$i \bmod 2 = 1$ 指静态 SID token。索引 $i$ 从 3 起,因为按 Eq.(10),SID token 从第三个元素开始;$\lfloor i/2 \rfloor - 1$ 与 $\lfloor i/2 \rfloor$ 把 decoder 输入索引 $i$ 转换成对应的动态/静态 SID 索引。$\text{DecInp}_{<i}$ 是位置 $i$ 之前的部分 decoder 输入(作为条件上下文),初始时 $\text{DecInp}_{<3} = [[\text{BOS}]_s, [\text{BOS}]_d]$。这是一个标准的 next-token prediction(NTP)目标,但交错生成静态/动态 token。
4.3.2 多任务学习(Multi-Task Learning)¶
多任务损失为:
$$ \mathcal{L}_{\text{MTL}} = \sum_{t=1}^{T} w_t \, \mathcal{L}_t(y_t, \hat{y}_t), \tag{16} $$
其中 $y_t$ 是任务 $t$ 的真值标签,$\mathcal{L}_t$ 是任务专属损失(如二分类用 binary cross-entropy),$w_t$ 是任务 $t$ 的权重。整体训练目标为:
$$ \mathcal{L}_{\text{Total}} = \mathcal{L}_{\text{MTL}} + \lambda_{\text{NTP}} \mathcal{L}_{\text{NTP}} + \lambda_{\text{Reg}} \|\Theta\|_2^2, \tag{17} $$
其中 $\lambda_{\text{NTP}}$ 控制语义 ID 预测损失的贡献,$\|\Theta\|_2^2$ 是 $L_2$ 正则项,$\Theta$ 是所有模型参数。即:判别式多任务损失为主,SID 生成的 NTP 损失为辅,共同优化——这就是"生成式辅助判别式"在损失层面的体现。
4.4 SSRLive 推理¶
4.4.1 Beam Fusion(束融合)¶
训练时 Eq.(15) 的 NTP 损失用 teacher forcing 策略最小化,每步喂入真值 token 引导生成。推理时则用 beam search 联合生成静态和动态 SID。与常规 beam search 不同,SSRLive 维护两组独立的 beam,分别为静态和动态 SID 各产出 $B$ 个候选序列。对每个静态候选序列,第 $b$ 个 beam 的得分为:
$$ p_b^s = \sum_{\ell=1}^{L} \log P\big(c_{b,\ell}^s \mid [\text{BOS}]_s, c_{b,1}^s, \ldots, c_{b,\ell-1}^s\big), \quad \hat{p}_b^s = \exp(p_b^s) \Big/ \sum_{b'=1}^{B} \exp(p_{b'}^s), \tag{18} $$
其中 $\hat{p}_b^s$ 是第 $b$ 个静态 SID 候选的归一化概率。动态 SID 的归一化概率 $\hat{p}_b^d$ 同理得到。
$B$ 个候选序列各自产生一组隐状态 $\mathbf{H}_{u,b}$(§4.2.3)。用每个候选对应的静态/动态归一化概率的平均值加权,得到融合表征:
$$ \mathbf{H}_u^{\text{Fuse}} = \sum_{b=1}^{B} \frac{\hat{p}_b^s + \hat{p}_b^d}{2} \cdot \mathbf{H}_{u,b}. \tag{19} $$
聚合表征 $\mathbf{H}_u^{\text{Fuse}}$ 再经 Eq.(13) 和 Eq.(14) 得到最终预测。这一 beam fusion 把多个 SID 候选的不确定性融入表征,而非硬选 top-1。
4.4.2 Fusion Score(融合分)¶
在线服务阶段,把 Eq.(14) 的多任务预测分组合成单一融合分用于粗排:
$$ y_{\text{Fuse}} = \prod_{t=1}^{T} \hat{y}_t^{\alpha_t}, \tag{20} $$
其中 $\alpha_t$ 是任务 $t$ 的权重,根据线上表现调优。这是工业多任务粗排常见的乘性融合形式。
4.5 复杂度分析(Time Complexity Analysis)¶
论文专门分析了计算复杂度,以论证 SSRLive 在粗排阶段的可部署性:
- 用户侧(User Side):encoder-decoder。encoder 复杂度 $O(N_u^2 d + N_u d^2)$,$N_u = N_{f_u} + N_{f_h}$;decoder 复杂度 $O(N_d^2 d + N_d d^2 + N_d N_u d + N_u d^2)$,$N_d = 2 + 2L + TQ$。由于 $Q, T \ll N_u$,decoder 成本相对低。
- 直播间侧(Live Room Side):实时直播特征先映射成 $\widehat{\mathbf{E}}_{f_v} \in \mathbb{R}^{(TQ) \times d}$(Eq.5),经 Transformer encoder 处理,复杂度 $O(N_q^2 d + N_q d^2)$,$N_q = TQ$。
- User-Live Cross Module:作用在 $\mathbf{H}_u, \mathbf{H}_v \in \mathbb{R}^{(TQ) \times d}$ 上,成本 $O(N_q^2 d + N_q d^2)$,因 $T, Q \ll N_u$,相比用户侧 encoder 微不足道。
关键洞察:用户侧(重)只计算一次,直播间侧和交叉模块(轻)因 $TQ \ll N_u$ 而成本极低,这正是 SSRLive 能在对延迟敏感的粗排阶段对每个候选直播间高效打分的工程基础。
实验设置¶
数据集。 由于不存在同时含直播间实时特征和历史直播片段多模态信息的公开数据集,作者从淘宝直播采集商业数据。收集了一周的用户-主播交互数据,约 10 亿(1B) 条交互记录。每条记录含:用户观看时长、是否下单、是否与主播互动等行为。
Baseline 方法。 与以下代表性方法对比:
- DLRM(淘宝直播线上 baseline):生产级粗排模型,双塔 + 特征交叉模块。用户塔对历史行为做 self-attention、对静态特征 query 做 target-attention;直播间塔编码其特征;顶层特征交叉拼接 user/live 表征 + cross 特征,经 MLP 并用 ppnet 做个性化门控(personalized gating)做多任务预测。
- SASRec:单向 Transformer decoder 建模用户历史、预测 next item。
- ReaRec:推理增强(reasoning-augmented)框架,对 item 序列做多步隐式推理(multi-step latent reasoning)。
- HSTU:面向工业级推荐的高性能 self-attention encoder,作为生成式推荐的骨干。
适配到 pre-ranking。 SASRec、ReaRec、HSTU 原本面向检索阶段,直接对比不公平。为公平起见,用它们的骨干分别编码 user 和直播间特征,得到的表征与 cross 特征拼接后喂进 MLP 做多任务预测,使各方法在同等条件下评估。
评估指标。 在粗排阶段用 AUC 和 GAUC。评估任务包含用户观看时长和用户下单(是否下单)。观看时长被离散成两档:watch30 和 watch200,分别表示观看时长是否超过 30 秒或 200 秒。
实现细节(附录 A.2)。 静态 SID 和动态 SID 各由三级(L = 3) 构成,每级 2048 个码本;每任务 query 数 Q = 2;推理 beam size = 10;学习率 $1 \times 10^{-3}$,weight decay $1 \times 10^{-2}$,优化器 AdamW。
主要实验结果¶
总体性能(Overall Performance)¶
Table 1:不同方法在粗排阶段的离线性能(粗体为最优、下划线为次优,带 * 表示相对次优有统计显著提升)。
| Model | Watch30 AUC | Watch30 GAUC | Watch200 AUC | Watch200 GAUC | Order AUC | Order GAUC |
|---|---|---|---|---|---|---|
| DLRM | 0.7610 | 0.6892 | 0.8229 | 0.7288 | 0.8312 | 0.6727 |
| SASRec | 0.7581 | 0.6781 | 0.8154 | 0.7105 | 0.8205 | 0.6689 |
| ReaRec | 0.7594 | 0.6806 | 0.8167 | 0.7145 | 0.8216 | 0.6689 |
| HSTU | 0.7613 | 0.6823 | 0.8192 | 0.7156 | 0.8249 | 0.6710 |
| SSRLive | 0.7692 | 0.6956 | 0.8255 | 0.7281 | 0.8358 | 0.6946 |
实验结论分析:
- SSRLive 整体最优。 相比强力线上 baseline DLRM 和其它代表性方法,SSRLive 在绝大多数指标上一致领先,验证了"生成式-判别式混合架构 + 动态 SID"的有效性。
- DLRM 是非常强的 baseline。 多数情况下 DLRM 优于其它代表性推荐模型(包括 HSTU)。值得注意的是,Watch200 GAUC 上 DLRM(0.7288)反而略胜 SSRLive(0.7281)——这是 SSRLive 唯一未夺第一的格子,说明在已训练充分的强 DLRM 上进一步提升确实困难。
- 更强骨干带来更好性能。 仅基于 Transformer decoder 的 SASRec 表现相对较差;融入隐式推理的 ReaRec、用更强骨干的 HSTU 取得明显更优结果,凸显骨干架构的关键作用。
消融与分析¶
消融研究(Ablation Study)¶
Table 2:SSRLive 消融结果("w/o"表示移除对应模块)。
| Model | Watch30 AUC | Watch30 GAUC | Watch200 AUC | Watch200 GAUC | Order AUC | Order GAUC |
|---|---|---|---|---|---|---|
| SSRLive | 0.7692 | 0.6956 | 0.8255 | 0.7281 | 0.8358 | 0.6946 |
| w/o SID | 0.7602 | 0.6809 | 0.8179 | 0.7156 | 0.8245 | 0.6773 |
| w/o Dynamic SID | 0.7637 | 0.6861 | 0.8214 | 0.7205 | 0.8280 | 0.6798 |
| w/o Task Queries | 0.7676 | 0.6929 | 0.8246 | 0.7266 | 0.8344 | 0.6960 |
| w/o Cross Features | 0.7593 | 0.6800 | 0.8149 | 0.7100 | 0.8269 | 0.6826 |
| w/o User-Live Cross Module | 0.7675 | 0.6910 | 0.8248 | 0.7253 | 0.8341 | 0.6878 |
逐项分析:
- 语义 ID 的作用。 移除 SID(w/o SID)导致明显性能下降,验证其有效性;移除动态 SID(w/o Dynamic SID)也带来下降,确认其价值。"w/o Dynamic SID" 优于 "w/o SID",说明静态 SID 同样有效——二者都正向贡献。
- Task Query 的作用。 移除 task query(直接用 decoder 最后隐状态做预测)导致性能退化,确认 task query 在从 SID 和用户特征中抽取任务相关信息上的有效性。(注:Order GAUC 上 w/o Task Queries 的 0.6960 略高于完整模型,属个别指标波动。)
- 特征交叉的作用。 移除 cross 特征(w/o Cross Features)或 User-Live Cross Module 均导致性能退化,验证用户-主播交叉特征(交互信息)的重要性。这也表明纯生成式 SID 方法不足以应对本场景——必须配合判别式的交叉交互信号。其中 w/o Cross Features 的下降最严重(如 Watch200 GAUC 从 0.7281 → 0.7100),凸显 cross 特征是性能基石。
动态 SID 案例研究(Case Study of Dynamic SID)¶
Table 3:同一主播在不同时刻的动态 SID 与对应直播间互动统计(5 分钟、30 分钟内的观看数与总观看时长)。聚合时把动态 SID 前两级相同的记录合并。该主播所有时刻的静态 SID 保持 (1512, 646, 631)。
| Dynamic SID | Views (5 min) | Views (30 min) | Total Watch Time (5 min, 分钟) | Total Watch Time (30 min, 分钟) |
|---|---|---|---|---|
| (111, 1559, *) | 92 | 193 | 24 | 84 |
| (111, 1551, *) | 509 | 3,769 | 420 | 3,755 |
| (111, 1194, *) | 773 | 4,441 | 725 | 4,172 |
分析: 同一主播在一天内不同时刻,随着直播间人气变化,动态 SID 也随之变化(第二级码字 1559 → 1551 → 1194 对应观看数与观看时长递增的不同人气档位),而静态 SID 始终保持不变。这直接证明:动态 SID 能有效捕捉直播间的实时时序变化,静态 SID 则稳定刻画主播的固有属性。
Task Query 可视化(t-SNE)¶
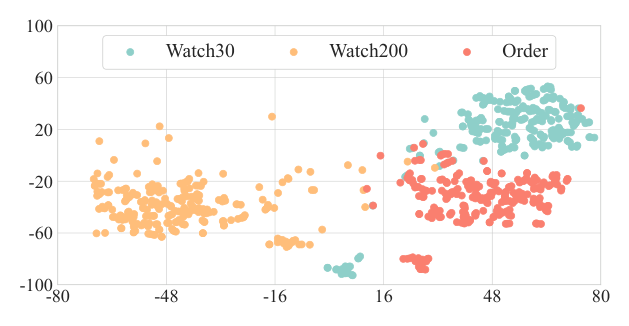
对 $\mathbf{H}_u$ 中 task query 抽取的表征做 t-SNE 降维(Figure 3)。不同任务的 query 产生彼此分离的簇,说明:一方面不同任务需要不同类型的信息;另一方面 task query 成功学到了多样化信息而未坍塌,确认其有效性。
Scaling 分析¶
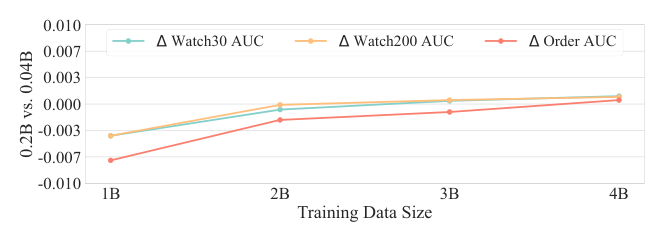
研究增大模型参数对各目标 AUC 的影响(Figure 4),对比 0.2B 参数模型与 0.04B 参数模型的 AUC 差值随训练数据量的变化。结论:训练数据有限时 0.2B 反而不如 0.04B;随数据量增大,0.2B 逐渐超越 0.04B。这表明更大模型收敛更慢、需要更多训练数据,但拥有更高的性能上限——这是生成式推荐"可扩展性"在直播场景的体现,也解释了为什么线上部署选择了相对较小的 0.04B 规模(数据规模与收敛速度的折中)。
Task Query 数量的影响(附录 B.2)¶
Table 7:每任务 query 数 Q 对整体性能的影响。
| #Task Query | Watch30 AUC | Watch30 GAUC | Watch200 AUC | Watch200 GAUC | Order AUC | Order GAUC |
|---|---|---|---|---|---|---|
| Q = 0 | 0.7676 | 0.6929 | 0.8246 | 0.7266 | 0.8344 | 0.6960 |
| Q = 2 | 0.7692 | 0.6956 | 0.8255 | 0.7281 | 0.8358 | 0.6946 |
| Q = 5 | 0.7712 | 0.6976 | 0.8284 | 0.7315 | 0.8381 | 0.6956 |
分析: Q = 0 表示无 query,直接用 decoder 最终隐状态预测。结果显示增大 query 数一致提升性能(Q = 5 在多数指标上最优),确认 task query 在抽取任务相关信息上的有效性。线上部署取 Q = 2 应是性能与延迟的折中。
静态 SID 案例研究(附录 B.1)¶

观察发现,共享同一静态 SID 前缀的直播间通常属于同一类目((613, , ) → 女鞋,(111, , ) → 男装),确认静态 SID 有效捕捉了直播内容的类目属性。
在线实验¶
实验设置¶
评估协议: 在线 A/B 测试,对比已部署的粗排 baseline 模型(DLRM)。
评估指标:
- 核心指标(Core metrics):Watch Time(观看总时长)、Watch Count(用户发起的观看会话数)、GMV(成交额)、Order Count(完成的订单数)。
- 互动指标(Interaction metrics):Follower Count(关注主播的用户数)、Interaction Count(在点赞/评论等活动中参与的去重用户数)。
- Hit Rate:对每个目标,定义为该目标的正样本出现在模型最终 top-$k$ 排序列表中的比例。
在线服务(Online Serving): 引入工程优化提升效率:
- Partial Run(部分预跑): 由于数据准备占在线延迟的相当一部分,提前启动生成式模块的计算(在候选直播间数据准备完成之前),有效缩短服务响应时间。
- Async Live Encoder(异步直播编码器,附录 C.1): 直播编码器独立于用户特定信息,可通过外部服务异步计算;当直播间状态变化时编码器刷新输出,该输出可被成千上万个用户请求并发复用。
在线结果¶
Table 4:线上直播平台 A/B 测试(所有指标提升均统计显著)。
| Model | Watch Time | Watch Count | GMV | Order Count | Follower Count | Interaction Count |
|---|---|---|---|---|---|---|
| SSRLive vs. DLRM | +3.38% | +1.89% | +0.72% | +2.36% | +3.12% | +2.92% |
Table 5:在线 Hit Rate。
| Model | Watch30 | Watch200 | Order | Interact |
|---|---|---|---|---|
| DLRM | 0.7172 | 0.6200 | 0.6065 | 0.6350 |
| SSRLive | 0.7438 | 0.6428 | 0.6274 | 0.6580 |
| Improv. | +0.0266 | +0.0228 | +0.0208 | +0.0230 |
Table 6:在线服务效率(延迟以 DLRM 为 100% 表示;Partial Run 指 §6.1.3 的优化)。
| Model | #Param Dense | FLOPs | Latency | Latency (Partial Run) |
|---|---|---|---|---|
| DLRM | 3M | 0.9T | 100% | 100% |
| SSRLive | 0.04B | 15T | 104.41% | 101.33% |
结论分析:
- 核心指标: SSRLive 把 Watch Time 提升 +3.38%、Watch Count +1.89%,说明观看时长更长、观看会话更多;GMV、Order Count 分别 +0.72%、+2.36%,体现变现能力提升。
- 互动指标: Follower Count +3.12%、Interaction Count +2.92%,说明 SSRLive 的推荐更好地连接观众与其偏好主播、鼓励更多互动行为。
- Hit Rate: 所有目标上 SSRLive 都取得更高 Hit Rate(+0.0208 ~ +0.0266),表明预测排序与真实用户行为更对齐。
- 效率: SSRLive 含 0.04B dense 参数、需 15T FLOPs(远大于 DLRM 的 3M 参数、0.9T FLOPs),说明对计算资源的利用率更高(直接回应了 motivation 中"DLRM 低 FLOPs/低 MFU"的问题)。尽管计算量大增,延迟未经优化仅 +4.41%,启用 Partial Run 后仅 +1.33%。
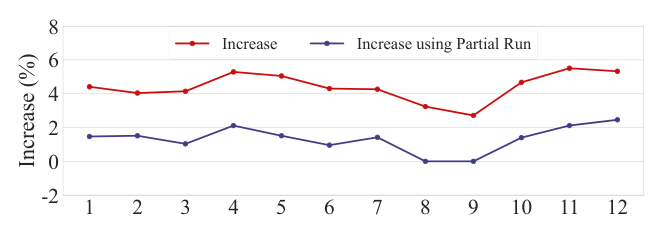
效率分析(附录 C.2,Figure 6):无工程优化时延迟增加约 +4%;启用 Partial Run 后增幅降到 +2% 以下、部分时段甚至 0%。总体而言,SSRLive 在带来显著线上收益的同时,端到端延迟开销可忽略——这是它能全量上线的工程前提。
核心贡献总结¶
- 问题诊断精准: 把"生成式推荐落地直播"的难点凝练为两个结构性挑战——静态 SID 与直播实时性的错配、纯生成式范式丢失用户-主播交互信号,并分别用动态 SID 和判别式 cross 模块对症下药。
- 静态 + 动态双 SID: 静态 SID 由历史多模态片段 + Swing 协同对比学习导出、刻画主播稳定属性;动态 SID 由实时直播特征导出、配合 EMA 在线更新码本以追踪人气/内容的分钟级变化。Table 3 的案例直接验证了动态 SID 的时效性。
- 生成式-判别式混合范式: 与"直接生成 SID 做检索"不同,SSRLive 把 SID 当作辅助特征,通过 task query 抽取任务表征、cross-attention 融合用户-直播交互、再叠加 $\mathbf{c}_{u,v}$ cross 特征做多任务粗排。NTP 损失为辅、MTL 损失为主。
- 工程可部署: 用户侧重计算一次、直播间侧轻量计算($TQ \ll N_u$),配合 Partial Run 与异步直播编码器,把 15T FLOPs 的大模型压进粗排阶段,延迟增幅 ≤ +1.33%,全量服务数亿用户。
与已归档相关工作的对比¶
FLUID FLUID: From Ephemeral IDs to Multimodal Semantic Codes(TikTok, 2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者殊途同归 · 同为直播场景 SID 化)· 已加载对方精读
- 共同关注的问题: 两篇都直面"直播间的标识表征如何刻画实时变化的多模态内容"。FLUID 把根因落在 item ID 易逝(中位生命周期约 40 分钟)→ ID embedding 长期欠训练 → ID-dominance 成为根本瓶颈;SSRLive 把根因落在 静态 SID 无法刻画直播实时性。两者都拒绝"让内容信号在 item ID 旁边作补充"的旧范式。
- 相近的技术骨架: 都用 RQ-KMeans 把直播多模态内容量化成分层语义码,并区分两种粒度——FLUID 是 slice-level(2 分钟瞬态) vs room-level(整场持久,多数投票),SSRLive 是 dynamic SID(实时瞬态) vs static SID(历史持久)。两者都坚持 RQ-KMeans 而非 RQ-VAE(FLUID 明确指出 RQ-VAE 在在线流式重训练下码本坍塌);都把 SID 作为判别式排序的特征而非生成式检索目标。
- 本文的差异与推进: SSRLive 用 encoder-decoder 生成式模块 + NTP 损失显式建模 SID 的自回归生成,并在推理时做 beam fusion;FLUID 则彻底退役 item ID、用 prefix n-gram embedding 把 LUCID 当独立 token 后融合进排序器、分阶段 warmup 替换 ID。SSRLive 额外引入 task query + user-live cross-attention 显式抽取任务表征、建模用户-主播交互,而 FLUID 聚焦候选侧表征替换、未强调用户-主播交叉建模。
- 可比的方法 / 实验差异: FLUID 的动态性靠 slice 切片的频繁重算体现,room 级靠多数投票稳定;SSRLive 的动态性靠 EMA 在线更新码本 + dynamic SID 直接量化实时向量。FLUID 线上 +0.55% Quality Watch Duration / +2.05% Cold-Start Room Views;SSRLive 线上 +3.38% Watch Time / +0.72% GMV。两者都在十亿/数亿用户级生产环境验证。
DSIRM DSIRM: Query-Bridged Discrete Semantic Identifiers(Alibaba 淘宝天猫, 2026-06-03)¶
关系:独立并发(同公司、相隔两天,本文未引用 · 共享"SID 重定位为判别特征"洞察)· 已加载对方精读
- 共同关注的问题: 两篇出自同一公司(淘宝天猫),几乎同期,且共享一个核心洞察:DSI/NCI/TIGER 等把 SID 当作生成式检索的预测目标,却欠缺判别式监督。SSRLive 与 DSIRM 不约而同地主张把 SID 从"生成式检索目标"重新定位为"增强判别式模型的结构化特征"。DSIRM 的 root cause 落在电商相关性的"细粒度判别难 + 语义纠缠";SSRLive 落在"实时性 + 用户-主播交互"。
- 相近的技术骨架: 都不把 SID 直接拿去 beam search 检索 item,而是把 SID 信号喂给下游判别式 DNN(SSRLive:task query 抽取 + 多任务 MLP;DSIRM:SID 前缀匹配分作为新特征进相关性 DNN)。都强调给量化注入业务监督——DSIRM 用 query-item InfoNCE 监督 RQ-VAE,SSRLive 用 Swing 协同对比 + NTP + 多任务联合训练塑造 SID。
- 本文的差异与推进: DSIRM 面向电商搜索相关性排序(query-item 匹配),核心是 query-bridged 对比量化 + LLM 生成 query SID + 层级前缀匹配;SSRLive 面向直播粗排(user-live 偏好),核心是静态/动态双 SID + 实时 EMA 码本 + 用户-直播 cross-attention。SSRLive 的独到处是动态 SID 的时序建模,DSIRM 无此维度;DSIRM 的独到处是 query 侧用 LLM 显式预测 SID 化解尾部 query,SSRLive 无 query 概念。
- 可比的方法 / 实验差异: DSIRM 离线 Tmall AUC +1.54%、线上 UCTR/UCTCVR +0.13%/+0.25%;SSRLive 离线 AUC 全面领先、线上 Watch Time +3.38% / GMV +0.72%。两者都印证"SID-as-feature 增强判别式"在阿里生产环境的有效性,从直播与电商搜索两个侧面相互佐证了同一范式转变。
DIG DIG: Discrimination Is Generation(Meituan, 2026-05-14)¶
关系:独立并发(本文未引用 · 共享"纯生成式 SID 欠判别/欠 cross 特征"诊断)· 已加载对方精读
- 共同关注的问题: DIG 把生成式检索落后于判别式排序的根因归为 SID 严重欠个性化:判别梯度从不回流码本、u2i cross 特征 $\mathbf{c}_{u,v}$ 从未参与码本构造。这与 SSRLive 消融中"w/o Cross Features 下降最严重、纯生成式 SID 不足"的结论高度一致——两者都认定用户-物品交叉交互信号是判别式排序的命脉,必须与 SID 协同。
- 相近的技术骨架: 都把 SID 与 cross 特征同时纳入一个判别式模型联合训练,而非两阶段串行。SSRLive 用 $\mathcal{L}_{\text{Total}} = \mathcal{L}_{\text{MTL}} + \lambda_{\text{NTP}}\mathcal{L}_{\text{NTP}}$ 让判别式损失主导、SID 生成损失为辅;DIG 让排序 BCE 损失直接驱动 SID 码本构造,把 tokenizer 嵌入排序器内部。
- 本文的差异与推进: DIG 的目标是用一个 tokenizer 同时服务排序与检索("判别即生成"),强调 codebook 由判别目标驱动;SSRLive 不追求服务检索,SID 仅作粗排辅助特征,且码本走 warm-start + EMA 在线更新路线(非排序损失驱动)。SSRLive 的核心增量是 动态 SID 的实时时序建模,这是 DIG 完全没有的维度;DIG 的核心增量是 feature assignment taxonomy + u2t 检索时近似,SSRLive 无检索诉求故不涉及。
- 可比的方法 / 实验差异: DIG 报告相对五个 SID baseline +52%~+220% R@10 并同时提升排序 AUC;SSRLive 报告离线 AUC 全面领先 + 线上多指标显著提升。两者从"统一排序检索"与"直播实时粗排"两个角度,共同强化了"SID 必须与判别式 cross 特征深度耦合"这一判断。
讨论与局限性¶
核心贡献与可借鉴设计。 SSRLive 最值得借鉴的是"动态 SID + EMA 在线码本" 这套刻画实时内容的机制,以及"生成式辅助判别式" 的混合范式——把 SID 的语义先验与 cross 特征的个性化信号在一个多任务粗排模型里融合,而非二选一。交错生成静态/动态 SID 以避免双倍延迟、task query 并行抽取、用户侧只算一次等设计,都是工业延迟约束下的实用工程取舍。Table 3 用真实数据点直接证明动态 SID 随人气变化,Figure 5 证明静态 SID 对齐类目,两个案例研究让"双 SID"的设计动机非常可信。
存在的局限 / 争议。 1. 唯一被反超的指标 Watch200 GAUC(DLRM 0.7288 > SSRLive 0.7281): 说明在已高度优化的强 DLRM 上,长时观看这种"高确定性"目标的提升空间有限,SSRLive 的增益更多来自短时观看、订单与互动。 2. 动态 SID 的更新频率与一致性: EMA($\gamma=0.99$)更新码本意味着码字语义在缓慢漂移,Table 3 中动态 SID 第三级标 (通配)聚合,暗示细粒度动态 SID 可能不够稳定;论文未深入讨论动态 SID 漂移对线上一致性/可复现性的影响。 3. 离线/在线协议差异: 离线评 AUC/GAUC(watch30/watch200/order),线上评 watch time/GMV/follower/interaction,两套指标口径不完全对应,且无公开数据集,外部难以复现。 4. 多模态编码器与 Swing 细节略:* 静态 SID 依赖"微调过的多模态模型"和 Swing 正样本挖掘,但论文未给这两部分的细节与消融,静态 SID 质量对最终效果的敏感度未知。
工业落地价值。 SSRLive 已全量部署于淘宝直播粗排,服务数亿活跃用户。部署关键在于:(1) 用户侧 encoder-decoder 只算一次、直播间侧 $TQ \ll N_u$ 轻量计算;(2) Partial Run 提前预跑生成模块,(3) 异步直播编码器让直播间表征被成千上万请求并发复用。最终把 15T FLOPs(DLRM 的约 16 倍)的大模型压进延迟敏感的粗排阶段,延迟仅 +1.33%,换来 Watch Time +3.38%、GMV +0.72%、Follower +3.12%、Interaction +2.92% 的可观业务收益。这是一个"用更高 FLOPs 利用率换在线指标、再用工程优化吃掉延迟"的典型工业范本。