DSIRM: Learning Query-Bridged Discrete Semantic Identifiers for E-commerce Relevance Modeling¶
研究动机与背景¶
电商搜索相关性(search relevance)的核心任务是把用户意图与海量商品目录精准对接,是电商系统的基础问题之一。尽管近年相关性模型进展迅速,一个长期未解的开放难题是:商品标题高度同质化——大量不同商品在词面(lexical)上严重重叠,仅在少数决定性属性(decisive attribute)上有差别。这种细粒度属性差异极难判别,往往导致召回 / 排序结果出现不相关项。与此同时,电商 query 通常很短且高度歧义,使相关性强烈依赖于具体 query(query-dependent)。因此,一个理想的相关性模型必须同时做到两件矛盾的事:语义泛化(semantic generalization)与细粒度判别(fine-grained discrimination)。
主流工业范式是双塔(dual-encoder)连续嵌入架构:query 与 item 被独立编码进共享的连续嵌入空间,配合对比学习能在粗语义层面取得很强的泛化。但连续嵌入存在两个固有局限:
- 细粒度判别困难:仅在决定性属性上不同的商品,在嵌入空间里被挤压得非常稠密(densely packed),难以区分;
- 语义纠缠:单个连续向量把多个语义侧面(semantic facet)纠缠在一起,难以做属性级解耦(attribute-level disentanglement),从而难以支撑 query-dependent 的相关性判断。
近年离散语义标识符(Semantic Identifiers, SID)作为一条替代路线兴起,尤其在生成式检索(generative retrieval)领域。SID 给 item 分配层级化的离散码(hierarchical discrete codes),天然支持显式的语义划分。然而 DSI、NCI、TIGER 等代表性方法主要面向检索(retrieval)阶段,依赖无监督 / 自监督聚类来生成 SID。缺乏显式的 query-item 相关性监督,它们难以捕捉电商排序所需的 query-dependent 区分能力——本质问题是:无监督量化无法"指挥"哪些 item 应该共享同一个 SID,因为 item 的相似性本身是 query-dependent 的。
为解决"无监督 SID"这一痛点,本文提出 DSIRM(Discrete Semantic Identifier Relevance Model),核心思想是把 SID 从"生成式检索的预测目标"重新定位(reposition)为"结构化的相关性特征",去增强(augment)而非替代连续表示。具体两条主线:
- Item 侧:提出 query-bridged contrastive quantization(query 桥接式对比量化),把 query-item 交互监督信号注入残差量化(Residual Quantization, RQ-VAE),主动学习"相关性感知"的语义划分;
- Query 侧:微调一个自回归 LLM,从 query 文本显式预测 item 的 SID,化解尾部 query(tail query)与意图歧义。
最终,query SID 与 item SID 之间做层级前缀匹配(hierarchical prefix matching)得到的离散得分,与连续稠密信号互补,一起喂给排序 DNN。在天猫(Tmall)十亿级生产环境上,离线 AUC 提升 +1.54%;通过高效的离线-在线混合架构部署后,线上取得 +0.13% UCTR、+0.25% UCTCVR 的显著业务收益。
主要贡献:
- 基于"连续嵌入纠缠多个语义侧面"这一观察,提出把 SID 重新定位为离散的相关性特征,专门设计用于增强电商排序的连续表示;
- 针对 SID 中无监督聚类的脆弱性,提出 query-bridged contrastive RQ-VAE,用 query-item 交互信号主动划分语义空间,得到更准确的语义表示;
- 在十亿级生产环境(天猫)上做了大量实验,证明 DSIRM 优于当前 SOTA baseline,并在线上取得显著业务提升。
核心方法 / 模型架构¶
整体框架(图 1)的目标是:用细粒度、结构化的离散信号去增强传统的连续嵌入相关性排序。为此引入一个新特征 SID score(ss)——通过 query 与 item 的离散语义标识符之间的层级前缀匹配计算得到。
baseline 的相关性预测为:
$$\text{logit} = \text{DNN}(dm, mm\_dm, ct, qs) \tag{1}$$
引入 SID score 后更新为:
$$\text{logit} = \text{DNN}(dm, mm\_dm, ct, qs, ss) \tag{2}$$
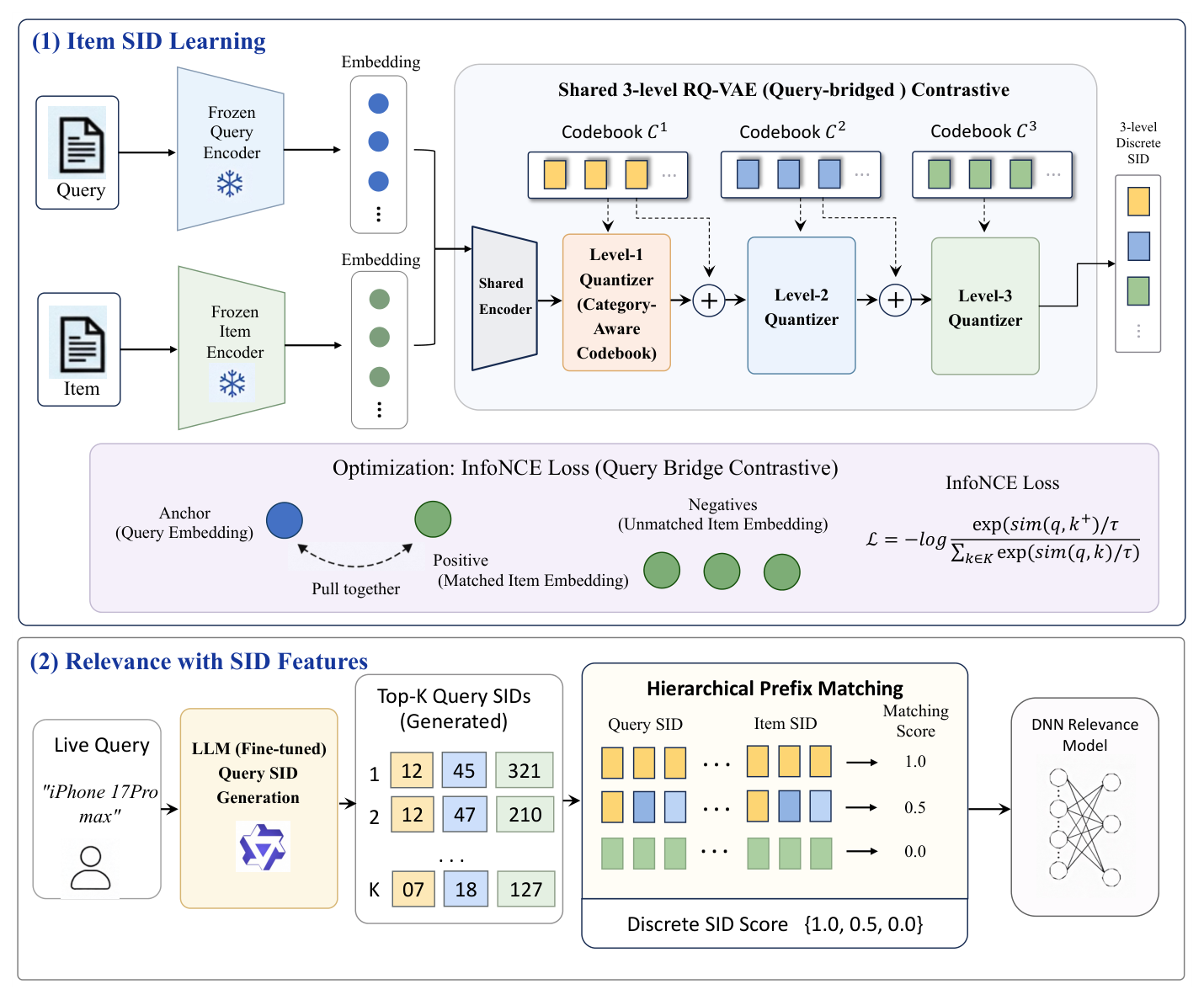
整个框架由三个主组件串联:(1) 通过对比 RQ-VAE 学习 item SID;(2) 通过 LLM 生成 query SID;(3) 层级 SID 匹配做相关性打分。下面分别展开。
预备:天猫搜索的相关性建模形式化¶
天猫搜索的相关性建模被形式化为一个序回归(ordinal regression)任务:一个 DNN 输出连续 logit,随后离散化为三档相关性等级 $y \in \{1, 2, 3\}$。输入特征由多种模态的 query-item 匹配信号构成:
- $dm$:query 与 item 连续文本语义嵌入之间的 cosine similarity;
- $mm\_dm$:由多模态嵌入(multi-modal embedding)计算的 cosine similarity;
- $ct$:离散类目匹配分(discrete category matching score);
- $qs$:额外的人工设计 query 侧统计特征(query-side statistical features)。
4.1 用于 Item SID 学习的对比 RQ-VAE¶
动机:Vanilla RQ-VAE 的局限¶
以往工作普遍采用 vanilla RQ-VAE 范式:拿一个固定模型预计算好的嵌入作为输入,用重建损失(reconstruction)和承诺损失(commitment)优化量化器,假设语义相似的 item 会被分到相同或相近的 SID。作者指出这个假设过于受限:
- 缺乏显式监督,聚类行为完全依赖于输入嵌入空间的几何结构;
- 更关键的是,这个假设本身会失效——item 的相似性在电商搜索里是 query-dependent 的。两个 item 在某个 query 下相似、在另一个 query 下却不相似,因此仅靠 item-only 的对比学习不足以学好 SID。
Query-Item 对比学习作为"桥梁"¶
为放松上述约束、更精确地计算语义聚类(transmission map),作者提出把 query 引入 item SID 学习作为桥梁,把"与同一 query 共现"的相似 item 连接到同一个 SID。具体构造一个双塔架构:query 与 item 都先经预训练双塔模型编码成"相关性感知"嵌入,再经同一个 RQ-VAE 进一步处理与量化。通过在匹配的 query-item pair 上施加 InfoNCE 损失,显式引导量化器把"与同一 query 共现"的 item 分配到相似的 SID。
双塔架构 + 共享 RQ-VAE¶
给定 query 文本 $q$ 和 item $i$,先从预训练双塔模型取相关性感知嵌入:
$$\mathbf{e}_q = \text{RelevanceEmb}_q(q), \quad \mathbf{e}_i = \text{RelevanceEmb}_i(i) \tag{3}$$
再用可学习的投影层 encoder 适配到量化空间:
$$\mathbf{z}_q = \text{Encoder}_q(\mathbf{e}_q), \quad \mathbf{z}_i = \text{Encoder}_i(\mathbf{e}_i) \tag{4}$$
其中 $\text{Encoder}_q$、$\text{Encoder}_i$ 把冻结嵌入变换到共享潜空间 $\mathbb{R}^d$。
采用共享的层级 RQ-VAE,含 $L$ 个 codebook $C_1, \ldots, C_L$,其中 $C_\ell = \{\mathbf{e}_\ell^1, \ldots, \mathbf{e}_\ell^{K_\ell}\}$ 包含 $K_\ell$ 个可学习码向量。量化迭代式地细化表示:
$$\mathbf{r}_0 = \mathbf{z}, \quad \mathbf{c}_\ell = \arg\min_{\mathbf{e} \in C_\ell} \|\mathbf{r}_{\ell-1} - \mathbf{e}\|_2^2, \quad \mathbf{r}_\ell = \mathbf{r}_{\ell-1} - \mathbf{c}_\ell \tag{5}$$
最终量化表示聚合所有层级:$\hat{\mathbf{z}} = \sum_{\ell=1}^L \mathbf{c}_\ell$。离散 SID 是 codebook 索引的拼接:$\text{SID} = [k_1, \ldots, k_L]$,其中 $k_\ell \in \{1, \ldots, K_\ell\}$。
训练目标由三项互补损失组成。第一,对称 InfoNCE 损失对齐 query-item pair:
$$\mathcal{L}_{\text{InfoNCE}} = \frac{1}{2}\left(\mathcal{L}_{q \to i} + \mathcal{L}_{i \to q}\right) \tag{6}$$
$$\mathcal{L}_{q \to i} = -\frac{1}{B}\sum_{m=1}^B \log \frac{\exp(\text{sim}(\hat{\mathbf{z}}_q^m, \hat{\mathbf{z}}_i^m)/\tau)}{\sum_{n=1}^B \exp(\text{sim}(\hat{\mathbf{z}}_q^m, \hat{\mathbf{z}}_i^n)/\tau)} \tag{7}$$
$$\mathcal{L}_{i \to q} = -\frac{1}{B}\sum_{m=1}^B \log \frac{\exp(\text{sim}(\hat{\mathbf{z}}_i^m, \hat{\mathbf{z}}_q^m)/\tau)}{\sum_{n=1}^B \exp(\text{sim}(\hat{\mathbf{z}}_i^m, \hat{\mathbf{z}}_q^n)/\tau)} \tag{8}$$
第二,承诺损失(commitment loss)稳定跨所有 $L$ 层的层级 codebook 学习:
$$\mathcal{L}_{\text{commit}} = \frac{1}{L}\sum_{\ell=1}^L \sum_{x \in \{q,i\}} \|\mathbf{z}_x - \text{sg}[\hat{\mathbf{z}}_x^{(\ell)}]\|_2^2 \tag{9}$$
其中 $\hat{\mathbf{z}}_x^{(\ell)}$ 表示累积到第 $\ell$ 层的部分量化和,$\text{sg}[\cdot]$ 为 stop-gradient。第三,重建损失用轻量共享解码器 $\mathcal{D}$ 重建连续嵌入:
$$\mathcal{L}_{\text{recon}} = \sum_{x \in \{q,i\}} \|\mathcal{D}(\hat{\mathbf{z}}_x) - \mathbf{z}_x\|_2^2 \tag{10}$$
最终联合目标:
$$\mathcal{L} = \lambda_{\text{InfoNCE}}\mathcal{L}_{\text{InfoNCE}} + \lambda_{\text{commit}}\mathcal{L}_{\text{commit}} + \lambda_{\text{recon}}\mathcal{L}_{\text{recon}} \tag{11}$$
Category-Aware Codebook Allocation(类目感知码本分配)¶
电商目录存在极端的类目不平衡(category imbalance)。若第一层量化不做显式的类目分离,RQ-VAE 学习会被高频类目主导,导致尾部类目(tail category)表示很弱。为此,作者把类目结构显式编码进第一层 codebook:维护一个类目映射 $\phi: C_{\text{cat}} \to \{1, \ldots, K_1\}$,把每个类目分配到第一层 codebook $C_1$ 中一个预定义的码。量化时,类目 $c$ 的 item 被强制使用码 $\phi(c)$:
$$\mathbf{c}_1 = C_1[\phi(c)] \tag{12}$$
类目感知的第一层 codebook 通过指数滑动平均(EMA)更新:
$$C_1[\phi(c)] \leftarrow \alpha \cdot C_1[\phi(c)] + (1 - \alpha)\cdot \mathbb{E}_{i \in c}[\mathbf{z}_i] \tag{13}$$
其中 $\alpha$ 是衰减率,$\mathbb{E}_{i \in c}[\mathbf{z}_i]$ 是类目 $c$ 下 item 的平均表示。
4.2 用于 Query SID 学习的生成式 LLM¶
动机:生成式 query 理解¶
设计动机来自电商 query 理解的两个固有挑战:
- 探索性 query 需要外部常识推理:电商搜索常遇到需要超越词面匹配、调用外部常识推理的探索性 query。预训练 LLM 内蕴大量世界知识,能增强泛化;
- query 短且高度歧义:自回归 LLM 可以生成潜在语义标识符的多样化分布(diverse distribution),显式建模用户意图的多侧面性质。
用于 SID 预测的有监督微调(SFT)¶
采用标准 SFT 范式训练一个自回归 LLM,以 query 文本为条件预测 item 的 SID。训练数据是从历史用户交互日志中抽取的 query-target pair:对每条 query $q$ 与 item $i$ 的交互,取出 item 此前由 RQ-VAE 分配的层级 SID $\text{SID}_i = [k_1, k_2, \ldots, k_L]$。LLM 最小化标准自回归交叉熵损失:
$$\mathcal{L}_{\text{SFT}} = -\sum_{t=1}^L \log P(k_t \mid q, k_{<t}; \theta) \tag{14}$$
推理:多簇解码(Multi-Cluster Decoding)¶
推理时,为显式"物化"所建模的意图歧义,用 beam search 解码近似相关 item 簇的条件分布,生成 top-$K$ 个最可能的 SID 序列:
$$\{\text{SID}_1, \text{SID}_2, \ldots, \text{SID}_K\} = \arg\max_{\text{SID}} P(\text{SID} \mid q; \theta) \tag{15}$$
通过生成多个 SID,模型同时捕捉 query 意图的不同侧面。
4.3 基于 SID 的相关性打分与排序¶
层级 SID 匹配(Hierarchical SID Matching)¶
给定 query $q$ 生成的 SID 集合 $\{\text{SID}_q^1, \ldots, \text{SID}_q^K\}$ 和 item $i$ 学到的 SID $\text{SID}_i = [k_1^i, k_2^i, \ldots, k_L^i]$,基于层级前缀匹配计算匹配分。匹配越深表示语义对齐越强,匹配以级联(cascading)方式进行。以 $L = 3$ 为例,算法 1 给出详细流程。
SID score(ss)根据最深匹配层级赋值:
$$ss(q, i) = \begin{cases} 0.0 & \text{if level} = 0 \\ 0.25 & \text{if level} = 1 \\ 0.5 & \text{if level} = 2 \\ 1.0 & \text{if level} = 3 \end{cases} \tag{16}$$
算法 1:层级 SID 匹配
输入:Query SID 列表 {SID_q^1, ..., SID_q^K},Item SID SID_i = [k_1^i, k_2^i, k_3^i]
输出:SID 匹配分 Score_SID(q, i)
1: level ← 0 # 最大匹配层级
2: for j = 1 to K do
3: ℓ ← 0 # 当前 SID_q^j 的匹配深度
4: if k_1^{q,j} = k_1^i then
5: ℓ ← 1
6: if k_2^{q,j} = k_2^i then
7: ℓ ← 2
8: if k_3^{q,j} = k_3^i then
9: ℓ ← 3
10: end if
11: end if
12: end if
13: level ← max(level, ℓ)
14: if level = 3 then
15: break # 全匹配则提前终止
16: end if
17: end for
18: return level
集成进相关性排序 DNN¶
SID score 作为附加特征加入 DNN。DNN 用一个嵌入层处理离散特征,并与连续特征拼接:
$$\mathbf{x}(q, i) = [dm, mm\_dm, ct, ss, qs] \tag{17}$$
相关性 logit 经多层感知机(MLP)算得:$\text{logit}(q, i) = \text{MLP}(\mathbf{x}(q, i))$。
实验设置¶
数据集与指标:SID 学习数据来自天猫的大规模真实数据,约 8000 万 query-item pair $(q, i)$。相关性打分数据集完全由 Qwen3-30B 用精心设计的 prompt 生成标注,验证子集与人工判断的一致率高达约 94%,证明 LLM 标注高度可信。最终训练集约 160 万标注 pair,测试集 10 万 pair。指标采用 Precision、Recall、AUC(ROC 曲线下面积)。
实现细节:
- Item SID 学习:以预训练多模态相关性嵌入为输入,层级 RQ-VAE 取 $K_1 = 216, K_2 = 512, K_3 = 512$。其中 $K_1 = 216$ 恰好等于天猫电商商品目录一级类目(1st-level category)的数量,与 category-aware codebook 分配策略严格对齐。优化用 batch size 256,温度 $\tau = 0.07$,$\lambda_{\text{InfoNCE}} = 1.0$,$\lambda_{\text{recon}} = 0.1$,$\lambda_{\text{commit}} = 1.0$。
- Query SID 学习:微调 Qwen3-0.6B,batch size 128,推理用 beam search $K = 5$。
- DNN 相关性模型:3 层 MLP。
- 公平对比设置:为与标准检索导向的 SID baseline(DSI、TIGER)公平比较,仅替换 item SID 的生成方法,而共用同一个 query 侧 LLM 生成器 + 同一个下游 DNN 相关性打分架构(式 2)。这样隔离了变量,保证性能差异严格反映 item SID 的质量,而非 query 编码或打分架构的差异。
主要实验结果¶
表 1:不同 SID 生成方法与输入表示策略的对比(Precision / Recall 在阈值 0.5 处计算)。这里考察 RQ-VAE 输入表示的根本设计选择:静态预训练嵌入(Static)vs 动态编码(Dynamic),以及与标准检索导向 SID baseline(DSI、TIGER)的对比。
| Method | Input Type | Prec. / Rec. (Positive) | Prec. / Rec. (Negative) | AUC |
|---|---|---|---|---|
| Baseline (w/o SID) | - | 87.00 / 90.00 | 81.40 / 76.50 | 0.9202 |
| DSI [24] | Dynamic | 85.73 / 92.30 | 84.58 / 73.33 | 0.9312 |
| TIGER [22] | Static | 85.37 / 93.54 | 85.42 / 70.24 | 0.9323 |
| exp0 (mT5) | Dynamic | 85.85 / 92.36 | 84.47 / 73.17 | 0.9308 |
| exp1 (BERT) | Dynamic | 85.90 / 92.29 | 84.37 / 73.32 | 0.9309 |
| exp2 (DSIRM) | Static | 85.57 / 93.62 | 86.39 / 71.97 | 0.9356 |
结论分析:
- DSIRM 取得最佳 AUC 0.9356,相对无 SID 的 baseline(0.9202)提升 +1.54%,并超过所有竞争 SID 方法。仅仅引入一个离散的 ss 特征就把 AUC 拉高 1.5 个点,说明离散结构化信号确实补上了连续嵌入缺失的细粒度判别能力。
- DSI 与 TIGER 分别依赖生成式 / 聚类式量化范式,缺乏显式的 query-item 交互监督,限制了它们的聚类行为;DSIRM 的 query-bridged 方法基于搜索相关性主动划分语义空间,因而更优。
- 一个值得注意的发现:静态嵌入(Static)显著优于动态编码(Dynamic)(exp2 DSIRM 用 static 0.9356,而 exp0/exp1 用 dynamic encoder 仅 0.9308/0.9309)。作者解释:把表示学习与量化解耦,能让 RQ-VAE 专注于发现层级离散结构,而不必同时承担表示学习的负担。
消融与分析¶
表 2:各组件消融。分别在动态编码(BERT)与静态预训练嵌入两种配置下,验证对比学习(Contr. Learning)与类目约束(Category Constraint)的贡献。
| Method | Contr. Learning | Category Constraint | Prec. / Rec. (Positive) | AUC |
|---|---|---|---|---|
| Dynamic Encoding (BERT) | ||||
| exp1 (Full) | ✓ | ✓ | 85.90 / 92.29 | 0.9309 |
| exp3 (w/o Cat.) | ✓ | ✗ | 85.96 / 92.21 | 0.9300 |
| exp4 (w/o Contr.) | ✗ | ✓ | 84.28 / 93.80 | 0.9288 |
| Static Pre-trained Embeddings | ||||
| exp2 (DSIRM) | ✓ | ✓ | 85.57 / 93.62 | 0.9356 |
| exp5 (w/o Cat.) | ✓ | ✗ | 85.64 / 93.42 | 0.9349 |
| exp6 (w/o Contr.) | ✗ | ✓ | 85.57 / 93.51 | 0.9347 |
结论分析:在静态配置下,去掉对比学习(exp6)AUC 下降 -0.09%(0.9356 → 0.9347),去掉类目约束(exp5)下降 -0.07%(0.9356 → 0.9349)。这说明:(1) query-bridged 对比学习成功地把"被动聚类"转化为"主动的相关性感知划分";(2) 类目约束对维持尾部类目表示至关重要。在动态编码配置下,去掉对比学习的损失(exp4 = 0.9288,相对 exp1 = 0.9309)更大,再次印证对比监督的价值。
表 3:静态嵌入上的损失权重敏感性分析。在静态嵌入配置下,分析对损失权重 $\lambda_{\text{recon}}$ 与 $\lambda_{\text{commit}}$ 的敏感性。
| $\lambda_{\text{InfoNCE}}$ | $\lambda_{\text{recon}}$ | $\lambda_{\text{commit}}$ | Prec. / Rec. (Positive) | AUC |
|---|---|---|---|---|
| 1.0 | 0.1 | 1.0 | 85.57 / 93.62 | 0.9356 |
| 1.0 | 1.0 | 0.25 | 85.65 / 93.50 | 0.9354 |
| 1.0 | 0.1 | 0.25 | 86.04 / 93.26 | 0.9348 |
| 1.0 | 1.0 | 1.0 | 85.85 / 93.26 | 0.9350 |
结论分析:更低的重建权重($\lambda_{\text{recon}} = 0.1$)优于更高值。作者解释:当利用高质量预训练嵌入时,精确重建不如学习有判别力的离散码重要——这与"静态优于动态"的发现一脉相承,都指向"解耦表示学习与量化"的设计哲学。同时,更高的承诺权重($\lambda_{\text{commit}} = 1.0$)能保证 codebook 学习更稳定。
在线部署与性能¶
离线-在线混合服务架构:把生成式 LLM 与复杂离散匹配逻辑塞进十亿级搜索引擎面临严苛的延迟约束。为此采用高效的离线-在线混合部署:
- Item 侧:item SID 用训练好的 RQ-VAE 离线预计算,存进分布式内存 KV 数据库,取一个 item 的 SID 只需 $O(1)$ 内存查找。对新增 item,用 fallback 机制赋默认值 $ss = 0.0$,保证它们仍能基于传统稠密匹配特征被稳健召回。
- Query 侧:用分层路由(tiered routing)平衡算力与延迟——约 88% 的搜索流量命中离线缓存(为历史 query 预生成好 SID),剩余 12% 的实时在线流量才走在线推理架构。
- 性能:服务平均响应时间(RT)17.9ms,P99 RT 24.3ms,对主排序链路几乎零延迟开销。
在线 A/B 测试结果:在天猫上的持续在线评估期内,相对连续匹配 baseline,DSIRM 取得显著业务提升:
- +0.13% 用户点击率(UCTR, User Click-Through Rate)
- +0.25% 用户点击转化率(UCTCVR, User Click-To-Conversion Rate)
这些结果有力验证了"把离散语义标识符从生成式检索重新定位为结构化相关性特征"是一条高效、低成本、可扩展的范式。
核心贡献总结¶
- 范式重定位:把 SID 从生成式检索的预测目标,重新定位为增强连续表示的离散相关性特征——这是一个轻量、即插即用(只多一个 ss 特征)、对主链路零延迟侵入的工业落地方案。
- query-bridged 对比量化:把 query-item InfoNCE 监督注入 RQ-VAE,主动学习"相关性感知"的语义划分,解决无监督量化"指挥不动哪些 item 共享 SID"的根本痛点。
- 类目感知码本 + 生成式 query SID + 层级前缀匹配:第一层 codebook 强制对齐类目体系(缓解类目不平衡、保护尾部);自回归 LLM 生成多 SID 显式建模意图歧义;层级前缀匹配产生离散 ss 分数与连续信号互补。
- 十亿级生产验证:离线 AUC +1.54%、线上 UCTR +0.13% / UCTCVR +0.25%,离线-在线混合架构 P99 仅 24.3ms。
与已归档相关工作的对比¶
CQ-SID CQ-SID: Efficient Generative Retrieval for E-commerce Search with Semantic Cluster IDs and Expert-Guided RL(Taobao & Tmall Group of Alibaba, 2026-05-14)¶
关系:独立并发(本文未引用 CQ-SID,两者同出阿里天猫、殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都来自阿里天猫,都瞄准"无监督 RQ-VAE 量化无法注入搜索相关性 / query 信号"这一 root cause,都用电商类目体系作为天然层级先验、都引入 query-item 监督来主动塑造量化簇。
- 几乎相同的技术骨架:二者的 item SID 构造高度同构——都是 (1) Category-Guided/Category-Aware 第一层码本(CQ-VAE 第一层按类目体系强制对齐,构造 1711 个 category bin;DSIRM 第一层 $K_1 = 216$ 对齐一级类目并用 EMA 更新)+ (2) 双向 query-item InfoNCE 对比学习嵌入 RQ-VAE(两篇的对称 InfoNCE 公式几乎一字不差)+ (3) 微调小号 Qwen 做 query→多 SID 生成(CQ-SID 用 Qwen2.5-0.5B 走 4 阶段渐进 SFT,DSIRM 用 Qwen3-0.6B 做 SFT + beam search K=5)。
- 本文的差异与推进:最关键的分叉在"SID 拿来干什么"。CQ-SID 把生成式检索定位为召回阶段(recall)的补充——LLM 生成 query SID 后直接召回该语义簇下的 item,并额外用 EG-GRPO(专家引导 GRPO,把 K 条 ground-truth SID 注入策略 group 稳定稀疏奖励)做召回-排序对齐。DSIRM 则把 SID 彻底下沉到排序(ranking)阶段:不做检索、不做 RL,而是把 query SID 与 item SID 做层级前缀匹配得到一个离散 ss 分数({0, 0.25, 0.5, 1.0}),作为一维特征喂给排序 DNN 去增强连续相关性信号。换句话说,CQ-SID 用 SID 替代/补充召回,DSIRM 用 SID 增强排序相关性——同一套 SID 学习底座,落在漏斗的两个不同环节。
- 可比的方法 / 实验差异:CQ-SID 主动追求"碰撞"(多个 item 共享 SID 形成语义簇,把 beam 复杂度从 $O(N_{items})$ 降到 $O(N_{clusters})$,并做 SID 后处理切分控制簇大小);DSIRM 不强调碰撞控制,而强调"静态嵌入 > 动态编码"的解耦哲学。CQ-SID 报告离线 hitrate +26.76%、线上 GMV +1.15% / UCTVR +0.40%、该召回通道贡献 72.63% 平台购买;DSIRM 报告离线 AUC +1.54%、线上 UCTR +0.13% / UCTCVR +0.25%——指标体系不同(召回 hitrate / GMV vs 排序 AUC / CTR),因为两者作用环节不同,无法直接数值对齐。
DIG DIG: Discrimination Is Generation — Unifying Ranking and Retrieval from a Tokenizer Perspective(Meituan, 2026-05-14)¶
关系:独立并发(本文未引用 DIG,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇指向同一个 root cause——现有 SID 由 reconstruction / contrastive 等"检索/无监督"目标训练,量化簇边界反映的是"内容相似度等高线"而非"任务决策边界",导致离散码缺乏任务(相关性/判别)感知。DIG 明确问"判别式排序目标能否直接驱动 SID 码本构造",DSIRM 明确问"如何把 query 相关性监督注入量化"——本质是同一诉求:给无监督 SID 注入下游任务监督。
- 相近的技术骨架:都把 SID 学习与排序任务耦合,让任务信号去塑造 codebook,而非两阶段串行的无监督量化;都用层级残差量化 + EMA 更新码本作为底座;都把得到的离散表示送进判别式排序器去提升排序质量(DIG 同时还能做 beam search 检索)。
- 本文的差异与推进:监督信号与耦合方式不同。DIG 把 RQ tokenizer 嵌入排序器内部端到端联训,用排序 BCE loss 直接驱动码本,并为绕开不可微 argmin 把 codebook 的"寻址"角色与"语义表达"角色解耦成两套参数(SID embedding 由判别 loss 端到端更新、无需 STE),SID embedding 直接即插即用替换 item embedding。DSIRM 则是两阶段:先用 query-item InfoNCE 把 RQ-VAE 训好(对比监督而非排序 BCE),再把训好的 SID 冻结、通过"层级前缀匹配分 ss"这一单一标量特征注入排序 DNN,不替换 item embedding、不要求端到端可微回传。
- 可比的方法 / 实验差异:DIG 追求"一次训练得两个模型"(同一 token 集同时服务判别排序与生成检索),还引入 u2i 交叉特征经 u2t token 级聚合隐式塑形码本,报告 R@10 相对 5 个 SID baseline 提升 +52%~+220% 且排序 AUC 同步提升;DSIRM 只做排序增强(不产出检索能力),优势是工程上极轻(离线预计算 + O(1) 查表 + 12% 流量在线推理,P99 24.3ms),代价是 SID 信息以离散 ss 标量形式注入、粒度较粗。两者代表"任务监督注入 SID"的两种极端:DIG 是深度端到端耦合,DSIRM 是轻量解耦旁路。
被剔除的近似候选(仅列理由,未写子节): - Snap Inc.(2604.03949):共享"SID 作为排序辅助特征"的高层定位,但解法骨架是 STE 优化 + 多模态融合 + codebook collapse 缓解 + bucket 内消歧,与本文 query-bridged 对比量化 + query 侧 LLM 生成不同构——仅高层定位重合。 - AKT-Rec(2605.23310):同为 Alibaba + RQ-VAE + InfoNCE,但问题是长尾 head-to-tail 知识迁移(stop-gradient 非对称 InfoNCE + 活跃度门控),非 query-dependent 相关性监督——组件词根撞车、问题不同构。 - QuaSID(2603.00632)/ AdaSID(2604.23522):都解决 SID collision 质量(区分有害碰撞 vs 良性重叠),问题是碰撞消歧而非把 query 相关性注入量化——问题不同构。 - FORGE(2509.20904):同为 Taobao SID 工业工作,但问题是 SID 生成质量 benchmark + 训练-free 质量指标,解法是 benchmarking——问题不同构。 - TIGER(2305.05065):显式引用的 baseline + RQ-VAE 技术祖先,本文把它当对比数据点,baseline 关系交由 Step 4 DAG 登记。
讨论与局限性¶
核心贡献与值得借鉴的设计:DSIRM 最值得借鉴的是它的工程务实性——它没有像 OneRec / OneSearch 那样追求"生成式端到端替代漏斗",而是把 SID 这个本属于生成式检索的"重武器"拆成一个离散标量特征 ss,以零侵入、O(1) 查表、P99 24.3ms 的代价插进既有排序 DNN。这种"重定位(reposition)"思路对工业团队极具吸引力:用最小的架构改动拿到 1.5 个 AUC 点 + 真实线上转化收益。其次,"query 桥接对比量化"把 query 信号注入 RQ-VAE 解决了无监督 SID 的根本痛点,并配合类目感知码本保护尾部,是一个干净自洽的设计。"静态嵌入 > 动态编码"的发现(解耦表示学习与量化)也是有普适价值的经验。
局限与争议:
- 消融增益偏小:表 2 中去掉对比学习仅掉 0.09% AUC、去掉类目约束仅掉 0.07%——相对于"无 SID → 有 SID"的 +1.54% 总增益,这两个被重点宣传的组件(对比 + 类目)各自的边际贡献其实很小,说明大头收益来自"引入离散 SID 特征"这件事本身,而非具体怎么学 SID。这与论文的叙事重心(强调 query-bridged 对比)略有张力。
- ss 信息粒度很粗:item SID 信息最终被压缩成一个 4 取值的标量 ss({0, 0.25, 0.5, 1.0})。相比 DIG 把整段 SID embedding 即插即用进排序器,DSIRM 的注入方式损失了大量结构信息——这是"轻量"换来的代价,可能限制了上限。
- 标注依赖 LLM:相关性训练标签完全由 Qwen3-30B 生成(94% 与人工一致),AUC 等指标其实是在"对齐 LLM 判断",而非纯人工 ground truth;线上 A/B 收益是更可靠的证据。
- 细节缺失:预训练双塔 RelevanceEmb 的具体来源、$L$(层数实际取 3)的选择依据、query SID 与 item SID 共享 codebook 的程度、beam search K=5 的多 SID 如何与"碰撞"交互等,论文(7 页 CIKM 短文)着墨不多。
与已有工作的差异:相比 TIGER/DSI/NCI 把 SID 当生成式检索目标、CQ-SID 把 SID 当召回簇、DIG 把 SID 端到端嵌进排序器,DSIRM 选择了最轻的一条路——SID 只作为排序 DNN 的一维离散增强特征。这条路的工业价值(零侵入、低延迟、可回退)明确,但也注定了它的天花板低于那些把 SID 作为一等公民的方案。它更像是"在不动主架构的前提下,用 SID 榨取一点确定的增量收益"的务实选择。