Quantizing Intent:把"组织活动"里的跨域行为意图量化成 Semantic ID,喂给工业广告排序¶
来自 LinkedIn(Julie Choi、Haoran Ye、Zhiwei Ding、Bo Long、Benjamin Zelditch、Arpita Vats,为共同一作),2026-05-31 挂 arXiv(2606.01396v1, cs.IR)。论文的核心主张:广告 CTR 预测长期受困于用户监督信号稀疏——绝大多数用户很少点广告,却在 organic feed(信息流)等自然消费场景里留下了海量行为证据。把这些跨域(cross-domain)信号注入广告排序却很难:域错配、serving 成本高、生产流水线复杂。本文用跨域用户 Semantic ID(viewer SID)作为"迁移接口",并给出三个可复用的工件:(1) RQ-FSQ 量化器(残差 VAE 量化 + 逐维有限标量量化),把预训练 dense embedding 压成 30–280× 更小的离散码却几乎不掉 AUC;(2) HDE Module(prefix n-gram 稀疏哈希表),把 K 级 SID 端到端编码进排序器;(3) Multi-Source SID(结构化 9 码 + backbone 兜底填补)。在大规模工业广告系统上,最冷启动用户段提升 +1.522% AUC,直接验证了跨域行为迁移机制。
研究动机与背景¶
广告域的根本困境:监督稀疏,尤其冷启动¶
广告推荐系统运行在极端交互稀疏之下。和 organic 场景相比——用户在那里频繁、多样地反馈——广告点击既稀少又在用户群里分布极不均匀。对于那一大批广告交互稀疏的用户,模型几乎没有信号去推断其意图。问题在 cold-start(冷启动)段最尖锐:新用户、或很少参与广告的用户,模型只能从 profile 属性去猜偏好。
一个自然的补充信号来源是 organic feed 活动:用户与 feed 内容的交互频率比广告高出数个量级,而且这些交互编码了话题兴趣、内容类型偏好、参与意图。但把 feed 信号迁进广告 CTR 模型面临三道难关:(1) feed 与广告的域错配(domain mismatch,特征空间不同);(2) dense 行为 embedding 的高维度与高 serving 成本;(3) 工业生产流水线无法容纳定制化的逐特征预处理。
Semantic ID 的"单域假设"被打破¶
Semantic ID(SID)[1, 2] 近年成为把 dense embedding 离散成紧凑 token 序列的有效手段——经由残差量化(RQ-KMeans 或 RQ-VAE [3]),从而能用标准 embedding 表查找 + 端到端微调接入下游任务。但既有 SID 工作几乎都聚焦 single-domain(单域):被量化的 embedding 与推荐目标来自同一个域 [1, 2, 4-6]。
本文研究一个不同的设定——cross-domain viewer SID:用户表征从 organic feed 行为派生,被量化后作为广告 CTR 预测的输入特征。据作者所知,这是首个对工业广告 CTR 建模中跨域 viewer SID 的实证研究。
本文把跨域 viewer SID 集成进一个生产级 decoder-only Transformer 广告 CTR 排序模型。关键设计挑战是 embedding 模块:如何把一个 K 级离散 token 序列映射成一个可端到端训练的 dense 表征——这正是 HDE Module 要解决的。
生产广告排序模型(前置基线)¶
系统建立在一个工业广告 CTR 用的 decoder-only Transformer(CADET [14]) 之上。给定用户在 trailing window 内的交互序列 $\mathbf{x}=(e_1,\dots,e_L)$,模型自回归地预测点击概率。每个事件 $e_t$ 携带广告 creative ID、campaign ID、format & charge type、OS、objective type 等上下文特征的 embedding。Context-conditioned attention 配 timestamp-based RoPE 处理位置信息;session masking 让 attention 在 serving 时对齐因果结构。训练用 DDP/FSDP2,跑在 H200 集群上。
本文的关键约束:只在输入侧加跨域 viewer SID,Transformer 骨干、attention 栈、prediction head 完全不动——所有提升都来自更丰富的用户输入表征。这使得方法可以"零架构改动"插进现有生产系统。
核心方法一:SID 构造(RQ-KMeans 与 RQ-FSQ)¶
对一个 dense 用户 embedding $\mathbf{v}\in\mathbb{R}^d$,残差量化产出一个 $K$-tuple 离散 token:
$$\text{SID}(\mathbf{v}) = (c_1, c_2, \dots, c_K),\quad c_k\in\{1,\dots,C\} \tag{1}$$
其中 $C$ 是码本大小,$K$ 是量化级数。论文用两种量化方法,取决于 SID 是"从零训练"还是"必须对齐一个预训练 embedding"。
RQ-KMeans(从零量化)¶
在 $K$ 个残差阶段上确定性地运行:(1) 把 $\mathbf{v}$ 分配到一个 $C$-entry 码本里最近的质心,记 $c_1$;(2) 计算残差 $\mathbf{r}_1 = \mathbf{v} - \boldsymbol{\mu}_{c_1}$;(3) 在后续残差上重复得 $c_2,\dots,c_K$。k-means 的均匀方差假设很适合"从零量化 embedding"的场景,带来优秀的码本利用率和可复现的离线分配(生产稳定性的关键)。
RQ-FSQ(残差 + 有限标量量化,为预训练 embedding 设计)¶
一种为预训练 embedding保留双尺度信息的量化方法:全局几何(经 RQ-VAE)与逐维细结构(经 FSQ)。FSQ [23] 独立地把 $\mathbf{v}$ 的每一维量化到一个有限整数字母表 $\mathcal{L}=\{-L,\dots,L\}$:
$$\hat{\mathbf{C}}_\text{FSQ} = \text{FSQ}(\mathbf{v}) = \text{round}(\tanh(\mathbf{v})\cdot L) \tag{2}$$
RQ-VAE [3] 在 $K$ 个阶段上量化逐次残差,产出 $\hat{\mathbf{C}}_\text{RQ}=(c_1,\dots,c_K)$,其中 $c_i$ 是第 $i$ 阶段最近的码本条目。两条流在下游模型里加性融合:
$$\mathbf{e}^\text{RQ-FSQ} = \mathbf{e}^{\hat{\mathbf{C}}_\text{RQ}} + f(\hat{\mathbf{C}}_\text{FSQ}) \tag{3}$$
其中 $\mathbf{e}^{\hat{\mathbf{C}}_\text{RQ}}$ 是 RQ 码的下游 embedding,$f$ 是到模型维度的线性投影。RQ-FSQ 用在 Feed Activity 源上。
方法选型(storage–fidelity 权衡,而非二选一偏好):RQ-KMeans 简单、确定、在每个源上都带来强 AUC 增益,且存储比 RQ-FSQ 小数倍;RQ-FSQ 匹配 dense float 的 AUC,但存储略大。两者都产出 $K$ 级 token 序列供 HDE Module 消费。
核心方法二:Multi-Source SID 与 backbone 兜底填补¶
本文研究三个跨域用户 SID 源。所有 viewer SID 都是 request-level:对给定用户,在序列所有位置上是常量,以 user ID 为键,且严格由 prediction timestamp 之前可得的数据生成。所有实验取 $K=3$ 码/源。
Multi-Source SID 把三个源(行为活跃度递增的阶梯)拼成一个结构化的 9 码表示:
- $c_1$–$c_3$:Activity-Tuned LLaMA SID —— 来自一个 LLaMA-3.1 模型,在跨域活动数据上对比微调,以用户 profile 文本作为输入 prompt。即便输入是 profile 文本,它也隐式编码了行为意图。
- $c_4$–$c_6$:Profile Qwen SID —— 来自一个 Qwen 语言模型,编码用户 profile 文本(title、skills、summary)。只有文本语义,没有直接行为信号。
- $c_7$–$c_9$:Feed Activity SID —— 从 1 年窗口的 feed 参与信号聚合而来。最丰富的直接行为信号。
Backbone-based imputation(用 Activity-Tuned LLaMA 兜底)¶
Activity-Tuned LLaMA 还扮演第二角色:当 Profile Qwen 或 Feed Activity 对某用户缺失时,作为填补 backbone。选它的原因:(i) 三源中用户覆盖率最高——最常在其它源缺失时仍存在;(ii) 它已经是 activity-trained 的,是缺失源行为信号的合理估计器。填补保留人群覆盖,而不是把缺失源的用户悄悄置零。
记 $\mathbf{u},\mathbf{v},\mathbf{w}$ 分别为 Activity-Tuned LLaMA、Profile Qwen、Feed Activity embedding,$\bot$ 表示缺失。Profile Qwen SID 为 $C_P=\text{RQ-KMeans}_P(\mathbf{v})$;当 $\mathbf{v}$ 缺失时,通过一个专用残差 VAE 量化器从 $\mathbf{u}$ 填补:
$$\hat{C}_P = \begin{cases} \bot, & \mathbf{v}=\bot,\ \mathbf{u}=\bot \\ \text{RQ-VAE}_P(g(\mathbf{u})), & \mathbf{v}=\bot,\ \mathbf{u}\neq\bot \\ C_P, & \mathbf{v}\neq\bot \end{cases} \tag{4}$$
其中 $g$ 是从 $\dim(\mathbf{u})$ 到 $\dim(\mathbf{v})$ 的线性投影,$\text{RQ-VAE}_P$ 是一个 $K$ 级残差 VQ-VAE,在 $\mathbf{u}$ 与 $\mathbf{v}$ 都存在的用户上训练,以 $\mathbf{v}$ 为重构目标,用标准目标:
$$\mathcal{L}_{\text{RQ-VAE}_P} = \Big\lVert \mathbf{v} - \sum_{l=1}^{K} \mathbf{e}^{(l)} \Big\rVert_2^2 + \sum_{l=1}^{K}\Big( \big\lVert \text{sg}[\mathbf{r}^{(l)}] - \mathbf{e}^{(l)} \big\rVert_2^2 + \beta \big\lVert \mathbf{r}^{(l)} - \text{sg}[\mathbf{e}^{(l)}] \big\rVert_2^2 \Big) \tag{5}$$
其中 $\mathbf{r}^{(l)}$ 和 $\mathbf{e}^{(l)}$ 是第 $l$ 级的残差与码本 embedding,$\text{sg}$ 是 stop-gradient,$\beta$ 是 commitment loss 系数。Feed Activity 源在 $\mathbf{w}$ 缺失时用一个独立训练的 $\text{RQ-VAE}_F$。每个源用自己的码本:$C_A=\text{RQ-KMeans}(\mathbf{u})$,$C_P=\text{RQ-KMeans}_P(\mathbf{v})$,$C_F=\text{RQ-KMeans}_F(\mathbf{w})$。
Cascade fallback(级联兜底):当填补 backbone $\mathbf{u}$ 也缺失($\mathbf{v}=\mathbf{u}=\bot$,$\mathbf{w}$ 对称),受影响的源在所有 $K$ 级吐 padding 码 $c_k=0$。HDE Module 把 padding 码在每一级映射到零 embedding(Eq. 6),于是用户表征干净地退化到剩余源的贡献,不产生无意义的查表。
核心方法三:Hierarchical Discrete Embedding(HDE)Module¶
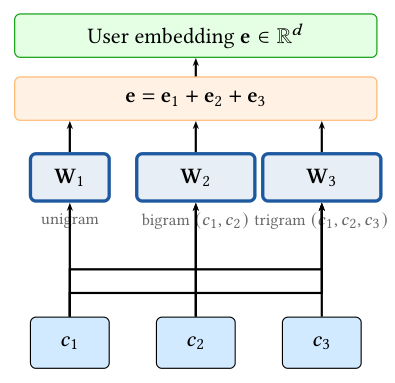
HDE 把任意 $K$ 级 SID 编码成 dense 用户 embedding,用的是带哈希查找的 prefix n-gram 稀疏 embedding 表,内存被上限 $H^\text{max}$ 约束。对 $K$ 级 SID $\mathbf{s}=(c_1,\dots,c_K)\in\{0,\dots,C\}^K$(0 表 padding),每个前缀 $(c_1,\dots,c_k)$ 被哈希成整数索引,在专属可训练稀疏表 $\mathbf{W}_k$ 里查得 level-$k$ embedding $\mathbf{e}_k$。这类比标准类别 embedding 表,前缀 $k$-gram 充当复合特征 ID。
Level 1 —— prefix unigram。直接查表:
$$\mathbf{e}_1 = \mathbf{W}_1[c_1],\quad \mathbf{W}_1\in\mathbb{R}^{(C+1)\times d},\quad \mathbf{W}_1[0]=\mathbf{0} \tag{6}$$
Level $k\geq 2$ —— prefix $k$-gram。对前缀 $(c_1,\dots,c_k)$ 做多项式哈希:
$$\text{idx}_k = \Big[\sum_{j=1}^{k}(c_j-1)\cdot C^{k-j}\Big]\bmod H,\quad \mathbf{e}_k=\mathbf{W}_k[\text{idx}_k],\quad \mathbf{W}_k\in\mathbb{R}^{H\times d} \tag{7}$$
所有哈希表共用同一上限:
$$H = \min\big(\lfloor C^K/\alpha\rfloor,\ H^\text{max}\big) \tag{8}$$
其中 $\alpha$ 是压缩因子,$H^\text{max}$ 给内存封顶。各级 embedding 求和得用户 embedding $\mathbf{e}=\sum_{k=1}^{K}\mathbf{e}_k$。所有表 $\{\mathbf{W}_k\}$ 随机初始化,在 CTR 目标下联合端到端训练。
与 SIDE [17] 的对比(设计取舍):HDE 与 Ramasamy 等的 SIDE 共享"为离散 SID 配可训练稀疏表"的目标,但 SIDE 用 collision-free 的位置 base-$C$ 编码,规模随 $O(C^K)$ 爆炸,无法在工业级部署不封顶的表;HDE 改用 prefix n-gram 哈希查找 + 内存封顶 $H^\text{max}$。用"受控碰撞"换"有界内存",正是大规模部署所必需的取舍。
Multi-Source SID:prefix n-gram 表独立作用于每个源的 $K$ 码块,所有 embedding 求和:
$$\mathbf{e}^\text{user} = \sum_{s=1}^{S}\text{HDE}(\mathbf{s}^{(s)}) \tag{9}$$
其中 $\mathbf{s}^{(1)}=(c_1,c_2,c_3)$,$\mathbf{s}^{(2)}=(c_4,c_5,c_6)$,$\mathbf{s}^{(3)}=(c_7,c_8,c_9)$,共 $S\times K=9$ 次查表(Figure 1)。
数据流水线:用户 SID token 离线物化,在 data loading 时归一化到恰好 $K$ 级,batch collation 时广播成 $[B,L,K]$ 整型张量,确保严格的 train-serve schema parity。
RQ-FSQ 的存储足迹¶
一个 RQ-FSQ token 序列需要 $\frac{K\cdot\lceil\log_2 C\rceil + D\cdot\lceil\log_2 L\rceil}{8}\approx 36$ 字节(生产配置 $K=3,C=1024,D=64,L=16$)。相对 float32 源的压缩比随源维度增长:Feed Activity 源 ~30×,Activity-Tuned LLaMA 源 ~280×——使 RQ-FSQ 对 LLM-based 编码器尤其有价值,且 serving 时无需任何定制预处理。
集成到广告排序模型¶
用户 SID 是 request-level:同一 $K$-token 序列广播到该用户序列的所有 $L$ 个位置。事件 $e_t$ 的输入表征:
$$\mathbf{h}_t = \text{LayerNorm}\Big(\sum_{f\in\mathcal{F}}\mathbf{e}_t^{(f)} + \mathbf{e}^\text{user}\Big) \tag{10}$$
其中 $\mathcal{F}$ 是标准特征集,$\mathbf{e}^\text{user}=\text{HDE}(\mathbf{s}_\text{user})$ 是 HDE 给出的用户 embedding,在所有位置上为常量。
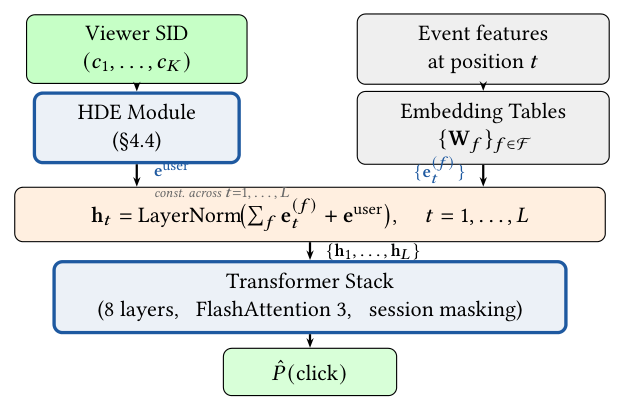
学习率:HDE embedding 表用更高学习率($\eta_\text{HDE}=0.02$)than Transformer 权重($\eta_\text{TR}=4\times10^{-4}$),遵循 embedding-heavy 排序系统的成熟实践 [11, 13]。
实验设置¶
- 数据:某大规模工业推荐平台的生产广告日志;60 天训练 + 随后 1 天评估。所有结果以相对 no-SID 基线的 AUC 增益报告,绝对值因保密隐去。
- 模型:第 3 节的生产广告 CTR 排序模型。SID 默认:码本 $C=1024$,级数 $K=3$,哈希 $H=\min(\lfloor C^K/\alpha\rfloor, H^\text{max})$,embedding 维度 $D=64$。RQ-VAE 的 commitment 系数 $\beta=0.25$。
- 指标:相对 no-SID 基线的 AUC。在工业规模下,+0.1% 离线 AUC 可靠地对应可测的线上 CTR 影响(在同一生产系统多次先前部署中验证)。
- 控制变量:随机种子、batch size、optimizer schedule、模型深度在所有变体间固定,以隔离 SID 效应。
- 超参敏感性:$K=3,C=1024,D=64$ 选自 pilot sweep——更小的 $K$ 欠拟合,更大的 $K$ 或 $C$ 在部署规模上无可测提升。RQ-FSQ 用 $L=16$ 级/维(4 bit)。
- serving 成本:HDE 增加的推理延迟可忽略(都是标准类别 embedding 表的本地内存访问),per-request 用户 SID 离线预算;训练成本基本不变(HDE 表与模型其余部分共享同一 SGD step)。
主要实验结果(RQ1–RQ3)¶
Table 1:跨域用户 SID 结果(RQ-KMeans 量化,K=3 码/源),ΔAUC 相对 no-SID 基线。
| 方法 | 描述 | Δ AUC |
|---|---|---|
| No SID | 参考基线 | — |
| 单源 SID(行为活跃度递增 ↗) | ||
| Profile Qwen SID | 仅文本语义,无行为信号 | +0.036% |
| Activity-Tuned LLaMA SID | activity-trained,profile-prompted | +0.107% |
| Feed Activity SID | 直接行为信号(1 年聚合) | +0.213% |
| 多源组合(K=3/源,共 9 码) | ||
| Independent combination | 3 个 SID 各自独立索引后求和 | +0.260% |
| Multi-Source SID | 结构化 9 码,Activity-Tuned LLaMA backbone | +0.296% |
RQ1:跨域 viewer SID 确实能在 no-SID 生产基线之上改进广告 CTR——所有 SID 变体都正增益。
行为活跃度丰富性原则(RQ2)¶
Table 1 上半部分揭示一个系统性关系:下游 AUC 增益随源表征里编码的行为活跃度单调上升。
- Profile Qwen SID(文本语义,无行为信号):+0.036%;
- Activity-Tuned LLaMA SID(在跨域活动上微调):+0.107%——训练时嵌入的隐式行为信号提供了实质价值;
- Feed Activity SID(直接聚合 1 年参与信号):+0.213%。
行为活跃度丰富性原则(behavioral activity richness principle):对跨域 SID 迁移,被迁移信号的质量,取决于源表征里编码了多少行为活跃度,而无论这活跃度是被直接编码(Feed Activity)还是隐式通过一个 activity-trained 模型编码(Activity-Tuned LLaMA)。Profile 属性单独提供的信号相对弱(+0.036%),印证了"用户做了什么比profile 如何描述他更能预测广告参与"的直觉。
机制:feed 活动捕捉了广告交互日志与 profile 描述里都缺席的高频、演变中的行为意图。把这些信号离散化、在 CTR loss 下端到端微调,执行的是隐式域适配:梯度把 embedding 表重新专化,将 feed 行为簇映射到广告参与概率上,无需任何显式的跨域对齐目标。
Multi-Source SID(RQ3)¶
- Independent combination(3 个独立索引的单源 SID 直接求和,无结构协调):+0.260%;
- 结构化 Multi-Source SID:+0.296%,在同等参数预算下比独立组合多 +0.036%。
增益来自两点:(1) 逐源 prefix n-gram 表避免了跨源哈希碰撞——独立索引的表直接相加而无源分区时会撞;(2) Activity-Tuned LLaMA backbone 对缺失的 Profile Qwen 码做兜底,保留人群覆盖而非把受影响用户悄悄置零。
RQ-FSQ 跨异构预训练 embedding(RQ4)¶
在两个异构预训练源——低维 Feed Activity 与高维 Activity-Tuned LLaMA——上,对比 dense float 基线、RQ-KMeans、单独 FSQ。
Table 2:RQ-FSQ 在两个异构预训练 embedding 源上的表现。ΔAUC 相对 no-SID 基线;Storage 是 per-user 序列化足迹相对同源 raw float32 embedding 的比值。
| 方法 | Feed Activity Storage | Feed Activity ΔAUC | Act-Tuned LLaMA Storage | Act-Tuned LLaMA ΔAUC |
|---|---|---|---|---|
| Raw float embedding (dense) | 1× | +0.349% | 1× | +0.264% |
| RQ-KMeans | ~0.004× | +0.213% | ~0.0004× | +0.107% |
| FSQ | ~0.03× | +0.343% | ~0.003× | +0.248% |
| RQ-FSQ (ours) | ~0.03× | +0.351% | ~0.003× | +0.265% |
分析:两源上模式一致。RQ-KMeans 大幅压存储但掉 AUC——确定性质心分配不优化重构目标。单独 FSQ 通过保留逐维结构补回了大部分缺口。RQ-FSQ 匹配甚至略超 dense float 基线,因为 RQ-VAE 分支保留全局几何、FSQ 分支保留逐维细结构,两者互补。存储收益随源维度增长(~30× / ~280×),使 RQ-FSQ 对高维 LLM 编码器尤其宝贵——那里 dense float 存储在生产规模下是不可行的。
跨域 SID 与冷启动(RQ5)¶
冷启动假说:跨域 viewer SID 对广告交互历史稀疏的用户最有价值。按 trailing window 内 distinct ad impressions 数把验证集分三段:most cold-start(近零广告历史,按历史规模排底部 8%)、infrequent(中间 64%)、frequent(顶部 28%)。
Table 3:Feed Activity SID 按用户活跃度分段的增益。
| 用户分段 | Δ AUC (Feed Activity SID) |
|---|---|
| Most cold-start | +1.522% |
| Infrequent | +0.874% |
| Frequent | +0.131% |
| Overall | +0.213% |
分析:模式直接验证了跨域迁移机制——增益随稀疏度单调放大。最冷启动用户受益最大(+1.522%),那里广告历史近乎空,跨域 feed 活动 SID 提供了主要的行为证据;frequent 用户(已有丰富第一方广告信号)只 +0.131%,feed SID 充当补充源。Feed activity SID 充当"行为冷启动桥梁",恰在现有模型最弱处给出最大的 per-impression 收益。
公开数据验证¶
在公开 MovieLens-100K 上复现 RQ-FSQ > RQ-KMeans 的序关系:用开源 all-MiniLM-L6-v2 句编码器,用户 embedding = 该用户喜欢的电影 embedding 均值(跨域行为聚合的公开类比)。用 RQ-KMeans / FSQ / RQ-FSQ($K=3,C=256,L=7$,为小数据集缩小)量化用户 embedding,训一个小 MLP 预测 held-out 用户-电影对评分是否 $\geq 4$。RQ-FSQ 从训好的 RQ-KMeans 权重 warm-start(镜像"在既有 RQ-KMeans 系统上叠 FSQ 残差"的部署方式)。
Table 4:MovieLens-100K 公开复现,ΔAUC 相对 no-SID(仅电影)基线。
| 方法 | AUC | ΔAUC |
|---|---|---|
| No SID (baseline) | 0.7689 | — |
| Dense user emb | 0.8078 | +3.89% |
| RQ-KMeans | 0.8215 | +5.26% |
| RQ-FSQ (ours) | 0.8343 | +6.54% |
RQ-FSQ 取得最高 AUC,超过 RQ-KMeans 和 dense user embedding,与 Table 2 在公开基准上一致。
核心贡献总结¶
- RQ-FSQ:一个为预训练 embedding 设计的通用离散化器,把逐维标量量化(FSQ,保留 per-dim 细结构)与残差 VAE 量化(RQ-VAE,保留全局几何)加性融合,在两个异构源上匹配/略超 dense float AUC,存储小 30–280×。
- 跨域 viewer SID + 行为活跃度丰富性原则:首个工业广告 CTR 中跨域 viewer SID 的实证,确立"迁移质量随源行为活跃度单调上升"的源选择规则(+0.036% → +0.107% → +0.213%),冷启动段达 +1.522%。
- HDE Module:prefix n-gram 哈希稀疏表,内存有界、端到端训练、零架构改动接入排序器。
- Multi-Source SID:结构化 9 码 + backbone 兜底填补,比朴素求和多 +0.036%,在同等参数预算下。
与已归档相关工作的对比¶
本文最显著的技术指纹是 prefix n-gram 哈希表编码 SID(HDE Module)+ 残差量化离散化跨域 dense embedding + 把 SID 当判别式排序器的输入特征(而非生成式 decode 目标)。文档库里有三篇 2026-05 的工业论文殊途同归地用了 prefix n-gram SID 编码,且本文均未引用(已核对参考文献列表 [1]-[23]),构成三组独立并发对比。
PrefixMem PrefixMem: LLMs Need Encoders for Semantic IDs Too(Pinterest,2026-05-29)¶
关系:独立并发(本文未引用 PrefixMem,两者殊途同归)· 已加载对方精读
- 共同关注的问题:SID 是一套对模型陌生的分层离散词表,同一个码在不同前缀下含义不同,扁平 embedding 无法区分。两篇都认定需要一个专用的前缀感知编码器把 SID 码映射回有意义的 dense 表征。
- 相近的技术骨架:几乎是同一个构造。PrefixMem 的 Eq. (1)(2) 与本文 HDE 的 Eq. (6)(7) 都是:对每一级,把递增长度的前缀 n-gram 哈希进多个/专属哈希表,检索向量求和后投影,加到该级 token 表征上,且都用 $\bmod$ 哈希封顶内存。两者都明确把这条思路类比成"多模态 LLM 给图像/音频配视觉/音频编码器"。
- 本文的差异与推进:(a) 下游任务不同——PrefixMem 把前缀表征加到 LLM 自回归 SID 预测(生成式检索)上,目标是提升最深层 SID 准确率;本文把 HDE 的输出作为 dense 用户特征summed 进判别式 CTR 排序器(Eq. 10),不做 SID 生成。(b) SID 来源不同——PrefixMem 是 item-side(PinCLIP 多模态 → 5 级 SID);本文是 user-side 且跨域(feed 行为 → user SID)。(c) 工程细节巧合一致:两篇都让投影层近零初始化、给哈希表更高学习率(PrefixMem 5×、本文 ~50×)以"预热"稀疏表。
- 可比的方法/实验差异:PrefixMem 用多头哈希($H=4$ 头)+ XOR 哈希,本文用单表 + 多项式(base-$C$)哈希;PrefixMem 还探索了编码器独立预训练(分类头/生成模型/小 LLM),本文的 HDE 表则纯端到端随机初始化训练。
FLUID FLUID: From Ephemeral IDs to Multimodal Semantic Codes(TikTok/ByteDance,2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:都把"dense 跨域编码器 embedding 难以廉价、可端到端地喂进工业排序器"当 root cause,且都瞄准冷启动——FLUID 的直播间中位寿命仅 ~40 分钟,item ID 永远欠训练;本文的冷启动用户广告历史近空。两篇都用"跨域语义码"作冷启动桥梁(FLUID:短视频→直播;本文:feed→广告)。
- 相近的技术骨架:几乎同一条流水线——跨域编码器 → RQ-KMeans 离散化成分层码 → prefix n-gram 方案转 embedding → late-fusion 进 token-based 排序器,零生成式 decode。FLUID 的 LUCID(§3.2 RQ-KMeans + §3.3 prefix n-gram)与本文的 RQ-KMeans SID + HDE 在抽象层面高度重合。
- 本文的差异与推进:(a) 侧别相反——FLUID 是 candidate/item-side(彻底退役候选侧 item ID),本文是 user/viewer-side(只加用户特征,不动事件特征)。(b) 量化创新点不同——FLUID 重心在跨域多模态编码器(SigLIP2+Qwen3 single-tower)与分阶段 warmup 退役 ID;本文重心在 RQ-FSQ 量化器本身(FSQ 残差保 per-dim 细结构)与 Multi-Source SID 的 backbone 填补。(c) 收益维度:FLUID 报 +2.05% Cold-Start Room Views,本文报最冷启动段 +1.522% AUC——都把最大收益定位在冷启动。
- 可比的方法/实验差异:两者都用 prefix n-gram + RQ-KMeans,但本文额外提出 RQ-FSQ 并实证其在两个异构源上匹配 dense float(Table 2),这是 FLUID 未涉及的量化保真度维度。
SIREN SIREN: 多粒度语义交互的早融合终身兴趣建模(Tencent,2026-05-25)¶
关系:独立并发(本文未引用 SIREN,两者殊途同归)· 已加载对方精读
- 共同关注的问题:都在解决"如何把离散化的语义码作为输入特征注入工业广告 CTR 判别式排序器"——而非生成式检索。两篇都强调 SID 是接入既有 ID-centric 排序系统的"离散接口"。
- 相近的技术骨架:SIREN 的 §4.1.1 用 RQ-VAE 产出 SemID 后,也采用 prefix encoding(Eq. 2-3:对每个递增前缀经共享查找表取 embedding 后拼接),把 prefix-encoded SemID 作为特征送进广告 CTR 模型——与本文 HDE 的"prefix → 表 → 特征 → CTR"骨架同构。
- 本文的差异与推进:(a) SID 语义不同——SIREN 的 SemID 是 item-side 多模态内容码;本文是 cross-domain user 行为码。(b) 融合方式不同——SIREN 的核心贡献是 item 级早融合(SemID + target-aware 相似度桶在 target-conditioned attention 内与 ID 协同特征交互);本文是 late fusion(user embedding 直接 summed 进每个位置,Eq. 10),刻意保持排序器骨干不变以零改动部署。(c) 前缀编码细节——SIREN 用共享查找表 + 拼接,本文用逐级独立哈希表 + 求和且内存封顶 $H^\text{max}$(SIREN 未强调哈希碰撞/内存上限)。
- 可比的方法/实验差异:SIREN 还研究 GSU 阶段的 SemID 硬检索(降 90%+ serving 成本),本文的 user SID 是 request-level 常量、不参与序列检索,这是两者应用粒度的关键差异。
讨论与局限性¶
核心贡献与值得借鉴的设计。本文最大的价值是用一套"离散瓶颈 + 端到端微调"的简单配方,把跨域行为信号迁进广告排序,且零架构改动——量化剥离掉 source 域特有的 embedding 几何,但保留语义簇结构,CTR 梯度再把 embedding 表重新专化到目标任务,这在概念上等价于"预训练-微调式迁移学习",只是发生在离散 token 空间。三个工件(RQ-FSQ、HDE、Multi-Source SID + backbone 填补)只依赖"一个预训练用户 embedding + 一个下游排序目标",可移植到任何满足该条件的系统;三个源(profile 文本编码器、activity-tuned 用户编码器、行为聚合)在大多数大型推荐系统里都有对应类目,可用开源等价物复现。
行为活跃度丰富性原则作为一般设计原则:把"行为特征 > 人口统计"的既有结论扩展到跨域设定——行为丰富性能挺过离散瓶颈,量化后仍驱动下游增益,给出"优先选编码近期行为而非静态属性描述的源"这一具体源选择规则。
RQ-FSQ 作为通用离散化器:在两个异构源上匹配/略超 dense float,因为两分支互补(FSQ 保 per-dim 细结构,RQ-VAE 保全局几何)。该设计可推广到任何"需要在预训练向量上做紧凑离散码"的流水线——item embedding、多模态编码器、LLM 表征。
局限与争议:(1) 所有线上数据以相对 ΔAUC 报告,绝对 AUC 因保密隐去,外部难以判断基线强度;(2) 缺真实线上 A/B 的 CTR/收入指标——只靠"+0.1% 离线 AUC ≈ 可测线上影响"的历史经验背书,未给出本次部署的线上结果;(3) Multi-Source SID 相对 independent combination 仅 +0.036%,结构化收益偏小,且依赖 Activity-Tuned LLaMA 高覆盖这一平台特性;(4) 三个源均为 LinkedIn 平台特有,公开复现仅在 MovieLens-100K 这一小数据集上、且只验证了 RQ-FSQ 的量化序关系,未复现跨域迁移与冷启动的核心论点;(5) 隐私维度作者自陈是双刃——离散瓶颈(每用户只物化 $K$ 个低 bit 码)相对 dense 向量曝露更友好,但跨域兴趣关联的粒度提升仍需既有同意/隐私管控兜底。
工业落地价值:方法 serving 延迟可忽略(标准类别表本地查找)、训练成本基本不变、user SID 离线预算,且严格 train-serve schema parity——这套"零架构改动、可叠加进现有 decoder-only 排序器"的工程属性,是其相对学术 SID 方案的最大落地优势。作者的 outlook 指出该 SID 接口可扩展到 CTR 之外的多任务头与其它排序面,用共享 HDE 表作为整个生产栈的统一用户表征底座。