LLMs 也需要为 Semantic ID 配一个编码器:PrefixMem 把 SID 当作一种模态¶
来自 Pinterest(Xiangyi Chen、Zelun Wang、Xinyi Li、Yi-Ping Hsu、Jaewon Yang、Jiajing Xu),2026-05-29 挂 arXiv(2606.00324)。论文的核心主张极其凝练:Semantic ID(SID)是和图像、音频一样的"非语言模态",理应像多模态 LLM 那样为它配一个专用编码器,而不是把 SID 码直接塞进词表、指望训练从零学会它的前缀依赖含义。 据此提出轻量编码器 PrefixMem——基于前缀 n-gram 哈希记忆表,为每个 SID token 注入"前缀条件表征"。在 Pinterest 十亿级数据、跨多个 LLM 家族上,匹配算力下最深层 SID 准确率相对提升最高 46%、全 SID 检索召回相对提升最高 22%,且收益高度集中在"贪心解码失败的硬样本"上(最高 +77% 相对)。
研究动机与背景¶
生成式推荐与 Semantic ID¶
生成式推荐(generative recommendation)让单个模型逐 token 地生成物品标识符。物品被表示为 Semantic ID(SID)——由 RQ-VAE 产出的分层码(hierarchical codes),这一范式由 TIGER 开创,后续在 YouTube、Kuaishou、Snapchat、Meituan、Pinterest 等工业系统大规模落地。本文的目标很明确:做一个小到能扛生产流量、却能理解十亿级物品语料 SID 层级结构的 LLM。
根本困境:同一个码在不同前缀下含义不同¶
SID 是一套对预训练 LLM 而言完全陌生的分层词表。论文反复强调的关键事实是:一个码的含义取决于它的前缀(prefix)。如 Figure 1 所示——前缀 1273 之后的码 505 可能索引"sneakers",而前缀 974 之后的同一个 505 却索引"vintage art"。如果把 SID 当成扁平词表 token,同一个 505 无论前缀如何都拿到同一个 embedding,模型根本无法区分这两种语义。
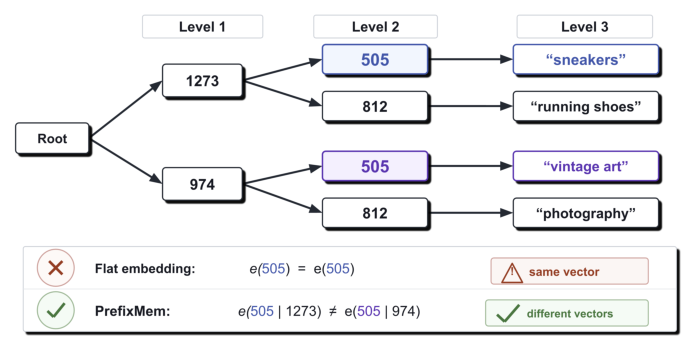
这一问题在结构上是组合爆炸且高度稀疏的:在第 $\ell$ 层存在 $K^{\ell-1}$ 种可能的前缀上下文,每一种都可能代表一个不同的物品簇。中间层还会遭遇 hourglass(沙漏)现象——码分布在层级中部坍塌。在十亿级规模下,每个物品都需要足够的训练曝光,其码才能在上下文中被学会;即便只过一遍数据,这个学习问题也已经很昂贵。
已有方法为什么不够¶
- 扁平词表 token:同一码无视前缀拿到同一 embedding,迫使 LLM 用其共享参数隐式记住所有 prefix→code 关系;
- Smart initialization(智能初始化):给新 embedding 一个更好的起点,但不解决前缀依赖含义问题,且只在小语料上验证过;
- Constrained decoding(约束解码):推理时阻止生成非法 SID 组合,但不提升模型对层级的理解;
- 大规模持续预训练(如 PLUM):有效,但需要数千亿 token,且把 SID 知识耦合到某个特定 LLM checkpoint 上。
来自多模态 LLM 的类比¶
多模态 LLM 社区早就用专用编码器解决了类似问题:视觉编码器把图像投影进 LLM 输入空间;音频 LLM 面对的结构挑战几乎相同——语音被 RQ-VAE token 化成分层音频 codec 码(与 SID 结构上完全同构),由专用 depth transformer 处理细码层级。本文把这一原则迁移到推荐:SID 就是又一种模态,需要一个专用编码器。
据此提出 PrefixMem:一个基于哈希前缀 n-gram 记忆表的轻量 SID 编码器。对每个 SID 层级,它把前面的码哈希成一个前缀条件向量,加到 token embedding 上,于是 LLM 对同一个码会因前缀不同而看到不同的输入表征。编码器在物品数据上独立预训练,因此 LLM 可以专注于"利用结构"而非"从零发现结构";其参数是稀疏查找表,可跨 LLM 家族迁移;并且与约束解码、初始化策略正交互补,可叠加使用。
核心方法 / 模型架构¶
用 Semantic ID 训练 LLM(单阶段多任务)¶
每个物品被 RQ-VAE 编码成 $L$ 层 SID,每层从 $K$ 码的码本中取值。用户的互动序列被表示为物品序列,每个物品配一段文本元数据(标题/描述)和它的 SID。把 LLM 的 tokenizer 扩展 $L\times K$ 个分层 SID token,使模型能原生消费和产出 SID。
在三类序列上用因果语言建模损失训练(训练时随机采样):
- Interleaved 交错序列:$(\text{text}_1, \text{sid}_1, \text{text}_2, \text{sid}_2, \dots)$(或 SID 在文本前);
- Single pair 单对:$(\text{text}_i, \text{sid}_i)$ 或 $(\text{sid}_i, \text{text}_i)$;
- SID-only 纯 SID 序列:$(\text{sid}_1, \text{sid}_2, \text{sid}_3, \dots)$,不含文本。
这套单阶段多任务训练比此前工作的多阶段流水线更简单,却同时覆盖了序列预测、物品-文本对齐、SID 理解三种核心能力。
SID 前缀记忆(PrefixMem)¶
上述设置的问题在于:每个 SID 层级码只有一个学到的 embedding,与前缀无关。PrefixMem 直接针对这点(见 Figure 2):在每个 SID token 进入 transformer 之前,编码器把它前面的层级码哈希成一个紧凑的前缀条件向量,加到 token embedding 上,使 LLM 对同一个码因前缀不同而看到不同输入。
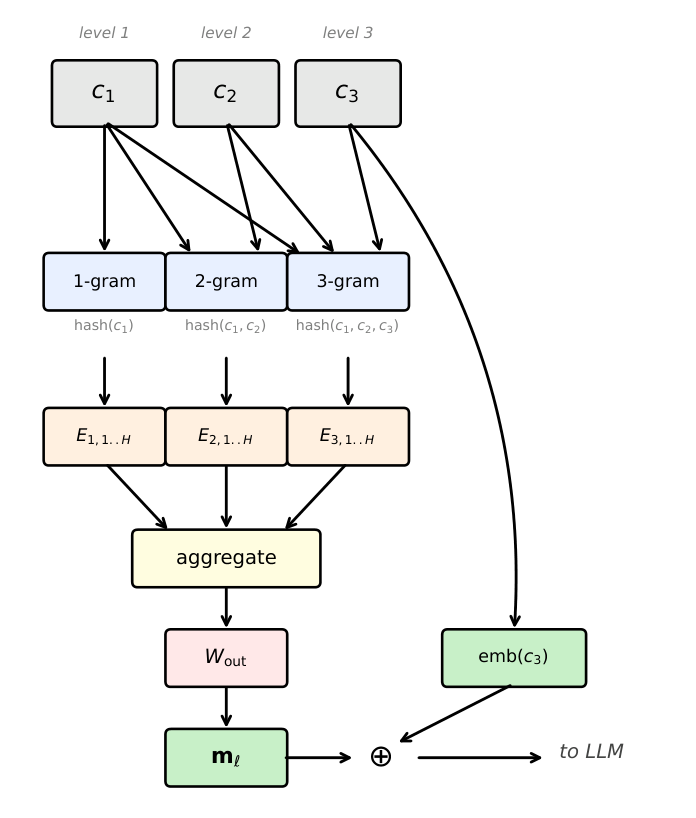
具体地,对一个 SID 跨度 $(c_1,\dots,c_L)$,编码器在每一层 $\ell$ 通过哈希递增长度的前缀 n-gram 计算前缀 embedding。给定前缀 $(c_1,\dots,c_\ell)$,对每个 n-gram 阶 $n\in\{1,\dots,\min(\ell,N_\text{max})\}$ 与每个哈希头 $h\in\{1,\dots,H\}$:
$$\text{idx}_{n,h} = \left( \bigoplus_{i=1}^{n} (c_i \times p_{i,h}) \right) \bmod T \tag{1}$$
其中 $\times$ 是整数乘法,$\bigoplus$ 是按位异或(XOR),$p_{i,h}$ 是固定的质数常量,$T$ 是哈希表大小。阶为 $n$ 的 n-gram 哈希前缀的前 $n$ 层:$(c_1),(c_1,c_2),\dots,(c_1,\dots,c_\ell)$。从表 $E_{n,h}\in\mathbb{R}^{T\times d/H}$ 检索到的 embedding 跨头拼接、跨 n-gram 阶求和,再投影:
$$\mathbf{m}_\ell = W_\text{out} \sum_{n=1}^{\min(\ell, N_\text{max})} \operatorname{concat}\left[ E_{n,h}[\text{idx}_{n,h}] \right]_{h=1}^{H} \tag{2}$$
输出 $\mathbf{m}_\ell \in \mathbb{R}^{d_\text{model}}$ 加到 $c_\ell$ 的输入 embedding 上,增强它,使 LLM 能更好地预测 $c_{\ell+1}$。关键工程细节:$W_\text{out}$ 初始化接近零,使编码器在初始化时贡献可忽略,让 LLM 在早期不受干扰地训练,同时哈希表慢慢"预热"。
这个设计的物理含义:哈希表为每一个"前缀模式"提供了专属容量——一次 $O(1)$ 查找就能直接取回前缀条件表征,而 LLM 若要达到同样效果,必须通过多层 attention 在前缀 token 上"组合"出这份知识。
编码器的预训练(像视觉编码器一样)¶
正如视觉编码器在接入 LLM 前先在图像数据上预训练,SID 编码器也可以预训练。即便不预训练,编码器已带来显著提升(见结果);而预训练好的 embedding 表能进一步加成。论文给出一个"信息逐级叠加"的预训练源阶梯:
- Classification head(分类头):用线性头 + 交叉熵从前缀 embedding $\mathbf{m}_\ell$ 预测 $c_{\ell+1}$。把"哪些码倾向于跟在哪些前缀后"的前缀→下一层转移统计写进表里。最便宜——只有稀疏表查找,无 transformer 前向。
- Generative retrieval model(生成式检索模型):把编码器接到一个生成式 SID 模型(如 Tiger)上,从用户历史产出 SID 序列。表里于是编码了从用户互动中学到的行为型 SID 生成模式。
- Small LLM(小 LLM):把编码器与一个更小的 LLM(如 Qwen3 0.6B)在 text+SID 数据上联合训练。表里被注入语言锚定的信息,因为编码器必须产出 transformer 能同时用于 SID 预测和文本生成的表征。
预训练后,把 embedding 表加载进目标 LLM,配一个全新初始化的投影层 $W_\text{out}$。
实验设置¶
数据集¶
采样 Pinterest 用户互动数据的一小部分:约 10M 子序列(每条最多 32 个互动事件),合计约 240M 物品出现,覆盖数千万唯一物品。每个物品用 RQ-VAE 对 PinCLIP 多模态 embedding 编码成 5 层 SID(每层 2048 码);码本在完整十亿级物品目录上训练。文本特征是由视觉-语言模型生成的图像描述。Table 1 给出 SID-文本对的样例(如 SID 1273,505,1934,1882,1288 对应"一只米棕色 Nike 运动鞋"的描述)。训练/评估按时间和用户双重切分:评估序列来自更晚的日期区间、用户集不相交,确保无数据泄漏。
模型与训练¶
默认 LLM 为 Qwen3 1.7B;为测泛化,还训练 Qwen3 0.6B / 4B、Llama 3.2 1B、Gemma 3 1B。学习率在 $10^{-3}\sim10^{-5}$ 上对 Qwen3 1.7B 扫描后,所有模型沿用同一设置以做受控对比。所有模型训练 50K 步。
PrefixMem 编码器超参:哈希头 $H=4$,默认表大小 $T=2\text{M}$,记忆维度 $d_\text{mem}=256$,最大 n-gram 阶 $N_\text{max}=4$。编码器只在第 4、5 层激活(此处前缀长 3–4 码,组合空间足够大,值得专用记忆);编码器学习率设为 LLM 的 5 倍,因为稀疏哈希表需要更激进的更新来预热。
对比配置:
- Baseline:混合 text+SID 序列训练,无任何 SID 编码器;
- + PrefixMem (random init):挂上 PrefixMem,哈希表随机初始化;
- + PrefixMem (pretrained):哈希表经分类预训练后加载做联合训练;
- SID-Transformer:在 SID 前缀上跑一个 4 层因果 transformer 编码器,作为替代架构。
评估协议与指标¶
在 100K 留出样本上评估。区分两类 SID 准确率:Per-level(逐层)——第 $\ell$ 层预测是否正确,与其它层无关,隔离每层独立知识;Prefix(前缀)——前 $1,\dots,\ell$ 层是否同时正确。三族指标:
- Teacher-forcing 逐层准确率(TF-Lℓ)——主指标。给定用户历史 + 目标物品的真值 SID token 作为输入,跑一次前向,检查每个层级位置上 top-1 预测是否匹配真值。TF-L5 即:给定历史和 1–4 层正确码,模型预测第 5 码是否正确。因为 teacher forcing 在每层都喂正确前缀,它隔离了每层知识,排除了自回归误差传播(自回归生成中第 2 层错会级联到所有深层,无法判断模型在第 5 层是否"知道"正确码)。
- Full-SID Recall@K——用 $K$ 路 beam search 自回归生成完整 5 层 SID,检查真值 SID 是否出现在 top-$K$ 候选集中(5 码必须在单一 beam 候选里全对),$K\in\{20,30,50,100\}$。
- BLEU(SID→文本锚定)——给定 SID 生成文本描述,与参考比 BLEU,衡量模型把 SID 锚定到自然语言的能力。
- SID hit rate(命中率)——对每个第 $\ell$ 层预测的 SID 前缀,检查目录查找表对应桶是否非空,衡量模型产出可检索而非幻觉 SID 的能力。
主要实验结果¶
逐层准确率与收敛(Section 5.1)¶
Table 2(Qwen3 1.7B,50K 步,L1–L3 几乎不变 ~42/29/29% 略去):
| Method | TF-L4 | TF-L5 |
|---|---|---|
| Baseline | 33.3 | 37.6 |
| + PrefixMem (500K) | 40.1 | 49.7 |
| + PrefixMem (2M) | 42.6 | 54.8 |
| + PrefixMem (5M) | 43.4 | 57.2 |
结论分析:模式非常清晰——L1–L3 基本不被编码器影响,而 L4、L5 大幅改善:默认 2M 表下 L4 +28% 相对、L5 +46% 相对。这与问题结构吻合:第 1 层无前缀可条件;第 2 层前缀只是单值(2048 种);但到第 4 层前缀已是 3 码,训练语料里观察到的前缀模式数量急剧增长。哈希表为这些前缀→码关系提供专属容量,而 LLM 只能把它们隐式塞进共享参数。Table 2 同时是表大小消融:500K→2M 在 L5 上 +10% 相对(49.7→54.8),2M→5M 仅 +4%(54.8→57.2),收益递减,故后续默认用 2M。
论文还测了在 L3–L5 激活(2M):L3 仅 +6% 相对(29.2→30.9),L4 +27% 相对(34.5→43.9),L5 +46% 相对(37.6→54.8),前缀空间从 $2048^3$ 指数增长到 $2048^4$。据此后续只在 L4、L5 激活。
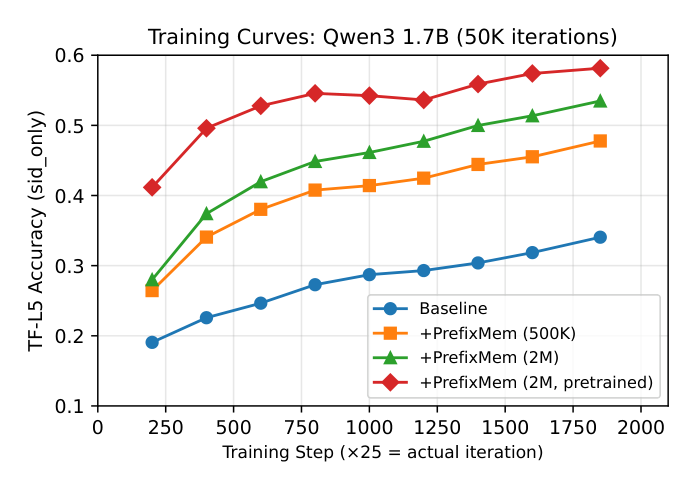
Figure 3 证实准确率差距不是收敛伪影:编码器在头几千步就领先,差距贯穿训练持续拉大。Baseline 平台期 ~35%,2M 编码器达 53%,预训练编码器达 58%。差距持续拉大表明编码器提供了 LLM 在匹配算力下难以获取的前缀模式专属容量。
编码器预训练与迁移(Section 5.2)¶
把 SID 编码器当独立模块的关键优势是它能独立预训练——就像在图像上训好的视觉编码器再接 LLM。Table 3(Qwen3 1.7B,50K 联合训练步,仅编码器起点不同):
| Initialization | TF-L4 | TF-L5 | R@100 | BLEU |
|---|---|---|---|---|
| Random init (2M) | 42.6 | 54.8 | 11.3 | 29.1 |
| Random init (5M) | 43.4 | 57.2 | 11.6 | 32.3 |
| Cls. pretrain (2M) | 43.2 | 58.5 | 11.2 | 26.3 |
| Cls. pretrain (5M) | 49.6 | 64.0 | 11.8 | 27.2 |
| LLM pretrain (2M, 1.7B) | 45.3 | 57.0 | 11.9 | 33.1 |
| LLM pretrain (2M, 0.6B) | 45.3 | 56.8 | 11.8 | 33.1 |
| Tiger pretrain (2M) | 46.7 | 61.2 | 12.3 | 28.2 |
结论分析:
- 分类预训练(简单的"从 $\mathbf{m}_\ell$ 预测 $c_{\ell+1}$")配 5M 表拿到最高 TF-L5 64.0%,相对 baseline +70%;且极便宜(只有稀疏表查找)。
- 可迁移性:LLM pretrain(1.7B)加载先前联合训练的表(配全新 $W_\text{out}$)得 TF-L5 57.0%,优于随机初始化 54.8%;LLM pretrain(0.6B) 把 0.6B 训的表装进 1.7B(重置 $W_\text{out}$ 以匹配更大隐维)仍得 56.8%——哈希表与模型无关,只有输出投影需匹配目标 LLM。
- BLEU 的有趣解离:LLM 预训练的表 BLEU(33.1)远高于分类预训练(26–27),尽管后者 TF-L5 更高(64.0 vs 57.0)。分类预训练优化"下一码预测"直接利好 TF;LLM 预训练优化"transformer 能同时用于 SID 预测和文本生成"的表征,利好 BLEU。这正对应视觉编码器里任务专用 vs 通用预训练的区别。
- Tiger 预训练(把表与 Tiger 联合训练后装进 Qwen3 1.7B)在同 2M 表下拿到最高 Recall@100(12.3)和强 TF-L5(61.2),优于分类和 LLM 预训练。归因:Tiger 的训练目标是"生成用户真正会互动的下一个 SID",直接把用户行为转移模式编码进哈希表;而分类预训练只抓静态共现统计,LLM 预训练把容量分给了 SID 和语言两个任务。
后续"pretrained 5M"指分类预训练 + 5M 表(最强 TF 配置)。
检索与目录有效性(Section 5.3)¶
Table 4(Full-SID Recall@K):
| Method | R@20 | R@30 | R@50 | R@100 |
|---|---|---|---|---|
| Baseline | 6.0 | 6.9 | 8.0 | 9.5 |
| + PrefixMem (2M) | 6.6 | 7.7 | 9.2 | 11.3 |
| + PrefixMem (5M) | 6.7 | 7.8 | 9.4 | 11.6 |
| + PrefixMem (pt. 5M) | 6.3 | 7.5 | 9.3 | 11.8 |
| Δ (5M vs. base) | +11% | +14% | +18% | +22% |
结论分析:编码器的检索收益随 beam 宽度单调增长——K=20 时 +11% 相对,K=100 时达 +22%。原因:更宽的 beam 探索更多前缀路径,让编码器改善的深层预测得以浮现到候选集中。
Table 5(beam 多样性,top-100 里平均不同 L1 簇数):Baseline 5.5 → +PrefixMem(2M/5M)6.0 → pt.5M 6.2(+13%)。编码器更锐利的 L4/L5 预测改变了累积 beam 分数,让不同 L1 前缀得以幸存,更宽的探索 = 更多真值前缀变得可达,与召回提升一致。
Table 6(SID hit rate,前缀桶非空比例,越高越少幻觉):
| Method | L1 | L2 | L3 | L4 | L5 |
|---|---|---|---|---|---|
| Baseline | 100 | 99.8 | 95.7 | 76.5 | 50.7 |
| + PrefixMem (500K) | 100 | 99.9 | 96.4 | 78.3 | 55.8 |
| + PrefixMem (2M) | 100 | 99.9 | 96.5 | 78.6 | 57.6 |
| + PrefixMem (5M) | 100 | 99.8 | 96.1 | 78.9 | 58.9 |
| Cls. pretrain (2M) | 100 | 100.0 | 97.0 | 81.6 | 62.8 |
| Cls. pretrain (5M) | 100 | 99.9 | 96.8 | 82.4 | 65.1 |
结论分析:L5 命中率从 50.7% 提到 65.1%(+28% 相对)——baseline 对近一半预测产出不存在的 SID,而预训练编码器把幻觉降到 1/3。论文指出 Deng et al. 用 GRPO 式强化学习改善 SID 有效性也观察到类似 ~30% 命中率;但近期工作表明 RL 训练的模型仍受基座模型固有能力约束,RL 能把生成引向有效物品、却未必扩大模型"能产出的物品集合"。PrefixMem 作用在不同层面:它提升基座对前缀→码转移的知识,扩大了模型能正确生成的物品池。二者互补、可结合。
消融与分析¶
编码器到底帮在哪里(Section 5.4)¶
硬样本 vs 易样本:引入条件评估——teacher forcing 下,在每层把 2048 个有效码按 logit 排序,检查真值码是否在 top-10。若在 L1–L4 每层都进 top-10 则该样本"reachable(可达)";若任一层掉出 top-10 则"unreachable(不可达)"。Table 7:
| Method | Reachable | Unreachable |
|---|---|---|
| Baseline | 43.3 | 36.4 |
| + PrefixMem (2M) | 44.8 | 54.8 |
| + PrefixMem (5M) | 45.1 | 57.3 |
| + PrefixMem (pretrained 5M) | 44.6 | 64.5 |
| Δ (pretrained vs. base) | +3.0% | +77.2% |
结论分析:鲜明的不对称——可达样本上编码器仅 +3% 相对,不可达样本上 +77% 相对(36.4→64.5)。编码器恰恰为"LLM 自己排不高的前缀模式"提供了知识。这种对硬样本的集中也解释了 Table 4 的召回随 beam 宽度增长:更宽 beam 才能让编码器在困难前缀上的知识浮现。
流行 vs 长尾物品:按真值 L4 前缀在训练数据中出现频次分桶——rare(底四分位,多为单例)、medium、popular(顶四分位)。Table 8:
| Method | Rare | Medium | Popular |
|---|---|---|---|
| Baseline | 26.8 | 34.8 | 52.5 |
| + PrefixMem (2M) | 42.9 | 67.9 | 68.9 |
| + PrefixMem (5M) | 46.4 | 71.1 | 69.5 |
| Cls. pretrain (5M) | 57.6 | 75.6 | 70.4 |
| Tiger pretrain (2M) | 51.9 | 76.3 | 70.3 |
结论分析:编码器不成比例地帮助稀有物品——rare +115% 相对(26.8→57.6)vs popular +34% 相对(52.5→70.4)。流行前缀有足够训练曝光,LLM 能用 transformer 权重学会其转移;稀有前缀缺曝光,但哈希表样本效率更高——一次 $O(1)$ 查找直接取回前缀条件表征,而 LLM 要靠多层 attention 在前缀 token 上组合出同样知识。这个效率差距在稀有前缀上最大。
跨家族/跨规模泛化(Section 5.5)¶
Table 9(全部编码器行用 2M 随机初始化 PrefixMem):
| Model | Encoder | TF-L5 | R@100 |
|---|---|---|---|
| Qwen3 0.6B | — | 32.1 | 8.4 |
| Qwen3 0.6B | PrefixMem | 54.1 | 10.5 |
| Qwen3 1.7B | — | 37.6 | 9.5 |
| Qwen3 1.7B | PrefixMem | 54.8 | 11.3 |
| Qwen3 4B | — | 45.0 | 10.9 |
| Qwen3 4B | PrefixMem | 55.8 | 12.0 |
| Llama 3.2 1B | — | 39.2 | 9.5 |
| Llama 3.2 1B | PrefixMem | 54.5 | 11.1 |
| Gemma 3 1B | — | 37.3 | 9.3 |
| Gemma 3 1B | PrefixMem | 54.4 | 11.1 |
结论分析:三点结论——(1)跨规模一致增益:TF-L5 在 0.6B 上 +69% 相对、1.7B +46%、4B +24%,最小模型相对增益最大;(2)编码器胜过模型放大:Qwen3 0.6B + PrefixMem(54.1%)超过没有编码器的 Qwen3 4B(45.0%)——在该评估协议下,2M 哈希表对 SID 预测的增益大于 8× 的 LLM 参数增长;(3)架构无关:Llama/Gemma 加 PrefixMem 后(54.5/54.4)+39%/+46% 相对,与 Qwen3 1.7B(54.8)相当。编码器不绑定特定 LLM 架构,像一个可插拔的"模态专用模块"。
超越 LLM:PrefixMem 不限于 LLM。Table 10 在 35M 参数生成式检索模型 Tiger 上:
| Encoder | TF-L4 | TF-L5 | R@10 L5 |
|---|---|---|---|
| None | 27.6 | 27.4 | 1.01 |
| PrefixMem | 46.3 | 60.6 | 1.35 |
| Δ | +68% | +121% | +34% |
Tiger 无编码器时 L4/L5 都 ~27%(说明它无法靠有限参数学到深层结构);加 PrefixMem 后 L5 达 60.6%(+121% 相对),Recall@10 +34%。任何分层产出 SID token 的模型都能受益。
编码器架构与设计(Section 5.6)¶
Table 11(架构对比,Qwen3 1.7B,50K 步):
| Method | TF-L5 | BLEU |
|---|---|---|
| Baseline (no encoder) | 37.6 | 23.3 |
| + PrefixMem (hash memory) | 54.8 | 30.9 |
| + SID-Transformer (4-layer) | 39.6 | 23.4 |
结论分析(全文最关键的设计洞见之一):鲜明反差——SID-Transformer(336M 稠密参数)仅 L5 +5% 相对、BLEU 无增益;PrefixMem 则 L5 +46%、BLEU +33%。尽管有 336M 稠密参数,transformer 仍无法靠学习计算记住组合爆炸的前缀空间;而 PrefixMem 把 ~2B 参数存进稀疏哈希表,每个前缀模式经 $O(1)$ 查找直接映射到专属 entry,无需梯度学习前缀组合。结论:SID 编码问题本质是"记忆容量"(存储前缀条件信息)而非"学习计算"(用 attention 组合表征)。如何在记忆容量、算力、超越哈希表的泛化(学习路由、MoE、混合方案)之间平衡,是开放问题。
Table 12(PrefixMem 内部设计选择,2M):
| N-gram scale | Slice direction | TF-L5 | R@100 | BLEU |
|---|---|---|---|---|
| Multi-scale | prefix | 54.8 | 11.3 | 30.9 |
| Multi-scale | suffix | 54.6 | 11.4 | 29.9 |
| Single-scale | N/A | 54.0 | 11.4 | 30.4 |
- N-gram scale:"Multi-scale"哈希长度 1 到 $\min(\ell,N_\text{max})$ 的前缀 n-gram,提供多粒度表征;"Single-scale"只哈希完整前缀。
- Slice direction(仅 multi-scale):取长度 $n<\ell$ 的部分 n-gram 时,"suffix"取最后 $n$ 码(最近),"prefix"取前 $n$ 码(位置锚定)。
结论:三种配置表现接近(TF-L5 54.0–54.8,R@100 11.3–11.4,BLEU 29.9–30.9),编码器对这些设计选择鲁棒,选择不关键。
开销分析(Section 6)¶
默认设置(T=2M, H=4, N_max=4, d_mem=256)下 PrefixMem 含 ~2B 参数,但与 transformer 参数本质不同:
- 算力:每个激活 SID 位置(默认 5 层里 2 层),编码器做 $H\times N_\text{max}=16$ 次表查找、一次跨阶求和、一次输出投影($256\times2048\approx0.5$M 乘加);每 5 层 SID 跨度 ~2M FLOPs,对比 LLM 在同 5 token 前向的 ~17B FLOPs——编码器增加 <0.02% 算力开销,实测匹配 batch 下训练吞吐降 <3%。
- 显存:embedding 表 + AdamW 优化器状态增加 ~10GB 峰值 GPU 显存;500K 表可减 4×(代价是小幅精度损失)。
- 服务:推理时每个生成 SID token 增加一次 embedding 查找 + 一次小投影,无 attention、无 layernorm、无序列依赖,相对 LLM 自回归解码可忽略。由于每 token 只访问 $O(1)$ 行,成熟的 embedding 基础设施优化(CPU offload、量化、混合维度表)可直接套用,进一步降本或扩表。
核心贡献总结¶
- 把 SID 框定为需要专用编码器的分层模态,与多模态 LLM 中的视觉/音频编码器类比——这是全文的概念主张。
- 提出 PrefixMem:前缀 n-gram 记忆模块,在 SID token 位置提供前缀条件表征。匹配算力下最深层 SID 准确率 +46% 相对、全 SID 检索召回 +22% 相对。
- 收益集中在硬样本:贪心解码失败的不可达样本上 +77% 相对;稀有物品上 +115% 相对。
- 改善 SID→文本锚定(BLEU +33%),证明它帮 LLM 理解 SID 含义,而不只是预测。
- 预训练便宜(稀疏表查找、无 transformer FLOPs)且与 LLM 解耦:同一编码器跨 LLM 家族(Qwen/Llama/Gemma)迁移;0.6B + PrefixMem 胜过无编码器的 4B。
- 对比哈希记忆 vs transformer 两种编码器架构,识别出"SID 编码的本质是记忆容量而非学习计算"。
与已归档相关工作的对比¶
一个值得记录的现象:2026 年 5 月这一个月内,至少四支独立团队(Pinterest / TikTok / 腾讯 / 香港城大)各自独立地收敛到"对分层 SID 码做前缀条件化"这一思路。它们互不引用、动机各异,却在"同一个码在不同前缀下含义不同、不该共享一个扁平 embedding"这一核心判断上殊途同归。这正是 tag/keyword 匹配抓不到、必须靠语义判断才能发现的孪生关系。
FLUID FLUID: From Ephemeral IDs to Multimodal Semantic Codes(TikTok/ByteDance,2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇论文给出了几乎逐字相同的核心判断。FLUID §3.3 明确论证:在残差量化里,深层级编码的是相对前缀路径的细化,同一个码 $c_l$ 在不同前缀 $[c_1,\dots,c_{l-1}]$ 下索引的是完全不同的语义区域;若用 level-wise decoding 让它们共享同一个 $\mathbf{E}_l(c_l)$ entry,就把不相关子区域混为一谈。这与本文 Figure 1(同一 505 在前缀 1273 vs 974 下含义不同,扁平 embedding 无法区分)是同一个 root cause。
- 相近的技术骨架:两者都用前缀 n-gram embedding 表为每一级码提供前缀条件表征。FLUID 用复合索引 $\bar{c}_l=\sum_{k=1}^{l}c_k\cdot N^{l-k}$ 把第 $l$ 级表从 $N$ 行扩到 $N^l$ 行;本文用哈希 $\text{idx}_{n,h}=(\bigoplus_i c_i\times p_{i,h})\bmod T$ 把前缀映射进固定大小哈希表。两者甚至引用了同源的 prefix n-gram 谱系(FLUID 引 [48],本文引 Zheng et al. [35] 在 DLRM 设定下用前缀 n-gram 哈希表)。
- 本文的差异与推进:(1)生成 vs 判别——本文把前缀记忆用在自回归生成 SID 的 LLM 上,$\mathbf{m}_\ell$ 以残差加($W_\text{out}$ 初始化近零)注入,评估 TF 逐层准确率/Recall/BLEU;FLUID 用在判别式 token 级排序器上,LUCID 以拼接替换 item ID。(2)模态框架与可迁移性——本文把 SID 提升为"需独立预训练编码器的模态",证明编码器跨 Qwen/Llama/Gemma 甚至 Tiger 迁移;FLUID 聚焦"退役易逝 item ID"。(3)量化器选择——FLUID 因在线流式重训会让 RQ-VAE 码本坍塌而改用 RQ-KMeans,本文沿用 RQ-VAE。
- 可比的方法/实验差异:FLUID 强调 slice vs room 双粒度(瞬态 vs 持久),并用早融合 vs 后融合 + 分阶段 warmup 处理 ID-dominance;本文则系统消融了哈希记忆 vs transformer 编码器(Table 11),给出"SID 编码本质是记忆容量"的判断,这是 FLUID 未触及的角度。
ComeIR ComeIR: Conditional Memory Enhanced Item Representation(香港城市大学,2026-05-12)¶
关系:独立并发(本文未引用 ComeIR,两者殊途同归)· 已加载对方精读
- 共同关注的问题:ComeIR 把 GR 流水线明确拆成 Quantization → Representation → Generation 三段,并指出中间的 Representation Stage 长期被冷落——绝大多数工作改 codebook 或解码,却没人好好做"量化与生成之间的这座桥"。本文 PrefixMem 恰好就作用在这同一个 Representation Stage:在 SID token 进 LLM 前注入前缀条件向量、保持 tokenizer 不变。两篇都把矛头指向"消费/预测端的表征构造",而非 SID 构造本身。
- 相近的技术骨架:两者都用稀疏哈希记忆注入 SID 前缀结构。ComeIR 的 Intra-item Engram 记忆 SID 内部码组合模式(如 $(c_n^1,c_n^2)$ 如何被 $c_n^3$ 细化)——这与本文前缀 n-gram 记忆"哈希前缀以条件化下一码"在机制上几乎等价;ComeIR 的 Inter-item Engram 记忆跨物品不同长度 SID 前缀的偏好转移,对应本文"行为型预训练源(Tiger)注入转移模式"。
- 本文的差异与推进:(1)目标不同——ComeIR 主打把 item 表征从 $L\times N$ 压到 $N$ 个 token(2.5× 推理加速)同时保留 SID 结构,并用 Memory-restoring Prediction Head 解决"输入 item 粒度、输出 token 粒度"的错配;本文不压缩 token、只在深层(L4/L5)加前缀记忆,核心卖点是"SID 即模态 + 编码器可独立预训练并跨 LLM 迁移"。(2)记忆的读取位置——ComeIR 在输入端(intra/inter Engram)和输出端(prediction head 重读同一套记忆)两处用记忆;本文只在输入端残差注入。
- 可比的方法/实验差异:ComeIR 还做了 MM-guided token scoring(用多模态 query 给 code 打分强调身份码),并观察到 Engram 容量与 H@5 的对数线性律——这与本文的表大小消融(Table 2,500K→2M→5M 递减)呼应,都验证了"SID 编码是记忆容量问题"。但 ComeIR 在公开学术数据集(Yelp/Amazon)上验证,本文在 Pinterest 十亿级工业语料上验证。
SIREN SIREN: Unified Multi-granularity Semantic Interaction(腾讯,2026-05-25)¶
关系:独立并发(本文未引用 SIREN);机制子模块同构、问题不完全同构 · 已加载对方精读
- 共同关注的问题:SIREN 的主问题其实不同——它解决的是终身用户兴趣建模(GSU-ESU CTR)里多模态空间与协同空间错配、以及 target-相似度过于粗粒度。但在构造 SID 边信息时,SIREN 独立地得出了和本文一致的判断:不该对每个码独立 embedding,而要保留分层语义。
- 相近的技术骨架:SIREN 的 prefix-encoded SemID(eq 2-3)构造前缀 token 集 $\{c^{(1)},(c^{(1)},c^{(2)}),\dots,(c^{(1)},\dots,c^{(K)})\}$,每个前缀经共享查找表映射后拼接——这与本文 PrefixMem 的 multi-scale 多粒度前缀 n-gram(哈希长度 1 到 $\min(\ell,N_\text{max})$ 的前缀)在构造上是所有孪生里最接近的一个。三家(本文/FLUID/SIREN)各自独立写出了形式高度一致的前缀编码公式。
- 本文的差异与推进:(1)用途不同——SIREN 把 prefix-encoded SemID 当作 CTR 排序器里与 ID 协同特征做早融合的边特征(判别式),本文则用前缀记忆改善生成式 LLM 的逐层 SID 预测;因此 SIREN 不汇报 TF 逐层准确率、召回这类"SID 生成能力"指标,二者评估轴不可直接对齐。(2)问题层面并不同构——SIREN 的 root cause 是模态-协同鸿沟 + 相似度桶内 CTR 异质性(其 Figure 2),前缀编码只是其解决方案的一个子模块;本文则把"前缀条件含义"本身作为核心问题。把 SIREN 列在此处,价值在于佐证"前缀条件化 SID 码"这一思路正在被跨场景独立复用,而非声称两文问题等同。
与 Step 4 DAG 的分工:上述三篇均为独立并发、本文未引用,故不在
dag.edges登记结构化对比边(DAG 记录的是论文自身声明的对比关系,如 baseline);本节是叙事性对比,二者互补。
讨论与局限性¶
编码器预训练即归纳偏置:不同预训练源给最终生成式推荐器注入不同归纳偏置——分类预训练编码静态转移统计(最高 TF),LLM 预训练编码语言锚定表征(最高 BLEU),Tiger 预训练编码行为生成模式(最高召回)。训练语料也会偏置表里编码的转移:互动加权数据偏向"利用已知偏好",目录均匀数据偏向"多样性与冷启动覆盖"。在真实流量下探索这些预训练策略及其下游效应是有前景的方向。
语言能力权衡:适配 LLM 做 SID 生成的已知挑战是"获取新 SID 知识 vs 保留预训练语言能力"的权衡(Verma et al. 用模型融合缓解但仍见退化)。本文编码器提供了潜在更优的权衡:SID 前缀知识被卸载到外部哈希表,LLM 的 transformer 权重不必再背负记忆前缀模式的负担——匹配训练迭代下,编码器在施加相同梯度更新量的情况下显著提升 SID 准确率,意味着语言能力退化应与 baseline 相当;或者,编码器能用更少训练步达到 baseline 的 SID 准确率(Figure 3),减少灾难性遗忘的总暴露。
局限性(论文坦诚列出):
- 编码器收益依赖 SID 前缀空间里存在可学结构。若 RQ-VAE 码本转移接近均匀(如重正则化导致),表可学的东西就少。
- 哈希表大小须随有效不同前缀模式数缩放。
- 编码器需要非平凡前缀才有用:第 1 层无前缀;第 2 层前缀只是 2048 词表里单码,LLM 可直接记住。编码器从第 3 层(2 码前缀、~4M 组合)开始有效,在第 4–5 层(前缀空间涨到百万级)收益最大。对层数少于 3 的 SID 层级,编码器几乎无益。
值得借鉴的设计:(1)把一个本属"表征质量"的问题,清晰地重构为"模态 + 专用编码器"的框架,直接迁移多模态 LLM 的成熟范式(独立预训练、可迁移、残差注入、$W_\text{out}$ 近零初始化让 LLM 早期不受扰);(2)用 teacher-forcing 逐层准确率 + reachable/unreachable 条件评估,干净地隔离出"编码器到底帮在硬样本上"这一机制级证据;(3)"记忆容量 vs 学习计算"的架构对照(哈希表 vs 336M transformer)给出了反直觉但有说服力的结论——对分层码,稀疏记忆 $O(1)$ 查找胜过稠密 attention 组合。潜在争议:~2B 参数 / ~10GB 显存的哈希表在更大词表或更深层级下如何扩展、在线流式更新是否会遇到 FLUID 所述的码本/表稳定性问题,论文用"成熟 embedding 基础设施可套用"一笔带过,真实工业 A/B 收益(而非离线指标)也尚未给出。