SIREN:多粒度语义交互,把多模态信号"早融合"进终身兴趣建模¶
来自腾讯(Tencent Inc.)与厦门大学信息学院,部署在微信广告系统(Weixin Moments / 公众号 / 视频号),已于 2025 年 7 月起全量上线服务全流量。SIREN = Semantic Interaction for Recommendation with Early fusioN(论文未给出严格缩写展开,此处依其核心主张"统一多粒度语义交互"理解)。
研究动机与背景¶
工业推荐系统(广告、信息流、电商)越来越依赖终身用户行为历史(lifelong behavior history)与丰富的多模态内容(图文/视频)来刻画演变中的用户兴趣。对超长行为序列直接建模在算力与在线延迟上不可行,因此业界普遍采用两阶段范式:
- GSU(General Search Unit,通用搜索单元):从完整行为历史 $H=(b_1,\dots,b_N)$ 中检索一段与目标物品相关的短子序列 $H_t=(b_1,\dots,b_L)$,$L\ll N$;
- ESU(Exact Search Unit,精确搜索单元):在检索出的 $H_t$ 上做细粒度兴趣建模。
把多模态信号有效注入这套范式仍然困难,根因是多模态空间与协同空间(ID 空间)的错配:预训练多模态 embedding 主要刻画内容相似性而非协同信号,其分布常与 ID embedding 不兼容,朴素融合容易引入噪声、损害推荐性能。
为缓解模态鸿沟,现有研究普遍采用分离建模(separate modeling)范式:多模态序列与行为序列各自独立建模,再用晚融合(late fusion)在序列聚合之后把两者拼起来(如 SOTA 基线 MUSE)。论文用 Figure 1 对比了这两种范式——分离建模把多模态当作辅助旁支,只在序列聚合后才与 ID 用户表征融合;而 SIREN 主张item 级早融合(item-level early fusion),让多模态语义与协同特征在统一序列建模框架内交互。论文明确指出分离建模有两个结构性缺陷:
缺陷一:多模态信号与协同信号未在统一表征空间内对齐,限制了特征交互。 既有方法(如 MUSE)把多模态当成辅助分支,只在序列聚合之后才与 ID 用户表征融合。这种晚融合阻止了多模态在序列建模过程中与协同信号充分交互——多模态信息主要充当注意力调制或序列级增强,而非直接参与表征学习,从而限制了模型刻画更具判别力的用户兴趣表征的能力。
缺陷二:target-behavior 相似度只给出粗粒度视角,忽略了多模态邻近性内部的协同异质性。 把"行为-目标"丰富关系压成一个标量或桶化的邻近度(如 SimTier),会隐式地把多模态邻近度相近的行为-目标对当成对预测用户响应"同等有信息量"。但论文用 Figure 2 揭示:即便落在同一个相似度桶内,不同 Semantic ID 组的 CTR 也差异显著,尤其在高相似度区域。这说明多模态邻近度只捕捉了粗粒度的目标相关性,并未保留支配用户反馈的协同结构——相似度表征单独使用,难以区分"在多模态空间里很近、但在协同 CTR 空间里行为迥异"的行为-目标对,从而限制了对细粒度用户兴趣的建模。
![Figure 2:同一 target-behavior 相似度桶内,不同 Semantic ID 组的 CTR 分布。上图为各相似度桶的平均 CTR;下图为三个代表桶 [0.2,0.3]、[0.5,0.6]、[0.9,1.0] 内按 SemID-pair 分组后的 CTR 分布。桶内 CTR 异质性在高相似度区尤其显著,印证了"高相似 ≠ 同质响应"。](figures/fig_01.png)
针对这两点,论文提出 SIREN——一个统一多粒度语义交互框架,在 GSU-ESU 两阶段范式内把多模态信号同时注入检索与精确建模。其核心思路是构造两种互补的 item 级多模态边信息——Semantic ID(SemID) 与 target-aware 相似度桶——并在 ESU 内与 ID 协同特征做 item 级早融合。
论文贡献归纳为四点:
- 提出一个把多模态信号有效注入工业 GSU-ESU 两阶段范式的终身用户兴趣建模框架;
- 在 GSU 阶段同时研究多模态相似度软检索与 SemID 硬检索,提供"检索质量 vs 在线服务效率"的实用权衡;
- 引入 target-aware 相似度桶与 prefix-encoded SemID 作为互补边信息,在 target-conditioned Transformer 上与 ID 协同特征做细粒度早融合;
- 大规模离线实验 + 在线 A/B + 表征分析,验证 SIREN 在工业场景的有效性与鲁棒性。
预备:问题形式化¶
研究的是多模态设定下的终身用户兴趣建模用于 CTR 预测。给定上下文 $c$、用户 $u$、目标物品 $v_t$,记 $H=(b_1,\dots,b_N)$ 为完整行为历史。GSU 先检索目标相关短子序列 $H_t=(b_1,\dots,b_L)$($L\ll N$),ESU 在 $H_t$ 上建模 $H_t$。
每个行为 $b_i$ 用 $x_i=(\mathbf{z}_i^{id}, e_i^{mm})$ 表示,其中 $\mathbf{z}_i^{id}$ 是 ID 类别特征,$e_i^{mm}\in\mathbb{R}^d$ 是与协同信号对齐的预训练多模态 embedding。目标是学习预测函数 $\hat y_t = P(y_t=1 \mid H_t, v_t, u, c)$,以二元交叉熵损失拟合真值标签 $y_t\in\{0,1\}$。
核心方法 / 模型架构¶
SIREN 的整体两阶段架构:
- GSU:提供两种多模态检索策略——相似度软检索与 SemID 硬检索,权衡检索质量与部署效率;
- ESU:一个统一序列建模框架,把 SemID 与相似度桶无缝纳入序列建模,并以 target-conditioned 交互增强。
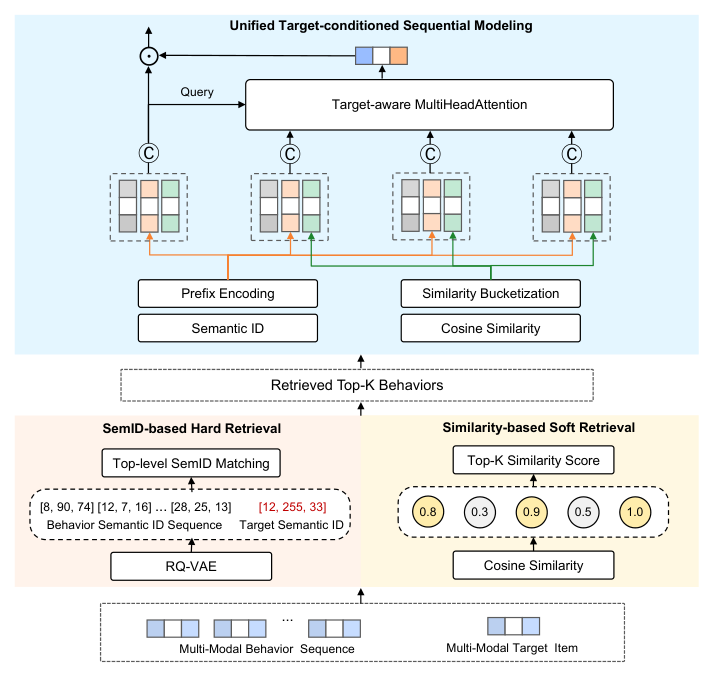
4.1 多模态特征构造¶
SIREN 从预训练多模态 embedding 构造两种互补特征:SemID 与 target-aware 相似度桶。
4.1.1 Semantic ID 构造¶
为让连续多模态 embedding 兼容以 ID 为中心的推荐系统,用 RQ-VAE 把每个物品 embedding 转成离散的 Semantic ID(SemID)。给定 $e_i^{mm}\in\mathbb{R}^d$,RQ-VAE 产出一个分层码序列:
$$\text{SemID}_i = \big(c_i^{(1)}, c_i^{(2)}, \dots, c_i^{(M)}\big) \tag{1}$$
不同层级的码在不同量化粒度上捕捉语义,形成从粗到细(coarse-to-fine)的物品表示。
与其对每个码独立 embedding,论文采用 prefix encoding(前缀编码)。对 $\text{SemID}_i$,构造前缀 token 集合:
$$\mathcal{P}_i = \Big\{\, c_i^{(1)},\ (c_i^{(1)}, c_i^{(2)}),\ \dots,\ (c_i^{(1)}, \dots, c_i^{(K)}) \,\Big\} \tag{2}$$
其中 $K\le M$ 是最大前缀深度。每个前缀 $p\in\mathcal{P}_i$ 经一张共享查找表映射到可学习 embedding,最终语义表示为各前缀 embedding 的拼接:
$$e_i^{sem} = \text{Concat}\big(\{\,\mathbb{E}_{\text{prefix}}[p] \mid p\in\mathcal{P}_i\,\}\big) \tag{3}$$
前缀编码的好处:既保留分层多模态语义(每个前缀代表逐级细化的语义类别),又提供一个离散接口,既能服务高效的 GSU 倒排检索,又能在 ESU 做细粒度表征。
4.1.2 Target-aware 相似度桶化¶
SemID 编码的是 item 自身的语义;相似度桶则显式建模每个历史行为与目标物品之间的 target-conditioned 相关性。对每个行为 $b_i$ 与目标 $v_t$,计算多模态余弦相似度:
$$s_{i,t} = \text{sim}(e_i^{mm}, e_t^{mm}) = \frac{(e_i^{mm})^\top e_t^{mm}}{\lVert e_i^{mm}\rVert \cdot \lVert e_t^{mm}\rVert} \tag{4}$$
再把连续分数离散化为桶索引:
$$q_{i,t} = \mathcal{B}(s_{i,t}) = \left\lfloor \frac{s_{i,t} - s_{\min}}{s_{\max} - s_{\min}} \cdot B \right\rfloor \tag{5}$$
其中 $B$ 为桶数,$[s_{\min}, s_{\max}]$ 是由数据统计估计的有效相似度区间,区间外的值被裁剪到边界桶。每个桶索引映射到一个可学习 embedding:
$$e_{i,t}^{Sim} = \text{Emb}^{Sim}(q_{i,t}) \tag{6}$$
这里要点在于:相似度桶是 target-conditioned 的(依赖目标 $v_t$),而 SemID 是 target-independent 的(只刻画 item 自身语义)。两者粒度互补——后文消融与条件熵分析正是围绕这一互补性展开。
4.2 General Search Unit(检索阶段)¶
GSU 的关键要求是在超长序列上平衡检索效率与相关性质量。传统 ID-based 检索语义表达力有限、抓不住内容级相关性,故 SIREN 引入两种多模态检索策略。
相似度软检索(Similarity-based Soft Retrieval)。 沿用 MUSE 的做法,基于历史物品与目标物品多模态 embedding 的余弦相似度取 Top-$K$ 行为:
$$\mathcal{S}_{Sim} = \text{Top-}K_{\,b_i\in\mathcal{B}}\ \text{sim}(e_i^{mm}, e_t^{mm}) \tag{7}$$
它能有效捕捉稠密内容相关性,但在线开销重:需要对全序列做相似度匹配,且维护实时多模态 embedding 索引带来巨大存储与系统复杂度,限制了大规模生产的可扩展性。
SemID 硬检索(Semantic ID-based Retrieval)。 为突破上述限制,用目标物品的顶层语义码 $c_t^{(1)}$ 去查倒排索引,取回所有共享同一顶层码的历史行为:
$$\mathcal{S}_{SemID} = \big\{\, b_i\in\mathcal{B} \mid c_i^{(1)} = c_t^{(1)} \,\big\} \tag{8}$$
相比软检索两大优势:(1) 用倒排查表替代稠密相似度计算,在线复杂度从 $O(|\mathcal{B}|\cdot d)$ 降到近常数时间;(2) 无需存储/传输高维 embedding,显著降低显存与带宽开销。
4.3 Exact Search Unit(精确建模阶段)¶
ESU 负责在检索出的行为上做细粒度序列建模。核心挑战仍是多模态 embedding 与 ID 信号的错配。SIREN 的解法是把 4.1 的两种多模态特征(SemID + 相似度桶)作为 item 级边信息,在统一的 target-conditioned 建模框架中整合——这正是 SIREN 与晚融合方法的根本分野。
统一物品表示(Unified Item Representation)。 对序列 $H_t$ 中每个行为 $b_i$,通过拼接协同特征与多模态特征构造统一表示:
$$h_i = \text{Concat}\big(e_i^{id},\, e_i^{sem}\big) \tag{9}$$
其中 $e_i^{id}$ 是 $\mathbf{z}_i^{id}$ 各 ID 特征 embedding 的拼接。目标物品 $v_t$ 同样表示为 $h_t = \text{Concat}(e_t^{id}, e_t^{sem})$。
Target-aware 序列建模。 用 target-aware 序列编码器抽取用户兴趣:
$$u_t = f\big(\{h_1, \dots, h_L\},\, h_t\big) \tag{10}$$
$f(\cdot)$ 实例化为多头 target attention,每个行为的重要性都以目标物品为条件:
$$\alpha_i = \text{Attn}\big(h_i \oplus e_{i,t}^{Sim},\ h_t \oplus e_t^{Sim}\big), \qquad u_t = \sum_{i=1}^{L} \alpha_i\, h_i \tag{11}$$
其中 $e_{i,t}^{Sim}$ 是行为 $b_i$ 的相似度桶 embedding,$e_t^{Sim}$ 是与目标物品关联的可学习 embedding,$\alpha_i$ 是行为 $b_i$ 的注意力权重,$\oplus$ 表示向量拼接。
这一设计的关键性质:所有特征类型——ID 协同、语义 SemID、target-aware 相似度——都在序列聚合之前就被整合进 $h_i$。因此这些信号会同时影响注意力权重和行为表征,而不像晚融合那样多模态只能在聚合后充当调制。注意相似度桶 $e_{i,t}^{Sim}$ 是拼到 query/key 上去算注意力权重(影响 $\alpha_i$),而 SemID $e_i^{sem}$ 已经在式 (9) 进了 $h_i$ 本身(既影响 $\alpha_i$ 又进入被加权的 value),两路边信息因此同时塑造注意力与表征。
Target-conditioned 交互(Target-conditioned Interaction, TI)。 为进一步把抽取出的用户兴趣与目标物品对齐,引入一个轻量的逐元素交互:
$$\tilde u_t = u_t \odot h_t \tag{12}$$
其中 $\odot$ 是逐元素乘。最终预测:
$$\hat y_t = \sigma\big(g\big([\,\tilde u_t,\, h_t,\, c\,]\big)\big) \tag{13}$$
这一交互捕捉用户兴趣与目标表征之间的细粒度相关性,得到超越纯注意力加权的细粒度兼容性模式。
方法小结: SIREN 的三个关键设计——(a) 用 prefix-encoded SemID 把多模态语义离散成可与 ID 共存的边特征;(b) 用 target-aware 相似度桶把"行为-目标"关系作为 query/key 增强直接参与注意力;(c) 把 (a)(b) 与 ID 在 item 级早融合进 target attention,再加 TI 逐元素交互。三者共同实现"协同依赖 + 粗粒度多模态相关性 + 细粒度语义异质性"在统一交互空间内的联合建模。
实验设置¶
数据集。 Taobao-MM(MUSE 提出的大规模公开多模态终身行为基准),采自淘宝展示广告系统真实流量,含与高质量多模态表征配对的长期行为序列。每个 item 关联标准 ID 类别特征 + 由 SCL 生成的 128 维预训练多模态 embedding。数据集含 99M 交互样本、8.79M 用户、35.4M 物品,每个用户的历史行为序列最长 1K 次交互。每个样本含匿名用户特征(user ID、年龄、性别、地域)、物品特征(item ID、类别)与二元点击标签。
基线。 与一组有代表性的终身兴趣建模方法对比:
- DIN:短期序列上的 target attention,无 GSU 检索;
- SIM-Hard:两阶段,GSU 按与目标的精确类别匹配检索;
- SIM-Soft:SIM 变体,GSU 按物品 embedding 内积相似度检索;
- TWIN:两阶段,GSU/ESU 用同一 target attention 保证一致性;
- MISS:多模态增强检索,在 ID-based GSU 旁引入一个多模态 GSU;
- MUSE:SOTA 多模态终身兴趣建模,GSU+ESU 双阶段都集成多模态信号;
- SIREN$_{\text{SemID-GSU}}$:GSU 用 SemID 硬检索、ESU 不变的 SIREN 变体;
- SIREN$_{\text{Sim-GSU}}$:GSU 用相似度软检索、ESU 不变的 SIREN 变体。
实现细节。 公平起见每个模型训练 1 个 epoch。DIN 用最近 50 个行为(单阶段无 GSU);所有两阶段模型从终身序列检索 Top-50 行为送入 ESU。SIM-Hard/SIM-Soft 沿用原始 GSU,但把 ESU 换成 SIREN 实现。SIREN 默认用相似度软检索。dense 参数用 AdamW、sparse embedding 用 SparseAdam,学习率分别 $2\times10^{-4}$ 与 $2\times10^{-3}$,batch size 1000。主指标为 Group AUC(GAUC)。
主要实验结果¶
整体性能(Table 1)¶
| Method | GAUC | Relative Lift |
|---|---|---|
| DIN | 0.6006 (3E-5) | – |
| TWIN | 0.6079 (6E-5) | +1.22% |
| MISS | 0.6087 (1E-5) | +1.35% |
| SIM-Hard | 0.6145 (6E-5) | +2.31% |
| SIM-Soft | 0.6144 (5E-5) | +2.30% |
| MUSE | 0.6148 (7E-5) | +2.36% |
| SIREN$_{\text{SemID-GSU}}$ | 0.6148 (7E-5) | +2.36% |
| SIREN$_{\text{Sim-GSU}}$ | 0.6155 (9E-5) | +2.48% |
(括号内为标准差,最优加粗。)
三点观察与结论分析:
- 终身行为建模一致优于短行为建模。 DIN(只用最近行为)GAUC 最低 0.6006;所有两阶段方法借 GSU 检索利用终身序列后均显著提升,印证了在工业推荐中建模长期兴趣的必要性。
- 多模态方法优于纯 ID 基线。 ID-centric 的终身模型(TWIN、MISS、SIM-Hard、SIM-Soft)逊于多模态方法。具体地,TWIN 的 ID-based 检索对长尾物品泛化差;MISS 与 SIM 变体在 ESU 阶段缺乏充分的多模态集成,因而排在 SIREN 之下。
- SIREN 取得最佳整体性能。 GAUC 0.6155,比强基线 MUSE(0.6148)高 0.11%。虽然绝对增益不大,但在大规模推荐/CTR 系统中,0.1% 级别的 AUC/GAUC 提升被公认具有实际意义。值得注意的是 SIREN$_{\text{SemID-GSU}}$ 用高效 SemID 倒排查表即达到与 MUSE 相当的性能,说明 SemID 可作为多模态相似度检索的有效、可扩展替代。全模型的性能增益来自 SIREN 的统一 target-conditioned 框架——prefix-encoded SemID 与相似度桶被直接整合进序列建模。
消融实验(Table 2)¶
所有变体都用相似度软检索作为 GSU;base 模型在检索出的终身序列上只用 ID 表征做 target attention;TI 表示 Target-conditioned Interaction。
| ESU Configuration | GAUC | Relative Lift |
|---|---|---|
| Target Attention (base) | 0.6080 | – |
| + SemID only | 0.6095 | +0.25% |
| + SimBucket only | 0.6142 | +1.02% |
| + SimBucket + SemID | 0.6153 | +1.20% |
| SIREN (SimBucket + SemID + TI) | 0.6155 | +1.23% |
逐项分析:
- 两种边信息都正向贡献。 单加 SemID 把 GAUC 从 0.6080 提到 0.6095;单加相似度桶提升更大,到 0.6142;两者组合进一步到 0.6153——说明二者捕捉互补信号。
- 相似度桶增益更大,SemID 细化语义区分。 相似度桶直接编码 target-aware 相关性,是兴趣建模最有信息量的信号,故增益更大;SemID 捕捉 target-independent 的语义内容,帮助区分"相似度分相近但语义不同"的行为。两者联合刻画"一个行为对目标有多相关"与"它代表什么",实现更全面的兴趣建模。
- Target-conditioned Interaction(TI)带来额外增益(虽不大),但 Fig.4 的互信息分析显示它显著增强表征判别力——即 TI 对预测指标贡献温和,但对表征质量贡献明显。
表征判别力分析(Fig.4 左)¶
进一步考察 SIREN 是否学到更有信息量、更具判别力的用户表征:评估用户兴趣表征 $\tilde u_t$(式 12)与点击标签的互信息(MI)。因 $\tilde u_t$ 连续高维,先用 $K$-means 聚类把表征空间量化为离散簇 $Q(\tilde u_t)$,再计算簇分配与二元点击标签 $Y$ 之间的 MI;MI 越高,表征对正负样本的分离越有效。结论:
- SIREN 一致产出更具判别力的表征。 在不同 $K$-means 簇数下,SIREN 的 MI 都高于 MUSE 兴趣表征,也高于两个独立多模态组件 SimTier(把 target-behavior 相似度聚成全局序列级直方图)与 SA-TA(Semantic-Aware Target Attention,把语义相似度注入 ID-based 注意力权重)。这归功于 SIREN 把粗、细粒度多模态信号统一进序列建模框架。
- TI 显著提升表征质量(Fig.4b):开启 target 交互机制明显抬高 MI,说明显式建模"抽取兴趣 ↔ 目标表征"的相关性增强了表征判别力。
- 相似度桶与 SemID 提供互补信息(Fig.4c):两者组合取得最高 MI,优于任一单独使用。

细粒度 Semantic ID 的必要性(§5.5)¶
论文从三个角度论证"为何需要超越粗相似度桶的细粒度 SemID":
(1) 条件熵分析。 用信息增益衡量不同分组策略对点击标签不确定性的削减:
$$I(Y;G) = H(Y) - H(Y\mid G) \tag{14}$$
其中 $Y$ 为点击标签,$G$ 为分组变量,$I(Y;G)$ 越大说明该分组越能解释点击变化。结果:Semantic-ID 分组 $I(Y;\text{SID})=0.0195$,远高于相似度桶分组 $I(Y;\text{Sim})=0.0056$。这说明 SemID 比标量相似度桶保留了更多与点击相关的信息,其细粒度划分更贴合用户反馈。
(2) 桶内 CTR 分布分析(Fig.2)。 即便在同一相似度桶内,不同 SemID 组的 CTR 也差异显著,且这种桶内离散度在高相似度区更大:CTR 区间从桶 [0.2,0.3] 的 [0.815, 0.949] 扩大到桶 [0.5,0.6] 的 [0.755, 0.956],再到桶 [0.9,1.0] 的 [0.735, 1.000];对应标准差从约 0.035 增至 0.052、再到 0.068。高 target-behavior 相似度并不意味着同质的用户响应——粗相似度桶单独不足以捕捉高相似区所需的细粒度异质性。
(3) 增大桶粒度的局限(Fig.4 右)。 一个自然的问题是:能否靠更多相似度桶来补回缺失的信息?实验显示桶数从 20 增到 40 时 GAUC 提升,但继续增大粒度反而退化。这说明瓶颈不在桶分辨率不足,而在于直方图式的相似度汇总把 item 级相似度序列压成了全局统计量,丢弃了 item 身份与时序结构。相比之下,SIREN 在 ESU 内于 item 级同时保留相似度与 SemID 信号,因而二者互补:相似度桶编码粗粒度 target-conditioned 相关性,SemID 编码细粒度语义与协同异质性——这种互补无法靠单纯细化桶粒度恢复。
在线 A/B 实验¶
SIREN 部署于腾讯微信在线广告系统(日服务数百亿广告请求)。生产模型用跨域行为序列(广告、视频号、内容信息流),覆盖最长两年的用户交互,每域最大序列长度 4000。在三大广告场景各取 20% 流量、最长 14 天实验,生产基线为 SIM-Hard。所有上报提升均经严格显著性检验。
Table 3:三场景 × 各流水线阶段的 GMV 提升¶
| Scenario | Stage | Feature | GMV Lift |
|---|---|---|---|
| Weixin Moments(朋友圈) | pCTR | Similarity | +1.58% |
| pCTR | SemID | +0.70% | |
| Weixin Official Accounts(公众号) | pCTR | Similarity | +1.64% |
| pCVR | SemID | +2.23% | |
| Weixin Channels(视频号) | pCTR | Similarity | +0.87% |
| LTR | SemID | +0.74% |
结论: SIREN 在三场景一致提升 GMV——朋友圈 +2.28%、公众号 +3.87%、视频号 +1.61%(各场景多个阶段增益累加),且增益横跨 pCTR/pCVR/LTR 多个流水线阶段,说明框架对多样真实场景泛化良好。
Table 4:朋友圈冷启动细分(相对整体均值的 GMV 提升)¶
| Side | Segment | Relative Lift vs. Overall |
|---|---|---|
| User-side | Low-activity users(<50 交互) | ~1.7× |
| Cold-start users(<10 交互) | ~3.6× | |
| Item-side | New ads(上线首日) | ~1.4× |
结论: GMV 提升随用户活跃度下降而单调增大,SIREN 对低活跃与冷启动用户带来显著更大的收益——这些稀疏交互场景下传统 ID 信号不可靠,多模态信号大幅改善兴趣建模。物品侧同理:SIREN 用视觉/文本内容增强对过去 24 小时内新上线广告的兴趣匹配,缓解新广告冷启动。
SemID 硬检索的部署效率¶
把 SemID 硬检索作为 GSU 的备选检索策略:相比需要维护稠密 embedding 索引、对高维向量做成对相似度计算的软检索,SemID 硬检索把在线服务的算力与存储成本都降低了 90% 以上,而性能仅有极小退化。这一效率增益提供了实用的"效率-性能"权衡,为大规模部署提供低成本替代方案。
核心贡献总结¶
- 范式转变:从晚融合到 item 级早融合。 SIREN 明确指出分离建模 + 晚融合(如 MUSE)的两个结构缺陷,主张把多模态语义在 item 级与 ID 协同特征拼接、共同进入 target attention,使多模态同时塑造注意力权重与行为表征。
- 两种互补的多模态边信息。 target-independent 的 prefix-encoded SemID(刻画"是什么")+ target-conditioned 的相似度桶(刻画"有多相关"),并用条件熵($I(Y;\text{SID})=0.0195$ vs $I(Y;\text{Sim})=0.0056$)、桶内 CTR 异质性、桶粒度饱和三组分析论证二者不可互相替代。
- GSU 双检索的效率-质量权衡。 相似度软检索质量最优;SemID 硬检索用倒排查表把在线成本降 90%+ 而性能几乎不降,SIREN$_{\text{SemID-GSU}}$ 即达 MUSE 水平。
- 工业全量落地。 微信广告三场景 +1.61%~+3.87% GMV,冷启动用户增益达整体 ~3.6×,2025 年 7 月起全量上线。
与已归档相关工作的对比¶
FLUID FLUID:用多模态语义码退役"短命 item ID"(ByteDance/TikTok, 2026-05)¶
关系:独立并发(SIREN 未引用 FLUID,两者同月、殊途而对立)· 已加载对方精读
- 共同关注的问题:两篇都在攻同一个 root cause——如何把内容衍生的多模态/语义信号注入 ID-centric 工业排序器,克服多模态与 ID 协同空间的错配;且都直面 FLUID 所谓的 "ID-dominance / shortcut" 现象(排序器倾向走 ID embedding 捷径、欠利用多模态)。两篇也都用 RQ 系量化 + prefix 编码把连续多模态 embedding 离散成分层码:SIREN 用 RQ-VAE 产 SemID + prefix encoding,FLUID 用 RQ-KMeans 产 LUCID + prefix n-gram。
- 相近的技术骨架:都是"多模态 embedding → 残差量化分层码 → prefix/前缀映射成可学习 embedding → 注入工业 CTR/排序器",抽象流程图高度重合。
- 本文的差异与推进(关键对照——融合取向相反):FLUID 的主张是彻底替换 item ID——LUCID 作为独立候选侧 token 晚融合(late-fusion)进排序器,通过分阶段 warmup 把 item ID 退役;因为直播间中位寿命仅 ~40 分钟,ID 永远欠训练,ID-dominance 从"可容忍麻烦"升级为"根本瓶颈"。而 SIREN 走相反路线:保留 ID,做 item 级早融合——它把晚融合本身列为缺陷一(多模态在序列聚合后才接入,无法与协同信号交互),坚持 SemID/相似度桶与 ID 在 $h_i$ 内 concat 后共同进 target attention。两者恰好示范了"同一套语义码技术、相反的融合哲学":FLUID 因 item 寿命极短而判定 ID 无价值故替换,SIREN 因 lifelong 长序列中 ID 仍承载丰富协同信号故保留并早融合。
- 可比的方法/实验差异:FLUID 是候选侧 item 表征(直播排序),SIREN 是用户侧 lifelong 行为序列 + target attention;FLUID 强调 cross-domain(短视频→直播)编码器训练,SIREN 直接用预训练多模态 embedding 不训编码器;两者都报告冷启动场景增益最大(FLUID +2.05% Cold-Start Room Views;SIREN 冷启动用户 ~3.6×)。
IDProxy IDProxy:为冷启动生成 proxy ID embedding(Xiaohongshu, 2026-03)¶
关系:独立并发(SIREN 未引用 IDProxy,问题同构、解法不同维度殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直指多模态/内容空间与工业 ID embedding 空间的错配,且都把这一错配当成 CTR 性能瓶颈、并以冷启动为核心收益场景。IDProxy 还明确批评既有多模态对齐方法(QARM、MOON、SimTier——与 SIREN 引用的 SimTier 同源)"依赖人工对齐目标、未充分利用排序模型结构、收益有限",这与 SIREN 对晚融合/分离建模的批评同构。
- 相近的技术骨架(核心 insight 同构):IDProxy 最关键的发现是 v5 把多模态特征直接塞进 ranker 的原子 ID 槽位、继承 ID-based 特征交互与 target attention 结构(+0.14%),显著优于 v4 把 MLLM 隐特征作为普通旁支特征拼接(+0.08%)。这与 SIREN 的核心论点完全同构——多模态必须在 item 级注入既有 ID-based 交互/注意力机制,而非作为晚/独立旁支接入。两者都得出"融合位置(fusion locus)比融合什么更重要"的结论。
- 本文的差异与推进:解法机制不同维度——IDProxy 走连续对齐路线(MLLM 中间层隐状态经对比学习 $\mathcal{L}_{\text{PAL}}$ 回归到 ID embedding 分布,产 coarse/fine proxy embedding 填 ID 槽),侧重冷启动新物品的 ID 槽补全;SIREN 走离散语义码路线(RQ-VAE SemID + 相似度桶作边信息),侧重 lifelong 序列的兴趣建模。一个把多模态"伪装"成 ID 来对齐分布,一个把多模态离散成与 ID 并存的边信息——殊途同归于"item 级早融合 > 晚融合"。
- 可比的方法/实验差异:两者都在高度优化的工业生产 base 上取得 0.1% 级离线 AUC 增益(IDProxy +0.14% ΔAUC;SIREN 比 MUSE +0.11% GAUC),都强调该量级在生产意义重大;都报告冷启动是最大收益来源。
Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices Semantic IDs at Snapchat(Snap Inc., 2026-04)¶
关系:独立并发(SIREN 未引用 Snap)· 已加载对方精读
- 共同关注的问题:Snap 系统性论证 SID 作为排序器辅助/边特征(auxiliary feature) 的工业价值——这与生成式推荐"把 SID 作为自回归预测目标"是两条不同路线。SIREN 的 SemID 用法正属于前者:不做生成,而把 SemID 作为 item 级边特征注入 CTR 排序。两者都站在"SID 是判别式排序的有用边特征"这一侧。
- 相近的技术骨架:都用 RQ 系 tokenizer(Snap 用 RQ-VAE、SIREN 用 RQ-VAE)从多模态/语义表征产分层 SID,作为辅助类别特征进排序模型;都强调多模态 embedding 融合对 SID 质量的作用。
- 本文的差异与推进:Snap 是广覆盖的工业实践综述(同时讲 SID 作辅助特征 + 作生成检索目标 + codebook collapse 的 STE 修复 + SID-to-item 落地),技术贡献偏部署经验;SIREN 聚焦"如何在 lifelong target attention 中早融合 SemID + 相似度桶",技术贡献偏建模机制。最直接的呼应:Snap 报告 SID 辅助特征在 Ads Ranking 上带来 +0.028%/+0.035% AUC、在冷启动重的 DPA 上 +0.67%;SIREN 则证明 SIREN$_{\text{SemID-GSU}}$ 用 SemID 倒排查表即达 MUSE 水平、在线成本降 90%+——两者共同支撑"SemID 是多模态相似度检索/稠密多模态特征的可扩展、低成本替代"这一结论。
讨论与局限性¶
核心贡献与可借鉴设计。 SIREN 最值得借鉴的是它把一个看似抽象的"晚融合 vs 早融合"之争落到了可操作的机制层:用 prefix-encoded SemID 解决"多模态如何与 ID 共存于一个序列",用 target-aware 相似度桶解决"行为-目标关系如何直接参与注意力",再用条件熵 + 桶内 CTR 异质性 + 桶粒度饱和三组分析,把"为什么粗相似度不够、必须要细粒度 SemID"论证得相当扎实($I(Y;\text{SID})=0.0195$ vs $I(Y;\text{Sim})=0.0056$ 是个干净有力的证据)。GSU 双检索(软检索质量 / SemID 硬检索效率)也是工业落地友好的设计——SemID 倒排把在线成本降 90%+ 而几乎不掉点,直接回答了"多模态终身建模太贵"的部署顾虑。
局限与争议。
- 离线增益偏小。 全模型相对 MUSE 仅 +0.11% GAUC、SemID-GSU 与 MUSE 持平。论文以"0.1% 在工业 CTR 有实际意义"作辩护(合理),但纯离线看 SIREN 相对 SOTA 多模态基线的提升并不显著,真正的卖点在在线 GMV(+1.61%~+3.87%)与冷启动收益、以及 SemID 的部署效率,而非离线精度的大幅领先。
- 依赖高质量预训练多模态 embedding。 SIREN 不训练多模态编码器,直接用 SCL 生成的 128 维 embedding;其有效性高度依赖该 embedding 与协同信号的对齐质量。对比 FLUID 专门联合短视频+直播训练 cross-domain 编码器,SIREN 在"多模态表征本身的获取"上着墨少,可能限制其向缺乏现成高质量多模态 embedding 的场景迁移。
- 相似度桶的超参敏感。 Fig.4 右显示桶数在 40 左右饱和、过大反而退化;$[s_{\min}, s_{\max}]$ 还需由数据统计估计并裁剪边界桶——这些都引入了需要调的工程超参,论文未深入讨论其跨场景稳定性。
- TI 的收益主要体现在表征而非指标。 Target-conditioned Interaction 对 GAUC 仅 +0.02%(0.6153→0.6155),其价值主要由互信息分析支撑;它在预测指标上接近"锦上添花",在算力受限场景下是否值得保留,论文未给出权衡讨论。
与已有工作的差异定位。 相对 MUSE(最直接的前驱/基线,晚融合 + 序列级多模态),SIREN 的本质区别是把多模态从"序列聚合后的旁支调制"提前到"item 级与 ID 共存的早融合";相对生成式推荐的 SID 路线(TIGER 系),SIREN 把 SemID 当判别式排序的边特征而非生成目标;相对同期独立工作 FLUID/IDProxy/Snap,SIREN 在"item 级早融合 > 晚融合/独立旁支"这一 insight 上与它们殊途同归,但在 lifelong target attention + 双粒度互补边信息(SemID + 相似度桶)的具体组合上是独特的。