OneRank:把多任务排序「内生」进 Transformer 的统一原生架构¶
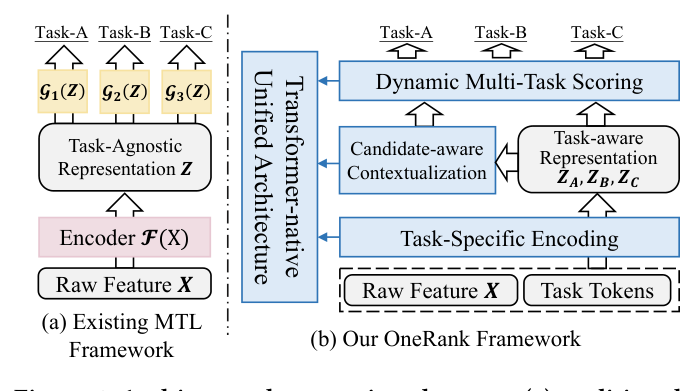
来自 中国人民大学高瓴人工智能学院 + Shopee + 南洋理工大学(Jiakai Tang、Sunhao Dai 共同一作,Xu Chen、Jun Xu 为通讯作者),KDD 2026,2026-06-15 挂 arXiv(2606.16838v1,cs.IR)。核心主张:现代工业排序已从 DNN 转向 Transformer 以增强序列建模与 scaling 能力,但仍沿用「编码器–预测器」(encoder–predictor,记作 $\mathcal{F}$–$\mathcal{G}$)分离的范式——Transformer 只当一个任务无关(task-agnostic)的编码器 $\mathbf{Z}=\mathcal{F}(\mathbf{X})$,下游再用一堆静态前馈 MLP 任务塔 $\mathcal{G}(\cdot)$ 出预测。本文论证这一分离带来三重结构性瓶颈:(1) 共享表示 $\mathbf{Z}$ 形成任务无关信息瓶颈,任务特异信号被纠缠丢失;(2) 共享底座诱发跷跷板现象(seesaw)——梯度冲突使优化一个任务损害另一个;(3) 把 $\mathcal{F}$ 里「注意力驱动、上下文自适应」的表征学习,硬交给 $\mathcal{G}$ 里「静态前馈」的预测,造成数据流与计算范式的不兼容断裂。OneRank 直接消除 $\mathcal{F}$–$\mathcal{G}$ 切分,把多任务推理内化进 Transformer 栈本身:前向上自底向上搭「任务私有通道 + 任务共享通路」(任务 token 互不可见实现早期特化、候选感知上下文化弥合训练–服务 gap、可配置跨任务关系注意力做受控知识迁移),后向上用策略性梯度解耦(gradient detachment)阻断跨任务梯度、把跨任务注意力变成「只读记忆」,预测时用动态匹配打分取代静态 MLP scorer。在 Shopee 大规模工业数据上离线全面超越 SOTA,线上 7 天 A/B 拿到 GMV/UU +1.01%、Paid GMV/UU +1.17%。
研究动机与背景¶
多任务学习(Multi-Task Learning, MTL)已是现代推荐系统的事实标准——联合建模「稠密但含噪」(如点击)与「稀疏但信息量大」(如下单)的多种用户反馈,能让任务之间互补学习。早期的深度学习推荐模型(DLRM)主要用两种方式利用任务依赖:
- 显式依赖建模(explicit dependency modeling):通过结构化知识迁移,如 ESMM、ESCM²、AITM、ResFlow;
- 隐式知识共享(implicit knowledge sharing):通过动态路由与专家平衡机制,如 MMoE、PLE。
受大模型进展启发,近年工作转向 Transformer-centric 架构以利用其强序列建模与良好 scaling 行为。但本文指出,这一转型并未构成真正的架构变革:现有方法大多仍保留编码器–预测器设计,可形式化为 $\mathbf{Z}=\mathcal{F}(\mathbf{X})$,其中 $\mathcal{F}(\cdot)$ 把原始输入 $\mathbf{X}$ 映射到共享、任务无关的表示 $\mathbf{Z}$,再由任务特定预测器 $\mathcal{G}(\cdot)$ 在 $\mathbf{Z}$ 上运算。这一范式有三个根本局限:
- 第一,任务无关信息瓶颈。 共享表示 $\mathbf{Z}=\mathcal{F}(\mathbf{X})$ 是任务无关的,任务特异信号在其中被纠缠、丧失辨识度。把 $\mathcal{F}(\cdot)$ 换成 Transformer 只是增大编码容量,并不改变这个结构性约束——下游预测器 $\mathcal{G}(\cdot)$ 仍缺乏显式机制把任务特异信息从混合 embedding 里解纠缠。这迫使复杂的解纠缠发生在「建模容量通常受限」的预测阶段。
- 第二,跷跷板现象。 共享底座架构容易出现 seesaw——共享参数上的梯度冲突会「改善一个任务却恶化另一个」。根因是任务无关瓶颈 $\mathbf{Z}$ 缺乏显式机制去分离「反传经过 $\mathcal{F}$ 的各任务优化方向」。
- 第三,数据流与设计范式断裂。 编码器–预测器分离强行造成一次数据流与设计范式的切换:上下文自适应的学习在 $\mathcal{F}(\cdot)$ 里完成,却被交给静态前馈任务预测器 $\mathcal{G}(\cdot)$。具体说,Transformer 通过注意力做迭代的、上下文相关的信息路由,而 DNN 预测器寻求一个全局非线性决策边界、适应动态用户上下文的能力有限。这种范式错配破坏了端到端任务推理与连贯的计算 scaling。
为此本文提出 OneRank,一个 Transformer-native 多任务排序框架,通过把多任务推理内化进 Transformer 栈本身来消除编码器–预测器切分。设计哲学是自底向上地在「任务共享通路」旁边搭建「任务私有通道」,在多个架构层级上同时实现任务特化与有益的知识共享:
- 前向传播:输入层用「带互不可见性的任务特定 token 注入」做早期特化;中间层用「候选感知上下文化」聚合跨候选信号、弥合训练–服务 gap;预测层用「受控跨任务关系注意力」在有益时选择性迁移领域特定的任务依赖。
- 后向传播:用策略性梯度解耦阻断跨任务梯度流,把任务特定参数的更新与共享组件隔离,有效地把跨任务注意力变成一块用于知识迁移的「只读记忆」,防止负迁移。
- 预测时:用动态匹配打分公式取代静态全局 MLP scorer——任务感知的全局表示直接与「上下文条件化的候选 embedding」做内积匹配,实现上下文感知、任务自适应的排序,且不引入额外架构组件。
核心方法 / 模型架构¶
OneRank 把方法组织为:结构化 tokenization(§2.1)把异质输入编成统一 token 序列;任务特定编码(§2.2)用「带互不可见性的任务 token 注入」实现早期特化、缓解梯度冲突;候选感知上下文化(§2.3)聚合跨候选信号弥合训练–服务 gap;多任务预测(§2.4)用「灵活跨任务关系注意力 + 策略性梯度解耦 + 可配置 mask」做受控知识迁移;最后是联合优化目标(§2.5)。
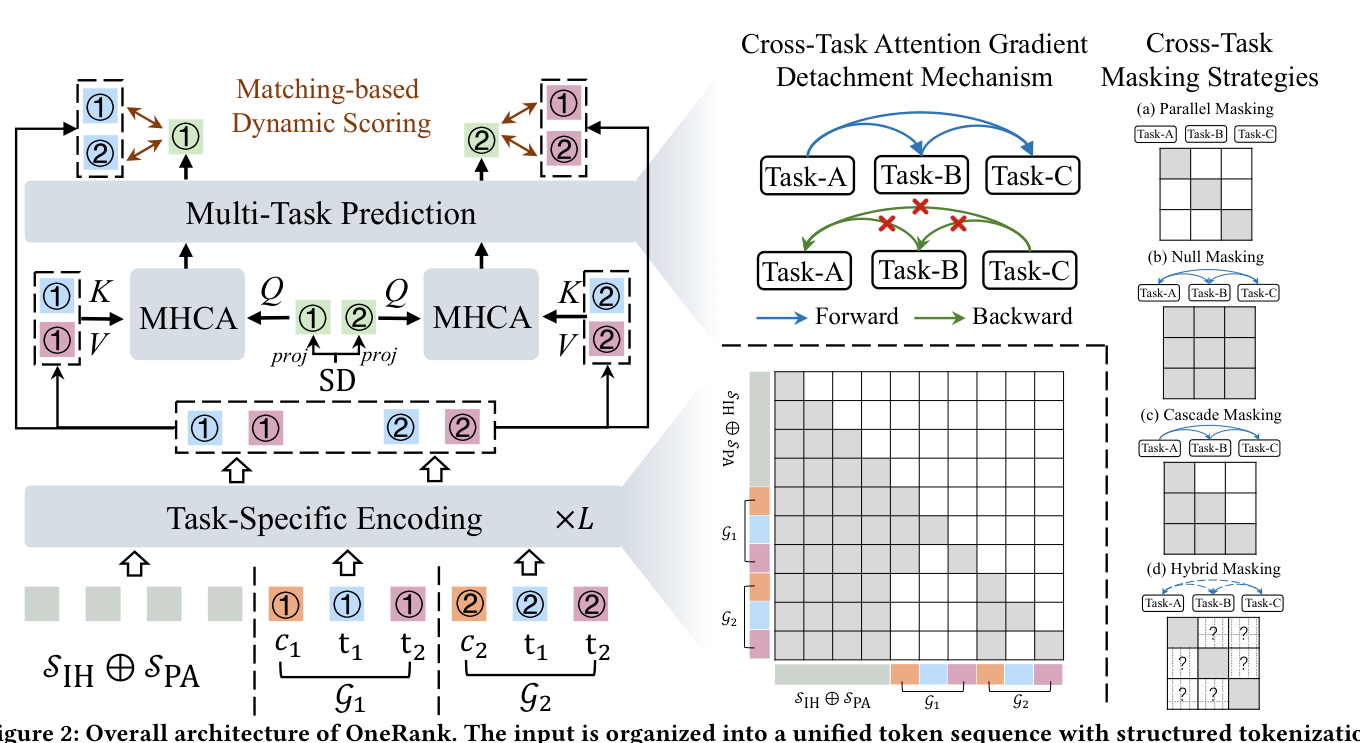
2.1 结构化 Tokenization¶
把多样输入模态转换为统一 token 序列表示,使序列模式与特征交互能被有效联合建模。
交互历史(Interaction History, IH)。 把用户行为序列按时间组织为 $\mathcal{H}=\{h_1,h_2,\dots,h_T\}$,$h_t$ 是时间戳 $t$ 的交互。为捕捉时序动态与偏好演化,对每次交互加可学习位置编码 $\mathbf{p}_t\in\mathbb{R}^d$:$\mathbf{e}_t^{\text{IH}}=\text{Embed}(h_t)+\mathbf{p}_t$,得到 $\mathcal{S}_{\text{IH}}=[\mathbf{e}_1^{\text{IH}},\dots,\mathbf{e}_T^{\text{IH}}]$。
偏好锚定(Preference Anchoring, PA)。 受大模型里检索增强生成(RAG)启发,用外部知识增强交互历史。引入偏好锚(Preference Anchors)$\mathcal{A}=\{\mathcal{A}_1,\dots,\mathcal{A}_M\}$,依领域知识动态选择多条序列:个性化搜索里检索与当前 query 相关的「top 点击 / top 购买」序列;推荐里选历史高互动序列作为互补信号。每条序列用可学习边界 token 封装:
$$\mathcal{S}_{\text{PA}}=\bigoplus_{i=1}^{M}\big(\langle\text{BOS}\rangle\oplus\mathcal{A}_i\oplus\langle\text{EOS}\rangle\big)\tag{1}$$
其中 $\oplus$ 是拼接,$M$ 是检索序列数,$\langle\text{BOS}\rangle/\langle\text{EOS}\rangle$ 是可学习的起止 token。
候选–任务 token 组(Candidate-Task Token Groups)。 对候选集 $\mathcal{C}=\{c_1,\dots,c_N\}$ 中每个候选 $c_i$,构造一个 token 组,含候选 embedding $\mathbf{e}_i^C\in\mathbb{R}^d$ 与 $K$ 个任务特定 token。任务 token $\{\mathbf{t}_k\}_{k=1}^K$ 是跨所有候选共享的可学习参数,每个 $\mathbf{t}_k\in\mathbb{R}^d$ 充当任务 $k$ 的「任务特定 query 模板」。对每个 $c_i$ 实例化这组共享任务 token,形成候选–任务组:
$$\mathcal{G}_i=[\mathbf{e}_i^C,\mathbf{t}_1,\mathbf{t}_2,\dots,\mathbf{t}_K]\in\mathbb{R}^{(1+K)\times d}\tag{2}$$
任务 token 跨组共享,但每组在编码时经结构化注意力 mask 独立运作,允许任务 token 通过注意力对不同候选 embedding 与共享用户上下文,抽取出候选特定的任务表示。
统一 token 序列。 最终输入把共享用户上下文置于所有候选–任务组之前:
$$\mathcal{X}_0=[\mathcal{S}_{\text{IH}},\mathcal{S}_{\text{PA}},\mathcal{G}_1,\mathcal{G}_2,\dots,\mathcal{G}_N]\in\mathbb{R}^{S\times d}\tag{3}$$
其中总长 $S=T+\sum_{i=1}^M(|\mathcal{A}_i|+2)+N\cdot(1+K)$。这种组织天然把「任务共享通路(用户上下文)」与「任务私有通道(任务 token)」分开,利于高效注意力计算与并行。
2.2 任务特定编码(Task-Specific Encoding)¶
为在输入层就实现早期任务特化、缓解共享底座的 seesaw,OneRank 不依赖「对所有任务共用一个 $\mathbf{Z}=\mathcal{F}(\mathbf{X})$」,而是把共享的任务特定 token 模板注入每个候选组,经结构化注意力机制实现独立的任务特定特征抽取。
结构化注意力 mask。 构造 $\mathbf{M}\in\{0,1\}^{S\times S}$,在保持「共享用户上下文可见」的同时,强制任务 token 之间互不可见:
- 因果用户上下文:$\mathcal{S}_{\text{IH}}$ 和 $\mathcal{S}_{\text{PA}}$ 内的 token 遵循因果注意力(只看自身与前序位置)做时序建模;
- 候选组隔离:每个组 $\mathcal{G}_i$ 与其它组 $\mathcal{G}_j(j\neq i)$ 互相隔离,实现「单用户多候选」的高效并行。$\mathcal{G}_i$ 内 token 可注意:用户上下文里所有 token(因果 mask)、同组内的候选 embedding $\mathbf{e}_i^C$、自身(self-attention);
- 任务 token 互不可见:不同任务的 token 即使在同一候选组内也互相不可见。组 $\mathcal{G}_i$ 里第 $k$ 个任务 token 只能注意用户上下文(因果)、候选 embedding $\mathbf{e}_i^C$、和它自己,看不到同组其它任务 token。
形式化,记 $\text{pos}(p)$ 为 token $p$ 在用户上下文里的序列位置,$\mathbf{t}_k^{(i)}$ 为组 $\mathcal{G}_i$ 里第 $k$ 个任务 token,则 mask 为:
$$\mathbf{M}_{pq}=\begin{cases}1, & \text{若 } p,q\in\{\mathcal{S}_{\text{IH}},\mathcal{S}_{\text{PA}}\}\text{ 且 }\text{pos}(q)\le\text{pos}(p)\\ 1, & \text{若 } p\in\mathcal{G}_i\text{ 且 }q\in\{\mathcal{S}_{\text{IH}},\mathcal{S}_{\text{PA}}\}\\ 1, & \text{若 } p\in\mathcal{G}_i\text{ 且 }q=\mathbf{e}_i^C\\ 1, & \text{若 } p=\mathbf{t}_k^{(i)}\text{ 且 }q=\mathbf{t}_k^{(i)}\\ 0, & \text{其它}\end{cases}\tag{4}$$
Transformer 编码。 用 $L$ 层带 mask 的多头自注意力(MHSA),配残差与 LayerNorm(pre-norm 风格):
$$\mathbf{H}^{(\ell)}=\text{LN}\big(\text{MHSA}^{(\ell)}(\mathcal{X}^{(\ell-1)},\mathbf{M})\big)+\mathcal{X}^{(\ell-1)},\qquad \mathcal{X}^{(\ell)}=\text{LN}\big(\text{FFN}^{(\ell)}(\mathbf{H}^{(\ell)})\big)+\mathbf{H}^{(\ell)}\tag{5}$$
$\ell\in\{1,\dots,L\}$。编码后,从每个候选组里选出对应任务 token 的输出,作为任务特定表示:
$$\mathbf{r}_k^i=\text{Extract}(\mathcal{X}^{(L)},\mathbf{t}_k^{(i)})\in\mathbb{R}^d\tag{6}$$
$\mathbf{r}_k^i$ 编码了候选 $i$ 在任务 $k$ 下的任务相关特征。尽管所有候选组共用同一套任务 token 参数 $\{\mathbf{t}_k\}_{k=1}^K$,每个任务 token 因注意不同候选 embedding $\mathbf{e}_i^C$、并整合共享用户上下文里的候选特定信号,会产出不同的 $\mathbf{r}_k^i$,从而在最早阶段达成任务特化。
2.3 候选感知上下文化(Candidate-Aware Contextualization)¶
传统 point-wise 打分有训练–服务 gap:模型在孤立样本上训练,却无法捕捉服务时存在的跨候选依赖。OneRank 用候选感知上下文化经「情境描述符」聚合跨候选信号来弥合。
情境描述符(Situational Descriptors, SD)。 定义 $\mathbf{s}\in\mathbb{R}^d$ 封装上下文信号——用户人口属性、query 信息、会话元数据(如时间、地点),作为聚合的上下文锚点。
任务特定的跨候选聚合。 对每个任务 $k$,用任务特定投影 $f_k(\cdot)$ 变换 SD:
$$\mathbf{q}_k=\text{LN}\big(f_k(\mathbf{s})\big)\in\mathbb{R}^d\tag{7}$$
$f_k(\cdot)$ 是各任务独立参数的可学习投影。再用任务特定的多头交叉注意力(MHCA)聚合候选感知全局信息:
$$\mathbf{h}_k=\text{MHCA}_k\big(\mathbf{q}_k,\{\mathbf{r}_k^i\}_{i=1}^N,\{\mathbf{r}_k^i\}_{i=1}^N\big)\in\mathbb{R}^d\tag{8}$$
$\text{MHCA}_k$ 带任务 $k$ 专属参数,$\mathbf{h}_k$ 是对整个候选集聚合得到的任务级全局表示。这种设计用独立参数集显式解耦各任务的信息流——每个任务有自己的聚合通路,同时仍捕捉跨候选的竞争动态。
2.4 多任务预测(Multi-Task Prediction)¶
为在尊重领域特定依赖的前提下做受控跨任务知识迁移,OneRank 设计「带策略性梯度解耦的灵活跨任务关系注意力」,而非固定的任务塔结构。
带策略性梯度解耦的跨任务注意力。 把候选感知上下文化得到的任务表示 $\{\mathbf{h}_k\}_{k=1}^K$ 组织起来,施加带可配置跨任务 mask $\mathbf{A}\in\{0,1\}^{K\times K}$ 的多头自注意力:
$$\hat{\mathbf{h}}_k=\text{MHSA}\big(\mathbf{h}_k,\{\mathbf{h}_j\}_{j:A_{kj}=1}\big)\tag{9}$$
任务 $k$ 只注意 $A_{kj}=1$ 的任务 $j$。
为「允许前向知识迁移、阻止后向梯度干扰」,采用策略性梯度解耦:定制跨任务注意力的反向算子,使其只允许对角线梯度流、阻断所有 off-diagonal 梯度。反传时计算任务 $k$ 的梯度,对被注意的任务 $j\neq k$ 设 $\partial\mathcal{L}/\partial\mathbf{h}_j=0$。这保证优化任务 $k$ 不会反过来损害其它任务的学习——既保留有益的前向信息迁移,又消除任务间梯度冲突,把跨任务注意力变成知识迁移的「只读记忆」。再接残差与 LN:
$$\hat{\mathbf{h}}_k=\text{LN}\big(\text{FFN}(\hat{\mathbf{h}}_k)\big)+\hat{\mathbf{h}}_k\tag{10}$$
动态匹配打分。 经一个带残差的前馈网络精化表示:
$$\mathbf{z}_k=\text{LN}\big(\text{FFN}(\hat{\mathbf{h}}_k)\big)+\hat{\mathbf{h}}_k\in\mathbb{R}^d\tag{11}$$
不同于「无视上下文、施加固定变换」的静态 MLP 打分,OneRank 用内积相似度计算任务–候选相关性:
$$s_k^i=\mathbf{z}_k^\top\mathbf{r}_k^i\tag{12}$$
$\mathbf{z}_k$(经受控跨任务交互富化)捕捉任务感知的全局上下文,$\mathbf{r}_k^i$(来自任务特定编码)捕捉上下文条件化的候选 embedding。这种 Transformer-native 匹配公式能动态适应会话上下文——同一用户–物品对在不同会话(如上午 vs 晚上浏览、搜索 vs 浏览模式)可拿到不同分数,实现真正的个性化排序。
灵活的跨任务 mask 策略。 跨任务 mask $\mathbf{A}$ 可依领域知识灵活配置:
- Parallel Masking:$A_{kj}=\mathbb{I}[k=j]$,任务间互不可见,每个任务只靠自己的全局表示,无跨任务信息流。适合探索性场景或数据充裕时的独立建模。
- Null Masking:$A_{kj}=1,\forall k,j$,所有任务互相注意,模型经双向注意力自主学习任务相关性。适合任务依赖的领域知识有限时。
- Cascade Masking:$A_{kj}=\mathbb{I}[j\le k]$,单向信息流,沿「稠密到稀疏」的依赖级联(rich-to-sparse cascade),让稀疏下游任务利用上游信号。如电商里 click → cart → purchase 的自然递进,purchase 受益于 click 与 cart 信号。
- Hybrid Masking:自定义 mask 编码部分可见或混合模式。如短视频里 like/follow/comment/forward 间行为关系缺乏清晰因果,可让 engagement 类任务(like、comment)双向注意,同时保持「从充裕的 click 信号单向流向稀疏的 follow 动作」。
2.5 联合学习目标¶
由动态匹配(§2.4)得到相关性分 $s_k^i=\mathbf{z}_k^\top\mathbf{r}_k^i$,采用「list-wise + point-wise」的混合学习策略。判别式排序用 InfoNCE 对比损失:
$$\mathcal{L}_k^{\text{list}}=-\sum_{i\in I_k^+}\log\frac{\exp(s_k^i/\tau)}{\sum_{j=1}^N\exp(s_k^j/\tau)}\tag{13}$$
$I_k^+$ 是正样本,$\tau$ 是温度,$N$ 是候选集大小。工业系统的校准概率估计用二元交叉熵(BCE):
$$\mathcal{L}_k^{\text{point}}=-\sum_{i=1}^N\big[y_k^i\log\sigma(s_k^i)+(1-y_k^i)\log(1-\sigma(s_k^i))\big]\tag{14}$$
$y_k^i\in\{0,1\}$ 是真值标签,$\sigma(\cdot)$ 是 sigmoid。跨所有任务的联合目标:
$$\mathcal{L}=\sum_{k=1}^K\big(\alpha\mathcal{L}_k^{\text{list}}+\beta\mathcal{L}_k^{\text{point}}\big)\tag{15}$$
$\alpha,\beta$ 平衡 list-wise 与 point-wise 优化(实验中 $\alpha=\beta=1$ 最优)。
设计原理讨论(三大核心原则)¶
论文用一整节论证统一框架相对传统 $\mathcal{F}$–$\mathcal{G}$ 解耦的根本优势,围绕三条原则:
1. 经上下文感知动态排序弥合训练–服务 gap。 传统 point-wise 学习优化孤立的「用户–物品对」分数,与「服务时模型必须对整组候选排序」的环境根本不匹配。OneRank 经 SD 驱动的全局信息建模(§2.3)跨整个候选集做交叉注意力聚合,使模型能捕捉相对偏好而非绝对分数;全局表示 $\mathbf{z}_k$ 编码了候选池的分布属性,让排序能依竞争上下文自适应调整。配合动态打分公式 $s_k^i=\mathbf{z}_k^\top\mathbf{r}_k^i$(共享几何空间里 $\{\mathbf{z}_k\}$ 与 $\{\mathbf{r}_k^i\}$ 联合优化语义对齐),相比架构隔离的 MLP 塔有更好的梯度流与更有效的多任务学习。
2. 经解耦优化缓解 seesaw。 三层解耦策略:(i) 输入层任务特定参数——注入带任务隔离 mask 的任务 token,在最早期就分配专属参数,使各任务在特征抽取时互不干扰梯度流;(ii) 中间层信息流解耦——全局建模阶段(§2.3)对 SD 投影 $f_k(\mathbf{s})$ 与跨候选聚合 $\text{MHCA}_k$ 都用任务特定参数,即使共享 SD 输入,每个任务也走自己的参数空间;(iii) 预测层梯度解耦——最终解码阶段(§2.4)的梯度解耦机制让任务 $k$ 在前向受益于其它任务(知识迁移),同时阻止其梯度反流向其它任务(优化隔离),实现「前向共享、后向隔离」的非对称信息迁移。
3. 经统一架构提升灵活性与效率。 可配置跨任务 mask 提供 ESMM 固定级联、MMoE 独立塔所不具备的灵活性——practitioner 可用简单 mask 设计编码领域知识(电商漏斗的严格级联、模糊 engagement 的双向注意、复杂旅程的混合配置),无需架构搜索或任务特定模型变体。消除 $\mathcal{F}$–$\mathcal{G}$ 切换后实现单一 Transformer 内的端到端优化,避免异质模块切换的计算开销;single-stage 多候选编码减少训练时冗余上下文编码,用户特定组件(IH、PA)的 KV-caching 使在线只需计算候选与任务 token,低延迟、高 GPU 利用,解锁 Transformer 全部 scaling 潜力。
实验设置¶
数据集。 Shopee(东南亚与拉美领先电商)大规模专有数据集,2025 年 12 月连续 30 天用户交互日志,覆盖 click(C)、add-to-cart(A)、order(O) 三类反馈。统计如下:
| #User | #Item | #Query | #Impression | #Click | #Add-to-Cart | #Order |
|---|---|---|---|---|---|---|
| 33M | 118M | 105M | 26.6B | 1.05B | 251M | 40M |
报告 click 的 AUC/GAUC(C-AUC/C-GAUC)、add-to-cart 的 A-AUC/A-GAUC、order 的 O-AUC/O-GAUC。从 #Click→#Add-to-Cart→#Order 的数量级递减(1.05B→251M→40M)正是典型的「稠密到稀疏」漏斗,凸显多任务 seesaw 的现实压力。
对比设计。 为解耦「编码器架构」与「MTL 策略」的影响,把二者正交组合。编码器:
- DNN(RecSys'16):Shopee 充分优化的生产基线,传统 DLRM 风格;
- MTGR(CIKM'25):美团的工业级生成式推荐框架,Transformer 序列建模;
- OneTrans(WWW'26):字节的统一 Transformer 架构(特征交互 + 序列建模),代表 Transformer 排序的 SOTA。
MTL 策略:noMTL(独立单任务,量化 MTL 收益的基线)、NSE(Naive Shared Embedding,共享 embedding 表的最简参数共享)、MMoE(KDD'18)、PLE(RecSys'20)、DCMT(ICDE'23,因果反事实去偏)、ResFlow(KDD'24,残差式跨任务信息流)。
实现细节。 OneRank 用 2 层 Transformer 编码器(pre-norm,每层 4 个注意力头);隐藏维 256,FFN 为隐藏维 2 倍;最大序列长 256;可学习位置编码;SD 经线性投影到 256。实例化 3 个任务 token(click、add-to-cart、order)+ 3 个排序 head token;多任务预测用「一层任务特定自注意力 + 一层带可配置 mask 的跨任务注意力」,均配 FFN 做非线性变换。InfoNCE 温度 $\tau$ 初始 0.2,list 与 point 损失等权($\alpha=\beta=1$),所有任务均匀权重。
主要实验结果¶
Table 1:不同编码器 × MTL 策略下的离线对比(含 Params 与 FLOPs)。 加粗为最优。
| Encoder | Predictor | Params | FLOPs | C-AUC | C-GAUC | A-AUC | A-GAUC | O-AUC | O-GAUC |
|---|---|---|---|---|---|---|---|---|---|
| DNN | noMTL | 9.5M | 226.7M | 0.7638 | 0.7664 | 0.8193 | 0.7813 | 0.8824 | 0.8128 |
| DNN | NSE | 6.7M | 161.5M | 0.7667 | 0.7693 | 0.8242 | 0.7863 | 0.8859 | 0.8181 |
| DNN | MMoE | 8.5M | 235.1M | 0.7682 | 0.7723 | 0.8246 | 0.7893 | 0.8881 | 0.8223 |
| DNN | PLE | 9.2M | 220.6M | 0.7688 | 0.7721 | 0.8277 | 0.7906 | 0.8872 | 0.8198 |
| DNN | DCMT | 9.6M | 302.3M | 0.7642 | 0.7669 | 0.8203 | 0.7817 | 0.8828 | 0.8125 |
| DNN | ResFlow | 9.5M | 226.7M | 0.7649 | 0.7688 | 0.8252 | 0.7886 | 0.8886 | 0.8204 |
| MTGR | NSE | 2.3M | 487.0M | 0.7720 | 0.7732 | 0.8304 | 0.7910 | 0.8924 | 0.8240 |
| MTGR | MMoE | 2.3M | 487.0M | 0.7718 | 0.7737 | 0.8304 | 0.7915 | 0.8914 | 0.8237 |
| MTGR | PLE | 2.7M | 496.0M | 0.7723 | 0.7737 | 0.8318 | 0.7930 | 0.8933 | 0.8260 |
| MTGR | DCMT | 2.8M | 497.7M | 0.7208 | 0.7282 | 0.7888 | 0.7583 | 0.8629 | 0.7986 |
| MTGR | ResFlow | 2.7M | 500.1M | 0.7703 | 0.7717 | 0.8294 | 0.7901 | 0.8919 | 0.8253 |
| OneTrans | NSE | 6.3M | 823.2M | 0.7773 | 0.7772 | 0.8359 | 0.7961 | 0.8991 | 0.8280 |
| OneTrans | MMoE | 6.1M | 822.7M | 0.7768 | 0.7765 | 0.8364 | 0.7934 | 0.8973 | 0.8241 |
| OneTrans | PLE | 6.4M | 823.5M | 0.7770 | 0.7775 | 0.8371 | 0.7982 | 0.8996 | 0.8336 |
| OneTrans | DCMT | 6.4M | 823.4M | 0.7574 | 0.7596 | 0.8141 | 0.7746 | 0.8869 | 0.8149 |
| OneTrans | ResFlow | 6.3M | 823.2M | 0.7764 | 0.7766 | 0.8372 | 0.7975 | 0.8987 | 0.8287 |
| OneRank (Ours) | — | 4.9M | 1.0G | 0.7910 | 0.7843 | 0.8463 | 0.8036 | 0.9024 | 0.8350 |
三个关键观察:
- MTL 在传统 DNN 编码器下一致有益。 相比 noMTL 基线,所有 MTL 方法在 C/A/O 三任务上都有明显提升,证实联合建模稠密与稀疏反馈提供了互补监督,MTL 是工业推荐的必要组件。
- 更强的编码器进一步放大 MTL 收益。 把 DNN 换成 MTGR、OneTrans 等 Transformer 架构,在大多数 MTL 策略下带来额外提升,凸显表达力强的序列与上下文建模的重要性。但 DCMT 在 Transformer 编码器下表现很差(如 MTGR+DCMT 的 C-AUC 仅 0.7208,OneTrans+DCMT 仅 0.7574),可能因其去偏导向的设计在高容量模型上过度校正稀疏任务、加剧任务失衡、导致优化不稳定。
- OneRank 以统一框架取得最优。 在所有指标与任务上一致超越所有「编码器 × 策略」组合(如 C-AUC 0.7910 vs 最强基线 OneTrans+NSE 的 0.7773;O-AUC 0.9024 vs OneTrans+PLE 的 0.8996),且参数更紧凑(4.9M,少于多数基线)、计算仅适度增加(1.0G FLOPs)。这验证了核心主张:统一的 Transformer-native 排序范式比「外部编码器–预测器分离」更适合大规模多任务推荐。
消融与分析¶
消融研究(Figure 3)。 逐项移除/替换关键组件:V1 去掉任务特定 token、直接在候选 encoding 上加线性投影;V2 把 $K$ 个任务 token 换成单个共享 token;V3 在 V2 上再去掉跨任务关系注意力;V4 去掉策略性梯度解耦;V5 把 SD 换成随机初始化参数;V6 用完整双向注意力(无选择性 mask)。
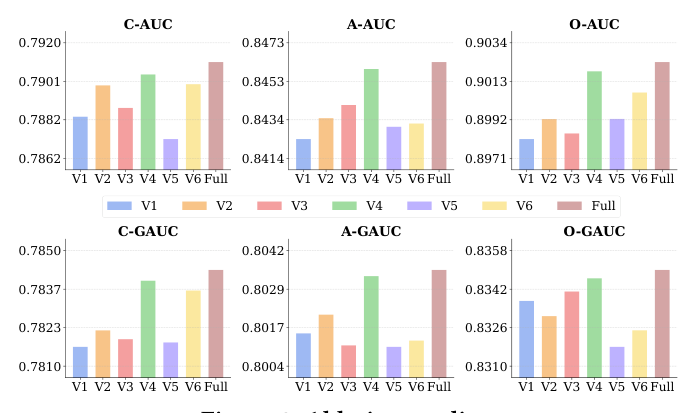
逐项分析:
- V1(去任务特定 token)显著退化——A-AUC 从 0.8463 掉到 0.8424、O-GAUC 从 0.8350 掉到 0.8337,验证早期任务特化的必要性;
- V2(单共享 token)不如完整模型——确认独立任务 token 对缓解梯度冲突至关重要;
- V3(去跨任务注意力)相对 V2 结果有好有坏——说明跨任务知识迁移在「配合恰当任务隔离」时才有益;
- V4(去梯度解耦)整体表现强但在 add-to-cart 上不稳(A-AUC 0.8460 vs 0.8463),证明策略性梯度控制的必要性;
- V5(随机 SD)严重退化——C-AUC 掉到 0.7872、O-GAUC 掉到 0.8318,确认候选感知上下文化对弥合训练–服务 gap 至关重要;
- V6(完整双向 mask)在所有任务上一致不如受控 mask 策略。
总体表明所有组件的协同对优越的多任务排序不可或缺。
Scaling 分析(Figure 4)。 研究两个基本 scaling 维度——编码器层数(深度,1→6 层)与隐藏维(宽度,128→512),其余不变,报告相对最小配置的绝对提升 ΔAUC/ΔGAUC。
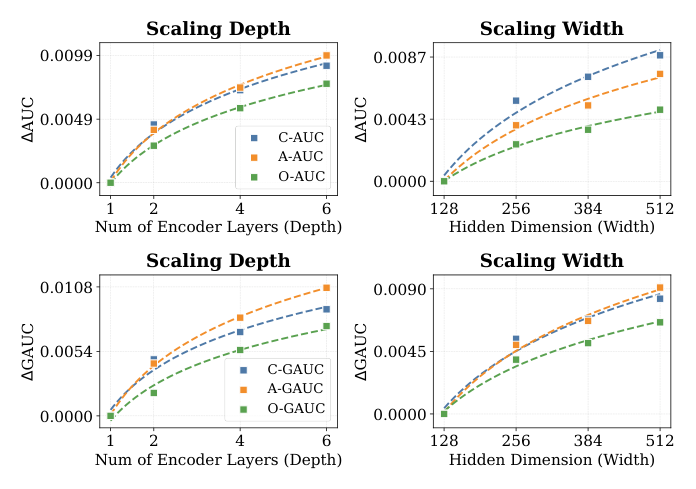
- 深度 scaling:随层数增加,所有反馈信号上一致提升;浅到中等深度时增益最明显,更大深度逐渐饱和(边际递减),说明更深的 Transformer 栈增强了对复杂序列模式与任务交互的建模能力,且统一架构在深度增加时保持优化稳定。
- 宽度 scaling:增大模型宽度一致提升性能,曲线比深度更平滑、增益更均匀,尤其利好 click 相关指标,反映更丰富表征容量对细粒度用户–物品交互建模的价值;且在增大容量时无严重任务失衡或优化不稳定,支持其工业大规模部署的可 scaling 性。
在线 A/B(Table 3)。 Shopee 主个性化排序场景,7 天周期(2026-01-08 至 01-14),10% 流量给 OneRank、10% 给基线(一个「充分优化的 Transformer 编码器 + 多任务预测器」的现网方案,全部部署在标准多阶段排序流水线、用打分融合平衡体验与商业目标)。
| GMV/UU↑ | Paid GMV/UU↑ | AR/UU↑ | Bad Query Rate↓ |
|---|---|---|---|
| +1.01% | +1.17% | +0.81% | −2.29% |
OneRank 在商业指标(GMV/UU +1.01%、Paid GMV/UU +1.17%、广告收入 AR/UU +0.81%)与用户体验指标(Bad Query Rate −2.29%)上同时正向——既提升变现效率,也改善推荐相关性与用户体验,验证统一 Transformer-native 设计的工业可部署性。在线部署用如下打分融合(附录 B):
$$s=a\cdot p_{\text{ctr}}\cdot p_{\text{cvr}}\cdot\text{price}+b\cdot p_{\text{ctr}}\cdot\text{ecpm}+c\cdot p_{\text{ctr}}\cdot\text{relevance}\tag{16}$$
第一项优化 GMV,第二项算广告收入,第三项强化搜索相关与用户意图对齐;$a,b,c$ 调参平衡体验与商业目标。在线推理时每个请求最多 4096 个候选,划分为 8×512 组并行打分,每组独立做候选感知注意力——在保持上下文感知 list 建模的同时高效 scale 到大候选池。
参数敏感性。 Table 4 研究 InfoNCE:BCE 损失权重比:
| InfoNCE : BCE | C-AUC | C-GAUC | A-AUC | A-GAUC | O-AUC | O-GAUC |
|---|---|---|---|---|---|---|
| 1 : 2 | 0.7851 | 0.7795 | 0.8384 | 0.7975 | 0.8938 | 0.8292 |
| 1 : 1 | 0.7910 | 0.7843 | 0.8463 | 0.8036 | 0.9024 | 0.8350 |
| 2 : 1 | 0.7881 | 0.7826 | 0.8440 | 0.8023 | 0.9006 | 0.8350 |
等权(1:1)最优:BCE 过重(1:2)限制了捕捉候选间相对排序信号的能力,InfoNCE 过重(2:1)虽改善排序但牺牲 point-wise 校准——list-wise 判别与 point-wise 校准在 OneRank 里互补,需平衡。
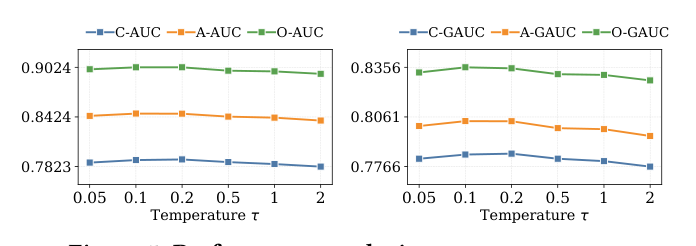
温度敏感性(Figure 5):性能随 τ 从大值下降而提升、在 0.2 附近达峰、过小又略降——τ 过大过度平滑相似度分布、弱化候选间判别监督,τ 过小锐化分布、放大噪声与 hard negative,0.2 兼顾判别强度与训练稳定,故设 τ=0.2。
核心贡献总结¶
- 识别并形式化了 Transformer-based MTL 推荐里编码器–预测器分离的三重结构性局限(任务无关信息瓶颈、seesaw 梯度冲突、数据流/计算范式断裂);
- 提出 OneRank——把多任务推理内化进 Transformer-native 设计的统一框架,自底向上支持任务特化、带上下文化的任务级全局表示、受控跨任务交互与稳定优化;
- 用 Transformer-native 匹配公式取代静态 MLP 预测 head,在一致的表示空间里实现上下文感知、任务自适应排序;
- 大规模工业离线 + 线上 A/B 全面验证在效果与效率上均超越 SOTA。
与已归档相关工作的对比¶
OneRanker OneRanker:用一个模型统一生成与排序(Tencent, 2026-03-03)¶
关系:独立并发(本文未引用 OneRanker,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都在攻击「多任务目标在共享表示空间里互相妥协(seesaw / optimization tension)」这一 root cause。OneRanker 称之为「兴趣覆盖 vs 商业价值的错位」,OneRank 称之为「任务无关瓶颈诱发的跷跷板」。两者也都不满足于「先编码再用独立 head 出预测」的解耦设计,主张把任务推理内生进统一的 Transformer/Decoder 栈。
- 相近的技术骨架:惊人地同构——都用可学习的任务 token 序列注入 Transformer,沿业务漏斗顺序(OneRank: click→cart→order;OneRanker: impression→click→conversion→value)排列,并用因果 / cascade mask 让后续任务访问前序任务表示;都坚持「共享底层用户表示以迁移知识、但用独立输出空间解耦任务」的同一条原则。OneRank 的 Cascade Masking($A_{kj}=\mathbb{I}[j\le k]$)与 OneRanker 的「Task Ordering Prior + Causal Mask」是同一招的两种实现。
- 本文的差异与推进:OneRank 是判别式排序(InfoNCE+BCE,动态内积匹配打分 $s_k^i=\mathbf{z}_k^\top\mathbf{r}_k^i$ 取代 MLP scorer),消除编码器–预测器分离;OneRanker 是生成式(基于 HSTU 的自回归 MTP 生成层次化 Semantic ID,价值感知地融合 eCPM、面向广告)。OneRank 的 mask 是可配置四态(parallel/null/cascade/hybrid)且独创策略性梯度解耦(前向迁移、后向 off-diagonal 清零),把跨任务注意力变成「只读记忆」;OneRanker 用因果 mask + Distribution Consistency Loss 保证双侧一致性,并引入 fake item token 做粗粒度目标感知——后者是 OneRank 没有的「目标感知」维度,而 OneRank 的梯度解耦是 OneRanker 没有的「后向隔离」机制。
- 可比的方法 / 实验差异:两者都强调「target/context-aware 动态表示」对抗静态表示,但 OneRank 用候选感知上下文化(SD + MHCA 聚合整组候选)显式弥合训练–服务 gap,OneRanker 用 fake item token(物品空间 K-means 聚类中心)做隐式目标感知。OneRank 在 Shopee 电商 C/A/O 三任务排序验证,OneRanker 在 Weixin Channels 广告全量部署、聚焦 eCPM 价值对齐。
DUET DUET:为站外转化设计的双用户嵌入 Transformer(Meta, 2026-06-08)¶
关系:独立并发(本文未引用 DUET,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都直指「稠密信号主导、淹没稀疏任务」这一 root cause。DUET 称之为「signal dominance under regime mismatch」——单一无差别编码器被稠密点击信号主导、欠拟合稀疏的站外转化;OneRank 则把它归为共享底座的 seesaw(#Click 1.05B vs #Order 40M 的数量级落差正是这种主导)。两者都认为「对统计性质根本不同的任务套同一套表征」是负迁移的元凶。
- 相近的技术骨架:都用任务/域特定的注意力通道来防止稠密任务压垮稀疏任务,而非共享一个表征。DUET 为点击流、转化流各预训练一个「架构与统计特性匹配」的专用 Transformer(稠密流用多层自注意力 ClickAUN、稀疏流用交错交叉/自注意力 ConvAUN),OneRank 则用任务特定 token(互不可见 mask)+ 任务特定 $f_k(\cdot)$/$\text{MHCA}_k$ 为每个任务开独立参数通路。两者都在「为不同任务分配专属表征管线」这点上抽象重合。
- 本文的差异与推进:根本的架构哲学相反——DUET 强化了上游/下游的分离(离线预训练两个冻结的互补嵌入 ClickAUE/ConvAUE,异步喂给下游 ranker,以满足 serving 延迟预算),而 OneRank 的整个论点是消除编码器–预测器分离、端到端内化进单一 Transformer。可以说两者对「同一个负迁移问题」给出了「分离 vs 统一」的对立解。此外 OneRank 在单模型内显式做受控跨任务迁移(梯度解耦的只读记忆),DUET 的跨任务交互发生在下游 ranker 联合消费两个嵌入时、上游编码器之间无直接交互。
- 可比的方法 / 实验差异:DUET 还引入「无归因转化合成数据」缓解稀疏、用事件触发推理(ETI)异步 serving,离线相对最强 baseline 取得至多 0.38% NE 下降、线上 CVR 持续正向(任务聚焦站外转化 OCVR);OneRank 覆盖 click/cart/order 三任务全链路排序,线上 GMV/UU +1.01%。DUET 的「为每条流匹配不同归纳偏置」与 OneRank 消融里「单共享 token(V2)不如独立任务 token」殊途同归地印证了同一结论:异质任务需要异质表征通路。
讨论与局限性¶
核心贡献与借鉴价值。 OneRank 最值得借鉴的是「把 MTL 的解耦从预测层一路前移到输入层」的设计思路:传统 MMoE/PLE 在共享底座之上靠门控/专家分离,本质仍是「先混合再分离」;OneRank 用任务 token + 互不可见 mask 在特征抽取的最早期就分配任务私有通道,从源头避免任务无关瓶颈。其「前向共享、后向隔离」的策略性梯度解耦是一个简洁而通用的 seesaw 缓解器——把跨任务注意力当「只读记忆」,理论上可移植到任何多任务 Transformer。可配置四态 mask(parallel/null/cascade/hybrid)把领域知识(电商漏斗、短视频 engagement 关系)编码成简单的二值矩阵,比 ESMM 固定级联、MMoE 独立塔灵活得多,且省去架构搜索。动态内积匹配打分取代 MLP scorer,使排序在统一几何空间里上下文自适应,是「Transformer-native」主张的关键落点。
局限与争议。 1. 仅在自有专有数据集验证。 所有离线实验都在 Shopee 私有数据上,无公开数据集复现,外部可比性与可复现性受限; 2. scaling 规模仍偏小。 论文 OneRank 主配置仅 2 层、4.9M 参数、1.0G FLOPs,scaling 实验也只到 6 层 /512 维,相比同期动辄 1B–15B 的工业 Transformer 排序模型(如 RankMixer、TokenMixer-Large),其「解锁 Transformer 全部 scaling 潜力」的主张尚未在真正大模型尺度上检验; 3. 候选感知上下文化的服务成本。 在线把候选分成 8×512 组并行打分,跨候选注意力随候选数增长带来额外计算;虽有 KV-caching 优化用户侧,候选侧的 list 级聚合在超大候选池下的延迟仍需关注; 4. 梯度解耦的「一刀切」。 off-diagonal 梯度全部清零是个强假设——某些任务对之间的后向耦合或许是有益的(如强相关 engagement 任务),论文未探讨「部分梯度解耦」或自适应解耦强度; 5. 任务数与 mask 设计依赖人工先验。 cascade/hybrid mask 仍需领域专家设计漏斗顺序,任务数增多时 mask 设计空间组合爆炸,缺乏自动化 mask 学习的讨论。
工业落地价值。 论文的部署细节相对完整:KV-caching 用户特定组件、8×512 候选分组并行打分、打分融合公式(式 16)平衡 GMV/广告收入/相关性,7 天线上 A/B 同时拿到商业(GMV/UU +1.01%)与体验(Bad Query Rate −2.29%)双正向,且参数比多数基线更紧凑(4.9M),说明其「统一架构降冗余」的效率主张在生产环境成立,对同类电商多任务排序系统有直接参考意义。