DUET:为站外转化预估设计的双用户嵌入 Transformer¶
来自 AI at Meta(Reazul Hasan Russel、Mingwei Tang、Rostam Shirani 等共同一作,作者列表含 Xiangyu Wang、Yawen He、Rob Malkin 等共 20+ 人),2026-06-08 挂 arXiv(2606.10243v1,cs.LG)。核心主张:站外转化率(OCVR)预估同时面临两类统计性质截然不同的行为信号——点击信号稠密、时序短,转化信号稀疏、长延迟、常无法归因。已有的上游预训练范式(Tang et al. 2024)用单一无差别编码器统一处理这两条流,必然被稠密的点击信号主导,欠拟合下游最关心的转化模式。DUET 把上游训练数据按语义路由成点击流与转化流两条「统计同质」的数据流,为每条流预训练一个架构与其统计特性匹配的专用 Transformer 编码器(稠密点击流用多层自注意力、稀疏转化流用交错的交叉/自注意力),产出两个互补的用户嵌入 ClickAUE / ConvAUE,由下游 ranker 联合消费,且不突破在线 serving 延迟预算。相对最强 baseline 取得至多 0.38% 的归一化熵(NE)下降,线上 A/B 转化率持续正向。
研究动机与背景¶
站外转化(Offsite Conversion, OC) 指的是:用户在宿主平台(host platform,如 Meta 的某个 app)看到一个被推荐的 item 后,去外部目的地(第三方网站或 app)完成一个目标动作——下单、注册等。预估这个动作发生的概率,就是 OCVR 预估任务。它的重要性正在快速上升,两个驱动力:(1) 零售媒体网络(retail media network)的扩张;(2) 第三方 cookie 的弃用——两者共同把预算推向那些握有第一方行为数据的平台。站外零售媒体被预测会逐年增长,使精准的 OCVR 预估成为推荐平台的差异化能力。
但 OCVR 任务本身极难:
- 正样本极稀疏:转化率通常低于 5%;
- 归因窗口长且不定:从数小时到数天;
- 大量转化无法归因:因产品分段或归因方法不同,一部分转化永远关联不到具体的曝光(cross-device 跨设备链路、cookie 限制、app tracking 政策)。
更要命的是,这一切都要在严格的在线训练与推理延迟约束下完成,于是「预测质量 ↔ serving 效率」之间存在一种持续的张力。
针对这种张力,一个自然的应对是聚焦更丰富的用户表征——能捕捉更深层行为模式的模型,理应给出更好的转化预测。Transformer 序列建模、自监督预训练、嵌入方法等都已在推荐/排序里证明了质量收益。但这些表达力强的架构计算开销大,直接部署到延迟敏感的 serving 路径上不现实。这催生了一种解耦设计:上游模型离线预训练丰富的用户嵌入,再作为静态嵌入特征异步地喂给 ranker。这种分离让表达力强的架构能服务于排序模型,而不违反延迟预算。
本文要攻击的痛点:这一范式的已有实例(Tang et al. 2024)已为点击预估验证了有效性,但它们只训练单个上游模型,把点击数据与站内转化数据当成同质流统一喂进去。当目标是 OCVR 时,这种单流设计有三个具体局限:
- 信号主导下的「机制错配」(signal dominance under regime mismatch):点击/站内转化数据稠密、归因窗口短,而站外转化数据稀疏数个数量级。单个模型在二者上训练,必然被稠密的点击信号主导,欠拟合最和下游任务相关的转化模式。
- 架构同质性(architectural uniformity):对统计性质根本不同的数据流套用同一套编码器架构,忽视了「稠密点击序列」与「稀疏转化序列」可能各自受益于不同归纳偏置这一可能性——本文在 §3.2.3 经实验验证了这一点。
- 浅层跨域迁移(shallow cross-domain transfer):跨应用的知识迁移以往局限于共享特征编码器或域解耦表征,没有纳入有机互动(organic engagement)与内容衍生的语义信号,而这些恰能丰富用户表征。
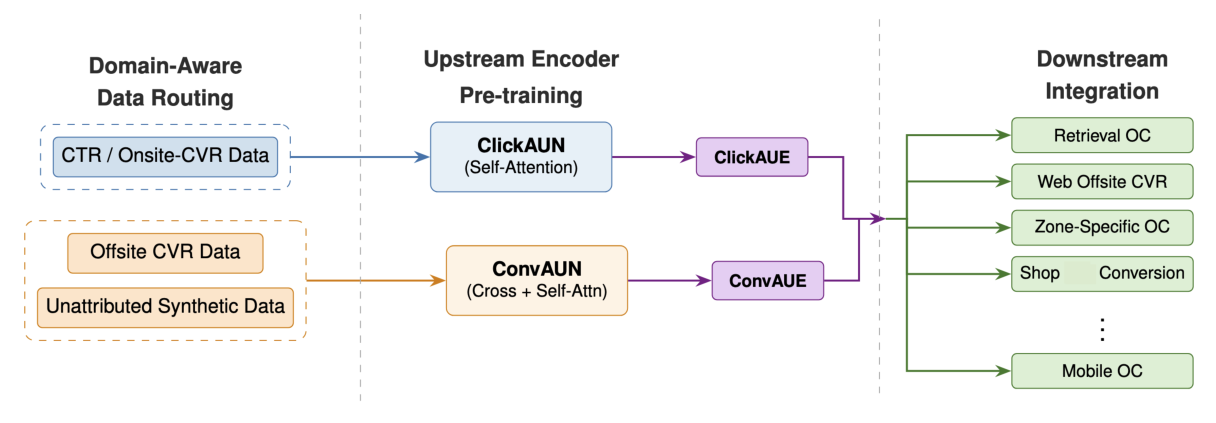
DUET(Dual User Embedding Transformers)用一个统一原则来回应这三点:从「统计同质的数据流」中学习专用的用户嵌入,再在下游 ranker 中把它们组合起来。具体地,DUET 把上游训练数据切成两条「域同质」的流——一条 点击/站内转化流、一条 站外转化流——为每条流预训练一个架构与其统计特性匹配的专用 Transformer 编码器。两个互补嵌入分别记为 ClickAUE(Click Attentive User Embedding)与 ConvAUE(Conversion Attentive User Embedding),由下游 ranker 联合消费。
四点主要贡献:
- 域特化的双嵌入学习:引入域感知数据路由,把异质行为数据切成点击流与转化流,并在每条流上预训练专用上游编码器。注意力架构按各自的统计机制匹配——稠密点击流用多层自注意力(LLaTTE,Xiong et al. 2026),稀疏转化流用交错的交叉/自注意力。消融确认每条流的架构选择都是「承重的」(load-bearing)。
- 多模态、跨应用的输入富化:两个上游编码器都消费事件型特征(Event-Based Features, EBF)序列,覆盖内容互动、有机 feed 参与、内容衍生的语义 ID(Roychowdhury et al. 2026),跨多个应用,以获得更丰富的用户表征。
- 可扩展基础设施上的异步 serving:用事件触发推理(Event-Triggered Inference, ETI)机制异步生成用户嵌入,把上游模型复杂度与 serving 延迟预算解耦。部署中加入限流(throttling)、checkpoint 校验、嵌入量化,实现可忽略的训练 QPS 与 serving 延迟开销。
- 实证验证:在 6 个下游 OCVR 模型上评估 DUET,展示出有意义的指标提升。
核心方法:DUET 框架¶
DUET 把 OCVR 建模分解为三个阶段:把训练数据划分成域同质的流(§3.1)、在每条流上预训练一个专用上游编码器(§3.2)、把产出的嵌入集成进下游 ranker(§3.3)。
3.1 域感知数据路由¶
把 pointwise 训练数据按标签语义与归因时长划分成两条流:
- CTR / 站内转化流(CTR / Onsite-CVR Stream):包含点击与站内转化事件,被标注的动作通常在「与被推荐 item 交互」之后很短时间内发生。在这条流上,负样本被下采样,正样本全部保留。
- 站外转化流(OCVR Stream):包含用户在外部网站或第三方 app 上的动作,归因窗口更长。不对 OCVR 样本做下采样,以保留训练数据量。为缓解 OCVR 的稀疏问题,这条流额外纳入来自无归因转化的合成数据(Synthetic data from unattributed conversion)——那些因 cross-device 链路、cookie 限制或延迟归因而无法确定性关联到某次具体 item 曝光的转化事件。合成方式是:为一个无归因转化推断出最可能关联的排序结果。这些事件单独看是有噪声的,但携带聚合层面的用户级意图信号,并增大了有效训练量。
两条流的统计反差——稠密短时序的点击数据 vs 稀疏长时序的转化数据——同时驱动了「数据分离」与下面将要描述的「架构选择」。
3.2 上游编码器设计¶
两个上游编码器从一个共享骨干架构实例化,各自只在一条数据流上训练。它们在注意力配置与输出维度上不同,但共享相同的输入表征与骨干结构。
3.2.1 输入表征¶
每个编码器都消费用户侧与目标 item 侧特征。目标 item 特征经 DLRM 骨干的非序列分支处理。用户侧特征由事件型特征(EBF)序列(Roychowdhury et al. 2026)构成,这些序列从用户在数月回看窗口内的多种参与行为构建——跨被推荐 item(曝光、站内转化)、有机 feed(浏览、点赞)、视频内容。每个事件由三部分表示:
- 时间戳(Timestamp):事件发生时间的稠密编码。
- ID 型属性(ID-based attributes):实体级特征,含 item ID、author ID、媒体类型、位置。
- 语义 ID(Semantic IDs):从实体内容(图像、文本、视频)经 KNN(Roychowdhury et al. 2026)或 RQ-VAE(Ramasamy et al. 2025)派生的紧凑离散码,捕捉超越 ID 表征的内容语义。
3.2.2 骨干架构¶
两个编码器都遵循 DLRM 结构(Figure 2 左),含两条并行分支:
- 序列分支(sequence branch):处理用户 EBF 序列与「按下游任务特征重要性筛出的 top 用户静态特征」;
- 非序列分支(non-sequence branch):消费排序 item 侧特征与用户非序列特征。
两条分支的输出在一个 overarch 交互层(Zhang et al. 2022,即 DHEN)中融合,做预训练期的联合预测。
在序列分支内,每种事件类型由一个专用的事件塔(event tower)处理,事件塔由 Transformer 块组成。所有事件塔的输出拼接后,过一个 DCN(Deep & Cross Network)用户摘要模块(Wang et al. 2017, 2021),产出最终用户嵌入。
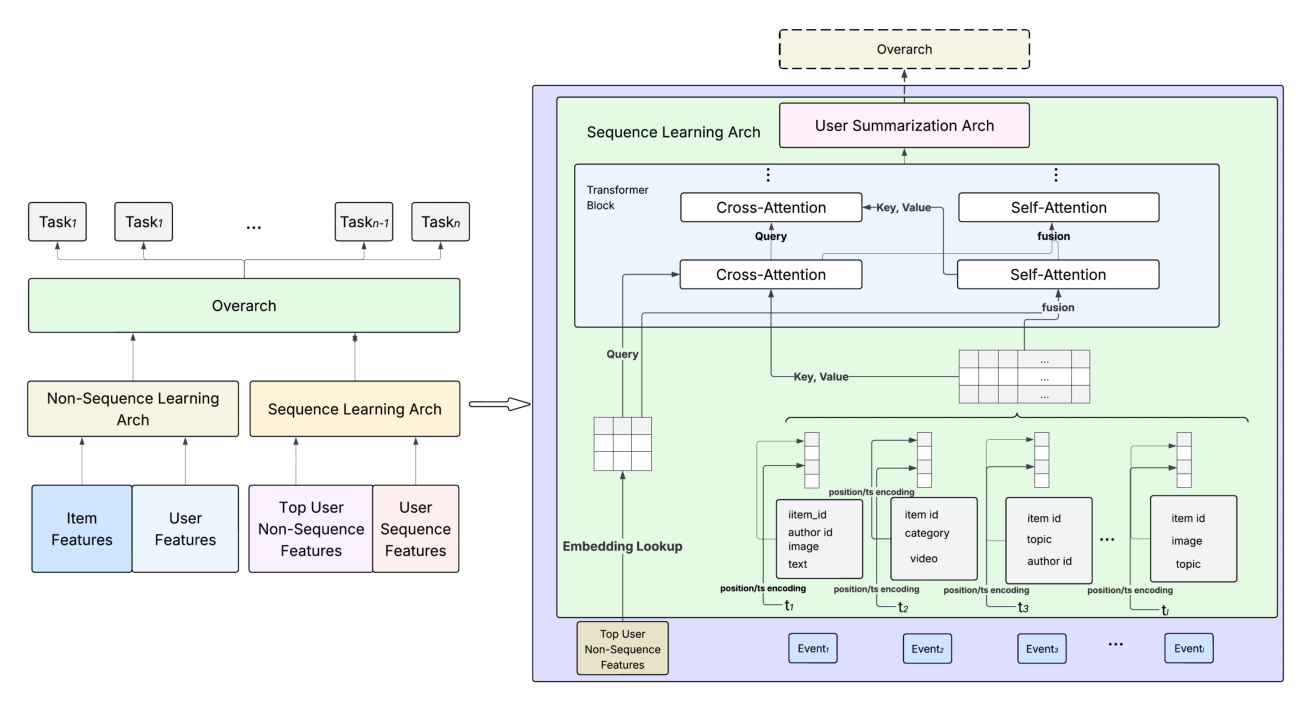
由此骨干实例化两个模型:
- ClickAUN(Click-Attentive Upstream Network):在 CTR/站内转化流上训练,产出 ClickAUE 用户嵌入。
- ConvAUN(Conversion-Attentive Upstream Network):在 OCVR 流上训练,产出 ConvAUE 用户嵌入。
3.2.3 注意力配置¶
每个事件塔在序列嵌入 $X_{\text{sq}}$ 与用户静态特征嵌入 $X_{\text{st}}$ 上应用 Transformer 块。定义两种块:
自注意力块(Self-Attention Block):静态与序列嵌入先拼接
$$X = \text{concat}(X_{\text{st}}, X_{\text{sq}}), \tag{1}$$
随后联合处理:
$$Y_{\text{self}} = X + \text{attention}\big(Q=\text{LayerNorm}(X),\, K=\text{LayerNorm}(X),\, V=\text{LayerNorm}(X)\big), \tag{2}$$
其中 $Q, K, V$ 分别是 attention 的 query、key、value 输入。这让模型能捕捉静态与序列特征类型之间的复杂交互。自注意力块的输出为
$$\text{SelfAttn}(X_{\text{st}}, X_{\text{sq}}) = Y_{\text{self}} + \text{FFN}\big(\text{LayerNorm}(Y_{\text{self}})\big). \tag{3}$$
交叉注意力块(Cross-Attention Block):静态嵌入作为 query 去查询序列嵌入
$$Y_{\text{cross}} = X_{\text{st}} + \text{attention}\big(Q=\text{LayerNorm}(X_{\text{st}}),\, K=\text{LayerNorm}(X_{\text{sq}}),\, V=\text{LayerNorm}(X_{\text{sq}})\big). \tag{4}$$
这让模型能用「高重要性的静态特征」去语境化序列用户行为。交叉注意力块的输出为
$$\text{CrossAttn}(X_{\text{st}}, X_{\text{sq}}) = Y_{\text{cross}} + \text{FFN}\big(\text{LayerNorm}(Y_{\text{cross}})\big). \tag{5}$$
流特化配置(关键设计):
- ClickAUN 堆叠多层自注意力,遵循 LLaTTE 范式(Xiong et al. 2026):稠密监督 + 短归因窗口,使深层自注意力对捕捉高阶交互模式有效。
- ConvAUN 交错交叉注意力与自注意力块。理由:在稀疏正标签下,对长序列做纯自注意力有过拟合到「无信息的多数负样本模式」的风险;而用交叉注意力去对齐稳定的用户级属性,能锚定序列表征、提供隐式正则化。这一设计还降低了计算成本——交叉注意力的 query 长度被「静态特征数量」而非「整条序列长度」所界定。该配置选择在 §5.6 经消融验证。
直觉小结:稠密流靠「深度自注意力挖高阶交互」,稀疏流靠「交叉注意力用稳定静态属性当锚正则化、防过拟合负样本」。这正是「架构匹配统计机制」原则的具体落地。
3.2.4 训练目标¶
记 BCE(二元交叉熵)损失 $\ell_{\text{BCE}}(\hat{y}, y) = -\big[y \log \hat{y} + (1-y)\log(1-\hat{y})\big]$,其中 $\hat{y} \in (0,1)$ 为预测概率、$y \in \{0,1\}$ 为标签。两个上游模型都用「组合多个任务特定 BCE」的多任务目标训练。
ClickAUN 在 CTR/站内转化流上优化:
$$\mathcal{L}_{\text{ClickAUN}} = \alpha_1\, \ell_{\text{BCE}}(\hat{y}_{\text{ctr}}, y_{\text{ctr}}) + \alpha_2\, \ell_{\text{BCE}}(\hat{y}_{\text{onsite}}, y_{\text{onsite}}), \tag{6}$$
其中 $\hat{y}_{\text{ctr}}, \hat{y}_{\text{onsite}}$ 为预测的点击与站内转化概率,$\alpha_1, \alpha_2 > 0$ 为任务权重。CTR 任务提供稠密监督信号;站内转化任务提供更稀疏但更「意图指示性」的监督。
ConvAUN 在站外转化流上优化:
$$\mathcal{L}_{\text{ConvAUN}} = \beta_1\, \ell_{\text{BCE}}(\hat{y}_{\text{off}}, y_{\text{off}}) + \beta_2\, \ell_{\text{BCE}}(\hat{y}_{\text{unattr}}, y_{\text{unattr}}), \tag{7}$$
其中 $\hat{y}_{\text{off}}, \hat{y}_{\text{unattr}}$ 为已归因 / 未归因站外转化的预测概率,标签 $y_{\text{off}}, y_{\text{unattr}} \in \{0,1\}$,任务权重 $\beta_1, \beta_2 > 0$。所有任务权重在留出验证集上调。
3.3 下游集成¶
记 $\mathbf{e}_{\text{click}}$ 与 $\mathbf{e}_{\text{conv}}$ 为某用户的 ClickAUE 与 ConvAUE 嵌入。下游 ranker 把它们当作额外输入特征,与标准特征向量 $\mathbf{x}$ 并列消费,不做任何其他架构改动。两个嵌入在下游训练期冻结——梯度不回传到 $\mathbf{e}_{\text{click}}$ 或 $\mathbf{e}_{\text{conv}}$——使上游与下游能按各自独立的节奏重训。下游模型用多任务目标训练:
$$\mathcal{L}_{\text{down}} = \lambda_1\, \ell_{\text{BCE}}(\hat{y}_{\text{cvr}}, y_{\text{cvr}}) + \sum_{k=1}^{K} \lambda_{k+1}\, \ell_{\text{BCE}}\big(\hat{y}_{\text{aux}}^{(k)}, y_{\text{aux}}^{(k)}\big), \tag{8}$$
其中主项是站外转化损失,$\{\hat{y}_{\text{aux}}^{(k)}, y_{\text{aux}}^{(k)}\}_{k=1}^{K}$ 是 $K$ 个辅助任务(如价值预测、参与度预测)的预测与标签,提供额外梯度信号做正则化,$\{\lambda_i\}_{i=1}^{K+1}$ 为对应任务权重。
Serving:嵌入经事件触发推理(ETI)系统异步生成(§4.1),存入特征库(feature store),在 serving 时于延迟预算内取回。
系统架构¶
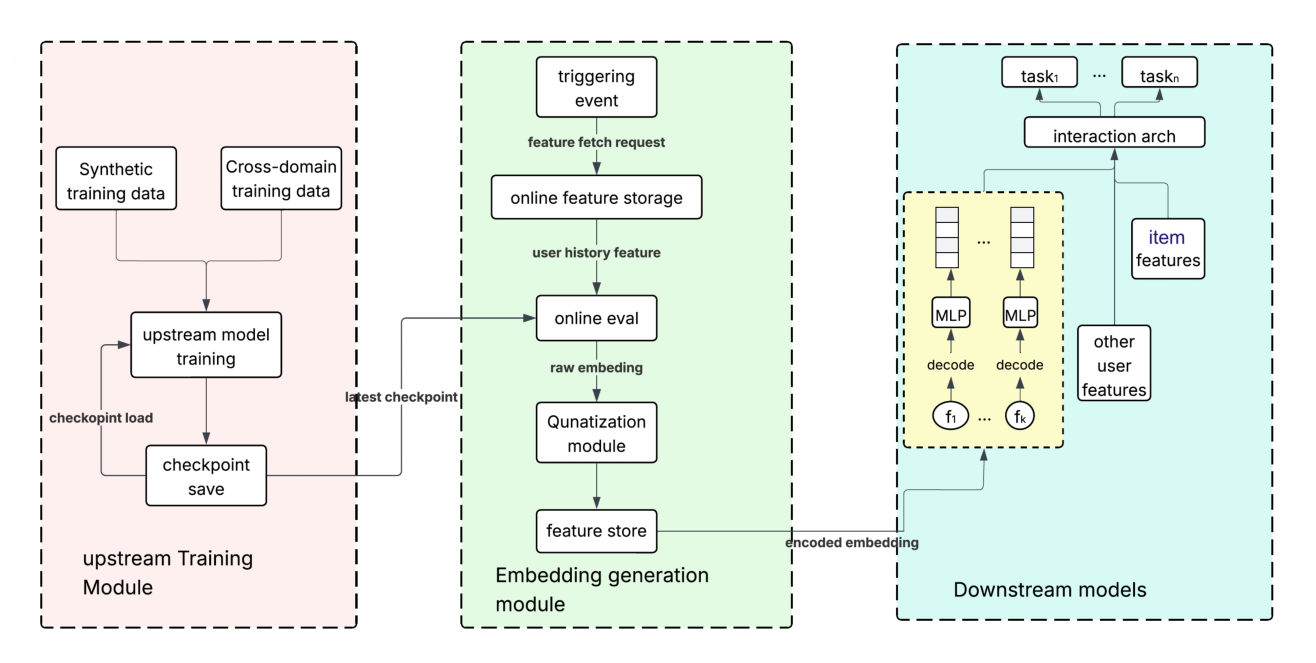
4.1 事件触发推理(Event-Triggered Inference, ETI)¶
传统嵌入流水线把「嵌入生成」耦合到「训练数据摄入」,以训练循环的节奏产出更新。这对 DUET 是个麻烦:CTR/OCVR 流数据量大,而 OC 流又太稀疏——两种节奏都给不出理想的「新鲜度 vs 基础设施负载」权衡。
DUET 改为用 ETI 架构把嵌入生成与训练解耦(Figure 3)。当模型按小时/天做预训练时,一个专门的 serving 模型从最近一次校验过的预训练 checkpoint 加载,按需生成嵌入:当用户执行一个合格动作(如一次站内转化)时,系统取回该用户最新的 EBF 与静态特征(来自在线存储),跑一次前向产出更新后的嵌入。站内转化提供了一个天然的触发器——其体量适中(高于 post-click 事件、低于曝光),且与用户价值相关,从而确保高活跃用户拿到更新鲜的表征。
- 独立流水线运行:ClickAUN 与 ConvAUN 各自以匹配其数据量的节奏迭代——ClickAUN 重训更频繁,ConvAUN 被更稀疏的转化数据节制。嵌入陈旧度与 serving 健康度按流水线分别监控,对 NE 退化与延迟自动告警。
- Checkpoint 校验:训练与推理在操作上分离——若某次训练产出了退化的 checkpoint(如梯度不稳),serving 模型会拒绝任何「相对其前代、验证 NE 超过预定阈值」的 checkpoint,从而无需人工干预即可维持嵌入质量。
- 效率优化:推理时只从训练 checkpoint 抽取序列学习组件,减小模型尺寸与 serving 主机数。一个固定的限流窗口抑制对「频繁触发事件用户」的冗余更新。
4.2 嵌入压缩¶
ETI 产出的原始嵌入在入库前由一个独立的量化模块压缩(Figure 3 中段)。采用 SIDE(Semantic ID Embedding) 技术(Ramasamy et al. 2025):把连续嵌入向量经向量量化映射到离散码本条目,并把多个量化向量融合成紧凑的语义 ID 表示。量化模块在原始嵌入上离线预训练。SIDE 相对 FP16 存储取得 4× 压缩,且对下游 NE 影响可忽略。
4.3 Serving 时解码¶
Serving 时,量化嵌入从特征库取回,经 SIDE 的规则解码器解回浮点向量。一个与下游模型联合训练的可学习 MLP,把解码后的嵌入投影到与其他输入特征对齐的维度,再进入 overarch 交互层。该设计除了这些额外嵌入输入外,不给下游 ranker 增加任何架构改动。
实验设置¶
5.1 评估指标:归一化熵(NE)¶
主指标是归一化熵(Normalized Entropy, NE)——定义为平均 log loss 除以「一个朴素模型(预测经验正样本率 $p$)的熵」:
$$\text{NE} = \frac{-\frac{1}{N}\sum_{i=1}^{N}\big[y_i \log(\hat{p}_i) + (1-y_i)\log(1-\hat{p}_i)\big]}{-\big[p\log(p) + (1-p)\log(1-p)\big]}. \tag{9}$$
NE 优于原始 log-loss,因为它对类别不平衡做了归一化,使「不同正样本率的任务/数据集」之间可比。本文报告相对 baseline 的 NE 相对下降(%ΔNE),下降越多越好。NE 在上游预训练与下游评估中一致使用,实现端到端性能追踪。
5.2 对比配置¶
四个配置,共享同一套下游 DLRM 架构与输入特征集:
- Baseline:现有下游 ranker,无预训练嵌入。
- ClickAUE Only:下游 ranker 增广 ClickAUE。
- ConvAUE Only:下游 ranker 增广 ConvAUE。
- DUET:下游 ranker 同时增广 ClickAUE 与 ConvAUE。
对比/掩码预训练方法(Ouyang et al. 2023a,b)被排除,因其增广式目标与本文的 pointwise BCE 形式不同。单嵌入配置(ClickAUE Only / ConvAUE Only)充当隔离每条流边际贡献的消融。
5.3 实现细节¶
ClickAUN 与 ConvAUN 都在 128 张 NVIDIA H100 GPU 上训练,达到约 ≈200K 离线训练 QPS——足以支撑持续训练与在严格延迟约束下及时部署更新的 checkpoint。
| 配置项 | ClickAUN | ConvAUN |
|---|---|---|
| 任务塔数 | 7(含 CTR、站内转化、视频观看预测等) | 7(含转化优化、link click、button click、合成转化) |
| 事件塔数 | 7(每个对应一个用户侧事件特征) | 13(采用「横向 scale」范式) |
| 最大序列/事件长度 | 1,000 | 不超过 200 |
| 注意力层数 $n$ | 2(堆叠) | 1 |
| 注意力头数 $h$ | 2 | 8 |
| 模型维度 $d_{\text{model}}$ | 256 | 128 |
| FFN 维度 $d_{\text{ff}}$ | 1024 | 256 |
| 输出嵌入 | 16 个 80 维嵌入 | 5 × 80 维 |
每个任务头的贡献经一个梯度缩放超参调制,以平衡监督信号强度与任务特定的标签噪声。Baseline 用现有下游模型,保持架构与训练数据完全一致,仅修改输入特征集以纳入 ConvAUE 与 ClickAUE。
注意两个编码器的规模反差恰好体现了「架构匹配统计机制」:ClickAUN(稠密流)更深更宽、序列更长($n{=}2$、$d_{\text{model}}{=}256$、seq≤1000);ConvAUN(稀疏流)更浅、头更多、序列更短但事件塔更多($n{=}1$、$d_{\text{model}}{=}128$、event≤200、13 塔横向扩展)。
主要实验结果¶
5.4 嵌入分析:ClickAUE 与 ConvAUE 是否冗余?¶
通过两个分析检验两个嵌入编码的是冗余还是互补信息:
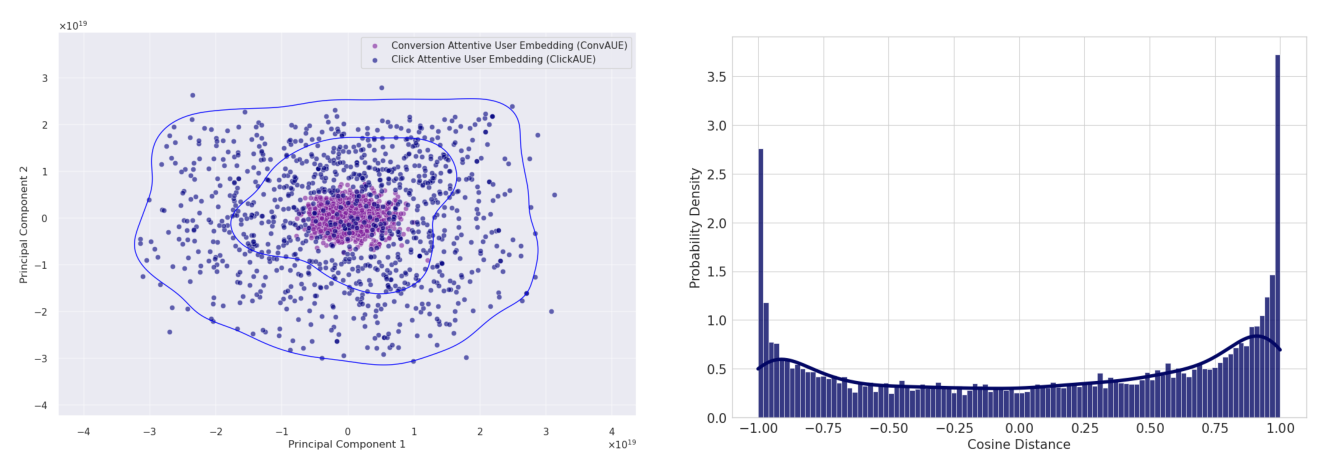
- 主成分可视化(Figure 4):把量化后的 ClickAUE 与 ConvAUE 向量投影到前两主成分,两类嵌入占据基本不相交的区域,说明它们捕捉的是用户行为的不同侧面而非冗余。
- 余弦距离分布(Figure 5):画同一用户的 ClickAUE 与 ConvAUE 两两余弦距离的概率密度。分布在 $[-1, +1]$ 上近似均匀,仅在两端有轻微聚集。均匀分布意味着两个嵌入空间在聚合层面近似正交——既不系统对齐、也不系统相反。$-1$ 与 $+1$ 附近的轻微峰值说明,一小撮用户的点击与转化模式强相关或强反相关,而大多数用户由「携带独立信息」的嵌入表示。这种近正交性与 §5.5 观察到的加性 NE 增益一致:两个表征向下游 ranker 贡献了很大程度上不重叠的预测信号。
5.5 主结果¶
Table 1:下游 ranker 的训练 NE 增益。DUET 优于单嵌入并逼近理论上界。
| 下游 ranker | %ΔNE 增益 |
|---|---|
| With ClickAUE | 0.21% |
| With ConvAUE | 0.30% |
| With DUET | 0.38% |
| 上界:ConvAUE ⊥ ClickAUE | 0.51% |
Table 1 报告主 OCVR 任务上的相对训练 NE 下降。ConvAUE 单独给出 0.30% 增益,ClickAUE 单独 0.21%,DUET(两者组合)达 0.38%。理论上界——在「ClickAUE 与 ConvAUE 完全正交、增益完全可加」假设下算出——为 0.51%。DUET 回收了约 75% 的上界(0.38 / 0.51),相对单嵌入至少有 ≈13% 的相对提升,既表明两个嵌入间的互补性,也暗示存在部分信息重叠(与 §5.4 的余弦距离分析一致)。值得注意的是,任一单流嵌入都达不到组合增益,确认点击流与转化流编码了不同的预测信号,联合起来比任一单独更有信息量。
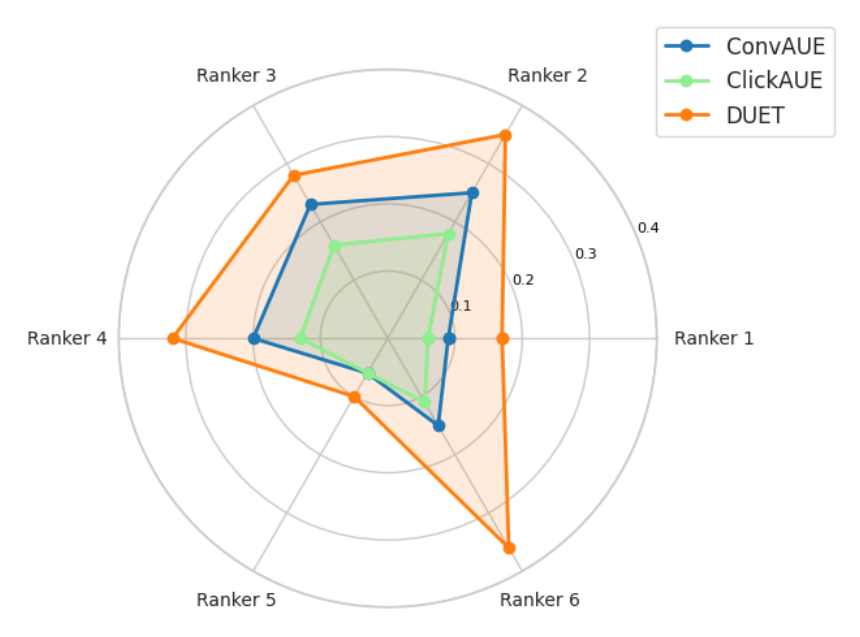
Figure 6 报告六个下游站外 CVR 模型上的评估 NE 增益。这六个是不同的 OCVR 排序模型,跨不同排序阶段(如终阶段 feed vs 早阶段 explore)与优化目标,流量、归因特性、baseline 特征集各异,但共享同一 DLRM 骨干,仅在增广 DUET 嵌入时输入特征集不同。三点观察:
- DUET 在所有六个模型上一致优于 ConvAUE/ClickAUE,ClickAUE 带来的加性提升从 +0.04%(Ranker 5)到 +0.21%(Ranker 6)不等。确认了点击衍生表征无论下游配置如何,都对转化衍生表征提供互补信号。
- 增益幅度随模型变化:Ranker 2、Ranker 6 受益最大(分别 0.35% 和 0.36%),Ranker 5 提升较温和(0.10%)。这反映了各模型在数据量、归因率、以及「自身现有特征集已捕捉多少点击/转化相关模式」上的差异。
- ClickAUE 的相对贡献(DUET 与 ConvAUE 之差)并非恒定:Ranker 6 的加性提升最大(+0.21%),说明它的 baseline 特征集最有「被点击流表征富化」的空间;而 Ranker 3、Ranker 5 增量较小,说明它们的现有特征已捕捉了部分 ClickAUE 所编码的信息。
5.6 消融研究¶
在「各组件如何影响预训练(PT)与下游 ranker(DR)性能」上做消融。Table 2 报告每个组件从其上游编码器移除后的 PT/DR NE 退化;值越大越重要。
Table 2:上游编码器消融。
| ConvAUE 组件 | PT %ΔNE | DR %ΔNE |
|---|---|---|
| Remove Synthetic Data(移除合成数据) | 0.13% | 0.03% |
| Reduce 1 Layer Attention(减一层注意力) | 0.06% | 0.025% |
| Remove User Journey Event(移除用户旅程事件) | 0.30% | 0.10% |
| Remove Item Impression Event(移除 item 曝光事件) | 0.04% | 0.015% |
| ClickAUE 组件 | PT %ΔNE | DR %ΔNE |
|---|---|---|
| Scaling Sequence/Non-sequence Arch(缩放序列/非序列架构) | 0.13% | 0.05% |
| Ablate Item Impression Event Feature | 0.04% | 0.01% |
| Ablate Page Event Feature(页面事件特征) | 0.07% | 0.03% |
逐项分析:
- ConvAUE 消融:用户旅程事件特征(user journey event)是跨两个编码器最有影响的单一组件——移除它造成 0.30% PT NE 与 0.10% DR NE 损失。该特征捕捉跨站浏览模式,提供转化意图的直接证据。无归因合成数据贡献 0.13% PT / 0.03% DR NE,确认「缺乏确定性归因的转化事件」仍提供有用的弱监督。架构深度(2 层 vs 1 层注意力)贡献 0.06% PT / 0.025% DR——一个温和但一致的增益,验证了「稀疏监督下交错交叉/自注意力」设计。
- ClickAUE 消融:缩放序列与非序列架构带来至多 0.13% PT / 0.05% DR NE 增益,说明稠密特征分支的模型容量对 ClickAUE 质量是「承重的」。在各事件特征里,页面参与(page engagement)最有影响(0.07% PT / 0.03% DR),其次是目标 item 曝光事件(0.04% PT / 0.015% DR)。
- 跨编码器对比:ConvAUE 由单一高信号源主导(用户旅程 0.30%),而 ClickAUE 的增益来自各特征的均匀贡献,无单一特征超过 0.07%。这反映了两种数据机制:稀疏转化流依赖少数高信号事件,稠密点击流则受益于「众多中等来源的广度」。
- PT→DR 迁移比:比较 PT 与 DR 的 NE 变化可见,序列架构改动与事件特征增加表现出 30%–40% 的迁移比(因为它们直接影响嵌入生成所用的序列学习组件);数据层改动(如合成数据)迁移比较低但仍可观(23%),确认上游数据改进会经学到的嵌入表征传播到下游 ranker。
5.7 A/B 测试结果¶
在两个 CVR 模型上做线上 A/B(实验资源密集,限制了可并发评估的模型数)。
Table 3:A/B 测试结果(相对 baseline 的提升)。
| 下游 ranker | 站外 CVR 提升 |
|---|---|
| Ranker 3 | +0.66% |
| Ranker 4 | +0.15% |
两个模型都取得统计显著提升:Ranker 3 +0.66% CVR,Ranker 4 +0.15% CVR。两者均在 $p < 0.05$(双边 $t$ 检验)显著。延迟开销可忽略——嵌入经 ETI 系统预计算、经特征库查找 serving,serving 时无额外模型推理。这与 §5.5 的离线 NE 增益相互印证:离线 NE 收益能转化为可测量的 A/B 影响。
附录要点¶
上游编码器优化器¶
用 Distributed Shampoo 优化器(Gupta et al. 2018)——一种利用 Kronecker 分解预条件来捕捉 pairwise 梯度相关的二阶方法。相比 Adam/AdaGrad/SGD 等一阶法,Shampoo 一致带来统计显著提升且不增加推理开销。配置:学习率 $\alpha = 0.04$,$\beta_1 = 0.9$,$\beta_2 = 1.0$,$\epsilon = 10^{-4}$,momentum $\mu = 0$,weight decay $\lambda = 10^{-5}$。线性学习率 warmup 跨 20,000 次迭代,从初始率插值到 $10^{-3}$。
「合并模型」与「分离模型」的等价性分析¶
附录用一个理论论证回答一个自然质疑:为什么要训两个分离的上游模型,而不是一个合并模型? 结论是:在线性交互假设下,分离设计不损失表征能力,且额外换来架构灵活性与工程收益。
- 假设 1:AFL 上游模型与 baseline 架构一致,只是多了序列学习组件(baseline 的序列组件是冻结的)。
- 假设 2:合并模型中不同数据源/中间嵌入的交互发生在上游;分离模型中该交互被推迟到下游模型(交互层或 overarch)。
- 假设 3:嵌入向量间的交互通过点积实现(简化假设;实践中 DLRM 用 DCN cross 层、MLP 等非线性交互层,可能偏离下面的等价推导)。
引理 1:用一个合并模型同时利用点击与转化数据学到的「联合用户嵌入」,与「在上游分别从两种数据学嵌入、再在下游集成」近似等价。
证明梗概:令 $\mathbf{u} \in \mathbb{R}^n$ 为 ConvAUE、$\mathbf{v} \in \mathbb{R}^n$ 为 ClickAUE。令 $\mathbf{w}$ 为合并上游中的标量权重,$\mathbf{w}', \mathbf{w}''$ 为 ClickAUN/ConvAUN 中的标量权重,$\mathbf{z}$ 为下游标量向量。由假设 2,无论上游合并与否,下游模型只学到 $\mathbf{z}$。
合并下游表示:
$$(\mathbf{u} \cdot \mathbf{v})\mathbf{w} = \sum_{i=1}^{n} w_i(u_i \cdot \mathbf{v}) = (w_1 u_1)\cdot \mathbf{v} + \cdots + (w_n u_n)\cdot \mathbf{v} = \Big(\sum_{i=1}^{n} w_i u_i\Big)\cdot \mathbf{v}. \tag{10}$$
分离下游表示(用假设 2,$\circ$ 为 Hadamard 积):
$$\mathbf{u}\mathbf{w}' \cdot \mathbf{v}\mathbf{w}'' = (\mathbf{u} \circ \mathbf{w}') \cdot (\mathbf{v} \circ \mathbf{w}'') = \sum_{i=1}^{n} u_i w_i' v_i w_i'' = \sum_{i=1}^{n} w_i^* u_i v_i = \Big(\sum_{i=1}^{n} w_i^* u_i\Big)\cdot \mathbf{v}. \tag{11}$$
由假设 1 比较式 (10) 与 (11),有 $\mathbf{w}^* \approx \mathbf{w}$,即近似等价。$\square$
讨论:近等价说明把嵌入拆成两个上游模型,在线性交互假设下不牺牲表征能力。但分离设计另有超越等价性的优势:(1) 它允许每个上游模型用为其数据域定制的、不同的注意力架构(ClickAUN 纯自注意力 vs ConvAUN 交错交叉/自注意力)——这是单个合并模型难以容纳的;(2) 操作收益——独立扩缩、故障隔离、各流水线按自己的节奏重训而互不影响。作者也指出实践中 DLRM 用的是非线性交互层而非纯点积,所以实际等价比线性推导更松;但实证结果(§5.5)确认分离设计至少与单流预训练表现相当,同时提供了上述架构灵活性。
核心贡献总结¶
- 「信号主导下的机制错配」这一问题诊断:明确指出单流上游编码器在 OCVR 上必然被稠密点击信号主导、欠拟合稀疏转化模式——把「为何要分流」讲清楚。
- 域感知数据路由 + 流特化编码器:按标签语义与归因时长把数据切成点击流/转化流,为每条流配「架构匹配统计机制」的编码器(稠密→深层自注意力;稀疏→交叉注意力锚定 + 隐式正则),并经消融逐项验证每个选择都承重。
- 无归因转化的合成弱监督:把「无法确定性归因的转化」通过推断最可能排序结果转成合成训练样本,缓解 OCVR 流稀疏(消融显示贡献 0.13% PT NE)。
- 解耦上游复杂度与 serving 预算的完整工程栈:ETI 事件触发异步生成 + checkpoint 校验自愈 + SIDE 4× 量化 + serving 时 MLP 解码投影,实现可忽略的延迟开销。
- 理论 + 实证双重验证分离设计:附录证明分离与合并近等价(线性假设下),实证 0.38% 训练 NE 下降(回收 75% 理论上界)、6 个下游模型一致正向、2 个线上 A/B 统计显著(+0.66% / +0.15% CVR)。
与已归档相关工作的对比¶
SCALR SCALR:把跨域事件迁移重铸为合成数据生成(Meta, 2026-05-29)¶
关系:独立并发 / 同团队姊妹工作(本文未引用 SCALR,且二者作者高度重叠——Xiangyu Wang、Yawen He、Rob Malkin 均在两篇作者列表中,发表仅相隔约 10 天)· 已加载对方精读
- 共同关注的问题:两篇都死磕 Meta 工业转化预估的数据稀疏这一 root cause。SCALR 的框架是「转化率 <1%、很多 item 一天只有几十次转化,难训准转化模型」;DUET 的框架是「站外转化稀疏 + 大量无法归因,单流编码器被稠密点击主导」。同一公司、同一任务族(conversion/CVR prediction)、几乎同期。
- 殊途同归的共同 insight:二者都把「解耦」作为核心设计哲学——SCALR 把跨域迁移解耦到数据层(model-agnostic,下游模型不改架构),DUET 把用户表征学习解耦到上游预训练(嵌入冻结、上下游独立重训)。二者也都强调多消费者复用:SCALR 一份合成数据集供多个下游模型复用,DUET 一套嵌入供 6+ 下游 ranker 共享。
- 直接同构的子组件——合成数据:DUET 的「来自无归因转化的合成数据」(§3.1:为无归因转化推断最可能排序结果,作为 ConvAUN 流的弱监督)本质就是 SCALR 思想的一个特例。SCALR 把它一般化为跨域事件翻译:用重叠用户共现统计估计 item 翻译分布 $\hat P(i_\mathcal{T}\mid j_\mathcal{S})$(频率法),从分布概率采样(而非确定性 top-K)生成合成目标域转化事件,再以加权辅助损失 $\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{orig}} + \lambda\sum w\cdot\ell(f_\theta, \tilde y)$ 训练。
- 本文的差异与推进:DUET 走的是架构/表征轴——双流专用 Transformer 编码器 + 流特化注意力 + 异步 serving;合成数据只是 ConvAUN 流的一个辅助子组件。SCALR 走的是纯数据轴——不碰任何模型架构,只在训练集里掺入翻译来的合成事件。两者高度互补:可以想象「用 SCALR 式跨域翻译来富化 DUET 的 ConvAUN 训练流」。可比的实验差异:两篇都用 NE 作离线指标、都报线上转化提升;DUET 报 0.38% 训练 NE / +0.66% A/B CVR,SCALR 报核心业务指标统计显著正向(其精读未给单一可比数值)。
RQ-FSQ RQ-FSQ:把跨域行为意图量化成 Semantic ID 喂给广告排序(LinkedIn, 2026-05-31)¶
关系:独立并发,殊途同归于「serving 子问题」(本文未引用,LinkedIn vs Meta,相隔约一周;核心方法骨架不同,但「预训练用户嵌入 → 量化压缩 → 冻结当输入特征喂广告 ranker」这条 serving recipe 高度同构)· 已加载对方精读
- 共同关注的问题:两篇都要把「有机互动(organic feed engagement)衍生的丰富用户信号」注入广告/转化排序,且都受困于「dense 用户嵌入的高 serving 成本」。DUET 把有机 feed 浏览/点赞纳入 EBF 序列、用 SIDE 4× 压缩嵌入;RQ-FSQ 明确把「广告点击稀疏、但 organic feed 行为多数个量级」当作切入点,把 feed 行为量化成 viewer SID 注入广告 CTR。
- 相近的技术骨架(serving 轴):二者都遵循「预训练用户嵌入 → 离散量化压缩 → 冻结当输入特征、下游 ranker 架构零改动」这条流水线。DUET 用 SIDE(向量量化融合成语义 ID,4× 压缩);RQ-FSQ 用 RQ-FSQ(残差 VAE + 逐维有限标量量化,30–280× 压缩,几乎不掉 AUC),并配 prefix n-gram 的 HDE 模块把 K 级 SID 端到端编码进 decoder-only ranker。两家公司独立地走到了「量化预训练用户嵌入以低成本 serving」这同一条工程路径上。
- 本文的差异与推进:核心贡献轴不同——DUET 的核心是「按统计机制分流 + 流特化编码器架构」,量化(SIDE)只是借用的部署组件;RQ-FSQ 的核心正是量化方法本身 + 跨域 SID 冷启动迁移研究(它的 root cause 更偏「存储成本 + 冷启动迁移质量」,并实证「行为活跃度决定迁移质量」,最冷启用户 +1.522% AUC)。换言之 DUET 在「编码器架构」上深耕、把量化当黑盒;RQ-FSQ 在「嵌入离散化/SID」上深耕、把骨干 ranker 当黑盒。两者拼起来恰好覆盖了「上游表征学习」与「下游嵌入接入」两端。
被剔除的近似候选(防止门槛放水): - HeteGenCTR(2605.24986, Alibaba):同样诊断「预训练中的信号/字段主导失衡」(易字段抢梯度、高信号 ID/序列字段欠拟合),与 DUET 的「信号主导下机制错配」problem 上有共鸣;但解法是「逐字段难度标量 + 难度引导注意力缩放」修正离散扩散 CTR 预训练,解法骨架完全不同(字段重加权 vs 数据流分离),剔除。 - IAT(2604.08933, ByteDance):同样「预计算紧凑嵌入供下游广告模型消费」,但 IAT 压缩的是历史训练实例(instance-as-token),不是双流用户编码器,recipe 不同,剔除。 - Coupang 工业 CVR scaling(2605.29232):同属「工业搜索 CVR 预估 + 解耦/scaling」任务族,但解法是「把 scaling 拆成 backbone/embedding/data 三维 + warmstart 重训 + CPU-GPU 解耦」,是 scaling-law 经验研究,非上游双流表征预训练,剔除。
讨论与局限性¶
值得借鉴的设计:
- 「架构匹配统计机制」是本文最可迁移的方法论:不要对稠密流与稀疏流套同一编码器——稠密流用深层自注意力挖高阶交互,稀疏流用交叉注意力把序列锚到稳定静态属性上做隐式正则。这条原则在任何「混合了高频/低频信号的上游表征学习」里都可复用。
- 无归因数据当弱监督而非丢弃:把因 cross-device/cookie/延迟而无法归因的转化「推断成合成样本」,是工业 CVR 场景里榨取稀疏正信号的实用手法(与 SCALR SCALR 的跨域合成数据一脉相承)。
- ETI 异步 serving + checkpoint 自愈校验:把「嵌入新鲜度」与「训练节奏」解耦、用站内转化当天然触发器、用「验证 NE 超阈即拒绝 checkpoint」自动维持质量——是一套完整可抄的部署护栏。
局限与争议:
- 增益温和:0.38% 训练 NE、+0.66%/+0.15% 线上 CVR——在 Meta 体量下有商业价值,但绝对幅度不大;作者也坦承「贡献不在单个组件(均为既有技术),而在其面向 OCVR 的有原则的组合」。这把它定位为扎实的工程组合工作而非方法论突破。
- 数据路由是静态规则:当前按标签语义/归因时长硬切两条流;学习式路由有望支持更细粒度的多流划分(作者列为 future work)。
- 注意力配置的指派未被充分对照:「点击→自注意力、转化→交叉注意力」经消融验证有效,但没有对照「反过来指派」或其他组合,缺一个干净的对照实验来证明这个指派是最优而非次优。
- 冻结嵌入的适应性代价:下游训练期冻结嵌入换来了操作解耦,但牺牲了对分布漂移的适应能力;轻量微调(如 adapter 层)可能缓解。
- 可复现性受限:所有下游 ranker(Ranker 1–6)与数据集匿名、全部内部 NE 指标、无公开学术 benchmark,外部难以复现或横向对标。
工业落地价值:DUET 已在 Meta 的多个站外 CVR 下游模型上验证,并跑通了完整部署栈(ETI + SIDE 量化 + checkpoint 校验 + 限流),serving 延迟开销可忽略。对「握有第一方多应用行为数据、做站外/零售媒体转化预估」的平台,这是一套已被线上 A/B 验证、可直接借鉴的上游用户表征 + 异步 serving 方案。