SCALR:把跨域事件迁移重铸为推荐系统的合成数据生成¶
- 作者:Xiangyu Wang, Yawen He, Shivendra Pratap Singh, Han Huang, Mengtong Hu, Sharath Ciddu, Yi-Hsuan Hsieh, Erik Groving, Yi Ding, Jieming Di, Tony Wang, Min Yun, Xiaoyu Chen, Ling Leng, Rob Malkin(均为 Meta,共同一作)
- Arxiv:2606.00282(cs.IR,2026-05-29)
- 机构:Meta(Work done at Meta)
- 关键词:Synthetic Data; Cross-Domain Recommendation; Data Augmentation; Conversion Prediction; Industrial Recommendation
研究动机与背景¶
合成数据(synthetic data)在大语言模型(LLM)训练里已成为最有影响力的范式之一:从预训练、指令微调、对齐到知识蒸馏,高质量合成样本被反复证明可以逼近甚至超过自然采集数据(Gunasekar et al. 2023 的 Phi-1 用合成的"教科书质量"数据让 1.3B 模型匹敌 GPT-3.5 级编码能力;Alpaca、Orca 等用合成指令-响应/推理轨迹做对齐)。然而在推荐系统里,合成数据作为一个显式范式长期被忽视——已有用法要么聚焦隐私保护(用部分/全合成用户画像替换敏感值,Slokom 2018;Drechsler and Reiter 2011),要么聚焦对抗训练(IRGAN,Wang et al. 2017),没有人把"生成跨域训练数据来缓解数据稀疏"当作目标。本文正是要填这个空白。
推荐系统在工业规模上面临一个根本困境:训练数据是隐式反馈(点击、转化、互动),天然噪声大、稀疏、长尾严重。尤其在转化预测(conversion prediction)场景,转化率通常低于 1%,很多 item 一天只有几十到几百次转化,难以训练准确的转化模型。
针对稀疏性,跨域推荐(Cross-Domain Recommendation, CDR)的思路是从数据丰富的源域(source domain)向稀疏的目标域(target domain)迁移知识。但现有 CDR 一律在模型层(model level)做迁移——共享用户 embedding、潜因子或网络参数,通过联合训练或学到的映射函数。本文尖锐地指出这条路有三个工业落地的硬伤:
- 架构耦合(architecture coupling):源域信号被吸收进共享模型参数,迁移机制与模型架构纠缠在一起。一旦换下游模型(例如从双塔换成基于 transformer 的 ranker),整套跨域组件就得重新设计——而工业系统里架构是频繁演进的。
- 训练耦合(training coupling):源域与目标域模型必须联合训练或顺序微调,源域数据或模型一变,整条 pipeline 就要端到端重训。
- 多消费者扩展性(scalability to multiple consumers):当多个下游模型(ranking、calibration、bidding)都想吃源域信号时,每个模型都得各自独立实现一套跨域迁移机制,重复劳动且引入不一致。
另一条路线是数据增强(data augmentation)(Wang et al. 2021 的反事实序列增强;Yao et al. 2021、Xie et al. 2022 的自监督对比;以及 LLM 幻觉伪先验交互 Liu et al. 2021)。但这些方法都在单域内部操作——通过 item masking、序列裁剪、反事实替换造出已有交互的扰动视图,改善的是表征学习,并没有把域外的行为信号引进来。
本文提出的 SCALR(Synthetic Cross-domain Augmentation and Learning for Recommendation) 走了一条根本不同的路:把跨域学习解耦为两个独立模块化阶段:
- 阶段一 · 合成数据生成(synthetic data generation):在任何模型训练开始之前,先把源域事件翻译成具体的、目标域格式的训练样本;
- 阶段二 · 跨域学习(cross-domain learning):下游模型在"原始 + 合成"事件的组合上训练,用一个加权目标控制每种数据源的影响力。
虽然阶段二本身也是一种跨域学习,但它与传统 CDR 不同:跨域对齐已经在数据生成阶段被解决了,所以学习阶段完全在目标域的数据格式里进行——下游模型自始至终不需要知道某些训练样本来自另一个域,因为它消费合成事件的方式与消费原始事件完全一致。这种解耦带来五个工业上极有价值的性质:
- 模型无关(model-agnostic):任何推荐架构无需改动即可受益,因为下游模型 $f_\theta$ 吃的合成事件格式与原始事件一模一样;
- 模块化(modular):合成数据生成 pipeline 可以独立于推荐模型迭代,多个下游模型可以复用同一份合成数据集;
- 多源组合(multi-source composition):来自多个源域(浏览行为、内容互动、搜索 query)的合成事件都被翻译成同一种目标域格式,直接拼接(concatenate)即可,无需额外架构或算法复杂度;
- 隐私保护(privacy preservation):合成事件是通过概率翻译生成的,而非直接拷贝源域日志,不对应任何单个用户的原始活动记录,相比直接共享/迁移原始跨域交互降低了隐私风险;
- 与传统 CDR(Zhu et al. 2021;Hu et al. 2018)形成鲜明对比——后者必须把跨域迁移机制直接嵌进模型,把数据迁移与模型训练焊死成单一的、架构特定的流程。
本文用频率法(frequency-based)做翻译分布估计的高效可扩展实现,并进一步探索了基于学习 embedding 的模型法(model-based)。核心实证结论之一:从翻译分布做概率采样优于确定性 top-K 选择。在线 A/B 测试中 SCALR 在核心业务指标上取得统计显著提升。作者声称这是最早把跨域事件迁移显式地构造为推荐系统合成数据生成的工作之一。
相关工作¶
LLM 中的合成数据:Gunasekar et al.(Phi-1)证明数据质量可替代模型规模;Alpaca 用合成指令蒸馏指令跟随能力;Orca 扩展到细粒度推理轨迹;Liu et al. (2024) 总结出两条关键经验——合成数据与真实数据的分布对齐、以及对合成/真实比例的谨慎控制,是成功的关键。但 LLM 合成数据操作在共享词表的连续 token 序列上,而推荐系统需要生成离散的、跨不相交 item catalog 的用户-item 交互事件,且服从重尾分布与隐式反馈噪声——数据模态根本不同。
推荐系统中的合成数据:Slokom (2018) 用 CART 合成数据替换隐私敏感值做评测(隐私机制,非提升性能);IRGAN(Wang et al. 2017)是一个 minimax 对抗框架,让生成器从候选池里挑选伪相关 item 来骗判别式检索器——但 IRGAN 不生成新数据,只挑已有 item,且完全在单域内运作,既不创造新交互事件,也不跨域迁移行为信号。SCALR 与两者都不同:它通过把跨域用户交互翻译进目标域格式来生成合成训练事件,目标明确是增强训练数据、提升下游性能。
跨域推荐(CDR):代表方法包括 Collective Matrix Factorization(Singh and Gordon 2008,跨域共享用户潜因子)、EMCDR(Man et al. 2017,学源/目标用户 embedding 的显式映射)、CoNet(Hu et al. 2018,双网络 cross-stitch 双向迁移)、以及更近的 DisenCDR(Cao et al. 2022,解耦域共享/域特定表征)。但 CDR 一律在表征层操作——共享参数、embedding 或潜因子。此前没有 CDR 工作把迁移构造为合成数据生成,即把源域交互翻译成目标域的具体训练事件、并与任何特定下游模型解耦。
推荐系统的数据增强:域内增强包括反事实序列增强(Wang et al. 2021)、item masking / feature dropout 的自监督对比(Yao et al. 2021;Xie et al. 2022)、以及幻觉伪先验交互(Liu et al. 2021)。更近的 LLM 增强:LLMRec(Wei et al. 2024)为图推荐生成合成用户-item 交互;TallRec(Bao et al. 2023)用指令微调把 LLM 适配到推荐。但这些都在单域内操作,不利用跨域行为信号。SCALR 的独特之处在于:通过把来自完全不同域的交互翻译过来生成合成事件,把跨域事件迁移类比为 LLM 里"教师模型输出充当合成训练数据"的合成数据生成问题。
SCALR 框架¶
问题设定与符号¶
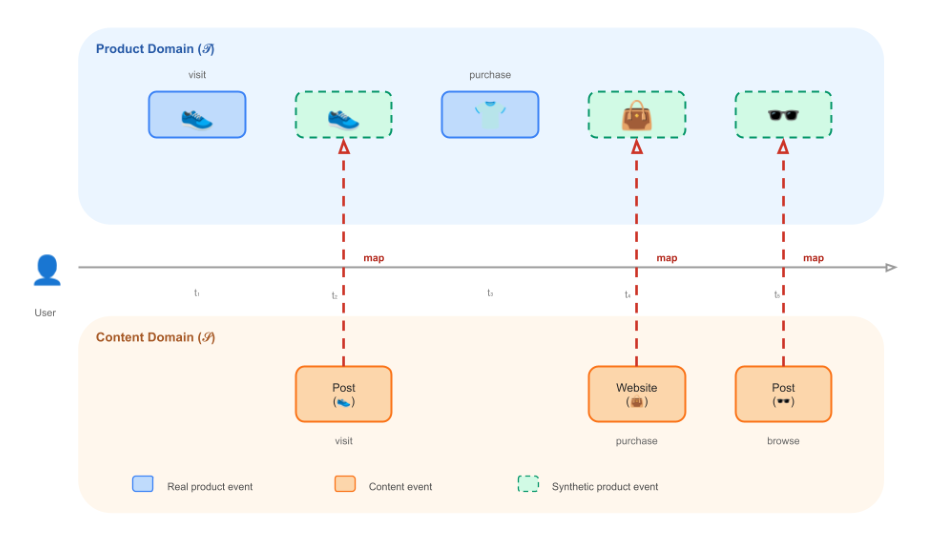
考虑一个平台,目标是预测用户 $u$ 在被展示 item $i$ 后是否会转化(convert)。目标域 $\mathcal{T}$ 的训练数据由观测到的 $\langle u, i \rangle$ 交互对组成——具体说,是发生了转化的用户-item 对。实践中转化事件极度稀疏:转化率通常低于 1%,很多 item 每天只有几十到几百次转化,难以训练准确的转化预测模型。
与此同时,同一平台在其他源域 $\mathcal{S}$ 里观测到丰富的用户行为。例如一个社交平台会记录 $\langle u, j \rangle$ 交互,表示用户访问网站、互动内容或浏览产品页。这些源域事件比转化事件多几个数量级,且携带关于用户偏好与意图的丰富信号。
形式化:令 $\mathcal{U}$ 为跨域共享的用户空间,$\mathcal{I}_\mathcal{S}$、$\mathcal{I}_\mathcal{T}$ 分别为源域与目标域的 item 空间。推荐场景下 $\mathcal{I}_\mathcal{T}$ 是推荐位、内容页或产品的集合,$\mathcal{I}_\mathcal{S}$ 是网站、内容页或产品的集合。一般地 $\mathcal{I}_\mathcal{S} \cap \mathcal{I}_\mathcal{T} = \emptyset$,即两个域的 item catalog 不相交。观测交互日志记为:
$$\mathcal{D}_\mathcal{S} = \{(u_k, j_k) : u_k \in \mathcal{U},\ j_k \in \mathcal{I}_\mathcal{S}\}_{k=1}^{N_\mathcal{S}} \tag{1}$$
$$\mathcal{D}_\mathcal{T} = \{(u_k, i_k) : u_k \in \mathcal{U},\ i_k \in \mathcal{I}_\mathcal{T}\}_{k=1}^{N_\mathcal{T}} \tag{2}$$
其中 $N_\mathcal{S} \gg N_\mathcal{T}$(源域事件远多于目标域)。核心问题是:能否利用丰富的源域事件 $\mathcal{D}_\mathcal{S}$ 来为稀疏的目标域 $\mathcal{T}$ 合成额外的训练事件?
合成数据生成¶
合成数据生成的目标是:给定一个源域事件 $\langle u, j_\mathcal{S} \rangle$,生成一个目标域事件 $\langle u, i_\mathcal{T} \rangle$。由于用户身份跨域共享,核心要估计的量是 item 翻译分布(item translation distribution):
$$P(i_\mathcal{T} \mid u, j_\mathcal{S}) \tag{3}$$
它定义了在所有目标域 item $i \in \mathcal{I}_\mathcal{T}$ 上、以用户 $u$ 和其交互过的源 item $j$ 为条件的概率分布。在推荐例子里它捕捉的是:已知用户 $u$ 访问了某商家的页面 $j$,他与该商家提供的每个产品 $i$ 交互的可能性有多大?
关键设计决策:Equation 3 定义的是一个分布而非单点预测。作者不去找单个最优目标 item $i^* = \arg\max_i P(i_\mathcal{T} \mid u, j_\mathcal{S})$,而是保留目标 item 空间上的完整分布——因为确定性选择 vs 随机采样的取舍对合成数据质量有显著影响(见 §5.3.1)。重要的是,翻译分布不是由生成模型学出来的,而是用频率法从目标域里观测到的共现统计估计的(模型法扩展见后文)。
频率法翻译(frequency-based translation):作为高效可扩展的估计 Equation 3 的方法,核心思路是利用重叠用户(overlapping users)集合 $\mathcal{U}_{\text{overlap}} = \{u : \exists (u, j, \cdot) \in \mathcal{D}_\mathcal{S}\ \text{且}\ \exists (u, i, \cdot) \in \mathcal{D}_\mathcal{T}\}$——即在两个域都活跃的用户——的共现统计。对这些用户,计算经验 item 翻译概率:
$$\hat{P}(i_\mathcal{T} \mid j_\mathcal{S}) = \frac{\sum_{u \in \mathcal{U}_{\text{overlap}}} \mathbf{1}[(u, j) \in \mathcal{D}_\mathcal{S}] \cdot \mathbf{1}[(u, i) \in \mathcal{D}_\mathcal{T}]}{\sum_{u \in \mathcal{U}_{\text{overlap}}} \mathbf{1}[(u, j) \in \mathcal{D}_\mathcal{S}]} \tag{4}$$
其中 $\mathbf{1}[\cdot]$ 是指示函数。直观理解:分子统计"既在源域有 $j$、又在目标域有 $i$"的用户数(即 $j$ 与 $i$ 的共现次数),分母统计"在源域有 $j$"的用户数,比值即在看到源 item $j$ 的条件下翻译到目标 item $i$ 的频率估计。
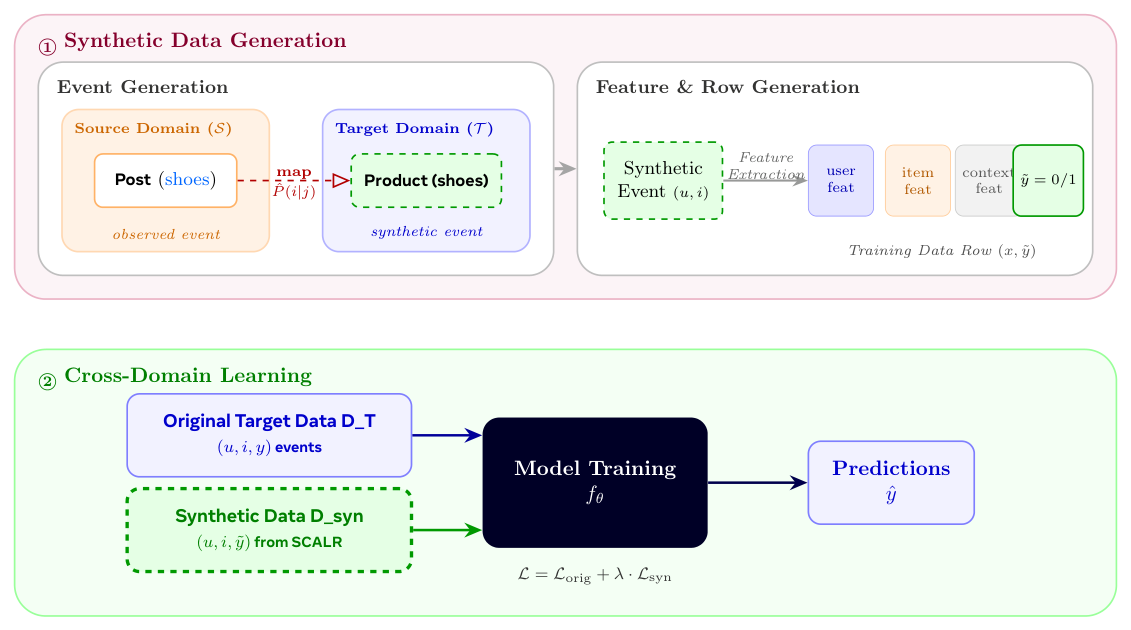
生成算法(Algorithm 1):给定估计好的翻译分布,对每个源域事件,计算其在候选目标 item 上的翻译分布,从该分布采样 $K$ 个目标 item 作为合成事件。原则上每个合成事件可被赋予一个置信权重 $w_k = g(\hat{P}(i_k \mid u, j))$($g$ 为某个加权函数),让下游模型区分高/低置信合成样本。但当前实现里对所有采样事件用统一权重 $w_k = 1$——因为采样分布本身已经编码了翻译概率:高概率 item 被采样得更频繁,所以聚合后的合成数据集天然就反映了估计的分布,无需逐事件重加权。
Algorithm 1 · SCALR:合成事件生成 输入:源域事件 $\mathcal{D}_\mathcal{S}$,翻译分布 $\hat{P}(i_\mathcal{T} \mid u, j_\mathcal{S})$,每个源事件的生成预算 $K$,加权函数 $g$ 输出:合成目标域事件 $\mathcal{D}_{\text{syn}}$ 1. $\mathcal{D}_{\text{syn}} \leftarrow \emptyset$ 2. for each $(u, j) \in \mathcal{D}_\mathcal{S}$ do 3. 计算候选 item $i \in \mathcal{I}_\mathcal{T}$ 上的 $\hat{P}(i_\mathcal{T} \mid u, j_\mathcal{S})$ 4. for $k = 1, \dots, K$ do 5. 采样 $i_k \sim \hat{P}(\cdot \mid u, j_\mathcal{S})$ 6. $\mathcal{D}_{\text{syn}} \leftarrow \mathcal{D}_{\text{syn}} \cup \{(u, i_k, w_k)\}$,其中 $w_k = g(\hat{P}(i_k \mid u, j))$ 7. end for 8. end for 9. return $\mathcal{D}_{\text{syn}}$
Top-K 选择 vs 概率采样:对 Algorithm 1 里采样的一个自然替代是确定性 top-K 选择——对每个源事件直接选翻译概率最高的 $K$ 个目标 item。虽然 top-K 最大化了每个事件的翻译概率,但它产生的合成数据集 item 多样性极低:同一批高概率 popular item 会在不同源事件间被反复选中,合成数据集聚集在目标 catalog 的一个狭窄切片上。
作者把这个取舍类比到语言生成里的解码策略选择:Holtzman et al. (2019) 证明 greedy / top-K 解码会导致退化、重复的文本,而 nucleus sampling(top-$p$)通过从分布的高概率部分采样产生更自然、更多样的输出;Fan et al. (2018) 同样证明带适当截断的随机采样比 beam search 生成更多样连贯的故事。底层原理:在每一步最大化似然并不最大化聚合(aggregate)输出的质量;相反,多样性与分布覆盖才是关键。在合成数据语境里,Gudibande et al. (2023) 与 Liu et al. (2024) 都发现合成训练数据的多样性是下游性能的关键驱动力,过度依赖高置信样本会导致覆盖窄、泛化退化。
这一原理同样适用于推荐的合成事件生成。从 $\hat{P}(\cdot \mid u, j_\mathcal{S})$ 做随机采样保留了翻译概率的分布形状(包括其尾部),产生的合成事件能集体覆盖目标 item 空间更广的部分。这种多样性在推荐里尤其有用——长尾 item 单个看概率低、但集体上很重要,恰恰是最受数据稀疏之苦的部分。作者在 §5.3.1 实证验证采样一致优于 top-K。
用合成数据做跨域学习¶
有了合成事件 $\mathcal{D}_{\text{syn}}$,把下游训练形式化为跨域学习问题。令 $f_\theta : \mathcal{U} \times \mathcal{I}_\mathcal{T} \to [0, 1]$ 为目标域推荐模型(如转化预测模型),参数 $\theta$。在原始目标域数据上的标准训练目标是:
$$\mathcal{L}_{\text{orig}}(\theta) = \sum_{(u, i, y) \in \mathcal{D}_\mathcal{T}} \ell\big(f_\theta(u, i),\ y\big) \tag{5}$$
其中 $y \in \{0, 1\}$ 是观测标签,$\ell$ 是损失函数(如二元交叉熵 BCE)。用合成数据训练时,在目标里加一项对合成事件的加权损失:
$$\mathcal{L}_{\text{total}}(\theta) = \mathcal{L}_{\text{orig}}(\theta) + \lambda \sum_{(u, i, w) \in \mathcal{D}_{\text{syn}}} w \cdot \ell\big(f_\theta(u, i),\ \tilde{y}\big) \tag{6}$$
其中 $\lambda > 0$ 控制合成数据的相对重要性,$w$ 是来自 Algorithm 1 的逐事件置信权重(当前实现统一为 1),$\tilde{y} \in \{0, 1\}$ 是合成标签——由对应源域交互里是否观测到转化事件决定。
这个形式自然体现了跨域学习:模型 $f_\theta$ 在目标域 $\mathcal{T}$ 上训练,但训练信号被源自源域 $\mathcal{S}$ 并翻译进目标 item 空间的事件所丰富。翻译概率 $\hat{P}(i_\mathcal{T} \mid u, j_\mathcal{S})$ 充当域间的软对齐。由于采用了基于采样的生成 + 统一权重,跨域信号隐式地通过被采样 item 的频率编码——翻译概率更高的 item 在 $\mathcal{D}_{\text{syn}}$ 里出现得更频繁,所以它们对训练的影响自然正比于估计的翻译似然。
这与传统 CDR 的根本区别在于:知识迁移完全发生在数据层(data level)而非模型层。主模型架构无需任何改动,因为下游模型 $f_\theta$ 消费合成事件的格式与原始事件完全一致。唯一的改动是加了一个辅助训练任务(Equation 6 的加权合成损失),这是一个最小的、架构无关的修改——使得 SCALR 适用于任何推荐架构(双塔 Covington et al. 2016、wide-and-deep Cheng et al. 2016、factorization machines Guo et al. 2017、或基于 transformer 的模型),集成成本极低。
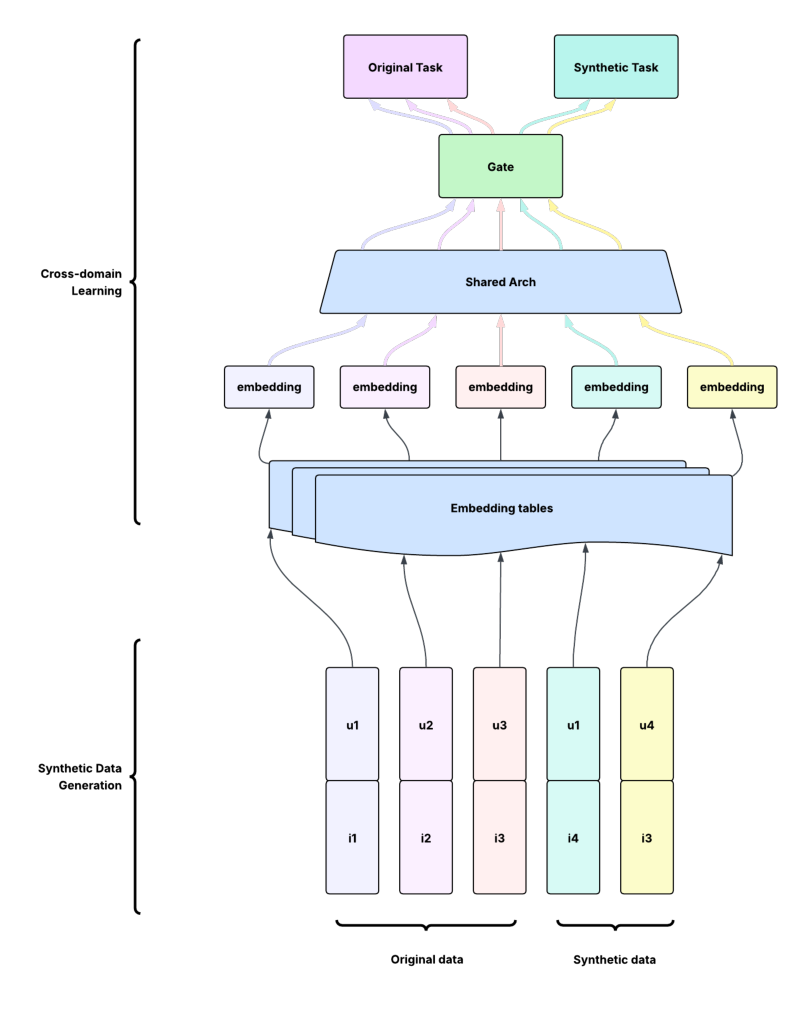
通过混合比例做分布对齐(distribution alignment via mixing ratio):超参 $\lambda$ 控制"对原始目标域分布的保真度"与"合成数据带来的额外覆盖"之间的取舍。$\lambda$ 太大,模型学到的分布会偏向源域特征、引入域偏置(domain bias);$\lambda$ 太小,合成数据贡献的信号可忽略。实践中需要恰当调 $\lambda$ 来平衡额外合成信号的收益与潜在的域不匹配。作者把"最优 $\lambda$ 与源/目标域属性(域重叠度、目标域稀疏度、源域体量)之间的关系"留作未来工作。
与 LLM 合成数据的系统对比¶
为更好地定位本工作,作者系统对比了 LLM 与推荐系统里的合成数据(Table 1):
| 维度(Aspect) | LLMs | 推荐系统(本文) |
|---|---|---|
| 数据类型(Data type) | 连续文本 token | 离散 (user, item) 交互事件 |
| 输出空间(Output space) | 跨域共享词表 | 跨域不相交 item catalog |
| 生成机制(Generation mechanism) | 自回归语言模型 | 条件概率估计 |
| 质量信号(Quality signal) | 人工评测、perplexity | 下游任务指标(NE、转化率) |
| 分布匹配(Distribution matching) | token 级分布 | 交互模式分布 |
尽管差异显著,二者共享一个根本原理:从一个辅助源(auxiliary source)生成逼近目标分布的训练样本。在 LLM 里"辅助源"是教师模型;在本文里是用户交互的源域。合成数据的价值——它对目标分布的保真度、多样性、以及对已有真实数据的互补性——在两个场景里同样决定其效用。
实验¶
实验设置¶
- 平台:工业级推荐平台。目标域 $\mathcal{T}$ 是转化预测(看到推荐后的转化事件)。源域 $\mathcal{S}$ 是同一平台上另一个产品界面的用户互动事件。
- 规模:源域包含每日海量交互事件;目标域(转化事件)稀疏几个数量级——转化率通常低于 1%。这种极端稀疏正是需要合成数据增强的动机。
- Baseline:仅在原始目标域数据上训练的深度学习推荐模型。对照组是相同架构但在"原始数据 + SCALR 合成事件"上训练。
- 核心指标:NE(Normalized Entropy,越低越好,衡量校准/拟合质量)、转化率 CVR、AUC。
在线 A/B 测试结果¶
在多周的真实流量上做在线 A/B。结果显示在其中一个主力模型上,转化率(CVR)在多周内一致提升约 0.14% – 0.24%,证明合成事件提供了能转化为真实世界性能提升的有用训练信号。(注:工业转化场景里 0.1%+ 的 CVR 绝对提升通常对应可观的营收,且"多周一致"是排除偶然性的关键。)
离线分析¶
作者通过受控离线实验研究四个研究问题(RQ):
- RQ1:生成策略(确定性 vs 概率)如何影响合成数据质量?
- RQ2:合成数据体量如何影响下游性能?
- RQ3:把合成数据分布对齐到原始数据能否改善结果?
- RQ4:还有哪些设计选择影响 SCALR 的有效性?
RQ1:生成策略(Table 2)¶
Algorithm 1 的一个根本设计选择是:确定性选 top-K 翻译概率最高的 item,还是按完整分布比例采样。作者在 $K=1$ 下做公平的、体量受控的对比——top-1 选 $i^* = \arg\max_i \hat{P}(i_\mathcal{T} \mid u, j_\mathcal{S})$,概率采样抽 $i^* \sim \hat{P}(\cdot \mid u, j_\mathcal{S})$,两者产生相同数量的合成事件。相对 NE 以"仅原始数据"基线为参照。
| 策略(Strategy) | 相对 Train NE (%) | 相对 Eval NE (%) |
|---|---|---|
| 无合成数据(No synthetic data) | 0.00 | 0.00 |
| Top-1 | −0.20 | −0.03 |
| 采样(Sampling) | −0.26 | −0.25 |
结论分析:Top-1 在训练集上取得了不错的 NE(−0.20%),但无法泛化(eval 仅 −0.03%);采样在训练(−0.26%)与评测(−0.25%)上都取得强劲收益。作者归因于两个因素: 1. 多样性(diversity):top-1 策略产生的合成事件只覆盖目标 item catalog 的约 4%,而采样覆盖约 30%。Top-1 把信号集中在一小撮 popular item 上,强化了流行度偏置(popularity bias),而非提供互补覆盖。 2. 分布保真度(distributional fidelity):采样保留了 $\hat{P}(i_\mathcal{T} \mid u, j_\mathcal{S})$ 的形状(含尾部),所以聚合后的合成数据更好地逼近真实的跨域交互模式(呼应 Holtzman et al. 2019;Liu et al. 2024)。
基于这一发现,后续所有实验都用概率采样。
RQ2:合成数据体量¶
研究合成数据体量与下游性能的关系。从每天几千行合成数据起步,逐步放大体量。性能随合成数据体量单调改善,但超过某一规模后收益递减(diminishing returns)。这说明存在一个最优的"合成/真实比例",在"额外跨域信号的收益"与"潜在分布不匹配"之间取得平衡。
RQ3:分布对齐(Table 3)¶
合成事件往往会过度代表(over-represent)某些高频源域模式。作者对比三种下采样(downsampling)策略,把合成数据分布对齐到原始训练数据,用 Day+2 评测数据上的相对 NE 衡量:
- Bucket-wise downsampling(按桶下采样):把合成事件按 item value 分桶,对每个桶下采样以匹配原始训练数据的 value 分布。
- Uniform positive downsampling(均匀正样本下采样):不论 item value 一律均匀下采样合成正样本,降低整体合成体量以匹配原始数据分布。
- Positive + negative downsampling(正负样本下采样):对合成正、负样本都均匀下采样,从两个标签类上降低总合成体量。
| 数据采样策略(Data Sampling Strategy) | 相对 NE (%) |
|---|---|
| 无下采样(参照基准 reference) | 0.00 |
| Bucket-wise downsampling | −0.13 |
| Uniform positive downsampling | −0.09 |
| Positive + negative downsampling | −0.07 |
结论分析:按桶下采样取得最大改善(−0.13% NE),证明把合成事件的 value 分布对齐到原始数据对下游性能很重要。这与 LLM 合成数据里"分布匹配是成功关键"的经验一致。
RQ4:其他设计选择¶
- 特征质量(Feature quality):移除在合成数据与真实数据之间表现出分布差异的特征,能改善 eval NE。这说明某些特征会泄露"该样本是合成还是真实"的信息;剔除它们迫使模型从跨域信号本身学习,而非利用合成痕迹(artifacts)。
- 置信过滤(Confidence filtering):基于翻译置信度 $\hat{P}(i_\mathcal{T} \mid u, j_\mathcal{S})$ 过滤合成事件能改善 eval NE,说明低置信翻译会引入噪声、损害学习。
- NE-AUC 背离(NE-AUC divergence):在某些模型变体里,eval AUC 改善而 eval NE 反而退化。模型的排序(ranking)质量受益于合成信号,但预测概率变得过度自信(over-confident),损害了校准(calibration)。这正是 RQ3 分布对齐策略的动机来源。
未来方向¶
作者把改进方向分两类。
改进合成数据质量:频率法估计器有已知局限——无法处理没有共现历史的冷启动 item,也无法建模超出成对共现(pairwise co-occurrence)的复杂用户-item 交互。为此作者已开始把 SCALR 扩展到模型法生成(model-based generation):不依赖共现统计,而是训练一个相关性模型 $g_\phi$,用预训练 embedding 估计"以源 item 为条件的用户-目标 item 亲和度":
$$s(u, i_\mathcal{T}, j_\mathcal{S}) = g_\phi(\mathbf{e}_u,\ \mathbf{e}_{j_\mathcal{S}})\ g_\phi(\mathbf{e}_{j_\mathcal{S}},\ \mathbf{e}_{i_\mathcal{T}}) \tag{7}$$
其中 $\mathbf{e}_u, \mathbf{e}_{j_\mathcal{S}}, \mathbf{e}_{i_\mathcal{T}}$ 分别是用户、源 item、目标 item 的预训练 embedding。该模型在观测到的跨域交互上训练,预测哪些(user, source item, target item)三元组会导致互动。生成时,给定源事件 $(u, j_\mathcal{S})$,从下式采样目标 item:
$$P_\phi(i_\mathcal{T} \mid u, j_\mathcal{S}) = \frac{\exp\big(s(u, i_\mathcal{T}, j_\mathcal{S}) / \tau\big)}{\sum_{i' \in \mathcal{I}_\mathcal{T}} \exp\big(s(u, i', j_\mathcal{S}) / \tau\big)} \tag{8}$$
其中 $\tau$ 是控制生成多样性的温度参数。这与频率法 $\hat{P}(i_\mathcal{T} \mid u, j_\mathcal{S})$ 直接对应,但用学到的表征替换共现计数,能泛化到冷启动 item(靠 embedding 相似度)并捕捉超出成对共现的更丰富用户-item 关系。在线预测试(online pretest)中,模型法生成在另一个模型上取得了 0.03% – 0.07% 的转化营收(conversion-based revenue)提升,验证了走向学习式生成的方向。
除模型法外,进一步的改进还包括:通过用户级重加权 $w_u = 1 / |\{(u, \cdot, \cdot) \in \mathcal{D}_\mathcal{S}\}|^\alpha$ 处理用户行为偏斜(user behavior skewness)、跨活跃度分层采样、以及对抗式质量过滤(Goodfellow et al. 2014;Ganin et al. 2016)来挑选最难与真实目标域事件区分的合成事件。
扩展生成框架:当前框架基于观测到的源域交互(真实发生的事件)生成合成事件。生成反事实(counterfactual)事件——表示用户很可能不会互动的交互——可在模型训练时提供额外的对比信号。此外,引入源域与目标域事件之间的时序对齐(temporal alignment)(如只用近期源交互而非全历史)可能进一步提升合成数据的相关性。
核心贡献总结¶
- 范式重铸:首次把跨域事件迁移显式构造为推荐系统的合成数据生成问题,与 LLM 合成数据范式建立类比,从而能把后者的最佳实践(质量过滤、分布匹配、合成/真实比例管理)迁移到推荐设定。
- 数据层而非模型层迁移:通过把跨域学习解耦为"生成 + 学习"两个模块化阶段,实现了模型无关、可复用、多源可拼接的跨域增强——绕开了传统 CDR 的架构耦合、训练耦合、多消费者扩展性三大工业硬伤。
- 频率法翻译分布 + 采样优于 top-K:用重叠用户共现统计高效估计 item 翻译分布,并实证证明从分布采样(保留多样性与尾部覆盖)显著优于确定性 top-K 选择——把 NLG 解码里"采样优于 greedy"的洞察迁移到推荐合成数据。
- 工业验证:在线 A/B 多周一致提升 CVR 约 0.14%–0.24%;模型法生成在预测试中再得 0.03%–0.07% 转化营收提升。
与已归档相关工作的对比¶
LGCD LGCD:Language-Guided Conditional Diffusion for Cross-Domain Recommendation(安徽大学,SIGIR'26,2026-04-07)¶
关系:独立并发(本文未引用 LGCD,两者殊途同归)· 已加载对方精读
-
共同关注的问题:两者都直指跨域推荐的同一 root cause——目标域信号稀疏、且"在两个域都有行为的重叠用户(overlapping users)极少",导致从源域到目标域的细粒度偏好迁移缺乏对齐锚点。SCALR 强调转化事件 <1% 的极端稀疏;LGCD 强调 inter-domain 冷启动用户(源域有行为、目标域零交互)占绝大多数。二者都认为单纯靠真实重叠数据不够,必须"造数据"。
-
相近的技术骨架:两者都不在模型参数层做迁移,而是以用户的源域行为为条件,生成/合成目标域的跨域交互数据,并且都强调"把生成结果锚定到目标域真实 item 空间"这一关键步骤——SCALR 用翻译分布 $\hat P(i_\mathcal{T}\mid u,j_\mathcal{S})$ 在真实目标 item 上采样;LGCD 用 LLM 生成 pseudo-item 文本后、再用语义相似度 Top-k 检索回 B 域真实 item 池(其 Eq 6)。两者的方法流程图可以抽象重合为"源域行为 → 条件生成 → 落地到真实目标 item → 喂下游"。
-
本文的差异与推进:SCALR 是数据层、模型无关的——合成产物是标准格式的训练行(rows),可被任意下游 ranker 经加权损失 $\mathcal{L}_{\text{orig}}+\lambda\mathcal{L}_{\text{syn}}$ 直接复用,多个消费者共享同一份合成集;生成器用的是廉价的频率共现统计(无需 LLM/扩散),并在工业在线 A/B 上拿到 CVR 提升。LGCD 则把生成耦合进一个特定架构(LLM 伪交互 + cross-attention 条件扩散去噪 + MoE 融合),产物是用户偏好表征而非可移植训练样本,依赖 LLM + Diffusion 的重型组合,验证停留在 Amazon Movie-Book / Food-Kitchen 等学术数据集。
-
可比的方法 / 实验差异:① 生成成本:SCALR 频率法 O(共现计数) vs LGCD LLM 推理 + 扩散去噪,前者更适合工业每日海量源事件;② 多样性手段:SCALR 显式论证"采样优于 top-K"以覆盖长尾(catalog 覆盖率 4%→30%),LGCD 靠扩散的随机性 + 温度/cyclic batch 控制生成方向;③ 落地形态:SCALR 模型无关可拼接多源,LGCD 是端到端单模型、迁移机制与扩散架构焊死——这恰好印证了 SCALR 在 intro 中批判传统 CDR "架构耦合"的论点,LGCD 可视为该论点的一个现实样本。
讨论与局限性¶
为什么叫"合成数据"而非"跨域推荐"? 作者在 Discussion 里专门回应:虽然 SCALR 本质上也在做跨域推荐,但其概念框架根本不同。经典 CDR 主要聚焦模型层迁移(共享参数/embedding/表征);SCALR 引入数据层迁移范式——生成增强目标域数据集的新训练事件。这种数据中心(data-centric)视角与机器学习"data-centric AI"的大趋势(Liu et al. 2024)一致,并带来模块化、模型无关的好处。更进一步,把推荐与 LLM 合成数据范式显式连接,使得可以把 LLM 领域积累的大量最佳实践(质量过滤、分布匹配、合成-真实比例管理)适配进推荐设定。
更广的愿景:如果合成数据对推荐系统的变革力度能像它对 LLM 那样,那么推荐模型的训练方式可能被根本性改变——不再局限于直接观测到的交互,而是系统性地利用跨平台、跨界面的全谱用户行为,把多样信号翻译成域特定的训练数据。这呼应了构建统一用户模型(unified user models)、整合所有触点信息的更大目标。
核心贡献与值得借鉴的设计: 1. "翻译分布 + 采样"这套配方很轻量也很 robust——不需要训练生成模型,只靠重叠用户共现统计即可冷启,工业上极易落地;把 NLG 的"采样优于 greedy"迁移到推荐合成数据是一个干净漂亮的类比。 2. 解耦为"生成 + 学习"两阶段是真正的工程洞察:它把"为什么工业 CDR 难复用"这个痛点(架构耦合/训练耦合/多消费者)一次性解掉,且只需加一个辅助损失,几乎零侵入。 3. RQ3/RQ4 的负面发现很诚实且有价值:合成数据会泄露"合成痕迹"特征、会导致 NE-AUC 背离(排序变好但校准变差)、需要按桶下采样对齐分布——这些是任何想上合成数据增强的团队都会踩的坑,作者把它们摆到台面上。
局限与争议: 1. 本质是数据增强而非新架构:SCALR 的贡献在"范式/框架"层面而非"模型能力"层面。频率法翻译分布说白了就是共现统计 + 重加权采样,技术深度有限;真正的难点(冷启动、超越成对共现的复杂交互建模)被推给了尚未充分验证的模型法(Eq 7/8)。 2. 实验披露非常粗:在线 A/B 只给了一个区间(0.14%–0.24% CVR)、未说明是哪个模型/多大流量/置信区间;离线 NE 提升都在 0.1%–0.26% 量级,绝对值很小,且平台、数据集、模型架构全部匿名("an industrial platform"),可复现性几乎为零。这是工业论文的通病,但本文尤其惜墨。 3. $\lambda$ 与域属性的关系完全留白:混合比例 $\lambda$ 是该方法最关键的超参(控制域偏置 vs 信号量),作者自己承认"最优 $\lambda$ 与域重叠度/目标稀疏度/源域体量的关系留作未来工作"——意味着每个新场景都要重新调参,缺乏可迁移的指导。 4. 隐私论证偏弱:声称"概率翻译比直接共享原始日志更隐私友好",但翻译分布本身就是从真实重叠用户共现里估计的,并未给出任何形式化隐私保证(如 DP),只是定性叙述。
工业落地价值:尽管技术深度有限,SCALR 的工业价值是实打实的——模型无关意味着 ranking / calibration / bidding 等多个下游模型可以共享同一份合成数据集,免去各自实现跨域迁移的重复劳动;模块化意味着合成 pipeline 可独立迭代。在线 A/B 多周一致的 CVR 提升 + 模型法预测试的营收提升,说明这套"轻量合成数据增强"在 Meta 规模的转化预测上确有正收益。对任何"目标域稀疏、但平台内有丰富旁路行为信号"的工业推荐场景,这是一个低成本、可先行试水的增强方案。