OneRanker: Unified Generation and Ranking with One Model in Industrial Advertising Recommendation¶
研究动机与背景¶
端到端生成式范式正在深刻变革广告推荐系统,推动架构从传统级联式(Retrieval → Pre-rank → Rank)向统一生成式演进。以 OneRec、GPR 等工业系统为代表,生成式推荐将推荐建模为基于层次化 Semantic ID 的自回归生成任务,在单次前向传播中即可完成多路兴趣路径的生成,具备高计算效率和直接优化终端目标的能力。
然而,当生成式方法深入广告系统的排序阶段时,三个核心挑战愈发突出:
-
兴趣目标与商业价值的错位(Optimization Tension):Multi-Token Prediction(MTP)基于用户行为(点击/转化)优化兴趣覆盖,而广告系统需要同时优化 eCPM 等商业价值目标。现有方案要么采用 single-stage fusion(如直接在 MTP head 中注入 eCPM 信号),导致兴趣覆盖和价值优化在共享表示空间中互相妥协(Figure 1(b));要么采用 stage decoupling(先生成再排序),导致生成器无法感知排序目标,系统性过滤高价值候选(Figure 1(a))。
-
生成过程的 Target-Agnostic 局限:现有生成式模型的用户表示在生成过程中保持静态,无法根据候选物品的特征动态调整。在广告场景中用户意图高度动态且受多因素影响,这种 target-agnostic 的特性严重限制了对用户细粒度意图的捕捉。
-
生成与排序的表示断裂(Triple Disconnection):传统 "generate-then-rank" 架构存在三重断裂——表示不一致(异构表示空间)、计算冗余(重复编码用户表示)、误差传播(生成阶段的语义偏移无法在排序阶段校正)。
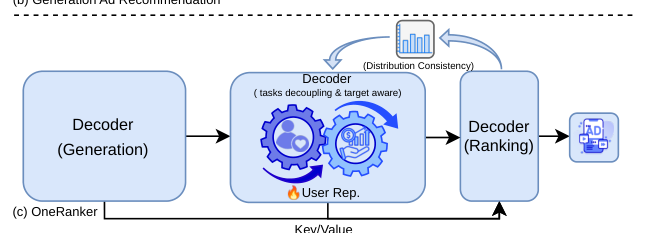
为解决上述挑战,本文提出 OneRanker,在架构层面实现生成与排序的深度融合,核心逻辑如 Figure 1(c) 所示:生成 Decoder 与排序 Decoder 共享用户表示(User Rep.),通过 Key/Value 传递机制实现输入侧一致性,通过 Distribution Consistency(DC)Loss 实现输出侧一致性,形成"价值引导生成、粗细协同感知、双侧一致性保障"的闭环优化系统。
核心方法/模型架构¶
OneRanker 是一个端到端生成式广告推荐框架,如 Figure 2 所示,包含三个逻辑递进的阶段:
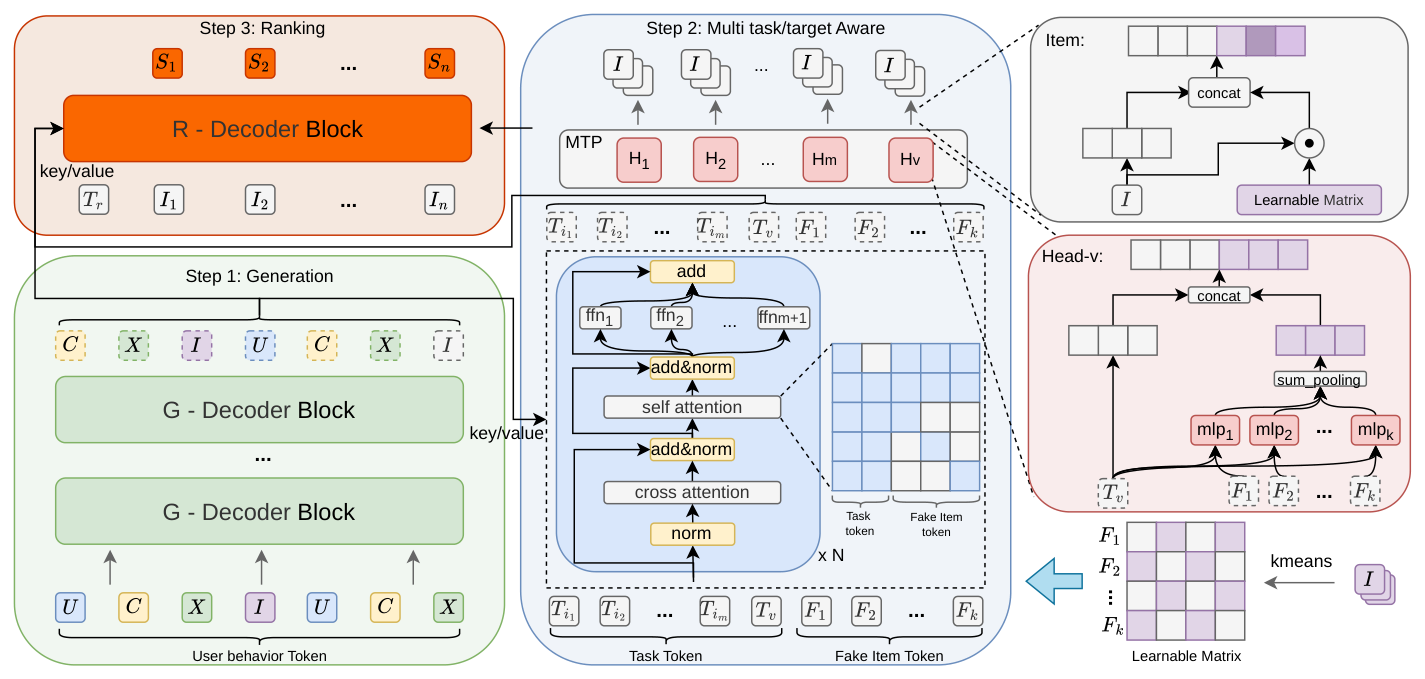
Step 1: Generation(生成阶段)¶
采用 GPR 的 tokenization 方法,将用户行为序列转换为异构 token 流,包括 User tokens (U)、Context tokens (C)、Content tokens (X)、Item tokens (I)。基于 HSTU Decoder-only 架构(G-Decoder Block),通过自回归 Multi-Token Prediction(MTP)机制在单次前向传播中并行生成多条完整的 Semantic ID 路径。该阶段的输出(Key/Value)将被后续阶段直接复用。
Step 2: Multi-Task/Target-Aware(多任务 + 目标感知增强阶段)¶
这是 OneRanker 的核心创新所在,作为生成流水线中的内生增强模块,同时提升 MTP 生成过程的两项关键能力:(1) 多任务解耦能力;(2) 粗粒度目标感知能力。
3.2.1 Value-Aware Multi-Task Decoupling Architecture(价值感知多任务解耦架构)¶
通过统一的 task token 序列实现兴趣建模与商业价值优化在架构层面的解耦。构造一个可学习的 task token 序列:
$$T = [\mathbf{t}_{i_1}, \mathbf{t}_{i_2}, \ldots, \mathbf{t}_{i_m}, \mathbf{t}_v] \tag{1}$$
其中:
- $\mathbf{t}_{i_1}, \ldots, \mathbf{t}_{i_m}$ 为 interest task tokens,分别对应不同的兴趣维度(如 impression → click → conversion),每个 token 通过独立预测 head 建模多兴趣分布,同时共同形成一条渐进式业务任务链。
- $\mathbf{t}_v$ 为 value-aware task token,专门学习商业价值(Final value)。
所有 token 共享底层用户表示以实现知识迁移,但通过独立输出空间实现任务空间解耦,从根本上缓解兴趣覆盖和价值优化之间的固有张力。
任务排序先验与因果掩码(Task Ordering Prior + Causal Mask):按业务序列和认知难度排列任务(impression → click → conversion → business value),并施加因果掩码,确保后续任务可以访问前序任务的表示,实现知识传递和渐进式精化。
3.2.2 Fake Item Token: Coarse-Grained Target Awareness(假物品 Token:粗粒度目标感知)¶
为缓解生成式模型的 target-agnostic 局限,引入 fake item tokens $\mathbf{F} = [\mathbf{f}_1, \ldots, \mathbf{f}_k]$ 作为目标感知的核心载体。这些 token 是对整个物品空间进行 K-means 聚类得到的 $k$ 个聚类中心向量,代表物品语义空间中的核心锚点。
在输入序列中,Fake Item Tokens 拼接在 Task Tokens 之后,形成完整的 Query 序列 $\mathbf{Q} = [\mathbf{T}; \mathbf{F}]$;同时 Step 1 的输出作为 Cross-Attention 的 Key/Value。这使模型能在生成过程中动态感知物品语义分布,实现粗粒度的隐式目标感知。
3.2.3 Heterogeneous Attention Decoder(异构注意力解码器)¶
以 Step 1 的输出作为 Key/Value,构造的 task tokens 和 fake item tokens 作为 Query,引入两项关键改进:
-
Cross-Attention Prioritization(交叉注意力优先):反转传统解码器的 Self-Attention → Cross-Attention 顺序,改为先做 Cross-Attention 再做 Self-Attention。动机是先通过 Cross-Attention 充分获取用户-物品交互信息,再通过 Self-Attention 进行任务内部整合和任务间协作。实验表明这种顺序更符合"先理解用户意图,再精化任务表示"的认知逻辑。
-
Heterogeneous Mask Strategy(异构掩码策略):
- Task Tokens 之间:因果掩码,确保时序建模和依赖捕捉
- Task Tokens → Fake Item Tokens:每个 Task Token 可以访问所有 Fake Items,实现隐式目标感知交互
- Fake Item Tokens → Task Tokens:每个 Fake Item 可以访问所有 Task Tokens,充分捕捉多任务语义
- Fake Item Tokens 之间:互不可见,避免不同聚类中心之间的干扰,确保每个 Fake Item 独立地进行与用户意图的"探索式"匹配
3.2.4 Dual-Channel Representation Construction(双通道表示构建)¶
异构注意力解码器的输出(Task Tokens + Fake Item Tokens)送入 MTP 模块,通过双通道融合机制构建精化的多兴趣表示:
Task Semantic Channel(任务语义通道):每个 Task Token $\mathbf{T}_i \in \mathbb{R}^{d_{task}}$ 提供任务维度的深层语义表示。
Target Aware Channel(目标感知通道):每个 Fake Item Token $\mathbf{F}_j \in \mathbb{R}^{d_{item}}$ 与当前 Task Token $\mathbf{T}_i$ 拼接,通过专用 MLP 映射为 $k$ 维偏好得分向量 $\mathbf{s}_j^{(i)} \in \mathbb{R}^k$,表示用户对 Fake Item Token $\mathbf{F}_j$ 在当前任务 $\mathbf{T}_i$ 下的偏好。所有 $k$ 个向量通过 sum pooling 聚合为目标感知表示:
$$\mathbf{s}_{\text{target}}^{(i)} = \sum_{j=1}^{k} \mathbf{s}_j^{(i)} \in \mathbb{R}^k \tag{2}$$
该设计使 $\mathbf{s}_{\text{target}}^{(i)}$ 充当物品语义分布上的"soft attention",为后续检索提供细粒度的 target-aware 信号。
每个 MTP head $i$ 的最终用户表示通过拼接两个通道构建:
$$\mathbf{e}_{\text{user}}^{(i)} = \text{Concat}\left(\mathbf{e}_{\text{task}}^{(i)}, \mathbf{s}_{\text{target}}^{(i)}\right) \in \mathbb{R}^{d_{task}+k} \tag{3}$$
对称增强的物品表示:物品侧同样融入 target-aware 通道。给定物品 embedding $\mathbf{e}_{\text{item}} \in \mathbb{R}^{d_{item}}$,计算其与所有 $k$ 个聚类中心的余弦相似度 $c_l = \cos\_\text{sim}(\mathbf{e}_{\text{item}}, \mathbf{f}_l)$,构建增强物品表示:
$$\mathbf{e}_{\text{item}}^{\text{enhanced}} = \text{Concat}\left(\mathbf{e}_{\text{item}}, [c_1, c_2, \ldots, c_k]\right) \in \mathbb{R}^{d_{item}+k} \tag{4}$$
检索时用户与物品的相关性通过内积计算:
$$\text{score}(user, item) = \mathbf{e}_{\text{user}}^{(i)} \mathbf{e}_{\text{item}}^{\text{enhanced}} = \mathbf{e}_{\text{task}}^{(i)} \mathbf{e}_{\text{item}} + \sum_{l=1}^{k} s_l^{(i)} \cdot c_l \tag{5}$$
这一内积运算自然地将语义匹配与 target-aware 匹配融合,赋予检索过程显式的候选物品感知能力。
Step 3: Unified Ranking(统一排序阶段)¶
3.3.1 Fine-Grained Target Awareness(细粒度目标感知)¶
设计一个专用的排序解码器(R-Decoder Block),将排序过程内化为生成流水线的自然延伸。
输入设计:R-Decoder 的 Query 由两部分组成:(1) 专用排序任务 token $\mathbf{T}_r \in \mathbb{R}^{d_{task}}$,作为排序意图的语义锚点;(2) Step 2 MTP 多路生成结果中的 $n$ 个候选物品 token $\mathbf{I} = [\mathbf{i}_1, \ldots, \mathbf{i}_n]$。Key/Value 融合 Step 1 的原始多兴趣表示和 Step 2 的精化表示,确保排序决策同时利用用户的基础兴趣分布和经过目标感知校准的高质量表示。
掩码策略:候选物品 token $\mathbf{I}$ 之间互不可见(对角掩码),确保各候选的评分独立性;所有候选物品 token $\mathbf{I}$ 可以访问排序任务 token $\mathbf{T}_r$。
架构与输出:R-Decoder 采用与 Step 2 相同的异构注意力解码器结构(Cross-Attention 优先 + Self-Attention),但仅使用单层以实现高效推理。每个候选物品 token 位置的输出向量通过轻量级 MLP 直接映射为标量得分 $s_i$,最终得分 $\mathbf{S} = [s_1, \ldots, s_n]$ 天然处于统一语义空间中,可直接用于排序。
3.3.2 Input-Side Consistency(输入侧一致性)¶
通过 Key/Value pass-through 机制实现三阶段的无缝衔接:排序解码器在 Step 3 中直接复用 Step 1 和 Step 2 的输出作为 Key/Value,实现高效的信息流连通。
该机制蕴含双重语义价值:
- Step 1 → Step 3:传递用户基础兴趣分布,提供宽广的覆盖保障
- Step 2 → Step 3:传递生成过程的隐含决策依据(中间表示),使排序器能完整理解生成逻辑并实现候选集的细粒度复用和校准
这一设计有效缓解了传统"外部排序"方法中的 representation fragmentation 问题——排序器不再面对生成结果的"黑箱",而是能感知生成过程的内部状态。
3.3.3 Output-Side Consistency and Optimization Objectives(输出侧一致性与优化目标)¶
通过三元联合损失函数对齐生成与排序的优化目标:
$$\mathcal{L}_{\text{total}} = \alpha \mathcal{L}_{\text{MTP}} + \beta \mathcal{L}_{\text{rank}} + \gamma \mathcal{L}_{\text{DC}} \tag{6}$$
其中 $\alpha, \beta, \gamma$ 为平衡系数。
Generation Loss($\mathcal{L}_{\text{MTP}}$):负对数似然损失,优化 Step 2 中的多兴趣路径生成。对每个任务 head $j$ 和 semantic ID 层级 $l$:
$$\mathcal{L}_{\text{MTP}} = -\sum_{j=1}^{m} \sum_{l=1}^{L} \log P(\mathbf{e}_{\text{item}}^{\text{gt}} | \mathbf{e}_{\text{user}}^{(j)}) \tag{7}$$
其中条件概率通过在全语义空间 $\mathcal{V}$ 上的 softmax 构建:
$$P(\mathbf{e}_{\text{item}}^{\text{gt}} | \mathbf{e}_{\text{user}}^{(j)}) = \frac{\exp(s_{j,\text{gt}})}{\sum_{k \in \mathcal{V}} \exp(s_{j,k})} \tag{8}$$
其中 $s_{j,i} = \mathbf{e}_{\text{user}}^{(j)} \mathbf{e}_{\text{item}}^{(i)}$ 表示用户 embedding 与物品 embedding 的内积。$\mathbf{e}_{\text{item}}^{\text{gt}}$ 是下一层级的 ground-truth semantic ID embedding。兴趣 head 优化点击/转化匹配,value-aware head 则采用价值加权采样策略优化生成分布偏向高价值物品。
Ranking Loss($\mathcal{L}_{\text{rank}}$):采用 pairwise BPR loss 优化 Step 3 中候选的相对排序:
$$\mathcal{L}_{\text{rank}} = -\mathbb{E}_{(i,j) \sim \mathcal{D}} \left[\mathbb{I}(y_i > y_j) \cdot \log \sigma(s_i - s_j)\right] \tag{9}$$
其中 $(i,j)$ 表示物品对,$y_i, y_j$ 为真实商业价值标签(eCPM),$y_i > y_j$ 表示物品 $i$ 的商业价值高于物品 $j$,$s_i$ 为 Step 3 排序解码器的输出。
Distributional Consistency Loss($\mathcal{L}_{\text{DC}}$):虽然 value-aware head 优化真实价值倾向性,但其信号稀疏且缺乏排序器校准评分空间的感知。为此将排序器视为 teacher model,通过最小化生成与排序偏好分布之间的 KL 散度实现决策边界对齐:
$$\mathcal{J}(\theta) = \mathbb{E}_{i \sim \pi_\theta}[s_i] - \lambda \cdot \text{KL}(\pi_\theta \| \pi_{\text{ref}}) \tag{10}$$
其中 $\pi_\theta$ 为生成器策略,$\pi_{\text{ref}}$ 为参考策略(原始 MTP 模型),$s_i$ 为排序器的校准得分,$\lambda$ 为 KL 权重。为避免强化学习采样的不稳定性,推导出其有监督代理损失——Distributional Consistency Loss:
$$\mathcal{L}_{\text{DC}} = -\mathbb{E}_{i \sim C} \left[p_i^{\text{target}} \cdot \log \pi_\theta(i | \mathbf{u})\right] \tag{11}$$
其中 $C$ 为当前候选物品集合,$p_i^{\text{target}} = \text{softmax}(s_i / \tau)$ 为排序得分归一化后的目标概率分布,$\tau$ 为温度参数。
与 $\mathcal{L}_{\text{rank}}$ 的局部 pairwise 优化不同,$\mathcal{L}_{\text{DC}}$ 在候选集层面约束全局分布一致性,建立"ground-truth propensity, model distribution for consistency"的双监督机制。该约束建立了从排序到生成的反向梯度通路,使生成器能"预判"排序器的决策偏好,并有效纠正价值偏差。
通过双侧一致性保障,OneRanker 框架建立了完整的闭环优化系统:生成为排序提供高质量、target-aware 的候选,排序为生成提供价值引导的反馈信号。
关键技术细节¶
实现参数¶
- Embedding 维度:所有 token 类型统一为 128 维
- 输入序列:U/C/X/I 序列固定最大长度 2048(截断或填充)
- G-Decoder(Step 1):4 层 Transformer
- Interest Task Tokens 数量:6 个(与 MTP 多兴趣预测 head 对齐)
- Value-Aware Task Token:2 个特定 task tokens,其输出通过 bagging 策略聚合
- Fake Item Tokens 数量:32 个(K-means 聚类中心)
- 异构注意力解码器(Step 2):2 层
- 排序任务 token(Step 3):1 个
- R-Decoder(Step 3):1 层,实现高效推理和校准
实验设置¶
数据集¶
遵循 GPR 的实验设置,在大规模真实世界数据集上评估。该数据集涵盖广告和有机内容的多样化用户交互场景,确保鲁棒的代表性和数据规模。所有历史行为按严格时间序列排列,使用统一的 Heterogeneous Token Architecture (U/C/X/I) 表示。对于每个目标物品,采样特定的候选集构建商业价值学习的训练和评估实例。
Baseline 模型¶
- HSTU:Meta 提出的万亿参数生成式推荐架构,已在大规模工业系统中广泛部署
- GPR:腾讯提出的端到端生成式推荐框架,本文使用其 MTP 版本
评估指标¶
- Hit Ratio (HR@K):Top-K 推荐列表中命中目标物品的比例
- Normalized Discounted Cumulative Gain (NDCG@K):考虑排名位置的归一化折损累计增益
主要实验结果¶
离线实验(RQ1)¶
Table 1. Comparison of Experimental Results on Key Metrics
| Model/Method | HR@1 | HR@3 | HR@5 | HR@10 | HR@15 | NDCG@1 | NDCG@3 | NDCG@5 | NDCG@10 | NDCG@15 |
|---|---|---|---|---|---|---|---|---|---|---|
| HSTU | 0.1741 | 0.3508 | 0.4648 | 0.6604 | 0.7953 | 0.6742 | 0.6712 | 0.6763 | 0.7025 | 0.7396 |
| GPR | 0.1824 | 0.3703 | 0.4935 | 0.6957 | 0.8207 | 0.6823 | 0.6776 | 0.6818 | 0.7070 | 0.7445 |
| OneRanker | 0.2639 | 0.4959 | 0.6213 | 0.7945 | 0.8894 | 0.8102 | 0.7954 | 0.7904 | 0.7970 | 0.8206 |
结果分析:HSTU 和 GPR 均为强竞争基线。GPR 在所有指标和区间上均优于 HSTU(如 HR@1 从 0.1741 提升至 0.1824,NDCG@1 从 0.6742 提升至 0.6823)。OneRanker 实现了大幅突破:HR@1 达到 0.2639,相对 GPR 提升 44.7%;NDCG@5 从 0.6818 提升至 0.7904;NDCG@15 从 0.7445 提升至 0.8206。这验证了 OneRanker 通过任务解耦和价值感知排序,能更精确地对齐模型输出与复杂推荐目标,在所有指标上全面领先。
消融与分析¶
关键结构组件消融(RQ2)¶
Table 2. Ablation Studies Results of Different Model Variants
| Model/Method | HR@1 | HR@3 | HR@5 | HR@10 | HR@15 | NDCG@1 | NDCG@3 | NDCG@5 | NDCG@10 | NDCG@15 |
|---|---|---|---|---|---|---|---|---|---|---|
| OneRanker (Full) | 0.2639 | 0.4959 | 0.6213 | 0.7945 | 0.8894 | 0.8102 | 0.7954 | 0.7904 | 0.7970 | 0.8206 |
| w/o DC Loss | 0.2629 | 0.4925 | 0.6173 | 0.7905 | 0.8867 | 0.8059 | 0.7912 | 0.7865 | 0.7936 | 0.8180 |
| w/o S2 token injection | 0.2610 | 0.4912 | 0.6161 | 0.7897 | 0.8868 | 0.8047 | 0.7904 | 0.7858 | 0.7930 | 0.8172 |
| with S3 ranker only | 0.2601 | 0.4901 | 0.6157 | 0.7880 | 0.8852 | 0.8037 | 0.7894 | 0.7849 | 0.7924 | 0.8168 |
| OneRanker S2 | 0.2214 | 0.4257 | 0.5448 | 0.7291 | 0.8435 | 0.7566 | 0.7460 | 0.7440 | 0.7579 | 0.7876 |
| w/o Target | 0.2080 | 0.4030 | 0.5203 | 0.7066 | 0.8276 | 0.7375 | 0.7286 | 0.7285 | 0.7465 | 0.7786 |
| w/o Target & MDA | 0.2035 | 0.3922 | 0.5066 | 0.6949 | 0.8212 | 0.7360 | 0.7273 | 0.7275 | 0.7453 | 0.7776 |
消融分析:
-
Step 2 内部组件:以 OneRanker S2 为基线(HR@5: 0.5448, NDCG@5: 0.7440),移除 Target 信息(w/o Target)导致 HR@5 下降至 0.5203(-4.5%),NDCG@5 降至 0.7285(-2.1%),有力证明了 Fake Item Token 机制的必要性。进一步同时移除 Target 和多任务解耦架构(w/o Target & MDA),HR@5 进一步降至 0.5066,NDCG@5 降至 0.7275,凸显了解耦架构在缓解共享表示空间中优化张力方面的关键作用。
-
Step 3 的价值:仅使用 S3 ranker(with S3 ranker only,HR@5: 0.6157, NDCG@5: 0.7849)已相比 S2-only 模型(HR@5: 0.5448)实现了跨越式提升,证明细粒度 target-aware 机制是有效排序的基础。引入 S2 信息注入(w/o S2 token injection → Full model),HR@5 从 0.6161 提升至 0.6213,说明排序器复用生成上下文能更好地校准预测。
-
DC Loss 的作用:加入 DC Loss 后(w/o DC Loss → Full),NDCG@5 从 0.7865 提升至 0.7904,HR@5 从 0.6173 提升至 0.6213,显式约束了跨阶段输出分布的一致性。
-
闭环协同效应:OneRanker (Full) 的最优性能源于协同效应:S2 为 S3 提供富化的特征注入,DC Loss 促进从 S3 到 S2 的价值驱动反馈,两者形成闭环。
Step 2 专用设计消融(RQ3)¶
Table 3. Ablation Studies on Dedicated Designs in Step 2
| Model/Method | HR@1 | HR@3 | HR@5 | HR@10 | HR@15 |
|---|---|---|---|---|---|
| OneRanker S2 (Baseline) | 0.2214 | 0.4257 | 0.5448 | 0.7291 | 0.8435 |
| w/o CA-Pri | 0.2117 | 0.4100 | 0.5277 | 0.7148 | 0.8337 |
| w/o H-Mask | 0.2149 | 0.4151 | 0.5335 | 0.7183 | 0.8368 |
分析:移除 Cross-Attention Prioritization(CA-Pri)或 Heterogeneous Mask Strategy(H-Mask)均导致所有指标显著下降。CA-Pri 的贡献更大(HR@5 下降 0.0171 vs 0.0113),验证了"先理解用户意图、再精化任务表示"的注意力顺序更优。异构掩码策略通过差异化的可见性规则调节信息流,防止不同任务 token 之间的信息泄露。
$\mathcal{L}_{\text{DC}}$ 有效性分析(RQ4)¶
通过 rank deviation boxplots 和 Top-K overlap curves 量化评估 DC Loss 的一致性效果。
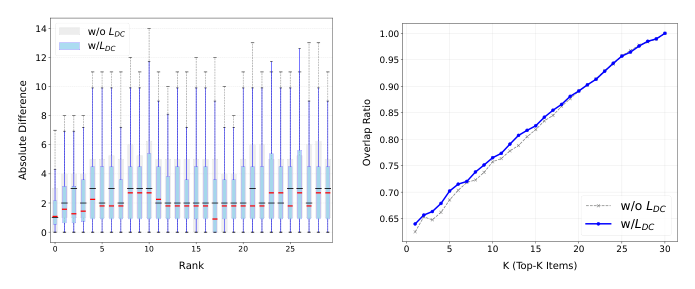
Figure 3(a) Absolute Rank Difference:加入 DC Loss 后(蓝色箱体),IQR(四分位距)显著收窄,表明 Step 2 和 Step 3 之间的决策一致性大幅提升,排名波动明显减少。
Figure 3(b) Top-K Item Overlap Ratio:优化后的蓝色曲线从 $K=1$ 起即表现出更高的起点,并在 $K$ 趋近全部候选数量时始终保持一致性领先。这证实了个体排名方差的减少直接转化为更强的一致性效果,建立了更鲁棒的多阶段协作框架。
在线 A/B 实验(RQ5)¶
在腾讯微信视频号广告平台上部署 OneRanker,该平台拥有数亿活跃用户和数千万动态广告。线上基线为级联式"生成 + 排序"框架(生成模型产出候选,送入独立训练的排序模型)。
Table 4. Online A/B Test Results of OneRanker
| Traffic Phase | GMV | GMV (CI) | GMV-Normal | GMV-Normal (CI) | Costs | Costs (CI) |
|---|---|---|---|---|---|---|
| 5% | +0.4067% | [-0.8320%, 1.6454%] | +1.3427% | [0.1637%, 2.5216%] | +0.7190% | [0.4632%, 0.9747%] |
| 20% | +0.7796% | [0.2849%, 1.2743%] | +0.6446% | [0.2139%, 1.0754%] | +1.1462% | [0.9958%, 1.2965%] |
| 80% | +0.0843% | [-0.4531%, 0.6217%] | +0.3500% | [0.0188%, 0.6812%] | +0.4493% | [0.3261%, 0.5725%] |
置信区间以 0.05 显著性水平计算。在 80% 流量阶段存在流量覆盖现象(traffic coverage phenomenon)。
结果分析:
- GMV-Normal(优化点击或转化的广告)在各流量阶段均实现统计显著提升:5% 流量 +1.34%,20% 流量 +0.64%,80% 流量 +0.35%,置信区间下界均大于 0。
- Costs(广告主支出)同步增长,证明平台营收能力提升。
- 在 80% 全量流量阶段,GMV-Normal 仍保持 +0.35% 的正向提升(CI: [0.0188%, 0.6812%]),虽然由于流量覆盖效应导致提升幅度有所收窄,但结果仍具统计显著性。
基于 A/B 实验结果,OneRanker 已全量上线(100% 流量),成为微信视频号广告推荐的线上生产系统。
讨论与局限性¶
核心贡献¶
OneRanker 的核心贡献在于提出了生成与排序的架构级深度融合方案,区别于此前 "single-stage fusion" 和 "stage decoupling" 两种极端:
-
Value-Aware Multi-Task Decoupling:通过 task token 序列 + causal mask 实现兴趣与价值的架构级解耦,既保留 MTP 的覆盖广度,又引入专用的价值学习空间。这种设计将多目标优化从"外部干预"转化为"内生逻辑"。
-
Coarse-to-Fine Target Awareness:Fake Item Token(粗粒度,K-means 聚类中心)+ Ranking Decoder(细粒度,cross-attention)形成渐进式的目标感知链路,系统性地解决了生成式模型的 target-agnostic 问题。
-
Dual-Side Consistency:输入侧的 Key/Value pass-through + 输出侧的 DC Loss 构成双侧一致性保障,实现了生成与排序之间的端到端协同优化,消除表示断裂和误差传播。
值得借鉴的设计¶
- Fake Item Token 机制:利用 K-means 聚类中心作为物品空间的"代理",以极低的计算开销(仅 32 个 token)实现生成过程中的 target awareness,这一思路可推广至其他 target-agnostic 场景。
- Cross-Attention Prioritization:反转 Self-Attention 和 Cross-Attention 的顺序,符合"先获取外部信息、再内部整合"的认知逻辑,消融实验验证了其优越性。
- DC Loss 的设计:将排序器的校准得分通过 softmax 温度归一化为目标分布,作为生成器的软监督信号。本质上是一种从排序到生成的知识蒸馏,但在候选集全局层面约束分布一致性,而非局部 pairwise。
局限性¶
- 实验评估局限:离线实验仅使用一个工业数据集(腾讯内部数据),且未在公开学术基准上验证,限制了结果的可复现性和可比性。Baseline 仅对比 HSTU 和 GPR 两个模型,缺少与 GRank、PROMISE、GRAM 等近期相关工作的直接对比。
- Fake Item Token 的粒度:32 个聚类中心是否为最优数量?论文未提供关于 $k$ 值选择的消融实验。
- 在线指标的解读:80% 流量阶段的 GMV 提升不显著(CI 包含 0),仅 GMV-Normal 显著。论文将此归因于"流量覆盖现象",但未深入分析该现象的成因。
- 计算开销:论文未报告模型参数量、训练时间、推理延迟等关键效率指标,无法评估 Step 2/3 增加的额外开销。
工业落地价值¶
OneRanker 已在腾讯微信视频号广告推荐系统全量部署(100% 流量),在 GMV-Normal 指标上取得 +1.34% 的显著提升。该工作完成了从"阶段解耦"到"架构集成"的范式转变,积累了生成式技术在复杂商业场景中落地的可行经验,为行业提供了一种可参考的端到端广告推荐架构方案。