Implicit Reasoning for Large Language Model-based Generative Recommendation¶
作者:Yinhan He†, Liam Collins§, Bhuvesh Kumar§, Jundong Li†, Neil Shah§, Donald Loveland§
† University of Virginia(弗吉尼亚大学) · § Snap Inc.(Snapchat 母公司)
(注:Yinhan He 的工作完成于其在 Snap Inc. 实习期间。)
ArXiv:2606.14142 · 2026-06-12(v2: 2026-06-15)· Preprint
提出方法:PauseRec —— 面向 SID-based 生成式推荐的轻量化隐式推理 (implicit reasoning) 范式。
1. 研究动机与背景¶
近两年,把大语言模型 (LLM) 当作生成式推荐 (Generative Recommendation, GR) 的骨干已成为主流路线:LLM 读入用户历史、自回归地生成下一个 item(P5、TIGER、TallRec 等)。这条路线的最大吸引力在于 LLM 预训练里沉淀的世界知识 (world knowledge)——理论上它能帮助模型推断历史 item 间的语义关系、识别用户潜在意图,并把意图映射到"记忆共现之外"的合理 next item。然而,如何高效、可靠地把 LLM 的预训练知识调动起来服务于推荐,至今仍缺乏系统理解。
核心障碍出在 item 的表示方式上。LLM-based GR 通常用 Semantic ID (SID) 表示 item,即从 item 语义关系中量化出来的一小段特殊 token 序列(如 <s_a_99><s_b_19><s_c_220><s_d_204>)。SID 紧凑、让"生成 item"这件事变得可解,但它们不是自然语言表达,且落在 LLM 预训练词表之外(Li et al. 2021)。这就制造了一个根本性的错配 (mismatch):LLM 通过自然语言访问世界知识,而推荐任务却要它在一堆非语言的 SID 条件下生成另一个非语言的 SID。论文据此提出贯穿全文的问题:
如何才能有效地把 LLM 预训练的世界知识,调动起来改善基于 SID token 的推荐?
沿着通用 LLM 文献的思路,一个自然的答案是引入显式思维链 (explicit Chain-of-Thought, CoT) 推理:让模型在产出最终答案前,先生成一段一步步的自然语言推理 trace。显式 CoT 在数学、科学、代码等知识密集任务上被反复证明有效。对 LLM-based GR,已有工作也沿着这个思路搭建了多阶段训练流水线:
- CPT(Continual Pretraining,持续预训练):在 SID 与 item 描述交错的语料上继续训练,把 item 语义 grounding 到 SID token embedding 上;
- Next-item SFT(监督微调):在用户历史上微调,预测 next item 的 SID;
- CoT SFT:在推理 trace 上微调,让模型在生成目标 SID 前先吐出自然语言 rationale;
- RL 后训练:用强化学习直接优化推荐 reward(计算代价高昂)。
但论文尖锐地指出:已有工作几乎没有解释清楚每个阶段在什么时候、为什么有用。考虑到每个阶段都极其耗算力,搞清这些问题对于"是否值得跑完整条流水线、能否找到更高效替代方案"至关重要。
本文的两大发现:作者首先逐级解剖这条显式推理流水线,得到两个反直觉结论:
- CPT 只能恢复粗粒度语义:CPT 后的模型能识别粗类别,但难以识别 item 标题或细粒度类别——grounding 提供了真实但不完整的语义信号;
- CoT SFT 一致地劣于简单的 next-item SFT:无论用模板生成、教师模型生成还是各种格式的 rationale,CoT SFT 都跑不赢朴素的 next-item SFT。显式 CoT 的收益只有在昂贵的 RL 后训练之后才会浮现。
为解释这个"显式 CoT SFT 为何失败"的反差,作者诊断出三大根因(见 Figure 1):
- 削弱了世界知识的言语化能力 (weakened world-knowledge verbalization):CoT SFT 没有抹掉 LLM 的世界知识,但让这些知识在标准解码下难以被言语化输出——知识仍在 logits 里,却吐不出来。
- 文本-SID 嵌入空间错位 (text–SID embedding misalignment):训练过程中,文本 token 和 SID token 的 embedding 在几何上逐渐分离。作者用理论证明:这种分离会限制自然语言 rationale 影响最终 SID 预测的能力。
- 对 rationale 质量的脆弱性 (performance fragility w.r.t. rationales):即便只对 ground-truth rationale 做轻微扰动(删类别、加/删几个词),推荐性能也会大幅波动——显式 CoT 依赖脆弱的 rationale 线索。
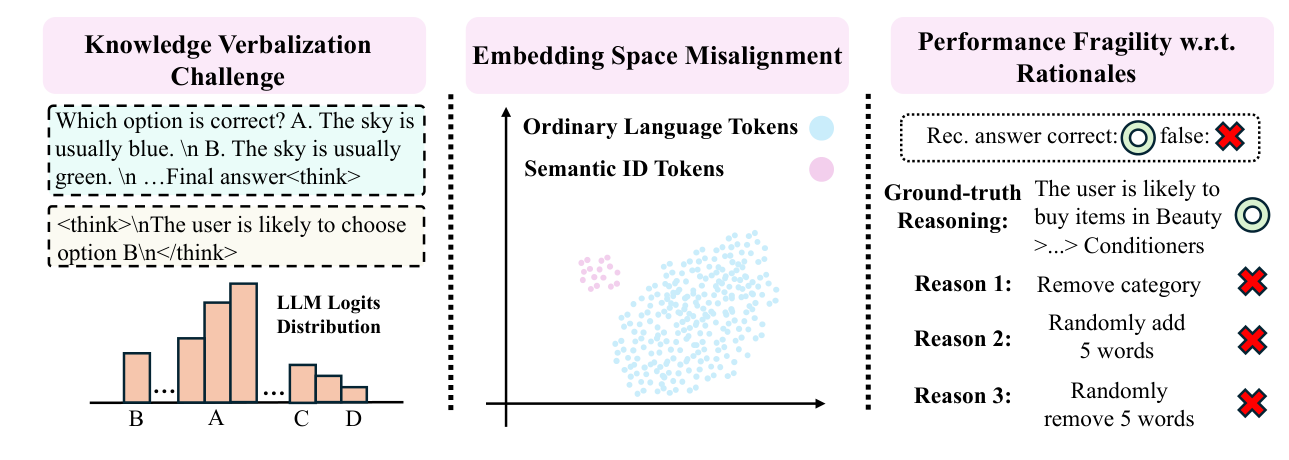
为绕开这三大障碍,作者提出 PauseRec——一个面向 SID-based GR 的轻量化隐式推理框架。核心思路:不再生成显式自然语言 rationale,而是在 SID 生成之前插入一小段可训练的 <pause> token,让模型在这些 latent 步上做"隐式计算",且 <pause> token 只通过最终的 next-item 预测目标来优化。PauseRec 不需要教师模型生成 rationale,也不需要 RL 后训练,因此极其实用。
三项贡献:
- 诊断分析:系统解剖 LLM-based GR 的显式推理流水线,识别出"无 RL 时为何失败"的三大根因(不完整的 SID grounding、世界知识言语化受损、文本-SID 嵌入错位、rationale 格式敏感)。
- 隐式推理框架:提出 PauseRec,用可训练的
<pause>token 触发 latent 推理,无需 rationale 监督。 - 实证评估:在三个 Amazon review 数据集上,PauseRec 相对标准 SFT 和 CoT 类方法最高提升 6.22%,同时降低训练和推理开销(训练 GPU 时数 ↓65%,推理 ↑71.3%、约 3.5× 加速)。
2. 预备知识与问题定义¶
2.1 问题形式化¶
遵循 GR 文献,考虑序列推荐。设全体 item 集合为 $\mathcal{I}$。给定用户的 $n$ 个按时间排序的历史交互 $H = [i_1, i_2, \ldots, i_n]$($i_j \in \mathcal{I}$),任务是预测用户下一个会交互的 item $i_{n+1}$。每个 item $i$ 被表示为一个长度为 $L$ 的 SID 序列 $s_i = [s_i^{(1)}, s_i^{(2)}, \ldots, s_i^{(L)}]$,这些 token 被加入 LLM 词表。推荐随即被表述为条件生成:
$$p(i_{n+1} \mid H) = p\big(s_{i_{n+1}} \mid \mathrm{Prompt}(H)\big) \tag{1}$$
其中 $\mathrm{Prompt}(H)$ 把历史交互转写成自然语言 prompt(罗列过去的 item,可选附带 metadata)。本文所有方法都共享这个生成式表述,区别仅在于"推理被插入到 SID 预测的哪个环节、以什么形式插入"。
2.2 已有的显式 CoT 流水线(GR 版)¶
论文先把已有显式推理流水线的各训练阶段及其损失写清楚,作为后续诊断的对照。
Continual Pretraining (CPT):在 SID 与 item 描述交错的语料上微调,只有 SID token embedding 可训练。给定 item $i$ 及其描述 $d_i$,目标是双向重构:
$$\mathcal{L}_{\mathrm{CPT}} = -\mathbb{E}_{(s_i, d_i)}\big[\log p(s_i \mid d_i) + \log p(d_i \mid s_i)\big] \tag{2}$$
该阶段的目的是把 item 语义 grounding 到 SID token embedding。
Next-item SFT:在 CPT 模型基础上,用用户历史微调,直接生成 next item 的 SID:
$$\mathcal{L}_{\mathrm{SFT}} = -\mathbb{E}_{(H, i_{n+1})}\big[\log p(s_{i_{n+1}} \mid \mathrm{Prompt}(H))\big] \tag{3}$$
CoT SFT:在 SFT 之后,进一步微调让模型在目标 SID 之前生成自然语言 rationale。训练目标把历史 $H$、rationale $r$、next item $i_{n+1}$ 配对:
$$\mathcal{L}_{\mathrm{Reasoning}} = -\mathbb{E}_{(H, r, i_{n+1})}\big[\log p(r, s_{i_{n+1}} \mid \mathrm{Prompt}(H))\big] \tag{4}$$
这里 rationale $r$ 是方法相关的:有的用推理模板(Liu et al. 2025),有的用教师 LLM 生成。
RL 后训练:已有方法进一步用 RL 直接优化推荐 reward(如带可验证奖励的 RLVR),但这一步计算极其昂贵。
3. 各训练阶段的贡献诊断¶
由于学界对"不同训练阶段何时、为何让 CoT 在 GR 中有效"理解不足,作者逐阶段拆解。本节聚焦 CPT 与 CoT SFT;next-item SFT 与 RL 留到实验部分(Section 6)评估。
3.1 CPT:LLM 能恢复多少 SID 语义?¶
CPT 的首要目的,是把 SID 语义 grounding 进 LLM,其前提假设是"LLM 只有理解了 SID 的语义后,才能在 SID 上做推理"。
实验设计:用 Qwen3-1.7B 骨干,在 Amazon Beauty 上做 2 epoch CPT,训练时每个 SID 都配上它的名称和类别。CPT 后,测试模型能否生成 (1) item 标题,(2) item 类别(1/2/3 级粒度)。用 SID 提示模型,测 exact-match 准确率。
结果与分析(Table 1):
| Metric | Beauty | Sports | Toys |
|---|---|---|---|
| 1-level Category | 98.00 | 97.83 | 99.56 |
| 2-level Category | 27.80 | 40.49 | 11.85 |
| Category (Full) | 7.19 | 1.30 | 6.74 |
| Title Recovery | 0.00 | 0.06 | 0.14 |
Table 1:CPT 后的 SID metadata 恢复。
结论非常清晰:
- 粗类别信号很强:1 级类别准确率高达 97.83%–99.56%,2 级最高 40.49%——CPT 确实捕获了宽泛的类别结构;
- 细粒度理解很差:标题恢复几乎为 0,全类别(3 级完整路径)准确率在所有数据集上低于 7.2%——item 级语义基本没被恢复。
含义:LLM 通过预训练把 SID 和语义关联了起来,但只到粗粒度。grounding 提供的是部分语义信息,而非精确的 item 级理解。接下来的问题是——CoT 能不能把这个粗信号转化成更好的 SID 预测?
3.2 CoT SFT:显式 CoT 的失败¶
实验设计:在 CPT + SFT 之后,对 Qwen3-1.7B 做 CoT SFT,用四类 rationale: 1. 模板生成 (Template-based): - Template-Category:"The user is likely to buy items in the {target item category} category." - Template-Extended:更长的、带 {characteristics}/{item title} 的模板。 2. 教师生成 (Teacher-generated):用 Gemini 3.1 Flash-Lite 和 Pro 产出自由形式 (free-form) trace; 3. 拒绝采样 (Rejection sampling):Gemini Flash-Lite 生成多条 trace,选其中目标 SID logit 最高的(Flash-Lite Rejection),或选 Gemini Pro 评判为"最能连接历史到目标"的那条(FL Gemini Rejection); 4. 格式受限 (Format-restricted):强制 rationale 必须引用 SID。
结果与分析(Table 2,Amazon Beauty):
| Method | Hit@5 | NDCG@5 |
|---|---|---|
| Next-item SFT (Baseline) | 0.0533 | 0.0381 |
| Template-Category | 0.0492 | 0.0343 |
| Template-Extended | 0.0425 | 0.0282 |
| Gemini 3.1 Flash-Lite Free-form | 0.0520 | 0.0361 |
| Gemini 3.1 Pro Free-form | 0.0422 | 0.0276 |
| Gemini 3.1 Flash-Lite Rejection | 0.0526 | 0.0362 |
| Gemini 3.1 FL Gemini Rejection | 0.0524 | 0.0367 |
| Gemini 3.1 Flash-Lite Restricted | 0.0449 | 0.0307 |
Table 2:Amazon Beauty 上的 CoT SFT 变体。所有显式 rationale 变体都跑不赢 next-item SFT。
所有 CoT 变体都劣于 next-item SFT。最强的变体(Gemini 拒绝采样)也只到 Hit@5 0.0526,仍低于 baseline 0.0533;较弱的教师变体相对 Hit@5 掉了 20% 以上。单靠 rationale 监督无法可靠改善 GR。
这与 CoT 在语言任务上的成功形成鲜明对比:此前报告显式 GR 推理收益的工作,依赖的是带可验证奖励 (RLVR) 的昂贵 RL,且都在 CoT SFT 之后。虽然 RLVR 能把性能救回来,但它每步需要多条 rollout,比 next-item SFT 昂贵得多。这就抛出了本文的核心问题:为什么 CoT SFT 对 SID-based GR 失败?
4. CoT SFT 失败的三大根因诊断¶
为理解显式 CoT SFT 为何失败,作者做了三组诊断实验,对应三大局限。
4.1 难以言语化世界知识¶
发现:CoT SFT 并没有抹除 LLM 的世界知识,但让这些知识难以被言语化。
实验设计:在推荐 CoT SFT 之后,把 Qwen3-1.7B 拿到通用语言基准 MMLU、HellaSwag、PIQA、ARC-Challenge 上以多选格式评测。报告两种准确率:
- text-match 准确率:模型实际生成 A/B/C/D 选项字母,做 exact-match;
- logit-based 准确率:看正确选项是否拥有最高 logit。
结果与分析(Table 3):
| Dataset | Base | Text Match | Logit-based |
|---|---|---|---|
| MMLU | 57.60 | 0.10 | 55.20 |
| HellaSwag | 61.00 | 9.00 | 60.40 |
| PIQA | 69.90 | 5.60 | 69.90 |
| ARC-C | 76.40 | 0.80 | 73.80 |
Table 3:推荐 CoT SFT 后的通用语言推理准确率。
现象触目惊心:CoT SFT 后,text-match 准确率崩塌(MMLU 从 57.6→0.10,几乎全军覆没),而 logit-based 准确率仍接近 base 模型(MMLU 55.2、PIQA 甚至持平 69.90)。这说明:LLM 的世界知识主要保留在 logit 空间,但已经很难以显式自然语言文本的形式被言语化输出。换言之,推荐 SFT 把模型"调哑"了——它还知道答案,却不会用文字说出来。既然显式 CoT 的全部价值在于"先用文字把推理说清楚",而模型恰恰丧失了言语化能力,CoT SFT 自然失败。
4.2 文本-SID 嵌入错位¶
发现:训练过程中,SID 与自然语言 token 在 token embedding 空间里几何分离,导致 LLM 难以在一段连贯 rationale 下统一文本与 SID。
实验设计:用 PCA 可视化 SID 初始化、CPT、SFT、CoT SFT 四个阶段后的 token embedding,对比普通文本 token 与 SID token 的分布。
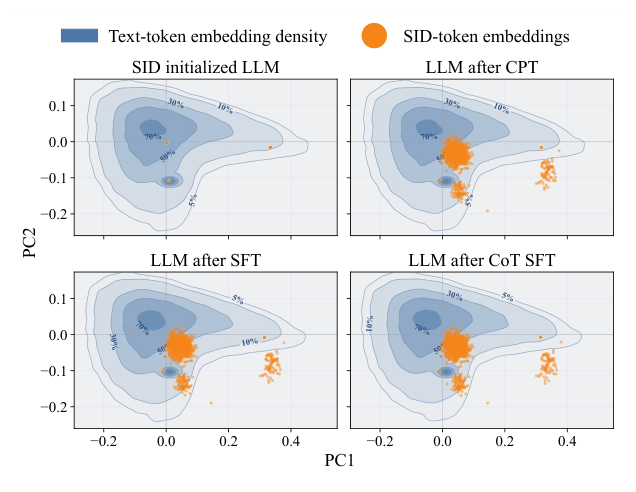
结果与分析(Figure 2):文本与 SID 的 embedding 随阶段推进越来越分离——CPT 后差距已经很明显,SFT 和 CoT SFT 阶段继续略微扩大。这种 token embedding 的几何分离,意味着把语言和 SID 统一进一个连贯表示是困难的。
理论分析(Appendix D,正式化"分离为何削弱显式 CoT"):
考虑 rationale 之后、模型必须生成 SID token 的最后一步。设 SID token $s$ 的输出 embedding 为 $v_s$,其 logit 为 $z_s(h) = v_s^\top h$($h$ 是 SID 生成前的 hidden state)。定义:
- $\mathcal{U}_{\text{text}}$:模型在生成/优化自然语言 rationale token 时 hidden state 移动所张成的子空间;
- $\mathcal{U}_{\text{SID}} = \mathrm{span}\{v_y - v_s : y, s \in \mathcal{S}\}$:控制 SID 间相对 logit 的子空间;
- 文本-SID 耦合系数:$\rho = \|P_{\mathcal{U}_{\text{SID}}} P_{\mathcal{U}_{\text{text}}}\|_2$,其中 $P_{\mathcal{U}}$ 是到子空间 $\mathcal{U}$ 的正交投影。$\rho$ 越小,文本诱导的 hidden-state 移动与 SID 判别方向分离越强。
Theorem 1(文本-SID 分离限制 rationale 的作用):假设加入一段 rationale 把 SID 生成前的 hidden state 从 $h$ 变为 $h+\Delta$,其中 $\Delta = \Delta_{\text{text}} + r$,$\Delta_{\text{text}} \in \mathcal{U}_{\text{text}}$,残差 $\|r\| \le \epsilon$。再设对所有合法 SID token $\|v_y - v_s\| \le B$。则对任意目标 SID token $y$ 与竞争 SID token $s$:
$$\Big|\big(z_y(h+\Delta) - z_s(h+\Delta)\big) - \big(z_y(h) - z_s(h)\big)\Big| \le B\big(\rho \|\Delta_{\text{text}}\| + \epsilon\big) \tag{7}$$
推论:若目标 SID 初始落后某竞争者一个 margin $\gamma$(即 $z_y(h) - z_s(h) \le -\gamma$),且 $\gamma > B(\rho\|\Delta_{\text{text}}\| + \epsilon)$,则这段 rationale 无论如何也无法把 $y$ 翻盘到超过 $s$。
直观含义:因为 $z_s(h) = v_s^\top h$,rationale 引起的 margin 变化 $= (v_y - v_s)^\top \Delta$,而只有 $\Delta_{\text{text}}$ 投影到 SID 判别子空间的那部分才会影响相对 SID logit,这部分被 $\rho$ 压住。当文本与 SID 几何分离($\rho$ 小)时,自然语言 rationale 只能微弱地改变 SID 上的 logits,对最终推荐的杠杆十分有限。这从理论上解释了为何"把推理用文字写出来"在 SID 空间里使不上劲。
4.3 对 rationale 的脆弱性¶
发现:CoT SFT 后,即便推理 trace 只略微偏离 ground-truth rationale,推理时的推荐性能也对 rationale 文本高度敏感。
实验设计:给 CoT SFT 模型喂入 ground-truth rationale 及其受控扰动——删除目标 item 类别、随机丢 5 个词、随机加 5 个噪声词——测 Hit@5 / NDCG@5。
结果与分析(Table 4,Amazon Beauty):
| Reasoning Variant | Hit@5 | NDCG@5 |
|---|---|---|
| Ground-truth | 0.1165 | 0.0836 |
| Remove category | 0.0540 | 0.0376 |
| Drop 5 words | 0.0950 | 0.0834 |
| Add 5 words | 0.1145 | 0.0682 |
Table 4:Amazon Beauty 上的 rationale 扰动敏感性。
性能对 rationale 内容高度敏感:删掉目标类别让 Hit@5 直接腰斩(0.1165→0.0540),NDCG@5 从 0.0836 掉到 0.0376。表面扰动也有影响:丢 5 个词让 Hit@5 降 18.5%,加 5 个噪声词让 NDCG@5 降 18.4%。显式 CoT 因此依赖脆弱的 rationale 线索,尤其取决于文本是否保留了目标 SID 所需的语义。(注意:这里 ground-truth rationale 0.1165 远高于 Table 2 的训练设置——因为这是给了"含答案信息的标准 rationale"作为输入的上界探针,凸显出"一旦 rationale 不完美就崩"。)
4.4 三大发现小结¶
诊断暴露三种 CoT 失败:言语化受损(答案信号留在 logits 里却解码不出来)、文本-SID 嵌入错位(rationale 对 SID logit 影响有限,且有理论上界)、脆弱 rationale(指标对微小编辑敏感)。这共同指向一个方向——在 latent 空间做隐式推理:学一个 <pause> token 来桥接语言到 SID,而不解码出脆弱的中间自然语言推理文本。
5. 方法:PauseRec¶
PauseRec 保留显式流水线里的 CPT 和 next-item SFT 两个阶段,但用基于 pause 的 latent 计算替换掉 CoT SFT 和 RL。

5.1 总览¶
如 Figure 3 所示,PauseRec 先做 CPT(同 Section 2.2),随后并行进行两个分支:next-item SFT 分支(同 Section 2.2)和 <pause> token 预训练分支——两者都从同一个 CPT 检查点出发。pause 分支在 CPT 语料上微调,把 <pause> token 注入到随机文本位置,让它学会语言与 SID token 之间的语义过渡。然后把预训练好的 <pause> embedding 装载进 SFT 检查点,在 next-item 数据上跑隐式推理 SFT(在用户历史与目标 SID 之间插入 $k$ 个 pause,只优化 SID 位置)。
PauseRec 针对性地解决前述三大失败:
1. 无需言语化的计算:用 latent <pause> 步做计算,这些步不必被解码成自然语言——绕开言语化受损;
2. 桥接 embedding 空间:通过 CPT-grounded 的 pause 预训练,让 <pause> token 落在文本与 SID embedding 的交界处(Appendix E 可视化证实)——缓解嵌入错位;
3. 避免 rationale 监督:对 pause 位置 mask 掉 loss,只优化目标 SID——消除对脆弱 rationale 的依赖。
5.2 <pause> token 初始化¶
把 <pause> 加入词表,并在 CPT 后用所有 token embedding 的均值初始化它,方差设为 embedding 方差的 $10^{-9}$ 倍(相当于一个近确定性的、落在词表中心的起点):
$$\mathbf{e}_{\langle\text{pause}\rangle}^{(0)} = \frac{1}{|\mathcal{V}|}\sum_{v\in\mathcal{V}} \mathbf{e}_v$$
其中 $\mathcal{V}$ 是全词表。这种中心初始化给 <pause> 一个介于文本与 SID 之间的中性起点。
5.3 两阶段训练¶
Stage 1:<pause> token 预训练。从 CPT 检查点出发,在 CPT 语料上微调,把 <pause> 随机插入到每条序列约 10% 的位置(见 Figure 3)。只有 $\mathbf{e}_{\langle\text{pause}\rangle}$ 可训练,其余所有参数冻结。这样把更新集中在"桥接 token"上,同时保留已 grounding 的 SID embedding 和预训练语言骨干。
Stage 2:隐式推理 SFT。把预训练好的 $\mathbf{e}_{\langle\text{pause}\rangle}$ 装载进 SFT 检查点,在用户历史与目标之间追加 $k$ 个 pause:
$$x' = \mathrm{Prompt}(H) \,\Vert\, \underbrace{\langle\text{pause}\rangle, \ldots, \langle\text{pause}\rangle}_{k\ \text{times}} \tag{5}$$
微调时对 <pause> 位置 mask 掉 loss,只优化目标 SID token:
$$\mathcal{L}_{\mathrm{implicit}} = -\sum_{l=1}^{L} \log p_\theta\big(s_{n+1}^{(l)} \,\big|\, x',\, s_{n+1}^{(1:l-1)}\big) \tag{6}$$
不对 pause 位置施加 loss 是关键设计:这样就不去模仿某个固定的教师 rationale 分布,而是让模型只在"pause 确实有助于 SID 预测"时才使用它们。实践中,pause slot 充当文本历史与离散 SID 输出之间的任务专属 latent 草稿纸 (latent scratch space)。
5.4 推理¶
测试时用与隐式推理 SFT 相同的 prompt 模板,在 <think> 与 </think> 之间插入 $k$ 个字面 <pause> token,然后自回归解码 next SID。推理时不生成任何 rationale 文本——既去掉了显式 CoT 的 token 开销,又为 SID 预测前保留了一个专属的"计算窗口"。
6. 实验¶
6.1 实验设置¶
数据集:三个 Amazon review 数据集(Ni et al. 2019)——Beauty、Sports and Outdoors、Toys and Games。过滤掉交互数 <5 的用户和 item,采用 leave-last-out 划分:最后一个 item 作测试,倒数第二作验证,倒数第三作训练目标(前面所有交互为输入)。
Baselines: 1. 传统序列推荐:GRU4Rec、SASRec、BERT4Rec、HGN; 2. 生成式检索:HSTU、TIGER; 3. LLM-based:next-item SFT(作者复现)、OneRec-Think(带 RLVR 的显式 CoT); 4. 隐式推理:ReaRec。
指标与实现:Hit@5、Hit@10、NDCG@10(NDCG@5/@10)。骨干 Qwen3-1.7B。CPT 跑 3 epoch(lr $10^{-4}$),pause 预训练 2 epoch(lr $10^{-3}$),隐式 SFT 5 epoch(lr $5\times10^{-5}$,AdamW,wd 0.01)。主结果用 $k=5$ 个 pause。
6.2 有效性与效率¶
主结果(Table 5,三个 Amazon 数据集):
| Method | Beauty H@5 | H@10 | N@5 | N@10 | Sports H@5 | H@10 | N@5 | N@10 | Toys H@5 | H@10 | N@5 | N@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GRU4Rec | 0.0395 | 0.0584 | 0.0265 | 0.0326 | 0.0190 | 0.0312 | 0.0122 | 0.0161 | 0.0330 | 0.0490 | 0.0228 | 0.0279 |
| SASRec | 0.0402 | 0.0607 | 0.0254 | 0.0320 | 0.0199 | 0.0301 | 0.0106 | 0.0141 | 0.0448 | 0.0626 | 0.0300 | 0.0358 |
| BERT4Rec | 0.0232 | 0.0396 | 0.0146 | 0.0199 | 0.0102 | 0.0175 | 0.0065 | 0.0088 | 0.0215 | 0.0332 | 0.0131 | 0.0168 |
| HGN | 0.0319 | 0.0536 | 0.0196 | 0.0266 | 0.0183 | 0.0313 | 0.0109 | 0.0150 | 0.0326 | 0.0517 | 0.0192 | 0.0254 |
| HSTU | 0.0424 | 0.0652 | 0.0280 | 0.0353 | 0.0268 | 0.0343 | 0.0173 | 0.0226 | 0.0366 | 0.0566 | 0.0245 | 0.0309 |
| TIGER | 0.0405 | 0.0623 | 0.0267 | 0.0337 | 0.0215 | 0.0347 | 0.0137 | 0.0179 | 0.0337 | 0.0547 | 0.0209 | 0.0276 |
| ReaRec | 0.0450 | 0.0704 | 0.0262 | 0.0344 | 0.0214 | 0.0332 | 0.0116 | 0.0154 | 0.0523 | 0.0764 | 0.0298 | 0.0376 |
| Next-item SFT | 0.0533 | 0.0733 | 0.0381 | 0.0445 | 0.0287 | 0.0409 | 0.0198 | 0.0237 | 0.0565 | 0.0781 | 0.0402 | 0.0471 |
| OneRec-Think | 0.0563 | 0.0791 | 0.0398 | 0.0471 | 0.0288 | 0.0412 | 0.0199 | 0.0239 | 0.0579 | 0.0797 | 0.0412 | 0.0482 |
| PauseRec | 0.0568 | 0.0746 | 0.0401 | 0.0467 | 0.0294 | 0.0422 | 0.0203 | 0.0245 | 0.0615 | 0.0838 | 0.0434 | 0.0509 |
Table 5:三个 Amazon 数据集主结果(粗体=最佳,下划线=次佳)。
三点观察: 1. 一致优于 next-item SFT:PauseRec 在每个指标上都超过 next-item SFT baseline,Toys Hit@5 相对提升最高达 8.85%(0.0565→0.0615); 2. 与/优于 RL-based CoT 持平甚至更好:PauseRec 在 12 个指标里的 10 个上超过 OneRec-Think(含 Sports 和 Toys 的全部指标),Toys Hit@5 最高相对提升 6.22%;OneRec-Think 只在 Beauty 的 Hit@10 和 NDCG@10 上更高。注意:OneRec-Think 用了昂贵的 RLVR,而 PauseRec 不用 RL; 3. 大幅超越非 LLM 推荐器:PauseRec 一致优于所有传统 baseline,凸显"通过 SID 兼容接口调用 LLM 知识"的价值。
效率(Table 6,Qwen3-1.7B,Amazon Beauty):
| Train (GPU hours) | Inference (s) | |
|---|---|---|
| PauseRec | 107.34 | 0.0586 ± 0.0093 |
| OneRec-Think | 305.62 | 0.2043 ± 0.0255 |
Table 6:效率对比。
通过避免 RL 后训练和自然语言 rationale 生成,PauseRec 用了约少 65% 的训练 GPU 时数(107.34 vs 305.62),每个推理样本约快 3.5×(0.0586 vs 0.2043,对应 71.3% 的推理耗时缩减)。注意 OneRec-Think 在此用的是相对短的模板 rationale;当生成 token 更多时,推理节省会更显著。
6.3 消融实验:pause token 初始化¶
作者把"CPT-grounded pause 预训练"与三种替代初始化对比:只用文本 token 均值、只用 SID token 均值、默认特殊 token 初始化。
| Initialization | Hit@5 | NDCG@5 |
|---|---|---|
| Center of text tokens only | 0.0559 | 0.0395 |
| Center of SID tokens only | 0.0548 | 0.0387 |
| Default Initialization | 0.0560 | 0.0394 |
| Pretrained (Ours) | 0.0568 | 0.0401 |
Table 7:Amazon Beauty 上的 <pause> 初始化消融。
预训练的 <pause> token 在 Hit@5 与 NDCG@5 上都拿到最佳,稳定但温和地超过仅文本、仅 SID、默认三种初始化。这支持了"pause 预训练用于桥接文本与 SID embedding 空间"的设计动机——只用单侧(纯文本中心 0.0559 / 纯 SID 中心 0.0548)都不如让 pause 在 CPT 语料上学到双向过渡。
6.4 参数分析:pause 数量 $k$¶
所有设置共享同一份 pause 预训练;隐式 SFT 时追加 $k$ 个 pause,推理时用相同的 $k$。
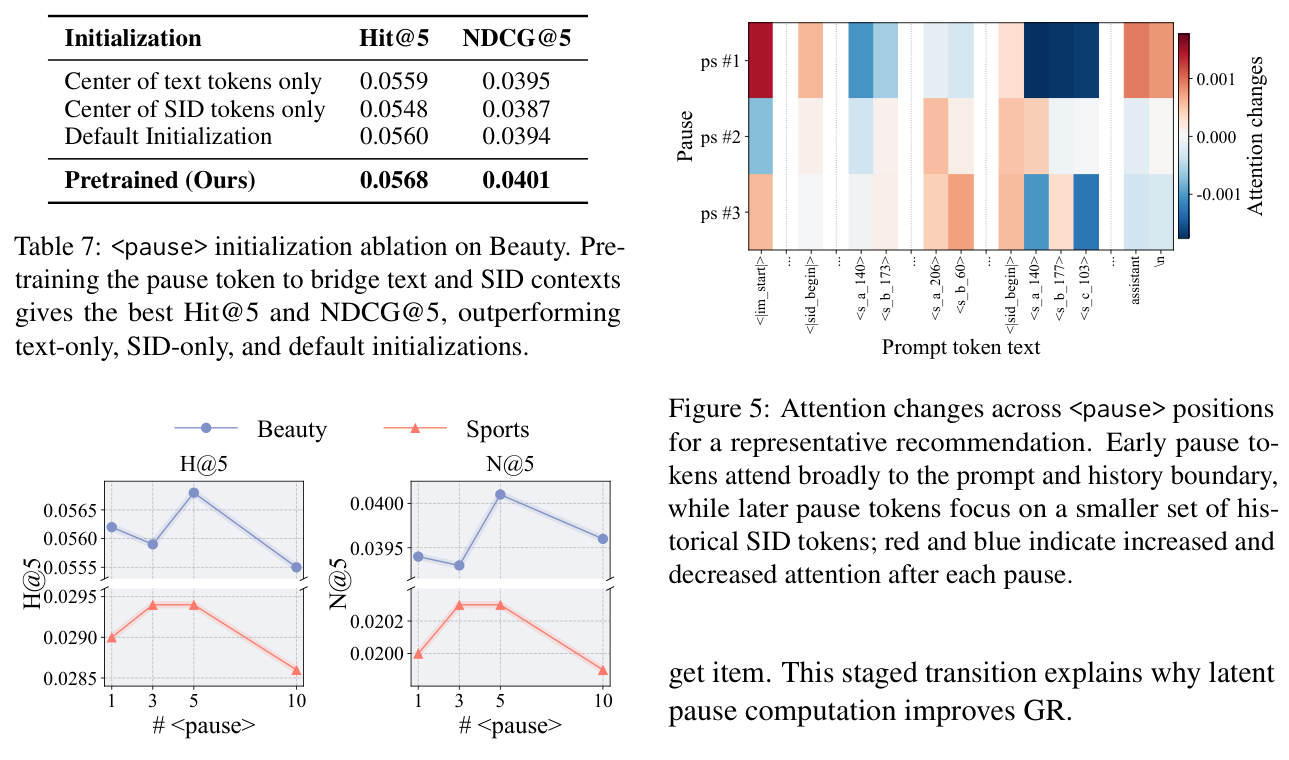
如 Figure 4,$k=5$ 时 Beauty 与 Sports 的 Hit@5/NDCG@5 均最优;加到 $k=10$ 并不能一致改善(Table 10)。这说明有用的 latent 计算在若干 pause 步后饱和——隐式推理需要一个"足够但不过量"的计算窗口。
6.5 定性分析:pause 注意力 + embedding 可视化¶
Pause 注意力(Figure 5):对每个 pause token,把它对上下文 token 的出向注意力在所有层和头上做平均,可视化注意力如何随 pause 位置变化。作者观察到一个多阶段过程: 1. 上下文定位 (Context orientation):早期 pause 广泛关注指令与历史边界,确立"next SID 应从购买历史推断"; 2. 偏好聚合 (Preference aggregation):中后期 pause 把注意力转向历史 SID,识别与用户意图相关的购买;随着 pause 位置推进,模型逐渐聚焦到一小撮显著 SID,定位到与目标相似的 item。
这个分阶段过渡解释了为何 latent pause 计算能改善 GR——它在 latent 空间里隐式地完成了"先看历史、再聚合偏好、最后锁定候选"的推理流程。
Embedding 可视化(Figure 6 / fig_07):

跨 CPT、pause 预训练、next-item SFT、隐式推理 SFT 四个阶段,<pause> token 始终停在自然语言簇与 SID 簇的边界,不塌进任何一边。这从经验上印证了 pause token 充当"语言→SID"的语义路由桥的角色。
7. 核心贡献总结¶
- 首个对 LLM-based GR "显式 vs 隐式推理"的系统对比:逐级解剖 CPT / CoT SFT / RL 流水线,量化各阶段贡献,揭示"CoT SFT 一致劣于 next-item SFT、收益只在 RL 后才浮现"的反直觉事实。
- 三大失败根因 + 理论刻画:言语化受损(知识留在 logits 里说不出来)、文本-SID 嵌入错位(并用 Theorem 1 给出"rationale 改变 SID margin 的上界 $B(\rho\|\Delta_{\text{text}}\|+\epsilon)$")、rationale 脆弱性。
- PauseRec:极简隐式推理范式:可训练
<pause>token + 中心初始化 + pause 预训练(桥接 embedding)+ 隐式 SFT(mask pause loss、不需 rationale 监督、不需 RL)。 - 效果与效率双赢:三数据集 10/12 指标超 RL-based 的 OneRec-Think,训练省 65% GPU 时、推理快约 3.5×(71.3%)。
8. 与已归档相关工作的对比¶
PauseRec 处在"用 latent / 隐式推理替代显式 CoT 来服务生成式推荐"这条并发赛道上。文档库里有两篇问题与解法双同构、且 PauseRec 未引用的独立并发工作,最值得对照。
LASAR LASAR: Latent Adaptive Semantic Aligned Reasoning for Generative Recommendation(北航 × Baidu,2026-05-11)¶
关系:独立并发(PauseRec 未引用 LASAR,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两文都直击"显式 CoT 在 SID-based 生成式推荐里又慢又不划算"。LASAR 明确指出 CoT 逐字生成"对延迟敏感的推荐是致命的",且文本生成与协同目标存在 mode 竞争;PauseRec 则用三组诊断(言语化受损、文本-SID 错位、rationale 脆弱)系统论证了"显式 CoT SFT 一致劣于 next-item SFT"。两文还独立撞上了同一个 SID 特有难点——LASAR 称之为 "semantic grounding gap"(SID 是从零构造的新符号系统,与 latent 推理 joint train 会优化塌陷),与 PauseRec 的"文本-SID 嵌入错位"是同一硬币的两面。
- 相近的技术骨架:两者都把推理搬进 latent 空间、推理时绝不解码自然语言 CoT,从而拿到数量级的推理加速(LASAR 比生成显式 CoT 快约 20×,PauseRec 约 3.5×)。都在 prompt 与 answer/SID 之间插入特殊 latent token(LASAR 的
<t>thought token、PauseRec 的<pause>)。 - 本文的差异与推进:PauseRec 远比 LASAR 轻。LASAR 仍需要:(a) 用 GPT-5 教师按 GREAM 5 段式生成 explicit CoT 作为训练期对齐锚点(stepwise bidirectional KL 把每个 latent step 对齐到 CoT 段),(b) RL 阶段(GRPO + Policy Head + REINFORCE)做自适应推理步数。而 PauseRec 既不要教师 CoT、也不要 RL——pause token 仅靠最终 next-item loss 端到端学出来,且对 pause 位置 mask loss(刻意不模仿任何 rationale 分布)。
- 可比的方法 / 实验差异:耐人寻味的是,LASAR 把 latent reasoning 严格定义为"真正的递归 hidden-state feedback loop"(Coconut 式:上一步最末层 hidden state 当下一步输入),并明确把"只是插入若干 token"的做法(如 LatentR³、S²GR)划为"非真正递归"而不屑。PauseRec 恰恰就是 LASAR 所贬低的"插入静态 token"路线——但 PauseRec 用诊断 + 理论 + 实验论证了:这种最简方案足以在 12 指标的 10 个上压过用了 RL 的 OneRec-Think。两文都用 Amazon Beauty/Sports(LASAR 另加 Instruments,PauseRec 另加 Toys),骨干都是 1.x B 量级(LASAR 未明示,PauseRec 用 Qwen3-1.7B),形成"递归 latent + 显式锚点 + RL"对"静态 pause + 无锚点 + 无 RL"的清晰路线对照。
FLR FLR: Factorized Latent Reasoning for LLM-based Recommendation(独立研究员 × Meituan LongCat × UNSW,2026-04-29)¶
关系:独立并发(PauseRec 未引用 FLR,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两文都认同"显式 CoT 对 LLM-Rec 代价高(依赖标注、100+ token 输出、低延迟场景吃不消),应转向 latent 推理"。FLR 把社区路线归纳为"显式 CoT vs 隐式/latent 推理",明确站队后者;PauseRec 则进一步用诊断把"为什么显式 CoT 失败"讲透。两者都强调隐式推理的低延迟卖点(FLR 推理仅多 1 个 thought token,PauseRec 仅多 $k=5$ 个 pause)。
- 相近的技术骨架:都属 COCONUT latent-reasoning 谱系,都在历史序列末尾/答案前插入特殊 latent token(FLR 的
<|Thought|>、PauseRec 的<pause>)做就地精炼,再解码 item,且都不依赖外部 CoT 标注。 - 本文的差异与推进:核心分歧在"latent 推理靠什么变强"。FLR 认为瓶颈是"单一 latent 向量容量不足",于是把 thought 拆成 $K$ 个解耦偏好因子(多因子注意力 + 正交/多样/稀疏三正则),并在 LatentR³ 之上用改版 GRPO(向 thought embedding 注高斯噪声做 latent 探索 + token-confidence/exact-match 混合奖励)做 RL。PauseRec 则认为瓶颈是"文本与 SID 的 embedding 错位",于是核心创新是pause 预训练把 token 定位到两空间交界处充当桥,且坚决不用 RL。一句话:FLR 在"latent 表达力"上加杠杆(更复杂、带 RL),PauseRec 在"text↔SID 接口"上做减法(更简、无 RL)。
- 可比的方法 / 实验差异:两文实验只在 Toys/Instruments 重叠(FLR 用 Toys/CDs/Games/Instruments,PauseRec 用 Beauty/Sports/Toys),不可直接比绝对数。但路线张力鲜明:FLR 主打"相对 LatentR³ 再提升 3.2%",把 latent 推理往"更结构化、更 RL"推;PauseRec 主打"无 RL 也能打过 RL-based 的 OneRec-Think + 训练/推理双省",把 latent 推理往"更极简"推。FLR 还用 textual identifier 而非严格 SID,对 PauseRec 强调的"SID 是非语言符号"这一前提是另一种处理方式。
被剔除的近似候选(附理由): - OneRec-Think OneRec-Think(Kuaishou)—— 是 PauseRec 的主对比 baseline(显式 CoT + RLVR),解法与 PauseRec 正相反(显式 verbal CoT vs 隐式 pause),属"foil/baseline"关系而非孪生 → 交由 Step 4 DAG 结构化登记,不在本节展开。 - RPORec RPORec(CityU HK)—— 独立识别了 PauseRec 三大根因里的两个("hidden-state distortion" + "text-to-item semantic gap"),问题诊断高度同构;但解法是"用文本接口解耦 backbone 与轻量 Rechead + 双阶段 RL",与"pause 隐式计算"骨架差异大,故剔除。 - SAPO SAPO(同为 University of Virginia 出品)—— 同样针对"reasoning for SID-decoded GR",但走的是 step-level 可验证奖励的 RL 路线优化显式推理,与 PauseRec 的"无 RL + 隐式"正交,非解法孪生。
9. 讨论与局限性¶
核心贡献与借鉴价值:PauseRec 最大的价值是"用最简方案撬动最大收益"——它证明了在 SID-based GR 里,昂贵的教师 rationale 和 RL 后训练都不是必需的,一个端到端学出来的 pause token(外加把它预训练成 text↔SID 桥)就能拿到甚至超过 RL-based 显式 CoT 的效果,同时训练省 65%、推理快 3.5×。对工业部署尤其友好:Snap Inc. 的参与说明这套"低成本隐式推理"对真实推荐系统的延迟/算力预算高度契合。值得借鉴的设计有三:(1) 诊断驱动方法——先用三组实验 + 理论把"显式 CoT 为何失败"钉死,再对症下药;(2) pause 预训练做 embedding 桥接(仅 pause embedding 可训练,冻结其余);(3) 对 latent 位置 mask loss,刻意不模仿任何 rationale 分布,让模型只在有益时使用计算窗口。
局限与争议: 1. 未穷尽 pause 设计空间:作者承认只用了紧凑的 pause 配置,没有详尽调 pause 放置策略、初始化日程、解码变体;$k$ 的最优值(=5)也可能随数据集/骨干规模变化。 2. 评估仅限离线 next-item 协议:全部实验在三个 Amazon 公开数据集上做离线评测,没有工业 A/B 或线上指标(尽管有 Snap 背景)。隐式推理对"感知有用性、多样性、推荐呈现"等用户侧效应的影响未被检验。 3. 可解释性折损:pause token 不是自然语言,其中间计算对用户和工程师都不可读——这是隐式推理相对显式 CoT 的固有代价,作者也指出需要额外的 probing/可视化工具(如本文的注意力分析)来理解 pause 如何支撑 SID 预测。 4. 路线张力未盖棺:LASAR 主张"只有真正的递归 hidden-state feedback 才算 latent reasoning",而 PauseRec 用静态插入 token 就打赢了 RL baseline——两条并发路线孰优孰劣(递归 vs 静态、带 RL vs 无 RL、带锚点 vs 无锚点)尚无公平的同条件横评,是该方向值得跟进的开放问题。 5. 通用风险:与其他推荐系统一样,PauseRec 可能放大流行度偏置、过度强化历史偏好,或继承交互数据与预训练 LLM 中的偏见,部署时需配套缓解措施。