Reinforced Preference Optimization for Reasoning-Augmented Recommendations (RPORec)¶
作者:Jingtong Gao¹*, Zeyu Song², Chi Lu², Xiaopeng Li¹, Derong Xu¹, Maolin Wang¹, Peng Jiang², Kun Gai², Qingpeng Cai²†, Xiangyu Zhao¹† 所属:¹City University of Hong Kong · ²Kuaishou Technology(*工作于快手完成,†通讯作者) ArXiv:2605.21967 · 2026-05-21 · Preprint
1. 研究动机与背景¶
推荐系统是数字平台分发个性化内容的核心。近年 LLM 在上下文理解、复杂推理与文本生成上的能力,让研究界开始从「小型深度模型」转向「LLM-based 高精度偏好建模」:借助 LLM 的世界知识与显式推理(explicit reasoning),推荐器可以更好地推断用户潜在意图、追踪偏好演化、挖掘 user–item 之间的语义关系,从而获得更高的准确率与可解释性。
但作者指出,现有 reasoning-based 推荐方法无法把 LLM 的推理过程与推荐目标充分对齐,根因有二,对应两条技术路线:
- Joint optimization(隐状态耦合):把 LLM 的 hidden states 与推荐模块拼在一起做端到端训练,典型如 R²ec——推理与预测通过 hidden-state coupling 联合优化。问题是:直接用下游推荐目标去更新 hidden states,会逐步侵蚀 backbone 本身的推理能力与可解释性(structural disruption during integration)。
- Fine-tuned generative(生成式):微调 LLM 直接用自然语言生成推荐,典型如 ReRe(直接生成)与 LatentR³(把推理优化挪到 latent space)。问题是:把自由文本生成翻译成精确的 item 检索很困难,尤其对训练时未见过的 item;即便引入 Semantic IDs (SIDs),推荐专用 tokenization 与 LLM 原生词表之间仍存在持久的语义鸿沟(semantic gap),损害准确率。
一句话概括根因:如何利用显式 CoT 推理来做推荐,同时既不让推荐专用梯度扭曲 LLM 的推理能力(路线 1 的病),又不掉进文本→item 的语义鸿沟(路线 2 的病)。
为此作者提出 RPORec(Reinforced Preference Optimization for Reasoning-Augmented Recommendations):用文本输出(而非 hidden states)作为 LLM backbone 与一个专用推荐头 Rechead 之间的接口,从而既保住推理完整性,又支持任务专用的 item 检索,规避语义鸿沟。但要把这套框架搭起来有三大挑战:(1) 如何联合优化 LLM backbone 与 Rechead 朝推荐目标;(2) 如何在过程中保护并提升 backbone 的推理质量;(3) 如何过滤推理上下文中的噪声、同时保留对推荐有用的信号。
RPORec 用三个关键设计回应:
- 迭代优化流水线(iterative optimization pipeline):先用一个冻结的 LLM backbone 训练 Rechead,再用 Rechead 产生的 verifiable reward 通过 RLVR(Reinforcement Learning with Verifiable Rewards) 反向精炼 backbone。两阶段设计避免推荐专用梯度直接扭曲 LLM 表征。
- reasoning-augmented recommendation modeling:一个 reasoning-aware 的 Rechead,把高质量推理信号整合进基于检索的架构做细粒度 next-item 预测。
- reasoning refinement and alignment:基于精心设计的多路 reward function,同时提升推理质量与 backbone 的任务对齐度。
2. RPORec 框架总览¶
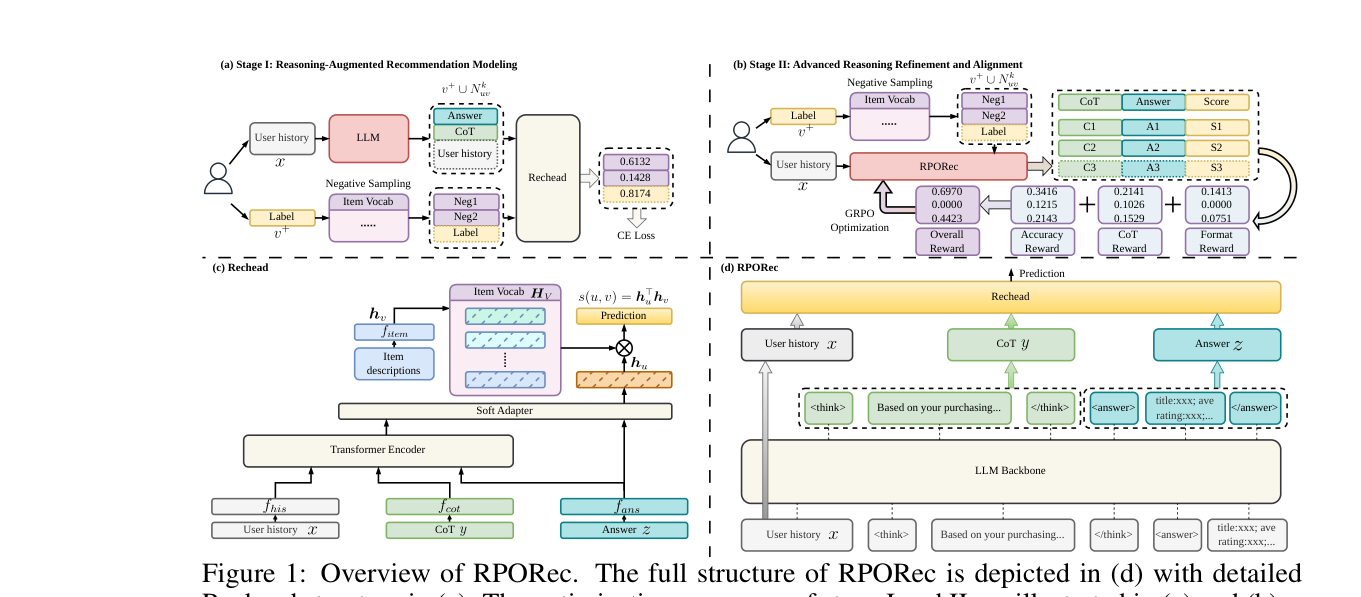
RPORec 由两个核心组件耦合而成(Figure 1(d)):
- Rechead:把 LLM 产出的高质量 CoT 当作辅助信号,在 user–item 表征空间里做检索式推荐。它不要求文本或 token 级对齐——这是它能规避语义鸿沟的关键。
- LLM Backbone:生成结构化输出,含一个推理段(CoT,
<think>...</think>)和一个答案段(<answer>...</answer>,用标题与属性描述推荐 item)。
训练分两个迭代阶段:
- Stage I — Reasoning-Augmented Recommendation Modeling:冻结 LLM backbone,训练 Rechead,使其从「用户历史 + 生成的 CoT + 答案段」中建模推荐信号。
- Stage II — Advanced Reasoning Refinement and Alignment:冻结 Rechead,把它当作稳定的 reward 源,用多路 reward 信号通过强化学习(GRPO)精炼 LLM backbone。
两阶段共同构成一个 reasoning-augmented 推荐框架,用高质量 CoT 推理提升推荐质量。
3. 核心方法¶
3.1 Rechead 结构(Reasoning-Augmented Recommendation Modeling)¶
把推理知识用于推荐并不平凡:直接在 LLM hidden states 上优化推荐目标会破坏内在推理(路线 1 的病),而把 CoT 朴素地编码进通用推荐器又会引入大量噪声。RPORec 因此设计了一个轻量的 reasoning-augmented recommendation head(Rechead)——把 CoT 当辅助信号,在 user–item 表征检索框架里工作,无需文本/token 级对齐。
如 Figure 1(c),Rechead 含四个文本编码器、一个 Transformer encoder block,以及一个控制 CoT 贡献、抑制无关推理的 soft adapter。
(1) 三路文本编码。 给定用户历史 $x$、CoT $y$、最终答案 $z$(如预测 item 的标题与属性),各自经由「预训练小型 sentence transformer + 前馈网络」组成的编码函数 $f$ 嵌入:
$$\boldsymbol{r}_x = f_{his}(x),\quad \boldsymbol{r}_y = f_{cot}(y),\quad \boldsymbol{r}_z = f_{ans}(z) \tag{1}$$
其中 $\boldsymbol{r}_x, \boldsymbol{r}_y, \boldsymbol{r}_z \in \mathbb{R}^d$。item 也由一个预训练小型 sentence transformer $f_{item}$ 从其文本描述编码成 dense 向量 $\boldsymbol{h}_v$,全部预存为 item 词表矩阵 $\boldsymbol{H}_V \in \mathbb{R}^{|V|\times d}$。
(2) 主表征选择(primary representation)。 为应对 CoT 与答案纠缠、或答案缺失/畸形的情况,Rechead 根据答案 $z$ 是否能被成功解析来选主表征:
$$\boldsymbol{r}_{sel} = \begin{cases} \boldsymbol{r}_z, & \text{若答案 } z \text{ 解析成功} \\ \boldsymbol{r}_x, & \text{否则} \end{cases} \tag{2}$$
即在答案畸形/缺失时回退到直接的历史建模,保证鲁棒性。
(3) reasoning-augmented 表征。 CoT 虽含有用推理知识,但长度长、可控性差,原始 CoT 直接用于推荐效果不佳。RPORec 用一个轻量 Transformer encoder 建模「用户历史、CoT、主表征」三者的交互,过滤无关内容,产出 reasoning-augmented 表征:
$$\boldsymbol{r}_{rea} = \mathrm{TransformerEncoder}([\boldsymbol{r}_x;\ \boldsymbol{r}_y;\ \boldsymbol{r}_{sel}]) \tag{3}$$
(4) 自适应门控(gating)。 一个门控网络自适应调节 reasoning-augmented 表征对最终表征 $\boldsymbol{h}_u\in\mathbb{R}^d$ 的贡献:
$$\gamma_0 = \gamma\cdot\sigma\bigl(f_{gate}([\boldsymbol{r}_{sel} \| \boldsymbol{r}_{rea}]) - 0.5\bigr),\quad \boldsymbol{h}_u = \gamma_0\cdot\boldsymbol{r}_{rea} + \boldsymbol{r}_{sel} \tag{4}$$
其中 $\gamma\in(0,1)$ 是超参,$\sigma$ 是 sigmoid,$\|$ 是拼接。该门控抑制噪声/离题 CoT,同时把有用的关系线索作为辅助增强保留——是「用 CoT 但不被 CoT 噪声拖累」的核心机制。
(5) 检索打分。 在共享嵌入空间里用点积算推荐分,取分最高的 item 作为检索结果:
$$s(u, v) = \boldsymbol{h}_u^\top \boldsymbol{h}_v \tag{5}$$
3.2 Rechead 优化(Stage I 训练目标)¶
如 Figure 1(a),对每个训练样本 $[x, v^+]$,先用 LLM 预先算好 CoT 段 $y$ 与答案段 $z$,构造 Rechead 的训练数据。推理时在全 item 空间 $\boldsymbol{H}_V$ 上打分,但训练时全量打分太贵,因此采用负采样:对每个训练实例采样 $k$ 个负样本 $N^k_{uv}$,与正 item $v^+$ 一起算交叉熵(CE)损失:
$$\mathcal{L}_{rec} = -\log\frac{\exp\bigl(s(u, v^+)\bigr)}{\sum_{v\in\{v^+\}\cup N^k_{uv}} \exp\bigl(s(u, v)\bigr)} \tag{6}$$
小结:Rechead 把 CoT 作为辅助推理信号、用自适应主表征选择稳住预测、并用「预编码 item + 高效对比学习」对齐 user 向量,得到一个参数高效、对噪声推理鲁棒的可扩展检索模块。
3.3 Advanced Reasoning Refinement and Alignment(Stage II)¶
Rechead 建好后,转去优化 LLM backbone。直接用预训练 LLM 往往与推荐目标错位,且倾向于产生冗长、低质量的推理链。RPORec 用 GRPO 微调 backbone,把冻结的 Rechead 当 verifier,提供推荐专用反馈。三路互补 reward 分别优化输出格式、推理质量、推荐准确率。
(1) Format Reward(格式奖励)。 为保证 Rechead 输入合法,prompt 要求 backbone 生成 <think>y</think><answer>z</answer>:
$$r_{fmt} = \begin{cases}1.0, & \text{格式正确}\\ 0.0, & \text{否则}\end{cases},\qquad r_{clean} = \max\Bigl(0,\ 1 - \frac{L_{out}}{\kappa}\Bigr) \tag{7}$$
其中 $L_{out}$ 是落在 think/answer 标签外的文本长度,$\kappa=100$ 控制惩罚强度。$r_{clean}$ 用来压制标签外的冗余内容。
(2) Accuracy Reward(准确率奖励)。 设计 ranking-based reward 把 LLM 与推荐任务对齐。给定用户 $u$、一个正 item $v^+$、$k$ 个采样负样本 $N^k_{uv}$,用 Rechead 的打分 $s(u,v)$(式 5)在候选集 $\{v^+\}\cup N^k_{uv}$ 上算 NDCG-based reward:
$$r_{ndcg} = \mathrm{NDCG}@k\bigl(\mathrm{rank}(v^+)\bigr) \tag{8}$$
其中 $\mathrm{rank}(\cdot)$ 是 $v^+$ 在候选集中的排名。这把「冻结 Rechead 给出的排序质量」转化为一个密集、连续的奖励——而不是 0/1 命中。
(3) CoT Reward(推理质量奖励)。 这是 RPORec 区别于同类工作的核心:显式 CoT 是 backbone 与 Rechead 之间的关键接口,因此直接优化推理轨迹本身的质量。两个子奖励鼓励「简洁、以推荐为中心」的推理:用一个冻结 LLM 作为 summarizer,把原 CoT $y$ 映射成短 rationale $\hat{y}$,再评估原 CoT 的鲁棒性与质量。用预训练 sentence transformer $e(\cdot)$ 度量语义一致性,并用长度奖励鼓励压缩:
$$r_{sim} = \mathbf{1}\{\cos(e(y), e(\hat{y})) > \delta\},\qquad r_{comp} = \mathrm{clip}\Bigl(\frac{|\hat{y}|}{|y|},\ 0,\ 1\Bigr) \tag{9}$$
含义:$r_{sim}=1$ 当压缩后 $\hat{y}$ 与原 $y$ 的编码余弦相似度超过阈值 $\delta$(即原 CoT 摘要后仍保留核心语义);$r_{comp}$ 是裁剪后的压缩比,奖励那些「抗进一步简化」的简洁轨迹、惩罚冗余。两者合力把 backbone 推向「语义稠密、信息密度高」的 CoT。
进一步从潜在决策视角引入 entropy-based reward。近期工作指出 token 熵 $E_t$ 是生成不确定性的指标,且 top-20% 高熵 token 对语义质量尤其关键——高质量推理应只在少量信息性、不确定的决策点保留高熵,而不至于全局失控。对一段 CoT $T$,定义平均熵 $E_\mu = \frac{1}{|T|}\sum_{t\in T} E_t$ 与 top-20% 熵均值 $E_{20\%}$,熵奖励为:
$$r_{ent} = E_{20\%} - E_\mu \tag{10}$$
即奖励含显著高信息 token(高 $E_{20\%}$)、同时惩罚整体过度不确定(高 $E_\mu$)的轨迹。
(4) 总奖励。 聚合所有信号做 GRPO 训练,并以 $r_{fmt}$ 作为乘性 gate 强制严格格式生成(格式错则全部奖励归零):
$$r = r_{fmt}\cdot\bigl(\alpha_0 r_{fmt} + \alpha_1 r_{clean} + \alpha_2 r_{ndcg} + \alpha_3 r_{sim} + \alpha_4 r_{comp} + \alpha_5 r_{ent}\bigr) \tag{11}$$
3.4 GRPO 预备知识与迭代优化算法¶
GRPO(Group Relative Preference Optimization) 是 RLVR 的代表方法。对策略 $\pi_\theta$,给定输入 $x$ 采样 $G$ 条候选响应 $\{o_i\}_{i=1}^G$,各得标量 reward $r_i$,组内归一化得优势:
$$\hat{A}_i = \frac{r_i - \mu_G}{\sigma_G} \tag{12}$$
$\mu_G, \sigma_G$ 为组内 reward 均值与标准差。token 级,可训练策略 $\pi_\theta$ 与固定参考 $\pi_{ref}$ 的比值 $w_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t}\mid x, o_{i,<t})}{\pi_{ref}(o_{i,t}\mid x, o_{i,<t})}$,优化目标为:
$$\mathcal{J}_{GRPO}(\theta) = \mathbb{E}\Bigl[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\min\bigl(w_{i,t}(\theta)\hat{A}_i,\ \mathrm{clip}(w_{i,t}(\theta), 1-\varepsilon, 1+\varepsilon)\hat{A}_i\bigr) - \beta\,\mathbb{D}_{KL}[\pi_\theta\|\pi_{ref}]\Bigr] \tag{13}$$
其中 token 熵定义为 $E_t = -\sum_{\hat{o}_t\in vocab}\pi_\theta(\hat{o}_t\mid x, o_{<t})\log\pi_\theta(\hat{o}_t\mid x, o_{<t})$,对应式 (10) 的熵奖励来源;近期 entropy-guided 工作发现仅 top $\rho=20\%$ 的高熵「decision token」对推理结果关键,对这些 token 做选择性更新即可达到可比对齐效果、并改善稳定性。
迭代优化(Algorithm 1):为避免同时优化多模块带来的非平稳奖励,RPORec 用两阶段迭代——
- Stage I:先用 $\Theta_{LLM}$ 对每个 $(x_j, v_j^+)$ 一次性生成固定的 $y_j, z_j$;冻结 backbone,按式 (1)–(6) 前向 Rechead、采 $k$ 个负样本、用式 (6) 更新 $\Theta_R$,收敛后冻结得到 $\Theta_R^*$。
- Stage II:用 $\Theta_{LLM}$ 实时生成 $y_j, z_j$,过冻结 Rechead 得 $s(u,v)$(式 5),算 $r_{fmt}, r_{clean}, r_{ndcg}, r_{sim}, r_{comp}, r_{ent}$,按式 (11) 聚合,用 GRPO(式 13)更新 $\Theta_{LLM}$ 最大化 $r$,收敛后返回 $(\Theta_{LLM}^*, \Theta_R^*)$。
4. 实验设置¶
数据集(Amazon Reviews 2023,3 个类目)。遵循前作的时间截断协议,从最近一年起收集至少 10k 有效 item;省略 5-core 过滤以保留自然推荐行为;每个用户历史按时序排列、截断至最近 20 个动作;按 8:1:1 划分 train/val/test,在全 item 集上评估。
| Dataset | Users | Items | Interactions |
|---|---|---|---|
| Musical Instruments | 15,656 | 10,320 | 34,373 |
| CDs and Vinyl | 7,701 | 12,024 | 13,435 |
| Video Games | 29,230 | 10,144 | 63,502 |
实现细节。LLM backbone 用 Qwen3-0.6B(小模型以满足推荐场景的效率要求),所有 LLM-based baseline 同样用 Qwen3-0.6B 保证公平;另用 Llama3.2-1B 验证跨 backbone 泛化。sentence transformer 用 static-retrieval-mrl-en-v1。4 GPU 训练;batch size:非 LLM 方法 256、LLM-based 方法 8;所有 LLM 最大生成长度 768。模型专用超参 grid search,共享超参跨实验固定;报告 10 次运行平均。
评估指标:Hit@K(H@K)与 NDCG@K(N@K),K ∈ {5, 10, 20}。
Baselines 分三类:
- 传统:GRU4Rec(RNN)、Caser(CNN)、SASRec(self-attention);
- 生成式检索 / LLM-based 生成:TIGER(SID + Transformer)、BIGRec(微调输出 tokenized item)、D³(去偏 LLM 解码);
- DPO/RL-based:S-DPO(softmax-enhanced DPO + 多负样本)、SPRec(self-play DPO 去偏)、R²ec(双头联合推理 + 预测,hidden-state 耦合)、ReRe(RL 生成 + verifiable reward + 约束 beam)、LatentR³(latent 推理、无显式 CoT)。
5. 主要实验结果(RQ1:整体性能)¶
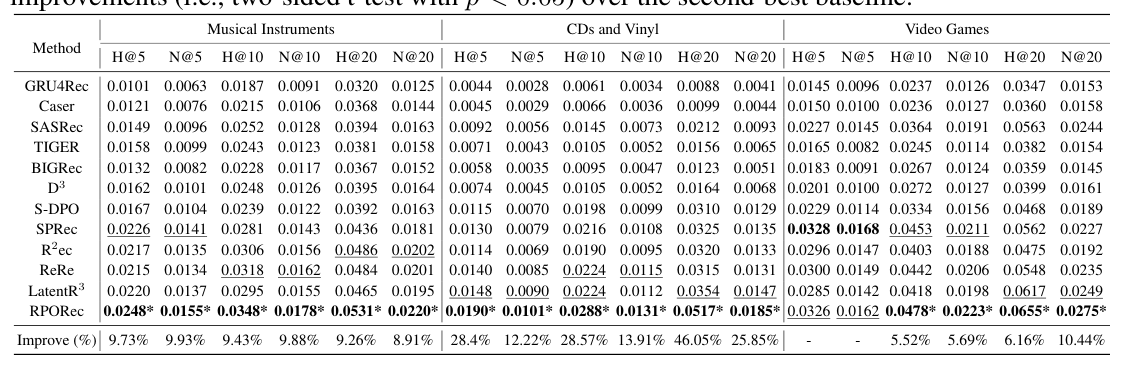
Musical Instruments
| Method | H@5 | N@5 | H@10 | N@10 | H@20 | N@20 |
|---|---|---|---|---|---|---|
| GRU4Rec | 0.0101 | 0.0063 | 0.0187 | 0.0091 | 0.0320 | 0.0125 |
| Caser | 0.0121 | 0.0076 | 0.0215 | 0.0106 | 0.0368 | 0.0144 |
| SASRec | 0.0149 | 0.0096 | 0.0252 | 0.0128 | 0.0394 | 0.0163 |
| TIGER | 0.0158 | 0.0099 | 0.0243 | 0.0123 | 0.0381 | 0.0158 |
| BIGRec | 0.0132 | 0.0082 | 0.0228 | 0.0117 | 0.0367 | 0.0152 |
| D³ | 0.0162 | 0.0101 | 0.0248 | 0.0126 | 0.0395 | 0.0164 |
| S-DPO | 0.0167 | 0.0104 | 0.0239 | 0.0122 | 0.0392 | 0.0163 |
| SPRec | 0.0226 | 0.0141 | 0.0281 | 0.0143 | 0.0436 | 0.0181 |
| R²ec | 0.0217 | 0.0135 | 0.0306 | 0.0156 | 0.0486 | 0.0202 |
| ReRe | 0.0215 | 0.0134 | 0.0318 | 0.0162 | 0.0484 | 0.0201 |
| LatentR³ | 0.0220 | 0.0137 | 0.0297 | 0.0155 | 0.0465 | 0.0195 |
| RPORec | 0.0248* | 0.0155* | 0.0348* | 0.0178* | 0.0531* | 0.0220* |
| Improve % | 9.73 | 9.93 | 9.43 | 9.88 | 9.26 | 8.91 |
CDs and Vinyl
| Method | H@5 | N@5 | H@10 | N@10 | H@20 | N@20 |
|---|---|---|---|---|---|---|
| GRU4Rec | 0.0044 | 0.0028 | 0.0061 | 0.0034 | 0.0088 | 0.0041 |
| Caser | 0.0045 | 0.0029 | 0.0066 | 0.0036 | 0.0099 | 0.0044 |
| SASRec | 0.0092 | 0.0056 | 0.0145 | 0.0073 | 0.0212 | 0.0093 |
| TIGER | 0.0071 | 0.0043 | 0.0105 | 0.0052 | 0.0156 | 0.0065 |
| BIGRec | 0.0058 | 0.0035 | 0.0095 | 0.0047 | 0.0123 | 0.0051 |
| D³ | 0.0074 | 0.0045 | 0.0105 | 0.0052 | 0.0164 | 0.0068 |
| S-DPO | 0.0115 | 0.0070 | 0.0198 | 0.0099 | 0.0310 | 0.0129 |
| SPRec | 0.0130 | 0.0079 | 0.0216 | 0.0108 | 0.0325 | 0.0135 |
| R²ec | 0.0114 | 0.0069 | 0.0190 | 0.0095 | 0.0320 | 0.0133 |
| ReRe | 0.0140 | 0.0085 | 0.0224 | 0.0115 | 0.0315 | 0.0131 |
| LatentR³ | 0.0148 | 0.0090 | 0.0224 | 0.0112 | 0.0354 | 0.0147 |
| RPORec | 0.0190* | 0.0101* | 0.0288* | 0.0131* | 0.0517* | 0.0185* |
| Improve % | 28.4 | 12.22 | 28.57 | 13.91 | 46.05 | 25.85 |
Video Games
| Method | H@5 | N@5 | H@10 | N@10 | H@20 | N@20 |
|---|---|---|---|---|---|---|
| GRU4Rec | 0.0145 | 0.0096 | 0.0237 | 0.0126 | 0.0347 | 0.0153 |
| Caser | 0.0150 | 0.0100 | 0.0236 | 0.0127 | 0.0360 | 0.0158 |
| SASRec | 0.0227 | 0.0145 | 0.0364 | 0.0191 | 0.0563 | 0.0244 |
| TIGER | 0.0165 | 0.0082 | 0.0245 | 0.0114 | 0.0382 | 0.0154 |
| BIGRec | 0.0183 | 0.0091 | 0.0267 | 0.0124 | 0.0359 | 0.0145 |
| D³ | 0.0201 | 0.0100 | 0.0272 | 0.0127 | 0.0399 | 0.0161 |
| S-DPO | 0.0229 | 0.0114 | 0.0334 | 0.0156 | 0.0468 | 0.0189 |
| SPRec | 0.0328 | 0.0168 | 0.0453 | 0.0211 | 0.0562 | 0.0227 |
| R²ec | 0.0296 | 0.0147 | 0.0403 | 0.0188 | 0.0475 | 0.0192 |
| ReRe | 0.0300 | 0.0149 | 0.0442 | 0.0206 | 0.0548 | 0.0235 |
| LatentR³ | 0.0285 | 0.0142 | 0.0418 | 0.0191 | 0.0617 | 0.0249 |
| RPORec | 0.0326 | 0.0162 | 0.0478* | 0.0223* | 0.0655* | 0.0275* |
| Improve % | - | - | 5.52 | 5.69 | 6.16 | 10.44 |
结论分析(why,不只 what):
- 传统模型(GRU4Rec/Caser/SASRec)中 SASRec 凭 self-attention 最强,但没有显式推理,难以捕捉细腻、演化的用户偏好。
- 生成式/联合优化(TIGER/BIGRec/D³)只有中等增益,尤其在稀疏的 CDs and Vinyl 上——说明直接 token 级优化会扭曲推理,而 TIGER 的 SID 生成没能充分利用 LLM 的预训练推理知识。
- 微调生成 / RL 类(S-DPO/SPRec/R²ec/ReRe/LatentR³)整体更好,印证 reasoning-aware 建模的价值;但 ReRe、LatentR³ 在聚合时可能掉性能(尤其训练未见过的候选 item),R²ec 的 hidden-state 耦合与 LatentR³ 的 latent-only 优化都让显式推理更难保留——这与 RPORec「保留显式 CoT、并通过专用头解耦检索」的设计动机正好呼应。
- RPORec 在几乎所有数据集与指标上超过全部 baseline:在稀疏的 CDs and Vinyl 上提升尤其夸张(H@20 +46.05%、N@20 +25.85%);在 Video Games 上 H@5/N@5 略逊于 SPRec(故 improve 标
-),但 H@10 起全面最优。验证了「显式 CoT 推理 + 专用推荐头 + verifiable-reward 迭代优化」的组合有效。
6. 消融与分析¶
6.1 消融实验(RQ2,CDs and Vinyl,H@10 & N@10)¶
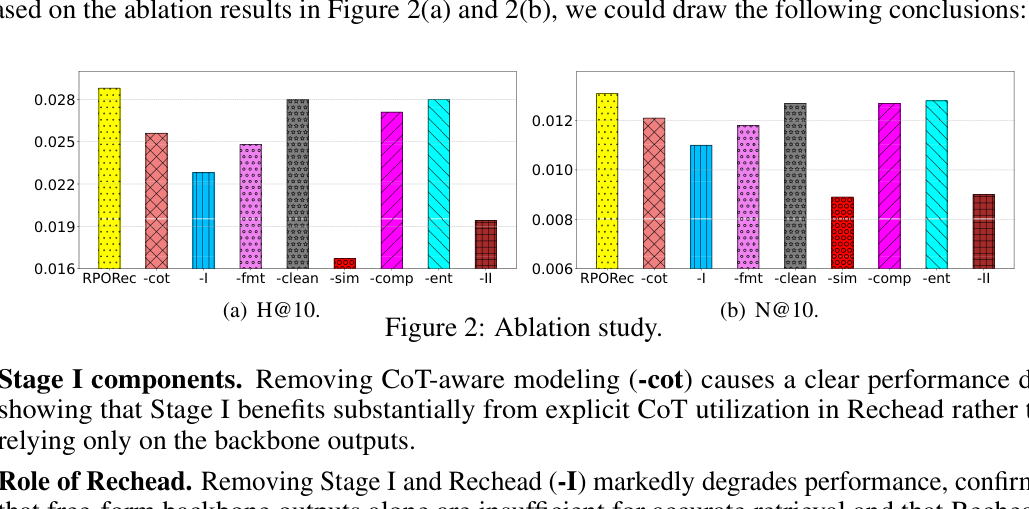
消融变体:
- -cot:移除 Rechead(Stage I)中的 CoT 输入与 reasoning-augmented 建模;
- -I:移除整个 Stage I 训练,直接用 LLM backbone 输出做 item 检索;
- -fmt / -clean / -sim / -comp / -ent:移除 Stage II 对应的单路 reward;
- -II:移除整个 Stage II,不微调 LLM backbone。
逐项结论:
- Stage I 组件:去掉 CoT-aware 建模(-cot)明显掉点,说明 Stage I 显著受益于 Rechead 里对显式 CoT 的利用,而非只靠 backbone 输出。
- Rechead 的作用:去掉 Stage I 与 Rechead(-I)大幅退化,证明自由格式的 backbone 输出本身不足以精确检索,Rechead 是连接「推理」与「推荐」的桥梁,不可或缺。
- Stage II 各 reward:去掉任一 reward 都掉点,说明它们互补;其中 -sim 掉点最大——相似度奖励对「让 CoT 优化保持语义 grounded」至关重要;缺了它,$r_{comp}$ 仍会缩短推理,但更可能把推理推离「与推荐相关」的内容。
- Stage II 的作用:去掉整个 Stage II(-II)急剧掉点,证明 RL-based 精炼对推荐对齐不可或缺。
6.2 Backbone 泛化(Table 2,CDs and Vinyl)¶
换用 Llama3.2-1B 重做,性能与 Qwen3-0.6B 相当,说明 RPORec 对底座鲁棒、可泛化。
| Model | H@10 | N@10 |
|---|---|---|
| RPORec (Qwen3-0.6B) | 0.0288 | 0.0131 |
| RPORec (Llama3.2-1B) | 0.0294 | 0.0128 |
6.3 Case Study:CoT 质量(RQ3,CDs and Vinyl)¶

由于 RPORec 的主要推理增强来自 CoT Reward(§3.3),作者对比施加该奖励前后,backbone 推理内容与平均输出长度的变化,并用 GPT-5.4 作为 LLM judge,从两个维度 0–1 打分:Information Density(推理是否简洁而有信息,而非冗余/噪声)与 Recommendation Utility(推理是否提供了有助于识别正确 item 的证据)。
- Without CoT Reward:推理冗长,反复复述 item 元数据(发行年份、背景描述),并夹带关于用户偏好的弱推测,稀释了与推荐相关的证据。GPT-5.4 评分:Information Density 0.34(case)/ 0.31(test-set 平均),Recommendation Utility 0.41 / 0.43。
- With CoT Reward:推理明显更短、更聚焦,只保留支撑推荐决策的核心线索。GPT-5.4 评分跃升:Information Density 0.78(case)/ 0.79(avg),Recommendation Utility 0.73(case)/ 0.71(avg)。
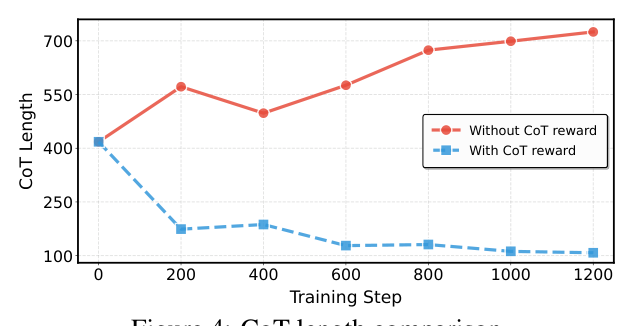
如 Figure 4,With CoT reward 的推理长度随训练从约 410 token 快速降到约 100 token 并保持;Without CoT reward 则一路涨到约 700 token。这不仅提升推理质量,还减少噪声、提高生成效率。
7. 工业部署(Online Application)¶
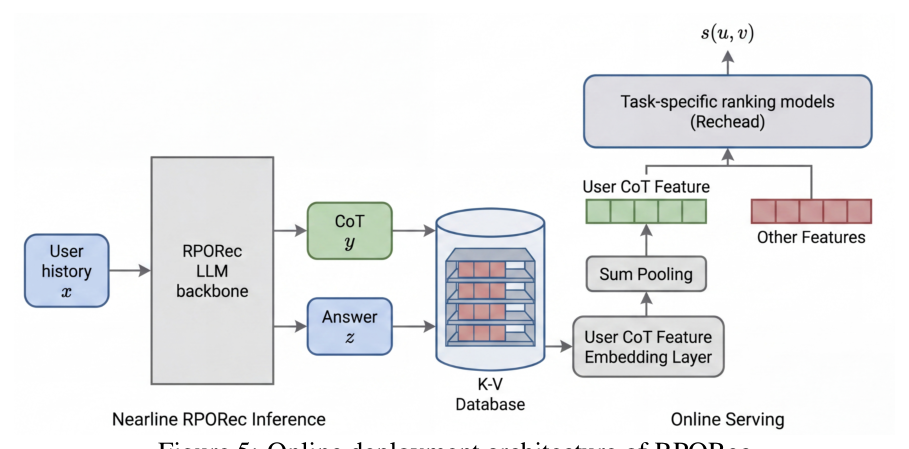
RPORec 已集成进一个大规模工业广告系统并做了严格线上 A/B。考虑生产环境对算力、推理延迟、特征交互复杂度的严苛约束,部署架构如下(Figure 5):
- Nearline RPORec Inference:把 LLM backbone 作为近线(nearline)用户理解模块,分析用户画像属性与历史行为预测兴趣,产出 CoT $y$ 与答案 $z$,抽取后存入 K-V 数据库。
- Online Serving:线上服务时,把 CoT token 嵌成 dense 向量(经 User CoT Feature Embedding Layer + Sum Pooling),作为辅助用户特征与其它在线特征一起喂给下游的 task-specific 排序模型(即线上版 Recheads),算 $s(u,v)$。
这样把「重的 LLM 推理」放近线、「轻的检索/排序」放在线,调和了多步推理的算力开销与实时延迟要求。
A/B 实验:跑 7 天、10% 流量,覆盖约 4000 万用户、21 亿广告曝光。baseline 是当前生产中的 SOTA 排序模型(含大量手工特征 + GSU-ESU 模块,0.8B 稀疏 + 0.2B 稠密参数)。结果:Revenue +1.348%、Advertiser Value (ADVV) +1.058%——在如此体量的成熟系统上是可观的业务收益。
8. 核心贡献总结¶
- RPORec 框架:首个把高质量 LLM 推理文本整合进推荐、实现 reasoning-augmented 决策的框架;用文本接口解耦 LLM backbone(产 CoT+答案)与专用 Rechead(检索式推荐),从而同时规避 hidden-state 耦合扭曲推理与文本→item 语义鸿沟两大病灶。
- 迭代优化流水线:Stage I 冻结 backbone 训练 reasoning-aware Rechead(门控过滤噪声 CoT、自适应主表征回退);Stage II 冻结 Rechead 当 verifier,用 format / NDCG accuracy / CoT-quality(similarity + compression + entropy)三类 verifiable reward 通过 GRPO 精炼 backbone——直接优化推理轨迹本身的质量是它区别于同类工作的关键。
- 充分验证:3 个 Amazon 公开数据集上全面超 SOTA(CDs and Vinyl 上 N@20 提升 25.85%),跨 backbone(Qwen3-0.6B / Llama3.2-1B)鲁棒,且在 40M 用户、2.1B 曝光的工业广告系统上线 A/B 取得 Revenue +1.348% / ADVV +1.058%。
9. 与已归档相关工作的对比¶
SAPO SAPO: Step-Aligned Policy Optimization for Reasoning-Based Generative Recommendation (University of Virginia & Nokia, 2026-05-17)¶
关系:独立并发(本文未引用 SAPO,发布仅差 4 天,殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都在攻「如何用 verifiable-reward RL(RLVR / GRPO)后训练一个显式-CoT 增强的推荐器」,并且都直面同一个结构性痛点——推荐场景里基于「最终命中」的奖励过于稀疏 / 粒度错配:大多数 rollout 命不中 ground-truth,组内优势相互抵消,训练动态不稳(length drift、KL 暴涨)。
- 相近的技术骨架:都采用「先对齐 / 训练一个推荐组件 → 再用 GRPO 精炼会生成 CoT 的 LLM」的多阶段结构,奖励里都显式拆出「格式项 + 准确率项」,都用 LLM 生成
<think>推理段后再产出 item 表征。 - 本文的差异与推进:SAPO 留在 SID 自回归解码范式内,把病根诊断为 action-granularity mismatch,解法是把 credit 下沉到「thinking block + 配对 SID token」的 reasoning-step 级(per-step match reward + per-step advantage + step-normalized 聚合)。RPORec 则直接换掉奖励来源与 item 表征:它放弃 SID 解码,用一个冻结的检索式 Rechead 给出密集、连续的 NDCG 奖励(式 8),从源头绕开了 SAPO 要修的「0/1 exact-match 稀疏奖励」问题;同时 RPORec 额外优化 CoT 质量本身(similarity / compression / entropy),这是 SAPO 完全没有的维度(SAPO 只关心 SID 命中的 credit 分配,不评判推理文本质量)。一句话:面对同一个「RLVR-for-reasoning-rec 奖励难用」的问题,SAPO 选择精修稀疏奖励的信用分配,RPORec 选择用学习到的检索头把奖励变稠密、并独立奖励推理质量——两条正交的解路。
- 可比的方法 / 实验差异:两者都在 Amazon Reviews 上评,但类目不同(SAPO:Office-Products / Video-Games / Industrial-and-Scientific,5-core leave-one-out;RPORec:Musical Instruments / CDs and Vinyl / Video-Games,无 5-core、截断 20、8:1:1),数值不可直接对照;RPORec 多了 40M 用户工业 A/B,SAPO 无线上实验但提供了 cumulative-match 与 exact-match 同最优解的理论证明(其 Proposition 1)。
OneRec-Think OneRec-Think: In-Text Reasoning for Generative Recommendation (Kuaishou, 2025-10-13)¶
关系:独立并发 / 同源先行(本文未引用 OneRec-Think,且同为快手系工作,约早 7 个月,是 RPORec 所属「显式推理 + 生成式推荐」谱系的更早一支)· 已加载对方精读
- 共同关注的问题:都想把 LLM 的显式、可控推理(in-text / explicit reasoning) 注入推荐,并都明确点出现有生成式推荐器是「隐式预测器、缺乏可解释推理」、以及离散推荐 item 与连续推理空间之间的语义鸿沟。两篇还都遇到并处理了「推荐 RL 奖励稀疏」这件事。
- 相近的技术骨架:都是「对齐 → 激活推理 → RL 强化」的三段式精神:OneRec-Think = Itemic Alignment(SFT)→ Reasoning Activation(bootstrapped CoT SFT)→ Reasoning Enhancement(GRPO);RPORec = (隐含的)backbone 推理对齐 → Stage I Rechead 建模 → Stage II GRPO 精炼。两者都用 GRPO,都在工业系统上做了「近线推理 + 在线服务」的拆分部署(OneRec-Think 的 Think-Ahead vs RPORec 的 nearline K-V 缓存 + 在线 Rechead)。
- 本文的差异与推进:item 表征与奖励来源是分水岭。OneRec-Think 仍走 itemic-token(SID 类)自回归生成,靠 trie/beam 约束解码到合法 item,奖励是 Rollout-Beam exact-match(在约束 beam 内取最佳匹配,式 6 缓解稀疏)——本质还是在「文本→item-token」的范式里。RPORec 彻底解耦:LLM 只产文本 CoT+答案,检索交给独立的 embedding Rechead(点积打分),用 Rechead 的 NDCG 当奖励,从设计上消除了 OneRec-Think 仍需面对的语义鸿沟与 beam 解码成本。此外 RPORec 显式优化 CoT 质量(similarity/compression/entropy)并用门控抑制噪声 CoT,而 OneRec-Think 的推理增强主要服务于「命中 item」而非「压缩/提纯推理本身」。
- 可比的方法 / 实验差异:OneRec-Think 面向快手短视频工业场景、报告 APP Stay Time +0.159%;RPORec 面向工业广告系统、报告 Revenue +1.348% / ADVV +1.058%。场景与指标不同,不可直接比,但两者共同佐证了「显式 in-text 推理 + RL 后训练」在大规模工业推荐里的落地价值。值得注意:SAPO 的精读正是把 OneRec-Think 列为它所改进的「典型 recipe」,说明这三篇(OneRec-Think → SAPO / RPORec)构成了一条清晰的「显式推理生成式推荐 + RLVR」演化脉络,而 RPORec 是其中唯一跳出 SID 解码、改用解耦检索头的一支。
被剔除的近似候选(门槛把关,未纳入对比):ReRec (2604.07851, HK PolyU) —— 同为 reasoning-augmented LLM 推荐的 RFT,但其问题是查询驱动的会话式推荐助手(RecBench+ 复杂 NL query),非 RPORec 的序列 next-item 检索;解法是 dual-graph 奖励整形 + 段落级优势 + 课程调度,与 RPORec 的解耦检索头 + CoT 质量奖励骨架不同。FLR (2604.26760) / LASAR (2605.10207) —— 都是 latent 推理(隐空间/递归 hidden-state),而 RPORec 明确反对 latent-only、坚持显式文本 CoT,推理表征轴相反。ReCast (2604.22169) —— 处理 sparse-hit GRPO 的组内可学习性,属通用 RL 奖励机制修补、不针对推理/CoT 质量;RPORec 用学习头的稠密奖励从另一路绕开稀疏性。
10. 讨论与局限性¶
核心贡献与值得借鉴之处:RPORec 最有价值的判断是——让 LLM 用文本(而非 hidden states 或 SID token)作为与推荐头的接口,一举同时回避了「联合优化扭曲推理」与「生成式的文本→item 语义鸿沟」两个困扰整条 reasoning-rec 路线的结构性难题。配套的两个设计也很实用:(1) Rechead 的门控 + 主表征回退,把「想用 CoT 又怕 CoT 噪声」这件事工程化了;(2) 把冻结的检索头当 verifier 输出稠密 NDCG 奖励,巧妙把推荐 RL 里最棘手的稀疏奖励问题转成连续信号——这与 SAPO「精修稀疏信用分配」、OneRec-Think「Rollout-Beam 取最佳」是三种对同一痛点的不同回答,且 RPORec 的回答可能最干净。(3) 直接奖励 CoT 质量本身(压缩 + 语义保真 + 熵),并用 case study + 长度曲线证明能让推理「更短更准」,是少见地把「推理质量」当一等目标来优化。
局限与争议: 1. 作者自陈(Appendix D):生成 CoT 的质量仍有提升空间,可引入 diversity-oriented 指标、幻觉缓解等额外优化信号。 2. 评估体量偏小:离线只在 3 个 Amazon 类目、且都是小数据集(interactions 仅 1.3万–6.3万),Hit@K 绝对值很低(多在 1%–6%),统计上虽显著,但稀疏长尾下的结论稳健性仍需更大规模公开数据验证。 3. 依赖外部组件:相似度/压缩奖励依赖一个冻结 LLM summarizer + sentence transformer,熵奖励依赖 top-20% 高熵 token 的经验假设,CoT 质量评测用 GPT-5.4 当 judge——这些环节的偏差/成本未充分讨论。 4. 两阶段而非真正联合:迭代优化避免了非平稳奖励,但 Stage I 用「一次性预生成的固定 CoT」训练 Rechead,而 Stage II 的 backbone 已经在变——Rechead 作为 verifier 的分布偏移(distribution shift)随迭代轮次是否累积,论文未深入分析。 5. 工业 A/B 中 LLM 仅作近线用户理解、CoT 经 embedding 当辅助特征喂排序模型,并非真正「在线生成推荐」,与离线检索式评测存在 setup gap;其收益更多来自「把推理产物作为特征增强」而非端到端的在线推理。
工业落地价值:作为快手系工作,RPORec 给出了清晰的「重推理放近线、轻检索放在线」落地范式,并在 40M 用户 / 2.1B 曝光的成熟广告系统上拿到 Revenue +1.348% / ADVV +1.058% 的正收益,对「想用 LLM 推理但受限于延迟/算力」的工业团队有直接参考意义。