Expand More, Shrink Less: Shaping Effective-Rank Dynamics for Dense Scaling in Recommendation¶
腾讯(Tencent Inc.)联合香港科技大学(广州)提出 RankElastor,从「有效秩(Effective Rank)动力学」视角系统诊断当前 SOTA 工业排序模型 RankMixer 的 embedding collapse(嵌入坍缩 / 维度坍缩) 问题:RankMixer 的 token mixing 与 per-token FFN(P-FFN)两个模块共同把有效秩的逐层演化压成一条「阻尼振荡(damped oscillatory)」曲线——浅层扩张、深层收缩,最终表征仍坍缩到低维子空间,使「加参数」无法兑现为「加表达能力」。RankElastor 用两件武器对症下药:(i) 参数化全混合(Parameterized Full Mixing)——把 RankMixer 的无参数块转置混合泛化为最细粒度、可学习的全混合矩阵,让 token mixing「expand more」;(ii) GLU 改进的 P-FFN(GLU-improved P-FFN)——用门控乘性激活替换 GELU,注入正交的二阶交互能量,让 FFN「shrink less」。两者均有谱鲁棒性的理论保证(4 个定理)。在 Criteo / Avazu 上 AUC 较最强基线提升达 0.001(工业级别显著),且展现出比 RankMixer 更强的稠密参数 scaling 行为,并能泛化到行为序列建模任务。
一、研究动机与背景¶
深度学习排序模型(DLRMs)是现代推荐系统的核心,从海量多域类别特征中预测用户–物品交互。受大语言模型 scaling law 启发,扩大模型容量成为推荐系统的自然方向,由此涌现了一批 scaling 导向的架构。其中 RankMixer(ByteDance, CIKM'25, [45])因其简洁设计、强经验性能和良好的 scaling 行为获得了广泛关注。RankMixer 可拆解为三个核心组件:
- Tokenization(词元化):把来自多个特征域的异构嵌入映射到统一的 token 表征空间;
- Token Mixing(词元混合):通过块转置(block-transpose)视角组合 token 表征矩阵,提供跨 token 信息交互;
- Per-token FFN(P-FFN,逐 token 前馈网络):用独立的前馈网络作用于每个 token,建模特征交互(类似「embedding-interaction」范式)。
通过交替堆叠 token mixing 与 P-FFN,RankMixer 形成了一个深而可扩展的排序架构,在多个 benchmark 和实际部署上达到 SOTA。
问题在哪里? 本文指出:RankMixer 从未被从 embedding collapse(嵌入坍缩) 的视角系统审视过。嵌入坍缩是 scaling 推荐系统的一个根本障碍——学到的表征集中在低秩子空间,多个奇异值趋近于零,表征多样性被削弱,模型「加参数」的收益被抵消。已有缓解坍缩的工作要么针对特定推荐器做架构修改,要么用优化策略,缺乏对 RankMixer 这类 token-transformation 架构中坍缩机制的系统理解。
本文的核心发现:从有效秩(effective rank)这一谱测度切入,作者实证观察到 RankMixer 在 token 表征的有效秩演化上呈现一条独特的「阻尼振荡(damped oscillatory)」轨迹:token mixing 模块逐步增大有效秩,而 P-FFN 模块收缩有效秩;两者交替形成「锯齿」形曲线。尽管这种交替行为相比传统推荐器(如 DCNv2、xDeepFM 那种单调衰减)带来了温和改善,但增益有限,并不能可靠地阻止表征坍缩随深度重新出现。
为解锁 token-transformation 架构的潜力,作者提出 RankElastor,一个能产生「谱鲁棒(spectrum-robust)」表征、并对坍缩有可证明缓解的新架构,包含两个关键设计:
- (i) Parameterized Full Mixing(参数化全混合):在 token 上做可学习的细粒度混合,提升谱表达力(spectral expressivity);
- (ii) GLU-improved P-FFNs:用 GLU 风格的门控激活稳定表征谱,缓解原 P-FFN 引起的坍缩放大。
口号即标题——「Expand More, Shrink Less」:让 token mixing 做更强的谱扩张,同时让 P-FFN 的谱收缩更弱。
本文贡献:
- 从 embedding collapse 视角分析 RankMixer,给出实证证据 + 理论论证,证明该架构对坍缩的处理是不充分的;
- 提出 RankElastor,用参数化全混合 + GLU 改进 P-FFN 缓解表征坍缩,并配有谱鲁棒性的理论保证;
- 在工业规模 benchmark 上做大量实验,证明 RankElastor 提升推荐性能、表征多样性与参数 scaling 行为,为推荐系统 scaling 提供了新方向。
二、预备知识与符号¶
2.1 推荐建模与「嵌入–交互」架构¶
推荐模型基于来自多个特征域的特征预测用户行为。本文聚焦 CTR/排序预测:设有 $n$ 个特征域,第 $i$ 个域记为 $\mathcal{X}_i$,联合特征空间 $\mathcal{X} = \mathcal{X}_1 \times \cdots \times \mathcal{X}_n$,目标是学习映射 $\mathcal{X} \to \mathcal{Y}$。
本文关注「嵌入–交互(embedding-interaction)」架构:先把输入样本 $X \in \mathcal{X}$ 转为特征嵌入 $E \in \mathbb{R}^{n \times k}$($k$ 为嵌入维度,第 $i$ 行 $E_i$ 为第 $i$ 域的嵌入向量),再送入特征交互(feature-interaction)模块建模跨域相关性,产出用于预测的信息表征。
2.2 Embedding Collapse 与 Effective Rank¶
维度坍缩(dimensional collapse):一般机器学习中指模型退化为把输入映射到近乎常量输出的平凡表征,可通过对学到表征的谱分析刻画。推荐系统中的 embedding collapse(嵌入坍缩) 是其关联现象:嵌入矩阵近似低秩,伴随多个接近零的奇异值。
衡量坍缩常用 有效秩(effective rank),刻画矩阵奇异值谱的分布。本文采用一种广泛使用、基于范数的定义,也称 stable rank(稳定秩):
$$ \text{erank}(X) \;=\; \frac{\sum_i \sigma_i^2}{\max_i \sigma_i^2} \;=\; \frac{\|X\|_F^2}{\|X\|_2^2} \tag{1} $$
其中 $\sigma_i$ 为 $X$ 的奇异值。该量越小表示能量越集中于少数主方向(坍缩越严重),越大表示信息在更多正交方向上均匀分布。
注:本文采用的是 stable rank($\|X\|_F^2/\|X\|_2^2$),与另一类基于谱熵的有效秩定义 $\exp(-\sum_i p_i \ln p_i)$($p_i=\sigma_i/\sum_j\sigma_j$)不同,但二者都用于量化「有效信息维度」。这一区别在后文「与已归档相关工作的对比」中会再次提及。
2.3 RankMixer 三模块回顾¶
- Tokenization:tokenization 模块把嵌入矩阵 $E$ 分组为 $T$ 个簇,经统一映射(线性/MLP)到共享的 $D$ 维空间,得到 token 矩阵 $X^{(0)} \in \mathbb{R}^{T \times D}$,每行 $x_i^{(0)} \in \mathbb{R}^D$ 称为一个 token 嵌入。该模块主要用于对齐异构来源的嵌入。
- Token mixing:把列维 $D$ 划分为 $H$ 个等长段、每段大小 $d = D/H$,形成 $T \times T$ 的块网格,每块 $\in \mathbb{R}^{1 \times d}$。在第 $l$ 个 RankMixer 块,先对输入 $X^{(l)}$ 做块转置(block-transpose)——交换块 $X^{(l)}_{i,j}$ 与 $X^{(l)}_{j,i}$;转置后的表征再经残差连接与输出层归一化与原 token 矩阵合并,产出增强后的混合 token 表征。
- P-FFNs:把混合后的 token 送入 token-specific 的 FFN(即 P-FFN),作为「embedding-interaction」式特征交互的函数。RankMixer 的 P-FFN 配置为两层、以 GELU 为激活。
堆叠 token mixing 与 P-FFN 即得到深而可扩展的排序架构(见图 3(a))。
三、RankMixer 的 Embedding Collapse 诊断¶
本节是全文的「靶心」:作者用实证 + 理论双轨论证 RankMixer 为何无法根治坍缩。
3.1 实证证据:阻尼振荡轨迹¶
作者在 Criteo、Avazu 两个工业规模数据集上、用 FuxiCTR 框架做 CTR 实验,把 RankMixer(两个 token-mixing 块 + 两个 P-FFN 块) 与 DCNv2、xDeepFM(配置成相当深度的四层推荐器)对比,跨测试样本测量各模块输出的平均有效秩。
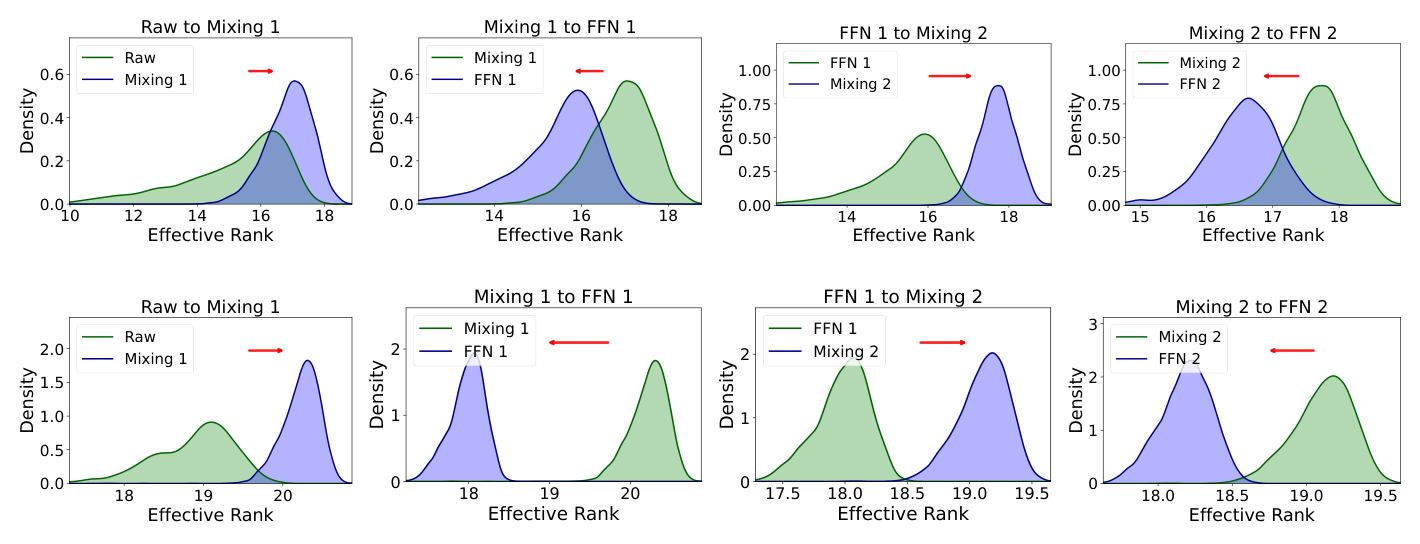
关键观察:
- 传统模型(DCNv2、xDeepFM):有效秩随深度单调衰减(monotonic decay);
- RankMixer:呈现交替模式——token mixing 增大有效秩,P-FFN 收缩有效秩,整体是一条阻尼振荡(锯齿)轨迹;
- 在 Criteo 上,末层有效秩仅微弱超过 raw embedding,说明 token mixing 的「秩增强」效应在实践中很温和;
- 在 Avazu 上问题更尖锐:P-FFN 引入的收缩跨层占主导,坍缩重新出现。
由于更高的有效秩通常意味着更好的表征容量利用、并与推荐性能正相关,这些结果同时揭示了 RankMixer 的优势与局限:它相比传统推荐器改善了表征秩,但没有从根本上解决坍缩。
3.2 理论论证:两个定理¶
作者把「有效秩提升」与「残留坍缩」分别追溯到 token mixing 与 P-FFN 两个模块,给出两个定理。
定理 2.1(块转置混合下的有效秩):设 $X \in \mathbb{R}^{T \times D}$,$D = Td$,$d \ge 1$。把 $X$ 视为 $T \times T$ 的行块网格、块 $X_{ij} \in \mathbb{R}^{1\times d}$。定义块转置算子 $\mathcal{T}$ 为 $(\mathcal{T}(X))_{ij} = X_{ji}$,令 $Y = \mathcal{T}(X)$。记 $X$ 的代数秩 $\text{rank}(X)=r$、有效秩 $\text{erank}(X)=k$。假设 $X$ 满足 Frobenius 正交性与谱不相干性:
$$ \langle X, Y\rangle_F \approx 0, \qquad \|X+Y\|_2^2 \approx \max\{\|X\|_2^2, \|Y\|_2^2\}. $$
令 $M = X + Y$、$\mu = \text{erank}(Y)$,则
$$ \frac{2k\mu}{(\sqrt{k}+\sqrt{\mu})^2} \;\le\; \text{erank}(M) \;\le\; 2(k+\mu), \qquad \mu \le \text{rank}(Y) \le \min\{T, rd\}. \tag{2} $$
含义:块转置混合产生的表征,其有效秩有一个正的下界 $\frac{2k\mu}{(\sqrt{k}+\sqrt{\mu})^2}$,即 token mixing 确实引入了秩扩张效应。但定理也揭示了其内在局限:可达到的提升被上界 $\text{erank}(X+Y) \le 2(k+\mu)$ 约束。由于推荐嵌入在初始化阶段往往已严重谱坍缩($k$ 很小),这种有界扩张在实践中只带来温和的秩提升——正好解释了图 1(a)、1(c) 中 token mixing 后秩增长很小的现象。
定理 2.2(标准 FFN 的有效秩失效):设 $X \in \mathbb{R}^{T \times D}$,$\text{erank}(X)=k$,且 $k/D \le \gamma$($\gamma \in (0,1)$ 为与 $D$ 无关的固定常数)。考虑逐行前馈网络 $\mathcal{F}(X) = \phi(XA)B$,其中 $A \in \mathbb{R}^{D \times m}$、$B \in \mathbb{R}^{m \times D}$ 的元素为 i.i.d. 亚高斯、方差 $1/D$,$\phi$ 为正齐次(positively homogeneous)激活(如 ReLU)。则:
- (确定性坍缩) 若 $X$ 代数秩为 1,则 $\text{rank}(\mathcal{F}(X)) \le 2$,$\text{erank}(\mathcal{F}(X)) \le 2$;当 $X$ 所有行同号时取等于 1;
- (概率性收缩) 若预激活满足一个非平凡的 response-gap 条件(见原文附录 B),则以至少 $1 - \exp(-ck)$ 的概率,$\text{erank}(\mathcal{F}(X)) \le \alpha\,\text{erank}(X)$,其中 $\alpha \in (0,1)$ 是仅依赖 $\gamma$ 与激活 $\phi$ 的常数。
含义:定理 2.2 刻画了 P-FFN 的互补(收缩)效应——当输入表征已低秩时,FFN 会进一步收缩有效秩,确定性下退化为秩 1,概率上退化为通用的「乘性收缩」(rank-$k$ 收缩为 $\alpha k$)。这解释了图 1(b)、1(d) 中反复出现的有效秩下降。
小结:token mixing 提供有界的秩扩张,P-FFN 表现出秩收缩行为,两者共同产生了那条特征性的阻尼振荡轨迹。这一诊断直接指向架构改良的原则方向——「Expand More, Shrink Less」:让 token mixing 产生更强的谱扩张,同时让 P-FFN 更少地收缩谱。
四、核心方法:RankElastor¶
RankElastor 通过对 RankMixer 的 token-mixing 与 P-FFN 两模块建立「坍缩鲁棒的 token 变换」来泛化它,包含两个核心组件,均有理论支撑。架构对比见图 3。
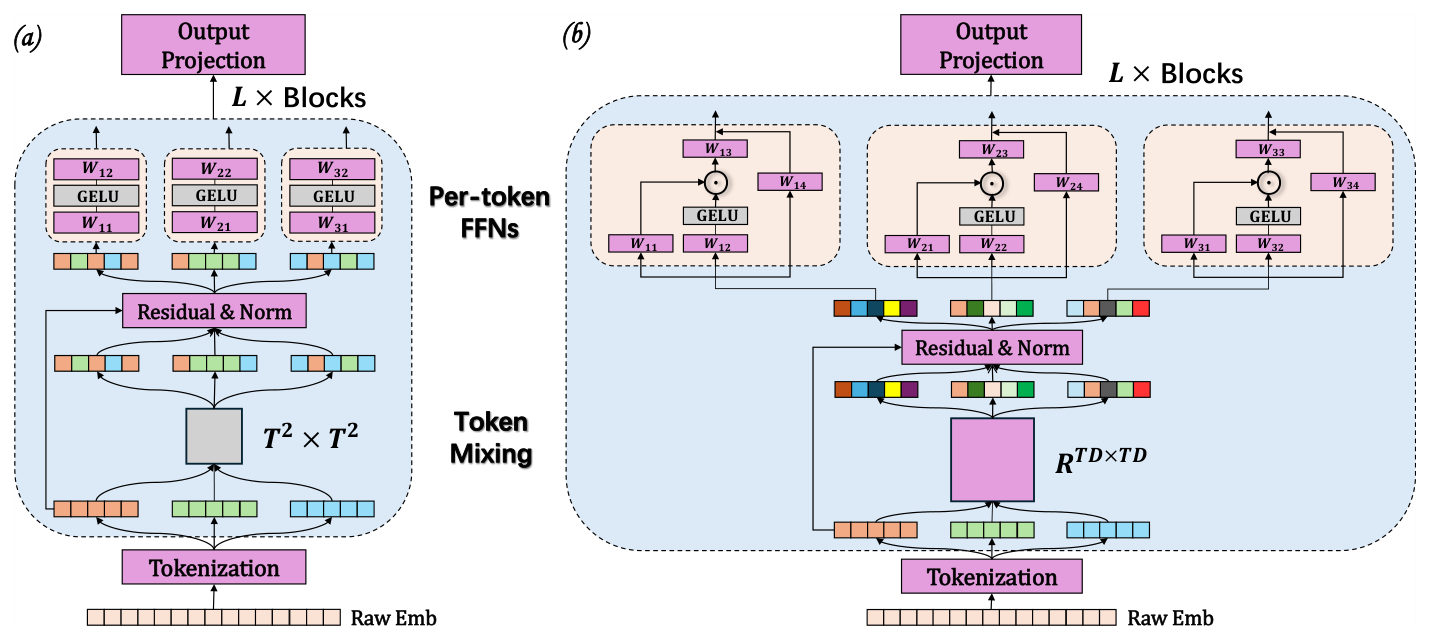
4.1 参数化全混合(Parameterized Full Token Mixing)¶
RankMixer 的 token mixing 是一个无参数的块转置操作,等价于:
$$ \text{vec}(M^\top) = \text{LN}\big((P \otimes I)\,\text{vec}(X^\top) + \text{vec}(X^\top)\big), \tag{2'} $$
其中 $P \in \mathbb{R}^{T^2 \times T^2}$ 是一个结构化的置换算子(commutation matrix,交换矩阵),$I \in \mathbb{R}^{\frac{D}{T} \times \frac{D}{T}}$ 为单位阵,$\text{vec}(\cdot)$ 为向量化算子,$\text{LN}$ 为层归一化,$\otimes$ 为 Kronecker 积。
这一表示揭示了一个重要结构性质:token mixing 被置换算子 $P$ 与网格尺度 $d = D/T$ 共同支配。修改 $P$ 或 $d$ 都会改变 mixing 行为。据此作者引入可学习的混合算子 $W$、并把网格尺度缩到最细分辨率,得到参数化全混合:
$$ \text{vec}(M^\top) = \text{LN}\big((W + I)\,\text{vec}(X^\top)\big), \tag{3} $$
其中 $W \in \mathbb{R}^{TD \times TD}$ 是可学习混合矩阵,$I$ 保留残差信息流。这对应于最细粒度 $d=1$、完全参数化的混合权重,允许跨所有 token–feature 坐标的交互。这种泛化通过让模型精化「受限块变换下可能导致谱坍缩」的表征,强化了 token-mixing 的谱表达力。
定理 3.1(参数化全混合的表达力):设 $X \in \mathbb{R}^{T \times D}$,$x = \text{vec}(X) \in \mathbb{R}^N$,$N = TD$。对 $N$ 的某个因子 $d^*$,把 $x$ 划分为 $K = N/d^*$ 个块 $\mathcal{B} = \{b_1, \dots, b_K\}$,$b_k \in \mathbb{R}^{d^*}$。以可学习权重 $W \in \mathbb{R}^{K \times K}$ 做参数化块混合,产出 $y = (W \otimes I_{d^*})x$,残差输出 $C = \Phi_{d^*}(X; W) \triangleq X + \text{reshape}((W \otimes I_{d^*})\,\text{vec}(X))$。则对任意 $d^* > 1$,$\Phi_{d^*}$ 可实现的线性变换集合严格包含于 $d^*=1$(参数化全混合)的可实现集合。特别地,Kronecker 约束 $(W \otimes I_{d^*})$ 阻止了表达 $d^*=1$ 时可达的细粒度、高秩坐标交互。
含义:定理表明,当网格尺度 $d^* > 1$ 时,总存在某些输入,其 token-mixing 输出仍受谱约束;而最细粒度 $d^*=1$(对应参数化全混合)去除了 Kronecker 约束,使更丰富的坐标交互成为可能,从而提升对表征坍缩的鲁棒性。这是 RankElastor 选择「最细粒度全矩阵」而非「块结构」的理论依据。
4.2 GLU 改进的 P-FFN(GLU-improved P-FFNs)¶
参数化全混合提升了矩阵层面(有效秩)的表达力,但其缓解坍缩的效应主要是统计性的而非确定性的。在高度偏斜或退化的输入下,表征仍可能退化。为进一步增强鲁棒性,作者改造 RankMixer 的第二个核心模块 P-FFN:用 GLU 风格的门控前馈模块替换 GELU FFN(省略偏置):
$$ Z_t = \big(\text{GELU}(M_t W_1) \odot (M_t W_2)\big) W_3 + M_t W_r, \tag{4} $$
其中 $W_1, W_2 \in \mathbb{R}^{D \times rD}$ 为提升投影(lifting projections),$r$ 为扩张比,$W_3 \in \mathbb{R}^{rD \times D}$ 为压缩投影,$W_r$ 为可学习残差映射,$\odot$ 为 Hadamard(逐元素)积。这一设计沿用 GLU 的门控激活原理,已被证明能提升现代深度架构的表达力与表征质量。
定理 3.2(GLU 改进 P-FFN 的有效秩恢复):设 $X \in \mathbb{R}^{T \times D}$,$\text{erank}(X)=k$,$k/D \le \gamma$。考虑带残差的 GLU 改进 P-FFN:
$$ \mathcal{G}(X) = \big(\phi(XA) \odot (XC)\big)B + XD, $$
其中 $A, C \in \mathbb{R}^{D \times m}$、$B \in \mathbb{R}^{m \times D}$ 元素为 i.i.d. 亚高斯、方差 $1/D$、$\psi_2$-范数 $\le K/\sqrt{D}$。若隐藏宽度 $m \ge C_0 k \log D$,则以至少 $1 - \exp(-ck)$ 的概率:
- (代数提升 Algebraic lifting) 乘性项诱导二阶(degree-2)交互,$\text{rank}(\phi(XA) \odot (XC)) \ge \min\big(D, \frac{k(k+1)}{2}\big)$;
- (有效秩增加) 输出满足 $\text{erank}(\mathcal{G}(X)) \ge \text{erank}(X) + \delta$,$\delta > 0$ 取决于 $\gamma$ 与初始化常数。
含义:GLU 改进的 P-FFN 通过乘性特征交互在统计上维持谱鲁棒性——乘性项把 token 的潜在坐标提升为二阶单项式,向原线性路径注入了与之正交的 Frobenius 能量(附录 D 用 Jacobian 迹下界证明这些新方向对应「非消失的奇异值」,是数值有效的);而传统基于激活的 FFN 仍可能呈现非平凡的失效(导致有效秩坍缩)。换言之,GLU P-FFN 让「收缩」变成「轻微收缩甚至增长」,与 token mixing 的「expand more」配合,构成「shrink less」。
4.3 复杂度分析¶
| 模块 | RankMixer 计算 | RankMixer 参数 | RankElastor 计算 | RankElastor 参数 |
|---|---|---|---|---|
| Token mixing | $O(TD)$(块转置置换) | $0$(无参) | $O(T^2D^2)$(全线性变换) | $O(T^2D^2)$ |
| P-FFN | $O(TrD^2)$ | $O(rD^2)$ | $O\big(T(3rD^2 + D^2)\big)$ | $(3r+1)D^2$ |
主要复杂度差异来自 token-mixing:RankElastor 的参数化全混合引入了 $O(T^2D^2)$ 的计算与参数;GLU 改进 P-FFN 只带来常数因子级别的增量。整体上,作者通过实验(§5.2 效率对比)说明这一额外开销对大规模推荐是实践上可忽略的(运行时仅增 10%–15%,GPU 显存与 DCNv2 等高效基线相当)。
五、实验设置¶
围绕 4 个研究问题展开:
- RQ1:RankElastor 在标准 CTR benchmark 上是否优于现有基线?
- RQ2:相比 RankMixer,RankElastor 缓解嵌入坍缩的效果如何?
- RQ3:相比 RankMixer,RankElastor 的 scaling 行为如何?
- RQ4:RankElastor 能否泛化到 CTR 之外的任务?
数据集:Criteo 与 Avazu 两个工业规模 CTR benchmark。
| 数据集 | 训练量 | 验证量 | 测试量 | 特征域数 |
|---|---|---|---|---|
| Criteo | 33.0M | 8.3M | 4.6M | 39 |
| Avazu | 32.3M | 4.0M | 4.0M | 24 |
指标:AUC(↑)、LogLoss(↓);评估表征坍缩用式 (1) 的有效秩。
基线:RankMixer,以及若干代表性特征交互模型——xDeepFM、DCNv2、AutoInt 和标准 DNN(MLP)。
配置:RankElastor 与 RankMixer 均用两层(两个堆叠块)。$(T, D) = (15, 26)$(Criteo)、$(16, 24)$(Avazu)。P-FFN 隐藏维设为 $D$,RankElastor 的 GLU P-FFN 扩张比 $r = 3$。其余超参用 FuxiCTR 库推荐配置。
协议:所有模型基于开源 FuxiCTR 库、按其官方推荐训练流水线实现。嵌入维度 Criteo 为 20、Avazu 为 16。最多训练 100 epoch,验证 LogLoss 连续 2 个 epoch 不下降则早停。batch size:Criteo 4096,Avazu 10000。每个结果在10 次不同随机初始化下平均以保证统计可靠性。
六、主要实验结果¶
6.1 RQ1:CTR 预测性能¶
表 2:RankElastor 与基线在 Criteo / Avazu 上的整体 CTR 预测性能。
| Model | Criteo AUC ↑ | Criteo LogLoss ↓ | Avazu AUC ↑ | Avazu LogLoss ↓ |
|---|---|---|---|---|
| MLP | 0.81307 | 0.43927 | 0.79226 | 0.37204 |
| xDeepFM | 0.81334 | 0.43849 | 0.79242 | 0.37236 |
| DCNv2 | 0.81365 | 0.43816 | 0.79258 | 0.37227 |
| AutoInt | 0.81331 | 0.43853 | 0.79072 | 0.37430 |
| RankMixer | 0.81375 | 0.43799 | 0.79270 | 0.37218 |
| RankElastor | 0.81482 | 0.43730 | 0.79323 | 0.37196 |
结论:RankElastor 在两个数据集的 AUC 与 LogLoss 上一致优于所有基线(含 RankMixer)。AUC 较最强竞争者提升达 0.001——在工业规模 CTR 上被认为是统计上有意义的改进。值得注意的是,RankElastor 的参数规模与其他基线相当,说明性能增益并非靠堆模型复杂度换来的。
七、消融与深入分析¶
7.1 模块贡献消融(RQ1)¶
表 3:RankElastor 与 RankMixer 的逐模块消融。
| Model | Criteo AUC ↑ | Criteo LogLoss ↓ | Avazu AUC ↑ | Avazu LogLoss ↓ |
|---|---|---|---|---|
| RankElastor | 0.81482 | 0.43730 | 0.79323 | 0.37196 |
| w/o Full Mixing(去参数化全混合) | 0.81413 | 0.43785 | 0.79289 | 0.37210 |
| ReLU-based FFN(GLU→ReLU) | 0.81326 | 0.43869 | 0.79241 | 0.37229 |
| GELU-based FFN(GLU→GELU) | 0.81349 | 0.43851 | 0.79288 | 0.37212 |
| RankMixer | 0.81375 | 0.43799 | 0.79270 | 0.37218 |
| + GLU-style FFN(仅给 RankMixer 加 GLU) | 0.81393 | 0.43802 | 0.79286 | 0.37212 |
| ReLU-based FFN(RankMixer 用 ReLU) | 0.81284 | 0.43917 | 0.79227 | 0.37238 |
结论:
- 参数化全混合与 GLU 改进 P-FFN 各自都显著贡献性能,移除任一组件都会带来一致的性能退化;
- 两模块呈明显的协同效应:组合二者的提升远大于单用任一模块;
- 把同样的 GLU 改造单独加到 RankMixer 上($0.81393$ vs RankMixer $0.81375$)只带来边际增益——说明 GLU 改进 P-FFN 的收益依赖于参数化全混合带来的增强 token-mixing 能力,与定理分析中「两模块互补缓解坍缩」一致。
7.2 效率对比¶
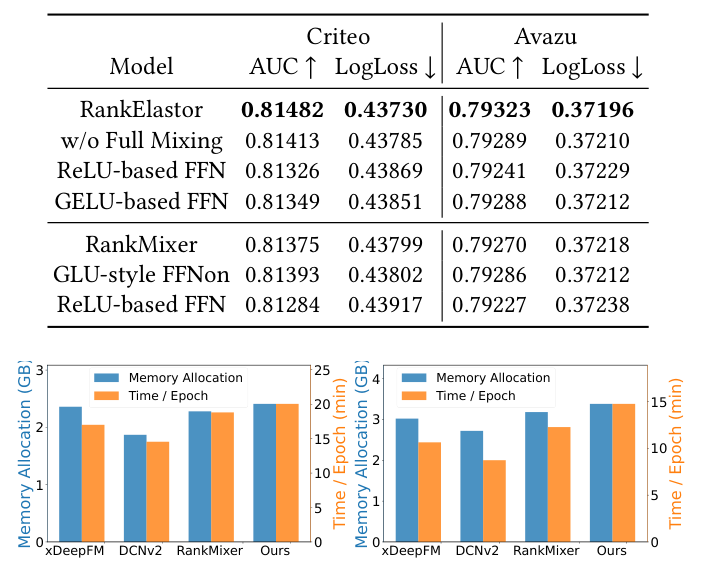
RankElastor 相比 RankMixer 运行时增加 10%–15%,但 GPU 显存需求相近,且与 DCNv2 等高效基线竞争力相当。这与 §4.3 的复杂度分析一致——额外计算成本对大规模推荐实践上可忽略,整体上是「以微小效率开销换取更优推荐性能」的良好折中。
7.3 RQ2:嵌入坍缩缓解¶
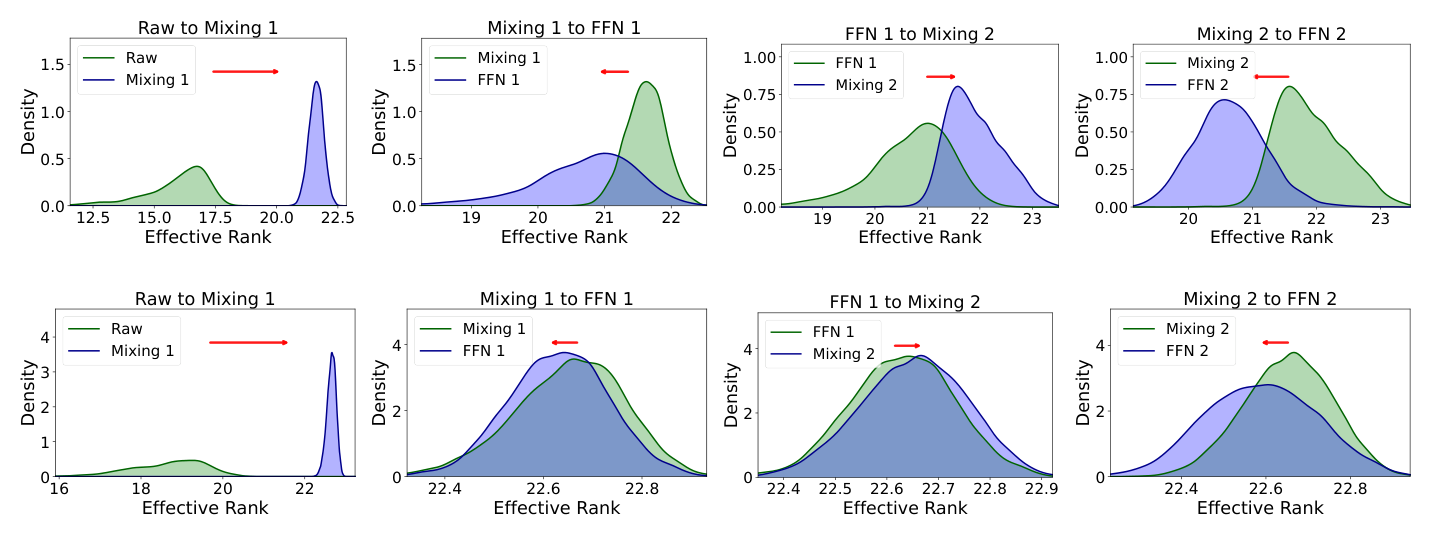
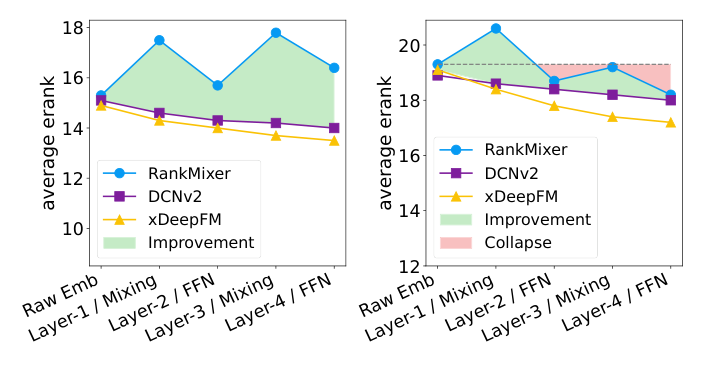
有效秩分布迁移:如图 5,RankElastor 在内部表征间展现出显著更大的有效秩分布漂移。两模型在 raw embedding 阶段分布几乎相同,但随表征前传而分道扬镳:RankElastor 的参数化全混合带来的有效秩增益明显大于 RankMixer 的块转置混合,而 GLU 增强的 P-FFN 相比 RankMixer 的 P-FFN 保持了更强的秩保留。
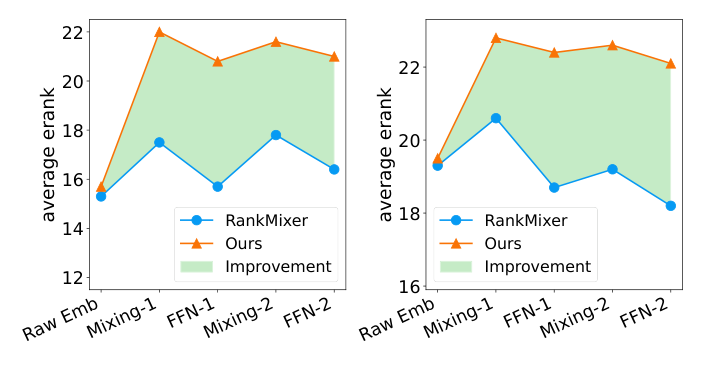
「Expand more, shrink less」的实证:如图 6,RankElastor 的谱动力学仍遵循 RankMixer 那种「token mixing 扩张、P-FFN 收缩」的交替特征——但相比 RankMixer,扩张效应明显更强、且每个 P-FFN 后的收缩明显更弱。这带来更稳定的跨层谱演化,使 RankElastor 在各数据集、各表征阶段一致维持更高的平均有效秩。尤其在 Avazu(RankMixer 表现出明显坍缩趋势)上,RankElastor 保持了稳定的有效秩增长,表明对表征坍缩有更强的鲁棒性。
7.4 RQ3:稠密参数 Scaling 分析¶
为评估 scaling 行为,作者在稠密参数(参数化全混合 + GLU P-FFN 内)上做 scaling-law 实验,分别变化深度(块数)与宽度(FFN 隐藏维),并考察单独与联合 scaling。
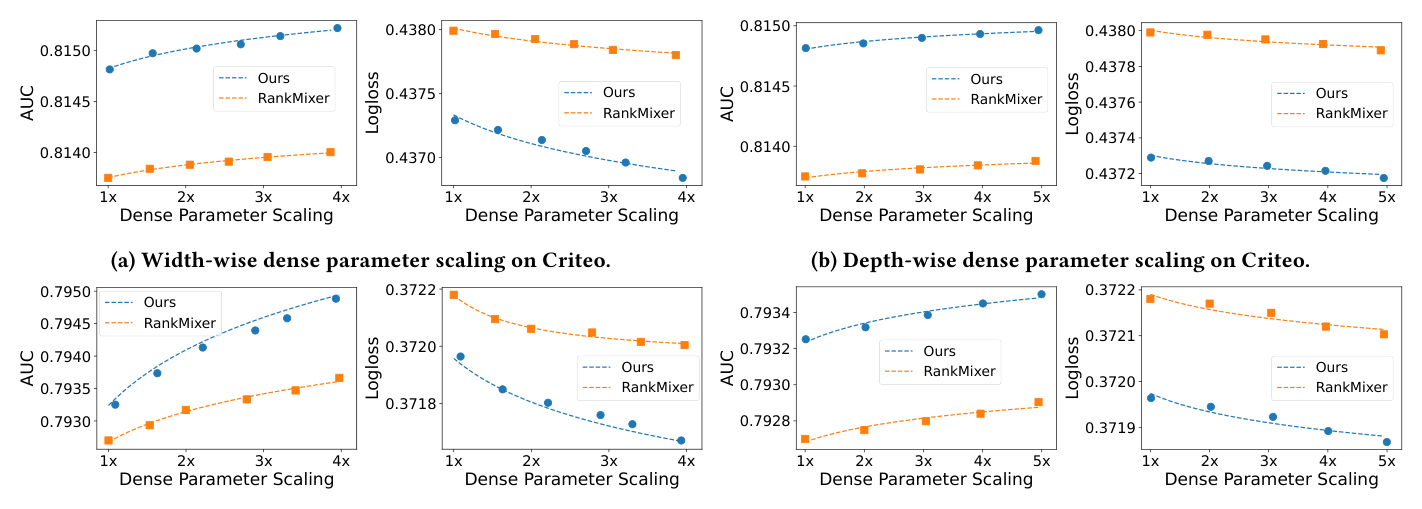
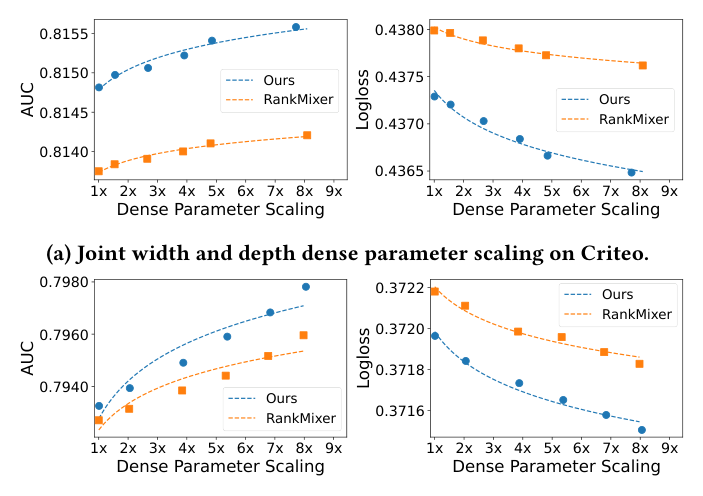
结论:
- 跨所有配置,RankElastor 都展现出显著优于 RankMixer 的 scaling 行为——随模型参数增加,AUC 提升更大、LogLoss 更低;
- 对比联合 scaling(图 8)与单维 scaling(图 7):同时增大深度与宽度带来的增益持续大于只 scale 单一维度——这与 LLM(Kaplan 等)及 RankMixer 中的先前观察一致,但 RankElastor 上的 scaling 性质更显著;
- 这表明 RankElastor 凭借其「缓解坍缩」的理论根基,能作为深度推荐系统更有效的 scaling 范式。
7.5 RQ4:行为序列建模泛化¶
为评估 CTR 之外的泛化,作者在 FuxiCTR 的两个行为序列建模数据集上额外实验:KuaiVideo (K)(短视频点击概率)与 TaobaoAd (T)(用户购物行为)。报告 AUC 与 Group-AUC(gAUC)。
表 4:RankElastor 与 RankMixer 等在行为序列建模任务上的对比。
| Model | gAUC (K) ↑ | AUC (K) ↑ | gAUC (T) ↑ | AUC (T) ↑ |
|---|---|---|---|---|
| AutoInt | 0.6667 | 0.7469 | 0.5744 | 0.6486 |
| DCNv2 | 0.6675 | 0.7470 | 0.5749 | 0.6495 |
| xDeepFM | 0.6696 | 0.7471 | 0.5729 | 0.6393 |
| RankMixer | 0.6691 | 0.7482 | 0.5763 | 0.6508 |
| RankElastor | 0.6731 | 0.7514 | 0.5778 | 0.6522 |
结论:RankElastor 在两个数据集、两个指标上全面取得最佳,且观察到与图 6 类似的谱动力学改善——说明其分析框架与统一混合设计能有效泛化到标准 CTR 估计之外的更广推荐场景。
八、核心贡献总结¶
- 诊断视角创新:首次系统地从 embedding collapse / 有效秩动力学视角剖析 SOTA 工业排序架构 RankMixer,提炼出「阻尼振荡」这一刻画——token mixing 扩张、P-FFN 收缩,并给出定理 2.1 / 2.2 的理论根因(有界秩扩张 + 乘性秩收缩)。
- 架构方法创新:提出 RankElastor,用参数化全混合(定理 3.1:最细粒度 $d^*=1$ 严格强于任何块结构 $d^*>1$)与 GLU 改进 P-FFN(定理 3.2:乘性二阶交互带来代数提升 + 有效秩增加)实现「Expand More, Shrink Less」。
- 完整实证:在 Criteo / Avazu 上 AUC +0.001(工业级显著)、消融证实两模块协同、效率开销可忽略;有效秩可视化证实坍缩缓解;scaling 实验证实更优 scaling law;并泛化到 KuaiVideo / TaobaoAd 行为序列任务。
- 开源:代码见
github.com/vasile-paskardlgm/RankElastor。
九、与已归档相关工作的对比¶
本文与文档库中两篇问题 + 解法双同构、但本文均未在参考文献中引用的并发工作(均为 2026-04)构成有价值的对照——它们都直面「RankMixer/MetaFormer 家族排序模型的有效秩 / 表征坍缩」这一同一 root cause,但在解法路径上做出了互补甚至相反的选择。
RankUp RankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems(Tencent, 2026-04-20)¶
关系:独立并发(本文参考文献未引用 RankUp,两者同攻有效秩坍缩,殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都把 root cause 锁定在「MetaFormer/RankMixer 家族中 token 表征的有效秩(Effective Rank)随层深退化、表征坍缩」,且都明确把病因归到同一对模块——Token Mixer 只能提供有界的跨 token 秩扩张、Per-token FFN 是秩收缩算子,两者叠加导致深层坍缩。RankUp 的精读甚至直接引用了一篇刻画「阻尼振荡(damped oscillatory)有效秩轨迹」的诊断工作(其 [19] "Expand, Pool and Shrink",与本文标题 "Expand More, Shrink Less" 出自同一研究脉络),与本文 §3 的诊断完全同构。
- 相近的技术骨架:两者都显式用有效秩作为核心诊断/优化指标,都在「不堆参数也要提升表达多样性」的目标下重构 MetaFormer 主干,都采用门控 FFN(RankUp 用 SwiGLU,本文用 GLU 改进 P-FFN)来增强高阶交互、抑制 FFN 侧收缩。
- 本文的差异与推进:解法路径正交分工——RankUp 主要在输入/词元化侧扩张潜空间多样性(随机置换分片、多嵌入表、全局 token、跨域预训练嵌入融合、任务专属 token 解耦五个机制),即「把潜空间基底做大」;而 RankElastor 直接重构两个内部模块(参数化全混合 + GLU P-FFN),即「把层内变换的谱行为做对」。耐人寻味的是,RankUp 在动机里明确点名并选择不走 "Full-Mix / Unimixer" 这条更复杂 token mixer 的路(认为是在受限空间内「挤」交互),而 RankElastor 恰恰用定理 3.1 论证了最细粒度全混合($d^*=1$)的表达力严格优越性——两篇对「该不该把 token mixer 参数化加重」给出了相反的设计判断。
- 可比的方法 / 实验差异:有效秩定义不同——本文用 stable rank $\|X\|_F^2/\|X\|_2^2$(式 1),RankUp 用谱熵型 $\exp(-\sum p_i\ln p_i)$;评测层面 RankUp 是腾讯广告 CVR 在线全量部署(GMV +3.41%/+4.81%/+2.21%),本文是 Criteo/Avazu 公开 benchmark + scaling law 离线分析。二者可视为「同一坍缩诊断下,输入侧增广(RankUp)vs 层内模块重构(RankElastor)」两条互补落地路线。
UniMixer UniMixer: A Unified Architecture for Scaling Laws in Recommendation Systems(Kuaishou, 2026-04-01)¶
关系:独立并发(本文参考文献未引用 UniMixer,两者独立得出「参数化 TokenMixer」同一核心洞察)· 已加载对方精读
- 共同关注的问题:两篇都从「TokenMixer 的无参数置换本质」出发,指向同一结构性瓶颈——无参数块混合限制了 scaling 时的特征交互/表达能力。两者都用几乎相同的代数事实作为出发点:TokenMixer 等价于一个置换矩阵 $W^{\text{perm}} = G \otimes I$(Kronecker 结构) 作用于展平输入(本文式 2':$(P\otimes I)\,\text{vec}(X^\top)$;UniMixer:$\text{reshape}(W^{\text{perm}}\,\text{flatten}(X))$,$W^{\text{perm}}=G\otimes I$)。
- 相近的技术骨架:两者的核心动作完全一致——把那个 Kronecker 结构的无参数置换参数化为可学习矩阵,从而把「固定的 token 重排」升级为「可学习的 token 混合」,以此打通更强的 scaling。
- 本文的差异与推进:在「参数化到多细的粒度」上做出了相反选择。UniMixer 保留块–Kronecker 结构($W_G \otimes \{W_B^i\}$,块尺度 $B$),并施加 Sinkhorn-Knopp 双随机 + 稀疏 + 对称约束,目的是统一 Self-Attention / TokenMixer / FM 三类 scaling 范式并兼顾效率(复杂度从 $O(L^2)$ 降到 $O(L^2/B + LB)$);而 RankElastor 走到最细粒度 $d^*=1$、无约束的全 $TD\times TD$ 矩阵 $W$,并用定理 3.1 直接论证:任何 $d^*>1$ 的 Kronecker 块混合的可实现变换集合严格小于 $d^*=1$ 的全混合——这正好与 UniMixer「为效率/统一而保留块结构」的选择构成理论对立面。
- 可比的方法 / 实验差异:UniMixer 追求「一个模块统一三范式 + 高效 scaling」,靠结构约束换效率;RankElastor 追求「最大谱表达力 + 坍缩鲁棒」,以 $O(T^2D^2)$ 的全矩阵换表达力(并论证此开销实践可忽略)。两篇是「同一参数化洞察」下,约束化块混合(UniMixer)vs 无约束全混合(RankElastor) 的一对镜像设计——对「token mixer 该参数化到多细」给出了可直接对照的答案。
说明:同属 TokenMixer 家族的 TokenMixer-Large TokenMixer-Large 与 SSR SSR 经语义初筛后被剔除——前者把深层 scaling 瓶颈归因于残差错位 / 梯度 / MoE 稀疏化(root cause 与「有效秩坍缩」不同),后者用维度级稀疏过滤而非有效秩扩张(解法路径不同);二者均与本文「问题 + 解法双同构」不成立。RankMixer(RankMixer)作为本文直接改进的 baseline,由 §四正文与 DAG 结构化对比承接,不在此叙事章节重复。
十、讨论与局限性¶
核心价值:本文最大的贡献不在于刷点(AUC +0.001 虽工业显著但绝对值不大),而在于给「scaling 推荐模型为何收益递减」提供了一个可操作的谱视角——把模糊的「embedding collapse」量化为逐层有效秩动力学,并精确归因到 token mixing(有界扩张)与 P-FFN(乘性收缩)两个模块。这把「加参数 ≠ 加表达能力」这一经验直觉,转化为可被定理刻画、可被架构修复的具体目标。两条修复路线(参数化全混合的表达力下界、GLU P-FFN 的有效秩恢复下界)都有相对扎实的理论支撑(附录 A–D 用块转置秩分析、正齐次激活的同质性壁垒、随机投影 Johnson–Lindenstrauss、Hanson–Wright / Matrix Bernstein 浓度、Jacobian 迹下界等工具完成证明)。
值得借鉴的设计:
- 「把无参数置换算子还原成 Kronecker 结构、再参数化、再推到最细粒度」是一个清晰可复用的设计动作(与 UniMixer 殊途同归,但 RankElastor 用定理 3.1 给了粒度选择的理论判据);
- 「GLU 乘性门控 = 注入正交的二阶单项式能量 → 提升有效秩」这一解释,把 GLU 在 LLM 中的经验优势迁移到了推荐场景,并给了谱层面的 why。
局限与争议:
- 绝对增益有限:AUC +0.001 虽被称工业显著,但论文主要在 Criteo/Avazu 公开 benchmark 验证,缺乏真实在线 A/B 与部署收益(对比并发的 RankUp 给出了腾讯广告全量部署的 GMV 数字)。其工业落地价值尚需在线验证。
- 复杂度代价:参数化全混合的 $O(T^2D^2)$ 计算/参数随 $T、D$ 平方增长,在 $T、D$ 较大的真实工业配置下,「实践可忽略」的结论是否依然成立存疑——论文实验的 $(T,D)$ 较小(15×26、16×24)。
- 理论假设较强:定理 2.1 依赖 Frobenius 正交性与谱不相干性、定理 2.2/3.2 依赖亚高斯随机权重与 response-gap / 隐藏宽度 $m \ge Ck\log D$ 等假设;这些在初始化阶段成立,但训练后权重分布是否仍满足,论文未充分讨论。
- 诊断与方法的适用边界:论文自陈,「阻尼振荡轨迹」是 RankMixer 这类 token-transformation 架构固有、与架构相关的现象,理论分析也聚焦此类模型,对其他架构(如纯 attention、FM 系)未必直接适用。
与已有工作的差异:相比 RankUp(输入侧增广)、UniMixer(块结构统一参数化)、TokenMixer-Large(残差/MoE 重构以 scale 到 15B),RankElastor 的独特定位是「在层内两模块上做最细粒度、有理论判据的谱修复」——它不追求最大规模或最强工程,而是把「为什么 RankMixer 的秩会振荡坍缩、以及怎样从架构层面让它 expand more / shrink less」这个问题讲清楚并给出可证明的解。这是一条偏「机理理解 + 原则化修复」的路线。