RankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems¶
Tencent WeChat 广告团队针对 MetaFormer 家族工业排序模型(RankMixer / HiFormer / MixFormer / TokenMixer-Large 等)在深层网络出现的表征坍缩与有效秩退化问题,提出 RankUp 架构,通过随机置换分片、多嵌入表、全局 token、跨域预训练嵌入融合、任务专属 token 解耦五个机制系统性提升 token 表征的 Effective Rank。已在微信视频号 / 公众号 / 朋友圈广告三大场景 100% 全量部署,GMV 相对提升 3.41% / 4.81% / 2.21%,在 Order Task 上 GMV 提升高达 7.18%,新广告冷启动场景 Weixin Official Accounts 上 GMV 提升 9.67%。
研究动机与背景¶
推荐系统的 scaling law 近年得到了越来越多经验验证:MetaFormer 结构(AutoInt / Hiformer / Wukong / Interformer / RankMixer / TokenMixer-Large / Mixformer)依赖加深模型深度、加宽隐藏维度、延长用户行为序列带来排序性能提升。然而一个被广泛忽视的问题是:表达能力(representation capacity)是否真的和参数规模成正比?
Chen 等人(Expand, Pool and Shrink, [19])的经验分析指出,在深度推荐模型(如 RankMixer)中,token 表征的 Effective Rank 随着层深呈现阻尼振荡(damped oscillatory)轨迹:浅层快速扩张,但深层反而逐层衰减甚至坍缩。从理论上看,这是因为:
- Token Mixer(跨 token 的特征交互模块)只能提供有界的跨 token 秩扩张;
- Per-token FFN(Channel 方向的独立变换)本质上是秩收缩算子(rank-contractive);
- 两者叠加,深层表征逐层向低维子空间坍缩,阻碍了进一步 scaling 的收益。
作者据此提出关键论点:scaling 模型规模不等于 scaling 表达能力。增加参数若不能突破结构性表征瓶颈,反而会加剧 embedding collapse 并在深层模型中产生递减收益。
与其通过更复杂的 token mixer(Self-Attention、Full-Mix、Unimixer)在受限空间内"挤"更多交互,RankUp 的思路是直接扩张潜空间本身的表达多样性——通过五个互补机制系统性地提升 Effective Rank,从根源上减缓 representation collapse。
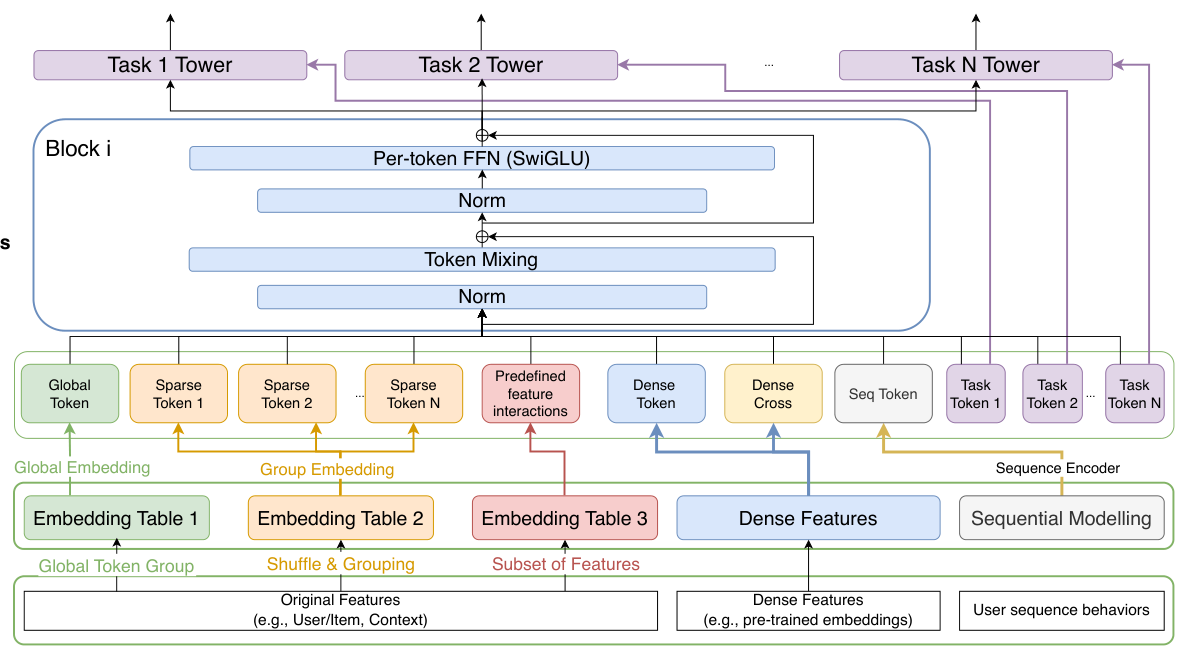
RankUp 已经在腾讯广告平台(微信视频号 / 公众号 / 朋友圈)大规模部署,主要评测任务为 CVR(Click-Conversion-Rate)预测,在 20% 流量的 A/B 实验上 Realtime AUC 获得显著提升,并翻译为可观的 GMV 收益(3.41% / 4.81% / 2.21%)。
预备知识¶
2.1 问题形式化¶
考虑工业排序系统的异构输入:稀疏特征、稠密数值向量、用户行为序列。对 $M$ 个稀疏特征 $\mathcal{F} = \{f_1, \dots, f_M\}$,每个 $f_i$ 经嵌入层映射到 $\mathbf{e}_i \in \mathbb{R}^{d_i}$。由于稀疏特征数量可达几百,工业界普遍采用"分组"(splitting)机制将高维向量切成 $T$ 个 token 表征。
Autosplit 方式(如 [42] RankMixer):将级联向量 $\mathbf{e}_{\text{input}} = [\mathbf{e}_1; \dots; \mathbf{e}_M]$ 平均切成 $T$ 段,每段长度 $d_s$,第 $i$ 个 token 为
$$\mathbf{x}_i = \text{Proj}_i(\mathbf{e}_{\text{input}}[d_s \cdot (i-1) : d_s \cdot i]) \tag{1}$$
Semantic Grouping 方式:利用领域经验预定义分组 $\mathcal{F}_i$,将组内嵌入先拼接再投影:
$$\mathbf{x}_i = \text{Proj}(\text{Concat}(\{\mathbf{e}_j \mid f_j \in \mathcal{F}_i\})) \tag{2}$$
其他辅助信息(稠密向量、序列表征)同样被投影到 $D$ 维空间。最终得到初始表征矩阵 $\mathbf{H}_0 \in \mathbb{R}^{T \times D}$。
现代工业排序模型基本沿用 MetaFormer 范式 [37],将 token 间交互与 channel 内变换解耦。主干由 $L$ 个 block 堆叠,每个 block 由 Token Mixer 与 Per-token FFN 组成:
$$\mathbf{H}'_l = \text{TokenMixer}(\text{LN}(\mathbf{H}_{l-1})) + \mathbf{H}_{l-1} \tag{3}$$
$$\mathbf{h}_{l,i} = \text{FFN}(\text{LN}(\mathbf{h}'_{l,i})) + \mathbf{h}'_{l,i}, \quad i = 1, \dots, T \tag{4}$$
其中 $\text{LN}(\cdot)$ 为 LayerNorm。在 RankMixer 中,Token Mixer 采用 multi-head shuffle 混合:每个 token 切成多个 head,所有 token 的子向量跨序列重组,无参数而高度并行;Per-token FFN 则独立作用在每个 token 上,保留 permutation equivariance。
2.2 表征的 Rank 缺陷¶
为量化潜空间利用情况,作者采用 Effective Rank 作为核心指标。对每层的表征 $\mathbf{H}_l \in \mathbb{R}^{T \times D}$,做 SVD 得到奇异值 $\sigma_1, \dots, \sigma_k$($k = \min(T, D)$),定义
$$\text{erank}(\mathbf{H}_l) = \exp\left(-\sum_{i=1}^{k} p_i \ln p_i\right), \quad p_i = \sigma_i / \sum_{j=1}^{k} \sigma_j \tag{5}$$
数值范围 $[1, k]$:接近 1 表示完全坍缩到一维方向,接近 $k$ 表示信息在所有正交维度上均匀分布。相比标准代数秩(对无穷小噪声高度敏感),Effective Rank 是对有效信息维度的稳健估计。
前序工作 [19] 实证指出,深层 MetaFormer 排序模型中 token 表征的有效秩并非单调递增,而是初期快速扩张后在深层逐层衰减。这意味着即便 scaling 参数,潜空间仍坍缩到低维子空间,无法被充分利用。两个根因:Token Mixer 的有界秩扩张、Per-token FFN 的秩收缩,二者共同压缩了跨层表征多样性的增长。因此仅依赖 token mixing 设计是不够的,需要在结构上直接扩张潜空间本身的表达多样性。
Rank-Up 方法¶
3.1 总体框架¶
RankUp 基于 MetaFormer 主干,包括五个核心机制:
- Randomized Permutation Splitting:降低 token 间的相关性和共线性,生成更丰富的组合性交互;
- Multi-embedding Representation Paradigm:扩展初始 token embedding 的自由度;
- Global Token Integration:引入一个全局 token,承载跨 token 的全局信息;
- Cross Integration of Pre-trained Embeddings:将跨域预训练嵌入(两塔得到的 user / item 向量)的结构化先验注入表征空间;
- Task-Specific Token Decoupling:在 multi-task 场景下,将任务相关信息独立为任务 token,缓解共享表征的梯度干扰。
同时采用 Pre-LayerNorm (PreNorm) [31, 36] 稳定深层梯度,采用 SwiGLU [7, 25] 作为 FFN 的门控激活来增强高阶交互建模。
3.2 随机置换分片(Randomized Permutation Splitting)¶
传统工业 Ranker 要么等距切分(Autosplit),要么按语义分组(Semantic Grouping)。这两类方式都对特征施加了固定的结构 / 语义先验,但往往会导致 信息冗余:高度共线的特征被分到同一个 token,压缩了信息熵。
RankUp 引入一个随机置换算子 $\sigma$,对稀疏特征集 $\mathcal{F}$ 的索引做随机重排:
$$\mathcal{F}_\sigma = \{f_{\sigma(1)}, \dots, f_{\sigma(M)}\} \tag{6}$$
之后每组内的特征再向量化、拼接、投影。通过把高相关特征随机分散到不同 token,token 间的相关性被解耦,初始表征矩阵 $\mathbf{H}_0$ 的几何基底被扩大,从而在后续层中减缓 rank collapse。
3.3 多嵌入表征范式(Multi-embedding Representation Paradigm)¶
常规工业 Ranker 用单张嵌入表 $\psi: \mathcal{F} \to \mathbb{R}^d$ 将稀疏特征映射到低维潜空间,这在计算上高效,但施加了固定、低维的限制,限制了 token mixer 可用的信息多样性。
RankUp 采用 Multi-embedding([11, 23]):用 $K$ 张独立嵌入表 $\psi_1, \dots, \psi_K$ 同时表示输入特征。每个特征 $f_j$ 的表征变成一个嵌入元组
$$\mathbf{e}_j = \{\psi_k(f_j) \mid \psi_k \in \mathcal{K}_j\} \tag{7}$$
其中 $\mathcal{K}_j$ 是分配给 $f_j$ 的表子集。这种冗余映射让同一个 categorical 信号从多个几何视角被投影出来,为 token 拼装提供更细粒度的初始化。
该设计显著提升初始 $\mathbf{H}_0$ 的多样性,缓解单嵌入系统在早期的低秩瓶颈,使深层模型更能捕获稀疏场景下的长尾信号。
3.4 全局 Token 融合(Global Token Integration)¶
典型 MetaFormer 中每个 token 仅表达局部特征视图。为给深层交互提供一个整体视图,RankUp 新增一个 Global Token $\mathbf{g}$,与所有局部 token 并行参与交互:
$$\mathbf{g} = A(f_1, f_2, \dots, f_M) = \text{func}(\text{Pool}(\{\text{Embed}(f_i)\}_{i=1}^{M})) \tag{8}$$
这里 $A$ 为聚合函数,$\text{func}$ 可以是 MLP,也可以是 FM [17, 18, 22] 或 DCNv2 [33] 等更复杂的跨特征交互模块。全局 token 被拼接到 token 序列前,形成新的输入
$$\mathbf{H}^{(0)} = [\mathbf{g}, \mathbf{e}_1, \dots, \mathbf{e}_T] \tag{9}$$
这一设计让每一层的 token mixing 都能在局部交互之外看到一个全局上下文,类似 Transformer 中的 [CLS] 语义,但目标更偏向给深层表征注入全局方向,防止潜空间被局部 token 交互压缩。
3.5 跨域预训练嵌入融合(Cross Integration of Pre-trained Embeddings)¶
工业排序中普遍引入从两塔模型(user / item retrieval)学习到的预训练嵌入作为基础特征。但这些嵌入主要优化"全局相似度"(距离目标),而非精细的特征交互,因此直接拼接或线性投影到 ranker 往往无法充分释放它们的结构先验。
RankUp 在特征级别显式注入交互先验:对给定的 user / item 嵌入 $\mathbf{z}_{ue}, \mathbf{z}_{ie}$,计算 element-wise 乘积,再投影:
$$\mathbf{e}_{\text{cross}} = \text{Proj}(\mathbf{z}_{ue} \odot \mathbf{z}_{ie}) \tag{10}$$
该 token 可视为对齐于 factorization 式排序模型的 inductive bias 的"软"特征交互,把预训练模型中的交互先验显式带入下游 token mixing 层。得到的 $\mathbf{e}_{\text{cross}}$ 被追加到初始 token 序列 $\mathbf{H}_0$ 中。
3.6 任务专属 Token 解耦(Task-Specific Token Decoupling)¶
工业 ranker 往往在多任务目标下训练(CTR / CTCVR / GMV / 时长等),共享同一个输入特征空间可能导致表征坍缩:大任务的梯度支配学习方向,把共享空间压缩到自己偏好的子空间,挤占异质任务所需表达。
RankUp 为每个任务显式分配一组可学习的任务 token $\{\mathbf{x}_{\text{task}}^{(k)}\}_{k=1}^{K}$(共 $K$ 个任务),这些 token 参与所有的 token mixing,但只会被送入其对应任务塔:
$$y^{(k)} = \text{Tower}^{(k)}(\mathbf{x}_{\text{task}}^{(k)}, \text{Pool}(\mathbf{H}'_L)) \tag{11}$$
这样,共享 backbone 负责挖掘通用特征交互,而 task token 承担任务偏向信息的累积,将共享潜空间解耦为任务相关的子空间。对多任务排序尤其重要——既缓解梯度干扰,又让 backbone 保持更高的表征能力。
实验设置¶
4.1 数据集¶
大规模真实工业数据集来自微信视频号(Weixin Video Accounts)广告场景,日样本 2000 万、超过 1200 个稀疏特征,覆盖 2024 年 7 月至 2026 年 3 月。训练用历史生产日志,评测在实时服务条件下进行。优化目标是 CVR(Click-Conversion-Rate) 预测,其由 32 个业务子任务组成,每个子任务对应一个独立业务目标。主基线为 RankMixer(SOTA 工业排序结构),所有实验使用一致的 2 层 backbone 配置。
4.2 评测指标¶
- Realtime AUC:在短而连续的时间窗口内计算,监控模型对漂移数据分布的判别能力;
- Effective Rank (erank):每个 block 的输出上,以 $\mathbf{H}_b \in \mathbb{R}^{B \times T \times D}$($B$ 为 batch)在每个样本 token 表征矩阵上计算并取批内平均,分别报告 Token Mixer 后(TM)和 FFN 后(FFN);
- 在线端:AUC / CTCVR / GMV。
主要实验结果¶
5.1 离线消融:各组件对 Realtime AUC 的贡献¶
在微信视频号广告系统上,以 Order / Book / Add Service 三个最核心、流量最大的子任务为评测对象,做组件级消融。
Table 1: Improvement of Realtime AUC over top-3 tasks
| 变体 | Order | Book | Add Service |
|---|---|---|---|
| Randomized Permutation Split | +0.06% | +0.06% | +0.08% |
| w/ Global Token + Multi-Emb | +0.21% | +0.18% | +0.13% |
| w/ Cross Embedding | +0.22% | +0.10% | +0.03% |
| w/ Task Token | +0.09% | +0.02% | +0.02% |
| Rank-Up(全部) | +0.41% | +0.23% | +0.25% |
结论:
- 每个组件都对基线有稳定的正增益;
- 最大贡献来自 Global Token + Multi-Embedding 组合,说明"扩展初始表征空间 + 全局信息汇聚"是减缓深层坍缩最有效的一对;
- Randomized Permutation 虽然单独提升不大,但它为后续组件提供了更去相关的初始空间(从而对整体有效秩的改善是"基建级"的);
- Cross Embedding 在 Order 上提升最明显(+0.22%),与转化率这类强依赖用户-商品精细交互的任务一致;
- Task Token 在 Order 上 +0.09%,在 Book/Add Service 更小,表明多任务解耦在强任务竞争场景下效果更显著。
5.2 Split 策略分析¶
5.2.1 token 独立性:互信息分析¶
将 token embedding 通过 k-means 聚类到 $K$ 个离散 cluster 得到离散状态 $c_i^{(b)}$,再在样本维度上计算两两 token 的 pairwise 互信息(MI)矩阵 $\mathbf{M} \in \mathbb{R}^{T \times T}$:
$$M_{ij} = \sum_{a=1}^{K} \sum_{b=1}^{K} p(a, b) \log \frac{p(a, b)}{p_i(a) \cdot p_j(b)} \tag{12}$$
其中 $p(a, b)$ 是 token $i$ 被分到 cluster $a$、token $j$ 被分到 cluster $b$ 的联合概率。更高的 $M_{ij}$ 表示两个 token 间统计冗余更大。为隔离 split 策略本身的影响,作者定义
$$\Delta \mathbf{M} = \mathbf{M}_{\text{Randomized}} - \mathbf{M}_{\text{Semantic}} \tag{13}$$
负值区域代表随机切分更好地降低了 token 间冗余。
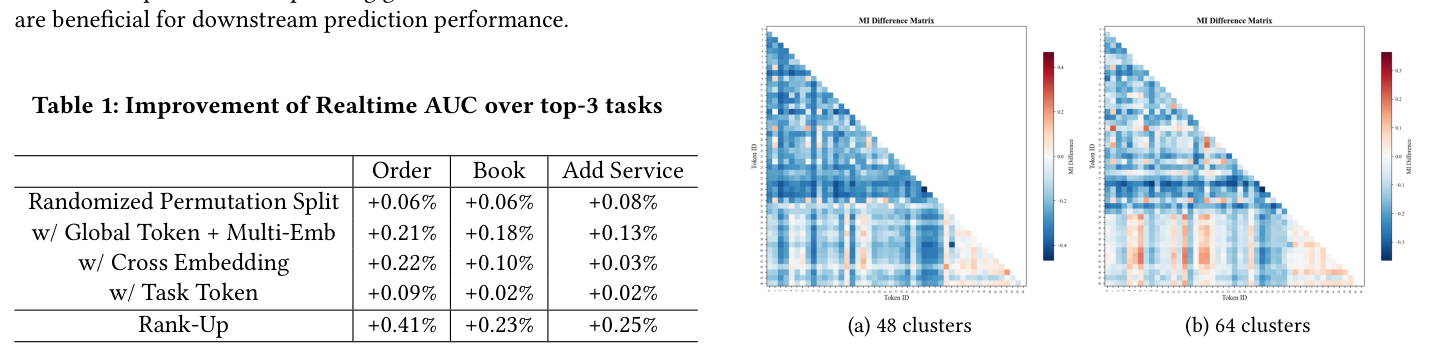
如 Figure 2(a)($K=48$)所示,稀疏 token 间(ID 0–31)的 MI 在 Randomized 下一致低于 Semantic Grouping,说明随机切分产生了更统计独立的 token 表征。非稀疏 token(ID 32–46)构造一致所以不变。稀疏 × 非稀疏交叉项也显著降低,说明该策略不仅在组内,还在异构组间有效解耦。Figure 2(b)($K=64$)验证结论对聚类粒度不敏感。
5.2.2 Effective Rank 对比¶
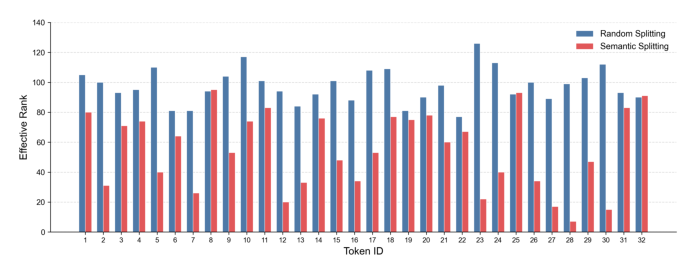
Figure 3 中,Random Splitting 在全部 32 个稀疏 token 上给出更高且更均匀的 Effective Rank;Semantic Grouping 在若干 token 上(12、29、31)erank 急剧下降(低于 20),原因是语义聚合把长尾共现的特征集中到同一个 token,形成 low-rank 子空间。随机切分将这类长尾特征分散开,避免了因长尾聚集导致的 rank collapse,让每个 token 都保留丰富且多样的表征。
5.3 Effective Rank 动态分析¶
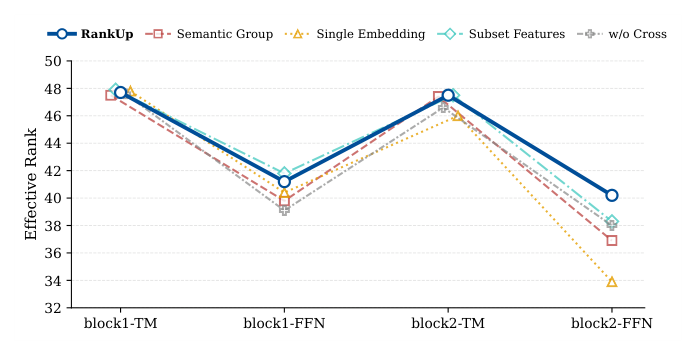
在两层 backbone 的 4 个检查点(Block1-TM → Block1-FFN → Block2-TM → Block2-FFN)上观察 erank:
- 所有变体在深层(尤其 FFN 后)都呈现不同程度的 rank 下降,与 [19] 报告的现象一致;
- RankUp 曲线在所有深度都高于其他消融变体,特别是 Block2-FFN 上明显更高,表明 RankUp 有效缓解了深层 rank 衰减;
- Multi-Embedding 的作用集中在初始阶段,通过独立子空间映射原始特征,避免早期压缩;
- Global Token 在深层交互上最有用,让 Subset-based 变体的深层 erank 不会过快塌陷;
- Cross Embedding 对 Block 0 的 erank 最关键,说明外部语义先验决定了初始表征的几何基底;
- Randomized Permutation 与 cross embedding 互补,共同在 token level 增强 rank。
这解释了组件的互补性:Multi-Emb 和 Cross Emb 主攻初始层的 rank 基底,Global Token 和 Permutation 负责深层交互的 rank 保持。
5.4 任务 Token 的作用¶
为度量任务 token 是否真把任务相关信息压入潜空间,作者用表征与任务标签的互信息来评估:将隐表征通过 k-means 聚到 $K$ 个区域得到 cluster $Z$,对二分类任务标签 $Y \in \{0, 1\}$ 计算
$$I(Z; Y) = \sum_{z, y} P(z, y) \log \frac{P(z, y)}{P(z) P(y)} \tag{14}$$
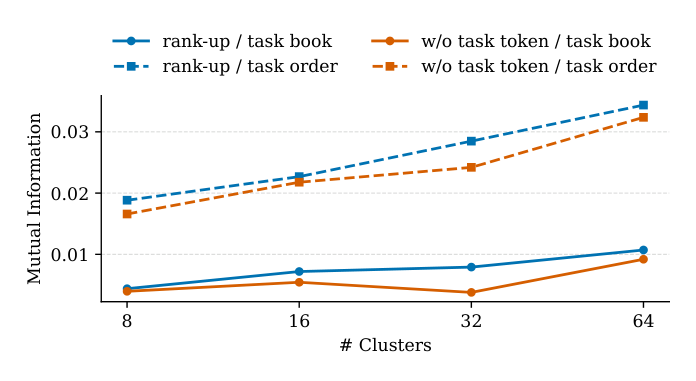
如 Figure 5 所示,在 Book 和 Order 任务上,带 Task Token 的 RankUp 变体 MI 始终高于不带 Task Token 的变体,且随 cluster 数增加 MI 差距愈加显著(从 K=8 增到 K=64)。这说明任务 token 不仅让模型获得"粗粒度"任务意识,还捕获了细粒度的任务子结构,在高分辨率聚类下体现出更好的潜空间任务分离。
在线部署与业务收益¶
6.1 部署细节¶
RankUp 已在腾讯微信视频号 / 公众号 / 朋友圈三个广告场景 100% 全量部署 服务 CVR 预测。关键工程数据:
- 训练数据:18 个月真实生产用户 × 广告交互日志;
- 输入层:> 1000 个特征字段(domain-specific 类别特征、序列行为 token、多个预训练语义嵌入);
- 多任务:jointly 优化 32 个预测任务;
- Backbone:2-layer MetaFormer;
- 参数量:从 ~10M 扩至 ~100M(同量级扩展);
- 部署 batch size:300,约 70 GFLOPs / batch;
- MFU(Model FLOPs Utilization)= 23%,说明计算效率良好;
- 满足实时服务延迟约束,能与既有在线排序系统(如微信公众号中的 rankmixer 子模块)无缝替换。
6.2 在线 A/B 收益¶
在 20% 生产流量上进行 14 天连续 A/B,核心指标:
Table 2: Online Performance Lift
| 场景 | ΔAUC | CTCVR | GMV |
|---|---|---|---|
| Weixin Video Accounts | +0.367% | +1.41% | +3.41% |
| Weixin Official Accounts | +0.331% | +0.21% | +4.81% |
| Weixin Moments | +0.269% | +0.87% | +2.12% |
Table 3: Online Performance Lift for New Ads(冷启动)
| 场景 | GMV |
|---|---|
| Weixin Video Accounts | +5.83% |
| Weixin Official Accounts | +9.67% |
| Weixin Moments | +2.84% |
Table 4: Order Task 上的 GMV 提升
| 场景 | GMV |
|---|---|
| Weixin Video Accounts | 5.18% |
| Weixin Official Accounts | 7.18% |
| Weixin Moments | 4.79% |
业务影响:3.41% / 4.81% / 2.21% 的 GMV 提升在微信广告体量下换算为数亿美元级的年度营收增量。冷启动场景(新广告)收益尤其可观:微信公众号 +9.67% GMV,说明 RankUp 丰富的表征空间与更强的特征交互确实对"行为信号稀缺"的样本群体极为有效,能显著改善新广告的发现与变现效率。Order Task 上 +7.18% GMV 也表明 RankUp 对转化质量高度相关的排序目标有细腻的捕获力。
讨论与相关工作¶
7.1 相关工作:Dense Scaling 与 Representation Collapse¶
- 和 Dense Scaling 线(AutoInt → Hiformer → Wukong → InterFormer → RankMixer → MixFormer)的区别在于:后者追求 token mixer 的表达力提升,或硬件友好的 scaling 架构;RankUp 并不改造 token mixing,而是扩张潜空间本身的表达多样性,与这些工作正交,可以叠加;
- Representation Collapse 在自监督 / 对比学习中被广泛研究,常通过加均匀性正则(uniformity, orthogonality)缓解;在推荐系统里 RankUp 是少数针对 MetaFormer ranker 的长尾分布和幂律数据显式引入结构性机制(permutation + multi-emb + task token)以防止 collapse 的工作;
- 与 LLM 中的注意力层 rank 分析 类似,RankUp 的发现也支持"在 residual / MLP 侧做 rank 保持"是防止深层表征退化的关键。
7.2 核心贡献¶
- 诊断:把工业 ranker 的性能瓶颈从"参数规模不够"重新框定为"表征能力不足",用 Effective Rank 给出量化度量;
- 架构:五个互补机制(Random Permutation / Multi-Embedding / Global Token / Cross Embedding / Task Token)协同提升深层 token 表征的多样性;
- 实证:首次在超大规模广告场景(微信)上验证 scaling recommender 应关注"有效秩"而非单纯参数量,并通过 100% 全量 A/B 取得数亿美元级收益。
7.3 值得借鉴的设计¶
- Randomized Permutation Splitting 是非常"便宜"的改动——几乎零成本,却能在初始表征的几何基底上给出显著的 erank 提升,对所有基于 split 的 MetaFormer ranker 都值得尝试;
- Global Token 的 FM / DCNv2 变体做聚合函数,这一小设计使得全局 token 不只是均值池化,而承载了高阶交互先验;
- Cross Embedding(user × item 的 element-wise 积投影)给出了一种把跨域预训练嵌入"translate"到 ranker 交互空间的便捷桥接,对大量有"向量召回"能力的业务都可复用;
- Task Token 的解耦范式把共享表征 vs. 任务专属信息的平衡显式化,对多任务排序(尤其 CVR / GMV / 时长等异构目标)极具工程价值。
7.4 局限与争议¶
- 论文未披露五个机制带来的训练 / 推理额外开销(除了整体 MFU=23% 和 GFLOPs),读者难以判断每个机制的性价比;
- erank 是有效信息维度的度量,但并非直接证明下游推荐性能——MI 分析、AUC、GMV 之间的因果链依赖 Effective Rank 这一代理指标;
- 消融未与其他常见的 rank-preserving 技巧(正交正则、orthogonal 初始化)对比,不能完全排除类似效果可以用更轻量的正则得到;
- Cross Embedding 采用 element-wise 乘积,是否在更高维 / 更稀疏场景下仍是最佳设计值得进一步验证;
- 数据截至 2026 年 3 月,且仅在微信场景上验证,迁移到其他广告平台(抖音、小红书、淘宝)需重新调优随机切分的 seed 分布、多嵌入表数量等超参。
7.5 结论¶
RankUp 把对 scaling recommender 的关注点从"参数量"转移到"有效秩"——只有在扩张参数的同时扩张表达空间,才能真正获得 scaling 的收益。工业 A/B 实验验证了这一视角的实践价值,其对应的五个机制为后续 MetaFormer 家族排序模型(OneTrans、MixFormer、TokenMixer-Large 等)的迭代提供了可直接复用的模板。