ChronoID:把显式时间信号注入生成式推荐的语义 ID¶
ChronoID 来自 University of Rochester、Meta MRS 与 MBZUAI 的合作。核心主张:当前生成式推荐里的语义 ID(Semantic ID, SID)是"时间无关(time-agnostic)"的——时间只在序列顺序、会话构造、偏好对齐等环节被隐式利用,却从未进入定义离散词表的"语义抽象(tokenization)"层。论文把"该不该、在哪里、怎样"把显式时间注入 SID 这一问题,系统拆解成三个正交设计维度(时间编码 × 融合顺序 × 量化机制),提出统一框架 ChronoID,并配套构造一个杜绝未来信息泄漏的"时间显式"评测基准,回答三个问题:注入时间的有效方式是什么、架构该怎么设计、增益从哪里来。
研究动机与背景¶
生成式推荐(Generative Recommendation)正在用端到端的序列生成替代传统多阶段流水线。OneRec、MiniOneRec 这类方法把推荐重新表述为"在离散语义 ID 上做条件生成",统一了召回、排序与多样化。它们的共同基石是 Semantic ID:用一个预训练 LLM 把 item 的文本描述(标题、类目)编码成高维向量,再用向量量化(最常见是 RQ-VAE)离散化成一串码本索引,作为生成模型的词表。
但论文指出这一范式有一个被普遍忽视的根本缺陷:时间信息没有被显式建模到语义抽象层面。现有框架里,时间只在两个层面起作用:
- 数据选择层:OneRec 依赖会话构造启发式与基于用户行为的奖励建模,时间影响"哪些交互被采样"以及"偏好如何对齐";
- 优化/序列层:时间感知被限制在序列顺序与相对位置编码里。
而学习 SID 的向量量化本身是彻底 time-agnostic 的——MiniOneRec 把 SID 直接由 item 文本嵌入经残差量化得到,时间动态根本进不了 tokenization 层。其后果是:同一个 item 在截然不同的时间上下文下发生的交互,被映射到完全相同的语义 ID,这隐含假设了"item 语义与用户意图在时间上是平稳的(temporally stationary)"。这一假设与真实推荐场景严重错配——那里 item 含义、相关性、用户意图都在随时间演化,交互节律(interaction rhythm)起着核心作用。论文用一句话概括这个 gap:时间被建模在序列和优化层面,却被排除在语义抽象本身之外。
作者由此提出贯穿全文的核心问题:时间应当在哪里、以何种方式进入语义抽象,才能支撑有效的生成式推荐? 围绕这个问题,他们沿三条反映不同归纳偏置的架构思路展开:(1) 时间嵌入方案、(2) 时间-语义融合策略、(3) 码本量化机制。
论文的三条主要贡献:
- 首个面向时间感知 SID 学习的统一框架 ChronoID,并沿三个正交维度系统刻画其设计空间:(1) 时间编码形式(绝对时间戳 vs 相对时间间隔)、(2) 融合顺序(在离散化之前的 early fusion vs 在 SID 层面的 late fusion)、(3) 量化结构(残差量化 vs 并行量化)。每个设计选择对应一种关于"时间如何与语义抽象交互"的不同归纳偏置。
- 一个时间显式的评测基准:严格定义时间感知生成任务,并扩展自 Amazon Industrial/Office、Mercari 等时间隐式基准。它保证离散 SID 学习、SFT、验证、测试各阶段都不会发生未来信息泄漏,为 next-item 生成提供更严谨、更贴近现实的评测。
- 大量实证结论(详见后文 RQ1–RQ4):时间显式信息显著提升性能;相对时间优于绝对时间;晚融合优于早融合(更复杂的融合架构相比简单拼接仅有边际收益);并行量化优于残差量化。论文还在附录里声称:增益来自更丰富的"时序-文本语义"而非单纯扩大 ID 空间(§C.1);时间信号不可或缺,移除或零填充会因引入分布外噪声而显著退化(§C.2);原子时间戳已足以让模型内化节假日、季节等高层时间模式(§C.3)。
说明:本 arXiv 版本(11 页)只含正文(1–10 页)与参考文献(11 页),正文反复引用的附录 §A/§B/§C.1–C.3/§D 并不在本 PDF 内,因此上面贡献 5–7(§C.1/C.2/C.3)与超参细节(§D)只能转述正文中的声明,其支撑数据无法在本版本核验。
核心方法 / 模型架构¶
预备知识:生成式推荐与基于量化的 Semantic ID¶
生成式推荐形式化。 令 $\mathcal{U}$、$\mathcal{I}$ 为用户与 item 集合。用户 $u$ 的交互历史是一条按时间排序的序列 $S_u = (i_1, i_2, \ldots, i_t)$,其中 $i_t \in \mathcal{I}$ 是在时间戳 $t$ 被交互的 item。目标是学一个模型 $f_\theta$,通过如下条件概率预测下一个 item $i_{n+1}$:
$$P(\mathbf{z}_{n+1} \mid \mathbf{z}_{\le n}) = \prod_{k=1}^{K} P(z_{n+1,k} \mid \mathbf{z}_{\le n}, z_{n+1,<k}) \tag{1}$$
其中 $\mathbf{z}_i = (z_{i,1}, z_{i,2}, \ldots, z_{i,K})$ 是 item $i$ 的离散语义 ID,由 $K$ 个层次化或并行的 token 组成。式 (1) 表明:生成下一个 item 等价于自回归地生成它那 $K$ 个 SID token。
基于量化的 Semantic ID。 给定 item $i$ 及其文本描述,预训练 LLM 抽取高维嵌入 $\mathbf{e}_i \in \mathbb{R}^d$,再用量化器 $\mathcal{Q}$(最常见是 RQ-VAE)把嵌入 $\mathbf{h}_i$ 映射到由 $K$ 个码本 $\{\mathcal{C}_1, \ldots, \mathcal{C}_K\}$ 张成的离散空间。在残差量化范式下,token 被逐层生成,每个后续 token 去精修前面各层的量化残差:
$$\hat{\mathbf{h}}_i = \sum_{k=1}^{K} \mathbf{c}_{k,z_{i,k}}, \qquad z_{i,k} = \arg\min_{j \in \{1,\ldots,V\}} \|\mathbf{r}_{k-1} - \mathbf{c}_{k,j}\|_2^2 \tag{2}$$
其中 $\mathbf{r}_{k-1}$ 是第 $(k-1)$ 层的残差,$\mathbf{c}_{k,j}$ 是第 $k$ 个码本中第 $j$ 个码向量。论文强调:这一范式依赖一个静态映射 $\mathbf{h}_i \to \mathbf{z}_i$,而 $\mathbf{e}_i$ 完全来自文本内容,这等于假设"item 在隐空间的身份对交互的时间上下文不变"。ChronoID 的全部工作就是打破这个静态假设。
ChronoID 总体流程与三个设计维度¶
ChronoID 的总流程是:先为每个 user–item 交互生成一个时间嵌入,再把时间嵌入与 item 嵌入融合,然后对融合后的嵌入做量化得到 time-aware SID;这些 SID 最终作为 LLM 的输入做 SFT 与推理。由此,语义 ID 学习的设计空间被刻画成三个关键维度:(1) 如何学时间嵌入、(2) 如何融合 item 嵌入与时间嵌入、(3) 如何把嵌入量化成 SID。
![Figure 1:ChronoID 的三种架构变体。(a) Early Fusion——先把 Text 与 Time 拼接再做 RQ-VAE 量化,得到 [ID1][ID2][ID3];(b) Late Fusion——Text 走 RQ-VAE、Time 走 VQ-VAE 各自独立量化,得到 [ID1][ID2][ID3] 与 [ID4] 后拼接;(c) Parallel Quantization——把拼接后的 Text+Time 喂给三组独立 Encoder/Codebook 并行量化,得到 [ID1][ID2][ID3],用独立码本捕捉解耦的 item 切面](figures/fig_02.png)
设计维度一:时间嵌入(Time Embedding)¶
不同于现有模型只靠序列顺序隐式编码时间,ChronoID 把时间视为学习 SID 时的一等公民。直觉是:item 语义(如价格、季节趋势、用户偏好)会随时间演化,高质量的时间编码能改善对用户与 item 的刻画,从而提升 next-item 生成。
时间先经一个时间编码器变成时间嵌入。作者采用经典正弦位置编码来编码"交互发生在何时",时间戳 $t$ 的 $d$ 维时间嵌入 $\mathbf{h}_t$ 为:
$$\mathbf{h}_t[2i] = \sin\!\left(\frac{t}{10000^{2i/d}}\right), \qquad \mathbf{h}_t[2i+1] = \cos\!\left(\frac{t}{10000^{2i/d}}\right) \tag{3}$$
其中 $i \in \{1, \ldots, d\}$。在"喂什么进时间编码器"上,论文对比两种选择:
- Choice 1:绝对时间戳(Absolute timestamp)。 用户与 item 交互的 UNIX 时间戳。它反映事件在全局交互数据中的绝对时间位置,捕捉全局趋势(如季节性)。一个关键直觉是:两个正弦时间嵌入的内积天然反映两个事件的时间跨度,有助于建模用户交互的频率与近因(recency)。因此绝对时间是时间编码器的"标准"输入。
- Choice 2:相对时间(Relative time)。 论文论证基于绝对时间的嵌入对 SID 不一定最优:时间嵌入随后会被量化成离散 SID 并输入生成模型,在序列生成过程中两个时间嵌入之间不再有显式内积,因而无法正确建模频率与近因。替代方案是用两次连续交互之间的相对时间。对用户 $u$ 的第 $i$ 次交互,定义相对时间 $\Delta t_{u,i} = t_{u,i} - t_{u,i-1}$(其中 $t_{u,i}$ 是第 $i$ 次交互的绝对 UNIX 时间戳,且首个相对时间 $\Delta t_{u,1} = t_{u,1}$)。这样把交互之间的时间跨度显式编码进 SID。
设计维度二:融合策略(Fusion Strategy)¶
时间编码完成后,关键问题是何时把时间信息与 item 嵌入融合以做 SID 量化。论文区分两种融合顺序:
- Strategy 1:早融合(Early fusion / Fuse-then-quantize)。 把时间当作 item 交互的内在组成,在离散化之前就与文本语义融合。设 item 嵌入为 $\mathbf{h}_{\text{item}}$,某用户交互该 item 的时间嵌入为 $\mathbf{h}_t$,拼接成 $\mathbf{h} = [\mathbf{h}_{\text{item}} \,\|\, \mathbf{h}_t]$,再喂进量化器 $\mathcal{Q}$ 得到 $\text{SID} = \mathcal{Q}(\mathbf{h})$。
- Strategy 2:晚融合(Late fusion / Quantize-then-fuse)。 用两个不同的量化器分别独立离散化,再在 SID 层面拼接:$\text{ID}_{\text{item}} = \mathcal{Q}_{\text{item}}(\mathbf{h}_{\text{item}})$,$\text{ID}_{\text{time}} = \mathcal{Q}_{\text{time}}(\mathbf{h}_t)$,最终 $\text{SID} = [\text{ID}_{\text{item}} \,\|\, \text{ID}_{\text{time}}]$。
设计维度三:量化机制(Quantization Mechanism)¶
与融合顺序正交的另一个关键设计是量化模型本身,论文考察两类:
- Type 1:残差量化(Residual quantization)。 即 RQ-VAE:用 $K$ 个码本 $\{\mathcal{C}_1, \ldots, \mathcal{C}_K\}$,每个码本用上一层的残差按式 (2) 顺序学习。当 $K=1$ 时自然退化为 VQ-VAE。
- Type 2:并行量化(Parallel quantization)。 来自 TokenRec(Qu et al., 2025),用 $K$ 个独立的码本与编码器去离散化融合表征,使不同编码器/码本捕捉 item 的不同切面。码本 $\mathcal{C}_k = \{\mathbf{c}_{k,1}, \ldots, \mathbf{c}_{k,V}\}$ 含 $V$ 个可学码向量,各自独立量化输入嵌入 $\mathbf{h}$:
$$z_k = \arg\min_{j \in \{1,\ldots,V\}} \|\mathbf{h} - \mathbf{c}_{k,j}\|_2^2 \tag{4}$$
最终 SID 是所有 $z_k\,(k \in \{1,\ldots,K\})$ 的拼接:
$$\text{SID} = (z_1, \ldots, z_K) \tag{5}$$
值得注意:在 ChronoID 里,并行量化的输入是早融合嵌入 $\mathbf{h} = [\mathbf{h}_{\text{item}} \,\|\, \mathbf{h}_t]$。也就是说,并行量化这条线没有"early/late 融合"的自由度(在 Table 1 里该维度标 N/A),它固定用早融合的拼接嵌入,再交给多个独立码本并行解耦——这一点在后文"讨论与局限性"里会引出一个值得注意的内部张力。
时间感知生成式推荐基准(§4)¶
论文指出:大规模、文本丰富、时间严谨且开源的推荐数据集很少。Mercari(MerRec)是 C2C 数据集但只有短期时间信息;而 Amazon Industrial/Office 等 B2C 数据集是时间隐式的。为此,作者用时间信息切分原始数据,构造一个时间显式基准。核心是定义一个固定且全局的时间切点(cutoff,例如 01/01/2028),并把它应用于三个阶段以杜绝 look-ahead 泄漏:
- 码本训练(Codebook Training):严格只用切点之前发生的交互学习 item 表征(正文此处写为"No interactions on or after 01/01/2018",与前文举例的 2028 不一致,疑为笔误);
- SFT 训练:每个训练实例(历史序列,目标 item)都保证目标 item 的交互时间戳严格早于切点;
- SFT 测试:所有待预测的目标 item 都保证发生在切点当天或之后。
在该协议下,用户是否纳入取决于其交互时间相对切点的位置:全部交互都在切点前的用户只用于训练,而首次交互在切点当天或之后的用户只出现在测试集。这保证了离散 SID 学习、SFT、验证、测试全程不发生未来信息泄漏,比原先时间隐式的随机切分更严谨、更贴近现实。
实验设置¶
论文围绕四个研究问题展开,并把框架拆成三个架构维度以隔离各自影响:
- RQ1(有效性):时间显式 SID 是否比时间隐式 baseline 更好?
- RQ2(时间嵌入):绝对时间戳 vs 相对时间,谁更适合建模交互动态?
- RQ3(融合策略):早融合 vs 晚融合,谁更契合 item 语义与时间这两个异质模态?
- RQ4(量化机制):并行量化是否优于残差量化?
Baselines(5 个):(1) SASRec——经典单向自注意力的判别式序列模型;(2) ActionPiece——用 BPE 式 tokenization 把行为序列里频繁共现的 item 合并成复合 token 的生成式方法;(3) HSTU——高度优化、用于高效捕捉长期兴趣的 transformer 架构;(4) MiniOneRec——有竞争力且高效的生成式推荐 baseline;(5) TokenRec——用并行量化器的生成式推荐框架。
评测指标:HR@K 与 NDCG@K,采用标准 leave-one-out,每个测试实例恰好含一个 ground-truth item。$\text{HR@}K = \frac{1}{N}\sum_{u=1}^{N}\mathbb{1}(\text{rank}_u \le K)$ 度量 ground-truth 落在 top-$K$ 的比例;$\text{NDCG@}K = \frac{1}{N}\sum_{u=1}^{N}\frac{\log 2}{\log(\text{rank}_u+1)}\,\mathbb{1}(\text{rank}_u \le K)$ 按对数衰减给靠前的命中更高权重(单正样本下 IDCG = $1/\log_2(1+1)=1$,故省略分母)。
三个设计维度的取值:时间嵌入 = {绝对时间 $T_{abs}$:把 Unix 时间戳投影成高维向量,捕捉全局季节性;相对时间 $T_{rel}$:编码相邻交互的相对间隔,捕捉局部用户节律};融合 = {Early:文本与时间拼成 $\mathbf{z}_{joint} = [\mathbf{h}_{\text{text}} \,\|\, \mathbf{h}_{\text{time}}]$ 再量化;Late:各自独立量化再拼接};量化 = {残差码本:粗到细的层次量化;并行码本:多个独立码本并行,捕捉解耦切面}。
数据集为 Amazon Industrial、Amazon Office、Mercari 三个公开数据集。
主要实验结果¶
RQ1:整体有效性(Table 1)¶
下表完整重现 Table 1(数值为百分比;粗体为各列最优,_下划线_为次优)。Baseline 中 HSTU 用 Random Absolute Time、MiniOneRec/TokenRec 用 Text + Random Absolute Time,SASRec/ActionPiece 为纯 ID-based。ChronoID 给出残差量化的 4 个配置(Early/Late × Absolute/Relative)与并行量化的 2 个配置(融合 N/A × Absolute/Relative)。
Amazon Industrial
| 模型 / 配置 | HR@3 | NDCG@3 | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
|---|---|---|---|---|---|---|
| SASRec (ID-based) | 7.99 | 7.12 | 9.30 | 7.68 | 10.68 | 8.46 |
| ActionPiece (ID-based) | 8.55 | 7.53 | 10.21 | 8.52 | 12.31 | 9.20 |
| HSTU (Random Abs Time) | 5.11 | 3.93 | 7.05 | 4.73 | 8.64 | 5.25 |
| MiniOneRec (Text+Rand Abs) | 9.26 | 8.44 | 10.95 | 9.14 | 13.53 | 10.01 |
| TokenRec (Text+Rand Abs) | 8.20 | 7.44 | 9.01 | 7.77 | 10.54 | 8.26 |
| ChronoID Residual, Early+Abs | 7.44 | 6.72 | 8.91 | 7.32 | 11.33 | 8.08 |
| ChronoID Residual, Early+Rel | 10.62 | 9.56 | 11.95 | 10.11 | 14.29 | 10.86 |
| ChronoID Residual, Late+Abs | 10.10 | 8.93 | 11.52 | 9.52 | 13.06 | 10.03 |
| ChronoID Residual, Late+Rel | 10.43 | 9.28 | 11.68 | 9.79 | 13.20 | 10.29 |
| ChronoID Parallel, Abs | 11.22 | 9.84 | 12.74 | 10.48 | 14.77 | 11.13 |
| ChronoID Parallel, Rel | 12.60 | 11.15 | 13.75 | 11.62 | 16.22 | 12.41 |
Amazon Office
| 模型 / 配置 | HR@3 | NDCG@3 | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
|---|---|---|---|---|---|---|
| SASRec (ID-based) | 6.81 | 6.07 | 7.40 | 6.20 | 9.18 | 6.95 |
| ActionPiece (ID-based) | 5.01 | 3.49 | 5.24 | 3.28 | 8.42 | 4.30 |
| HSTU (Random Abs Time) | 3.43 | 2.70 | 4.64 | 3.11 | 7.04 | 3.96 |
| MiniOneRec (Text+Rand Abs) | 6.01 | 4.89 | 7.22 | 5.42 | 9.53 | 6.22 |
| TokenRec (Text+Rand Abs) | 7.54 | 6.40 | 9.10 | 7.06 | 12.10 | 8.01 |
| ChronoID Residual, Early+Abs | 4.82 | 3.90 | 5.88 | 4.34 | 7.98 | 5.02 |
| ChronoID Residual, Early+Rel | 8.04 | 6.88 | 9.46 | 7.46 | 12.24 | 8.34 |
| ChronoID Residual, Late+Abs | 7.74 | 6.66 | 9.00 | 7.20 | 10.70 | 7.74 |
| ChronoID Residual, Late+Rel | 8.22 | 6.86 | 9.68 | 7.46 | 11.71 | 8.12 |
| ChronoID Parallel, Abs | 7.52 | 6.14 | 9.44 | 6.92 | 12.30 | 7.84 |
| ChronoID Parallel, Rel | 8.42 | 7.08 | 10.74 | 8.04 | 13.59 | 8.95 |
Mercari
| 模型 / 配置 | HR@3 | NDCG@3 | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
|---|---|---|---|---|---|---|
| SASRec (ID-based) | 0.07 | 0.04 | 0.13 | 0.06 | 0.20 | 0.09 |
| ActionPiece (ID-based) | 0.13 | 0.10 | 0.13 | 0.10 | 0.20 | 0.13 |
| HSTU (Random Abs Time) | 0.02 | 0.01 | 0.02 | 0.01 | 0.03 | 0.01 |
| MiniOneRec (Text+Rand Abs) | 1.61 | 1.08 | 2.42 | 1.43 | 2.98 | 1.82 |
| TokenRec (Text+Rand Abs) | 1.34 | 1.04 | 1.51 | 1.16 | 1.77 | 1.26 |
| ChronoID Residual, Early+Abs | 1.79 | 1.41 | 2.47 | 1.65 | 3.35 | 1.97 |
| ChronoID Residual, Early+Rel | 2.16 | 1.69 | 2.72 | 1.91 | 3.82 | 2.28 |
| ChronoID Residual, Late+Abs | 1.96 | 1.58 | 2.69 | 1.81 | 3.58 | 2.10 |
| ChronoID Residual, Late+Rel | 2.49 | 1.87 | 2.95 | 2.02 | 3.93 | 2.30 |
| ChronoID Parallel, Abs | 2.07 | 1.65 | 3.08 | 2.36 | 3.26 | 2.74 |
| ChronoID Parallel, Rel | 3.28 | 2.59 | 4.34 | 3.03 | 5.78 | 3.50 |
结论分析。 ChronoID(并行量化 + 相对时间)在三个数据集所有指标上一致最优。相比时间隐式的 MiniOneRec,它在 Industrial 上 HR@3 取得 36.1% 相对提升(12.60 vs 9.26),在 Office 上 HR@3 取得 40.1% 相对提升(8.42% vs 6.01%)。这印证了仅依赖时间隐式文本语义的不足,以及把显式时间整合进 SID 的重要性。值得注意的现象:在 Mercari 上,纯 ID-based 的 SASRec/ActionPiece/HSTU 几乎全线崩溃(HR@10 仅 0.0x–0.2x 量级),而所有带文本语义的方法(含 MiniOneRec/TokenRec 与 ChronoID)都高出一到两个数量级,说明在 C2C、长尾、文本驱动的 Mercari 上文本语义不可或缺;而 ChronoID 在文本语义之上再叠加显式时间,把 HR@10 进一步从 MiniOneRec 的 2.98 抬到 5.78。
RQ2:时间嵌入的影响——相对时间 > 绝对时间¶
对照 Table 1,相对时间在所有架构配置与数据集上都一致且显著地优于绝对时间。最显著的提升出现在 Industrial 上"早融合 + 残差量化"配置:HR@3 从 7.44(Early+Abs)跃升到 10.62(Early+Rel),相对提升 42.7%。论文把改善归于两点:其一,绝对时间戳虽捕捉全局季节性,但序列用户行为更受交互节律(如"浏览到购买"的时间间隔)影响,这更适合用相对时间建模;其二,绝对时间戳单调递增且不重复,天生有潜在的分布漂移(distribution shift)风险,而相对时间提供更鲁棒、更可泛化的表示来建模长程序列生成所需的时间间隔。
RQ3:融合策略的影响——晚融合优于早融合,复杂融合仅边际收益(Table 2)¶
从 Table 1 可见,在残差量化这条线内,ChronoID 的晚融合一致优于早融合(尤其在绝对时间下,如 Industrial 的 Late+Abs 10.10 远高于 Early+Abs 7.44)。论文归因:item 文本语义与交互时间信息处在高度异质的特征空间;早融合迫使模型把两个分布压进同一个码本,可能导致"塌缩(collapse)",无法准确刻画任一方;而晚融合让文本语义与时间各自保留独有信息,得到的 SID 对两个模态都更具信息量。
为进一步探索"除简单拼接外的其他早融合方法",论文在 Industrial(相对时间)上额外评测了两种更复杂的早融合机制:(i) MLP-based——把拼接的文本+时间嵌入过一个 2 层 MLP 再进 RQ-VAE 编码器;(ii) Cross-Attention——让 item 文本嵌入作 Query(Q)去注意时间信号(K, V)。结果见 Table 2:
| 方法 | HR@3 | NDCG@3 | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
|---|---|---|---|---|---|---|
| Early Fusion (Concatenation) | 10.62 | 9.56 | 11.95 | 10.11 | 14.29 | 10.86 |
| MLP-based Fusion | 10.53 | 9.47 | 11.84 | 10.16 | 13.55 | 10.62 |
| Cross-Attention Fusion | 10.72 | 9.50 | 11.05 | 10.20 | 12.49 | 10.76 |
结论分析。 三种早融合方式性能彼此相当——更精巧的 MLP / Cross-Attention 相比朴素拼接没有稳定优势(各列最优在三者间互有胜负,差距很小)。这说明在该设置下,融合机制的复杂度不是性能瓶颈,简单拼接已足够;真正决定性能的是"融合顺序(early/late)"与"量化机制",而非融合算子本身的花哨程度。
RQ4:量化机制的影响——并行量化 > 残差量化¶
并行量化 + 相对时间是一致最优的设计选择。除相对时间带来的优势外,论文认为并行量化的根本优势在于其在一个 SID 里同时建模文本语义与时间信息的灵活性:RQ-VAE 虽善于捕捉层次化的粗到细信息,但它强加了一个刚性的残差约束——每个后续码本必须解释上一层的误差;然而时间并不天然呈现层次结构,文本语义与时间这类多模态信息更适合用"独立切面"而非"层次"来刻画。并行量化能自然地在不同码本集合里学到 item 的解耦视角,这种灵活性避免了残差量化里的误差传播,从而在需要整合异质信息时为两个模态都生成更具信息量的 SID。
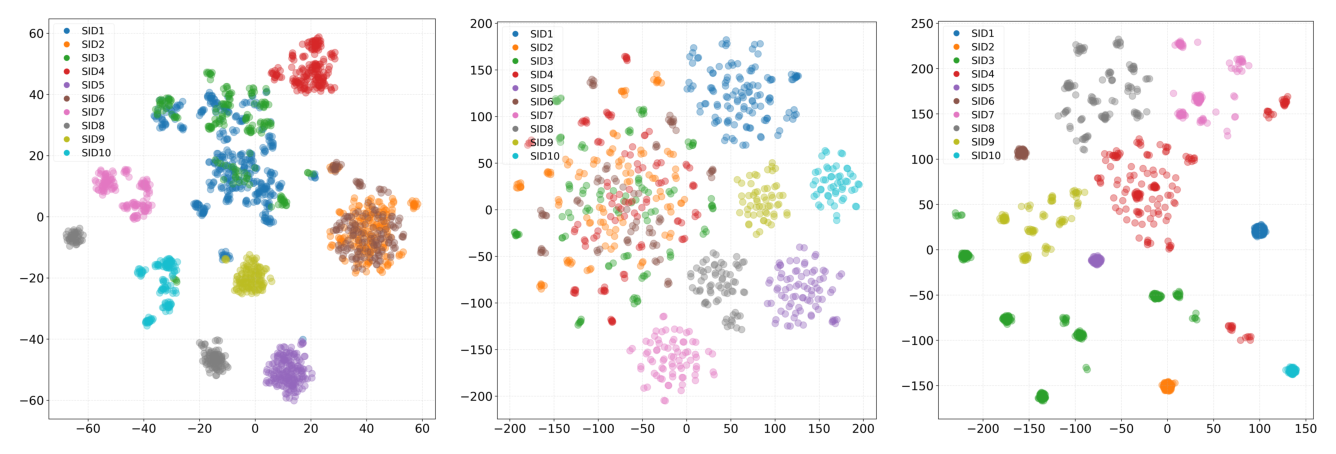
t-SNE 分析(Figure 2)。 论文可视化 top-10 最频繁 SID 对应的 item 嵌入:相对时间(c)生成的嵌入比绝对时间(b)更聚类、簇内密度更高、边界更清晰;绝对时间(b)的簇更分散、互相重叠更多,说明绝对时间戳的时间嵌入无助于区分 item。对比并行量化(a)与残差量化绝对时间(b):并行量化产生更紧凑的簇,而残差量化更分散、纠缠——进一步支持"残差量化迫使后续码本去建模可能含前序模态噪声的残差,导致语义空间模糊"这一判断。
核心贡献总结¶
- 问题层面:首次明确指出生成式推荐的语义 ID 是"时间无关"的,把"时间被排除在语义抽象之外"识别为一个结构性 gap,并将"如何把时间注入 SID"形式化为三个正交设计维度。
- 框架层面:统一框架 ChronoID 覆盖 时间编码(绝对/相对)× 融合(早/晚)× 量化(残差/并行)的设计空间,给出清晰的归纳偏置解释。
- 基准层面:贡献一个时间显式、严格杜绝未来信息泄漏的 next-item 生成评测协议(固定全局时间切点贯穿码本训练/SFT/测试)。
- 实证层面:系统验证了"相对时间 > 绝对时间""晚融合 > 早融合(且复杂融合算子无显著增益)""并行量化 > 残差量化",并用 t-SNE 给出表征层面的解释。
与已归档相关工作的对比¶
SSRLive SSRLive:用动态语义 ID 驱动的直播推荐(Taobao & Tmall Group of Alibaba, 2026-06-05)¶
关系:独立并发(本文未引用 SSRLive,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都从同一个 root cause 出发——现有 Semantic ID 是"静态且不变(static and invariant)"的,隐含假设 item 语义在时间上平稳,因而无法刻画随时间演化的信息。ChronoID 把它表述为"同一 item 不同时间上下文的交互被映射到相同 SID";SSRLive 表述为"短视频用的静态 SID 无法刻画直播间随时间实时变化的内容"。问题陈述实质同构。
- 相近的技术骨架:两者都让 SID 变得"时间感知",且都把额外的时间维度信息经向量量化注入码本(ChronoID 用 RQ-VAE/并行量化,SSRLive 用 RQ-KMeans + EMA)。
- 本文的差异与推进:时间进入 SID 的"载体"不同。ChronoID 注入的是交互的时间戳本身——为每个 user–item 交互生成一个绝对/相对时间嵌入,与 item 文本嵌入融合后量化,时间是交互的元数据。SSRLive 注入的是item(直播间)随时间演化的实时内容特征——它给每个直播间同时生成"静态 SID"(历史多模态向量)与"动态 SID"(实时房间特征经 RQ-KMeans 量化),时间体现在"内容本身在变,故重新量化"。换言之:ChronoID 让 SID 记住"交互发生在何时",SSRLive 让 SID 跟随"item 内容此刻是什么"。
- 可比的方法 / 实验差异:ChronoID 是用公开 Amazon/Mercari 数据集的纯生成式、设计空间分析论文,无线上实验;SSRLive 是生成式-判别式混合的工业系统,把 SID 当作辅助判别式排序的特征(而非生成目标),已全量部署淘宝直播粗排,线上 watch time +3.38%、GMV +0.72%。两者恰好示范了"时间感知 SID"的两条互补落地路径:学术设计空间刻画 vs 工业混合架构部署。
Pro-GEO Pro-GEO:用 Geo-RoPE 把地理邻近性嵌入语义码本(BUPT / Meituan 数据, 2026-04-25)¶
关系:独立并发(本文未引用 Pro-GEO,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都在解决"语义 ID 只编码文本语义,缺失某个关键的外部上下文信号"这一同构问题——ChronoID 缺的是时间,Pro-GEO 缺的是地理。更深一层的共鸣是:两者都发现把外部信号朴素地 concat 进嵌入,该信号会沦为被高维文本语义淹没的"弱正则(weak regularizer)"。Pro-GEO 明言"即使把经纬度 concat 进去,地理信号仍只是 weak regularizer";ChronoID 则发现早融合把时间拼进单一码本会被压缩塌缩,这正是它转向晚融合/并行量化的原因。
- 相近的技术骨架:两者都主张在 SID 量化层面给外部信号一个专门的结构性位置,而非简单拼接。Pro-GEO 把第三层换成专门的 geo-codebook(geo-centroid 局部坐标 + Geo-RoPE 正交旋转);ChronoID 用晚融合给时间一套独立量化器、或用并行量化给时间独立码本切面。两者都在反对"外部信号当弱特征拼接",主张"给它独立的离散表示空间"。
- 本文的差异与推进:注入的信号(时间 vs 地理)与机制不同。Pro-GEO 的机制是旋转式相对编码(把地理邻近性等价为语义空间中的小角度旋转,且只动一层码本),针对的是本地生活的地理可达性硬约束;ChronoID 的机制是正弦时间嵌入 + 融合顺序 + 量化结构的系统设计空间,针对的是交互节律与时间漂移。Pro-GEO 是单点最优方案,ChronoID 是把"注入一个外部信号"抽象成可枚举的设计维度框架。
- 可比的方法 / 实验差异:Pro-GEO 报告把平均地理聚类距离降低 45.60%、Hit@50 +1.87%(工业本地生活数据);ChronoID 报告 HR@3 在 Industrial/Office 上相对提升 36.1%/40.1%(公开数据集)。两者都用"外部信号显式进 SID"换来了检索质量提升,可视为同一设计哲学在不同信号上的独立验证。
被剔除的近似候选(门槛防放水):SIREN(2605.25726, Tencent) 同样辩论 SID 的早融合 vs 晚融合,但其 root cause 是多模态终身兴趣建模与在线服务成本,信号是多模态内容而非时间,只在"融合顺序"这一子维度重叠 → 问题不同构,剔除。AsymRec(2605.14512)/ DRQ(2606.01844) 与本文在"残差 vs 并行/解耦量化"这一子维度重叠,但其问题分别是信息瓶颈、tokenizer 质量权衡,与本文的时间问题不同构 → 剔除。CARD(2604.26427) 涉及"把异质信号融合进 SID 并处理分布问题",但信号是文本/视觉/协同等内容模态、核心机制是可逆均匀化变换,与时间无关 → 剔除。FORGE(2509.20904) 被本文在 related work 引用,但其问题(工业级 SID 规模化与碰撞)与本文不同构,且非 Table 1 baseline → 仅作引用关系,不入孪生对比。
讨论与局限性¶
值得借鉴的设计。 (1) 把"时间该不该进语义抽象层"提升为一等问题,并拆成时间编码/融合/量化三个正交维度,是一个干净、可复用的分析框架——任何"想给 SID 注入某个外部信号"的工作(地理、价格、上下文)都能套用这套维度去定位设计选择。(2) 时间显式基准的"固定全局时间切点贯穿码本训练/SFT/测试"是一个被很多生成式推荐工作忽视的严谨性细节——若码本在含未来交互的数据上训练,评测就已泄漏。(3) "相对时间 > 绝对时间"的论证(因为量化后失去内积、且绝对时间单调漂移)对任何要把连续时间离散化的工作都有警示价值。
局限与争议。 (1) 一个内部框架张力:论文的标题性结论之一是"晚融合优于早融合",但全局最优配置却是"并行量化 + 相对时间",而并行量化在论文里固定使用早融合的拼接嵌入 $[\mathbf{h}_{\text{item}}\|\mathbf{h}_t]$。也就是说最佳模型其实用的是早融合。"晚融合更优"只在残差量化这条线内成立,被并行量化这个不同的轴所主导。三个维度被宣称"正交",但 early/late 融合维度对并行量化整条线不适用(标 N/A),使得"晚融合优越"这一普适表述与"最优解用早融合"之间存在表述上的不一致,论文未充分调和。此外在相对时间下,残差量化的 Early+Rel 在 Industrial 上甚至略高于 Late+Rel(10.62 vs 10.43),"晚融合一致更优"的说法主要由绝对时间的情形撑起。(2) 技术新颖性有限:核心构件多为借用——正弦时间编码(Vaswani 2017)、残差量化(RQ-VAE/TIGER)、并行量化(TokenRec)。ChronoID 的贡献更多是"系统组合 + 设计空间刻画 + 基准",而非新机制。(3) 缺乏工业验证:尽管有 Meta MRS 作者,论文只在公开学术数据集上评测,没有任何在线 A/B 或部署细节,与 SSRLive 这类已部署的工业孪生形成对照。(4) 附录缺失:本 arXiv 版本不含正文反复引用的 §A–§D,其中 §C.1(增益来自语义而非 ID 空间扩大)、§C.2(零填充引入 OOD 噪声)、§C.3(原子时间戳已可内化节假日/季节)三条声明的支撑实验无法核验。(5) 方法论可扩展性隐患:与所有"先离线学码本、再 SFT 生成"的 SID 范式一样,ChronoID 的码本一旦固化即限制下游表征空间,量化器与生成模型无法端到端联合优化——参数量 scaling 时"如何表征 item(含时间)"与"如何建模序列"两条路径难以同步扩充,长期上限存疑。
综合来看,ChronoID 是一篇动机清晰、分析扎实但创新偏框架/组合的设计空间研究:它把"时间进 SID"这件被忽视的事讲透了,贡献了一个严谨的时间显式基准,实证结论一致可信且有解释;但受限于借用式构件、缺乏线上验证与附录缺失,以及"晚融合优越 vs 最优解用早融合"的内部张力,它更像一份高质量的方向性指南而非开创性突破。