Pro-GEO:用 Geo-RoPE 把地理邻近性嵌入语义码本¶
研究动机与背景¶
生成式推荐近年成为本地生活服务(Meituan、DoorDash、Yelp 等)平台的主流范式:把每个 POI 通过 RQ-VAE / RQ-Kmeans 等量化方法压缩成一个层次化的离散 Semantic ID(SID),再用 LLM 自回归生成下一个 POI 的 SID 序列。然而,本地生活与电商/视频推荐有一个根本差异:相关性必须满足严格的地理可达性约束。论文给出了一个非常直观的失败案例(Figure 1)——在通州区搜索汉堡的用户被推到了河北廊坊,距离超过 35 km,明显是跨城无效推荐。
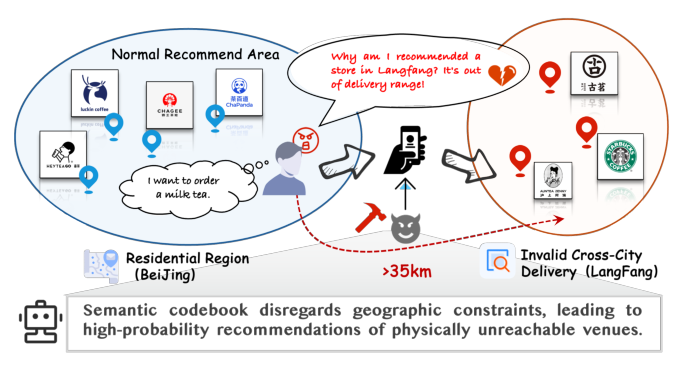
作者在中国某主流本地生活平台(即 GNPR-SID 用的同一数据集)上做了一项基础统计:超过 50% 的 POI 与同一个 SID 下其他 POI 在地理上相距 >40 km。这是一个结构性问题,而不是模型容量不够。其根因在于:SID 的聚类目标里语义信号高维度且方差大,几何信号被淹没。即使把经纬度作为辅助特征 concat 到嵌入里(GNPR-SID、OneLoc 等已尝试的全局表示),地理信号仍只是 weak regularizer。
为此,作者提出两个核心研究问题:
- Q1:全局地理特征(lat-lon、geohash)是否足以建模本地服务的空间关系?还是应该用相对的、行为感知的局部坐标系?
- Q2:如何在码本里联合编码语义相关性和地理邻近性,使得二者既不互相塌缩、又都不退化为 weak regularizer?
针对 Q1,作者证明了"全局坐标差异"在大尺度数据集上对应的物理距离可能差异巨大(北京两个 lat-lon 仅差 0.001° 也可能横跨地铁站),不利于表示学习捕捉簇内的精细空间关系。他们的答案是:定义地理质心(geo-centroid)局部坐标系。
针对 Q2,他们将 RoPE 从序列位置外推到空间域,用正交旋转编码两个 POI 在高维语义空间中的相对地理位置——即 Geo-RoPE。设计目标是让"几何邻近性"等价于"语义嵌入空间中的小角度旋转",从而 birds of a feather (语义相近的 POI) cluster nearby (地理相近的 POI) 在 SID 空间真正对齐。
主要贡献: 1) 提出 geo-centroid 局部坐标系,将每个语义簇锚定到一个地理质心,显式保留簇内细粒度空间关系; 2) 设计 Geo-RoPE 编码机制,把相对地理位置直接嵌入到 token 空间,与语义结构一并保留; 3) 在大规模工业数据集上验证 Pro-GEO 把平均地理聚类距离降低 45.60%(无 codebook collapse),Hit@50 提升 1.87%。
整体框架¶
Pro-GEO 沿用 RQ-Kmeans / TIGER 风格的三层 SID 框架,但把第三层换成特殊的 geo-codebook layer。Figure 2 给出了完整 pipeline:前两层是 standard codebook layer(语义聚类),第三层是 special geo-codebook layer(geo-centroid 局部坐标 + Geo-RoPE 调制后的 K-means 聚类)。最终 SID 形如 <a_2, b_11, g_8>,其中 a_2/b_11 编码语义结构,g_8 编码相对地理偏移。一个微调过的 LLM 基于用户意图生成推荐候选 POI 的 SID,不再产生跨城无效配送。
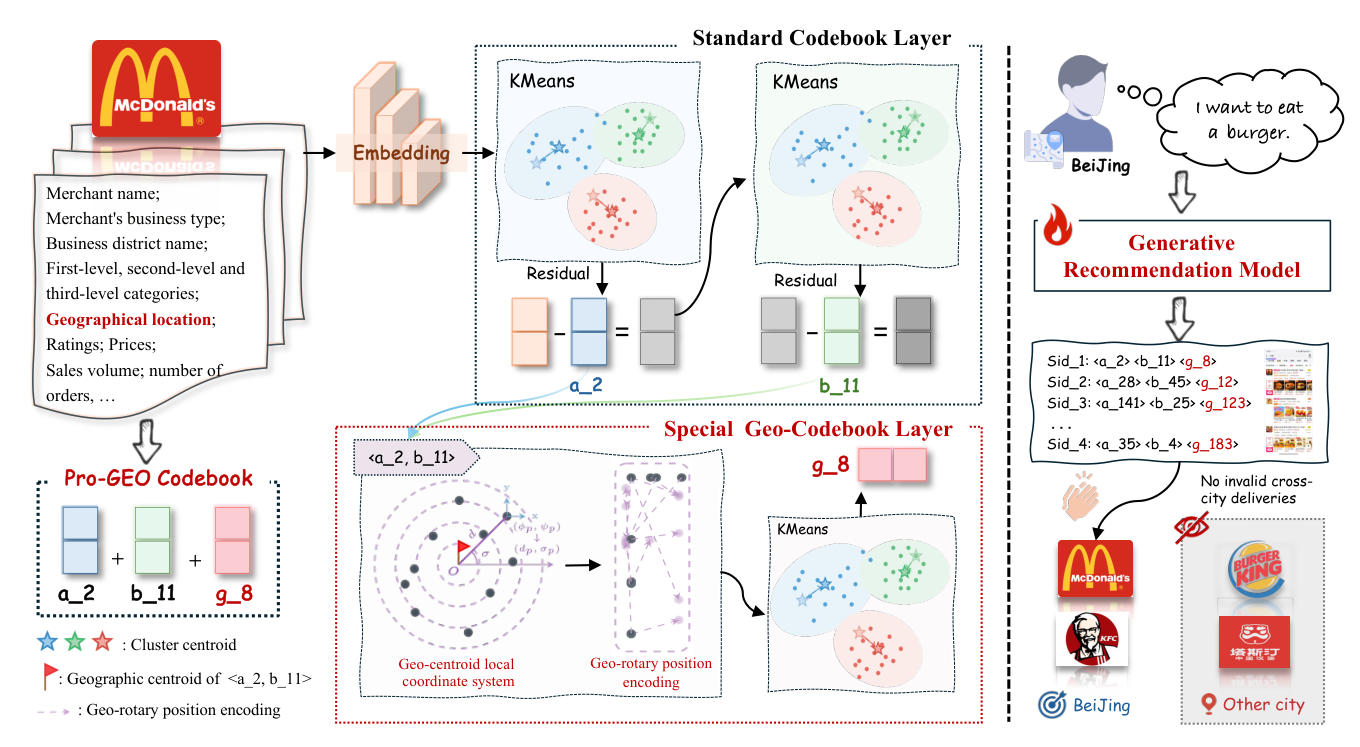
形式化地,POI 集合 $P = \{p_1, p_2, ..., p_N\}$,每个 POI 用元组 $p_N = (s, \phi, \psi)$ 表示:$s$ 包含类别、品牌、评分、价格等语义特征,$(\phi, \psi)$ 是地理经纬度。生成式推荐任务即在 POI 集合上建模条件概率 $P(\text{next POI} | \text{user intent})$。
核心方法¶
语义码本聚类(前两层)¶
给定 POI 表示 $\mathcal{X} = \{\mathbf{x}_i \in \mathbb{R}^M\}_{i=1}^N$,传统 RQ-Kmeans 用欧氏距离做聚类。论文论证欧氏距离在高维下因维度灾难判别力弱、且与工业推荐常用的相似度目标不对齐。借鉴 HyMiRec,作者改用余弦相似度作为聚类度量。
第 $l$ 层第 $i$ 个 POI 的残差 $\mathbf{r}_i^{(l-1)}$ 的簇分配:
$$j_i^{(l)} = \arg\max_j \frac{\mathbf{r}_i^{(l-1) \top} \mathbf{c}_j^{(l)}}{\|\mathbf{r}_i^{(l-1)}\|_2 \|\mathbf{c}_j^{(l)}\|_2}, \tag{1}$$
其中 $\mathbf{r}_i^{(0)} = \mathbf{x}_i$。余弦相似度只关注方向、对尺度变化更鲁棒。
接下来对残差做正交投影去冗余:把 $\mathbf{r}_i^{(l-1)}$ 在所选质心方向上的分量减掉:
$$\mathbf{r}_i^{(l)} = \mathbf{r}_i^{(l-1)} - \frac{\mathbf{r}_i^{(l-1) \top} \mathbf{c}_{j_i^{(l)}}^{(l)}}{\|\mathbf{c}_{j_i^{(l)}}^{(l)}\|_2^2} \mathbf{c}_{j_i^{(l)}}^{(l)}. \tag{2}$$
这样残差被投到正交于簇方向的子空间,沿簇方向的冗余被滤掉,只保留正交方向的结构。两次迭代后得到层次语义 ID $(j_i^{(1)}, j_i^{(2)})$。
Geo-Centroid 局部坐标映射¶
全局坐标系有两个困难:(1) 微小坐标差对应巨大物理距离;(2) 缺乏支持局部相对定位的参考标准。作者借鉴 Figure 3 的对比:在全局坐标里 $P_1=(116.417, 39.941)$、$P_2=(116.480, 39.923)$ 差 5.97 km,但全局坐标差异本身没有局部参考意义;引入局部坐标后,把同一簇的 POI 用相对极坐标表达,5.97 km 变成相对质心的 $(d, \sigma)$ 二元组,捕获该簇内的相对空间布局。
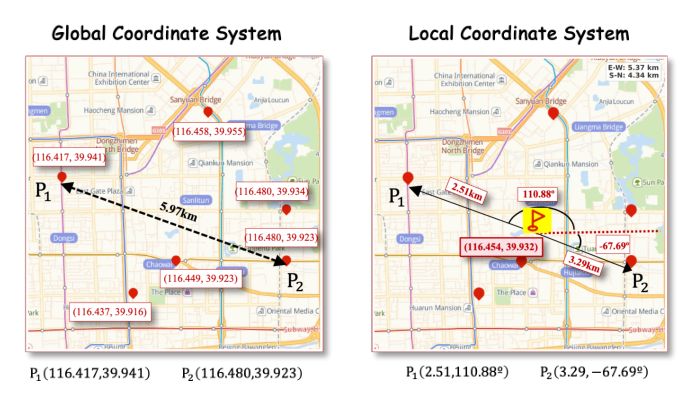
具体做法:令 $\mathcal{S}_{(j^{(1)}, j^{(2)})}$ 为分到两层 SID $(j^{(1)}, j^{(2)})$ 的 POI 集合。每个 POI $p$ 的全局坐标为 $(\phi_p, \psi_p)$。簇的地理质心为:
$$O_p^j = (\phi_0, \psi_0) = \left(\frac{1}{|\mathcal{S}|}\sum_{s \in \mathcal{S}} \phi_s,\ \frac{1}{|\mathcal{S}|}\sum_{s \in \mathcal{S}} \psi_s\right). \tag{3}$$
每个 POI 用相对于质心的相对极坐标 $(d_p, \sigma_p)$ 表示:
$$d_p = 2R \arcsin\left(\sqrt{\sin^2\left(\frac{\phi_p - \phi_0}{2}\right) + \cos\phi_0 \cos\phi_p \sin^2\left(\frac{\psi_p - \psi_0}{2}\right)}\right), \tag{4}$$
$$\sigma_p = \arg(x + iy),$$
其中 $R$ 是地球平均半径(6371 km),$\arg(\cdot)$ 是复数辐角主值,
$$\begin{aligned} x &= \cos\phi_0 \sin\phi_p \cdot \cos\phi_p - \sin\phi_0 \cos(\psi_p - \psi_0), \\ y &= \sin(\psi_p - \psi_0) \cdot \cos\phi_p. \end{aligned} \tag{5}$$
公式 (4) 是 Haversine 距离(球面大圆距离),$d_p$ 给出 POI 相对簇质心的可达性距离;$\sigma_p$ 是从质心看 POI 的方位角,捕获该簇内 POI 的方向分布。这种相对极坐标表达有两个关键优势:(1) 半径距离 $d_p$ 直接编码相对簇质心的可达性;(2) 方位角 $\sigma_p$ 捕捉局部区域内的方向性分布。
Geo-Rotary Position Encoding¶
RoPE 原本用于 Transformer 序列位置编码,把相对位置建模为正交旋转。作者把它外推到空间域:用复值旋转编码地理邻近性,所有变换都直接作用在第二层残差嵌入 $\mathbf{r}_p^{(2)} \in \mathbb{R}^M$ 上。
定义块对角旋转矩阵:
$$\mathcal{R}(\theta_p) = \mathrm{diag}\big(\underbrace{R(\theta_p), R(\theta_p), \ldots, R(\theta_p)}_{m\ \text{times}}\big) \in \mathbb{R}^{M \times M}, \tag{6}$$
其中 $m = M/2$,
$$R(\theta_p) = \begin{bmatrix} \cos\theta_p & -\sin\theta_p \\ \sin\theta_p & \cos\theta_p \end{bmatrix}. \tag{7}$$
与原始 RoPE 不同的是,频率参数 $\theta_p$ 不是序列位置;它直接来自地理量:$\theta_p \in \{d_p, \sigma_p\}$。换言之,码本不在残差向量内部建模上下文,而是建模 POI 之间的相对空间关系。
为了反向旋转的可学习性、对称性,作者引入前向 + 反向旋转双策略。以 $\theta_p = \sigma_p$ 为例,Geo-RoPE 变换 $\mathcal{T}_{\sigma_p} : \mathbb{R}^M \to \mathbb{R}^{2M}$ 定义为:
$$\mathbf{r}_p^{(2)\rightarrow} = \mathcal{T}_{\sigma_p}(\mathbf{r}_p^{(2)}) = \begin{bmatrix} \mathcal{R}(\sigma_p) \mathbf{r}_p^{(2)} \\ \mathcal{R}(-\sigma_p) \mathbf{r}_p^{(2)} \end{bmatrix} \in \mathbb{R}^{2M}. \tag{8}$$
对于任意两个向量 $\mathbf{r}_i^{(2)}$、$\mathbf{r}_j^{(2)}$,余弦距离为:
$$D_{\cos}(\mathbf{r}_i^{(2)}, \mathbf{r}_j^{(2)}) = 1 - \frac{\langle \mathbf{r}_i^{(2)}, \mathbf{r}_j^{(2)} \rangle}{\|\mathbf{r}_i^{(2)}\| \|\mathbf{r}_j^{(2)}\|}. \tag{9}$$
经过 Geo-RoPE 变换前后,余弦距离变化为:
$$\Delta D_{\cos} = D_{\cos}(\mathbf{r}_i^{(2)\prime}, \mathbf{r}_j^{(2)\prime}) - D_{\cos}(\mathbf{r}_i^{(2)}, \mathbf{r}_j^{(2)}) = 2 \cdot \frac{\langle \mathbf{r}_i^{(2)}, \mathbf{r}_j^{(2)} \rangle}{\|\mathbf{r}_i^{(2)}\| \|\mathbf{r}_j^{(2)}\|} \cdot \sin^2\left(\frac{\Delta \sigma}{2}\right), \tag{10}$$
其中 $\Delta \sigma = \sigma_i - \sigma_j$。把 $\sigma$ 限制在 $[-\pi/2, +\pi/2]$ 保证 $\Delta\sigma$ 准确刻画两 POI 的相对旋转角。$\Delta D_{\cos}$ 在 $\Delta\sigma = 0$ 时为零,在 $\Delta\sigma \in [-\pi, +\pi]$ 时取最大值。这一性质保证了变换自然保留空间相邻 POI 的相似性,同时把空间远 POI 适当推离。
进一步,公式 (10) 可分解为两个可解释因子:
$$\Delta D_{\cos} \propto \underbrace{\sin^2\left(\frac{\Delta \sigma}{2}\right)}_{\text{Positional difference factor}} \times \underbrace{\frac{\langle \mathbf{r}_i^{(2)}, \mathbf{r}_j^{(2)} \rangle}{\|\mathbf{r}_i^{(2)}\| \|\mathbf{r}_j^{(2)}\|}}_{\text{Semantic similarity factor}}. \tag{11}$$
这是最关键的设计闭环:余弦距离的变化是空间因子和语义因子的乘积,而不是各自独立。语义相似的 POI(高余弦相似度)下 $\Delta\sigma$ 才会显著拉开它们的距离,即"语义近、空间远"会被适当分开;语义不相似的 POI(低余弦相似度),不论空间布局如何,变换几乎无影响——避免地理信号污染语义判别。这反过来也对 $d$(在 $[0, \pi]$ 上)成立。
最终经过 Geo-RoPE 后的二层残差向量为:
$$\overrightarrow{\mathbf{r}_p^{(2)}} = \begin{bmatrix} \mathcal{T}_{\alpha \cdot \sigma_p}(\mathbf{r}_p^{(2)}) \\ \mathcal{T}_{\beta \cdot d_p}(\mathbf{r}_p^{(2)}) \end{bmatrix} \in \mathbb{R}^{4M}, \tag{12}$$
其中 $\alpha, \beta \in \mathbb{R}^+$ 是控制方位角 $\sigma_p$ 和半径距离 $d_p$ 各自贡献的超参数(实验默认 $\alpha=\beta=0.5$)。
变换后的嵌入 $\overrightarrow{\mathbf{r}_p^{(2)}}$ 再做一次 K-means 聚类得到第三层 ID。完整 SID 即:
$$\mathrm{SID}_p = (j^{(1)}, j^{(2)}, j^{(3)}). \tag{13}$$
前两层编码语义结构,第三层通过 Geo-RoPE 增强的聚类整合相对地理信息。
关键证明(Eq. 10 的几何含义)¶
附录 A 给出了完整证明,核心是 Lemma A.1:对于两个镜像对偶向量 $\mathbf{r}_1, \mathbf{r}_2$(即 $\mathbf{v} = \begin{bmatrix} v_1 \\ v_1 \end{bmatrix}$ 形式),分别施加 Geo-RoPE 变换 $\mathcal{T}_{\theta_1}, \mathcal{T}_{\theta_2}$ 后,内积满足:
$$\langle \mathbf{r}_1', \mathbf{r}_2' \rangle = \cos(\Delta\theta) \cdot \langle \mathbf{r}_1, \mathbf{r}_2 \rangle, \quad \Delta\theta = \theta_1 - \theta_2. \tag{19}$$
证明思路是:把每个 mirror-duplicated 向量分解成 $m$ 对 2D 子向量;利用旋转矩阵性质 $\langle R(\alpha) u, R(\beta) v \rangle = u^T R(\beta - \alpha) v$;前向 / 反向两个旋转部分相加后,交叉项 $\sin\Delta\theta$ 因镜像对偶性自动相消,只剩 $2\cos\Delta\theta \sum_i d_i$(即 $\cos\Delta\theta \cdot \langle \mathbf{r}_1, \mathbf{r}_2 \rangle$)。这个对称的 forward-reverse 结构是为什么 Pro-GEO 的余弦差只依赖相对旋转角差 $\Delta\theta$,而与绝对旋转角无关——这是论文反复强调的"前向反向双方向"设计的核心动因。
进一步利用 $1 - \cos\Delta\theta = 2\sin^2(\Delta\theta/2)$,即可推出 Eq. 10。
实验设置¶
工业数据集:来自一个中国主流本地生活服务平台(与 GNPR-SID 同来源)。两个月用户交易记录用于训练,额外一天用于验证。每条数据包含完整的用户搜索 query、用户地理位置、商家曝光序列、商家信息、真实交互行为。
公开数据集:Foursquare-NYC、Foursquare-TKY、Yelp。NYC 1083 用户/5135 POI;TKY 2293 用户/7873 POI;Yelp 150,346 POI。NYC/TKY 包含商家和用户行为信息;Yelp 仅有商家。三个公开数据集都用于评估聚类效果,推荐效果只在 NYC、TKY 上评估。预处理沿用 GNPR-SID:去掉交互少于 10 的商家和打卡少于 10 的用户。
实现细节:
- 工业数据集码本配置 $[512, 512, 512]$;公开数据集 NYC/TKY $[32, 32, 32]$,Yelp $[64, 64, 64]$。
- RoPE-based 旋转编码加在第三层量化层,超参数 $\alpha=\beta=0.5$。
- 文本嵌入用预训练 Qwen3-Embedding-8B,128 维。
- 生成式推荐模型用 Qwen2.5-1.5B,max sequence length 512,batch size 64。
- AdamW 优化器,学习率 8e-5,weight decay 0.01。推理时取距用户位置最近的 10 个 SID 作为候选集,beam search 宽度 20。
- 8 张 80GB GPU。Prompt template 形如:
Instruction: ... Input: Query:<query>, City:<city>, GeoHash:<geohash>, Output: SID list:<Sid_1>,...,<Sid_N>。
评估指标:
- 量化指标:CUR (Codebook Utilization Rate)、ICR (Independent Coding Rate),以及本地服务专属的 Avg. Dist.(簇内 POI 到中心点的平均欧氏距离,单位 km)、p90 Dist.、p95 Dist.——这三个空间指标越小越好。
- 推荐指标:Hit@N、NDCG@N(N=50, 100),以及 Hit@1。
对比方法:RQ-VAE、RQ-Kmeans、Zhou et al.(HyMiRec 路线)、RQ-OPQ。
主要实验结果¶
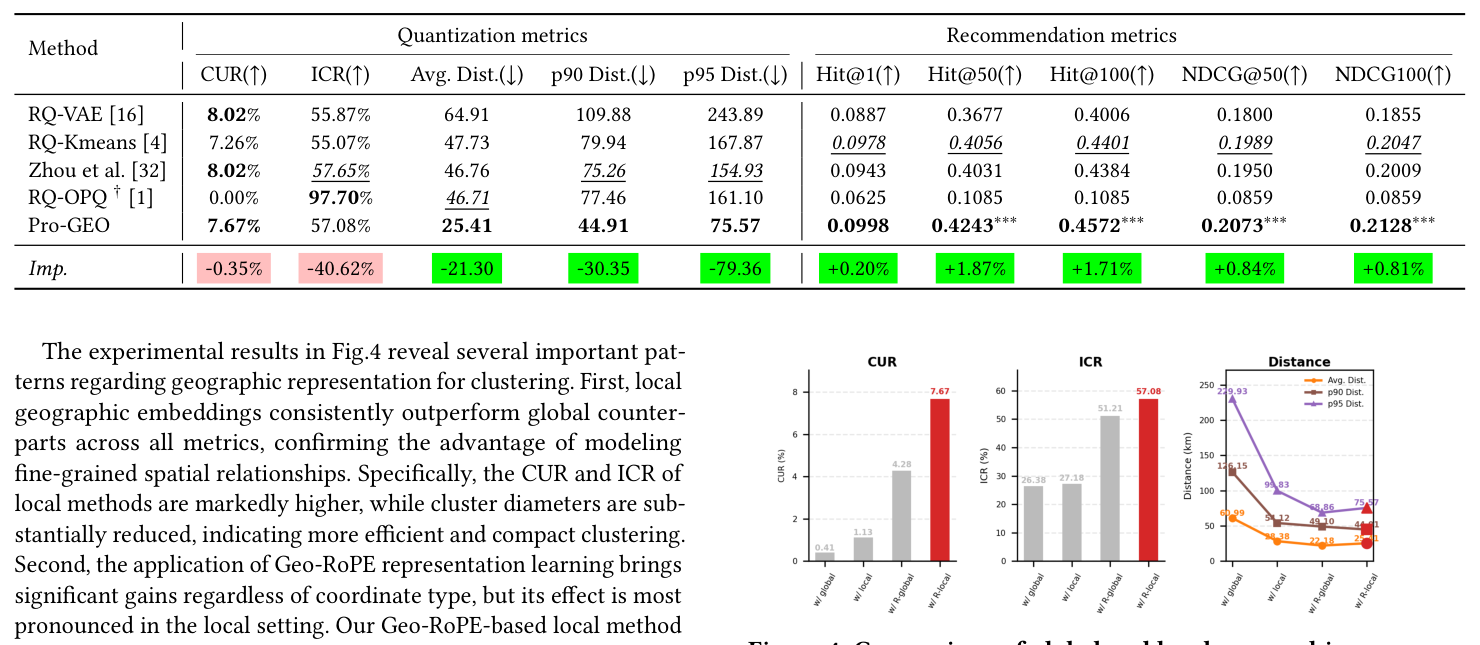
Q1:与 SOTA 对比(Table 1)¶
| Method | CUR↑ | ICR↑ | Avg. Dist.↓ | p90 Dist.↓ | p95 Dist.↓ | Hit@1↑ | Hit@50↑ | Hit@100↑ | NDCG@50↑ | NDCG@100↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| RQ-VAE | 8.02 | 55.87 | 64.91 | 109.88 | 243.89 | 0.0887 | 0.3677 | 0.4006 | 0.1800 | 0.1855 |
| RQ-Kmeans | 7.26 | 55.07 | 47.73 | 79.94 | 167.87 | 0.0978 | 0.4056 | 0.4401 | 0.1989 | 0.2047 |
| Zhou et al. | 8.02 | 57.65 | 46.76 | 75.26 | 154.93 | 0.0943 | 0.4031 | 0.4384 | 0.1950 | 0.2009 |
| RQ-OPQ | 0.00 | 97.70 | 46.71 | 77.46 | 161.10 | 0.0625 | 0.1085 | 0.1085 | 0.0859 | 0.0885 |
| Pro-GEO | 7.67 | 57.08 | 25.41 | 44.91 | 75.57 | 0.0998 | 0.4243 | 0.4572 | 0.2073 | 0.2128 |
| Imp. | -0.35 | -40.62 | -21.30 | -30.35 | -79.36 | +0.20 | +1.87 | +1.71 | +0.84 | +0.81 |
Pro-GEO 在所有三个空间距离指标上碾压所有 baseline:Avg. Dist. 从 RQ-OPQ 的 46.71 km 跌到 25.41 km(−45.6%),p95 Dist. 从 154.93 km 跌到 75.57 km(−51.2%)。同时 CUR/ICR 与最佳 baseline(不算 RQ-OPQ 那种 0% CUR 的退化解)相当,没有 codebook collapse;推荐效果在所有 Hit@N、NDCG@N 上 p<0.001 显著优于 RQ-Kmeans。RQ-OPQ 虽然 ICR 高达 97.7%,但 CUR 为 0% 意味着 codebook 完全没被利用,是个 trivial 解,对应的 Hit@1 只有 0.0625——量化指标和推荐指标必须联合判读。这个对比表明:单纯增加正交编码不能解决问题,必须把空间结构内化进表示学习。
Q2:消融研究¶
4.3.1 不同地理特征的有效性(Figure 4)¶
四个变体:(i) w/ global = 全局经纬度直接作为输入嵌入;(ii) w/ local = geo-centroid 局部坐标;(iii) w/ R-global = Geo-RoPE 增强全局坐标;(iv) w/ R-local = Geo-RoPE 增强局部坐标(Pro-GEO)。
结论:局部表示一致优于全局表示;Geo-RoPE 在两种坐标系下都带来增益,但局部 + Geo-RoPE 收益最大。Pro-GEO(R-local)拿到最高 CUR (7.67%)、ICR (57.08%),且簇直径最紧凑。这验证 Q1:全局坐标对本地服务建模不够,必须用相对的、行为感知的坐标系。
4.3.2 Geo-RoPE 注入层(Figure 5)¶
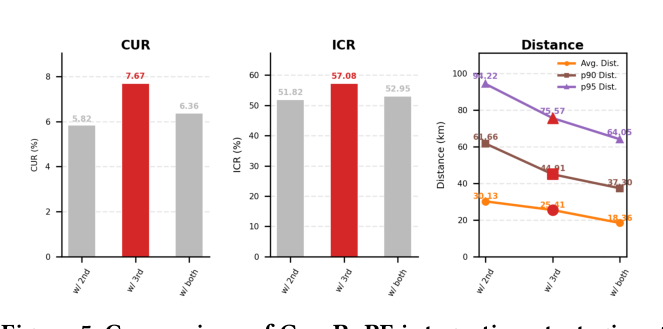
三种策略:仅第二层、仅第三层(Pro-GEO 默认)、两层都用。结果:仅第三层最优——CUR 7.67%、ICR 57.08%、Avg. Dist. 25.41。两层都用反而把空间紧凑性继续推到 Avg. Dist. 更小,但 CUR 跌到 6.36%、ICR 跌到 52.95%,几何紧凑性和整体聚类有效性出现 trade-off。仅第二层最差。这反映:地理信号应该在语义骨架已建立的最后一层作精修;过早注入会污染中层语义特征。
4.3.3 增强方式(Figure 6)¶
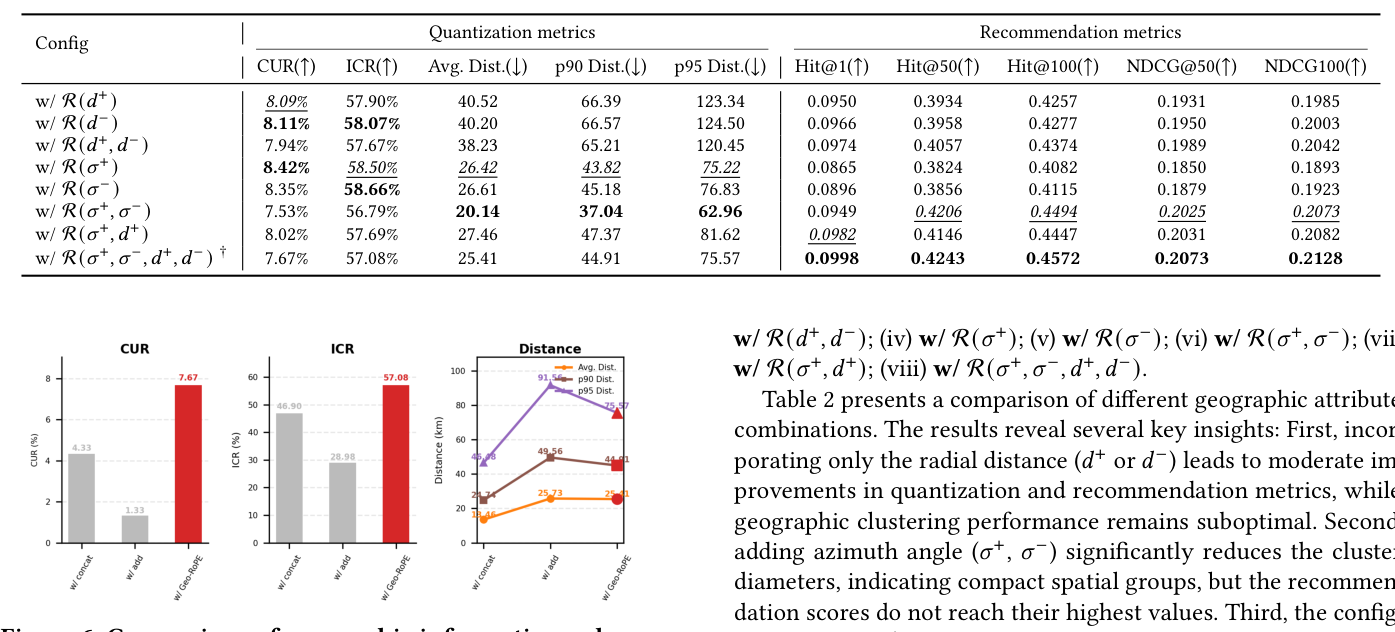
三种增强方式:(i) w/ concat = 拼接(128 → 130 维);(ii) w/ add = 直接加到 128 维向量;(iii) w/ Geo-RoPE = 旋转编码。结论:Geo-RoPE 在 CUR/ICR 上明显领先。concat 仅产生最小簇直径(Avg. Dist. 13.46),但聚类利用率中等,说明拼接虽然能减小直径但容易导致过分散、可解释性差;add 在所有指标上都最差,因为直接相加把地理信号稀释进了语义特征空间。Geo-RoPE 的优势是把空间信号编码为正交变换而非简单拼接——这也是论文核心方法论:辅助约束应该通过 attribute-aware 变换嵌入表示空间。
4.3.4 地理属性组合(Table 2)¶
| Config | CUR↑ | ICR↑ | Avg. Dist.↓ | p90 Dist.↓ | p95 Dist.↓ | Hit@1↑ | Hit@50↑ | Hit@100↑ | NDCG@50↑ | NDCG@100↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| w/ R(d⁺) | 8.09 | 57.90 | 40.52 | 66.39 | 123.34 | 0.0950 | 0.3934 | 0.4257 | 0.1931 | 0.1985 |
| w/ R(d⁻) | 8.11 | 58.07 | 42.20 | 66.57 | 124.50 | 0.0966 | 0.3958 | 0.4277 | 0.1950 | 0.2003 |
| w/ R(d⁺, d⁻) | 7.94 | 57.67 | 38.23 | 65.21 | 120.45 | 0.0974 | 0.4057 | 0.4374 | 0.1989 | 0.2042 |
| w/ R(σ⁺) | 8.42 | 58.50 | 26.42 | 43.82 | 75.22 | 0.0865 | 0.3824 | 0.4082 | 0.1850 | 0.1893 |
| w/ R(σ⁻) | 8.35 | 58.66 | 26.61 | 45.18 | 76.83 | 0.0896 | 0.3856 | 0.4115 | 0.1879 | 0.1923 |
| w/ R(σ⁺, σ⁻) | 7.53 | 56.79 | 20.14 | 37.04 | 62.96 | 0.0949 | 0.4206 | 0.4494 | 0.2025 | 0.2073 |
| w/ R(σ⁺, d⁺) | 8.02 | 57.69 | 27.46 | 47.37 | 81.62 | 0.0982 | 0.4146 | 0.4447 | 0.2031 | 0.2082 |
| Pro-GEO w/ R(σ⁺, σ⁻, d⁺, d⁻) | 7.67 | 57.08 | 25.41 | 44.91 | 75.57 | 0.0998 | 0.4243 | 0.4572 | 0.2073 | 0.2128 |
关键发现:
- 径向距离单独($d^+$ / $d^-$)只能轻微改善量化和推荐,不显著改善聚类紧凑性(Avg. Dist. 仍 ≈40 km)。
- 加方位角($\sigma$ 类)显著降低簇直径,但单方向 $\sigma$ 推荐分数没拉满。
- 方位角双向 $\mathcal{R}(\sigma^+, \sigma^-)$ 已经能让 Avg. Dist. 跌到 20.14 km、p90 Dist. 37.04,并把 NDCG@100 推到 0.2073。
- 完整 $\mathcal{R}(\sigma^+, \sigma^-, d^+, d^-)$ 不是几何最紧凑,而是推荐指标全面最高——前向 + 反向双向旋转的对称结构能捕获更复杂的方向模式,避免方向偏置。这印证了对称 forward-reverse 设计的必要性。
4.3.5 Codebook 冲突解决策略(Table 3)¶
| Config | Hit@1 | Imp. |
|---|---|---|
| Random | 3.23% | – |
| Layer-4 hard coding | 5.97% | +2.74% |
| 2_256_opq | 6.38% | +3.15% |
| Closest match (Ours) | 9.98% | +6.55% |
当多个 POI 共享同一 SID(即 codebook 冲突)时,Pro-GEO 在推理时通过地理邻近匹配消歧——即在共享同一 SID 的 POI 中,用户位置最近的优先。这一策略让 Hit@1 从 random 的 3.23% 推到 9.98%,+6.55% 的相对提升远超传统消歧方法(hard coding +2.74%、2_256_opq +3.15%)。这进一步说明:地理邻近性既是聚类目标,也是推理时的 disambiguation 信号。
4.4 超参数分析(Figure 7, Q3)¶
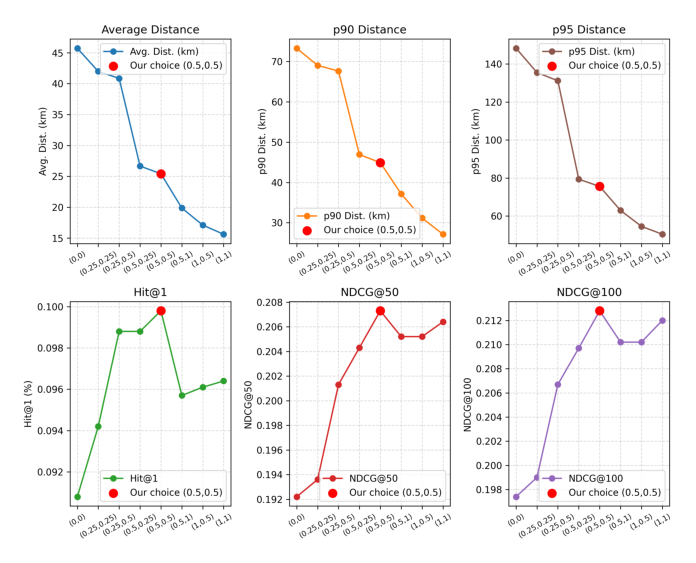
8 种 $(\alpha, \beta)$ 配置:从 (0,0) 到 (1,1)。结论:随着 $(\alpha, \beta)$ 增大:
- 距离指标显著下降:Avg. Dist. 从 45.72 km 降到 25.41 km,p95 Dist. 从 148.27 km 降到 75.57 km;
- 推荐指标也提升:Hit@1 从 0.0908 → 0.0998,NDCG@50/100 在 (0.5, 0.5) 附近达到峰值 0.2073/0.2128。
- (0.5, 0.5) 是最佳折衷——在所有指标上都最优或近最优。这说明 $\alpha$、$\beta$ 不是越大越好,需要平衡空间紧凑性和推荐准确性。
4.5 案例分析(Q4)¶
码本聚类可视化(Figure 8)¶
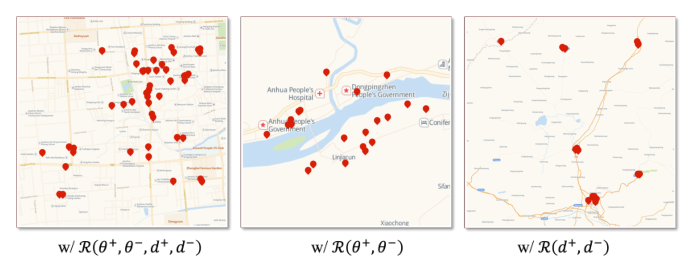
三种配置可视化:(a) 仅 $\mathcal{R}(d^+, d^-)$——簇松散、缺方向结构;(b) 仅 $\mathcal{R}(\sigma^+, \sigma^-)$——簇按方向聚集但容易过度组合;(c) Pro-GEO 完整版——簇既紧凑又方向均匀,避免过分散和过聚集。直观印证 Table 2 的结论。
推荐结果可视化(Figure 9)¶
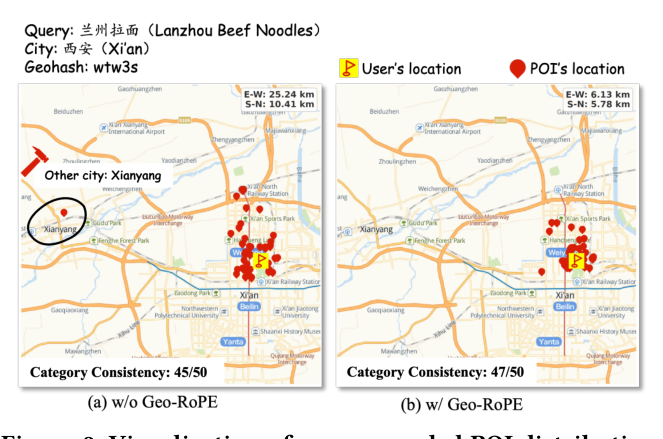
Lanzhou Beef Noodles 在西安市的查询。w/o Geo-RoPE:推荐 POI 在更广区域分散(最远 30 km,部分推到邻市咸阳),类目一致性 45/50;w/ Geo-RoPE:POI 集中在用户 6 km 半径内,类目一致性 47/50。Geo-RoPE 同时改善空间精度和类目一致性——即更可靠的语义对齐。
附录 C 中 Figure 10 给出了 4 个额外案例(Tao Tao Ju 深圳、KFC 北京、Zhou Hei Ya 武汉、Chaoshan beef hotpot 厦门),同样规律——没有 Geo-RoPE 的推荐常包含 20-36 km 远的甚至跨城 POI;加了 Geo-RoPE 后大都集中在用户 6-10 km 半径内。
公开数据集结果(附录 D,Table 6)¶
| Metric | NYC | NYC | NYC | TKY | TKY | TKY | Yelp | Yelp | Yelp |
|---|---|---|---|---|---|---|---|---|---|
| RQ-Kmeans | Pro-GEO | Imp. | RQ-Kmeans | Pro-GEO | Imp. | RQ-Kmeans | Pro-GEO | Imp. | |
| CUR↑ | 4.51 | 5.25 | +0.74 | 5.21 | 5.59 | +0.38 | 28.93 | 28.69 | -0.24 |
| ICR↑ | 52.13 | 55.29 | +3.16 | 49.12 | 45.60 | -3.52 | 60.95 | 58.98 | -1.97 |
| Avg. Dist.↓ | 6.96 | 6.10 | -0.86 | 7.21 | 6.19 | -1.02 | 115.67 | 75.35 | -40.32 |
| p90 Dist.↓ | 15.35 | 13.15 | -2.20 | 14.10 | 12.11 | -1.99 | 137.64 | 27.10 | -110.54 |
| p95 Dist.↓ | 18.60 | 16.62 | -1.98 | 16.65 | 14.75 | -1.90 | 614.16 | 322.43 | -291.73 |
| Hit@1↑ | 0.2308 | 0.3587 | +0.1279 | 0.1911 | 0.2833 | +0.0922 | – | – | – |
| Hit@5↑ | 0.4123 | 0.5300 | +0.1177 | 0.3000 | 0.4927 | +0.1927 | – | – | – |
| Hit@10↑ | 0.4591 | 0.5763 | +0.1172 | 0.3396 | 0.5583 | +0.2187 | – | – | – |
公开数据集上 Pro-GEO 显著降低空间距离(Yelp 上 p90 Dist. 降 110.54 km、p95 Dist. 降 291.73 km)。NYC/TKY 推荐指标上 Hit@1 大涨:NYC +12.79%、TKY +9.22%;Hit@5/10 类似。在 TKY/Yelp 上 ICR 略降,说明 Pro-GEO 在小数据集上用部分 codebook 多样性换取更紧凑空间结构,但 codebook 仍未塌缩。
讨论与局限性¶
核心贡献: 1. 把"地理可达性"从一个事后约束(如配送过滤)提升为生成式推荐 SID 的内嵌结构。这对工业部署意义重大:之前依赖 LLM "学会"避免跨城推荐,现在变成码本结构上的 "geometric impossibility"。 2. 把 RoPE 从序列位置编码外推到空间域,给出了 closed-form 的余弦距离变化分解(Eq. 11),证明地理信号和语义信号呈乘积关系,互不污染。这种"乘法解耦"的代数表达是 Pro-GEO 设计上最优雅的部分。 3. 提出前向 + 反向双向旋转结构,消除方向偏置,提升对称性——这是消融里 Hit@1 拉到 0.0998 的关键。 4. 工业级实证:在 Meituan 量级的数据集上把平均聚类距离降低 45.6%,Hit@50 提升 1.87%。同时给出公开数据集(NYC/TKY/Yelp)可复现性结果。
值得借鉴的设计思想:
- 辅助属性应通过 attribute-aware 变换注入表示空间,而非 concat 或 add——论文在 Conclusion 里明确提出:"auxiliary constraints can be more effectively integrated through attribute-aware transformations in the representation space instead of simple feature concatenation"。这一原则可类推到 SID 中注入价格、配送时间、库存等其他领域约束。
- Geo-centroid 局部坐标系——不要直接用绝对坐标,而是相对簇质心建立局部参考。这一思想可外推到任意数值属性的层次化簇内表示(如价格段内的相对价位)。
- Closest match disambiguation——SID 冲突在推理时用领域信号(地理近邻)消歧,比 hard coding 更优雅。
局限性: 1. Geo-codebook 仅作用在最后一层。前两层仍是纯语义聚类。如果用户的语义偏好本身与地理强相关(如某些菜系只在特定城市集中),可能错过早期注入的机会。但作者通过 4.3.2 实验证明早期注入有副作用——这是个固有 trade-off。 2. 静态地理表示。质心 $O_p^j$ 在簇形成后就固定了,没有动态调整机制。如果某簇 POI 分布随时间漂移(如新店开张、老店关闭),需要重训。 3. 公开数据集上 ICR 略降(TKY -3.52%,Yelp -1.97%)。说明小数据集场景下,注入地理信号会在 codebook 多样性和空间紧凑性之间做妥协。 4. 超参数 $(\alpha, \beta)$ 需要数据集级调优。虽然 (0.5, 0.5) 是论文推荐配置,但不同地理尺度(城市级 vs 全国级)下最优值可能不同。 5. 与 GNPR-SID/OneLoc/LGSID 等已有 geo-aware SID 工作没有直接对比——只对比了 RQ-VAE/Kmeans/OPQ 等通用 baseline。读者无法判断 Pro-GEO 相比同方向工作的边际收益。 6. 本质仍是事前 SID 设计,不能动态适应推理时的临时约束(如配送范围突然收紧)。
与已有工作的差异:相对于 RQ-Kmeans/OPQ 等通用 SID,Pro-GEO 的差异在于把领域约束代数化进表示空间;相对于 GNPR-SID/OneLoc 等 geo-aware SID,Pro-GEO 的差异在于不再把地理坐标作为辅助特征 concat,而是通过正交旋转主动改造残差嵌入的几何结构。这种"约束 → 几何变换"的思路是更深层的方法论贡献。
工业落地价值:直接在 Meituan 体量数据集上验证;架构改动局限在 SID tokenizer,对下游 LLM 训练 / 推理 pipeline 几乎透明。是适合产品迭代的小切口工程。