VCG:在"极端冷启动"下用多模态检索做电商短视频召回¶
VCG = Video Candidate Generation,来自 Zalando(欧洲大型时尚电商,作者来自 TU Wien + Zalando SE Berlin + Zalando Switzerland AG)。论文把一个新上线的"沉浸式短视频信息流"放进时尚电商场景,直面新视频"零交互历史"的极端冷启动(extreme cold-start)问题,提出一套完全 zero-shot、无需训练交互数据的双塔多模态召回引擎,并附带一个值得记住的实证结论:生成式(LLM)embedding 擅长内容标注,却因表征坍塌(anisotropy / collapse)而不适合做向量检索;判别式对比模型(CLIP)才是召回引擎的正确选择。
研究动机与背景¶
从"目标导向的目录"到"沉浸式视频流"¶
传统电商是一个数字目录(digital catalog):用户带着明确意图进入,搜索、比较、下单。在目录环境里商品生命周期长、能持续累积交互数据,这天然支撑了下游(商品推荐、用户建模)的鲁棒表征学习。但社交媒体把用户"喂"成了习惯无限信息流被动发现内容的人群。为顺应这一预期,Zalando 在其大型时尚电商网站上引入了一个视频信息流(video feed)。
转向 feed 架构带来的"极端冷启动"¶
把架构从目录切到 feed,引入了一个 Extreme Cold-Start 问题。论文把它拆成几条根因:
- 内容易逝且海量(ephemeral and voluminous):目录里商品长寿,而视频流里新视频源源不断、没有任何交互历史,使标准的矩阵分解(Matrix Factorization)或基于自编码器(Autoencoder)的推荐器直接失效——它们都需要稠密的交互信号。
- 时长偏置(duration bias):为标准"watch-time"优化会偏向更短的视频,而不论其相关性 [2]。
- 位置偏置(position bias):偏向更早出现的内容。
论文的核心立场转换是从协同信号转向语义信号:与其问 "还有谁看过这个视频?"(collaborative signal),VCG 问 "这个视频看起来是什么样、它是否匹配用户的视觉风格?"(semantic signal)。这被称为 semantic-first recommendation。
三条贡献¶
- Zero-Shot Two-Tower Architecture:用预训练多模态编码器把表征与交互解耦,绕开海量训练数据的需求。
- Generative Adjudication Protocol(生成式裁决协议):一套 "LVLM-as-a-judge" 评估框架。论文证明:由于曝光偏置(exposure bias),传统离线指标无法预测线上成败,而一个大型视觉语言模型(Qwen-VL)能成功充当人类相关性的代理裁判。
- Embedding Space Analysis:对生成式 vs 判别式 embedding 在检索任务上的对比分析,论证为什么对比模型(CLIP)在向量检索上优于生成式模型(LLM)。
相关工作定位¶
- 双塔架构:沿袭 YouTube [3]、Pinterest [4] 的 dual-encoder 范式。这些经典工作多在交互数据上训练编码器、并修正采样偏置 [5];VCG 反过来,用预训练多模态编码器直接在交互图稀疏的 zero-shot 场景工作,结构上类比数据集成里的 Siamese / GNN 实体匹配 [6,7]。
- 多模态学习:核心引擎是领域适配版 CLIP [8],类似 FashionCLIP [9]。把表征适配到低资源电商领域通常需要昂贵的 reinforced active learning 标注流水线 [10,11,12];VCG 通过转入 zero-shot 多模态空间,完全绕开人工 metadata 标注。
- 生成式 vs 判别式:近期大量研究用 LLM 弥合结构化数据检索的语义鸿沟,从 zero-shot ranker [13] 到 NL-to-API / Text-to-SQL [14,15,16]。但这些生成式模型虽擅长把抽象意图翻译成结构化逻辑约束,直接拿来给原始视觉检索生成 embedding 时常导致各向异性(anisotropy)与表征坍塌——embedding 挤在向量空间一个狭窄的锥体里,严重削弱判别力 [17]。
- LLM 评估:采用 "LLM-as-a-judge" [18,19] 模拟人类偏好;论文也坦承当前依赖受约束的直接打分,未来可引入不确定性量化、一致性假设、相似度聚合(SIMBA)[20,21] 来缓解生成式评估器的幻觉与方差。
核心方法 / 模型架构¶
VCG 采用可高吞吐推理的双塔(Two-Tower)架构(图 1),把交互历史从在线推理中解耦出来。
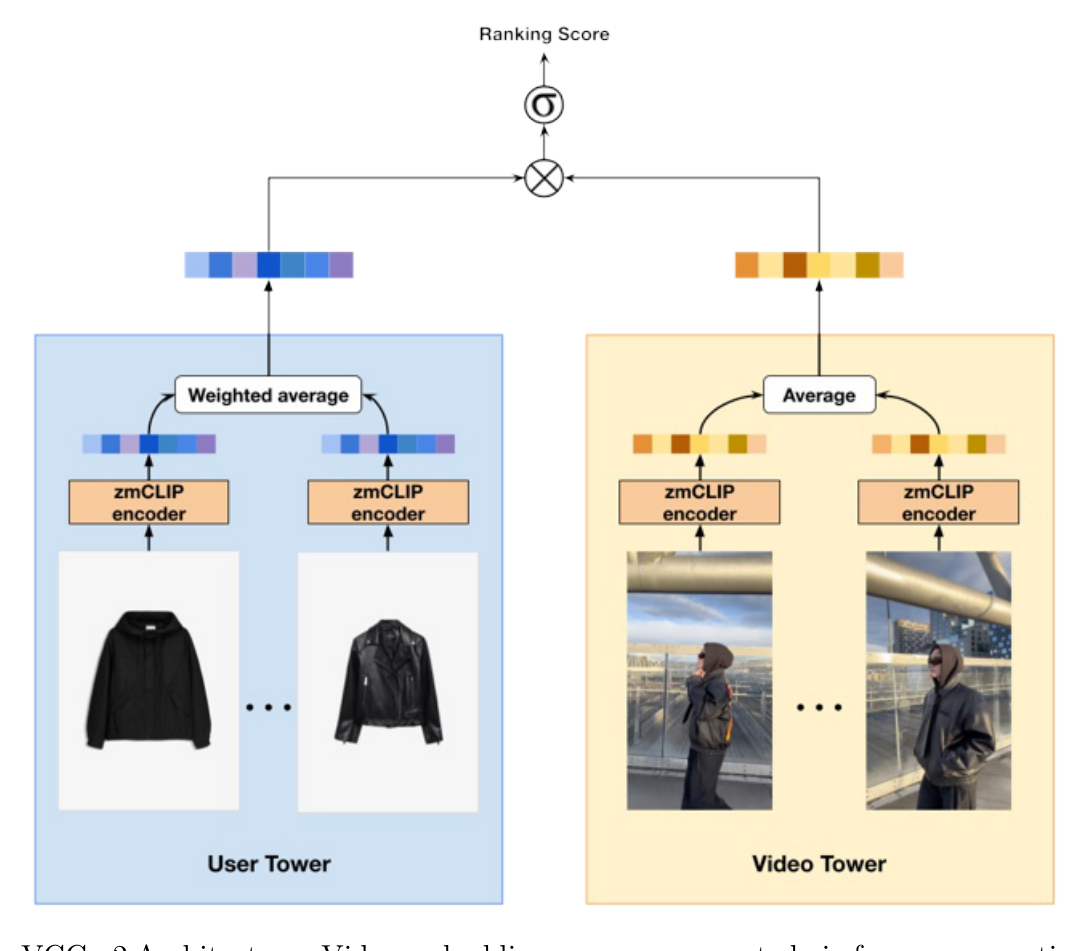
从 VCG v1(基于 metadata)演进而来¶
在多模态方案之前,团队先做了 VCG v1:一个常规的有监督双塔。它复用了主目录推荐系统里高度优化的 User Tower 来生成不可训练的用户 embedding [24],并从零训练一个 Video Tower,输入是可得的视频 metadata(创作者 ID、hashtag、关联商品链接)。尽管理论上比朴素的"按时间排序(recency)"更强,VCG v1 在线上 A/B 失败了。论文归纳出三条致命失效模式:
- 语义鸿沟(Semantic gap):用户表征是在"加购(Add-to-Cart)"和购买信号上训练的,这种强转化意图与视频流的 inspirational(被种草/激发灵感) 意图不对齐。
- Metadata 稀疏(Metadata sparsity):依赖创作者生成的标签导致覆盖差,模型退化为流行度偏置(popularity bias)。
- 缺乏视觉信号(Lack of visual signal):模型忽略了视频的实际像素内容,无法捕捉审美偏好(如 Boho 波西米亚风 vs Streetwear 街头风)。
正是这三点驱动了向 VCG v2(多模态) 的转向:基于视觉内容为用户和视频构建共享 embedding 空间。
多模态表征(VCG v2)¶
视频表征。 一个视频 $v \in V$ 被当作"帧袋(bag-of-frames)"。从视频均匀采样 $N=10$ 帧,每帧用内部 CLIP-based 模型(图 1 中标为 zmCLIP)编码——该模型在一个约 2 亿(200 million)图文对的大规模时尚数据集上 fine-tune。最终视频 embedding $e_v$ 是各帧向量的均值:
$$e_v = \frac{1}{N}\sum_{j=1}^{N} E_{\text{CLIP}}(\text{frame}_j) \tag{1}$$
论文显式排除文本 metadata,以规避 VCG v1 遇到的噪声。
用户表征(经领域适配)。 设 $U$ 为用户集合。对每个用户 $u$,有按时间排序的目录交互历史 $H_u = [(s_1,t_1),\dots,(s_n,t_n)]$,其中 $s_k$ 是商品、$t_k$ 是时间戳。用户由这些交互的时间衰减加权组合表示:
$$e_u = \frac{\sum_{k=1}^{|H_u|} w_k \cdot E_{\text{CLIP}}(s_k)}{\sum_{k=1}^{|H_u|} w_k}, \quad w_k = \exp\!\big(-\lambda(t_{\text{now}} - t_k)\big) \tag{2}$$
关键在于 $E_{\text{CLIP}}$ 是领域适配版:该过程对齐了向量空间,使得"视觉化"的视频内容与"商业化"的商品内容落在同一个流形(manifold) 上。这正是 user 塔(基于商品交互)与 video 塔(基于视频帧)能直接做相似度比较的前提。
问题形式化与推理¶
目标是学一个打分函数 $f: U \times V \to \mathbb{R}$,预测视频 $v$ 对用户 $u$ 的相关性,输出每个用户的视频排序列表。打分函数被建模为共享 $d$ 维空间里 user 与 video embedding 的点积相似度:
$$f(u,v) = e_u^{\top} e_v \tag{3}$$
由于视频 embedding 离线预计算,在线推理被压缩为一次快速的向量相似度检索,实测中位延迟(P50)17.5ms、尾延迟(P99)30ms。这就是"zero-shot 检索引擎"的全部在线开销——没有任何排序模型在线打分。
实验设置¶
评估框架:那个"悖论"¶
直接在历史日志上算标准离线指标(NDCG、AUC)时,VCG 相对 recency 基线没有显著提升。根因是曝光偏置:历史日志是由旧系统生成的,无法验证新视频的相关性。
为破解这个悖论,论文采用 LVLM-as-a-judge:用 Qwen 2.5-VL 作为外部评估器。其 prompt(图 2)充当"系统指令",让模型在标准 5 点 Likert 量表上对"用户历史"与"被推荐视频"之间的视觉一致性打分,类别为 excellent_match / good_match / partial_match / poor_match / no_match,并被明确要求"挑剔(be discerning),除非有具体证据否则不要默认给正面评价"。

主要实验结果¶
模型选择:为什么是 CLIP 而非生成式模型(属性预测)¶
为严格论证"召回核心用 CLIP 而非更新的生成式模型",论文在一个辅助任务 Zero-Shot Attribute Prediction 上对比两类模型。做法:在 CLIP 和 Qwen2.5-Omni/VL 抽取的原始视频 embedding(取最后一层 hidden representation)之上训练轻量 MLP 分类器,预测"content theme"(如 fashion/sports)、"editorial format"(如 unboxing/review)等标签。
Table 1 — Zero-Shot 属性预测(F1):
| Task (Label) | CLIP | Qwen2.5-Omni |
|---|---|---|
| Content Theme | 0.92 | 0.94 |
| Editorial Format | 0.75 | 0.78 |
| Video Source Classification | 0.86 | 0.93 |
结论分析:Qwen embedding 在 F1 上一致领先 6–10%,说明生成式模型捕捉了更丰富的语义细微差别,在"离线内容富化(content enrichment)"任务上更优。但是——这正是论文最有价值的反转——Qwen embedding 在语义检索时表现出高各向异性(high anisotropy):所有向量挤在一个狭窄锥体里,导致 k-NN 检索可分性极差。相反,CLIP 的对比损失(contrastive loss)强制 embedding 在超球面上更均匀分布,这才是检索引擎的正确选择。一句话:生成式 embedding 适合"标注/分类",判别式对比 embedding 适合"检索/k-NN"。
离线评估:视觉一致性¶
论文引入 visual coherence 指标,在一个纯图像 embedding 空间 28里用相似度衡量,同时报告 CLIP 空间的语义相似度增益,以及 LVLM 裁判的 Top-K 平均分。
Table 2 — 离线评估:VCG vs Recency 基线(括号内为标准差):
| Method | fDNA S. | CLIP S. | LLM Top-5 | LLM Top-10 |
|---|---|---|---|---|
| Recency | 13.8 (6.48) | 0.41 (0.06) | 2.72 (0.30) | 2.43 (0.24) |
| VCG | 18.9 (8.23) | 0.50 (0.04) | 3.12 (0.35) | 3.09 (0.32) |
| Gain | +37% | +22% | +14.7% | +27% |
结论分析:VCG 在所有离线语义一致性指标上都超过 recency——fDNA 相似度 +37%、CLIP 相似度 +22%。LVLM 裁判佐证了这一点,把 Top-10 平均分从 2.43 显著推高到 3.09,即分布明显向"相关(Relevant)"偏移。
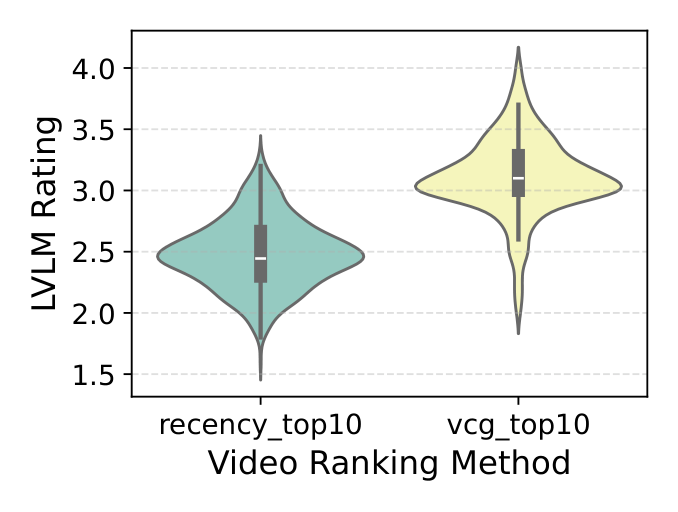
图 3 的小提琴图直观展示了这种质变:recency 基线的分布集中在中低区间,而 VCG 把密度重重压向 good_match 与 excellent_match。
在线:A/B 测试¶
一次为期 4 周的线上 A/B(Table 3)确认了"语义相关性驱动 engagement"。
Table 3 — 线上 A/B 结果(Treatment vs Control):
| Metric | Lift | 95% 置信区间 |
|---|---|---|
| VideoProgress @ 25% | +40.97% | [21.25, 60.69]% |
| VideoProgress @ 50% | +50.10% | [22.03, 78.17]% |
| Video Start Rate | +8.17% | [-0.57, 16.91]% |
| Start → 25% Conv. | +30.32% | [16.69, 43.96]% |
| Start → 50% Conv. | +38.76% | [17.01, 60.52]% |
结论分析:视频起播率(Video Start Rate)只涨了 +8%(且置信区间跨 0,不显著),但消费深度(consumption depth)的增益巨大——看到至少一半的视频 +50%。这说明用户起播略增,但他们真正点开的视频相关性高得多,从而留住用户更久。这恰好对冲了 clickbait 问题:高点击率往往掩盖了内容匹配差的事实,而 VCG 改善的是"看进去"而非"骗点击"。
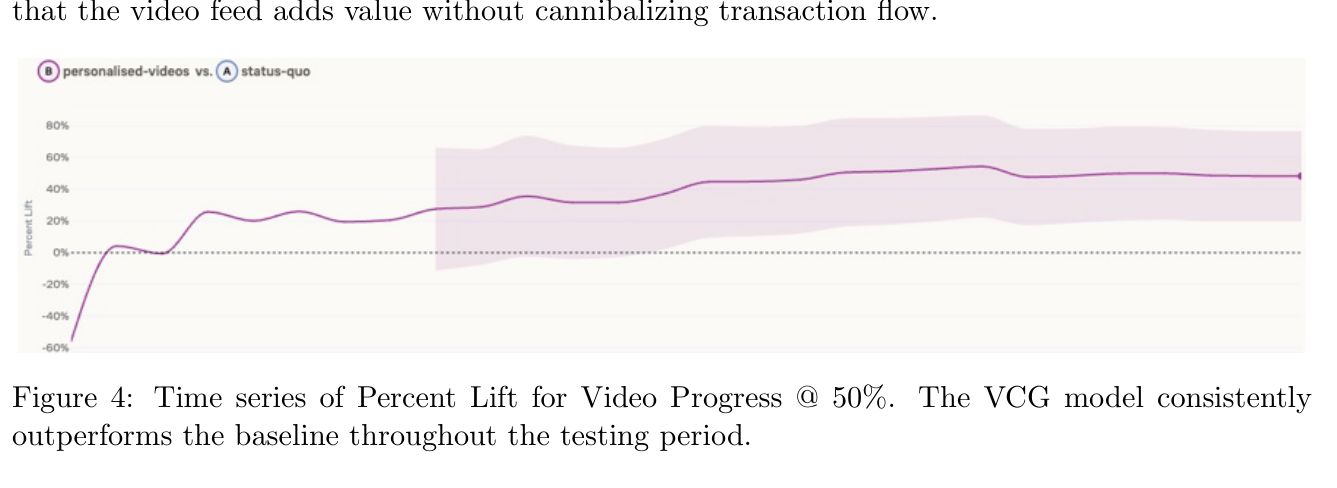
图 4 的时序进一步证明:这种提升贯穿整个 4 周、稳定且持续,并非短期新鲜效应。更重要的是,核心业务指标(营收、用户留存率)保持稳定——证明视频流在不蚕食(cannibalize)交易流的前提下创造了增量价值。
消融与分析¶
论文最核心的"分析性"贡献其实就是上面 §模型选择 里那条 generative vs discriminative embedding 的对比:
- 属性预测/分类:Qwen(生成式)F1 领先 6–10% → 生成式擅长语义标注。
- 检索/k-NN:Qwen 高各向异性、向量挤成锥体 → 可分性差;CLIP 对比损失给出更均匀的超球面分布 → 检索更优。
这条 insight 把"用哪种 embedding 做向量检索"从一个看似显然的工程选择,变成了一个有实证支撑的判断:不要因为 LLM embedding 在标注任务上更强,就想当然地把它塞进召回引擎。
此外,Table 4 给出 VCG 相对两类标准工业方法论的定性对比:
Table 4 — VCG vs 标准工业方法论:
| Capability | VCG (Ours) | Collaborative Filtering | Metadata Search |
|---|---|---|---|
| Handles Extreme Cold-Start | Yes (Zero-Shot) | No (需交互) | Partial (需标签) |
| Visual Semantic Understanding | High (像素级) | None | None |
| Cross-Modal (Product ↔ Video) | Yes (共享空间) | No | No |
| Susceptibility to Popularity Bias | Low | High | High |
演示场景与交互界面¶
论文配套一个交互式 demo(图 5,演示视频 https://youtu.be/ClF6iv_PH4A),用同一个共享多模态 embedding 空间支撑三类双向检索:
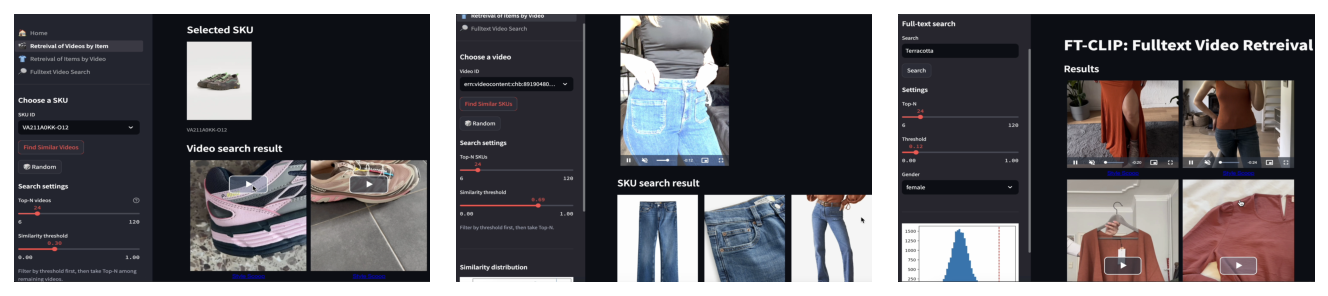
- Get the Look(Product → Video):用户选一个静态商品(如碎花裙),系统用商品 embedding 当查询向量对视频索引做 k-NN,检索出含相似单品的视频。这解决了 content association 问题——无需人工打标,自动把库存关联到内容。
- Shop the Look(Video → Product):用户选一个视频,系统用视频 embedding 查询商品目录,展示匹配该视觉风格的商品列表,让纯 UGC 内容变得"可购买(shoppable)"。
- Zero-Shot Semantic Search(Text → Video):用户输入文本(如 "Cyberpunk street style"),经 CLIP 文本编码器查询视频索引——即使视频没有任何文本 metadata/标签也能检索到,展示了模型对抽象视觉概念的理解,极大扩展内容可发现性。
核心贡献总结¶
- 一套 zero-shot、无需训练交互数据的双塔多模态召回引擎:user 塔(商品交互的时间衰减 CLIP 聚合)与 video 塔(帧均值 CLIP)在领域适配后的同一流形上做点积召回,在线只需 17.5ms 的向量检索,直接攻克新视频"零交互历史"的极端冷启动。
- LVLM-as-a-judge 评估协议:用 Qwen-VL 当裁判,绕开"历史日志由旧系统生成"导致的曝光偏置,使离线评估首次能预测线上成败。
- generative vs discriminative embedding 的检索可用性实证:生成式(LLM)embedding 标注强但检索时坍塌/各向异性;判别式(CLIP 对比)embedding 才适合 k-NN 召回。
- 强工业验证:4 周线上 A/B,VideoProgress@50% +50.1%,且不蚕食营收/留存。
与已归档相关工作的对比¶
FLUID FLUID:用多模态语义码退役直播推荐的"短命 item ID"(TikTok / ByteDance, 2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都把"内容易逝 → item ID 表征不可用"识别为根本瓶颈。FLUID 给出的关键事实是直播间中位生命周期仅约 40 分钟,ID embedding 的 $\ell_2$ 范数在生命周期内远未收敛;VCG 面对的是海量新短视频"零交互历史"。结论一致:ID-based CF 在 ephemeral 内容上失效,必须用多模态内容表征取代行为/ID 信号。
- 相近的技术骨架:都用一个领域适配的多模态编码器把视频内容编码成 embedding,绕开 item ID 累积交互的需要(VCG: 在 200M 时尚图文对上 fine-tune 的 zmCLIP;FLUID: SigLIP2 + Qwen3 在短视频与直播上跨域联合训练)。
- 本文的差异与推进:FLUID 仍保留一个训练好的判别式排序器——它把内容 embedding 经 RQ-KMeans 离散化成分层语义码 LUCID,再以 prefix-n-gram + 后融合 + 三阶段 warmup 注入 token 级排序骨干,本质是"用语义码替换 ID 特征,继续做排序",其全部工程难点在于对抗 ID-dominance、把内容信号稳定地塞回既有 ID-centric ranker。VCG 则走到更极端的 zero-shot dense retrieval:不离散化、不训练任何排序模型,user/video 直接在同一 CLIP manifold 上做 dot-product k-NN 召回。一个是"替换 ID 特征但保留排序模型",一个是"连排序模型都不要、用语义相似度本身做召回"。
- 可比的方法 / 实验差异:FLUID 用线上 AUC + Quality Watch Duration(+0.55%)/ Cold-Start Room Views(+2.05%)证明;VCG 用 LVLM-as-a-judge + VideoProgress@50%(+50.1%)证明。FLUID 的 cross-domain 训练(短视频→直播)解决冷域监督稀疏问题;VCG 的 cross-modal 对齐(商品↔视频)解决 user/video 同空间问题——两者都靠"跨某种 gap 的对齐"换来对冷内容的零样本表征能力。
Shallow-RHS Shallow-RHS:非对称图架构下的内容冷启动(Tubi, 2026-06-04)¶
关系:独立并发(本文未引用,两者殊途同归)· 已加载对方精读
- 共同关注的问题:流媒体平台新内容"零交互边"→ CF / 图消息传递无法给它生成有意义表征,必须仅凭内在(内容)特征产出可被 ANN 高效检索的 embedding。这与 VCG 的"extreme cold-start + 需要可索引 embedding 做召回"完全同构,连"双塔 + 近邻检索"的服务形态都一致。
- 相近的技术骨架:都是双塔 + ANN / dot-product 检索,且都让 item / content 塔不依赖 ID、不依赖交互子图,仅从内容特征编码新物品;训练/适配后,同一个内容编码器既服务暖物品也服务零历史新物品。
- 本文的差异与推进(关键分歧):两者对"内容相似 vs 行为偏好"的态度截然相反。Shallow-RHS 明确提出 "语义-协同鸿沟(semantic-collaborative gap)"——担心内容相似只反映语义而非受众偏好,于是用非对称设计(device 塔做消息传递学 CF 结构,content 塔虽"浅"但被监督对齐到 CF-aware 空间),再"检索暖代理邻居"做隐式图补全,本质是把内容表征拉回协同信号。VCG 反其道而行:它论证商品行为信号(加购 / 购买意图)与视频的 inspirational 意图根本错配(这正是 VCG v1 失败的首因),因此主动抛弃协同信号、纯赌视觉语义一致性,并用 LVLM-judge + A/B 证明语义一致性确实驱动了 engagement。一个"补回 CF",一个"丢掉 CF"——殊途而立场相反,构成了一组很有价值的对照。
- 可比的方法 / 实验差异:Shallow-RHS 用 GNN / 时序链接预测(Kumo 平台),报告 TVT(总观看时长)与冷内容晋升提升,并把同一"表征补全"原则扩展到 device(用户)冷启动(用 demographic cohort 先验);VCG 用无训练的 frozen CLIP manifold,报告 VideoProgress 提升,其 user 塔靠时间衰减加权的商品交互聚合天然支持轻历史用户,但未单独处理零历史新用户——这恰是 Shallow-RHS 补齐的一块。
讨论与局限性¶
值得借鉴的设计:
- "semantic-first"立场在 ephemeral 内容场景下确有道理:当内容生命周期短到交互信号来不及累积,与其修补 CF,不如换一个不依赖交互的相关性定义(视觉语义一致)。
- generative-vs-discriminative embedding 的检索可用性结论是可迁移的工程经验:别因为 LLM embedding 在分类/标注上更强就拿去做向量检索。
- LVLM-as-a-judge 破解曝光偏置:当离线指标因"日志由旧系统产生"而失真时,用一个独立的 VLM 裁判提供与历史点击无关的相关性代理,是一个低成本、可规模化的评估补丁。
- Responsible AI:把召回与历史点击图解耦,降低对流行度信号的依赖;按"客观审美"而非创作者身份 / 人群标签匹配,理论上给长尾、欠曝光创作者更公平的曝光(但论文也承认 creator-level 曝光的度量仍是 future work)。
局限 / 争议:
- 方法新颖性有限:核心是"fine-tuned CLIP 帧均值 + 时间衰减加权用户聚合 + 点积 zero-shot 检索",是已知组件的直接组合;真正的工程内核 zmCLIP(类 FashionCLIP 的领域适配)本身不是本文创新。
- demo / 系统论文体量:全文约 8 页,实验没有任何公开学术 benchmark,Table 1 的属性预测是小规模辅助任务,消融较薄;generative-vs-discriminative 这条结论虽有趣,但证据偏轻(主要靠 Table 1 + 定性的各向异性陈述,缺定量的均匀性 / 各向异性度量)。
- 关键 A/B 指标的稳健性:Video Start Rate 的置信区间跨 0;消费深度指标置信区间普遍较宽(如 VideoProgress@50% 的 CI 达 [22%, 78%]),样本/时长可能有限。
- 抛弃 CF 的代价未量化:VCG 主动放弃协同信号,但视觉一致 ≠ 受众偏好——这正是 Shallow-RHS 担心的"语义-协同鸿沟";论文用 A/B engagement 间接回应,但没有正面比较"纯语义"与"语义 + 轻量 CF"的差距。
- 用户冷启动未覆盖:user 塔依赖商品交互历史,对完全零历史的新用户如何召回,论文未展开。
一句话总结:这是一篇工程立场清晰、线上收益强、并附带一个可迁移实证结论(生成式 embedding 不适合做检索) 的工业 demo 论文,方法本身朴素,但它把"ephemeral 内容场景下应当语义优先、并用 LVLM 破解曝光偏置"讲得干净有说服力。论文结尾的告诫值得记下:在生成式 AI 时代,相关性最好用语义一致性来度量,而非历史点击——离线代理(NDCG)与线上现实的背离,是给研究社区的一记警钟。