Bridging the Semantic-Collaborative Gap: An Asymmetric Graph Architecture for Cold-Start Item Recommendation¶
Tubi × Kumo AI · arXiv 2606.06225 · 2026-06-04 · RecSys 投稿格式
研究动机与背景¶
协同信号的"冷启动悖论"¶
现代推荐系统高度依赖协同过滤(Collaborative Filtering, CF):从用户与物品的交互中抽取行为信号,再由模型传播这些信号、学到能捕获高阶受众偏好模式的表征。图(graph)类方法在这个设定下尤其有效——它们沿交互边传播行为信息,天然地把 CF 结构编码进节点表征。
但 CF 的力量恰恰构成了它的软肋:新加入的内容没有交互历史,因此在图中是"零边节点",无法接收任何协同信号。论文把这种困境称为推荐系统的根本性"冷启动挑战"。对于一个流式媒体平台(streaming platform)而言,这个问题尤为尖锐:
- 内容侧:新标题(new title)在积累任何有意义的设备-内容交互之前就必须被曝光、被推荐;
- 设备侧:新激活的设备(newly activated device)在观察到任何个性化行为之前,也必须立即收到推荐。
本文工作开发并部署于 Tubi——一个大规模、有广告支撑(ad-supported)的流式平台,服务数亿用户、拥有大规模内容目录,底层用 Kumo GNN 平台作为图建模骨干。
生产服务接口带来的额外约束¶
Tubi 的生产环境对冷启动方案施加了超出"标准冷启动"的工程约束。服务系统要求内容侧和设备侧都要有可被高效索引、检索、比较的 embedding,并通过近似最近邻(Approximate Nearest Neighbor, ANN)检索完成召回。这导致两个直接后果:
- 方案不能只依赖成对的设备-内容相似度打分(pairwise scoring),也不能通过目标侧(物品侧)"交互衍生子图"来为冷内容构造 embedding——因为冷内容根本没有交互子图;
- 新摄入的内容没有任何观看历史边,模型必须直接从内在特征(intrinsic features)计算其 embedding,同时保证这个表征仍然与 embedding 空间的协同结构对齐。
语义-协同鸿沟(The Semantic-Collaborative Gap)¶
一类常见的冷启动解法是基于内容(content-based)的推荐:用物品的元数据、文本、音频、图像等内在特征来表示新物品。这类方法天然支持物品冷启动(不需要历史交互),但它们存在论文标题点名的核心病灶——
内容相似往往只反映语义层面的相似(semantic-level similarity),而非受众偏好(audience preference)。 内容特征提供了泛化能力,却没有直接编码 CF 方法所捕获的行为信号。这就是语义-协同鸿沟(semantic-collaborative gap)。
混合方法试图把 CF 与语义信息结合(如概率内容-CF 模型、多关系协同矩阵分解、协同主题回归 CTR),但它们大多假设存在可直接重构的部分交互历史、支持样本或暖物品 embedding。本文聚焦的是最严苛的物品冷启动设定:零观测设备-内容交互的新内容。
把冷启动重新形式化为"归纳式图补全"¶
论文的核心视角转换是:把冷启动推荐看成一个在时序二部图上的归纳式图补全(inductive graph completion)问题——
节点存在,且其旁路信息(side information,即内在特征)可得,但围绕它的交互结构(边)是缺失的。冷启动是图补全的一种极端形式。
- 对内容冷启动:目标是学一个归纳函数,把元数据、分类法(taxonomy)和基于 LLM 的语义特征映射到一个 CF 感知(CF-aware)的内容 embedding,即使该内容节点有零观测边;
- 对设备冷启动:在缺乏观看历史时,用人口统计学(demographic)与上下文 cohort 先验来近似缺失的设备表征。
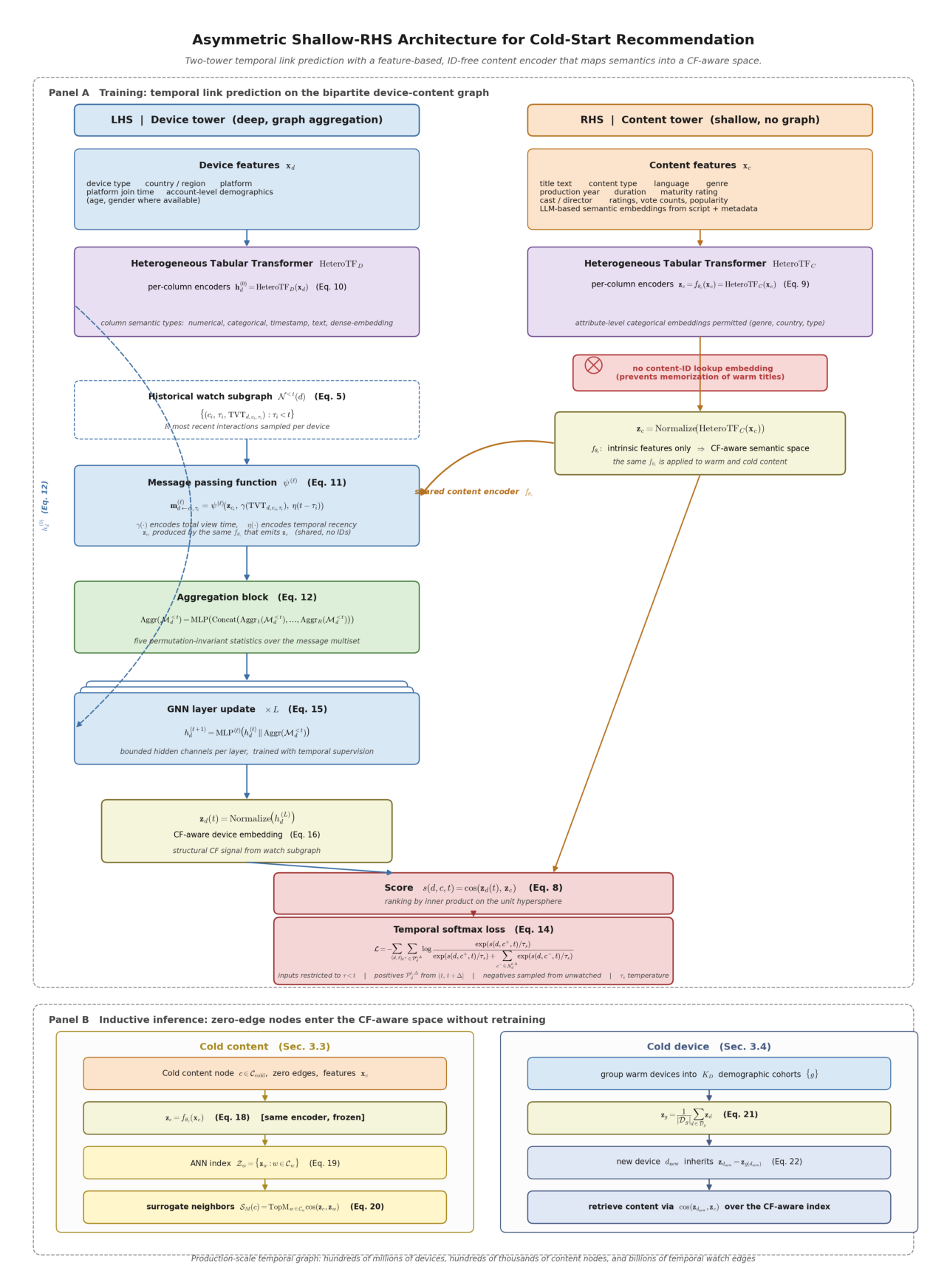
为此论文提出 Shallow-RHS,一个用于时序链接预测的非对称(asymmetric)双塔架构。其核心设计是一种刻意的不对称:
- 左塔(LHS, device tower):用设备特征 + 时序有效的观看历史消息传递(message passing)编码查询设备,让它能从交互丰富的邻域学到协同结构;
- 右塔(RHS, content tower):相对于图是刻意"浅"的(intentionally shallow)——不使用基于 ID 的 embedding、不使用内容侧子图、不做邻居聚合、不使用任何交互衍生表征,只从内在特征编码内容。
这种不对称约束是关键:它阻止目标塔靠"记忆"暖标题来解释未来的设备-内容链接,逼迫内容编码器仅凭内容特征就把内在特征映射进一个 CF 感知的 embedding 空间。训练完成后,同一个内容编码器既能为暖内容、也能为新摄入的零历史标题生成 embedding,从而通过"检索暖代理邻居(warm surrogate neighbors)"实现隐式图补全。
本文主要贡献¶
论文自述五点贡献:
- 把内容冷启动形式化为归纳式图补全问题,其中零边内容需要超越观测图结构的、基于特征的表征推断;
- 提出 Shallow-RHS——非对称时序链接预测架构,产出设备与内容 embedding,同时让 RHS 内容塔不含内容侧子图与交互衍生表征;
- 提出一个隐式图补全流程:用学到的内容编码器嵌入新摄入内容,并在 CF 感知的内容空间中检索暖代理邻居;
- 把同一"表征补全"原则扩展到设备冷启动,用人口统计 cohort 先验 + CF 感知检索;
- 通过大规模线上实验验证:在总观看时长、冷内容晋升速度、曝光获取、首触设备参与度上均有提升。
相关工作¶
冷启动推荐¶
冷启动问题出现在模型需要为交互极少或无历史的新用户/新物品排序时。对 CF 方法尤其困难:矩阵分解、隐因子模型主要靠观测到的用户-物品共现来推断表征;物品没有交互时,其协同表征要么无定义、要么估计极差,导致模型为它生成无意义的表征。基于内容的方法(用元数据/文本/图像表示新物品)天然支持物品冷启动,但只反映语义相似而非受众偏好——这正是"语义-协同鸿沟"的来源。早期混合方法(概率内容-CF、协同矩阵分解、协同主题回归)改进了纯内容法,但多假设存在可重构的部分交互或暖物品 embedding;本文则针对零观测交互的严苛冷启动。
基于 GNN 的推荐系统¶
物品推荐可自然地建模为图学习任务:用户(设备)节点与物品(内容)节点构成二部交互图,推荐被表述为链接预测(link prediction)。这一表述天然契合 CF 的多跳图结构,而图神经网络(GNN)通过消息传递聚合局部与高阶邻域信息、同时融合节点与边特征,非常适合该场景。代表方法包括:PinSage(随机游走邻域构造 + 局部图卷积,把 GCN 扩展到 web 规模图)、NGCF(在用户-物品交互图上显式传播 embedding 以编码高阶协同信号)、ContextGNN(把推荐建模为链接预测,结合局部图上下文与双塔检索,超越成对无关 embedding 的排序)。本文的 Shallow-RHS 即建立在这条"链接预测 + 双塔检索"的脉络上,但通过非对称设计专门解决冷启动。
核心方法¶
问题形式化(§3.1)¶
论文把冷启动内容推荐建模为时序二部交互图上的时序链接预测。令 $\mathcal{G}_{\le t} = (\mathcal{D} \cup C, \mathcal{E}_{\le t}, \mathbf{X}_\mathcal{D}, \mathbf{X}_C)$ 表示截至时间戳 $t$ 观测到的时序图。节点集是二部的:$\mathcal{D}$ 表示设备(streaming 平台上等价于用户身份),$C$ 表示内容节点(节目或标题)。边只出现在设备与内容节点之间,每条边是一个带时间戳的观看事件:
$$e = (d, c, \tau, \text{TVT}_{d,c,\tau}), \qquad d \in \mathcal{D},\; c \in C,\; \tau \le t \tag{1}$$
其中 $\text{TVT}_{d,c,\tau}$(Total Viewing Time)是设备 $d$ 在时间戳 $\tau$ 对内容 $c$ 的总观看时长,作为边特征。于是边集为:
$$\mathcal{E}_{\le t} \subseteq \mathcal{D} \times C \times \mathbb{R}_+ \times \mathbb{R}_+ \tag{2}$$
依据时间戳 $t$ 时的图连通性,区分暖(warm)内容与冷(cold)内容。暖内容节点是在图中至少有一条观看边的内容:
$$C_{warm}(t) = \{c \in C \mid \exists d,\, \tau \le t \text{ s.t. } (d, c, \tau, \cdot) \in \mathcal{E}\} \tag{3}$$
冷内容节点则在图中没有任何观测观看边:
$$C_{cold} = \{c \mid (d, c, \tau, \cdot) \notin \mathcal{E},\; \forall d, \tau\} \tag{4}$$
冷节点因此无法通过标准图消息传递接收协同信号,其表征在传统图推荐模型下是未定义的——这是问题的本质难点。
图中每个节点带异构特征。设备特征向量 $\mathbf{x}_d \in \mathbf{X}_\mathcal{D}$ 可包含设备类型、国家、平台加入时间、可得的人口统计/账户级属性(年龄、性别等)。内容特征向量 $\mathbf{x}_c \in \mathbf{X}_C$ 可包含标题文本、内容类型、语言、出品年份、时长、类型(genre)、结构化元数据,以及用预训练大语言模型从元数据/简介/剧本派生的稠密语义 embedding。
对设备 $d$,定义其截至 $t$ 的历史上下文:
$$\mathcal{N}^{<t}(d) = \{(c, \tau, \text{TVT}_{d,c,\tau}) \mid (d, c, \tau, \text{TVT}_{d,c,\tau}) \in \mathcal{E},\; \tau < t\} \tag{5}$$
把 $\mathcal{N}^{<t}(d)$ 扩展到 $d$ 的多跳邻域,即能纳入"其他有重叠观看历史的用户都看了什么节目"。核心学习问题是:仅用零边内容节点的内在特征,为它推断一个与 CF 一致的表征。为此学两个 embedding 函数:
$$\mathbf{z}_d(t) = f_{\theta_d}(\mathbf{x}_d, \mathcal{N}^{<t}(d)), \qquad \mathbf{z}_c = f_{\theta_c}(\mathbf{x}_c) \tag{6}$$
设备 embedding $\mathbf{z}_d(t)$ 既依赖设备历史观看子图 $\mathcal{N}^{<t}(d)$,又依赖设备输入特征;而内容 embedding $\mathbf{z}_c$ 被约束为只依赖内在内容特征。这个非对称约束至关重要:内容函数 $f_{\theta_c}$ 必须同时适用于暖内容与冷内容(含无任何历史观看边的新标题)。
冷启动推荐被表述为极端图补全:冷内容节点存在但其周围交互子图缺失。给定设备的历史上下文,任务是对设备将在未来窗口 $(t, t+\Delta]$ 内观看的内容排序。该任务的正标签集定义为:
$$\mathcal{P}_d^{t,\Delta} = \{c \in C_{warm}(t) \mid \exists \tau \in (t, t+\Delta] \wedge (d, c, \tau, \cdot) \in \mathcal{E}\} \tag{7}$$
其中 $C_{warm}(t)$ 是时间戳 $t$ 时可得的暖内容集合。时序链接预测打分定义为设备与内容 embedding 的余弦相似度:
$$s(d, c, t) = \cos(\mathbf{z}_d(t), \mathbf{z}_c) = \frac{\mathbf{z}_d(t)^\top \mathbf{z}_c}{\|\mathbf{z}_d(t)\|_2 \|\mathbf{z}_c\|_2} \tag{8}$$
值得强调的训练机制:监督标签来自暖内容节点的交互边,但要求 $f_{\theta_c}$ 仅凭内容特征就解释这些协同行为。如此一来,学到的内容编码器实际充当一座"语义-到-协同"的桥梁:它把零历史物品映射进一个由历史用户行为塑形的 embedding 空间。这个形式化把冷启动从"为每个新物品要求部分边"转变为"学一个把特征映射进协同空间的函数",使冷内容一被摄入即可被编码进图。
Shallow-RHS 架构(§3.2)¶
Shallow-RHS 专门针对上述冷启动任务:新内容节点有内在特征向量 $\mathbf{x}_c$ 但无观看历史边。它满足服务系统的硬性要求——embedding $\mathbf{z}_c$ 可被立即检索并用于为平台上新内容打分。因此模型不仅要预测时序设备-内容链接,还要输出具代表性的 embedding 函数,且内容侧函数对零历史标题仍然有效。
采用非对称双塔:LHS(左塔)用设备特征 + 时序有效的观看历史消息传递(在 $\mathcal{N}^{<t}(d)$ 上)编码查询设备,从交互丰富邻域捕获协同信号;RHS(右塔)相对于图刻意"浅"——只用内在内容特征编码目标内容,不访问任何交互衍生信息。学到的内容编码器是一个从内在内容特征到 CF 感知 embedding 空间的归纳映射。
两塔都用 HeteroTF 风格的表格编码器(基于 PyTorch Frame 的 FT-Transformer)来编码原始异构特征。语义类型特定的编码器把数值、类别、时间戳、文本和预计算 embedding 列映射到共享的列 embedding 上;FT-Transformer 的自注意力在列间混合信息,然后池化成节点表征。
RHS 内容表征对图是"浅"的:
$$\mathbf{z}_c = f_{\theta_c}(\mathbf{x}_c) = \text{HeteroTF}_C(\mathbf{x}_c) \tag{9}$$
RHS 上不施加从设备到内容的消息传递,用于打分的内容 embedding 不由连接到该内容的用户/设备计算。这正是冷启动泛化要求的核心:同一个函数 $f_{\theta_c}$ 因为只依赖内在内容特征,便可同时作用于暖内容与冷内容。
LHS 设备表征则把设备特征与时序有效的历史观看事件结合。首先计算设备节点内在特征的初始 embedding:
$$\mathbf{h}_d^{(0)} = \text{HeteroTF}_D(\mathbf{x}_d) \tag{10}$$
然后,对每条历史边 $(d, c, \tau, \text{TVT}_{d,c,\tau})$($\tau < t$),模型用内容编码器输出和边特征构造一条内容-到-设备的消息:
$$\mathbf{m}_{d \leftarrow c, \tau}^{(\ell)} = \psi^{(\ell)}\big(\mathbf{z}_c,\; \gamma(\text{TVT}_{d,c,\tau}),\; \eta(t - \tau)\big) \tag{11}$$
其中 $\gamma(\cdot)$ 编码总观看时长、$\eta(\cdot)$ 编码时间近因性(temporal recency)。给定消息多重集 $\mathcal{M}_d^{<t}$,用一个聚合块(aggregation block):
$$\text{Aggr}(\mathcal{M}_d^{<t}) = \text{MLP}\big(\text{Concat}(\text{Aggr}_1(\mathcal{M}_d^{<t}), \ldots, \text{Aggr}_R(\mathcal{M}_d^{<t}))\big) \tag{12}$$
每个 $\text{Aggr}_r(\cdot)$ 是对消息多重集的置换不变(permutation-invariant)聚合器,如均值或最大算子。设备表征再由一层或多层异构聚合层更新:
$$\mathbf{h}_d^{(\ell+1)} = \text{MLP}^{(\ell)}\big(\text{Concat}(\mathbf{h}_d^{(\ell)}, \text{Aggr}(\mathcal{M}_d^{<t}))\big) \tag{13}$$
最后一层 $L$ 的输出即为最终设备 embedding $\mathbf{z}_d(t) = \mathbf{h}_d^{(L)}$。
注意这里的关键不对称:消息函数 (11) 用 $\mathbf{z}_c$(内容塔输出)作为输入构造"内容→设备"的消息,因此 LHS 设备塔依赖图结构与内容表征;而 RHS 内容塔 (9) 完全不接收任何"设备→内容"的消息,保持对图的"浅"——这就是 Shallow-RHS 名字的由来。
训练目标采用时序 softmax 链接预测损失。对每个"设备-时间戳对" $(d, t)$,正样本对应未来观看窗口内的内容 $\mathcal{P}_d^{t,\Delta}$,负样本 $\mathcal{N}_d^{t,\Delta}$ 是在预测窗口内 $d$ 未观看的候选内容:
$$\mathcal{L} = -\sum_{(d,t)} \sum_{c^+ \in \mathcal{P}_d^{t,\Delta}} \log \frac{\exp(s(d, c^+, t)/\tau_s)}{\exp(s(d, c^+, t)/\tau_s) + \sum_{c^- \in \mathcal{N}_d^{t,\Delta}} \exp(s(d, c^-, t)/\tau_s)} \tag{14}$$
其中 $\tau_s$ 是温度超参。防标签泄漏的时序约束是这套训练的灵魂:送入设备塔的输入被限制为时间戳 $\tau < t$ 的边,而标签只从 $(t, t+\Delta]$ 抽取,从而在消息传递过程中不会"偷看"未来。整个模型端到端最小化损失 $\mathcal{L}$。由于监督只来自暖物品的边、却强制内容塔仅用特征解释,最终内容塔学会把语义特征投影到与历史行为对齐的协同空间。
隐式图补全:通过代理邻居(§3.3)¶
Shallow-RHS 训练完成后,学到的内容编码器被用于为所有暖内容或新摄入冷内容生成 embedding:
$$\mathbf{z}_c = f_{\theta_c}(\mathbf{x}_c) \tag{15}$$
随后在暖内容 embedding 集合 $\mathcal{Z}_{warm} = \{\mathbf{z}_w \mid w \in C_{warm}\}$ 上构建 ANN 索引。对每个冷内容 $c \in C_{cold}$,检索其 top-$M$ 暖代理邻居:
$$\mathcal{S}_M(c) = \text{TopM}_{w \in C_{warm}} \cos(\mathbf{z}_c, \mathbf{z}_w) \tag{16}$$
这隐式地补全了冷内容周围的图。与"向图里添加合成的设备-内容边"不同,这套方法在学到的 embedding 空间里把冷内容连接到附近的暖内容。代理邻居集合 $\mathcal{S}_M(c)$ 提供了一座可解释的桥,把冷内容接入既有的交互丰富暖内容目录,使冷标题能与暖标题并列被晋升。
在生产中,这些代理邻居不被当作 ground-truth 观看边对待,而是作为服务时的行为代理(serving-time behavioral proxies):一个冷标题在 CF 感知空间里继承附近暖标题的证据,用于晋升(promotion)、检索(retrieval)和校准(calibration)。因此,代理补全把"冷物品缺失的邻域"在不修改观测交互图的前提下操作化了。
冷启动设备表征:人口统计先验(§3.4)¶
前述方法处理的是冷启动的内容侧(从语义先验生成物品表征)。同样的原则可应用到查询(设备)侧。新设备同样对应"图结构缺失"的节点:它们没有观看历史邻域,无法通过 LHS 图编码器嵌入。因此设备冷启动改用人口统计与上下文先验。
把暖设备依据可得的设备与账户级属性聚为约 $K_D$ 个人口统计 cohort。对每个 cohort $g$,用分配到该 cohort 的暖设备 embedding 的均值作为代表性 embedding:
$$\mathbf{z}_g = \frac{1}{|\mathcal{D}_g|} \sum_{d \in \mathcal{D}_g} \mathbf{z}_d \tag{17}$$
对每个新激活设备 $d_{new}$,从其人口统计特征推断 cohort 归属 $g(d_{new})$,并用对应 cohort embedding 作为其初始设备表征:
$$\mathbf{z}_{d_{new}} = \mathbf{z}_{g(d_{new})} \tag{18}$$
这使得可以在 cohort-based 设备 embedding 与 Shallow-RHS 学到的 CF 感知内容 embedding 之间立即做 ANN 检索。于是物品冷启动与设备冷启动共享同一套底层方法论:缺失的图表征都从旁路信息先验(内容侧用语义先验、设备侧用人口统计先验)重建,再用于协同 embedding 空间中的检索。
实验设置¶
从关系数据构建图(§4.1)¶
Shallow-RHS 实现于 Kumo GNN 平台之上,并为 Tubi 的生产冷启动场景适配。论文用 Tubi 一年的观看历史日志构建时序二部图。令 $t_0$ 为图构造截止时间,$T = 365$ 天为历史回看窗口,$r_{min}$ 为最小总观看时长阈值。只保留观看时长足够的观看事件:
$$\mathcal{E}_{train} = \{(d, c, \tau, r) \in \mathcal{E} \mid t_0 - T \le \tau \le t_0,\; r \ge r_{min}\} \tag{19}$$
其中 $d$ 是设备节点、$c$ 是内容节点、$\tau$ 是观看时间戳、$r = \text{TVT}_{d,c,\tau}$ 是总观看时长。过滤短观看可去除弱/偶发交互、丢弃图中噪声边。
构建出的图规模为:数亿设备节点、数十万内容节点、数十亿时序观看边。同一设备-内容对的多次观看被保留为时序边而非折叠成单条静态边,使模型能条件于近因性与重复参与。
论文把历史上下文构造与监督信号分离:完整一年图用于构造时序设备观看历史,但链接预测标签只从最后 $K$ 天采样,定义监督窗口 $\mathcal{T}_{sup} = [t_0 - K\text{ days}, t_0]$。对每个训练锚点时间 $t \in \mathcal{T}_{sup}$,设备塔只观测 $\tau < t$ 的历史边,正样本是 $(t, t+\Delta]$ 内的未来观看。这样既能用长程行为上下文,又能强调近期目录趋势与近期偏好。
为保证训练可扩展,对每个训练实例采样有界的时序设备历史,只保留最近 $K$ 个交互。初始的 9 月实验用 $D$ 维输出 embedding;10 月实验把输出 embedding 维度翻倍,以提升对更丰富节目元数据与剧本派生语义特征的表征容量。
评估设置(§4.2)¶
所有实验都是 Tubi 生产推荐系统内的随机化在线 A/B 测试。主要目标是衡量真实服务条件下用户参与度与冷启动内容曝光的提升。报告以下关键指标:
- Total View Time(TVT,总观看时长):每设备的日均观看时长,反映对推荐内容的整体参与度;
- Qualified View Days(合格观看天数):设备达到最小参与阈值(如至少 K 分钟观看)的天数,捕获持续活跃度;
- Conversion Metrics(转化指标):短期参与信号,如主页 5 分钟转化(homepage 5-minute conversion),衡量用户是否快速参与到被推荐内容。
每个 A/B 测试中,treatment 变体与一个生产基线对比,指标在足够长的滚动窗口上聚合以保证统计稳定。评估同时关注全局性能与冷启动特定行为,包括晋升速度与新摄入内容的早期曝光。
主要实验结果¶
渐进式 Bootstrapping 与消融分析(§4.3)¶
论文通过一系列在线 A/B 实验,渐进式地把协同过滤信号注入内容 embedding 空间。贯穿多个阶段的核心机制是:改善内容侧特征的覆盖度与质量 → 改善学到的内容 embedding → 进而改善内在内容语义与图派生协同行为之间的对齐。
Phase 1:Semantic-to-CF Replacement(语义到 CF 的替换)。 第一个实验用 Shallow-RHS embedding(treatment)替换原有的"纯内容语义表征"(control)。Shallow-RHS 模型用内容元数据 + 可得处的 LLM 派生语义摘要 embedding + 训练期的图派生设备历史。与原始语义 embedding 不同,得到的内容 embedding 是经时序设备-内容链接预测优化的,因此反映了协同偏好结构。该阶段取得 +0.10% 全局 TVT 提升,并使冷标题晋升速度提升 13%。考虑到通过冷启动内容优化驱动参与提升历来很难,这个量级的提升是一个重大胜利,表明 Shallow-RHS 学到的 CF 感知 embedding 空间对冷启动晋升比纯语义空间更有效。
Phase 2:Metadata Coverage and Decision Calibration(元数据覆盖与决策校准)。 第二个实验在保持同一 Shallow-RHS 架构的前提下,改善输入特征覆盖与晋升决策逻辑。内容 schema 被更高覆盖度的类型特征、预算元数据、票房与流行度信号丰富,并提升了预训练 LLM embedding 覆盖。同时把原先粗糙的 tier-score 决策规则替换为服务系统使用的、经校准的二元晋升资格信号(calibrated binary promotion-eligibility signal)。该阶段产生 +0.16% 全局 TVT 提升,说明更好的元数据覆盖增强了"语义-到-CF 对齐"的有效性。
Phase 3:Content-Side Feature Completion(内容侧特征补全)。 第三个实验进一步扩展内容特征覆盖、减少关键内容属性上的缺失值,使整个目录的特征覆盖约提升 10%,对最重要的语义特征达到近乎完整覆盖。由此相似度分布更平滑、更适配冷启动检索,表明学到的内容空间此前曾受缺失特征伪影的影响。新标题更快达到关键曝光里程碑,该实验产生 +0.42% 全局 TVT 提升——是各滚动阶段中最显著的改进,凸显了零边内容泛化中内容侧表征质量的重要性。
Phase 4:Surrogate Completion and Semantic Enrichment(代理补全与语义增强)。 第四个实验进一步用目标受众与人口统计描述符(用预训练 OpenAI LLM embedding 初始化)丰富并扩展内容表征,使 Shadow-RHS 模型训练更鲁棒。此外,为解决少数长尾标题上"纯主特征策略不足"的问题,利用这些预训练 LLM embedding 来计算并填充其代理表征——作为一个 fallback 机制,确保所有标题的代理补全。这套联合策略带来 +0.17% 全局 TVT 提升。
下表汇总各主要组件在分阶段滚动中的增量贡献:
Table 1:渐进式系统迭代下的相对 TVT 提升(报告为相对基线的百分比 lift)
| Model | GNN | Semantic | Calibration | Feature Enhancement | Surrogate | TVT Lift |
|---|---|---|---|---|---|---|
| V1 | ✓ | ✓ | ✗ | ✗ | ✗ | +0.1% |
| V2 | ✓ | ✓ | ✓ | ✗ | ✗ | +0.16% |
| V3 | ✓ | ✓ | ✓ | ✓ | ✗ | +0.42% |
| V4 | ✓ | ✓ | ✓ | ✓ | ✓ | +0.17% |
实验结论分析:这四个变体是作为连续的在线系统迭代(而非孤立的离线组件移除)来评估的,因此提供的是真实服务条件下冷启动流水线的一种实用消融。整体上,结果支持论文假设——内容冷启动性能联合地取决于特征覆盖与内容侧特征的语义质量。从 V2 到 V3,仅通过补全内容侧特征覆盖就把 lift 从 +0.16% 拉到 +0.42%,是单步增量最大者,印证了"内容侧表征质量是零边泛化瓶颈"的论断。V4 的代理补全 lift(+0.17%)相对 V3 回落,但论文强调其价值在于为长尾标题提供 fallback 鲁棒性,而非进一步堆高头部 TVT。需要注意:由于每个 phase 同时改动多个因素(如 V4 同时引入 OpenAI embedding 初始化与代理补全 fallback),Table 1 是多变量混合的粗粒度系统消融,不能等同于严格的单组件因果归因。
相似度分布分析(§4.4)¶
为理解所提架构如何重塑冷启动内容的 embedding 空间,论文分析了不同 embedding 策略下成对相似度分数的分布(相似度在聚合的冷启动评估 cohort 上归一化计算)。
- 传统 CF embedding:冷物品缺乏交互历史,无法与现有物品建立有意义关系。冷物品的相似度倾向集中在低相似度区间,有效限制了它们在检索与排序阶段的可见性。
- 纯语义 embedding(如预训练 LLM 派生):产生更中心化(centralized)的相似度分布。它提供了泛化与合理相似度,但分数相对中性,只反映语义接近度而非真实受众偏好——因此缺乏有效推荐所需的行为信号。
- Shallow-RHS 模型:产生明显不同的分布。如 Figure 1 所示,相似度分数向更高相似度区间移动,呈右偏(right-skewed)分布。这一移动表明学到的内容 embedding 不再表示纯语义相似,而是捕获了由历史交互诱导的协同过滤行为。
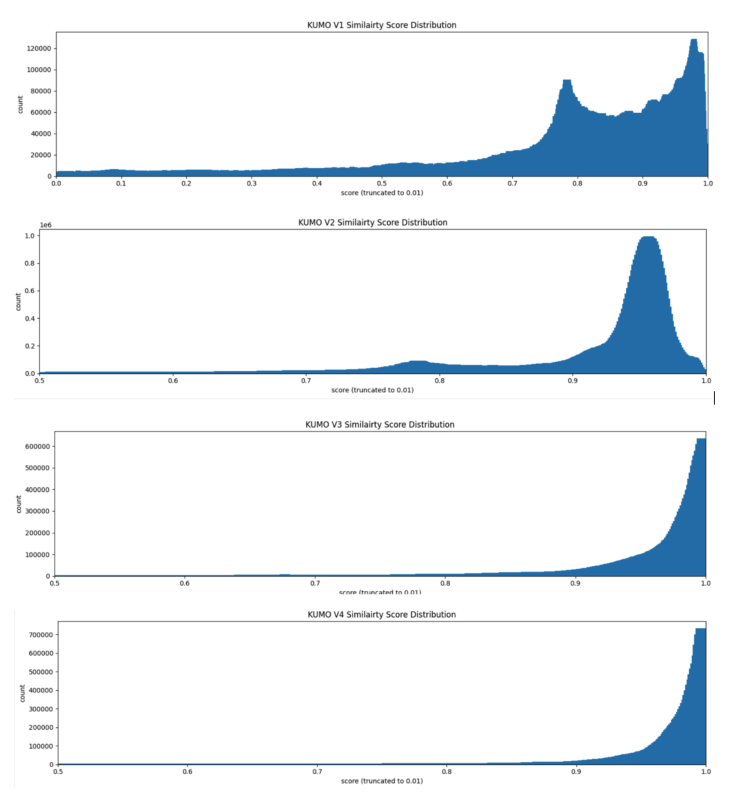
实验结论分析:这种分布层面的变换为论文的核心假设提供了直接证据——所提架构成功地把语义表征与协同过滤行为对齐。其结果是:冷启动内容能被嵌入一个 CF 感知空间、与既有内容目录建立有意义连接、并在推荐中被有效曝光。该分析是定性的(distributional evidence),与 Table 1 的在线 TVT lift 互为佐证:分布右偏 ⇔ 冷物品在检索中更"可见" ⇔ 线上晋升与参与提升。
设备冷启动评估(§4.5)¶
论文还在新激活、观看历史极少或没有的设备上评估了所提模型。对这些设备,模型用人口统计 cohort embedding(§3.4)从 CF 感知内容 embedding 索引中检索候选内容,使检索层能在观察到设备特定交互之前就提供个性化参与度。
在一次在线 A/B 测试中,这套设备冷启动检索策略改善了多个参与度指标:
| 指标 | 提升 |
|---|---|
| Qualified View Days(合格观看天数) | +0.29% |
| Capped Daily Total View Time(封顶日总观看时长) | +0.39% |
| Homepage 5-minute Conversion(主页 5 分钟转化) | +0.43% |
实验结论分析:这些结果表明,从人口统计先验重建缺失的设备表征可以改善首触(first-touch)推荐质量,与内容侧"语义-到-CF 对齐"形成互补。三个指标的一致正向(参与天数、观看时长、快速转化)说明 cohort 均值 embedding 虽然粗粒度,但足以让冷设备在缺乏个性化历史时获得一个"合理的协同起点"。
核心贡献总结¶
- 视角转换:把内容冷启动从"缺历史的特殊推荐任务"重述为"时序二部图上的归纳式图补全问题"——节点在、特征在、只是边缺失。这个形式化把问题从"为每个新物品索要部分边"转为"学一个把内在特征映射进协同空间的归纳函数"。
- 非对称双塔(Shallow-RHS):刻意让内容塔对图"浅"(无 ID embedding、无内容侧子图、无邻居聚合),逼迫内容编码器仅凭特征进入 CF 感知空间,从而同一编码器可无缝服务暖内容与零历史新内容。
- 隐式图补全:训练后用冻结内容编码器嵌入冷内容、在暖内容 embedding 上建 ANN 索引、检索 top-$M$ 暖代理邻居作为服务时行为代理——在不污染观测交互图的前提下补全冷物品邻域。
- 方法论统一:把同一"表征补全"原则推广到设备冷启动(人口统计 cohort 均值 embedding),让物品侧与设备侧冷启动共享统一框架。
- 真实生产验证:在数亿用户的 Tubi 上以多组在线 A/B 验证,报告全局 TVT、冷内容晋升速度、设备首触参与度的一致提升。
与已归档相关工作的对比¶
Towards Generalizable and Efficient Large-Scale Generative Recommenders Netflix 大规模生成式推荐缩放(Netflix Research, 2026-05-22)¶
关系:独立并发(本文未引用 Netflix,两者在"冷启动物品表征"模块上殊途同归)· 已加载对方精读
- 共同关注的问题:两者指向同一 root cause——在视频流式平台的生产推荐器中,新上线标题缺乏可靠的协同/ID-based 物品 embedding,因为它们没有足够时间窗累积交互让协同表征收敛。Netflix 明确把"冷启动 ID 证据稀疏"列为缩放之后才暴露的三大生产挑战之一,并断言"靠加容量无法解决冷启动,要换物品表征通道";本文则把它命名为"语义-协同鸿沟"。两者同为视频流式平台(Netflix ↔ Tubi),问题陈述实质同构。
- 相近的技术骨架:两者都设计了一个让模型学会"不依赖协同 ID 也能为冷物品打分"的训练机制,逼出对语义/内容特征的依赖。Netflix 的做法是"语义物品塔 + 协同 embedding 掩码":保留成熟标题的协同 ID,但以对齐线上冷启动率的概率随机掩码成 OOV,让同一解码器同时处理"有 ID"和"无 ID"两个 regime。本文的 Shallow-RHS 是"非对称双塔 + 浅 RHS":内容塔在结构上根本不设 ID 查表 embedding、也不接收图消息,从源头上让内容编码器只能靠特征进入 CF 空间。抽象流程图重合:[内容/语义编码 → CF 感知物品向量 → 训练时弱化/抹除协同 ID 依赖 → 冷物品凭特征即可被打分/检索]。
- 本文的差异与推进:对"协同 ID"的处置策略不同,是一对漂亮的对照。Netflix 把 ID 当一等公民、用概率掩码"逼出"语义依赖(仍是一个塔,掩码是训练技巧);本文则用结构性的不对称——把"深度图聚合"全部留给设备塔、把内容塔削成纯特征塔——在架构层面而非训练采样层面实现"无 ID"。此外本文多出一层显式的服务时图补全:用暖内容 ANN 索引为冷物品检索代理邻居 (Eq 15-16),把"冷物品 embedding"进一步落地为"冷物品的暖代理证据",而 Netflix 侧重 shadow 离线 MRR 的表征质量。
- 可比的方法/实验差异:Netflix 报告 shadow 冷启动 +28.1% MRR(1B vs 2M 骨干,离线 MRR);本文报告线上 +0.10%~+0.42% 全局 TVT、冷标题晋升速度 +13%、设备首触 +0.29%~+0.43%(在线 A/B 业务指标)。两者评估口径完全不同(离线 MRR vs 在线 A/B),不可直接数值比较;但共同 insight 一致:冷启动要靠"换/重塑物品表征通道",而非靠加交互或加容量。
IDProxy IDProxy:MLLM 代理 ID embedding(Xiaohongshu, 2026-03-02)¶
关系:独立并发(本文未引用 IDProxy,两者殊途同归且解法方向恰好相反)· 已加载对方精读
- 共同关注的问题:IDProxy 的问题陈述与本文逐字同构——"新物品缺乏交互历史,其 ID embedding 训练不充分,导致排序效果差"。更关键的是,IDProxy 的精读直接点名了本文命名的那道鸿沟:它把 CB2CF/CLCRec 这类"协作嵌入映射方法"总结为"用 MLP 把内容特征映射到协作嵌入空间,但工业 ID embedding 分布不规则、非聚类化,浅层 MLP 难以桥接语义空间与协作空间的差异"。这正是本文"semantic-collaborative gap"的另一种表述。
- 相近的技术骨架:两者都要为冷物品从内容/语义特征产出一个落在协同空间里的表征,再用于下游召回/排序。
- 本文的差异与推进:解法方向恰好相反,构成最有价值的对照。IDProxy 的策略是"合成缺失的协同 ID"——保留既有 ID-based CTR 排序器,用 MLLM 中间层隐藏态经对比对齐(把 $\bar{\mathbf{h}}_i$ 拉向真实 ID embedding $\mathbf{e}_i$)造出一个 proxy ID embedding,注入排序器原子 ID 槽位;它显式承认"浅层 MLP 映射会失败",于是把重担压在 MLLM + 端到端对齐上。本文 Shallow-RHS 则根本不去拟合任何既有 ID embedding 分布:它不合成 ID,而是用图链接预测损失(Eq 14)端到端地把整个内容空间训练成 CF 空间——因此天然绕开了 IDProxy 所说的"浅层 MLP 桥接难"问题(因为它压根不映射到一个预先存在的不规则 ID 分布上)。集成形态也不同:IDProxy 服务于判别式 CTR 排序(特征注入,输出 CTR),Shallow-RHS 服务于双塔检索(余弦打分,输出排名)。
- 可比的方法/实验差异:IDProxy 报告新笔记离线 ΔAUC +0.23%~+0.32%(约为全量的 2 倍)、内容流 Time Spent +0.22%/Reads +0.39%、广告 ADVV +1.93%;本文报告冷标题晋升速度 +13%、全局 TVT +0.10%~+0.42%。两者都验证了"把语义信息迁移到无交互历史物品上能显著改善冷启动",但 IDProxy 用 AUC(判别式排序口径),本文用 TVT/晋升速度(检索+参与口径),数据点不可直接对齐。
被剔除的近似候选(问题相近但解法路径不同构,未入选): - FLUID(TikTok, 2605.21832):同样"退役候选侧 item ID、从多模态内容派生物品表征",但其骨架是 RQ-KMeans 离散语义码(LUCID)+ prefix-n-gram late fusion,核心轴在"离散化";本文是连续 CF 感知 embedding + 图链接预测 + 代理邻居检索,无离散码、无 SID,解法骨架在关键轴上分叉。 - Next-User Retrieval(ByteDance, 2506.15267):同为"冷启动物品晋升",但解法是翻转检索方向、为冷物品生成式预测下一个潜在用户(transformer 序列建模),与本文"为冷物品造 CF 感知物品 embedding 再被设备检索"方向相反、骨架不同构。 - GrowthGR(Taobao, 2605.17994):同为"生成式检索的新物品冷启动/成长",但解法是 counterfactual ItemLTV + MultiGR 多值 GRPO 奖励整形(RL 路径),与本文表征对齐路径不同构。 - GenRecEdit(RUC, 2603.14259):同为"生成式推荐冷启动",但解法是模型编辑(model editing),与本文图补全/表征对齐完全不同。
讨论与局限性¶
核心贡献与可借鉴的设计。本文最大的方法论价值在于那个刻意的不对称:把"深度、含图聚合"的能力全部分配给查询(设备)侧,把目标(内容)侧削成一个纯特征塔。这个看似"减法"的设计恰恰是冷启动泛化的关键——因为只有当内容塔在结构上无法依赖 ID 或子图时,它才被真正逼着把语义特征投影进协同空间。配合"训练只用暖物品的边、服务用同一冻结编码器嵌冷物品 + 暖代理邻居 ANN 检索"的闭环,整套方案在工程上非常干净:冷内容一被摄入即可被嵌入并立即检索,无需为它构造任何合成边或重训。把同一原则对称地推广到设备侧(人口统计 cohort 均值)也体现了框架的一致性。对任何"有立即服务约束、且持续有新内容/新用户涌入"的流式平台,这套"冷启动 = 归纳式图补全 + 浅目标塔"的范式比单点技巧更有参考价值。
局限与争议。
- 实验严谨度偏弱。论文没有任何公开学术数据集的离线 benchmark,也没有与具名 SOTA 基线(如 PinSage、NGCF、ContextGNN、CLCRec、IDProxy 等)的对照实验——所有证据都是 Tubi 生产 A/B 上对"内部 control"的相对 lift。这使得"Shallow-RHS 相对其他冷启动方法好多少"无法被外部判断。
- Table 1 是多变量混合的粗粒度系统消融,而非干净的单组件因果归因:每个 phase 同时改动了若干因素(如 V4 同时引入 OpenAI embedding 初始化与代理补全 fallback),因此"GNN/Semantic/Calibration/Feature/Surrogate 各自贡献多少"无法从该表严格分离。
- 线上 lift 量级较小(+0.10%~+0.42% TVT)。论文论证了"冷启动驱动参与历来很难,这个量级即重大胜利",这在大盘指标上确有道理,但也意味着方法的边际收益主要来自特征覆盖与质量(V2→V3 的 +0.16%→+0.42% 是最大单跳),而非架构本身——架构 V1 的孤立增益仅 +0.1%。换言之,"喂好特征"可能比"Shallow-RHS 这个结构"贡献更大,这一点论文没有进一步拆解。
- 代理邻居作为"行为代理"缺乏直接的可靠性验证:Eq 16 的 top-$M$ 暖邻居被当作服务时证据,但论文未给出"这些代理邻居有多大程度真的预测了冷物品的真实受众"的离线度量(如代理邻居的受众 vs 冷物品最终实际受众的重合度),只能间接由 TVT lift 与相似度分布右偏来佐证。
- 设备 cohort 的粗粒度:$\mathbf{z}_{d_{new}} = \mathbf{z}_{g(d_{new})}$ 让同一 cohort 内所有新设备共享同一个 embedding,个性化粒度受限;论文未讨论 cohort 数 $K_D$ 的选择敏感性或 cohort 内方差。
- 方法论可扩展性:Shallow-RHS 不存在"先离线压缩再在线建模"那类两阶段解耦的硬瓶颈(内容塔与设备塔端到端联合训练),这是它相对 SID/量化路线的优点;但"浅内容塔"也意味着内容侧表征容量受限于纯特征 + FT-Transformer,当需要更强的内容理解时,可能要回到引入更重的内容侧建模——而那又会与"对图保持浅"的初衷张力。
与已有工作的差异。相比 Netflix 的"语义塔 + 协同掩码"(用训练采样技巧逼出语义依赖)与 IDProxy 的"合成代理 ID"(保留 ID 排序器、用 MLLM 造 ID 替身),本文走的是第三条路:结构性地让内容塔无 ID 无图、用图链接预测把内容空间直接训成 CF 空间。三者共享"语义-协同鸿沟"这一共同问题,却给出"掩码/合成/结构性削减"三种不同处方,构成冷启动表征对齐这一方向上一组很有意思的并发对照。