Towards Generalizable and Efficient Large-Scale Generative Recommenders:把"规模能涨"翻译成"生产能用"的 Netflix 案例研究¶
来自 Netflix Research(Qiuling Xu、Ko-Jen Hsiao、Moumita Bhattacharya)。这是一篇坦诚的工业案例报告:把一个生成式推荐骨干从 2M 缩放到 1B 参数(不含 embedding 与 decoding 层),然后回答一个比"模型能不能变大"更现实的问题——规模的红利能不能真正传导到生产下游任务。论文的立场很克制:scaling 有用,但不均匀;模型规模只是"生产迁移问题"里的一个变量,与任务剩余空间(task headroom)、解码成本、服务延迟对齐、物品泛化并列。
研究动机与背景¶
生成式推荐的"语言模型范式迁移"¶
生成式推荐(generative recommendation)把语言模型的序列建模范式搬到用户行为上:一个用户的历史被表示为事件序列,模型被训练去预测未来事件。这个范式对工业推荐极有吸引力,因为单个骨干可以支撑众多下游任务——召回、排序特征、用户 embedding、冷启动打分等等都能复用同一套表征。
但论文一开篇就泼了一盆冷水:单纯把模型做大,本身并不能保证更好的生产推荐质量。规模红利取决于三个被以往 scaling-law 工作忽略的现实因素:
- 哪些任务还有剩余空间(headroom) —— 不同下游任务的可预测性不同,有的早已逼近经验天花板,继续加容量收益甚微;
- 模型能否被足够频繁地重训 —— 用户行为、物品目录持续演变,十亿参数模型如果不能高频刷新,就退化成"一次性离线产物";
- 训练目标是否匹配推荐被实际服务的方式 —— 很多生产系统缓存 embedding / candidate / score,导致"下一个 token"标签在被消费时已经过期。
论文用一句话概括其核心发现:scaling is useful but uneven(规模有用但不均匀)——不同推荐任务遵循不同的缩放轨迹、有不同的表观天花板。这让 scaling-law 分析从"一张诊断图"变成"一个实用工具":它帮你判断下一步该投资更多容量、更好的目标函数,还是更好的物品表征。
三个缩放之后才暴露的生产挑战¶
论文聚焦缩放之后才出现的三个生产约束,并各给一个工程解法,构成全文骨架:
| 生产挑战 | Root cause | 论文解法 |
|---|---|---|
| 大模型要被反复重训(trillions of tokens) | 训练 / 解码效率成为瓶颈 | 采样 softmax + 投影解码头(d→d/8) |
| 缓存服务让"立即的下一个 token"目标过期 | next-token 标签与服务时刻错配 | 多 token 预测(MTP),监督一组带权未来高价值目标 |
| 新上线标题缺乏可靠协同 ID embedding | 冷启动 ID 证据稀疏 | 语义物品塔 + 协同 embedding 掩码 |
最终在 1M 用户、为期一周的生产 shadow 评估中,1B 骨干在所有上报任务上的 MRR 都优于 2M 骨干基线,其中在可预测性最低的 Task A 上取得 +22.5% 相对增益。
相关工作的定位¶
论文把自己放在四条脉络的交叉点上,并明确"互补而非替代"的姿态:
- 生成式推荐:TIGER 用语义 ID(SID)做生成式检索与未见物品泛化;HSTU(Meta)把这一思路扩展到高基数流式推荐数据,并展示生成式推荐质量可随训练计算量可预测地缩放;LONGER、PinFM 等工业系统进一步推进长序列与基础模型方向。本文的贡献是正交的:研究 scale 如何在反复重训、缓存服务、新 / 弱表征物品下跨下游任务传导。
- 推荐中的 scaling law:已有工作研究过 ID-based 序列推荐与 CTR 模型的幂律行为,HSTU 报告了大计算区间下生成式推荐的缩放行为。但这些工作没有回答"哪些生产任务还有剩余空间"——这正是本文用任务相关的 offset scaling law 去解决的问题。
- 工业规模高效训练 / 服务:LONGER、HSTU context parallelism 处理长历史成本;embedding offloading 把超大 embedding 表搬到主存;输出打分侧有 sampled softmax、scalable cross-entropy、Cut Cross-Entropy、sub-item inference 等。本文的效率配方刻意简单:1% 均匀采样负样本 + 共享投影 d/8 解码头,与 Cut Cross-Entropy 这类精确内存高效核互补。
- 语义表征与冷启动:SID 用内容衍生的离散结构替代 / 增强随机物品 ID;PinFM 把新物品处理作为核心挑战。本文的贡献针对互补的"模型-表征"问题:成熟物品仍用协同 ID embedding,而多模态语义塔 + 协同 embedding 掩码训练同一个解码器,在 ID 证据弱或不可用时从内容与元数据打分。
此外论文还点名了 serving-aware objectives:RADAR 用 deferred asynchronous retrieval 缓存由更昂贵排序路径生成的高质量候选;这类系统促成了一种"服务感知"的建模视角——当缓存输出在用户状态前移后才被消费,"立即的下一个 token 标签"会变陈旧。本文的 MTP 正是针对这一问题。
第 3 节:推荐中的 Scaling Law¶
任务分类:用可预测性切分¶
论文先问:更大的生成式推荐器是否在所有下游任务上均匀地变好?为降低时间分布漂移,作者把用户活动归并为三类匿名任务,它们在可预测性与服务敏感度上不同(Table 1)。这种粗粒度分组是刻意的:它保留了工业上"长期口味 / 短期参与 / 时间驱动行为"的主要区分,同时回避任务特定的实现细节。
| Task | 可预测性 | 描述 |
|---|---|---|
| Task A | 较低(Lower) | 长视野口味(long-horizon taste);正样本稀疏 |
| Task B | 中等(Moderate) | 短视野参与(short-horizon engagement);近期上下文 |
| Task C | 较高(Higher) | 时间 / 可用性驱动的群体信号 |
评估采用受控时间切分(time-split):每个样本包含一段在 cutoff 时刻前结束的用户历史,模型推断针对 cutoff 之后的未来行为标签评估。跨模型规模,训练数据、测试样本、测试窗口、物品词表、embedding 维度、解码设置全部固定,消融只改变骨干大小——因此 Figure 1 的差异主要反映序列模型容量,而非数据 / embedding / 评估分布的变化。
由于阈值化指标会让平滑改进显得不连续(emergent abilities 的"海市蜃楼"问题),作者用 Mean Reciprocal Rank (MRR) 作主缩放指标:它连续到足以捕捉增量增益,又被 1 上界,天然适合建模任务特定的天花板。他们在 test loss、Hit Rate、NDCG 上观察到相似的定性趋势。
Offset Power Law:带饱和天花板的拟合¶
每个任务用一条 offset power law(偏移幂律) 拟合,仅针对非 embedding、非 decoding 参数:
$$P(N) = P_0 - \left(\frac{N}{N_0}\right)^{-a}, \quad a > 0 \tag{1}$$
其中 $P(N)$ 是规模 $N$ 下的验证性能,$P_0$ 是规模隐含的饱和水平,$N_0$ 是尺度参数,$a$ 控制改进速率。$P_0$ 被用来比较"在当前数据、目标、评估分布下的剩余空间":
- Task A:$P_0 = 0.311$ —— 观测到的缩放轨迹已经接近其经验天花板,单靠加容量不太可能带来大增益;
- Task B:$P_0 = 0.604$;
- Task C:$P_0 = 1.075$ —— 实际上已贴近 MRR 上界 1(超过 1 的小部分是估计误差),说明该任务在充分数据与规模下仍高度可预测。
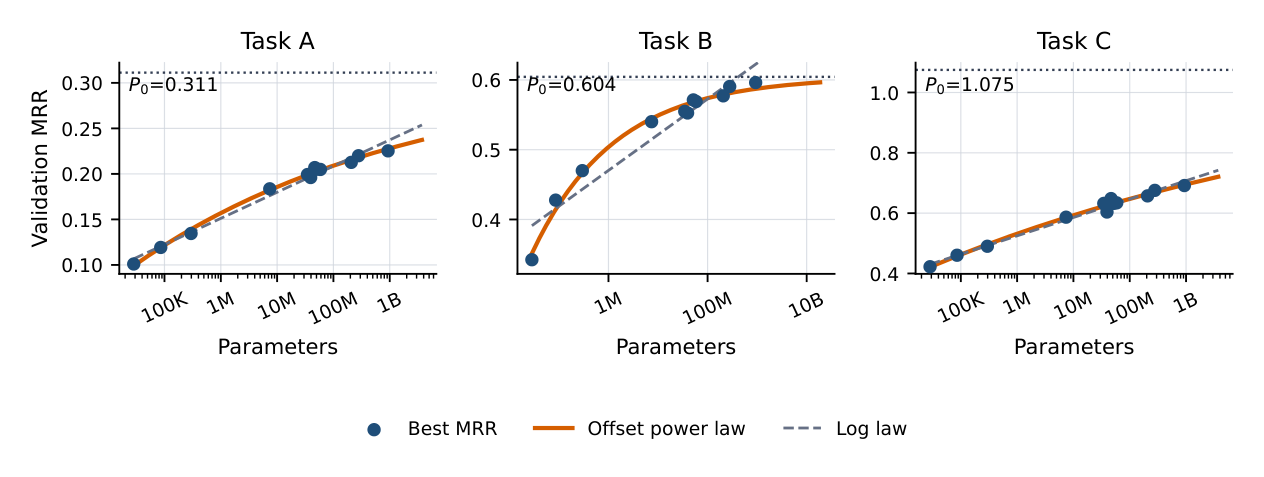
Figure 1 把原始 MRR 对 log 缩放的参数量作图。offset 幂律在这个视图下弯向 $P_0$,只有当把 $\log(P_0 - P)$ 对 $\log N$ 作图时才线性。
与 log-linear 形式的对比:offset 拟合误差更小¶
作者把这个拟合与以往生成式推荐工作(HSTU,[21])使用的 log-linear 形式 $P = a\log(N) + b$ 对比。log-linear 模型能在有限尺度范围内匹配单调改进,但无法表达逼近任务特定天花板的有界指标。Table 2 显示 offset 形式在三个任务上都降低了 RMSE:
| Task | Offset RMSE ($10^{-3}$) | Log RMSE ($10^{-3}$) | 误差降低 |
|---|---|---|---|
| Task A | 2.80 | 5.43 | 48.4% |
| Task B | 8.16 | 21.34 | 61.8% |
| Task C | 9.33 | 10.97 | 14.9% |
结论分析:误差降低在 Task B 最显著(61.8%),正因为 Task B 处于"中段拐弯"区间——既不像 Task A 已贴近天花板、也不像 Task C 仍近似线性,log-linear 在这里最容易高估远端外推。Task C 降低最小(14.9%)是因为它在观测区间内仍近似线性,两种形式都拟合得不错。这从经验上支撑了论文的核心论点:推荐指标有界,缩放分析必须用能表达饱和的函数形式,否则会对"加容量还能涨多少"给出过度乐观的外推。
关于参数计数,作者只数骨干参数,排除 embedding 与最终 decoding 层,遵循 scaling-law 惯例(embedding 常有次级效应),把分析聚焦在序列模型容量而非表征 / 打分选择上。经验上,把这些层计入并不会实质改变任务排序或对 offset 拟合的偏好。
第 4 节:高效训练与推理¶
效率是"有前途的大型推荐器"与"可运营的推荐器"之间的主要差别之一。与许多语言模型不同,推荐模型必须频繁刷新以反映偏好变化、季节效应、目录更新。这个反复重训(repeated-training) 需求让效率成为核心——即便词表压力已被检索剪枝等输出空间设计缓解。论文的预训练语料是每个周期 2 万亿行为 token(与主流 LLM 预训练语料量级相当),但以反复刷新的节奏处理。在直接物品打分仍需保留(兼容现有评估 / 服务路径)的前提下,作者聚焦于对解码成本的简单削减。
4.1 高效解码:采样 softmax + 投影头¶
即使 SID 或检索类方法缩小了有效输出空间,直接物品打分仍是常见且有用的接口。对一个 vanilla transformer,随着候选集增长,输出层会成为训练成本的一大块。Figure 2 用一个 6 层、隐藏维 1024、序列长 512 的 transformer 演示这一效应;y 轴报告按训练 token 数归一化的训练 FLOPs,因此总语料计算量随 token 数线性缩放。
论文做两件事削减解码成本:
(1) 训练时采样 softmax。 只对正样本 + 均匀采样的 1% 负样本集计算 logit,而非全部候选物品。等于目标的采样负样本会被拒绝。本实现不做 LogQ 校正,刻意保持训练配方简单,把校正采样策略留作正交方向。
(2) 共享投影解码头。 在物品 logit 计算前,加一个共享的投影头,把骨干隐藏状态从维度 $d$ 降到 $d/8$。在生产中这对应从 4096 下投影到 512。这针对的是目录相关的矩阵乘法,同时保持骨干隐藏维度不变(即 scaling-law 分析里研究的那个容量维度不动)。
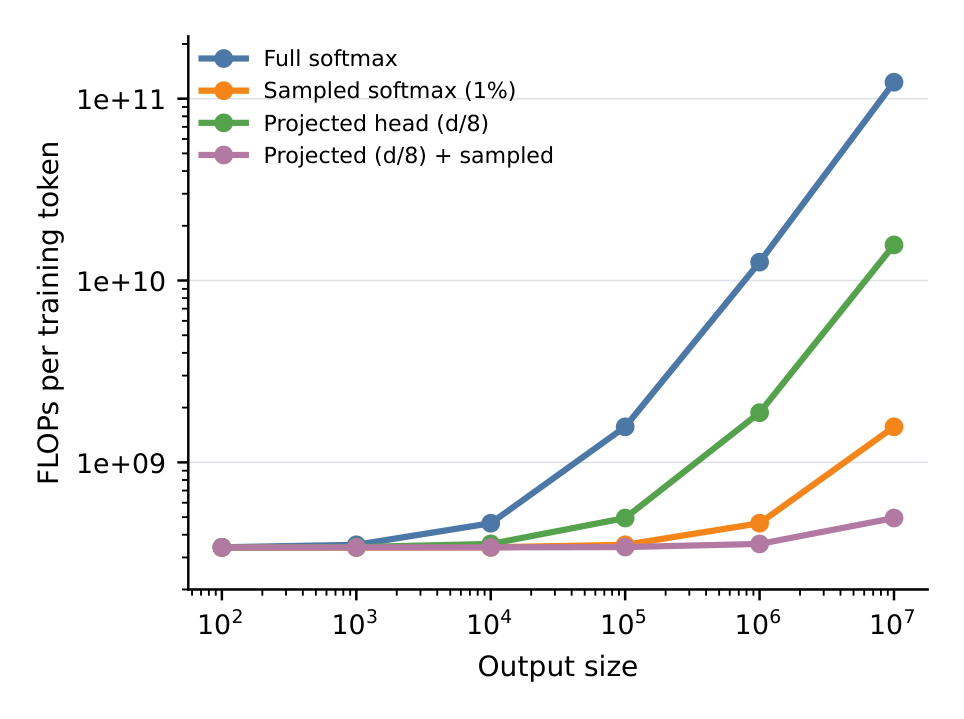
关键数字:在输出规模 $10^6$ 时,演示用的 vanilla 配置需要 $1.26 \times 10^{10}$ 训练 FLOPs / token,而采样 softmax + 投影 d/8 头只需 $3.56 \times 10^8$ FLOPs / token,即此估计下 35.5× 的削减;在输出规模 $10^7$ 时,估计的削减增长到约 249×。作者强调这些是解析的输出层估计,而非端到端训练吞吐测量。这些输出层削减让"反复刷新大模型"在该场景下可运营,而非把十亿参数模型当成一次性离线产物。
4.2 高效编码¶
论文的事件表征也不同于那些把异构动作流与特征流分开建模的架构。作者把每个用户事件的动作、观测上下文、物品元数据压缩成单一的 token 级表征。这个选择让序列接口对下游应用保持简单,同时语义物品塔(第 6 节)在 ID embedding 弱或不可用时提供额外的物品理解。
4.3 高效开发¶
最后,作者用一个 small-to-large 的实验漏斗:候选改动先在较小骨干 + 为检测任务特定回归而设计的缩放测试集上评估,只有通过漏斗的改动才被整合进昂贵的十亿参数训练。这本身不是建模贡献,但运营上很重要——没有它,验证 scaling-law、解码、MTP、冷启动这些改动的成本会高到无法承受。
第 5 节:多 Token 预测(MTP)¶
5.1 Next-Token Prediction 的延迟问题¶
大型推荐器很少以纯同步方式服务。为控制延迟与成本,许多生产系统缓存用户 embedding、候选列表或预排序结果,在固定时间间隔或积累足够新活动后才刷新(这与 RADAR 的 deferred retrieval 相关)。这制造了一个对 next-token 训练的标签对齐问题:紧跟上下文的那个物品,可能在缓存输出被使用时已经被消费了。
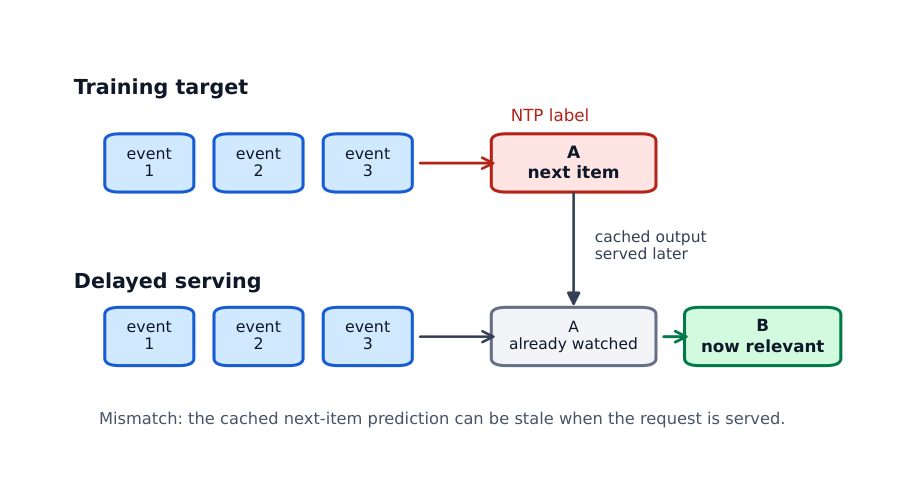
Figure 3 图示了这一错配:训练时,近期用户历史之后的立即 next-token 标签是标题 A;若模型输出被缓存并稍后服务,用户可能已经看过 A,此时标题 B 才是相关推荐目标。只针对立即 next-token 优化的模型,会把概率质量放在一个陈旧目标上。
Figure 4 量化了这一效应:在不断增大的服务延迟下重放评估。
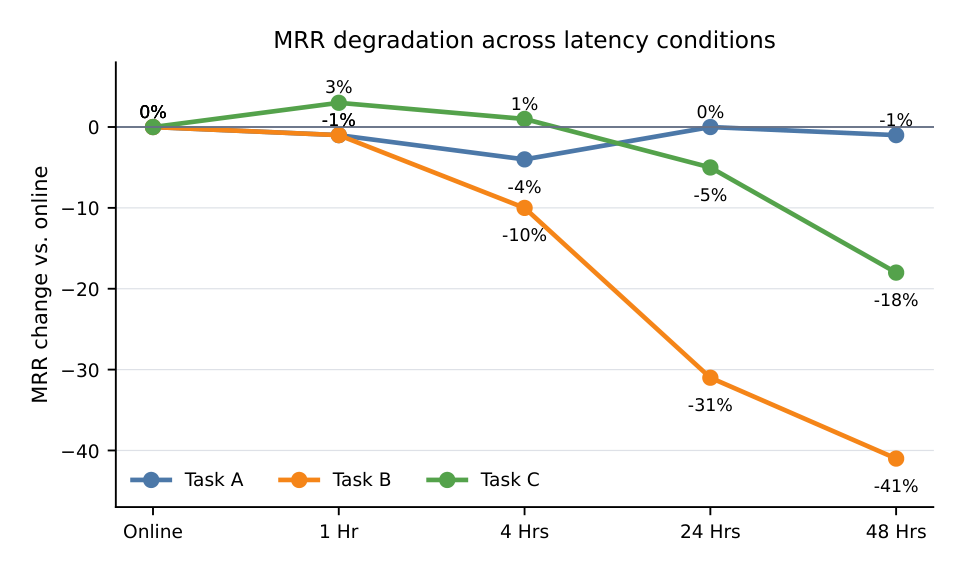
| 服务延迟 | Task A | Task B | Task C |
|---|---|---|---|
| Online | 0% | 0% | 0% |
| 1 Hr | −1% | −1% | +3% |
| 4 Hrs | −4% | −10% | +1% |
| 24 Hrs | 0% | −31% | −5% |
| 48 Hrs | −1% | −41% | −18% |
结论分析:Task A 相对鲁棒,在测量范围内最多变化 4%;Task B 对延迟高度敏感,24 小时掉 31%、48 小时掉 41%;Task C 比 B 不敏感但 48 小时仍掉 18%。这说明延迟对齐对短视野任务最重要,而长视野口味任务能更好地容忍陈旧表征——这与 Figure 1 的可预测性切分自洽:Task B(短视野参与)既最敏感于延迟、也是缩放误差降低最大的任务。
5.2 集合值未来目标(Set-Valued Future Targets)¶
第二个错配是:很多推荐目标是集合式(set-like) 的。语言建模里 token 顺序通常有语义;但推荐里,若干未来物品可能同样有效、顺序部分任意。如果用户很可能很快都看 A 和 B,那么"A 然后 B"或"B 然后 A"都可接受。标准 NTP 把全部概率质量分给一个观测到的顺序,惩罚其它合法未来,使目标对长期口味与探索任务变得脆弱。
论文用 multi-token prediction (MTP) 同时解决这两个错配。对每个上下文,从未来高价值目标构造一个带权标签集,并施加一个一小时半衰期的指数时间衰减。模型用与 NTP 相同的解码头对候选集打分一次,优化一个针对该未来集合的带权多标签目标。MTP 因此只改监督目标:服务时模型仍以单次解码对候选打分,不需要迭代生成或多次模型调用。
损失定义为:
$$\mathcal{L} = -\sum_{y_i \in \mathcal{Y}} w_i \log p_\theta(y_i \mid x), \quad w_i = r_i \exp\left(-\ln(2) \frac{t_i - t_{\text{context}}}{\beta}\right) \tag{2}$$
其中:
- $\mathcal{Y}$ 是未来高价值目标集;
- $r_i$ 是奖励权重,可编码效用信号——观看时长、完成度、新鲜度、多样性;
- $\beta$ 设为一小时,让模型从未来标签学习,同时强调那些更接近服务状态的标签;
- $\exp(-\ln(2)\cdot\frac{t_i - t_{\text{context}}}{\beta})$ 即按 $\beta$ 为半衰期的指数时间衰减(权重每过一个 $\beta$ 减半)。
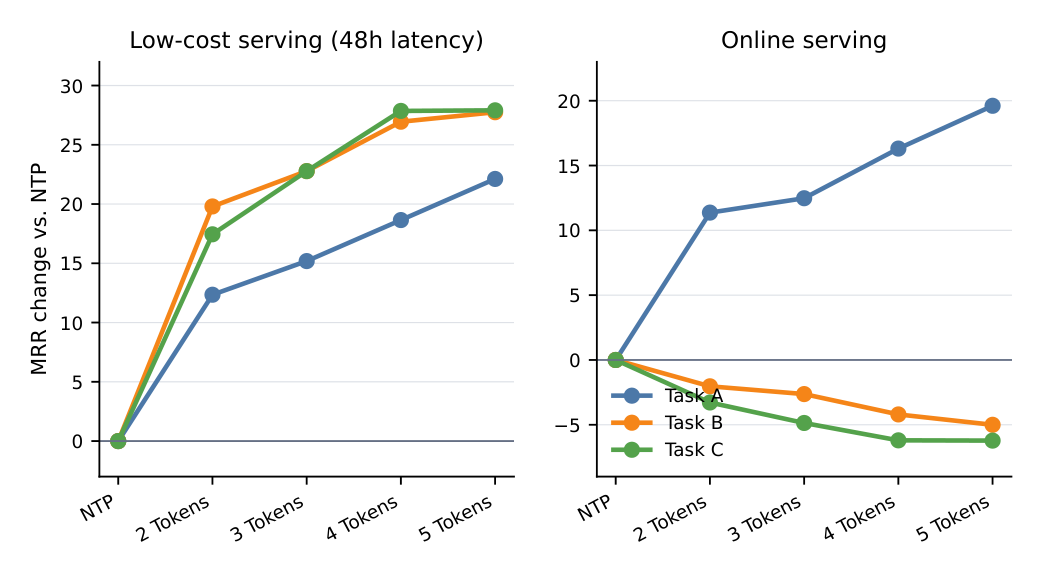
Figure 5 在两种服务场景下对比 NTP 与 MTP:在线服务(p95 延迟低于一秒) 与 低成本缓存路径(48 小时服务视野)。
- 48 小时视野下,MTP 改善所有三个任务,最佳的五 token 窗口分别带来 +22.1%、+27.8%、+27.9% 的相对 MRR(Task A / B / C)。随窗口从 2 增到 5,三个任务的增益单调上升。
- 在线服务下,MTP 改善 Task A(五 token 时 +19.6%),但随窗口增长降低 Task B 和 C(它们跌到 0 以下)。
结论分析:这说明 MTP 应当按服务视野与任务类型来选择——它对缓存或顺序可置换(permutation-tolerant) 的用例最有用,对顺序敏感的在线任务则不太适合。直观上:在线低延迟时,"立即下一个"标签并不陈旧,把概率摊到一个未来集合反而稀释了对真正立即目标的预测(尤其对短视野的 B/C);而 48 小时缓存路径下,立即标签早已陈旧,集合值监督正好对上服务时刻的"集合式相关性"。
第 6 节:未见与冷启动标题¶
冷启动标题暴露了一个靠缩放无法解决的失败模式。成熟标题可以用交互历史学到的协同 ID embedding 表示,但新 / 稀疏标题对这条通道几乎没有证据。论文的设计是互补的:对成熟标题保留协同 ID embedding,同时加入多模态语义物品塔,让同一个生成式解码器在 ID 证据弱时从内容与元数据打分。
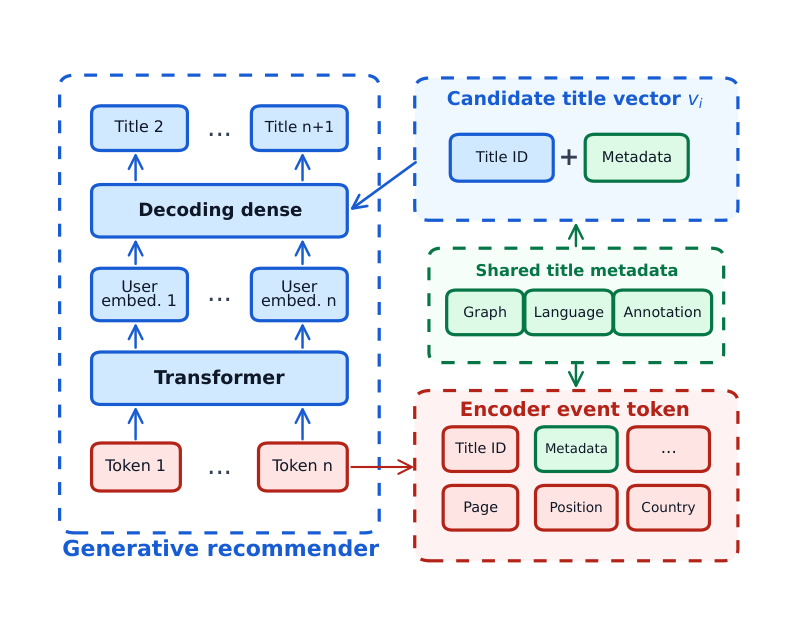
Figure 6 图示了编码器侧事件表征与解码器侧标题打分的分离。左侧是标准生成式路径:事件 token 被 Transformer 编码,转成用户表征,送入 dense 解码层。右侧,语义标题元数据被两个消费者共享。这些元数据来自三个源:
- 图特征(graph):在标题知识图谱上做消息传递学到;
- 语言 embedding(lang):用 LLM2Vec 产生;
- 编辑标注特征(ann):来自人工标签。
它们既丰富编码器事件 token(当该标题出现在用户历史中时),也贡献被解码器打分的候选标题向量。而 page、position、country 等上下文字段仍是输入侧事件特征:它们 condition 用户表征,但不属于候选标题向量。颜色编码正反映这一区分:蓝=学到的模型表征 / 计算,红=编码器侧事件 / 上下文字段,绿=可复用的标题元数据。
解码时刻,语义信息通过 dense 输出头使用的标题表征进入。设 $h_u$ 为 Transformer 产生的用户表征,$\mathcal{V}$ 为模型使用的物品词表,$v_i$ 为标题 $i$ 的候选标题向量。解码器打分计算为:
$$z_i = \phi_{\text{sem}}\!\left(e_i^{\text{graph}}, e_i^{\text{lang}}, e_i^{\text{ann}}\right) \tag{3}$$
$$\bar{e}_i^{\text{ID}} = \begin{cases} e_i^{\text{ID}}, & i \in \mathcal{V} \\[2pt] e^{\text{OOV}}, & i \notin \mathcal{V} \end{cases}$$
$$v_i = \psi_\theta\!\left(\bar{e}_i^{\text{ID}}, z_i\right)$$
$$s(u, i) = g_\theta(h_u)^\top v_i$$
其中:$e_i^{\text{graph}}, e_i^{\text{lang}}, e_i^{\text{ann}}$ 是标题 $i$ 的知识图谱、语言 embedding、标注特征 embedding,$\phi_{\text{sem}}$ 把它们映射成语义标题表征 $z_i$;$e_i^{\text{ID}}$ 是词表内标题的协同 ID embedding,$e^{\text{OOV}}$ 是学到的out-of-vocabulary embedding,$\bar{e}_i^{\text{ID}}$ 是解码器实际使用的 ID 侧 embedding;学到的函数 $\psi_\theta$ 与 $g_\theta$(参数 $\theta$)构造 $v_i$ 并把 $h_u$ 投影到解码空间;$(\cdot)^\top$ 是用于打分的内积;$s(u,i)$ 是最终的用户-标题分。
核心机制:词表内标题同时用 $e_i^{\text{ID}}$ 和 $z_i$;不在 $\mathcal{V}$ 中的冷启动标题被赋予学到的 OOV embedding,只能依靠 $z_i$ 提供标题特定证据。这把稳定的标题证据(语义元数据可定义候选标题向量)与瞬态的服务上下文(page/position/country 只 condition 用户侧表征)分离开。
训练关键思想:把解码器同时暴露在成熟-ID 与弱-ID 两个 regime 下,使它学会组合协同 ID 证据与语义标题证据,而非孤立依赖某一方。预训练时,作者随机把输入侧或输出侧的协同物品 embedding 替换成学到的 OOV embedding,使用一个与线上实测冷启动率对齐的掩码概率。这些被掩码的样本匹配了词表外标题的服务路径,从而训练解码器仅凭学到的 OOV embedding 加语义证据就能给标题打分——当物品 ID 不可用时,语义塔承载了标题特定的信息。
第 7 节:生产 Shadow 评估¶
7.1 评估设置¶
前面几节通过 scaling-law 拟合、解析成本估计、服务延迟重放、MTP 对比分别评估各个设计问题。最后,作者对组合后的模型做一次生产 shadow 评估,超出预训练目标本身。具体:在 1M 用户、为期一周的生产 shadow 流量上运行候选模型。对每个被 shadow 的请求,下游系统通过与生产推荐相同的集成路径消费候选模型,但候选模型不影响用户体验。作者记录 shadow 输出,并用同一窗口收集的下游标签评估。这个设置衡量的是基础模型是否在多个下游集成中产生有用的表征与打分,而非测量单个产品表面的因果 lift。
7.2 结果¶
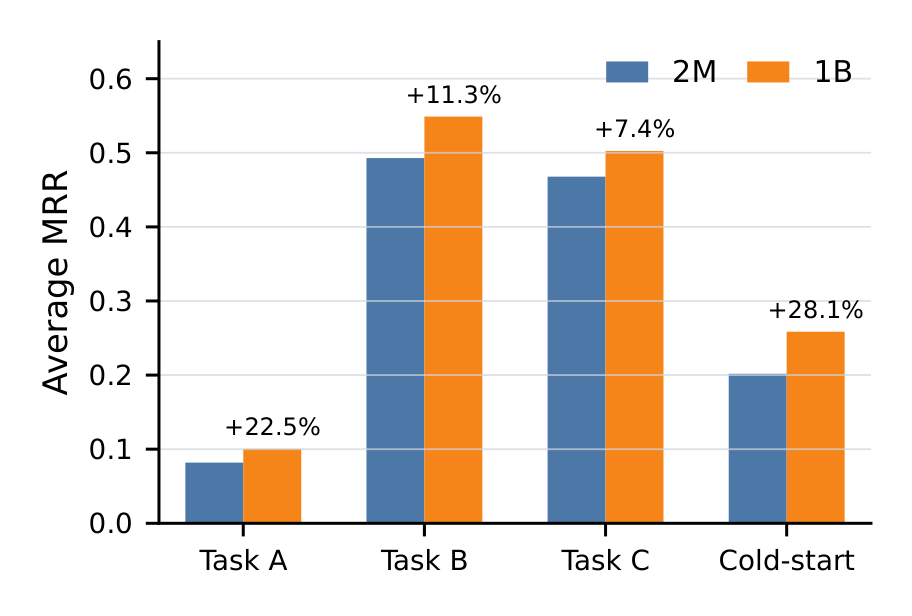
Figure 7 对比 1B 骨干与 2M 骨干基线(均排除 embedding 与 decoding 层)在 1M 用户 shadow 流量上的表现:
| 切片 | 相对 MRR 增益(1B vs 2M) |
|---|---|
| Task A | +22.5% |
| Task B | +11.3% |
| Task C | +7.4% |
| Cold-start | +28.1% |
结论分析:
- 冷启动标题增益最大(+28.1%),支撑了第 6 节的语义塔设计——当 ID 证据稀疏时,语义元数据确实在打分中起决定作用。
- Task C 增益最小(+7.4%),与 scaling-law 分析一致:Task C 已贴近天花板($P_0 = 1.075$),剩余空间小,加容量收益自然小。
- Task A 增益第二大(+22.5%),虽然它在 Figure 1 中 $P_0 = 0.311$ 已近经验天花板——这里要区分:Figure 1 的天花板是"在当前数据 / 目标下加骨干容量的极限",而 shadow 评估里 1B 模型还叠加了 MTP + 语义塔等改动对长视野稀疏任务的帮助,因此整体仍有可观提升。
作者把这些结果解读为"1B 骨干在下游集成中良好传导"的广泛 shadow 证据。与该 shadow 评估一致,模型的下游集成也在多个生产 A/B 测试中产生了正向结果。
核心贡献总结¶
- 任务相关的 offset scaling law 作为生产诊断工具:用 $P(N) = P_0 - (N/N_0)^{-a}$ 拟合有界 MRR,$P_0$ 直接读出"剩余空间",在三个任务上比 log-linear 形式降低 14.9%–61.8% 的拟合 RMSE。把 scaling-law 从"展示规模有用"升级为"判断下一步该投容量 / 目标 / 表征"的决策工具。
- 刻意简单的高效解码配方:1% 均匀采样 softmax(无 LogQ 校正)+ 共享投影 d/8 头(4096→512),在 $10^6$ 输出下解析估计削减 35.5× FLOPs、$10^7$ 下约 249×,让十亿参数模型可被反复重训。
- MTP 对齐缓存服务的标签错配:用带时间衰减权重的未来高价值目标集合做监督,同一解码头单次打分。48 小时缓存路径下五 token 窗口带来 +22.1% / +27.8% / +27.9%;同时诚实指出在线顺序敏感任务上 MTP 会反伤 B/C。
- 语义物品塔 + 协同 embedding 掩码做冷启动:成熟标题用协同 ID,冷启动标题用 OOV embedding + 图 / 语言(LLM2Vec)/ 标注语义证据,训练时按线上冷启动率随机掩码 ID,迫使同一解码器学会"无 ID 也能打分"。shadow 评估冷启动 +28.1%。
- 诚实的工业案例方法论:把"模型规模"明确降格为生产迁移问题的一个变量,与任务剩余空间、解码成本、服务延迟对齐、物品泛化并列;用 small-to-large 漏斗控制验证成本;用 1M 用户 / 一周 shadow 评估组合系统。
与已归档相关工作的对比¶
HSTU HSTU: Actions Speak Louder than Words(Meta, 2024-02)¶
关系:显式引用([21]),原文 §2/§3 在 scaling-law 函数形式层面对比、但未做模型级 head-to-head · 已加载对方精读
- 共同关注的问题:两者都研究"生成式推荐器的质量能否随规模可预测地提升"。HSTU 首次在推荐中展示类语言模型的幂律缩放,跨三个数量级训练计算量、最大扩到 1.5 万亿参数,所有主要指标(HR@100/500、NE)随训练计算量幂律缩放;本文把缩放研究从"骨干视角"推进到"哪些下游任务还有剩余空间"。
- 相近的技术骨架:都把生成式推荐建模为序列转导 + 自回归 next-token,都用受控缩放实验去拟合性能-规模曲线。本文复用了 HSTU 确立的"生成式推荐可缩放"前提作为出发点。
- 本文的差异与推进:HSTU 用 log-linear 形式 $P = a\log(N) + b$ 表达单调改进;本文论证推荐指标(如 MRR)有界,改用 offset 幂律 $P_0 - (N/N_0)^{-a}$ 显式建模饱和天花板,并在 Table 2 报告 offset 在三任务上 RMSE 降低 48.4% / 61.8% / 14.9%。关键观念差异:HSTU 强调"规模一直涨",本文强调"规模不均匀地涨、有的任务已近天花板"——因此 scaling-law 在本文是决策工具而非存在性证明。
- 可比的方法 / 实验差异:HSTU 的核心贡献是 HSTU 注意力层 + M-FALCON 推理 + 工程内核(把缩放当架构能力的副产品来展示);本文骨干刻意用 vanilla transformer、不引入新注意力结构,把创新放在生产传导(效率 / MTP / 冷启动)上。两者是"架构-缩放"与"缩放-传导"的互补视角。结构化对比已登记入 DAG(本文 offset law vs HSTU log law)。
FLUID FLUID: From Ephemeral IDs to Multimodal Semantic Codes(TikTok / ByteDance, 2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者在"冷启动物品表征"模块上殊途同归)· 已加载对方精读
- 共同关注的问题:两者指向同一 root cause——在生产推荐器中,协同 / ID-based 物品 embedding 对新 / 短命物品不可靠,因为这些物品没有足够时间窗累积交互让 ID embedding 收敛。Netflix 说"新上线标题缺乏可靠协同 ID embedding";FLUID 用 Figure 1 量化"直播间中位生命周期仅 40 分钟,ID embedding 范数在其生命周期内只到稳态的 72%"。问题陈述实质同构。
- 相近的技术骨架:两者都从内容 / 多模态信号派生物品表征去替代 / 补充弱 ID,并设计一个让解码器 / 排序器学会"不依赖 ID 也能打分"的训练机制。Netflix:多模态语义塔(图 + LLM2Vec 语言 + 标注)产 $z_i$,与 ID-or-OOV 融合成 $v_i$;FLUID:跨域 SigLIP2 + Qwen3 编码器经 RQ-KMeans 产分层语义码 LUCID,prefix-n-gram 转 embedding,late-fuse 进排序器。抽象流程图重合:[内容编码 → 物品语义向量 → 与 ID 融合 → 训练时弱化 / 退役 ID]。
- 本文的差异与推进:对 ID 的态度不同。Netflix 是"保留成熟标题的协同 ID + 随机掩码成 OOV(掩码率对齐线上冷启动率),训练同一解码器同时处理两个 regime"——ID 仍是一等公民,只是被概率性地抹掉以逼出语义依赖。FLUID 更激进:完全退役候选侧 item ID,用分阶段 warmup(先加 LUCID,再 phase-out item ID),论证"当 ID 易逝时 ID-dominance 从可容忍麻烦升级为根本瓶颈"。另一差异:FLUID 强调离散化(RQ-KMeans 而非 RQ-VAE,避免在线流式重训下码本坍塌) 与 slice/room 双粒度;Netflix 用连续语义 embedding,不做离散码,且语义源更偏知识图谱 + 编辑标注(平台有人工标签资产)。
- 可比的方法 / 实验差异:Netflix 报告 shadow 冷启动 +28.1% MRR(1B vs 2M);FLUID 报告线上 +2.05% Cold-Start Room Views、+0.55% Quality Watch Duration。两者都在十亿级用户的生产系统上验证,但 Netflix 测的是 shadow 离线 MRR、FLUID 是线上 A/B 业务指标,不可直接数值比较。共同 insight:冷启动不是靠加容量解决的,而要换物品表征通道——这也呼应 Netflix"靠缩放无法解决冷启动"的明确论断。
被剔除的近似候选(问题相似但解法路径不同构,不入选):
- ULTRA-HSTU(Meta, 2602.16986):同样关注"生成式推荐器的生产级效率",但解法是注意力 / 拓扑 / 混合精度系统协同优化(5× 训练 / 21× 推理),Netflix 是输出层侧采样 softmax + 投影头。同向(效率)不同路(attention/system vs decoding-layer)。
- STCA(ByteDance, 2511.06077):同样观测推荐中"scaling-law-like 增益",但路径是长序列(500→10k)+ 外推,Netflix 是骨干参数缩放 + 任务剩余空间诊断 + 服务侧补丁。缩放方向相同、缩放轴与方法骨架不同。
- IDProxy(Xiaohongshu, 2603.01590):同样用多模态内容为冷启动物品造表征,但目标是把 proxy ID embedding 注入既有 CTR 排序器,而非在生成式解码器内做 ID/OOV 掩码;与 FLUID 在冷启动维度上重叠,取生产骨架更贴近的 FLUID。
- GrowthGR(Taobao, 2605.17994):同样针对生成式检索的新物品冷启动,但解法是 counterfactual ItemLTV + MultiGR 多值 GRPO 奖励整形(RL 路径),与 Netflix 的语义塔 + 掩码(表征路径)不同构。
讨论与局限性¶
值得借鉴的设计:
- 把 scaling-law 当决策工具而非论文卖点。offset 幂律的 $P_0$ 给了一个可读的"剩余空间"标量,直接回答"这个任务再加容量值不值"。对任何要决定"下一笔算力投哪"的工业团队,这个诊断框架的迁移价值高于具体数值。
- MTP 只改监督、不改服务路径。用同一解码头单次打分,把"缓存服务标签错配 + 目标集合化"两个问题用一个带时间衰减权重的多标签损失一并解决,且诚实标注了"在线顺序敏感任务会反伤"的适用边界——这种"按服务视野选择目标函数"的工程纪律很实用。
- 冷启动用掩码对齐线上分布。把掩码概率对齐实测线上冷启动率,让训练分布匹配服务分布,是个简单但常被忽略的对齐技巧。
局限与争议:
- 匿名化导致不可复现 / 不可校准。Task A/B/C 是匿名任务类别,MRR 是相对值,FLOPs 削减是解析估计而非端到端测量,生产 shadow 用"相对增益"而非绝对数。这让论文的工程 insight 可借鉴,但外部无法验证或横向对标。
- 效率配方刻意简单,可能不是 Pareto 最优。1% 均匀采样 + 不做 LogQ 校正,作者自己承认把校正采样留作正交方向;与 Cut Cross-Entropy 等精确内存高效核相比,这套配方在偏差 / 方差上的代价没有量化。
- MTP 的负面效应未被根治。在线服务下 MTP 随窗口增长降低 Task B/C,论文给的是"按任务选择"而非统一解法——意味着生产中需要按任务 / 服务视野切换目标函数,增加了系统复杂度。
- scaling 只到 1B、只一种骨干。缩放上限 1B(不含 embedding/decoding),且未探索架构变体(对比 HSTU 扩到 1.5T、引入新注意力层),offset 拟合的外推可靠性在 1B 之外未被验证。
- Task A 在 shadow 评估中的 +22.5% 与 Figure 1 的"近天花板"存在张力:scaling-law 说 Task A 加容量空间小,shadow 却给出第二大增益,论文未完全拆解这部分增益里"骨干容量 vs MTP/语义塔"各自的贡献,组件归因不够干净。
工业落地价值:这是一篇典型的"生产传导"案例研究——它的价值不在单点 SOTA,而在把一个被反复重训的十亿参数生成式推荐骨干变成可运营产物的完整工程清单:用 scaling-law 决定投资方向、用输出层削减撑起重训节奏、用 MTP 对齐缓存服务、用语义塔接住冷启动,最后用 1M 用户 shadow + 多个 A/B 验证传导。对正在把生成式推荐从"离线 demo"推向"在线生产"的团队,这套"规模只是变量之一"的方法论比任何单个技巧都更有参考价值。