UniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale¶
研究动机与背景¶
现代工业推荐系统几乎都是多阶段漏斗(multi-stage funnel):候选生成(candidate generation / retrieval)从百万级语料里召回数千个 item,排序(ranking)用更丰富的特征给这些候选打分,最后由 blending 拼装出整页结果。每个阶段都用各自独立的架构、目标函数、训练数据孤立训练。这种分割带来一个根本性的代价:检索与排序都在从同一份用户行为数据里学表征,却无法共享参数、也无法跨阶段迁移学到的信号。
随着 transformer 序列模型成为每个阶段的主导骨干,这种冗余变得更加尖锐。当检索与排序都由大 transformer 编码同一段用户行为历史时,重复就成了低效的首要来源:参数重复、训练算力重复、serving 成本重复。这就形成了一个明确的机会——把两个阶段统一进一个模型,对用户只编码一次,让两个阶段共享同一份表征,并实现信号共享:排序的监督可以指导检索,而检索对更广语料的暴露可以正则化排序。
作者把这个目标称为全栈统一(full-stack unification):不只是共享模型架构,而是共享整条流水线——输入格式、训练、serving 基础设施。

为什么全栈统一很难? 论文指出三个挑战阻碍了前人工作:
- 使用方式分歧(Usage divergence):尽管骨干网络收敛了,二者的计算范式仍然迥异。检索必须在毫秒级延迟下给数百万候选打分(靠 ANN 点积),而排序只给数百个候选打分,可以承担更昂贵的逐候选计算(如 cross-attention)。
- 训练复杂度(Training complexity):检索与排序目标不同——检索是对全语料的 sampled softmax,排序是对小 impression 集合的二分类。已有关于 next-action 预测的工作暗示两者可能互补,但现有统一流水线为了调和它们不得不退化为多阶段流水线(预训练、微调、RL 对齐),这种复杂度本身就阻碍了全栈统一。
- serving 与运维挑战:统一模型必须以比分开部署更低的成本运行才值得切换;还需要保持与现有候选生成器(关键词、trending 等)的可组合性,保留决定统一程度的灵活性,并能对每个阶段独立 A/B 测试和回滚。这些挑战基本未被探索,极少有系统在生产中部署过统一的检索-排序模型。
为什么现有方法不够?(见 Figure 1)作者把现有工作归为两个方向:
- 统一架构方向:HSTU 用共享 transformer 范式,但检索(非交错)和排序(交错)需要不同的输入格式,因此两个阶段仍然独立训练、无法共享计算。OnePiece 加了统一多任务训练,但只部署为检索或排序之一,从未用一个统一模型同时服务两个阶段。这些方法共享了架构,但离全栈统一仍很远。
- 端到端生成式方向:OneRec、OneRanker 通过自回归解码 semantic ID 产生候选,从构造上实现了统一。但替换掉整个生产漏斗使得与现有候选源的组合更难,也丧失了对每个阶段的运维控制。
本文的设计原则:组合现有的、经过验证的组件(ANN 索引、cross-attention 排序、KV 缓存),而不引入新机制,让统一模型成为现有生产基础设施里的 drop-in 替换。统一不只是优雅的目标——一个独立的排序器会重复检索已经在做的昂贵的用户历史编码;通过共享这份计算,UniPinRec 以边际成本加上了排序,使得在与"仅检索"相同的延迟预算内做排序成为可能。
UniPinRec 用三个设计选择实现这一点:(1) Masked Action Modeling(MAM) 把排序监督加到检索所用的同一条非交错用户序列上;(2) 混合训练样本(blended training examples) + 联合损失在单阶段内同时训练检索与排序;(3) 跨阶段 KV-cache 共享 让排序复用检索算好的用户历史计算,避免重复的 transformer 工作。三者合起来即:两个阶段同一格式、单阶段联合训练、部署在现有 serving 基础设施内。
结果概览:统一模型在加上排序能力的同时,保持了检索召回并降低了 serving 成本。离线上,UniPinRec 把排序 Hit@3 相比生产排序器提升 +14.8%,同时匹配生产检索召回。增量上线方案从 L0 侧开始:先把检索 + L1 轻量排序作为单一服务(L0+L1)上线,再把 L2 精排作为后续扩展,保持下游 ranker/blender 不变、尽早获得干净的 A/B 归因。尽管离线排序提升会被下游 ranker/blender 衰减,线上仍取得一致的互动收益:Board More Ideas 的 saves +0.95%、Notifications 的 push opens +0.91%。serving 上,跨阶段 KV-cache 复用带来 >3× 的总排序前向加速(Table 2),生产中 e2e 延迟降低 11.1%、QPS 提升 63.6%(Table 3)。这是已知首个全栈统一检索与排序、覆盖输入/模型/训练/serving 并部署在生产推荐系统中的工作。
核心方法 / 模型架构¶
3.0.1 背景:PinRec¶
UniPinRec 建立在 PinRec(一个生成式检索模型)之上。每个 item 由预训练的 item 嵌入(Omnisage)和 CLIP 视觉多模态嵌入表示,搜索 query 用预训练的搜索嵌入。这些特征经一个 MLP 投影成 $L_2$-归一化的嵌入。给定用户对正向交互 item 的历史 $H(u, t_{max})$,PinRec 把这段嵌入序列喂入一个因果 decoder-only transformer,用对 in-batch 与随机负样本的 sampled softmax 损失训练:
$$\mathcal{L}_s(\hat{i}_{u,t}, i_{u,t+1}) = -\log \frac{\exp\big(s(\hat{i}_{u,t}, i_{u,t+1})\big)}{\exp\big(s(\hat{i}_{u,t}, i_{u,t+1})\big) + \sum_{i_n \in N} \exp\big(s(\hat{i}_{u,t}, i_n)\big)} \tag{1}$$
其中 $s(\hat{i}_{u,t}, i_c) = \lambda \cdot \hat{i}_{u,t}^\top i_c - \log Q(i_c)$ 是频率校正的相似度,$Q(i_c)$ 是候选 $i_c$ 的估计采样概率(用 count-min sketch 估算),$N$ 是负样本集合。模型对历史中所有位置上的 $\mathcal{L}_s$ 取平均后最小化。直观上,$-\log Q(i_c)$ 项校正了高频 item 在 in-batch 负采样中被过度采样导致的偏差。
3.1 把 PinRec 改造成排序模型¶
把 PinRec 扩展到排序需要三处改动:
- 目标(Objective):不再最大化全语料上的 next-item 似然,而是对一个小 impression 集合预测逐候选的动作概率。
- 目标标签(Targets):监督从"对 item 嵌入做 softmax"切换为"对每种动作类型 $c \in \{1,\dots,C\}$(click、save、hide 等)的二分类标签",用 per-head 二元交叉熵训练。
- 数据(Data):训练样本必须包含 impression 负样本(曝光了但没被交互的 item),而不仅是正向交互(详见 §3.2)。
3.1.1 Masked Action Modeling(MAM)¶
核心问题是:如何把动作预测表述成一个序列学习问题,使排序目标能够共享检索的骨干。HSTU 的做法是在 item 之间交错插入动作 token以保证动作预测是 candidate-aware 的,但这会让上下文长度翻倍,并破坏与检索的输入格式兼容性。
作者提出 Masked Action Modeling(MAM):动作沿特征维度与每个 item 嵌入拼接,并在训练时随机 mask(模型在预测一个动作之前看不到它,保留因果性),不膨胀序列长度。类似的 mask-and-predict 思路在 feed impression 场景中出现过 [16],但作者是首个把动作监督直接施加到检索所用的用户序列骨干上的工作。这在同一次前向中实现了排序,同时通过更密集的逐位置梯度提升了检索质量。
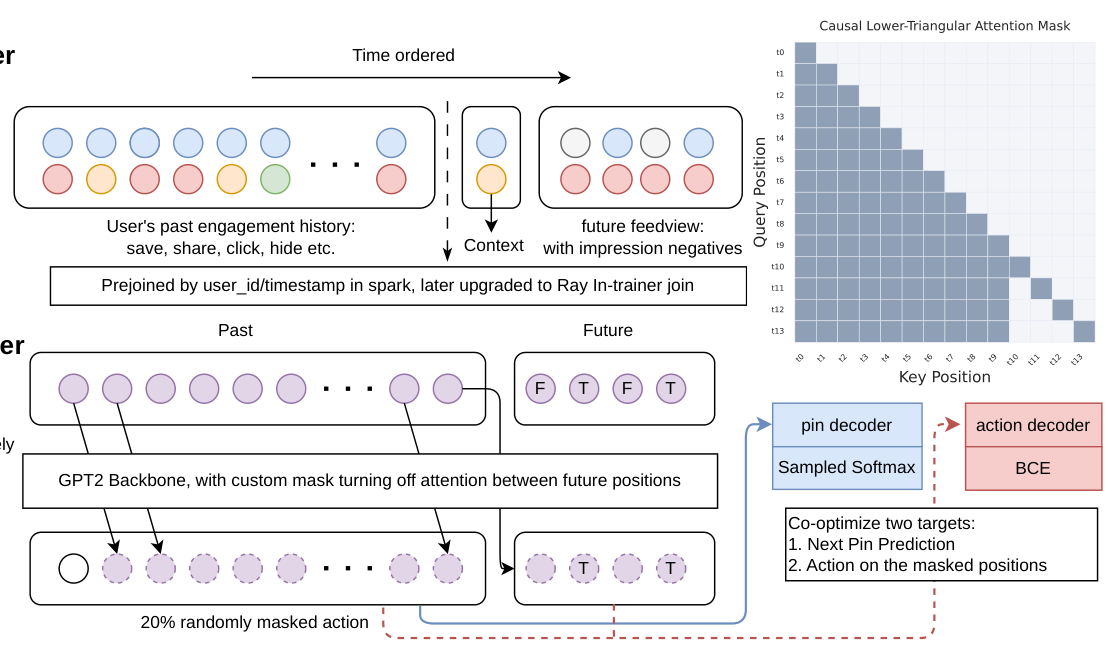
(1) 输入表示。不在每个 item 后交错一个专用动作 token,而是把动作 one-hot 向量 $a_i$ 经一个线性层编码成稠密嵌入,沿特征轴与 item 嵌入拼接,再送入 input projector。projector 把拼接后的表示映射到 transformer 隐藏维度。
(2) Masking schedule。对用户已观测历史(past)中的每个位置,动作以概率 $p_{mask}$ 被独立 mask。对候选(future)位置,动作始终被 mask($m_j = 0$ for all $j$),因为推理时候选上的动作未知。当一个位置被 mask 时,它的动作类型输入被替换为专用的 [MASK] 类(在动作词表上追加一个额外的 one-hot 维度),使模型能区分"动作未知"与"没有动作"。输入 mask($m_i = 0$)把 $a_i$ 替换为 [MASK] token,因果注意力把位置 $i$ 限制在 $\{0,\dots,i\}$,从而隐藏态满足:
$$z_i = f_\theta\big(\hat{\Phi}_i, \{\hat{\Phi}_t\}_{t<i}\big), \quad \hat{\Phi}_i \perp\!\!\!\perp a_i \ \text{ when } m_i = 0, \tag{2}$$
保证 $h_{\psi_c}(z_i)$ 只依赖 $\Phi_i$ 和 $\{(\Phi_t, m_t \odot a_t)\}_{t<i}$——即被 mask 位置的动作信息不会泄露给对它自身的预测。
(3) 注意力模式。transformer 处理拼接序列 $[\hat{\Phi}_1,\dots,\hat{\Phi}_n \,|\, \hat{\Phi}'_1,\dots,\hat{\Phi}'_k]$,采用一个改造过的因果 mask(Figure 2 右上),遵循 [32] 的 M-FALCON 模式:past 位置保留标准因果注意力;每个候选位置 $n+j$ 注意到所有 past 位置 $1,\dots,n$,但被禁止注意其它候选。所有候选位置共享固定的 position ID、feedview 类型和时间戳,以保证打分无偏。由于候选之间互不注意,该 mask 把注意力成本从 $O((n+k)^2)$ 降到 $O(n^2 + nk)$;作者用 flex attention [14] 把这个块稀疏模式编译成融合的 CUDA kernel。这一模式也使跨阶段的 KV-cache 共享成为可能(§3.3.3):检索缓存 $O(n^2)$ 的历史计算,排序以 $O(nk)$ 复用它。
(4) 训练目标。序列的 past 部分 $\hat{\Phi}_1,\dots,\hat{\Phi}_n$ 保持与检索模型输入相同的长度和位置结构,事实上就被用于检索:同样的 next-item 预测目标施加在这些位置上。$k$ 个候选 item $\hat{\Phi}'_1,\dots,\hat{\Phi}'_k$ 被追加在 past 之后,整条序列单次前向处理。这实现了与检索模型的完整参数共享,并用两个联合优化的损失训练:
(a) Next-item 预测损失(检索目标):与 §3.0.1 的 sampled-softmax 损失相同,施加在每个未被 mask 的 past 位置上:
$$\mathcal{L}_{item} = \frac{1}{|H|} \sum_{t \in H} \mathcal{L}_s(\hat{i}_{u,t}, i_{u,t+1}) \tag{3}$$
(b) 动作预测损失(排序目标):在每个动作被 mask 的位置,模型必须独立预测每种动作类型。对每种动作类型 $c \in \{1,\dots,C\}$,一个专用 MLP head $h_{\psi_c}$ 产生一个标量 logit,per-head 权重 $w_c$ 控制其贡献。past(被 mask)位置和 future(始终 mask)位置分别有独立的损失项:
$$\mathcal{L}_{action} = \sum_{c=1}^{C} w_c \left[ \frac{1}{|\mathcal{M}_{past}|} \sum_{i \in \mathcal{M}_{past}} \ell_{BCE}\big(h_{\psi_c}(z_i), a_i^{(c)}\big) + \frac{1}{k} \sum_{j=1}^{k} \ell_{BCE}\big(h_{\psi_c}(z'_j), a_j'^{(c)}\big) \right] \tag{4}$$
其中 $C$ 是动作类型数,$z_i$ 是位置 $i$ 的 transformer 隐藏态,$h_{\psi_c}$ 是动作类型 $c$ 的 MLP head,$a_i^{(c)}$ 是位置 $i$ 上动作 $c$ 的二分类标签,$\mathcal{M}_{past} = \{i : m_i = 0\}$ 是被 mask 的 past 位置集合,$w_c$ 是超参数调出来的标量权重,用于平衡各动作类型(save、click、hide)之间以及相对 next-item 预测损失的贡献。
总损失为两项之和:
$$\mathcal{L} = \mathcal{L}_{item} + \mathcal{L}_{action} \tag{5}$$
(5) 相比交错(interleaving)的关键优势:
- (a) 不膨胀上下文长度:序列长度与检索模型完全一致。
- (b) 完整权重共享:排序模型可以直接从检索 checkpoint 初始化。
- (c) 去噪正则化:随机 mask 鼓励模型在动作不可用时依赖 item 内容,提升推理时的泛化能力。
章节路线图¶
论文随后逐一解决 §3.1 引入的挑战:§3.1 用 MAM 和联合损失解决架构与训练分歧;§3.2 描述使大规模联合训练可行的数据基础设施;§3.3 用跨请求 KV-cache 共享解决 serving 与运维挑战。
数据基础设施(§3.2)¶
联合训练引入了单任务模型没有的数据需求:每个训练样本必须同时包含用户的交互历史(用于检索目标)和带负反馈的完整 impression slate(用于动作预测目标)。现有检索数据集和排序数据集都不能同时满足这两个约束。构造这种统一格式的大规模数据是全栈统一的前提条件。
3.2.1 以 feedview 为中心的数据集构造¶
检索模型通常在仅含动作的序列(按时间排序的交互)上训练,排序模型则在 impression 日志(展示给用户的完整 slate,含交互和无动作两类结果)上训练。前人统一模型工作没讨论过如何构造同时满足两个目标的数据;而联合训练两者都需要:检索目标需要正向动作历史来预测 next item,排序目标需要完整 impression slate 来学习。
作者的桥接做法是:用一个 past 动作序列配对一个 future feedview(来自后续请求的完整 impression slate,带交互标签)来构造每个训练样本。序列中每个位置是一个 (Pin, surface, action, timestamp) 四元组,其中 action 跨越模型要预测的整个交互词表(仅曝光 impression-only、click、save、share、hide 等)。
由于交互事件相对 impression 天然稀疏,训练流水线对未交互的 feedview 子采样(保留 10%)以放大稀有交互类别。评估流水线不做任何下采样,用一个随机化的 replay 数据集,保留自然的无偏分布——这也通过反映真实流量分布而使检索受益。
3.2.2 Ray in-trainer join¶
为消除离线 join 中用户动作历史 fanout 带来的开销,作者用 Ray 分布式 dataloading 层做 in-trainer bucket join。用户动作序列和 feedview 记录作为两张独立的 Iceberg 表维护,各自按 user ID 做 hash 分桶,在训练时在内存里 join。这彻底避免了数据重复,并把上下文长度、采样比例、过滤条件变成训练时可调的参数,而非数据生成时就固化的参数。
Serving 基础设施(§3.3)¶
一个统一模型只有在能替换两个独立模型而不让 serving 成本翻倍时才能兑现效率收益。两个性质让这件事可行:第一,非交错架构 + 统一联训(§3.1.1)保证两阶段用相同的模型权重并产生 candidate-independent 的用户表征,可以缓存一次、跨阶段复用;第二,检索和排序共享相同的 item 嵌入空间,因此无需维护单独的候选表征。
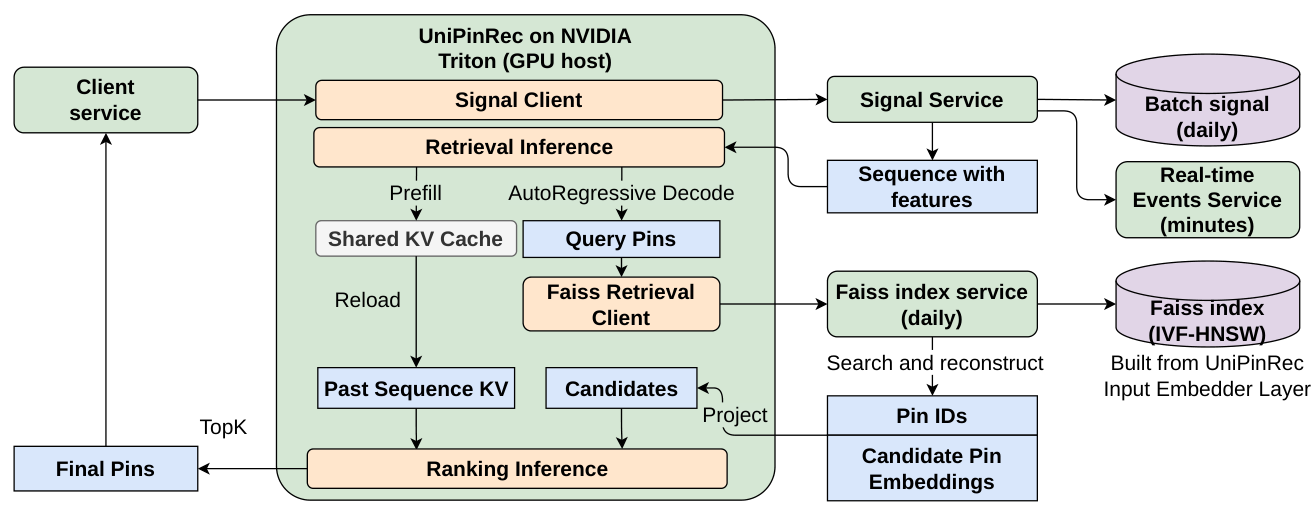
3.3.1 背景与 3.3.2 整体 serving 设计¶
作者建立在生产 PinRec serving 栈之上——它用一个 Triton ensemble 装配用户历史、跑自回归检索、并通过 CPU 托管的 Faiss 索引做 ANN lookup。UniPinRec 保留这套栈的大部分,在 Faiss 下游挂上一个新的排序节点。该排序节点消费 ANN 的候选集合以及一个 KV-cache slot 标识符(§3.3.3)。它不重新处理整段用户历史,而是跑一个增量前向:只处理候选 token,注意力回看 KV cache 历史,产出逐候选的动作概率。
ANN 索引里已经存了每个 Pin 的嵌入向量(embedder MLP 在建索引时算好的输出)。作者用 Faiss.search_and_reconstruct,一次调用同时返回候选 Pin ID 和它们存储的嵌入。这些预嵌入向量直接作为排序阶段的候选 token,省掉了候选侧额外的 embedder 前向和特征获取,也保证了检索和排序两阶段用完全相同的表征。
3.3.3 跨阶段 KV-cache 共享¶
transformer 中的主导成本是编码用户动作历史($n$ 个 token,$O(n^2)$ 的 self-attention);给定该历史给 $k$ 个候选打分只有 $O(nk)$。作者在排序时彻底避免 $O(n^2)$ 成本:把 PinRec 的 per-request KV cache(§3.1.1)扩展到跨阶段、跨进程——排序直接注意到缓存的历史 KV 而不重新编码它。进一步遵循 M-FALCON 的 identity-mask 设计,使每个候选的分数与 batch 组成无关。净排序成本为 $O(nk)$。
检索和排序运行在独立的 OS 进程上,各有独立的 CUDA context(微服务 serving 栈的典型形态)。朴素地把 KV tensor 跨进程序列化会引入 GPU-host-GPU 往返,主导延迟。作者改为预分配一个 GPU 显存池,两个进程都把它映射进各自的地址空间,使检索写入的 KV 状态可被排序读取,无需 CPU↔GPU 数据传输。
具体地,预先按形状 $[L, S, H, n, D]$(层数、slot 数、KV head 数、past 序列长度、head 维度)分配 GPU 池,在启动时把它存储的 CUDA IPC handle 导出到一个 per-instance 文件;排序进程打开这些 handle,把同一块物理 GPU 分配映射进自己的地址空间。slot 以 round-robin 复用,每个排序消费者在前向时把本请求的 past KV 从它在映射池里的 slot 拷进自己的 decode cache。
3.3.4 FP8 量化¶
为进一步提升 serving 效率,作者用混合精度 FP8 训练与推理。用 Transformer Engine 库的融合模块把 layer normalization、线性投影、激活合进单个 kernel,避免中间全精度物化。训练用混合 FP8 格式:前向用 E4M3、反向用 E5M2,使前向激活和反向梯度都在精度和动态范围之间取得合适平衡。量化代价是离线指标下降 0.5%,作者认为这是换取效率收益可接受的折中。
实验设置¶
实验围绕三个研究问题组织:
- RQ1:能否训练一个同时胜任检索和排序的统一模型?
- RQ2:能否协同 serving 检索和排序以实现最小的计算冗余?
- RQ3:能否让这个统一模型成为对现有生产推荐系统的简单扩展?
Baseline 与训练策略(§4.1):
- TransAct V2 + DCNv2:当前生产排序模型,带长用户序列和特征交叉模块的 transformer-based 模型。
- HSTU:SOTA 的统一检索-排序模型,用动作-item 交错。作者在统一交错范式、匹配等效序列长度下评估它的检索和排序任务。
- PinRec:生产检索模型,12 层 transformer,用 next-item 预测(sampled softmax)训练;只服务检索、无排序能力。
- PinRec finetuned:顺序训练——取上面的 PinRec snapshot,通过加动作预测损失微调出排序能力。关键约束:item embedder 在微调时必须冻结,以保持与预训练检索模型 Faiss 索引的部署兼容性。
- UniPinRec w/o item loss:仅用动作预测损失训练的排序-only 变体,用与统一模型相同的 MAM 架构。该消融通过去掉检索目标来隔离联合训练的效果。
- UniPinRec(ours):带 MAM 的统一模型,检索和排序用相同的非交错序列格式,用 next-item 预测(检索)+ 动作预测(排序)两个损失联合训练。item embedder 可训练,从两个目标同时受益。
主要实验结果¶
4.1 训练统一的检索与排序模型(RQ1)¶
Table 1:统一联合训练 vs 分离的预训练/微调。两种方法都用相同的 12 层 MAM 骨干。两列在不同评估数据集上:Hit@3 衡量排序、Recall@10 衡量检索。加粗为最佳。
| Strategy | Hit@3 ↑ | Recall@10 ↑ |
|---|---|---|
| TransActV2 + DCNv2 | 0.088008 | N/A |
| HSTU | 0.097326 | 0.76161 |
| PinRec | N/A | 0.77486 |
| PinRec finetuned | 0.095869 | N/A |
| UniPinRec w/o item loss | 0.097345 | N/A |
| UniPinRec (ours) | 0.10096 | 0.77659 |
结果分析:
- 检索侧:UniPinRec 匹配了 PinRec 的 Recall@10(0.77659 vs 0.77486,+0.2% 边际提升),表明与排序目标联合训练不会损害检索质量。这对部署至关重要——统一模型可作为生产检索系统的 drop-in 替换。
- 排序侧:UniPinRec 以 14.7% 的优势超过当代生产排序模型 TransActV2+DCNv2(0.10096 vs 0.088008),尽管它在单一模型里同时处理检索和排序、而后者带专门的特征交叉模块。UniPinRec 也在相同上下文长度预算下超过 HSTU(0.10096 vs 0.097326)。
- 联合训练的价值:UniPinRec 超过排序-only 变体(w/o item loss,0.10096 vs 0.097345),说明联合的检索目标进一步提升了排序质量——这正是 §1 所说的"检索对更广语料的暴露正则化排序"。
- 架构兼容 ≠ 充分:PinRec finetuned(0.095869)尽管从强检索模型出发却表现欠佳。冻结 embedder 的约束阻止模型为排序适配 item 表征,而联合训练让 embedder 同时从两个任务学习。这个 gap 证明:仅有架构兼容性不够,必须联合优化才能充分利用统一训练。
4.2 协同 serving 检索与排序模型(RQ2)¶
统一骨干只有在不作为两个不相交模型 serving 时才能宣称效率胜利。排序前向中的主导计算是对用户历史的 self-attention;当检索和排序分开 serving 时,这份成本每个请求要付两次。统一设计在检索时编码历史一次,把得到的 keys/values 复用为后续排序的 KV cache,把排序从一次完整的 prefill 变成一次从候选注意到冻结历史的 decode 步。
Table 2:单次排序前向的 eval-time 延迟。加速比相对 bf16/SDPA/compile 的 prefill 行。测试设备 NVIDIA L40S($B=8$, $n=992$, $k=656$, $L=12$)。"Runtime" 控制前向如何 dispatch:eager、torch.compile 或 CUDA graph capture。fp8 decode 用 graph 是因为 torch.compile 的 fusion 会回退 Transformer Engine kernel。加粗为最佳,* 表示用于线上实验。
| Dtype | Attn | Runtime | Lat. (ms) ↓ | Speedup ↑ |
|---|---|---|---|---|
| Prefill(重新计算历史) | ||||
| bf16 | SDPA | compile | 25.72 | 1.00× |
| bf16 | flex | compile | 19.70 | 1.31× |
| fp8 | SDPA | eager | 18.92 | 1.36× |
| fp8 | SDPA | compile | 18.91 | 1.36× |
| Decode(KV-cache 复用,含 GPU memcpy 开销) | ||||
| bf16 | SDPA | compile | 10.42 | 2.47× |
| bf16 | flex | compile* | 8.57 | 3.00× |
| fp8 | SDPA | graph | 8.77 | 2.93× |
| fp8 | flex | graph | 6.56 | 3.92× |
作者拆解三个正交杠杆:
- KV-cache 复用(prefill→decode):约 ~2.4×(10.42 vs 25.72,对应同为 bf16/SDPA/compile)。
- fp8 + Transformer Engine matmul + CUDA graph capture:在 bf16+compile 基础上约 ~1.25×。
- flex attention:在任意 dtype 之上稳定贡献约 ~1.3×。
- 三个杠杆大致正交,叠加得到最大 端到端 3.92×(Table 2 右下角格)。
Table 3:受控 GPU 活动/预算下的线上 serving 收益。Baseline 检索和排序都用 (bf16, SDPA, torch.compile),所有数字是相对该联合 baseline 的百分比变化。* 表示用于 §5 线上实验。
| Variant | E2E latency ↓ | QPS lift ↑ |
|---|---|---|
| baseline | — | — |
| + bf16 decode flex compile* | −11.1% | +63.6% |
| + fp8 decode flex graph | +6.7% | +109.1% |
结果分析:作者观察到 fp8 kernel 的一个权衡——为满足 Transformer Engine 对扁平化 leading 维度 $[B*S, D]$ 必须是 8 的倍数的形状约束,需要等待并累积请求凑出更大的 batch;这主要约束了检索前向(自回归步 $S=1$)的吞吐,导致 QPS 提升(+109.1%)但延迟反而增加(+6.7%)。因此线上实验用的是 bf16(−11.1% 延迟、+63.6% QPS),fp8 作为下一步计划。
消融与分析¶
4.3.1 MAM 中 masking 比例的影响¶
MAM 的核心设计选择是 masking 概率 $p_{mask}$,它控制训练时用户序列中历史动作被随机 mask 的频率。作者在相同数据和超参数下、固定所有其它架构决策,训练 $p_{mask} \in \{0, 0.1, 0.2, 0.3\}$ 的变体。
Table 4:MAM 中动作 masking 比例 $p_{mask}$ 的影响。加粗为最佳。
| $p_{mask}$ | Hit@3 ↑ |
|---|---|
| 0.0(不 mask) | 0.09923 |
| 0.1 | 0.10078 |
| 0.2 | 0.10096 |
| 0.3 | 0.10075 |
结果分析:任何 masking 都优于不 masking——零 mask baseline 的 Hit@3 最低,确认额外的动作预测信号和正则化两者都贡献了更好的排序,$p_{mask}=0.2$ 达到最佳。更高的 masking(0.3)出现收益递减,很可能是因为过度激进的 mask 从用户历史中移除了太多信号。
4.3.2 模型 scaling 的影响¶
作者研究模型容量沿两个维度对排序性能的影响:transformer 深度和序列长度。训练变体:深度 (2, 4, 8, 12, 24 层) 固定序列长度 1024 token;序列长度 (256, 512, 1024, 2048 token) 固定 12 层。两个维度都用 MAM、$p_{mask}=0.2$。
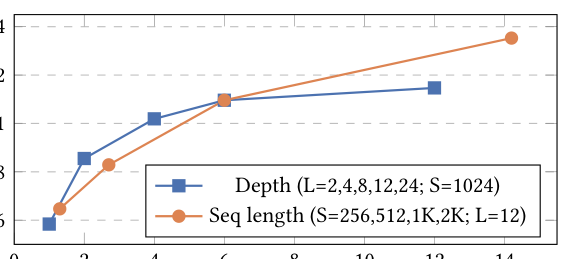
结果分析:性能沿两个 scaling 轴一致提升,表明统一模型尚未在容量上饱和。但成本含义差别显著:深度随计算线性增长,而序列长度对注意力是二次成本。这使得序列长度成为延迟敏感应用中更严峻的瓶颈——尽管两个维度都持续改进质量。来自更长序列的强劲收益暗示序列压缩技术是一个很有前景的方向(用更低成本捕获更长上下文的质量收益)。
在线 A/B 实验(RQ3)¶
5.1 实验设置¶
作者在生产中通过受控 A/B 实验评估 UniPinRec,与生产检索 baseline PinRec 对比。两种候选生成器配置都返回 $K\,(<3000)$ 个候选给下游:
- Baseline (PinRec):生产检索模型经 ANN 搜索生成 $K$ 个候选,直接送下游排序。
- UniPinRec:统一模型先经 ANN 搜索过量召回候选(L0),再立即用排序 head(L1)配合动作预测对它们排序,返回 top $K$(基于 head utility 函数)给下游。
值得注意的是,线上实验中作者替换检索阶段为统一的 L0+L1 打分服务器,仍把精修后的候选送给基于 TransAct V2 的下游生产排序器,以严格验证指标提升。这意味着离线提升在线上会被衰减和稀释。实验在两个生产 surface 上跑:Board More Ideas(L0 过召回比 ~2x)和 Notification(L0 过召回比 ~3x),两者每天服务数百万用户。
5.2 Board More Ideas¶
Board More Ideas(BMI)推荐锚定到用户 board 的 Pin。为支持它,作者把 UniPinRec 扩展到支持 "Board" 作为一种新序列模态(超出 Pin 和搜索 query)。
Table 5:Board More Ideas 上的线上 A/B 结果(UniPinRec L0+L1 vs PinRec baseline)。
| Metric | UniPinRec |
|---|---|
| BMI surface saves | +0.95% |
| Site-wide saves | +0.08% |
结果分析:BMI surface saves +0.95% 的强互动提升表明统一检索-排序相比仅检索显著改善了候选质量,同时还带动 +0.08% 的站点级 saves——更好的 BMI 推荐对整体平台互动有正向影响。
5.3 Notifications¶
Pinterest 用 email 和 push 通知投递相关内容;通知是用户激活和长期留存的重要杠杆。
Table 6:通知上的线上 A/B 结果(UniPinRec vs PinRec baseline,按 unique-user 衡量)。
| Metric | UniPinRec |
|---|---|
| Push opens | +0.91% |
| Push opens(dormant users) | +1.72% |
| Notification surface saves | +3.84% |
| Email clicks | +0.30% |
| Weekly active users | +0.09% |
结果分析:用 UniPinRec 排序器替换仅检索的 PinRec baseline,在所有通知互动指标上带来一致增益,notification surface saves 提升最大(+3.84%)。沉睡用户的 push-open 提升 +1.72%,约为全体用户提升的两倍,说明更个性化的通知推荐对召回流失用户尤其有效,并显著改善 WAU(+0.09%)。
核心贡献总结¶
- 首个全栈统一检索与排序并部署在生产中的工作:不只统一架构,而是统一 input format、model、training、serving 四个维度,作为现有生产基础设施的 drop-in 替换。
- Masked Action Modeling(MAM):把动作沿特征维拼接并随机 mask,不交错、不膨胀序列长度,第一个把动作监督直接施加到检索骨干上的方法;带来不膨胀上下文、完整权重共享、去噪正则化三重优势。
- 混合训练样本 + 单阶段联合损失:用 (Pin, surface, action, timestamp) 四元组桥接"动作序列"和"impression slate"两类数据,配合 Ray in-trainer join 在训练时联结两张 Iceberg 表,使大规模联合训练可行。
- 跨阶段、跨进程 KV-cache 共享:用预分配 GPU 显存池 + CUDA IPC handle 实现零 CPU↔GPU 拷贝的 KV 复用,把排序成本从 $O(n^2)$ 降到 $O(nk)$,端到端 3.92× 加速。
- 生产验证:离线排序 +14.8%、匹配检索召回;线上 BMI saves +0.95%、通知 push opens +0.91%、e2e 延迟 −11.1%、QPS +63.6%。
与已归档相关工作的对比¶
HSTU HSTU: Generative Recommenders(Meta, 2024-02)¶
关系:显式引用,原文 §3.1.1 + Table 1 已对比 · 未加载对方精读
HSTU 是本文最直接的架构对照物,也是 Table 1 的统一检索-排序 baseline。两者共享"用单一 transformer 骨干同时承载检索与排序"的目标,关键分歧在于如何把动作监督注入序列:HSTU 在 item 之间交错插入动作 token 以保证候选-感知,代价是上下文长度翻倍、且检索(非交错)与排序(交错)的输入格式不兼容,导致两阶段实际仍独立训练、无法共享计算;UniPinRec 的 MAM 把动作沿特征维拼接 + 随机 mask,序列长度与检索完全一致,从而允许完整权重共享和跨阶段 KV-cache 复用。原文报告:相同上下文预算下 UniPinRec 排序 Hit@3 0.10096 对比 HSTU 0.097326、检索 Recall@10 0.77659 对比 0.76161,均胜出。HSTU 的 M-FALCON 注意力模式(候选 identity-mask、共享 position ID)被 UniPinRec 直接借用来实现无偏打分和 KV 复用。详细精读见 HSTU。
DIG DIG: Discrimination Is Generation(Meituan, 2026-05-14)¶
关系:独立并发(本文未引用 DIG,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直击"检索与排序作为两个独立模型重复学同一份用户/交互信号"的结构性冗余,并都主张用一个模型同时承载检索和排序、让排序的判别信号反哺检索。DIG 甚至与本文共享同一句洞察——"排序与检索是同一优化问题在不同粒度上的两面"(DIG:item 空间 $\arg\max_v f(u,v)$ vs token 空间 $\arg\max_{(s_1,\dots,s_L)} g$;UniPinRec:同一骨干分叉出 ANN 点积与 cross-attention 两个 head)。
- 相近的技术骨架:都靠联合训练让排序目标改善检索质量(DIG 用排序 BCE 直接驱动 SID codebook 构造;UniPinRec 用动作 BCE + next-item softmax 联训共享 embedder),都强调单次训练得到两个能力。
- 本文的差异与推进(殊途同归的分叉点):检索的底层基质完全相反。DIG 拥抱生成式 SID / beam-search 检索,核心创新是 feature assignment taxonomy 和 SID-embedding 解耦,让判别梯度流回 codebook;UniPinRec 则明确反对生成式 SID(认为其 lossy compression、生成目标低效、冷启动失败),坚持 dense embedding + ANN 点积检索,把"统一"落在共享 transformer 骨干和 KV-cache 复用上。可以说两者从同一问题出发,分别押注了"生成式"与"判别/稠密式"两条统一路线。
- 可比的方法/实验差异:DIG 在公开数据集报告 +52%~+220% R@10(相对 SID baseline)并同时提升排序 AUC;UniPinRec 在 Pinterest 生产报告匹配检索召回 + 排序 +14.8% + 线上互动收益。DIG 的卖点在离线公开 benchmark 的检索-排序双赢,UniPinRec 的卖点在生产部署的全栈统一 + serving 效率(3.92× / −11.1% 延迟)。
ResRank ResRank: Unifying Retrieval and Listwise Reranking(Alibaba Qwen, 2026-04-24)¶
关系:独立并发(本文未引用 ResRank,跨域殊途同归)· 已加载对方精读
- 共同关注的问题:ResRank 在信息检索(IR)域提出与本文同构的问题——把检索器和重排器统一进端到端联训的一套体系,消除两阶段独立训练带来的表征割裂和流水线复杂度;并都把"是否要用自回归生成"作为关键设计抉择。
- 相近的技术骨架:两者的方法流程图高度可抽象重合——(1) 用稠密 embedding 做第一阶段检索(ResRank 的 Encoder-LLM 余弦 / UniPinRec 的 ANN 点积),(2) 用更富的 attention 做重排/精排(ResRank 的 Reranker-LLM causal self-attention 让候选互相感知 / UniPinRec 的 cross-attention head),(3) 端到端联合多任务损失(ResRank:InfoNCE 保检索 + RankNet 学排序;UniPinRec:next-item softmax + 动作 BCE),(4) 都刻意杀掉自回归解码以换取吞吐(ResRank 生成 token 从 O(n) 降到 0;UniPinRec 用 MAM 非交错避免 interleaving、并把排序变成 decode 步)。
- 本文的差异与推进:统一的粒度和单位不同。ResRank 仍是两个 LLM(Encoder + Reranker),靠 residual 把压缩 embedding 加回 reranker hidden state、靠同源同尺寸省掉 projector;UniPinRec 是真正单一骨干、单次前向,靠跨进程 KV-cache 共享让排序复用检索算好的用户历史。ResRank 的"被压缩对象"是候选段落(passage→1 embedding),UniPinRec 的"被复用对象"是用户历史的 KV。此外 ResRank 在公开 IR benchmark(TREC DL / BEIR)验证、近 GPT-4 效果且零生成 token,UniPinRec 在工业推荐生产验证全栈统一与 serving 效率。两篇在不同领域独立得出"稠密 + 联训 + 去自回归"优于"生成式"的相同判断。详见 ResRank。
讨论与局限性¶
核心贡献与值得借鉴的设计。UniPinRec 最大的价值在于证明了"全栈统一"——不只是统一模型架构(前人已做),而是连 input format、training pipeline、serving infra 都统一——在生产规模下今天就可行。MAM 是其中最优雅的一招:用"沿特征维拼接动作 + 随机 mask"这一个简单改动,同时解决了三件事(不膨胀序列、可从检索 checkpoint 初始化、去噪正则),且天然兼容 KV-cache 复用。跨进程 GPU 显存池 + CUDA IPC handle 的 KV 共享是一个非常实用的工程贡献,对任何"多微服务进程想共享 transformer KV"的场景都有借鉴意义。
局限与争议: 1. 只统一了上半漏斗。UniPinRec 当前统一的是检索 + upper-funnel(L0+L1 轻量)排序——backbone 冗余在这里最严重;它尚未替换 L2 精排(L2 有额外的 score calibration、训练数据 logging、运维工具依赖)。因此线上是"统一 L0+L1 + 下游仍接 TransAct V2 L2 ranker"的折中部署,离线排序提升被显著衰减。 2. 线上提升幅度有限。受下游 ranker/blender 稀释,线上互动收益是 +0.9% 量级(BMI saves +0.95%、push opens +0.91%),相比离线 +14.8% 有明显落差——这是统一上半漏斗而非全漏斗的必然代价。 3. fp8 尚未上线。fp8 虽能进一步 +109% QPS,但因 Transformer Engine 的 batch 形状约束(leading dim 须为 8 的倍数)导致延迟反升 +6.7%,线上仍用 bf16,fp8 列为下一步。 4. 序列长度是 scaling 瓶颈。Figure 4 显示质量沿深度和序列长度都未饱和,但序列长度是二次成本,长序列收益强烈暗示需要序列压缩技术——这是未解的方向。
与 RAG 的类比(作者的前瞻):架构上 UniPinRec 镜像了 retrieval-augmented generation——骨干 formulate 一个 query,ANN 索引充当非参数记忆,排序器在同一份缓存上下文上生成动作概率。作者建议借鉴 RAG 文献的 iterative retrieval 和 learned retrieval-depth control 作为未来方向。下一步计划是把统一扩展到 L2 精排,并横向扩展到 Search、Ads 等更多 surface。
工业落地价值:作为已知首个全栈统一检索-排序的生产部署,UniPinRec 给出了一条非常具体的增量上线路径(先 L0+L1 单服务、保持下游不变拿干净 A/B 归因,再扩 L2),加上可直接复用的 serving 工程(Faiss search_and_reconstruct 省嵌入获取、跨进程 KV 池、flex attention 块稀疏 kernel),对任何已有 PinRec/HSTU 式生成式检索栈的团队都有很高的可迁移性。