ResRank: Unifying Retrieval and Listwise Reranking via End-to-End Joint Training with Residual Passage Compression¶
一、研究动机与背景¶
1.1 LLM 列表式重排器的工业落地瓶颈¶
现代信息检索(IR)系统通常采用多阶段流水线:先用轻量第一阶段检索器(BM25 等)从大规模语料中召回候选段落,再交给更精细的重排器对排序进行精修。随着大语言模型(LLM)的兴起,基于 LLM 的列表式重排(listwise reranking) 成为 SOTA 范式:模型同时接收 query 和数十至上百个候选段落,直接输出一个排列(permutation),效果显著优于传统 cross-encoder。
但要把 LLM 列表式重排器部署到真实搜索引擎,工业界面临两大瓶颈:
- 输入侧 — "lost in the middle" 与超长上下文。把数十至上百个候选段落的全文拼接为单条 prompt,序列长度极易超过万 token。研究表明 LLM 对长上下文中部信息利用能力显著下降(Liu 等 2024),直接损伤排序质量。工业界常用 sliding window 缓解此问题:每次只看 w 个段落,多次推理后聚合,但这等于把单次推理放大成多次,延迟与候选数线性相关。
- 输出侧 — 自回归解码生成 permutation。listwise 重排器要逐 token 生成段落 ID 序列,约 n 到 4.5n 个输出 token(n 为候选数);即便用 constrained decoding 把输出空间限制在段落 ID 上,自回归本身的串行性仍是延迟瓶颈。
近期沿不同方向的缓解工作各有局限:
- 长上下文 LLM full-list ranking(Liu 等 2024)用一次前向覆盖全部候选,但 self-attention 的二次复杂度仍然限制了规模化。
- CompLLM(Berton 等 2025)做 segment-wise soft compression,但只是把输入压短,没碰生成瓶颈。
- PE-Rank(Liu 等 WWW 2025)借鉴多模态 LLM(LLaVA 类)的思路,把每个 passage 用一个独立的 retrieval encoder 压成单 embedding,再投影进 reranker 输入空间——但训练过程是 解耦两阶段:先训 projector 做表征对齐,再训 reranker 做排序,这增加了流水线复杂度,且输出仍依赖 dynamic-constrained decoding 自回归生成 permutation,限制了吞吐。
- C2R(Zhi 等 AAAI 2026)扩展为多向量 surrogate 并端到端微调 compressor 和 reranker,但仍保留 autoregressive generation 与 sliding window 推理,效率收益受限。
- E2Rank(Liu 等 arXiv 2510.22733)把 listwise prompt 重新解释为伪相关反馈 query,用 embedding-空间余弦替代 AR decoding——但推理时仍需把所有 top-K 候选段落的 完整文本 输入模型来构造 enriched query,输入长度问题没解决。
1.2 ResRank 的整体定位¶
ResRank(Alibaba Qwen Applications Business Group)针对上述两个瓶颈给出一站式端到端解法。三大核心创新:
- Residual passage compression(残差段落压缩):用一个 Encoder-LLM 把每段独立压成单个 dense embedding,直接 喂入 Reranker-LLM 的 input embedding 空间(不需要 projection 模块),并通过残差连接把原始 encoder embedding 加回 reranker hidden state,缓解压缩导致的信息损失。
- Cosine similarity-based scoring(余弦相似度打分):把 [EOS] 位置的 reranker 隐藏态作为 global aggregation embedding,和每个 fused passage embedding 做单步 cosine similarity 得到分数。生成 token 数从 O(n) 降到 0。
- Dual-stage、multi-task、end-to-end joint training:encoder 和 reranker 从一开始就一起训,loss = λ × InfoNCE(保留 encoder 的检索能力)+ RankNet(让 reranker 的排序对齐 cross-passage 信号),且采用粗-细两阶段 SFT。
实验在 TREC DL 19/20 与 BEIR 八个 OOD 数据集(Covid, NFCorpus, Touche, DBPedia, SciFact, Signal, News, Robust)上展开。在单次前向(single-pass)模式下,ResRank 平均 nDCG@10 = 0.5440 (BEIR),超越 PE-Rank(0.4843,>5 绝对点)和所有 distillation-trained 基线,并接近 GPT-4 驱动的 RankGPT-4(0.5368);同时 每段处理 token = 1,生成 token = 0。当配合 BM25 做 reciprocal rank fusion (RRF) 时,ResRank+BM25 在 TREC DL19 上达到 0.7821,DL20 达到 0.7499,全面 SOTA。
二、核心方法 / 模型架构¶
2.1 系统总览¶
记 query 为 $q$,候选段落集合为 $\mathcal{D} = \{d_1, d_2, \ldots, d_n\}$,ResRank 的推理分三步:
- 段落压缩:Encoder-LLM 独立把每个 $d_i$ 压成一个 embedding $\mathbf{e}_i$。
- 列表式重排:Reranker-LLM 接收 query 文本与 $\{\mathbf{e}_1, \ldots, \mathbf{e}_n\}$ 拼接的输入,通过 causal attention 让所有候选互相感知,输出每个 passage 位置的 contextualized hidden state $\mathbf{h}_i^p$,并经残差融合得 fused passage embedding $\mathbf{r}_i$。
- 余弦打分:取 [EOS] 位置 hidden state $\mathbf{h}_{\text{eos}}$ 作为 global aggregation embedding,对每个 $\mathbf{r}_i$ 算 cosine 相似度,按降序排即得到最终排名。整个过程零自回归 token、两次前向(一次 encoder、一次 reranker)。
整体架构如图 1 所示:
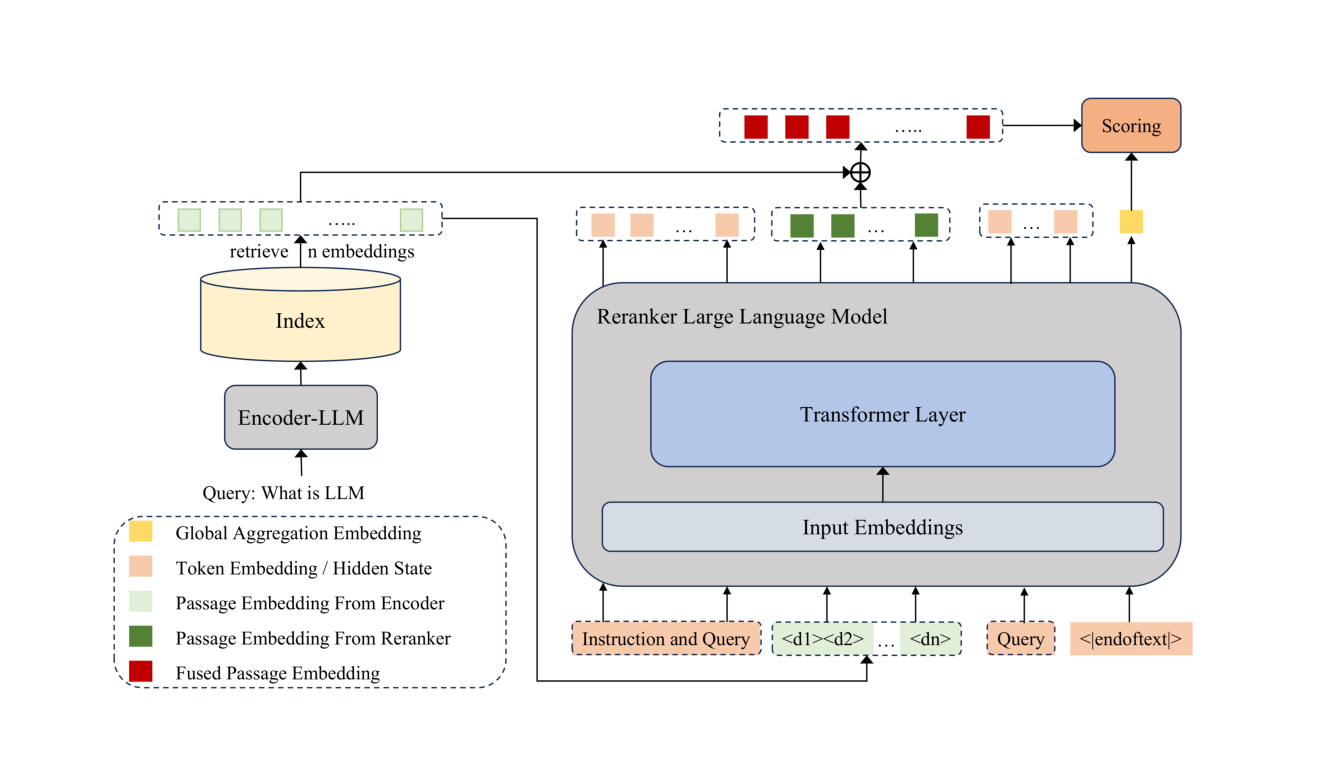
2.2 Encoder-LLM 段落压缩¶
设第 $i$ 个段落 token 序列为 $d_i = (w_1^i, w_2^i, \ldots, w_{L_i}^i)$,长度 $L_i$。Encoder-LLM $f_{\text{enc}}$ 独立处理每段,提取一个 $d$ 维 embedding:
$$\mathbf{e}_i = f_{\text{enc}}(d_i) \in \mathbb{R}^d \tag{1}$$
这个 embedding 把整段语义压缩进单个表示,per-passage token 数从 $L_i$ 降到 1(≥两个数量级压缩)。
Encoder 的选择至关重要:encoder embedding 质量直接决定了下游 reranker 能用到的信息上限。论文采用 Qwen3-Embedding-4B(Qwen 团队 2025),SOTA 文本 embedding 模型,且与 Reranker-LLM 同源同尺寸同 hidden dim(Qwen3-4B),这一关键设计意味着 encoder 输出的 embedding 可 直接 注入 reranker 的输入层,完全不需要中间 projector 或 alignment 模块——这是相对 PE-Rank(必须用 projection 层桥接异质表示空间)的关键架构简化。
2.3 Residual-Enhanced Listwise Reranker¶
Encoder 输出的 passage embedding 被当作特殊输入 token,与文本指令、query 拼接成 reranker 输入:
$$\mathbf{X} = [\mathbf{t}_{\text{inst}}; \mathbf{t}_q; \mathbf{e}_1, \mathbf{e}_2, \ldots, \mathbf{e}_n; \mathbf{t}_q'; \mathbf{t}_{\text{eos}}] \tag{2}$$
其中 $\mathbf{t}_{\text{inst}}$ 与 $\mathbf{t}_q$ 是 instruction 与 query 的 token embedding,$\mathbf{t}_q'$ 是 passage embeddings 后的额外 query anchor,$\mathbf{t}_{\text{eos}}$ 是 EOS token。Reranker $f_{\text{rer}}$ 通过 causal self-attention 处理:
$$\mathbf{H} = f_{\text{rer}}(\mathbf{X}) = [\ldots; \mathbf{h}_1^p, \ldots, \mathbf{h}_n^p; \ldots; \mathbf{h}_{\text{eos}}] \tag{3}$$
其中 $\mathbf{h}_i^p \in \mathbb{R}^d$ 是第 $i$ 个 passage embedding 位置的隐藏态。由于 causal attention 的因果性,$\mathbf{h}_i^p$ 已经包含来自 instruction、query 与所有更早 passage 的 cross-passage 交互信号(这是原始 encoder embedding $\mathbf{e}_i$ 没有的)。
残差连接:把整段语义压成单 embedding 必然丢失部分信息;而且在训练初期 reranker 与 encoder 的对齐尚未稳定,单靠 reranker 的 hidden state 作为 passage 表示有学习困难。论文引入残差结构:
$$\mathbf{r}_i = \mathbf{h}_i^p + \mathbf{e}_i \tag{4}$$
$\mathbf{e}_i$ 保留了原始 passage 级语义,$\mathbf{h}_i^p$ 补充 cross-passage 上下文信号;二者相加既给反向传播提供 gradient shortcut,也降低优化难度。这一设计在消融实验中被证实是 ResRank 性能的关键支柱(见 §6.2)。
2.4 Cosine-Similarity-Based Scoring¶
传统 listwise 重排器要 AR 解码 ~n 到 4.5n 个 token(即便用 constrained decoding,串行性也无法避免)。ResRank 直接把生成阶段去掉:
$$s(q, d_i) = \frac{\mathbf{h}_{\text{eos}}^\top \mathbf{r}_i}{\|\mathbf{h}_{\text{eos}}\| \cdot \|\mathbf{r}_i\|} \tag{5}$$
[EOS] 位置已经 attended 全部 instruction、query 与 passage 信号,是 global aggregation embedding,封装了整个排序问题的全局上下文;与每个 fused passage embedding $\mathbf{r}_i$ 算余弦相似度即得分数。最终排序仅按 $s(q, d_i)$ 降序排序即可。
生成 token 数 = 0,把"逐 token 生成排列"变成"一次并行向量比较"。整个推理流水线只需两次前向(encoder 一次、reranker 一次),无任何自回归循环。
2.5 Multi-Task 训练目标¶
Encoder 端:标准 InfoNCE 对比学习(保留 encoder 的检索能力)。对训练 query $q_i$,有正样本 $d_i^+$ 和负样本集 $D^-$,batch 大小 $N$:
$$\mathcal{L}_{\text{InfoNCE}} = -\frac{1}{N}\sum_{i=1}^{N}\log\frac{e^{s_{\text{enc}}(q_i, d_i^+)/\tau_1}}{e^{s_{\text{enc}}(q_i, d_i^+)/\tau_1} + \sum_{d_j \in D^-} e^{s_{\text{enc}}(q_i, d_j)/\tau_1}} \tag{6}$$
其中 $\tau_1 = 0.05$,$s_{\text{enc}}$ 为 encoder 端 query/document embedding 的 cosine 相似度。
Reranker 端:RankNet pairwise ranking loss(对所有 inversion 对惩罚)。记融合表示对 query 的得分 $S(q_i, d_j) = \cos(\mathbf{r}_j, \mathbf{h}_{\text{eos}})$,文档相关性序为 $r_j$(小者更相关),$D$ 包含正负样本:
$$\mathcal{L}_{\text{RankNet}} = \frac{1}{N}\sum_{i=1}^{N}\sum_{\substack{d_j, d_k \in D \\ r_j < r_k}} \log\left(1 + e^{(S(q_i, d_k) - S(q_i, d_j))/\tau_2}\right) \tag{7}$$
其中 $\tau_2 = 0.05$ 缩放相似度,indicator $r_j < r_k$ 确保只对应当 $d_j$ 排在 $d_k$ 之前的对计算损失。
联合目标:
$$\mathcal{L} = \lambda \mathcal{L}_{\text{InfoNCE}} + \mathcal{L}_{\text{RankNet}}, \quad \lambda = 0.1 \tag{8}$$
权重 $\lambda = 0.1$ 让 reranker 损失主导优化方向,但 InfoNCE 的存在确保 encoder 不退化为 reranker 内部表示——后者会让 encoder 失去独立检索能力,无法在端到端流水线中扮演第一阶段检索器。这一设计动机在消融 §6.2 中得到验证:去掉 InfoNCE 后排序指标几乎不变,但 encoder 的 standalone retrieval 能力崩溃。
2.6 Dual-Stage SFT 训练¶
两阶段监督微调,从粗粒度对齐过渡到细粒度排序精修:
- Stage 1(Coarse-grained alignment):用 232,419 条来自 PE-Rank 的样本(经 Qwen3-Max 重新标注),让模型学到从 passage embedding 到排序行为的基本映射。第一阶段 1 个 epoch,effective batch size 128,学习率 $6\times 10^{-6}$。
- Stage 2(Fine-grained refinement):用约 87,000 条高质量样本(来自 E2Rank,经 Qwen3-Max 重标注),每条包含 1 个 query、1 个正样本、15 个负样本,提供细粒度对比信号。第二阶段 1 个 epoch,超参与 stage 1 一致。
两阶段都优化式 (8) 的联合 loss——这保证 encoder 的 retrieval capability 在整个训练过程中始终被维护,避免 stage 2 把 encoder 跑偏。
2.7 End-to-End Joint Optimization¶
与 PE-Rank 的"先训 projector 做表征对齐、再训 reranker 做排序"的解耦流程不同,ResRank 从训练开始就 同时 全参数微调 Encoder-LLM 与 Reranker-LLM。设计动机有二:
- 解耦训练限制 encoder 输出空间:单独训出的 passage embedding 未必适合下游 reranker 任务,joint training 让 encoder 根据 reranker 的反馈信号自适应调整表征。
- 协同适应:encoder 持续根据 reranker 反馈进化,而 reranker 也学会更好地利用 encoder 不断变化的输出,形成两个模块互相塑形的 synergy。
实现上:Reranker = Qwen3-4B(强 instruction-following),Encoder = Qwen3-Embedding-4B;FlashAttention 加速、DeepSpeed ZeRO-2 分布式训练。
三、关键技术细节¶
3.1 输入构造模板¶
Reranker 的输入(式 2)按顺序拼接:
[Instruction tokens][Query tokens][<d1><d2>...<dn>][Query tokens (anchor)][<|endoftext|>]
<di>是 placeholder token,被替换为 encoder 输出的 $\mathbf{e}_i$ 向量(直接注入 input embedding 空间)- 末尾追加的 query anchor 让 reranker 在每个 passage embedding 之后再次 "看到" query,强化 query-passage 关联
<|endoftext|>即 EOS,其 hidden state 作为 global aggregation embedding
3.2 Sliding-window 与 single-pass 两种推理模式¶
为公平对比基线,论文同时报告:
- ResRank:single-pass 模式,所有候选一次性输入 reranker——为 真实工业部署目标配置
- ResRank_sw:sliding window 模式(与 RankGPT、RankZephyr 等基线一致的评测协议)——纯做对比用
论文明确强调"in practical industrial search engines, sliding window 会导致 multiplicative latency overhead,部署难度大;除非显式标注 sliding window,所有其他实验都用 single-pass"。
3.3 与 PE-Rank 的架构差异¶
| 维度 | PE-Rank | ResRank |
|---|---|---|
| Encoder 与 Reranker 关系 | 异构(embedding model + reranker LLM),需 projector 桥接 | 同源(Qwen3-Embedding-4B + Qwen3-4B),同 hidden dim,无需 projector |
| 训练流程 | 两阶段:先训 projector 对齐表征,再训 reranker 排序(解耦) | 端到端 joint training,dual-stage SFT 一致优化 |
| 残差连接 | 无 | 有,$\mathbf{r}_i = \mathbf{h}_i^p + \mathbf{e}_i$ |
| 输出形式 | dynamic-constrained AR decoding(生成 ~180 tokens) | cosine similarity(生成 0 token) |
| Multi-task loss | 仅 ranking loss | RankNet + InfoNCE,保护 encoder retrieval 能力 |
四、实验设置¶
4.1 数据集与评估¶
- In-domain:TREC Deep Learning 2019 (DL19) 与 2020 (DL20) test set
- Out-of-domain:BEIR 八个数据集 — Covid, NFCorpus, Touche, DBPedia, SciFact, Signal, News, Robust
- 所有方法重排 BM25 检索的 top-100 候选
- 主指标:nDCG@10(与该领域标准做法一致)
4.2 训练数据¶
- Stage 1:232,419 条样本(源自 PE-Rank),用 Qwen3-Max 重新标注以保证一致高质量相关性判断
- Stage 2:约 87,000 条高质量样本(源自 E2Rank),同样 Qwen3-Max 重标注;每条 = 1 query + 1 正样本 + 15 负样本
- 标注 prompt 在 Appendix A 给出(图 5、6),让 Qwen3-Max 同时输出 ranking permutation 和 4 级 relevance label(0=Irrelevant, 1=Slightly Relevant, 2=Relevant, 3=Highly Relevant)
4.3 Baselines¶
四类基线:
| 类别 | 模型 |
|---|---|
| Cross-encoders(监督训练) | monoBERT, monoT5 |
| Zero-shot LLM 重排器 | RankGPT-3.5, RankGPT-4, TourRank |
| Full-text fine-tuned LLM 重排器 | ListT5, RankVicuna, RankZephyr, RankMistral |
| Compressed-token fine-tuned LLM 重排器 | PE-Rank |
ResRank 同时报告 single-pass(默认部署配置)与 ResRank_sw(sliding window,便于公平对比)两条结果。
五、主要实验结果¶
5.1 BEIR Out-of-Domain 评估(Table I)¶
| Model | Ret. | Covid | NFCorpus | Touche | DBPedia | SciFact | Signal | News | Robust | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| BM25 | – | 0.5947 | 0.3375 | 0.4422 | 0.3180 | 0.6789 | 0.3305 | 0.3952 | 0.4070 | 0.4380 |
| Supervised (human annotations) | ||||||||||
| monoBERT | BM25 | 0.7001 | 0.3688 | 0.3175 | 0.4187 | 0.7136 | 0.3144 | 0.4462 | 0.4935 | 0.4716 |
| monoT5 | BM25 | 0.8071 | 0.3897 | 0.3241 | 0.4445 | 0.7657 | 0.3255 | 0.4849 | 0.5671 | 0.5136 |
| Unsupervised LLM listwise | ||||||||||
| RankGPT-3.5 | 3×BM25 | 0.7667 | 0.3562 | 0.3618 | 0.4447 | 0.7043 | 0.3212 | 0.4885 | 0.5062 | 0.4937 |
| RankGPT-4 | 3×BM25 | 0.8551 | 0.3847 | 0.3857 | 0.4712 | 0.7495 | 0.3440 | 0.5289 | 0.5755 | 0.5368 |
| TourRank | 3×BM25 | 0.8259 | 0.3799 | 0.2998 | 0.4464 | 0.7217 | 0.3083 | 0.5146 | 0.5787 | 0.5094 |
| LLM listwise distillation-trained | ||||||||||
| RankMistral | 6×BM25 | 0.7800 | 0.3310 | 0.2746 | 0.3771 | 0.6622 | 0.3004 | 0.3710 | 0.3954 | 0.4365 |
| ListT5-base | 6×BM25 | 0.7830 | 0.3560 | 0.3340 | 0.4370 | 0.7410 | 0.3350 | 0.4850 | 0.5210 | 0.5090 |
| ListT5-3B | 6×BM25 | 0.8470 | 0.3770 | 0.3360 | 0.4620 | 0.7700 | 0.3380 | 0.5320 | 0.5780 | 0.5300 |
| PE-Rank | 6×BM25 | 0.7772 | 0.3639 | 0.3306 | 0.4005 | 0.6938 | 0.3374 | 0.4970 | 0.4740 | 0.4843 |
| ResRank | 6×BM25 | 0.8409 | 0.3973 | 0.3948 | 0.4583 | 0.7642 | 0.3527 | 0.5485 | 0.5964 | 0.5440 |
| ResRank_sw | 6×BM25 | 0.8500 | 0.3994 | 0.3994 | 0.4547 | 0.7696 | 0.3337 | 0.5332 | 0.6182 | 0.5448 |
关键发现:
- distillation 类内全胜:ResRank 平均 0.5440 显著超越所有 distillation-trained 基线,比同样基于 compressed-token 的 PE-Rank 高出 >5 绝对点——直接验证残差结构 + 余弦打分 + 端到端联合训练三件套的累积收益。
- single-pass 模式逼近 GPT-4:ResRank single-pass(0.5440)已超过 RankGPT-3.5(0.4937)和 TourRank(0.5094),逼近基于最强商用 LLM 的 RankGPT-4(0.5368),并在 Signal、News 等数据集上拿到该榜全场最优。
- sliding window 拉满 effectiveness:ResRank_sw 平均 0.5448 取得跨基线全场最高,并在 NFCorpus、Robust 等数据集摘下榜首——但论文反复强调这只是为公平对比留作参考,实际部署应当用 single-pass。
5.2 TREC DL In-Domain 评估(Table II)¶
| Model | Ret. | DL19 | DL20 |
|---|---|---|---|
| BM25 | – | 0.5058 | 0.4796 |
| Supervised (human annotations) | |||
| monoBERT | 2×BM25 | 0.7050 | 0.6728 |
| monoT5 | 2×BM25 | 0.7183 | 0.6889 |
| Unsupervised LLM listwise | |||
| RankGPT-3.5 | 3×BM25 | 0.6580 | 0.6291 |
| RankGPT-4 | 3×BM25 | 0.7559 | 0.7056 |
| TourRank | 3×BM25 | 0.7163 | 0.6956 |
| LLM listwise distillation | |||
| RankVicuna | 8×BM25 | 0.6682 | 0.6549 |
| RankZephyr | 8×BM25 | 0.7420 | 0.7086 |
| RankMistral | 8×BM25 | 0.7173 | 0.6807 |
| ListT5-base | 8×BM25 | 0.7180 | 0.6810 |
| ListT5-3B | 8×BM25 | 0.7180 | 0.6910 |
| PE-Rank | 8×BM25 | 0.7048 | 0.6354 |
| ResRank | 8×BM25 | 0.7359 | 0.6865 |
| ResRank_sw | 8×BM25 | 0.7457 | 0.6906 |
关键发现:
- ResRank single-pass 在 DL19 和 DL20 都显著超越 PE-Rank(DL19: 0.7359 vs 0.7048,DL20: 0.6865 vs 0.6354),证明改进在 in-domain 同样成立。
- ResRank_sw 在 DL19 拿到 0.7457,仅次于 RankGPT-4;在 DL20 上与 ListT5-3B 持平——它运行的是 single-token compressed representation,却能与基于 full-passage 的 distilled reranker 匹敌,是根本不同的效率范式。
5.3 端到端检索-重排(Table III)¶
ResRank 的 multi-task 设计的一个独特优势是 encoder 本身可作为第一阶段检索器,整套系统形成统一 pipeline。
| Model | Ret. | Covid | NFCorpus | Touche | DBPedia | SciFact | Signal | News | Robust | BEIR Avg. | DL19 | DL20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResRank | BM25 | 0.8409 | 0.3973 | 0.3948 | 0.4583 | 0.7642 | 0.3527 | 0.5485 | 0.5964 | 0.5440 | 0.7359 | 0.6865 |
| ResRank | ResRank | 0.8643 | 0.4313 | 0.3245 | 0.4885 | 0.7941 | 0.2773 | 0.4113 | 0.6626 | 0.5317 | 0.7634 | 0.7462 |
| ResRank | ResRank+BM25 | 0.8839 | 0.4342 | 0.3626 | 0.5038 | 0.7809 | 0.3094 | 0.4698 | 0.6771 | 0.5527 | 0.7821 | 0.7499 |
关键发现:
- ResRank 自身做 retriever 在 TREC DL 大幅胜过 BM25 retriever(DL19: 0.7634 vs 0.7359, DL20: 0.7462 vs 0.6865),证明 joint training 让 encoder 输出的候选集比 BM25 更"对齐 reranker 期望"——单测 retrieval 时 encoder 在 dense-friendly 数据集(NFCorpus、Robust、SciFact)也取得明显优势。
- ResRank dense retrieval 在 lexical-friendly 数据集(Signal, News, Touche)反不如 BM25——和 dense vs lexical 检索的经典权衡一致。
- 最佳配置为 ResRank+BM25(RRF 融合,K=60),结合 sparse 与 dense 互补优势:BEIR avg 0.5527、DL19 0.7821、DL20 0.7499,全场最优。这个数字从根本上验证了 end-to-end joint training 的设计假设——encoder 学到 reranker-aligned 表征,reranker 拥抱 encoder 进化中的输出,两侧之合协同放大整体收益。
5.4 推理效率分析(Table IV、Figure 2)¶
| Model | TREC DL19 nDCG | TREC DL19 #Proc. | TREC DL19 Avg. $L_p$ | TREC DL19 #Gen. | Covid nDCG | Covid #Proc. | Covid Avg. $L_p$ | Covid #Gen. |
|---|---|---|---|---|---|---|---|---|
| RankMistral_p | 0.7196 | 9635 | 96.4 | 910 | 0.7780 | 40039 | 400.4 | 987 |
| RankMistral_s | 0.7050 | 6021 | 60.2 | 882 | 0.7385 | 9702 | 97.0 | 930 |
| RankMistral_t | 0.4543 | 653 | 6.5 | 865 | 0.7540 | 2636 | 26.4 | 917 |
| PE-Rank | 0.7048 | 100 | 1.0 | 180 | 0.7772 | 100 | 1.0 | 180 |
| ResRank | 0.7359 | 100 | 1.0 | 0 | 0.8409 | 100 | 1.0 | 0 |
下标说明:RankMistral_p = 原文,RankMistral_s = 摘要,RankMistral_t = 标题。$L_p$ 为平均 per-passage token 数。
关键发现:
- 效果-效率全面碾压:ResRank 同时满足 nDCG 最高(DL19: 0.7359, Covid: 0.8409)、#Processed token 最少(100,每段 1 token)、#Generated token = 0;坐标系上它孤悬于左上角,是唯一同时占据"高效果 + 低开销"两极的方法。
- PE-Rank vs ResRank 关键差距在生成阶段:两者输入端都是 100 token、$L_p = 1.0$,但 PE-Rank 仍要 constrained-decode 180 个输出 token,ResRank 直接 0 token——这是把 listwise reranker 的"生成排列"任务彻底改写为"并行打分"的根本性收益。
- 粗暴文本压缩走不通:RankMistral_s(摘要)和 RankMistral_t(仅标题)在显著降低 token 数的同时性能也大幅退化,特别是 $t$ 变体在 DL19 上 nDCG 跌至 0.4543,证明 naive text compression 会丢失关键语义信号——必须在 embedding 空间 做压缩并配合端到端联合训练。
六、消融与分析¶
6.1 整体消融(Table V & Figure 3)¶
| Variant | Covid | NFCorpus | Touche | DBPedia | SciFact | Signal | News | Robust | BEIR Avg. | DL19 | DL20 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ResRank (full) | 0.8409 | 0.3973 | 0.3948 | 0.4583 | 0.7642 | 0.5485 | — | 0.5964 | 0.5440 | 0.7359 | 0.6865 |
| W/O 1st Stage | 0.8249 | 0.3948 | 0.4366 | 0.4436 | 0.7694 | 0.3523 | 0.5366 | 0.5903 | 0.5436 | 0.7091 | 0.6295 |
| W/O 2nd Stage | 0.8469 | 0.3940 | 0.3937 | 0.4421 | 0.7551 | 0.3534 | 0.5365 | 0.5385 | 0.5385 | 0.7210 | 0.6791 |
| W/O Hidden State | 0.8528 | 0.3883 | 0.2850 | 0.4338 | 0.7300 | 0.2877 | 0.5180 | 0.5771 | 0.5091 | 0.7245 | 0.6585 |
| W/O Residual Conn. | 0.8293 | 0.3871 | 0.4314 | 0.4486 | 0.6960 | 0.3227 | 0.5350 | 0.5936 | 0.5305 | 0.7250 | 0.6652 |
| W/O Encoder SFT | 0.8327 | 0.3920 | 0.4268 | 0.4496 | 0.7482 | 0.3598 | 0.5324 | 0.5927 | 0.5418 | 0.7148 | 0.6633 |
| W/O Encoder Loss | 0.8406 | 0.3960 | 0.4072 | 0.4589 | 0.7643 | 0.3610 | 0.5419 | 0.5995 | 0.5462 | 0.7352 | 0.6791 |
注:W/O Hidden State 在 News 列原文未列数值。
关键观察:
- Dual-Stage Training:去 Stage 1 在 in-domain DL20 暴跌 5+ 点(0.6865 → 0.6295),但 BEIR avg 几乎不变;去 Stage 2 在 in-domain 较温和但 BEIR 全面降低。第一阶段建立基础排序行为,第二阶段做细粒度精修,二者贡献互补。
- W/O Hidden State(仅用 $\mathbf{e}_i$ 作 passage 表示,丢弃 $\mathbf{h}_i^p$):BEIR avg 跌 3+ 点(0.5440 → 0.5091),Touche、Signal、SciFact 均大幅下降——丢失全部 cross-passage 上下文信号,等同于退化为纯 embedding cosine 检索。
- W/O Residual Conn.(仅用 $\mathbf{h}_i^p$ 作 passage 表示,丢弃 $\mathbf{e}_i$):BEIR avg 跌至 0.5305,Signal 和 SciFact 较为受影响——证明 encoder 的 passage-level 信号对 reranker 的稳定优化不可或缺。两个 ablation 一起表明残差结构(两侧叠加)确实是各取所长。
- W/O Encoder SFT(冻结 encoder):性能在 TREC DL 和 BEIR 都有所下降——只让 encoder 跟随 reranker 反馈进化才能产生 better-aligned 表征。
- W/O Encoder Loss(去 InfoNCE 仅留 RankNet):reranking 性能反而 marginally 提升(BEIR avg 0.5462 vs 0.5440),但 encoder 的 standalone retrieval 能力 severely degraded,无法在 end-to-end 流水线中担任第一阶段检索器。这一 trade-off 明确论文为何要保留 multi-task:稍微牺牲 reranker 性能,换 encoder 的双重身份。
6.2 输入文档顺序敏感性(Table VI)¶
| Input Order | Covid | NFCorpus | Touche | DBPedia | SciFact | Signal | News | Robust | BEIR Avg. | DL19 | DL20 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Original (BM25 desc.) | 0.8409 | 0.3973 | 0.3948 | 0.4583 | 0.7642 | 0.3527 | 0.5485 | 0.5964 | 0.5440 | 0.7359 | 0.6865 |
| Inverse | 0.8260 | 0.3829 | 0.2646 | 0.3782 | 0.6892 | 0.2318 | 0.5131 | 0.5672 | 0.4816 | 0.6822 | 0.6313 |
| Random | 0.8699 | 0.3856 | 0.3423 | 0.4003 | 0.7246 | 0.2769 | 0.5457 | 0.5856 | 0.5164 | 0.6993 | 0.6577 |
讨论:
- 原序(BM25 降序)效果最好,因为 causal attention 让靠后的位置看到更多 context;如果相关段落本来就排在前面,cross-passage 信号有更多机会汇聚到末尾。
- Inverse 顺序(相关段落放最末)严重退化(BEIR avg -6.24 点),Touche 和 Signal 跌幅最大——这是因果注意力的固有特性:靠前位置看不到靠后位置,把 relevant passage 塞到末尾会导致前面的 less-relevant 段落得不到 cross-passage 校正信号,造成 "信息流失衡"。
- Random 介于两者之间。
- 论文承认这是 causal attention 类 listwise reranker 的共性缺陷,但实际部署中第一阶段检索器的输出本来就大致按相关性排序,positional bias 自然被缓解;future work 可探索 bidirectional attention 或 position-aware data augmentation。
七、与已归档相关工作的对比¶
SumRank SumRank: Aligning Summarization Models for Long-Document Listwise Reranking (RUC, 2026-03-25)¶
关系:独立并发(ResRank 未引用 SumRank,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇论文都直面"LLM listwise reranker 输入长度爆炸 → 延迟 + lost-in-middle"的核心痛点,且都把 TREC DL 系列作为主要 in-domain benchmark;都把"压缩 candidate 文档以减少 reranker 输入长度"作为核心思路;都采用"压缩模块 + 重排模块"的两模块流水线,并都强调要让两个模块的 learning objective 对齐。值得注意的是,SumRank 在 Limitations 中明确写到 "未来计划探索统一的端到端架构,同时压缩文档并输出相关性分数" — 这恰恰就是 ResRank 给出的方案,两篇相隔 1 个月独立提出。
- 相近的技术骨架:两者都用 LLM-as-compressor + LLM-as-reranker,都依赖多阶段对齐训练(SumRank: cold-start SFT → GRPO;ResRank: dual-stage SFT 全程联合优化),都把"对齐 compressor 与 ranker"作为效果的关键。
- 本文的差异与推进:
- 压缩粒度:SumRank 做文本级压缩(passage → query-aware 摘要文本),仍要把摘要 token 喂给 reranker,per-passage 仍是几十至上百 token;ResRank 做 embedding 级压缩,per-passage 严格 1 token,token 数差 1-2 个数量级。
- 生成 vs 打分:SumRank 的 reranker 仍 AR 生成 permutation(Qwen2.5-72B sliding window),延迟 1.95-6.98 秒/query;ResRank 用 cosine similarity 替代 AR decoding,输出 token = 0。
-
训练范式:SumRank 通过 GRPO 用 reranker NDCG 反馈训 summarizer(独立 reward 模型),训练流水线仍是分阶段串联(先 SFT 再 RL);ResRank 是 从初始 全参数 joint training,encoder 与 reranker 互相塑形——这是 SumRank 自己列为"future work"的方向。
-
可比的方法 / 实验差异:两者都在 TREC DL 上比对,但量纲和数据集略不同。SumRank (7B) 在 DL19 上 0.6730 (NDCG@10) / 6.98s 延迟;ResRank (4B) 在 DL19 single-pass 上 0.7359——ResRank 的效果与效率均更优,证实"embedding 级压缩 + 余弦打分 + end-to-end joint training"的组合相对"文本摘要 + AR 排序"具有方法论级别优势。但需注意:SumRank 主打长文档(数千词的网页),ResRank 主打短段落(约 100 词的 MS MARCO 段落);ResRank 是否适用于长文档还有待验证,SumRank 的文本可读性优势(摘要可被人类审阅)也是 ResRank 没有的。
Step 2.5 排除候选(仅记录,不写入正文):
- 2604.03642 DebiasFirst — 同样针对 LLM listwise reranker,但主攻 positional bias 用 IPS-based 校准 + position-aware data augmentation;解法路径与"压缩 + 端到端"完全正交,未入选。
- 2604.15650 SIF / 2604.08933 IAT — 都做"把样本压缩成 token"的工作,但应用领域是工业推荐排序(Meituan / ByteDance ad),目标是延展用户行为序列长度而非 IR 重排器的候选输入;问题陈述与 ResRank 不同构,未入选。
- 2603.02999 OneRanker — 同样讲"统一生成与排序",但场景是工业广告 rec 而非 IR retrieval-reranking;问题域不同,未入选。
八、讨论与局限性¶
8.1 核心贡献¶
ResRank 给出一个干净自洽的 "统一检索-重排" 框架,通过三个互锁创新同时解决 LLM listwise reranker 落地的两大瓶颈:
- Residual passage compression 把 per-passage token 从 hundreds → 1 个,且通过残差连接保住 passage-level 语义;
- Cosine similarity-based scoring 把 per-query 生成 token 从 ~n 到 4.5n → 0,把 listwise ranker 的 AR 解码改写成并行向量比较;
- End-to-end joint multi-task training 让 encoder 和 reranker 互相塑形,既保住 encoder 的 retrieval 能力又让 reranker 充分利用 encoder 不断进化的输出。
8.2 值得借鉴的设计选择¶
- 同源 encoder + reranker 消除 projector:选用同 backbone 同 hidden dim 的 Qwen3-Embedding-4B + Qwen3-4B,让 passage embedding 直接进 reranker input space;这种"借力多模态 LLM 范式但去掉 alignment module"的简化值得搜索/推荐场景借鉴。
- 加性残差作为 gradient shortcut:在表征空间 fusion 时,简单叠加($\mathbf{h}_i^p + \mathbf{e}_i$)比 concat 或门控更稳——尤其是训练初期对齐尚不稳定时,加性结构提供天然 gradient shortcut,降低优化难度。
- multi-task loss 的 dual-purpose 设计:保留 InfoNCE 不为 reranking 性能(其实关掉 InfoNCE 反而 marginally 更好),而是为了 encoder 的"双角色"——既做 reranker 内部 compressor 又做独立 first-stage retriever。这种把"模块功能复用"显式写进 loss 的设计模式可推广到 multi-stage 系统。
8.3 局限性¶
- Causal attention 导致顺序敏感:W/O 表 VI 显示 inverse ordering 会让 BEIR avg 跌 6+ 点。论文承认这是该范式的共性缺陷,建议未来用 bidirectional attention 或 position-aware augmentation 缓解。
- 未在更长候选列表 / 更大 backbone 上验证:所有实验在 top-100 候选 + 4B 参数模型上展开;scaling 到 top-1000 候选或 32B 模型的可行性未知。
- Cosine 打分的天花板:global aggregation embedding 是单向量,要承载 query + n 个 passage 的全部排序信息;当 n 极大或语义需要复杂 pairwise 比较时,单向量可能不够。论文未讨论 vector-of-vectors(multi-vector retrieval 类思路)的 trade-off。
- 生成数据依赖 Qwen3-Max:训练数据由 Qwen3-Max 重新标注,在弱评分模型或 domain-shift 场景下泛化性如何,未在论文中探讨。
8.4 工业落地价值¶
ResRank 是少数把 LLM listwise reranker 的两大延迟来源(输入长度 + AR 生成)同时斩断的方案:top-100 候选下 #Processed = 100 + #Generated = 0,理论上可做到 真实工业搜索引擎延迟预算内 的 LLM listwise rerank 部署。论文出自阿里 Qwen Applications Business Group,与 Qwen3 同源同尺寸的工程选型暗示这套方案有潜力嵌入阿里搜索/电商 stack。对于已经在用 GPT-4 类商用 LLM 做 reranker 的团队,ResRank 提供了一条"用开源 4B 模型在 single-pass 模式下逼近 GPT-4 效果"的迁移路径,性价比清晰。