Structuring and Tokenizing Distributed User Interest Context for Generative Recommendation (G2Rec)¶
Ruizhong Qiu (UIUC, 实习于 Meta), Yinglong Xia, Dongqi Fu, Hanqing Zeng, Ren Chen, Xiangjun Fan, Hong Li, Hong Yan (Meta MRS), Hanghang Tong (UIUC) · arXiv 2606.20554 · 2026-06-18
研究动机与背景¶
生成式推荐(Generative Recommendation, GR)是工业推荐系统中一个新兴范式:把用户历史行为当成一段序列,借助大语言模型(LLM)式的自回归架构,直接预测用户下一个会交互的 item。它的吸引力在于天然契合"用户行为本质上是序列"这一事实,能够建模交互之间的时序依赖,从而给出更个性化、更及时的推荐。GR 已在电商、在线广告、内容流等多个场景展现潜力。
GR 的核心环节是 item tokenization——它是连接"item 语义"与"推荐模型"的桥梁。然而,现有 GR 方法很难同时把"复杂的用户行为上下文"和"item 语义上下文"有效地组织(organize)并注入(inject)到推荐模型中。本文指出现有两条路线各有硬伤:
- 图集成方法(graph-based integration):利用 user-item 关系图中的关系信息,但要么不可扩展,要么只用到局部图信息。
- 图序列化(graph serialization):把图转成序列喂给 LLM,但长序列会带来昂贵的 LLM 计算开销;
- 图神经网络(GNN):每个用户通常只感知到一个很小的子图,无法充分利用整体(holistic)图信息。
-
这些局限使得基于图的方法在工业级 GR 中难以奏效。
-
语义 tokenization(semantic tokenization):把每个 item 表示成若干语义 token。但它们通常依赖启发式(heuristic)学习目标、缺乏明确的监督信号,因此不能保证学到准确的语义表征,在推荐任务上可能次优。
为解决用户兴趣上下文建模中的这些关键局限,本文提出 G2Rec(Sparse Co-Engagement Graph Schema for Generative Recommendation),一个把"整体图级用户共参与建模"与"语义 tokenization"统一起来、面向工业级 GR 的可扩展框架。三步走:
- First:构造一张稀疏化的 item-item 共参与图(item co-engagement graph),边数仅 $O(M\log M)$($M$ 为总交互数),作为 item schema;
- Second:设计一个可扩展的"软(soft)"聚类算法,每轮迭代时间复杂度 $O(\rho M\log M)$($\rho$ 是表征软聚类成员分布稀疏度的小常数),从图上抽取分布式兴趣原型(distributed interest prototypes);
- Third:基于软聚类抽出的 interest prototypes 和 item interest profiles,把这些画像与用户感兴趣的 item 一起 tokenize,训练生成式序列推荐模型。
整体上,G2Rec 让推荐模型在不需要 ground-truth 用户兴趣的前提下,捕捉到整体的、且有语义根基的用户兴趣原型,从而对用户行为上下文做更全面、更准确的建模。
本文把 §3 的整体流程概括为下图(原文无架构图,此处据正文重绘):
flowchart LR
A["用户交互历史<br/>I_u = [i_1,...,i_N]"] --> B["① 构造 item-item 共参与图 G*<br/>消去 user 节点<br/>(i,j) 共参与 ⇔ ∃u 同时交互 i,j"]
B --> C["② 谱稀疏化<br/>每用户采样 m 条边<br/>|E| = O(M log M)<br/>(Theorem 2 保 Laplacian)"]
C --> D["③ 可微软图聚类<br/>最大化 soft modularity Q_soft(P)<br/>得软成员矩阵 P (item interest profile)"]
D --> E["④ 兴趣画像 tokenization<br/>原型 embedding V=PᵀX/(Pᵀ1)<br/>兴趣 token Y=PV (连续 token)"]
E --> F["⑤ 交替序列 R_u=[BOS,x_1,y_1,...,x_N,y_N]<br/>Llama2-13B+LoRA 自回归<br/>L = L_item + λ·L_profile"]
核心方法:G2Rec 框架¶
记号与问题定义¶
令 $\mathcal{U}$ 为全体用户集合,$\mathcal{I}$ 为全体 item 集合,每个 item $i$ 有嵌入向量 $x_i\in\mathbb{R}^d$,item 嵌入矩阵 $X:=[x_1,\dots,x_{|\mathcal{I}|}]^\top\in\mathbb{R}^{|\mathcal{I}|\times d}$。对每个用户 $u$,其历史交互序列记为 $\mathcal{I}_u=[i_1,\dots,i_N]$($N$ 为历史长度),称为 interaction history;假设 $\bigcup_{u\in\mathcal{U}}\mathcal{I}_u=\mathcal{I}$ 以避免冷启动。令 $M:=\sum_{u\in\mathcal{U}}|\mathcal{I}_u|$ 为总交互数。交互可以是点击、浏览、评论、购买等多种形式。
Problem 1(生成式序列推荐):输入 (i) 用户 $u$;(ii) 历史长度 $N$;(iii) 历史序列 $\mathcal{I}_u=[i_1,\dots,i_N]$;(iv) 每个 item 的嵌入 $x_i$。输出:按"成为 $u$ 下一次交互的可能性"对候选 item 排序。
3.1 用稀疏化 item 共参与图建模用户行为¶
为什么不用 user-item 二部图? 已有图方法常用 user-item 二部图建模用户行为,但工业级场景下用户规模巨大、历史很长,频繁更新这种图代价极高。
共参与图(Co-engagement graph):本文提出消去 user 节点,改用 item-item 图。两个 item $i,j$ 称为"共参与(co-engaged)",当且仅当存在某用户 $u$ 同时与 $i,j$ 都交互过(这里的 $u$ 不必唯一)。这样可以聚焦于更静态的 item 关系,降低更新频率。形式化地,item-item 共参与图 $\mathcal{G}^*=(\mathcal{I},\mathcal{E}^*)$ 以 item 为节点,共参与关系为边:
$$ \mathcal{E}^* := \bigcup_{u\in\mathcal{U}}\mathcal{I}_u\times\mathcal{I}_u = \{(i,j): \exists u\in\mathcal{U}\ \text{s.t.}\ i\in\mathcal{I}_u, j\in\mathcal{I}_u\} \tag{1} $$
其中 $\times$ 是集合笛卡尔积。共参与图能捕捉超出 item 特征相似度的用户行为模式:例如智能手机与手机壳——它们特征上并不相似,却常被"买了新手机后再配配件"的用户一起交互。这类信息正是 item 特征相似度无法提供的。
Observation 1(表达力):对任意用户 $u$,其历史序列 $\mathcal{I}_u=[i_1,\dots,i_N]$ 都是共参与图 $\mathcal{G}^*$ 上的一条路径,即 $(i_t,i_{t+1})\in\mathcal{E}^*$ 对所有 $t=1,\dots,N-1$ 成立。换言之,共参与图上的边编码了用户兴趣的转移行为。
图稀疏化(Graph sparsification):$|\mathcal{E}^*|$ 最坏可达 $O(M^2)$,工业场景下直接用原图计算不可行。为保证可扩展性,本文做了有理论保证的稀疏化——目标是近似保持图的 Laplacian(它编码了图的本质结构信息)。给定 $m\ll N^2$,定义稀疏共参与图 $\mathcal{G}=(\mathcal{I},\mathcal{E})$,对每个用户只采样 $m$ 条共参与边:
$$ \mathcal{E} := \bigcup_{u\in\mathcal{U}}\text{sample}(\mathcal{I}_u\times\mathcal{I}_u,\ m) \tag{2} $$
其中 $\text{sample}(\cdot,m)$ 表示有放回采样 $m$ 条边构成无向图。
Theorem 2(近线性复杂度 + 谱保持):设每个用户有 $N$ 次交互。令 $L_{\mathcal{E}^*}$ 为 $\mathcal{E}^*$ 的 Laplacian,$L_{\mathcal{E}}$ 为 $\mathcal{E}$ 的 Laplacian(边权设为 $\frac{N(N-1)}{2m}$ 以匹配 $L^*$ 的总边权)。给定任意 $0<\delta<1$、$\epsilon>0$,若取
$$ m := \left\lceil 2N\Bigl(\frac{1}{3\epsilon}+\frac{1}{\epsilon^2}\Bigr)\log\frac{2|\mathcal{I}|}{\delta}\right\rceil, $$
则 $|\mathcal{E}|\le O(M\log M)$,且以至少 $1-\delta$ 的概率,
$$ (1-\epsilon)L_{\mathcal{E}^*}\preceq L_{\mathcal{E}}\preceq(1+\epsilon)L_{\mathcal{E}^*}, $$
其中 $\preceq$ 为 Loewner 序。该定理表明:仅需 $O(M\log M)$ 条边就能近似保持图 Laplacian——相对总交互数 $M$ 近线性,远比 $|\mathcal{E}^*|=O(M^2)$ 稀疏。这是 G2Rec 可扩展性的理论基石(谱稀疏化思路源自 Ng et al., 2001 的图谱结构理论)。
3.2 用软图聚类做 item 兴趣画像¶
为什么要聚类? 稀疏共参与图 $\mathcal{G}$ 里有些共参与关系是随机噪声。直觉是:若一组 item 频繁地两两共参与(即属于同一簇),它们的共参与更可能是有意义的。于是本文用图聚类抽取有意义的共参与,把簇称为 item 兴趣原型(item interest prototypes),可解释为潜在的兴趣类别。结合 Observation 1(共参与图编码兴趣转移),把每个簇当作一个兴趣原型,能帮推荐模型洞察驱动用户行为的潜在兴趣转移。
为什么要"软"聚类? Louvain、Leiden 等现有图聚类假设每个节点只属于一个簇(硬分配),不适合"一个 item 同时对应多个兴趣原型"的复杂场景。例如一段牛油果吐司食谱短视频,既吸引关注"健康饮食"的用户,也吸引关注"晨间例程"的用户。为此本文采用 soft graph clustering:允许连续的簇成员关系与可微优化。
软成员(item interest profile):对每个 item $i$,求一个成员分布 $p_i\in\mathbb{R}^C$($C$ 为兴趣原型数,$p_{i,a}$ 为 item $i$ 属于原型 $a$ 的概率),称为 item $i$ 的 item interest profile。为保证 $\sum_{a=1}^C p_{i,a}=1$,用参数化 $p_i:=\text{softmax}(z_i)$,logits $z_i\in\mathbb{R}^C$ 为待优化变量;用 Leiden 算法初始化并稀疏化这些变量。软成员矩阵 $P:=[p_1,\dots,p_{|\mathcal{I}|}]^\top\in\mathbb{R}^{|\mathcal{I}|\times C}$。
可微模块度目标:设 $A\in\{0,1\}^{|\mathcal{I}|\times|\mathcal{I}|}$ 为 $\mathcal{G}$ 的邻接矩阵,度向量 $k\in\mathbb{N}^{|\mathcal{I}|}$ 满足 $k_i=\sum_j A_{i,j}$。给定硬成员 $h\in\{1,\dots,C\}^{|\mathcal{I}|}$,经典图模块度 $Q_{\text{hard}}$(Newman, 2006)定义为:
$$ Q_{\text{hard}}(h) := \frac{1}{|\mathcal{E}|}\sum_{i,j\in\mathcal{I}}\Bigl(A_{i,j}-\gamma\frac{k_ik_j}{|\mathcal{E}|}\Bigr)\mathbb{1}_{[h_i=h_j]} \tag{3} $$
其中 $\frac{k_ik_j}{|\mathcal{E}|}$ 是 Newman–Girvan 零模型下 $i,j$ 之间的期望边数,$\gamma>0$ 为聚类分辨率;这里采用无向图的重复表示($(i,j)$ 与 $(j,i)$ 都在 $\mathcal{E}$ 中)。
由于 $\mathbb{1}_{[h_i=h_j]}$ 不可微,无法直接对软成员 $P$ 优化 $Q_{\text{hard}}$。本文转而最大化分布 $P$ 下的期望模块度,并给出闭式解。
Proposition 3(闭式期望模块度):
$$ Q_{\text{soft}}(P) := \mathbb{E}_{h\sim P}[Q_{\text{hard}}(h)] = \frac{1}{|\mathcal{E}|}\sum_{(i,j)\in\mathcal{E}}p_i^\top p_j - \gamma\frac{\|P^\top k\|_2^2}{|\mathcal{E}|^2} \tag{4} $$
称 $Q_{\text{soft}}$ 为 soft modularity。当 $\mathcal{E}$ 与 $P$ 稀疏时可在 GPU 上高效计算。
Proposition 4(近线性复杂度):若 $P$ 的每一行至多有 $\rho$ 个非零元,则 $Q_{\text{soft}}(P)$ 可在
$$ O(\rho|\mathcal{E}|) = O(\rho M\log M) \tag{5} $$
时间内算完。
直觉解读:内积 $p_i^\top p_j=\sum_{a=1}^C p_{i,a}p_{j,a}$ 表示在软成员 $P$ 下 item $i,j$ 属于同一原型的概率,是硬模块度中 $\mathbb{1}_{[h_i=h_j]}$ 的连续类比。$Q_{\text{soft}}$ 鼓励重度共参与的 item 对有高的同簇概率 $p_i^\top p_j$,同时惩罚那些零模型下本不该相连的 item 对的"过度同簇"。与原始 $Q_{\text{hard}}$ 不同,$Q_{\text{soft}}$ 关于 $P$ 完全可微,适合作为优化 item interest profiles 的目标函数。
3.3 兴趣画像 tokenization 用于生成式序列推荐¶
兴趣画像 tokenization:软兴趣画像是连续的,故用连续 token 表示。先定义兴趣原型的嵌入。对每个原型 $a$,原型嵌入 $v_a\in\mathbb{R}^d$ 是该原型下所有 item 嵌入的加权平均:
$$ v_a := \frac{\sum_{i\in\mathcal{I}}p_{i,a}x_i}{\sum_{i\in\mathcal{I}}p_{i,a}},\qquad a\in\{1,\dots,C\} \tag{6} $$
令原型嵌入矩阵 $V:=[v_1,\dots,v_C]^\top\in\mathbb{R}^{C\times d}$,则 (6) 的矩阵形式为 $V=\frac{P^\top X}{P^\top \mathbf{1}}$,因 $P$ 稀疏可高效计算。
再定义每个 item $i$ 的 interest profile token $y_i$ 为其各原型嵌入的加权平均:
$$ y_i := \sum_{a=1}^C p_{i,a}v_a,\qquad i\in\mathcal{I} \tag{7} $$
令 $Y:=[y_1,\dots,y_{|\mathcal{I}|}]^\top\in\mathbb{R}^{|\mathcal{I}|\times d}$,矩阵形式 $Y=PV$。$y_{i_1},\dots,y_{i_N}$ 即 item $i_1,\dots,i_N$ 的基于图的语义 tokenization。
序列构造(Sequence formulation):核心点子是设计一种把 item 兴趣画像考虑进去的新序列格式。给定用户历史 $\mathcal{I}_u=[i_1,\dots,i_N]$,定义 user interest transition sequence:
$$ \mathcal{R}_u := [\langle\text{BOS}\rangle, x_{i_1}, y_{i_1}, \dots, x_{i_N}, y_{i_N}] \tag{8} $$
即在每个 item 嵌入 $x_{i_t}$ 之后交替插入其兴趣画像 token $y_{i_t}$。
训练目标:令 $F$ 为自回归预测下一 token 的生成式序列推荐器,目标是预测用户下一个交互 $i_{t+1}$。对每个 $t=1,\dots,N-1$,item 预测的交叉熵损失为:
$$ \mathcal{L}_{\text{item}}^t := -\log F(i_{t+1}\mid\langle\text{BOS}\rangle, x_{i_1}, y_{i_1}, \dots, x_{i_t}, y_{i_t}) \tag{9} $$
$$ = -\log F\bigl(i_{t+1}\mid(\mathcal{R}_u)_{\le 2t+1}\bigr) \tag{10} $$
为帮助推荐器理解兴趣转移行为,还训练它预测每次交互的兴趣。由于没有 ground-truth 用户兴趣,本文用 item interest profile 作为软标签,对每个 $t=1,\dots,N$:
$$ \mathcal{L}_{\text{profile}}^t := -\sum_{a=1}^C p_{i_t,a}\log F(a\mid\langle\text{BOS}\rangle, x_{i_1}, y_{i_1}, \dots, x_{i_t}) \tag{11} $$
$$ = -\sum_{a=1}^C p_{i_t,a}\log F\bigl(a\mid(\mathcal{R}_u)_{\le 2t}\bigr) \tag{12} $$
两个损失加权联合训练:
$$ \mathcal{L}^t := \mathcal{L}_{\text{item}}^t + \lambda\,\mathcal{L}_{\text{profile}}^t \tag{13} $$
其中 $\lambda>0$ 控制 profile loss 的权重。注意 $\mathcal{L}_{\text{item}}$ 在序列偶数位(item 位置)做预测、$\mathcal{L}_{\text{profile}}$ 在奇数位(item 之后、下一兴趣 token 位置)做预测,二者交替,自然契合 (8) 的交替序列结构。
工业部署¶
本文已把 G2Rec 在 Meta 多个产品表面(product surfaces)上产线化。考虑到 Meta 产品(如 Instagram Reels)有数十亿月活,部署的主要挑战在可扩展性与实时效率。为保证 item 兴趣画像的时效性,团队实现了一个自研高性能图处理引擎,能在分布式环境中高效执行图聚类算法(Blondel et al., 2008,即 Louvain)。关键工程选择:图聚类周期性离线运行,因此聚类的执行时间不影响对用户的响应时延。
实验设置¶
围绕四个研究问题(RQ1 离线对比 SOTA;RQ2 Meta 线上表现;RQ3 训练/推理效率;RQ4 软聚类与兴趣画像对推荐质量的影响)展开。
公开数据集:四个广泛使用的真实数据集——Beauty、Sports、Toys(均为 Amazon 评论数据集,McAuley et al., 2015)与 Yelp(Asghar, 2016,取 2019-01-01 之后的数据)。统计见 Table 1,全部高度稀疏(≥99.93%),保证序列推荐评测足够有挑战性。
Table 1:公开数据集统计
| Dataset | #Users | #Items | #Interactions | Sparsity |
|---|---|---|---|---|
| Beauty | 22,363 | 12,101 | 198,502 | 99.93% |
| Sports | 25,598 | 18,357 | 296,337 | 99.95% |
| Toys | 19,412 | 11,924 | 167,597 | 99.93% |
| Yelp | 30,431 | 20,033 | 316,354 | 99.95% |
Baseline(6 大类共 9 个):
- Classic:POP(按流行度排序的启发式强基线);MF(矩阵分解,用 BPR 损失)。
- Sequential / Tokenization-Based:GRU4Rec(GRU 建模序列);SASRec(多头自注意力);BERT4Rec(用 BERT 的 cloze 目标做双向自监督,而非只预测下一个);Caser(横向+纵向卷积捕捉复杂交互);EAGER(双流生成式推荐器,行为-语义协同)。
- Graph-Based:LightGCN(协同过滤的强 GCN);HeLLM(用超图增强 LLM-based 推荐器)。
评测协议与指标:先按时间戳升序排序构造历史序列;5-core 过滤(剔除交互少于 5 的 item);leave-one-out 划分——最后一个 item 作测试、倒数第二个作验证、其余作训练。测试时对每个用户取其最后交互 item 作正样本,从剩余 item 中随机采样 99 个负样本。指标:Recall@1、Recall@5、Recall@10、NDCG@5、NDCG@10、MRR(平均倒数排名)。
实现细节:
- 骨干:用 Llama 2 13B 作推荐器骨干,微调 3 个 epoch,用 LoRA(16 ranks,rank dropout 0.05);
- Xavier 初始化,Adam 优化器,初始学习率 0.0003,cosine 学习率调度,100 warmup steps;
- 用 SASRec 嵌入($d=64$)作为 item 嵌入,所有方法最大序列长度限 50(在所有数据集上以避免 OOM 并保证公平);
- 控制原型数量:$\gamma=0.8$(Beauty、Toys),$\gamma=1$(Sports、Yelp);
- Baseline 用原作者开源代码并适配到本文实验设置。
主要实验结果¶
5.2 离线评测(RQ1)¶
Table 2:与 baseline 在公开数据集上的对比(每行最优加粗)
| Dataset | Metric | POP | MF | GRU4Rec | SASRec | BERT4Rec | Caser | EAGER | LightGCN | HeLLM | G2Rec |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Beauty | Recall@1 | 0.0678 | 0.0405 | 0.1870 | 0.1531 | 0.1337 | 0.1337 | 0.1213 | 0.1435 | 0.1690 | 0.2067 |
| Recall@5 | 0.2105 | 0.1461 | 0.3741 | 0.3640 | 0.3032 | 0.3125 | 0.2678 | 0.3081 | 0.2802 | 0.3917 | |
| Recall@10 | 0.3386 | 0.2311 | 0.4696 | 0.4739 | 0.3942 | 0.4106 | 0.3663 | 0.4042 | 0.3413 | 0.4892 | |
| NDCG@5 | 0.1391 | 0.0934 | 0.2848 | 0.2622 | 0.2219 | 0.2268 | 0.1962 | 0.2286 | 0.2278 | 0.3035 | |
| NDCG@10 | 0.1803 | 0.1207 | 0.3156 | 0.2975 | 0.2512 | 0.2584 | 0.2278 | 0.2596 | 0.2474 | 0.3334 | |
| MRR | 0.1558 | 0.1096 | 0.2852 | 0.2614 | 0.2263 | 0.2308 | 0.2060 | 0.2340 | 0.2359 | 0.3034 | |
| Sports | Recall@1 | 0.0763 | 0.0489 | 0.1455 | 0.1255 | 0.1135 | 0.1160 | 0.0417 | 0.1226 | 0.1021 | 0.1750 |
| Recall@5 | 0.2293 | 0.1603 | 0.3466 | 0.3375 | 0.2866 | 0.3055 | 0.1398 | 0.2841 | 0.2214 | 0.3903 | |
| Recall@10 | 0.3423 | 0.2491 | 0.4622 | 0.4722 | 0.4014 | 0.4299 | 0.2232 | 0.3855 | 0.2946 | 0.5093 | |
| NDCG@5 | 0.1538 | 0.1048 | 0.2497 | 0.2341 | 0.2020 | 0.2126 | 0.0906 | 0.2056 | 0.1641 | 0.2869 | |
| NDCG@10 | 0.1902 | 0.1334 | 0.2869 | 0.2775 | 0.2390 | 0.2527 | 0.1174 | 0.2383 | 0.1875 | 0.3254 | |
| MRR | 0.1660 | 0.1202 | 0.2520 | 0.2378 | 0.2100 | 0.2191 | 0.1078 | 0.2133 | 0.1750 | 0.2867 | |
| Toys | Recall@1 | 0.0585 | 0.0257 | 0.1878 | 0.1262 | 0.1114 | 0.0997 | 0.1201 | 0.1310 | 0.1507 | 0.2006 |
| Recall@5 | 0.1977 | 0.0978 | 0.3682 | 0.3344 | 0.2614 | 0.2795 | 0.2717 | 0.2799 | 0.2717 | 0.3779 | |
| Recall@10 | 0.3008 | 0.1715 | 0.4663 | 0.4493 | 0.3540 | 0.3896 | 0.3777 | 0.3721 | 0.3375 | 0.4691 | |
| NDCG@5 | 0.1286 | 0.0614 | 0.2820 | 0.2327 | 0.1885 | 0.1919 | 0.1977 | 0.2078 | 0.2147 | 0.2931 | |
| NDCG@10 | 0.1618 | 0.0850 | 0.3136 | 0.2698 | 0.2183 | 0.2274 | 0.2319 | 0.2374 | 0.2359 | 0.3225 | |
| MRR | 0.1430 | 0.0819 | 0.2842 | 0.2338 | 0.1967 | 0.1973 | 0.2075 | 0.2154 | 0.2228 | 0.2942 | |
| Yelp | Recall@1 | 0.0801 | 0.0624 | 0.2375 | 0.2405 | 0.2188 | 0.2053 | 0.0976 | 0.2696 | 0.2148 | 0.2558 |
| Recall@5 | 0.2415 | 0.2036 | 0.5745 | 0.5976 | 0.5111 | 0.5437 | 0.2903 | 0.5517 | 0.4053 | 0.6105 | |
| Recall@10 | 0.3609 | 0.3153 | 0.7373 | 0.7597 | 0.6661 | 0.7265 | 0.4088 | 0.6756 | 0.4909 | 0.7736 | |
| NDCG@5 | 0.1622 | 0.1333 | 0.4113 | 0.4252 | 0.3696 | 0.3784 | 0.1960 | 0.4165 | 0.3160 | 0.4598 | |
| NDCG@10 | 0.2007 | 0.1692 | 0.4642 | 0.4778 | 0.4198 | 0.4375 | 0.2343 | 0.4566 | 0.3436 | 0.4927 | |
| MRR | 0.1740 | 0.1470 | 0.3927 | 0.4026 | 0.3595 | 0.3630 | 0.2009 | 0.4025 | 0.3142 | 0.4180 | |
| Average Rank | 8.62 | 9.75 | 2.46 | 2.83 | 6.35 | 5.23 | 7.94 | 4.50 | 6.27 | 1.04 |
分析(why,不只 what):
- G2Rec 的平均排名 1.04,几乎在所有 24 个(4 数据集 × 6 指标)格子里都是第一;相比之下,baseline 的平均排名在不同数据集间波动很大(如 EAGER 在 Sports 上崩到 7.94,最强基线 GRU4Rec 也只有 2.46)。这说明 G2Rec 的共参与图 + 软聚类能稳定地建模复杂用户行为与 item 关系,而单一路线的 baseline 在不同分布上不稳。
- 性能差距显著:在 Sports 上 G2Rec 的 NDCG@5(0.2869)比最强基线 GRU4Rec(0.2497)高 14.9%。
- 一处需如实指出的例外:在 Yelp 的 Recall@1 上,LightGCN(0.2696)才是最优,G2Rec(0.2558)排第二——这是唯一一个 G2Rec 未夺第一的格子(也正是平均排名为 1.04 而非 1.00 的来源)。因此原文"在所有四个数据集的所有六个指标上一致超越所有 baseline"的表述略有夸大,应理解为"24 格中 23 格第一、1 格第二"。
- 一个有趣现象:GRU4Rec 是最强的非本文基线(avg rank 2.46,甚至优于 SASRec 的 2.83),与"越新越强"的直觉相反;而生成式/图类的 EAGER、HeLLM 反而在多数数据集上偏弱,侧面印证"把图/语义信号正确注入 GR"并不容易,G2Rec 的设计才是关键。

如 Figure 1,在 Beauty / Sports / Toys / Yelp 四个数据集上,随 cutoff $k$ 变化 G2Rec 的 Recall@k 曲线始终位于所有 baseline 之上,验证了优势的稳健性。
5.3 大规模线上测试(RQ2)¶
G2Rec 已在 Meta 多个产品表面产线化(每个表面做了内部适配,但核心方法不变)。通过短期(7 天)与长期 A/B 测试评估(因公司政策,细节无法披露)。观察到用户参与度、内容多样性、服务效率多个顶线指标上的一致提升:采用整体兴趣建模的产品上线带来 >0.03% 的 in-session 提升,并在 total time-spent、likes、shares 等多个用户参与度指标上有 0.06%–0.19% 的稳健正收益。在 Meta 这种体量下,这类幅度通常已具备显著业务价值。
5.4 效率研究(RQ3)¶
Table 3:每 batch 训练/推理时间(Beauty)
| Method | Training (s) | Inference (s) |
|---|---|---|
| Item-Only(仅 item) | 0.763 | 0.0534 |
| G2Rec (Ours) | 0.806 | 0.0561 |
| Overhead(额外开销) | +0.043 | +0.0027 |
分析:加入兴趣画像 token 后,训练每 batch 仅多 0.043s、推理仅多 0.0027s,开销可忽略。原因在于:兴趣画像 token 是用共参与图离线算好的,训练/推理时只是与 item 嵌入拼接,不需要昂贵的在线计算。这让 G2Rec 能在不引入显著算力开销的前提下,把图结构信息塞进推荐系统——在效果与效率间取得良好平衡,适合工业落地。
消融与分析(RQ4)¶
软图聚类的有效性¶
Table 4:软聚类 vs 硬聚类的模块度(modularity,越高越好)
| Method | Beauty | Sports | Toys | Yelp |
|---|---|---|---|---|
| Hard (Leiden) | 0.419 | 0.365 | 0.437 | 0.691 |
| Soft (Ours) | 0.499 | 0.452 | 0.550 | 0.757 |
分析:本文软聚类在所有四个数据集上的模块度都显著高于硬聚类 Leiden(例如 Sports 上 0.365→0.452,提升 23.8%)。模块度是评估聚类质量的常用指标,这说明软聚类能捕捉更细腻、更复杂的 item 兴趣画像——正是准确建模用户兴趣的关键,验证了"软分配优于硬分配"的设计选择。
兴趣画像损失的有效性¶
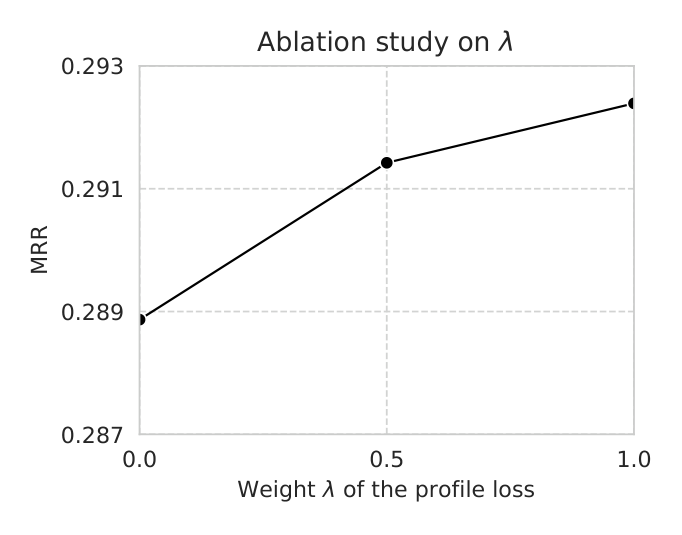
如 Figure 2(在 Beauty 上),随 profile loss 权重 $\lambda$ 从 0 增大到 1.0,推荐指标 MRR 单调上升(约从 $\lambda=0$ 的 0.289 升到 $\lambda=1.0$ 的约 0.293)。特别地,当 $\lambda=0$(即不用 profile loss)时 MRR 明显低于 $\lambda>0$。这表明 $\mathcal{L}_{\text{profile}}^t$ 在捕捉 item 间复杂关系、提升推荐准确度上起到关键作用——让模型显式预测每次交互的兴趣(用软画像作标签)确实有增益。
核心贡献总结¶
- 稀疏图 schema 作为共参与上下文:提出稀疏化 item 共参与图作为 item schema,理论证明采样 $O(M\log M)$ 条共参与边即可近似保持结构信息(Theorem 2),远比原始 $O(M^2)$ 的共参与图稀疏。
- 可扩展软图聚类:基于可微的模块度目标 $Q_{\text{soft}}$(Proposition 3 闭式解),近线性时间 $O(\rho M\log M)$ 可算、可 GPU 加速(Proposition 4)。
- 基于聚类的 item 兴趣画像:(i) 用共参与图的簇作 item 兴趣原型;(ii) 用每个 item 的软成员作 item 兴趣画像,提供超越 item 特征相似度的用户行为信息。
- 面向 GR 的兴趣画像 tokenization:提出新的用户交互序列表示——item 与 item 兴趣画像交替(Eq. 8),让生成式推荐器学到用户兴趣转移模式,并以画像作软标签加 profile 预测损失。
- 强线上表现:在 Meta 产品表面的大规模 A/B 测试中验证了 G2Rec 的优越性。
与已归档相关工作的对比¶
CapsID CapsID: Soft-Routed Variable-Length Semantic IDs(HK PolyU,2026-05-06)¶
关系:独立并发(本文未引用 CapsID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都认定 GR 的"item tokenization 算子"是质量瓶颈,且都把矛头指向"硬分配"这一步。G2Rec 反对硬图聚类(Louvain/Leiden 把一个 item 强制归入唯一簇);CapsID 反对 RQ-VAE 的"硬最近邻 argmax 分配"。两者的 root cause 高度一致:当一个 item 天然属于多个语义/兴趣面时,硬性的一对一分配会丢信息(G2Rec 的"牛油果吐司 = 健康饮食 + 晨间例程"与 CapsID 的"量化前需先表达不确定性,argmax 后无法挽回"是同一论证)。
- 相近的技术骨架:两者都把 item 表示成在一组离散原型/码本上的软成员概率分布,再由该分布加权导出 item 的 token——G2Rec 用 $p_i$(softmax 软成员)加权原型嵌入得连续 token $y_i=\sum_a p_{i,a}v_a$;CapsID 用 capsule routing 系数 $c_{i,\ell k}$(softmax)做"路由后加权重构"。流程图能抽象重合为"软分布 over 原型 → 加权 token"。
- 本文的差异与推进:(i) 底物不同——G2Rec 的软分布来自协同共参与图上的可微模块度聚类(行为信号);CapsID 的软分布来自 item 内容/嵌入上的 capsule routing(内容信号)。(ii) 输出形态不同——G2Rec 一路用连续 token($y_i$ 直接拼进序列,无离散化);CapsID 软路由仅在训练/路由阶段,最终仍
argmaxemit 离散 SID 以兼容 trie 受限 beam search。(iii) 可扩展性根基不同——G2Rec 有谱稀疏化定理把图压到 $O(M\log M)$ 并给出软模块度闭式与复杂度界;CapsID 靠置信驱动变长 + SemanticBPE 子词合并控制序列长度与碰撞。 - 可比的方法/实验差异:评测数据集有交集(CapsID 用 3 个 Amazon 基准;G2Rec 用 Beauty/Sports/Toys/Yelp),但 baseline 与指标口径不同,难以直接并表。两者各自的最强卖点:G2Rec 平均排名 1.04、最强基线 NDCG@5 +14.9%(Sports)、Meta 线上 A/B 正收益;CapsID 在 3 个 Amazon 基准上 R@10 比最强单表征基线高 8.9%–11.0%,并以 51% 推理时延匹配/超越 COBRA。一个共同的洞见落点:"item→token 的硬一对一分配是错的原语,应换成软的分布式成员"——G2Rec 从协同图、CapsID 从内容码本,分别独立到达。
说明:另有三篇近似候选经语义初筛后剔除——DACT DACT(同为"协同 tokenizer"底物,但其问题是持续学习下的协同漂移/稳定性,解法是漂移识别+锚定更新,与本文"静态整体图注入+多兴趣软成员"问题不同构);TIGER TIGER(GR 语义 tokenization 的奠基工作,但走内容 RQ-VAE 量化路线、且为 >2 年前奠基工作,结构化对比交由 DAG 兜底);RAGR RAGR(同样构造"交替双 token 序列",但第二条流是评论文本语义、问题是内容增强,与本文"注入协同共参与图结构"问题不同构)。
讨论与局限性¶
核心贡献与值得借鉴的设计:
- 消去 user 节点、改用 item-item 共参与图是个很"工业"的选择——把高频变动的 user 侧从图里拿掉,换来更静态、更新更便宜的 item 图,再配合谱稀疏化的 $O(M\log M)$ 理论保证,是兼顾效果与可扩展性的漂亮设计。
- 可微软模块度(Eq. 4)把经典图模块度从硬成员推广到软成员并给出闭式 + 近线性复杂度,是本文最有理论分量的部分,可单独作为"GPU 上可端到端优化的图聚类"工具复用。
- 连续兴趣 token 交替进序列 + 软标签 profile loss:用离线算好的连续 token 几乎零成本地把全局协同结构塞进 GR,工程上很实用(Table 3 的开销可忽略)。
局限与争议:
- 两阶段解耦的可扩展性隐患:图聚类与兴趣画像是离线周期性计算、再与 item 嵌入拼接,并未与推荐器 $F$ 端到端联合优化。这正是"先离线压缩/聚类、再在线建模"范式的典型瓶颈(与 SIF/IAT 同类):当推荐器规模上扩(如换更大的 LLM 骨干)时,"如何表征历史兴趣"(聚类/原型数 $C$)不会随之自动增长,兴趣表征能力可能成为天花板。
- 离线聚类的时效性:周期性离线运行图聚类,意味着新 item / 兴趣漂移的反映存在滞后——这恰是 DACT 关注的"协同漂移"问题,本文未处理。
- online A/B 披露不足:因公司政策,线上提升幅度(>0.03% in-session、0.06%–0.19%)和实验细节都很笼统,难以独立评估业务价值的真实量级。
- 效果声明略有夸大:如前述 Yelp Recall@1 一格 G2Rec 实为第二名,与"在所有指标上一致超越"的措辞不符。
- 依赖现成 item 嵌入:$x_i$ 直接用 SASRec 的 $d=64$ 嵌入,原型嵌入 $v_a$(Eq. 6)只是其加权平均,画像 token 的语义上限受这套预训练嵌入约束。
与已有工作的差异:相对图序列化(喂 LLM 太贵)和 GNN(只看局部子图),G2Rec 用"图聚类得到的全局兴趣原型"作为压缩后的整体图信息,绕开了二者的代价;相对依赖启发式、缺监督的语义 tokenization,G2Rec 的软模块度提供了明确的(自)监督目标。其与 CapsID 的"殊途同归"(软成员替代硬分配)则进一步说明这是 2026 年 GR tokenization 的一条被多方独立验证的方向。