研究动机与背景¶
生成式推荐与 Semantic ID 的瓶颈在 Tokenizer¶
生成式推荐(Generative Recommendation, GR)已成为传统"召回 + 排序"流水线的统一替代:每个 item 被编码为一段短的 Semantic ID(SID) token 序列,序列模型自回归生成下一个用户可能消费 item 的 SID。这种范式有三个吸引力——把召回变成受限生成、可在语义近邻 item 之间共享前缀、并通过内容驱动的 ID 天然支持冷启 item。但它把"推荐质量"的相当一部分负担转嫁给了 tokenizer:如果 SID 损失了关键信息,生成器只能学到一个被劣化的目标。
UniRec 在判别 / 生成两类 recommender 的表达力分析中已经形式化论证了这一点:当生成器能拿到完整 item 属性时,两者表达力相当,差距主要来自 SID 仅覆盖了一小部分属性。GRID 风格的实证研究进一步显示,盲目加深 RQ 层数并不能单调改善推荐——更深的 SID 位置反而会放大早期量化误差;GLASS 观察到一个相关的 rank degradation 现象:第一个 SID token 的预测错误会先把真实 item 在 rank 中推开,后面的 token 只能勉强补救。
现有路线的两类设计与它们的代价¶
针对"信息瓶颈在 tokenizer"这一共识,已有工作分两条路:
- 稀疏 SID 之上打补丁(Patch route):COBRA 在稀疏 SID 后串接 dense vector 并做 BeamFusion;UniRec 在 SID 前缀拼接属性 chain-of-attribute;LIGER 风格在生成检索旁保留 dense 检索通道。这类方法效果好但推理变重——需要二次检索 / 重排路径、额外 ANN 基础设施、精心调参的融合函数;一旦 SID 本身被改良,它们的边际收益就会萎缩。
- 改造 tokenizer 本身(Tokenizer-centric):TIGER 用 RQ-VAE 建立 SID 骨干;LETTER 把协同信号注入 tokenizer;ReSID 用 recommender-native embedding + 全局对齐量化替代通用 LLM 语义嵌入。它们都保留了"残差量化的硬最近邻分配"这一步——而这正是本文要替换掉的关键算子。
一个合格的 tokenizer-centric 方案必须满足三条性质:(i) 语义充分性——SID 不能只是粗糙桶号;(ii) 预测简洁性——生成器仍能建模 token 序列;(iii) 部署兼容性——受限 beam search 与 trie 过滤仍然有效。这三条联合排除了"无脑放大码本 / 加深 SID"的廉价路线。
CapsID 的核心思想¶
CapsID 把焦点压在"分配算子"这一步:用 soft probabilistic capsule routing 替换 winner-take-all 的 argmax。每一层维护多个 semantic capsule;item 残差按概率路由到多个 capsule,残差更新由路由后的加权重构完成而非单一胜者码字;当 active capsule 的置信度足够高,SID 就提前停止生成(confidence-driven 变长)。在此之上,SemanticBPE 通过共现 + 嵌入兼容性的差异化打分把相邻 SID token 合并为可复用的 sub-word,但只在共现与嵌入兼容性都支持时才合并。
四点贡献:
- 把已有 SID 系统按 patch-based / tokenizer-centric 重新组织,论证更好的 tokenizer 让大部分 dense / attribute patch 变得不必要;
- 设计 CapsID tokenizer:capsule routing + soft 残差分配 + 迭代自纠 + 置信驱动变长;
- 设计 SemanticBPE:可微 sub-word 模块,按共现 + 嵌入兼容性双重打分进行合并;
- 在三个公开数据集 + 35M item 工业目录上,CapsID+SemanticBPE 一致优于 SOTA tokenizer-centric 与 patch-route 系统,且只用其一小部分推理代价。
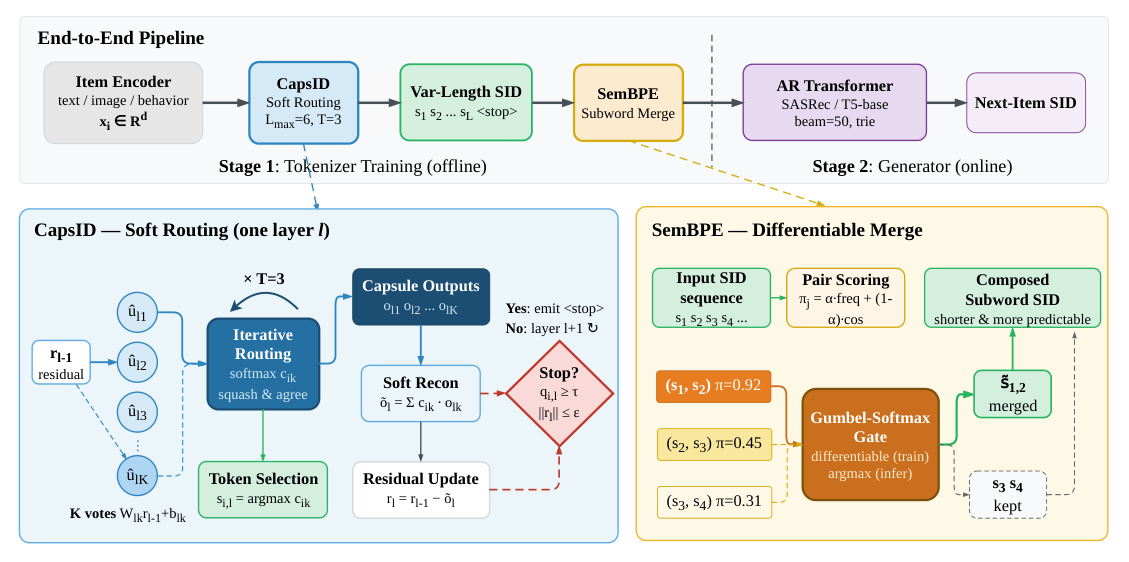
核心方法¶
设 item $i$ 的输入嵌入为 $\mathbf{x}_i \in \mathbb{R}^d$,由 content / collaborative / multi-modal encoder 给出。目标是把 $\mathbf{x}_i$ 映射为变长 SID $\mathbf{s}_i = (s_{i,1}, \ldots, s_{i,L_i})$,使其紧凑、可预测、低碰撞。整体 pipeline 如 Figure 1:item feature 经过若干层 capsule(每层带 confidence-driven early stopping),SemanticBPE 合并语义兼容相邻 token,最后送入 SASRec / T5-base 自回归 Transformer 通过 trie-constrained beam search 生成下一 item 的 SID。
设计三不变式¶
CapsID 围绕三条不变式设计:
- 离散有限序列:emit 出来的表示必须仍是有限离散 token 序列,所有受限解码机制不变;
- 量化前先表达不确定性:不确定性必须在离散化之前被建模,不能在 argmax 之后再补救——一旦塌陷为错误 token,已无法挽回;
- 可解释诊断:routing weight 暴露各语义 facet 解释力、capsule 激活强度衡量置信度、residual norm 衡量未解释信息量。这三个量在 §4 用于检验"提升来自更好的 tokenizer 而非更大的输出空间"。
软残差路由(Soft residual routing)¶
在第 $\ell$ 层维护 $K_\ell$ 个 capsule,capsule $k$ 拥有 pose 变换 $\mathbf{W}_{\ell k}$ 与偏置 $\mathbf{b}_{\ell k}$。给定残差 $\mathbf{r}_{i,\ell-1}$($\mathbf{r}_{i,0} = \mathbf{x}_i$ 经 $\ell_2$ 归一),每个 capsule 给出一票:
$$ \hat{\mathbf{u}}_{i,\ell k} = \mathbf{W}_{\ell k}\,\mathbf{r}_{i,\ell-1} + \mathbf{b}_{\ell k} \tag{1} $$
路由从 logits $a^{(0)}_{i,\ell k} = 0$ 开始,迭代 $T$ 轮(默认 $T=3$):
$$ c^{(t)}_{i,\ell k} = \mathrm{softmax}_k\bigl(a^{(t-1)}_{i,\ell k}\bigr) \tag{2} $$
$$ \mathbf{v}^{(t)}_{i,\ell} = \sum_k c^{(t)}_{i,\ell k}\,\hat{\mathbf{u}}_{i,\ell k} \tag{3} $$
$$ \mathbf{o}^{(t)}_{i,\ell} = \mathrm{squash}\bigl(\mathbf{v}^{(t)}_{i,\ell}\bigr) \tag{4} $$
$$ a^{(t)}_{i,\ell k} = a^{(t-1)}_{i,\ell k} + \hat{\mathbf{u}}^{\top}_{i,\ell k}\mathbf{o}^{(t)}_{i,\ell} \tag{5} $$
squash 非线性 $\mathrm{squash}(\mathbf{z}) = \tfrac{\|\mathbf{z}\|^2}{0.5+\|\mathbf{z}\|^2}\,\tfrac{\mathbf{z}}{\|\mathbf{z}\|}$ 把范数压在 $[0,1)$,对小幅度敏感。每个 capsule 的 per-capsule 输出 $\mathbf{o}_{i,\ell k} = \mathrm{squash}(\hat{\mathbf{u}}_{i,\ell k})$ 与迭代轮次 $t$ 无关,仅用于残差更新。emit 的 token 与置信度为:
$$ s_{i,\ell} = \arg\max_k c^{(T)}_{i,\ell k}, \qquad q_{i,\ell} = \max_k c^{(T)}_{i,\ell k}\,\|\mathbf{o}^{(T)}_{i,\ell}\| \tag{6} $$
关键差异——残差更新使用路由后的加权重构而非单一胜者:
$$ \mathbf{r}_{i,\ell} = \mathbf{r}_{i,\ell-1} - \sum_k c^{(T)}_{i,\ell k}\,\mathbf{o}^{(T)}_{i,\ell k} \tag{7} $$
公式 (7) 是 soft routing 与 hard quantization 的根本分水岭:不再"扔掉"非胜出 capsule 与残差的部分一致性,而是把所有部分一致性扣除掉,只把真正未解释的部分流向下一层。例如一个 boundary item "travel cooking kit"——它兼有"travel"与"cooking"两个 facet,hard argmax 会强迫它在两者间二选一,而 soft routing 让两个 capsule 同时贡献到其重构,真正不可解释的剩余信号才进入下一层残差。
这与"用 Gumbel-Softmax 替代 argmax"不同:CapsID 的残差更新本身使用了路由后重构,更深层看到的是更小、更干净的误差信号。两个实现细节在实践中很关键:(a) routing 之前要对 item embedding 做 $\ell_2$ 归一,否则高范数 item 会主导一致性分数;(b) capsule 参数在每层独立,让浅层专注粗 facet、深层精炼残差。
Confidence-driven 变长¶
固定长度 SID 给"易"和"难"item 同一 token 预算。CapsID 在残差被解释充分后立即停止:
$$ L_i = \min\bigl\{\ell : q_{i,\ell} \ge \tau \;\text{or}\; \|\mathbf{r}_{i,\ell}\|_2 \le \epsilon \;\text{or}\; \ell = L_{\max}\bigr\} \tag{8} $$
这一条规则同时使用 三个前向停止判据(hard cap $L_{\max}$、residual-norm $\epsilon$、confidence $\tau$)+ Eq. (10) 的 训练时长度正则 $\mathcal{L}_{\text{len}} = \mathbb{E}[L_i]$。四重保险一起防止长度爆炸,同时呼应 GRID 的观察:盲目加深会伤害——不确定 item 应当多走几层,置信 item 应当尽早停。
变长还改变了"碰撞"的语义:固定深度 hard SID 中两个尾部 item 在四个位置上完全相同时无法被区分,常被人为附加 disambiguation token;CapsID 中两个 item 即便 argmax 相同,也可能在 routing 权重 / 停止 confidence 上不同。生成器看到的是更干净的 token 目标——模糊 item 被鼓励停在稳定前缀而非走到低 confidence 的残差层。
SemanticBPE 组合¶
给定 CapsID 输出的 SID 序列,SemanticBPE 学习是否把相邻 token 合并为可复用 subword。对每个相邻对 $(s_j, s_{j+1})$:
$$ m(s_j, s_{j+1}) = \alpha\,\widehat{\mathrm{freq}}(s_j, s_{j+1}) + (1-\alpha)\,\cos(\mathbf{e}_{s_j}, \mathbf{e}_{s_{j+1}}) \tag{9} $$
第二项防止"频率高但语义无关"的对被合并——这是 BPE 在推荐中的常见失败模式:极高频但语义宽泛的前缀对会主宰词表,放大流行度偏置。Gumbel-Softmax gate 提供训练时可微,推理时 $\arg\max$ 硬合并。合并阈值 $\theta$ 从 0.90 线性退火到 0.55,前期严苛防止"频率主导前缀对"先抢占词表;保守的合并策略(一对仅当频次超过 $n_{\min}=20$ 且 $\cos(\mathbf{e}_{s_j}, \mathbf{e}_{s_{j+1}}) > \theta$ 才被考虑)让 SemanticBPE 仅压缩"稳定的多 token motif",而非每个序列都被压。
训练目标:两阶段¶
借鉴 ReSID 的 recommender-native tokenizer 思路,分两阶段训:
- Stage 1(Tokenizer pretraining):仅训 item projection、capsule 变换 $\{\mathbf{W}_{\ell k}, \mathbf{b}_{\ell k}\}$、SemanticBPE 合并 MLP;序列生成器不训。
- Stage 2(Generator adaptation):冻结 capsule 中心与 SemanticBPE 合并 MLP,联合训练序列生成器、低秩路由 adapter(rank $r=8$)和 SemanticBPE Gumbel gate 的可学习标量偏置。
最终目标:
$$ \mathcal{L} = \mathcal{L}_{\text{NTP}} + \lambda_r \mathcal{L}_{\text{route}} + \lambda_s \mathcal{L}_{\text{spread}} + \lambda_l \mathcal{L}_{\text{len}} + \lambda_b \mathcal{L}_{\text{BPE}} \tag{10} $$
其中 $\mathcal{L}_{\text{NTP}}$ 是 next-token cross entropy(仅 Stage 2);$\mathcal{L}_{\text{route}} = \|\mathbf{x}_i - \hat{\mathbf{x}}_i\|_2^2$ 与 $\mathcal{L}_{\text{spread}}$ 是 tokenizer 损失,margin 从 0.2 退火到 0.9。
为何不全联合? 完全联合训练让生成器追逐一个被 tokenizer 持续改写的"移动目标",ReSID 与 ETEGRec 的分析显示这种自指训练不稳定。CapsID 先学到"对推荐充分的 code geometry",再让生成器适应已稳定的几何;Stage 2 仍允许有限路由适配,但 capsule 中心被冻结以防止后期坍塌。
算法(一条 item 的前向)¶
Algorithm 1: CapsID Tokenizer Forward (one item)
Require: x_i, {W_{ℓk}, b_{ℓk}}, T, τ, ε, L_max
Ensure : SID s_i = (s_{i,1},...,s_{i,L_i}), confidences {q_{i,ℓ}}
1: r_{i,0} ← x_i / ||x_i|| # ℓ2 normalize
2: for ℓ = 1, ..., L_max do
3: compute votes û_{i,ℓk} = W_{ℓk} r_{i,ℓ-1} + b_{ℓk} for all k # Eq.(1)
4: initialize agreement logits a_{i,ℓk}^(0) ← 0
5: for t = 1, ..., T do
6: c_{i,ℓk}^(t) ← softmax_k(a_{i,ℓk}^(t-1)); v_{i,ℓ}^(t) ← Σ_k c û
7: o_{i,ℓ}^(t) ← squash(v); a_{i,ℓk}^(t) ← a_{i,ℓk}^(t-1) + û^⊤ o
8: end for
9: s_{i,ℓ} ← argmax_k c_{i,ℓk}^(T); q_{i,ℓ} ← c_{i,ℓs_{i,ℓ}}^(T) · ||o_{i,ℓ}^(T)||
10: o_{i,ℓk} ← squash(û_{i,ℓk}); r_{i,ℓ} ← r_{i,ℓ-1} − Σ_k c_{i,ℓk}^(T) o_{i,ℓk} # Eq.(7)
11: if q_{i,ℓ} ≥ τ or ||r_{i,ℓ}||_2 ≤ ε then
12: L_i ← ℓ; break
13: end if
14: end for
15: return (s_{i,1}, ..., s_{i,L_i}), (q_{i,1}, ..., q_{i,L_i})
理论分析¶
Proposition 1(软路由重构接近硬路由). 设 $\mathbf{c}_{\ell k}$ 为深度 $\ell$ 第 $k$ 个 codebook 中心,$s_{i,\ell} = \arg\max_k c^{(T)}_{i,\ell k}$ 为 argmax token。定义硬 / 软重构
$$ \hat{\mathbf{x}}^{\text{hard}}_i = \sum_{\ell=1}^{L_i}\mathbf{c}_{\ell s_{i,\ell}}, \qquad \hat{\mathbf{x}}^{\text{soft}}_i = \sum_{\ell=1}^{L_i}\sum_{k=1}^{K_\ell} c^{(T)}_{i,\ell k}\,\mathbf{o}_{i,\ell k} $$
在 $\|\mathbf{o}_{i,\ell k} - \mathbf{c}_{\ell k}\|_2 \le \delta$ 与 $\|\mathbf{c}_{\ell k}\|_2 \le C$ 假设下,
$$ \|\hat{\mathbf{x}}^{\text{soft}}_i - \hat{\mathbf{x}}^{\text{hard}}_i\|_2 \;\le\; L_i\delta + 2C\sum_{\ell=1}^{L_i}\bigl(1 - c^{(T)}_{i,\ell s_{i,\ell}}\bigr) \tag{11} $$
物理意义:当胜者权重 $w_s = 1$ 且 $\delta = 0$(hard regime),软 / 硬重构重合;CapsID 实验中平均胜者质量 $\bar{w}_s = 0.86$、$\delta$ 在 capsule warmup 后小,因此 soft routing 近似 hard 重构,但又把质量分到次要 capsule——这正是 intra-code similarity 上升的原因,但不是靠"丢失重构精度"换取的。
Proposition 2(期望长度上界). 设 $g_\ell(\mathbf{x}) = \Pr[q_{i,\ell} \ge \tau \text{ or } \|\mathbf{r}_{i,\ell}\|_2 \le \epsilon \mid \ell \le L_i]$ 为分层停止概率。若 $\inf_{\mathbf{x}} g_\ell(\mathbf{x}) \ge g > 0$ 对所有 $\ell \ge 1$ 成立,则
$$ \mathbb{E}[L_i] \;\le\; 1 + \sum_{\ell=2}^{L_{\max}}(1-g)^{\ell-2} \;\le\; \min\bigl(L_{\max},\, 1 + 1/g\bigr) \tag{12} $$
四重停止保险使期望长度即便 $L_{\max}$ 不绑定也是有限的。Figure 2(b) 实测:confidence + residual 规则覆盖 90-92% 的 item 停止,hard cap 仅占 8-10%。
Proposition 3(路由 ≡ 单步 capsule EM 的 E-step). 在残差服从各向同性高斯混合 $\sum_k \mathcal{N}(\boldsymbol{\mu}_{\ell k}, \sigma^2 \mathbf{I})$、等权混合假设下,E-step 后验责任
$$ p(k\mid\mathbf{r}_{i,\ell-1}) \propto \exp\Bigl(-\tfrac{1}{2\sigma^2}\|\hat{\mathbf{u}}_{i,\ell k} - \boldsymbol{\mu}_{\ell k}\|^2\Bigr) \propto \exp\Bigl(\tfrac{1}{\sigma^2}\hat{\mathbf{u}}^{\top}_{i,\ell k}\boldsymbol{\mu}_{\ell k}\Bigr) \tag{13} $$
与 Eq. (2)-(5) 中 $c^{(t)}$ 的函数形式一致——只要把 GMM 均值 $\boldsymbol{\mu}_{\ell k}$ 与一致性目标 $\mathbf{o}^{(t-1)}_{i,\ell}$ 对应、把 $1/\sigma^2$ 吸收入路由温度。这给"$T \ge 3$ 时 routing agreement 饱和"提供了 EM 收敛的解释,与 Figure 3(c) 的实证曲线一致。
计算复杂度. Tokenizer 训练 $\mathcal{O}(N L_{\max} K T d d_c)$,$N$ 是目录大小,$K = \max_\ell K_\ell$。推理由 trie 约束 beam search 主导 $\mathcal{O}(B \bar{L} |V|)$,CapsID $\bar{L} \approx 3.6$ vs 固定长度 baseline $\bar{L}=4$,per-beam step 少 ~10%,残差 routing + SemanticBPE gate 把净成本控制在 1.05×-1.08× TIGER(Table 4),远低于 dense-patch 的 2.10×。
实验设置¶
数据集¶
| Dataset | Users | Items | Interactions | Avg. length |
|---|---|---|---|---|
| Beauty | 22,363 | 12,101 | 198,502 | 8.9 |
| Sports | 35,598 | 18,357 | 296,337 | 8.3 |
| Toys | 19,412 | 11,924 | 167,597 | 8.6 |
| Industrial (ours) | 8.6M | 35.8M | 331.1M | 38.5 |
公开 benchmark 用 5-core leave-one-out;工业数据集来自一家大型社交媒体平台的 35M item 多模态目录(text/image/behavior 嵌入)。
Baselines¶
11 个:TIGER, LC-Rec, LETTER, ETEGRec, ADA-SID, ActionPiece, COBRA, UniRec-style Chain-of-Attribute, DIGER, SA²CRQ, ReSID。所有方法共用同一 SASRec / T5 风格生成器与 beam search 协议;dense-patch 变体走 COBRA-style BeamFusion 路径。
指标¶
- 推荐指标:Recall@k 与 NDCG@k(公开 $k\in\{5,10\}$,工业 $k\in\{50,100\}$);
- Tokenizer 质量:Collision rate(不获唯一 SID 的比例)、Code utilization(被使用 codebook 比例)、Gini(utilization 均匀度)、Intra-code similarity(共享首 token 的对的均 cosine)、CodeRecall@$M$(SASRec 在 SID 序列上预测下一 item 真实首 token 落在 top-$M$ 概率,$M=50$)、head/torso/tail Recall@10、平均 SID 长度 $\bar{L}$、归一化推理代价。
公平控制¶
所有 SID 方法共用 item encoder、生成器架构、beam size、invalid-ID 过滤。需要附加信息(UniRec 属性、COBRA dense vec)的方法单独列推理代价并以 $\dagger$ 标注,防止 patch 系统与 single-SID 系统在不同检索预算下被混比。
主要实验结果(Q1)¶
Table 3:三个公开 benchmark 主结果¶
| Method | Beauty R@5 | Beauty R@10 | Beauty N@5 | Beauty N@10 | Sports R@5 | Sports R@10 | Sports N@5 | Sports N@10 | Toys R@5 | Toys R@10 | Toys N@5 | Toys N@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TIGER | 0.0454 | 0.0648 | 0.0321 | 0.0384 | 0.0264 | 0.0400 | 0.0181 | 0.0225 | 0.0521 | 0.0712 | 0.0371 | 0.0432 |
| LC-Rec | 0.0478 | 0.0675 | 0.0334 | 0.0397 | 0.0276 | 0.0417 | 0.0188 | 0.0233 | 0.0540 | 0.0734 | 0.0384 | 0.0447 |
| LETTER | 0.0500 | 0.0708 | 0.0340 | 0.0406 | 0.0288 | 0.0435 | 0.0198 | 0.0244 | 0.0547 | 0.0741 | 0.0389 | 0.0452 |
| ETEGRec | 0.0513 | 0.0725 | 0.0348 | 0.0415 | 0.0294 | 0.0444 | 0.0201 | 0.0249 | 0.0560 | 0.0756 | 0.0397 | 0.0460 |
| ADA-SID | 0.0524 | 0.0740 | 0.0355 | 0.0422 | 0.0302 | 0.0456 | 0.0206 | 0.0254 | 0.0566 | 0.0762 | 0.0401 | 0.0465 |
| ActionPiece | 0.0553 | 0.0775 | 0.0379 | 0.0424 | 0.0330 | 0.0500 | 0.0224 | 0.0264 | 0.0559 | 0.0760 | 0.0398 | 0.0463 |
| DIGER | 0.0535 | 0.0752 | 0.0362 | 0.0431 | 0.0306 | 0.0463 | 0.0210 | 0.0258 | 0.0572 | 0.0771 | 0.0407 | 0.0472 |
| SA²CRQ | 0.0520 | 0.0732 | 0.0352 | 0.0419 | 0.0298 | 0.0451 | 0.0203 | 0.0252 | 0.0562 | 0.0758 | 0.0399 | 0.0463 |
| ReSID | 0.0548 | 0.0770 | 0.0374 | 0.0438 | 0.0314 | 0.0475 | 0.0215 | 0.0266 | 0.0583 | 0.0786 | 0.0414 | 0.0481 |
| COBRA$^\dagger$ | 0.0537 | 0.0725 | 0.0395 | 0.0456 | 0.0305 | 0.0434 | 0.0215 | 0.0257 | 0.0619 | 0.0781 | 0.0462 | 0.0515 |
| UniRec-CoA$^\dagger$ | 0.0540 | 0.0763 | 0.0368 | 0.0434 | 0.0316 | 0.0478 | 0.0217 | 0.0268 | 0.0596 | 0.0802 | 0.0422 | 0.0485 |
| CapsID | 0.0574 | 0.0808 | 0.0398 | 0.0460 | 0.0337 | 0.0507 | 0.0229 | 0.0281 | 0.0602 | 0.0803 | 0.0432 | 0.0498 |
| CapsID+SemanticBPE | 0.0594 | 0.0839 | 0.0411 | 0.0477 | 0.0351 | 0.0527 | 0.0237 | 0.0290 | 0.0636 | 0.0855 | 0.0465 | 0.0528 |
结论:相对最强 single-representation baseline(ReSID),CapsID Recall@10 提升 4.9% / 6.7% / 2.2%(Beauty / Sports / Toys),加上 SemanticBPE 进一步推到 8.9% / 11.0% / 8.8%。CapsID+SemanticBPE 在每个公开 benchmark 上追平或超越 COBRA-style sparse-dense 系统,但不付额外的 dense-vector 推理代价。最大单项收益是把 hard argmax 换成 soft routing 那一步——4-7% 的相对 R@10 提升。COBRA 在 Toys(NDCG@10 0.0515 vs ReSID 0.0481)上的优势主要来自更广的 item vocabulary,而 CapsID+SemanticBPE 在不引入 dense retrieval channel 的前提下把这道差距合上。
显著性:CapsID+SemanticBPE 显著优于每个 single-rep baseline at $p<0.01$(三数据集);显著优于 COBRA at $p<0.05$(Beauty / Sports)与 $p<0.10$(Toys);CapsID(无 SemBPE)显著优于 ReSID at $p<0.01$(三数据集)。
Table 4:Tokenizer-centric vs patch(Q2,Beauty)¶
| Configuration | Representation | R@10 | N@10 | Cost |
|---|---|---|---|---|
| TIGER | RQ SID | 0.0648 | 0.0384 | 1.00× |
| TIGER + dense$^\dagger$ (COBRA) | RQ SID + dense vec | 0.0725 | 0.0456 | 2.10× |
| UniRec-CoA$^\dagger$ | Attribute prefix + RQ SID | 0.0763 | 0.0434 | 1.34× |
| CapsID | Routed SID | 0.0808 | 0.0460 | 1.05× |
| CapsID + dense$^\dagger$ | Routed SID + dense vec | 0.0829 | 0.0473 | 2.14× |
| CapsID + SemanticBPE | Routed subword SID | 0.0839 | 0.0477 | 1.08× |
关键 takeaway:把 dense vector 加在 TIGER 上提升 R@10 11.9%(0.0648 → 0.0725),代价是 2.10× 推理延迟;把同一 dense vector 加在 CapsID 上仅提升 2.6%(0.0808 → 0.0829),却仍要 2× 延迟——dense path 的边际价值在更好的 SID 之后直接缩水。SemanticBPE 在 1.08× 代价下把 R@10 推到 0.0839,两个轴上同时支配 dense 变体,验证了"更好的 tokenizer 让 dense patch 不必要"这一论点。
消融与分析(Q3)¶
Table 5:在 Beauty 上的消融¶
| Variant | R@10 | Drop | Interpretation |
|---|---|---|---|
| Full CapsID+SemanticBPE | 0.0839 | – | Complete pipeline |
| w/o soft residual, hard winner only | 0.0702 | -16.3% | assignment is the main factor |
| w/o routing iterations ($T=1$) | 0.0731 | -12.9% | no self-correction |
| fixed length $L=4$ | 0.0765 | -8.8% | over-encodes easy items |
| fixed length $L=2$ | 0.0658 | -21.6% | under-encodes complex items |
| w/o spread loss | 0.0770 | -8.2% | capsule collapse hurts |
| w/o SemanticBPE | 0.0808 | -3.7% | composition gain is stable |
| frequency-only BPE | 0.0817 | -2.6% | semantic gating matters |
逐项解读:
- soft residual 是首要因素(-16.3%):换回 hard winner-only 损失最大,说明真正重要的不是 codebook 初始化或额外监督,而是分配算子——把 argmax 换成 soft routing。
- iterative agreement 真有自纠作用(-12.9%,$T=1$):单遍 Gumbel 松弛抓不到的多轮一致性优化有 12.9% 的真实贡献。
- 变长两端都有用:固定 $L=4$ 过编码(-8.8%);固定 $L=2$ 欠编码(-21.6%,最严重)。confidence-driven 长度让简单 / 复杂 item 各自得到合适的 token 预算。
- spread loss 不可或缺(-8.2%):失去它会出现 capsule collapse,召回直接掉。
- SemanticBPE 中的语义门控关键(-3.7% w/o BPE,-2.6% frequency-only BPE):纯频率合并能补回 SemanticBPE 大部分增益,但残余 1.1% 来自 cosine 兼容性项——"高频但语义无关的前缀对"必须被语义阻断才不主宰词表。
Figure 2:变长的工作机制¶
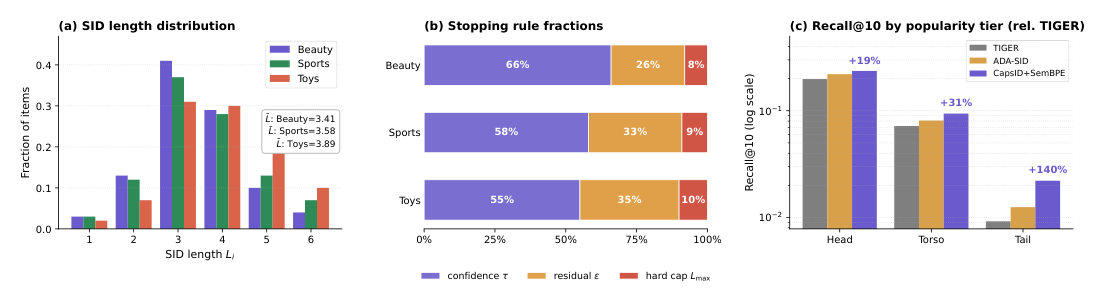
(a) 三数据集上 SID 长度分布:mode 都在 $L=3$,均值 $\bar{L} \in [3.41, 3.89]$,远低于 hard cap $L_{\max}=6$,与 Proposition 2 的 $\mathcal{O}(1+1/g)$ 上界一致。 (b) 三种停止规则各自的覆盖率:confidence threshold $\tau$ 触发 55-66% 的 item,residual norm 触发 25-35%,hard cap 仅 8-10%——cap 仅作为安全网而非主导规则。 (c) Beauty 上按 popularity tier 分解的 R@10 相对 TIGER:head +19%、torso +30%、tail +140%。尾部增益最大——这与 soft-routing 重构界(Proposition 1)一致:boundary item 在尾部居多,多 capsule 重构正是它们最受益的场景。
Figure 3:Tokenizer 几何诊断¶
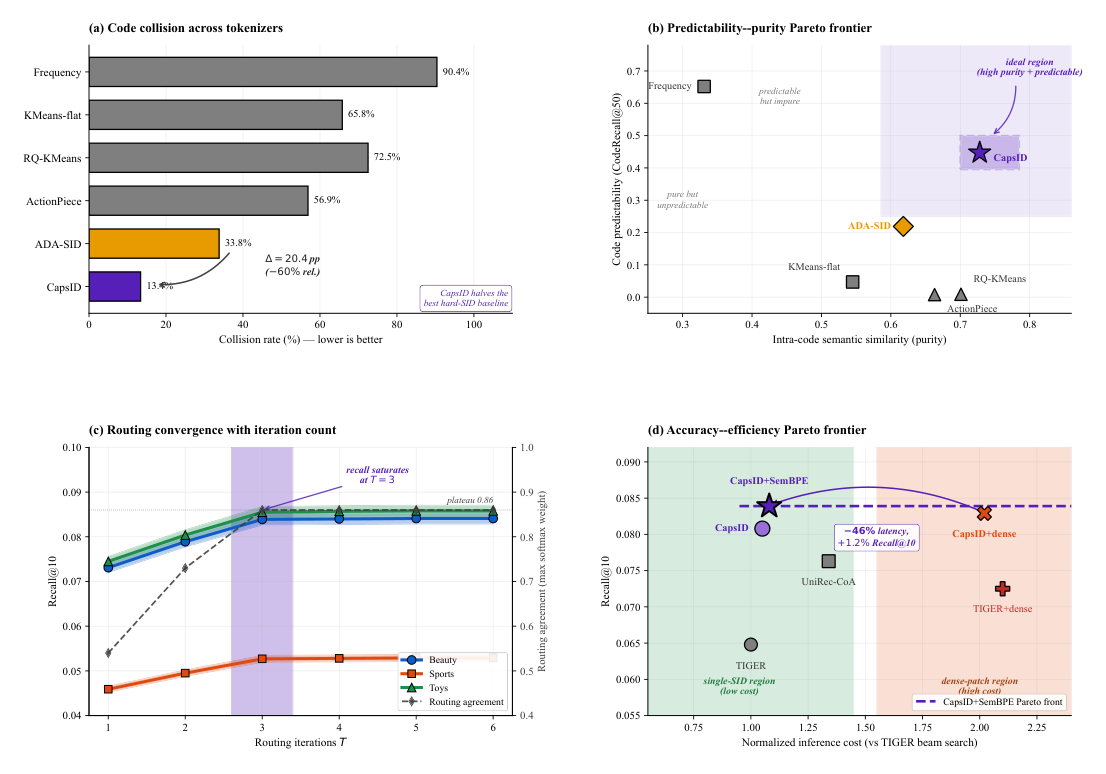
(a) Code collision:CapsID 13.4% 是所有 tokenizer 中最低,约为 ADA-SID(33.8%)的 40%、Frequency tokenization(90.4%)的 1/6。 (b) purity-predictability Pareto:Frequency 在左上(可预测但语义不纯),RQ-KMeans / ActionPiece 在右下(纯但不可预测),CapsID 独占右上理想区——同时具有最高 intra-code similarity(0.728)与 CodeRecall@50(0.447),后者比 RQ-KMeans 高两个数量级。 (c) 路由收敛:recall 在 $T=3$ 处饱和,与 Proposition 3 的 EM 解释一致;routing-agreement score(max softmax weight)平台在 0.86,与 Prop 1 中的 $\bar{w}_s$ 假设吻合。 (d) Accuracy-cost Pareto:CapsID+SemanticBPE 在 Pareto 前沿,同时支配 COBRA 与 dense-augmented CapsID+dense 变体。
工业 35M 目录评估(Q4)¶
Table 6:工业大规模设置¶
| Method | R@50 | R@100 | N@100 | Collision↓ | $\bar{L}$ |
|---|---|---|---|---|---|
| RQ-KMeans (fixed $L=4$) | 0.1835 | 0.2421 | 0.1216 | 73.2% | 4.00 |
| TIGER | 0.2217 | 0.2843 | 0.1482 | 51.4% | 4.00 |
| ADA-SID | 0.2772 | 0.2926 | 0.1714 | 37.5% | 4.00 |
| ReSID | 0.2881 | 0.3105 | 0.1836 | 31.8% | 4.00 |
| COBRA$^\dagger$ | 0.3014 | 0.3275 | 0.1935 | 51.4% (SID) | 4.00 + dense |
| CapsID | 0.2996 | 0.3286 | 0.1943 | 22.1% | 3.8 |
| CapsID+SemanticBPE | 0.3096 | 0.3356 | 0.1974 | 19.4% | 3.3 |
三点观察:
- CapsID alone 在 R@100(+0.3%)与 N@100(+0.4%)上追平 patch-route COBRA——不需要 dense channel,仅在 R@50 上落后 0.6%(dense vector 对头部 item 最有判别力的指标)。
- CapsID+SemanticBPE 更进一步,三项指标稳定领先 COBRA 2.0-2.7%;同时 collision rate 19.4% 是 RQ-KMeans 的 27%、ADA-SID 的 52%;平均 SID 长度 3.3 是 ADA-SID 的 83%——更短 + 更低碰撞。
- head/tail 模式持续:按 popularity tier 分解,CapsID+SemanticBPE 仅在 head item 上落后 COBRA 3.2%(dense vec 对热门 item 最有用),但在 torso +8.8%、tail +25.4%、cold-start +8.6% 上反超。在同一 ANN 基础设施测端到端推理延迟,CapsID+SemanticBPE 跑 COBRA 51% 的 per-query 延迟,保留 102% 的 R@100——tokenizer-centric 设计在保留率上追平或微超 patch-route,serving cost 减半。
Robustness checks:(i) CapsID+dense 相对 CapsID alone 仅 +2.6%——SID 已经几乎不漏 dense vector 的信息;(ii) collision 与 tail R@10 同时改善(Figure 3(a)、Figure 2(c)),排除"靠扩大解码空间"的解释;(iii) 相对 ADA-SID 的增益不来自"用更多 code"——Table 7 给出更低 Gini 与同 codebook 大小下更高 utilization 的反向证据。
Table 7:Tokenizer 质量诊断(Beauty)¶
| Tokenizer | Collision↓ | Utilization↑ | Gini↓ | Intra-code sim↑ | CodeRecall@50↑ |
|---|---|---|---|---|---|
| Frequency | 90.4% | 0.08% | .92 | 0.331 | 0.652 |
| KMeans-flat | 65.8% | 14.1% | .57 | 0.545 | 0.047 |
| RQ-KMeans | 72.5% | 47.2% | .69 | 0.701 | 0.009 |
| ActionPiece | 56.9% | 3.4% | .65 | 0.663 | 0.008 |
| ADA-SID | 33.8% | 43.7% | .37 | 0.618 | 0.219 |
| CapsID | 13.4% | 55.1% | .23 | 0.728 | 0.447 |
CapsID 在所有 tokenizer 量纲上都最优或并列最优——除了 CodeRecall 略低于 Frequency(0.447 vs 0.652),但 Frequency 的高 CodeRecall 来自语义不纯(intra-code sim 仅 0.331)的"廉价"可预测性。CapsID 在保持高语义纯度(0.728)的同时仍维持高 token 可预测性(0.447),处于 purity-predictability Pareto 前沿的右上理想区域。
Figure 4:四数据集变长分布¶
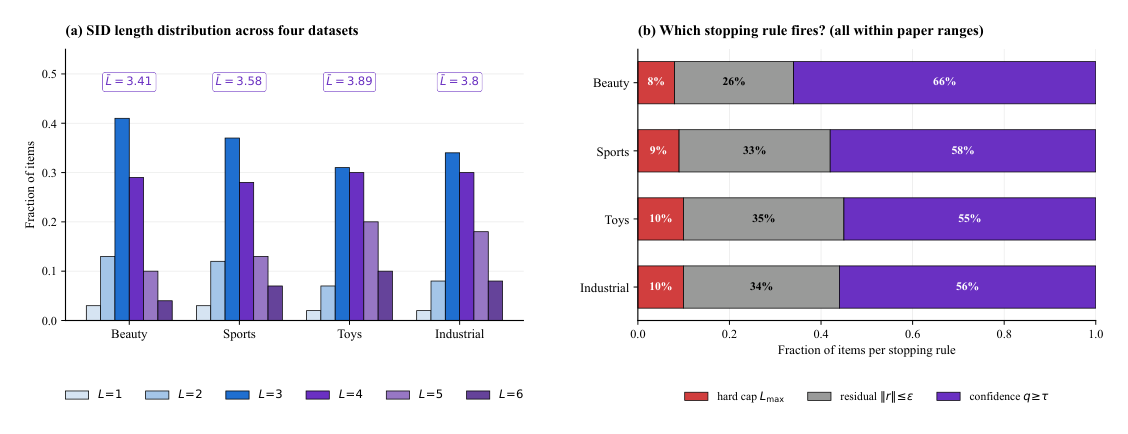
各数据集 mode 都是 $L=3$,工业目录 $\bar{L}=3.8$ 反映其多模态多属性 item 空间。停止规则分解:confidence 启动 55-66%,residual ~30%,hard cap 至多 10%——长度来自学习到的信号,而非"撞到预算"。
Figure 5:Codebook 几何与按位置 prediction accuracy¶
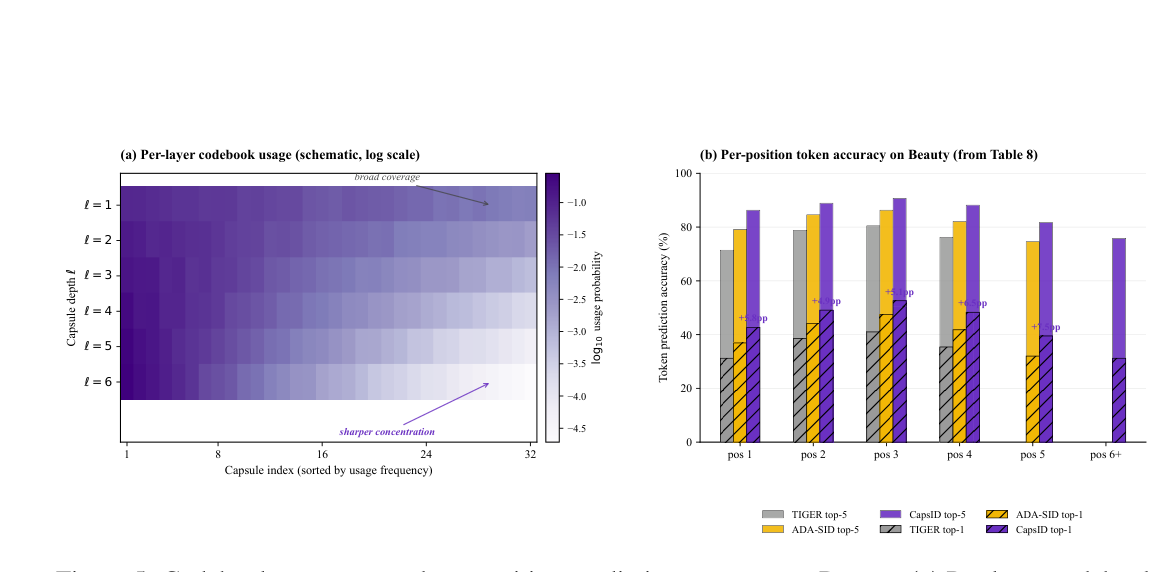
(a) Per-layer codebook usage(top-32 capsule,log scale):浅层 mass 广泛分布(粗 facet),深层集中于少数 capsule(残差精炼),与 Prop 3 EM 行为吻合。 (b) Per-position top-1 / top-5 token accuracy:CapsID 在每个位置上都支配 TIGER / ADA-SID,相对 ADA-SID 的 top-1 边距从 position 1 的 +5.8pp 升到 position 5 的 +7.5pp,这是残差结构最难辨别的位置。
Per-position 与冷启评估¶
Per-position(Table 9,Beauty):CapsID+SemanticBPE 在 position 1 达 44.1%/88.4% top-1/top-5(vs ADA-SID 36.9%/79.1%、TIGER 31.2%/71.4%),证明 soft routing 在前缀位置保留了足够多 facet 信息使 prefix 不再"任意";位置 6+(仅 $L_i > 4$ 的 item)也在 32.4%/76.9%,说明深层 token 仍可预测。
冷启(Table 10,Beauty):定义为训练集 5-core 后 item-side 信号最少的 ~12% item。CapsID 的冷启子集 R@10 retention(cold-subset / full-corpus)为 73.1%,CapsID+SemanticBPE 73.9%——比 TIGER(57.3%)、ADA-SID(68.6%)、COBRA(72.8%)都高。soft routing 在先验协同信号弱时帮助最大,与 Figure 2(c) 的 head/tail pattern 吻合。
与已归档相关工作的对比¶
AdaSID AdaSID: Beyond Static Collision Handling — Adaptive Semantic ID Learning (UESTC + Kuaishou, 2026-04-26)¶
关系:独立并发(CapsID 未引用 AdaSID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都把 RQ-VAE 在 SID 学习中的"硬最近邻分配"识别为生成式推荐 tokenizer 的核心病灶——argmax 在 cluster boundary 处把多 facet item 塌陷成单一码字,导致碰撞 / 早期错误向后传播 / 尾部 item 受损。两者都用 Amazon Beauty/Sports/Toys 公开 benchmark + 工业大目录评估(CapsID 35M item 多模态目录,AdaSID Kuaishou 电商 4 天 A/B),并都把 collision rate / codebook utilization 作为一等公民诊断指标。
- 相近的技术骨架:两者都不满足"统一惩罚所有重叠"的静态 collision-aware 损失(ReSID / QuaSID),都引入了"哪些 item 该被分得开 / 多分得开 / 何时分"的 instance-aware 调控,并都通过两阶段训练把推荐目标与 tokenizer 几何分离学习。
- 本文的差异与推进:AdaSID 仍保留 RQ-VAE 的 hard argmax 分配,在外部加 collision 损失——SeAR 决定 overlap 是否有害(基于编码器侧 cosine 一致性),LAS / PAR 在空间 / 时间维度自适应排斥强度。CapsID 则直接替换分配算子——不再有 argmax + 后置惩罚,而是 capsule routing 的软概率分配 + 路由后加权重构进入下一层。CapsID 的优点是把"多 facet"信息保留在前向 pass 内(通过 soft 重构),AdaSID 的优点是机制完全可加在已有 RQ-VAE 之上。换句话说,AdaSID 把"碰撞"当成需要后处理的现象,CapsID 把它当成应在前向中预防的现象。
- 可比的方法 / 实验差异:AdaSID 未报告 SID 平均长度(固定 $L=4$),CapsID $\bar{L}\in[3.41, 3.89]$ 在公开数据集、3.3 在工业目录,端到端推理 step 少 ~10%。CapsID 公开数据 R@10 0.0839(Beauty),AdaSID 同数据集 R@10 在 0.07-0.08 区间(同 ReSID 系族 baseline 之上 ~4.5%)。两者尾部增益方向一致:AdaSID 在 cold-start / 冷类目上线上获 +1.16% GPM;CapsID Beauty tail R@10 +140% over TIGER。两者在工业 SID 学习的 collision 测度都做了主动呈报,CapsID 把 collision rate 推到 19.4%,AdaSID 在工业相同数据集未直接报告但 codebook utilization 显著改善。
QuaSID QuaSID: Qualification-Aware Semantic ID Learning (UESTC, 2026-02-28)¶
关系:显式引用但原文未展开对比(CapsID Section 2 只在一句"collision-aware approaches show collisions are a ranking-quality bottleneck"中提及,未列入 Table 3 主对比)· 已加载对方精读
- 共同关注的问题:QuaSID 与 CapsID 都聚焦 RQ-VAE SID 的碰撞问题,且都在 Kuaishou/工业级目录上做工业化验证。两者都同意"码本利用不均 + 质心坍塌"是 hard quantization 的副作用。
- 相近的技术骨架:QuaSID 用 Hamming guided margin repulsion (HaMR) + collision-aware valid-pair masking (CVPM) 区分有害 / 良性碰撞,对剩余有害对施加 margin-based hinge loss。这与 CapsID "把多 facet 信息扣除掉,只把未解释残差送入下一层"的思路在最终诊断指标上殊途同归,但在算子层面截然不同:QuaSID 完全不动 argmax,而 CapsID 完全替换 argmax。
- 本文的差异与推进:CapsID 论文中 QuaSID 仅作为 collision-aware 路线代表被简短提及(Table 1 design space matrix 中标 hard assignment / 无 var length / 无 sub-word),但未在 Table 3 公开 benchmark 主对比中作为定量基线。CapsID 的工业目录 collision 19.4% 比 QuaSID 在 Kuaishou 报告的 codebook 多样性指标更直接刻画了"argmax 替换"路线的极限值。详细机制对比见 QuaSID。
- 可比的方法 / 实验差异:QuaSID 在 Amazon Beauty/Toys 上相对 RQ-VAE baseline 单数据集报 ~2-4% Recall 提升;CapsID+SemanticBPE 在同数据集相对 RQ-VAE 路线最强 baseline (ReSID) 提升 8.9%/8.8%(Beauty/Toys),机制层面验证"动算子比加损失"上限更高。
核心贡献总结¶
CapsID 把生成式推荐 SID 信息瓶颈直接攻在分配算子上。它用 capsule routing 的软概率分配 + 路由加权重构取代 winner-take-all argmax,让 multi-facet item 的多个解释在残差中显式保留;用 capsule confidence 驱动变长 SID,按 item 复杂度按需分配 token 预算;在此之上的 SemanticBPE 用共现 + 嵌入兼容性双重打分把稳定的相邻 token 合并为可复用 sub-word,但只在两个信号都支持时才合并。整套方案保持 SID 仍是有限离散序列,受限 beam search 与 trie 过滤完全适用——没有给生产系统增加 dense 通道或二次检索路径。
值得借鉴的设计:
- 算子先于损失:从"加 collision 损失"转向"换分配算子",前者只能事后修补,后者从结构上消除 boundary 塌陷。
- 置信驱动变长 + 多重停止保险:confidence threshold + residual norm + hard cap + 训练时长度正则四重保险,理论给出 $\mathcal{O}(1+1/g)$ 期望长度上界,实证只占 8-10% item 撞到 cap。
- 两阶段训练防止 self-referential collapse:Stage 1 学到对推荐充分的 code geometry,Stage 2 让生成器适应稳定几何,capsule 中心冻结防晚期坍塌。
- 可解释诊断指标的一等公民地位:collision、Gini、intra-code sim、CodeRecall 与 routing convergence 在论文中直接以表格 / 图形列出,让"提升来自更好 tokenizer 而非更大输出空间"成为可证伪声明。
讨论与局限性¶
局限性:
- 训练成本上升:capsule routing 让 tokenizer 训练成本相对 RQ-KMeans 上升 20-30%,但推理仍保留 discrete SID 接口、仅 1.05-1.08× TIGER beam search 成本。
- 静态 capsule 结构:当前固定最大 capsule 深度与每层 capsule 数量;动态目录增长可能需要 capsule 扩展或周期 refresh,作者明确留作 future work。
- EM 收敛的理论假设:Proposition 3 的 capsule-EM 联系基于各向同性高斯混合假设,放松到 anisotropic capsule 协方差是开放理论问题。
- 流行度偏置风险:CapsID 与其他 recommender 一样,若部署时不做 fairness-aware 采样或曝光校准,可能放大流行度偏置;作者建议在生产中监控 exposure 分布、本论文中头 / 尾分层指标已显示对这一风险的主动关注。
值得后续延伸的方向:
- 把 CapsID 与轻量 content adapter 配对进一步攻击极端尾部 item(论文中残差 gap 仍存在)。
- 将 dynamic codebook(如 MERGE 风格的 streaming cluster monitor)与 CapsID 结合,使 capsule 数量 / 中心可在线扩展。
- 把 SemanticBPE 的频率 + 兼容性双门控推广到跨 item 序列层面,可能进一步压缩有效 token 数量。
CapsID 的核心 insight 是:当 tokenizer 是真正瓶颈时,应当从"补 SID"转向"换分配算子"——前者带来 dense / attribute 通道这类沉重副作用,后者直接修复信息丢失的根源。论文 9.6% 平均 R@10 增益(相对 ReSID)+ 50% 推理延迟降低(相对 COBRA)+ 73% 工业碰撞率削减(相对 RQ-KMeans)三点同时成立,验证了这一设计理念在工业规模下站得住。